
Abstract
(1) Medical image segmentation is crucial for disease diagnosis, surgical planning, and therapeutic monitoring, but existing methods face significant challenges due to the complex structures of human organs, including substantial size variations, indistinct boundaries, and low inter-tissue contrast. (2) To address this, we propose SDM-UNet, a hybrid network integrating CNN and Transformer modules to enhance segmentation performance. The architecture features a Multi-Attention Feature Refinement (MAFR) block replacing the Swin-UNet bottleneck, which combines adaptive kernel convolution, enhanced convolution, and channel attention to improve local feature extraction, and Multi-Fusion Dense Skip Connections that facilitate multi-scale feature fusion between the encoder and decoder to mitigate spatial information loss during downsampling. (3) Validated on the Synapse multi-organ CT and ACDC cardiac MRI datasets, SDM-UNet was trained using the PyTorch framework with ImageNet-pretrained weights and evaluated via Dice Similarity Coefficient (DSC) and 95th percentile Hausdorff Distance (HD95). (4) Experimental results show that SDM-UNet achieves an average DSC of 80.51% and HD95 of 22.09 mm on Synapse, and an average DSC of 90.58% and HD95 of 1.12 mm on ACDC, outperforming state-of-the-art methods like Swin-UNet and SCUNet++ and demonstrating its superiority in balancing global context understanding and local detail preservation.
Keywords
Introduction
With advancements in medical technology and growing health awareness, the importance of precise medical image analysis in clinical diagnosis and treatment has become increasingly prominent. Medical image segmentation, as a critical step in this process, has attracted widespread attention. By performing pixel-level classification, medical image segmentation enables accurate identification of lesion regions or target organs, playing a vital role in preoperative assessment and auxiliary diagnosis. Precise segmentation of organs and tissues in medical images serves as a foundational requirement for clinical practice, with computed tomography (CT) images being particularly crucial for disease diagnosis. High-quality, well-defined images significantly facilitate the diagnosis of critical conditions.
However, achieving high-accuracy medical image segmentation remains a significant challenge due to inherent complexities such as substantial size variations among human organs, blurred boundaries, and low contrast between tissues. These challenges make it difficult to meet the demands of real-world clinical applications. Developing novel medical image segmentation algorithms can not only provide reliable quantitative support for clinical decision-making but also markedly improve diagnostic efficiency. 1 Consequently, medical image segmentation has remained a focal point of research.
In recent years, CNN-based segmentation methods have achieved breakthroughs in medical image segmentation. 2 This method achieves automatic feature extraction through stacked convolutional layers and pooling layers, effectively capturing local spatial information and contextual dependencies. It is particularly suitable for modeling complex textures and boundaries in medical images. In CNN-based semantic segmentation methods, U-Net 3 has demonstrated outstanding segmentation potential. It extracts features through an encoder and upscales the encoded features via a decoder, enabling the network to extract semantic information about image boundaries and perform precise segmentation of critical morphological structures such as organs. Because of the success of U-Net, 3 many improved versions have emerged, such as U-Net++, 4 U-Net3+, 5 and Res-U-UNet, 6 which combines residual connections, Attention U-Net 7 with attention mechanisms, and Dense U-Net, which uses dense connections, and Dense U-Net, 8 which combines residual connections.
Despite their enhanced capability to capture critical features, CNN-based methods suffer from inherent limitations of convolutional operations. Convolutions can only learn local feature representations, making it difficult to effectively model long-range dependencies and global semantic interactions. Moreover, deep CNNs exhibit notable limitations in extracting high-level semantic features, often losing key details and leading to homogenized representations of different organs or tissues. For instance, in CT images, the soft-tissue contrast between kidneys and the liver is often subtle, causing traditional CNNs to blur their boundaries due to excessive focus on global semantics. 9 These limitations make CNN-based segmentation methods fall short of the precision required for clinical diagnosis. Furthermore, complex pathologies can exacerbate feature confusion and degrade segmentation accuracy. 10
In medical image segmentation, lesion morphology exhibits significant diversity and often lacks deterministic structural patterns. Thus, accurate segmentation of pathological regions cannot rely solely on local information; it necessitates the incorporation of global context to holistically delineate lesion boundaries.
The introduction of the Transformer architecture 11 has effectively addressed the shortcomings of traditional CNNs in global feature extraction. Vision Transformer (ViT) has achieved groundbreaking progress in visual research, demonstrating strong global modeling capabilities in computer vision tasks such as object detection and semantic segmentation. 12 In medical image segmentation, Chen et al. were the first to incorporate Transformers, proposing TransUNet 13 to enhance both local and global feature extraction. Subsequently, Hu et al. introduced Swin-UNet, 14 a U-shaped encoder-decoder network based on Swin Transformer. 15 By employing a windowed self-attention mechanism, this model effectively captures long-range dependencies among local features, achieving remarkable performance in medical image segmentation. Following this, researchers have proposed a series of advanced CNN-Transformer hybrid architectures, such as DS-TransUNet, 16 MISSFormer, 17 and H2Former. 18 These hybrid models combine the local feature extraction strengths of CNNs with the long-range dependency modeling of Transformers, significantly improving segmentation performance.
Although Transformer excel at modeling long-range dependencies and have demonstrated strong performance in medical image segmentation, they require dividing images into patch sequences and progressively downsampling features through multilayer self-attention mechanisms. This process inevitably leads to the loss of boundary detail information in low-resolution features. At the same time, Transformers have weak modeling capabilities for local textures and fine structures, facing technical bottlenecks such as scarce 3D annotation data and complex anatomical structure boundaries, all of which affect segmentation performance.
