
Abstract
In today’s era, English is exceptionally important to our work and life. The rapid development of Artificial Intelligence has driven the development of various industries, and the education industry is no exception. This study aims to construct a Transformer-based model and apply it to several teaching tasks to improve the quality and efficiency of English teaching. The model integrates the functions of vocabulary teaching, reading teaching, and grammar teaching into one and sets up the roles of teachers, students, and online question-answering platforms to provide students with a personalized and high-quality knowledge learning model. After experimental validation, the model has an advantage over similar benchmark models in terms of model generalization ability, training time, and correct rate.
Introduction
In this era of increasing technological development and profound impact on people’s lives, artificial intelligence has undoubtedly become one of the most prominent representatives. Its arrival has not only revolutionized our daily life to a great extent but is also gradually changing the traditional way of work. With its wide range of applications and efficient mode of operation, AI has emerged in many fields, and it has also gradually penetrated into the education sector. Especially in the aspect of language teaching, artificial intelligence has great potential for development. 1
Although China has made great achievements in English education, there are still many problems that cannot be ignored. First of all, insufficient attention has been paid to the individual differences of individual students, which has led to various difficulties encountered by students in the process of English learning. 2 In addition, insufficient teaching resources is another important problem that needs to be solved. To address these problems, an effective solution may be found through the use of artificial intelligence. 3
Over the past few years, a number of researchers and scholars have been focusing on the application of artificial intelligence in English language teaching. The results of these studies show that AI not only helps to improve students’ learning efficiency and academic performance, but also can provide teachers with more practical teaching tools, thus improving their teaching quality.
4
However, the specific model of AI applied to English teaching has yet to be further explored and developed.
5
The difference between the traditional English learning model and the AI-assisted English learning model is shown in Figure 1, and the core difference lies in the flow of knowledge, with the traditional model flowing to various types of tasks, and the AI-assisted flow of knowledge to the students.
6
Traditional English learning model and AI-enabled English learning model.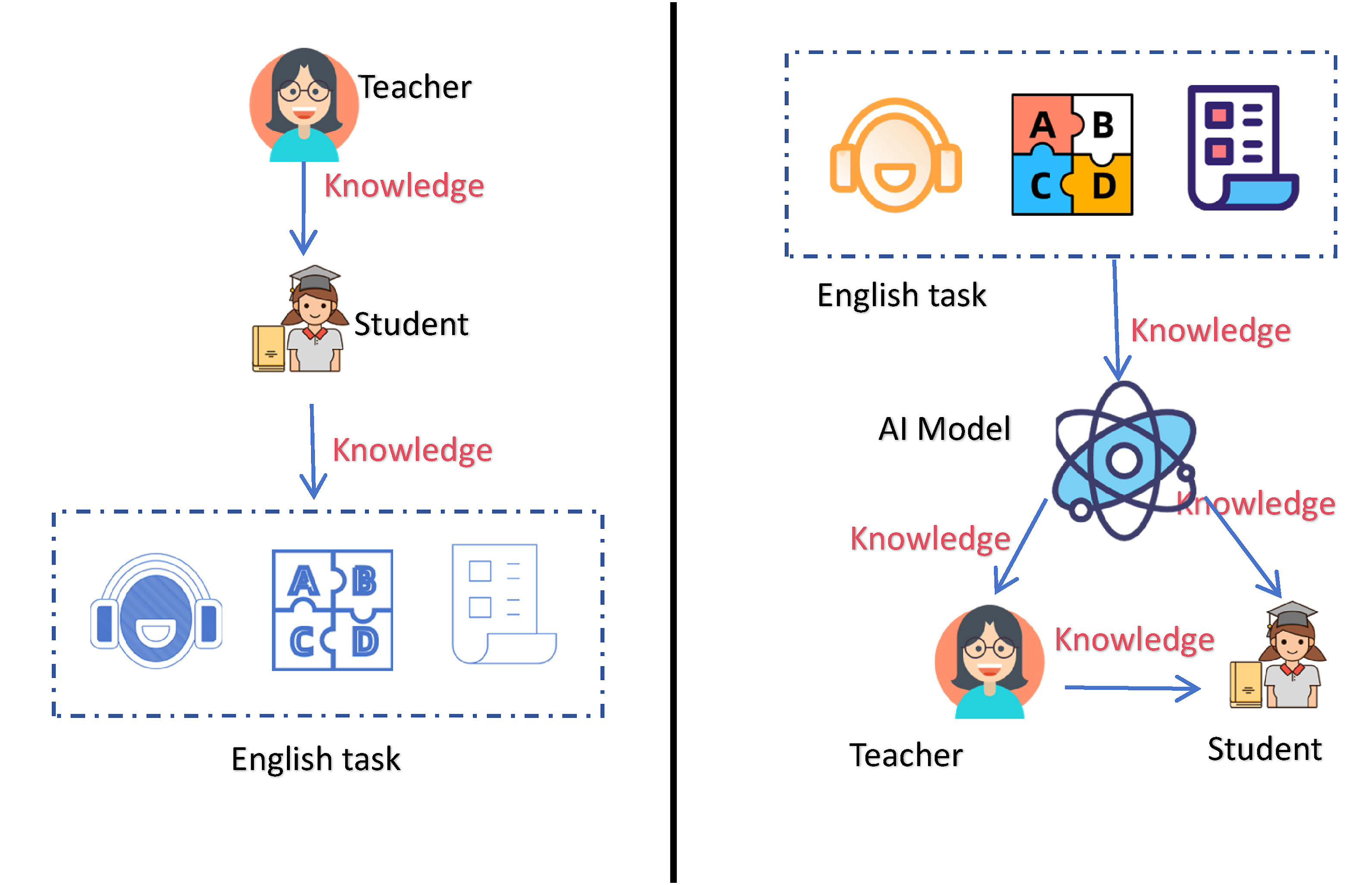
