
Abstract
To address the difficulties of traditional 2D image processing methods in segmenting crops and backgrounds in complex natural environments, and the inability to accurately obtain 3D phenotype information, this study proposes a 3D image processing technology that integrates depth information. Firstly, a dual branch multi-scale feature encoder was designed to process RGB images and depth images separately, and the feature extraction and fusion capabilities were enhanced by improving the residual module. Then, based on this encoder, a deep image completion network, a deep image super-resolution network, and an image edge detection algorithm were constructed. Finally, the effectiveness of the proposed method was validated on multiple datasets such as BSDS500 and KITTI. The results show that in the ablative experiment, the dual branch multi-scale feature encoder performs the best in accuracy, recall, F1 score, and mean square error, with values of 0.98, 0.82, 0.83, and 0.12, respectively. In the task of completing 200 incomplete image samples, the signal-to-noise ratio of the deep image completion network is mainly distributed between 6 dB and 8 dB. Research outcomes show that the raised method performs well in computer deep image processing, providing strong support for fields such as precision agriculture.
Introduction
With the transformation of Chinese agriculture towards modernization and informatization, precision agriculture has become the key to solving the problems of resource scarcity and environmental degradation.1,2 In precision agriculture, image vision analysis technology has been widely applied, and accurate acquisition and processing of image information are crucial for detecting the position, yield, and maturity of crops.3,4 However, traditional two-dimensional image processing methods are difficult to achieve effective segmentation of crops and backgrounds in complex and changing natural environments, and cannot accurately obtain three-dimensional phenotype information of crops. Therefore, 3D image processing techniques that integrate depth information have emerged.5,6 Depth images not only provide rich spatial structural information, but also effectively compensate for the shortcomings of two-dimensional images in localization and recognition. In view of this, more and more researchers are paying attention to the study of image processing methods.
Peng Xianlin proposed a content constrained convolutional network method for image restoration, which utilized frequency transformation and adaptive spatial change activation function to address the issues of visual appreciation damage caused by ancient mural damage and digital cultural heritage protection. The outcomes indicated that this approach performed better in restoring mural images, generated fewer artifacts, and outperformed existing methods. 7 Li Zhenmin proposed a regularized deep matrix factorization model for image restoration problems, combining implicit low rank bias and total variation explicit bias of deep neural networks. The outcomes indicated that this approach performed well in image restoration, especially surpassing existing models when there was very little observed data, providing a new framework for combining deep learning implicit bias and explicit regularization to solve inverse problems. 8 Liu Kun proposed a lightweight low-dose Positron Emission Tomography (PET) super-resolution (SR) network grounded on convolutional neural networks to address the issue of poor imaging quality in low-dose PET. This method could accurately restore high-resolution PET images from low resolution images. The results showed that SRPET-Net performed well in peak signal-to-noise ratio (PSNR) and structural similarity index (SSIM), and had low memory consumption and computational cost. 9
Jianrun Shang proposed a pixel attention feedback network for image SR reconstruction. This method utilized multiple feedback networks and gated feedback modules to fully utilize initial features, and enriched output features through pixel attention mechanisms. The outcomes showed that the raised method outperformed existing methods in both subjective and objective evaluations, effectively improving the quality of CT images. 10 Yan C proposed a new image multi-segmentation model for prostate cancer MRI image segmentation. This approach incorporated SE-Net, Cased Pyramid Convolution, and Attention Gate, alongside a purely convolutional edge detection module. The findings revealed that the model exhibited superior performance in terms of both average boundary distance and Hausdorff distance on MRI images sourced from Guizhou Provincial People’s Hospital, demonstrating robust generalization capabilities. 11 Chen Shi raised a method that combined multi-scale structures and multi-scale attention schemes to address the issues of insufficient multi-attention mechanisms and multi-scale feature fusion in image SR. A fusion pyramid attention network was designed at the architecture level, and a fusion pyramid attention module was designed at the module level. The outcomes indicated that the method achieved outstanding results in both quantitative and visual aspects. 12
In summary, existing research has achieved significant results in the field of image processing, but most studies only focus on a single image processing task and lack a deep image processing method that can efficiently complete multiple tasks simultaneously. For example, Peng Xianlin’s mural restoration method is only applicable to image restoration tasks and has limitations in integrating multiple depth image processing tasks. In addition, existing methods often simply use depth information as auxiliary input when fusing depth information, failing to fully leverage the complementary advantages of depth information and color information, resulting in poor feature extraction and fusion effects. In view of this, the research innovatively designs a dual branch multi-scale feature encoder that integrates color and depth information. By improving the residual module, the feature extraction and fusion capabilities are enhanced, and the dual branch multi-scale feature encoder is applied to tasks such as depth image completion, SR, and edge detection. The research objective is to apply this encoder to tasks such as depth image completion, SR, and edge detection, achieving high-quality image processing and providing strong support for image applications in precision agriculture and other fields. This study effectively fills the gap in existing research on multi task fusion deep image processing, improves the efficiency and accuracy of deep information fusion, and provides an efficient and accurate deep image processing solution for precision agriculture and other fields.
Computer deep image processing methods
Structure design of dual branch multi-scale feature encoder
Computer deep image processing is a complex and challenging field that faces multiple challenges: Firstly, the massive amount of image data is a significant issue.13,14 A high-definition image may contain millions or even more pixels, which means processing such data requires enormous computing resources and time. Secondly, images may be subject to various interferences during acquisition, transmission, and storage, resulting in information loss or introduction of noise, which in turn affects the accuracy of image processing. To address these challenges, feature encoding structures have emerged.15,16 Feature encoding can convert raw image data into a more compact and easily processed form of feature representation. This representation not only reduces the dimensionality and computational complexity of the data, but also preserves key information in the image, improving the efficiency and accuracy of image processing. Through feature encoding, computers can more effectively extract useful information from images. The schematic diagram of the traditional single-branch feature encoding structure is shown in Figure 1.