To address the limitations of existing medical image segmentation methods—specifically, CNNs’ insufficient global feature extraction and Transformers’ limited local feature capture—this study proposes SDM-UNet, a novel network that innovatively integrates the strengths of CNNs and Transformers to achieve synergistic modeling of local detail features and global contextual information, thereby improving segmentation accuracy and robustness. First, we design the Multi-Attention Feature Refinement Block (MAFR) block to replace the original bottleneck module in Swin-UNet, enhancing local feature extraction. By employing multiple convolutional and attention mechanisms, MAFR processes data from diverse perspectives, improving the model’s adaptability to challenges such as blurred organ boundaries and morphological ambiguities. Second, we introduce Multi-Fusion Dense Skip Connections
19
into Swin-UNet to strengthen feature propagation across the network. This module enables the model to effectively leverage multi-scale features extracted at different depths: shallow features are directly transmitted to corresponding decoder stages and fused with deep features. By integrating information across scales and abstraction levels, the model gains a more comprehensive understanding of complex feature patterns. The proposed SDM-UNet achieves superior medical image segmentation quality. Extensive experiments on the Synapse and ACDC benchmark datasets validate the model’s effectiveness. Our key contributions are summarized as follows: (1) We innovatively designed the MAFR module to improve the bottleneck part of the model. By effectively combining the advantages of CNN and attention mechanisms, this module enhances the model’s ability to capture both local and global features. Simultaneously, it reduces the original complex calculations of the model, enabling the new module to better capture subtle texture differences and blurred boundaries in medical images. (2) By incorporating dense skip connections, the model fully exploits multi-scale and multi-level features, enabling effective integration of shallow-layer spatial details and deep-layer contextual information. This design enhances the model’s capability to handle targets of varying sizes by bridging feature gaps across network layers. (3) The model designed in this paper has the ability to adaptively focus on key information in diverse image data, effectively suppressing noise and interference from irrelevant information. Furthermore, the model converges more quickly during training, reducing fluctuations in the training process. Experimental results on the Synapse and ACDC datasets show that the model outperforms existing advanced methods in key metrics such as DSC and HD, demonstrating excellent generalization ability and clinical application value.
Related work
CNNs for medical image segmentation
Due to their powerful feature extraction and representation capabilities, U-shaped CNN architectures, particularly U-Net and its variants, have demonstrated outstanding performance in medical image segmentation. There are many improved versions of the U-Net model commonly used today, Res-Unet, which introduces a weighted attention mechanism and borrows the skip connection method from ResNet, significantly improving semantic segmentation performance. Attention U-Net introduces an attention gate mechanism in skip connections, enabling the model to focus more on target-relevant feature regions and enhancing feature interaction. The MultiResUNet 20 incorporates MultiRes blocks, which fuse convolutional operations with varying kernel sizes to enhance multi-scale feature extraction. R2U-Net 21 combines recurrent neural networks with residual connections, adding a recurrent structure to the convolutional layers of U-Net to better capture context and sequence features. Dense U-Net adopts the dense connection strategy from DenseNet, introducing dense blocks in both the encoder and decoder to reduce the number of parameters while optimizing feature fusion efficiency. Through feature integration, depth supervision, classification guidance, and hybrid loss functions, the aforementioned methods effectively address common challenges in medical image segmentation, including blurred boundaries, small object detection, and low computational efficiency. It can be said that CNN has indeed made great progress in medical image segmentation, and these improved U-Net models have played an important role. However, CNN itself has insufficient global feature modeling capabilities, and deep CNNs also exhibit obvious limitations in extracting high-level semantic features, which may lead to the loss of key detailed information and result in feature homogenization of different organs or tissues.
Vision transformers
With the remarkable success of Transformers in various tasks, Dosovitskiy et al. pioneered their application to computer vision, achieving significant results. Due to Transformers’ inherent ability to capture global information, Vision Transformers (ViTs) have been increasingly integrated into computer vision tasks: The Uformer model uses a non-overlapping window self-attention mechanism, which eliminates the need to calculate high-resolution feature maps during processing, thereby avoiding the computational burden associated with high-resolution feature maps. At the same time, it obtains local contextual information through deep separable convolutions. The data-efficient image Transformer 22 uses a knowledge distillation strategy to reduce data dependency during training. The Swin Transformer introduces a window-shift-based self-attention mechanism, which reduces computational costs while enabling multi-scale feature learning. The latest Segment Anything model 23 (SAM) combines interactive prompts with the Transformer architecture to achieve general-purpose segmentation without the need for task-specific training. Compared with CNN, Transformer-based medical image segmentation architectures better model long-range dependencies. However, due to the high computational complexity brought by Transformer itself, Transformer-based models may over-focus on global semantics, leading to a decline in local feature capture capabilities. In general, Transformer brings new vitality to computer vision, allowing many tasks to break through.
Transformers for medical image segmentation
Inspired by the success of Transformers, researchers have adapted them to medical image segmentation, leveraging their global context modeling to extract finer details: Swin-UNETR 24 combines Swin Transformer with U-Net, proposing a hierarchical windowed attention mechanism for multi-scale feature learning. Another model called TransAT-TUNet 25 enhances non-local feature interaction through multi-level attention mechanisms, including Transformer self-attention (TSA) and global spatial attention (GSA). Coupled with multi-scale skip connections, it mitigates detail loss caused by stacked convolutional layers, improving segmentation across modalities. MISSFormer utilizes multimodal self-supervised learning, dynamic feature routing, and lightweight design to boost segmentation accuracy using cross-modal data. H2Former integrates CNN’s local feature extraction with Transformer’s global modeling via a hierarchical architecture and a gated feature pyramid module, addressing CNN’s limited global modeling and Transformer’s high computational costs. Compared with pure CNN and Transformer architectures for medical image segmentation, hybrid approaches combining CNN and Transformer better coordinate local feature extraction and global feature modeling. On this basis, we have proposed SDM-UNet, which further enhances the model’s ability to capture both local and global features, thereby improving the segmentation performance.
Methodology
Overview
The SDM-Unet model consists of four core components: the encoder module, the MAFR module, the decoder module, and the skip connection module. In the encoder module, first use a convolutional layer to process the input image, dividing it into multiple non-overlapping image blocks. These image blocks are then mapped to a predefined embedding space dimension through linear projection. Specifically, each image block is flattened and projected to the target dimension through a linear transformation. Finally, the projected features are processed using a Swin Transformer Block.
The features output by the encoder are fed into the bottleneck module, which innovatively employs a combination of convolutions and attention mechanisms in a parallel architecture. This design improves computational efficiency, expands the model’s receptive field, and enables the capture of long-range contextual dependencies. The incorporation of attention mechanisms enhances features from multiple perspectives, ensuring robust performance across diverse input data types. Additionally, residual connections facilitate direct information propagation, mitigating error accumulation. In the decoder, the input features undergo feature extraction through three successive Swen Transformer Blocks. The feature maps are then upsampled by a factor of 4 to match the resolution of the input image, progressively restoring spatial resolution. Finally, the expanded feature maps are normalized to stabilize the training process.
