
Abstract
The platform needs to design a reasonable resource recommendation mechanism to push learning resources and services that are selected, suitable, and satisfactory to users based on their personalized information. In this paper, we aim to build an AI-based personalized English learning recommendation platform, which adopts a self-attention mechanism to capture long-term dependencies in user learning data from a dialogue-based perspective, and uses position encoding and residual connection to enhance the expression of the model. Connection to enhance the expressive ability of the model. The system as a whole adopts the B/S architecture and uses Mysql and mongodb databases to build a front-end and back-end separated database. The final experimental results show that the new system significantly outperforms the old system in terms of click rate, recall rate, learning efficiency, user experience, user satisfaction, and user participation, which proves the effectiveness of this paper in combining AI algorithms to optimize the English learning recommendation system.
Introduction
With the rapid development of information technology and artificial intelligence theories, artificial intelligence (AI) has been increasingly used in the field of English learning in China, and has provided learners with a brand-new learning experience and convenient ways. Intelligent speech recognition data allows English learners to receive timely feedback and obtain feedback information on pronunciation, intonation and other aspects, so that they can easily make oral correction.1,2 For example, apps such as English Fluent Speaking and IELTS Speaking are designed to improve learners’ English by correcting their spoken pronunciation. In addition, Natural Language Processing has important applications in machine translation and dialog generation, making English learning more convenient. With the rise of Transformer and Attention Mechanism, Natural Language Processing (NLP) has made further breakthroughs, which has led to the development of machine translation, dialog generation and other fields. 3 Many English learning software also use NLP technology to provide learners with personalized essay correction and vocabulary testing services, which further promotes the application of AI in the field of English learning. However, there are still many shortcomings in the application of AI technology in English learning, such as the content quality of AI-recommended English learning materials and the effectiveness of AI-assisted English learning. However, we can’t deny that AI brings development opportunities to the field of English learning. The application of AI in the field of English learning will provide English learners with an intelligent and convenient learning environment and promote the efficiency of their English learning.4,5
The contradiction between teaching and learning is a major problem in English language learning. In today’s era of massive growth of e-learning resources, how to deal with the relationship between output and input of English learning resources is an urgent problem for educators to solve. 6 If this problem is not emphasized, both sides of teaching and learning will be seriously affected. On the one hand, it is difficult for English learners to choose suitable learning materials for themselves from the vast amount of English learning materials. English learners spend a lot of time and energy, but they cannot find the “treasure resources” they crave, which easily leads to their loss of confidence in English learning and trust in the platform. On the other hand, the inability to help English learners choose the right English materials will lead to high customer turnover, and the platform will need to spend extra time and energy to focus on the marketing of the platform, thus creating a vicious cycle. 7 Ultimately, this may affect the platform’s emergence of low completion rates and poor e-learning resources, thus causing the platform to lose its own competitive advantage. To sum up, we must solve this pain point in the English learning industry, and platforms need to establish a suitable resource recommendation mechanism to recommend accurate, suitable and user-satisfying learning resources to users based on their personalized information.8,9
In the era of big data, English learning faces many difficulties. English learners may be faced with a huge amount of learning resources, but often do not know how to choose the right content for themselves, or waste too much time and energy on screening. They have diverse learning needs, but often don’t know how to set reasonable learning plans and goals, or lack motivation and feedback in their execution. English learners also face a complex learning process, but often don’t know how to keep track of their learning effectiveness and progress, or lack support and help when they encounter difficulties. All of these problems can be solved by a personalized English learning recommendation system.
In the era of big data, the process of knowledge learning for users has become more explicit.
9
Teachers and the Internet act as inputs and students as receivers.
10
The intermediate process is a black box with a complex process of converting information into knowledge. Specifically, as shown in Figure 1. The same knowledge is clustered and related knowledge is found by means of both expansion and correlation, and the work of transforming a priori knowledge to a posteriori knowledge is realized according to the human learning process. In such a situation using artificial can only understand the intrinsic mechanism of human learning knowledge, so as to produce a targeted recommendation program is very necessary and valuable.