Transformer is a neural network model that utilizes the self-attention mechanism to efficiently process natural language sequences and enhance language comprehension and generation. The aim of this study is to construct a model based on Transformer and apply it to several teaching tasks in order to improve the quality and efficiency of English language teaching. This model will also provide students with personalized suggestions to help them improve their learning effectiveness and interest by giving them some appropriate learning resources, activities, and strategies according to their learning goals, interests, levels, and progress. 7 This model will also realize online Q&A, which will give an accurate, concise, and easy-to-understand answer according to the student’s question and provide some relevant examples, explanations, references, etc., to help students to solve their doubts and difficulties. 8
Relevant studies
Principles of artificial intelligence
Artificial Intelligence (AI) is closely related to Transformer, a revolutionary neural network architecture in the field of deep learning, which plays a key role in Natural Language Processing (NLP) in particular. Proposed by Google in 2017, Transformer eschews the Recurrent Neural Network (RNN)’s processing of sequential data limitations and introduces the self-attention mechanism, which enables the model to process the entire input sequence in parallel, greatly improving computational efficiency and model performance. To preserve the positional information of the words in the sequence, Transformer also uses a positional encoding, which is a vector of the same dimension as the word embeddings and can be computed by some trigonometric functions. The position encoding and the word embedding are added together to get the input representation of Transformer. Assuming that the length of the input sequence is n and the embedding dimension is d, the input representation can be represented by an n × d matrix X, where each row of X is a representation of a word. The positional encoding can be represented by an n × d matrix PE, where each row of PE is a representation of a position. The formula for positional encoding is shown in equation (1)9–11:
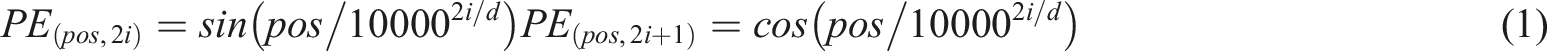
The core part of Transformer is the self-attention mechanism, which calculates how much attention each word in a sequence pays to other words, thus capturing the semantic and syntactic relationships between words. The coding layer structure of Transformer is shown in Figure 2.
12
The input of the self-attention mechanism is an n × d matrix, which can be X or the output of the previous layer. The output of the self-attention mechanism is also an n × d matrix, where each row is a new representation of a word that contains information about other words. The input matrix is transformed into a query matrix Q, a key matrix K, and a value matrix V by three different linear transformations, all of which have dimension n × d. The parameters of the linear transformations are the learnable weight matrices, denoted WQ, WK, and WV, respectively, and all of which have dimension d × d. The computational formulas are shown in equation (2).