Encoder & decoder block
The encoder is primarily composed of Double Swin Transformer blocks. The encoding process begins by partitioning the input image into non-overlapping patches and embedding each patch into a fixed-dimensional vector. Specifically, the Patch Partition module divides the image into 4×4 non-overlapping patches. These patch embeddings are then processed by Swin Transformer Blocks for feature learning and representation extraction. Leveraging the self-attention mechanism, the Swin Transformer Blocks capture long-range dependencies in the image, enabling richer feature representation. A hierarchical encoder structure is constructed by three repeated stages, each consisting of a Double Swin Transformer Block followed by a Patch Merging layer. This design progressively extracts multi-scale features at different resolutions. The decoder performs upsampling to restore spatial resolution while reducing feature dimensions. Specifically, it doubles the spatial resolution of feature maps while reducing the channel dimension by a factor of 4. The upsampled features are then normalized to stabilize training. Similar to the encoder, the decoder employs Swin Transformer Blocks to model long-range dependencies. Finally, skip connections fuse multi-scale features from the encoder with the upsampled decoder features, enhancing segmentation accuracy by leveraging hierarchical feature information.
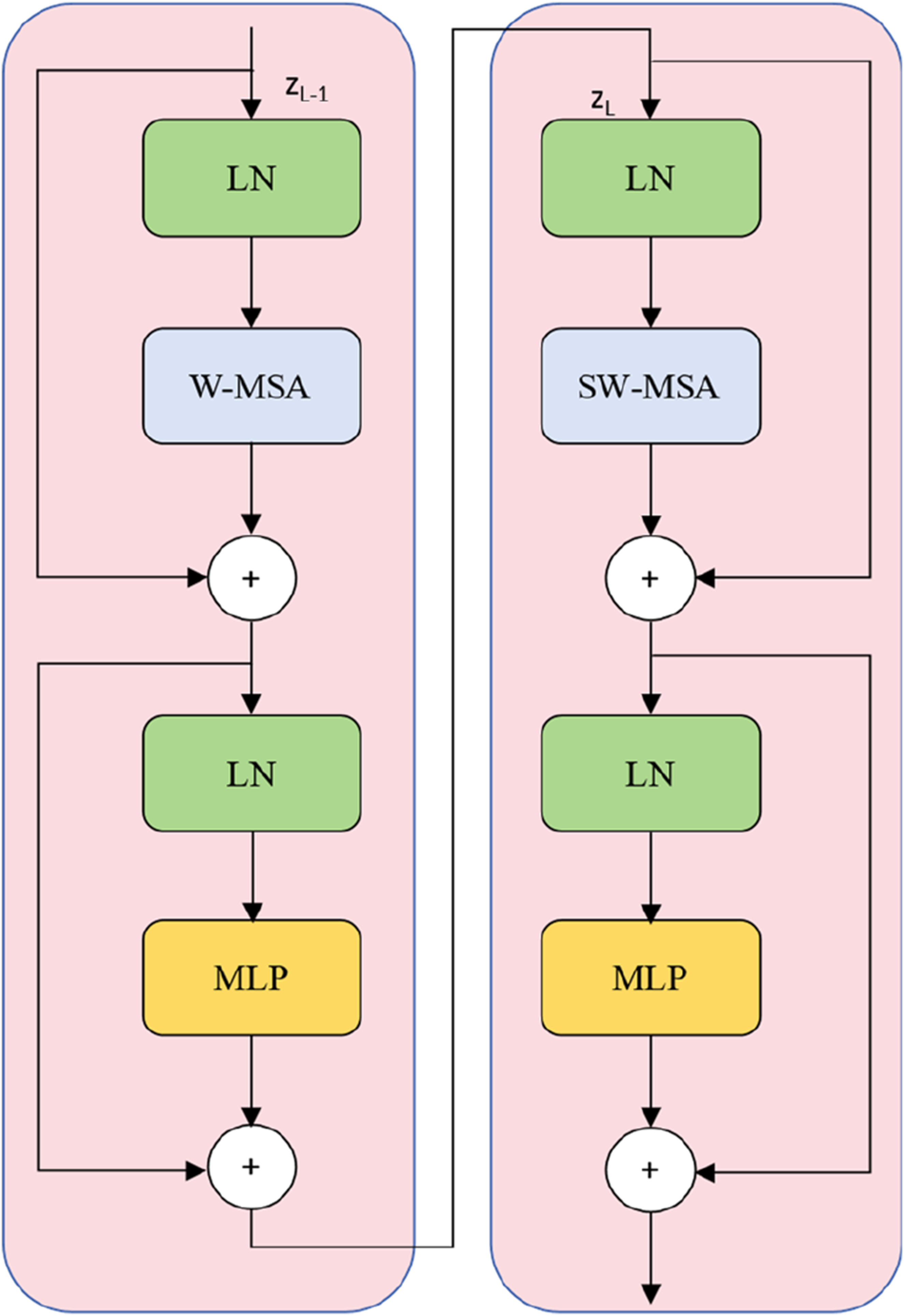
Double Swin transformer block
As illustrated, to strengthen the model’s ability to learn long-range dependencies, we introduce a Double Swin Transformer Block, which sequentially applies: 1. A Window-based Multi-Head Self-Attention (W-MSA) module, and 2. A Shifted Window-based Multi-Head Self-Attention (SW-MSA) module. This dual-block design enhances the model’s capacity to capture both local and global semantic interactions, improving its ability to model long-range dependencies while maintaining computational efficiency.
