
Abstract
This study developed a computer-assisted language learning system based on English syntactic structure using long short-term memory (LSTM) network. Through dynamic learning models and adaptive learning paths, personalized and efficient learning experiences were provided, aiming to address the shortcomings of traditional systems and improve learners’ mastery of syntactic structure. The system processed language sequence data by designing an LSTM model, combined with a dynamic adjustment mechanism and real-time feedback system, to achieve dynamic adjustment of personalized learning content and difficulty. Based on data-driven teaching strategies, teaching methods were continuously optimized and learning outcomes were improved by collecting and analyzing learning data. The experimental results of this study indicated that the system had significant effects in improving learners’ mastery of syntactic structures, overcoming the limitations of traditional computer-assisted language learning systems. In the experiment, 120 English learners were selected and divided into an experimental group and a control group, using the system developed in this study and the traditional system, respectively. After the experiment, learners in the experimental group significantly improved their mastery of syntactic structures, with their scores jumping from 70 to 94, while those in the control group increased from 68 to 85. The percentage of correct learning increased from 75% to 94% in the experimental group and from 73% to 86% in the control group. The study shows that the computer-assisted language learning system is effective in improving the mastery of syntactic structures.
Keywords
Introduction
In today’s globalization, the importance of English as an international common language is self-evident. However, traditional language learning methods1,2 are limited by classroom teaching and paper textbooks, which are difficult to meet individualized learning needs, especially in the learning of complex syntactic structures. The emergence of Computer-assisted Language Learning (CALL)3,4 systems has revolutionized language learning through multimedia, interactive content and instant feedback. However, existing CALL systems still have limitations when dealing with complex grammars, such as the lack of personalized learning paths5,6 and dynamic adjustment mechanisms.7,8
To overcome these limitations, this article proposes a novel CALL system design based on the long short-term memory (LSTM) network9,10 technique. The system uses LSTM technology to deal with the hierarchical and recursive nature of English syntactic structures,11,12 and designs personalized learning paths for learners by collecting learning data, constructing learning portraits, and analyzing their learning characteristics and trends in real-time. During the learning process, the system dynamically adjusts the learning content and difficulty, provides rich interactive resources and instant feedback, and enhances the learning efficiency and interest. Experimental results show that the system significantly improves learners’ mastery of English syntactic structures, verifying its effectiveness and practicality. This innovation not only provides new ideas for the development of language learning systems, but also lays the foundation for the future development of personalized learning.
Related work
The research on computer-assisted language learning systems has gone through multiple stages. Early CALL systems mainly focused on speech recognition13,14 and basic language learning functions. With the development of technology, multimedia elements and interactive functions have gradually been applied, making learning more vivid and interesting. Shen Lanlan 15 applied the CALL system to English listening classroom teaching to improve students’ English listening proficiency. Nian Yue et al. 16 also explored the application of computer-assisted teaching in English classrooms, summarized its advantages and disadvantages, and provided suggestions. However, traditional CALL systems still lack the ability to handle individual differences among learners and dynamically adjust based on their learning progress and needs. Different from the traditional CALL system, the system in this study utilizes the long-distance dependency processing capability of LSTM to effectively cope with the challenge of complex syntactic structures. Traditional systems usually rely on rules or template matching, which makes it difficult to capture subtle differences in grammar. However, LSTM can dynamically adjust the capture of grammar information through its gating mechanism, significantly improving the generalization ability of the model. In addition, the dynamic learning model introduced in this article can adjust learning content in real time, further improving the teaching effect of the system. This approach overcomes the limitations of traditional CALL systems in adapting to the needs of different learners.
In recent years, with the advancement of deep learning technology, especially the widespread application of long short-term memory networks, many studies have begun to explore how to apply this technology into the field of language learning. LSTM is widely used in tasks such as natural language processing,17,18 machine translation,19,20 and speech recognition due to its advantages in sequence data processing. Ye Junqiao et al. 21 applied LSTM to language learning, extracting statistical and sequential features from learners’ memory behavior history, learning memory behavior sequences using LSTM, and predicting the recall probability of foreign language learners for words. Shao Dangguo et al. 22 proposed a segmentation model based on bidirectional long short-term memory (Bi-LSTM) network, which achieved good segmentation results in this field. Compared with the segmentation model trained solely on Chinese medical corpus, it showed significant improvement. Liang Dengyu 23 designed a Chinese text classifier based on long short-term memory networks and achieved good results. Research has shown that LSTM can effectively capture long-distance dependencies in language, providing learners with a more accurate learning experience. Meanwhile, data-driven teaching strategies are gradually gaining attention. By collecting and analyzing learners’ data, teaching content and strategies can be continuously optimized to improve learning outcomes. Based on the research of language learning based on syntactic structure, some works have explored how to use syntactic analysis to improve language learning effectiveness.24,25 This study innovatively combines LSTM and dynamic learning model to achieve personalized learning and effectively improve the mastery of English syntactic structure. This innovation opens a new direction for the development of CALL system.
Methods
System architecture design
This system architecture integrates the front-end, back-end, database and machine learning modules, as shown in Figure 1. The front-end module is mainly responsible for improving the user experience, providing an interactive interface and functional entry, including learning resource display, task submission and feedback reception. The front-end exchanges data with the back-end service through the API, sends user requests to the back-end, and receives responses from the back-end. The back-end module adopts a microservice design to process requests from the front-end, perform business logic processing, and drive the operation of the machine learning module. The back-end receives data requests from the front-end, distributes the requests to the corresponding services, calls the machine learning module for data processing, and obtains or stores data from the database. The database module integrates relational and non-relational storage to ensure data security and efficient access. Relational databases are used to store structured data (such as user information and learning records), while non-relational databases are used to store unstructured data (such as learning resources). The database module performs data read and write operations with the back-end, and provides data support through SQL queries operations. The core machine learning module uses LSTM technology to perform in-depth analysis of English syntax, generate syntax trees, identify and correct grammatical errors, and dynamically adjust learning tasks and difficulty. The machine learning module receives data input from the back-end, processes it, and returns analysis results and learning suggestions. These results are fed back to the front-end through the back-end for users to review and adjust their learning paths. Through the collaborative work of these modules, the system achieves personalized learning paths and feedback, effectively improving English grammar skills. System architecture.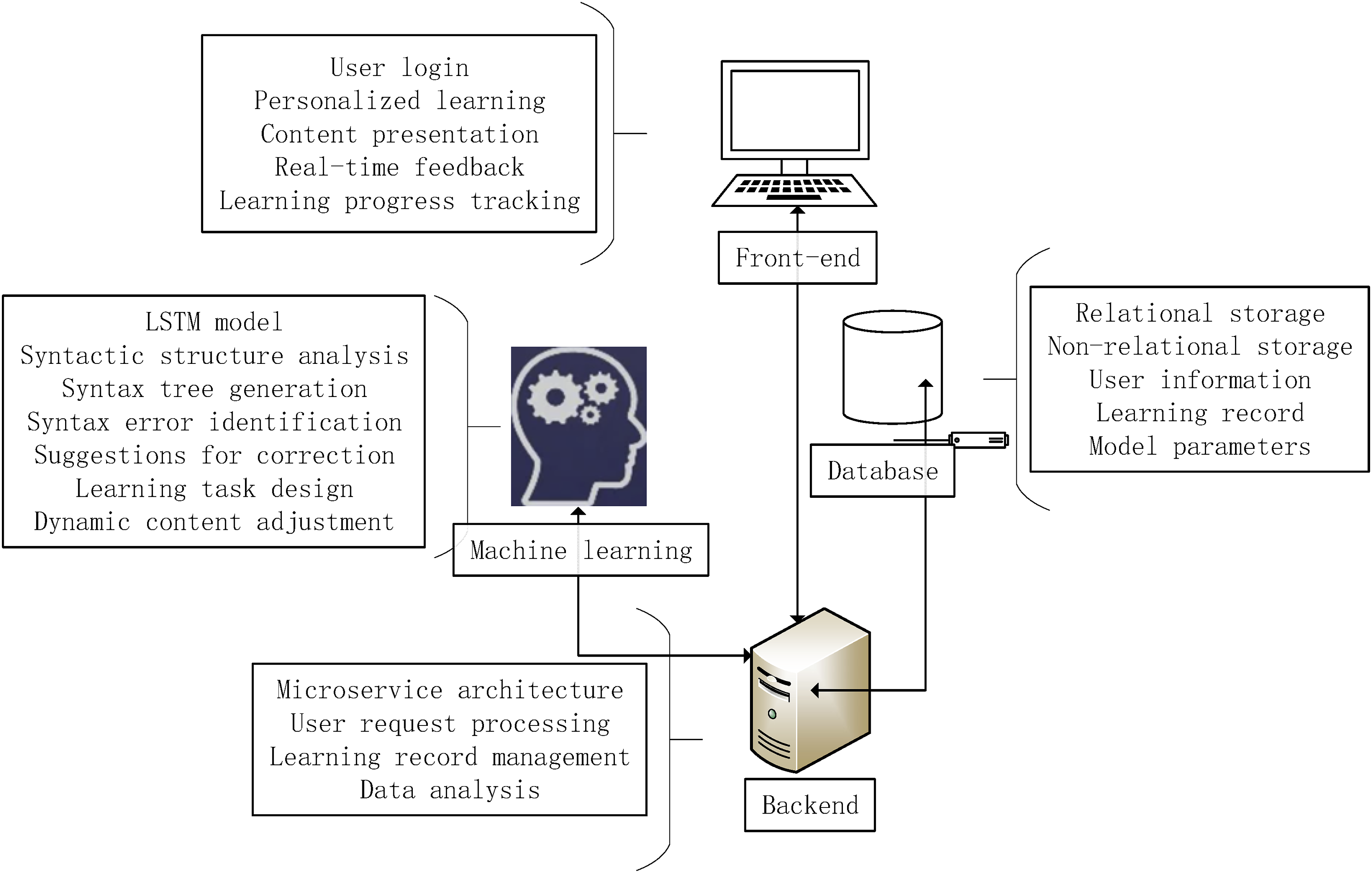
The front-end is designed with a main interface for grammar exercises. Users can select different grammar exercises, such as verb tense or noun phrase structure, by selecting the exercise type drop-down menu. The interface includes an exercise display area, an answer input area, an instant feedback area, and a progress tracking function. The exercise display area displays specific questions; the answer input area supports text and voice input; the feedback area provides correct answers and detailed analysis; the progress tracking function displays the user’s practice progress and performance. Through these designs, users can efficiently practice grammar and get instant learning feedback.
