
Abstract
The primary aim of this research is to develop and implement a piano evaluation mechanism enhanced with an error correction feature utilizing AI. Precisely, the study discovers to overcome the limitations of traditional piano teaching evaluations which frequently suffer from poor convergence and a tendency to fall into local extremes. We propose a novel AI method called Selfish Herds Search-integrated Improved Probabilistic Neural Network (SHS-IPNN), for piano music evaluation. The method leverages the Improved Probabilistic Neural Network (IPNN) for its robustness in handling data and for improving convergence in learning. In addition to using the short-term energy difference (STED) technique to precisely determine the temporal assessment of every note in the audio of a piano performance. Additionally, the Discrete Wavelet Transform (DWT) is applied to assess pitch accuracy. The entire system is integrated within a Musical Instrument Digital Interface (MIDI) framework to facilitate detailed evaluation of piano performances. The piano performances are categorized as “Good,” “Fair,” or “Poor” in this examination, which is structured for a classification problem. Our findings emphasize the efficacy of the SHS-IPNN technique, as demonstrated by its overall performance in terms of recall (90.5%), accuracy (96%), F1-score (93.5%), and precision (95.5%). The experimental outcomes indicate that the SHS-IPNN model outperforms existing methods in terms of accurately detecting performance errors and evaluating piano performances. The model’s increased accuracy in providing expressive, rhythmic, and overall judgments is demonstrative of this development. The innovative application of the SHS-IPNN method in piano music education demonstrates a significant advancement in the field. This approach not only improves accuracy in performance evaluation but also improves the learning procedure by providing error correction, which is crucial for developing proficient piano skills.
Keywords
Introduction
The piano is becoming more and more popular across the world as a vital instrument for performing music.
1
A thorough music education must include piano music instruction and assessment as it promotes both technical proficiency and creative expression. This introduction explores the many facets of teaching piano, the many pedagogical philosophies, and the techniques used to assess student development and competency. Structure in piano education
Piano learning commonly starts with foundational capabilities which include analyzing music, keyboard layout, and primary hand positioning. 2 As students’ progress, they explore greater complex elements of piano playing, such as scales, arpeggios, chord progressions, and finally superior interpretative capabilities. Instruction may be formal, taking region in academic institutions or private training, or informal, which includes self-taught musicians gaining knowledge via online platforms. 3
A vital factor of piano education is repertoire development. Students examine several pieces that now not only enchantment their musical tastes but also undertake their technical and interpretive capabilities. Teachers frequently encourage students to interact with an extensive variety of musical genres, from classical and jazz to modern famous music, improving their versatility and appreciation for special musical traditions. 4
Contemporary piano learning often integrates generation, the usage of digital equipment to enhance traditional knowledge of Software for notation, rhythm education, or even digital pianos with demonstrated keys are not unusual in current school rooms. Online systems and video tutorials have additionally broadened get right of entry to piano learning, permitting students from various backgrounds to learn remotely and in their own steps.
5
Cognitive and Emotional Benefits of Piano Education
Learning piano not handiest develops musical capabilities but also complements cognitive capabilities which include reminiscence, attention, and spatial-temporal reasoning. The problematic challenge of analyzing musical notation and translating it into motor moves requires complex neural processing. Moreover, playing the piano includes emotional interpretation and expression, fostering emotional intelligence and empathy. 6
Piano training also gives big emotional advantages, imparting a creative outlet that could reduce pressure and enhance mental well-being.
7
For many, piano playing is a lifelong adventure that enriches personal and social life, connecting people across cultures and generations. Evaluation in Piano Music Education
A key component of teaching piano music is evaluation, which ensures that students gain technical proficiency as well as musicality and self-expression. Formative and summative approaches can be used to broadly categorize evaluation processes in piano teaching. Continuous feedback is given to students during the learning process through formative assessment, which aids in identifying their areas of strength and growth. However, the final assessment frequently takes various types of events, tests, or performances and serves as an indicator of students’ performance and suitability for progressing to more advanced education.
8
Limitations
The accessibility and cost of piano music education are frequent issues, which makes high-quality instruments and instruction pricey for many conventional methods, which broadly communicate consciousness on the classical tune, and might not be capable of capturing students’ interest in a wide range of musical styles. Additionally, traditional training may also forget about improvisation and originality in want of an unduly technical emphasis. 9 Evaluations with subjective biases might not be fair while judging performances. Learning important physical and audio complications may also be compromised by too much reliance on technology. We presented the novel use of the selfish herds search-integrated improved Probabilistic Neural Network (SHS-IPNN) technique for piano music education and evaluation.
Contribution and motivation of the work
The motivation and contribution of the study are discussed in this part. The shortcomings of conventional coaching techniques, which regularly lack accuracy and are ineffective in guiding students, are addressed via the introduction of the SHS-IPNN model for piano assessment. Through the combination of advanced AI algorithms and dependable record processing, this model improves assessment precision for piano performances. It uses techniques to assess pitch accuracy and temporal dynamics, in addition to techniques together with IPNN for advanced knowledge of convergence. The intention is to offer assessments that are more thorough and responsive, enabling quick fixes and customized comments. Increasing the precision of performance evaluations and the quality of the learning process overall greatly increases piano education. Thus, the contributions of this study could be summarized as follows. • Data Collection: Ten piano students and five piano teachers make up a total of fifteen “participants.” 15 participant piano recordings, 23 songs for students, 6325 distinct samples, 1265 testing data samples, and training data samples including 5060 samples, were utilized to assess the model’s efficacy in each group, evaluate the outcome measures accurately, and ensure the accuracy of the outcomes. • Data Splitting: The initial stage of creating a model involves creating training and testing sets from the dataset, with training data being the initial set and testing set the finalized model fit. 80% as training and 20 as testing. • Temporal Note Value Analysis in Piano Performance using STED: The primary objective of the STED approach is to accurately discern the beginning and end of the audio recording from the noise outside. • Assessing Pitch Accuracy using DWT: Radical frequency is the term used to describe the inherent tone in any musical style that has the highest intensity and lowest pitch. The pitch of the whole tone is directly determined by the pitch of the basic tone. • Model building with selfish herds search-integrated improved Probabilistic Neural Network (SHS-IPNN): The network, SHS-IPNN, is utilized for piano music evaluation, enhancing data handling robustness and learning convergence through the use of IPNN.
This work is structured as follows: Part 2 related work. The methods and materials are described in Part 3. Part 4 presents the model evaluation, while Part 5 concludes the study.
Related work
The possibility that mobile AR apps may help with piano instruction was investigated in study. 10 As mobile applications were being employed in educational activities, the connected sequence “Piano for Beginners” aim was described in the study. Learn to play the piano with Flowkey, Simply Piano, Skoove: Learn to Play Piano, and AR Apps: AR Pianist: VR Piano Concerts and Music All Around. The study’s findings could be useful to working piano instructors that are looking for fresh approaches to update their methods.
Examining novel approaches to teaching music and aesthetics using intelligent technology was the goal of study. 11 A total of 343 students 112 from elementary school, 123 from middle school, and 98 from high school participated in the study, which was conducted in the areas of piano, violin, and percussion in several Beijing music institutions. The students’ competency were assessed in multiple phases. First, the student’s level of proficiency was compared to its pre-experiment level using an average eight-point system. The findings indicated that the percussion class had improved the most, while the violin class had improved the least.
An RNN-based, Spark-based MIDI piano evaluation system was presented in Study 12 using the Deeplearning4J DL framework. Parallelization in feature extraction, model training, and preprocessing music data was realized with the Spark distributed computing engine. The RNN parameters are also evaluated. The outcomes demonstrated that the three-layer RNN structure’s error value was lower than that of its nearest competitors’ methods. The findings demonstrated that, with ensured efficiency, the assessment outcomes of the piano evaluation and performance framework were essentially commensurate with the real skill levels of the performers.
Techniques for automatic piano evaluation were established by study. 13 Two distinct piano articulation techniques were taken into consideration: legato, which features staccato, and sustain pedals, and vibrating notes, which feature unconnected notes with the addition of sustain pedals. Piano noises were examined for each kind and categorized as “Good,” “Normal,” and “Bad.” For this task, the study looked into four different methods. LSTM, CNN, NB, and SVM. 4680 test items, including kids’ tunes and disconnected scale sounds performed by 13 singers, were used in the research. With a classification accuracy of over 80%, the findings demonstrate that the CNN technique was better than the other techniques.
