
Abstract
As the growth of network technology, the network intrusion has become increasingly serious. An elephant herding optimization algorithm and support vector machine-based network intrusion detection method are proposed to address the difficulties and low detection accuracy of the detection. This method first uses an optimized elephant swarm optimization algorithm to select features from the intrusion data and then uses the elephant swarm optimization method to optimize the parameters of the support vector machine algorithm. Finally, a detection model is constructed based on support vector machines. The main contribution of the research is the proposal of a network intrusion detection method based on improved swarm optimization algorithm and support vector machine. By using an improved swarm optimization algorithm to optimize the parameters of the support vector machine classification algorithm, this method significantly improves the accuracy and stability of detection when dealing with the classification task of network intrusion detection. The experimental results show that the detection model has a stable average accuracy of around 94% in detecting four types of intrusion data, surpassing the performance of other commonly used algorithms. The results validate the effectiveness of introducing the improved elephant swarm optimization algorithm and demonstrate its superiority in intrusion detection tasks.
Keywords
Introduction
Due to the quick advancement of network, more users are participating in online interactions, and the internet has become an indispensable part of human’s daily life. However, as the number of users increases, network intrusion events have become increasingly frequent.1,2 By 2025, the global cost of network crime is expected to reach $10.5 trillion per year, highlighting the necessity of enhancing network security measures. According to statistics, the Asia Pacific region is the region most affected by network attacks, accounting for 31% of all reported incidents, while Europe and North America account for 28% and 25%, respectively.3,4 Over the past year, the global threat of ransomware attacks has been rapidly evolving. The number of victims of ransomware attacks worldwide has increased by 46%, setting a record high in history. Large enterprises have become the target of most attacks, accounting for approximately 40%. Small organizations account for 25% of all victims, followed closely by medium-sized enterprises at 23%. Overall, the number of attacks on enterprises is steadily increasing.5,6 In response to frequent network intrusion events, efficient and accurate network intrusion detection (NID) methods have become a hot topic in recent years. Intrusion detection is the identification and detection of malicious use of computer and network resources. It contains external intrusion of the system and unauthorized behavior of internal users. This technology is built to safeguard the computer systems’ security by promptly identifying and reporting any irregularities in the system. It can also be utilized to monitor and analyze the compliance of users with established security policies within computer networks. There are many methods for intrusion detection, such as expert system-based intrusion detection methods and neural network-based intrusion detection methods. However, facing a large amount of intrusion data and diverse intrusion attack methods, most current detection methods are still difficult to handle well. Most current models are trained on outdated or imbalanced datasets, resulting in poor generalization ability in real-world applications. Traditional machine learning methods are sensitive to high-dimensional data and rely on manual adjustment of model parameters, which can lead to overfitting. Feature selection and classification modeling are often independent of each other, which limits the overall improvement of detection performance. Faced with increasingly complex network intrusion behaviors, these limitations have become the main reason why traditional intrusion detection methods are unable to handle them effectively. In response to this issue, an NID method with the improved elephant herding optimization (IEHO) and SVM is raised, aiming at raising the efficiency and accuracy of detection. Although SVM has good performance in handling high-dimensional datasets, training directly on raw high-dimensional data may lead to overfitting and reduce the model’s generalization ability. Therefore, feature selection is crucial as it can help reduce data dimensionality, improve training efficiency, and enhance model accuracy and stability. The main contributions of the research are as follows: The IEHO algorithm was proposed, which improved the global search capability and convergence speed. We have developed a unified detection framework that combines IEHO and SVM optimization, achieving the integration of feature selection and model parameter tuning, and designed and implemented a parallel version of IEHO based on Apache Spark to improve the efficiency of large-scale intrusion data processing.
Related work
Exploring efficient and accurate NID methods is of great significance for addressing the increasingly serious network intrusion behaviors. Wei et al. proposed an improved K-means clustering network security detection model for NID. Through the clustering calculation method of k-means, the model could more effectively calculate and select special data. The results showed the effectiveness of the model. 7 Regarding the issue of anomaly detection in network traffic, Imran M et al. proposed a new anomaly detection method that utilizes an artificial neural network optimized with the cuckoo search algorithm. The results showed that compared with methods that do not use parameter optimization, this method had significant advantages. 8 Regarding the problem of detecting abnormal traffic behavior in IoT systems, Li et al. used artificial neural networks to detect abnormal behavior in medical IoT systems. In the proposed method, the butterfly optimization algorithm was used to select the best features for the learning process of artificial neural networks. The results obtained demonstrated the ability of the butterfly optimization algorithm to determine the distinguishing features of network traffic data. The results proved the effectiveness of the method. 9 Sarkar et al. proposed an effective machine learning ensemble technique for NID classification. They demonstrated that preprocessing data can effectively improve detection quality, and correcting the training dataset can aid in category recognition, especially for abnormal attacks such as Root to Local attacks (R2L) and User to Root attacks (U2R). The results indicated that after preprocessing the data, the classification accuracy has been significantly improved. 10 The above literature indicates that there are multiple types of intrusion in NID, which poses challenges for detection models. In addition, the above research indicates that preprocessing intrusion data will benefit the detection quality of the model.
Methods and materials
A new detection method was proposed to address the issues of low accuracy and high false alarm rates in NID. Firstly, the study introduced the Levy flight strategy and sparrow search algorithm (SSA) to improve the traditional elephant herding optimization algorithm (EHO). Subsequently, the study utilized an IEHO algorithm to address the high-dimensional issue of intrusion data while improving SVM parameters. Finally, an NID model based on improved SVM was proposed.
Attribute selection of network intrusion data based on IEHO algorithm
Network intrusion data often contains high-dimensional and other complex and useless data, which greatly reduces the processing speed and accuracy of detection behavior.11–13 To better detect intrusion data, preprocessing the data is of great significance. The study used IEHO to preprocess intrusion data. IEHO introduces Levy flight strategy and SSA on the basis of EHO. EHO is utilized to address global unconstrained optimization problems, originating from the animal husbandry behavior of elephants in nature. So far, EHO has been successfully utilized to multi-level thresholds, and many other issues. Although EHO algorithm is a relatively new metaheuristic algorithm, it has the characteristics of simple structure, few control parameters, and easy combination with other methods, which can effectively solve optimization problems.14–16 In EHO, local searches represent natural elephant clans, while global searches represent leaving clans. In the fundamental EHO algorithm, the initial operations are those of updating, which serve to determine the search direction and the level of detail at which the local search is conducted. These are then followed by the operations of separation. This process includes two stages: clan renewal and clan separation.17–19 In the clan update operation, elephants live together and are led by a female elephant, as shown in equation (1).