13
Transformer coding layer structure.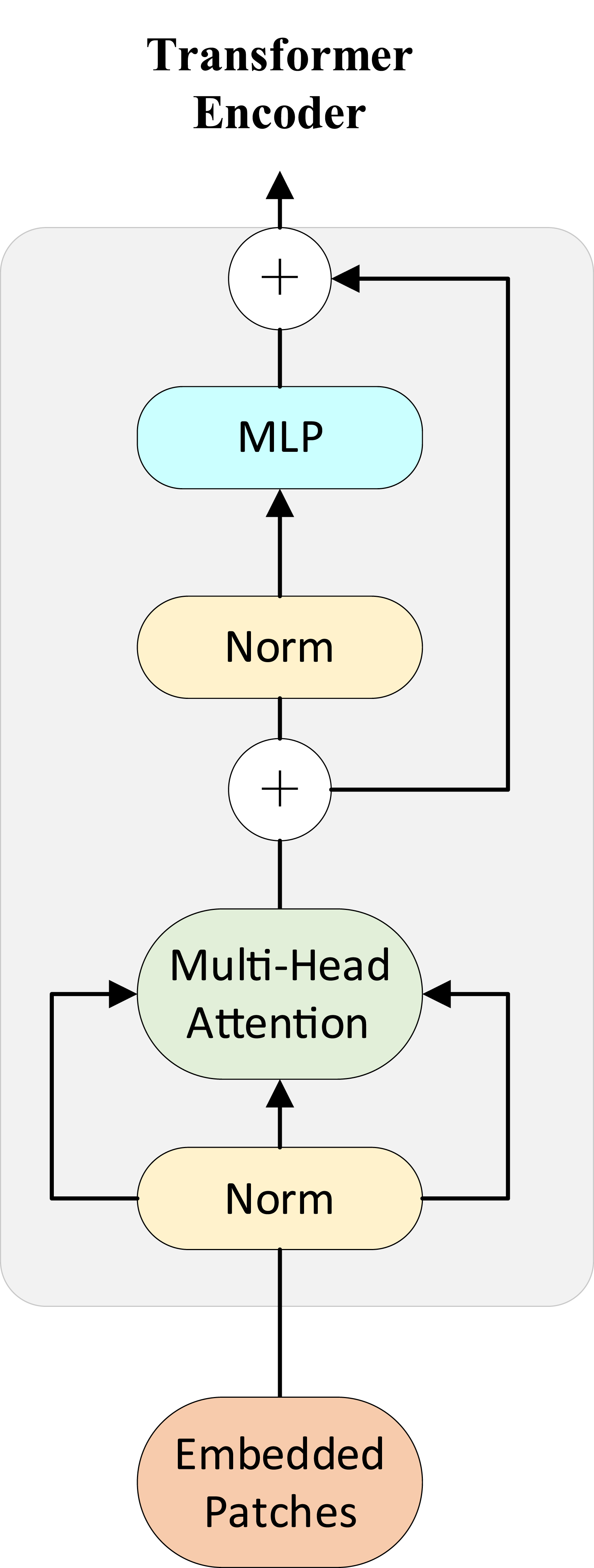

An n × n attention score matrix S is obtained by computing the dot product of the transpositions of Q and K, where each element of S represents how well a query matches a key. In order to avoid the gradient vanishing due to too large dot product, it is also necessary to divide S by a scaling factor, that is, the square root of the embedding dimension. The formula is shown in equation (3)
14

Next, an n × n attention weight matrix A is obtained by performing softmax operation on each row of S, where each element of A represents the degree of attention a query pays to a value. The computational formula is shown in equation (4)
15

Finally, an n × d output matrix Z is obtained by computing the dot product of A and V, where each row of Z is a new representation of a word, which is a weighted sum of all the values, with weights determined by the attention weights. The computational formula is shown in equation (5)
16

The Transformer consists of two parts, the encoder, which is used to encode the input sequence, and the decoder, which is used to generate the output sequence based on the encoding result. Both the encoder and decoder consist of multiple layers stacked on top of each other, and each layer contains a multi-head attention mechanism and a feed-forward neural network, as well as residual connectivity and layer normalization. The formula for each layer of the encoder is shown in equation (6)
17
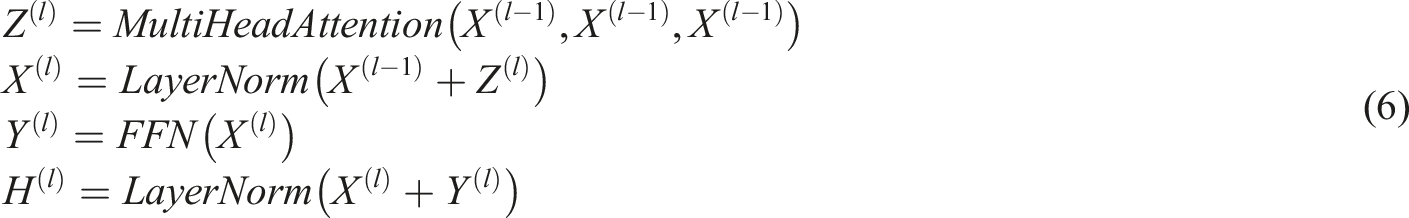
Current status of domestic and international research
In China, artificial intelligence has been widely researched and applied in the field of education, which both improves the learning effect of students and reduces the workload of teachers. Among them, personalized learning is an important advantage of AI, which can personalize teaching according to the characteristics of each student. However, AI English teaching in China is not mature enough and needs more research and demonstration. 18 In foreign countries, AI is also very active in the field of education, providing automatically generated practice questions and automatic evaluation systems for English teaching .AI helps teachers to understand the learning status of students and assists teachers to make accurate decisions to promote the learning process of students. However, the application of AI in education also faces the challenges of ensuring its security, fairness, and reliability. 19
In China, teaching English is an important educational task involving tens of millions of students and teachers. In order to improve the effectiveness and quality of English teaching, artificial intelligence (AI) technology has played an increasingly important role in recent years. First of all, intelligent guidance systems use AI technology to provide personalized learning guidance and feedback based on students’ characteristics and needs. These systems can recommend appropriate learning resources, strategies and paths for students based on their learning progress, abilities, interests and goals, as well as monitor students’ learning behaviors and effects, and provide timely evaluation and advice to help students improve their learning efficiency and effectiveness. Secondly, educational robots form a novel form of interactive teaching by adjusting teaching content and methods. These robots can simulate the voice, expression, and movement of real people, engage in natural conversations and communication with students, stimulate students’ learning interest and participation, and at the same time dynamically adjust the teaching difficulty and rhythm according to students’ feedback and performance to adapt to the different levels and needs of students. 20 Finally, speaking scoring systems utilize automation technology to improve spoken English. These systems can accurately assess and analyze students’ spoken English through speech recognition, speech synthesis, natural language processing and other technologies, give specific scores and feedback, point out students’ strengths and weaknesses in pronunciation, grammar, fluency, etc., and at the same time, provide corresponding training and practice to help students improve and enhance their spoken English skills. 21