For professional self-improvement while studying or to engage in a collaborative learning environment in higher music education, study 14 utilized a smartphone. The study’s objective was to assess the effectiveness of an application intended to enhance sheet music reading skills. A pertinent innovation in many educational institutions was the use of a mobile app to improve the perspective of music education. The test group followed the application program and utilized the software both inside and outside of the classroom. Using the Student’s t-test, the test outcomes were compared.
The quality of training in the traditional preschool piano curriculum was raised by a study. 15 DL technology was employed in piano training to boost kids’ interest in studying music. A focused music education plan was created after the issues with children’s traditional piano instruction were examined using the teaching methodologies covered by educational psychology. Second, technology for recognizing musical instruments was unveiled, and DL was used to implement the model for the purpose. Thirdly, to help kids learn music and increase their enthusiasm for studying the piano, the suggested approach was implemented in children’s piano instruction. The suggested approach shows increased feature identification and acquisition.
A specific technique for evaluating the potential correlation between ML and piano teaching was provided. 16 The enhanced T-test approach was integrated with the ML association rule mining technology. A novel measure and degree of effect on association rules are presented, and the enhanced T-test was used to measure association rules. The result indicated that the degree of interaction can serve as a measure of association regulations for predicting the application of multimedia-assistant piano teaching evaluation data.
The usage of electronic piano teaching, its drawbacks, the notion of digital instruction as a single route of knowledge, and the lack of connectivity were all explored. 17 The piano performance can be evaluated using the NN model, and it serves as a teacher substitute for assisting students with their exercises. The piano piece “Ode to Joy,” which was different from the set of NN training samples, was used to assess the effectiveness of the suggested system. Student A and student B, along with another piano teacher, performed the piece 10 times.
Investigating the role of interactive piano instruction in distance learning was the goal of the study. 18 The study offered innovative methods for interactive piano teaching. The training program’s foundations include interactive groups, the Flowkey application, technical and psychological elements, role-shifting, improvisation, and the growth of self-control. Out of 120 pupils, 83% exhibited a good level of knowledge, according to the program findings. The remaining 2% indicated a poor level, which might be attributed to absence.
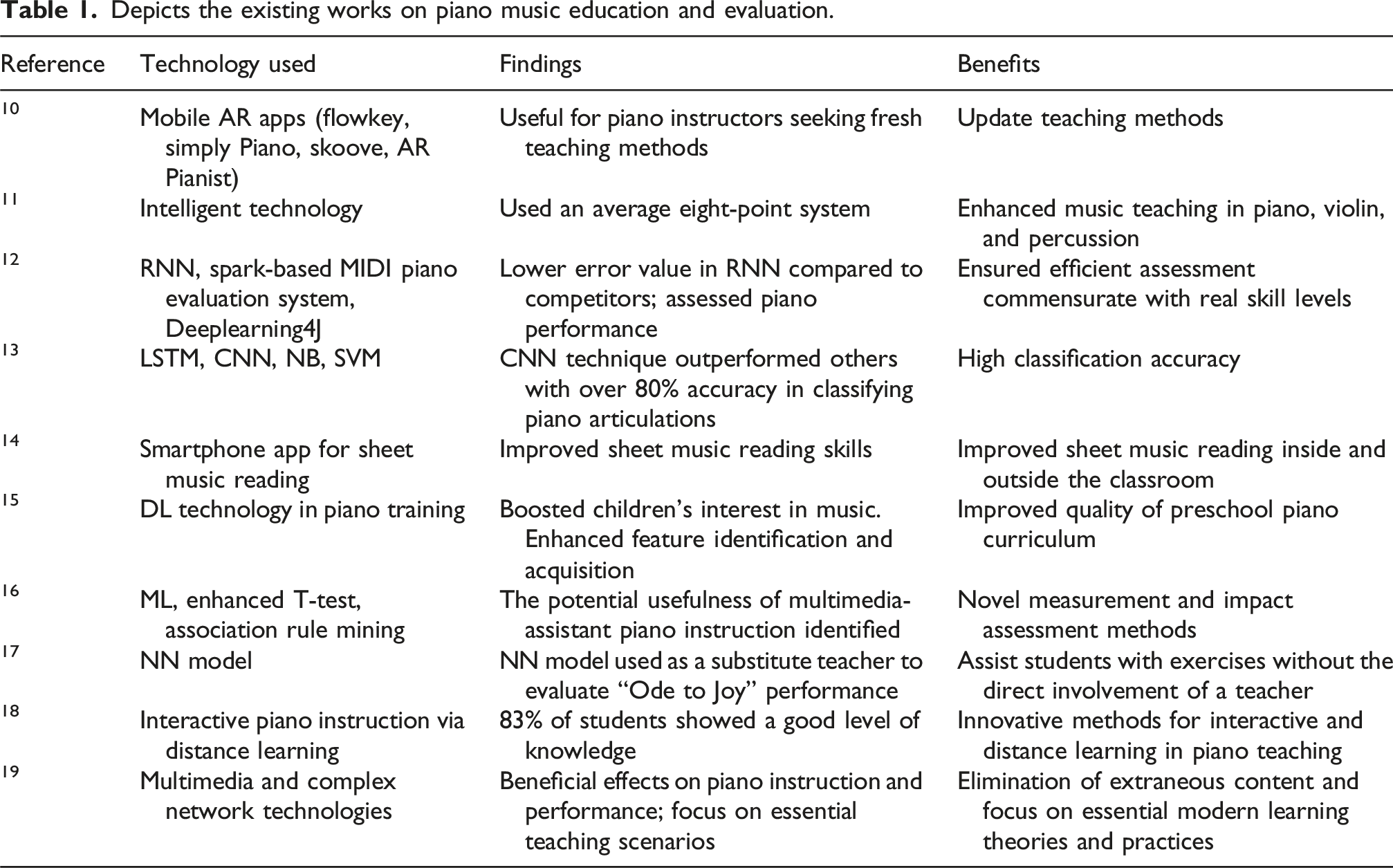
Depicts the existing works on piano music education and evaluation.
Proposed methodology
• Data Collection: Ten piano students and five piano teachers make up a total of fifteen “participants.” 15 participant piano recordings, 23 songs for students, 6325 distinct samples, 1265 testing data samples, and training data samples including 5060 samples, were utilized to assess the model’s efficacy in each group, evaluate the outcome measures accurately, and ensure the accuracy of the outcomes. • Data Splitting: The initial stage of creating a model involves creating training and testing sets from the dataset, with training data being the initial set and testing set the finalized model fit. 80 training, 20 testing. • Temporal Note Value Analysis in Piano Performance using STED: The primary objective of the STED approach is to accurately discern the beginning and end of the audio recording from the noise outside. • Assessing Pitch Accuracy using DWT: Radical frequency is the term used to describe the inherent tone in any musical style that has the highest intensity and lowest pitch. The pitch of the whole tone is directly determined by the pitch of the basic tone. • Model building with selfish herds search-integrated improved Probabilistic Neural Network (SHS-IPNN): The network, SHS-IPNN, is utilized for piano music evaluation, enhancing data handling robustness and learning convergence through the use of IPNN.
Dataset
This study collected 10 piano students and five piano teachers making up the total of fifteen “participants.” 15 participant piano recordings, 23 songs for students, 6325 distinct samples, 1265 testing data samples, and training data samples including 5060 samples, were utilized to assess the model’s efficacy in each group, evaluate the outcome measures accurately, and ensure the accuracy of the outcomes. There were 275 samples from every experiment participant in each of the 23 songs that were provided to the students. 80 training, 20 testing.
Based on the training data, the six individuals can be categorized into the following categories: We utilized the information from the 1st, and 2nd teachers to indicate “Good” achievement; 4th, and 5th students indicating “Fair” achievement; and the 2nd and 3rd students to indicate bad achievement. As a result, there are 5060 performers in the training sample, and nine of them provide data for assessment. We selected data from the 6th and 8th students to indicate fair achievement, data from the 3rd 4th, and 5th teachers to indicate “Good” achievement, and data from the 1st, 7th, 10th, and 9th students to indicate “Poor” achievement. Consequently, a total of 1265 test datasets were available.
