
Abstract
The experiment proposes an English learning video recommendation method based on user preference differences with sequential recommendation. The experiment first introduces a collaborative filtering algorithm to preprocess user behavior and filter abnormalities and mutations in user behavior to further improve the accuracy. Then a deep learning algorithm for sequence recommendation based on user behavior is proposed, which mainly uses short-term user behavior for learning and representation. In addition, a model based on the attention mechanism is introduced to represent the long- and short-term user behaviors. At the same time, the difference between the long- and short-term behaviors is utilized for selective learning, which solves the need of identifying the change of user interests in educational scenarios. The results indicated that when the number of iterations reaches 250, the research method has a minimum loss value of 0.658. In the comparison of model accuracy, at the 50th iteration, the accuracy of the constructed method is as high as 94.89%. In the comparison of recommendation time, when the data volume is 4 MB, the recommended time of the research method is 0.072 s. When the data volume is 20 MB, the recommended time of the research method is always less than 0.100 s. The results indicate that the research method is the most effective approach for creating English learning videos. Furthermore, the reliability of data transmission is consistently high, ensuring that students’ online learning needs are met with accuracy.
Keywords
Introduction
With the rapid development of online education and the increasing demand for personalized learning, providing learners with teaching resources that meet their individual needs has become a major challenge in the field of educational technology. 1 As one of the most widely spoken languages in the world, there is a growing demand for learning resources, especially video content, for English. 2 Recently, recommendation system (RS) has been playing an increasingly important role in various online platforms, especially in the field of education, where RS can help learners find the most suitable content among the huge amount of learning materials. 3 However, existing RSs frequently lack a comprehensive understanding and consideration of individual users’ learning preferences, resulting in discrepancies between recommendation outcomes and users’ actual needs. In the domain of English language learning, the necessity for personalized recommendations is particularly evident due to the diverse backgrounds, learning objectives, and interests of each learner. 4 Consequently, the creation of an English learning video (ELV) RS that can support customization with high efficiency is a topic of significant interest in current research. Recent years have seen the development of sequence recommendation (SR), an efficient recommendation technique that uses behavioral sequence analysis to forecast users’ future actions. This method performs well in many scenarios, but still has shortcomings in ELV recommendation. 5 Traditional SR models usually focus on analyzing users’ short-term behaviors while ignoring the impact of long-term learning behaviors and preferences. In light of the aforementioned considerations, the experiments propose an innovative ELV recommendation method that incorporates user preference (UP) differences and SR algorithms. First, users’ long-term learning preferences and needs are identified through an in-depth analysis of their historical learning behaviors. Subsequently, the SR technique is integrated with an analysis of users’ behavioral sequences and preference changes, thereby facilitating more precise video recommendations. The objective of this study is to provide new insights and tools for the field of online English education, with the aim of enhancing learners’ learning efficiency and interest.
The innovations of this study contain two points: (1) By analyzing the historical behavior data of different users, an innovative method is proposed to identify and adapt to the unique learning preferences of each user. (2) The constructed method considers the long-term and short-term behavior patterns of users in a comprehensive manner, thereby enabling more accurate recommendations of ELVs to users.
Currently, many scholars are interested in how to use intelligent algorithms to meet the practical needs of different research objects. Scholars Ahmed proposed a technology based on augmented intelligence to address the problem of content recommendation. In the process, the telemedicine environment and smart city electronic medical facilities were used to collect data, and the intelligent enterprise management system was used to build the technical framework. Experimental results showed that the proposed method has good recommendation accuracy. 6 Shin proposed a method based on artificial intelligence to address the research issues of software recommendation technology. In the process, the over-the-top platform was used as a research environment to analyze user understanding results, and measure the ranking weight of recommended content based on content credibility. Experimental results showed that the proposed method has good recommendation accuracy. 7 Wu proposed a fairness-based multi-objective optimization method for the product recommendation problem of sales software. In the process, Pareto optimality was used to balance the fairness among stakeholders, constraints were established to restrict the relationship between consumers and sellers, and smooth sorting was introduced for optimization. Experimental results showed that the proposed method has good recommendation fairness. 8 Shin proposed a method based on artificial functions for the content recommendation problem of the platform. In the process, the algorithm structure that drives embedded values was constructed, the user experience caused by recommendations was conceptualized, and a dual-process model was introduced to improve the performance of the algorithm. The results showed that the proposed method can effectively improve the quality of recommended content. 9 To analyze the potential influencing factors between users and items in RS, Mu and Li’s team proposed a recommendation algorithm based on knowledge graph with untangled representation learning. At the same time, an alignment strategy based on mutual information maximization was designed to solve the entanglement generated during user-item interaction. The results revealed that the algorithm is able to reasonably optimize the solution entanglement, which in turn significantly improves the recommendation performance. 10
Meanwhile, with the popularity of online learning platforms, various learning resources begin to become increasingly abundant, and some scholars have analyzed the relationship between courses and recommendation methods. To process the large amount of user-generated information in social media, Chen et al. proposed a fine-grained privacy detection network-based approach (GrHA). The method explored the semantic relevance of personal aspects through graph convolutional networks and combined with hierarchical attention representation learning with graph regularization to detect hidden information. The outcomes showed that the algorithm performs noticeably better and can recognize genuine data with accuracy. 11 Mubarak and other researchers proposed a visualization method based on long- and short-term memory networks in order to analyze the clickstream data of the interaction between learners and instructional videos from the perspective of course instructors and educational experts. The process predicted the implicit features obtained from the video clickstream data. The data showed that the accuracy of the proposed model was as high as 95% throughout the course cycle, which far exceeded the accuracy of general algorithms. 12 Huan’s team proposed a text categorization algorithm based on the convolutional dual LSTM model in order to reduce the difficulty of natural semantic feature extraction. The experiment additionally introduced an embedding layer to vectorize the text features and sent the text information to the convolutional neural network model. Finally, the MCNN-LSTM features were fused and transmitted to the softmax layer for classification. The results indicated that the model has the highest accuracy in classifying different texts. 13 Geng et al. proposed a method based on machine learning and text mining in order to have a positive impact on increasing learners’ participation in online courses. The process utilized multiple regression to analyze the relationship between learners’ emotions and extracted content features. Using real data as a task set, the validation found that learners began to show positive attitudes towards online courses, positively enhancing their interest in teaching on the platform. 14 Scholars Bıyık proposed a method based on differences in UPs for the problem of parameter setting of intelligent robots. In the process, a comprehensive framework was used to integrate information sources, and preference analysis was performed based on the robot’s task goals to distinguish the robot’s information acquisition sequence. Experimental results showed that the proposed method can effectively improve the work quality of robots. 15
An in-depth analysis of the existing literature reveals the great potential and challenges of RS in the field of learning video recommendation. Despite the significant theoretical and technical advances in existing research, how to more effectively integrate UP differences with complex SR algorithms is still a problem that needs to be further explored. Future research needs to focus on developing more accurate UP recognition methods, as well as optimizing SR algorithms to better accommodate users’ dynamic learning needs. In addition, interdisciplinary approaches, such as combining cognitive science, educational psychology, and artificial intelligence techniques, may bring new breakthroughs for personalized ELV recommendation. Because of this, the experiment suggests an ELV recommendation approach that takes into account SR and UP differences. This method is anticipated to offer guidance and insights for the future design of tailored learning environments.
Improved English learning video recommendation method
To address users’ individualized needs and preference differences in the learning process, the experiment herein proposes an ELV recommendation method based on users’ long- and short-term interest differences and SR, aiming to provide English learners with a more personalized and efficient learning experience. The core motivation of the research stems from an in-depth understanding of the problems existing in the current online English learning environment and a critical analysis of existing recommendation techniques.
Graph wandering representation based on item collaborative filtering
The advancement of the Internet has facilitated the acquisition of information. In the field of English teaching, the advent of video learning platforms has provided educators with a plethora of online resources, which has enhanced the efficacy of instruction and the depth of course content.
16
However, existing recommendation algorithms are widely used, such as collaborative filtering-based methods. But those still have problems. If only popular products are recommended, the sequential nature of user behavior is not taken into account.
17
In view of this, based on the above problems, this experiment proposes an ELV recommendation method that combines collaborative filtering with graph walk item representation learning. This method employs the user’s historical behavior sequence to construct a user behavior graph, which is then traversed using a random walk strategy. First, the experiment uses item-based collaborative filtering to deal with the abnormal behavior of learning users. The definition of item similarity is shown in equation (1).

