
Abstract
Student behavior recognition is of great significance in the intelligent classroom environment for improving teaching quality, achieving personalized learning, and optimizing classroom management. However, the accuracy and real-time performance of existing technologies in complex scenarios still have limitations. To improve the accuracy and real-time performance of student behavior recognition, the study improved the eighth-generation model of “You Only Look Once” based on the squeezing—incentive attention mechanism, feature pyramid network structure, and anchor box mechanism, significantly enhancing the accuracy and robustness of student behavior recognition. The SE attention mechanism improves the efficiency of feature extraction by enhancing the dependency relationship between feature channels. The FPN structure enhances the multi-scale feature fusion ability by fusing features at different levels. Meanwhile, combined with the DeepSort real-time multi-object tracking algorithm based on deep learning, the problems of identity switching and trajectory loss in object tracking have been effectively solved, continuous tracking of students’ behaviors has been achieved, and the real-time performance has been significantly improved. In the experimental results, the average accuracies of the improved You Only Look Once eighth-generation model on the SCB-dataset3 and CampusGuard datasets reached 82.3% and 83.0%, respectively, which was significantly better than that of the control models. The multi-target tracking accuracy of the DeepSort algorithm is 84.2% and 83.7% respectively, and it also performs well in terms of robustness and real-time performance. The results show that the improved You Only Look Once eighth-generation model and the real-time multi-object tracking algorithm based on deep learning can effectively improve the performance of student behavior recognition and tracking, providing strong technical support for teaching management and personalized learning in the intelligent classroom environment.
Introduction
With the continuous advancement of educational informatization, intelligent classrooms have gradually become an essential development direction in education. In the Intelligent Classroom Environment (ICE), Student Behavior Recognition (SBR) technology, as one of the key technologies for achieving efficient teaching management and personalized learning, has received widespread attention. By automatically identifying various behaviors of students in the classroom, such as raising hands, reading, leaning against the table, writing, playing with mobile phones, teachers can real-time understand students’ classroom participation and learning status, and adjust teaching strategies promptly to improve teaching quality.1,2 In addition, SBR technology can also provide data support for personalized learning, helping students better grasp their learning progress and improve learning outcomes.3,4 For example, by identifying whether students actively participate in classroom interactions (such as raising their hands to speak), teachers can judge the students’ comprehension level and provide targeted guidance. Meanwhile, identifying whether students are distracted (such as playing with mobile phones) can help teachers intervene in time and maintain good classroom order. Currently, with the rapid growth of Deep Learning (DL) technology, significant progress has been made in object detection and tracking algorithms. However, in ICE, there may be differences in the behavior patterns of different students, and the behavior of the same student may also change at different times.5,6 Secondly, the accuracy and real-time performance of the existing technologies in complex scenarios still have limitations, especially in target tracking, there are problems such as identity switching and trajectory loss. These problems have seriously affected the practical application effect of student behavior recognition technology in intelligent classrooms. Furthermore, the robustness of target tracking is insufficient: Existing technologies are prone to problems such as identity switching and trajectory loss in target tracking, especially in multi-person scenarios, which seriously affects the continuity and accuracy of behavior tracking. The You Only Look Once (YOLO) algorithm is a revolutionary method in the field of object detection and has received extensive attention for its fast and accurate detection ability. The core idea of the YOLO algorithm is to transform the object detection problem into a regression problem, directly predicting bounding boxes and category probabilities in the image, thereby achieving end-to-end object detection. Among them, YOLOv8, as the latest version, has been comprehensively optimized in aspects such as feature extraction, model architecture, and training strategies, achieving higher detection accuracy and faster speed. DeepSort is a real-time multi-target tracking algorithm based on deep learning. By combining Kalman filtering and appearance feature matching, it achieves continuous tracking of targets. The core idea of the DeepSort algorithm is to solve the problems of identity switching and trajectory loss in target tracking through prediction and matching. Real-time DeepSort achieves higher real-time performance by optimizing the algorithm structure and computing process, and is suitable for large-scale target tracking scenarios.
At present, some scholars have also conducted research on student behavior recognition. Jia et al. proposed a DL-based student behavior detection framework to address the difficulty of real-time and accurate detection of student behavior in traditional classroom environments. This framework consisted of the You Only Look Once Version 5-Advanced (YOLOv5-A) network and OpenPose. The model achieved a mean Average Precision (mAP) of 0.821 for multi-class tasks, which was superior to the control model and could accurately detect various behaviors of students in the classroom. 7 Alruwais proposed a DL-based framework to address the current situation of student recognition and behavior monitoring in online classrooms. This framework was mainly implemented by Convolutional Neural Betwork (CNN) models for student recognition and emotion monitoring, to detect students’ emotional states. This framework could effectively identify students and monitor their behavior, thereby enhancing student engagement and learning outcomes in online learning environments. 8 Pabba et al. proposed a visual intelligence system based on body posture and facial features to address the current situation of student behavior classification in intelligent classrooms. The system contained OpenPose and CNN, which could recognize multiple behaviors and emotional states, and improve classification accuracy through multi-modal data fusion. The system performed well in student behavior classification tasks, providing real-time feedback to teachers, helping optimize the teaching process, and enhancing student participation and learning outcomes. 9 Sharma et al. proposed a 3DCNN-based approach to recognize the behavior of students and teachers in classroom environments. This algorithm mainly used a single detection method to identify whether the scene belongs to students or teachers, and then classified the behavior through 3DCNN. The algorithm achieved an average recognition accuracy of 83.5% on the dataset and was able to effectively recognize single person behaviors. However, its accuracy was relatively low in multi-person behavior recognition. 10 Wang et al. proposed a 3DCNN-based SBR algorithm to handle the current situation of SBR in ICE. This algorithm modeled the spatiotemporal features in video data using 3DCNN, which could efficiently and accurately automatically recognize the diverse and subtle behaviors of students in actual learning environments. This algorithm performed well in SBR tasks, providing educators with a tool to gain a deeper understanding of students’ learning habits and behavior patterns. It also provided data support for classroom management, personalized learning path design, and innovative teaching interactions. 11 In conclusion, the research fills the gap of existing technologies in student behavior recognition and tracking in intelligent classrooms by optimizing the YOLOv8 model and combining it with the improved DeepSort algorithm. The improved YOLOv8 model significantly enhances the detection accuracy and robustness by introducing the SE attention mechanism and the feature pyramid network structure. The improved DeepSort algorithm effectively solves the key problems in target tracking by optimizing the matching strategy and the appearance feature update mechanism. These innovations provide more powerful technical support for teaching management and personalized learning in the intelligent classroom environment.
Although the above research has achieved good experimental results, there are issues with identity switching and trajectory loss in target tracking. This study proposes an improved YOLOv8 model and DeepSort algorithm based on this to identify and track students’ classroom behavior. The paper tries to improve the precision and Real-Time Performance (RTP) of SBR by optimizing the YOLOv8 model and combining it with the DeepSort algorithm, while achieving continuous tracking of student behavior. The innovation lies in introducing the Squeeze-and-Excitation (SE) attention mechanism and Feature Pyramid Network (FPN) structure, which makes the improved YOLOv8 to capture the student behavior’s features, thereby optimizing the accuracy and robustness of detection.
Methods and materials
Intelligent classroom SBR based on improved YOLOv8
In today’s education field, digital transformation has become a key strategy to improve the education quality. By introducing an artificial classroom intelligent feedback system, real-time collection and analysis of data such as teacher-student voice, behavior trajectory, and interaction frequency can be achieved, greatly enhancing the scientificity and precision of teaching management. 12 Additionally, artificial intelligence technology has also promoted innovation in educational evaluation and teaching research models, providing teachers with more scientific management basis.13,14
To improve the accuracy of SBR, an intelligent classroom SBR method based on improved YOLOv8 is proposed. The model can more accurately detect and recognize various behaviors of students in the classroom by perfecting the model architecture and training strategy. The core idea of YOLOv8 is to characterize the detection task of related targets as a regression problem. In the context of smart classrooms, students’ behaviors are diverse and complex, such as raising hands, reading, leaning against the table, writing, playing with their phones, etc.15,16 The relevant diagram is shown in Figure 1. Intelligent classroom student behavior diagram. (a) Raise one's hand and (b) Read.
