
Abstract
The individualized demand for cigarettes from customers is growing quickly with the rapid expansion of e-commerce, posing a significant challenge to the finished cigarette warehouse system. This study proposes an automated warehouse picking optimization method based on the FP-growth algorithm and an improved genetic algorithm. This method significantly improves warehouse operational efficiency by optimizing product combination packing, storage location of goods, and order batching. Specifically, the study introduced two mechanisms to improve the genetic algorithm and optimize the storage location of goods: a dynamic parameter adaptive mechanism and an evolutionary reversal operator. It also combined the improved K-means algorithm (IKMA) for order batching optimization. Compared with existing methods, this study achieved rapid convergence to an approximate optimal solution and significant reductions in warehouse inbound and outbound operations and picking time. These reductions were 16.8–32.0% and 33.2%, respectively. Compared to the other two methods, the enhanced genetic algorithm stabilized the total number of bin entries and exited after approximately 420 iterations of product location optimization. These results indicate that the method proposed in this study has significant advantages in responding to the rapid changes in order demand in the e-commerce environment, providing a new direction for warehouse management.
Introduction
The logistics system’s foundation is the warehouse system, which has a big impact on the enterprise’s operational expenses, efficiency, and level of service. Cigarette finished goods warehousing system can enhance the flow of cigarettes, speed up the completion of warehouse operations, save enterprise warehousing management costs and improve enterprise profits. 1 A warehousing system is a logistics activity that uses advanced technology to integrate, manage, control, and execute information related to all aspects of commodity entry and exit. 2 With the development of electronic computer technology, through the use of appropriate algorithms to assist the storage system for storage and picking, the realization of intelligent and automated warehousing that is automated warehousing system. This has a decisive impact on the automated warehouse picking system in the whole warehouse operation on reducing the labor intensity of workers, improving the picking efficiency and reducing the picking error rate.3,4 At present, the placement of goods in automated warehousing is only for single products, and the placement is not considered to explore the correlation rules between the quality and volume of various types of cigarettes. The distribution of goods is mainly considered to be influenced by factors such as access efficiency and the walking path of shuttle cars, and the placement of goods for each space is not considered to be studied. There are mainly two methods for order batching, one is similar order batching, and by calculating the degree of similarity between orders. Generally, the picking time of an order is used as the similarity index.5,6 The other is time window batching, where orders are picked as a batch within the same time period. The current automated warehouse picking equipment only considers the optimization of the goods position, ignoring the problem of combining goods into boxes. In light of this, an automated warehouse picking system is proposed based on the FP-growth algorithm for commodity merging box model, introducing parameter adaptation and evolutionary reversal operator to improve the genetic algorithm for goods position optimization, and combining the improved K-means algorithm (IKMA) for order batching for optimization, expecting to improve the response speed of the warehouse picking system, reduce the picking error rate, and improve the picking accuracy. The goal of the research is to propose an efficient, integrated optimization method that can quickly converge on near-optimal solutions in complex data environments. This method would significantly improve warehouse operational efficiency and provide strong technical support for the logistics industry’s transformation and upgrading.
Related works
The most critical link in modern logistics is the warehouse system, which affects the cost, service quality and efficiency of logistics, so many scholars have studied the warehouse system. To make the warehouse system more flexible and agile in the face of large-scale personalization and a service-oriented approach, Leng et al. used optimization models to extract online data on perceived physical warehouse products and generate regular optimal decisions. The above research methods were difficult to adapt to the rapid changes in order demand in the e-commerce environment and lack dynamic response capabilities. However, this study introduced an adaptive mechanism with dynamic parameters that could respond in real time to changes in order demand. This mechanism could adapt to rapid changes in the e-commerce environment. Sun et al. group members to integrate the scheduling problem of various types of resources of the smart warehouse system. The use of a triangular fuzzy function in a collaborative scheduling model based on genetic algorithms is presented to reduce the completion time. The model’s optimal scheduling is determined by genetic algorithm calculations for vector encoding and fuzzy number ranking. Experiments show that the picking time is significantly reduced and optimal coordination of various resources is achieved. 7 To enhance the efficiency of warehouse picking systems, Pier and Weidinger present a framework for strategic decision assistance based on neural networks. The optimal order system is selected for the order structure by neural networks and the optimal parameters are calculated for the framework to select a suitable picking system. Comparing three different order picking systems, the framework finds the optimal order structure system. 8 Bansal and Roy both proposed an analytical framework based on a hybrid model of matrix geometry algorithm. The data in the queuing network is extracted using the matrix geometry algorithm and the network data performance metrics are obtained through hybrid simulation. The testing findings demonstrate a 15% reduction in warehouse throughput time, which is superior to competing framework systems. 9 To improve the effectiveness of automated warehouse management, the picking system of stacker crane outbound is optimized by mathematical functions, Yang et al. combined with an optimization model of cargo space allocation based on the space allocation principle, to realize the efficiency improvement of automated warehouse management, reduce cargo handling and storage costs, and lower logistics costs. 10
FP-growth algorithm has powerful data mining ability, so it is used in various industries to mine the association rules of data. Wang et al. proposed a multicluster particle swarm optimization frequent pattern algorithm that combines the particle swarm optimization algorithm and the FP-growth algorithm. This algorithm solved the memory overflow problem caused by an unbalanced computational load in a Spark cluster computing environment. To overcome the issue of memory overflow brought on by excessive data volume, parallel computation was realized by grouping the data to achieve the creation of FP trees and using parallel conditional frequent pattern trees for computation. 11 The above research methods mainly focus on optimizing computational performance and do not involve applications in logistics scenarios. However, this study applies the FP-growth algorithm innovatively to the field of logistics, optimizing product combination packing by mining frequent item sets. This provides a new solution to optimization problems in logistics scenarios. The optimized FP growth algorithm proposed by He et al. can deeply explore data association rules in information systems and optimize confidence algorithms to solve problems such as delayed or missed short message core alerts caused by large-scale network alerts. The results of the experiment demonstrate that the algorithm can efficiently aggregate the alert information and offer convenience for use and upkeep. 12 Nasyuha et al. used the FP-growth algorithm to mine the arrangement sales data among products in the store, determine the frequent item set in the dataset, and use the data to guide the store to place products according to the frequency of product demand, which facilitates customers to find the demanded products. 13 Jang et al. proposed a region based frequent pattern growth (RFP growth) algorithm to address the issue of association rules that might not be detected due to different regions. The algorithm searched for association rules through dense regions. The experimental results showed that RFP growth could discover new association rules that the original FP growth cannot find in the entire data. 14 Wei et al. aimed to conduct a comprehensive literature review of the latest research on retail product recognition based on deep learning. The study reviewed the main challenges of deep learning in retail product recognition and discussed techniques that may contribute to the research on this topic. 15 Lin et al. used object detection methods in deep learning to automatically count plants using multispectral images. In order to fully utilize the advanced YOLOv8 network, their architecture was modified to adapt to different band combinations and extensive data preprocessing work was carried out. The results showed that the counting accuracy was as high as 99.53%. The combination of drones, multispectral data, and powerful deep learning methods has shown broad application prospects in disease and pest control. 16
In summary, significant progress has been made in researching automated warehouse picking systems. However, there are still shortcomings when it comes to meeting the rapidly growing personalized cigarette demand of customers in the e-commerce environment. Existing methods primarily focus on optimizing the storage location of a single product. These methods do not fully explore the correlation between the quality and volume of different types of cigarettes. They also have limitations when it comes to optimizing product combination packaging and order batching. The aim of this study is to propose an innovative integrated optimization method that explores high-frequency co-occurrence product combinations, optimizes the dynamics of location allocation, and improves the overall efficiency of the system. To this end, this study proposes a cigarette box combination model based on the FP-growth algorithm. This model uses an improved genetic algorithm to optimize cargo location and combines the seed-based IKMA algorithm to optimize order batches.