Construction and training of LSTM model
Model selection and parameter settings
This study adopts a bidirectional LSTM architecture, aiming to accurately capture syntactic complexity and long-distance dependency. LSTM stabilizes the information flow in long-term memory and accurately parses the syntactic structure of sentences by virtue of its unique gating mechanism (Figure 2). Figure 2 shows the basic structure of LSTM. LSTM includes three main gating mechanisms: forget gate (f), input gate (i), and output gate (o). The forget gate determines the degree of forgetting of the previous state information; the input gate controls the update of the current input to the unit state; the output gate determines the impact of the current unit state on the final output. Each gating mechanism generates a value between 0 and 1 through the sigmoid activation function, which is used to perform weighted operations on information. In this study, the forward and backward LSTM outputs are integrated to comprehensively capture the bidirectional context of a sentence, enhance the model’s contextual understanding, and significantly improve the accuracy of syntactic analysis. LSTM structure.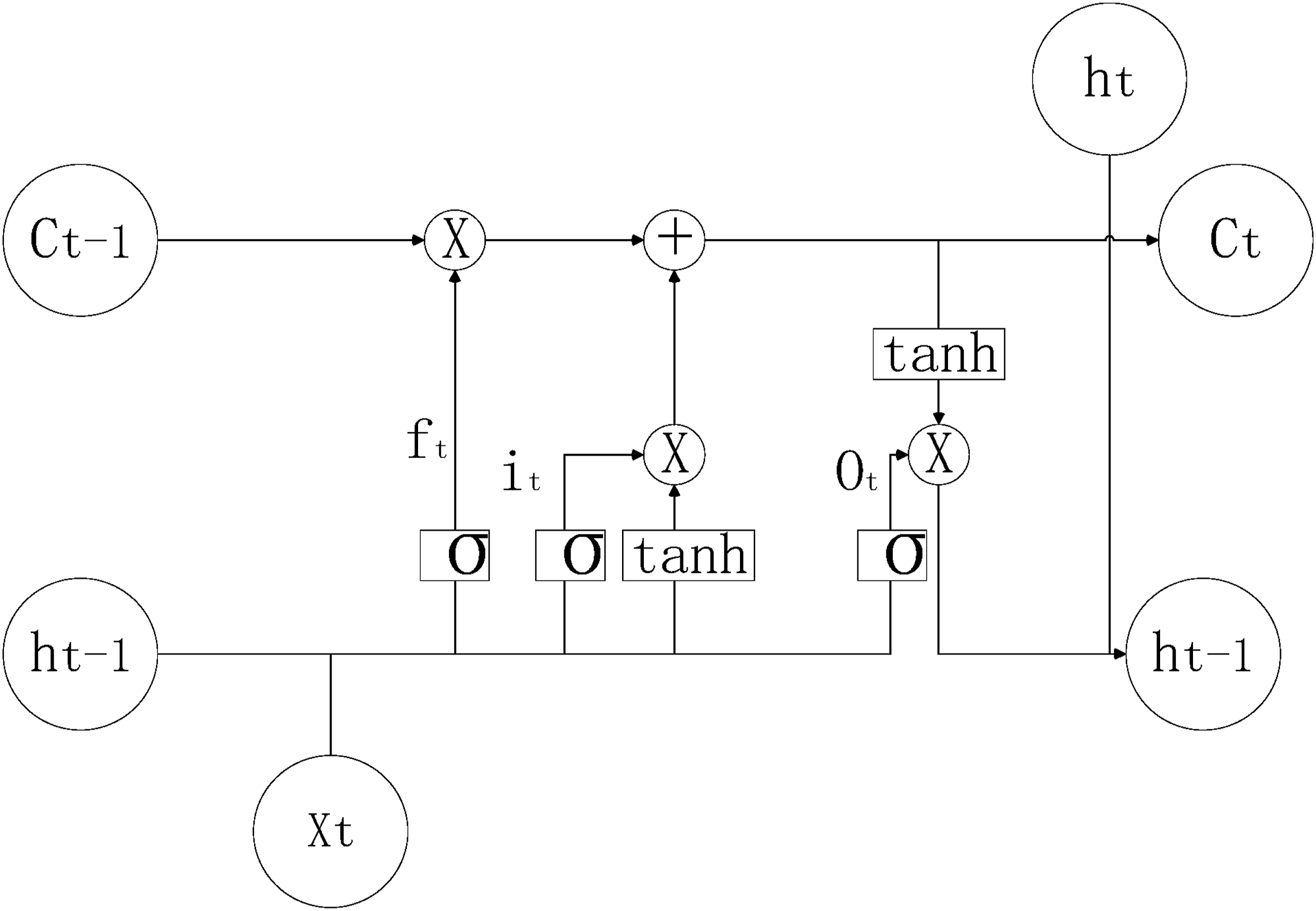
The forget gate controls the retention of old information:

Input gates regulate the amount of new information coming in:

The output gate determines the amount of current state information output:

In the process of model design, this article constructs the model architecture shown in Figure 3. In order to ensure the training efficiency and convergence speed of the model, the Adam optimizer
26
is used, and the initial learning rate is set to 0.001. During the training process, the learning rate is dynamically adjusted according to the performance of the validation set to adapt to the training requirements of different stages, so as to ensure that the model can converge stably. In addition, in order to improve the training efficiency and reduce the consumption of computing resources, the batch size is set to 64. This setting not only improves the training speed, but also improves the update effect of the model parameters. To further improve the generalization ability of the model, a dropout of 0.5 is introduced between the LSTM layer and the fully connected layer. This measure reduces the model’s dependence on specific training data by randomly discarding some neurons, thereby reducing the risk of overfitting. At the same time, L2 regularization is added to the model, and the regularization coefficient is set to 0.0001. The momentum decay rate (β1) of the Adam optimizer is set to 0.9, which means that when calculating the first moment of the gradient, the current gradient accounts for 0.9 and the past gradient accounts for 0.1. The squared gradient decay rate (β2) is set to 0.999 to ensure that the estimate of the square of the historical gradient has a long memory. The small constant (ε) is 1e-8 to prevent numerical instability caused by too small a denominator during the calculation process. This method effectively controls the complexity of the model and further reduces the possibility of overfitting on the training set. In terms of the selection of activation functions, the LSTM layer uses the tanh function to control the state update and output of the memory unit, respectively, so that the model can better capture the complex patterns in the input sequence. The fully connected layer uses the ReLU (Rectified Linear Unit)
27