The application of AI in the field of education has become a hot topic in the academic community at home and abroad, and all countries are actively exploring and promoting the integration and development of AI and education. According to the analysis of literature, the current situation and trend of relevant research at home and abroad can be summarized as follows: foreign research is relatively mature and in-depth, and domestic research is relatively backward and superficial. Foreign research is mainly concentrated in developed countries such as the United States, the United Kingdom, Australia, and other countries, involving multiple disciplines and fields, with rich and in-depth research content and diverse and innovative research methods. Domestic research mainly focuses on educational technology, computer science and other disciplines, the research content is relatively single and superficial, and the research method is relatively traditional and conservative. According to the keyword analysis of the literature, the hotspots of foreign research reflect the wide application and in-depth exploration of AI technology in the field of education, focusing on the characteristics of education such as personalization, intelligence, diversification and synergy, as well as the mechanisms of education such as interaction, scenario, adaptation, integration, and collaboration. 22
Modeling
This chapter will introduce the design principles, pedagogical framework, modeling principles, and modeling process of the Transformer-based English teaching model constructed in this research, so as to comprehensively elaborate the design ideas and implementation ideas of this model. 23
Design principles
The design principles of the model constructed in this study are threefold: 1. Student-centered: Focus on students’ individual needs and learning effects. The model should not only be able to accomplish multiple teaching tasks but also be able to give some appropriate learning resources, activities, strategies, etc., according to the students’ learning goals, interests, levels, progress, etc., to help students improve their learning effectiveness and interest.
24
2. Based on Transformer: Utilizing its powerful self-attention mechanism and parallel computing ability to realize efficient and flexible English teaching. Transformer is a neural network model based on the self-attention mechanism, which can effectively capture the long-distance dependencies of sequential data, and at the same time has low computational complexity and high parallelism. Transformer has already achieved significant Transformer has achieved remarkable results in the field of natural language processing, and this study applies it to English teaching, expecting to improve the quality and efficiency of English teaching.
25
Aided by online Q&A to provide timely and accurate feedback and guidance. The model should also be able to realize online Q&A, which gives an accurate, concise and easy-to-understand answer based on the student’s question and provides some relevant examples, explanations, references, etc., to help students solve their doubts and difficulties. Online Q&A is an effective teaching aid that increases student interaction and participation, and improves student confidence and satisfaction. 26
Teaching and learning framework
The pedagogical framework of the model constructed in this study is shown in Figure 3 and consists of the following four main components: Pedagogical framework of the model.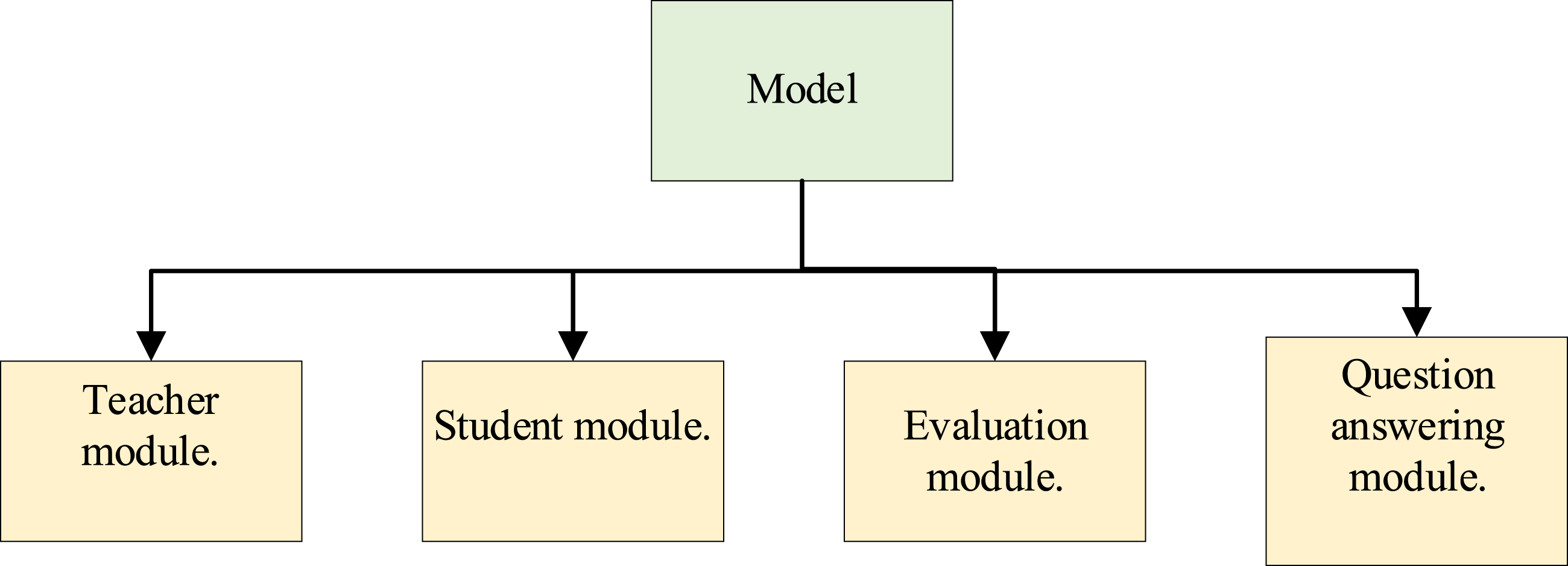
Student module