Evaluation of the short-term energy difference (STED) for an enhanced endpoint detection algorithm
Detection of endpoints searches for the starting and ending points of the musical note signals within a segment of the audio file to ascertain the signature of every note’s duration in the audio. There is usually noise while recording audio. The primary objective of the STED approach is to accurately discern the beginning and end of the audio recording from the noise outside. Consequently, the double-threshold approach, which uses inputs from the time-domain defining factors, is the most often utilized endpoint-detecting methodology. It uses three parameters and a secondary assessment to primarily determine endpoints. However, there are several disadvantages to the dual threshold detection method, including its low noise resistance, threshold setting complexity, and over-reliance on threshold setting. By using the STED generated by those problems, this study suggests an enhanced endpoint detection technique. The primary method used by this algorithm to identify the energy mutation information and establish the note’s beginning is the STED. Next, based on the initial point position, by creating two levels of assessment, each starting point’s corresponding final position is identified. It is necessary to frame, window, and calculate the STED of the sound waveform to treat each note touched while performing the piano as an STED, as shown in
Equation (1) uses window
The STED 
By calculating the energy difference between two frames, rather than the energy difference between two sample points, this approach may remove minute energy variations from the audio stream. Furthermore, the difference function may allow for a more precise determination of the note’s starting point and precisely depict the unexpected decrease in energy. To determine the endpoint that matches the commencement point of each message, two fundamental thresholds are set: the STE and the STZCR standards. When as the signal’s two parameters fall below the threshold, the point is identified as roughly matching the current note’s start point. The destination that matches the starting position Architecture for STED.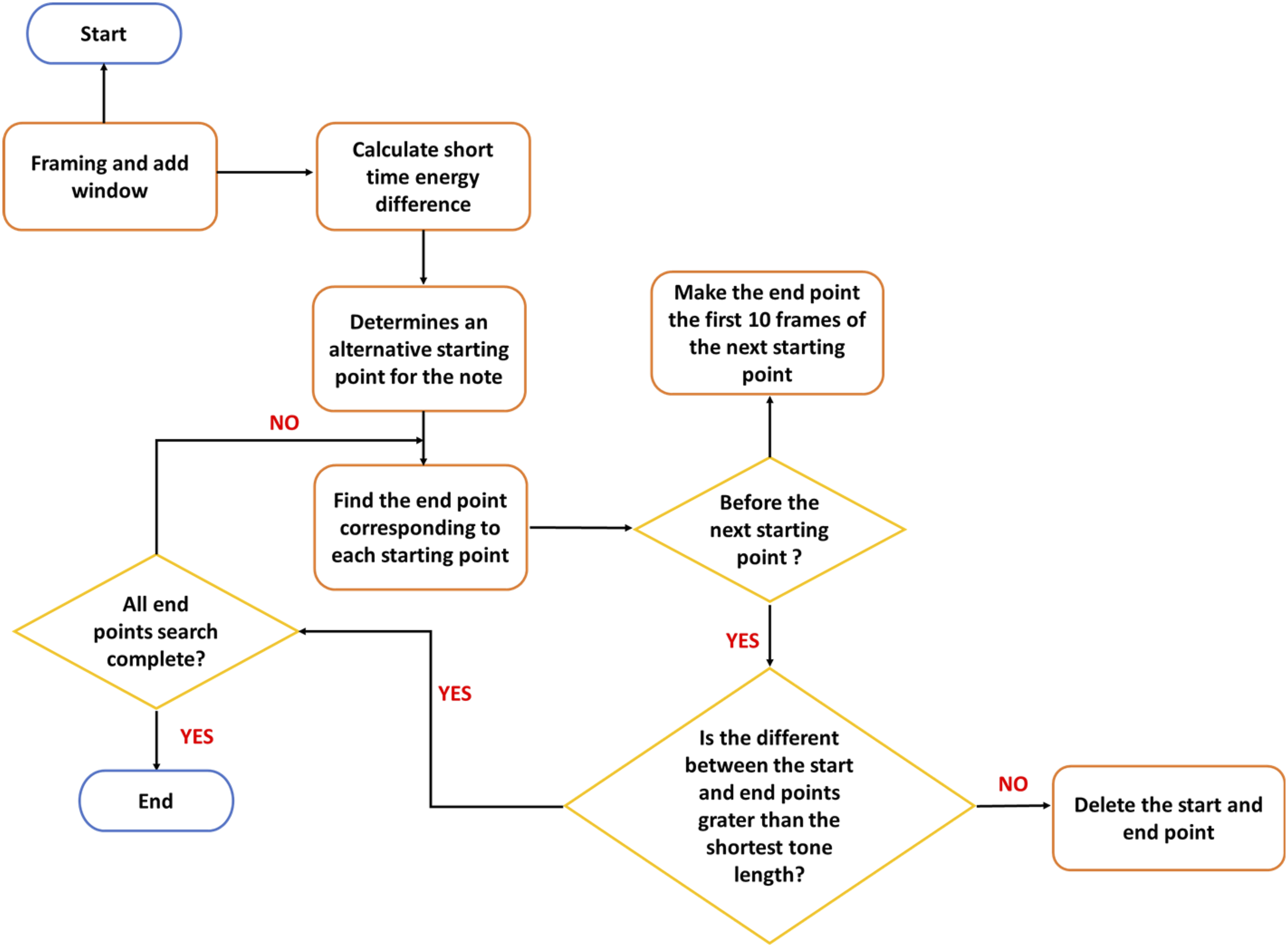
Evaluation of the modified standard harmonic method for the RFE technique
In every musical style, the natural tone having the lowest pitch and highest intensity is referred to as radical frequency. The pitch of the whole tone is determined directly by the RFE, which is the pitch of the fundamental tone. The three primary types of extreme frequency extraction techniques are statistics-based frequency-domain and time-domain-based techniques. In this section, the RFE methods that are frequency-domain-based are generally employed. The HP technique and the assurance factor are the two types of extraction algorithms via the frequency domain. One common approach used by Discrete Wavelet Transform (DWT) is the HP technique.
The DWT provides good duration-frequency analysis by using long time frames for low-frequency signals and short-time windows for higher frequencies. A signal’s DWT decomposed employs two down samplers by two and sequential high-pass and low-pass filtering of the time sequence. As the discrete mother wavelet, the high-pass filter
The wavelet function 

The primary frequency elements of the provided signal determine the maximum level of decomposition that can be defined. The initial time series and the required foundational functions are multiplied to get the coefficients of the DWT, which are called the product of dots. Equation (5) represents the detailed coefficients 



The highest degree of decomposition is indicated by a “
The relative wavelet frequency is represented by the normalized energy values.
Selfish herds search-integrated improved Probabilistic Neural Network (SHS-IPNN)
There are several benefits to using the SHS-IPNN for piano music evaluation and education. By emphasizing on the most important modules for instructional suggestions, the SHS algorithm exploits the selection of characteristics from piano performances. After that, the IPNN component assesses these data and offers accurate evaluations of difficulties such as dynamics and timing. The hybrid model offers great assessment accuracy and customized education recommendations by incorporating the sophisticated pattern recognition of IPNN with the robust optimization of SHS. This integration allows for customized learning knowledge that improves student development in piano studies as well as the effectiveness of teachers.
Selfish herd optimization algorithm
The SHO optimizes teaching techniques based totally on each student’s overall performance, as a result enhancing individualized understanding in piano training. Evaluating information to discover strengths and defects and offer specific recommendations, complements the evaluation method. This method efficiently customizes piano courses to increase knowledge of goals and student involvement.
Initialization
The 
Furthermore, these equations are used to determine the numbers of predators 

Distribution of the survival values
The capacity to survive is represented by an individual’s survival value 
Movement of the prey
This section mostly consists of the predator leader’s movements and the prey followers’ escape or following movements.
