
Abstract
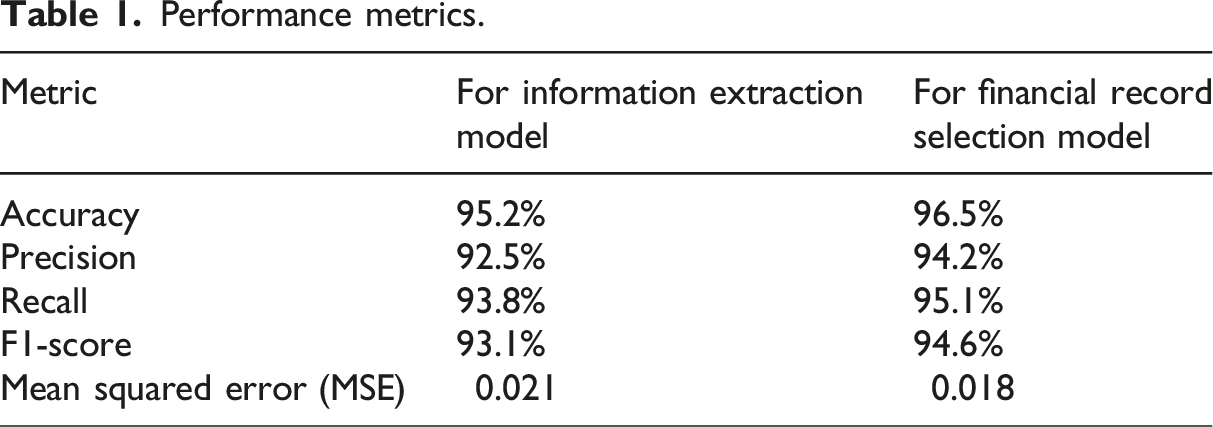
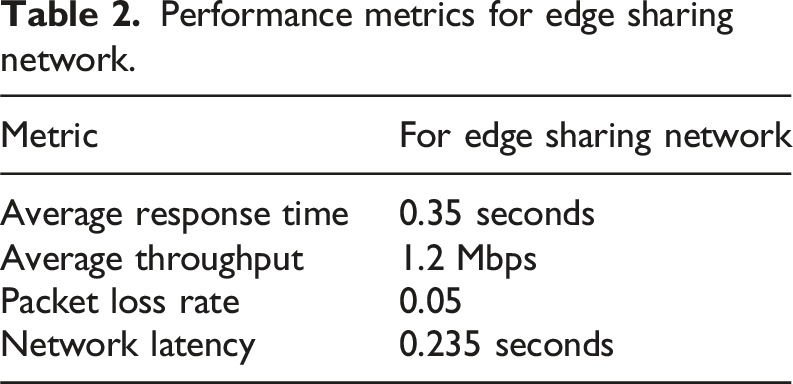
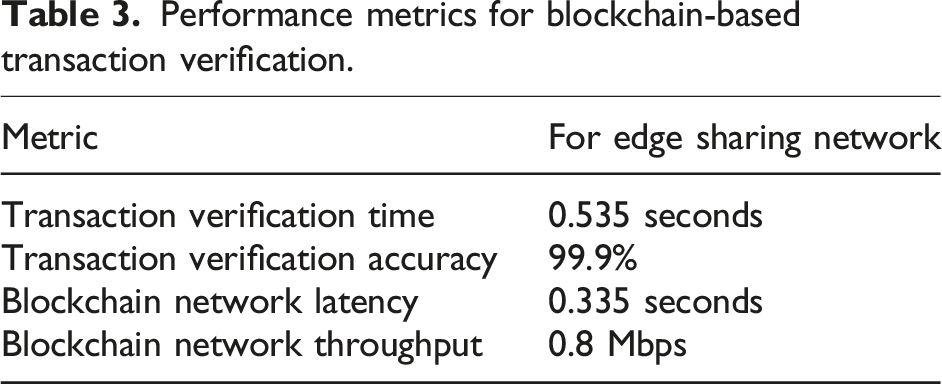
This work proposes a blockchain-based computing model with differential privacy for fraud detection in mobile edge computing (MEC) environments. The model enables edge nodes to collaborate securely, ensuring accurate and trustworthy fraud diagnosis. A top-down structure is recommended for financial records, adaptively partitioned for efficiency. The differential privacy mechanism employs randomized responses, while the blockchain-secured computational model (BSCM) safeguards customer and transaction privacy. Traditional fraud detection may delay detection and response due to real-time detection restrictions. The proposed system identifies fraud in real time, saving financial losses. The blockchain paradigm provides transparent, tamper-proof transaction records and secure data storage, unlike current systems. The proposed solution employs oversampling and undersampling to handle imbalanced datasets with more fraudulent transactions than lawful ones. Theoretical analysis shows real-time fraud detection is achievable with minimal error rates while preserving privacy. Compared to client-server models, BSCM reduces data write execution time by 2.6x and improves data retrieval efficiency by 20x. Experiments also evaluate the impact of larger financial datasets. The financial record selection and information extraction models achieved 96.5% and 95.2% accuracy, respectively, with F1-scores of 94.6% and 93.1%, balancing precision and recall. The edge-sharing network demonstrated strong performance in response time, throughput, packet loss, and latency. Additionally, the blockchain-based transaction verification system achieved 99.9% accuracy, excelling in verification speed, network latency, and throughput.
