
Abstract
The spread of false news has hurt both individual practitioners and the media. To enhance the efficiency of false news detection, this study constructs a multi-modal news detection model. The model includes a text encoding module, a contextual semantic encoder, a news propagation encoder, and a false news detection model that integrates semantic features and image recognition. In the results, the multi-modal model showed significantly higher accuracy and F1 score in detecting false news than the unimodal model. Its accuracy and F1 score improved by an average of 7.57% and 7.34% on the POL and GOS datasets, and 7.20% and 6.38% on the WEIBO and TWITTER datasets. In addition, hyperparameter analysis showed that the model performance reached its optimum when the parameters r and k were adjusted to their optimal values. The ablation experiment further validated the importance of the channel attention mechanism and graph comparison method in improving model performance. The results indicate that multi-modal models have significant advantages in detecting false news and can effectively utilize information from different modalities to improve detection accuracy. This study is meaningful for evaluating the reliability of false news information and the media’s credibility in society. Although certain achievements have been made in the research, there are still some limitations. For example, the model may have generalization issues when tested on specific datasets, and the complexity of the model may make deployment difficult in resource-constrained environments. Future work will explore simplified versions of the model and conduct tests on more diverse datasets to enhance the model’s generalization ability and practicability.
Introduction
The promotion of information technology has made the Internet the main channel for information dissemination, greatly promoting the rapid and widespread dissemination of information.1,2 However, the other side of this phenomenon is the proliferation of false news, which not only damages the news’ authenticity and the media’s credibility but also poses a serious threat to social order and the psychological safety of the people.3,4 Therefore, it is urgent to address the issue of effectively detecting and curbing the spread of false news. At present, some scholars have also researched the detection of false news. Altheneyan et al. developed a false news recognition model that integrates big data technology and machine learning, focusing on the widespread dissemination of false news on Twitter. The F1 score of this model was 92.45%, better than the baseline method. 5 Capuano et al. designed a content-based False News Detection (FND) model to address the shortcomings of manual checks in mitigating the spread of false news. This model could accurately identify false news and achieve accurate classification. 6 Abualigah et al. proposed a model based on the fusion of a Convolutional Neural Network and a Long Short-Term Memory Network (CNN-LSTM) to address the acceleration of the spread of false information caused by the development of the Internet. The fusion model had a high accuracy in handling and classifying false news, with a value of 98.974%. 7 Mohawesh et al. proposed a recognition model based on relational variables to deal with the difficulty of detecting false news caused by language complexity. The model improved the language conversion rate by 3.97% and the accuracy of detecting false information by 2.88%. 8 The above-mentioned research on FND faces limitations in dataset generalization, timeliness of social context features, and insufficient fusion of multi-modal features. By introducing the Multi-Head Self-Attention (MHSA) mechanism, this study proposes an FND model combined Multimodal News Detection Model (MNDM) with Capsule Networks (CapsNet). The innovation lies in proposing a multi-modal detection model that integrates text, image, and social network information while introducing CapsNet to strengthen the model’s capacity to capture and represent entities and their attributes in images. This study aims to accurately identify false news and reduce its harm to society and humanity by constructing MNDM.
Compared with traditional news dissemination methods, the novelty of the research model lies in the mode fusion approach. Methods such as SAFE, SpotFake, and HMCAN are all in the form of text + image, while the proposed model is text + image + social network. Second, the proposed model feature extraction method is the CapsNet + channel attention + graph comparison method, which is superior to the traditional CNN and attention mechanisms of other methods. The contribution of this study lies in four aspects. (1) Through the dynamic routing mechanism of the CapsNet, the model can capture the entities and their attributes in the image more effectively, enhance the representation ability of image features, and thereby improve the accuracy of FND. (2) The channel attention mechanism enables the model to pay more attention to important feature channels, while the graph contrast rule enhances the processing ability of social network information through contrastive learning. The combination of the two further improves the model’s performance. (3) Through experiments on multiple datasets, the stability and superiority of the multi-modal model in different scenarios have been proved, providing a more reliable solution for FND. (4) The optimal parameter configuration of the model is determined through hyperparameter analysis, and the importance of the channel attention mechanism and the graph comparison method in improving the model performance is verified through ablation experiments, providing valuable references for subsequent research.
Methods and materials
Construction based on MNDM
The harm of false news is multifaceted. It not only damages the authenticity of the news and the credibility of the media but also poses a threat to social order and the psychological safety of the people. Strengthening the detection of false news has become particularly important.9,10 This study constructs MNDM based on this. In the text encoding module, when forwarding news for the first time, the written copy is defined as a copy vector, and the encoded news is the news vector. All news texts are processed using word segmentation and termination words. A single news text is defined as