activation function to enhance the nonlinear expression ability of the model, thereby improving the ability to fit complex nonlinear relationships. In summary, by optimizing the training strategy and structural design, the generalization ability and training efficiency of the model are significantly improved. The update rules for the Adam optimizer are as follows. Among them, Model architecture.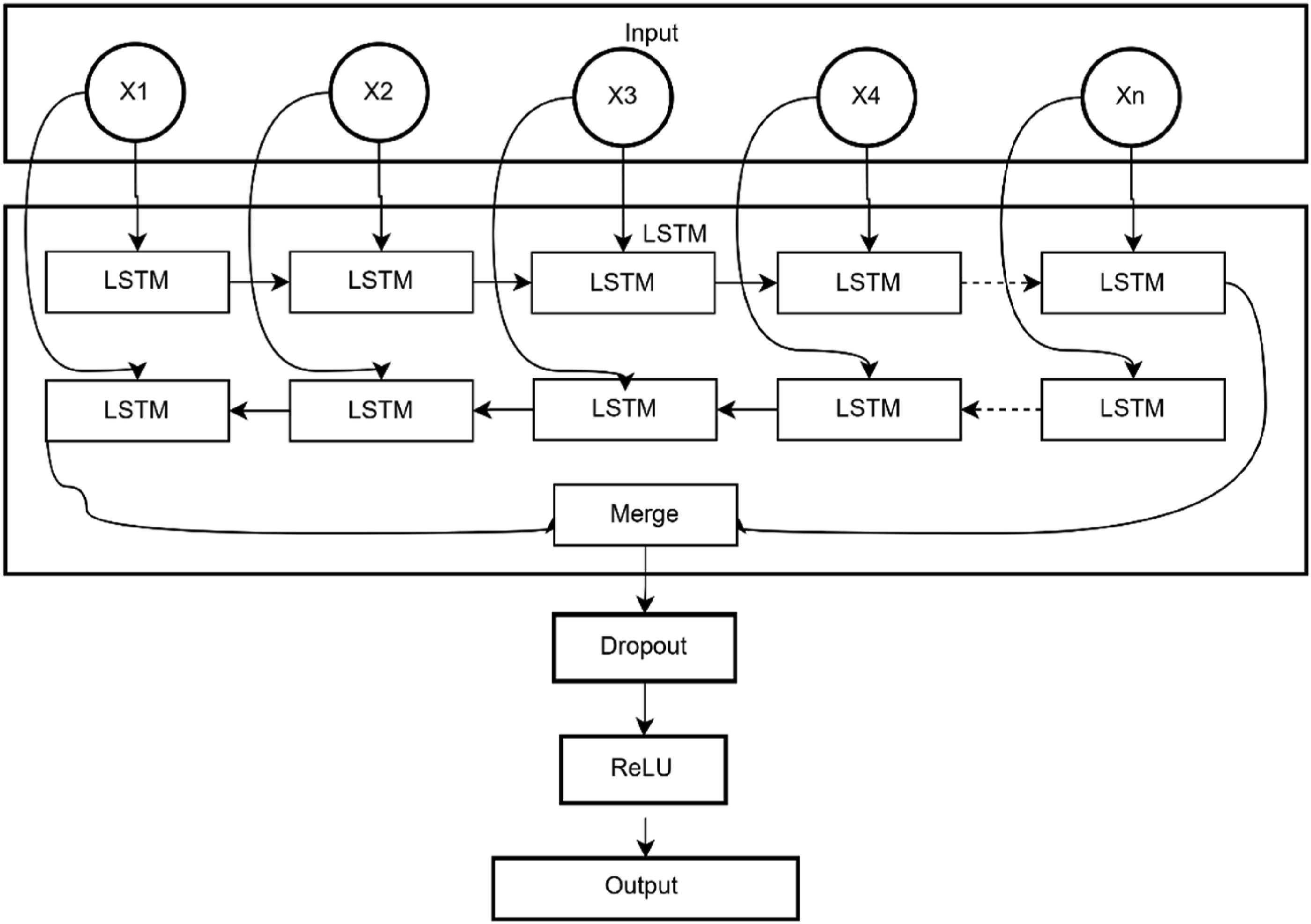





Unidirectional LSTM (long short-term memory) and bidirectional LSTM (bidirectional LSTM) each have their own advantages and disadvantages. The structure of one-way LSTM is relatively simple and the amount of calculation is relatively small, so it can provide efficient performance when processing many sequence modeling tasks. However, its main limitation is that context can only be obtained from past sequence information, which may affect tasks that need to consider future context information. In contrast, bidirectional LSTM can capture comprehensive information of the surrounding context by simultaneously processing the forward and reverse information of the sequence, significantly improving the understanding of the entire sequence context.
Data preprocessing and annotation
Part of speech tagging.
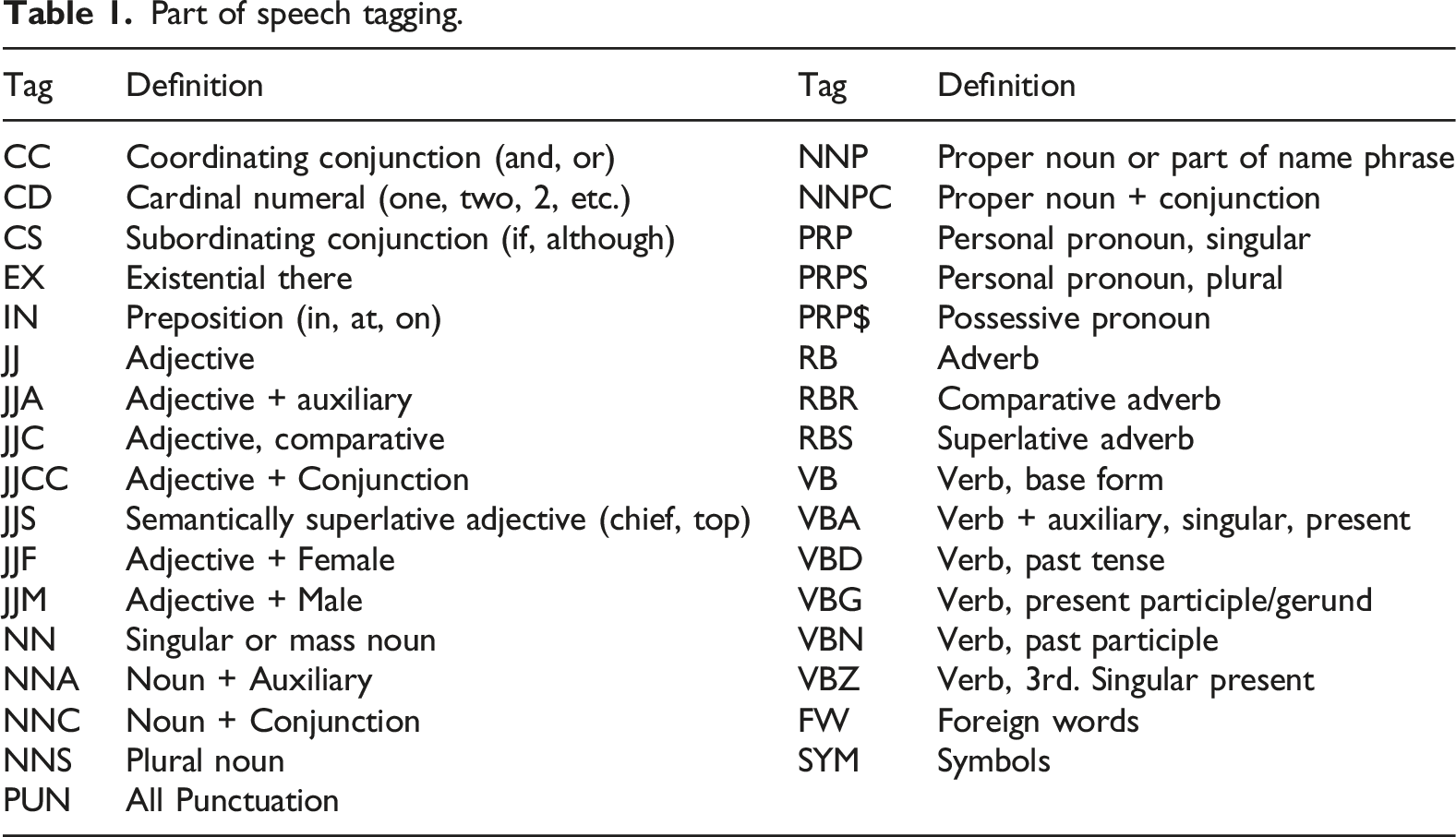
After completing text cleaning, segmentation, and syntactic annotation, serialization processing is performed to convert the processed text data into a format acceptable to the model. Firstly, a mapping dictionary is established based on the vocabulary in the dataset, and each unique vocabulary is mapped to a unique index. Then, the segmented sentence is converted into the corresponding index sequence, and special markers are used to represent words that are not in the vocabulary. Finally, the sequence is filled or truncated to ensure uniform input sequence length, and the maximum input length of the model is selected as the standard. After completing data preprocessing, the dataset is divided into a training set and a validation set. The preprocessing step helps the model better understand the language structure and reduce unstable factors in training, thereby improving the accuracy and stability of the model. The training set is used to train the LSTM model, accounting for 80% of the total dataset, while the validation set is used to evaluate model performance, accounting for 20%.
Model training and optimization
During the model training phase, multiple epochs were used for iterative training. In each epoch, the model learned the data features through a complete forward propagation and back propagation. The number of epochs was set to 40 to ensure that the model could fully learn the patterns in the data. After each iteration, the model parameters were adjusted according to the feedback of the loss function 28 to improve the prediction accuracy and the robustness of the model. During the model training process, it is clarified that the model learns data features through forward and backward propagation in each epoch, with an epoch count of 40. In order to accelerate training speed and reduce the impact of gradient fluctuations, this article adopts a small batch gradient descent algorithm29,30 with a batch size set to 64. This method not only speeds up the calculation process, but also improves the stability and convergence speed of the model to a certain extent. At the end of each epoch, the loss values and accuracy of the training and validation sets are recorded. These indicators can intuitively reflect the performance of the model during the learning process and provide real-time feedback.