17
Schematic representation of the single-branch feature encoding structure.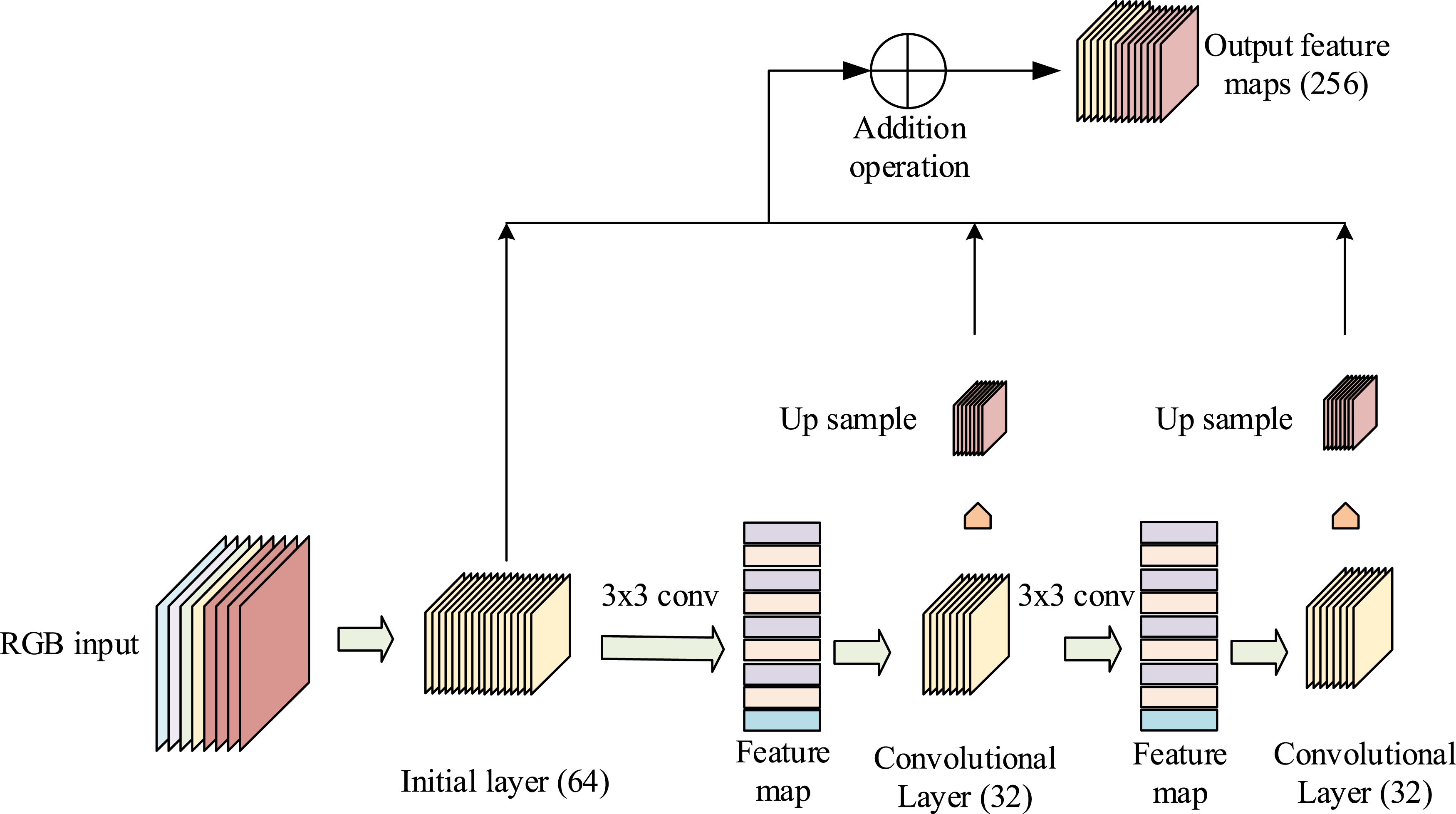
Firstly, the RGB input data is processed through an initial layer containing 64 nodes, which may perform convolution operations to capture the fundamental features of the image. This step is the starting point of feature extraction, laying a key foundation for subsequent processing. Subsequently, the feature map enters the upsampling stage, and through two stages of upsampling operations, the spatial resolution of the feature map is gradually restored. The second upsampled feature map passes through a convolutional layer containing 32 nodes again, as shown in equation (1).

In equation (1), Schematic representation of the double-branching multi-scale feature encoder structure.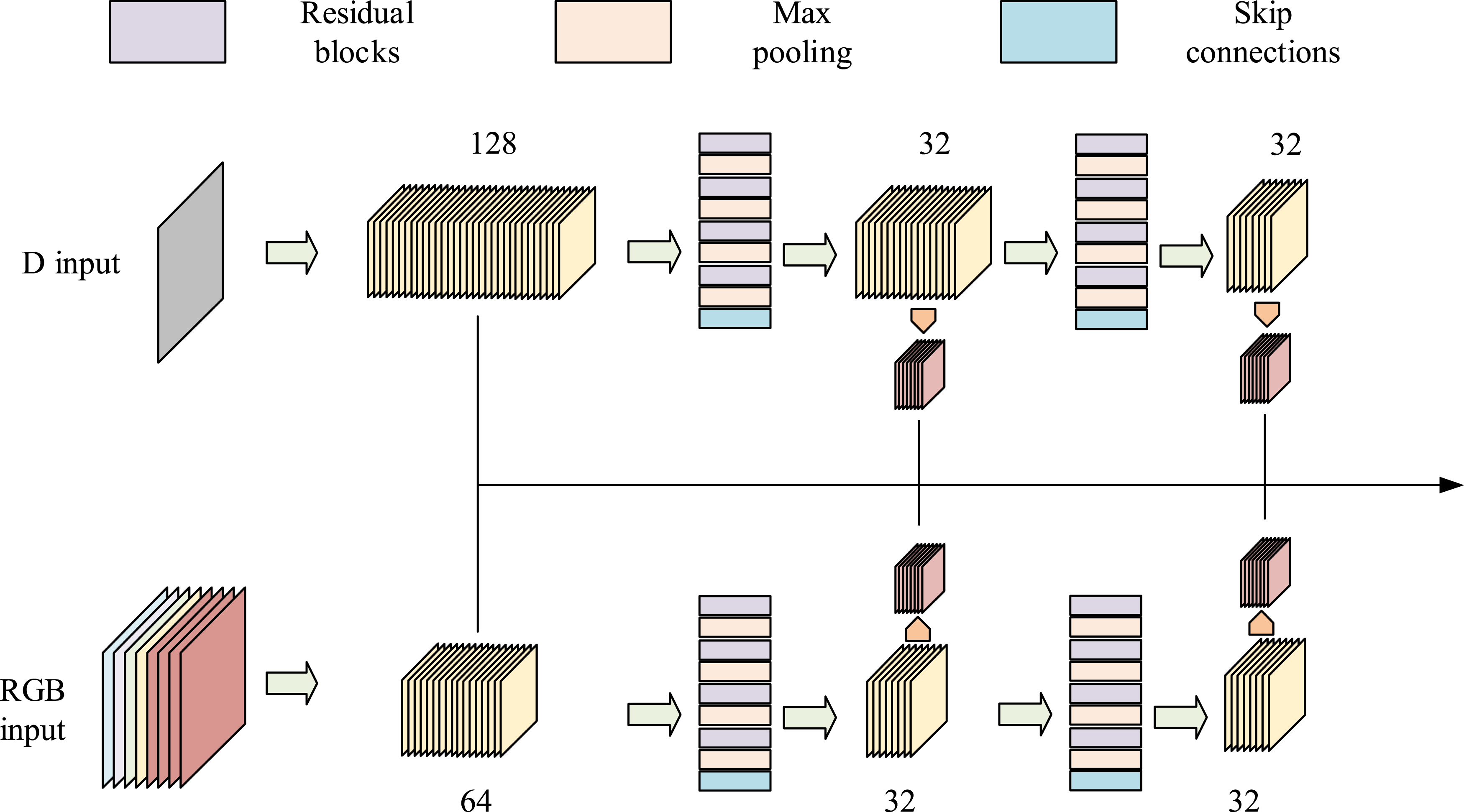
Figure 2 shows a more complex “dual branch multi-scale feature encoder” structure, which is intricately designed specifically for processing RGB image data and D input data to extract and fuse multi-scale features. The encoder consists of two core branches: the left branch focuses on processing RGB images, while the right branch specializes in processing D input data. In the left branch, the RGB input data is first subjected to preliminary feature extraction through a convolutional layer with 128 kernels. Subsequently, the data enters a deep convolutional network composed of multiple residual blocks, each of which contains multiple 3 × 3 convolutional layers for gradually extracting deeper features. The residual module processing is shown in equation (2).