Based on the input image information in Figure 1, the YOLOv8 model can directly predict the bounding box and category probability of the target from the behavioral image. In the YOLOv8 model, it mainly includes a backbone network, a neck network, and a head network. The backbone network is mainly responsible for extracting features of student behavior images, the neck network fuses and enhances the features of the images, and the head network generates the final detection results.17,18 Firstly, for the backbone network part, this study introduces the SE mechanism module. It learns the dependency relationships between channels, weights feature channels, and suppresses unimportant channels while enhancing the response of important feature channels. In the model, the SE attention mechanism first performs a global average pooling operation on the input feature map, compressing the feature map of each channel into a scalar to obtain a one-dimensional feature vector the same as the number of channels. Secondly, the feature vectors after global average pooling are input into the two fully connected layers. A weight vector is generated through the nonlinear activation function and is used to weight the features of each channel. Finally, the generated weight vector is multiplied channel by channel with the input feature map to obtain the weighted feature map. Through the above steps, the SE module can dynamically adjust the feature weights of each channel, enabling the model to pay more attention to the feature channels related to students’ behaviors, thereby improving the accuracy of detection. The SE module is integrated into the backbone network of YOLOv8. Each residual block is followed by an SE module for enhancing the feature representation. Specifically, this study defines the dimension of the student behavior input Feature Map (Fmap) as

In formula (1),

In formula (2),

In formula (3), FPN structure diagram.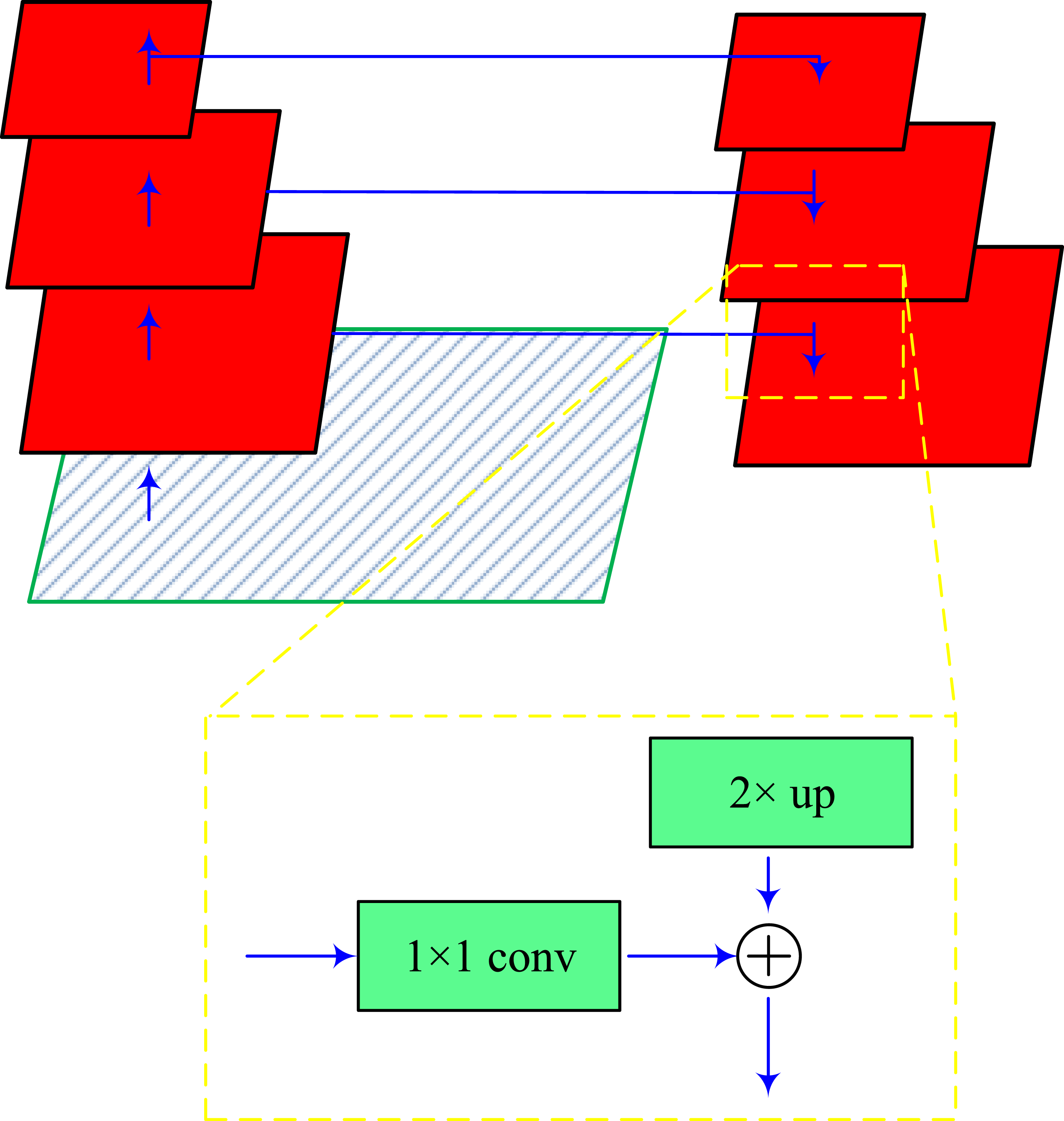
In Figure 2, the FPN structure fuses different hierarchical features in the backbone network to generate a feature pyramid with rich semantic and spatial information. FPN is a network structure used for multi-scale feature fusion, aiming to generate a feature pyramid with rich semantic and spatial information by fusing features at different levels. It first extracts the multi-scale feature map of the input image through the backbone network. Secondly, the low-resolution feature map is upsampled to the size of the high-resolution feature map through the upsampling operation, and then added element by element with the high-resolution feature map to achieve feature fusion. After this approach, the FPN structure can fuse features at different levels, enabling the model to better capture the characteristics of students’ behaviors at different scales, thereby improving the accuracy and robustness of detection. The FPN structure is integrated into the neck network of YOLOv8 to enhance the multi-scale feature fusion capability. Specifically, the Fmaps output by the backbone network are defined as

In formula (4),

By introducing FPN structure to optimize the neck network of YOLOv8, it can better capture the features of student behavior at different scales, thereby improving the detection robustness. Finally, in the head network, the paper introduces anchor box mechanism to improve it, as shown in Figure 3. Anchor frame mechanism.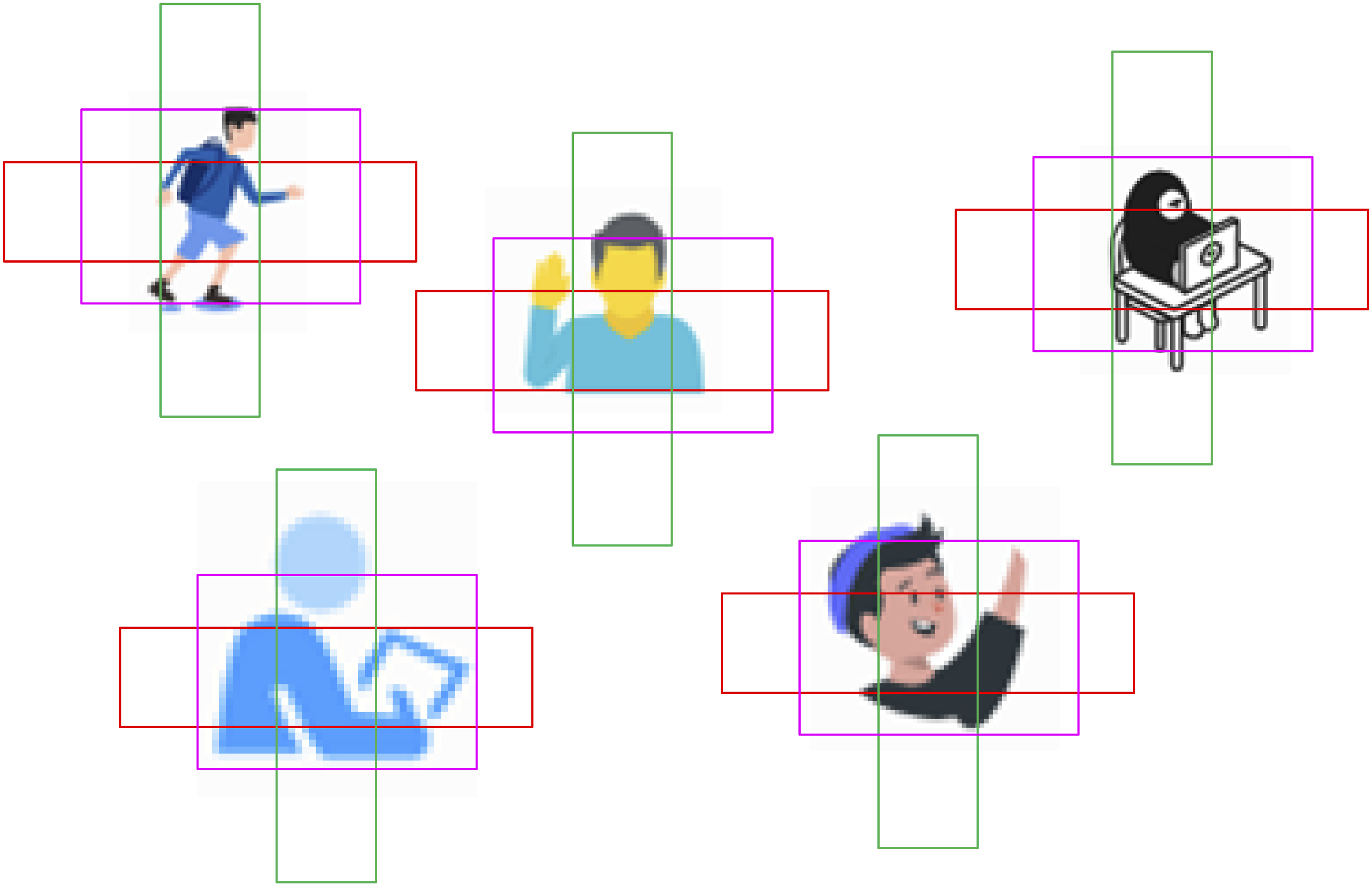