In formula (1), Semantic encoder structure diagram.
Figure 1 shows the structure diagram of a semantic encoder, which is used to handle a collection of text sequences. The core idea of the max pooling layer is to obtain the most important feature information by selecting the maximum activation value. The average pooling layer focuses on less obvious features. It uses a max pooling layer to obtain local features and an average pooling layer to obtain global features. The main function of the FCL is to integrate news words into vectors and grammatical features and then integrate all features into a news text matrix. Shared networks are mainly composed of hidden layers and perceptrons, which are mapped based on local and global features to achieve dimensionality reduction. By assigning weights to the channel space of news texts and completing the summation process, a news text channel space with better semantic features can be obtained, as shown in formula (2).

In formula (2),

The news dissemination module mainly includes graph data augmentation, Graph Sample and Aggregation (GSA), and contrastive loss calculation, as shown in Figure 2. News communication module structure diagram.
Figure 2 shows the structure diagram of the news dissemination module, which is used to analyze and process the sequence of tweet text. Graph data augmentation technology improves the classification and prediction ability of neural networks. This method can remove edges with features in the user propagation network, and finally transform the propagation network into a subgraph for display. The core of GSA is to update the representation of the target node by sampling neighboring nodes and aggregating them. This model generally consists of several aggregation layers, and a single aggregation layer contains multiple aggregation functions. The workflow is to first randomly obtain node information from the aggregation layer, and fuse the feature information of the central node and the obtained nodes based on the aggregation function. The process of fusion and node acquisition can be carried out between different layers, enabling the network model to capture distant nodes.11,12 The relevant calculation is shown in formula (4).

In formula (4),

In formula (5), the temperature parameter of

The predicted result of
Construction of FND model integrating semantic features and image recognition
Model overview and structure
This study proposes an FND model based on semantic features and image recognition by combining the obtained news text features with image recognition. The model mainly consists of four modules, and the model structure is shown in Figure 3. The structure of FND model combining semantic feature and image recognition.
Figure 3 shows the structure of an FND model that combines semantic features and image recognition. In the visual enhancement encoder module, the input source is collected news images. There are two specific network models in this module. Predictive networks can represent the presentation forms of multiple enhanced perspectives in images. The target network defines the presentation form as the object to be predicted. By using a loss function to connect and train, the ability to express the target object can be improved. The module uses the image enhancement method to improve image quality and highlight the feature information of key graphics, facilitating subsequent network training.13,14 After calculating the corresponding errors based on the projection vector of the prediction layer and the target vector, the subgraphs of the target network and the prediction network can represent the comparative loss, as shown in formula (7).

In formula (7),

In formula (8),
Semantic encoder and CapsNet
The visual enhancement encoder is followed by the semantic encoder of the context. This module mainly consists of two encoders and a CapsNet. To accurately obtain global features, this study first uses a BERT encoder. This encoder does not adopt the structure of a Recurrent Neural Network (RNN). Therefore, this study adopts Positional Encoding (PE) to preserve the positional information of individual phrases in news samples, and the positional information

In formula (9),

In formula (10),

By inputting all the outputs of the self-attention heads into MHSA, a text vector based on the global context of the news sample can be obtained, as shown in formula (12).

In formula (12),
Multi-modal fusion and model evaluation
In addition to the BERT encoder, this study uses the CNN-BiLSTM encoder to obtain local contextual features. In CNN, convolutional kernels adopt a shared weight approach, where kernels of the same class have the same parameter values, significantly lowering the number of parameters in the network model. In Bi-LSTM, due to the presence of forward and backward hidden layers, the output values obtained by CNN convolution are imported into Bi-LSTM to obtain the mathematical expression of the local context, as shown in formula (13).