Movement of the predator leader
The definition of the predator leader is as follows:
Its present position is as the following: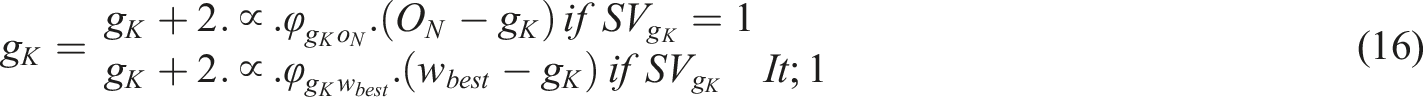


Escape movement of the prey followers
Following prey (
The definitions of 




The following is the location update formula for various prey: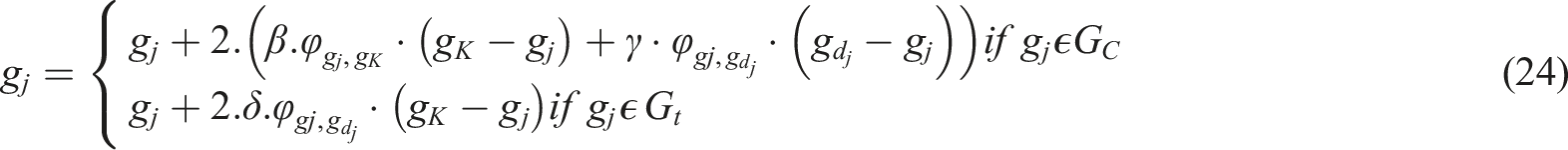
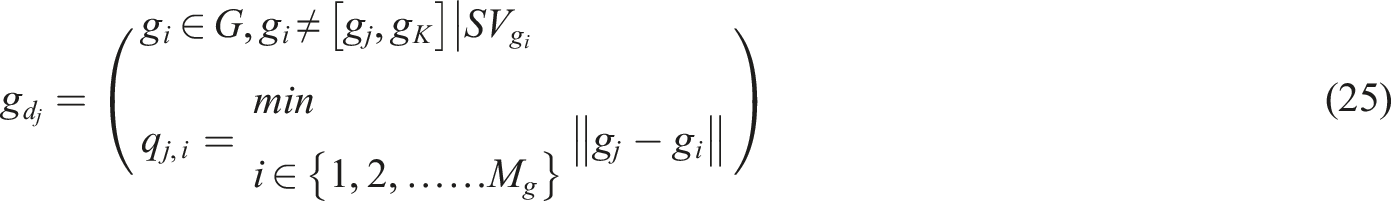

The following is the escape prey position update formula: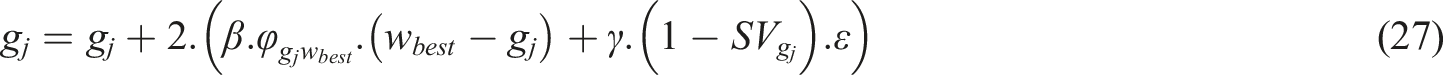
Predator hunting process
Predators use the following equation to update their position:


Restoration stage and predation stage
Restoration stage
Through mating behaviors, every prey that has been slain by predators will regenerate. The following definition applies to the chance of prey mating:
M stands for prey, which is not the target of hunting. The following are the individuals that result from mating:
Predation stage
Predators use dangerous regions as hunting grounds. The following radius circle surrounds the risky domain:

Prey’s likelihood of becoming preyed upon in hazardous places is as follows:
Improved Probabilistic Neural Network (IPNN)
The highly accurate pattern identification of the IPNN enables extensive assessment with customized information for efficient learning, greatly improving piano music teaching and evaluation. Real-time analysis and rapid interactive adjustments during courses are ensured by its quick processing speed.
In this part, the IPNN design is displayed, which substitutes the f-mean for the dot product of the initial instruction sequence and the evaluation sequence. The neuron located in the accumulation component of the PNN combines up each Gaussian generated by the layout element. Because the total of all Gaussians is nonlinear, PNN design is more complicated. Because Gaussian is a nonlinear exponential function, it may be made linear by applying a mean-containing logarithm function. This simplifies the design and reduces the amount of time needed to calculate the unidentified pattern’s categorization. There are the complete derivations. Give the PNN the design that it received as input.
A series of patterns unit’s output matches the training pattern 
The weighted average of the 



Changing the value of 
The calculation for 

The accuracy of a training dataset’s categorization will alter as sigma 
Then, equation (44) can be altered as
The weightlifting schedule pounds are the ones that belong to class 
Instead of four levels, IPNN only has three. For every input characteristic, there are neurons in the first layer. There is one neuron in the subsequent layer for every category in the initial information.
The weight between the neurons in the first and second layers,
The size of the training set determines how much computation is required to classify an unknown point in a probabilistic NN, where the whole set could be saved and utilized through analysis. These are PNN’s two main shortcomings. However, with IPNN, the amount of sessions in the initial information determines how long it takes to categorize an unknown point because the second layer of the network has one neuron for each class. In general, IPNN can categorize an unknown location computationally easily since there are too few classes compared to the number of sequences in the initial information. Therefore, IPNN eliminates PNN’s limitations.
IPNN’s development of a piano evaluation of performance framework
MIDI standards-based music performance
Digital music uses MIDI as a standard. A MIDI instrument translates a player’s movements into MIDI signals, which are then sent to the sequencing via the MIDI device when the player produces music. A synthesizer is an instrument that arranges, modifies, and exports the notes, rhythm, and other elements needed for a musical composition to noise source for audio generation. A MIDI file represents the recorded MIDI signal. Sound properties, including pitch and time value, may be examined as the MIDI signal has been obtained. Different MIDI musical equipment’ MIDI inputs are linked directly to the computer audio chip in a MIDI system that consists of a desktop computer. Software on computers called sequencers is designed to receive MIDI signals, which are primarily received by the computer’s operating system. The audio card on a computer provides the API. The computer system receives MIDI messages that consist of many bytes.
Establishing the structure of IPNN
In the input layer of the NN, the input parameters that had been established correspond to 153 neurons overall. An output neuron must adapt to the player’s performance for it to be evaluated overall. Measurements of creativity and rhythm are also frequently employed in performance assessment.
Both are represented by two neurons, and the number of neurons in the NN output layer is found to be three. Based on past experiences, it may be inferred that, given the estimated amount of hidden layer neurons, compared to the entire amount of output and input layer nodes, there can be more hidden layer nodes collectively. After that, it is recommended to raise the number of disconnected layer nodes through performance parameters that are satisfied to the optimal level. After several trials, the number of hidden layer nodes for the NN structure of the minuet proved to be 168. Figure 2 depicts the framework of the IPNN-designed piano assessment framework. IPNN-based piano assessment model’s architectural design.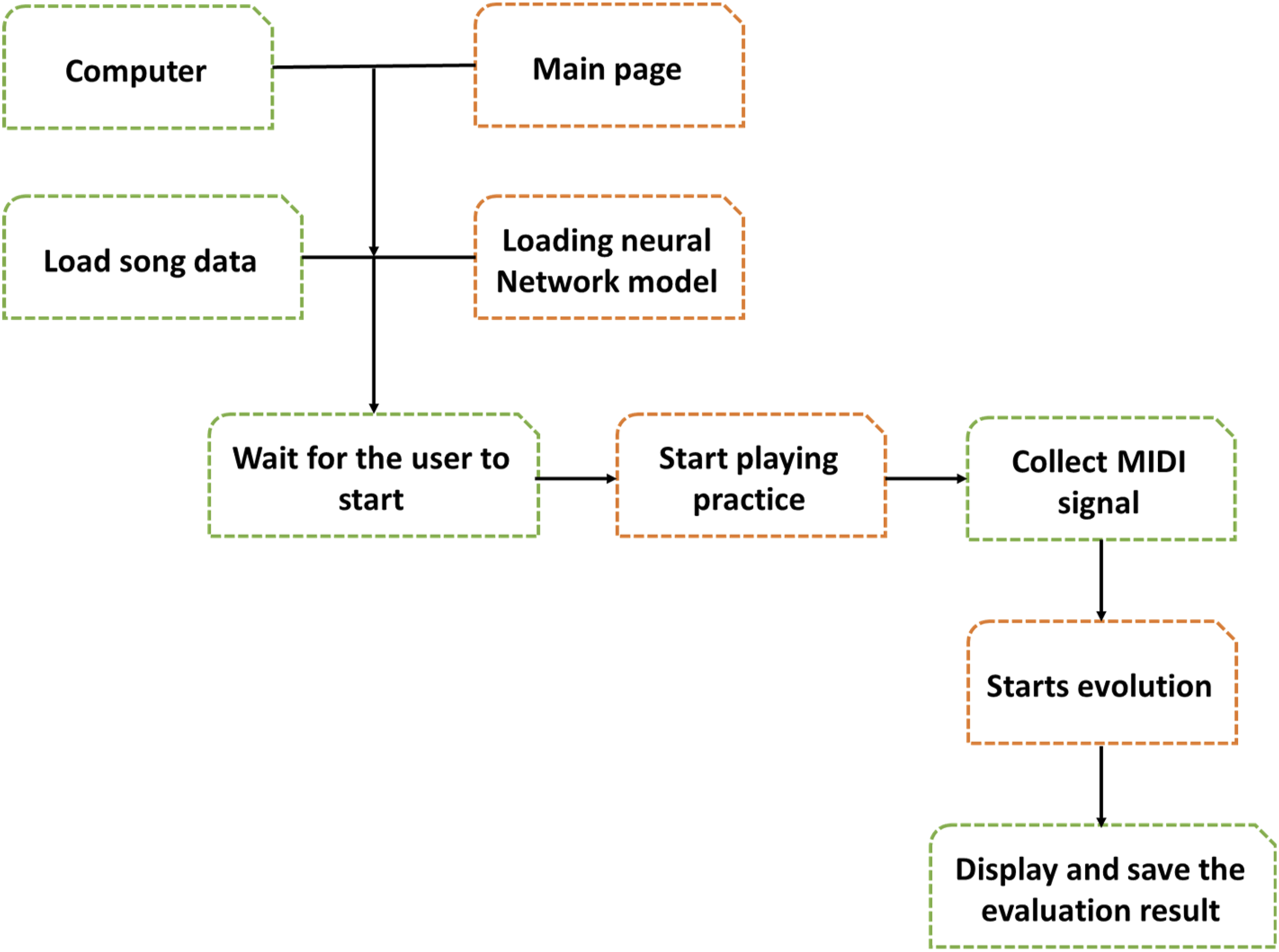
MIDI files for the correction of errors in piano playing music
Initially that have a recording of a piano playing, use the above-mentioned STED to extract the end and start points of every note using the enhanced endpoint identification technique. At this point, the note’s time value data is also established. To collect every letter in the audio and to determine the rhythm, the analysis separates the initial audio signal. Secondly, determine every note’s pitch data using the enhanced standard harmonics technique’s RFE technique. To identify the incorrect note that the player performed, the note time duration and pitch information that was acquired in the first two phases will be compared to the matching standard information in MIDI music.