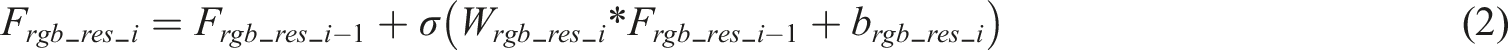
In equation (2), the output of the

In equation (3), Architectural diagram of the improved residual module. (a) Before improving the residual module, (b) After improving the residual module.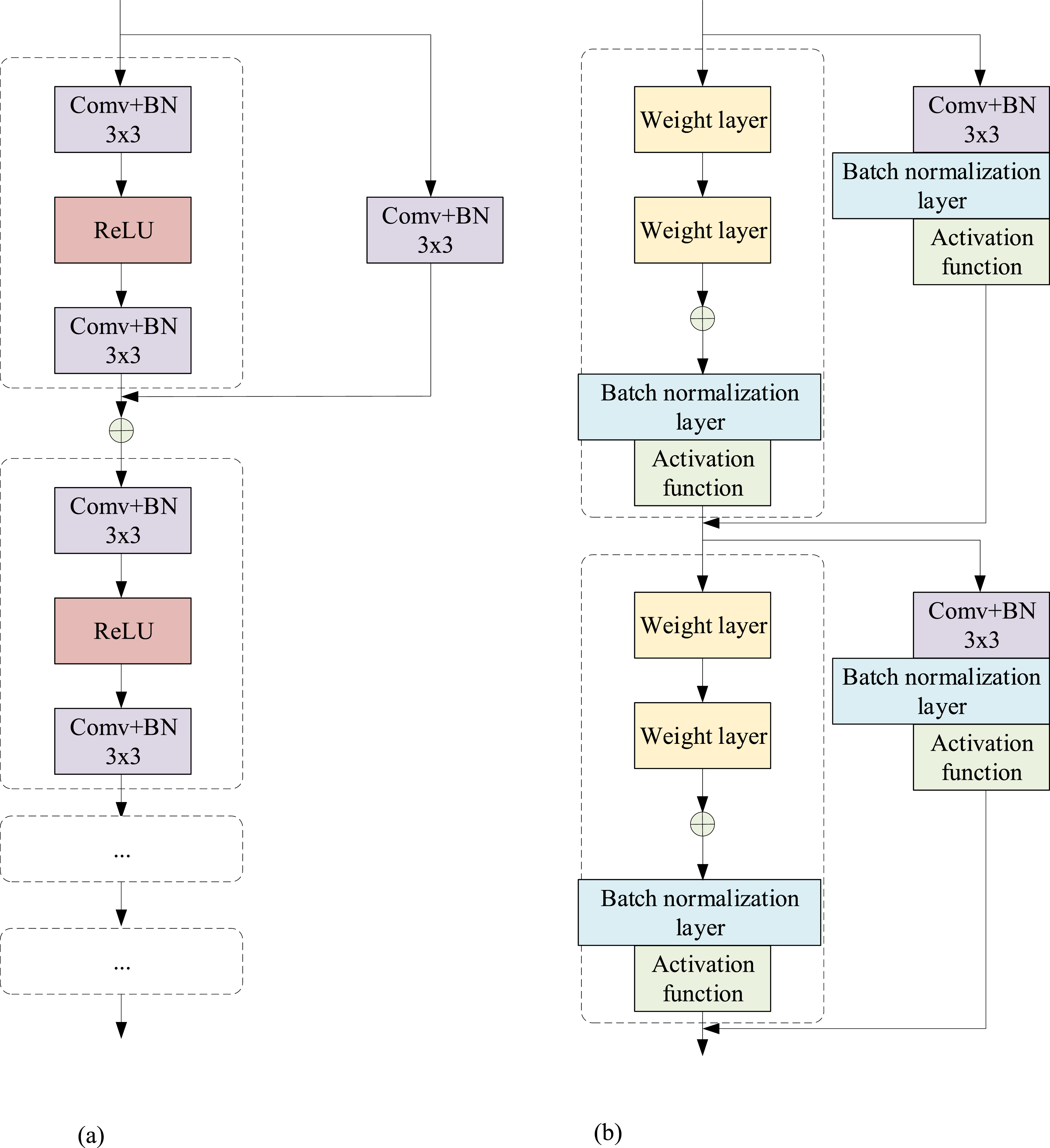
The core of this module lies in its multi-level structural design. The weight layer, also referred to as the convolutional layer, is tasked with extracting features from the input data, performing local perception on the data through 3 × 3 convolution kernels, and capturing key information in the image. Subsequently, the batch normalization layer normalizes the output of the convolutional layer to ensure stable data distribution. After the convolutional and batch normalization layers, an activation function is introduced to introduce nonlinear factors. The improved residual module calculates the input information as represented in equation (4).

In equation (4), H (x) means the output of the residual module, F (x) means the residual mapping, and x represents the input of the residual module. Y is used for element level addition in residual connections, as shown in equation (5).

In equation (5),

This enables neural networks to capture complex patterns and nonlinear relationships in input data, enhancing the model’s expressive power. Multiple such sub-modules are stacked through skip connections to form a deeper neural network. On the basis of retaining the advantages of the original residual module, the study embedded more convolutional layers, batch normalization layers, and nonlinear activation functions, which have the ability to extract sparse nonlinear features while achieving cross layer information interaction. In addition, to more effectively extract sparse nonlinear features, this study also introduced a spatial attention submodule after the convolution batch normalization activation operation of each residual submodule. The spatial attention mechanism generates a two-dimensional spatial weight map through learning, which can automatically learn the importance of different positions in the input feature map. This enables the network to focus on key areas when extracting sparse nonlinear features and suppress the interference of irrelevant or noisy information. Finally, construct a cross layer attention module that connects residual modules of different depths. This module calculates the correlation between shallow and deep features, determines the contribution weight of shallow features to deep feature extraction, and enables the deep module to more targetedly obtain information from the shallow module that helps extract sparse nonlinear features, enhancing the effectiveness of cross layer information exchange. In summary, the proposed dual branch multi-scale feature encoder includes RGB image branch and depth image branch. The RGB branch uses a 128 convolutional kernel convolutional layer to initially extract features, and then extracts deep features through multiple residual modules and max pooling layers, and uses skip connections to transfer shallow features. The deep branch uses a 64 convolutional kernel convolutional layer for initial feature extraction, which also undergoes multi-layer extraction, pooling, and skip connections. The two branch features are integrated through the feature fusion module. Improve the residual module by adding convolution, batch normalization, and activation functions on the original basis, while adding a spatial attention submodule to generate weight maps to focus on key regions. In addition, a cross layer attention module was constructed to calculate the correlation between shallow and deep features, determine contribution weights, and enhance cross layer information exchange.
Computer deep image processing based on dual branch multi-scale feature encoder
After completing the structural design of the dual branch multi-scale feature encoder, the research applied it to computer deep image processing. A Deep Image Completion Network (DCNet), a Deep Image Superresolution Network (DSRNet), and an image edge detection algorithm based on the dual branch multi-scale feature and completion network were designed. These tools perform image processing operations such as intelligent image completion, image resolution enhancement, and image edge detection. The DCNet structure is mainly categorized into three core parts: feature extraction, multi-modal feature fusion, and depth prediction. In the feature extraction stage, DCNet adopts a dual branch structure to process color images and depth images separately. The completion objective function of the depth map is shown in equation (7).