In formula (13),

In formula (14), Schematic diagram of CapsNet connection.
Figure 4 shows a schematic diagram of the connections between capsules in the CapsNet. CapsNet is a new type of neural network structure, aiming to improve the model’s understanding and processing ability of spatial hierarchical relationships. The dynamic routing mechanism is a key innovation of CapsNet, used to dynamically allocate connection weights between capsules at different levels. Through repeated iterations, the routing mechanism can determine the optimal connection method between low-level capsules and high-level capsules, effectively conveying entity information. In CapsNet, shallow capsules are typically obtained by multiplying a weight matrix with low-level capsules, and the weight matrix is a shared matrix between intermediate features and low-level capsules.17,18 When training the capsule model, the capsule activates shallow capsules with a certain probability. The expression of probability is shown in formula (15).

In formula (15),

In formula (16),

In formula (17),

In formula (18),

In formula (19),
Finally, in the process of developing and deploying the FND model, ethical issues, potential biases of the dataset, and the challenges of technical implementation must be carefully considered. First of all, ethical issues involve user privacy and data protection. The model needs to ensure compliance with relevant privacy regulations and ethical standards when processing personal data to prevent data leakage or abuse. Secondly, the bias of the dataset may affect the fairness and accuracy of the model. For example, if certain groups or viewpoints in the training dataset are over-represented or under-represented, the model may learn these biases and reflect them in the predictions. Therefore, it is necessary to ensure the diversity and representativeness of the dataset and introduce fairness considerations in the model design. The deployment challenges of the model include how to ensure its robustness and reliability in different environments, as well as how to enable non-technical users to understand and trust the predicted results of the model. The solution to these problems requires not only technological progress but also interdisciplinary cooperation, including the joint efforts of experts in fields such as law, sociology, and ethics.
Results
Performance testing based on MNDM
In the performance testing of the news detection model, POL and GOS datasets from FakeNewNet are selected. The experimental environment is as follows: the processor is Intel Xeon E5-2698 v4, the memory is 30 GB, the graphics card is NVIDIA GeForce RTX 3050, the programming language is Python 3.8, and the deep learning framework is PyTorch 1.11.0. The learning rate of the network structure is 0.05, and the temperature parameter is 0.1. The dimension of the hidden layer is 128 and the learning rate is 0.05. Before conducting model training, the data need to be preprocessed. (1) Text cleaning: Unrelated characters and punctuation are removed, words are extracted from the text, and stem extraction or morphological restoration is performed. (2) Image preprocessing: The input image is resized, normalized, and grayscale converted to meet the input requirements of the model. (3) Data Annotation: It is necessary to ensure that all data samples are correctly labeled as true or false news. (4) Data augmentation: The diversity of data is increased through methods such as rotation, flipping, and cropping, especially for image data. (5) Text vectorization: Text can be converted into numerical vectors using word embedding techniques. (6) Image feature extraction: Pre-trained CNN models are used to extract image features. Meanwhile, the Epochs of the model is 50. The dataset is divided into the training set, the validation set, and the test set in a ratio of 6:2:2. The License type of the POL dataset is Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License (CC BY-NC-SA 4.0). The License type of the GOS dataset is Creative Commons Attribution 4.0 International License (CC BY 4.0). This study introduces four common news detection models for comparative experiments, and the performance evaluation indicators are compared as shown in Figure 5. Comparison of network performance indicators based on POL and GOS datasets. (a) Comparison of network performance indicators of POL data sets (b) Comparison of network performance indicators of GOS data sets.
In the POL dataset of Figure 5(a), the accuracy (87.93) and F1 score (87.96) of MNDM are significantly higher than those of the control model, with an average improvement of 7.57% and 7.34%, respectively. In the GOS dataset of Figure 5(b), the accuracy and F1 score of MNDM are 97.64% and 97.61%, which are significantly higher than those of other models. Further hyperparameter analysis is conducted on the parameters r and k of the news detection model, and the results based on the POL dataset are shown in Figure 6. MNDM performance of parameters k and r in POL dataset. (a) Performance of News detection model model in parameter k. (b) Performance of News detection model model in parameter r.
Comparison of ablation results of MNDM.