In equation (1),

In equation (2),

In equation (3),
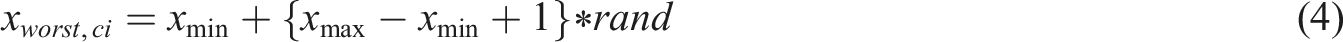
In equation (4),

In equation (5),
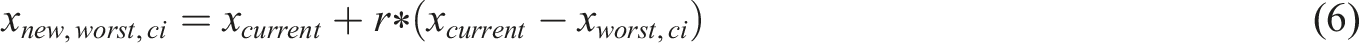
In equation (6), IEHO algorithm flowchart.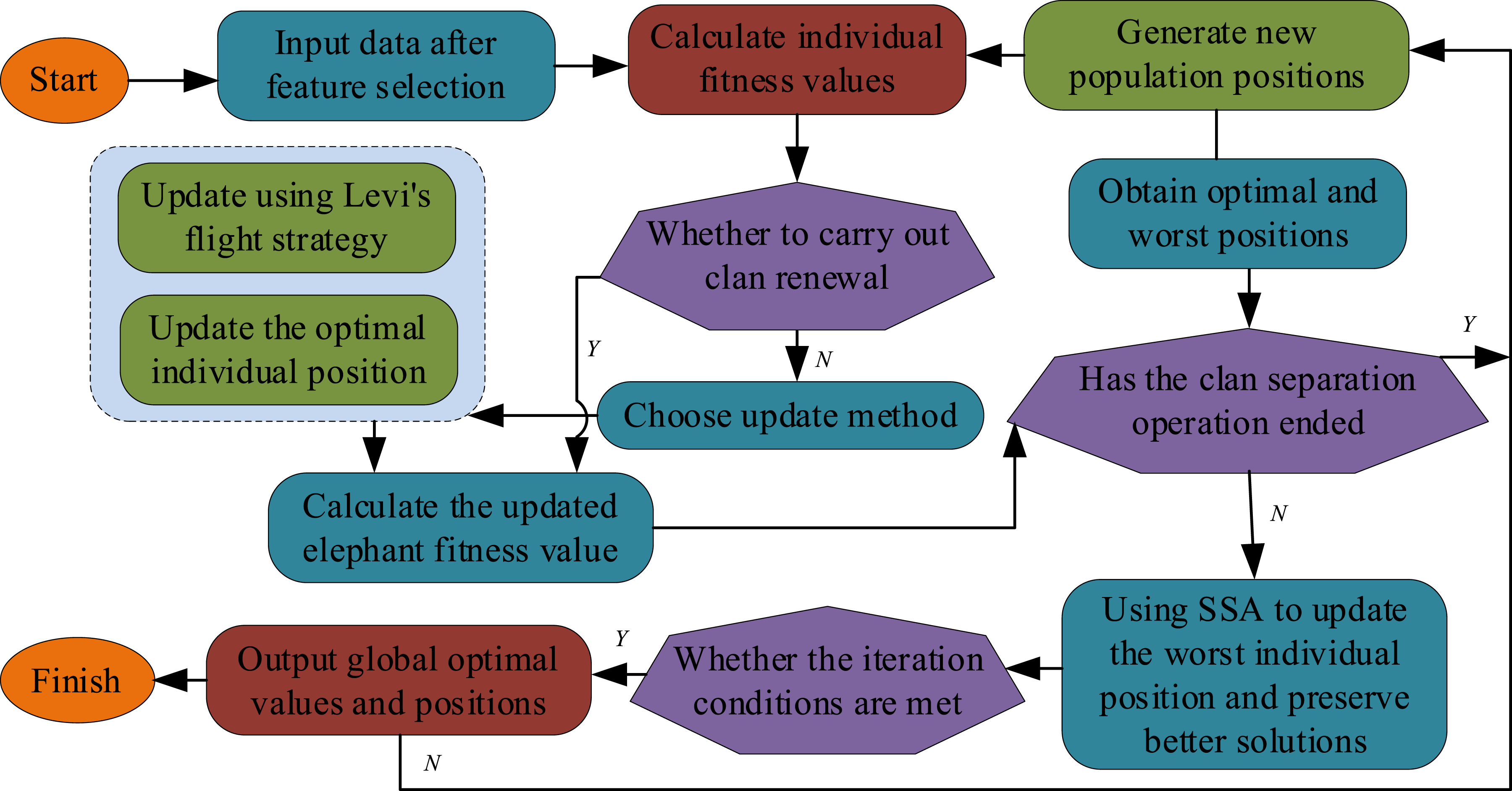
In Figure 1, the steps of the IEHO algorithm are to first initialize the population and set the amount of populations. Subsequently, the clan position is randomly set and its fitness value is calculated. After updating and separating the clan, it can obtain the local optimal position and decide whether the algorithm termination condition is satisfied. If it is satisfied, update it. If it is not satisfied, continue with the update operation. Due to the fact that intrusion data often contains a large amount of useless data, it is necessary to preprocess the data. The algorithm pseudocode is shown in Figure 2. Pseudocode of the IEHO algorithm.
The basic process of feature detection is shown in Figure 3. Feature detection flowchart.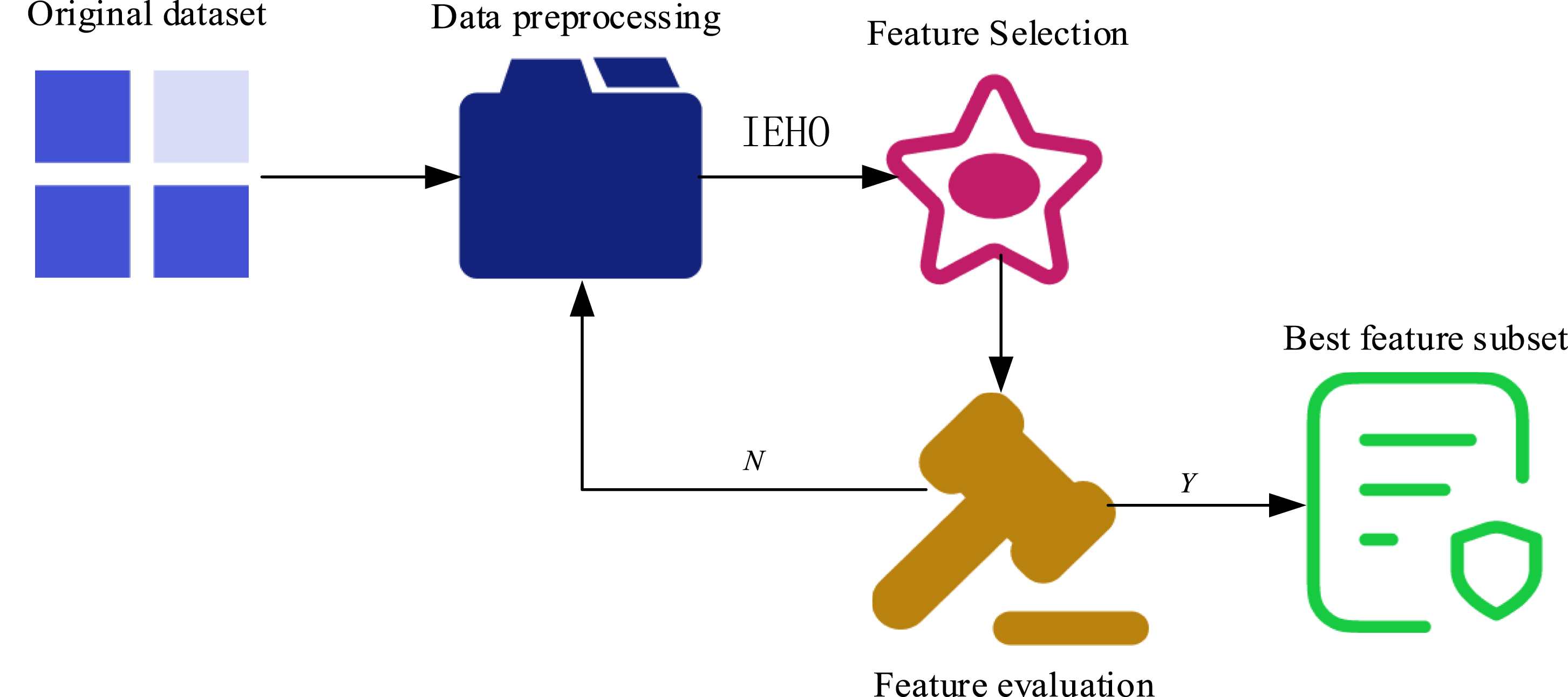
In Figure 3, the raw data is first preprocessed to ensure that the data quality is suitable for subsequent analysis. Using IEHO to select the most relevant features, IEHO evaluates the contribution of each feature to the classification model and selects the feature with the highest predictive ability. After completing the feature selection, the selected features are evaluated and cross validation is used to verify the performance of a subset of the selected features. In this process, the features are sorted based on the evaluation results to ensure that the final selected feature subset not only has efficient data representation capabilities but also significantly improves the detection accuracy of the model. In response to the low efficiency of IEHO in handling massive intrusion data, this study introduces Apache Spark to complete large-scale data processing. Apache Spark is a fast and versatile computing engine that transforms the process of finding the best location and solution for an elephant into a parallel solving process for each individual. Parallel processing greatly improves the efficiency of IEHO in selecting intrusion data features, as shown in Figure 4. Flowchart of IEHO algorithm for Spark parallelization.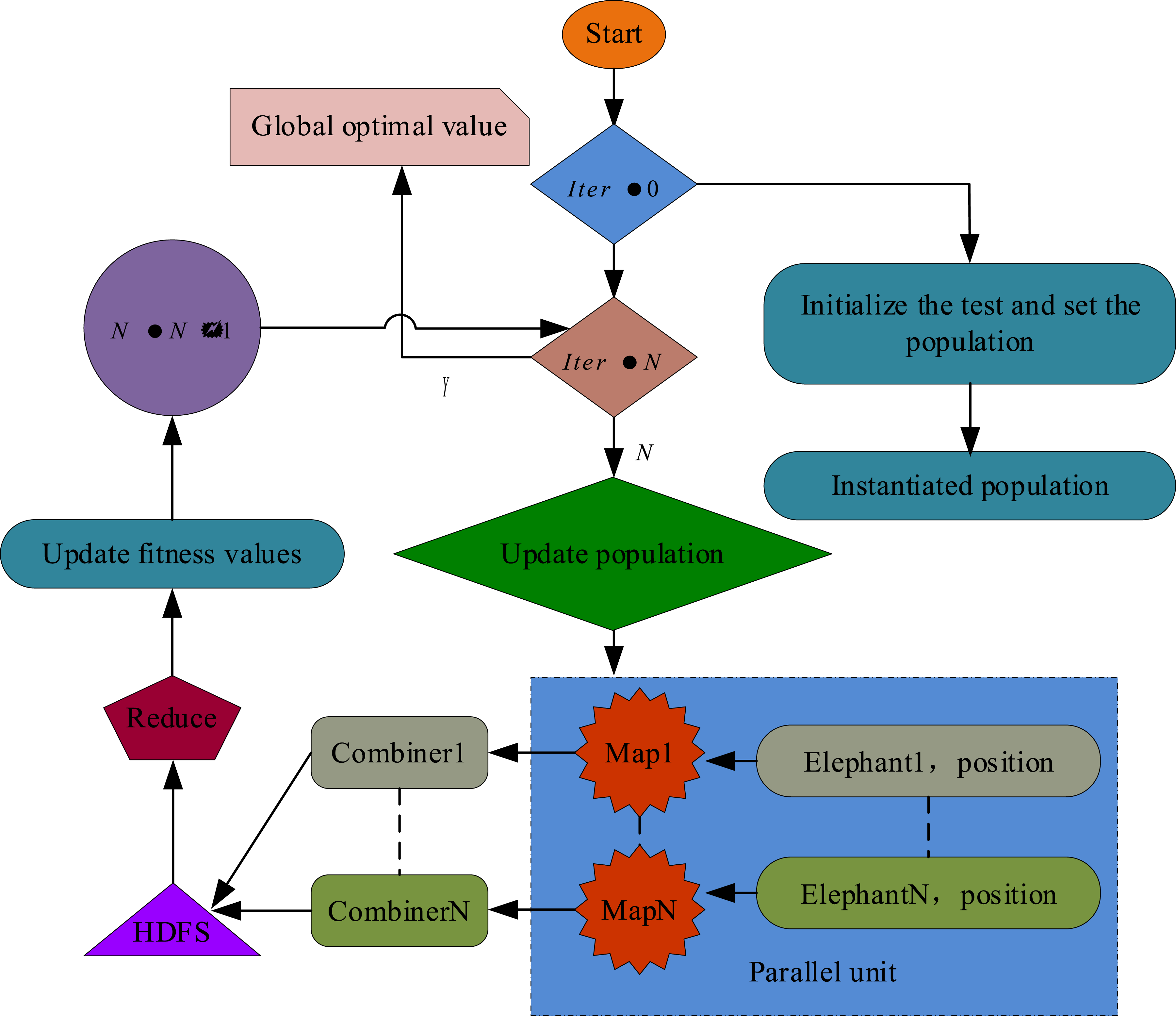
In Figure 4, the solving steps of Spark Parallel IEHO (SPIEHO) are the same as solving IEHO separately, but the optimization of each individual’s position and optimal value are carried out in parallel. In traditional IEHO algorithms, the calculation process is often serial, which may result in low computational efficiency and time delay when processing large amounts of feature data. When the IEHO algorithm is combined with Apache Spark, its powerful distributed computing capability is utilized to enable parallel processing of location updates and optimal value evaluations for each individual. This parallelization not