Keywords
Introduction
Modern technological advancements have profoundly reshaped industries, including finance and education. This modernization has extended to financial transactions, shifting from conventional currencies to digital forms and digitizing virtually all monetary exchanges. While offering convenience, these digital transactions are increasingly exposed to digital threats, including fraud, anomalies, and privacy breaches. The sheer volume of digital financial transactions directly correlates with a rise in fraudulent activities, leading to billions of dollars in global losses annually. 1 Anomalous network activity, a critical concern in cybersecurity and digital finance, involves identifying these irregularities to prevent network fraud and illicit operations. While anomaly detection software has proven effective in pinpointing hackers and fraudsters in centralized financial systems, the emergence of digital currencies and blockchain technology introduces new challenges and a growing need for specialized detection tools. 2
The rise of Artificial Intelligence (AI) and Machine Learning (ML) has led to the development of numerous methods for identifying digital transaction abnormalities and fraud. 3 For centralized systems, various supervised ML algorithms have been explored, with studies comparing their efficacy.4,5 For instance, Random Forest and XGBoost classifiers have been successfully applied to examine over 300,000 accounts for fraudulent business identification. 6 XGBoost has also been utilized to predict driver performance and telematic data from insurance datasets, even addressing issues of skewed data.7,8
However, traditional approaches to fraud detection, particularly in credit card transactions, face inherent data mining challenges. 9 A significant hurdle for researchers is the lack of access to real-time, sensitive client data due to stringent bank privacy policies. 10 Efforts to overcome this include distributed data mining methodologies for credit card transactions 11 and proactive algorithms to address the “cold-start” problem without relying on historical fraud data. 12 Techniques like uncertain association law mining have been proposed to extract meaningful patterns from credit card transactions. 13 Specific ML models, such as Support Vector Machines, have been trained to identify transaction errors. 14 Furthermore, hybrid approaches combining Bayesian, rule-based, and Dempster-Shafer theories have been used to reduce fraud identification noise. 15 Transaction aggregation to assess consumer behavior and detect fraudulent patterns has also been explored, with the primary aim of identifying anomalies in unknown datasets, respecting data privacy by not ranking participant traits. 16
With the increasing adoption of blockchain technology in both public and private sectors for auditing systems and protecting auditor privacy, new methods are emerging. While consensus algorithms are crucial for transaction verification, 17 blockchain’s inherent design introduces new complexities. In the context of IoT-driven smart cities, centralized systems face challenges in trust, privacy, security, and verifiability. 18 Solutions involving encryption, such as asymmetric, symmetric, and homomorphic encryption, have been proposed to address privacy, though often at the cost of high processing power and time. 19 Blockchain, integrated with deep learning algorithms, has been used to detect cyberattacks and ensure security and privacy in cloud-migrated virtual machines. 20 Approaches like Gaussian Mixture-of-Localization-based Outliers (MLO) systems have been developed for cloud-based collaborative anomaly detection to identify insider and outsider threats. 21 Privacy-preserving anomaly detection frameworks using Gaussian Mixture Models (GMM) have also been presented for cyber-physical systems. 22
Despite these advancements, several critical limitations persist. Many robust AI/ML anomaly detection methods are primarily optimized for centralized systems and do not offer viable solutions for the decentralized nature of blockchain. 2 While blockchain offers decentralization and immutability, transaction identification and fraud detection within blockchain networks can be inefficient. 17 The presence of “malignant” participants further complicates security. 23 A fundamental impediment for academics in fraud detection is the inability to access real-time, sensitive financial data due to bank privacy policies, hindering the development and validation of robust models. 10 Cryptographic methods used for data privacy, while effective, often demand significant processing power and time, limiting their real-time applicability. 19 Existing privacy-preserving anomaly detection techniques may be ineffective against sophisticated, contemporary IoT attacks. 22 Traditional centralized systems often struggle with the real-time processing, low latency, and scalability required to handle the escalating volumes of digital transactions effectively, especially in rapidly evolving fraud scenarios.
Contribution
This work makes significant contributions to the field of fraud detection in financial systems, particularly in Mobile Edge Computing (MEC) environments. A new blockchain-based computing paradigm is developed to facilitate safe cooperation across edge nodes for precise and reliable fraud diagnosis. A differential privacy technique is used, using randomized replies to safeguard sensitive financial data and maintain client and transaction confidentiality. A hierarchical structure is advised for financial records, which is adaptively segmented for efficiency and facilitates rapid and secure processing of financial data. The proposed Blockchain-Secured Computational Model (BSCM) surpasses conventional client-server models, decreasing data write execution time by 2.6 times and enhancing data retrieval efficiency by 20 times. The financial record selection and information extraction models attain accuracy rates of 96.5% and 95.2%, respectively, with F1-scores of 94.6% and 93.1%, indicating a commendable equilibrium between precision and recall. The edge-sharing network exhibits robust performance in reaction time, throughput, packet loss, and latency, making it appropriate for real-time fraud detection applications. The blockchain-based transaction verification system attains an accuracy of 99.9%, demonstrating superior performance in verification speed, network latency, and throughput.
The rest of the paper is organized as follows: Section 2 presents the overall workflow of the proposed system, including Financial Record Extraction, Financial Record Selection, Edge Sharing Network, Blockchain-based Secure Computation Model, and Fraud Detection Recommendation; Section 3 presents Results and Discussion. Finally, Section 4 draws the Conclusion.
The process model of the proposed system workflow
Figure 1 shows the suggested system process. To resolve missing values, an information extraction model processes a financial record and its timestamp to build an information space. The system clusters optimum records, uses differential privacy for security, and stores them in edge nodes. A blockchain-derived threshold governs this network’s information sharing. Blockchain data is analyzed by a financial specialist to identify client identification (fraudulent or authentic). The system sends transaction results to update records and store feedback, providing a continuous learning loop. Proposed system workflow.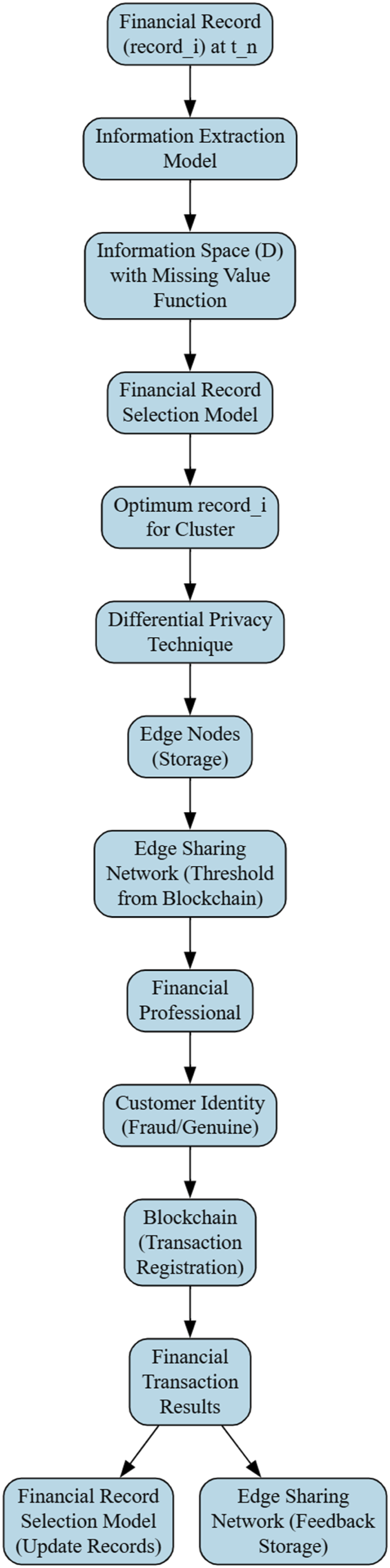
The proposed system follows these steps: (1) Financial record (2) The information extraction model uses a missing value function to extract client information into information space (3) After finding the optimal information subspace, the financial record selection model partitions the data to get the best (4) Use differential privacy to preserve customer privacy since the ideal (5) Edge nodes in the edge sharing network may cooperate to share information according to the private blockchain threshold. This level determines the one-step neighboring node’s trustworthiness. (6) The relevant customer information is submitted to the appropriate specialist, who determines the client’s identity (fraud or real). The blockchain records this transaction in the header of a block to safeguard the integrity of all financial transactions among its users. These steps avoid transaction disclosure. (7) Get financial transaction results (fraud or real). (8) The current treatment input is supplied to the financial record selection model to update records. In addition, the edge sharing network will save the associated input for future fraud detection.