In order to further analyze the learning dynamics of the model, a visualization tool was used to draw the change curves of the loss and accuracy. Through these curves, it is possible to intuitively observe whether the model has potential problems such as overfitting or underfitting during the training process, thereby providing a basis for subsequent adjustments. During the model training process, the changes in loss values at each stage are shown in Figure 4. The red curve represents the loss value of the training set, and the blue curve represents the loss value of the validation set. Figure 4(a) shows the trend of gradual decrease in training and verification loss values as the number of training rounds increases under conventional training, which shows that the model is continuously optimized and gradually learns the patterns in the data. In Figure 4(b), the training loss value drops significantly, while the validation loss value rebounds, which shows that the model performs well on the training set, but has an overfitting problem on the validation set, indicating that its generalization ability is insufficient. Figure 4(c) shows the case where both training and validation loss values remain at a high level, which means that the model is not complex enough to effectively capture the complex patterns in the data. In Figure 4(d), the loss value curve fluctuates greatly, which may affect the stability and convergence of the model. Based on the performance of these loss curves, this article finally selects the training model corresponding to Figure 4(a) as the final model to ensure its most stable and excellent performance on the verification set. Through a comprehensive analysis of these loss curves, this article selects the model trained in Figure 4(a) as the final model for further analysis and verification. Curve of loss value variation.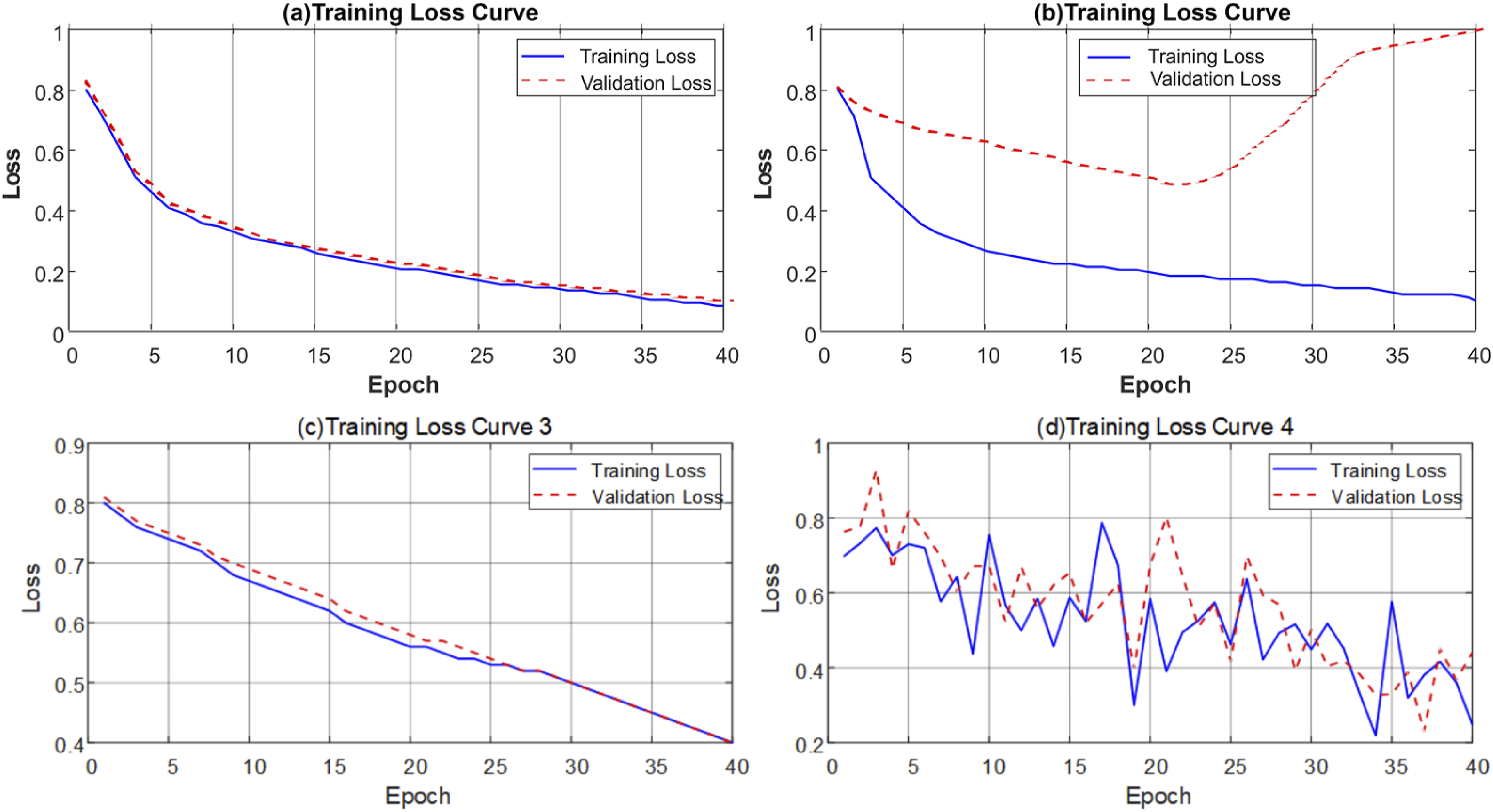
After training, an independent validation set is used to evaluate model performance, calculate accuracy, and verify whether the expected results have been achieved. If the performance does not meet the standard, the hyperparameters are adjusted based on the verification results. To enhance the reliability of the results, this article conducts 10-fold cross-validation, dividing the dataset into 10 subsets and alternately using one subset as the validation set and the rest as the training set, providing more comprehensive performance evaluation information. Figure 5 shows the accuracy of the model. It is observed that the accuracy of the model fluctuates between 0.91 and 0.94, indicating the performance changes of the model on different subsets of data. From the average accuracy, it can be seen that the overall performance of the model is stable, with an average accuracy of over 0.92, which is in line with the expected effect. Accuracy evaluation.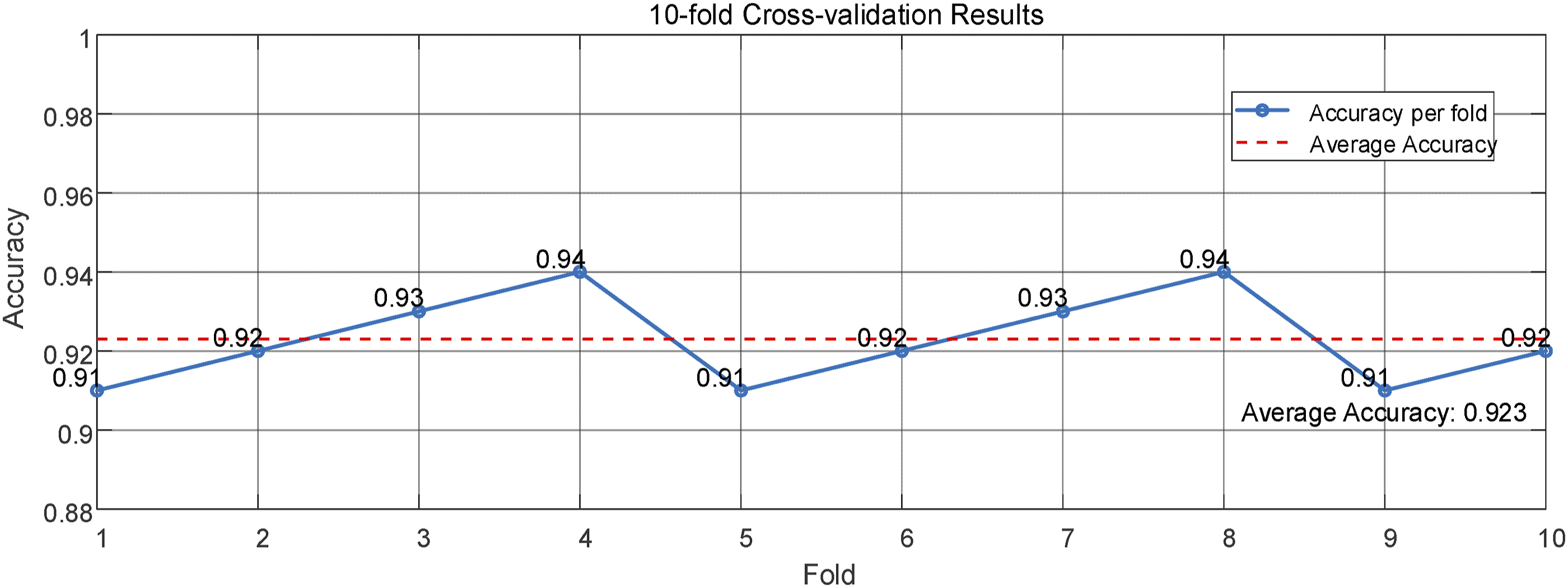
This article discusses in detail hyperparameter optimization strategies. Specifically, a grid search method is employed to explore different learning rate values to determine the optimal parameter settings. At the same time, regularization techniques such as L2 regularization and dropout (set to 0.5) are applied to prevent overfitting and improve the generalization ability of the model. During the training process, an early stopping strategy (Early Stopping) is introduced to avoid overtraining and shorten training time. In addition, the number of layers and hidden units of the LSTM network are adjusted; the model performance under different configurations is evaluated; the optimal configuration is selected for final training. These optimization measures significantly improve the accuracy and robustness of the model on test data.