11
Structure of knowledge transfer.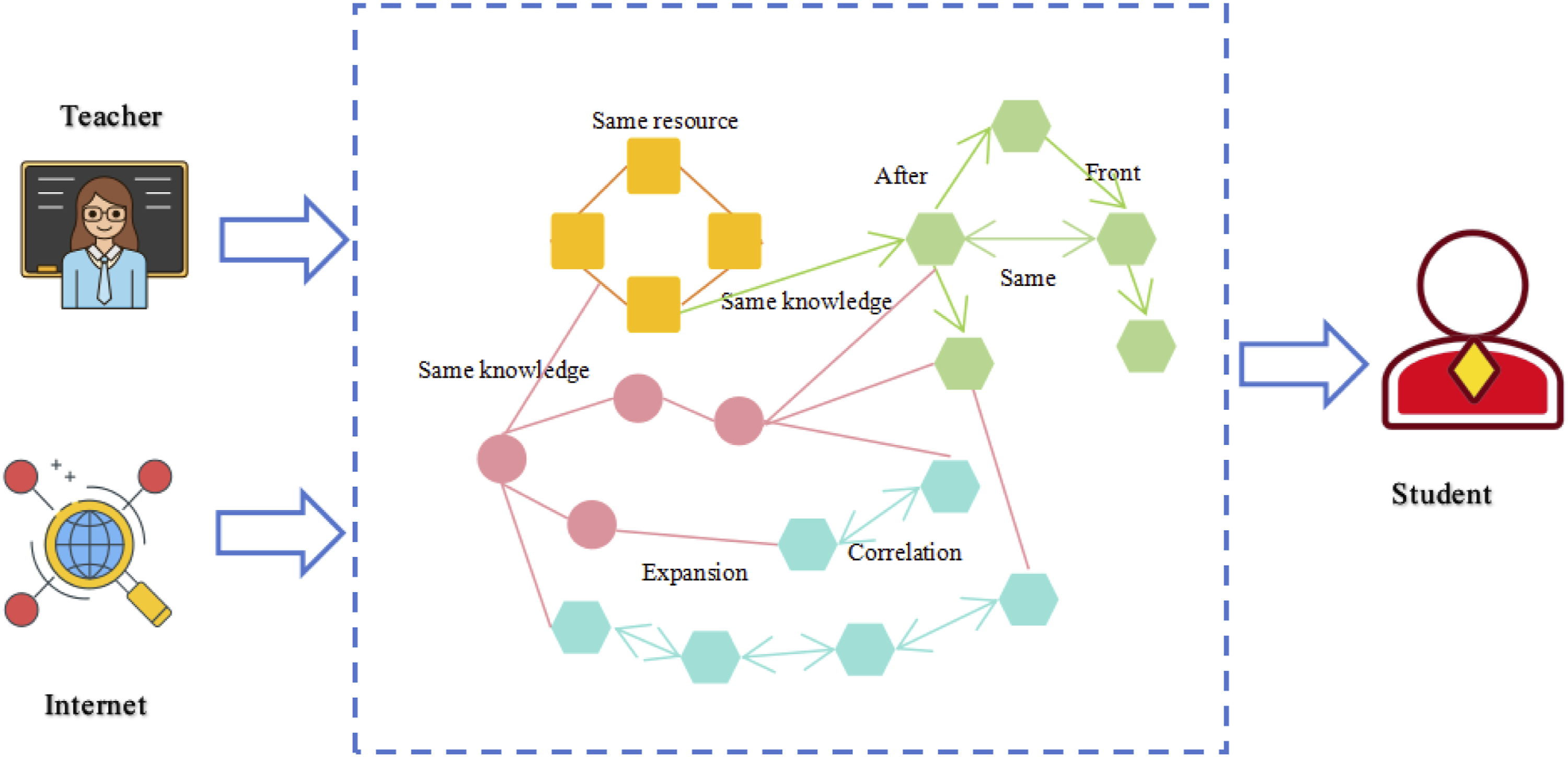
Artificial Intelligence is an intelligent system that integrates perception, thinking, learning, and behavioral capabilities. Artificial Intelligence has strong strength in the field of pattern learning, user profiling, etc., and can learn patterns in massive data based on data-driven learning to explore the value of data. Artificial intelligence technology also has significant applications in personalized English learning recommendation algorithms, AI can carry out user profiling from massive user data, learn the learner’s basic English proficiency level, learning interests, goals, learning habits, and other personalized learning information, so as to screen massive e-learning resources and provide users with appropriate resources. At the same time, the personalized learning plan can address the learners’ deficiencies, help them improve faster, and promote the long-term development of students. Artificial Intelligence technology can customize learning programs and learning paths for users based on their relevant information to enhance their satisfaction.12,13
This study aims to explore the intrinsic connection between AI and English learning, and to design an AI-based English learning platform that can provide users with personalized resources and services, thus enhancing the efficiency and communicative competence of English learners.