In Figure 3, by introducing anchor boxes into the head network, the YOLOv8 model can more accurately predict the location and size of the target’s bounding box.21,22 The anchor box mechanism enables the model to predict the bounding box position and size of the target more accurately by predefining a set of anchor boxes of different sizes and aspect ratios. The size and aspect ratio of the anchor boxes are set according to the distribution of the targets in the dataset to cover the majority of the targets. Meanwhile, the number and distribution of the anchor boxes are adjusted through experiments to optimize the detection performance. The anchor box mechanism is integrated into the header network of YOLOv8 to predict the category probability and bounding box offset at each position. The calculation process of the head network is as follows: for each input Fmap, each position is defined as having

In formula (6),

In formula (7), Flow chart of intelligent classroom SBR.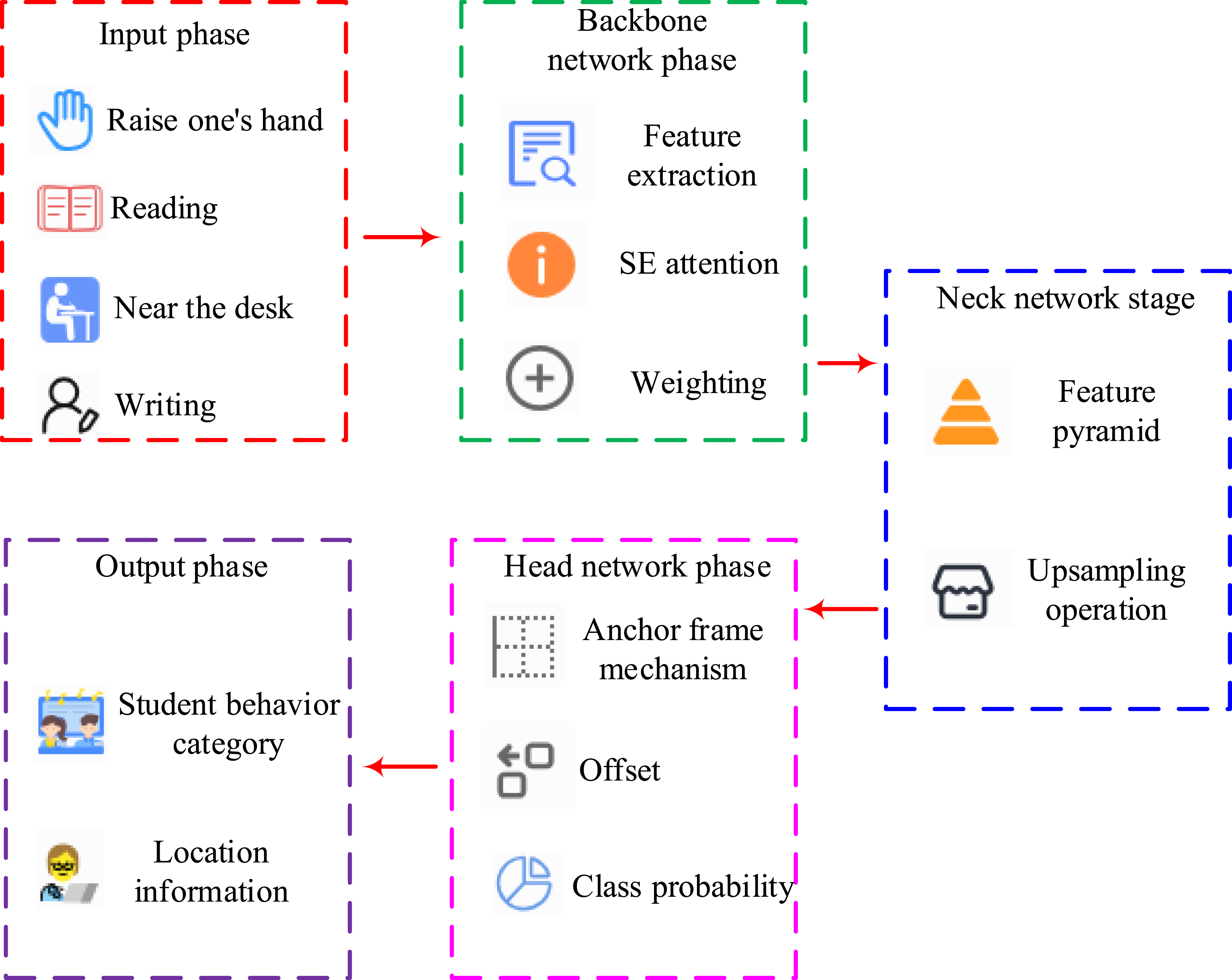
In Figure 4, the input stage mainly involves inputting student behavior images in an intelligent classroom scenario. The image contains various behaviors such as raising hands, reading, leaning against a table, writing, playing with a phone, etc. Next is the backbone network stage, which includes extracting features from the input image to obtain a Fmap, and using the SE mechanism to gain a weighted Fmap. Next is the neck network stage, which uses FPN structure to fuse features at different scales in the Fmap. In the head network stage, the anchor box mechanism YOLOv8 model can more accurately predict the boundary box position and size of student behavior. Finally, based on the predicted category probability and bounding box offset, the final prediction result is generated, including the category and location information of student behavior.23,24
Student target behavior tracking based on DeepSort algorithm
After implementing precise detection of student behavior based on improved YOLOv8, to further achieve continuous tracking of student target behavior, this study introduces the DeepSort algorithm. This algorithm is based on appearance features and Kalman Filter (KF), which can effectively solve the problem of continuous tracking of targets. The core of DeepSort lies in combining KF and Hungarian Algorithm (HA) to achieve continuous tracking of student targets through prediction and matching.25,26 Specifically, the workflow of DeepSort can be divided into four steps: object detection, KF prediction, object matching, and trajectory update and management. Firstly, object detection adopts the improved YOLOv8 model mentioned above to detect student behavior targets in each frame of the image, obtaining the bounding boxes and feature information of the targets. Secondly, KF predicts the position and velocity of each known tracking target in the next frame based on the KF. The state vector of student goals is defined as

In formula (8),

In formula (9),

In formula (10),

In addition, in cascade matching, besides cosine distance, this study introduces Mahalanobis distance to filter out unreasonable matching terms, as shown in formula (12).

In formula (12),
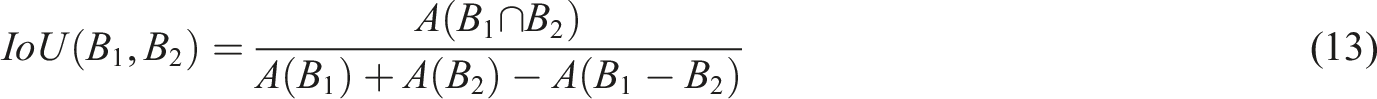
In formula (13),

In formula (14), Flow chart of student goal behavior tracking.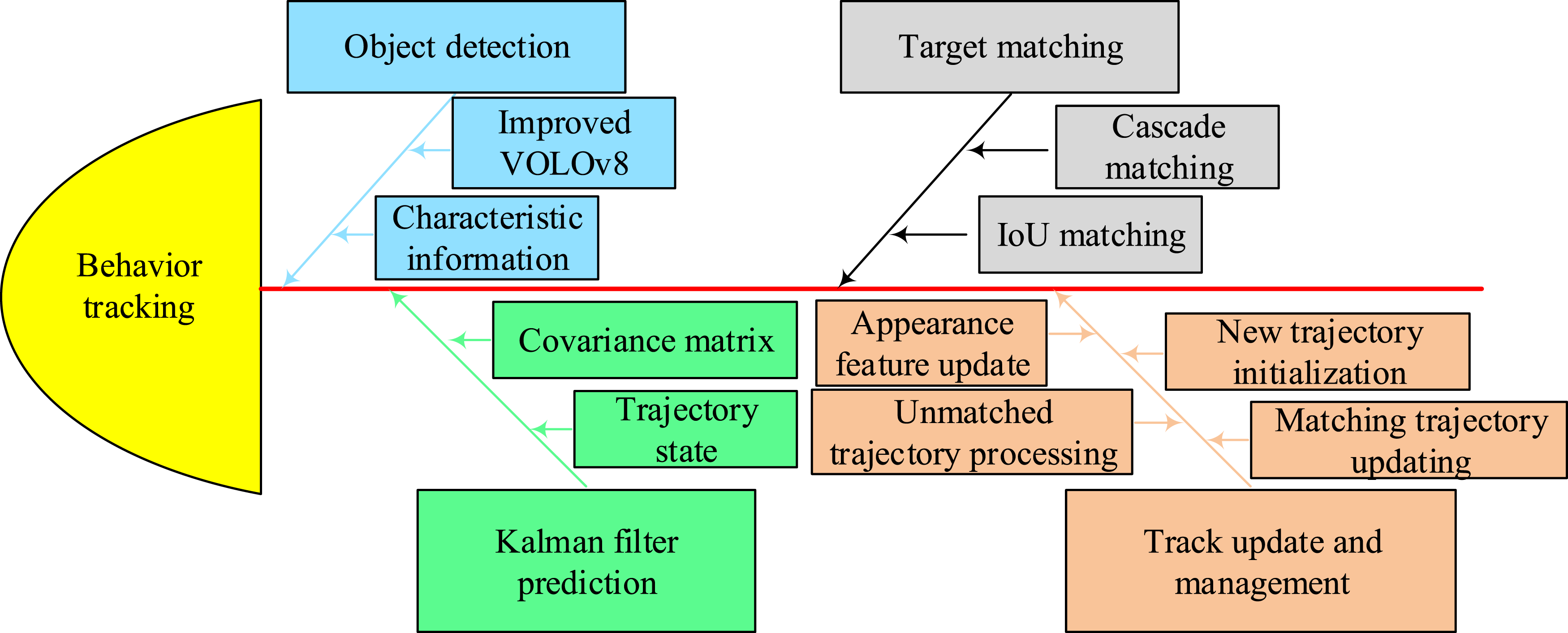
Figure 5 shows the tracking process. Firstly, in terms of object detection, the student behavior targets in each frame of the image are detected based on the improved YOLOv8 model to obtain the bounding boxes and feature information of the targets. Subsequently, KF predicts the state information of the known tracking target in the previous frame as the basis, and outputs the predicted trajectory state and covariance matrix by predicting the position and velocity of the target in the next frame. Subsequently, the trajectories are matched through cascade matching and IoU matching, and successful and unsuccessful matches are outputted. Finally, based on the matching results, after updating and initializing the trajectory, the updated trajectory information is output to complete the DeepSort algorithm’s continuous tracking task of student target behavior.
Results
Improvement of YOLOv8 model performance and analysis of SBR results
Experimental environment and algorithm parameter information.
