
Abstract
To address the issues of insufficient accuracy and significant impact of image noise on model performance in current facial recognition systems, this study proposes a new framework that integrates wavelet transform, an improved multi-task cascaded convolutional neural network (MTCNN), and genetic algorithms (GA). This framework utilizes wavelet transform for image denoising; optimizes MTCNN by introducing a hybrid threshold function and a confidence candidate box retention mechanism to effectively address information loss issues; and applies GA for feature compensation and optimization. Experimental results demonstrate that this method significantly improves the accuracy, recall rate, regression value, and model stability of facial recognition, effectively enhancing the system’s robustness under noise interference, and provides an effective solution for optimizing facial recognition performance.
Keywords
Introduction
Facial recognition technology has always been highly concerned and extensively applied in many fields, including security systems, social media, finance, healthcare, etc. 1 With the continuous development of computer vision and deep learning fields, significant progress has been made in practical recognition technology. Deep learning methods are the main research direction currently. 2 Facial recognition is commonly used in several applications, such as providing security access control at airports, commercial buildings, residential areas, and other places. Facial recognition is used for identity verification in banks and other financial institutions, which is used for mobile banking login. Personalized services or recommendations based on customer’s facial data can be provided in retail and marketing. Facial recognition can help police identify suspects or find missing persons, etc. Despite its great potential, facial recognition technology faces some technical and ethical challenges, such as recognition accuracy in different lighting and postures, as well as privacy and data protection. The Multi-Task Cascaded Convolutional Neural Network (MTCNN) algorithm is a deep learning algorithm for facial detection that uses cascaded deep Convolutional Neural Network (CNN) to achieve multi-task processing of faces, including facial detection, keypoint localization, and bounding box regression. 3 MTCNN has achieved an efficient facial recognition system by effectively handling the information flow between different tasks. 4 Rathnayake et al. addressed the challenges posed by the regional dependency of fruit types in automatic fruit recognition. To fill the gap in existing research on convolutional neural network algorithms, which did not fully cover the 131 categories of the Fruit-360 dataset and had poor computational efficiency, they proposed a novel study based on a cascaded adaptive network fuzzy reasoning system. The research results show that this method achieves a relative accuracy rate of 98.36%, with high weighted accuracy, recall rate, and F-score, and demonstrates better applicability and computational efficiency compared to the latest algorithms. 5 It is evident that this method can be used for fruit species identification analysis, but further exploration is needed for facial recognition analysis. Shakrani KV et al. proposed the use of open-source computer vision (OpenCV) and convolutional neural network (CNN) technologies for real-time recognition and detection of mask wearing in public places, airports, and army bases. The research results indicate that by constructing a dataset containing specific directories and subdirectories, and applying data augmentation preprocessing methods, the proposed model trained using TensorFlow and Keras achieved a training accuracy of 0.93, validation accuracy of 0.94, and classification accuracy of 0.95. 6 It can be seen that the new method can achieve recognition and analysis of different scenarios, but further exploration and analysis are still needed for the effectiveness of face recognition.
This study aims to improve the accuracy and overall performance of facial recognition using feature extraction techniques such as MTCNN algorithm and wavelet transform, as well as Genetic Algorithm (GA) to improve the system model. The study proposes an improved MTCNN algorithm that uses a hybrid threshold function for the initial and fixed thresholds of the algorithm. Confidence candidate frames are used to enhance the information representation of the image, in order to solve the losing candidate frames in the algorithm and improve its performance. This study is structured from 4 parts. The first one is an overview of the current domestic and international research content. The second part analyzes the designed algorithm. The third part is performance testing of the system model through experiments. The fourth is a summary analysis of the current research content. The core innovations of this study mainly include the original improvement of the MTCNN framework, innovative application of GA, collaborative innovation of wavelet transform and deep learning, and key innovative evidence in performance verification. The study optimized the face detection process of MTCNN by combining threshold functions and confidence candidate box retention mechanisms, solving the problem of candidate box loss caused by fixed thresholds in traditional methods. At the same time, an information loss compensation mechanism was introduced to enhance the robustness of the model to low-quality images.
Related works
Under the context of artificial intelligence, social recognition technology has become a research hotspot. This technology is widely used in security authentication, monitoring systems, intelligent interaction, and other fields. Zhi Yang Wang et al. put forward a low-rank representation solution to address the neglected specific local structures and noisy samples from different views. This led to decreased recognition ability in multi-view real recognition. 7 The new method was implemented through a layered Bayesian approach, which constrained and matched it with a linear combination. The experiment outcomes demonstrated that compared with the most advanced classification and clustering methods, this method was more effective. Chen et al. put forward a feature extraction solution supported by neighborhood weighted average and central symmetry to solve the facial recognition under complex lighting conditions. 8 A feature fusion algorithm was proposed, which combined the advantages of directional gradient histograms. Compared with other latest algorithms, this algorithm had more robust performance under complex lighting conditions. McGugin et al. put forward a method based on 7T ultra high-resolution magnetic resonance imaging to investigate the relationship between facial recognition and vehicle recognition ability with cortical thickness. The research results indicated that individuals with strong facial recognition abilities had relatively thin cortical areas in the selective brain regions of the face. 9 Those with strong vehicle recognition abilities had relatively thick cortical areas in the same regions. Xue et al. proposed a robust prototype dictionary and robust change dictionary construction method to improve the accuracy of single sample factual recognition per person. The new method utilized dictionary learning methods to obtain atoms. Effective atoms through suggested function indexing methods were selected to construct robust prototype dictionaries and robust change dictionaries. The experimental results showed that RPRV had strong robustness to facial recognition in unconstrained environments, which was superior to state-of-the-art SRC-based methods. 10
He et al. put forward a novel occlusion simulation method for the robustness of facial recognition to occlusion, which involved discarding in carefully selected channels. This method simulated real occlusion through spatial regularization and local perception channel removal. A module was designed to improve the contribution rate of non-occluded areas. The experiment outcomes displayed that the designed method had significant improvements on various benchmarks. 11 Liu et al. proposed a multi-factor joint normalization network based on generative adversarial networks to address the challenges faced by unconstrained facial recognition. This method could normalize multiple factors simultaneously, including posture, lighting, and facial expressions. The experiment outcomes said that the proposed solution could synthesize multi-factor normalization results while preserving identity. 12 Xiaoqian et al. conducted an experiment to investigate at what spatial resolution the human brain could recognize familiar faces from unfamiliar individuals. Whether this process depended on the distance between the observer and the face was investigated. The results showed that in blurred images with increased spatial resolution, the neural response in the occipital temporal region appeared and quickly reached saturation at approximately 6.3–8.7 cycles. The neural response disappeared when resolution decreased. 13 Hao et al. proposed a hyperspectral real recognition solution to address the band misalignment and high data dimensionality in hyperspectral real recognition. The experiment outcomes demonstrated that the algorithm achieved excellent results on three popular hyperspectral facial databases, outperforming most other methods. 14
In summary, in the current field of social recognition, there are many problems such as insufficient accuracy, high noise in facial image data, invasion of personal privacy in social recognition, and low recognition accuracy caused by occlusion. These are key issues in social recognition. How to improve the accuracy of current facial recognition and reduce data noise is the main issue of current research. This study proposes a new wavelet transform MTCNN and GA-based facial recognition system to reduce the impact of noise in facial data recognition. Meanwhile, the GA model is used to improve the feature compensation and expression. The recognition of facial data processing may need to protect the privacy of the individual data. Different races and groups of people directly affect recognition effects. There are differences. Therefore, the research proposes to improve the MTCNN method, which can solve the denoising problem in facial data recognition. The improved method can also improve the recognition performance of the model. GA can realize the feature compensation and data representation in facial recognition. Therefore, GA is used to improve MTCNN for facial recognition.
Facial recognition model for improving deep CNN algorithms
This work focuses on the facial recognition accuracy by building a new facial recognition model. The study analyzes the main framework and structure of the model. Then, the model is improved by adding GA and feature extraction techniques to improve the precision and accuracy of facial image recognition.