Optimization study of automated cigarette storage picking system
Ferris wheel storage modeling
To optimize the automated storage picking system for finished cigarette products, a mathematical model of the warehouse shelves must first be established. This model combines the actual state of the shelves with the operation of the mechanical equipment, known as the Ferris wheel storage model. The objective function of the access efficiency of this model is shown in equation (1).

In equation (1),

In equation (2),
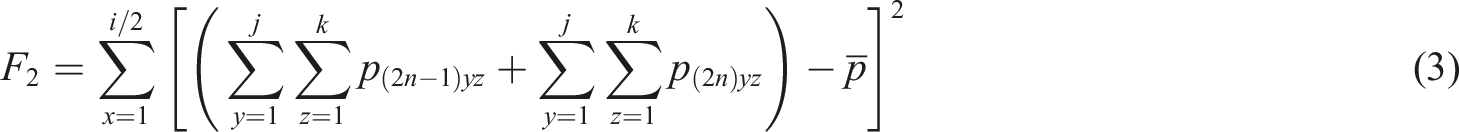
In equation (3),
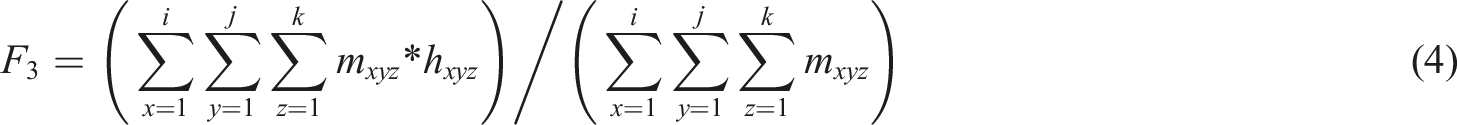
In equation (4), Ferris wheel storage simplified structure.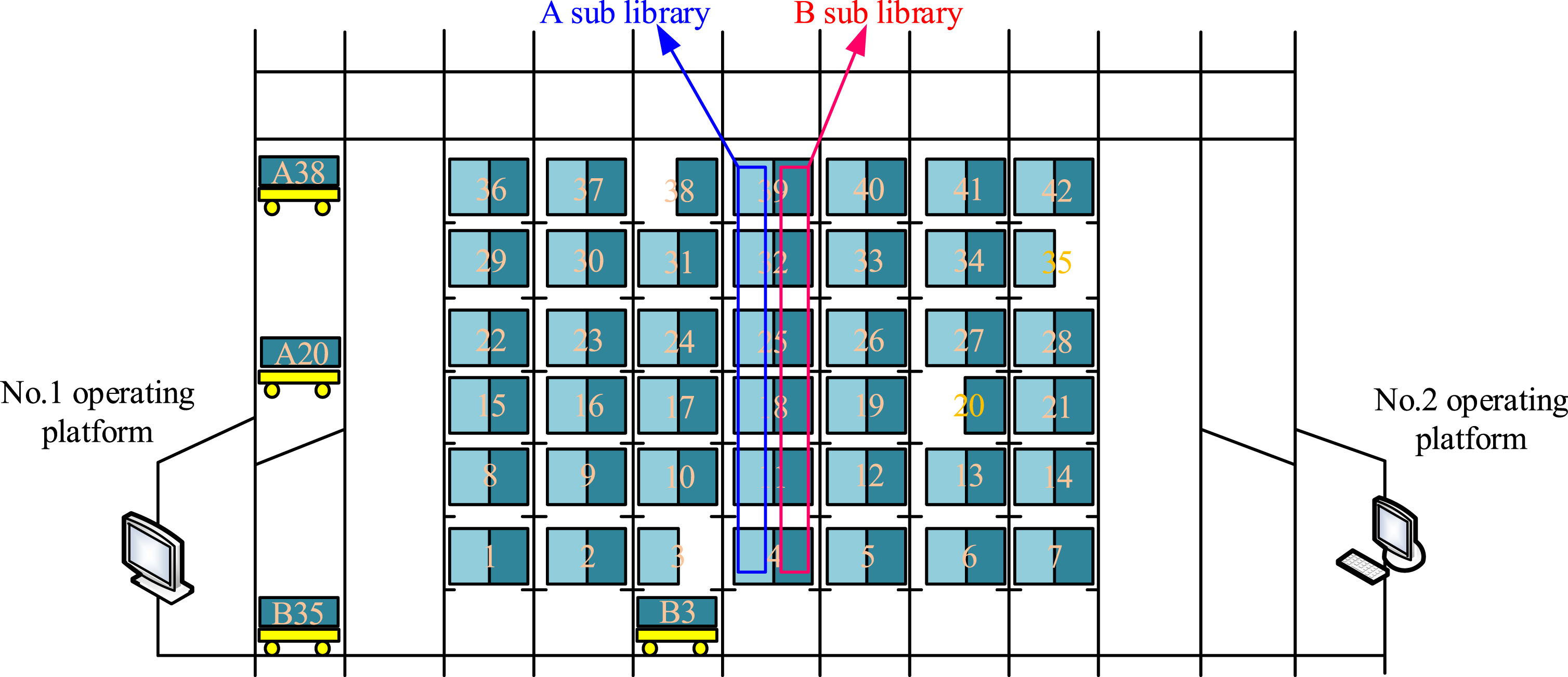
Optimization study of cargo space allocation based on FP-growth algorithm for commodity consolidation and improved genetic algorithm
FP-growth-based item combination
The commodity combination bin model is based on a large-scale cigarette order dataset and a FP-growth algorithm, respectively. It is formed by placing identical orders and cigarettes that fulfill frequent simultaneous occurrences into the same bin without exceeding the volume and mass of the bin design. In the first step, an order record table database is created for customers to purchase cigarette products, with the order number as the identifier. In the second step, the set of goods items for each type of cigarette is scanned for the first time, and the support degree of the goods items is summarized. The third step involves creating the frequent pattern tree (FP-tree) of the order cigarette item set based on the set of non-frequent items as shown in Figure 2. When the support degree of the scanned item is greater than the minimum support degree threshold, the item will be considered a frequent item and saved, and the opposite is rejected. The FP-tree is mapped to the number of occurrences of commodity items on that path and the commodity items as null nodes, and this is the starting point. Figure 2(a) represents the FP-tree constructed after the first order cigarette commodity item set. Figure 2(b) represents the FP tree constructed after the second-order cigarette product itemset. According to this condition, all order cigarette product itemsets are mapped to the FP tree. The FP tree for all order cigarette product itemsets is generated, as shown in Figure 2(c). FP tree for constructing order cigarette product itemsets.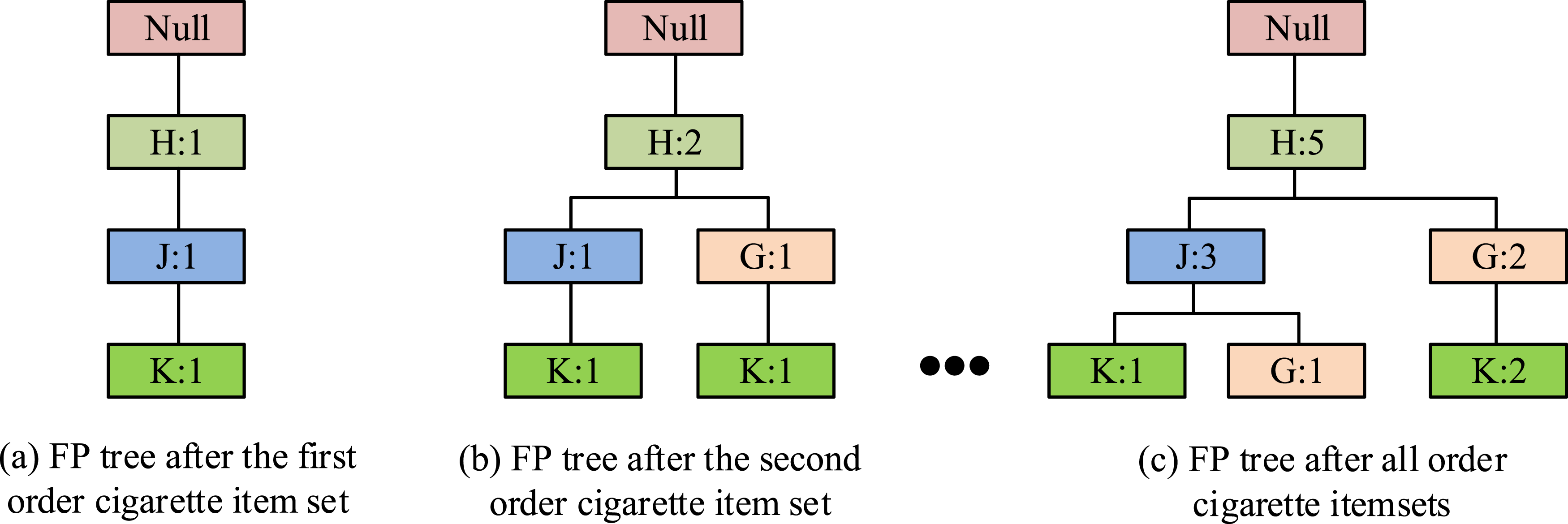
In the fourth step, the bottom-up iterative approach is employed to continue mining frequent itemsets in the FP-tree. New FP-trees are generated by using different suffix nodes to continue mining, and all the mined frequent itemsets are formed into a complete FP-tree model. In the fifth step, the mined frequent itemsets are combined by the bin storage volume constraint formula in the automated picking equipment, and the constraint formula is shown in equation (5).