Syntactic structure analysis
Syntactic analysis is the process of understanding sentence structure in natural language, which involves not only the grammatical relationships between vocabulary, but also the hierarchical structure of various components in a sentence. Due to its unique memory unit design, the LSTM network can effectively capture and process long-distance dependencies in natural language, which is difficult for traditional RNN (recurrent neural network) to handle. In syntactic structure analysis, LSTM dynamically selects which information to retain or discard through its gating mechanism (input gate, forget gate, and output gate), so that it can maintain sensitivity to the context in the sentence. This makes LSTM outperform other models in complex syntactic structure analysis. Dependency syntactic parsing
31
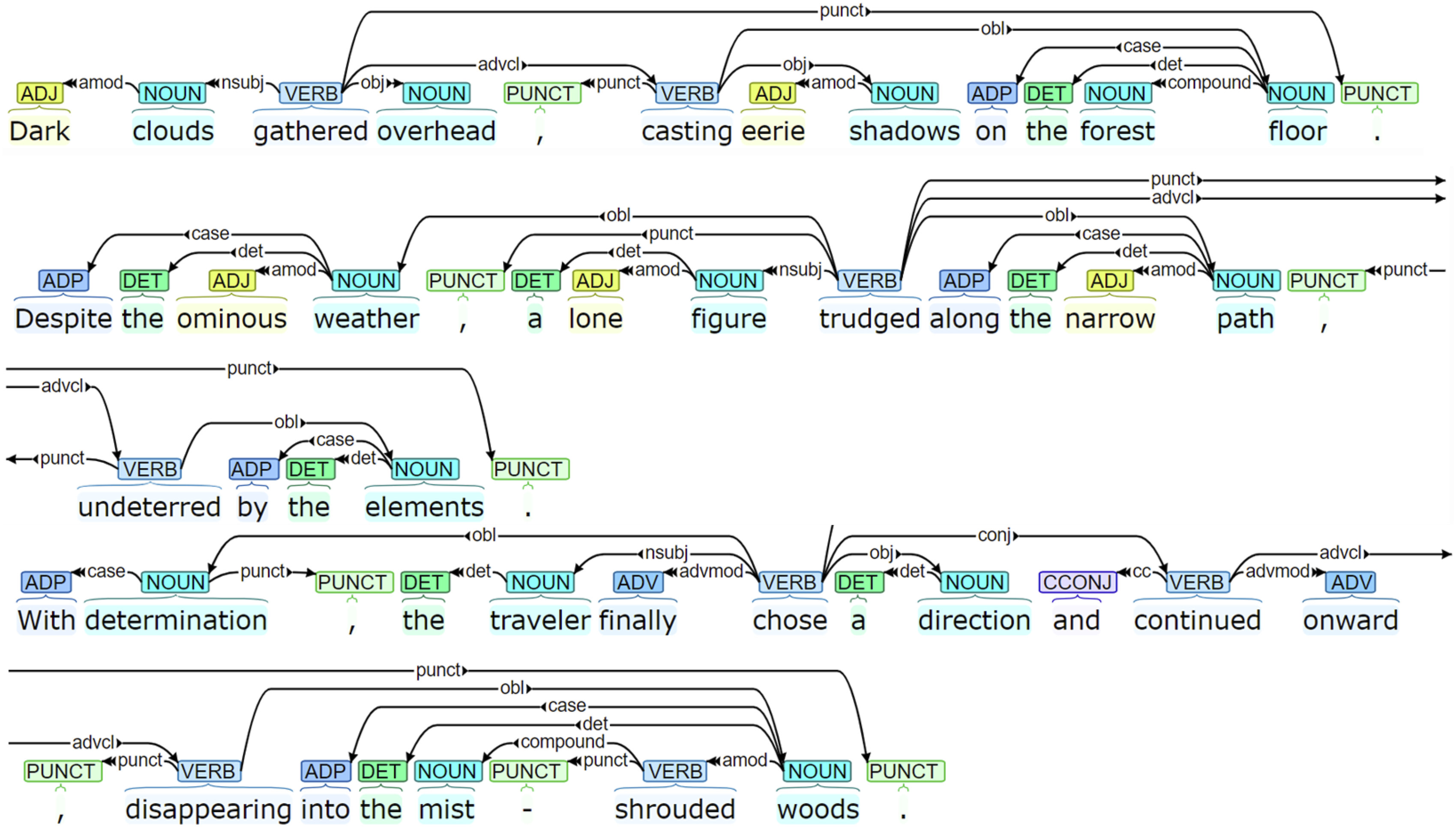
involves identifying the dependency relationships between words in a sentence, such as which words have subject-verb relationships, verb-object relationships, etc. LSTM trains to learn the dependency relationships between each word in a sentence, thereby constructing a dependency tree to represent the grammatical relationships between words in the sentence. Figure 6 shows the dependency syntactic parsing results of an actual sentence, where different arrows represent the dependency relationships between words. The key lies in utilizing the long short-term memory units in the LSTM network structure to memorize and predict the dependency relationships between vocabulary, thereby achieving accurate dependency syntactic parsing. This can be represented by the following formula: Dependency syntactic parsing.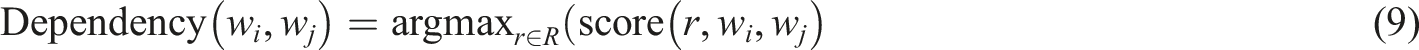
Among them,
Component syntax analysis involves identifying and analyzing phrase organization in sentences, such as noun phrases, verb phrases, etc. LSTM can automatically infer the organization and hierarchical structure of different phrases in a sentence by learning the long-term dependencies of language sequences. Figure 7 shows the results of component syntax analysis. The LSTM model is good at predicting phrase structure and deepening sentence syntax understanding based on lexical sequences and context. In terms of grammatical function annotation, it recognizes the syntactic roles of words, such as subject-object, and automatically classifies and labels them through training. Relying on memory units and gating mechanisms, LSTM flexibly applies syntactic rules and contextual information to accurately predict lexical grammatical functions and realize efficient grammatical annotation. This process demonstrates LSTM’s ability to adaptively learn complex grammatical structures, and builds a comprehensive grammatical analysis tool for language learners. Component syntax analysis.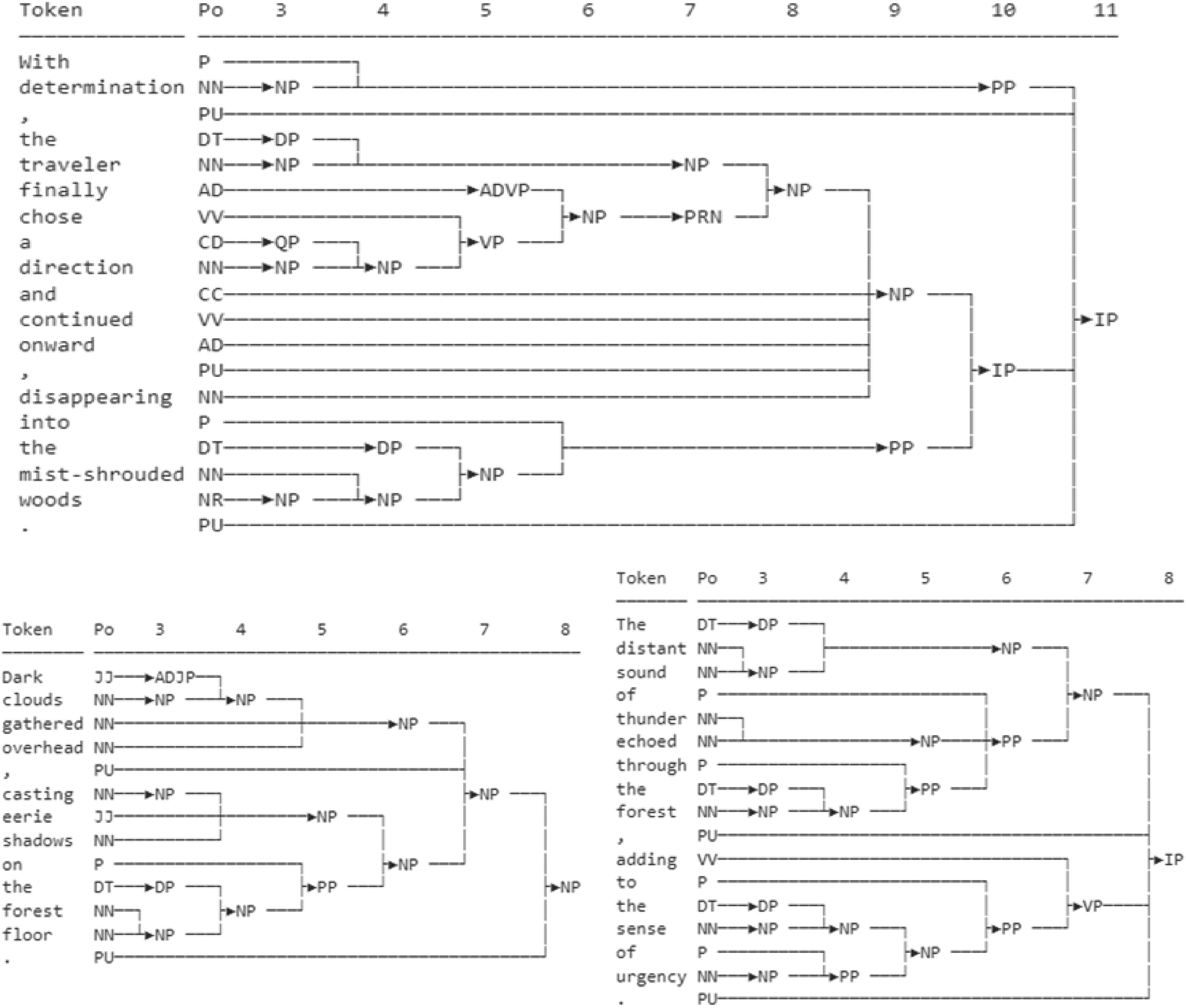
Dynamic learning
Dynamic adjustment mechanism
The real-time monitoring system continuously tracks learners’ activity data, covering key indicators such as question-answer accuracy, learning time and frequency, etc. The LSTM deep learning model is good at capturing and analyzing patterns and trends from these data sequences, and accurately identifying learners’ typical errors in syntax learning, such as common grammatical errors or comprehension bias by means of its memory and gating mechanism. The specific adjustment process is achieved by setting the threshold. In addition, the system parameter settings such as learning rate, batch size and training rounds are optimized in the experiment to ensure the effectiveness and real-time performance of the model. By analyzing learning behavior patterns and cognitive processes, the system assesses learners’ syntactic mastery and weak areas in real-time, and then intelligently adjusts the difficulty and type of learning content to achieve personalized teaching. For learners with significant learning results, the system flexibly adds complex syntax exercises to broaden the depth and breadth of learning. The dynamic adjustment mechanism formula is shown below. Among them, 
Real-time feedback
The real-time feedback system monitors the learner’s grammatical analysis process and provides timely corrective feedback. For example, when a learner makes a long-distance dependency error in sentence parsing, the system immediately prompts and displays the correct parsing method. In addition, the system dynamically adjusts the learning content of the next stage according to the learner’s error type and frequency to strengthen weak links. This form of feedback not only improves learning efficiency, but also enhances learners’ grammatical comprehension ability. The real-time feedback system integrates the dynamic adaptability of the LSTM model to provide immediate feedback on the accuracy of learners’ inputs and answers, as well as to keenly capture their common errors (such as grammatical errors, comprehension bias) in syntactic tasks, and supplement them with detailed error profiling and correction guidance. The system also uses visualization to show the learning results and progress, which enhances learners’ self-knowledge and motivates them to continue learning. At the same time, the system analyzes learning behavior data, such as progress, correctness, and response speed, to accurately assess the degree of syntax mastery, and flexibly adjust the difficulty and sequence of the learning content to balance challenges and growth. With LSTM intelligent regulation as the core, the system brings an efficient, personalized and intelligent learning experience to the computer-assisted platform for English syntax learning, significantly optimizing learning effectiveness and language proficiency improvement.
Data-driven teaching strategies
The computer-assisted language learning system in this study, with LSTM as the core engine, realizes the intelligent optimization of teaching strategies through in-depth data analysis, tailors efficient and personalized learning paths for learners, and significantly accelerates the process of mastering English syntactic structures. The system transcends the traditional static teaching mode, utilizing data-driven strategies to dynamically adjust the difficulty and type of courses, instantly pushing advanced syntax exercises to learners with excellent performance, and broadening the learning boundaries. At the same time, the system empowers learners to adjust the order of learning modules on demand, increasing motivation and interest in learning. The system’s built-in real-time feedback and LSTM dynamic adjustment functions complement each other, not only providing instant feedback on learning effectiveness, but also accurately capturing common mistakes in syntax learning and providing detailed error analysis and correction strategies. The visual learning report shows the progress and achievements of the learners, which continuously motivates the learners and gives them a sense of achievement. To sum up, the data-driven teaching strategy has revolutionized the computer-assisted language learning system, and through accurate data analysis and personalized instruction, it effectively improves learners’ syntactic comprehension and application abilities, opening a new chapter of language learning.