Deep CNN algorithm for facial recognition
In facial recognition analysis, it is crucial to analyze and detect the data and location information of the face. To analyze facial data stably, wavelet transform and improved MTCNN facial detection algorithm are used. The MTCNN algorithm is an efficient facial detection and alignment technique widely used to accurately detect faces and their key feature points from images. The advantage of MTCNN lies in its hierarchical structure, which consists of three stages of CNNs connected in series to achieve fast and accurate facial detection. The current system framework structure is shown in Figure 1. System model framework structure. (Image source: https://www.1001freedownloads.com/free-photo/boy-face-happy-child).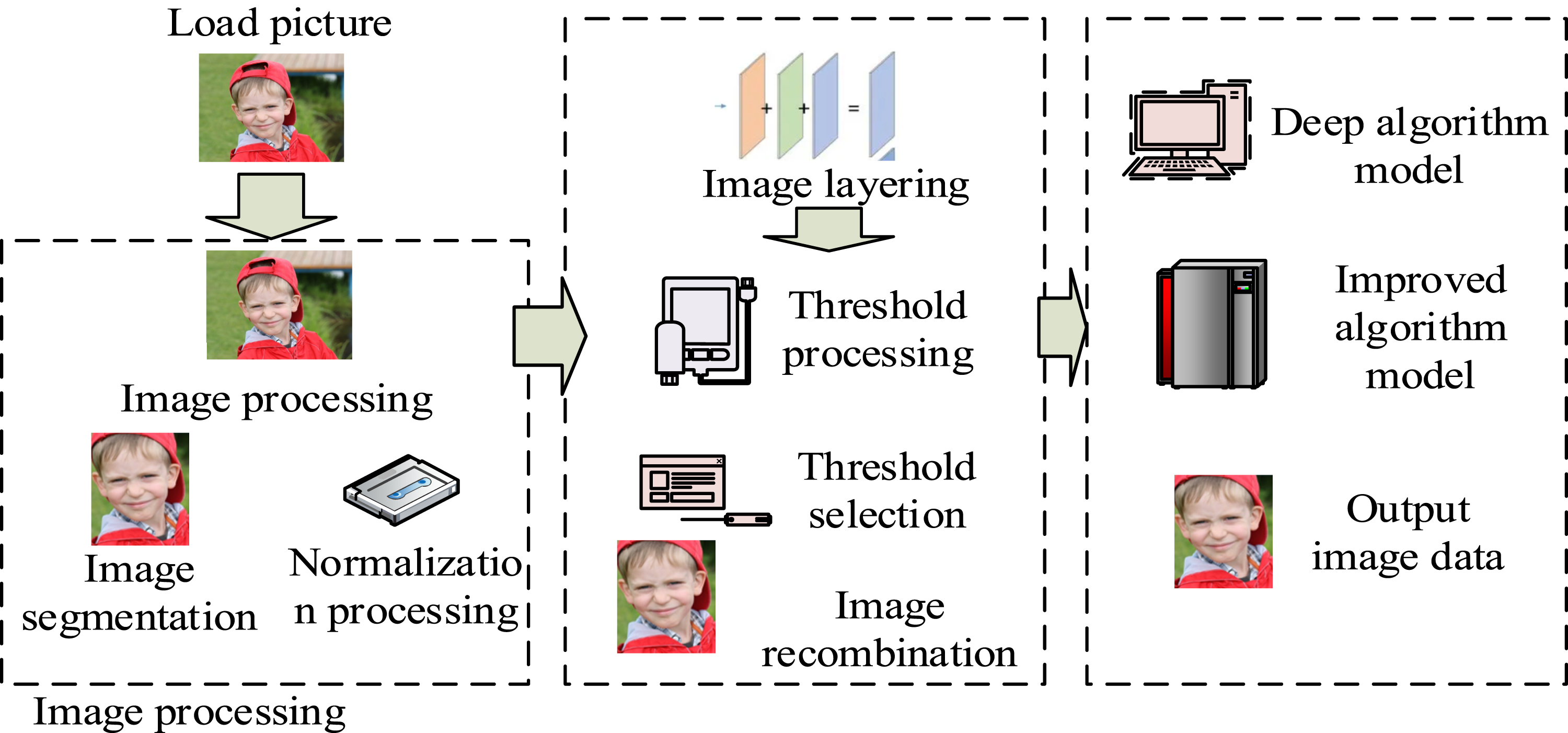
In Figure 1, the data processing and loading module for facial images includes several operational steps, including facial image segmentation, data normalization, and balanced distribution of facial images. Then, in the data denoising, the image data are first subjected to threshold conversion and processing. Then, the threshold is selected and analyzed to transfer the reconstructed facial image data into the algorithm. The processed facial data can only be input into the simulation model. The obtained facial used to construct the facial image. In the denoising process of the model, analyzing the original image to reduce its resolution size is of great significance. A relative threshold size is set. The eliminated noise data with a threshold coefficient are simply retained. The data below the threshold are set to 0. Finally, the wavelet transform coefficient is used to reconstruct the facial image through the wavelet inverse transform. At this point, the obtained facial data have already eliminated the influence of noise. Wavelet transform is used in the denoising process of face recognition. Firstly, Daubechies series wavelet bases are used to capture local features. Secondly, at the decomposition level, an adaptive hierarchical strategy is adopted, where the first and second layers mainly handle random noise, while the third and higher layers capture structural noise. In terms of threshold processing, a hybrid threshold function is proposed, which uses differential thresholds for different frequency sub bands and optimizes threshold weights through GA to dynamically balance denoising and feature preservation. The schematic diagram of the current MTCNN main stage process framework is shown in Figure 2. Schematic diagram of MTCNN main stage process framework. (Image source: https://www.1001freedownloads.com/free-photo/boy-face-happy-child).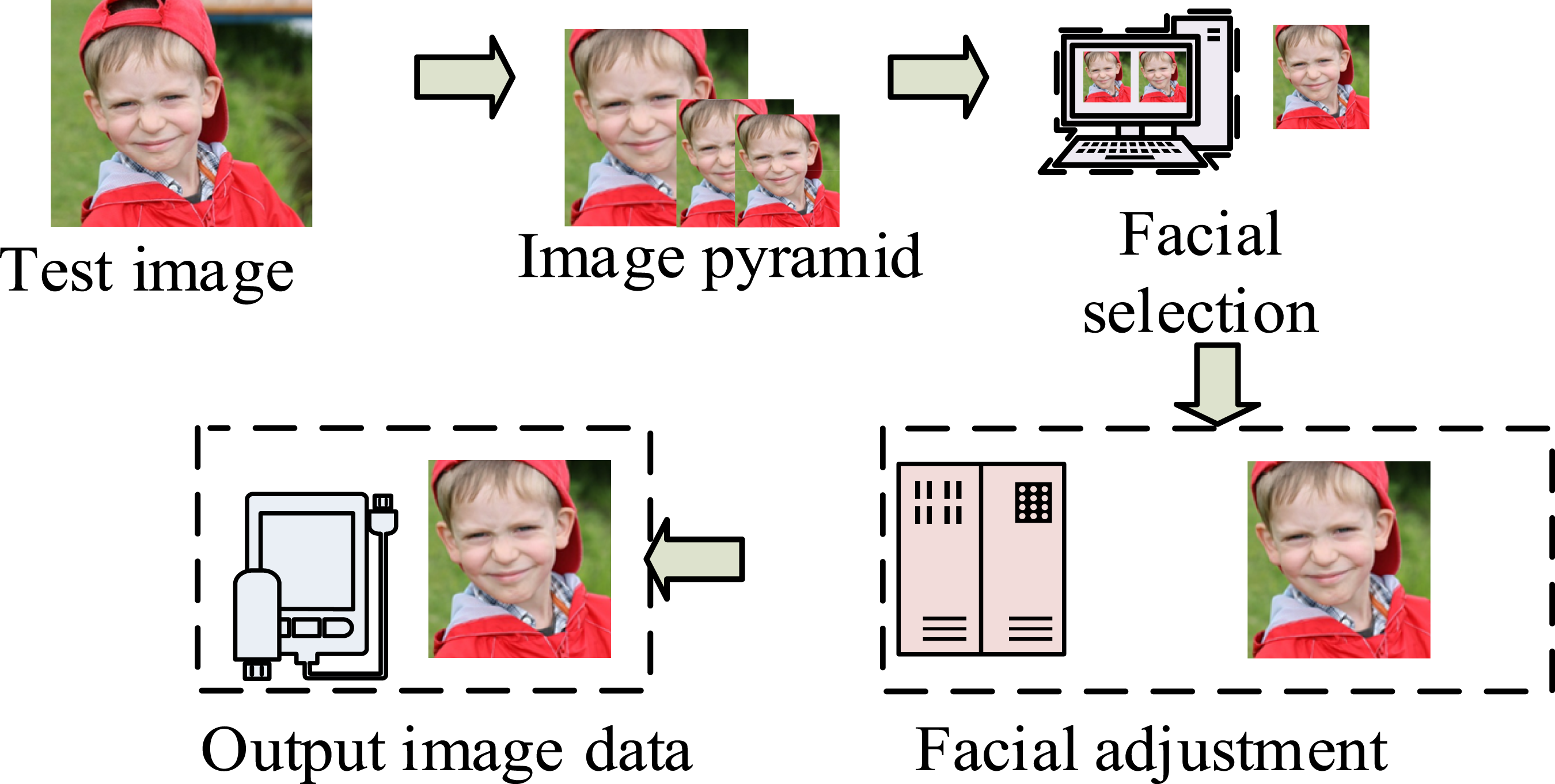