In equation (5),

In equation (6),
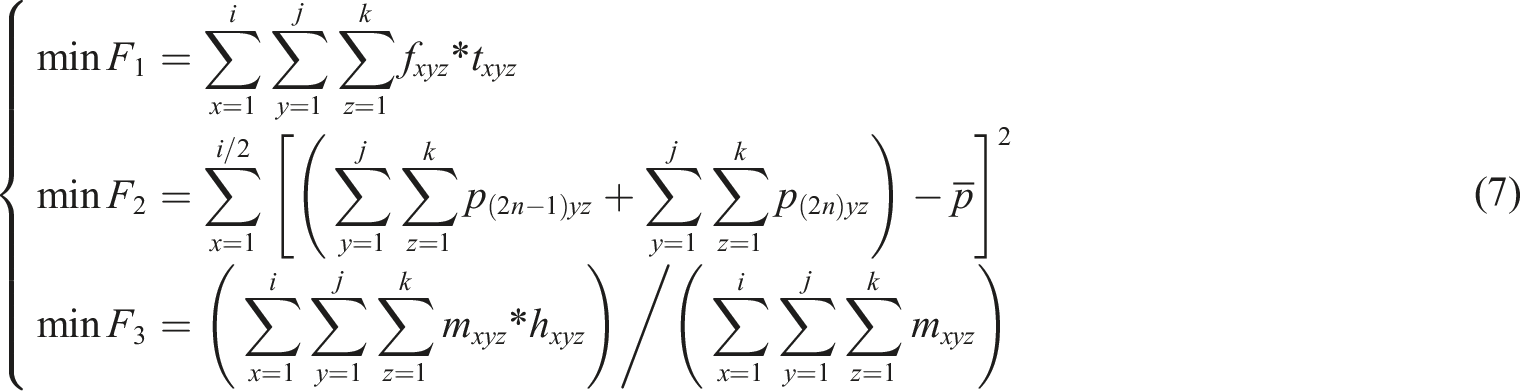
The weight method is used to multiply each of the three objective functions by the respective weight values in order to fuse them into one objective function, the expression of which is presented in equation (8). Optimizing three objective functions is the basic way for optimizing cargo space.

In equation (8),

In equation (9),
Genetic algorithm enhancement
The selection operator selects a portion of the parent population for the offspring reproduction operation, and the probability of its individuals being selected is shown in equation (10).

In equation (10),

In equation (11),
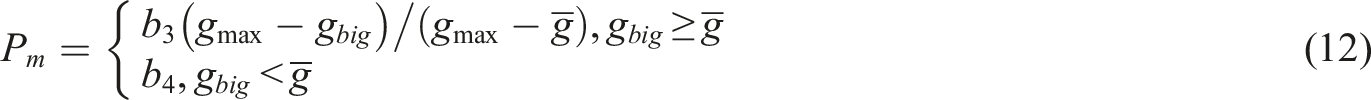
In equation (12),
Two-stage batching via IKMA
The pre-order cut-off and post-order cut-off of the order batch optimization are separated based on the FP-growth algorithm based on the combined bins. For the pre-order cut-off order batching optimization, orders with frequent warehouse item purchases are pooled to reduce the number of bin sampling. The seed order-picking model is constructed based on the purchase frequency of warehouse items. The purchase frequency of an order is the sum of the purchase frequencies of all the warehouse items in a given order. This equation is shown in equation (13).

In equation (13), Flow chart of order batch algorithm before order cut-off.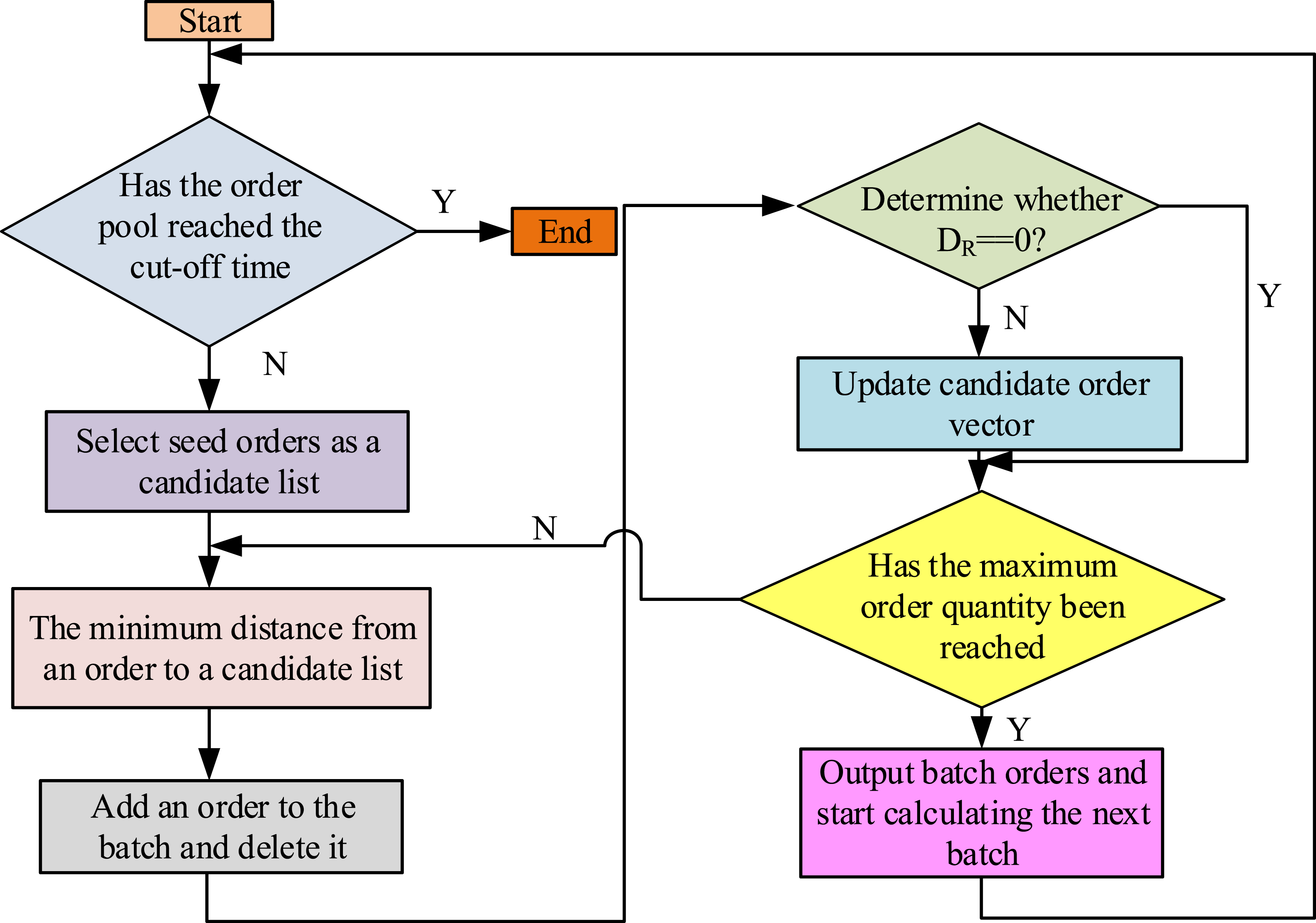
As shown in Figure 3, the order data is subjected to FP-growth mining of frequent itemsets to generate candidate order combinations. Then the genetic algorithm optimizes the path using dynamic crossover rate and calculates the fitness function. Afterward, IKMA clustering is carried out in two stages. The first stage is based on initial clustering using the Euclidean distance method. Then, two-stage dynamic adjustment of the center point is performed. Finally, the picking batch and path plan are output. The distance from order R to the candidate order based on the warehouse item storage bin information is shown in equation (14).