The design of AI-based personalized English learning recommendation system
The personalized English recommendation platform can be divided into a learner module and a recommendation resource module, where the learning algorithm is continuously optimized by interacting with people, and the recommendation resource module recommends suitable items according to the state space of the recommended items.14,15 The specific principle is shown in Figure 2. System module diagram.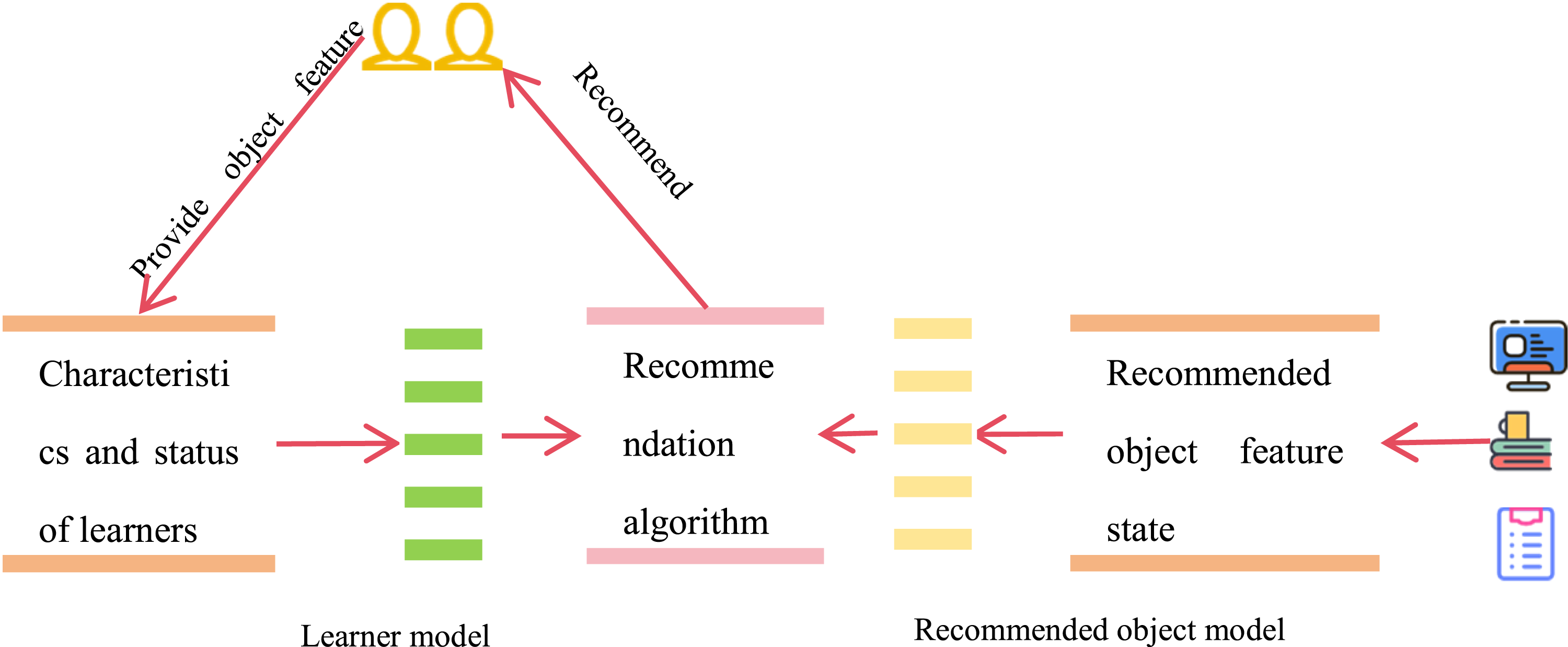
Design objectives and principles
The purpose of this study is to design an English learning recommendation platform based on AI technology, so as to provide better resources and services for users. The system needs to have the following functions: 1. Provide personalized learning content: Provide personalized learning content in response to users’ differentiated learning information. Provide each English learner with learning resources that are appropriate for their different levels, needs and preferences Ref. 16. 2. Provide personalized learning paths: Develop appropriate learning paths for users’ differentiated learning information. By personalizing the topic, difficulty, duration and sequence of English learning, thus improving the effectiveness and efficiency of English learning.
17
3. Provide personalized feedback: Provide timely feedback, including assessment, analysis, guidance, and encouragement, to each ELL according to their learning performance, problems, and needs, so as to enhance their motivation and interest in learning.
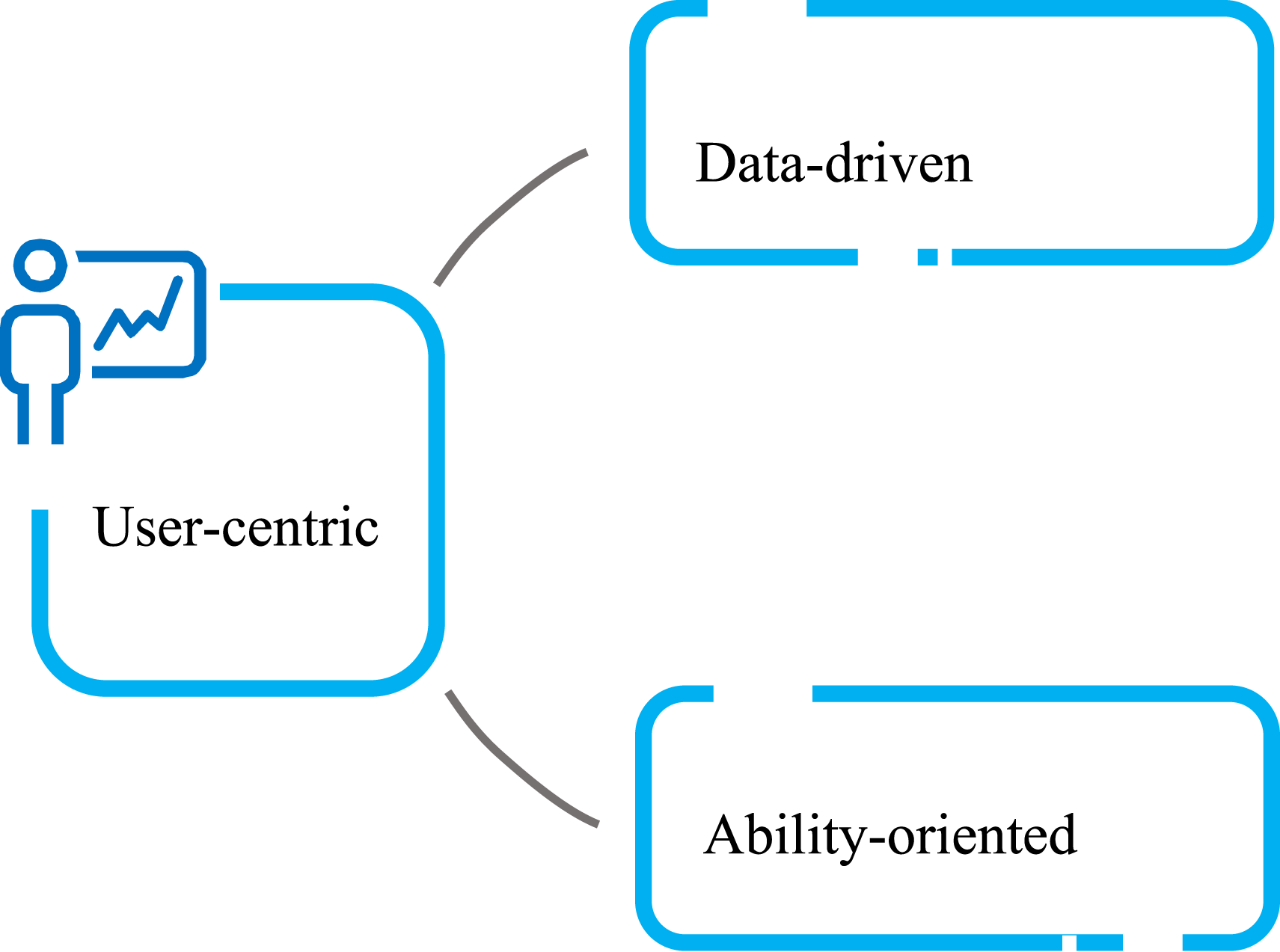
The design principle of the system is shown in Figure 3. 1. User-centered, matching learners’ English proficiency, interests and preferences with learning content that suits them to improve learning efficiency and satisfaction.
18
2. Competence-enhancement oriented, through resources and personalized learning methods, to develop learners’ competence and to improve the effectiveness and sense of achievement in English learning. 3. Supported by data-driven, it utilizes AI technology to achieve dynamic iterative updating of English learning programs and paths through AI accurate assessment, user profiling, recommendation algorithms and other functions to promote users’ learning efficiency. System design principles.