The student module is the input side of the model and is responsible for collecting and processing student information, including students’ basic information, learning objectives, learning interests, learning levels, learning progress, learning problems, etc. The student module also has to be able to dynamically update students’ information based on their feedback so that the model can adjust the teaching content and methods in a timely manner. The student module is also able to dynamically update students’ information according to their feedback, so that the model can adjust the teaching content and methods in a timely manner. Teaching Module: The teaching module is the core part of the model and is responsible for accomplishing a number of teaching tasks, including vocabulary teaching, grammar teaching, reading teaching, writing teaching, listening teaching, and speaking teaching.. 27 The teaching module is based on the Transformer model, which utilizes its self-attention mechanism and parallel computing capability to achieve efficient and flexible English teaching. The teaching module should also be able to give personalized suggestions based on the inputs of the student modules, including some appropriate learning resources, activities, strategies, etc., to help students improve their learning effectiveness and interest. 28
Q&A module
The Q&A module is an auxiliary part of the model, which is responsible for realizing online Q&A, giving an accurate, concise and easy-to-understand answer based on the inputs from the students’ modules and providing some relevant examples, explanations, references, etc., to help the students to solve their doubts and difficulties. The Q&A module is also based on the Transformer model, which utilizes its self-attention mechanism and parallel computing capabilities to achieve efficient and flexible online Q&A. 29
Assessment module
The assessment module is the output of the model, which is responsible for evaluating the learning effectiveness of the students, including learning achievement, learning progress, and learning satisfaction. The assessment module also has to give some feedback and suggestions to help students identify and improve their learning problems and deficiencies. The assessment module should also be able to give some feedback and suggestions to help students identify and improve their learning problems and deficiencies. 30
Modeling principles
Vocabulary teaching is the foundation of English language teaching, and the model constructed in this study can give some appropriate vocabulary learning resources, activities, strategies, etc., according to students’ learning levels and interests, helping students to expand their vocabulary and improve their vocabulary use ability. The specific implementation of vocabulary teaching is as follows: firstly, the model uses an encoder to encode students’ information and input sequences into a series of hidden state vectors, and then uses a decoder to generate a sequence of outputs for vocabulary learning tasks, such as a vocabulary test, a vocabulary game, a vocabulary mnemonic, and so on. The model should also be able to assess the students’ vocabulary learning effectiveness based on the students’ feedback and give some feedback and suggestions to help the students identify and improve the problems and deficiencies in their learning. The effect of the model in Ref. 31 is that if the student’s input sequence is “I want to review some vocabulary words about food,” the model may generate a vocabulary game output sequence. The principle of the model is that the student’s information and input sequence are first passed through an encoder to obtain a hidden state vector h, which contains information about the student’s learning level and interest. As shown in equation (7).

Then, based on the value of h, an appropriate task is selected from a library of predefined vocabulary learning tasks, such as vocabulary test, vocabulary game, and vocabulary mnemonic. An attention mechanism is used to calculate the similarity between h and each task, and the task with the highest similarity is selected as the output sequence. As shown in equation (8).