In equation (1), User behavior sequence diagram and two ways of abnormal user behavior.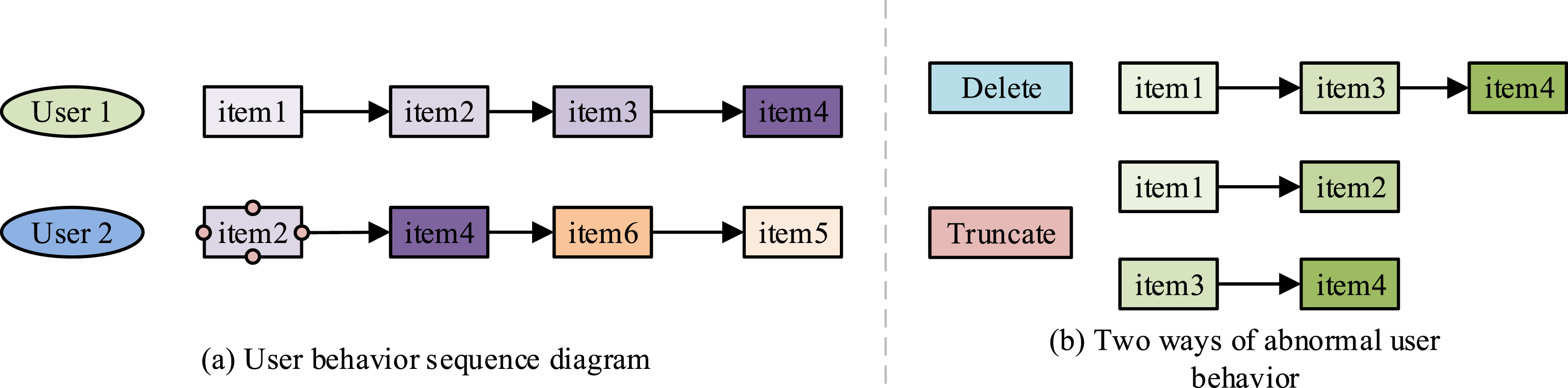
In Figure 1, there are two means of handling the abnormal ITEM experiment, namely, deletion and truncation. The first one is the deletion operation. If the similarity difference between the current item and its similar items on the left and right is large, the current item can be considered as an abnormal behavior produced by the learning user interfered by some external factors. This anomalous behavior must be eradicated, as it fails to align with the user’s interests during that period. The second is the truncation operation. If the similarity difference between the current item and its right item is small, but the similarity difference with the left item score is large, then it can be assumed that the next sequence obtained is a completely new behavioral sequence for the learning user.
20
At this point a new user sequence is created using truncation. The user’s behavioral sequence fragments can be accurately obtained in these two ways, and the obtained behavioral sequence fragments are saved and subsequently used to create a graph of the behavioral sequence. Based on the obtained user behavioral sequence fragments, the behavioral sequence relationship graph is then constructed using the knowledge of graphs. In the behavioral relationship graph, different nodes have an id attribute to represent the item id to which the corresponding node belongs, and there are corresponding pointers between different ids.
21
Through such a representation of the relationship can be obtained behavioral relationship with behavioral sequences and their corresponding attribute sequence representation, as shown in Figure 2. Behavior diagram, behavior sequence, and corresponding attribute sequence.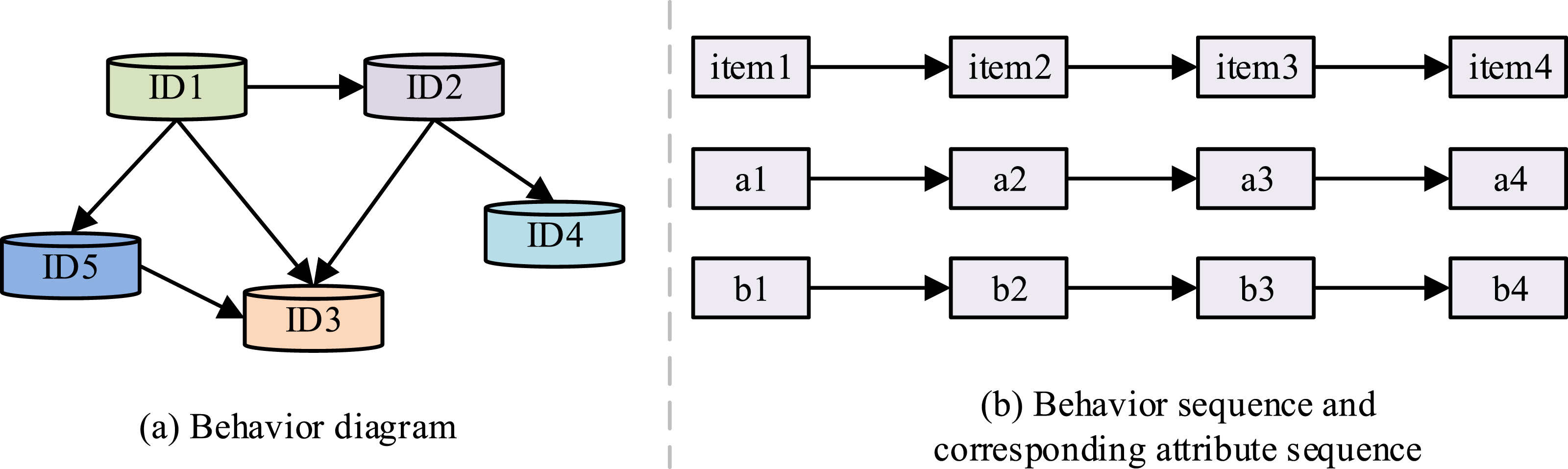
Through the behavioral relationship graph in Figure 2(a), all the user behavioral relationships can be constructed in a large network graph all together, and the relationship between different nodes can be obtained more naturally in the behavioral graph, and the constructed graph is saved in order to randomly generate behavioral sequences. When experimenting with the use of random wandering sequences to obtain a large number of behavioral sequences, it is also possible to generate corresponding sequences by using special attributes related to behavioral items. For example, in Figure 2(b), the first row corresponds to a sequence of video courses for a user’s behavior. The second row then corresponds to the lessons of different video courses. The third row indicates the academic segments corresponding to different videos. When a large number of sequences of user behaviors have been generated, it is then necessary to carry out representation learning for different video courses.