The data set for this project comprises a comprehensive collection of English learning materials, including articles, videos, podcasts, and interactive exercises, sourced from reputable educational platforms. Additionally, user interaction data, such as time spent on each material, completion rates, and user feedback, are collected to inform the recommendation algorithm. Demographic information about the users, such as age, educational background, and English proficiency levels, is also included. Preprocessing steps include cleaning the data to remove irrelevant or duplicate entries, normalizing numerical features to ensure consistent scales, creating new features that capture user preferences and learning styles through feature engineering, and processing text-based content through tokenization, lemmatization, and removal of stop words. For participants, only those who have provided consent for their data to be used in the study and have completed at least five learning sessions are included. For content, materials that have been rated by at least 10 users and have a minimum quality score based on expert reviews are selected. User feedback is included if it was submitted within 24 hours of completing a learning session. These criteria ensure that the data set is robust, relevant, and suitable for training a high-quality recommendation system that can effectively personalize English language learning experiences.
System framework structure
System architecture design: the system adopts B/S solution to realize front-end and back-end separation. The front-end is responsible for displaying the interface and user interaction, and the back-end is responsible for responding to user requests and for the core logic and algorithm part of the system. The module structure of the back-end part of the system is shown in Figure 4. Structure of the back-end module.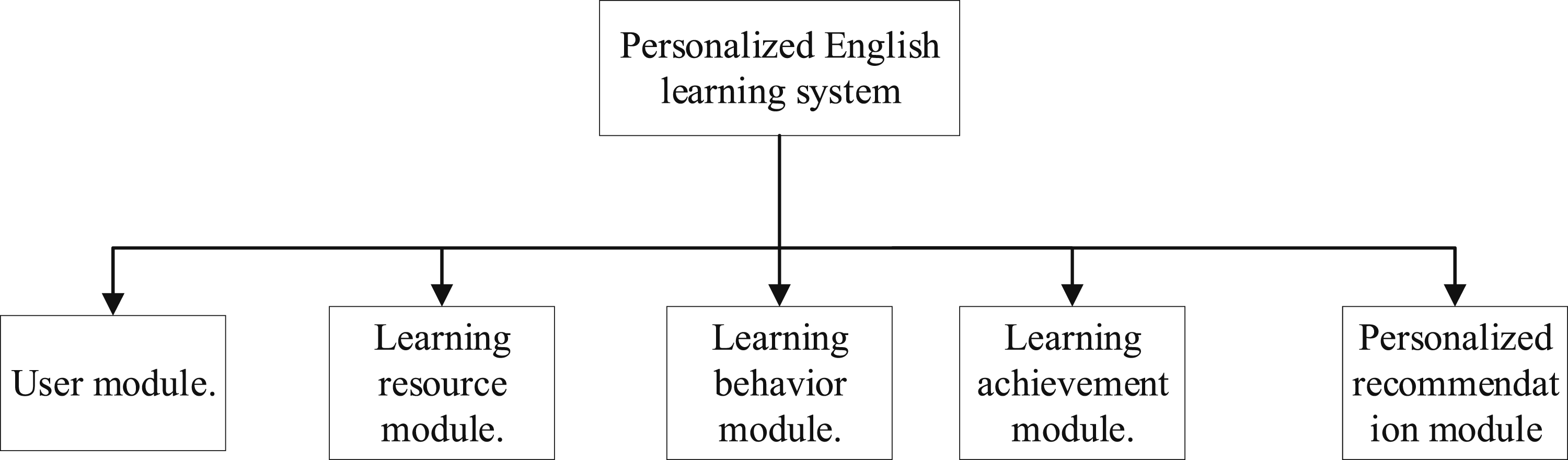
User Module: The user module is responsible for managing user registration, login, information modification and other functions, as well as collecting and storing basic user information, such as age, educational background, occupation, learning objectives and so on. 19
Learning Resource Module: The Learning Resource Module is responsible for managing the learning resources in the system, such as text, audio, video, games, tests, etc., as well as providing uploading, downloading, categorizing, and retrieving functions of the resources. 20