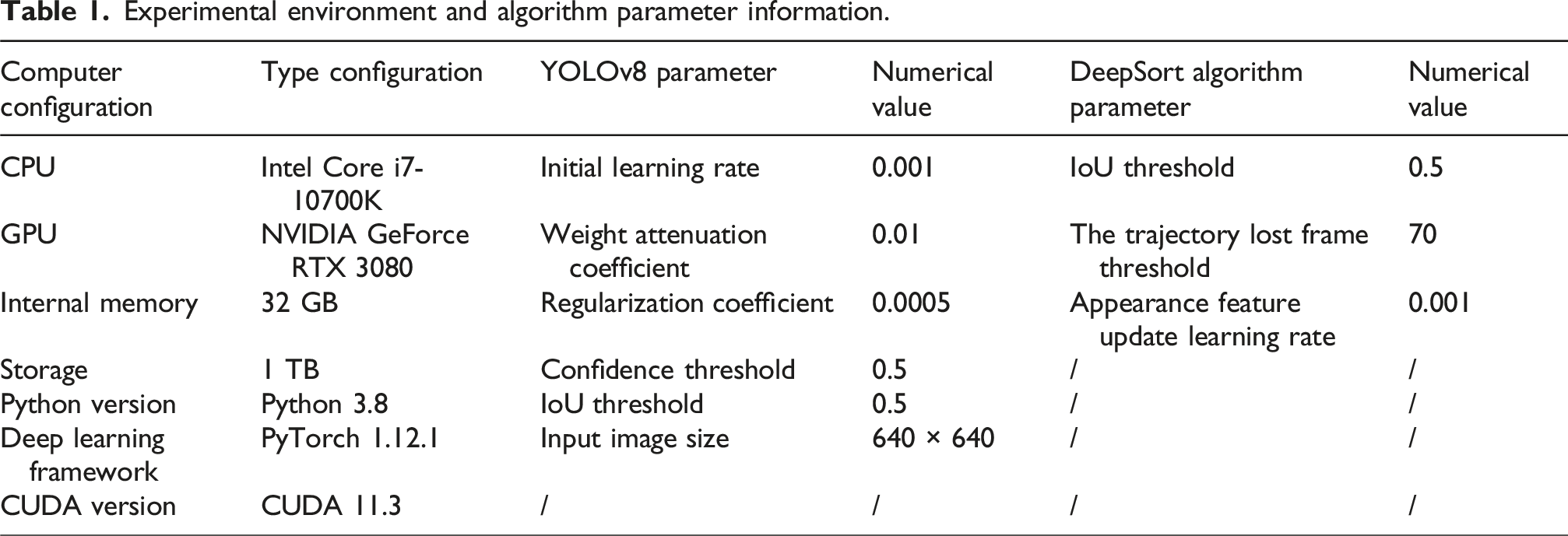
Based on Table 1, SCB-dataset3 and CampusGuard are selected as the datasets. The SCB-dataset3 dataset is specifically designed for student behavior detection research and contains student behavior annotations in various classroom scenarios. The dataset contains approximately 5000 images, covering seven behavioral categories: raising hands, reading, leaning against the table, writing, playing with mobile phones, lowering the head and lying on the table. The image resolution is 1920 × 1080, and the annotation information includes the bounding box of the target and the category label. The CampusGuard dataset focuses on student behaviors in campus environments and contains 3000 images labeled with six behavioral categories: walking, standing, talking, using mobile phones, reading, and writing. The image resolution is 1280 × 720, and the annotation information also includes the bounding box and category label of the target. Furthermore, the annotation information of the SCB-dataset3 dataset is accurate and reliable, including the bounding boxes and category labels of the targets, providing a high-quality data basis for model training and evaluation. The CampusGuard dataset is publicly available, facilitating the reproduction and comparison of experimental results by other researchers and enhancing the verifiability and transparency of the research. In order to improve the training effect and detection performance of the model, the following preprocessing steps were carried out on the two datasets. Adjust all images to a uniform input size of 640 × 640. (2) Adopt data enhancement methods such as random cropping, color jitter and horizontal enhancement. (3) Convert the original labeled bounding box coordinates to the normalized format required by the YOLOv8 model. The actions such as Hand Raising, Reading, Leaning on Desk, and Writing were tracked, respectively, in the two datasets. The training process is based on the parameter Settings and strategies shown in Table 1 for training. 16 images are trained in each batch, and the total number of training rounds is 300. Meanwhile, the evaluation indicators selected include mean Average Precision (mAP), Accuracy, Recall, Frames Per Second (FPS), and robustness score. mAP is a commonly used performance metric in object detection and tracking tasks, which is used to measure the comprehensive detection accuracy of the model under different confidence thresholds. In real-time behavior tracking, mAP can help evaluate whether the model can strike a balance between high precision and high efficiency in real-time scenarios. Accuracy is an intuitive indicator that can directly reflect the performance of the model in practical applications. In real-time behavior tracking, accuracy directly affects teachers’ judgment of the classroom situation. Recall can evaluate whether the model can detect as many behaviors as possible and avoid missed detectives. In real-time behavior tracking, the model needs to detect as many behaviors as possible within a short period of time. The recall rate can help evaluate whether the model can meet this requirement in real-time scenarios. FPS is an important indicator for measuring the real-time performance of a model. It calculates the number of image frames that the model can process per second. In an intelligent classroom environment, FPS can reflect the utilization efficiency of