22
The experiments use the classical skip-gram model for representation learning, and make some improvements to the model to complete the recommendation of learning videos for student users. The skip-gram model based on multi-attribute sequence input is shown in Figure 3. Skip-gram model based on multi-attribute input.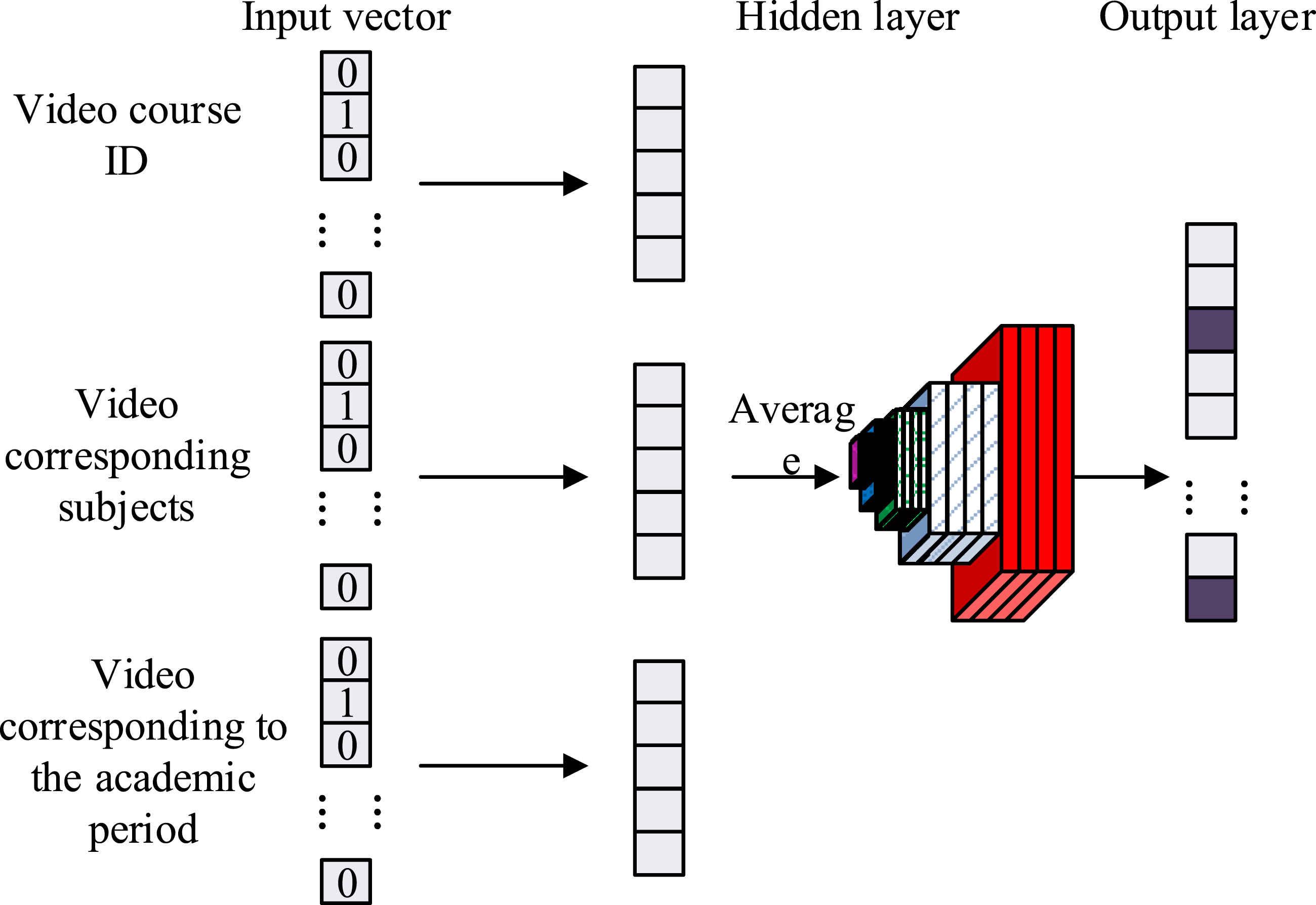
Optimized English learning video recommendation method
The prevailing SR model primarily employs the user’s recent behavioral preferences to forecast the user’s future behavior, yet it fails to incorporate the user’s long-term historical behavioral data. At the same time, there is no in-depth design and innovation for the integration of user behavior.23,24 These problems will have a great impact on the accuracy of the recommendation results. Based on the above-mentioned problems, the study designs a deep learning recommendation algorithm model based on long-term and short-term interest differences. The model employs not only long-term behavior information in SR but also incorporates enhancements and novelties in the integration of long-term and short-term behaviors, thereby rendering it more suitable for the specific requirements of video course recommendation at Seewo Academy. The long-term and short-term interest difference model is shown in Figure 4. User long-term and short-term interest difference model.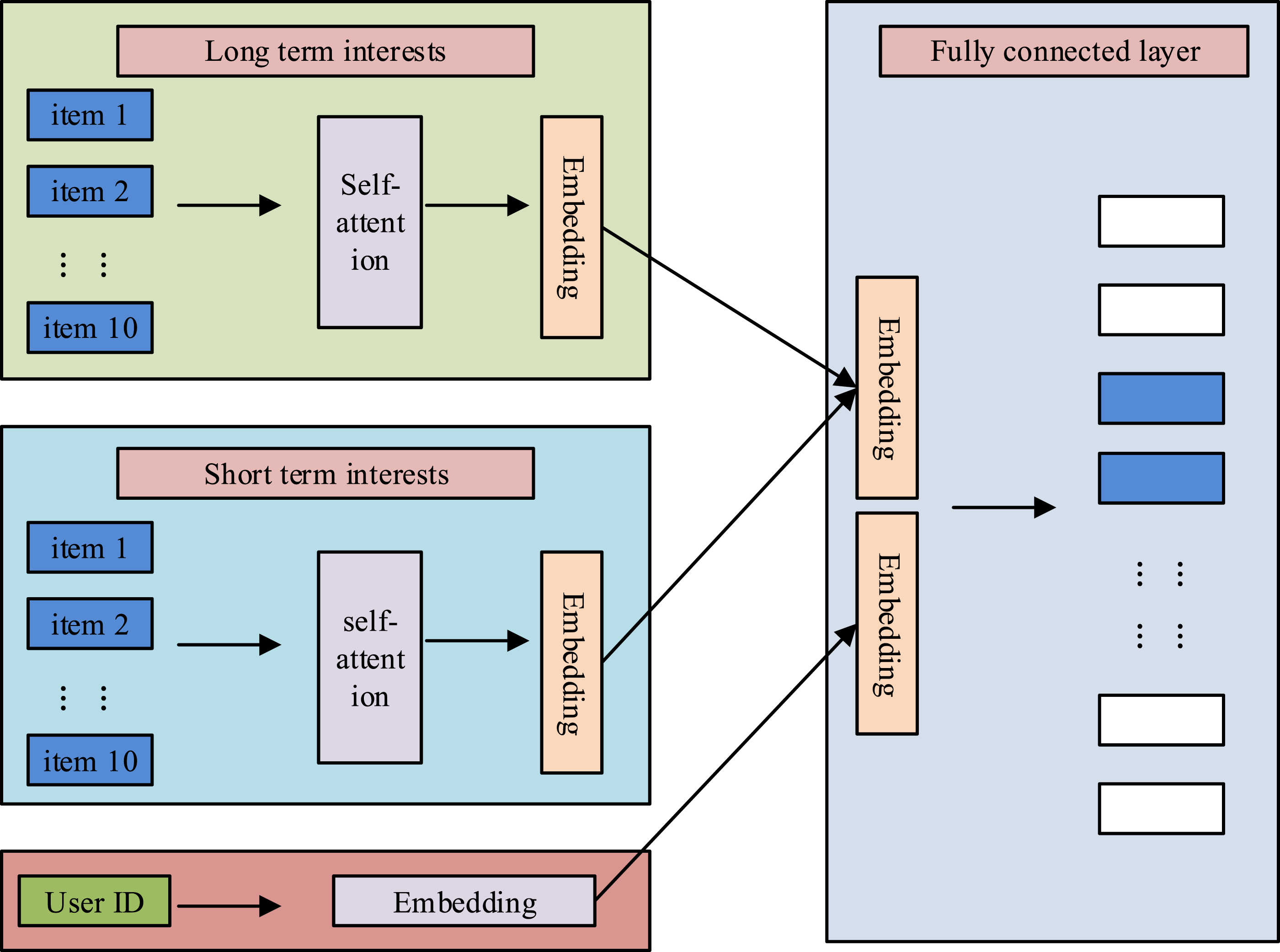
In reality, long-term interest is a behavioral preference that users have upheld in the past, and learning users’ preferences essentially remain constant over time. The long-term preference of a learning user is not only for a particular learning video, but more should be the learning user’s preference for a particular type of learning video.
25
In view of this, the experiment extracts the historical behaviors of individual users in chronological order, followed by the start of sampling and a uniform sampling length of ten. The LSTI sequences obtained by sampling the behavior of individual learning users are shown in Figure 5. User long-term interest sequence sampling and short-term interest sequence construction.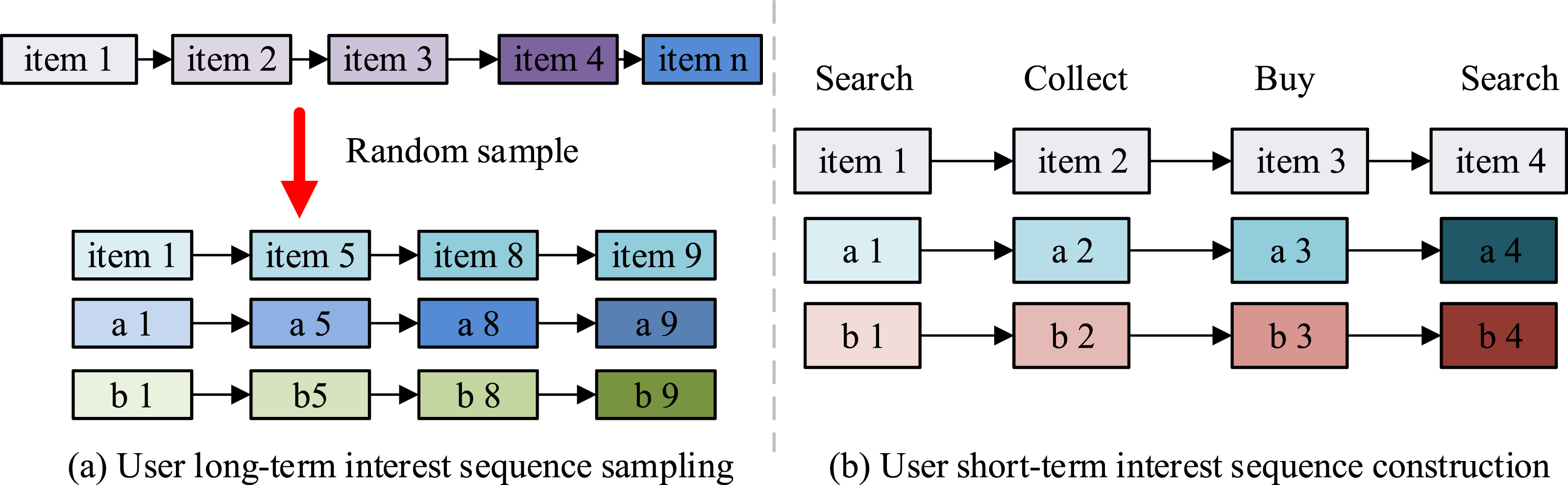
In Figure 5, the last two rows in the sampling process of the user’s long-term interest sequences represent the user attribute sequences corresponding to the data collection sequences. The input to this part of the model is the result of synthesizing the sampled sequences and their marginal information sequences such as academic segments. Four steps are included in the user short-term interest sequence, which are searching, collecting, purchasing and searching. The learning site contains a large number of inactive users who have less strong demand behavior for ELVs. This may make less data available to train such users.