MAFR module
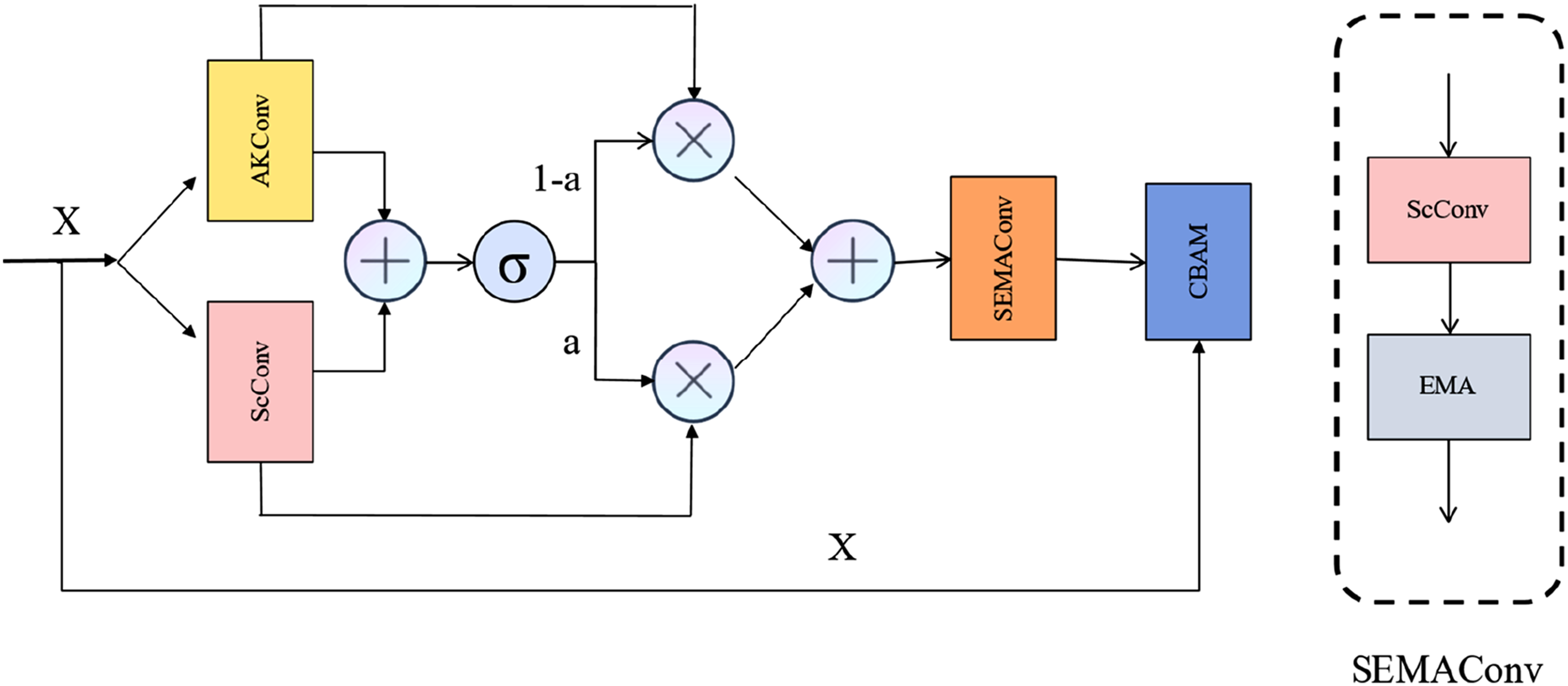
This paper uses multiple convolutions and attention to construct a new MAFR module to replace the bottleneck layer originally constructed by the Swin Transformer module. This design enhances the model’s ability to obtain global and local feature information, enabling it to capture more comprehensive semantic information. It solves the problems of introducing complex calculation processes, increasing calculation complexity, and insufficient feature extraction when using the Swin Transformer module to extract local spatial features. The MAFR module inputs the feature X into AKConv 26 and ScConv. 27 By connecting the two modules in parallel, the receptive field of the module is expanded, enabling it to capture distant contextual information. The output results are multiplied by the weight a obtained from sigmoid and the output results from ScConv, while 1-a is multiplied by the output results from AKConv. The results are then added together and input into the SEMAConv module, which captures features through a series of ScConv modules and EMA 28 modules, combining convolution and spatial and channel attention to obtain information about objects of different sizes in the image and improve the model’s adaptability to multi-scale objects. This significantly improves model performance while reducing the amount of computation. Subsequently, the CBAM 29 module further optimizes feature responses. The initial input features X are processed through global average pooling and a fully connected layer to learn channel dependencies and highlight important channels. Finally, residual connections ensure the transmission of detailed information and prevent information loss during computation. The module improves the bottleneck part’s ability to extract local spatial features by using attention and convolution without introducing a large amount of computation. Each module works together to process and enhance features from different angles, capturing image features more comprehensively and in greater detail, and improving the model’s feature expression ability. It reduces computational complexity while maintaining feature size and resolution, ensuring feature consistency.
Multi-Fusion Dense Skip Connection
In order to better extract local and global features from images and reduce information loss during downsampling, this paper introduces Multi-Fusion Dense Skip Connection in the skip connection part. Feature maps of different scales are upscaled, and the concatenated feature maps are input into the corresponding VggBlock for convolution and nonlinear transformation. The Vgg block can comprehensively utilize feature information from different levels and stages to enhance the feature expression ability of the model. The process of feature concatenation and fusion is repeated to gradually integrate more feature information. The fused feature maps are then flattened and dimension-adjusted. By introducing the Multi-Fusion Dense Skip Connection, the original limitations of the Transformer module in the Swin-Unet architecture for feature extraction at different levels are addressed, enabling the capture of more diverse information (Figures 1–3). The overall structure of the SDM—Unet model. Swin Transformer block. MSA denotes the multi-head self-attention module, and MLP represents the multilayer perceptron. The structure of the MAFR module.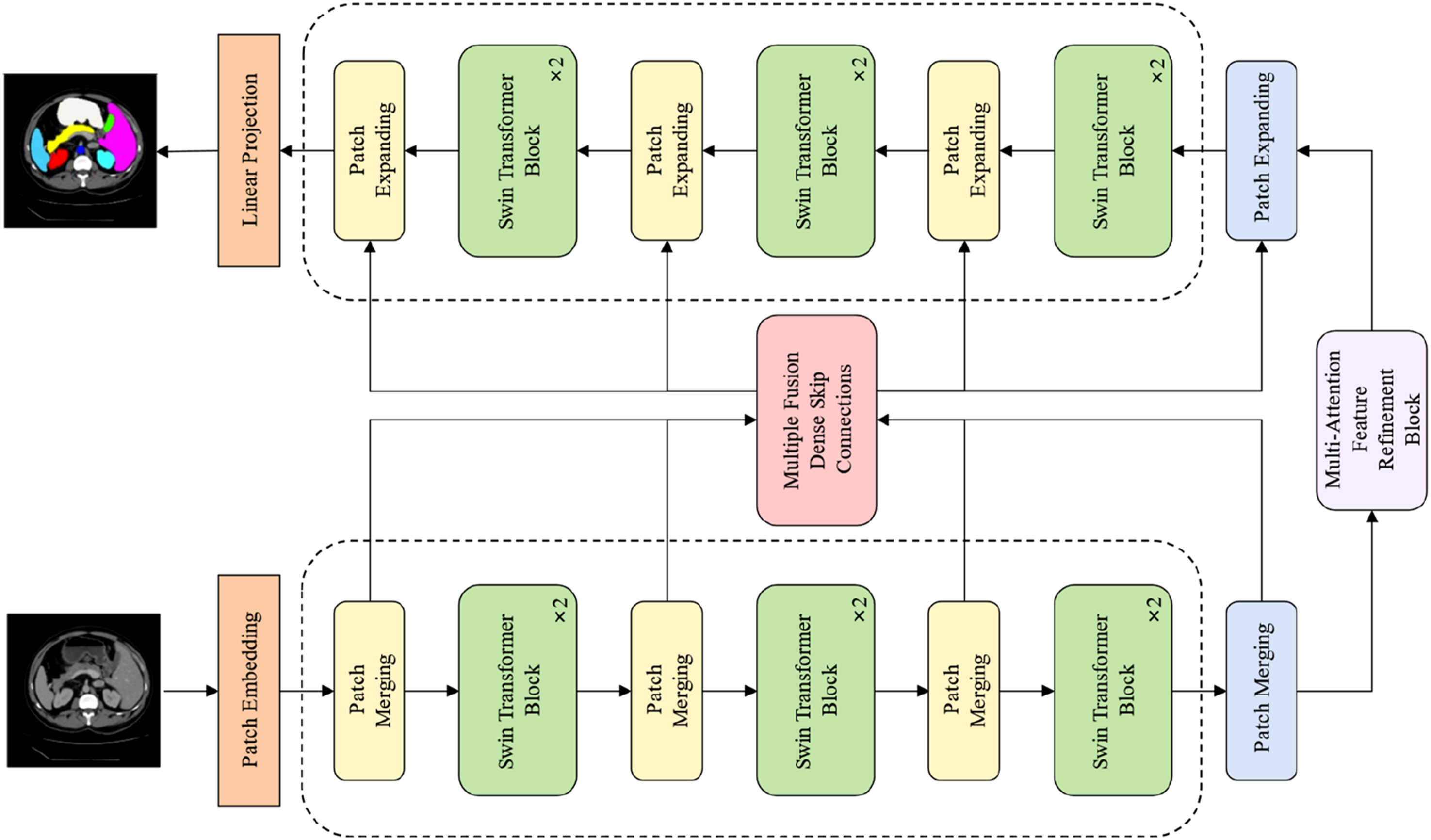