computing resources by the model. Finally, the robustness score is a comprehensive indicator used to evaluate the stability and reliability of the model in complex scenarios. In the intelligent classroom environment, it can help assess the model’s performance in these complex scenarios and ensure the stable operation of the model in practical applications. This study simultaneously selects the traditional YOLOv8 model, YOLOv5, and YOLOX model for comparison. The accuracy and recall curves based on four network models are shown in Figure 6. Accuracy curve and recall curve comparison. (a) Accuracy curve comparison and (b) Recall curve comparison.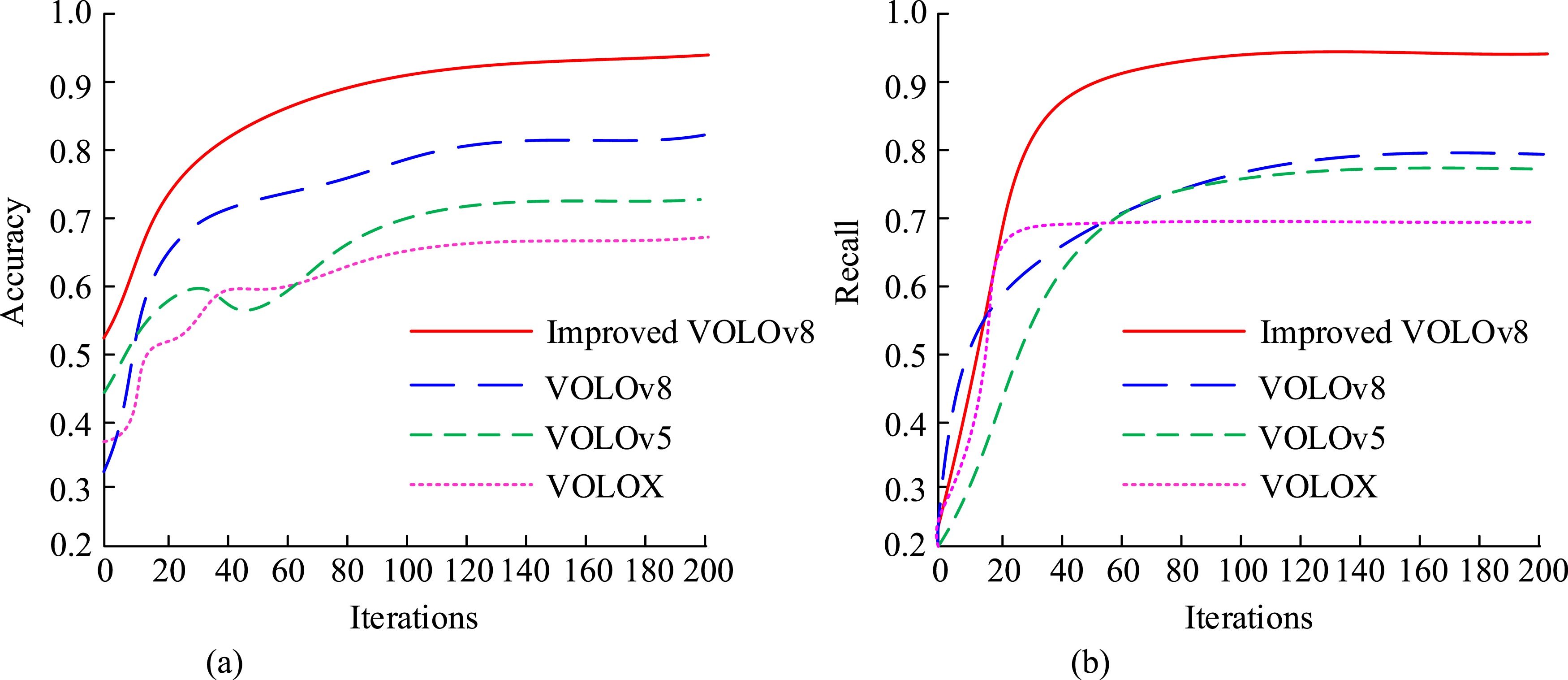
In the comparison of accuracy curves in Figure 6(a), the accuracy rate of the improved YOLOv8 (the solid red line) rose rapidly in the early stage of training and tended to stabilize after approximately 100 iterations, eventually reaching a high accuracy rate close to 0.931. This indicates that the improved YOLOv8 model has a very high classification accuracy in the task of student behavior recognition. YOLOv8 (blue solid line) The accuracy rate of the YOLOv8 model also rose rapidly in the early stage of training, but eventually stabilized at a level slightly lower than that of the improved YOLOv8, approximately 0.823. The accuracy of YOLOv5 (the green dotted line) gradually increased during the training process, but eventually stabilized at approximately 0.722, which was lower than that of YOLOv8 and the improved YOLOv8. The accuracy of YOLOX (purple dot line) rose slowly during the training process and eventually stabilized at approximately 0.652, which was the lowest among the four models. This indicates that the YOLOX model performs relatively poorly in the task of student behavior recognition. In the recall curve of Figure 6(b), the improved YOLOv8 model is higher than the comparison model, and its recall tends to 0.952 after convergence. It indicates that the improved YOLOv8 model can detect most student behaviors with a low rate of missed detection. The difference in recall convergence between the traditional YOLOv8 model and YOLOv5 is relatively small, with values of 0.784 and 0.772. The recall rate of YOLOX is also minimized after convergence, and it converges at 20 iterations, with a value approaching 0.692. It indicates that its performance in terms of recall rate is relatively poor. Further comparison of mAP among the three models is shown in Figure 7. Comparison of mAP values of network models.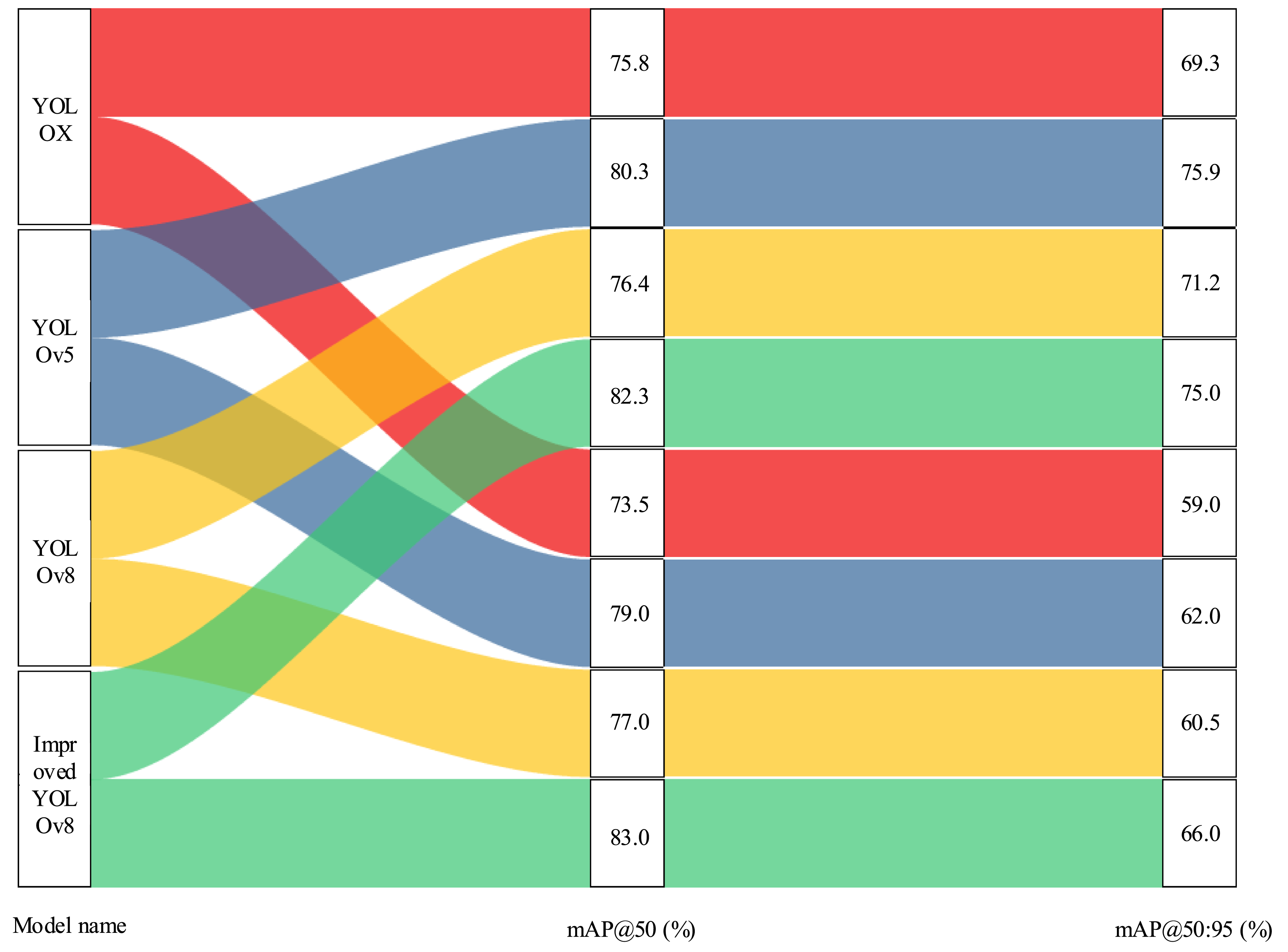
Figure 7 shows the comparison of four models for mAP@50 and mAP@50:95. The two color bands for each model represent the SCB-dataset3 and CampusGuard datasets. The results show that YOLOX (red) performs relatively poorly on the two datasets with values of mAP@50 and mAP@50:95 of 75.8%/73.5% and 69.3%/59.0%, respectively; YOLOv5 (blue) performed well on the two datasets mAP@50 and mAP@50: The 95 values were 80.3%/79.0% and 75.9%/62.0%, respectively; mAP@50 and mAP@50 on the two datasets of YOLOv8 (yellow): The 95 values were 76.4%/77.0% and 71.2%/60.5%, respectively, performing poorly. The improved YOLOv8 (green) performed best on two datasets: mAP@50 and mAP@50:95 values of 82.3%/83.0% and 75.0%/66.0%, respectively. To sum up, the improved YOLOv8 model achieved the highest mAP values on both datasets, indicating that it has higher detection accuracy and robustness