Establishing the input parameters
Establish the chord characteristics’ parameters
Pronunciation occurring simultaneously at one moment creates a chord. The musical score and standard MIDI files provide the period point of each chord in progress. Each chord is evaluated at a different time point throughout the playing procedure. The basic tone is judged correct or incorrect based on the pitch difference. When playing a faulty chord, the amount of chord judgment mistakes is 1, and if the other one is incorrect, it is regarded as 0.5. Determine chord judgment errors and chord quantity to determine the input variable of chord pitch, similar to 2 input layer neurons. Determine chord time and strength using the same methodology.
Establish the pitch feature parameters
The opening bar of this piano piece consists of five notes. The notes D, G, A, B, and C are the greatest. Those are the MIDI messages 74, 79, 69, 83, and 72. When performing five tones, when playing four types, the input parameter is
Establish the melody characteristics parameters
The artificial arrangement of musical notes is called a melody. The initial melody may be split into four phrases, while the minuet can be separated into two sections. The portion that is played again is the second melody. The strength, pitch, and time value characteristics of each note segment may be added collectively to determine the typical song parameters. The neurons in the 6 input layers should have standard minuet melodic characteristics.
Establish the rhythm characteristics parameters
A sound’s rhythm may be used to characterize its duration, and the score’s representation of time is comparative. The variation in the sound’s duration must be obtained by converting it to absolute time. Utilize the initial calculation of the minuet as an illustration. The initial note has a time frame of one-quarter note, and the final four notes have a duration of one-eighth note and 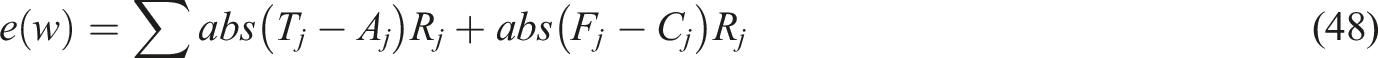
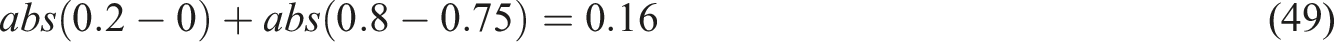
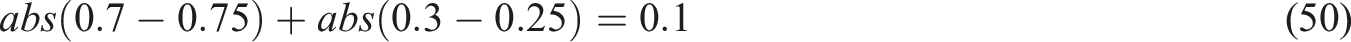
Establish the beat feature parameters
The power of the sound may be described by the beat. The force is expressed as a relative number, thus the score only minimally depicts the sound’s intensity. Use a MIDI standard signal that is artificially designed to represent the median value of samples entered with exceptional beat control. The additional bar of the minuet piano value consists of three beats:
Technique of experimental analysis
Training of IPNN model
The NN training procedure uses the Mean Square Error (MSE), whose description is provided in:
Equation (51), where
The NN must be developed to achieve the required accuracy standards after the input variables that influence the performance impact, as well as the characteristics and framework of the IPNN, have been identified. First, MIDI files and the piano teacher’s performance provide the standard data for each attribute. Then, using varying piano capabilities, features are entered and extracted. Three students and two piano teachers repeatedly playing the minuet piano provide training samples for the NN training technique. After receiving the NN input data, the group’s overall performance, rhythm, and expressiveness are assessed manually. The training set consists of 10 samples, with the data input ranging from 0 to 1.
Results
Experiment configuration
A directional condenser shotgun microphone with selectable intensity was used to record the piano sounds, and it was attached to an Aputure V-Mic D2. The baseline configuration used a monophonic channel with a 16-bit quality and an average sample rate of 22,050 Hz. The TensorFlow Dl architecture is used in the network, and the dataset is split 80:20 between training and test data. An Intel i7-10870H CPU, an RTX3080 8 GB graphic cards,
Confusion matrix
A 3x3 confusion matrix is a tool used to show and examine the accuracy of predictions produced by a classification system in the framework of piano music instruction and evaluation. This matrix contributes to evaluating the effectiveness of the technique or system and classifies items into three predetermined groups in this case, “good,” “Fair,” and “poor.” These categories can be used to describe instructional strategies, piano performance quality, or any other component that is being assessed. The confusion matrix can be organized and explained in Figure 3. Confusion matrix obtained with SHS-IPNN.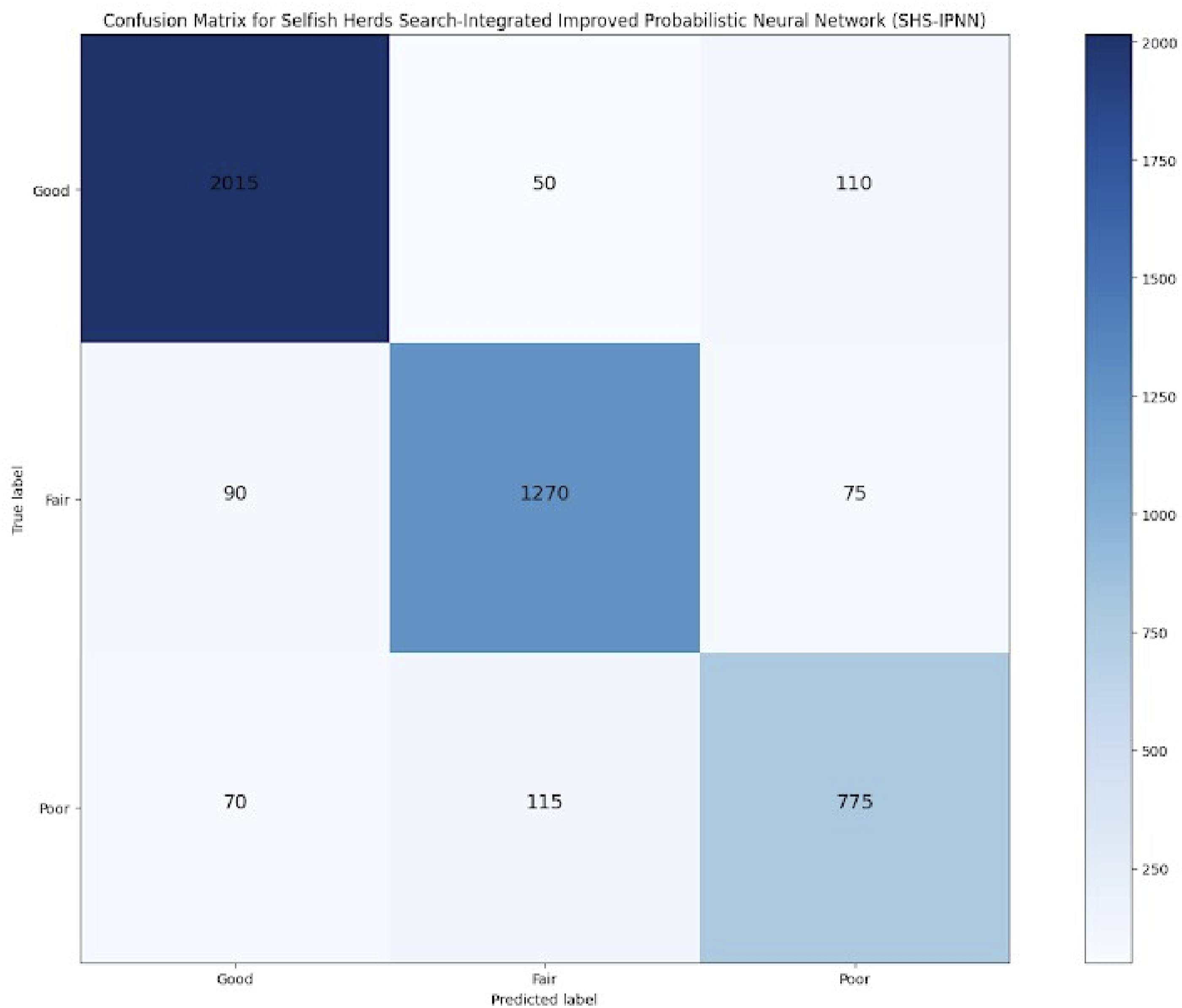
Outcomes of the model evaluation
The metrics of precision, accuracy, F1-score, and recall are examined in this section. The effectiveness of traditional and suggested methods is being compared.