Financial data searches may be injected with noise proportionate to their sensitivity using the Laplace technique, ensuring good privacy. For high-dimensional data, the Gaussian technique might be utilized. The method and noise calibration depend on the application and privacy level. The blockchain threshold may be based on a consensus method like Proof of Stake (PoS) or Byzantine Fault Tolerance (BFT) to ensure network integrity and trustworthiness. Smart contracts may also govern node interactions like transaction validation and data exchange. A node trust score may assess network node repute. Public Key Infrastructure (PKI) authentication and management of edge nodes with unique public–private key pairs are expected.
The noise calibration process would involve calculating the sensitivity of queries and adding noise accordingly. The privacy budget, represented by the epsilon (ε) value, would be carefully managed to balance privacy and accuracy. A smaller ε value would provide stronger privacy guarantees but might compromise accuracy. The exact calibration and budget allocation would depend on the specific requirements of the financial fraud detection application.
The differential privacy implementation involves the following steps: Step 1: Calculate the sensitivity of the query, which represents the maximum change in the query result when a single record is added or removed. Step 2: Calibrate the noise scale based on the sensitivity and the desired privacy budget (ε value). Step 3: Add noise to the query result using the Laplace or Gaussian mechanism. Step 4: Evaluate the trade-off between privacy and accuracy, adjusting the ε value as needed to achieve the desired balance.
Model for the extraction of financial data
Each individual customer Block diagram for the extraction of financial data.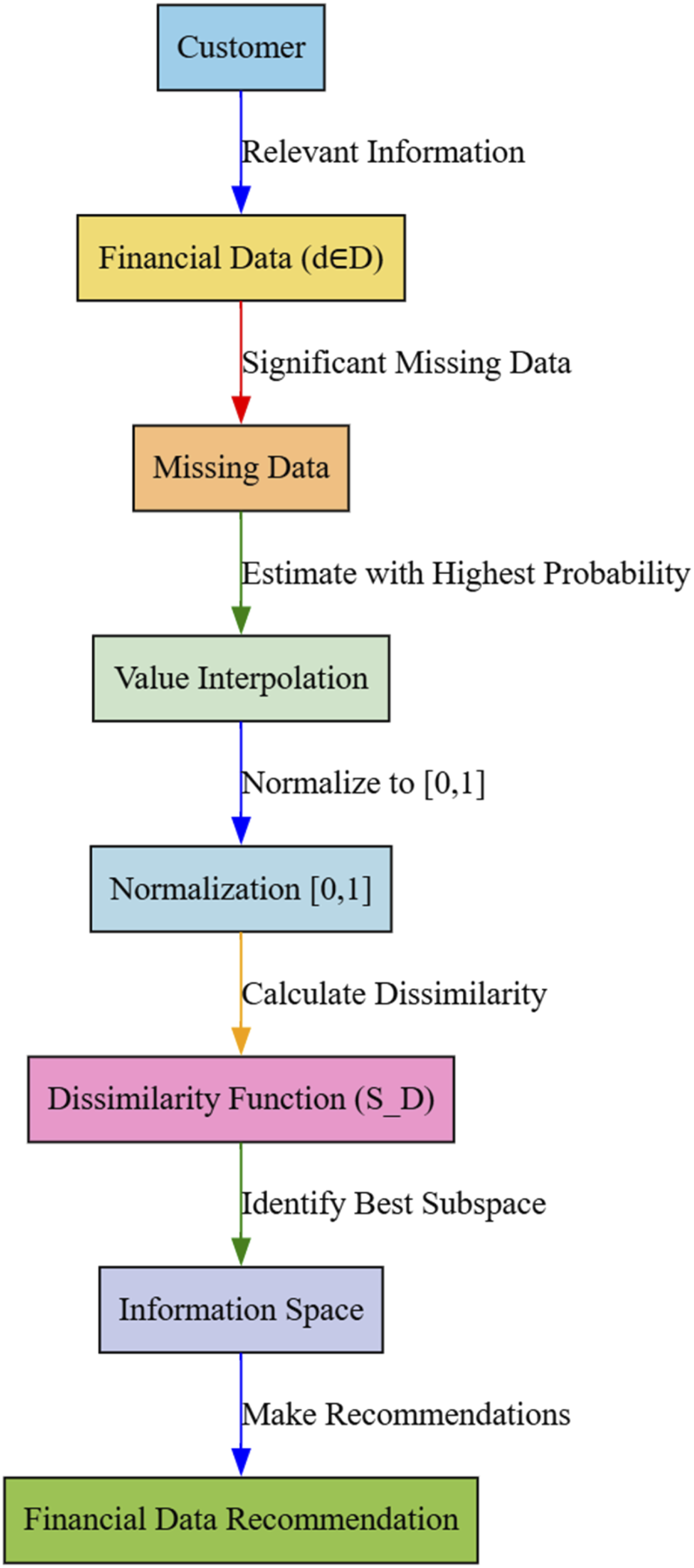
The assumption is made that every
Model for blockchain-enabled differential privacy: Financial record selection
The financial record selection is constructed using the history of financial data of several customers and condition feedbacks from those customers, and is denoted by the notation
In addition, because of the restricted capacity of the nodes, it should first constrain the maximum and minimum size and then split them in an adaptive manner according to the increasing amount of incoming financial information. A limit on the size of the nodes has been set and is subdivided into more valuable sub-nodes, which will allow us to provide more precise fraud findings as the number of system working cycles increases. However, after the ideal node that has the most relevant financial