in the task of student behavior recognition. The improved YOLOv8 model significantly enhances the recognition accuracy and robustness of the model for student behaviors in complex scenarios by introducing the SE attention mechanism and the feature pyramid network structure. This study further compares the processing speed of four models to evaluate their RTP under ICE, as shown in Figure 8. The processing speed of four models. (a) Real-time performance comparison of the SCB-dataset3 dataset and (b) Real-time performance comparison of the CampusGuard dataset.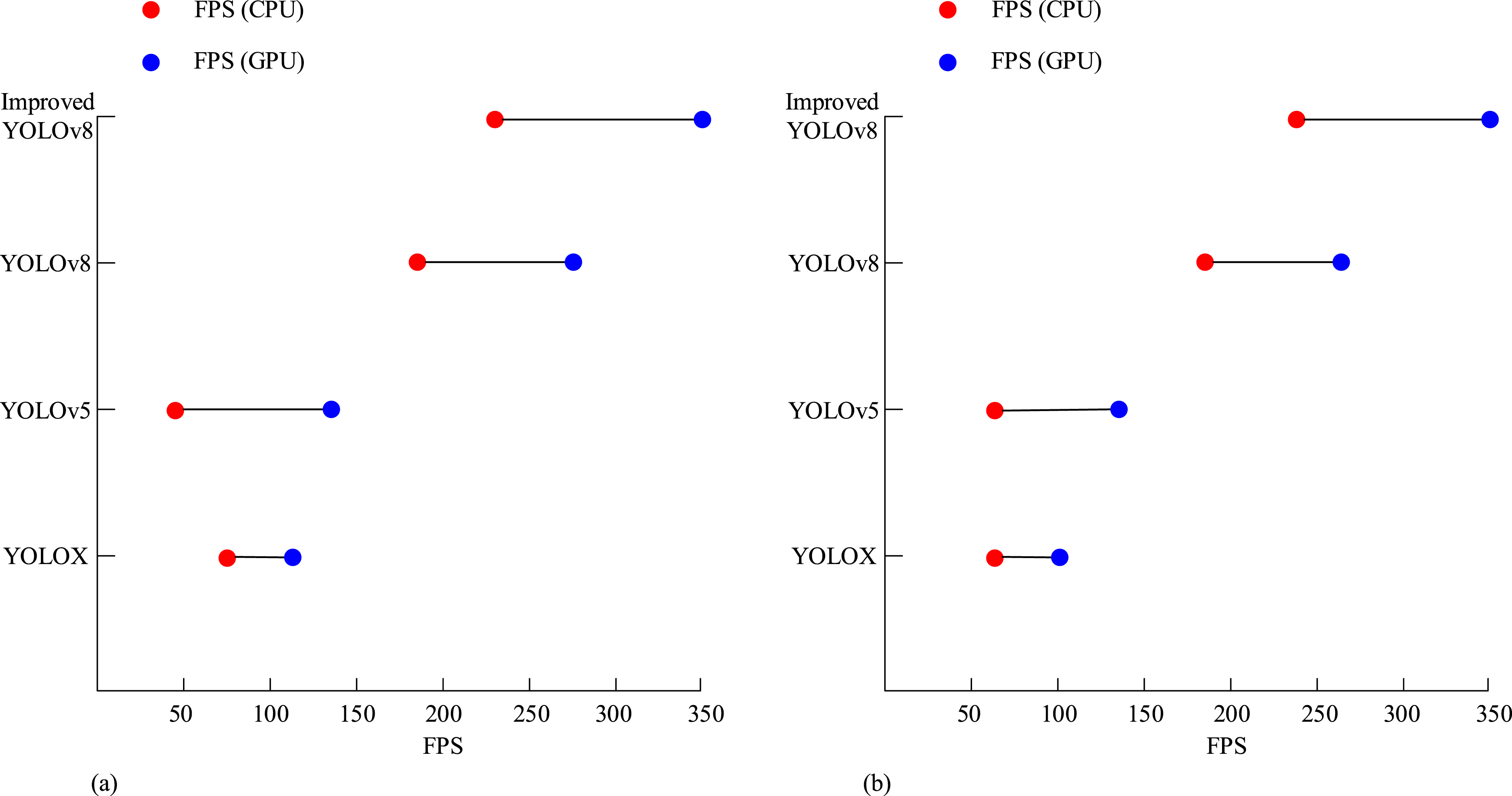
Comparison of model complexity and robustness scores.
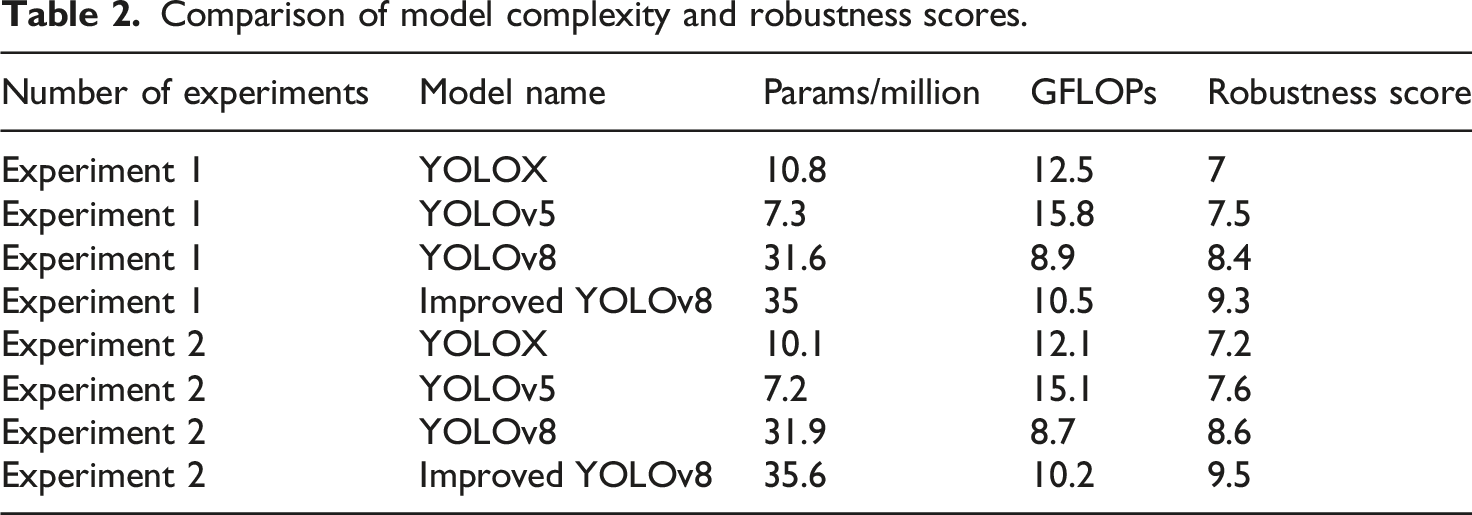
In terms of model complexity in Table 2, the improved YOLOv8 has an average parameter count of 35.3 million and an average computational complexity of 10.4 GFLOPs. This demonstrates that the improved YOLOv8 has slightly increased in terms of parameter and computational complexity, but the changes are not significant compared to the YOLOv8, indicating that its model structure is also relatively stable. In terms of robustness score, the improved YOLOv8 model has the highest score, with values of 9.3 and 9.5, indicating a slight improvement in its performance in complex scenarios compared to YOLOv8. Overall, the proposed model performs well in both model complexity and robustness, meeting the high requirements for model accuracy and stability under ICE. Finally, this study compares the recognition effects of four models on student behaviors such as raising hands and reading, as shown in Figure 9. Student typical behavior identification comparison.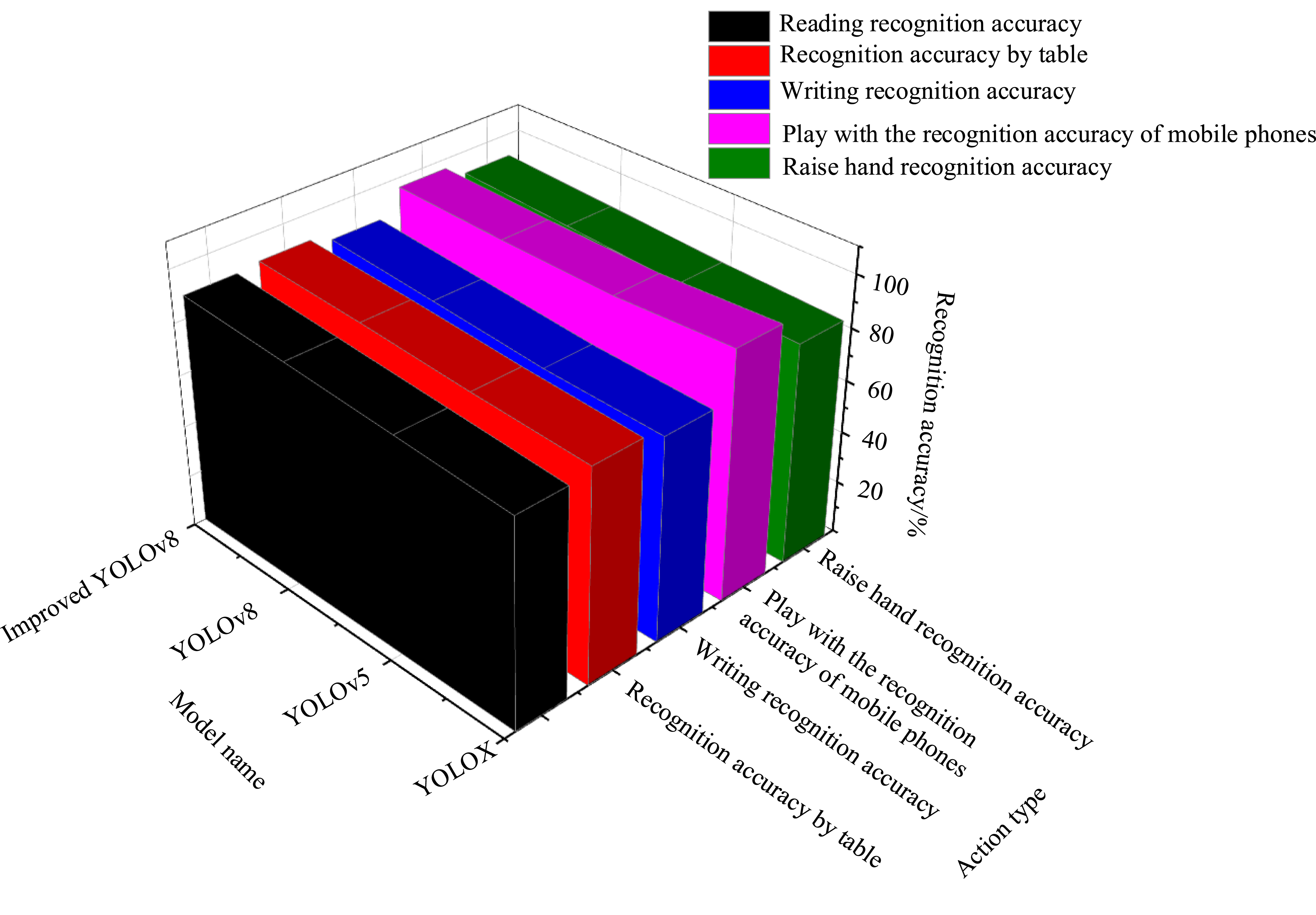
Figure 9 shows the comparison of recognition accuracy among four models. YOLOX performs well in recognizing the behavior of “playing with mobile phones” with a recognition accuracy of 95.8%, which may be due to the visual uniqueness of this behavior and its ease of differentiation by the model. In the recognition of other behaviors, the average recognition accuracy is around 80%. YOLOv5 has a slight advantage in recognizing “raising hands” and “leaning against the table” behaviors, with recognition accuracies of 86.3% and 84.1%, which may be related to the sensitivity of the model to target shape and position. The recognition accuracy of YOLOv8 is generally above 85%, demonstrating higher detection accuracy and robustness. It performs particularly well in recognizing “raising hands” and “leaning against a table” behaviors, with recognition accuracies of 88.9% and 87.3%. The improved YOLOv8 performs well in recognizing all behaviors, with recognition accuracy generally above 90%, significantly higher than the other three models. It performs the best in recognizing “raising hands” and “reading” behaviors, with recognition accuracies of 91.4% and 88.7%. This means that the improved model has stronger discriminative ability when dealing with complex scenes and similar behaviors. In summary, the improved YOLOv8 is excellent in identifying the five behaviors of “raising hands, reading, leaning against the table, writing, and playing with the phone.” High recognition accuracy and robustness make it perform excellently in SBR tasks under ICE.
Performance evaluation and behavior tracking analysis of DeepSort algorithm
Comparison of tracking accuracy of four algorithms.
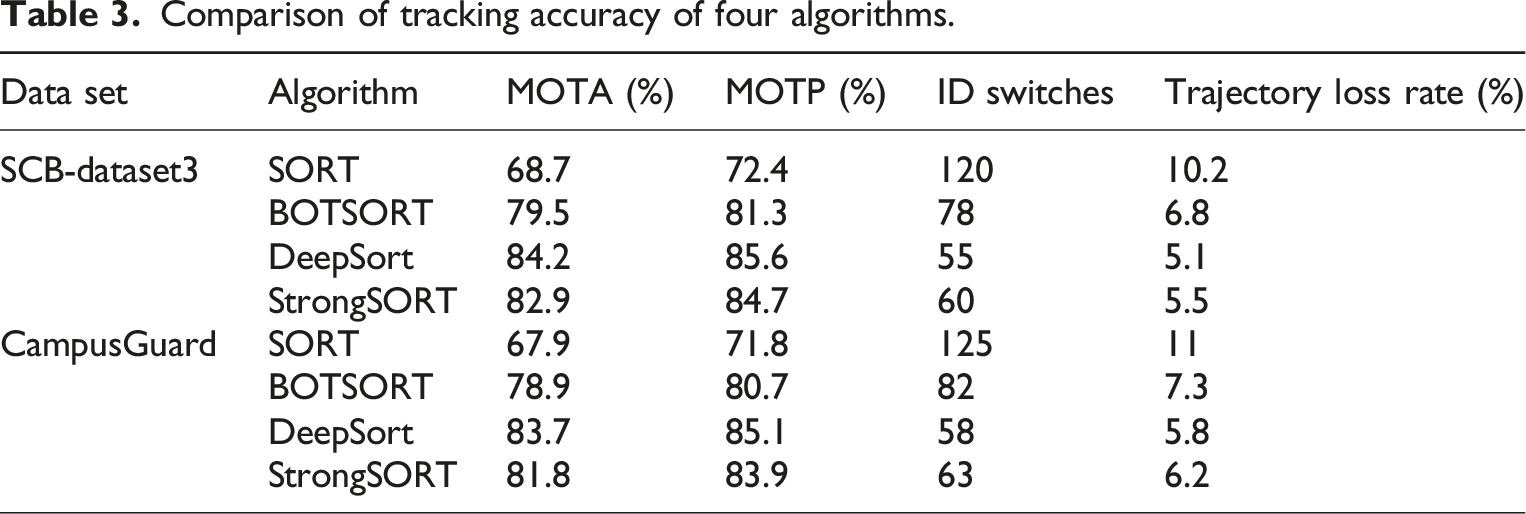