Learning Behavior Module: Learning Behavior Module is responsible for collecting and analyzing user’s learning behavior data, such as browsing history, answering of practice questions, completion of courses, etc., as well as providing visualization and reporting functions of learning behavior. 21
Learning Outcomes Module: The Learning Outcomes Module is responsible for assessing and providing feedback on user learning outcomes, such as test scores, assignment grading, and other forms of assessment results, as well as providing visualization and reporting capabilities for learning outcomes. 22
Personalized Recommendation Module: Personalized recommendation module is the core module of the system. 23
It is responsible for providing users with personalized learning content, paths and feedback based on their basic information, learning behaviors, learning outcomes and feedback, using knowledge graph and machine learning technologies, as well as providing visualization and reporting functions of the recommendation results.
Recommendation algorithm selection and optimization
Adopting a session-based approach to optimize recommendation algorithms can provide better recommendation services by obtaining more timely information conveyed by changes in users’ short-term interests and obtaining information about users’ preferences Ref. 24. Transformer, with its superior computational power and ability to process time-series data, is often combined with a session-based approach to optimize various types of recommendation algorithms.
25
In this paper, we propose a knowledge tracking model using Transformer, which employs self-attention mechanism to obtain long-term dependencies in user learning data, and position encoding and residual connection to optimize the expressive power of the model.
26
Optimize the expressive ability of the model. In this model, the feature vectors of the model inputs are entered into multi-layer neural networks for encoding and decoding operations, which contain multi-head attention and feed-forward networks at each level. This structure can learn the implicit features in the input sequence and improve the expressive ability of the model.
27
The specific structure of the model is shown under Figure 5: Model specific structure.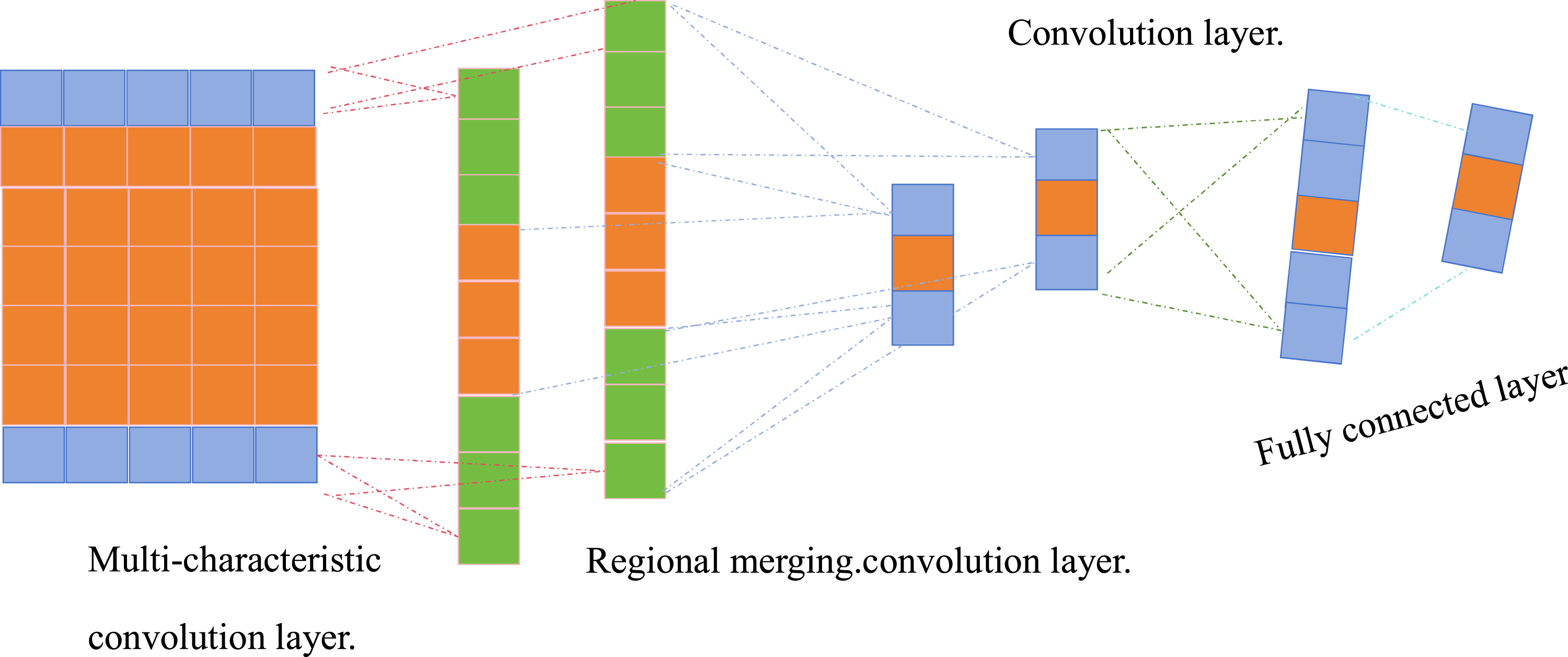
Self-attention mechanisms
Self-attention mechanism is the core of the algorithm, which can solve the long-range dependency problem.