data has been chosen, the internal interested attackers will utilize certain program analysis abilities in order to masquerade themselves as financial professionals when they are in the financial institution in order to get the personal fraud detection findings. In order to protect the confidentiality of our customers, the Blockchain-enabled differential privacy (BEDP) has been used here. Figure 3 presents the block diagram for financial record selection. Block diagram for financial record selection.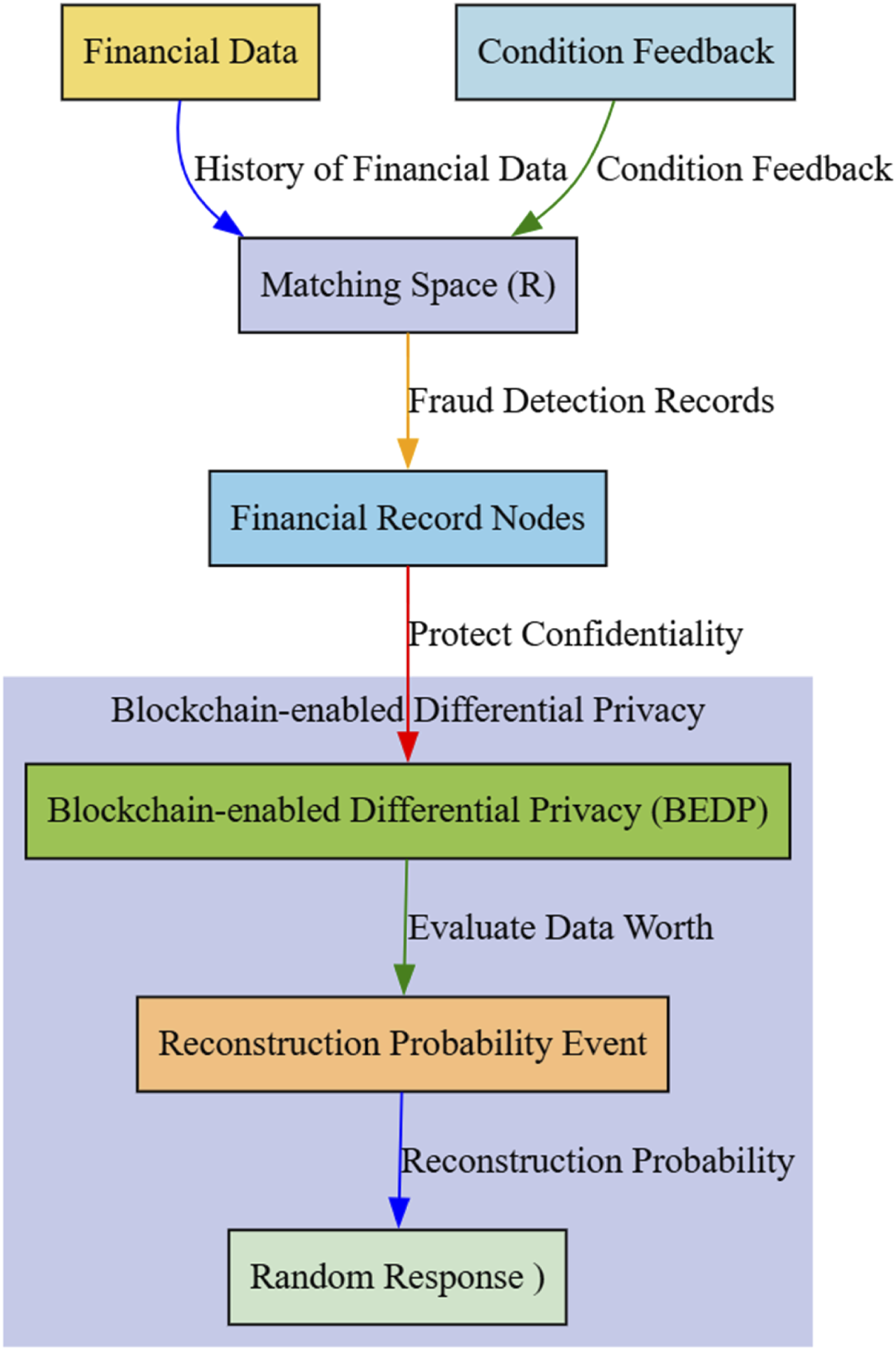
In order to evaluate the data’s worth without jeopardizing the BEDP, a reconstruction probability event is implemented. The likelihood of successfully recreating the person’s records using the modified data is given by the
Sharing network at the leading edge
The edge sharing network has Block diagram for sharing network at the leading edge.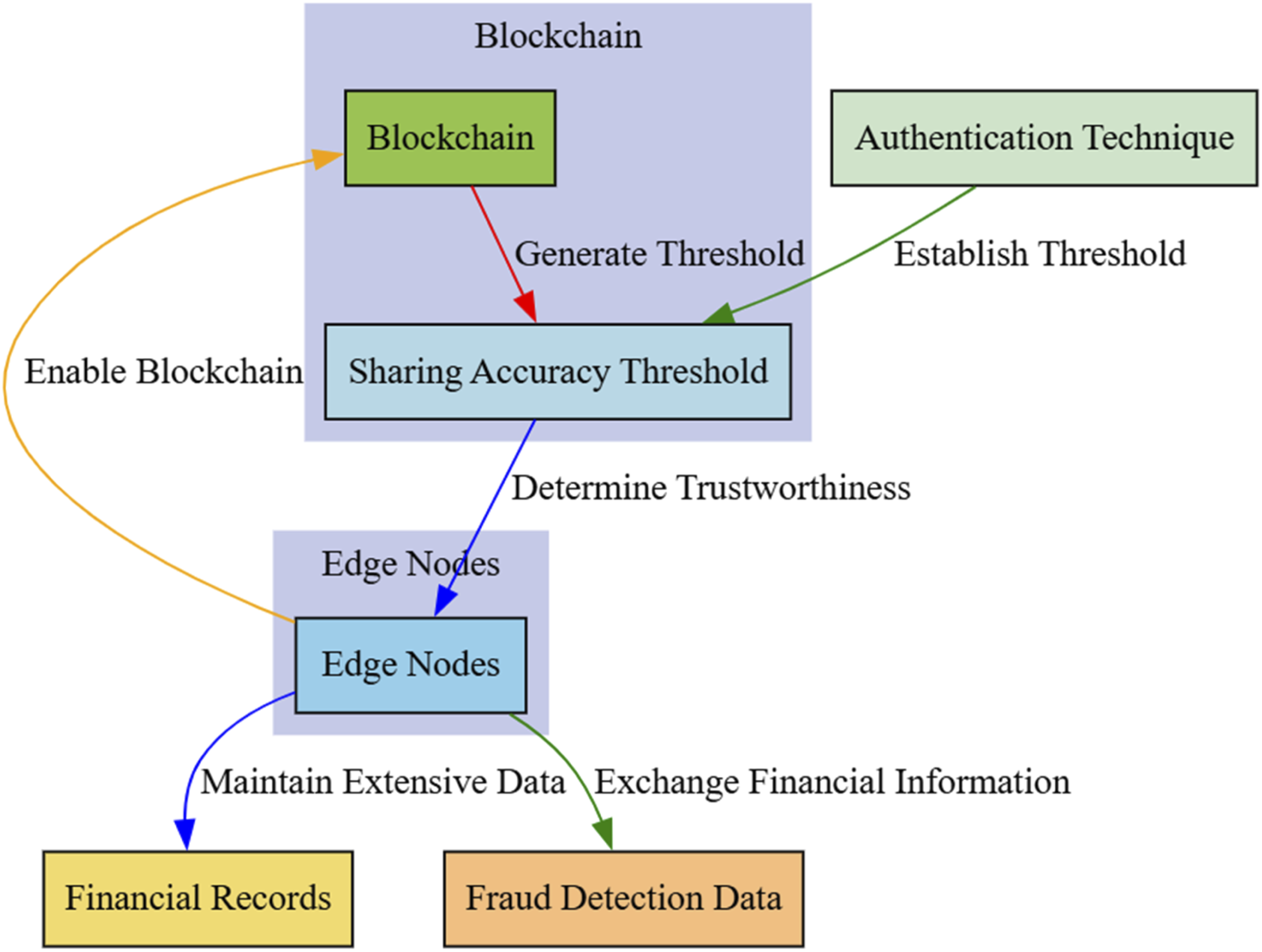
Blockchain-based secure computation model
The blockchain is constructed up of linked blocks, each of which has inside its body a decentralized hash sub-table, in which are stored certain references to the various financial transactions. In addition, the block head includes a variety of characteristics (such as a timestamp, version number, and so on) that manage the dataflow, guarantee that the block cannot be altered, and accomplish the bulk of the blockchain’s most essential operations. In this configuration, secure multiparty computation (SMPC) ensures that the data is partitioned such that it may be discretely calculated. As a result, neither party is able to deduce any significant financial information from the neighboring edge nodes since they are unreliable. 24 To ensure the safety of the customers’ financial transactions, first generalize the fraud detection recommendation issue using the blockchain-based secure computation model (BSCM). A protocol is devised that is based on SMPC to produce sharing randomness and assess the amount of correctness in order to ensure the accuracy of the information that is being shared and choose which edge node would be most suited for us to work with. Each shared record is represented by a unique identifier (logical ID) and an additive share in the sharing protocol, which supports additive homomorphism of various financial records. This allows for computations to be performed on the shared data without revealing the individual shares. The efficient cooperative fraud detection is performed by using this updated system, which enables us to compute the accuracy of data sharing across many edge nodes, each of which stores a separate set of information.