In equation (14),
To shorten the order picking time, an order batching strategy based on the IKMA for seed orders is proposed. It has been determined that the class centers of order batches are inadequate for the purpose of reflecting the differences between samples and classes, whether utilizing sample means or employing Euclidean distances. To address this limitation, the K-means algorithm has been enhanced through the refinement of the model of order batches post-order cutoff, as illustrated in equation (15).

In equation (15),

In equation (16), Flow chart of order batch algorithm after order cut-off.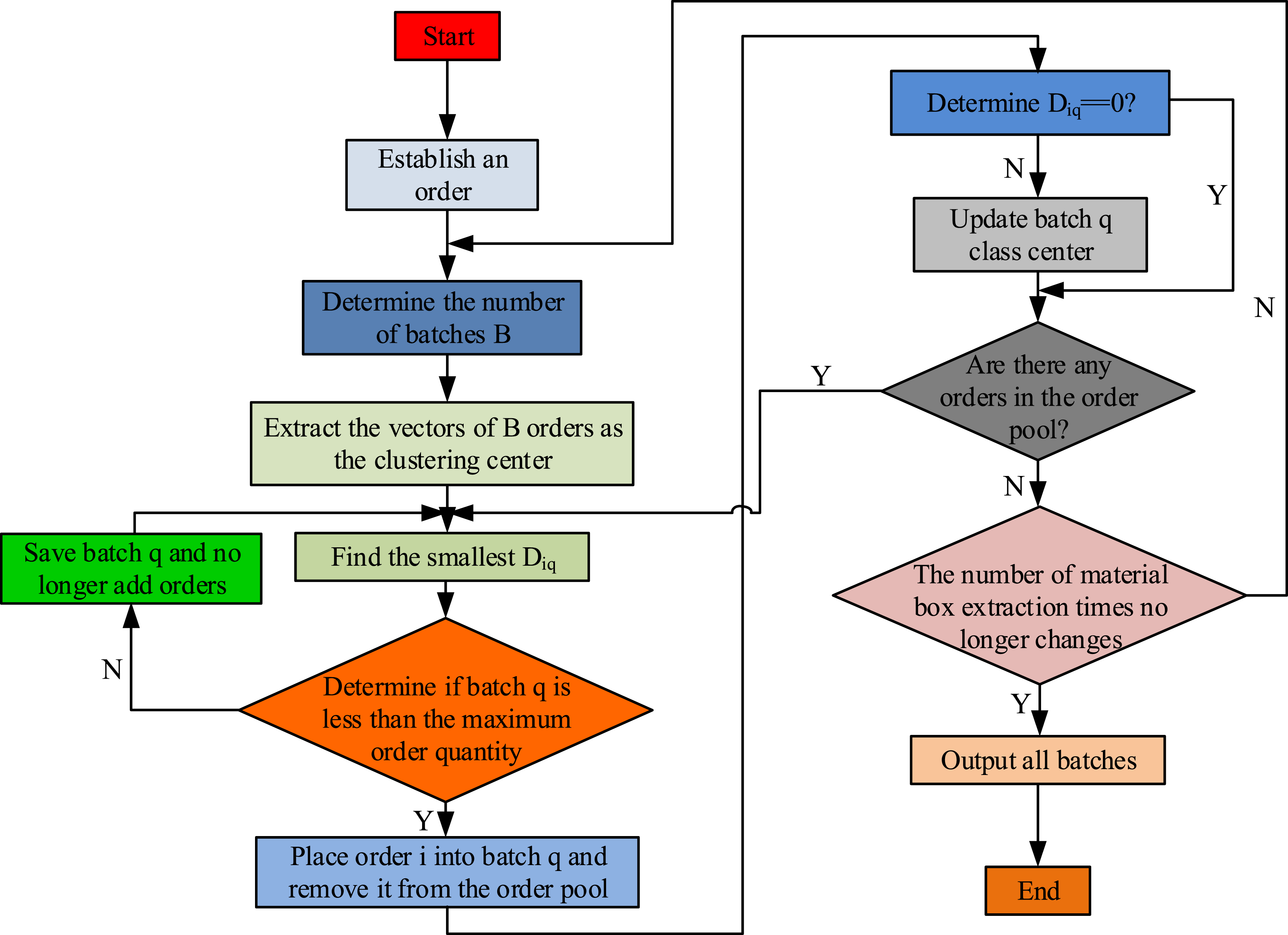
First, order batching calculates the number of orders in the order pool to determine the number of batches, as shown in Figure 4. Then, it establishes the storage vector of the bins where a certain order is located through the storage bins mapped by warehouse items. Finally, it calculates the distance from the order to the center of batch clustering. This calculation is based on the warehouse item storage bin information and is demonstrated in equation (17).

Select the batch
Analysis of the effect of optimized automated warehouse item storage picking
Analysis of the effect of combining boxes and cargo space optimization
The number of bins extracted over the course of 4 days and the overall number of bins extracted each day were computed using the order first come first served choosing pattern to assess the effectiveness of the FP-growth algorithm based on the product bin combining.