The ratio of accurately anticipated observations (including true positives and true negatives) to all observations is known as accuracy.
Figure 4 illustrates the accuracy rate achieved by the proposed methodology. Compared to other traditional method, the suggested model achieves an accuracy rate of (96%). SHS-IPNN has superior outcomes compared to the traditional method. Results of accuracy.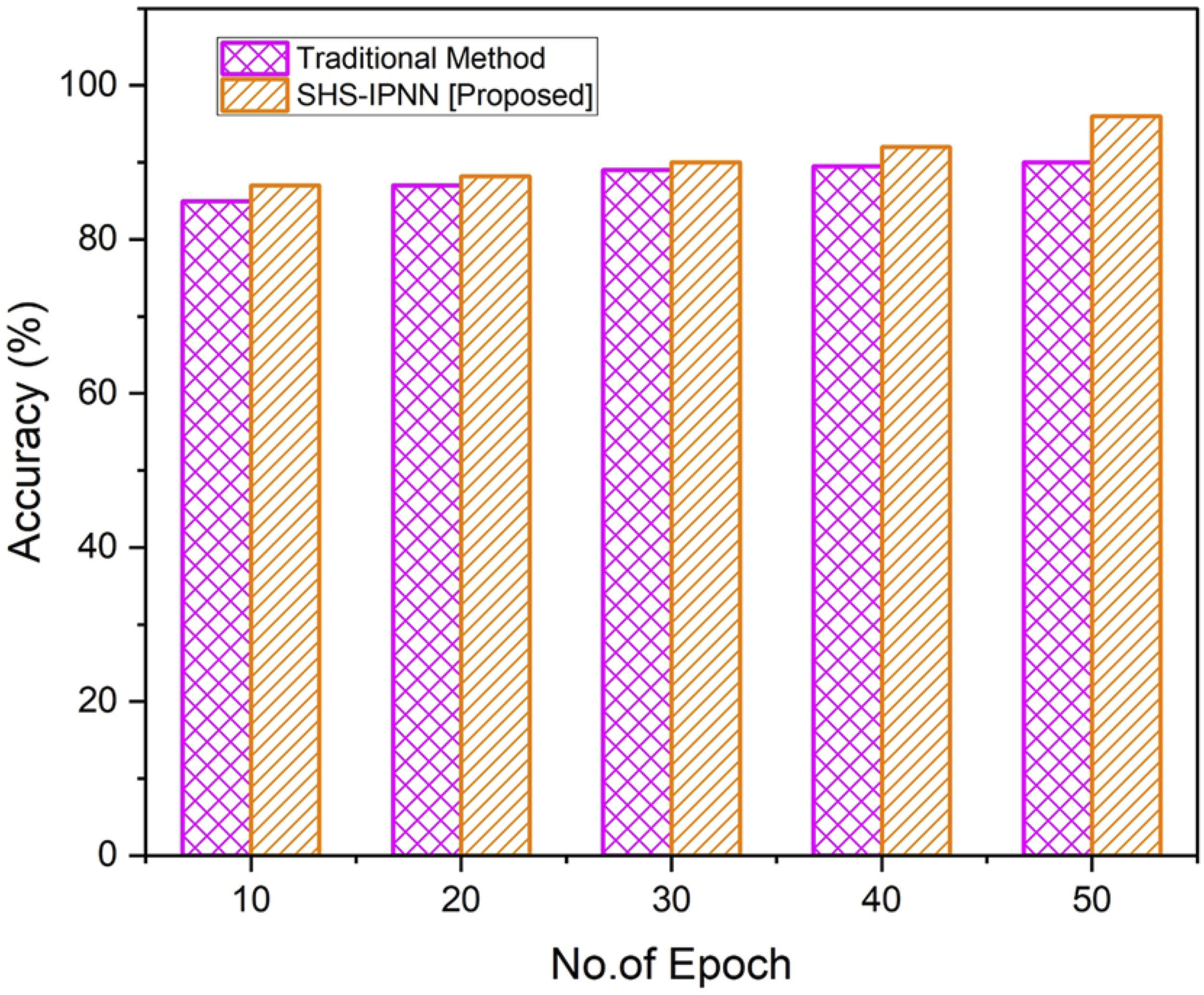
The ratio of accurately predicted positive observations to all expected positives is called precision, or positive predictive value. It serves as a measure of the precision of the positive forecasts performed.
The precision rate obtained by the suggested technique is shown in Figure 5. When compared to other traditional methods, the proposed model achieves a precision rate of (95.5%). When compared to the traditional method, SHS-IPNN produced better results. Results of precision.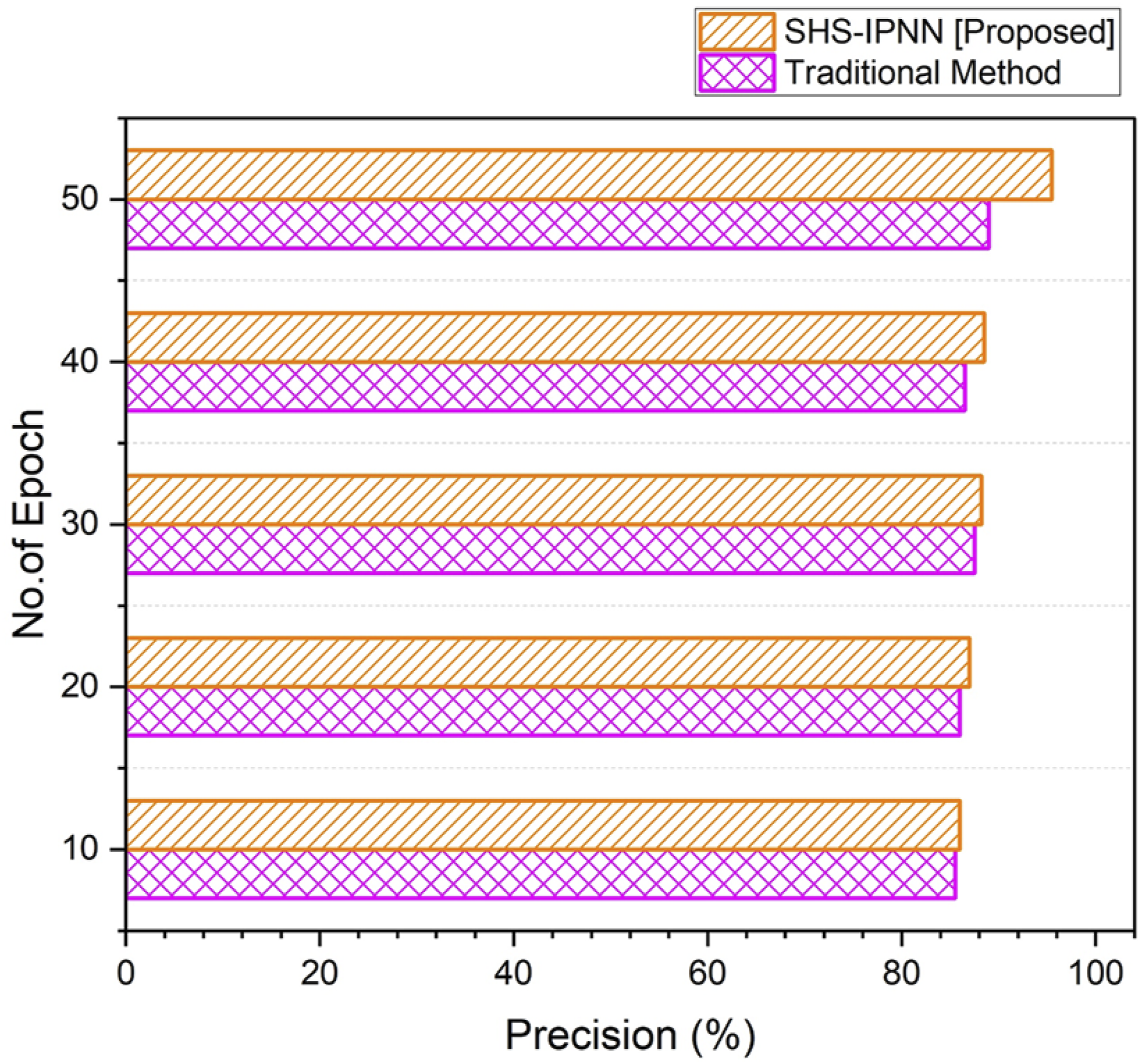
The ratio of accurately anticipated positive observations to all actual class observations is known as recall. It assesses a model’s capacity to identify all pertinent cases or positive observations.