Fraud detection recommendation
Error rates (ERs) are determined by tallying up the frequency with which false negatives (FNs) and false positives (FPs) occur. A false negative example is one in which the malicious result is correctly detected as being negative, whereas a false positive example is one in which the malicious outcome is incorrectly identified as being positive. The authors of this paper examine the discrepancies between ideal fraud detection input and practical feedback and why they occur. Our objective is to reduce the number of errors as much as possible while also ensuring that the regret is sublinear. This will ensure that the regret may converge to a low level. As a result, the issue of making a fraud detection be stated as
Results and discussion
The experiment was conducted on a robust system with an Intel Xeon E5-2698 v4 CPU, 128 GB of RAM, and 1 TB SSD storage, running Ubuntu 20.04 LTS. The software environment consisted of Python 3.8 as the programming language, Hyperledger Fabric 2.2 as the blockchain framework, and BlockSim for blockchain simulation. Custom Python scripts were developed to simulate the client-server model, and Docker 20.10 was used for containerization, with Docker Compose managing multi-container applications. The simulation setup included 6 nodes: one client node and two server nodes for the client-server model, and three peer nodes for the blockchain network. A 25.86 GB dataset comprising financial records was used for the experiment. The objective was to compare the performance of the Blockchain-based System for managing financial data (BSCM) with the traditional client-server model in handling large-scale financial data. The experiment measured latency, throughput, resource utilization, and scalability, with each test scenario executed 100 times to ensure statistical significance. The BSCM utilized a block structure with an 80-byte block header and a block body containing financial transaction data, leveraging cryptographic techniques for data integrity and non-repudiation.
The performance of proposed BSCM is evaluated in comparison to the client-server method of handling financial data using open source data.25–27 This work simulates both the client-server and blockchain networks by using three nodes each. A client, which is a stand-in for a customer, will send a query request to two servers, each of which will represent a hospital that is in possession of the customer’s financial information. The request will be submitted by the client, who will act as the customer. The customer will behave as though the customer is making the inquiry in order to get the information. A file of 25.86 gigabytes in size is used in order to demonstrate a financial data record that is capable of being shared across both networks. This was done for the goal of proving that both networks are compatible with the data record. The financial information that was used to compile the dataset was gathered from references 28–30. A block on a blockchain network is made up of two parts, the block header and the block content. These two parts make up the block. These two pieces come together to form a block. The information on the block’s metadata is stored in the header of the block. 31 This information includes the date, the version, and the hash of the block that was there before it. The data pertaining to the transactions are saved inside the “body” of the block. Throughout the whole of our simulation, the typical block header size, which is 80 bytes, has been used. This setting was maintained throughout. This was done so that it could more realistically depict the situations that exist in the actual world. Time required to handle a growing number of financial records is contrasted between the BSCM and the client-server paradigm. By conducting this comparison, the method that is most effective in terms of processing the ever-increasing volume of financial data is identified in the shortest amount of time. Both approaches were put to the test using an increasing quantity of financial information. Both of these evaluations are carried out with the assistance of an ever-growing number of customer records.
In the first of many potential scenarios, a write transaction is simulated by uploading 50 financial files, each of which will have a size of 25.86 terabytes. This will be done in order to test how well the system handles large amounts of data. To do this, client-server and blockchain networks function in tandem. The client makes requests to the server, which the server then fulfills based on the client’s needs. For example, the client may ask the server to incorporate 50 financial files into the database. When a successful data upload has been completed on a particular server, the server will communicate with the client by means of acknowledgments. To get started, determine the overall length of time that will be necessary to complete this task. The client transfers 50 distinct financial files to the blockchain network so that the blockchain network may process the data contained inside those files. Every file is copied onto both of the servers that are connected to the network so that they are both up to date. In order for all of the servers in the network to come to a conclusion about the transaction, each server in the network has to first generate a block that is pertinent to the transaction and then communicate that block to the other servers in the network. Only then will all of the servers in the network be able to come to a decision regarding the transaction. The client will get acknowledgments alerting them that the data modifications were successfully completed as soon as the two servers have come to an agreement on anything. The block will be added to the chain as soon as the two servers have come to an agreement regarding anything. To get started, the overall length of time is determined that will be necessary to complete this task. Once again, the client-server protocol and the blockchain network are used in the process of writing transactions. The quantity of written financial files will be raised from 50 to 100 at intervals of 10 this time around.
In the second scenario, client-server and blockchain networks are used to simulate the read activity of querying 50 financial files in order to simulate the read activity. It is the client’s responsibility to initiate the communication process with the server in a model of computing that is referred to as a client-server architecture. This may be done by submitting a request to the server that includes a data query. Once the server has provided a response and sent it to the client, the client is the one who will get the pertinent financial files. The server will send them to the client. In order to get started on this job, you need to first determine the entire length of time that will be necessary to accomplish it. The user is actively participating in the functioning of the blockchain network by sending data query requests for a total of 50 unique financial files. These queries cover a wide range of conditions. These inquiries are in reference to the individual customer’s personal financial records. Both of the servers get each request while it is being processed simultaneously. Every server in the network has the duty of producing a block that is specific to the transaction that includes data access and then transmitting that block to the other servers in the network. This is to ensure that the integrity of the network is maintained. This procedure has to be carried out again for each transaction that requires accessing the data. This obligation is recognized in the industry as “producer responsibility.” This is done to ensure that there will be no issues with the functioning of the network. The block will be uploaded to the network as soon as everyone has come to an agreement about a solution to any difficulty, and the client will be provided with the relevant financial information at that time. When a client makes a request for data, the data will come from one of two places: the client’s local database, or, if the client already has a copy of the ledger, it will come from the server that is situated in the area that is geographically closest to the client. If the client does not already have a copy of the ledger, the data will come from the server that is located in the area that is geographically closest to the client. The client’s local database will be queried for the information in the event that the client does not own a copy of the ledger. When a client makes a request for data, the data will arrive from one of two locations: the client’s local database, or the server that is located in the region that is positioned in the area that is geographically nearest to the client. When a client makes a request for data, that client’s local database will provide the information that the client needs. The data read procedure is carried out for both the client-server and blockchain networking systems. However, at this point in time, the number of financial files that are being requested has gone from 50 to 100, and there is a break of 10 seconds between each increment of 10.