26
When users do not have recent strong demand learning behaviors, training can be initiated using recent weak demand behaviors to ensure sufficient training data during the training process. Modeling the user’s interaction is the most crucial stage in understanding UP because understanding the user’s behavioral sequence can practically influence the user’s subsequent behavior. The experiment here introduces the self-attention mechanism to model the user’s behavioral path, through which the behavioral interest preferences of different learning users are better captured. The self-attention model is shown in Figure 6. Self-attention model.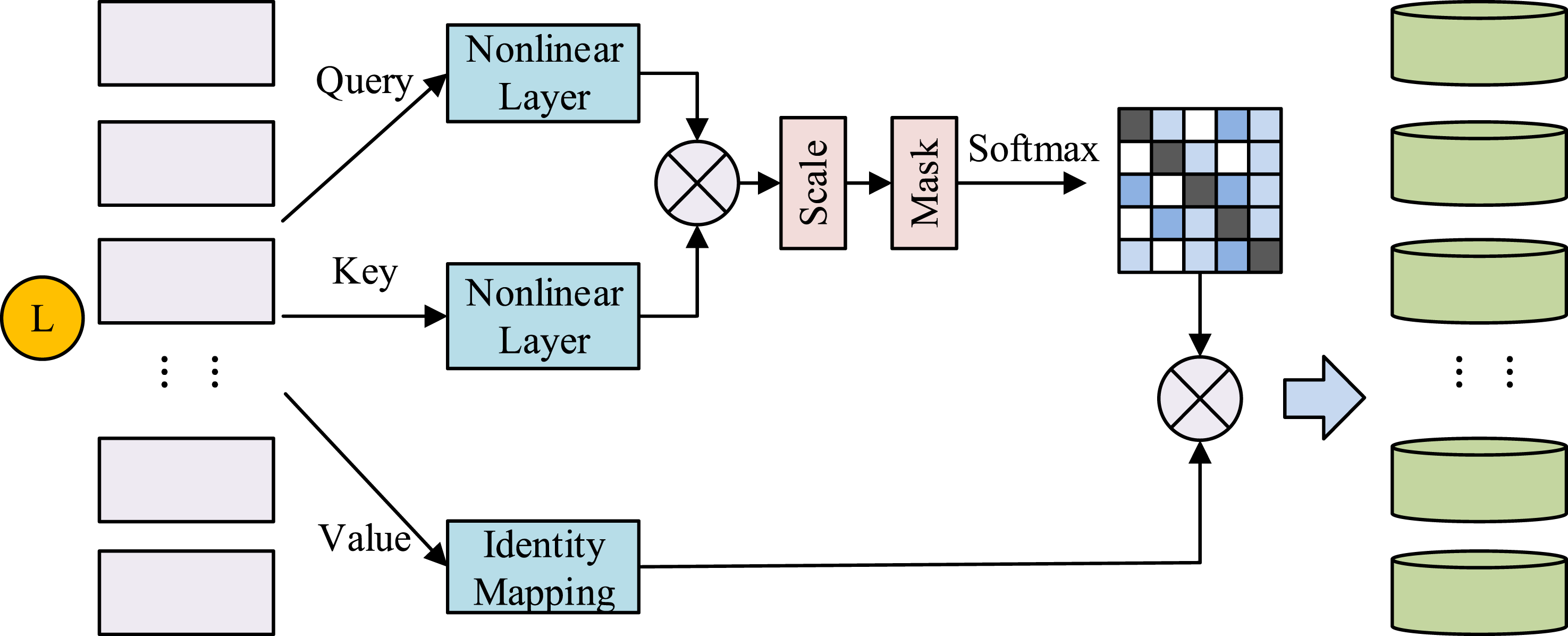
The self-attention mechanism is a special attention mechanism that differs from other models in that the mechanism has limited accommodation of the entire background knowledge, but precisely for this reason it is possible to maintain contextual sequential information in an orderly manner and capture useful elements of the relational sequence. Self-attention is utilized in the experiments to engage users’ past behaviors. However, since the inputs of short and long interests are very similar across users, the experiments are represented using the inputs of the user’s short-term interest sequences. It is assumed that each behavioral item of interest to the learning user can be represented as an
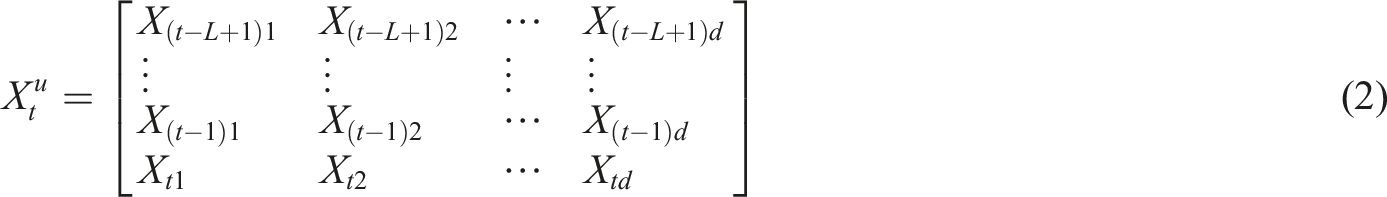
In equation (2),
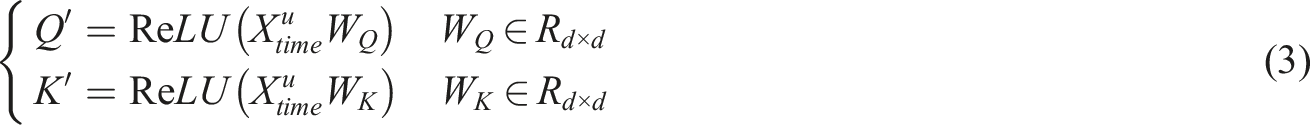
In equation (3),

In equation (4),

In equation (5),

The obtained attention mechanism does not contain a temporal signal, which leads to the degradation of the input into an overall embedded package, which in turn fails to preserve the sequential pattern.
27
As a result, the experiment adds sinusoids of various frequencies to the input using a time-scale ensemble sequence. In equation (7), the temporal embedding is defined.

In equation (7),

It is also possible to acquire the user’s LSTI preferences. However, because students’ interests in learning English might change quickly, course preference connected to the prior interest declines when a user’s interest changes.28,29 Based on this, the experiment is designed in the form of segmented function utilized in the long-short interest fusion last time, as shown in equation (9).