Experimental evaluation
Experimental design
The experimental design is the basis of the assessment and covers the detailed elaboration of experimental subjects, experimental tools and experimental cycles. This experiment selects 120 college students from different English proficiency backgrounds as research subjects. The specific selection process is as follows: through preliminary testing, students with relatively balanced English proficiency are screened to ensure that there is no significant difference in the experimental subjects’ ability to understand syntactic structures and overall English proficiency. The preliminary testing includes standardized English proficiency tests and syntactic structure comprehension tests, covering multiple aspects such as vocabulary, grammar, and reading comprehension. After the screening is completed, the 120 students are randomly divided into two groups: the experimental group and the control group, with 60 students in each group. The random grouping method aims to ensure that the two groups of students are balanced in terms of gender, age, and English proficiency, thereby reducing the potential impact of individual differences on the experimental results. Finally, basic information of all experimental subjects is collected, including age, gender, and subject background, to ensure that there are no significant differences between the experimental group and the control group on these background factors, thus enhancing the validity and reliability of the experiment.
Two learning systems are used in the experiment. The experimental group adopts a computer-assisted language learning system based on English syntactic structure combined with LSTM. The system integrates dynamic learning models and adaptive learning paths, adjusts learning content and difficulty in real-time according to student performance, and provides personalized learning experience. The control group uses traditional computer-assisted language learning systems, including fixed learning paths and traditional teaching methods, lacking personalized adjustments and immediate feedback. In terms of evaluation tools, standardized English syntactic structure understanding tests are used, including multiple-choice questions, sentence reconstruction, and syntactic analysis. The test results are used to evaluate students’ learning outcomes and the effectiveness of the system.
During the experiment, this article uses the following hardware configuration: in terms of processor, Intel Core i7-12700K is used, which is a high-performance CPU with 12 cores and 20 threads, with a base frequency of 3.6 GHz and a maximum turbo frequency of 5.0 GHz. In terms of graphics card, it is equipped with NVIDIA GeForce RTX 3080, which has 10 GB GDDR6X video memory, and can meet high-load deep learning tasks. In terms of memory, 32 GB DDR4-3200 MHz memory is installed to support large-scale data processing. In terms of storage, a 1 TB NVMe SSD is used to store data and models to ensure fast reading and writing. The motherboard uses ASUS ROG STRIX Z690-E to support high-performance CPU and GPU.
The design of the experimental cycle ensures sufficient learning time and data collection to accurately evaluate the experimental results. The specific arrangement is as follows: the experimental period is set at 12 weeks to ensure that students have sufficient time for systematic learning and practice. The setting of the experimental period takes into account the formation of learning habits and the consolidation of knowledge points. A minimum of three study sessions are scheduled per week, with each session lasting 1 hour. Both the experimental group and the control group maintain the same learning frequency and duration to ensure consistency in learning time between the two groups and avoid any impact on the experimental results due to differences in learning time. In terms of controlling the learning environment, it is ensured that the experimental group and the control group learn in similar learning environments. The learning environment includes classrooms, learning equipment, network conditions, etc., and efforts should be made to minimize the impact of external interference factors on learning outcomes. In terms of progress monitoring and support, during the experiment period, students’ learning progress and performance are regularly monitored, and necessary support and guidance are provided in a timely manner, to ensure the smooth progress of the experiment and effective data collection. The experimental group and the control group are tested once a week to evaluate their learning effectiveness.
Data collection
This study focuses on evaluating the effectiveness of a computer-assisted language learning system based on the long short-term memory (LSTM) network, which centers on the data collection and analysis process. Data collection begins with the systematic recording of learning behaviors of the experimental and control groups, covering the tracking of learning progress, correctness statistics, classification of error types, and the recording of the number of corrections, in order to comprehensively measure the effectiveness of the system. The size of the dataset includes weekly learning data for each student, with a cumulative data point of over 2000. Subsequently, a standardized test is administered, with a variety of question types covering multiple-choice, sentence reconstruction and syntactic analysis, aiming to objectively evaluate students’ progress in understanding and applying English syntactic structures. SPSS software is used in the data analysis session to analyze the effect of the LSTM-CALL system on the students’ syntactic structure ability by comparing the weekly test scores of the experimental group and the control group, and t-tests are used to ensure the statistical significance of the evaluation results. In addition, in order to examine the error correction function of the system, the common types of errors and their frequency are recorded and analyzed, so as to comprehensively assess the effectiveness of the system as a teaching aid.