18

In equation (7), Architectural diagram of the DCNet of the deep image completion network.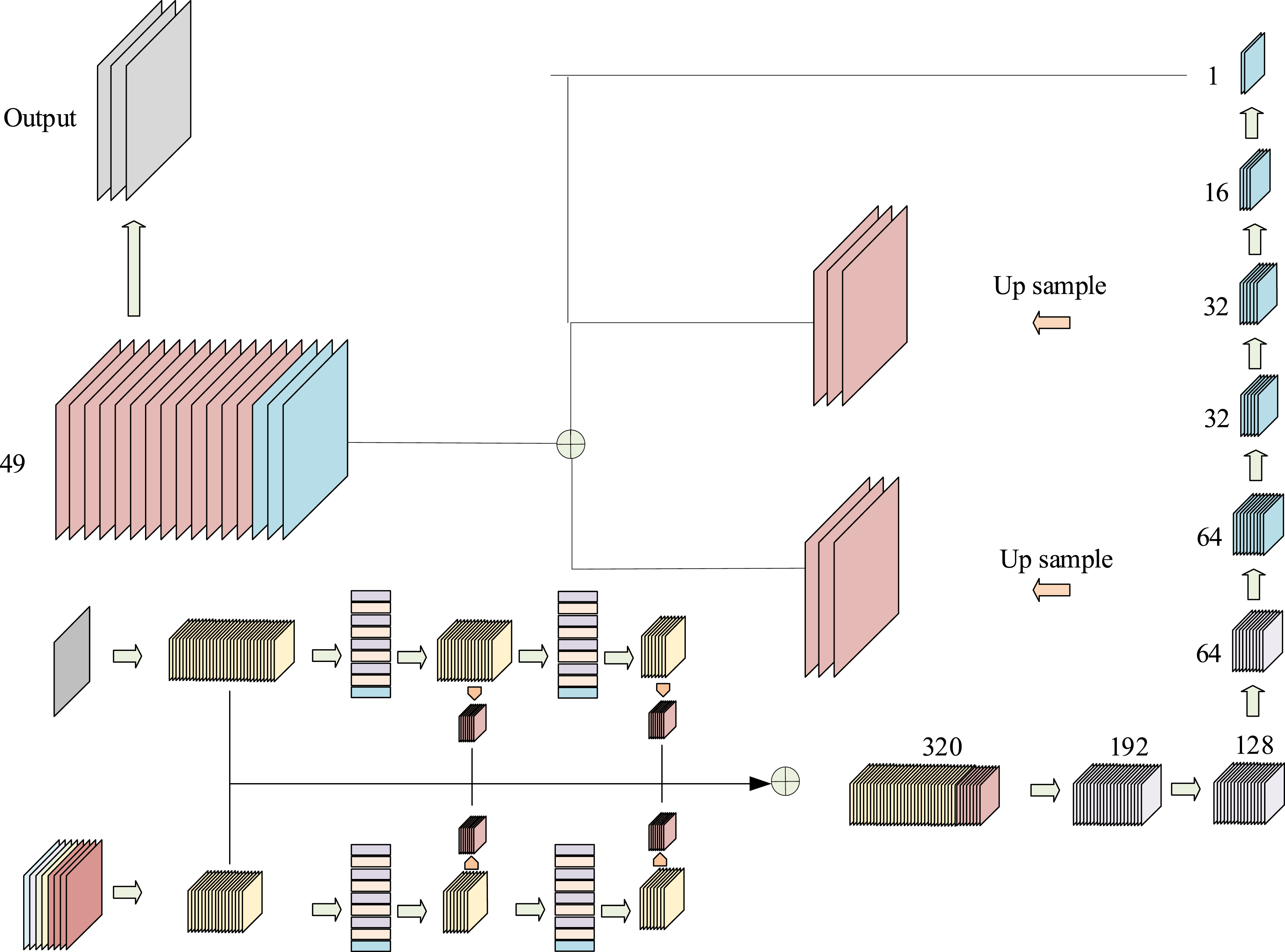
For color images, the network extracts multi-level features from local to global levels through residual modules and convolutional layers. For depth images, a specially designed convolutional layer is used for feature extraction to adapt to the characteristics of the depth image. The output features of the two branches are consistent in size and hierarchy, preparing for subsequent feature fusion. The loss function during the training process is shown in equation (8).

In equation (8),

In equation (9), Schematic of DSRNet structure of deep image superresolution network.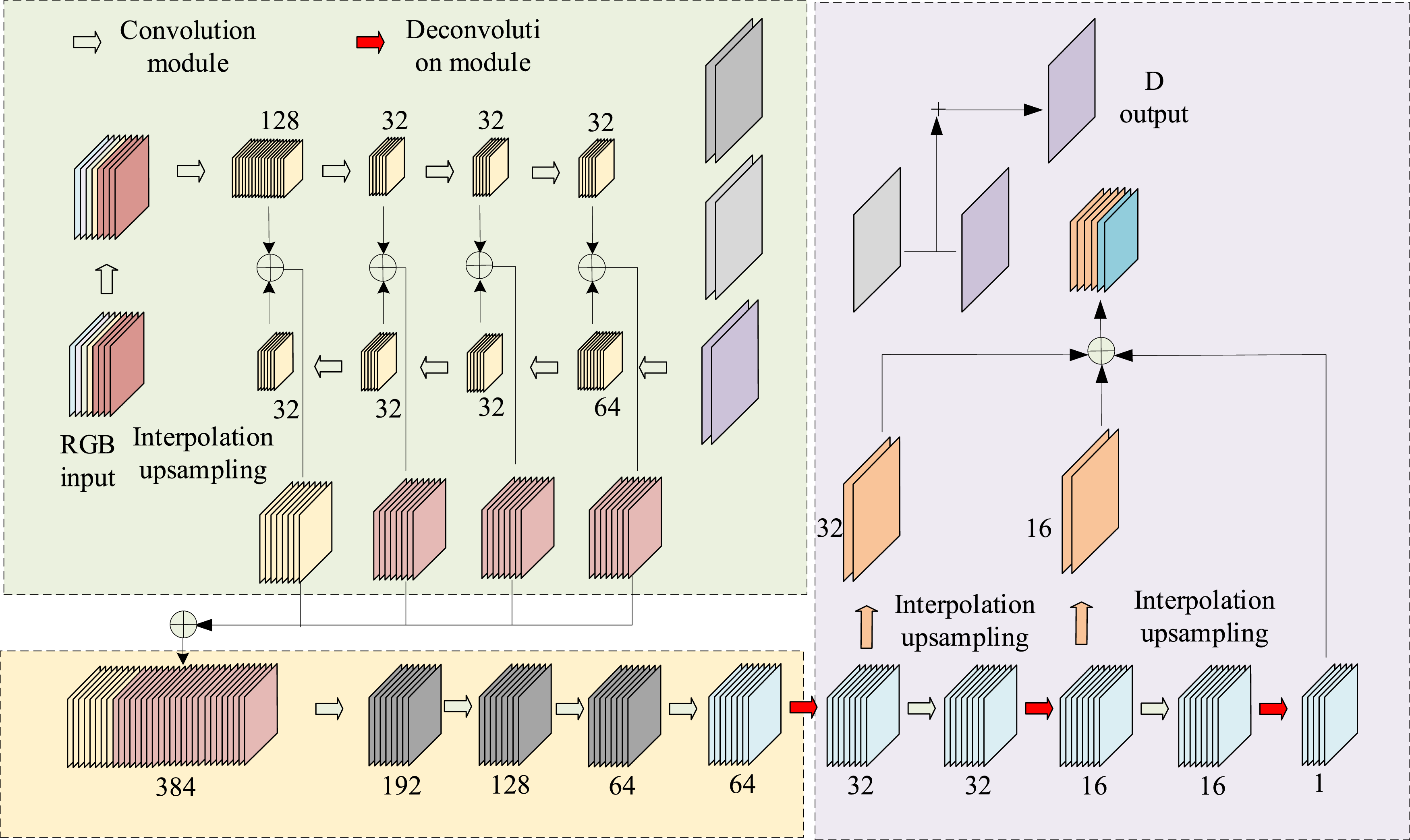
Firstly, there is RGB input: responsible for receiving high-resolution three channel color images, which provide rich color information for the network and facilitate subsequent feature extraction and fusion. Before the image enters the network, the color and depth images are decomposed in the frequency domain. The study uses discrete Fourier transform to transform them into the frequency domain for decomposition, as shown in equation (10).