only improves the efficiency of the algorithm but also makes it more scalable when dealing with large-scale datasets. Regarding the time and space complexity issues of SPIEHO, the analysis of the algorithm shows that it is mainly affected by feature selection, parameter optimization, and model training stages in terms of time complexity. The spatial complexity is mainly affected by the storage of feature sets, individual storage and fitness storage, and SVM model storage. Under the Apache Spark framework, by utilizing Spark’s RDD and data frame structure, algorithm execution can be parallelized, thereby reducing the load on each computing node and improving the response speed of the entire system. When processing datasets of millions of levels, Apache Spark can effectively integrate computing resources, optimize memory usage, and enable algorithms to adapt to larger training sets.
Intrusion detection model based on IEHO-SVM
To build an intrusion data detection model, in addition to using IEHO to preprocess intrusion data, it is also necessary to classify incoming data. Based on this, SVM is introduced in the study. SVM is utilized for classification and regression analysis. The basic aim is to find an optimal hyperplane in the feature space to maximize the distance between the classification boundary and the nearest training sample.20,21 Kernel function is an important concept in SVM, which can map data from the original space to high-dimensional space, thereby handling nonlinear problems. The kernel function avoids the computational cost of high-dimensional space by calculating the similarity between samples. The performance of SVM is affected by the penalty coefficient

In equation (7),

According to equation (8), the distance between hyperplanes can be calculated as

In equation (9),

All data points must be located on one side of the interval and can be merged into equation (11).

In equation (11),

When the constraint condition is on the correct side of the interval, equation (12) is equal to 0. For the data on the other side of the interval, it is expected to be minimized. When the data is linear, the SVM classification effect is the same. When the data is non-linear, the soft interval method also has a certain classification ability, as shown in equation (13).
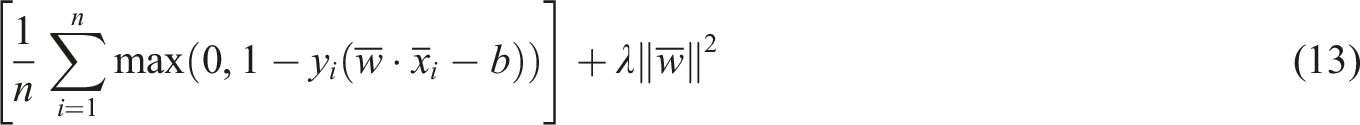
In equation (13),

In equation (14),

In equation (15),
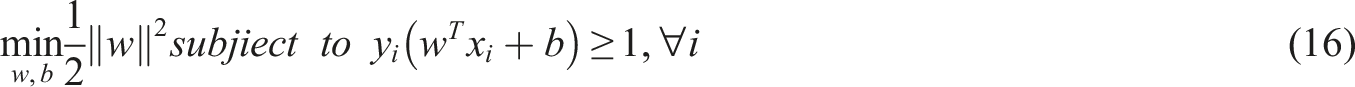
This theorem indicates that the goal of SVM is to minimize the complexity of the classification model by maximizing the decision boundary. The boundaries of the hyperplane are determined by the data points located in the support vectors, which are crucial for the final performance of the model. The schematic diagram of high-dimensional space partitioning of the SVM dataset after kernel function optimization is shown in Figure 5. Higher dimensional hyperplane.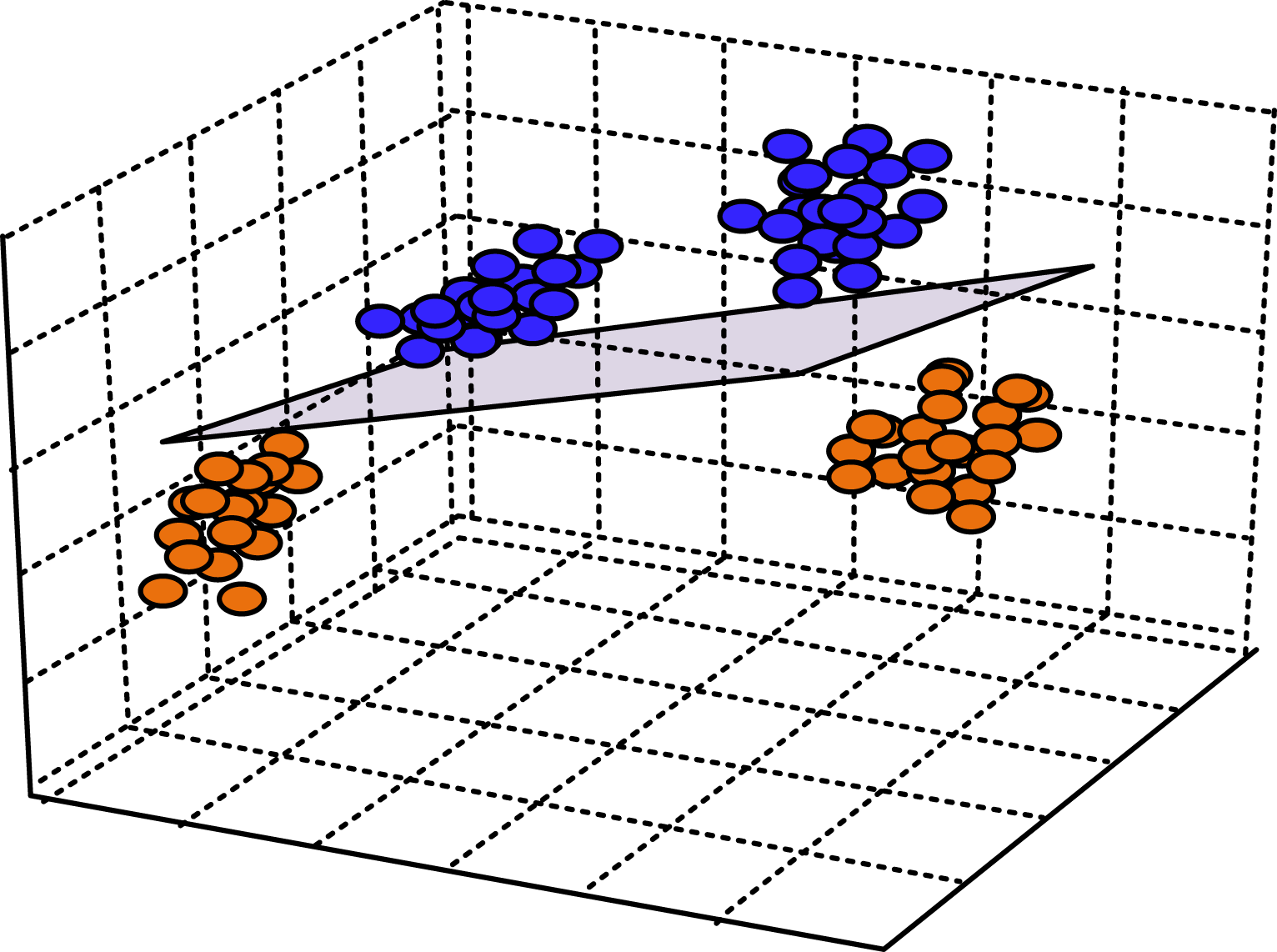