In equation (9),

In equation (10),
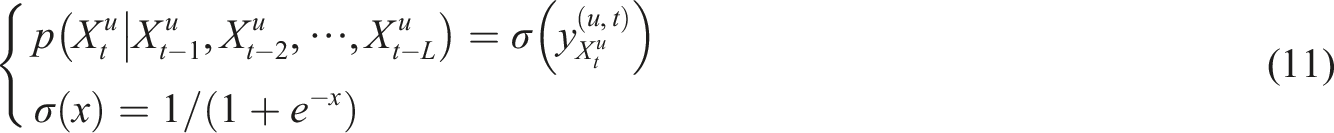
In equation (11),
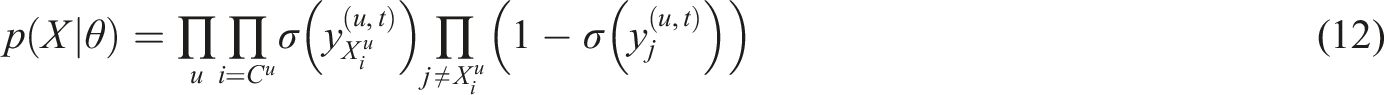
Also to enhance the generalization of the model, the experiment was planned to predict multiple outcomes. A sequence is used to predict
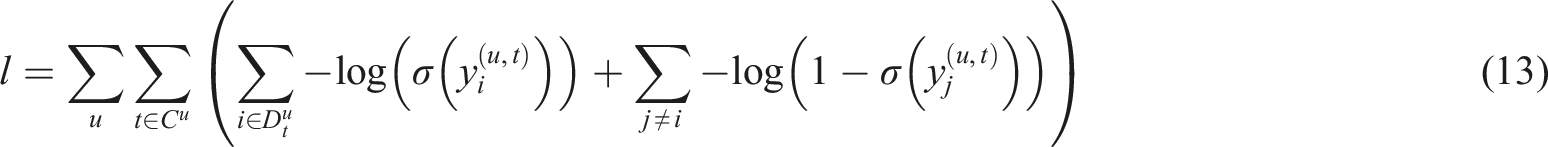
In equation (13), Overall architecture of the recommendation system.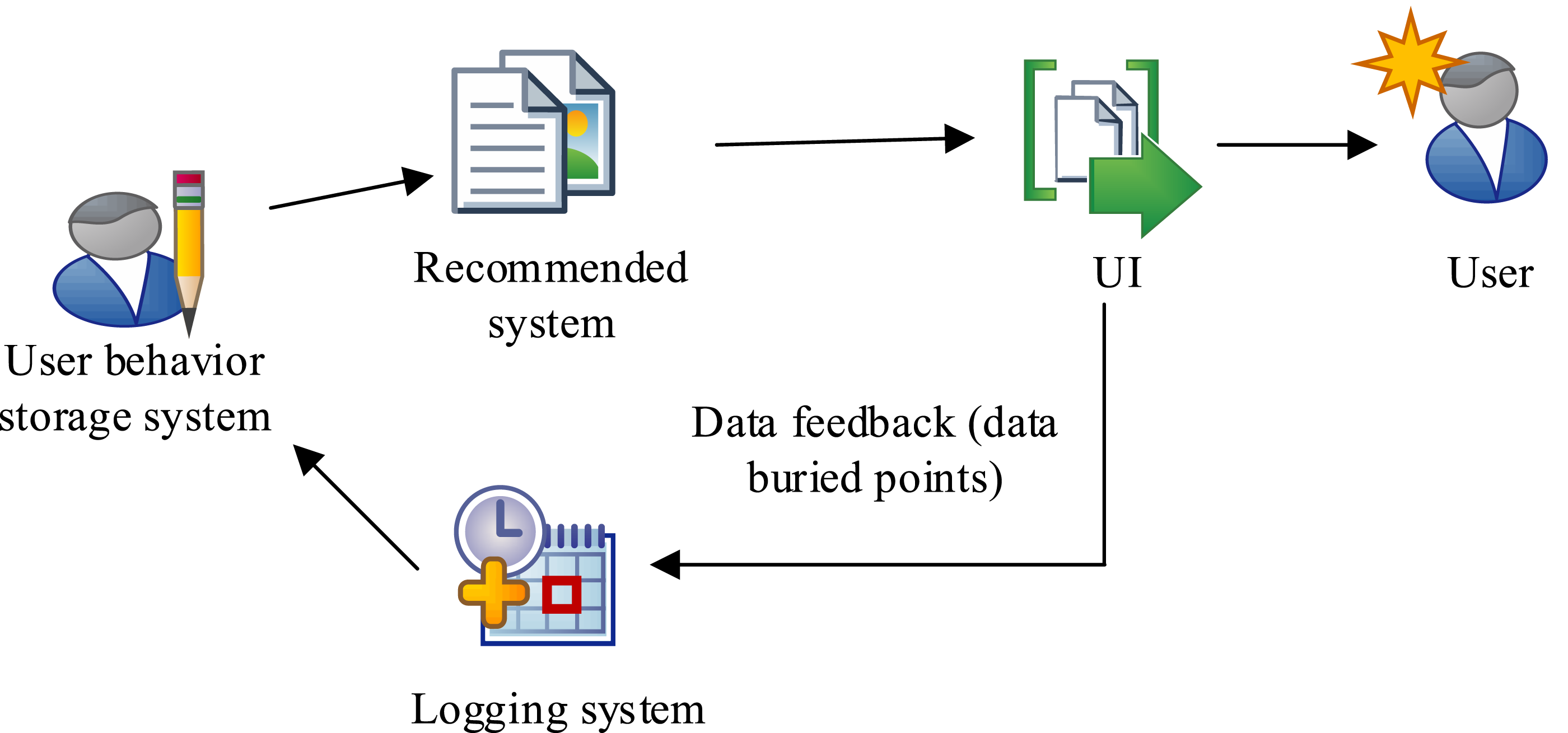
Performance analysis and application effect of English learning video recommendation
Experimental environment settings and comparison of loss function values
To verify the superior performance of the experimentally proposed user preference differences and sequence recommendation (UPD-SR) in ELV recommendation more completely, the experiment analyzes the actual performance of the improved video recommendation model in user English learning. Meanwhile, in order to ensure the smoothness and effectiveness of the experiments, the study firstly sets up the experimental parameters. The relevant simulation environment parameters are as follows: Simulation tools are Simulink. Operating system is Windows 10. System PC side memory is 36G. CPU main frequency is 2.62 Hz. GPU is RTX-2070. Central Processing Unit is Intel i7-3770k CPU. Graphics card is NVIDIA GTX 1060. Data storage is MySQL. Data regression analysis platform is SPSS 26.0.
Three methods are selected for the experiments to compare their performance with the institute constructed methods. These three methods are, respectively, a personalized music recommendation method based on deep learning and feature extraction (DL-FE), a personalized product RS based on user interest mining and meta-path discovery (user interest mining and meta-path discovery, UIM-MPD) and e-commerce product personalized advertising recommendation method based on recurrent neural networks and distributed expressions (Recurrent Neural Networks and Distributed Expressions, RNN-DE).30–32 The data source for the experiment is the ZhihuRec dataset. 5,800 historical data of ELVs from March 2021 to January 2022 are randomly selected as the task dataset. The data generated from March 2021 to June 2021 are used as the training set, and the data generated from June 2021 to September 2022 are used as the test set. All algorithms are tested under the same experimental conditions to ensure the smooth progress of the experiment and avoid accidents. First, the comprehensive loss function values and model accuracy of the four algorithms when they are trained on the total task dataset are compared, as shown in Figure 8. Comparison of training loss and model accuracy of different algorithms.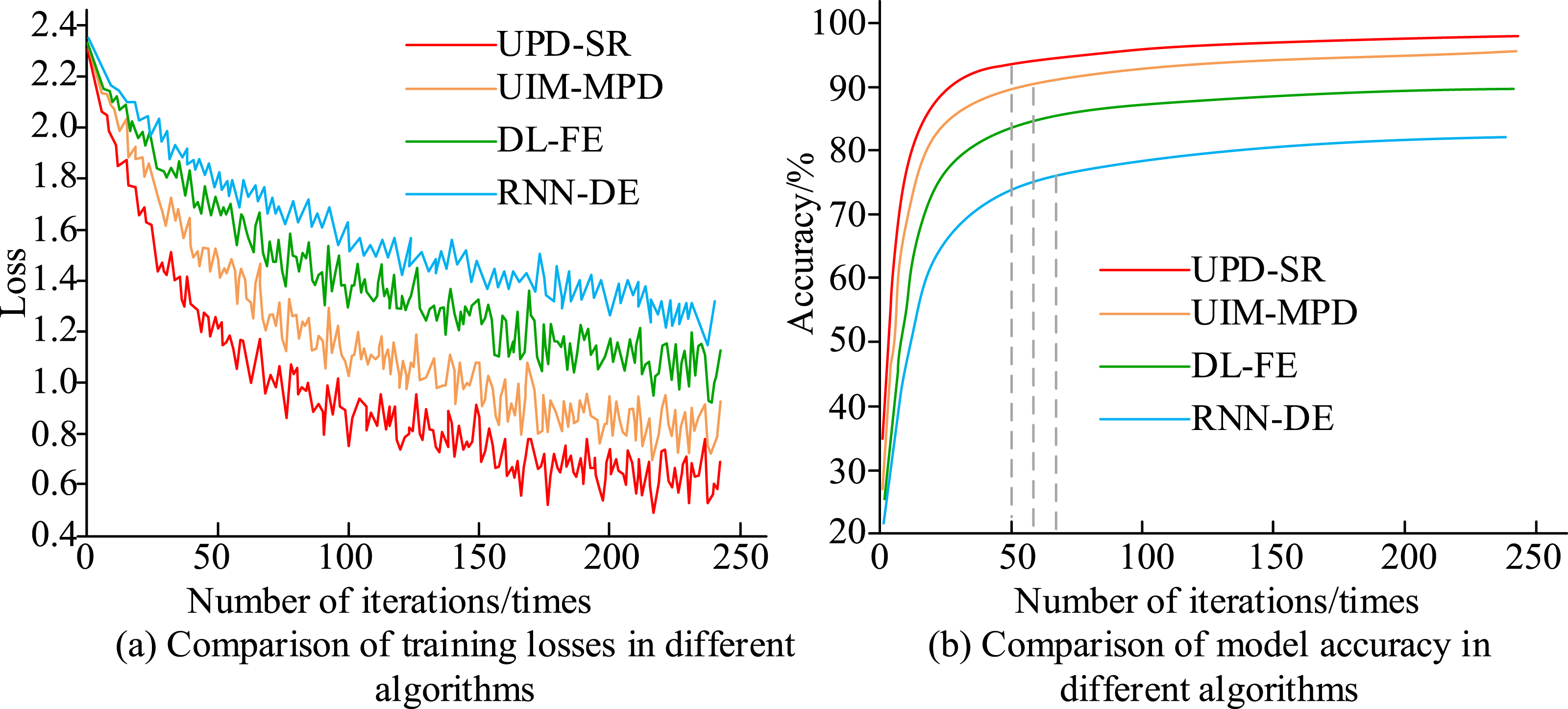
The comparison of the loss values from various algorithms’ training is displayed in Figure 8(a). It is discovered that as the number of iterations rises, the loss values of all four algorithms exhibit a diminishing trend. Among them, the proposed UPD-SR algorithm is able to achieve lower training loss values under the same number of iterations. When the iterations reach 250, the research method has the minimum loss value of 0.658. However, at this time, the loss values of UIM-MPD, DL-FE, and RNN-DE are 0.874, 1.169, and 1.352, respectively. Comparison demonstrates that the research approach performs the best. This is because more student users will participate in longitudinal learning training as a result of the UPD-SR model’s introduction of the concept of long- and short-term sequence of users. More user participation also translates into a greater demand on computational resources throughout the training phase. Figure 8(b) shows the comparison of the training accuracy of different models. The model accuracy of all four algorithms increase with the number of iteration rounds, and the growth trend is fast first and then leveling off, and the model accuracy are basically unchanged, which indicates that all four algorithms are convergent. However, the difference lies in the fact that the UPD-SR model proposed in the experiment has the fastest growth rate and the highest accuracy at the 50th iteration, when the accuracy is as high as 94.89%, and keeps the highest and stable state afterward. The accuracy of UIM-MPD, DL-FE, and RNN-DE at this time is 88.41%, 81.32%, and 74.11%, respectively. The comparison shows that the proposed UPD-SR algorithm has the highest accuracy rate and can recommend accurate ELVs for the users.