From Figure 2, when the detected image information is input, the MTCNN structure will enlarge and shrink the image structure, and build a pyramid model of the image. Then, the three CNN structures of MTCNN are used to detect and adjust the facial image. Finally, the current required facial image data are output. The largest detection structure in the MTCNN model is the selection of facial frames. This structure calculates the intersection of the human facial images based on the detection results, while retaining only the maximum result for the intersection values. At this point, the obtained threshold will not be too low, which will reduce the accuracy of the filtered image. The intersection calculation is shown in equation (1)15,16

In equation (1), The main image processing flow of the MTCNN model. (Image source: https://www.1001freedownloads.com/free-photo/boy-face-happy-child).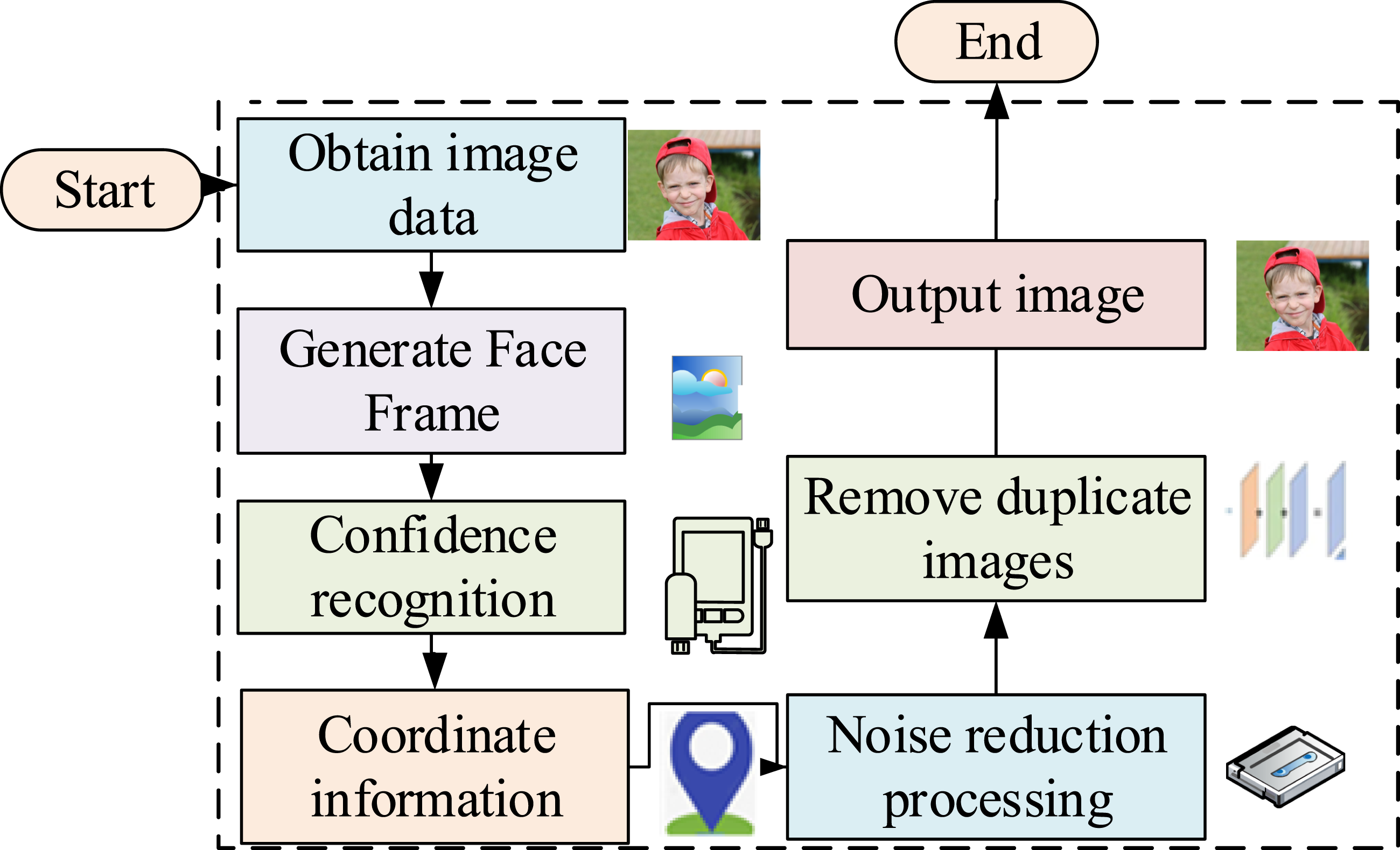
From Figure 3, the MTCNN model first obtains the height and width. Then, if the image data are too large, a facial frame is generated. The coordinate information of the image is obtained through confidence recognition. Then, the image data are denoised and input into the network model. The frame is then calculated for fit while removing duplicate facial images. Finally, the final size of the facial wireframe is obtained. The input sample value size of the algorithm at this time is shown in equation (2)17,18
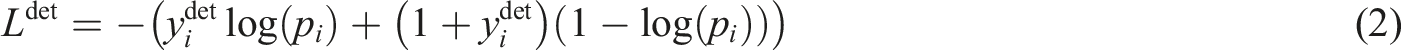
In equation (2),

In equation (3),

In equation (4),

In equation (5),
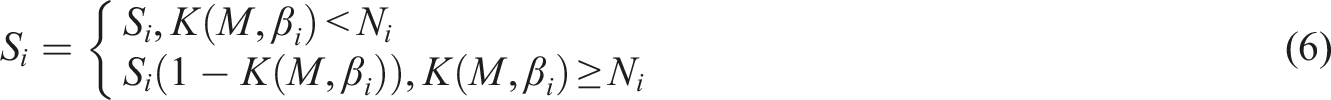
In equation (6),
Improvement of facial recognition algorithm and system model building for deep CNN
The study improves the model in the above subsection to improve the recognition accuracy of the current system. This is achieved by adding the computational factor, the original image feature extraction, and GA into the system model. The improved model calculates the initial compensation factor of the MTCNN algorithm to obtain the original image. Then, the feature data through GA are compensated and selected to obtain the weighted image feature map of the feature model. At this time, the obtained facial feature image is the most accurate feature image. Figure 4 shows the process of extracting the initial model feature image. Process of initial image extraction of model features. (Image source: https://www.1001freedownloads.com/free-photo/boy-face-happy-child).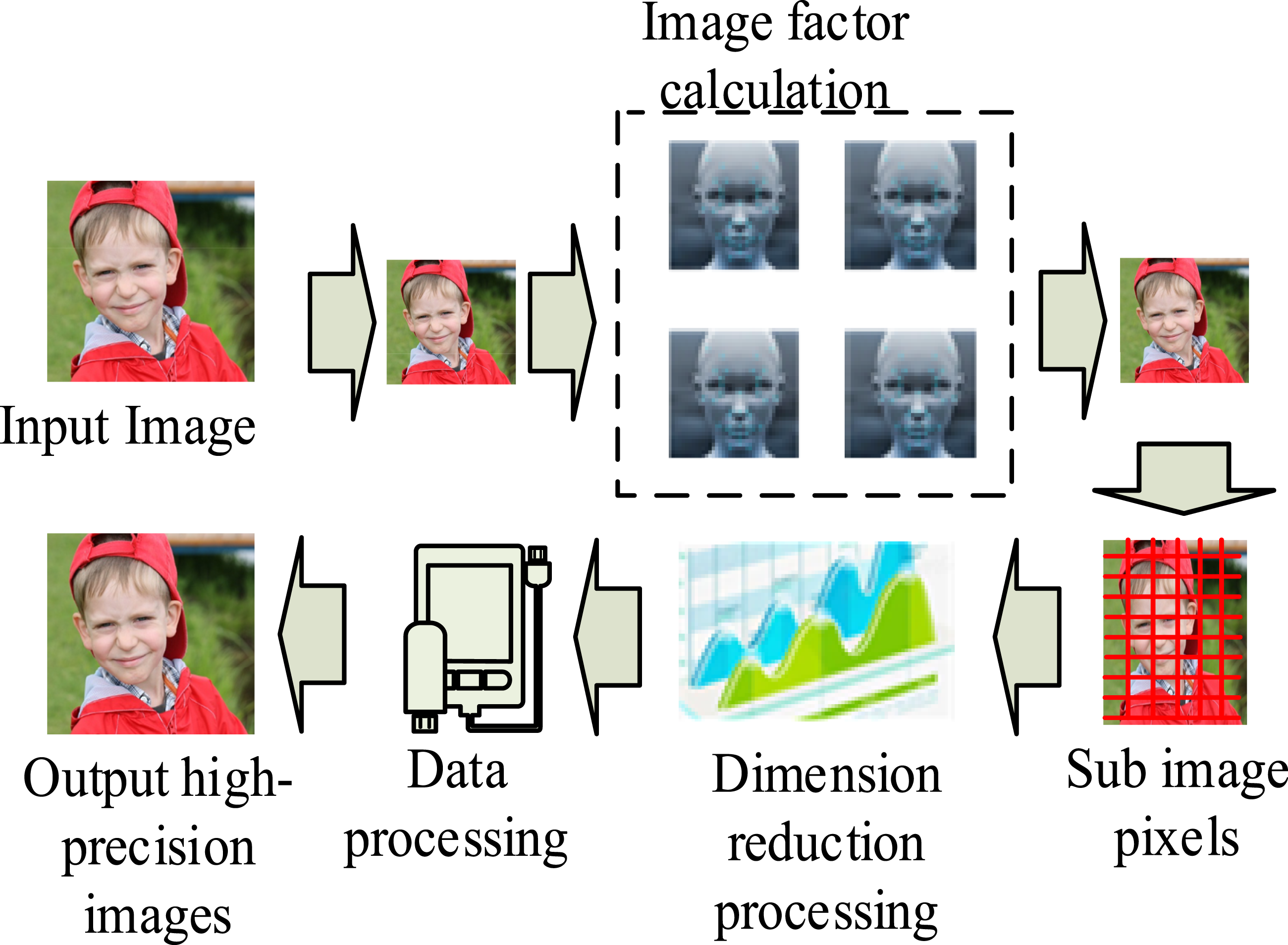
In Figure 4, first, the improved feature image converts the inserted facial data to an image with a larger gray value. Second, a new compensation factor is generated on the basis of the gray image. The optimal compensation coefficient is solved through GA for the compensation factor. Then, the obtained optimal compensation coefficient is input into the image recognition system of MTCNN to generate the most original feature description image. The image is then split into multiple sub-image data. A new facial image is obtained by calculating the pixel size of the sub-images. Finally, the obtained image information is dimensionally reduced to obtain the final high-precision image. Among them, GA, with its powerful global search capabilities and adaptability, dynamically adjusts compensation coefficients to perform