28
As shown in the figure, the input layer is a two-dimensional matrix composed of answer records and practice questions, where the columns correspond to the knowledge points and the rows correspond to the practice questions, and the value in the matrix is 1 if the practice question is in a containment relationship with the knowledge point, and 0 otherwise. The output layer is a number of 0–1 vectors of n dimensions, which represent the correctness of the learner’s answer to the next practice question.
29
Correctness is 1, otherwise 0. The multi-head self-attention layer (MHSA), which splits the matrix of the input layer, performs individual self-attention computations on each sub-matrix, and then stitches the results into a new matrix. The formula for performing the computation on each sub-matrix is shown in equation (1):
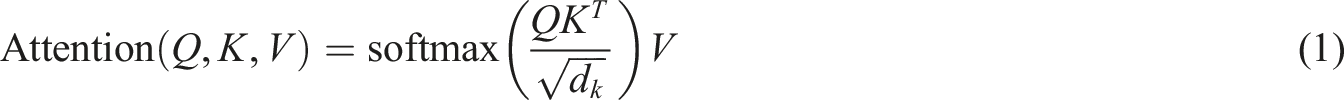
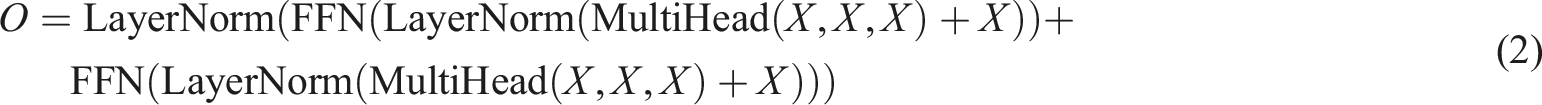
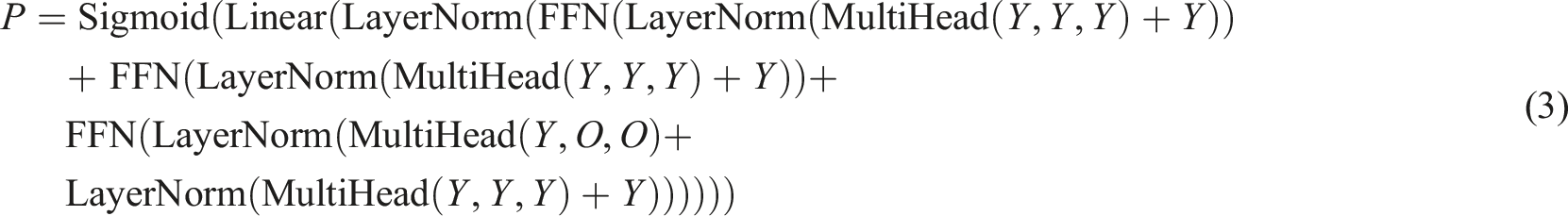
The output of the model is a matrix of the middle layer converted into a vector of the output layer representing the learner’s probability of being correct on the next practice question using a fully connected layer and a sigmoid activation function. Equations (4) and (5) for the fully connected layer and sigmoid activation function are shown
32
:


Location coding
Using Transformer as a featurizer can effectively extract features from the output data, but the Transformer model does not have a sequential structure like RNN, but is completely based on the attention mechanism, positional coding can compensate for the shortcomings of Transformer by encoding the positional information of the word into a new feature vector, which is often used in the representation of augmentation vectors. Positional coding is intended to help with word order information in positions in sequential data. In this paper, we use sine and cosine functions to generate waveforms of different frequencies and then stitch them together by dimension to form a position vector with the same dimension as the word vector.