Comparison of changes in PR curve values and recommendation time
Next, training on the task dataset, comparing the precision rate and recall rate of the four algorithms, the obtained PR curves are shown in Figure 9. Changes in PR curves corresponding to the four algorithms.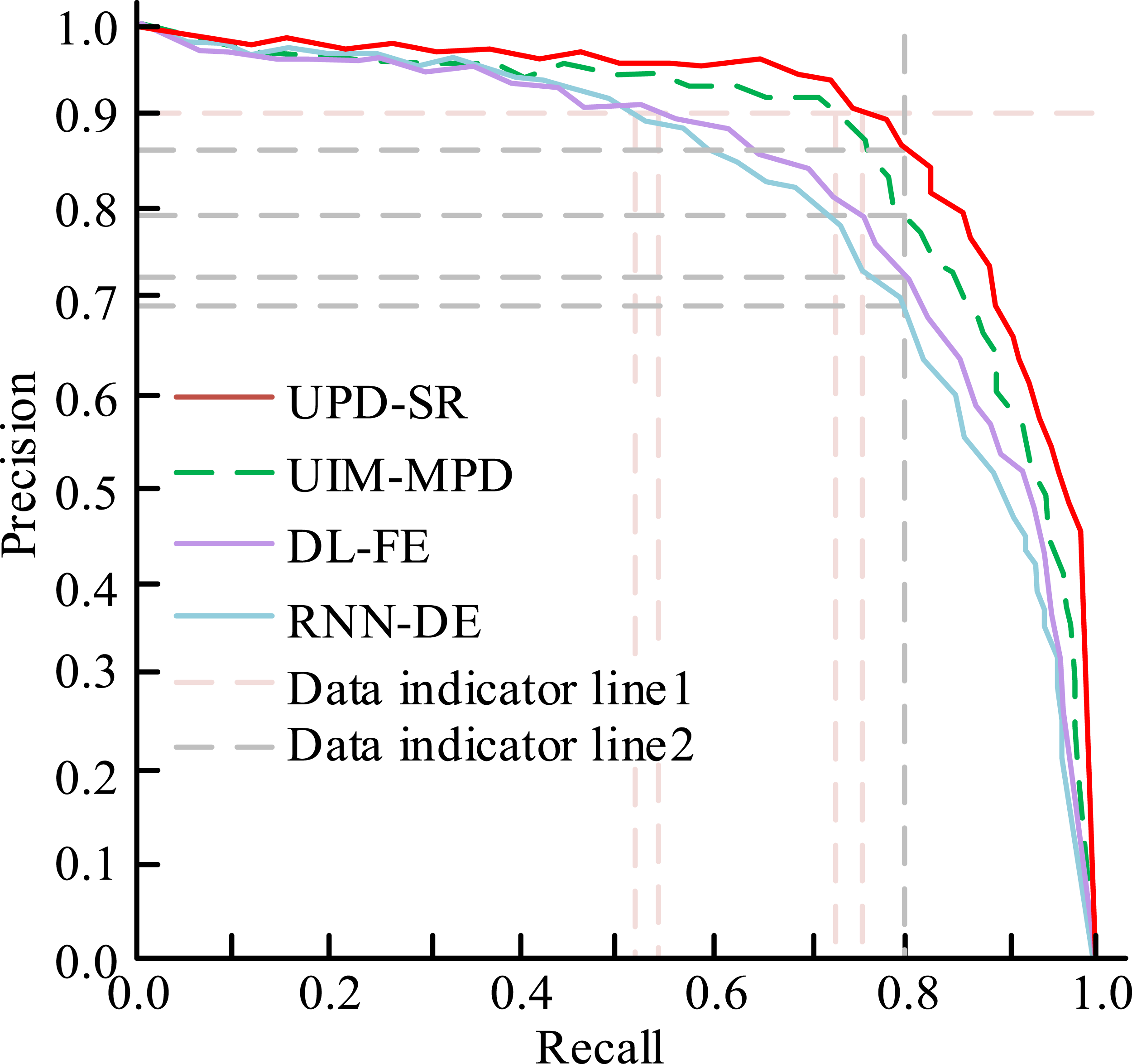
In Figure 9, when the precision rates of the four algorithms are equal, UPD-SR has the highest recall rate. In addition, when the recall rates of all the models are equal, UPD-SR has the highest precision rate. This shows that when the UPD-SR algorithm recommends ELVs to users, it can accurately target users’ interests and hobbies, and indirectly improve students’ course participation. A comparative test for the suggested period of student course needs is carried out in order to confirm the applicability of the experimental approach even further. The results on the two datasets are shown in Figure 10. Comparison of recommendation times of different algorithms.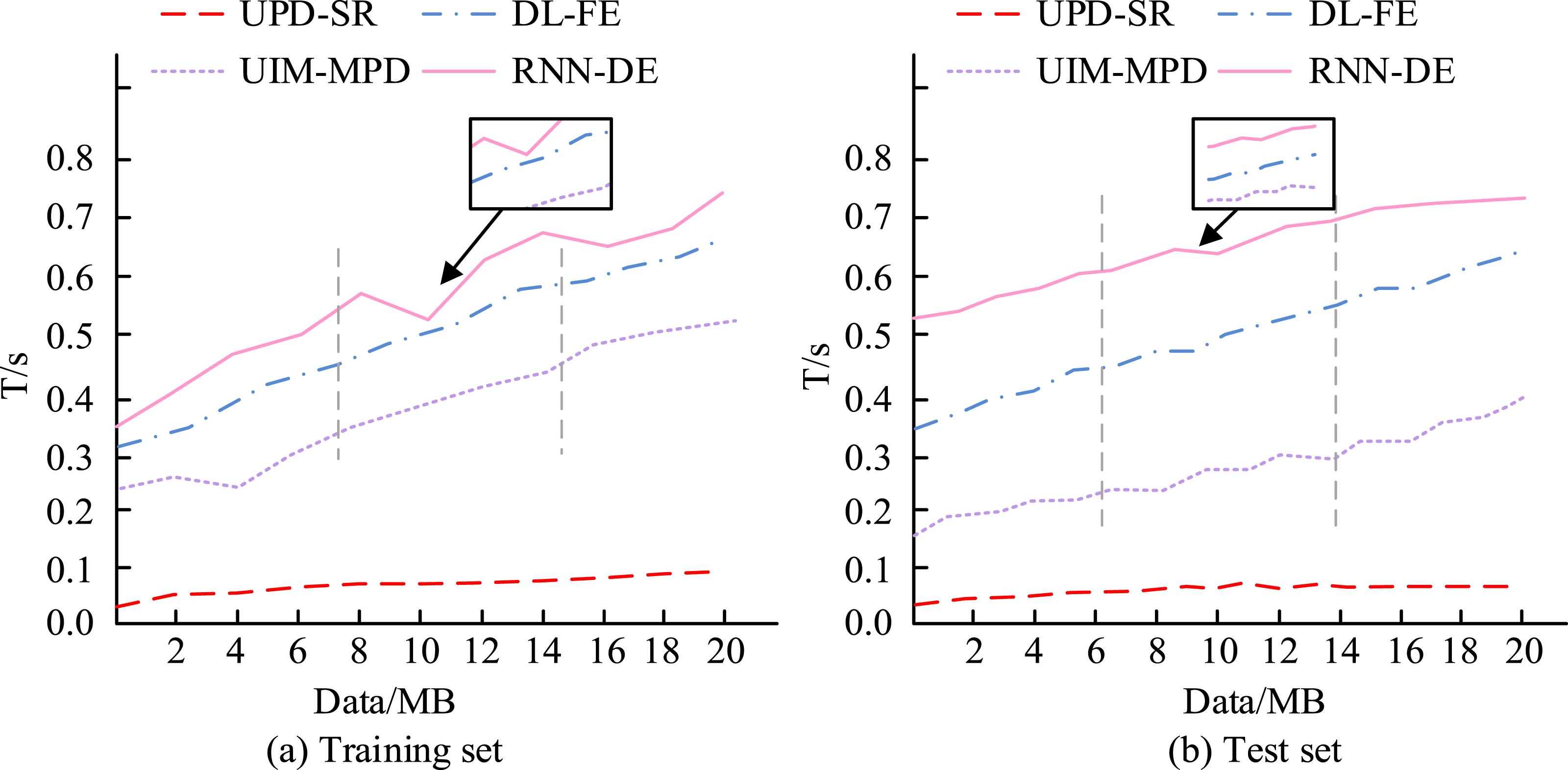
Figure 10(a) shows the comparison of the recommendation time of different algorithms when running on the training set. It can be found that the recommendation time of the four algorithms increases accordingly with the increase of data and is always in a changing state with large fluctuations. However, the fluctuation of the time consumed by the UPD-SR algorithm is smaller throughout the time period when the data increases. When the amount of data is 4 MB, the recommendation time of UPD-SR algorithm is 0.072 s. When the amount of data is 20 MB, the recommendation time of UPD-SR algorithm is always less than 0.100 s. Moreover, no matter what the amount of data is, the recommendation time of the remaining three methods is significantly greater than 0.200 s. Figure 10(b) shows the comparison of the recommendation time of different algorithms when they are run on the test set. The recommendation time of UPD-SR algorithm has been less than 0.100 s, which is significantly smaller than other algorithms, during the change of data volume from 0 MB to 20 MB. This indicates that the UPD-SR algorithm is more computationally efficient and can quickly recommend interested ELVs for users and improve the utilization of the system. At the same time, the fluctuation of the algorithm is smaller, indicating that the personalized demand recommendation using the experimentally constructed method has the advantage of being faster. In today’s era of popularized Internet, fast speed also means high market popularity, and the wider the applicability of the system is relatively.