32
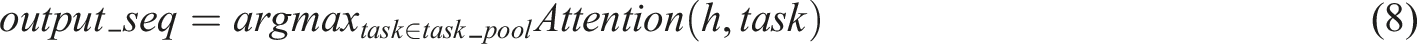
Finally, the output sequence is returned to the students and based on the students’ feedback, the parameters and task library are updated to improve my vocabulary teaching. As shown in equations (9) and (10).
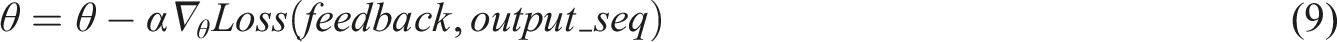
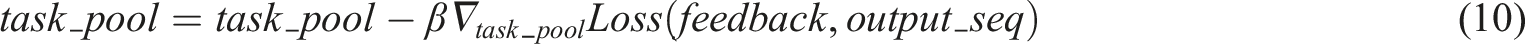
The model also involves grammar teaching and reading teaching functions. The Transformer receives information and inputs from students through an encoder, transforms them into hidden state vectors, and then produces relevant outputs using a decoder. For grammar learning, the model suggests appropriate ones for students to help them master English grammar rules and enhance the accuracy and fluency of their expressions. Once the student completes the assigned task, the model evaluates the learning outcomes and gives appropriate suggestions based on the feedback. If students want to learn about specific grammatical concepts, such as tense rules, the model will generate corresponding explanations and tasks. For reading, the Transformer model follows a similar process, recommending articles based on the student’s needs and interests and conducting follow-up assessments. At the same time, the model will also give appropriate advice based on the student’s performance, for example, generating appropriate materials if the student wants to learn articles about environmental protection.33,34 This feature will also be useful for vocabulary learning as well. The implementation of these two functions is similar to that of vocabulary teaching and will not be repeated. The flowchart of the model is shown in Figure 4. Model flow chart.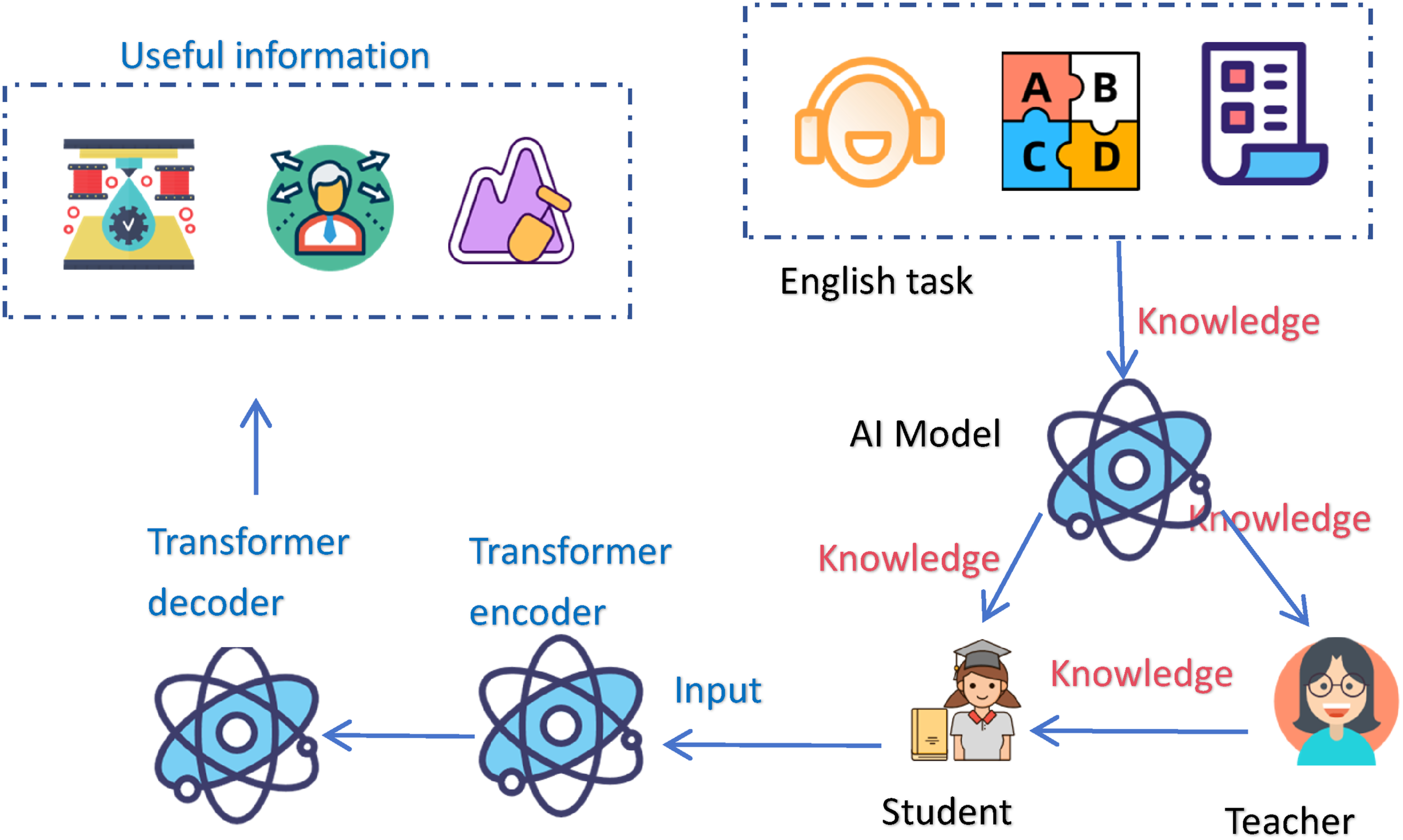
Model flow
The training of the model is divided into two parts: pre-training and fine-tuning yes. In the pre-training stage, we have to acquire and process the pre-training data. In this study, we collect a large amount of text data related to English teaching from different data sources, including textbooks, courseware, test questions, essays, teacher comments, and student feedback. And these data are cleaned to remove irrelevant information, such as images, audio, video, formatting, and so on. And these data are cleaned to remove irrelevant information, such as images, audio, video, format, and labels. Then these data are subjected to the basic tasks of natural language processing such as lexical segmentation, lexical annotation, named entity recognition, and syntactic analysis in order to extract the structural and semantic information of the text. 35 Finally these data are converted into input formats acceptable to the model such as word vectors, sequence labels, and dependencies. We use BERT as a pre-training model Yes, further pre-training of BERT on the collected data related to English language teaching is carried out in order to adapt to the domain and task. Two pre-training tasks are used: Masked Language Modeling (MLM) and Next Sentence Prediction (NSP). The purpose of MLM is for the model to learn to populate the text with random masked words, thus enhancing the model’s language comprehension. The purpose of NSP is for the model to learn to determine whether two sentences are coherent or not, thus enhancing the model’s language generation. 36