The amount of time required to read a financial file from a database that contains an increasing number of financial files is shown in Figures 5 and 6 for write and read operations, respectively. The Figures 5 and 6 provide information on these timeframes. This time is broken down into two categories: client-server and BSCM. It demonstrates that the time required to execute BSCM is noticeably less than that required by the client-server strategy. This is due to the fact that the data is downloaded from the centralized server in the client-server strategy, but in the BSCM approach, the data is retrieved from a local copy of the ledger. The only thing that contributes to the length of time it takes for BSCM to carry out an operation is the sending of data query requests to each and every server in the network, followed by the addition of those requests as transactions in blocks after consensus has been reached. Data write operation when employing a client-server and BSCM with increasing number of financial records. Data read operation when employing a client-server and BSCM with increasing number of financial records.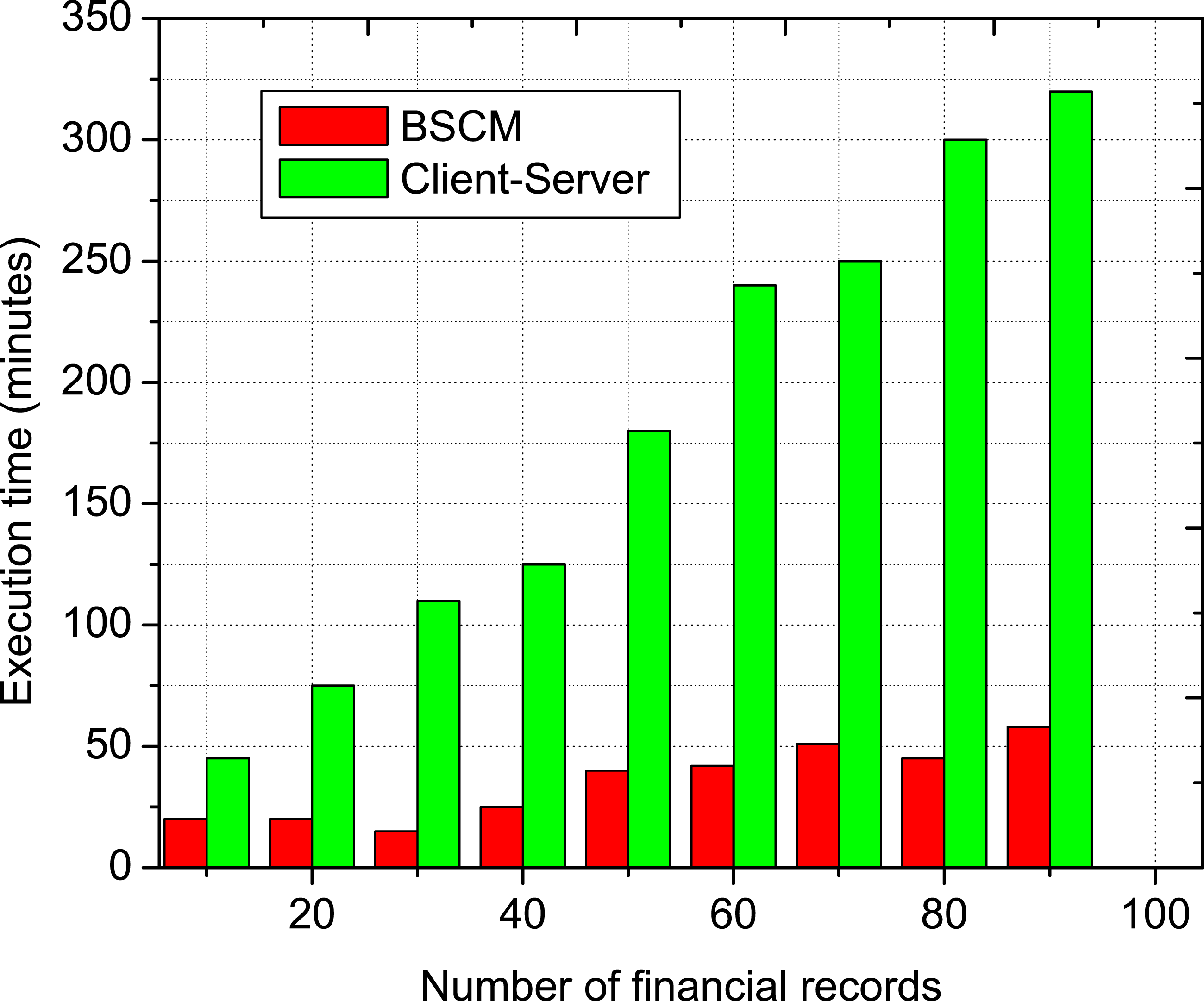
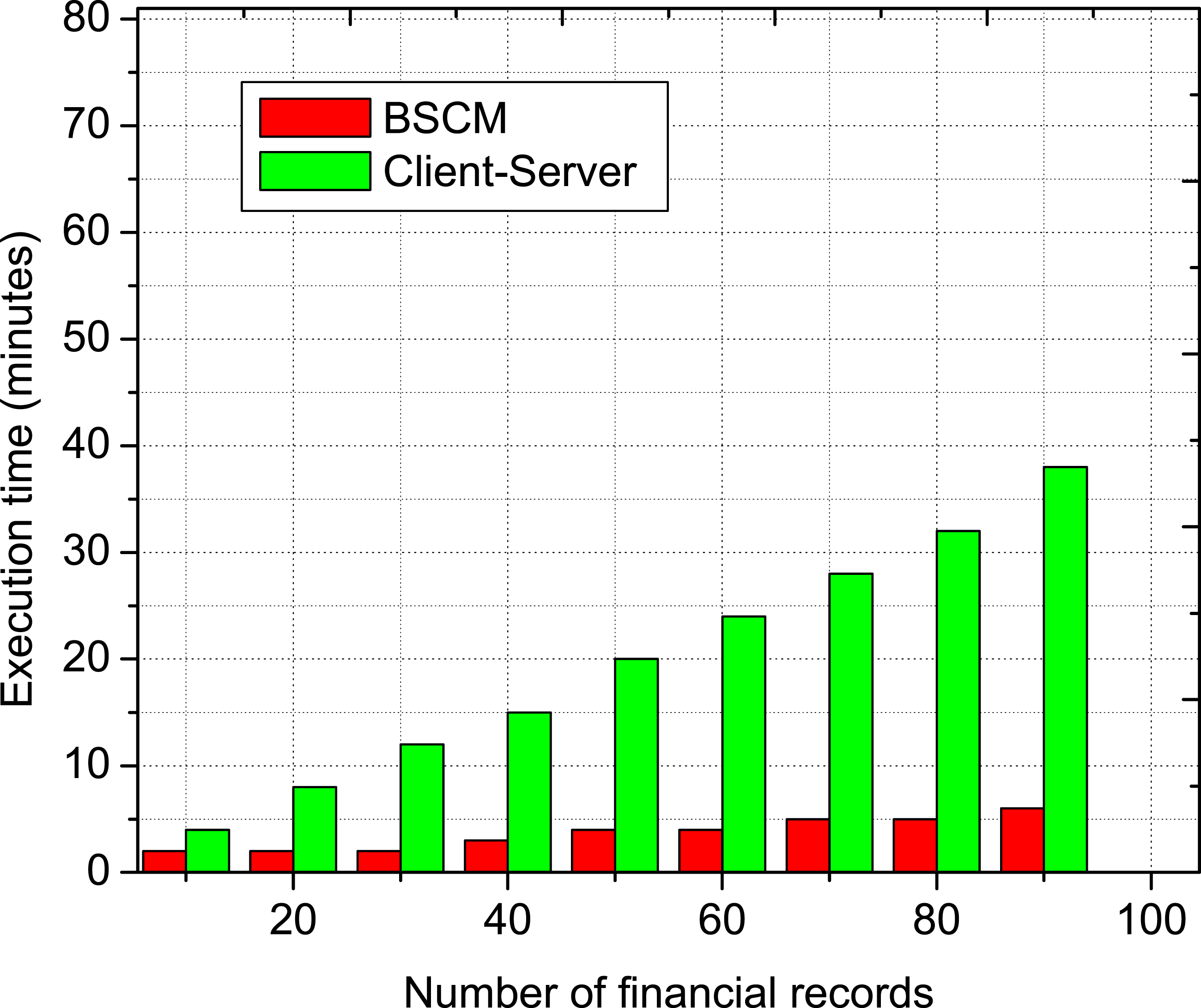
The number of financial files that need to be processed will directly correlate to an increase in the total amount of time that will be necessary to complete these procedures. According to the results, the amount of time that is required to carry out the client-server and BlockHR techniques grows in a linear manner as the number of financial files that need to be processed increases. This is the case regardless of whether strategy is used. This is the case regardless of the strategy that is used in the scenario that is being discussed. On the other hand, in comparison, the amount of time required to carry out the client-server method is much smaller than the amount of time required to carry out the BSCM methodology. Because the BSCM employs a technique that is based on consensus for the validation and replication of data, one of the probable conclusions that may be drawn from this observation is that it is a consequence of the approach that was used. The genesis of this realization may be traced back to the aforementioned observation. The procedure in issue is entirely responsible for the results that were obtained. The financial data that has to be kept up to date on the ledger will be transmitted here so that it may be checked, and here is the spot where the check will take place. It is necessary to obtain this information from each and every server that is a part of the network and keeps its own independent copy of the ledger. In addition, in order to add a new block to the ledger, every server in the network must first come to an agreement with the other servers in the network over that server’s block. This must be done before the new block can be added to the ledger. Before the new block can be added to the ledger, this step has to be