Experiments
This paper evaluates the effectiveness of SDM-Unet in medical image segmentation tasks. First, the benchmark dataset, implementation details, and evaluation metrics are introduced. Then, the method is compared with state-of-the-art methods and ablation studies are conducted to validate the superiority and scientific validity of the proposed architecture.
Datasets
The experiments were conducted on two publicly available datasets: Synapse and ACDC. Synapse is designed to address the challenges of diverse organ shapes and sizes in medical image segmentation, facilitating precise segmentation in complex scenarios. The dataset consists of 512 × 512-pixel axial CT scans in PNG format. The training set contains 2212 images covering multi-organ segmentation tasks, including the aorta, gallbladder, liver, left kidney, right kidney, pancreas, spleen, and stomach, enabling comprehensive model learning. 30 ACDC comprises 150 clinical cases from the University Hospital of Dijon, France, covering five cardiac pathologies (normal, dilated cardiomyopathy, hypertrophic cardiomyopathy, myocardial infarction, and abnormal right ventricle). It includes short-axis cardiac MRI slices at end-diastole (ED) and end-systole (ES) phases. The dataset provides expert-annotated labels for three structures: the left ventricle (LV), right ventricle (RV), and myocardium (MYO). 31
Implementation details
SDM-UNet was implemented in PyTorch and trained on an NVIDIA GeForce RTX 3070 Ti GPU (8 GB memory). The model was trained from scratch. For both Synapse and ACDC datasets, the input image size was set to 224 × 224, with an initial learning rate of 0.05, a batch size of 24, and 150 training epochs.
Evaluation metrics
To accurately evaluate the model’s performance in segmentation, this paper uses the Dice similarity coefficient (DSC)
32
and 95% Hausdorff distance (HD95)
33
to assess segmentation accuracy. Given a predicted segmentation mask (X) and the ground-truth label (Y), the DSC is computed as:

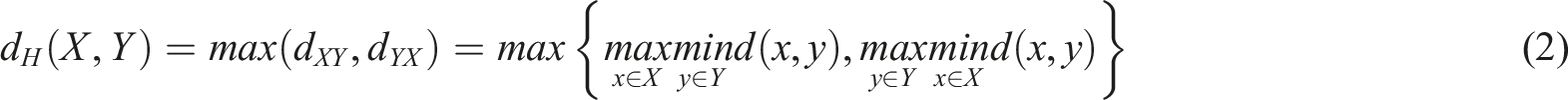
HD95 focuses on the “maximum boundary distance” between the prediction area and the label. The smaller the distance, the closer the prediction image is to the boundary of the segmented image, indicating higher segmentation accuracy. The DSC metric measures the overlap between the segmentation results and the label. The larger the value, the greater the overlap between the segmented areas and the labeled areas, indicating higher segmentation accuracy.
Comparison with other segmentation models
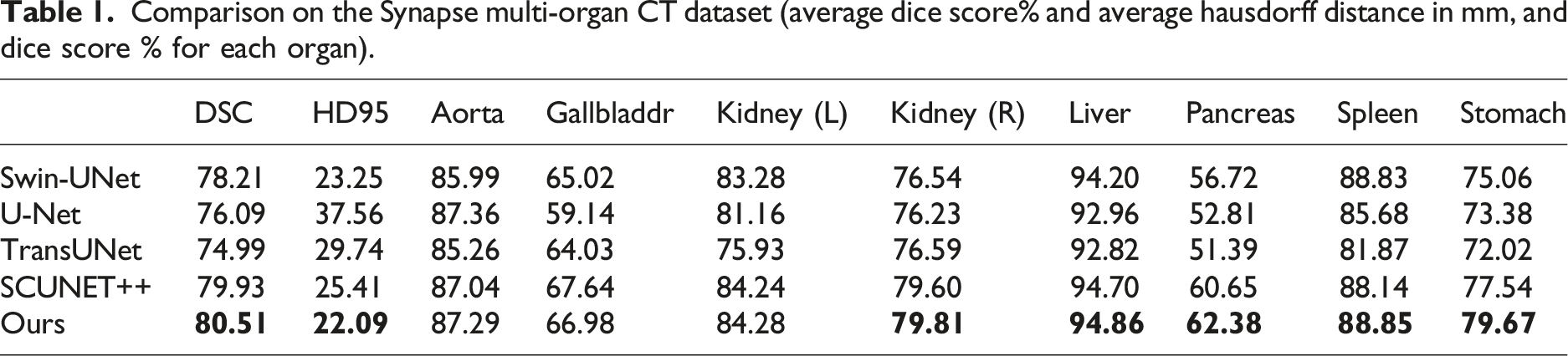
Comparison on the Synapse multi-organ CT dataset (average dice score% and average hausdorff distance in mm, and dice score % for each organ).