In Table 3, MOTA mainly measures the overall accuracy of the tracking algorithm. MOTP measures the mean distance between the tracked trajectory and the real trajectory. The number of times the target’s identity is mistakenly switched during the tracking process. Trajectory loss rate refers to the proportion of targets that are not successfully tracked in consecutive frames. DeepSort performs the best in tracking accuracy and robustness, significantly outperforming SORT and BOTSORT algorithms. By introducing appearance features and KF, the number of identity switches and trajectory loss rate have been reduced, improving the accuracy and robustness of tracking. StrongSORT performs well in tracking accuracy and robustness, but slightly lower than DeepSort. The SORT algorithm performs poorly in tracking accuracy, especially in complex scenarios where there are a large number of identity switches and a high trajectory loss rate. This study further compares the trajectory integrity of four algorithms, as shown in Figure 10. Trajectory integrity of four algorithms. (a) SCB-dataset3 dataset comparison and (b) CampusGuard dataset comparison.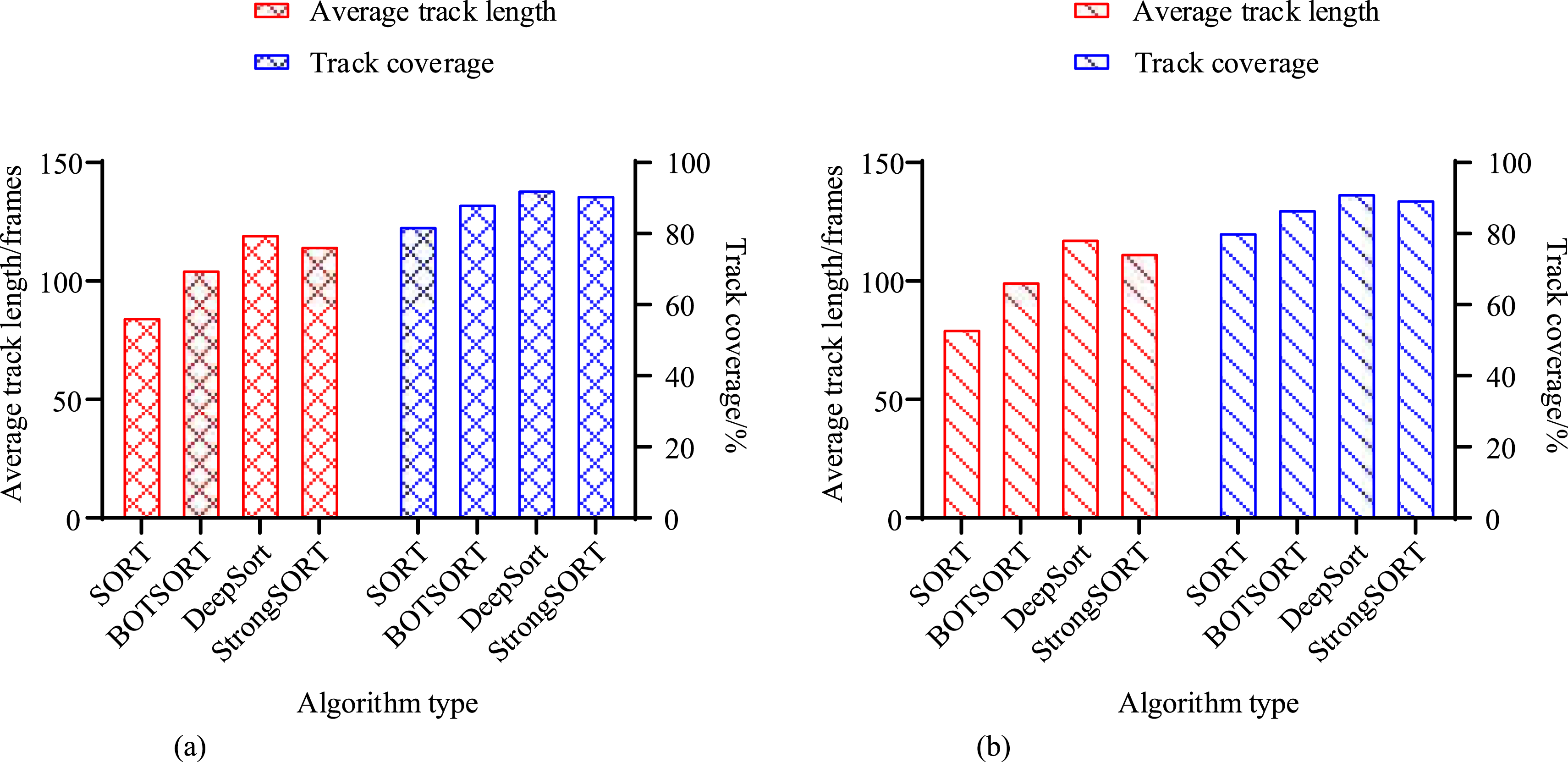
Figure 10(a) shows the comparison of average trajectory length and trajectory coverage under the SCB-dataset3 dataset. DeepSort performs the best in trajectory integrity, with an average trajectory length and coverage of 120 frames and 92.5%. The algorithm has the longest average trajectory length and the highest trajectory coverage, indicating its ability to generate continuous and complete trajectories, effectively reducing trajectory loss and breakage. SORT shows weak performance in trajectory integrity, with a short average trajectory length and low trajectory coverage, indicating that it is prone to losing targets in complex scenes. Figure 10(b) shows the comparison under the CampusGuard dataset. DeepSort still performs the best, with an average trajectory length and trajectory coverage of 118 frames and 91.5%. Figure 11 compares the RTP and appearance feature updating ability of four algorithms. Comparison of updating ability of real-time algorithm and appearance feature. (a) SCB-dataset3 dataset comparison and (b) CampusGuard dataset comparison.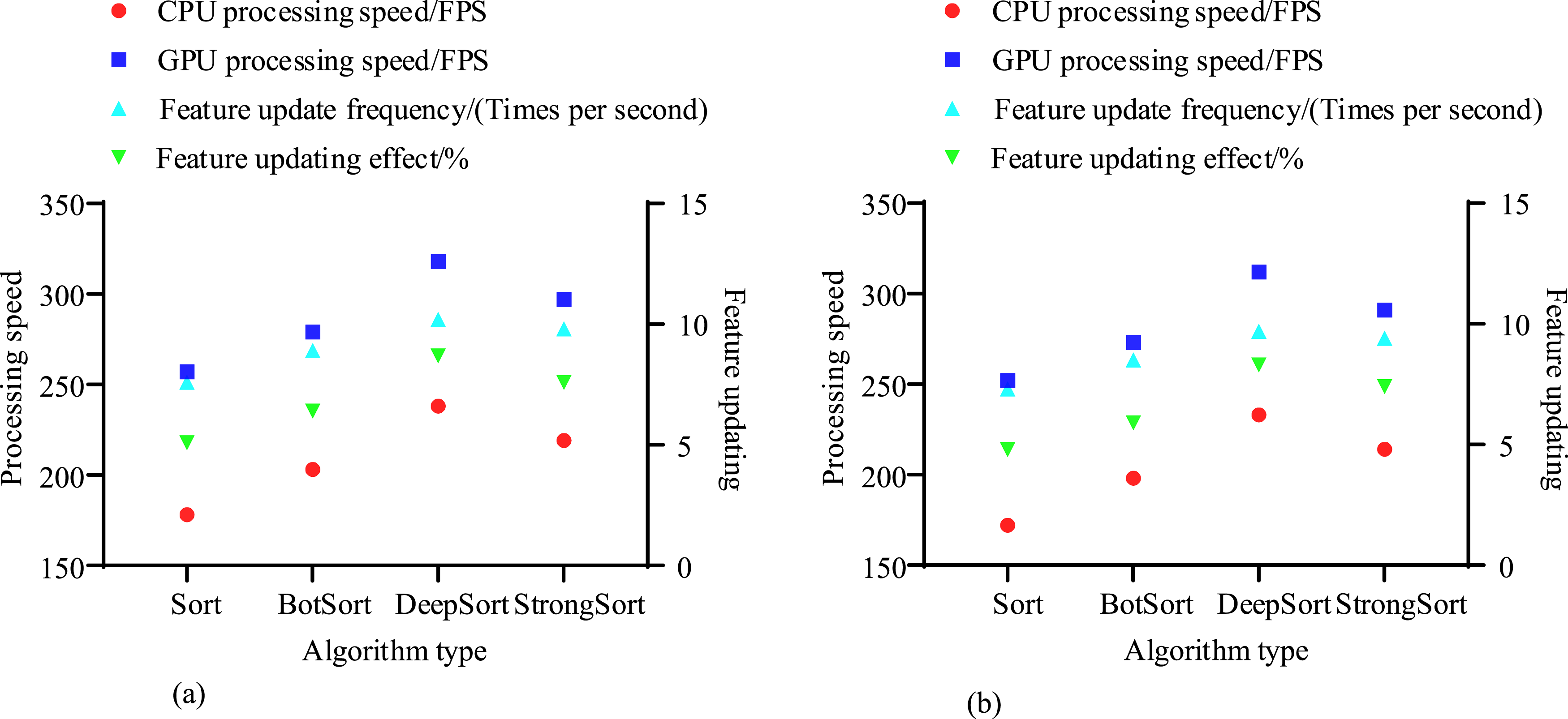
Figure 11(a) compares the real-time and appearance feature update capabilities of the SCB-dataset3 dataset, while Figure 11(b) compares the average trajectory length and trajectory coverage under the CampusGuard dataset. In terms of RTP, DeepSort has an average CPU and GPU processing speed of 235FPS and 315FPS, respectively. It performs well in real-time and has significantly higher processing speed than other algorithms. In terms of appearance feature update capability, DeepSort’s feature update frequency is 10.2 times/second and 9.7 times/second, with feature update effects of 8.7% and 8.3%, respectively. This indicates that DeepSort performs well in updating appearance features, with significantly higher update frequency and effectiveness than other algorithms, and can adapt to changes in target appearance in a timely manner, improving tracking accuracy and robustness. Figure 12 compares the trajectory management capabilities of four algorithms. Comparison of trajectory management capabilities. (a) SCB-dataset3 dataset comparison and (b) CampusGuard dataset comparison.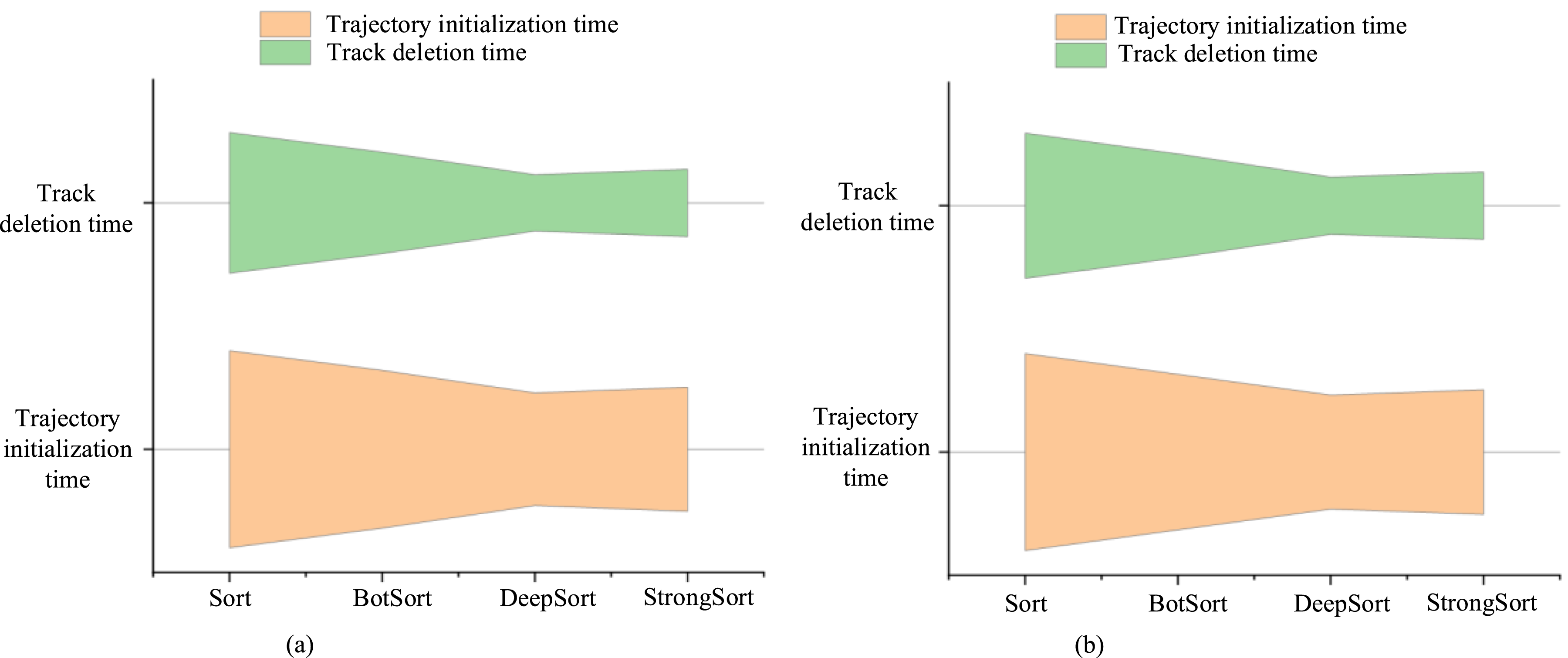
Ablation experiment results.