In Figure 5, the non-linear dataset’s dot product in low-dimensional space is replaced with a dot product in high-dimensional space, which helps to use SVM for partitioning. The spatial normal vector separates data that cannot be separated by the original low-dimensional space through algorithms. In response to the problem of SVM needing to adjust too many parameters, the study adopts IEHO to optimize its parameters (IEHO-SVM). IEHO mainly optimizes SVM parameters by adjusting the penalty coefficient and kernel function parameter SVM parameter optimization flowchart.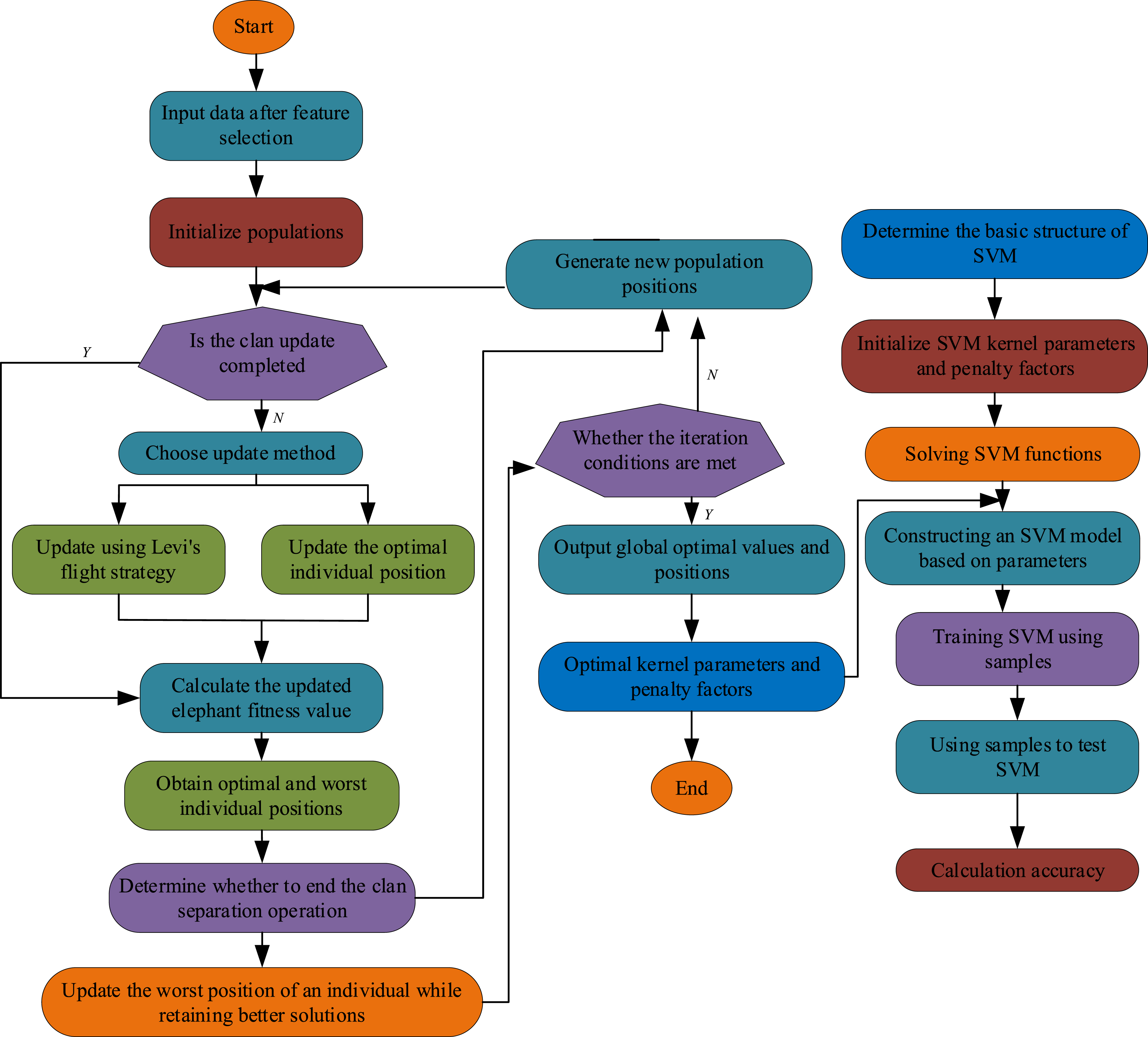
In Figure 6, optimization of SVM parameters involves initializing the population, learning samples of invasion data using SVM, and optimizing SVM parameters using IEHO. Fitness values are calculated to determine the optimal location for population renewal and population separation operations. The optimal solution and locally optimal position of the community are updated to determine whether the termination condition is satisfied. If satisfied, the global optimal solution and optimal location are updated. If unsatisfactory, the clan update and separation operations are performed again. SVM is applied to classify the samples and build the model. Finally, the model is used to classify the intrusion data and output the obtained data results. The IEHO algorithm optimizes the parameters of the SVM, especially the penalty factor and kernel function parameters. Proper parameter selection not only improves the classification accuracy of the model but also reduces the risk of overfitting. IEHO optimizes the potential parameter space to find the parameter combinations that maximize the classification performance of the SVM. In terms of feature selection, IEHO’s parallel processing capability greatly improves the efficiency of feature space exploration. By efficiently selecting features that are highly relevant to the intrusion detection task, IEHO reduces the amount of data that the SVM model needs to process, thus speeding up the training process and improving model performance. The pseudocode for Figure 7 is as follows. Pseudo code for SVM parameter optimization flowchart.
The SVM classification detection model optimized by IEHO algorithm is shown in Figure 8. Structure diagram of intrusion detection model based on IEO-SVM.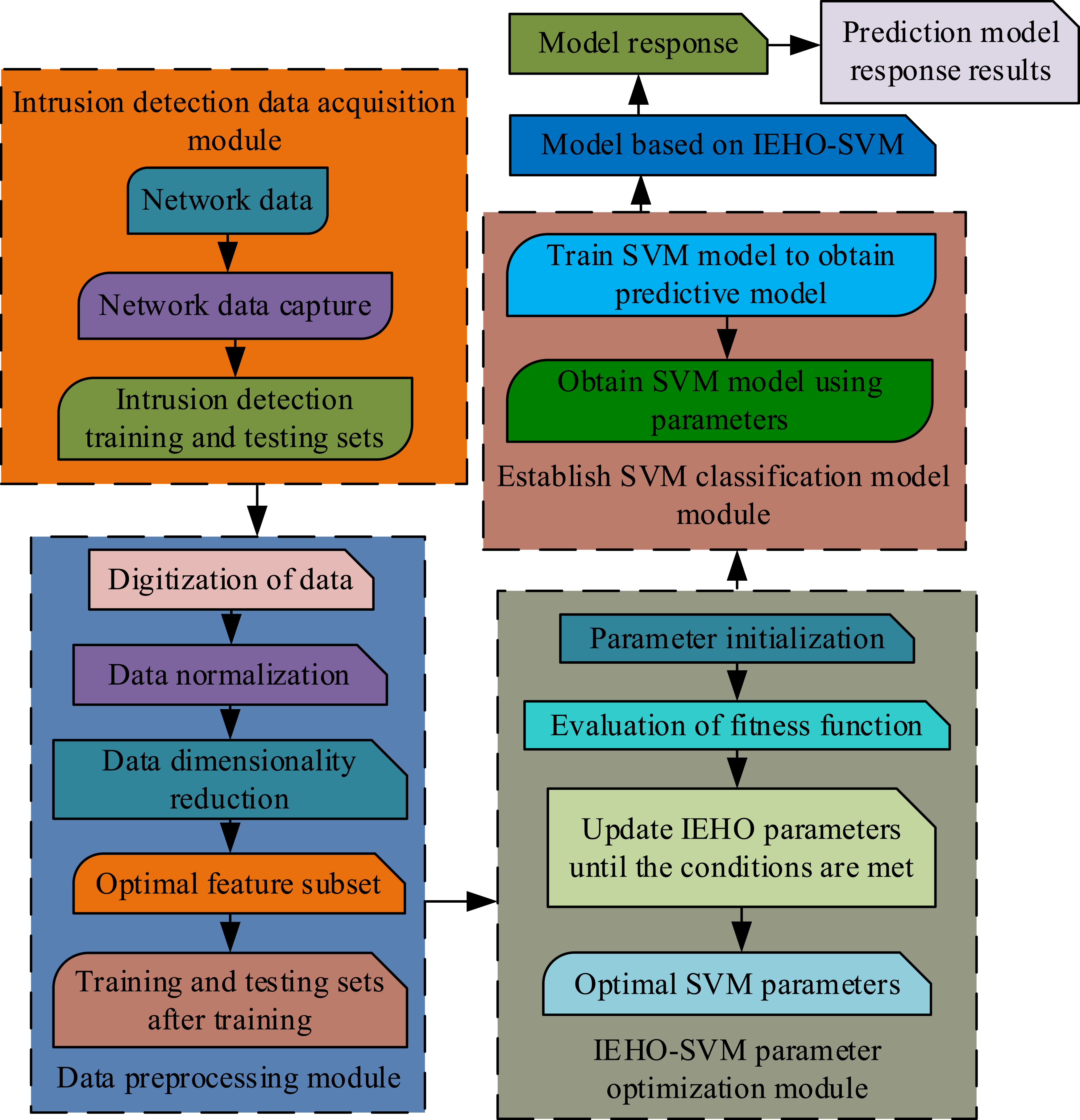
In Figure 8, the detection model processes intrusion data by first extracting the intrusion data, performing dimensionality reduction on the extracted data, and transforming it into type data that SVM can process. Then it will initialize the parameters and iterate using the fitness function until the termination condition is met. Finally, IEHO is utilized to optimize SVM parameters and a prediction model is obtained. The obtained prediction model is used to train intrusion samples to construct an intrusion detection model.