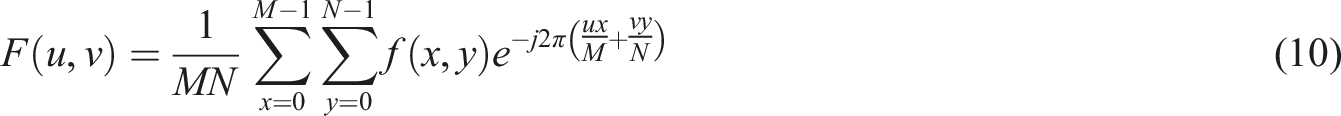
In equation (10), Process of image edge detection algorithm based on double-branching multi-scale features and complete network.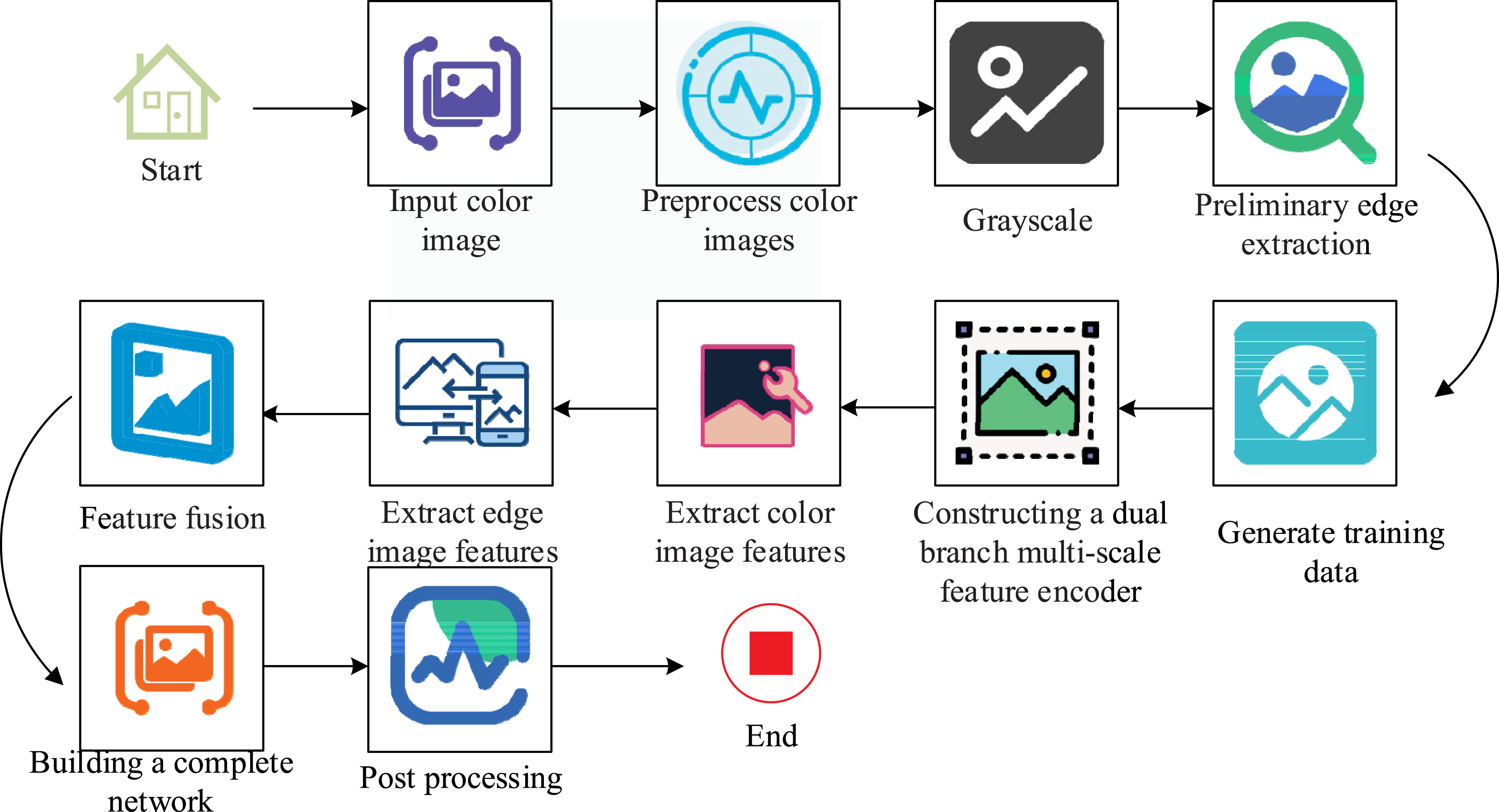
Step 1: The color image is input, and the color image intended for edge detection is obtained. Step 2: The color image is preprocessed, including steps like image denoising and resizing, to ensure it meets the requirements for network processing. Step 3: The preprocessed color image is converted into a grayscale image, with the values of the three color channels being combined according to specific weights. Step 4: Preliminary edge extraction is performed on the grayscale image using the Canny operator, with the parameters of the Gaussian kernel being dynamically adjusted grounded on the local features of the image. By calculating the local variance and mean of the image, the Gaussian kernel standard deviation required for each pixel is determined to more accurately smooth the image, while effectively reducing the impact of noise and preserving the edge details of the image to the greatest extent possible. Step 5: A large number of color images are processed using preliminary edge extraction methods, generating corresponding initial edge images, and a training dataset is constructed. Step 6: A dual branch multi-scale feature encoder is built, with one branch being processed with color images and the other branch being processed with initial edge images. Step 7: Multi-scale features of color images are extracted using convolutional layers, residual modules, and other structures through the color image branching. Step 8: Multi-scale features of the initial edge image are extracted using a network-like structure through the edge image branching. Step 9: The color image features and edge image features are merged to obtain a comprehensive feature that combines color and edge information. Step 10: A DCNet image completion network is constructed based on the fused features for predicting more accurate edge images. Step 11: The completion network is trained using the training dataset, with the network parameters being optimized by calculating the difference between the predicted edge image and the real edge image. The predicted edge image is then post-processed to obtain the final edge detection result.
Performance testing and applicability analysis of computer deep image processing system
Performance testing of dual branch multi-scale feature encoding structure and image processing methods
Outcomes of double-branched multi-scale feature encoding structural ablation experiments.