Comparison of changes in recommendation accuracy and coverage of different algorithms
ELV’s content is different, then take four kinds of content as the main content to compare the recommendation accuracy of different algorithms, the specific results are shown in Figure 11. Comparison of recommendation accuracy rates of different systems.
Figure 11 shows the recommendation accuracy of different algorithms for the four ELVs of Basic English, Selected Newspapers and Periodicals, English Audiovisual, and Advanced English, respectively. It can be found that the recommendation accuracy of UPD-SR algorithm for the above four ELVs is 98.89%, 99.01%, 98.92%, and 99.20%, respectively. Compared to the UPD-SR algorithm, the recommendation accuracy of the remaining three approaches is considerably lower. Taking the UIM-MPD algorithm as an example, its recommendation accuracy for basic English, selected newspapers and magazines, English audiovisual, and advanced English are 98.75%, 98.76%, 98.06%, and 98.84%, respectively. This indicates that the UPD-SR algorithm has the highest accuracy rate for meeting the personalized needs of students’ online learning, and has obvious advantages over the other three methods. Almost all students reported that they could accurately find the course content they were interested in and study it through the system in this paper. Subsequently, the coverage trends of the four recommended algorithms are compared with the number of system runs. The specific results are shown in Figure 12. Comparison of coverage of different algorithms.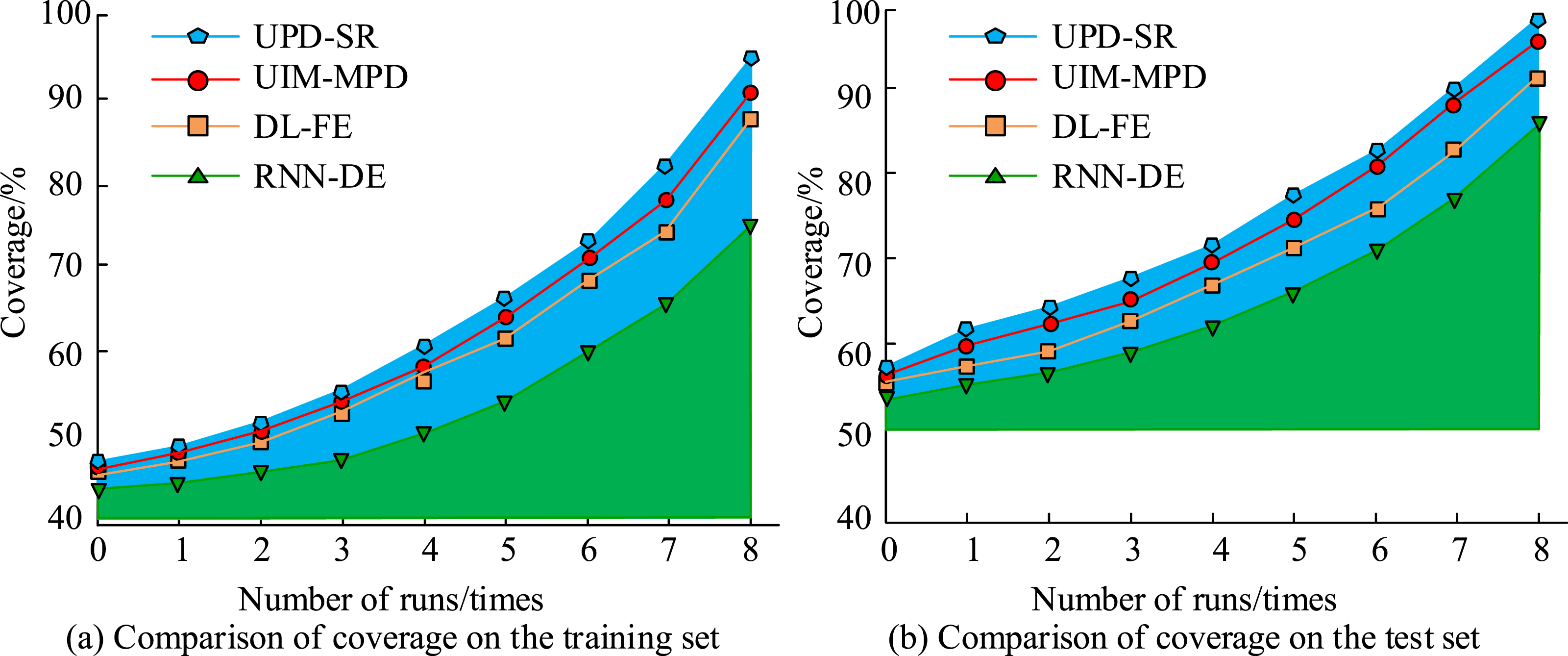
Figure 12(a) shows the coverage changes of different algorithms on the training set. As the number of algorithm runs increases, the coverage rates of the four algorithms begin to increase. Among them, the coverage rate of UPD-SR algorithm has always been at the maximum value. When running for the 8th time, the coverage rate of the UPD-SR algorithm has a maximum value and begins to approach 100%. The coverage of the UIM-MPD algorithm and RNN-CG algorithm is far less than 100%. Figure 12(b) illustrates the coverage changes of different algorithms on the test set. When the UPD-SR algorithm exhibits extensive coverage, the number of runs reaches its eighth iteration. Concurrently, the coverage rates of other algorithms consistently lag behind the UPD-SR algorithm. The results demonstrate that the algorithm proposed in the experiment consistently achieves the highest coverage, the highest reliability of data transmission, and the broadest collection of ELVs available to users.