Experimental results
By recording the learning progress changes of the experimental group and the control group within 12 weeks, the progress of the two groups of students under different learning systems was observed. Figure 8 shows the learning progress curves of the two groups during the experimental period. The learning progress of the experimental group was always ahead of the control group, and as time went by, the gap between the two groups gradually widened. In the early stages of the experiment, the learning progress of the experimental group improved rapidly. In the first 4 weeks of the experiment, the experimental group’s progress jumped significantly, from 5% to 25%, exceeding the 18% increase in the control group. This achievement was attributed to the personalized learning path and instant feedback provided by the system, which greatly improved learning efficiency. Over the next 4 weeks, the advantage of the experimental group continued to expand, with progress rapidly increasing from 32% to 55%, while the control group only improved from 22% to 38%. By the end of the 12th week of the experiment, the progress of the experimental group reached 85%, significantly ahead of the 60% of the control group, demonstrating the outstanding performance of the English syntactic structure computer-assisted language learning system based on LSTM technology in promoting long-term learning motivation and effectiveness. To further verify the statistical significance of these results, this article conducted an independent sample t test, and the results showed that the changes in learning progress between the experimental group and the control group were statistically significant (p < 0.05). Changes in learning progress.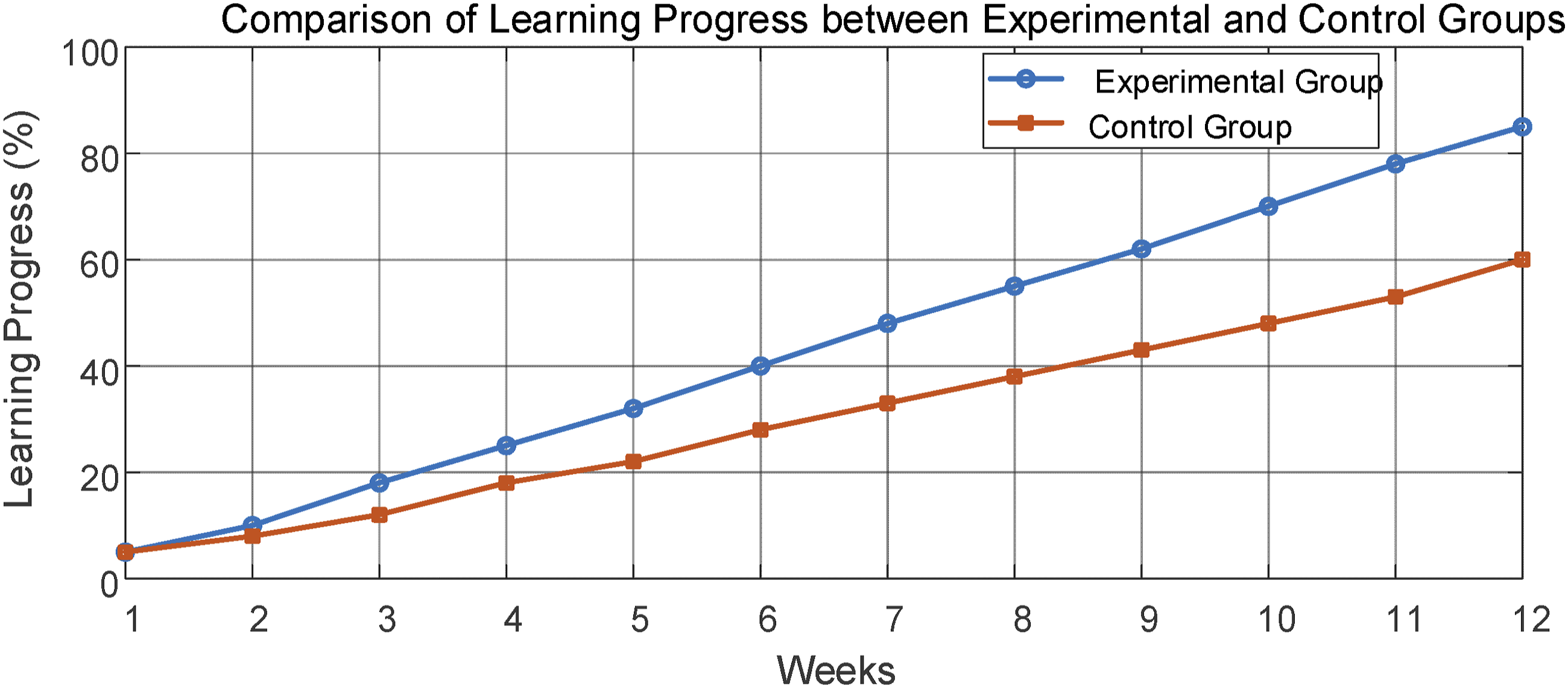
Figure 9 reveals the change trend of the test scores of the two groups within 12 weeks: the experimental group steadily climbed from 70 points in the first week to 94 points in the last week, while the control group’s score increased from 68 points to 85 points, but The increase was significantly lower than that of the experimental group. This sharp contrast highlights the significant advantage of the experimental group in improving their scores and further proves the efficiency of the system in enhancing students’ English syntax understanding. It is worth noting that the improvement process of the experimental group’s performance was more stable and sustained, while the control group encountered a growth bottleneck in the later period. This difference further shows that the computer-assisted language learning system based on the English syntactic structure has important advantages in personalized learning path design and real-time learning. Excellent performance in the feedback mechanism can accelerate students’ learning process and achieve significant learning results. Changes in test results.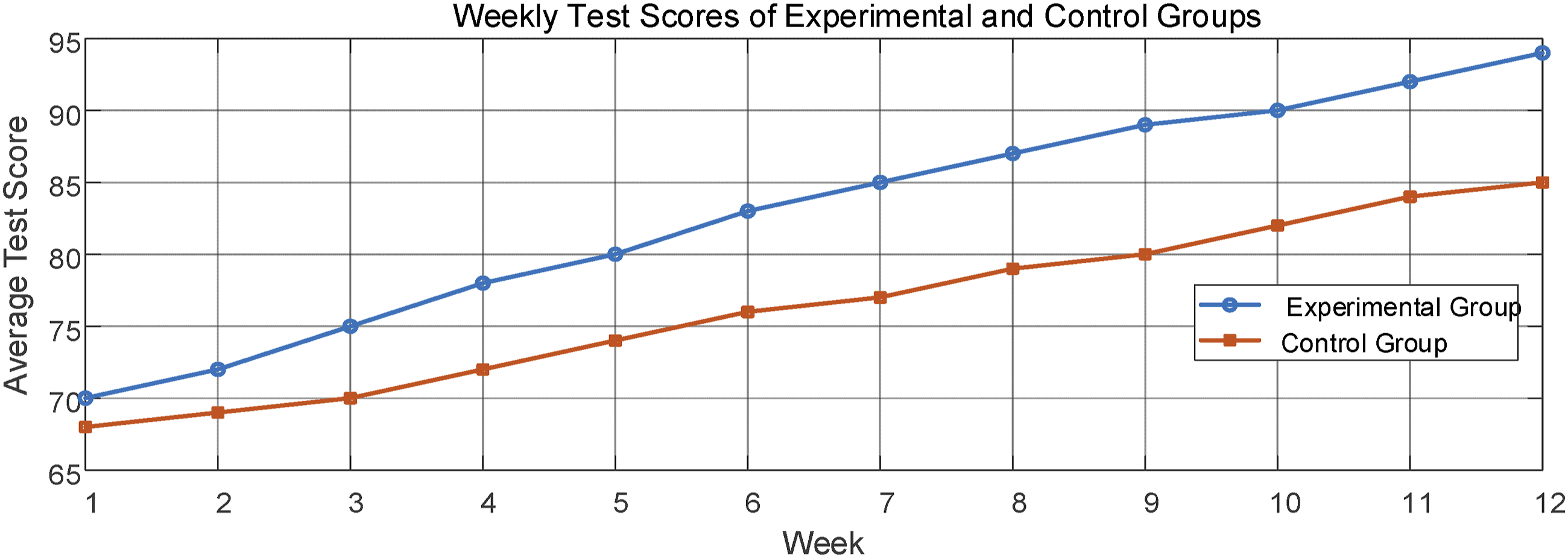
As a core indicator to evaluate the accuracy of students’ knowledge mastery, the learning accuracy rate directly reflects the effectiveness of the system in promoting the improvement of students’ English ability. The data in Figure 10 shows that although the learning accuracy of both groups improved significantly within 12 weeks, the accuracy of the experimental group was always higher than that of the control group. The accuracy rate of the experimental group increased from 75% in the first week to 94% in the 12th week, while the accuracy rate of the control group increased from 73% to 86%. This gap reflects the system’s strengths in personalized learning and instant feedback. Statistical analysis showed that the learning accuracy rate of the experimental group was statistically significantly higher than that of the control group (p < 0.05). This gap reflects the advantages of the system in personalized learning and instant feedback. Changes in learning accuracy.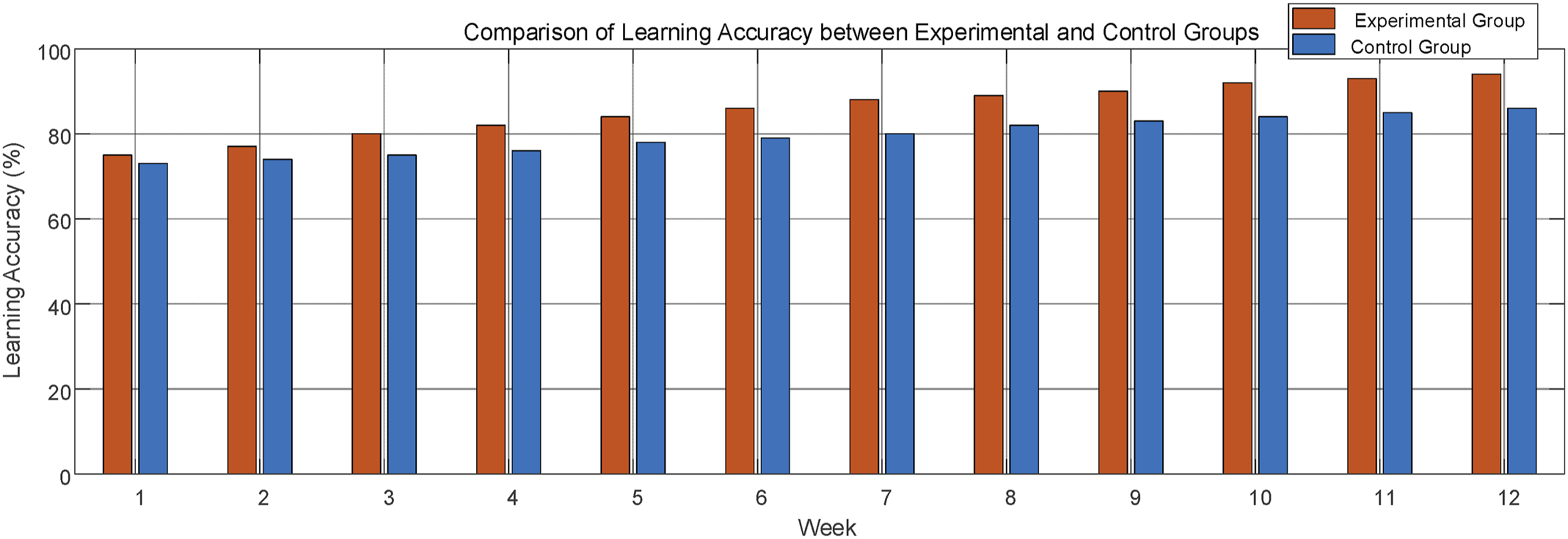