Figure 6 illustrates the recall achieved by the proposed methodology. Compared to other traditional method, the suggested model achieves a recall rate of (90.5%). When SHS-IPNN was compared to the traditional method, better results were obtained. Results of recall.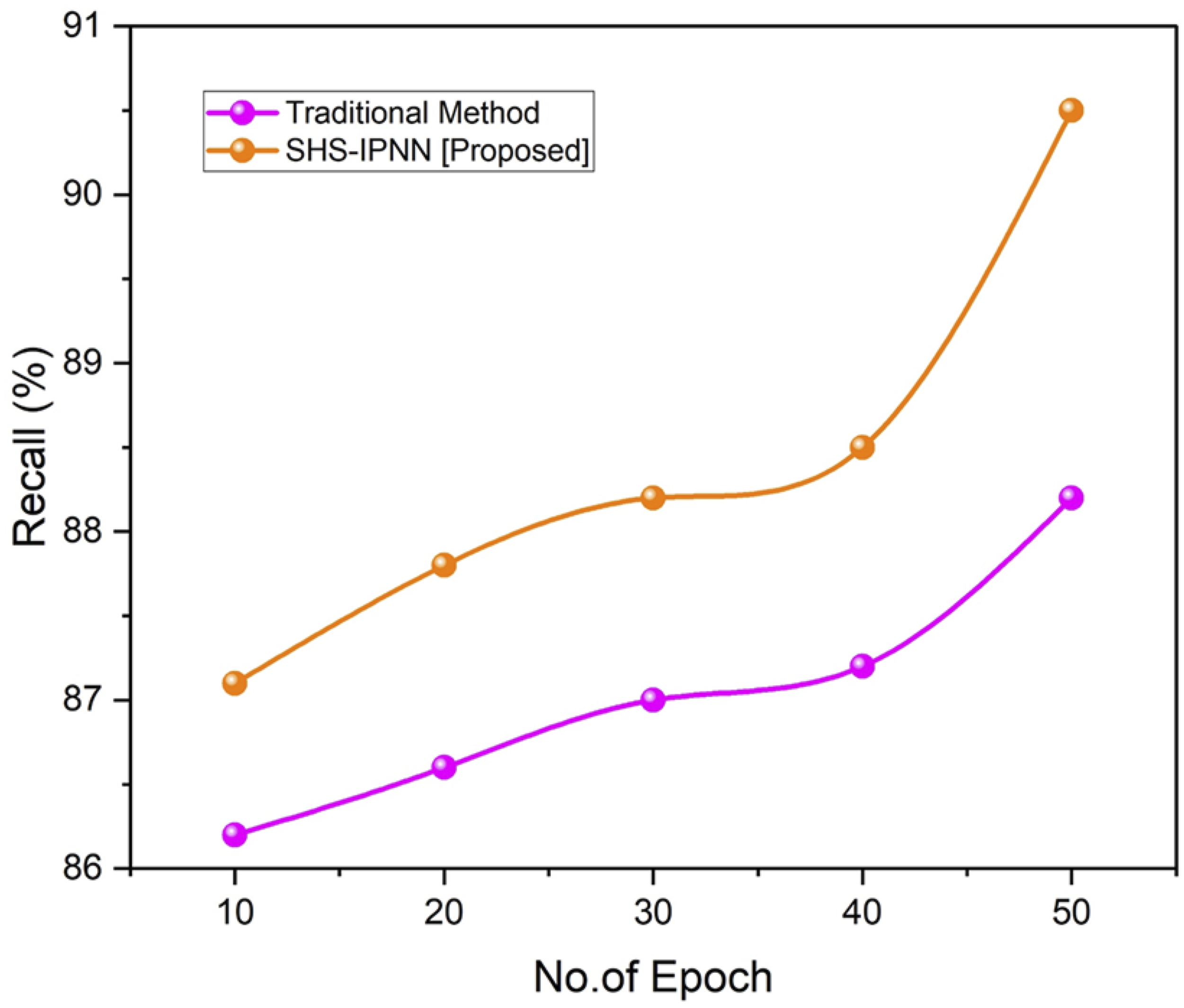
The calculated average of Precision and Recall is known as the F1-Score. False positives and false negatives are subsequently taken into consideration in this score.
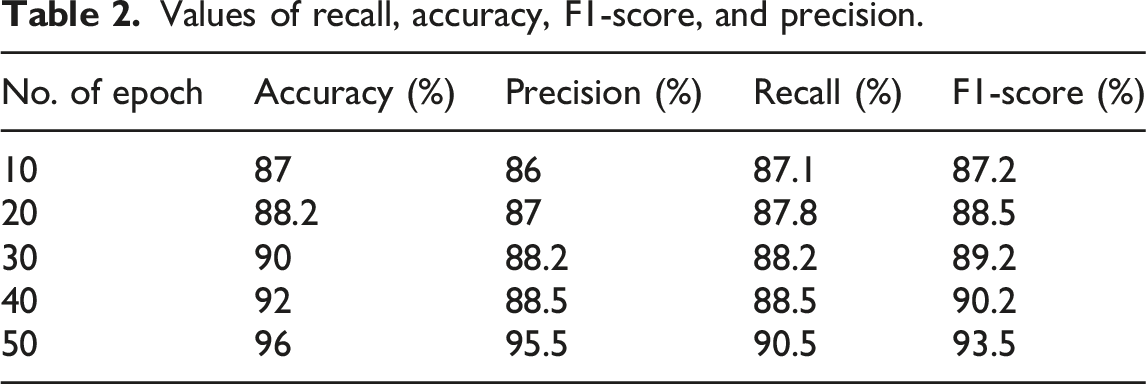
The F1-score rate obtained by the suggested technique is shown in Figure 7. When compared to the traditional method, the proposed model achieves an F1-score rate of (93.5%). Better results were observed when SHS-IPNN was compared to the traditional method. Table 2 depicts the values of recall, accuracy, F1-score, and precision. Results of F1-score. Values of recall, accuracy, F1-score, and precision.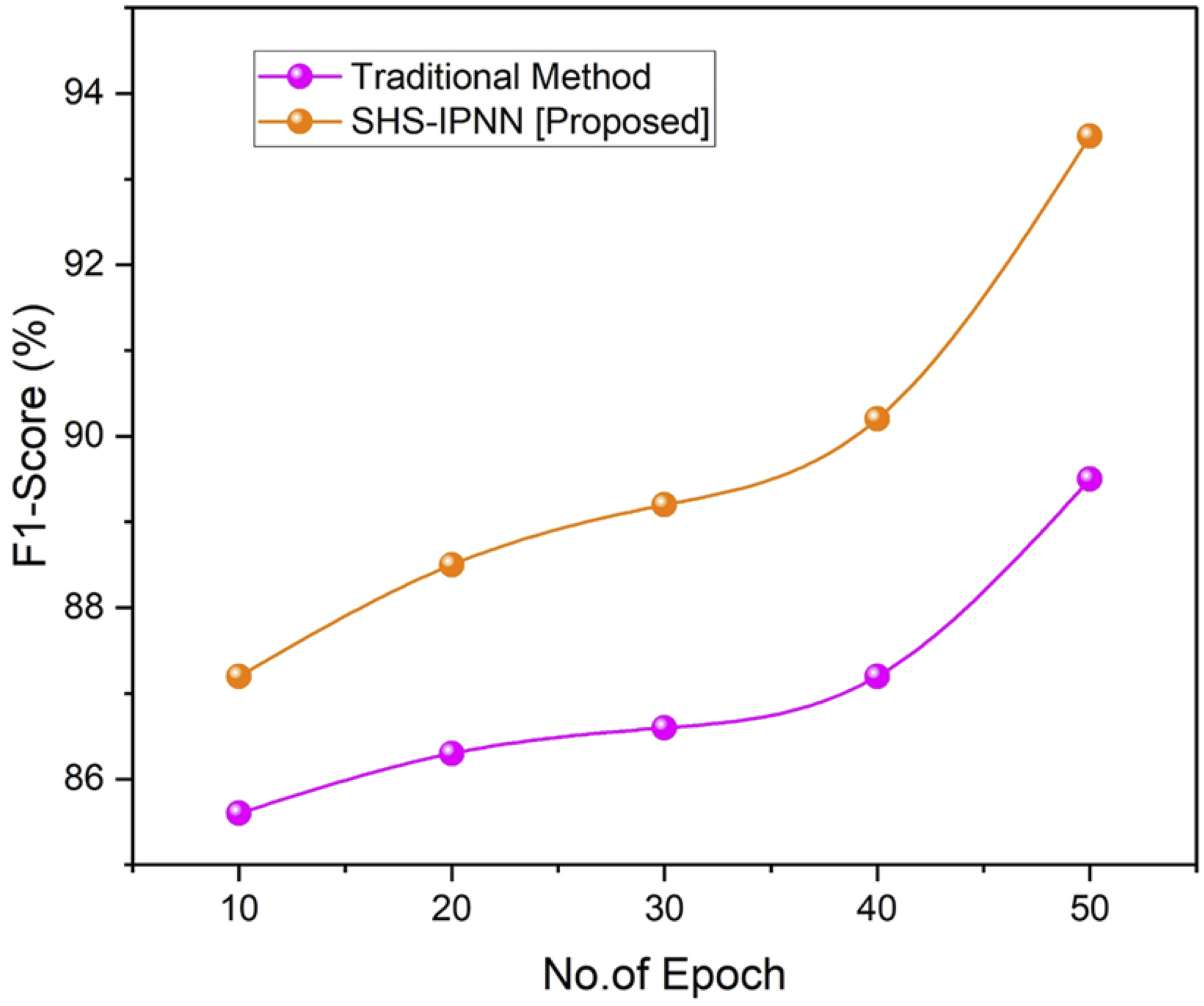
The accuracy test outcome with error correction
Figure 8 displays the ECR outcome of the IPNN piano presentation assessment framework. The accuracy of the participant’s pitch error correction has been greatly enhanced by the SHS-IPNN. The model can assist learners at the piano in addressing mistakes and increase the accuracy and efficacy of their learning process. Test findings for the evaluation model’s error correction.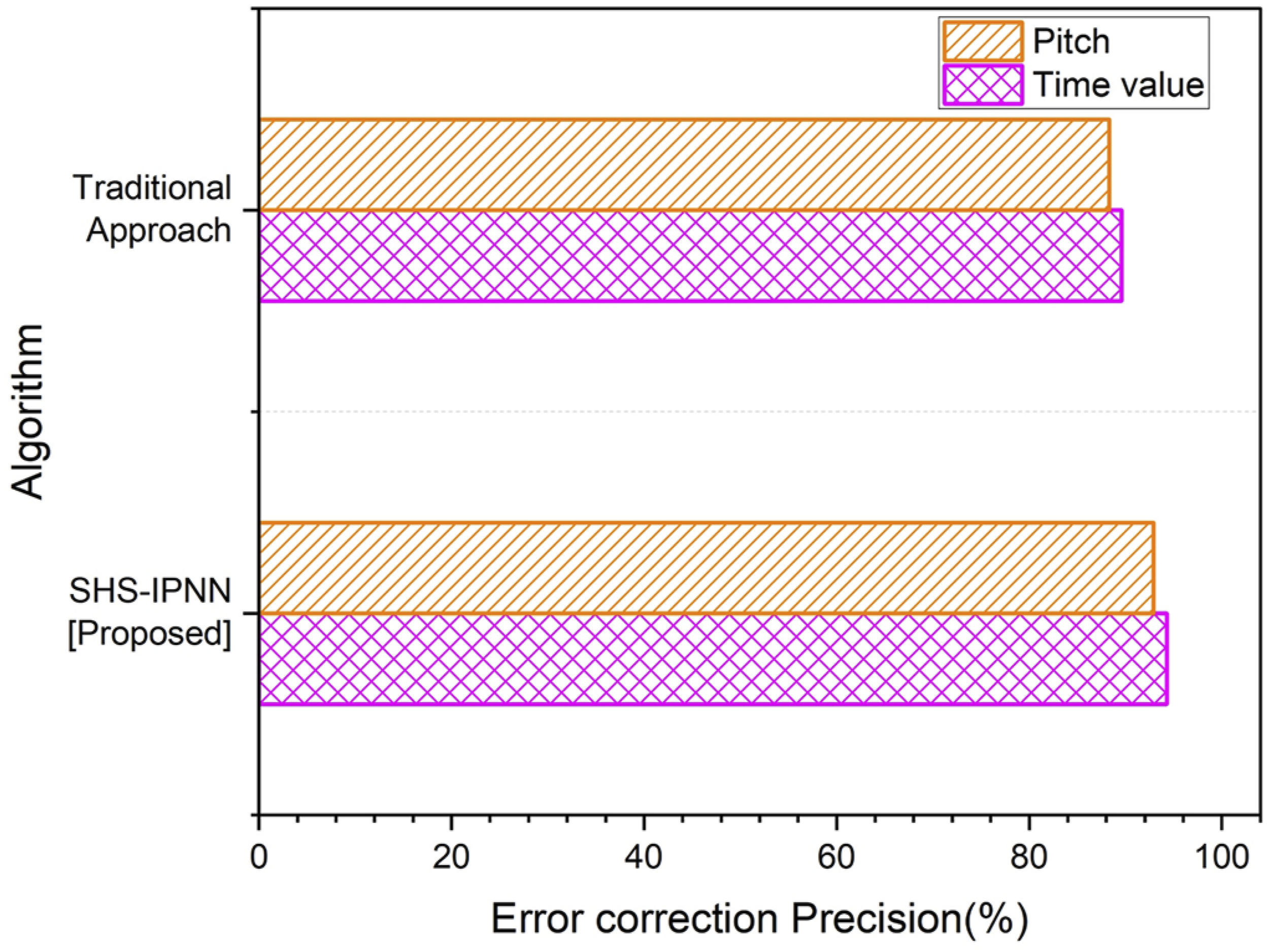
Conclusion
The study proposes a distinctive use of AI in teaching piano music by way of developing an Improved Probabilistic Neural Network (SHS-IPNN) that is Search-included for Selfish Herds. By using DWT for pitch accuracy and STED for unique note timing, the SHS-IPNN framework improves evaluation precision. Furthermore, the model’s overall performance evaluation abilities are much enhanced via optimizing IPNN using the SHS technique. Utilizing a MIDI framework, the SHS-IPNN version correctly assesses rhythmic, expressive, and trendy execution elements of piano playing. The version turned into education and tested the usage of statistics from minuet performances using teachers and students, teaching a strong basis for confirming its efficacy. The SHS-IPNN model represents a significant development in piano teaching as experimental findings