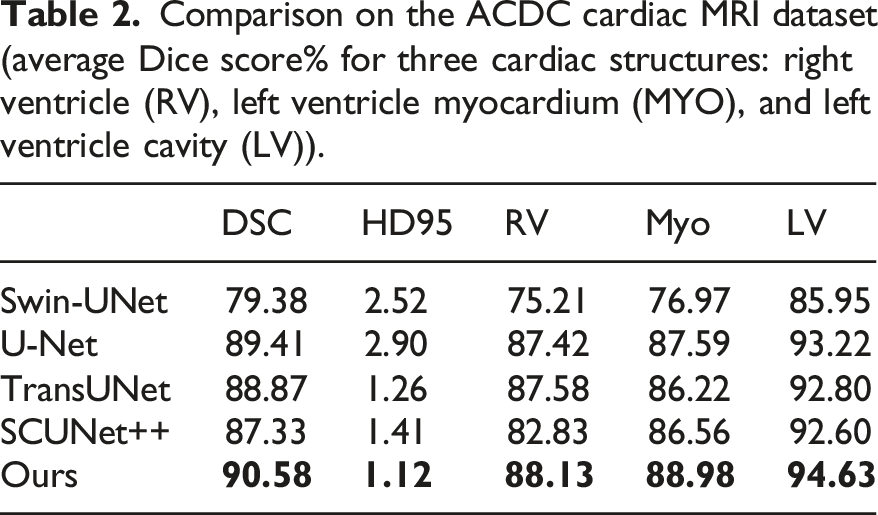
Comparison on the ACDC cardiac MRI dataset (average Dice score% for three cardiac structures: right ventricle (RV), left ventricle myocardium (MYO), and left ventricle cavity (LV)).
In the Synapse dataset, compared with U-Net, the DSC of SDM-Unet improved from 76.09% to 80.22%, while HD95 decreased from 37.56% to 23.20%. This improvement in metrics can be attributed to the Swin Transformer module in the model, which enables the model to better capture global features while capturing more detailed semantic information about image boundaries.
In addition, this paper compares the performance of SDM-Unet with TransUNet. The results show that on the Synapse dataset, the DSC of SDM-Unet improved from 74.99% to 80.22%, while HD95 decreased from 29.74 to 23.20. This improvement can be attributed to the introduction of multiple convolutions and attention mechanisms, which enhance the model’s ability to capture more local information while reducing the complex computations introduced by the Transformer architecture. The SDM-Unet model effectively integrates the multi-scale information captured, thereby improving segmentation performance.
When compared with SCUNet++, the results show that the DSC improved from 79.93% to 80.22%, while HD95 decreased from 25.41% to 23.20%.
Additionally, experiments were conducted on the ACDC dataset, with results similar to those on Synapse. Compared to U-Net, the DSC of SDM-Unet improved from 89.41% to 90.58%, while HD95 decreased from 2.90 to 1.12. Compared with TransUNet, the DSC of SDM-Unet improved from 88.87% to 90.58%, while HD95 decreased from 1.26 to 1.12. Compared with SCUNet++, the DSC improved from 87.33% to 90.58%, while HD95 decreased from 1.41 to 1.12.