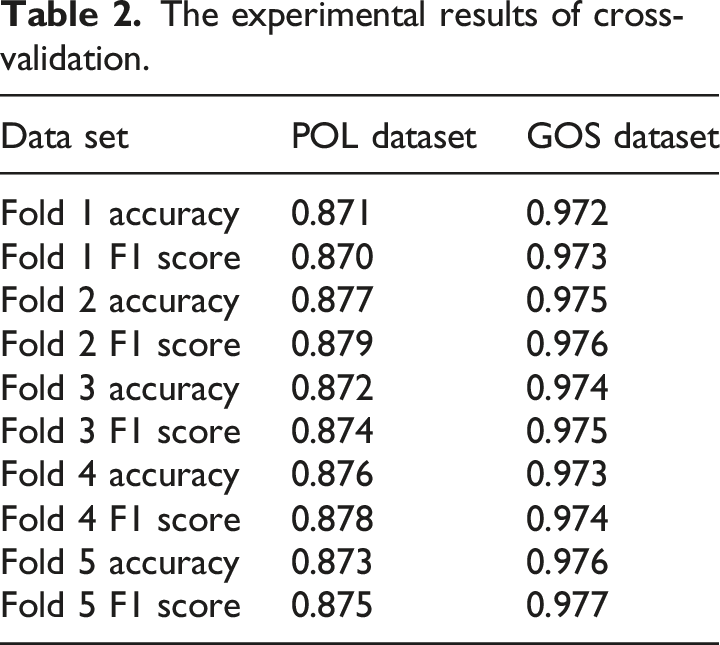
The experimental results of cross-validation.
Analysis of model error results.

In Table 3, the error indicators of the NT-UP model on both datasets are superior to those of other models. The MSE of the NT-UP model is 0.10 on the POL dataset and 0.05 on the GOS dataset, indicating that NT-UP has smaller errors in predicting false news and the prediction results are closer to the true values. The MAE of NT-UP is 0.08 on the POL dataset and 0.03 on the GOS dataset, further demonstrating the advantage of NT-UP in prediction accuracy.
Performance detection of FND model integrating semantic features and image recognition
For single-mode and multi-mode news detection, this study selects four typical datasets to evaluate the FND model that integrates semantic features and image recognition. The single modal performance comparison based on the WEIBO dataset and the TWITTER dataset is shown in Figure 7. Comparison of accuracy of single-modal models based on WEIBO and TWITTER datasets. (a) Accuracy comparison of single-modal model in WEIBO data set. (b) Accuracy comparison of single-modal model in TWITTER data set.
Figure 7(a) shows the performance comparison of five single-modal models in the WEIBO dataset. The accuracy value of the BERT is the highest, at 77.37%, which is an average improvement of 7.11% compared to other models. Figure 7(b) shows the performance comparison results in the TWITTER dataset. The CapsuleNet model has the highest accuracy in identifying false news, with a value of 79.92%, while the BERT has an accuracy of 78.26%, which is 1.66% higher than the CapsuleNet model. Further comparisons are made between the performance of five single-modal models on the PHEME and THUCNews datasets, as shown in Figure 8. Comparison of accuracy of single-modal models based on PHEME and THUCNews datasets. (a) Accuracy comparison of single-modal model in PHEME data set. (b) Accuracy comparison of single-modal model in THUCNews data set.
In the PHEME dataset of Figure 8(a), the accuracy and F1 score of the CapsuleNet model are both at the highest numerical level. The two values of the BERT model are 76.38% and 71.25%, indicating that the model has poor accuracy in identifying false news on PHEME. In the CapsuleNet dataset shown in Figure 8(b), the BERT model has the highest accuracy and F1 score, at 81.24% and 82.61%, respectively. This study further validates the performance of multi-modal models on the WEIBO and TWITTER datasets, as shown in Figure 9. Performance comparison of multi-modal models in WEIBO and TWITTER datasets. (a) Performance comparison of multi-modal models in WEIBO data set. (b) Performance comparison of multi-modal models in TWITTER data set.
Figure 9(a) shows the parameter comparison on the WEIBO dataset. The accuracy and F1 score of the proposed MNDM, which integrates semantic features and image recognition, are higher than other models. Its values are 90.62% and 91.25%, with an average improvement of 7.20% and 6.38%. In the comparison of the TITTER dataset in Figure 9(b), the research model performed the best in accuracy and F1 score, with an average improvement of 11.03% and 13.85%, at 91.63% and 94.45%. This indicates that the performance of the MNDM used is better in the WEIBO and TWITTER datasets. Figure 10 compares the performance parameters on the PHEME and THUCNews datasets. Performance comparison of multi-modal models in PHEME and THUCNews datasets. (a) Performance comparison of multi-modal models in PHEME data set. (b) Performance comparison of multi-modal models in THUCNews data set.
Results of multi-modal model ablation experiment.