pixel-level compensation on image sub regions, generating high-precision feature maps that enhance the model’s robustness to low-quality images. GA not only optimizes compensation coefficients but also further improves feature expression capabilities through global optimal solution search, avoiding the feature degradation issues encountered by traditional methods in complex scenes. Many coefficients need to be compensated in the improved system model, which can be used to lift the size of the feature values. The obtained feature images can be represented by compensation factors, as shown in equation (7)
23
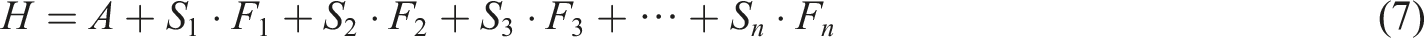
In equation (7), Comparison of new images obtained after compensation. (Image source: https://www.1001freedownloads.com/free-photo/boy-face-happy-child).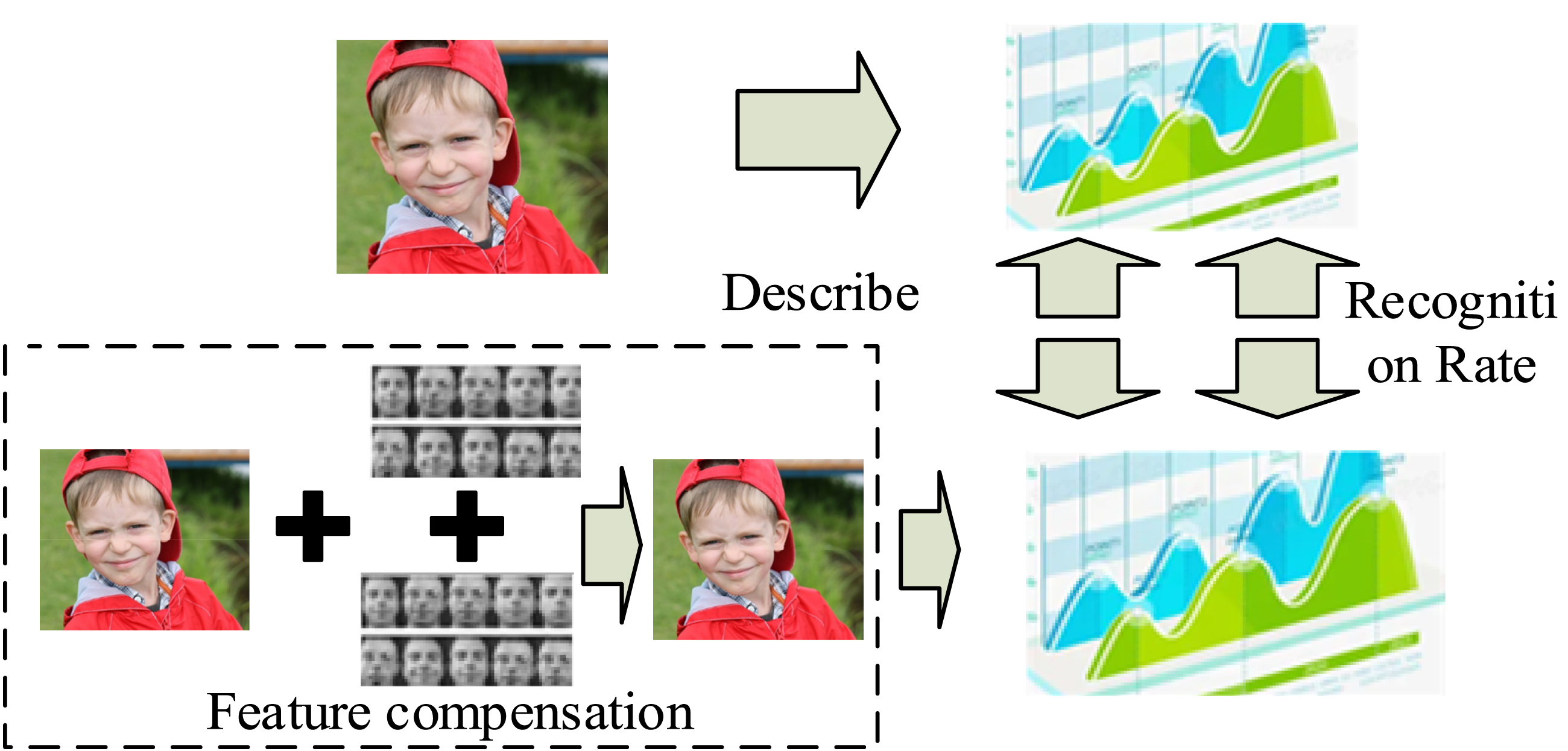
From Figure 5, the obtained new image data obtain a new histogram data image after improving the recognition rate and data layout. Meanwhile, the pixel value of the generated image also changes. The image value obtained by feature compensation can also generate new image pixels. At this time, the pixel size of the two images depends on the compensation coefficient size and calculation factor. Therefore, when these two values change, the clarity and accuracy of images can be greatly improved. A new compensation factor calculation method needs to be added to obtain a better compensation coefficient, as shown in equation (8)

In equation (8),

In equation (9),

In equation (10),

In equation (11),

In equation (12),

In equation (13), Improved system model process. (Image source: https://www.1001freedownloads.com/free-photo/boy-face-happy-child).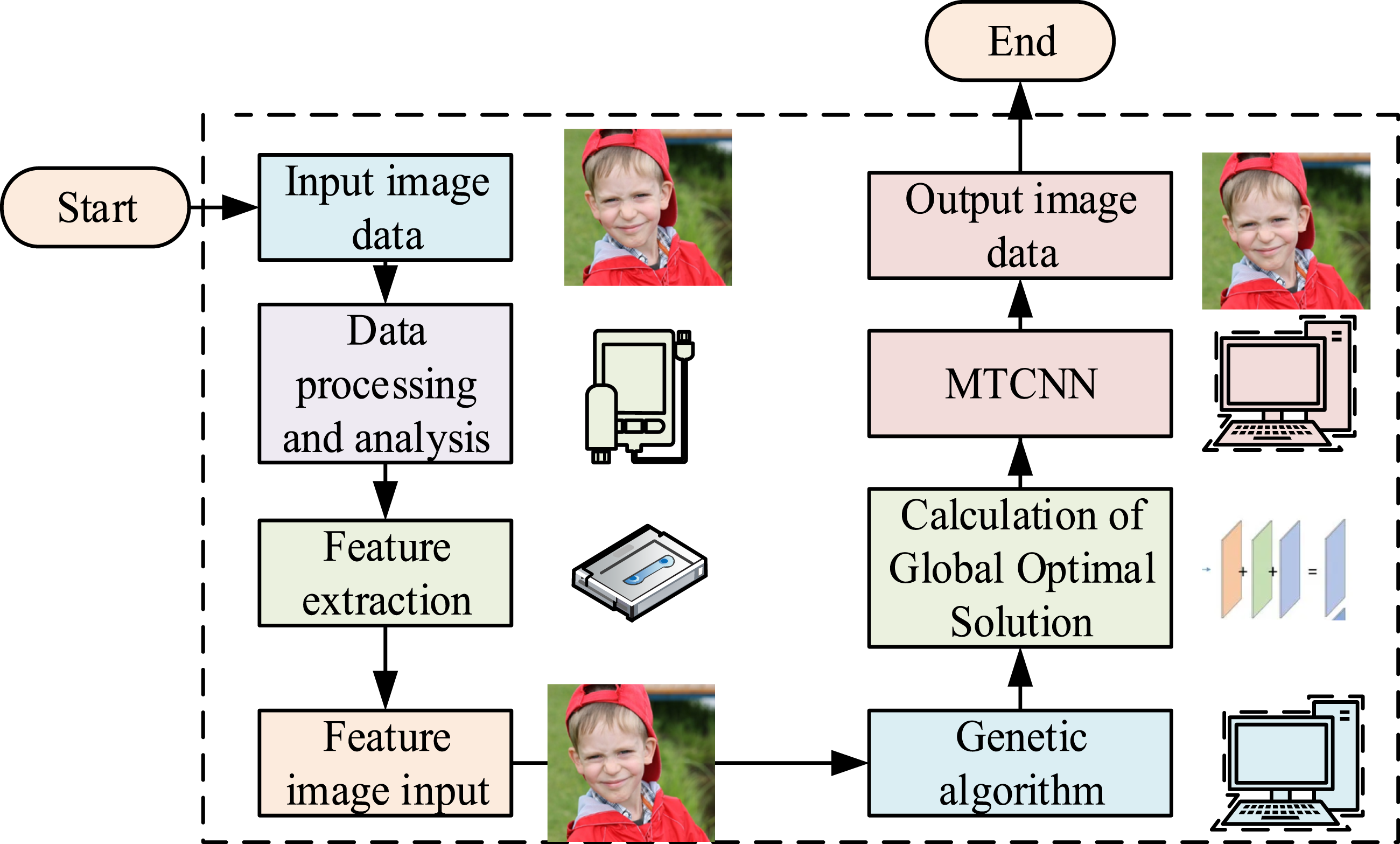
In Figure 6, when the facial image data are input, the image is firstly processed and analyzed on the basis of the three levels of CNN through the MTCNN model. The initial image information is subjected to normalization, segmentation, and equalization. The data information of the image is obtained through the feature extraction after obtaining the new image data. The obtained featured image is inputted into the GA. GA is applied to remove the signal from the image. Signal noise is reduced to get the population optimum of the facial image data. Then, the boundary is pulled based on the confidence of the image. The global optimal solution of the current image data is calculated. Then, the global optimal solution obtained is input into the MTCNN again to calculate the final image data. The dimensionality is reduced. The image is scaled to the size 24*24 through the MTCNN model of the image cropping. The overlap between the image borders is calculated. The image repetition is removed through the model. Then, the final image obtained at this point is a clearer and more accurate facial image. Finally, the facial data are analyzed through simulation experiments to explore the practical feasibility and performance effect of the research algorithm.