In this experiment, the performance of the experimental group and the control group in error correction was analyzed in detail by drawing a line chart of the number of error corrections. Figure 11 shows the average number of error corrections and error types for the two groups over 12 weeks. The average number of error corrections in the experimental group decreased significantly, from 15 in week 1-2 in week 12. The number of error corrections in the control group also dropped from 12 to 9. Although there was a decrease, the magnitude was not as obvious as that of the experimental group. The t-test results showed that the difference between the experimental group and the control group was statistically significant (p < 0.05), further supporting the improvement effect of the experimental group. The experimental group performs better than the control group in common types of errors, especially in correcting grammar errors and improper vocabulary use, while the control group lags behind in correcting sentence structure errors, possibly due to a lack of personalized adjustment and immediate feedback support. Error correction.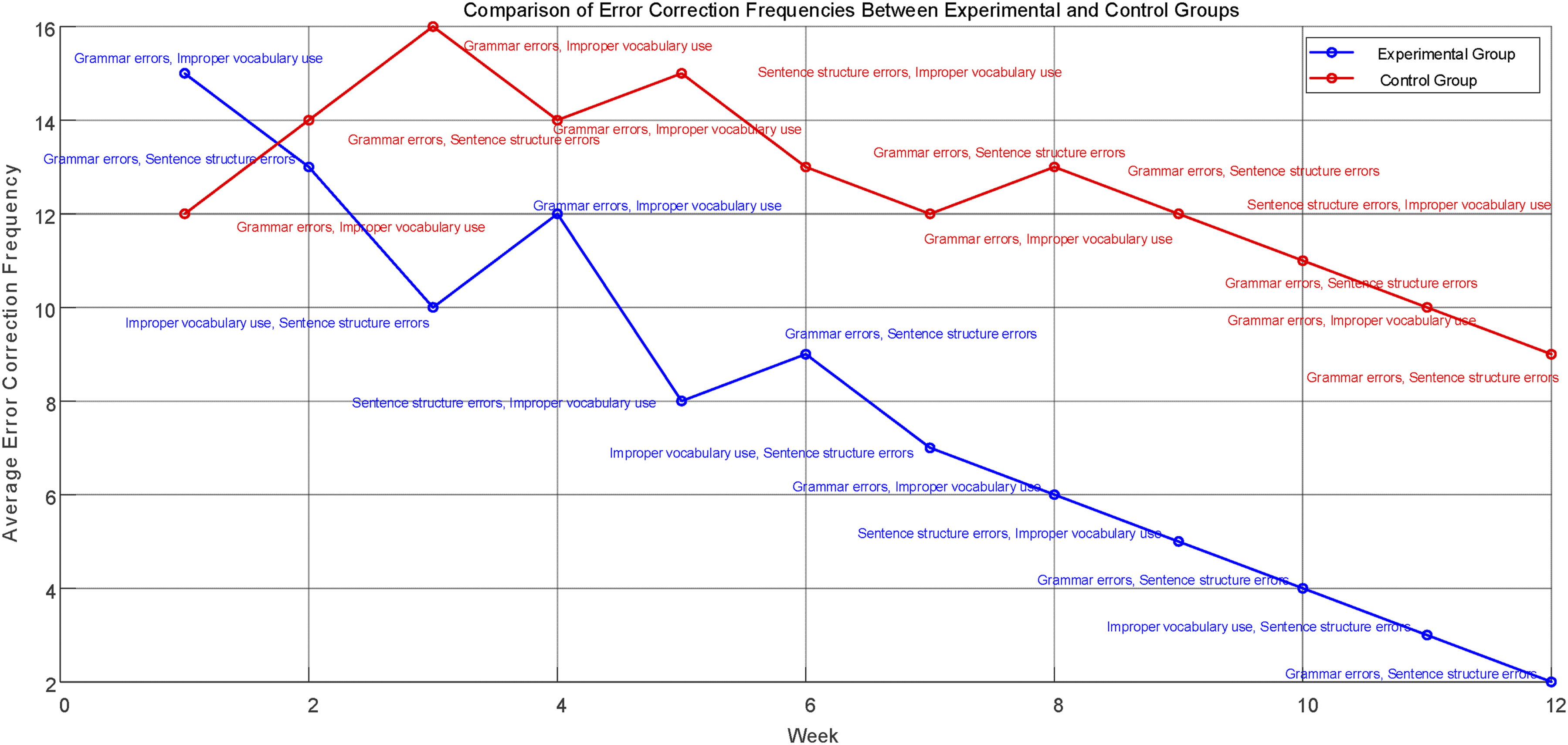
Overall, the experimental results indicate that computer-assisted language learning systems based on English syntactic structures exhibit significant advantages in improving learning progress, test scores, and learning accuracy, and also have significant effects in error correction. This system can effectively help students improve their understanding and application ability of English syntactic structures by providing personalized learning paths and instant feedback.
In order to further improve the system and enhance the user experience, this article conducts a detailed analysis of user feedback and explores the performance of the system in actual use and potential improvement directions. The user feedback analysis of the system shows that most users are satisfied with the personalized learning path and real-time feedback mechanism, and believe that the system performs well in dynamically adjusting the learning progress and performance. In particular, the application of the LSTM model in syntactic structure analysis has been highly praised by users. However, users suggest adding more custom setting options and point out that the system has a long response time under high concurrency. In response to these feedbacks, this article plans to add custom options, optimize system performance, and strengthen user support functions in future versions. Continuous collection and analysis of user feedback can help further optimize the system and improve the user experience.
Conclusions
This study successfully developed a computer-assisted language learning system based on English syntactic structure by applying long short-term memory network technology, significantly improving learners’ syntactic mastery and learning experience. The experimental results showed that the system performed well in personalized learning path generation, dynamic adjustment of learning content, and real-time feedback, effectively overcoming the limitations of traditional systems. However, there are still some shortcomings in this study, such as the limitation of sample size that may affect the universality of the results, and the need for further improvement in the performance of LSTM models in handling extremely complex syntactic structures. In the future, it is necessary to further optimize the intelligence and personalization level of the system, continuously improve system functions based on user feedback, and expand the application scenarios of the system, including the generation of personalized learning paths in different languages and fields. At the same time, strengthening interdisciplinary cooperation and combining the latest research results in fields such as psychology and education can inject new vitality into the innovative development of computer-assisted language learning systems.
Footnotes
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.