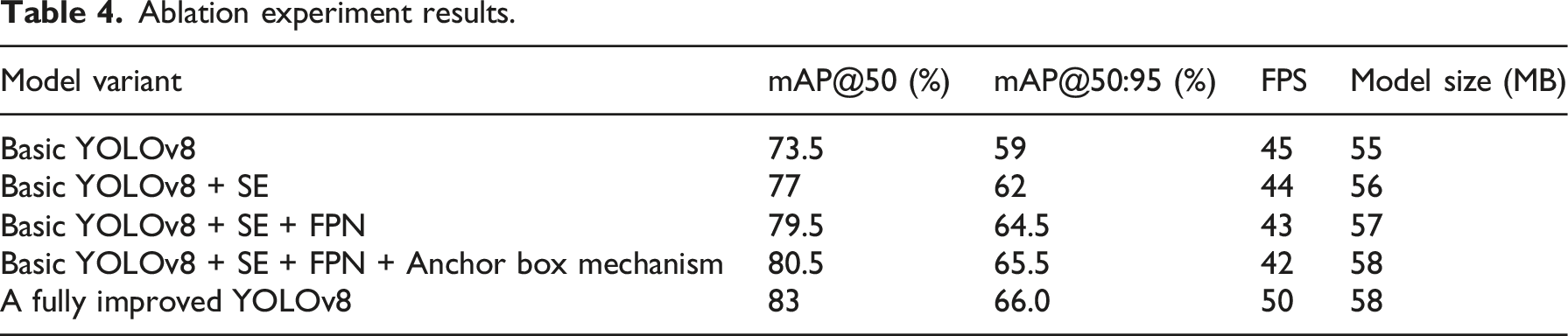
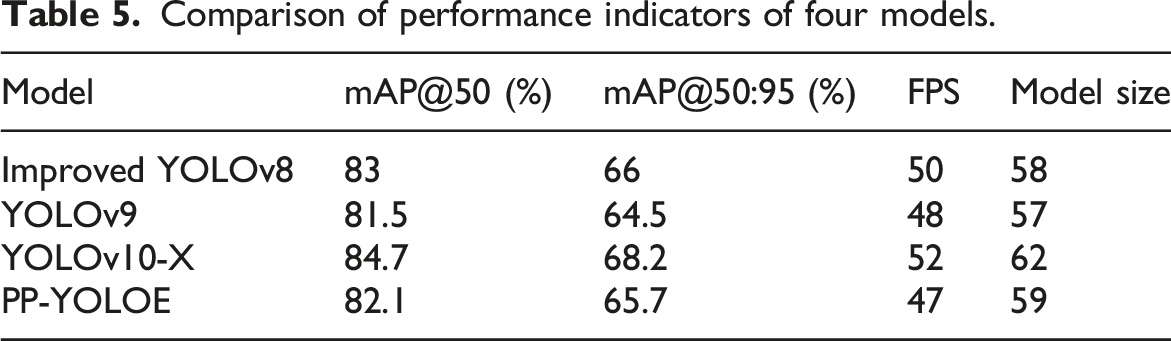
Comparison of performance indicators of four models.
Comparison of behavior recognition effects in different scenarios.
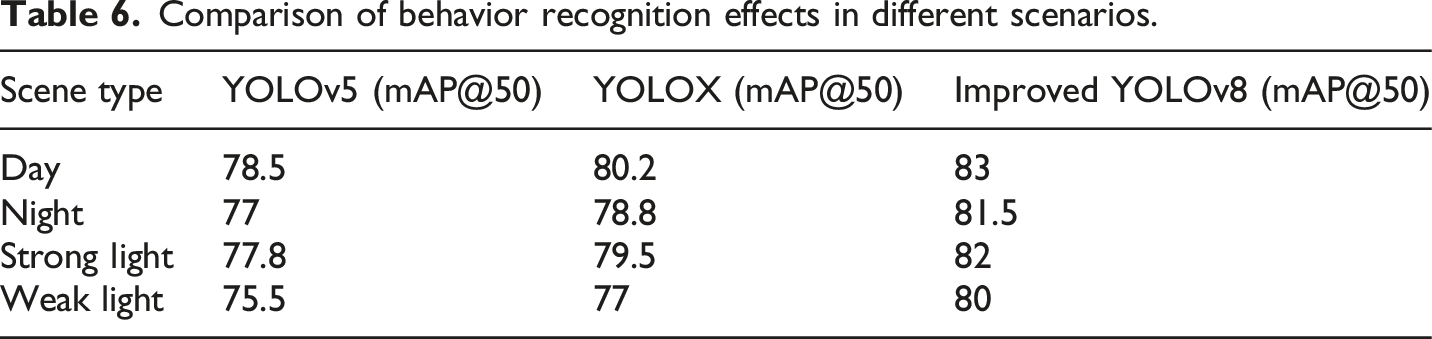
In Table 6, the overall improved YOLOv8 model achieved the highest average accuracy in all test scenarios, demonstrating its strong generalization ability and robustness under different lighting conditions. YOLOX performs slightly better than YOLOv5 in all scenarios, but still lags behind the improved YOLOv8. In well-lit daytime scenarios, all models had relatively high mAP@50 values, with the improved YOLOv8 model reaching 83.0% for the best performance. In the night scene, the average accuracy of all models declined, but the improved YOLOv8 model still maintained a high accuracy of 81.5%, demonstrating its superior performance in low-light conditions. Under strong light conditions, the improved YOLOv8 model also performed best, achieving an 82.0% mAP@50 value, which indicates good robustness in dealing with overexposure caused by strong light. In low-light conditions, the improved YOLOv8 model had a mAP@50 value of 80.0%, which was lower but still higher than that of YOLOv5 and YOLOX, indicating high recognition accuracy even in low-light conditions.
Discussion
To improve the accuracy and RTP of SBR under ICE, this study improved the YOLOv8 model by introducing SE mechanism, FPN structure, and anchor box mechanism, and used DeepSort algorithm to achieve continuous tracking of student behavior. In the numerical results, the improved YOLOv8 model achieved mAP of 82.3% and 83.0% on SCB-dataset3 and CampusGuard datasets, significantly better than YOLOX, YOLOv5, and YOLOv8 models. This result was consistent with the study by Mu et al. proposed an improved lightweight YOLOv8 model with an average accuracy of 90.2%, reduced parameter count to 1.4 × 106, and reduced floating-point computational complexity to 4.8 G, significantly better than 12 existing object detection models. 29 However, Mu et al.’s research mainly focused on the lightweighting and computational efficiency of the model, while this study focused more on improving the recognition accuracy and robustness of the model for student behavior in complex scenarios by introducing SE and FPN structures. The introduced SE mechanism could enable the model to better focus on feature channels related to student behavior, thereby improving detection accuracy in complex scenarios. The study by Mu et al. did not involve similar optimization of attention mechanisms. The DeepSort algorithm performed well in tracking accuracy, with MOTA values of 84.2% and 83.7%, and also performed well in robustness and RTP, which was consistent with M Shili’s conclusion. Shili et al. proposed a customer behavior tracking and heatmap analysis model based on YOLOv5 and DeepSort, which accurately tracked customer behavior through DeepSort. In contrast, although Shili et al. also used the DeepSort algorithm, they did not conduct detailed experimental analysis on DeepSort’s capabilities in trajectory integrity, appearance feature updating, and trajectory management. Moreover, this study also demonstrated excellent RTP, with DeepSort’s average CPU and GPU processing speeds of 235FPS and 315FPS. It performed well in real-time and had significantly higher processing speed than other algorithms, but the study by Shili et al. did not mention the specific performance of DeepSort in real-time. 30
In summary, the improved YOLOv8 model and DeepSort algorithm perform well in intelligent classroom SBR and tracking tasks. The improved YOLOv8 significantly improves detection accuracy and robustness by optimizing model architecture and training strategies, and can better adapt to complex scenarios. DeepSort effectively solves the problems of identity switching and trajectory loss in target tracking by combining Kalman filtering and appearance feature matching, improving the accuracy and stability of tracking. The application of these technologies gives strong technical support for teaching management and personalized learning under ICE. However, in an intelligent classroom environment, multiple students may exhibit similar behaviors simultaneously (for example, multiple students raise their hands at the same time). This situation poses a challenge to the model’s discrimination ability because similar behaviors may make it difficult for the model to accurately identify the specific behaviors of each student. In order to improve the discrimination ability of the model when dealing with similar behaviors, visual information and data of other modalities (such as audio or sensor data) are combined to provide richer context information and help the model better distinguish similar behaviors. Meanwhile, by using the time series information of students’ behaviors, the dynamic changes of the behaviors are analyzed, thereby improving the model’s ability to recognize similar behaviors.
Furthermore, in different classroom environments, the number of students and the size of the classroom may vary greatly, which may pose challenges to the model’s detection and tracking capabilities. The model can adapt to classrooms of different scales by dynamically adjusting detection parameters (such as the size and quantity of anchor boxes). For example, in large classrooms, the number of anchor boxes can be increased and their sizes adjusted to better detect and track more students. Meanwhile, in large classrooms, multiple cameras can be deployed to monitor students’ behaviors from different angles. Through the collaborative work of multiple cameras, students’ behaviors can be captured more comprehensively, reducing blind spots and missed detections. In dealing with the diversity of students’ behaviors, students’ behaviors may show diversity due to individual differences, differences in classroom activities and teaching contents. The model needs to be able to adapt to and identify these different behaviors. By combining visual information with data from other modalities (such as audio or sensor data), richer contextual information can be provided to help the model better understand and identify different behaviors.
Conclusion
This study used improved YOLOV8 and DeepSort to identify and track students’ behavior. The proposed algorithm was found to have excellent performance in SBR and tracking scenarios. In different classroom Settings, the number of students can vary greatly, ranging from small seminars to large lectures. More students mean more goals that need to be identified and tracked. The improved YOLOv8 model effectively handles the problem of multi-scale object detection through the Feature Pyramid Network (FPN) structure. FPN can extract information from feature maps at different levels, thereby better identifying and tracking targets of different sizes and distances. Meanwhile, the model can dynamically adjust its detection and tracking strategies. When more targets are detected, the model can automatically increase the detection frequency or adjust the size of the anchor box to ensure that the behaviors of all students can be accurately captured. The DeepSort algorithm combines Kalman filtering and appearance feature matching, effectively solving the problems of identity switching and trajectory loss in target tracking, and improving the accuracy and stability of tracking.
Although significant achievements have been made in SBR and tracking in this study, there are still some limitations. Firstly, the robustness of the improved YOLOv8 in dealing with extreme lighting changes and background interference still needs improvement. Secondly, the RTP of the DeepSort algorithm in handling large-scale targets still needs to be optimized. The future research direction will focus on further improving the model’s robustness and RTP, exploring more efficient object detection and tracking algorithms, and applying these technologies to a wider range of educational scenarios to achieve more intelligent teaching management and personalized learning. Furthermore, in order to improve the robustness of the model when dealing with more complex or noisy data, data augmentation can be achieved by introducing more noisy data (such as blurring, illumination changes, occlusion, etc.), enabling the model to adapt to various noisy environments during the training process. Meanwhile, robustness regularization terms, such as Adversarial Training or noise robustness loss functions, are introduced during the model training process to enhance the model’s resistance to noise. In addition, explore more advanced deep learning techniques, such as self-supervised learning and graph neural networks, to further enhance the generalization ability and recognition accuracy of the model. After the model optimization, the research results will be applied to more diverse educational scenarios, such as online education, distance teaching and personalized tutoring, in order to achieve a wider application of educational technology.