The experimental results demonstrate that SDM-Unet significantly outperforms existing state-of-the-art models on multiple standard medical image segmentation datasets. Quantitative analysis shows that the model achieves the best results on key metrics such as Dice similarity coefficient and Hausdorff distance, fully validating its superior segmentation performance and clinical applicability.
Visualization results
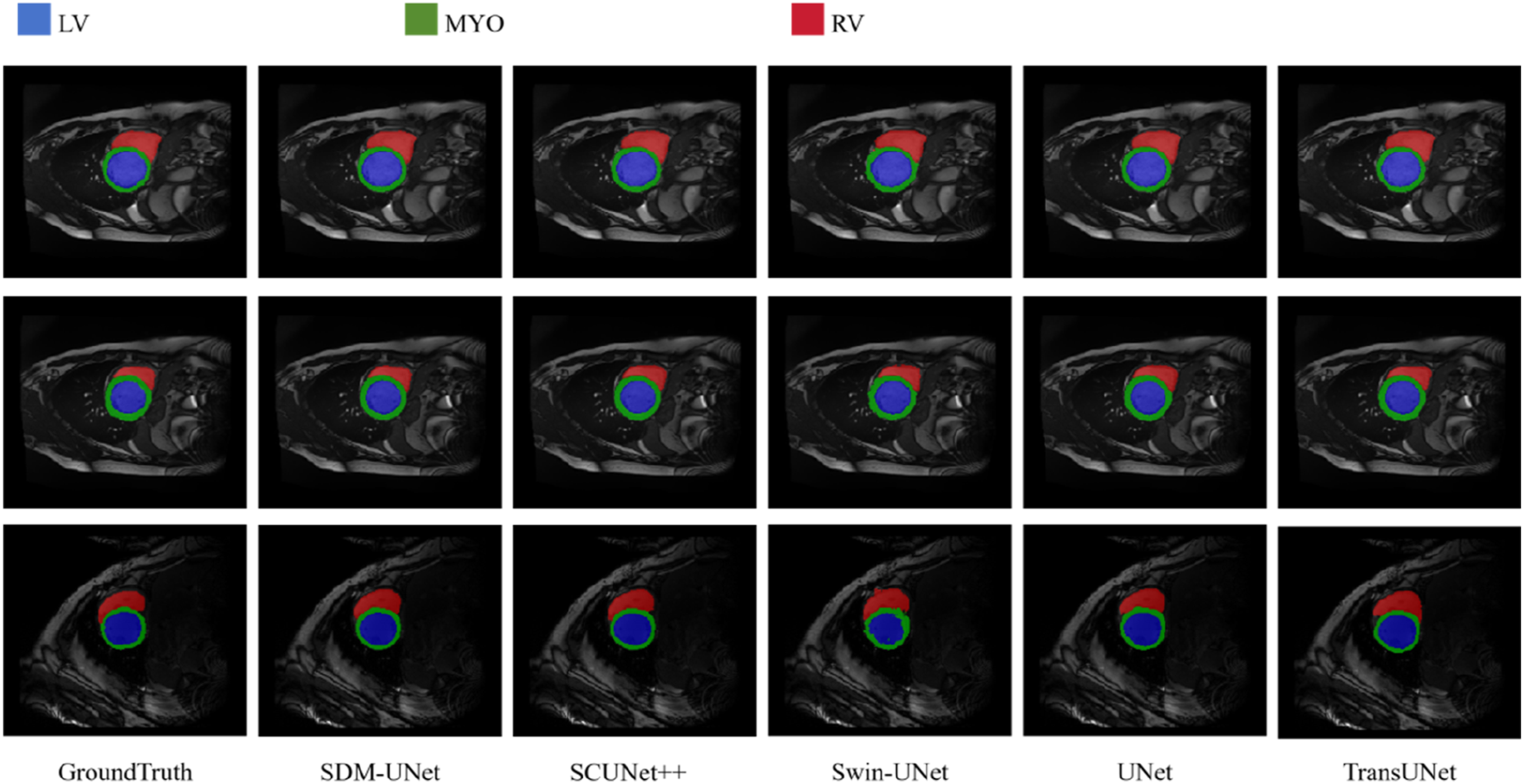
Figures 4 and 5 show a comparison of the 2D visualization results of the model proposed in this study and other advanced models. For the Synapse dataset, quantitative analysis indicates that SDM-Unet can effectively identify subtle feature differences between different anatomical structures. Its segmentation results are highly consistent with the ground truth. On the ACDC dataset, SDM-Unet significantly improves segmentation performance for the left ventricle (LV), right ventricle (RV), and myocardium (Myo), with clear segmentation boundaries and high similarity to ground truth, demonstrating superior segmentation performance. These segmentation results of different methods on the Synapse multi-organ CT dataset. Visualization results of automatic cardiac segmentation on ACDC dataset, red, green, and blue denote the LV, Myo, and RV, respectively.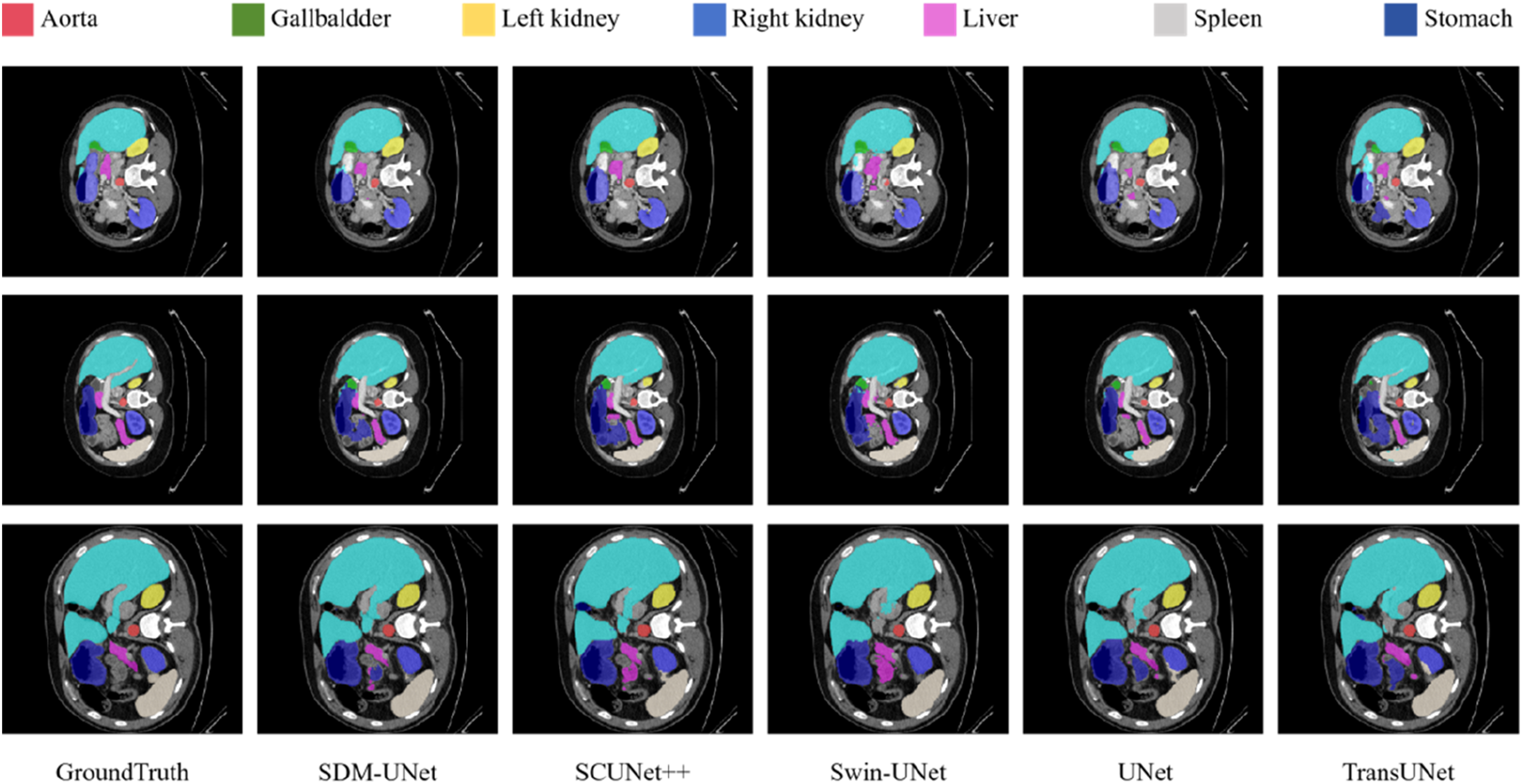
Ablation experiments
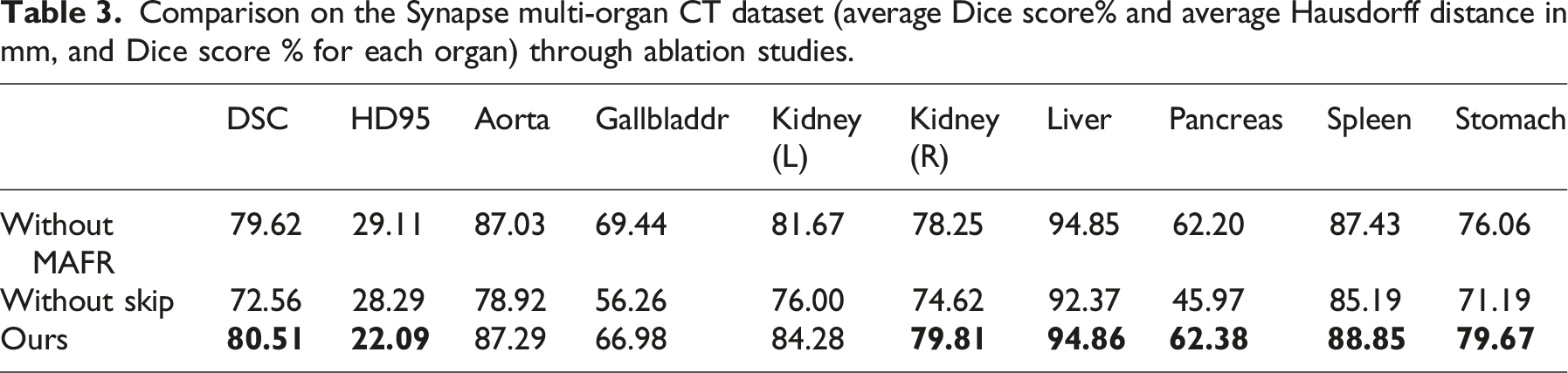
To validate the effectiveness of each module in the model, this study designed systematic ablation experiments, focusing on evaluating the contribution of the Multi-Fusion Dense Skip Connections module and the MAFR module to segmentation performance. The following three comparison models were set up: (1) the base model with the MAFR module removed; (2) the architecture with the designed skip connection module removed; and (3) the complete SDM-Unet model.