Results
To assess the efficacy of the proposed NID model, feasibility testing was first conducted on the proposed IEHO in the experiment. Subsequently, the effectiveness of optimizing IEHO in selecting intrusion data attributes was verified. Finally, the efficacy comparison was conducted between the proposed NID model with other models to verify the superiority.
Analysis of network intrusion detection methods based on IEHO
Bearing parameters.
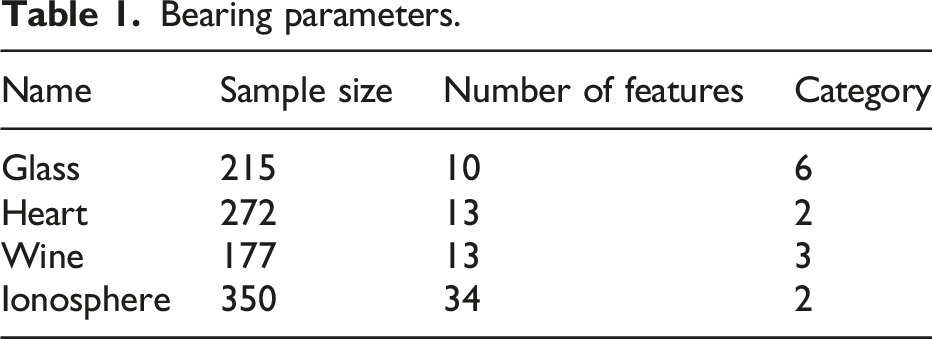
To prove the efficacy of the designed IEHO algorithm, two unimodal and multimodal functions were selected for testing in the experiment, as shown in Figure 9. Fitness curves of algorithms in different peak functions. (a) Performance testing of two algorithms in the Rosenbroc function. (b) Performance testing of two algorithms in the SumSquare function. (c) Performance testing of two algorithms in the Griewank function. (d) Performance testing of two algorithms in the Schaffer function.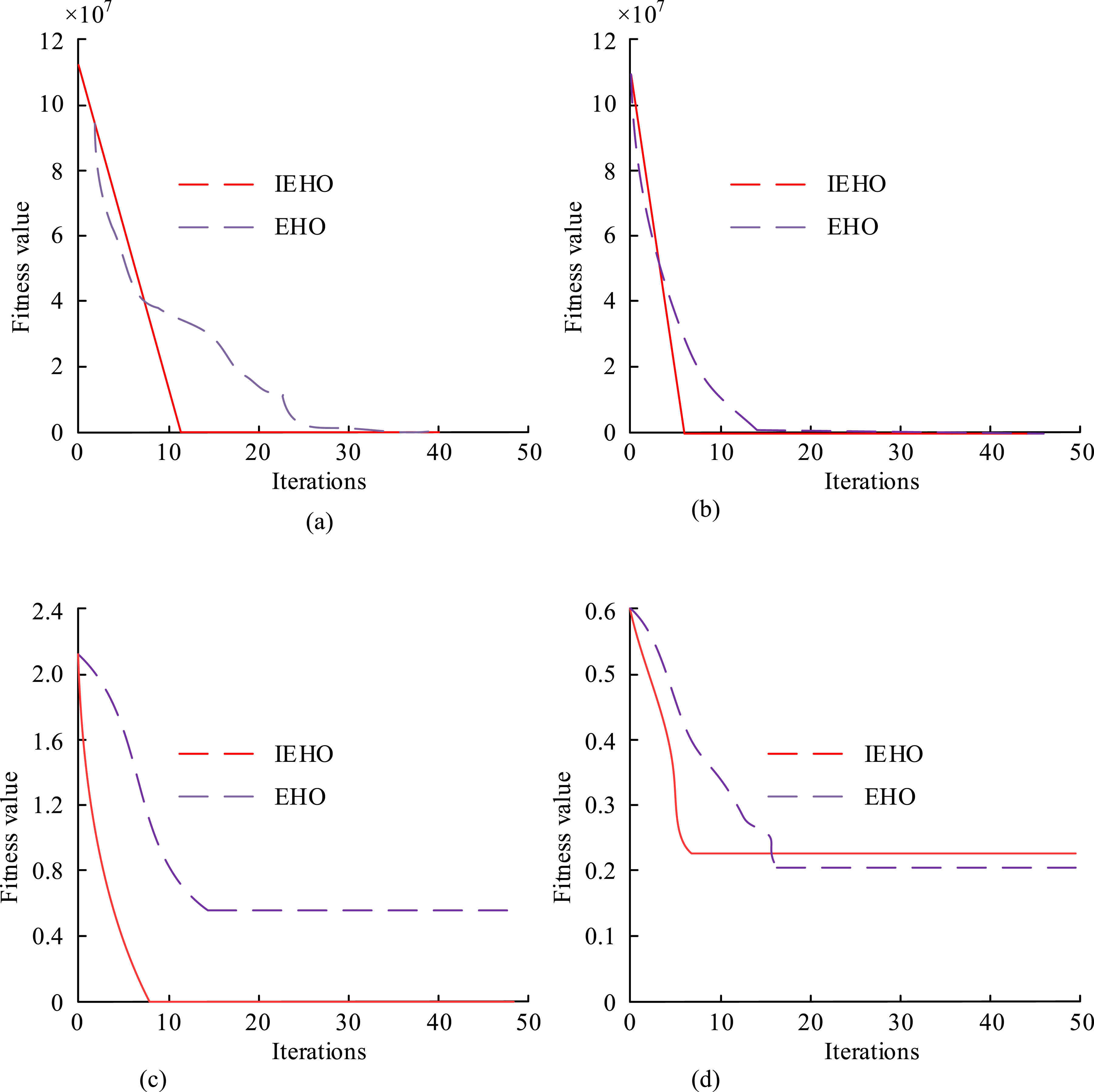
In Figure 9(a), in the unimodal function Rosenbrock, IEHO completed convergence after 12 iterations and EHO completed convergence after 25 iterations. In Figure 9(b), in the unimodal function SumSquare, IEHO completed convergence after 6 iterations and EHO completed convergence after 14 iterations. In Figure 9(c), in the multimodal function Griewank, IEHO completed convergence after 8 iterations and EHO completed convergence after 12 iterations. In Figure 9(d), in the multimodal function Schaffer, IEHO completed convergence after 7 iterations and EHO completed convergence after 16 iterations. Experimental data showed that IEHO achieved faster convergence and stronger performance than EHO, proving the IEHO algorithm’s feasibility. To verify the efficacy of the IEHO algorithm in selecting intrusion data attributes, experiments were conducted to compare the convergence of fitness values for different datasets using four algorithms: IEHO and the moth flame optimization (MFO), ant colony optimization (ACO), and EHO algorithms, as shown in Figure 10. Fitness values in different datasets. (a) The optimal number of feature selection subsets for different algorithms in wine datasets. (b) The optimal number of feature selection subsets for different algorithms in glass datasets. (c) The optimal number of feature selection subsets for different algorithms in Lonosphere datasets. (d) The optimal number of feature selection subsets for different algorithms in heart datasets.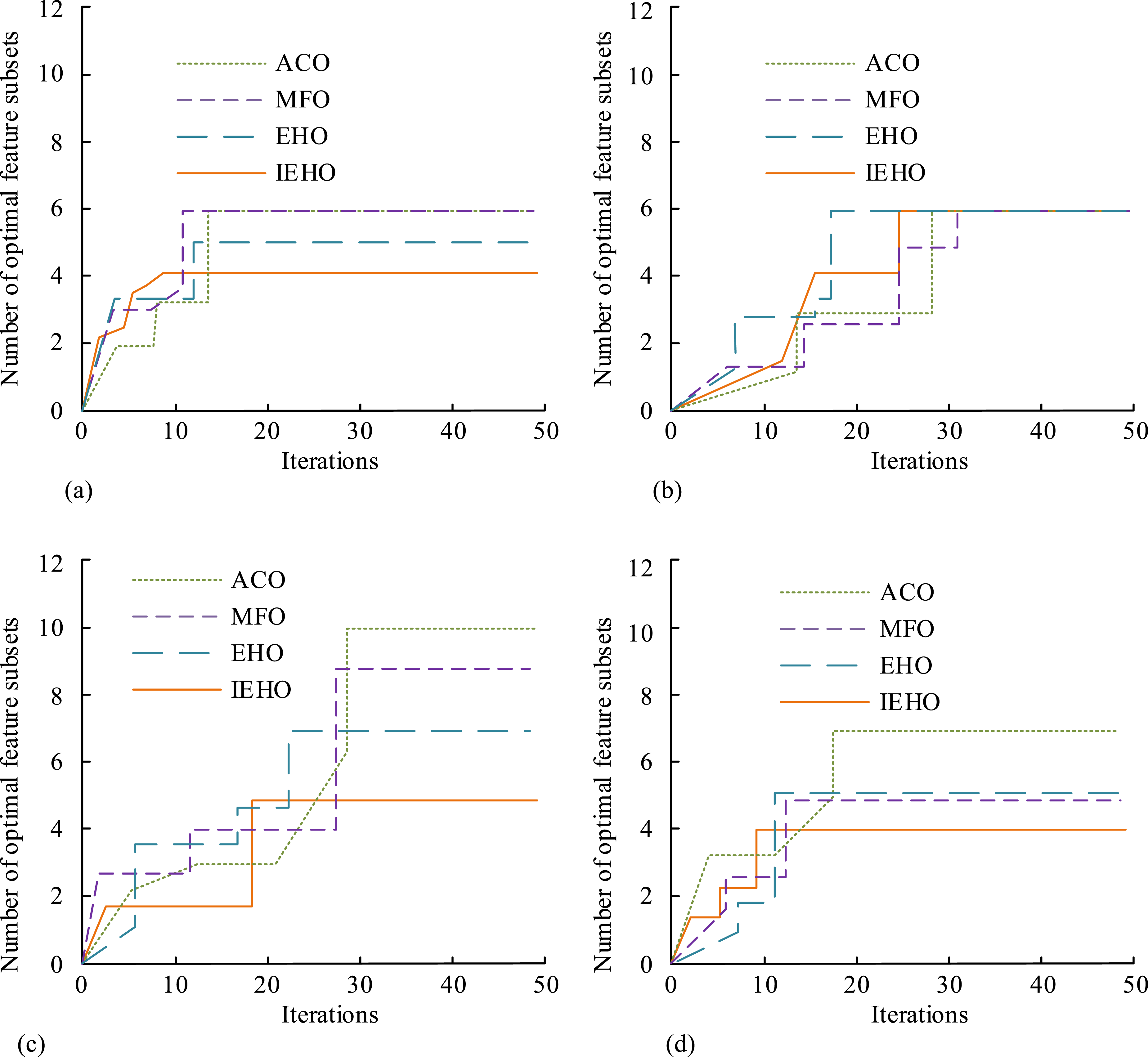