From Figure 5(a), the total number of times the bins were extracted by single item placement picking for four consecutive days was 4718, while the total number of times the bins were extracted by combined box placement picking was 4036, a decrease of 682 times, a decrease of 14.5%. From Figure 5(b), the total number of times the bins were extracted by single item placement picking for completed orders was 4958, while the total number of times the bins were extracted by combined box picking was 4218, a decrease of 740 times, a decrease of 14.9%. It proved that the FP-growth algorithm based on the item-combined bins improved the order picking efficiency and also increases the cargo space utilization. Further validation of the effectiveness of the improved genetic algorithm-based cargo space assignment is shown in Figure 6 for various cargo space assignments. Comparison of the number of material box extraction times for single item placement and combined box placement. Comparison of performance of various cargo location algorithms.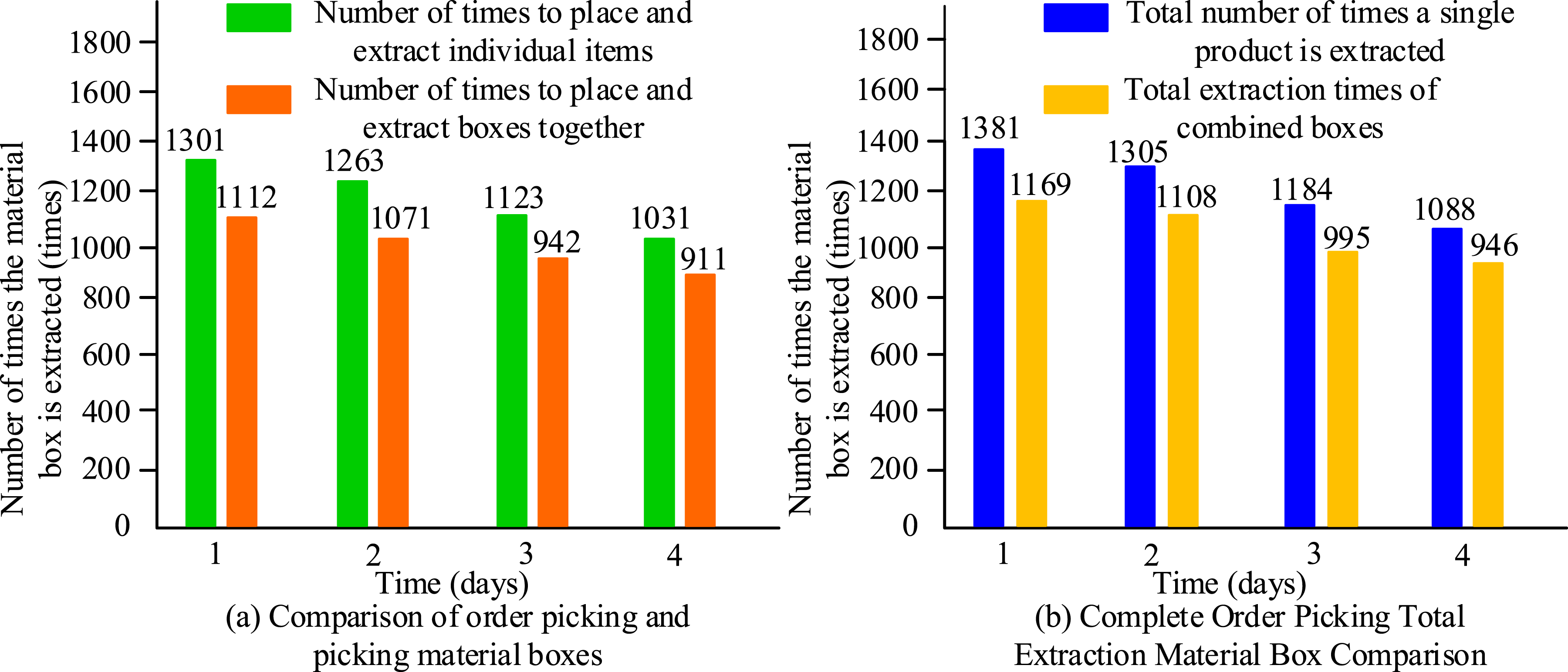
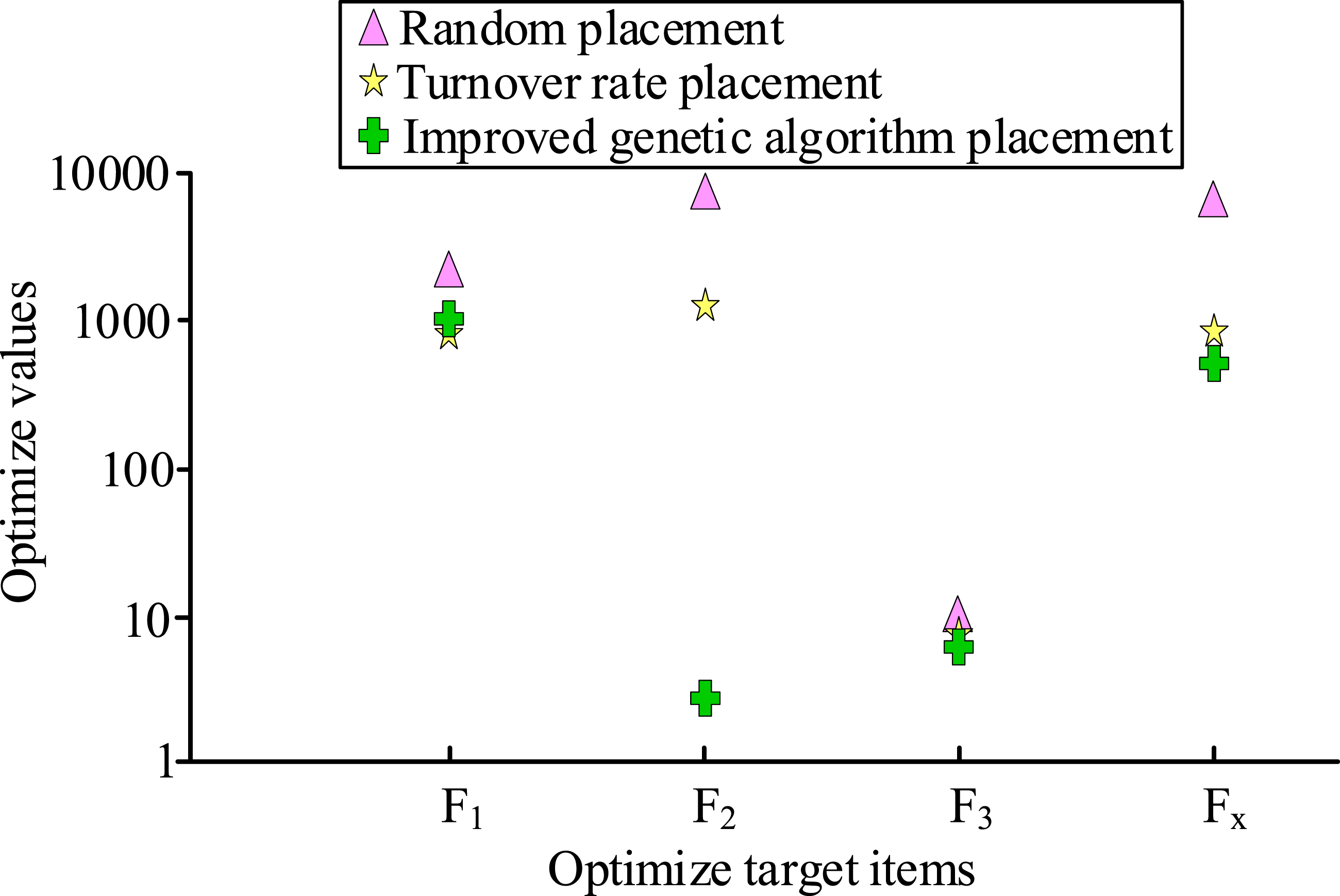
In Figure 6, the value of goods picking rate based on the improved genetic algorithm (F1) was larger than that of F1 based on the turnover-space correspondence principle. However, the value of the degree of disequilibrium of the aisle picking task (F2) and the center of gravity of the shelf (F3) were both lower than those of the free placement and the turnover-space correspondence principles, with values of 2.8 and 6.60, respectively. The objective function (Fx) had a value of 503.2, which was lower than the values of the other two placement methods. The lower the value of Fx, the better the optimization effect of cargo placement. The optimization of cargo