Comparison of learning effects and satisfaction of different users
Statistics on the learning effect of e-learning users after applying the system.
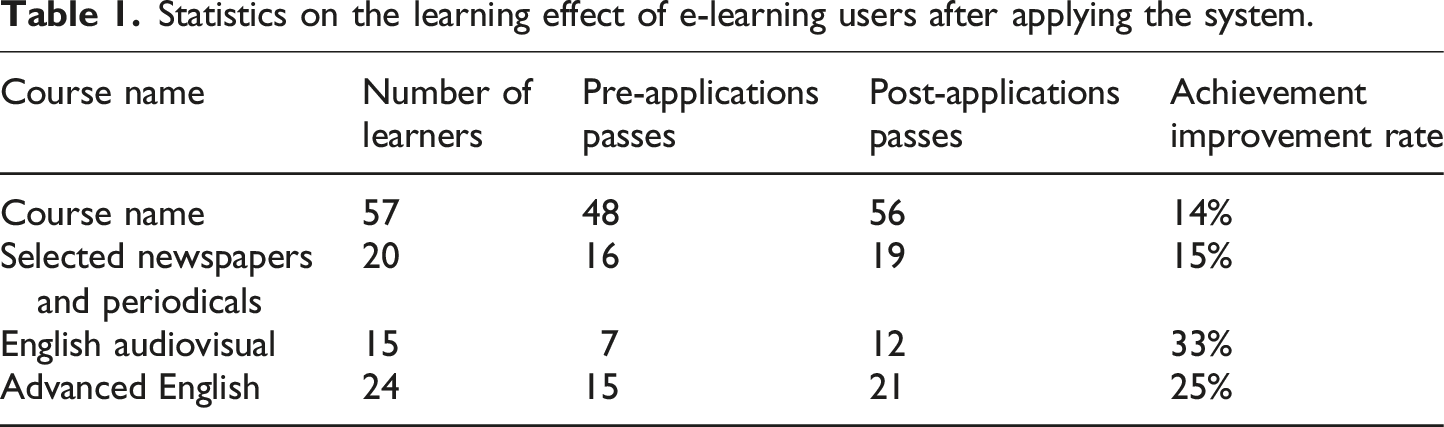
In Table 1, after applying the experimental algorithm, there is a significant increase in the number of students passing each course. Since basic English is a compulsory course for every student, the students’ foundation is generally good. However, after learning by applying the research method, there is still a 14% improvement rate in the grades. This shows that the UPD-SR algorithm has more significant advantages both in terms of meeting students’ individualized needs and in terms of improving students’ learning results, which indicates that the UPD-SR algorithm has good applicability and superiority in students’ English learning. Finally, the four methods are applied to all the students and 50% of the students in a selected domestic university. Then, the student user satisfaction of the system’s teaching resources recommendation is compared and analyzed. Additionally, Figure 13 displays the particular outcomes. Comparison of user satisfaction of system resource recommendations.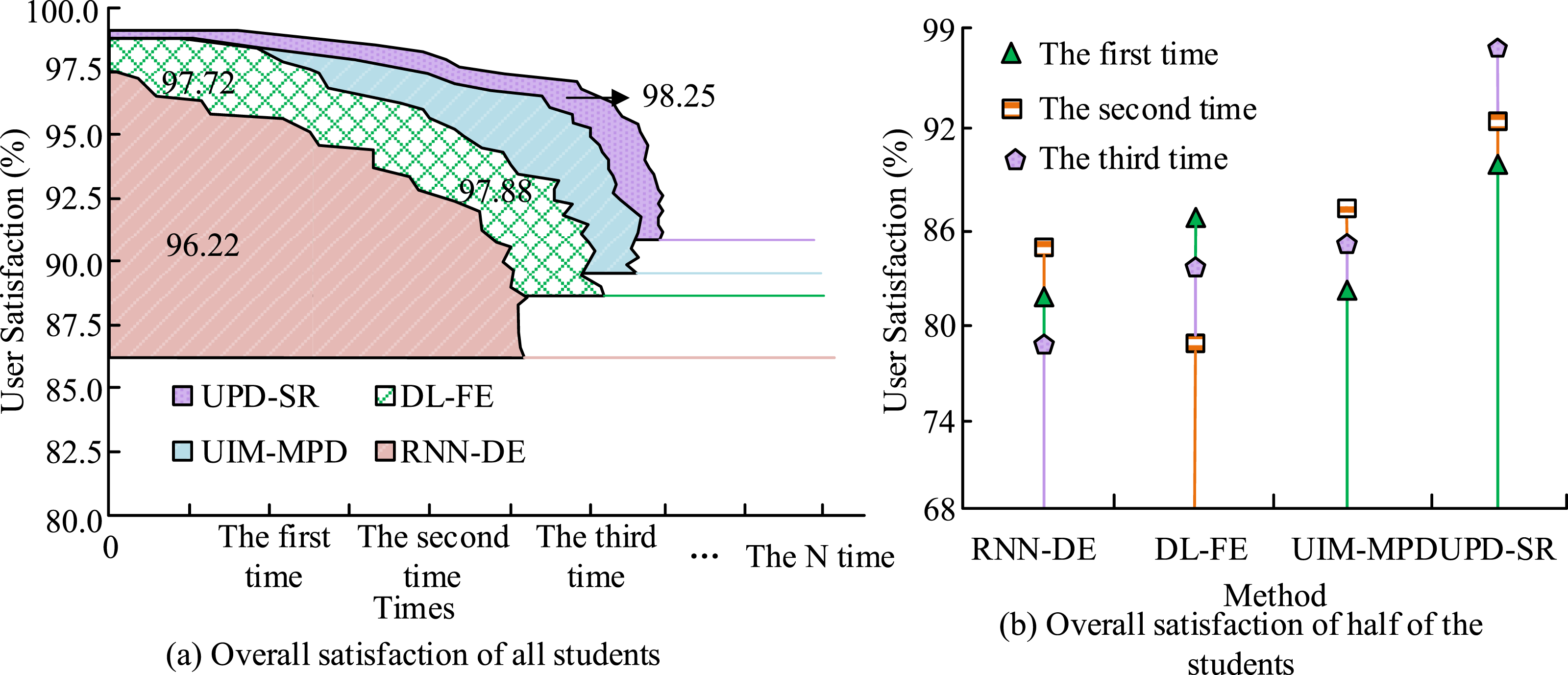
Figure 13(a) shows the combined satisfaction of all student users. When the system was run to the third time, the satisfaction of all students was higher under all four algorithm runs. The user satisfaction under the UPD-SR algorithm run is 98.25%, and the user satisfaction of UIM-MPD, DL-FE, and RNN-DE are 97.88%, 97.72%, and 96.22%, respectively. The number of system operations has continued to increase, but the overall satisfaction of student users has remained above 85%. Figure 13(b) shows the combined satisfaction of half of the student users. The whole experiment was conducted three times, and when the system ran to the third time, the UPD-SR algorithm had the highest user satisfaction of 98.88%. Moreover, the user satisfaction of the remaining three algorithms is significantly smaller than the research methods. Subsequently, the number of system operations continued to increase, yet the satisfaction of student users remained on the rise. This indicates that under the UPD-SR algorithm run, the users are more satisfied with the obtained ELVs and are able to get the needed content from them.
Conclusion
The experiments proposed an ELV recommendation method that incorporates UP differences and SR, aiming to provide users with a more personalized and efficient English learning experience. The study conducted experiments on two datasets, the test set and the training set, and analyzed the model performance using metrics such as loss value, model precision, accuracy, and user satisfaction. The data showed that the UPD-SR algorithm’s recommendation accuracy for four types of ELVs: basic English, newspaper selections, English audio-visuals, and advanced English are 98.89%, 99.01%, 98.92%, and 99.20%, respectively. Moreover, when the signal-to-noise ratio is 8 dB, the bit error rate of the UPD-SR algorithm has a minimum value. After applying the UPD-SR algorithm, student performance increased significantly by 14%. The preceding analysis indicates that the UPD-SR algorithm, developed by the research team, exhibits the highest degree of accuracy in recommending ELVs. This capability has the potential to significantly enhance the motivation and efficiency of learning users, while also facilitating the provision of learning resources in a more efficient manner. Although the research has achieved positive results, there are still some limitations, such as the diversity of the dataset, the computational efficiency of the algorithm, etc. Future research needs to explore more diverse data sources, optimize the performance of the algorithm, and consider more complex user behavior patterns.
Footnotes
Acknowledgments
Thanks to Henan Finance University and Zhengzhou Business University for all the necessary support during this research.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data availability statement
All data generated or analyzed during this study are included in this article. Further enquiries can be directed to the corresponding author.