From Table 1, experimental group 1, as the original dual branch multi-scale feature encoder, performed the best in accuracy, recall, F1 score, and MSE, with values of 0.98, 0.82, 0.83, and 0.12, respectively. This validated the effectiveness of the dual branch structure. Compared with other experimental groups, after removing the left branch skip connection in experimental group 2, all indicators decreased, especially the accuracy decreased by 0.1 (from 0.98 to 0.88), indicating that skip connection is crucial for maintaining feature continuity. The removal of the max pooling layer from the residual module of the right branch in experiment group 3 also resulted in a performance decline, with an accuracy decrease of 0.09 (to 0.89), indicating that the max pooling layer plays a critical role in feature extraction. In order to perform image completion on computer deep images, a deep image completion network DCNet structure was designed based on a dual branch multi-scale feature encoding structure. The study used this structure to complete 200 incomplete image samples, with SSIM, PSNR, and root mean square error (RMSE) as evaluation indicators. The outcomes are shown in Figure 7. DCNet structure performance test results of the deep image completion network. (a) Changes in PSNR of various books, (b) Changes in SSIM of each sample, (c) Changes in RMSE of each sample.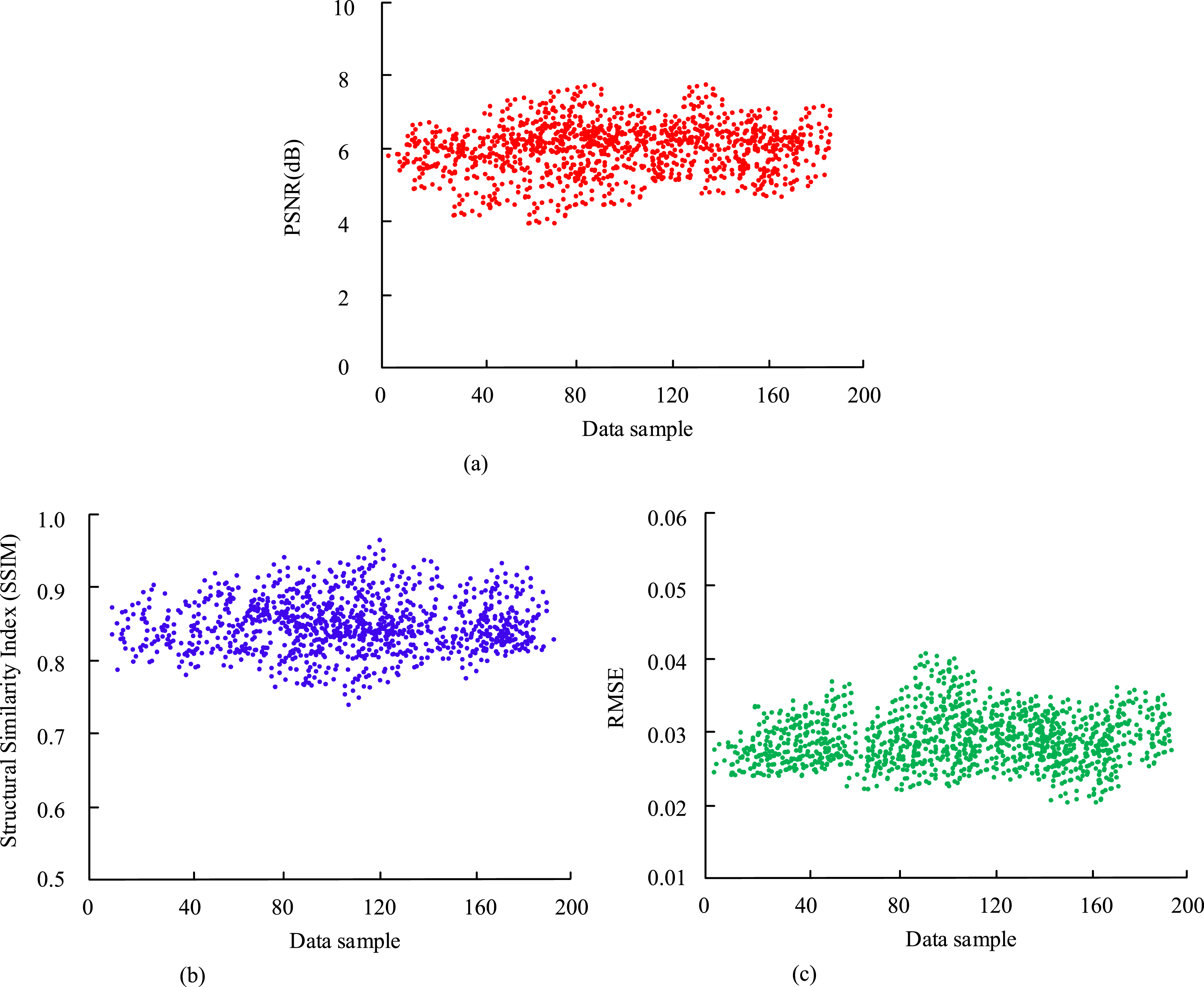
Figure 7 indicates the performance of DCNet in the task of completing 200 incomplete image samples. From Figure 7, the PSNR values were mainly distributed between 6 dB and 8 dB, indicating that the overall quality of the completed image was high, but there was still a certain gap compared to the original image. The fluctuation range showed that the stability of the image quality needed to be improved. The SSIM values were mostly concentrated between 0.7 and 1.0, indicating that the completed image had a high similarity in structure to the original image, but some samples had low SSIM values. In addition, the RMSE values were distributed between 0.02 and 0.04. Smaller RMSE values indicated that there was not much difference between the completed image and the original image at the pixel level, but some samples had slightly higher RMSE values, indicating that there was still room for improvement in the pixel accuracy of these samples. In order to verify the effectiveness and robustness of the proposed image edge detection algorithm based on dual branch multi-scale features and completion network, this study conducted tests on the BSDS500, Canny, KITTI, ImageNet, SWED, and MNIST datasets. The BSDS500 dataset contains 500 RGB images of natural scenes, providing rich edge annotation information. The Canny dataset consists of edge images generated by the Canny edge detection algorithm. The KITTI dataset mainly contains images and depth information in autonomous driving scenarios, with rich scene diversity. The ImageNet dataset is a large-scale image dataset that provides rich categories and scenes. The SWED dataset contains images from specific scenes. The MNIST dataset is a handwritten digit image dataset. Through the diverse datasets covering natural scenes, synthetic data, autonomous driving, general objects, special imaging, and simple structures mentioned above, the stability and adaptability of the algorithm can be comprehensively verified under different data distributions. With ODS index, average OIS index, and average accuracy as evaluation indicators. The experimental results are shown in Figure 8. Performance test results of image edge detection algorithm based on two-branch multi-scale features and complete network. (a) The ODS index performance of algorithms proposed by various research institutes in different datasets, (b) The OIS index performance of algorithms proposed by various research institutes in different datasets, (c) The average accuracy performance of algorithms proposed by various research institutes in various datasets.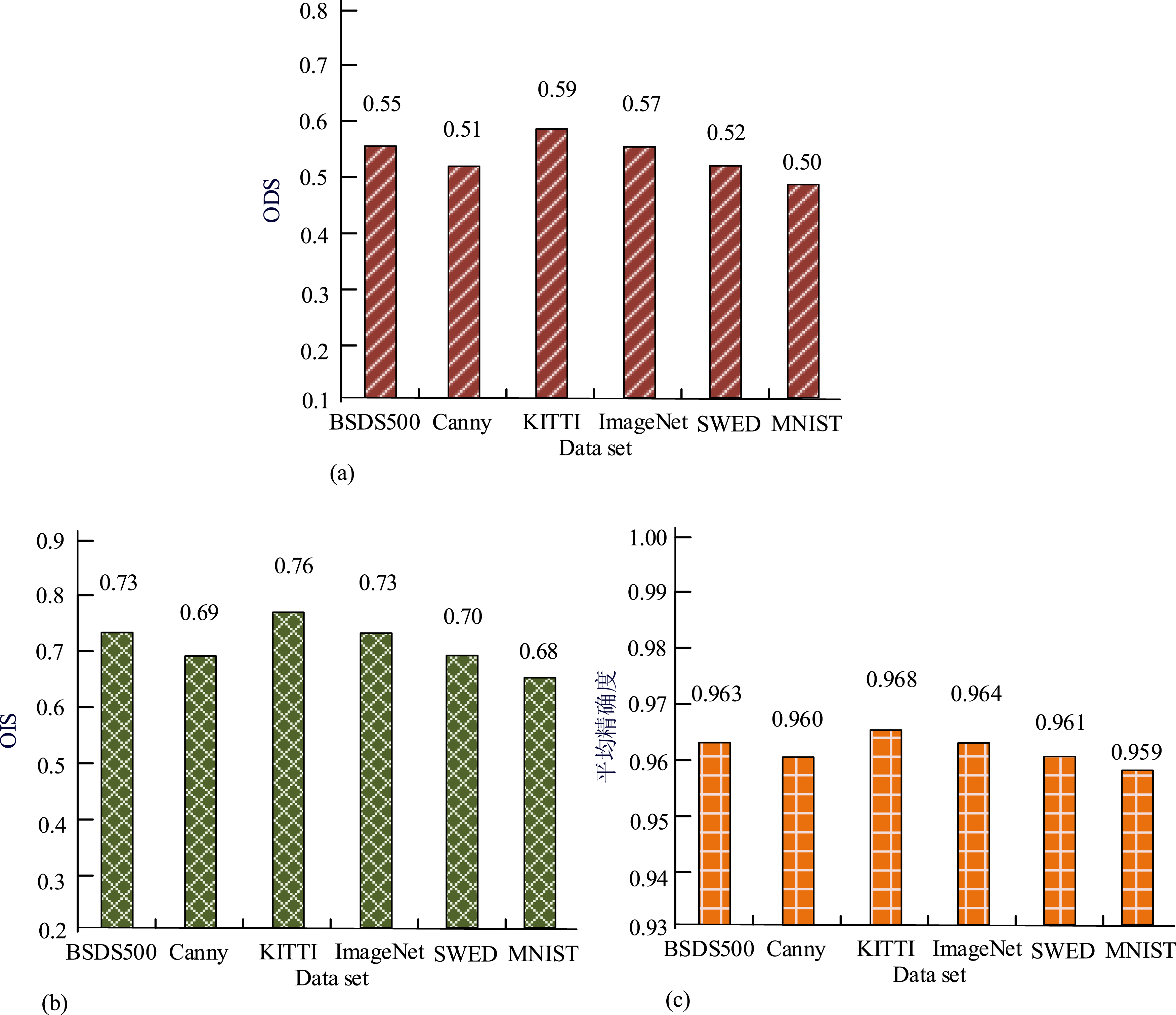
From Figure 8(a), using the ODS index as the evaluation metric, the algorithm achieved an index of 0.55 on the BSDS500 dataset, slightly lower than the 0.57 on the KITTI dataset and the 0.59 on the other dataset, but significantly higher than the 0.52 on the SWED and MNIST datasets, demonstrating its wide applicability on different datasets. From Figure 8(b), the algorithm also performed well in terms of OIS index. On the BSDS500 dataset, the OIS index was 0.73, while on the Canny, KITTI, and ImageNet datasets, the OIS indices were 0.69, 0.76, and 0.73, respectively, indicating that the algorithm’s performance evaluation on a single image was relatively stable.