In Figure 10(a), in the wine dataset, the optimal feature subsets for ACO, MFO, EHO, and IEHO were 6, 6, 5, and 4, respectively. In Figure 10(b), in the glass dataset, the optimal feature subsets for IEHO, ACO, MFO, and EHO were all 6. In Figure 10(c), in the ionospheric dataset, the optimal feature subsets for IEHO, ACO, MFO, and EHO were 5, 10, 9, and 7, respectively. In Figure 10(d), in the heart disease dataset, IEHO had the least number of optimal feature subsets, only 4, while there were at least 5 optimal feature subsets for ACO, MFO, and EHO. Experimental data showed that the IEHO algorithm is suitable for data attribute selection. SPIEHO has been proposed in response to the problem of processing large amounts of data. The experiment compared the running time of IEHO and SPIEHO on different datasets to verify the superiority of SPIEHO, as shown in Figure 11. Comparison of runtime between IEHO and SPIEHO on different datasets. (a) Two algorithms processing 2.5 million data speeds. (b) Two algorithms processing 5 million data speeds. (c) Two algorithms processing 7.5 million data speeds. (d) Two algorithms processing 1 million data speeds.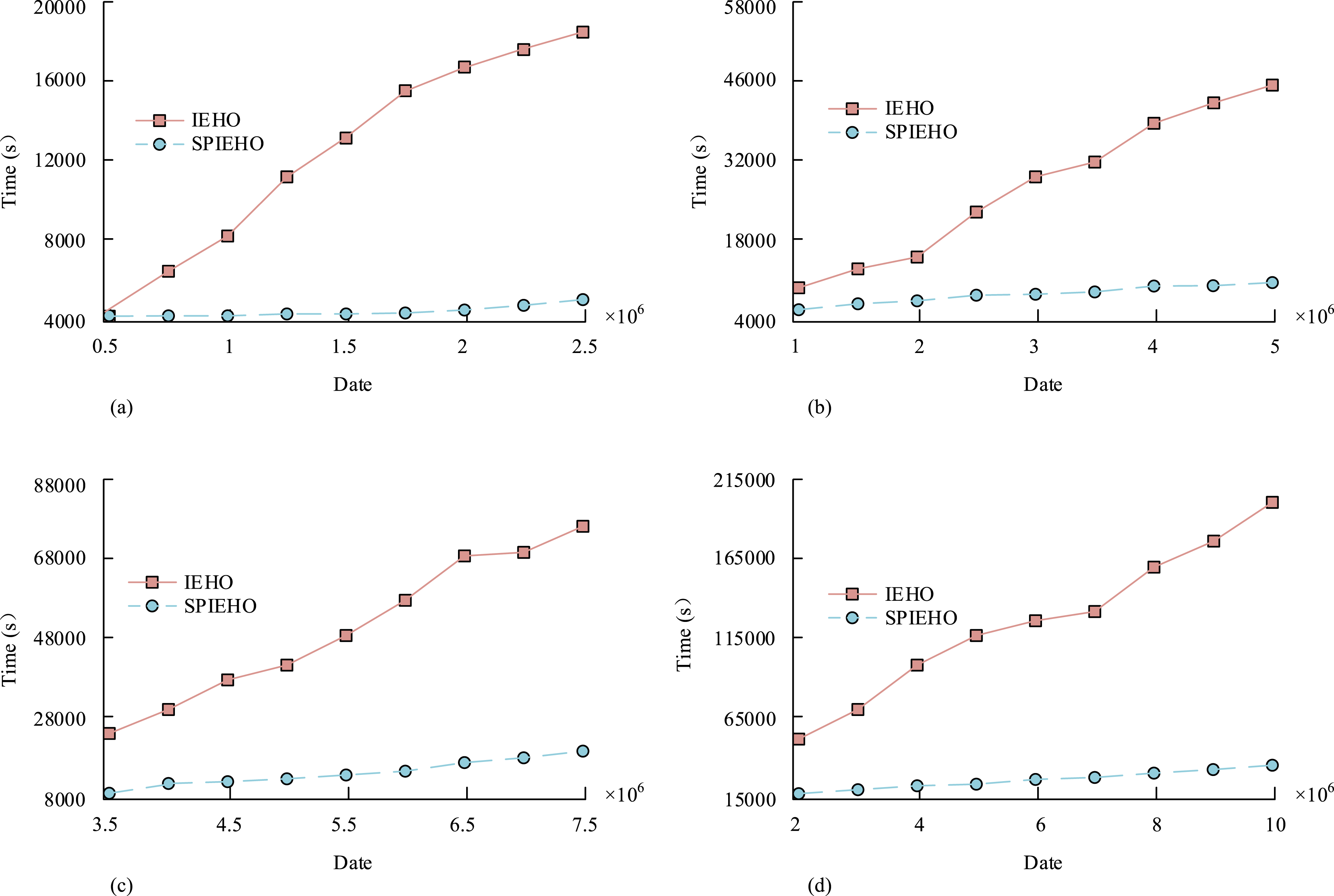
In Figure 11(a), in a dataset of 2.5 million, IEHO ran for 18561 seconds and completed processing; SPIEHO ran for 4125 seconds and completed processing. In Figure 11(b), IEHO and SPIEHO ran on a 5 million dataset with processing times of 42659 seconds and 8614 seconds, respectively. In Figure 11(c), in the 7.5 million dataset, SPIEHO ran faster and only took 16842 seconds to complete, while IEHO ran slower and took 75689 seconds to complete. In Figure 11(d), in a dataset of 10 million, IEHO processed data much slower than SPIEHO, taking 196485 seconds to complete, while SPIEHO only took 32671 seconds. Experimental data showed that SOIEHO processed large amounts of data faster and more efficiently.