In Table 4, when using visual enhancement encoders, CNN-BiLSTM, or CapsNet, the model performance is improved, that is, the ability to identify false news is enhanced. The average accuracy and F1 score without using encoder and CapsNet are 89.88% and 90.37%. When using visual enhancement encoder, CNN-BiLSTM, and CapsNet, the average accuracy of the model is improved to 91.57% and 90.62%, with an average improvement of 1.69% and 0.25%. Finally, the distribution of attention weights for the sentence “The quick brown fox jumps over the lazy dog” is analyzed. The higher the weight value, the more important the model considered the word to be for judging the authenticity of the news. The result is shown in Figure 11. Attention heat map of news sentences.
Figure 11 shows the weighted attention heat map of each word. The results show that the attention weight of the word “fox” is the highest, which is 0.30. This means that when the model processes this sentence, it considers “fox” to be the most important for judging the authenticity of the news. Other words such as “quick” and “brown” also receive relatively high weights, which are 0.20 and 0.15, respectively.
Discussion
In the study, on the POL dataset, the accuracy of the news detection model was 87.93%, and the F1 score was 87.96%, with an average improvement of 7.57% and 7.34%. On the GOS dataset, the accuracy is 97.64% and the F1 score was 97.61%, significantly higher than other models. In the performance testing of FND models that integrate semantic features and image recognition, multi-modal models outperformed single-modal models on WEIBO, TWITTER, PHEME, and THUCNews datasets. For example, on the WEIBO dataset, the accuracy of the multi-modal model was 90.62%, the F1 score was 91.25%, and the average improvement was 7.20% and 6.38%. In the ablation experiment of the news detection model, after removing the channel attention mechanism and graph comparison method, the accuracy decreased by 3.62% and 0.53%, indicating that these components are crucial for improving model performance. In the ablation experiment of the multi-modal model, the average accuracy and F1 score without encoder and CapsNet were 89.88% and 90.37%. However, after using these components, the average accuracy of the model increased to 91.57% and 90.62%, with an average improvement of 1.69% and 0.25%. Tufchi et al. constructed a GAN for detecting false news using TWITTER and news on Facebook as research subjects. Similar to the research, this study also uses accuracy and F1 score as evaluation indicators and introduces an encoder similar to the model. The performance of the improved model has been enhanced, enabling it to better identify false news. 19 Comito C et al. developed a deep learning-based MNDM to address the increasingly widespread spread of false news. After introducing a multi-modal mechanism, the performance of the model has been significantly improved, and its ability to detect false news has become even better. 20 However, in some failed cases, the model performed poorly in identifying certain specific types of news, such as satirical news or news containing puns. These news often require deeper semantic understanding and cultural background knowledge, but the proposed model has limited capabilities in this regard. Meanwhile, in some cases, the model overly relies on image information while ignoring the text content. For example, when the image is irrelevant or misleading to the content of the news text, the model may make wrong predictions. In summary, the proposed MNDM and FND models that integrate semantic features and image recognition have demonstrated superior performance on multiple datasets, providing effective technical means for detecting false news.
Conclusion
This study explores the detection of false news by constructing an MNDM and an FND model that integrates semantic features and image recognition. The results indicate that multi-modal models exhibit better performance on multiple datasets compared to single-modal models, highlighting the importance of utilizing different modal information to improve FND accuracy. Introducing encoders and CapsNet into the model can improve its ability to detect false news. However, there are some limitations in the research. First, the generalization ability of the model has not yet been verified on a broader dataset, which may affect its applicability in different language and cultural contexts. Second, the ethical impacts of the model, such as privacy protection and algorithmic bias, need to be further explored. Future work will focus on evaluating the generalization ability of the model on more diverse datasets. Meanwhile, the model structure can be simplified to adapt to resource constrained environments. Finally, in-depth research will be conducted on the ethical implications of the model to ensure its fairness and transparency.
Footnotes
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.