The proposed facial recognition system should process biometric data, which may pose a risk of identity exposure, especially in financial security applications. The experiments used the CelebA dataset, which is dominated by celebrities, and the VGGFace2 dataset, which has an imbalanced demographic distribution, which may amplify racial and gender biases. Therefore, in future research improvements, wavelet denoising techniques should be used to remove identity-related features, fairness metrics should be used to test the model across different subgroups, and “privacy by design” principles should be integrated to achieve GDPR-compliant deployment. The formula for testing indicators used in the study is shown in equation (14)

In equation (14),
Test of the proposed deep CNN for facial recognition
When processing input images using the MTCNN model, pyramid scaling is first performed to construct multi-scale images. The images are then uniformly scaled to 24×24 pixels through cropping. The images are normalized and histogram equalized, and segmentation is performed to balance the distribution of different categories of faces. The CelebA dataset is divided equally into two independent subsets for cross-validation. The dataset used for the research experiments is the CelebA dataset, which consists of 200,000 facial image data. The CelebA dataset includes several different facial expression information. More than 10,000 real face instances include facial images obtained under different environmental conditions. The selected system CPU for the study is 4Cores, with 32 GB of RAM and 100 GB of disk. The initial learning rate of the algorithm is set to 0.01, and the weight value is set to 0.0005. In the pre-experiments, multiple learning rates (0.001, 0.01, and 0.1) are compared. A learning rate of 0.01 avoids excessive oscillation and quickly converges at the beginning of the model. The weight decay parameter is set to 0.0005, which is chosen after testing different values (0.0001, 0.0005, and 0.001) on the validation set. The selected value of 0.0005 provides good results between suppressing overfitting and maintaining dynamic balance in model training. The dataset is divided into two equally sized facial image datasets. The recognition accuracy of the traditional algorithm, Local Binary Patterns (LBP), Internal Gateway Protocol (IGP), Load Average Algorithm (LAA), and the algorithm used in the study is compared to test the feasibility of the current research method model, as shown in Figure 7. Accuracy of four algorithms. (a) Dataset 1, (b) Dataset 2.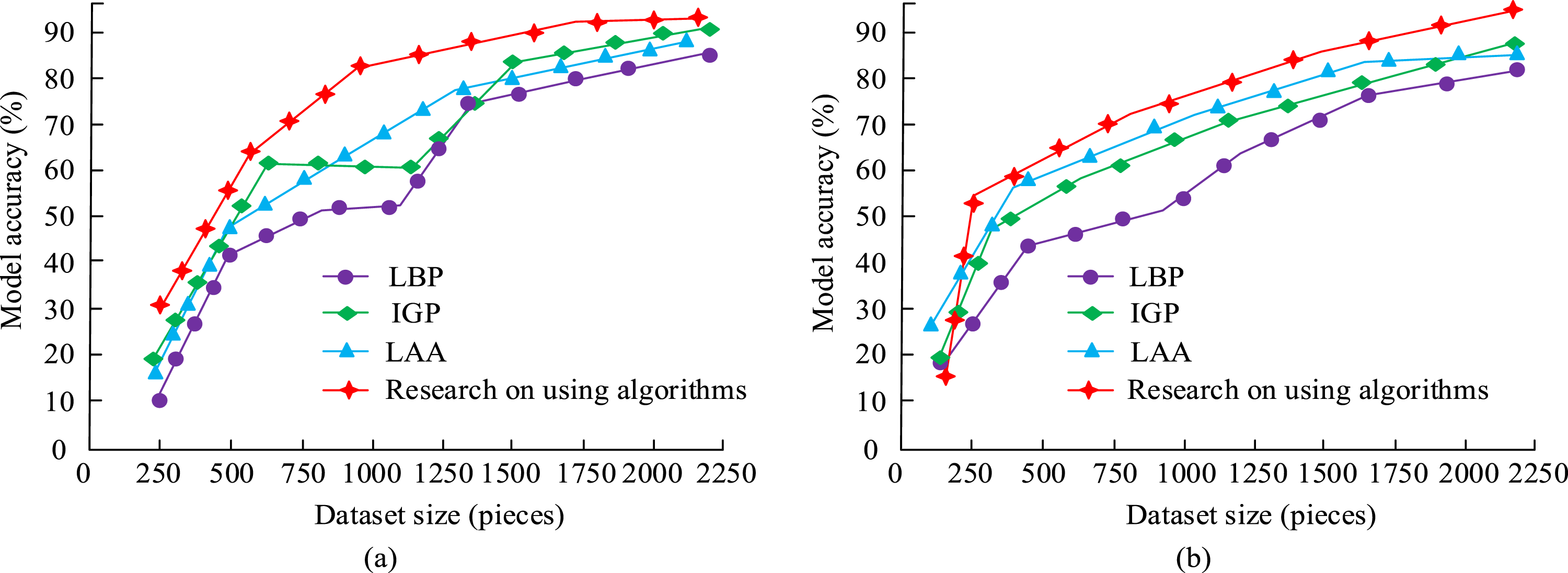