placement was better the lower the value of F. It demonstrated that a stronger genetic algorithm improved cargo placement performance. The convergence curves of the three genetic algorithms were compared with the regular genetic algorithm and the elite retention genetic algorithm, as illustrated in Figure 7, to confirm the convergence of the enhanced genetic algorithm. Comparison of convergence curves of three genetic algorithms.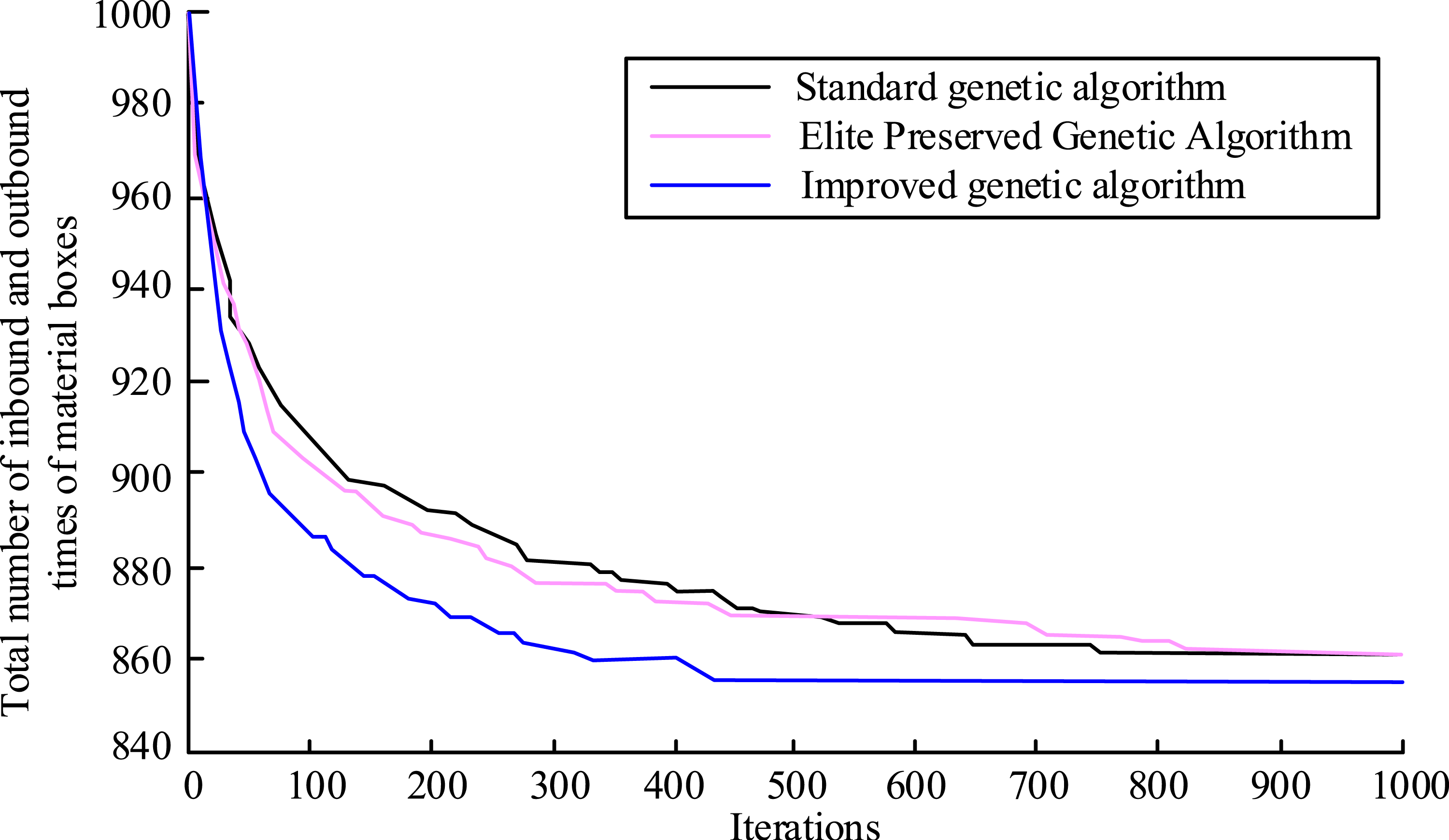
According to Figure 7, the improved genetic algorithm reached stability after 420 iterations of the total number of bin entries and exits, whereas the other two algorithms require about 800 iterations to stabilize. The standard genetic algorithm converged the slowest. It showed that the improved genetic algorithm could find the optimal solution after less iterations, which improved the solution accuracy and could satisfy the large-scale data solution. The above results might be due to the elite retention strategy accelerating the search for the global optimal solution and reducing ineffective iterations. At the same time, the FP-growth algorithm efficiently mined frequent patterns in data by constructing FP trees, which provided valuable clues for solving optimization problems.
Analysis of the effect of optimized order batches
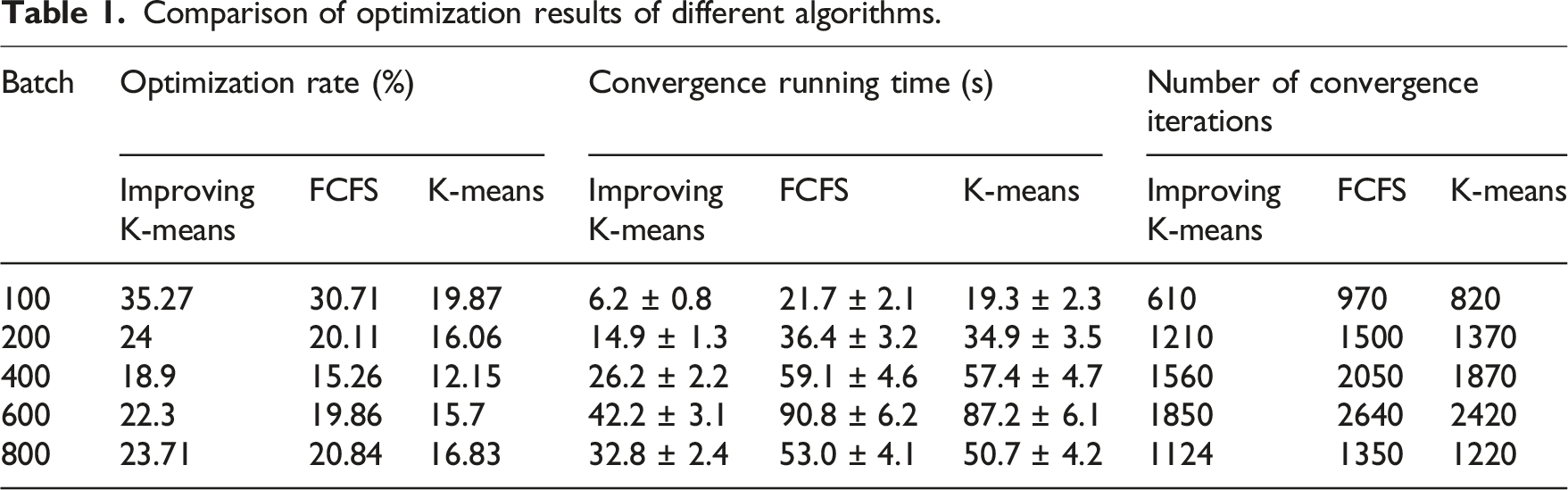
To confirm the effectiveness of the IKMA based on the seed idea for two-stage order batching optimization, the convergence performance of the two algorithms at various job sizes was compared with the first-come, first-served batching algorithm, as shown in Figure 8. Comparison of convergence between two algorithms under different task scales.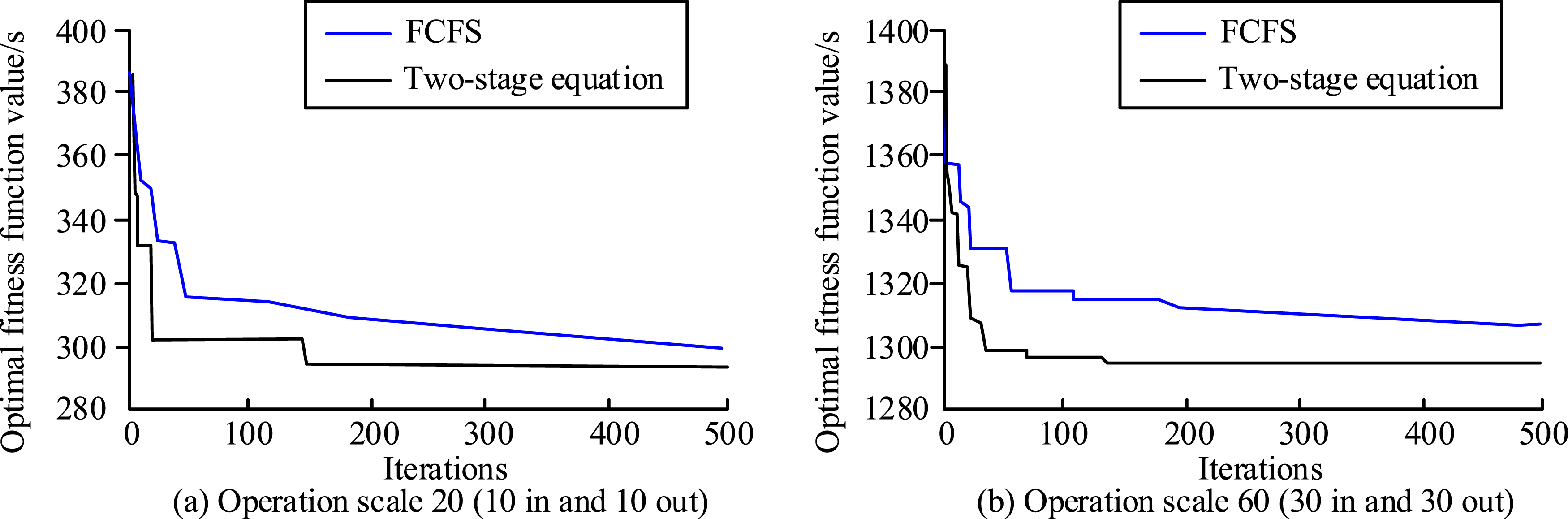
Comparison of optimization results of different algorithms.