completed first. This may be accomplished by instructing the relevant server to send a copy of the block it is responsible for maintaining to each of the other servers that are a member of the network. When everyone has reached a decision upon anything, the new block will be able to be added to the ledger as soon as it is possible to. In contrast, while using the client-server technique, the request to update the data is only sent to the centralized server. This ensures that the data is always accurate. This guarantees that the data are correct all of the time. This is because the client-server method is, in and of itself, a strategy that utilizes client-server architecture. As a direct consequence of this fact, the amount of time required for the execution of a data write operation when utilizing the client-server technique is a significant lot less than the amount of time required by BSCM. When compared to BSCM, the client-server technique results in a time reduction that is 2.6 times less than what is required to generate a financial file. This time reduction is due to the fact that the two components communicate directly with one another.
Financial records play a crucial role in reducing errors in financial applications, often more so than increasing the number of customers. This is because financial records provide richer datasets, containing valuable information about customers’ financial behavior, transactions, and history. As the number of financial records increases, models can learn from more diverse and detailed data, leading to better performance and reduced errors. In contrast, increasing the number of customers may not lead to proportional improvements in error reduction due to diminishing returns, as each additional customer may not contribute equally valuable information. Financial records also provide increased precision, enabling models to make more accurate predictions and reduce errors. Furthermore, analyzing financial records helps models handle outliers and anomalies more effectively, leading to more robust patterns and relationships. Ultimately, financial records enable more accurate risk assessments, reducing the likelihood of errors and improving overall performance. By leveraging financial records, financial institutions can build more accurate models, reduce errors, and improve decision-making.
An analysis of error rate
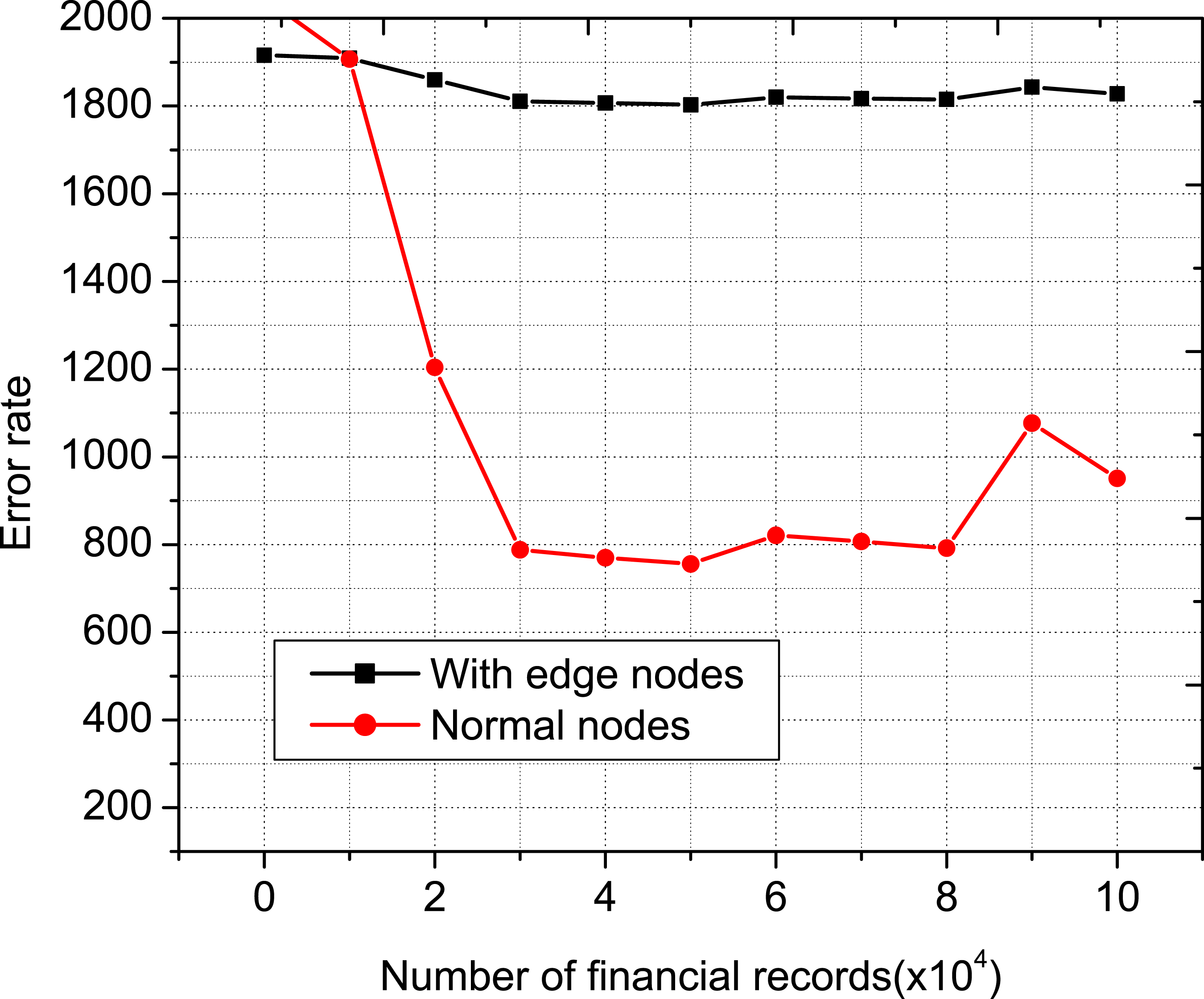
Error rate comparison can be seen in Figures 7 and 8. In the very beginning, the error rate has a bigger value and then the slope decreases as the number of customers and financial record increases. This work is analyzed for the two network cases, that is, without edge nodes and with edge nodes (BSCM). Figures 7 and 8 show the impact of the number of edge nodes on error rate. This indicates to effectively use the dataset to provide more accurate financial suggestions, which in turn results in a significant rise in the number of successful fraud detection. However, due to the fact that the information space is set and it is unable to acquire any new information in order to fulfill additional demands. An increase in financial record is more advantageous for decreasing performance losses than an increase in customers, which is appropriate in the context of the real-world situation. Error rate comparison with number of customers. Error rate comparison with number of financial records.