From Figure 7(a), the accuracy of the algorithm increased with the increase of sample data. However, when the image data is between 250 and 2000, except for the algorithm used in the study, the accuracy change curves of all other algorithms showed significant fluctuations. This may be due to the better denoising effect and algorithmic performance of the research algorithm for image data. However, in Figure 7(b), the accuracy changes of the four algorithms showed an upward trend, without significant fluctuation. This may be due to the increase in dataset improving algorithm performance. However, the algorithm tended to a steady state subsequently. The accuracy values of the research algorithms used in datasets 1 and 2 were higher than those of the other three algorithms. The highest accuracy of the research algorithms used in dataset 1 was 92.3%. The highest accuracy was 94.6% in dataset 2. In dataset 1, the accuracy was 16.0%, 10.0%, and 8.7% higher than that of 76.3%, 82.3%, and 83.6% of LBP, LGP, and LAA algorithms. In dataset 2, the accuracy was 15.3%, 10.1%, and 13.3% higher than that of 79.3%, 84.5%, and 81.3% of LBP, LGP, and LAA. This is due to the fact that the study uses methods that use better noise reduction processing and optimal solution of the data. In Figure 7(a), it is shown that the accuracy of LAA and the algorithm used in the study deviates from a linear relationship and decreases in some cases. This is mainly due to the complexity of the dataset, including factors such as noise, low-quality images, and lighting variations. In addition, when the sample size is small, the performance of the algorithm may also be greatly affected. Figure 7(b) shows a slight deviation from the linear relationship, which may be due to the diversity of the dataset, the degree of model optimization, and the randomness in the training process. To test the effectiveness of the current research method in ablation testing, the recognition accuracy of the research algorithm is compared with the MTCNN and GA. The results are shown in Figure 8. Comparison of accuracy of ablation pressure recognition using algorithm models. (a) Dataset 1, (b) Dataset 2.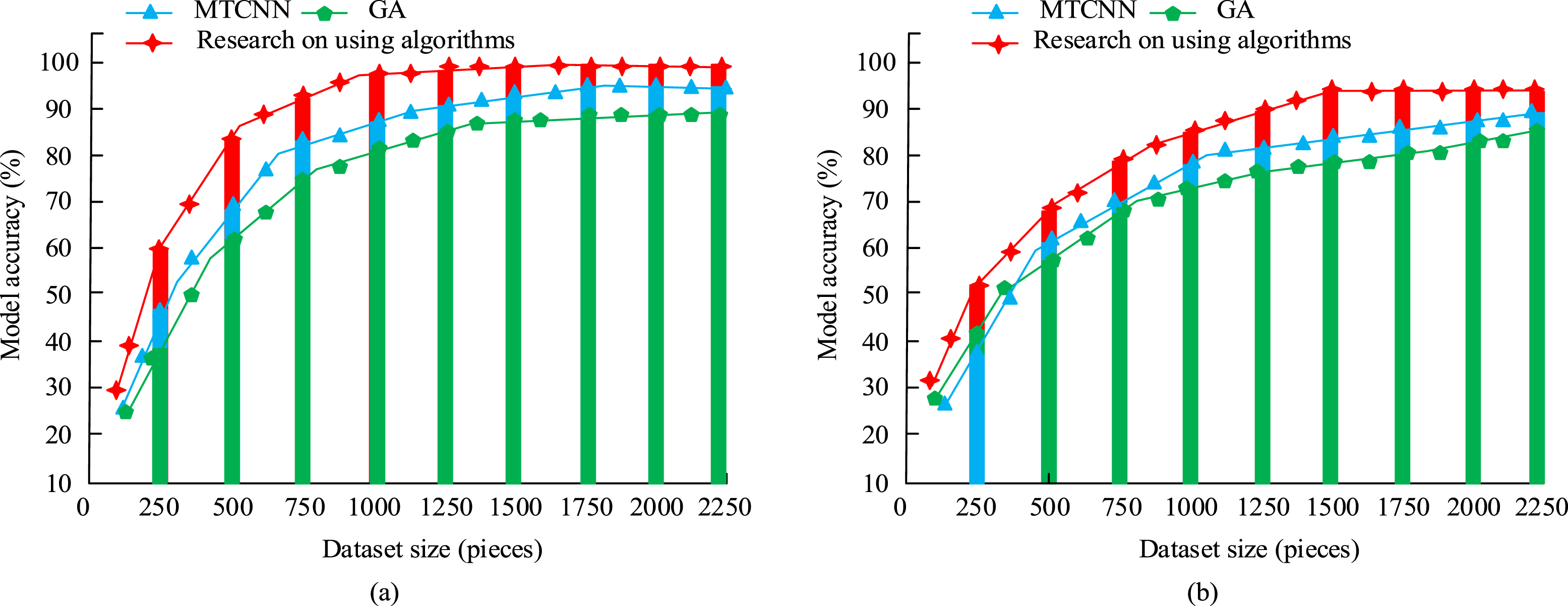
Performance comparison of different algorithms.
Comparison test of accuracy of random compensation coefficients for three algorithms.
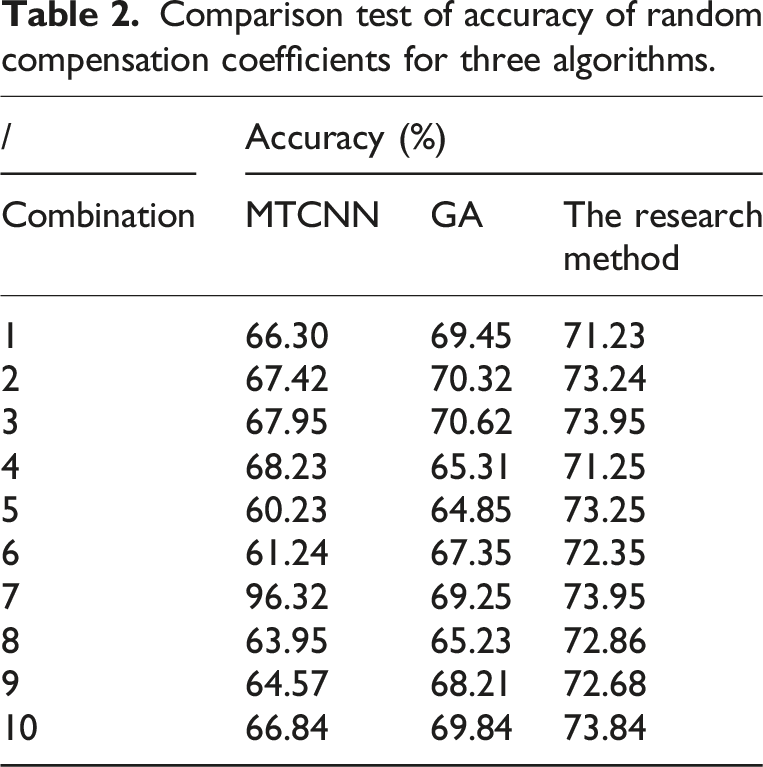
From Table 2, the proposed method had the highest accuracy value among different compensation coefficient combinations. When combining the compensation coefficients of 3, the accuracy of the research algorithm was 73.95%. Compared with the accuracy of 67.95% in the MTCNN model, it was 6.00% higher. Compared with the accuracy of 70.62% in GA, it was 3.33% higher. The algorithm accuracy is improved after adding compensation coefficients. This may be due to the improvement of the overall validation effect of the model after adding compensation coefficients, which enhances the accuracy of facial image recognition. The half error rate and error rate of the current model, GA, and MTCNN model are analyzed and compared, as shown in Figure 9. The smaller the value of the half error rate, the better the model. Comparison of half error rate and error rate of three models. (a) Error rate, (b) Half error rate.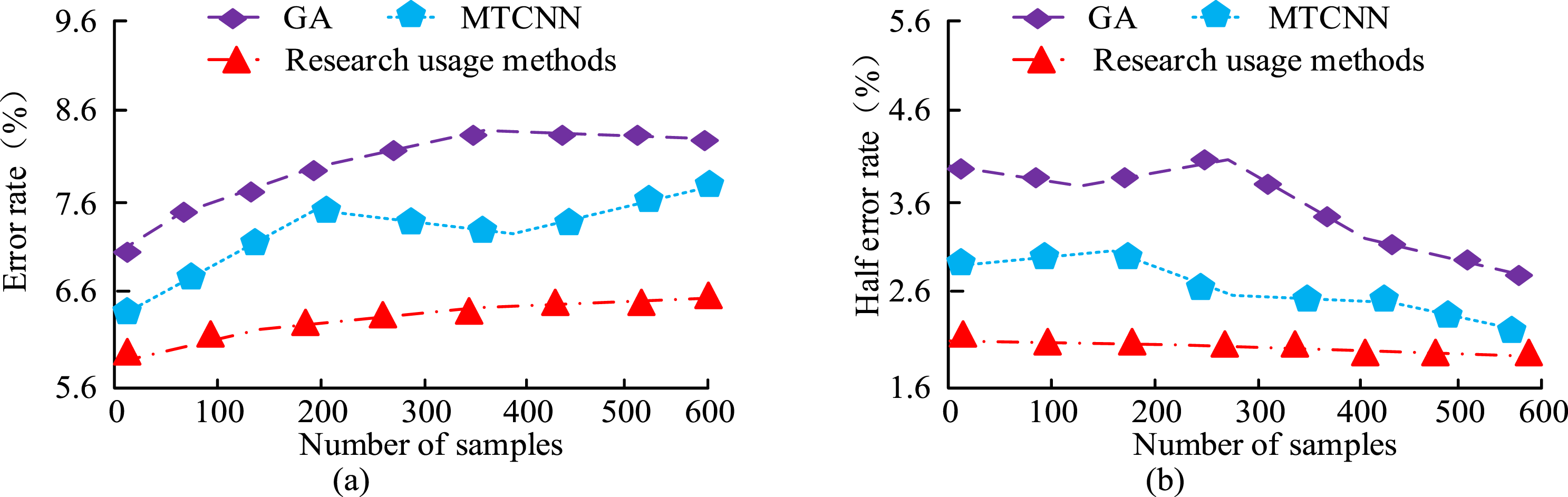