Analysis of intrusion detection model based on IEHO-SVM
To assess the efficacy of the NID model based on IEHO-SVM, experiments were organized on the same dataset to compare the detection models of different algorithms combined with SVM algorithm with the IEHO-SVM detection model, as shown in Figure 12. Fitness changes of four algorithm models for different attack types. (a) Adaptation changes of different algorithms to DOS attacks. (b) Adaptation changes of different algorithms to probe attacks. (c) Adaptation changes of different algorithms to R 2 L attacks. (d) Adaptation changes of different algorithms to DOS attacks.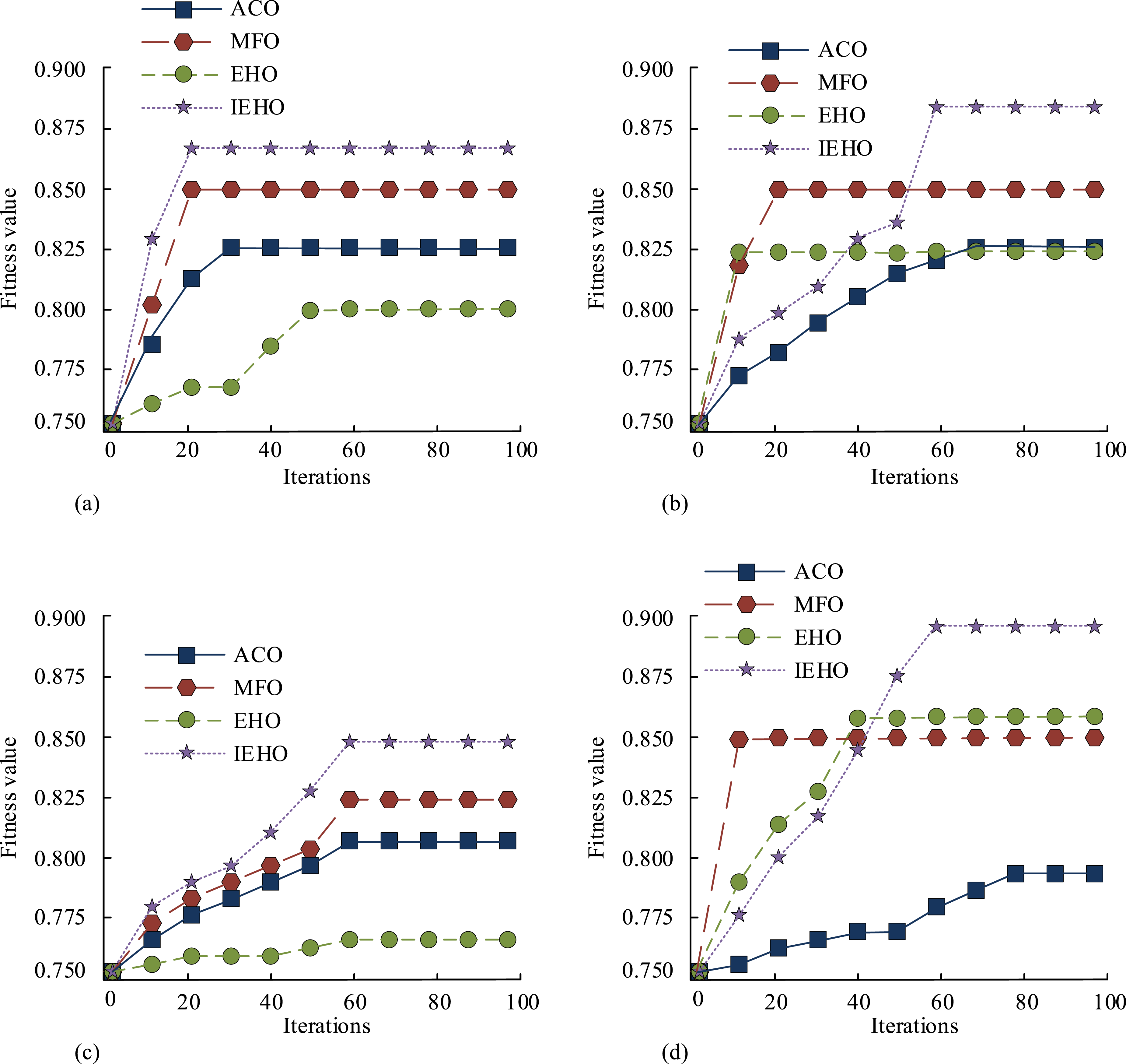
As shown in Figure 12(a), in the Denial Of Service (DOS) attack, the IEHO-SVM detection model converged after 19 iterations, ACO-SVM, MFO-SVM, and EHO-SVM iterated 22, 21, and 45 times respectively, to complete convergence, and the IEHO-SVM model had the highest fitness value of 0.842. As shown in Figure 12(b), in the Probe attack, the IEHO-SVM detection model converged after 62 iterations and ACO-SVM, MFO-SVM, and EHO-SVM completed convergence by iterating 58, 19, and 12 times, respectively, with the IEHO-SVM model having the highest fitness value of 0.675. According to Figure 12(c), in remote to Login (R2L) attack, the IEHO-SVM detection model completed convergence after 57 iterations, ACO-SVM, MFO-SVM, and EHO-SVM iterated 58, 57, and 58 times, respectively, to complete convergence, and the IEHO-SVM model had the highest fitness value of 0.846. According to Figure 12(d), it can be seen that in the U2R attack, the IEHO-SVM detection model completed convergence after 52 iterations, ACO-SVM, MFO-SVM, and EHO-SVM iterated 79, 8, and 40 times, respectively, to complete convergence, and the IEHO-SVM model had the highest fitness value of 0.894. Experimental data showed that the IEHO-SVM detection model had the highest fitness value and fast convergence speed, which verified the effectiveness of the model. To verify the stability of the IEHO-SVM detection model, precision experiments were conducted by comparing three other models. Advanced methods of the same type, Convolutional Neural Networks (CNN) and Random Forest (RF), were selected for comparison. The results are shown in Figure 13. Comparison of detection accuracy of four models for different intrusion data.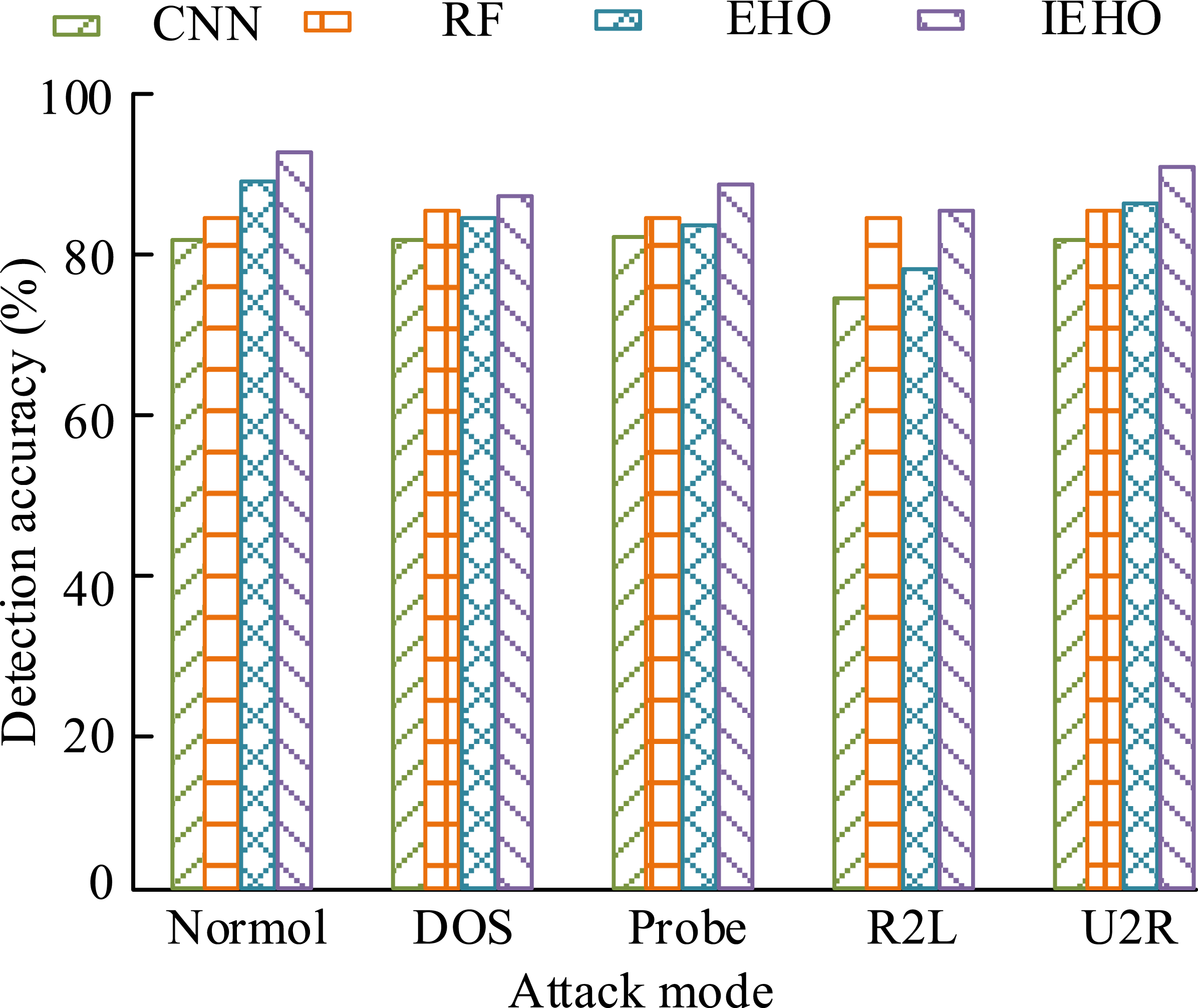
In Figure 13, the IEHO-SVM detection model had a detection accuracy of 94% in normal attacks. The EHO-SVM model had a second highest detection accuracy, at 89%. The IEHO-SVM detection model had a detection accuracy of 87% in DOS attacks. That of the RF model was 82%. In Probe attacks, that of the IEHO-SVM detection model was 85%, except for the IEHO-SVM detection model, the RF model had the highest detection accuracy, at 81%. The IEHO-SVM detection model had a detection accuracy of 89% in R2L attacks. The IEHO-SVM detection model had an accuracy rate of 92% in U2R attacks. Experimental data showed that the IEHO-SVM detection model had the highest detection accuracy for different intrusion data. To further verify the superiority of the IEHO-SVM detection model, the experiment ran four independent models to detect different intrusion data and verified the superiority of the IEHO-SVM detection model through average accuracy, as shown in Figure 14. Comparison of average accuracy of four models for detecting different intrusion data.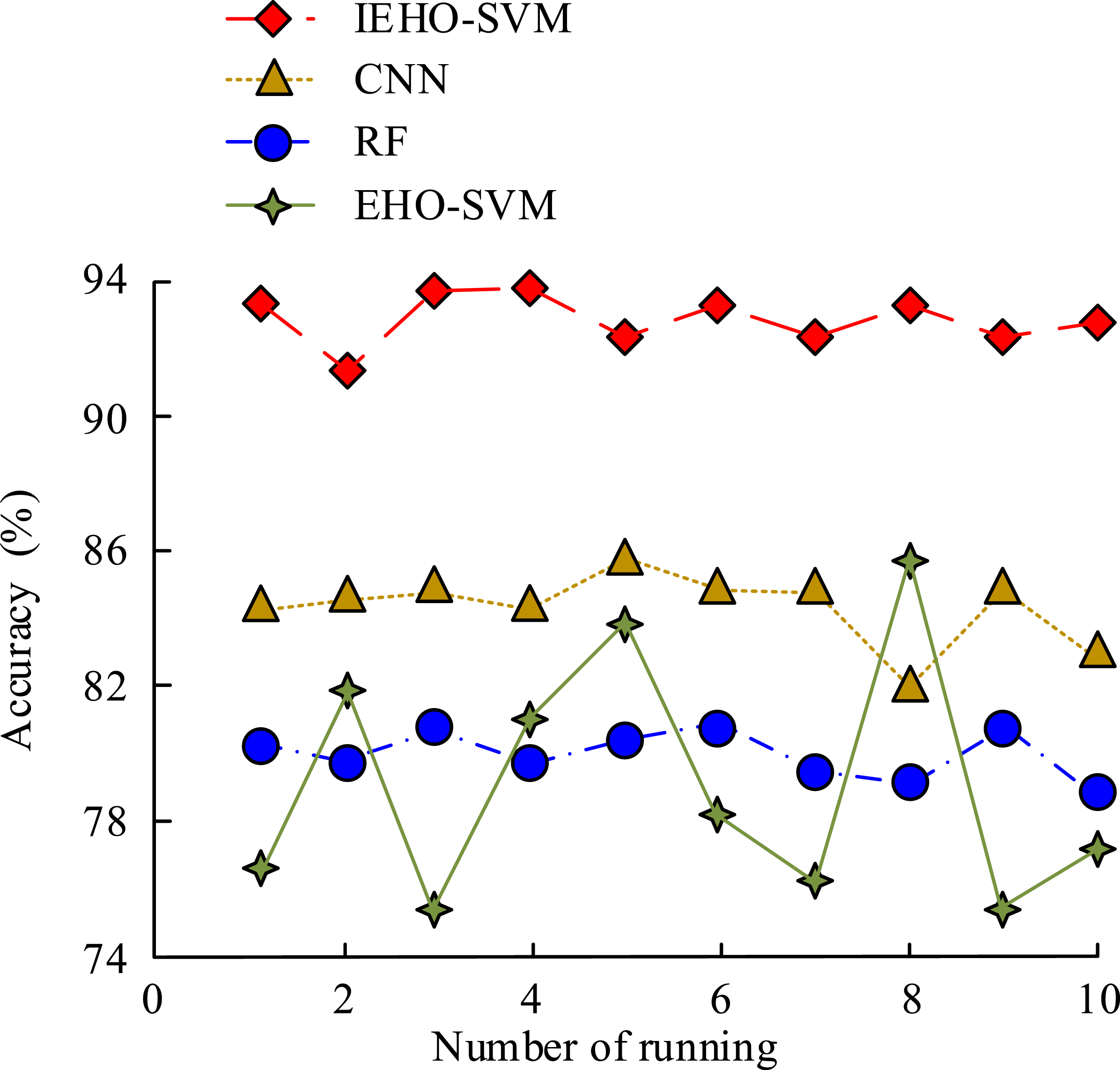