In order to allow the model to accomplish several teaching tasks, the model is fine-tuned, that is, some task-specific output layers, such as classification layer, regression layer, and sequence annotation layer, are added on top of the pre-trained model and trained on task-related data. We design the following kinds of teaching tasks: teaching content recommendation, teaching activity recommendation, teaching strategy recommendation, teaching evaluation, teaching feedback, online Q&A, and so on. Each kind of task has its corresponding input and output formats, such as text, label, score, suggestion, and so on. We use metrics such as cross-entropy loss, mean square error loss, and F1 score to evaluate the fine-tuning effect of the model.
Once the model has been pre-trained and fine-tuned, it is deployed online to provide personalized English teaching services to students. Students can input their learning goals, interests, levels, and progress to get suggestions from the model, such as appropriate learning resources, activities, and strategies. Students can also ask their own questions to get answers from the model, such as accurate, concise, and easy-to-understand explanations, examples, and quotes. The model can also provide assessment and feedback based on students’ performance, such as scores, comments, encouragement, guidance, and so on. And during the operation of the model, student feedback and data are continuously collected so that the model can be updated and optimized.
Evaluation of the model
Data sets
Data set information.

Experimental environment setting
This study uses a model based on Transformer, which is a deep neural network that can process natural language and is capable of capturing long-range dependencies. BERT can be adapted to a variety of downstream instructional tasks, such as reading comprehension, text categorization, and text summarization. In this study, we add a multi-task learning framework to BERT, which can handle multiple instructional tasks at the same time, as well as a personalized recommendation module, which can give some appropriate learning resources, activities, strategies, etc., based on students’ characteristics and feedback. In this study, the model was implemented using Python language and PyTorch framework and experiments were conducted on a server configured with NVIDIA Tesla V100 GPU, Intel Xeon CPU, and 128 GB RAM. 38
Model evaluation
Comparison of models.

Experimental results.