Application analysis of computer deep image processing methods
The study fully verified the superior performance of the proposed computer deep image processing method system. In order to further verify that these methods also have equally good performance in practical applications, the study implemented these algorithms on the Windows platform using Python language and performed a range of practical experiments. Firstly, the deep image completion network DCNet was applied to the actual image completion task, and the completion outcomes are in Figure 9. Experimental results of the applicability of DCNet deep image completion network.
Figure 9 indicates the experiment outcomes of the application of the deep image completion network DCNet in animal video sequences. In the figure, DCNet effectively completed images of different animals. In the first sequence, DCNet processed the scene of two dogs interacting. In the completed image, the posture and motion coherence of the dog were significantly restored, with the PSNR increasing from 18.3 dB to 25.6 dB and the SSIM increasing from 0.68 to 0.89, indicating a significant improvement in image quality. The last sequence was a scene of a monkey in the jungle. DCNet not only filled in the blank areas of the image, but also restored the shape and background environment of the monkey, making the completed image more consistent with before completion. The PSNR value of the sequence increased from 20.2 dB to 27.3 dB, and the SSIM increased from 0.75 to 0.91, further verifying the completion ability of DCNet in complex environments. The experimental results of the applicability of the deep image SR network DSRNet structure are shown in Figure 10. Experimental results of DSRNet structure application of deep image superresolution network. (a) Resolution changes of images before and after restoration using DSRNet, (b) Information entropy changes of images before and after restoration using DSRNet.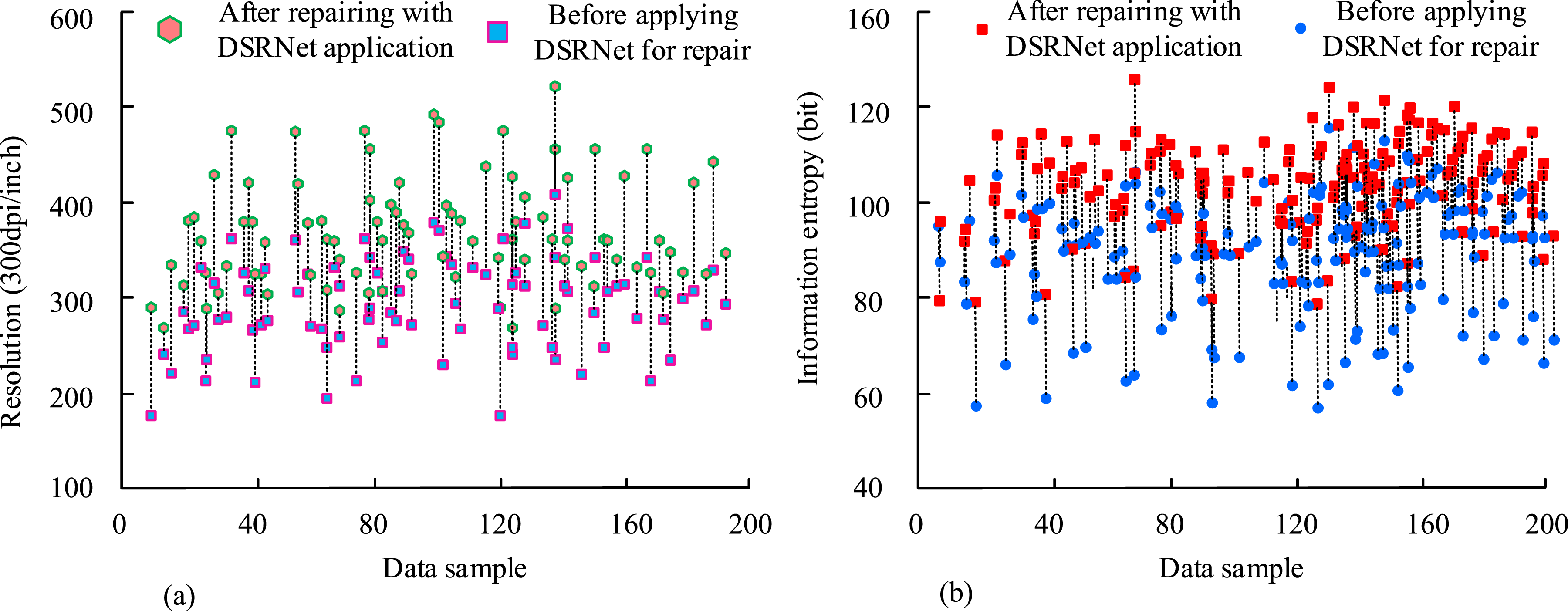
From Figure 10(a), in terms of resolution changes, the left figure reveals significant differences before and after DSRNet repair. The resolution data before repair is presented as blue squares, while the repaired data is represented by green circles. By comparison, on most data points, the green circle is located above the blue square, especially in the range of 100–150, and the resolution after repair was significantly improved. For example, in the sample interval of 60–80, the resolution before restoration is mostly concentrated around 350, while after restoration it jumps to above 450, demonstrating the significant effect of DSRNet in improving image resolution. Figure 10(b) shows the variation of information entropy. To fully confirm the validity of the image edge detection algorithm based on dual branch multi-scale features and completion network proposed by the research, this algorithm was used to perform edge detection on 30 typical computer depth maps, and the Edge Detection Algorithm Based on Adaptive Morphology (EDA-BAM) proposed in reference 20 was introduced for comparison. The experiment outcomes are in Figure 11. Applied experimental results of image edge detection algorithm based on two-branch multi-scale features and complete network. (a) Comparison of accuracy between two edge detection algorithms, (b) Comparison of MSE between two edge detection algorithms.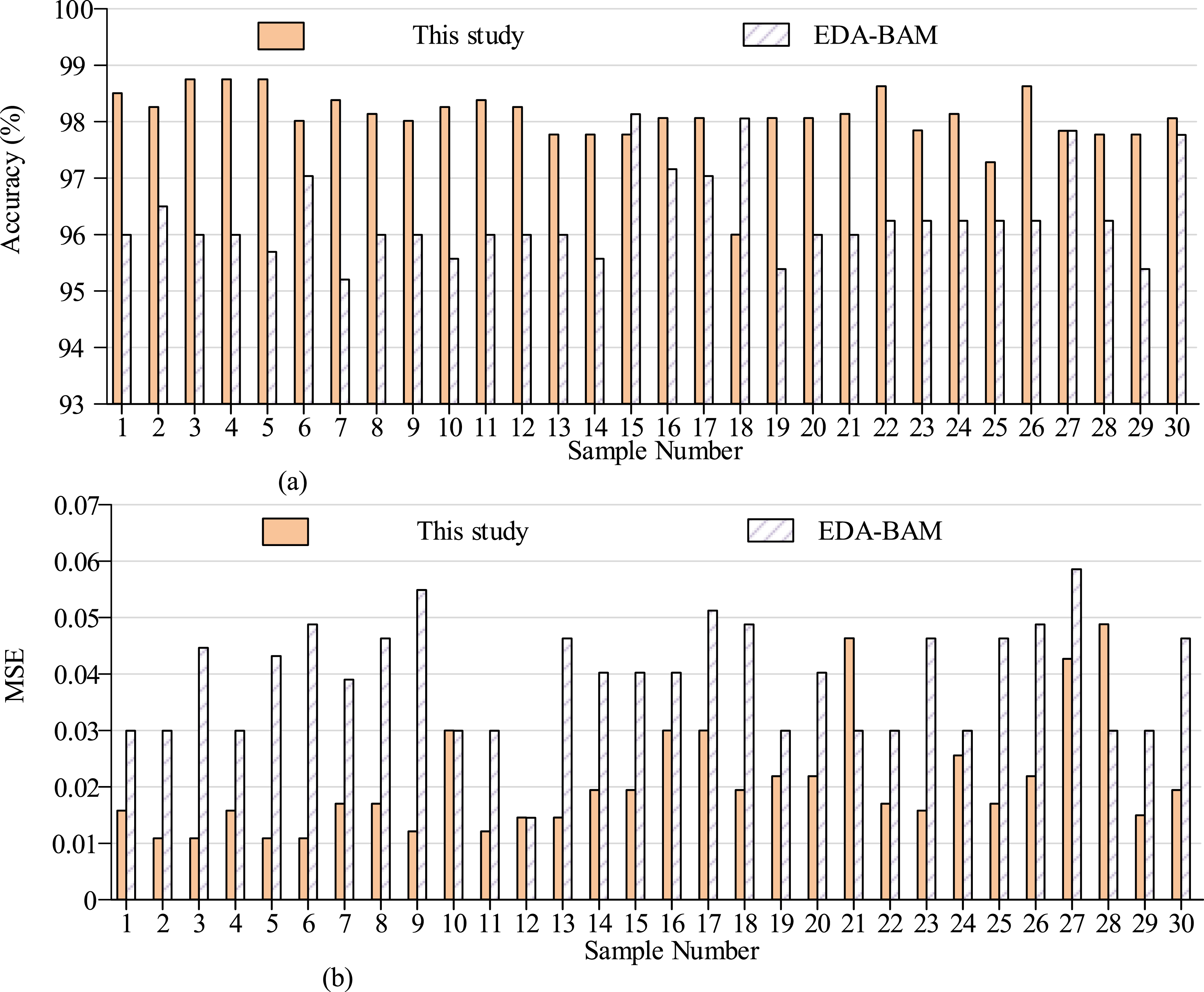
From Figure 11(a), in terms of accuracy, the research algorithm performed well in most sample numbers, with an accuracy rate stabled at over 96%. Especially in sample numbers 1, 4, 5, 10, 11, 13, 17, 22, etc., the accuracy rate was close to or reaches 100%. In contrast, although the overall accuracy of the EDA-BAM algorithm was relatively high, it fluctuated greatly, and in sample numbers 3, 7, 18, 21, etc., the accuracy was about 2%–3% lower than the algorithm proposed in the study. From Figure 11(b), the research algorithm also demonstrates significant advantaged in terms of MSE, with most samples maintaining MSE values below 0.03. The MSE values of the EDA-BAM algorithm were relatively high in sample numbers 8, 14, 18, 21, 27, etc., exceeding 0.04 or even close to 0.05, indicating a large error between its edge detection results and the true values.