Comparison on the Synapse multi-organ CT dataset (average Dice score% and average Hausdorff distance in mm, and Dice score % for each organ) through ablation studies.
Comparison on the ACDC cardiac MRI dataset (average Dice score% for three cardiac structures: right ventricle (RV), left ventricle myocardium (MYO), and left ventricle cavity (LV)) through ablation studies.
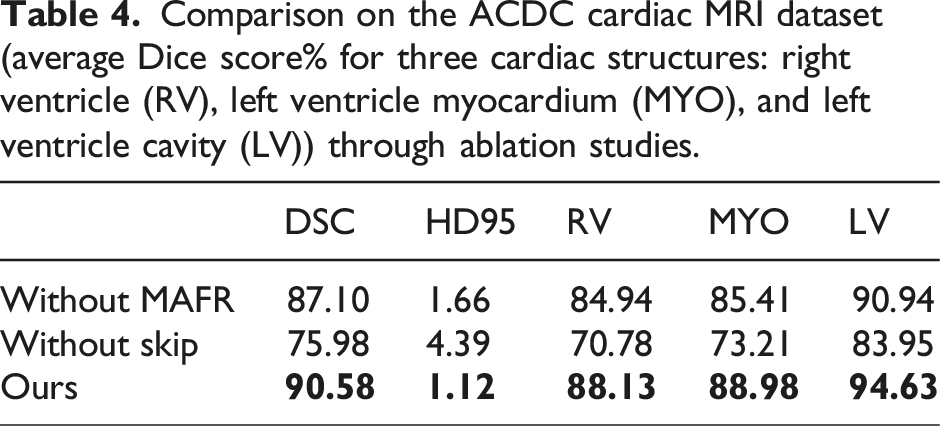
Furthermore, as shown in Tables 3 and 4, the experimental results on the ACDC dataset indicate that when the Multi-Fusion Dense Skip Connection module is added based on the MAFR module, the DSC metric improved from 75.98% to 90.58%, while the HD95 metric decreased from 4.39 to 1.12. When the MAFR module was added to the Multi-Fusion Dense Skip Connection module, the DSC metric improved from 87.10% to 90.58%, and the HD95 metric decreased from 1.66 to 1.12.
Cross-dataset ablation experiments demonstrate that both the Multi-Fusion Dense Skip Connections module and the MAFR module significantly contribute to improving model performance.
The SDM-Unet model, by introducing the Multi-Fusion Dense Skip Connection module, can further capture the rich semantic information obtained during model downsampling. Additionally, by comprehensively utilizing feature information from different layers and stages, the model enhances its ability to extract and express complex features. This structure can fully capture features across different layers and obtain rich multi-scale information. In addition, the model uses SDM-Unet as the bottleneck, which fully utilizes the module’s powerful local feature capture ability and global feature capture ability, enabling the module to work in coordination with the entire model and compensating for the original network’s insufficient local feature extraction ability.
Ablation experiments validated the core hypothesis of this study, namely, that the Multi-Fusion Dense Skip Connection module and the MAFR module can effectively improve the DSC metric of the model segmentation and effectively reduce the HD95 metric. These modules effectively utilize the obtained local feature information to perfectly complement the global feature information obtained by the original Swin Transformer structure. Ultimately, the model achieves significant improvements in segmentation accuracy and stability.
Conclusion
This paper proposes a novel medical image segmentation network, SDM-UNet. First, the Multi-Attention Feature Refinement Block (MAFR) module is designed to enhance local feature extraction capabilities, significantly improving the model’s ability to capture subtle and blurry boundaries. Additionally, the Multi-Fusion Dense Skip Connection module is incorporated into the skip connection pathways, effectively enhancing the model’s ability to retain downsampling information and enabling it to work synergistically with the original Swin Transformer architecture. The results show that the model achieved an average DSC of 80.51% and an HD95 of 22.09 mm on the Synapse dataset, and an average DSC of 90.58% and an HD95 of 1.12 mm on the ACDC dataset. Experimental results on the Synapse and ACDC datasets demonstrate that the proposed method outperforms existing models in segmentation performance.
We have noticed significant DSC differences in the segmentation of left and right kidneys, indicating that the model’s performance in segmenting similar structures still has room for improvement. Additionally, the model requires minor adjustments when facing multimodal tasks, demonstrating certain limitations in generalization. The next step is to look at how to make the network architecture better, mainly to solve the problem of how to confuse parts of the body that look like it is easy to get confused when they are divided, we will apply the model to medical image segmentation tasks with 3D data and enhance the model’s generalizability to adapt to multimodal medical image segmentation tasks. We will also find ways to make a lighter and easier model, which is not only fast, but also better than now, so that doctors can get more reliable data results.
Footnotes
Funding
The author received no financial support for the research, authorship, and/or publication of this article.
Declarations of conflicting interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.