display that it could become attentive and correct faults performance more accurately than current approaches. Our findings emphasize the efficacy of the SHS-IPNN technique, as demonstrated by its overall performance in terms of recall (90.5%), accuracy (96%), F1-score (93.5%), and precision (95.5%). This method improves educational findings and the efficiency of piano teaching by assisting students in identifying and correcting errors on their own, to improve evaluation accuracy. A of the limitations facing the SHS-IPNN in piano music education and evaluation are its high computational demand, and the requirement for huge, high-quality data. Due to its dependency on particular scientific parameters, its performance evaluations could not accurately represent the restraints of musical appearance. In the future, the model’s adaptation to various piano types could be prolonged, its computational efficiency could be maximized, and its sensitivity to expressive components might be improved. Making SHS-IPNN a more flexible tool that may be applied to different musical instruments and performance settings is possible by increasing the training dataset to include a range of performing levels and styles.
Footnotes
Funding
The author disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was funded by the Exploration and Practice of Integrating Music and Virtual Reality Technology in Higher Education from the Perspective of New Liberal Arts, grant number: 220900583051429.
Declaration of conflicting interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data availability statement
The authors declare that the data supporting the findings of this study are available within the article. The raw/derived data supporting the findings of this study are available from the corresponding author at request.
Appendix
Augmented reality = AR
Machine learning = ML
Deep learning = DL
Neural network = NN
Recurrent neural network = RNN
Application Programming Interface = API
Musical Instrument Digital Interface = MIDI
Short-term energy = STE
Long Short-Term Memory = LSTM
Short-term zero-crossing rate = STZCR
Convolutional Neural Network = CNN
Radical Frequency Extraction = RFE
Naive Bayes = NB
Harmonic peak = HP
Support Vector Machine = SVM
Error correction rate = ECR