30
Where the position encoding is shown in equations (6) and (7):


Residual connections
Residual connectivity is an important means of optimizing models, allowing them to learn more complex and sampled features embedded in the data, thus optimizing the expressive power of the model. The principle of residual learning is to treat the difference between input and output as a new feature for model learning. The model in this paper uses residual linking, which can be combined with positional coding to jointly optimize the expressive power of the model. The principle of residual connection is shown in equation (8):

To improve the performance and stability of the recommendation system, residual connections are employed in the deep learning architecture. Residual connections, or skip connections, are particularly useful in deep neural networks where the vanishing gradient problem can hinder the training process. In our system, residual connections are introduced after every few layers to facilitate the flow of gradients during backpropagation. For instance, in the deep learning model used for content recommendation, residual blocks are implemented after every two or three convolutional or fully connected layers. This approach helps in mitigating the degradation problem often encountered in deeper networks, allowing the system to learn more complex representations without losing performance. By enabling the network to train more effectively, residual connections contribute to more accurate and personalized recommendations, ultimately enhancing the user experience and satisfaction.
Detailed design of each part
System database design: the database design of the system uses a hybrid database. The system uses a relational database mysql to store structured data such as user information, learning resource information, learning behavior information, learning outcome information, etc., and a non-relational database mongodb to store unstructured data such as knowledge graph, recommendation model, and recommendation results. 33
System interface design: The system uses HTML, CSS and javascript technologies to design user-friendly web interfaces, including home page, login page, registration page, personal center page, learning resources page, learning behavior page, learning results page, personalized recommendation page and so on.
A robust user feedback mechanism is crucial for continuously improving the recommendation system. Feedback is collected both quantitatively and qualitatively. Quantitative feedback includes user ratings, completion times, and engagement metrics, which are automatically recorded and analyzed to adjust the recommendation algorithm. Qualitative feedback is gathered through surveys and direct user comments, which provide insights into user preferences and areas for improvement. For example, a user might rate a video tutorial highly but comment that the accompanying transcript contains errors. This feedback would trigger a review of the transcript and potentially lead to its correction or replacement. Additionally, if several users report difficulty with a particular type of exercise, the system may adapt by recommending more supportive resources or altering the sequence of recommended materials. The system iteratively improves based on these insights, ensuring that it remains effective and responsive to user needs over time.
System implementation and evaluation
Systematic assessment
Quantitative assessment indicators
In order to qualitatively measure users’ interest and loyalty to the AI-based recommendation platform for English learning, we use click-through rate and retention rate as two indicators to evaluate the effectiveness of the new system. Click-through rate is the ratio of the number of times an e-resource is clicked on to the number of times it appears. Retention rate is the probability that some users start using the platform on a certain day and still use the platform over a period of time. The click-through rate represents the first impression that the content provided by the platform leaves on the user, while the retention rate reflects the value that the platform provides to the user and the user stickiness.
In order to measure the two metrics, the observed data relayed to the new system was counted during the 1 week of its operation, and the metrics of click-through rate, retention rate, learning efficiency and learning performance were calculated.
Indicators for quantitative assessment of old and new systems.
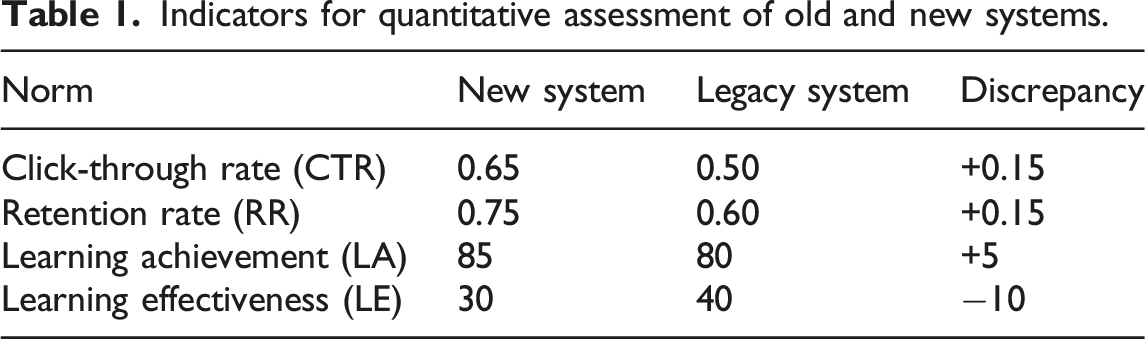
Qualitative assessment methods
Indicators for quantitative assessment of new and old systems.