From Figure 9(a), the error rates of the three algorithms increased with the increase of sample size, and then tended to a relatively stable state. The algorithm used in the study had the lowest error rate in a relatively stable state, only 6.2%, which was 1.5% and 1.9% lower than the 7.7% and 8.1% of other algorithms, respectively. The performance of the research algorithm is better, with relatively lower recognition errors. This may be because research algorithms adopt better processing mechanisms when processing data. From Figure 9(b), the half error rate of the three algorithms decreased with the increase of sample size. The lowest half error rate of the research algorithm was 1.9%, which was 0.1% and 0.9% lower than the half error rate values of other algorithms of 2.0% and 2.8%. The research algorithm has better performance. From the comparison, the model in facial data recognition has a more efficient recognition efficiency, while the recognition effect and accuracy are better improved. In Figure 9, the error rate of the MTCNN model shows a small linear deviation. This is mainly because the MTCNN model adopts a multi task cascaded convolutional neural network structure in its design, which can effectively handle multiple subtasks in face detection. To test the stability of the current research method, the loss function changes of five algorithms are compared and tested, as shown in Figure 10. Comparison of loss function changes among five algorithm models.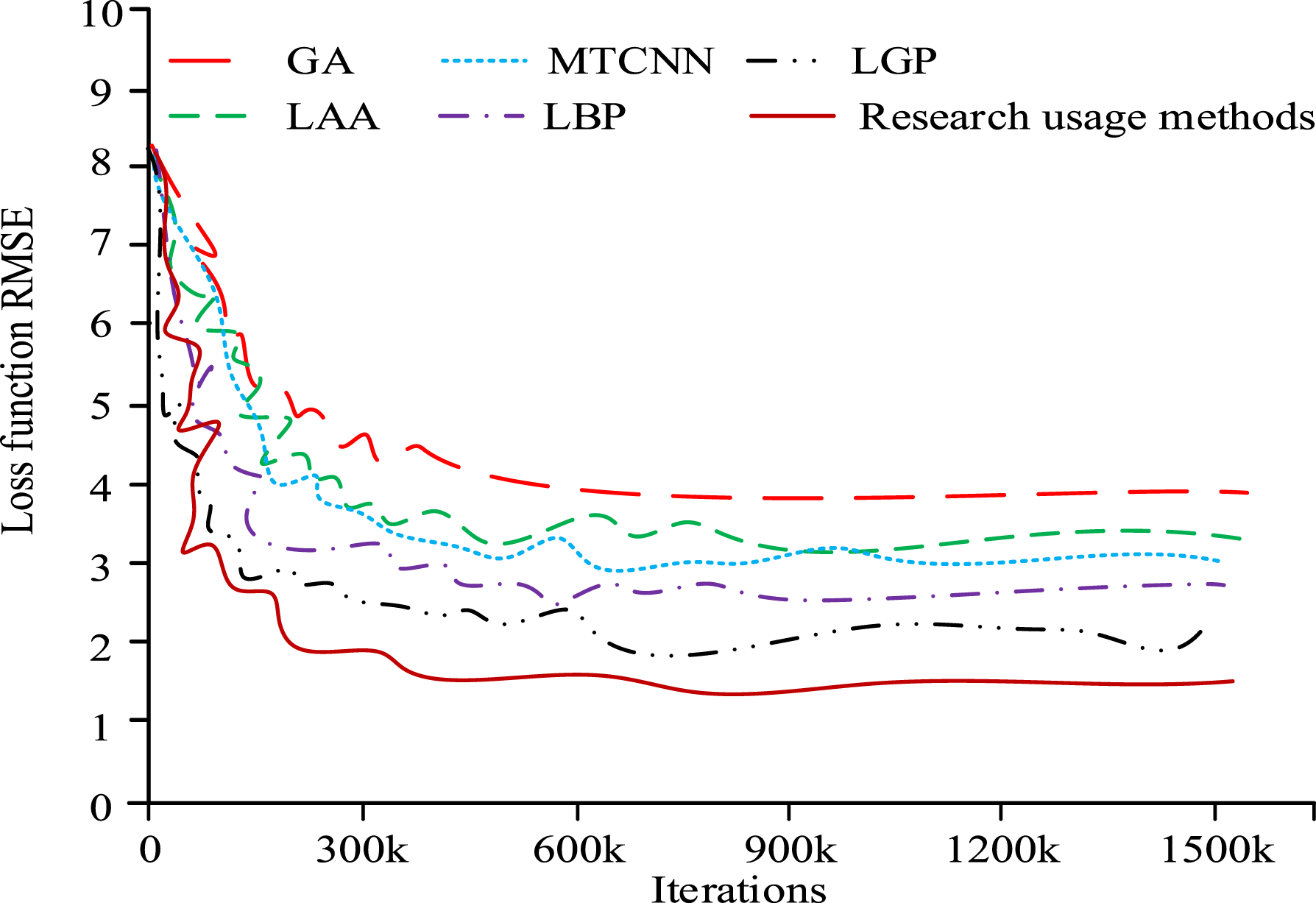
Comparison of test results for different datasets.
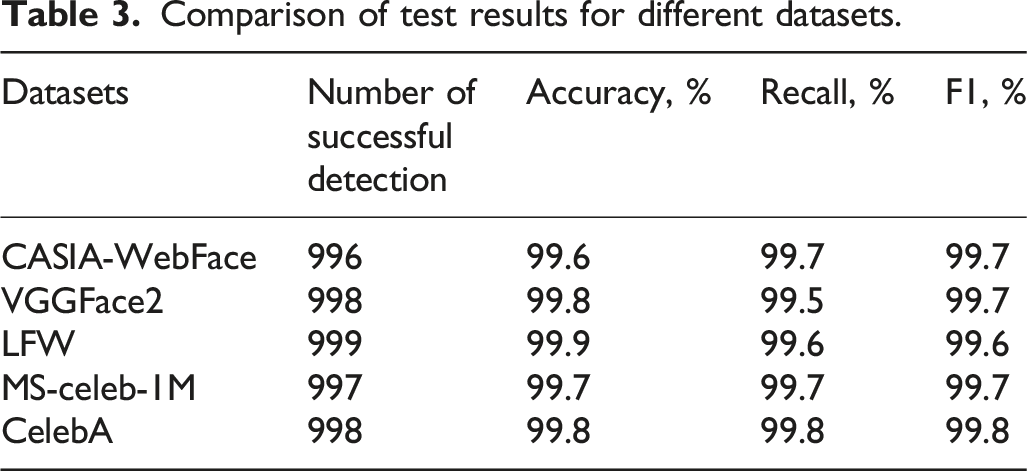
From Table 3, in the five datasets, the number of faces recognized by the research algorithm exceeded 990. The recognition accuracy of all the datasets was greater than 99.5%. These results indicate that the research algorithm is able to effectively analyze and recognize the facial data in the dataset. In the tests of the recall rate and the F1 value, the recall and the F1 value of the research algorithm were at a very high level. Therefore, the research algorithm can effectively recognize facial data, which has good recognition performance. The accuracy of different algorithms is compared between the testing set and the training set, as shown in Figure 11. Comparison of model test set and training set test results. (a) Training set, (b) Testing set.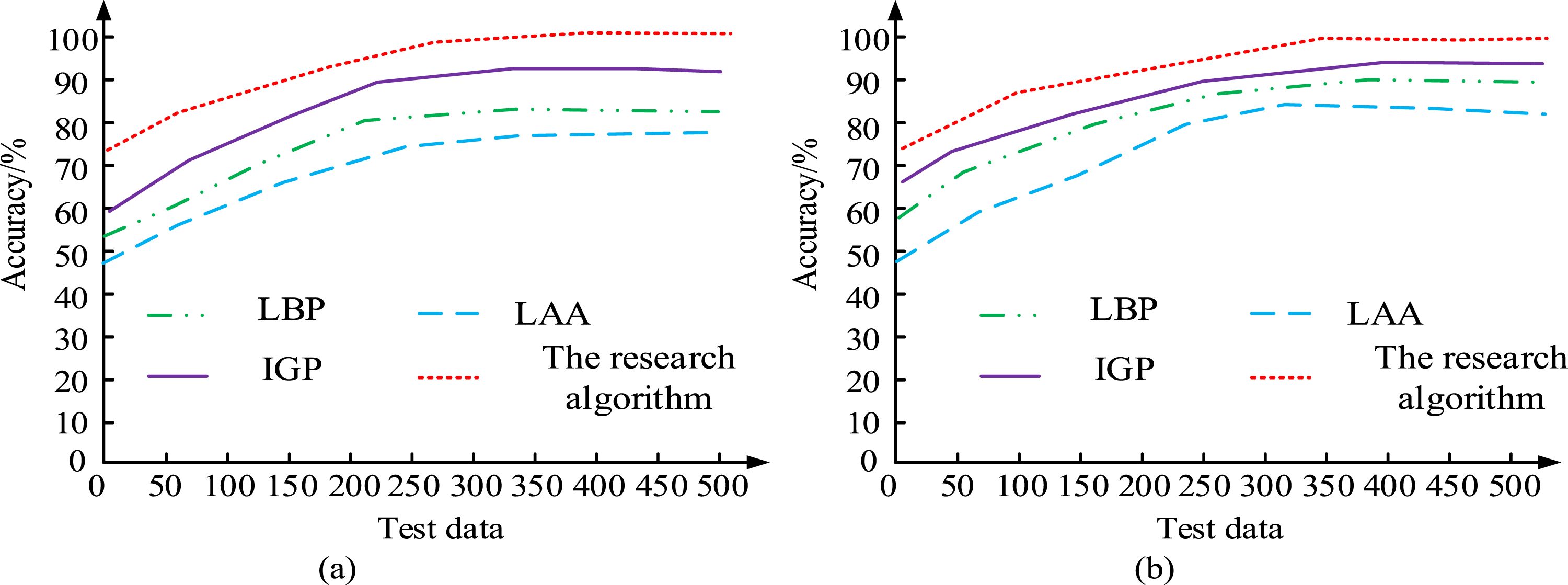
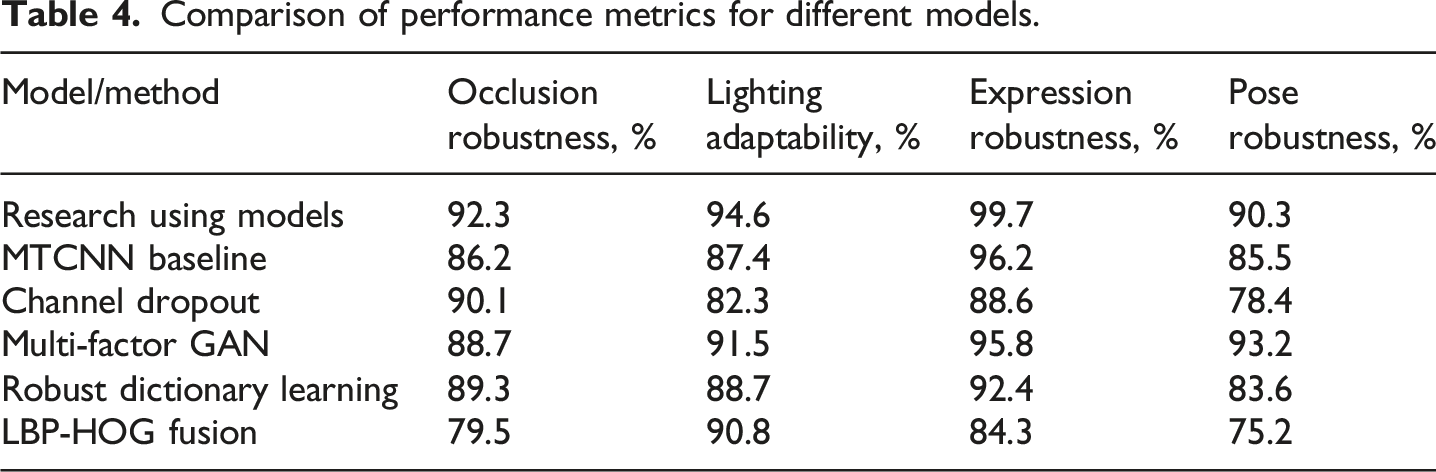
Comparison of performance metrics for different models.
Results of failure case analysis.

From Table 5, it can be seen that most recognition failure cases can be avoided by adjusting the model performance and testing process. Therefore, further adjustments should be made to the model performance and testing recognition process in the future research.