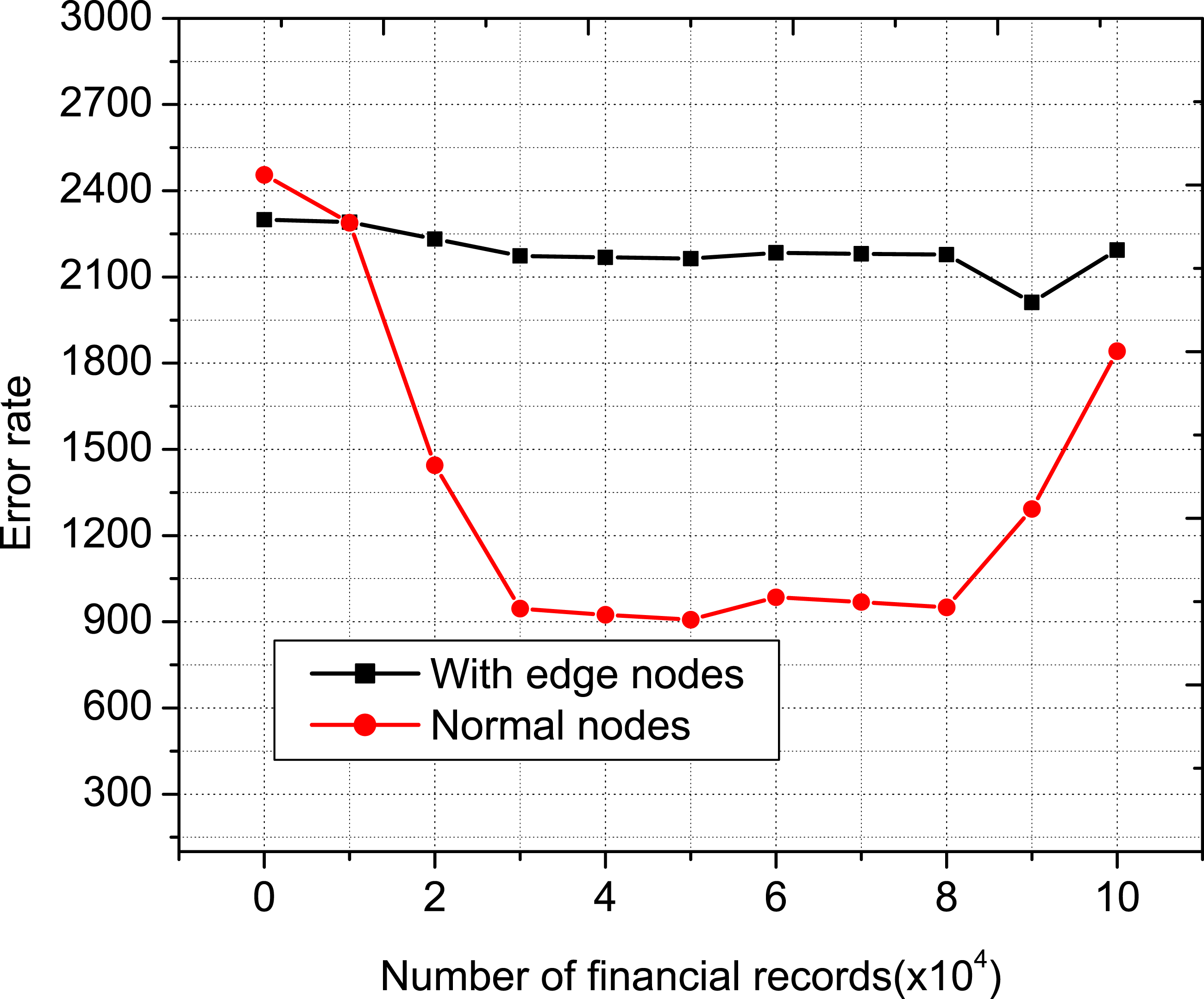
Performance metrics.
Performance metrics for edge sharing network.
Performance metrics for blockchain-based transaction verification.
Conclusion
In order to send and receive financial records with information sharing, this study requires specific mobile devices that are modeled as edge nodes. Additionally, this research requires certain devices that can operate as containers in order to store essential information. This is necessary in order to safeguard the confidentiality of the information. Our approach does have some potential drawbacks, however, including the fact that it is dependent on the fruitful cooperation of a large number of technologies in order to produce desirable results; failing to do so would result in unfavorable outcomes; and the quantity of information that can be communicated between edge nodes is limited. In this research, a blockchain-enabled secure computing platform is introduced for fraudulent detection that operates under a differential privacy mechanism. Computing on the edge of mobile networks and the processing of large amounts of data are both facilitated by the approach.
Our performance testing revealed that as compared to the BSCM technique, the client-server method is 2.6 times faster when it comes to writing the contents of financial files. This is the case even though both methods use the same number of steps. The read operation that is carried out by BSCM, on the other hand, is 20 times faster than the client-server technique. The proposed system’s performance is highlighted by several key metrics. The proposed model achieved an accuracy of 95.2%, while the Financial Record Selection Model performed even better with an accuracy of 96.5%. The Edge Sharing Network demonstrated rapid responsiveness with an average response time of 0.35 seconds. Transaction verification was also efficient, taking 0.535 seconds with an impressive accuracy of 99.9%. Furthermore, the blockchain network latency was recorded at 0.335 seconds, indicating swift data transmission. These metrics collectively underscore the system’s effectiveness in handling financial data and transactions securely and efficiently.
Within the scope of the work that is planned for the foreseeable future, to actually develop the framework in order to carry out exhaustive testing on its privacy, security, and performance.
Footnotes
Funding
The author received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
Data may be obtained from the authors upon reasonable request.