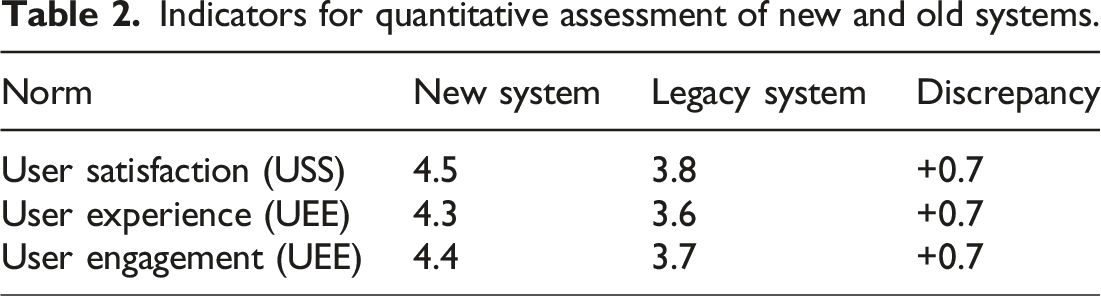
To evaluate the impact of the new system’s operation comprehensively, we administered a questionnaire survey targeting English learners, collecting 8000 valid responses over the course of a week. The data from these questionnaires were statistically analyzed to derive the three key indicators of user satisfaction, user experience, and user engagement, as presented in Table 2. Table 2 quantitatively assesses the performance of the new and legacy systems, revealing a clear superiority of the new system across all metrics. The user satisfaction score for the new system is 4.5, a notable increase over the legacy system’s 3.8, with a discrepancy of +0.7 points. This indicates a strong level of contentment among users, who have expressed high regard for the new system’s content relevance, interface design, interactivity, and overall functionality. In terms of user experience, the new system scores 4.3, surpassing the legacy system’s 3.6 by the same margin of +0.7 points. This improvement suggests that the new system provides a more intuitive and enjoyable learning environment, effectively addressing users’ emotional and educational needs. The enhanced user experience is likely a result of the system’s streamlined navigation, aesthetically pleasing design, and user-centric features. User engagement is also higher for the new system, scoring 4.4 compared to the legacy system’s 3.7, again with a discrepancy of +0.7 points. This indicates that users are more actively and consistently involved with the new system, which can be attributed to its ability to deliver personalized content that aligns with users’ interests and learning goals. The increased engagement level points to a stronger interaction and a developing trust relationship between the users and the system. Overall, the results in Table 2 underscore the new system’s effectiveness in meeting and stimulating users’ learning needs and emotions. The consistent +0.7 point advantage across all three indicators demonstrates the new system’s comprehensive improvement over the legacy system, making it a more satisfying, engaging, and enjoyable platform for English language learning.
Application scenarios and effects
Proportion of applications of personalized English recommendation system.
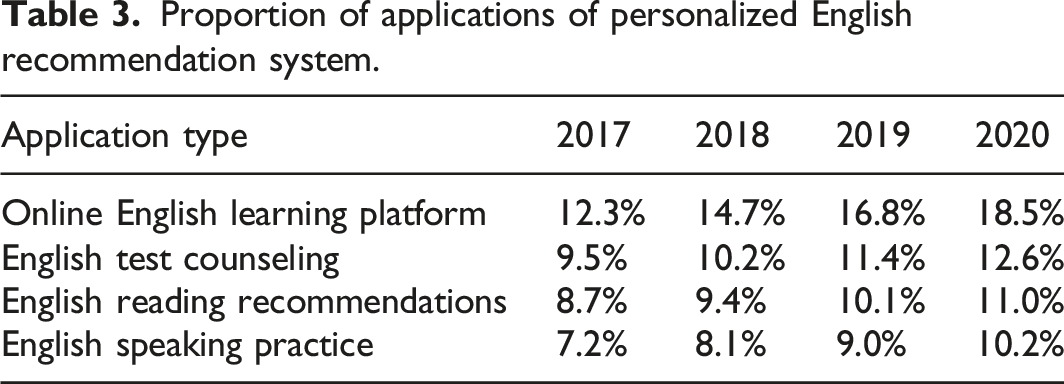
In conclusion, by providing users with highly personalized and accurate English learning resources and assistance, the model can significantly enhance users’ learning effectiveness, satisfaction and learning emotions, providing them with comprehensive and effective English learning support.
Conclusion
In this paper, an AI-based personalized English learning recommendation platform is proposed, which can intelligently recommend the most suitable and satisfactory learning resources, including courses, videos, audios, articles, exercises, tests, and other forms of content for users based on their learning goals, levels, interests, preferences, and other personalized information, so as to help users improve the effect and experience of English learning. The article uses the self-attention mechanism as the core component of the model, which can effectively obtain the long-term dependency relationship in the user learning data, that is, the correlation between the user’s learning behaviors and feedbacks at different points in time, so as to improve the model’s learning ability and recommendation accuracy. The article also adopts position encoding and residual connection as auxiliary components of the model. Position encoding can provide the model with temporal information in user learning data, and residual connection can provide the model with more information flow and gradient flow, thus enhancing the expressive ability and generalization ability of the model. Experiments are conducted on real English learning datasets and compared and analyzed with the old system, and the results show that the new system significantly outperforms the old system in terms of click rate, recall rate, learning efficiency, user experience, user satisfaction, and user participation, which proves the effectiveness of this paper’s optimization of the English learning recommender system by combining AI algorithms.
The innovations of the article are (1) the use of attention mechanism, residual connection, etc. To carry out the optimization of recommendation algorithms. (2) Qualitative and quantitative evaluation methods are used to evaluate the system.
Footnotes
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.