Comparison results of order two-stage batch and sequential batch.
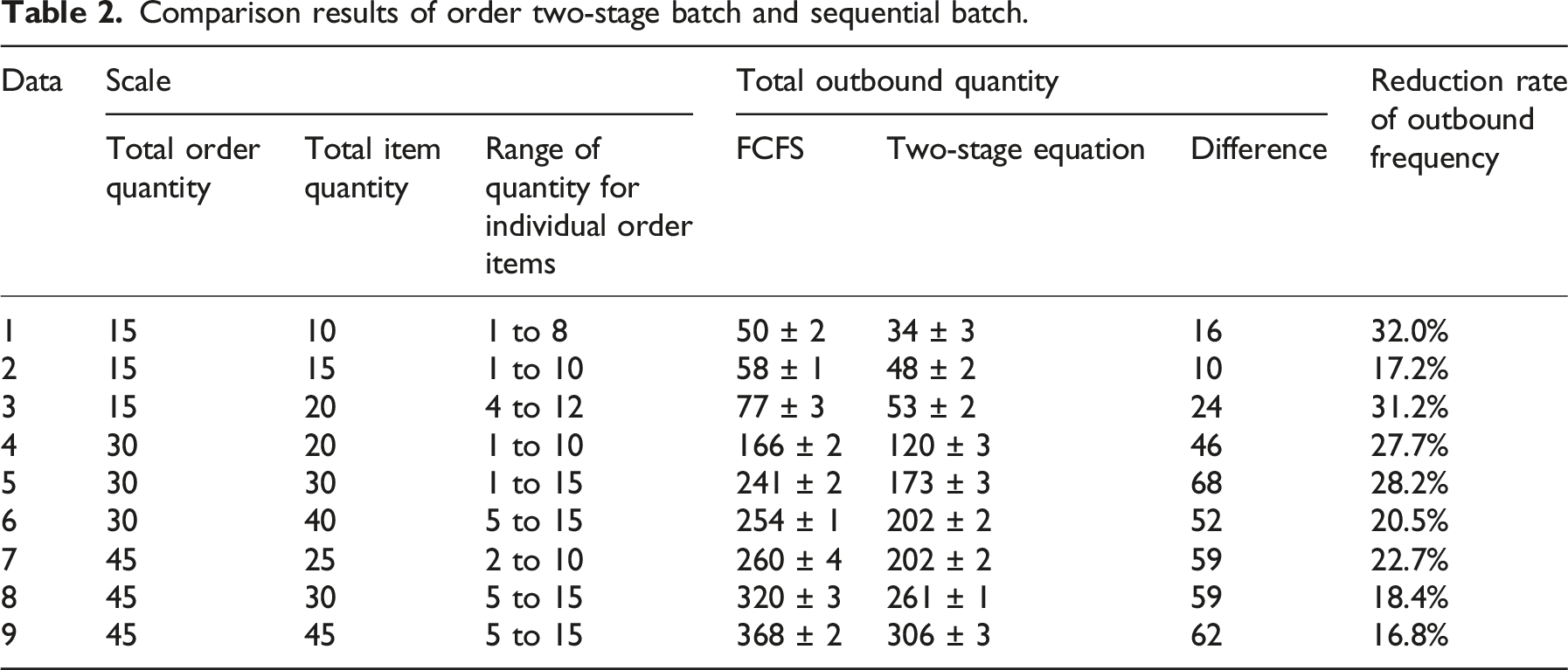
In Table 2, the total number of discharges after two-stage order batching optimization in different data sets was less than the total number of discharges after FCFS batching in all of them, with a reduction rate ranging from 16.8% to 32.0%. In Data 1, the total number of discharges after batching optimization was reduced by 16 times with a reduction rate of 32%, and the total number of discharges after total batching optimization was reduced by 62 times with a reduction rate of 16.8% in Data 9. It suggested that the order batching optimization performance of the IKMA based on seed idea was improved.
Analysis of the effect of automated warehouse picking
A simulation experiment was conducted to compare the effectiveness of goods level allocation using the turnover-goods level correspondence principle and the improved genetic algorithm. This experiment was designed to verify the performance of the automated warehouse picking system, which combined the improved genetic algorithm-based goods level optimization and the improved K-means algorithm based on the seed idea for two-stage order batching optimization of finished warehouse items using the FP-growth algorithm.