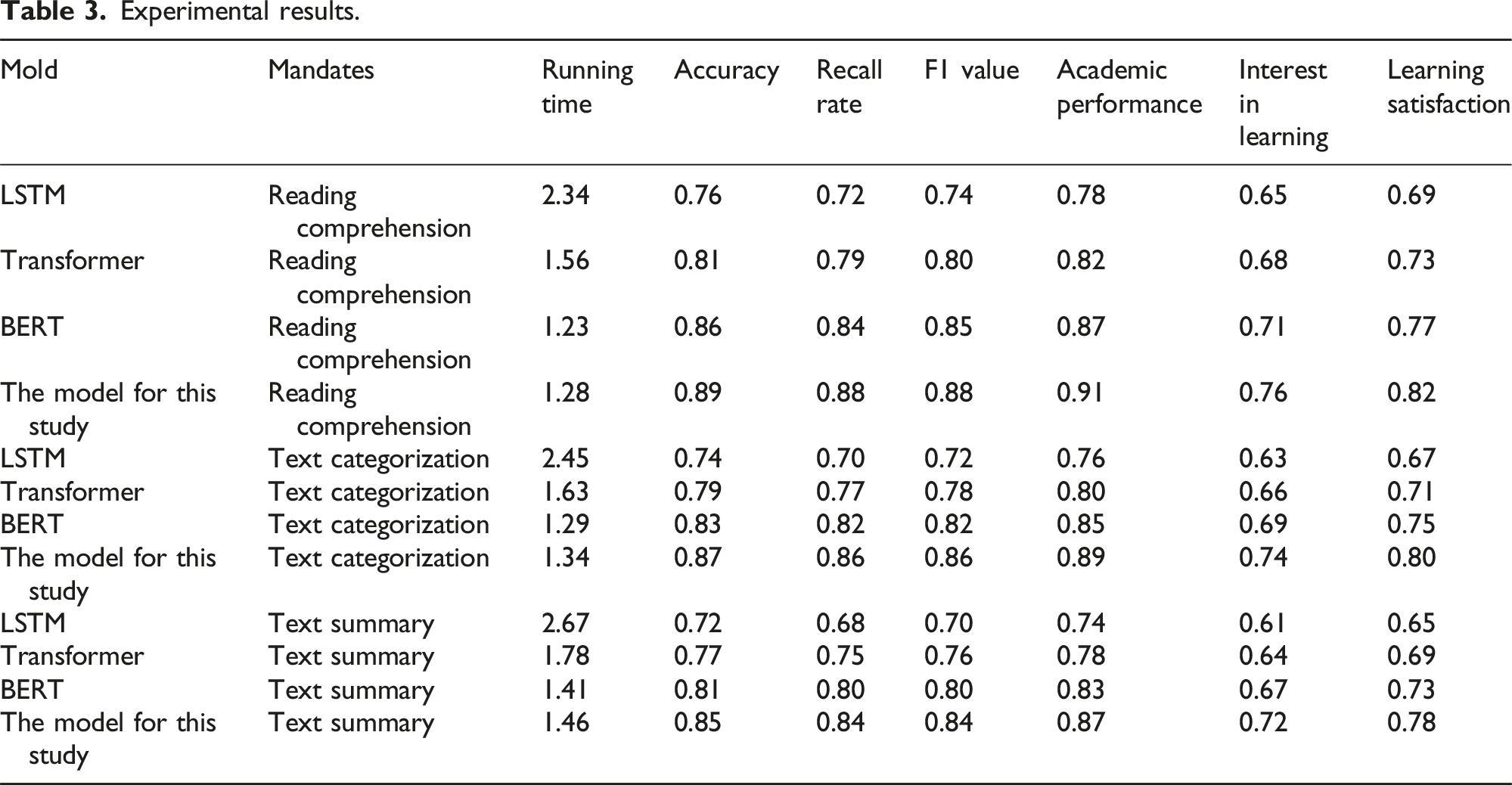
As can be seen in Table 2, the model in this study outperforms the benchmark model on all instructional tasks, illustrating the significant advantages of the Transformer-based model, which combines the strategies of pre-training and multi-task learning, supplemented by personalized measures. The running time of the model in this study is slightly higher than that of BERT, but still lower than that of LSTM and Transformer, which indicates that the model in this study also has some advantages in computational efficiency. The model in this study can process a large amount of data in a shorter period of time, thus saving time and resources for both teachers and students. The model in this study has some limitations and shortcomings, for example, the generalization ability of the model may be affected by the dataset.
Conclusion
English language teaching is a complex and important field involving multiple teaching tasks and multiple teaching roles. To improve the quality and efficiency of English language teaching, this study proposes a Transformer-based model that applies it to multiple teaching tasks, including vocabulary teaching, reading teaching, and grammar teaching. The model takes advantage of the powerful linguistic representation and computational efficiency of the Transformer model, combines the strategies of pre-training and multi-task learning, and the function of personalized recommendation, thus providing a personalized and high-quality knowledge learning model for students. The model also sets up three roles: teacher, student, and online question-answering platform, to realize the interaction and collaboration of teaching and learning. This study experimentally verified the effectiveness and superiority of the model, which demonstrated significant advantages in terms of model generalization ability, training time, and correctness rate compared with similar benchmark models. This study provides a new way of thinking and methodology for English language teaching, as well as some insights and references for future research.
The model constructed in this paper can deal with a variety of teaching tasks, which improves the coverage and flexibility of teaching; it can give personalized suggestions based on students’ characteristics and feedback, which improves the relevance and effectiveness of teaching. The model can realize the interaction and collaboration of teaching roles, which improves the participation and interest of teaching. However, the personalized recommendation function of the model may have some deviations or errors because the model gives suggestions based on students’ characteristics and feedback, and this information may be incomplete or inaccurate.
Footnotes
Funding
The author received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.