As shown in Figure 14, the average accuracy of the IEHO-SVM detection model for detecting four types of intrusion data remained stable at around 94%. The average accuracy of CNN and RF detection models was around 84% and 80%, respectively. The accuracy curve of the EHO-SVM model fluctuated greatly and had poor stability. Experimental data showed that the IEHO-SVM detection model had the highest detection accuracy and the most stable performance for different intrusion data. The experiment proved the superiority of the IEHO-SVM detection model in terms of detection performance compared to other models.
Discussion and conclusion
The rapid development of network technology has brought about numerous security issues, and traditional NID methods have become increasingly difficult to handle current network intrusion problems. In response to this difficulty, research was conducted to optimize SVM parameters using IEHO and established a detection model based on IEHO-SVM. Experimental data showed that in the wine dataset, the optimal feature subsets for ACO, MFO, and EHO were 6, 6, and 5, respectively. The optimal subset of features for IEHO was 4. In the glass dataset, the optimal feature subsets for IEHO, ACO, MFO, and EHO were all 6. In the ionospheric dataset, the optimal subset of features for IEHO was 5. The optimal feature subsets for ACO, MFO, and EHO were 10, 9, and 7, respectively. In the heart disease dataset, IEHO had the least number of optimal feature subsets, only 4, while there were at least 5 optimal feature subsets for ACO, MFO, and EHO. In a dataset of 2.5 million, IEHO ran for 18561 seconds and completed processing. In a dataset of 2.5 million, IEHO ran for 18561 seconds and completed processing, and SPIEHO ran for 4125 seconds and completed processing. IEHO and SPIEHO ran on a 5 million dataset with processing times of 42659 seconds and 8614 seconds, respectively. In a 7.5 million dataset, SPIEHO ran faster and only took 16842 seconds to complete, while IEHO ran slower and took 75689 seconds to complete. In a dataset of 10 million, IEHO processed data much slower than SPIEHO, taking 196485 seconds to complete, while SPIEHO only took 32671 seconds. The IEHO-SVM detection model was suitable for general attacks. The detection accuracy in network attacks such as DOS, Probe, R2L, and U2R was 94%, 87%, 89%, 85%, and 92%, respectively. The accuracy of other models in detecting different intrusion data was lower than that of the IEHO-SVM detection model. The outcomes indicated that IEHO had the best preprocessing effect on intrusion data and SPIEHO had the highest efficiency in processing data. Meanwhile, it is proved that the EHO-SVM detection model proposed by the research is effective in dealing with network intrusion problems. The current IEHO-SVM model is mainly trained and tested based on traditional network traffic characteristics. However, the increasing number of adversarial attacks against NID may lead to a decline in model performance. Attackers can evade detection through carefully designed traffic patterns. In the future, it is necessary to evaluate the robustness of the IEHO-SVM model to determine its performance in the face of adversarial attacks. The introduction of an adaptive mechanism is considered to improve the stability and accuracy of the model in such situations. Deep learning techniques are combined with the IEHO-SVM model. Deep learning performs well in automatic feature extraction and complex pattern recognition, providing a more powerful foundation for IEHO-SVM. Deep learning is used to generate an initial feature set and further optimize the selection through IEHO, which can improve the overall accuracy and robustness.