In Figure 9, darker colors indicated a higher turnover rate of warehouse items placed in bins. According to the turnover-space correspondence principle, lower shelf utilization was associated with darker colors. The improved genetic algorithm achieved higher shelf utilization and a more uniform distribution of space utilization. Additionally, it balanced the aisle picking task and reduced the shelf center of gravity while considering picking efficiency. Table 3 compares the effectiveness of the whole automated warehouse picking system before and after optimization. Comparison of location distribution between two algorithms under the condition of two-stage order batching. Comparison of order picking efficiency before and after overall equipment optimization.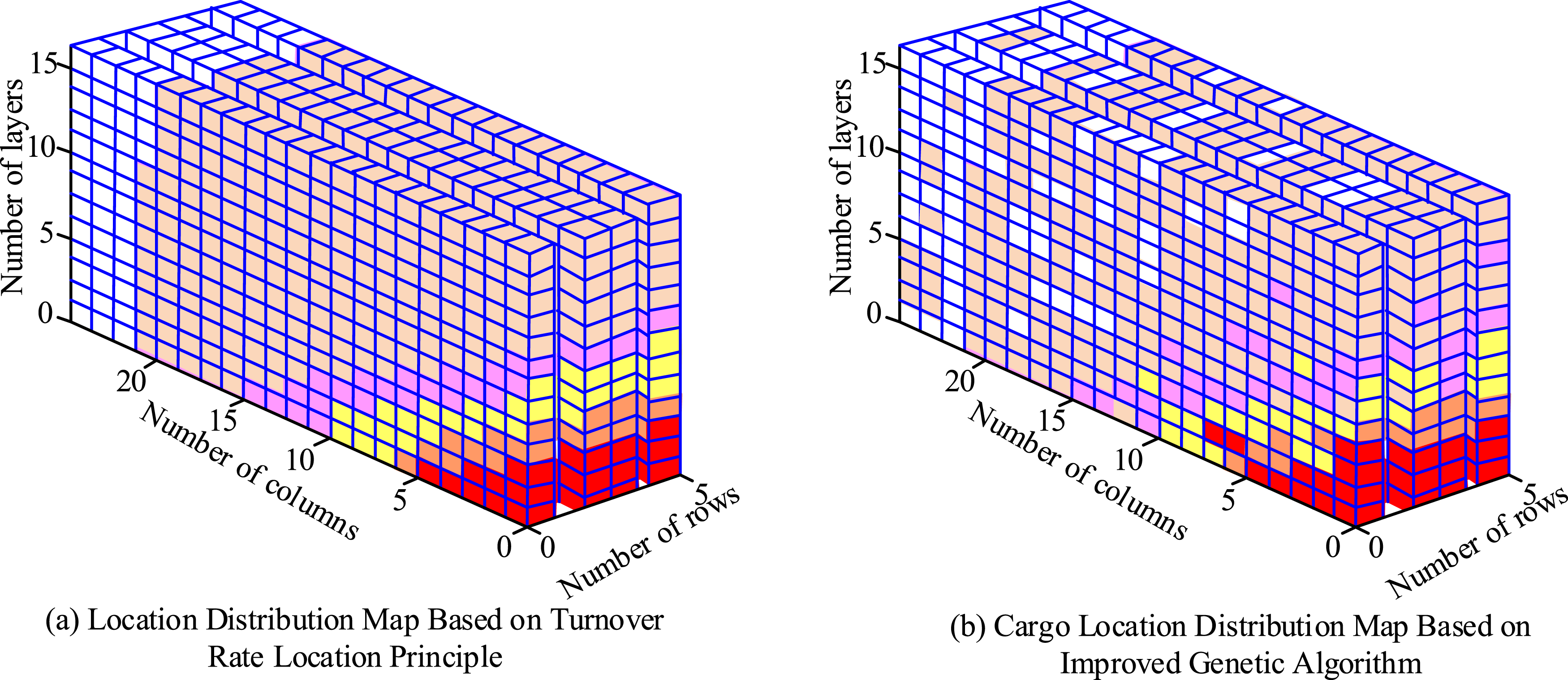
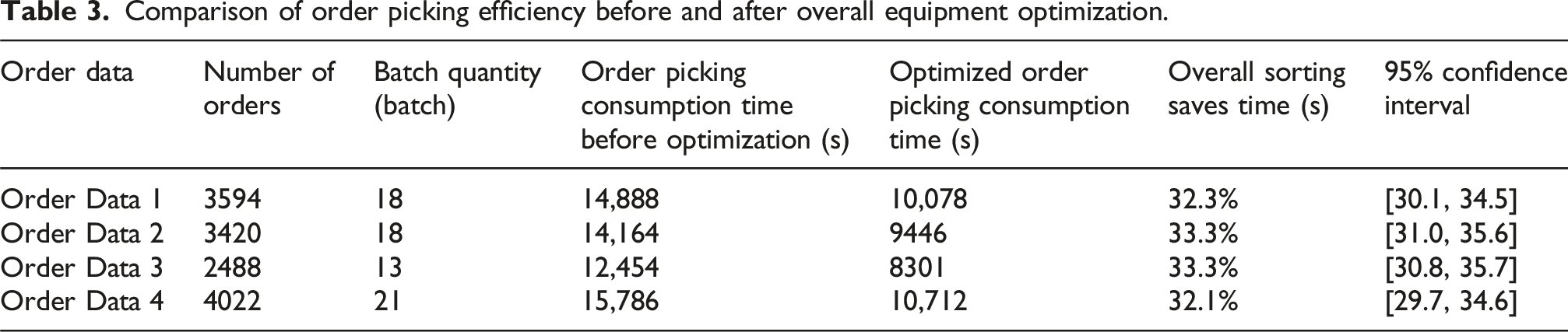
Table 3 shows that the efficiency of optimized warehouse picking improves with different order data. Compared to the pre-optimization period, the order picking time is reduced by about 33.2%, which proves the superiority of the optimized warehouse picking system. In addition, the time saving confidence interval for all datasets ranges from 29.7% to 35.7%, indicating statistical significance of the results.
Discussion
The research proposed an automated method for optimizing the storage and picking of cigarettes based on the FP-growth algorithm and an improved genetic algorithm. This method demonstrated significant value in practical industrial applications. Specifically, reference 6 proposed using optimization models to extract online data and make decisions regarding warehousing systems. However, it mainly focused on resource allocation in static environments. In contrast, this study used a dynamic, parameter-adaptive mechanism that enabled the system to respond to changes in orders in real time. This made the system more suitable for the rapidly changing order demands of the e-commerce environment. Reference 7 used triangular fuzzy functions to handle warehouse scheduling problems, which considered time uncertainty but have high computational complexity. The improved genetic algorithm in this study introduced an evolutionary reversal operator, which significantly reduced the computational burden while ensuring solution accuracy. It could converge within 420 generations and was more practical than the fuzzy scheduling model in reference 7.
In terms of applying the algorithm, the neural network framework proposed in reference 8 could automatically select the optimal picking system. However, it required a large amount of historical data for training. This study was based on the FP-growth algorithm, which optimized product combinations without requiring prior training. It could directly mine association rules from order data, making it ideal for scenarios with rapidly changing order patterns. The hybrid simulation model in reference 9 achieved a 15% optimization of throughput time, whereas this study increased the optimization rate to between 16.8% and 32.0% by combining packing and cargo location optimization. This approach demonstrated a more significant improvement in performance.
Although the parallel FP-growth algorithm proposed in reference 11 solved the memory problem under large data volumes when applying data mining technology, it mainly focused on optimizing computational performance. This study innovatively applies the FP-growth algorithm to optimize the packaging of product combinations. By combining it with genetic algorithms, the entire process from data mining to warehouse decision-making was optimized. Reference 12 used the FP-growth algorithm for alarm correlation analysis. This study extended the algorithm to the logistics field, opening up new application possibilities.
In summary, compared with existing mainstream methods, the efficiency and performance of the research method was significantly improved, providing new ideas for intelligent warehousing research and reliable solutions for industrial applications. The innovation of this study mainly lied in two aspects. On the one hand, it combined the dynamic parameter adjustment strategy of the FP-growth algorithm with an improved genetic algorithm and IKMA clustering. This provided a new method for warehouse optimization. On the other hand, in the tobacco logistics scenario, the universality of the hybrid algorithm was verified, and the picking error rate achieved a breakthrough from 1.2% to 0.4%. However, the research is still limited. The real-time response of the research method has a one-second delay, which cannot meet scenarios that demand millisecond-level response times. Therefore, future research should explore the potential application of quantum computing in path optimization through parallelization and hardware implementation for collaborative optimization.
Conclusions
As people’s living standards improve, the demand for warehouse items increases. The order volume has increased so much that it overwhelms the traditional warehouse picking system. The study proposed a methodology for enhancing the efficacy of automated warehouse picking. This methodology utilizes the FP-growth algorithm to optimize warehouse item case combining. It incorporates parameter adaptation and evolutionary reversal operator to enhance the genetic algorithm, thereby optimizing the cargo position of the warehouse. Additionally, it integrates the improved K-means two-stage algorithm based on seed orders to optimize the entire automated warehouse picking system. The main contributions are reflected in three aspects. First, a dynamic, parameter-adaptive mechanism is proposed that reduces the convergence algebra of genetic algorithms by 30%, all while maintaining an optimization rate of 89%. Second, the two-stage clustering strategy significantly improved the accuracy of order batch processing. Finally, the constructed hybrid optimization framework improved system-level efficiency while maintaining algorithm universality. In summary, this research method offers significant advantages for mining frequent item sets. It provides valuable information for path planning and effectively improves warehouse space utilization. This has also improved the overall efficiency of the automated warehouse picking system, providing useful reference and inspiration for research in related fields.
Footnotes
Consent for publication
All authors have given their consent to publish.
Authors’ contributions
ZRW: conceptualization, methodology, software, validation; L L: formal analysis, investigation, resources; J W, B W: data curation; Dl S: writing original draft preparation; YC C, BY Y: writing review and editing, visualization, funding acquisition. All authors have read and agreed to the published version of the manuscript.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.