The study statistically validated different algorithm models, specifically verifying the significant differences between the research algorithm and the traditional LBP model. The results showed z = 18.6, p < 0.001. This indicates that the research algorithm achieved a 16.0% improvement in accuracy compared to the LBP model, with significant statistical significance (p < 0.001). In the 95% confidence interval comparison, the confidence interval for the research algorithm is [91.5% and 93.1%], while that for the LBP algorithm is [74.5% and 78.1%]. In the statistical validation of the genetic algorithm, z = 3.96, p < 0.001. All comparisons were significant (p < 0.01), and there were significant statistical differences between the validation effects of the research algorithm and the traditional algorithm (p < 0.01). Figure 12 shows some pseudocode used in the study. Pseudocode.
To reduce the complexity of the model used in the study, the processing of each frequency band in the wavelet transform can be performed in parallel. Additionally, the compensation coefficients can be fixed to eliminate the need for online optimization, and wavelet convolution can be accelerated using a GPU. Overall, the proposed wavelet-GA-MTCNN fusion strategy achieves a significant improvement in accuracy at the cost of approximately a 33% increase in runtime, with occlusion robustness improved by 6.1%, but real-time performance reduced to 6.25 FPS. This makes it suitable for security or access control systems that prioritize accuracy over real-time performance. Therefore, further optimization of feature expression efficiency will be pursued in subsequent research. Since the accuracy difference between the training and testing datasets is minimal, it indicates that the model performs well on unseen data. Additionally, the use of multiple diverse and representative datasets, combined with regularization techniques (such as weight decay) and stability validated through multiple experiments, further supports the model’s generalization ability. Therefore, the high accuracy is more likely due to reasonable model design, proper data preprocessing, and the effective application of regularization techniques, rather than overfitting.
Conclusion
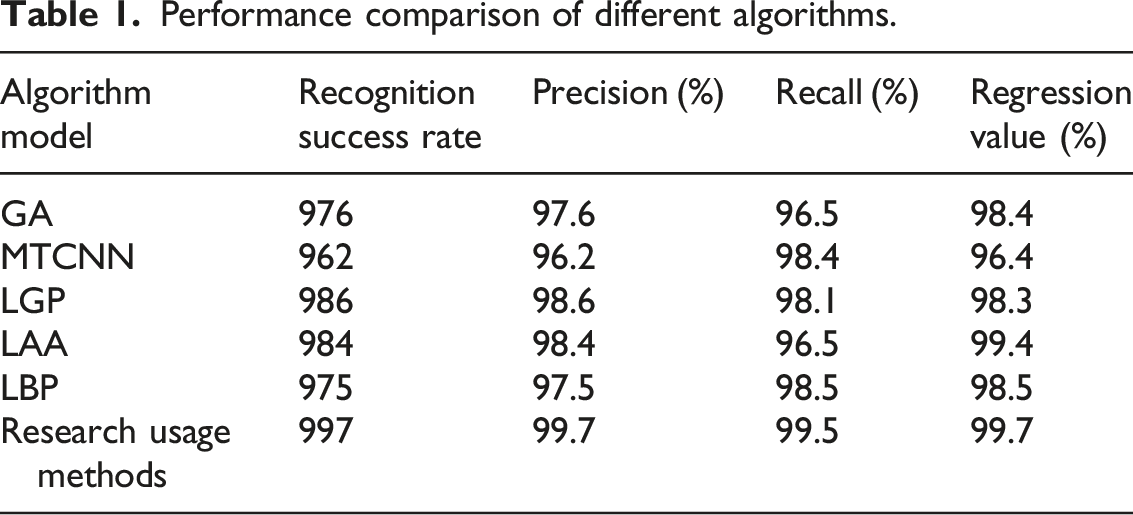
The study proposes a new facial recognition model that integrates wavelet transform, MTCNN, and GA, effectively addressing the issues of insufficient accuracy and significant image noise in existing facial recognition systems. Experiments show that on Dataset 1 and 2, the model achieves maximum accuracy rates of 92.3% and 94.6%, respectively, representing improvements of 8.7%–16.0% over traditional algorithms such as LBP and LGP. The model achieves a recognition success rate of 99.7%, with recall and precision rates of 99.5% and 99.7%, respectively, and an error rate as low as 6.2%, demonstrating significantly superior stability compared to the comparison algorithms. The new method significantly improves the accuracy and robustness of face recognition through wavelet transform denoising, GA-optimized feature compensation, and MTCNN framework improvements. However, the model’s adaptability to facial expressions still requires further optimization.
Footnotes
Funding
The author received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.