Conclusion
The study is devoted to addressing the problem of traditional 2D image processing methods being difficult to effectively segment crops and backgrounds and obtain 3D phenotype information in complex natural environments. An innovative dual branch multi-scale feature encoder was designed, which significantly improved the accuracy and efficiency of image processing by fusing color and depth information. The experiment outcomes indicated that the encoder performed excellently in accuracy, recall, F1 score, and MSE, with an accuracy of 0.98, recall of 0.82, F1 score of 0.83, and MSE of 0.12. In practical applications, the deep image completion network DCNet based on this encoder showed that the PSNR values were mainly concentrated between 6 dB and 8 dB on 200 incomplete image samples, the SSIM values were mostly between 0.7 and 1.0, and the RMSE values were between 0.02 and 0.04. The deep image SR network DSRNet had a significant effect on improving image resolution, with a significant increase in resolution and a general increase in information entropy. In addition, the image edge detection algorithm based on dual branch multi-scale features and completion network was tested on multiple datasets, showing excellent performance in ODS index, OIS index, and average accuracy, reaching 0.55, 0.73, and 0.963, respectively. These results fully validated the superior performance of the proposed method and its potential applications in precision agriculture and other fields. In summary, the design of a dual branch multi-scale feature encoder effectively improved the accuracy and efficiency of image processing, providing strong support for fields such as precision agriculture.21,22 The proposed model is designed based on a universal deep learning architecture, with good portability and compatibility, and can adapt to various hardware platform operating environments. For example, for CPU platforms, algorithms can utilize their powerful general-purpose computing power for sequential execution. For GPU platforms, the large number of parallel computing tasks in algorithms can fully utilize the parallel computing advantages of GPUs to achieve efficient acceleration. For FPGA platforms, the modular structure and reconfigurability of algorithms enable efficient hardware implementation through hardware description languages. In practical applications, the proposed model integrates color and depth information through a dual branch multi-scale feature encoder, demonstrating high accuracy in tasks such as image completion, super-resolution, and edge detection. It is not only suitable for image processing in the agricultural field, but also has broad application prospects in other fields that require deep image processing. However, this study mainly focuses on improving algorithm accuracy and functionality, and has not yet systematically evaluated the computational efficiency and latency of the model in real-time image processing tasks. Exploring the real-time performance of image processing is crucial in target application scenarios such as autonomous driving environment perception and real-time monitoring systems. Therefore, in future work, the computational efficiency of the proposed model in real-time image processing tasks should be further validated, and lighter backbone networks or more efficient attention mechanism modules should be explored, or the parallel computing capabilities of hardware such as GPUs, NPUs, or FPGAs should be utilized for model optimization and deployment.
ORCID iD
Footnotes
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The research is supported by: Project for Enhancing Young and Middle-aged Teacher's Research Basis Ability in Colleges of Guangxi (2025KY1557, 2024KY1330); University level scientific research project of Guangxi Vocational & Technical Institute of Industry (GYKY2024008B, GYKY2023012B).
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.