
Abstract
The significance of this research lies in the application of data mining techniques to analyze badminton competitions, allowing for the identification of players’ tactics, strategies, and weaknesses. By uncovering these insights, targeted training and improvement plans can be developed, enhancing player performance and optimizing competitive outcomes. Association rules in data mining techniques are used, and the Apriori algorithm in association rules is analyzed and improved. The ACARMI algorithm (an improved algorithm of constrained association rule mining based on item) is then applied. Then, data from six top badminton competitions is collected and converted into Boolean data suitable for this algorithm. A data mining module is designed to mine the tactical association rules of all players, and a specific analysis is conducted on one of the players, successfully analyzing their tactical strategies. Finally, to verify the effectiveness of the algorithm proposed in this article, FP-Growth algorithm and DHP algorithm are applied to comparative experiments. The experiment shows that compared with the FP-Growth algorithm, the initial and final running times of the algorithm in this article with minimum support and different constraint numbers are around “355 ms and 75 ms,” “150 ms and 45 ms,” respectively; similarly, compared with the DHP algorithm, they are around “165 ms and 35 ms,” “175 ms and 55 ms,” respectively. Under two sets of experiments, the algorithm proposed in this article presents better operational efficiency. This article demonstrates that the use of data mining techniques can provide effective tactical optimization, opponent research, real-time decision support, and long-term development planning assistance for athletes and coaches.
Keywords
Introduction
Badminton,1,2 with its rich history and widespread global popularity, has evolved into a highly competitive sport. Success in badminton demands not only exceptional physical fitness and technical skills but also precise control of shuttle trajectory in constrained time and space. Players must make swift tactical decisions during high-speed exchanges to secure points. Effective tactical strategies are crucial in helping players gain a competitive edge, minimize errors, maximize their technical strengths, and limit the opponent’s performance. Currently, the analysis of tactics and strategies in badminton matches predominantly relies on the experience of coaches and players, video replays, and manual statistics. While these methods provide some guidance, they present significant limitations: traditional tactical analysis is heavily dependent on subjective judgment; manual statistics and video analysis often cover only a fraction of match data; and manually capturing match details makes it challenging to track subtle technical nuances and tactical shifts. These constraints diminish the effectiveness and practicality of tactical analysis, highlighting the need for a more scientific and systematic approach to enhance the analysis of tactics and strategies in badminton competitions.
To address the aforementioned issues, this article investigates the use of data mining techniques to analyze the tactics and strategies of players in badminton competitions. By automatically processing and analyzing a large amount of competition data, the patterns hidden in the data can be revealed, providing scientific basis for tactical analysis. In terms of data sources, there are competition videos and sensor data, which can cover a more comprehensive range of data compared to traditional manual statistical methods. Moreover, the automated data processing and analysis process reduces manual intervention and errors, ensuring the accuracy and consistency of data analysis. In terms of tactics, in-depth analysis of each player’s technical movement can be conducted to identify subtle differences and improvement points and explore strike speed, placement distribution, opponent reaction, etc. In complex prediction models based on data mining, it is also possible to predict key events in competitions, such as scores, mistakes, and physical exertion, providing early warning and guidance. Overall, utilizing big data mining 3 to analyze the tactics and strategies of badminton players can promote the scientific development of badminton and improve the competitive level of players.
Related work
There are currently two main methods used in the academic field for analyzing player tactics and strategies in badminton competitions. The first method is traditional data analysis methods. Cai Ruiqing 4 conducted a comparative analysis of the defensive techniques of world-class male doubles players using observation methods,5,6 mathematical statistics methods,7–9 and interview methods. 10 His research found that when facing a combination of double pressure playing methods, it is necessary to reduce the use of drive shots in defense and appropriately increase the use of backcourt lift techniques. Jia Minjuan et al. 11 used literature analysis, 12 video analysis, 13 and mathematical statistics to conduct a statistical analysis of the use of men’s doubles tactics in competition videos. They found that if players focus too much on how to attack, they might overlook the importance of defense, resulting in a certain gap in the coordination of teammates and easily creating an attacking gap for opponents. Zhu Jiaxing et al. 14 used the three-phase indicator evaluation method as a method to evaluate the technical and tactical abilities of athletes in various stages of the competition. By conducting data statistics and analysis on the serve attack phase, receival attack phase, and rallying phase, they calculated the scoring rate and utilization rate of athletes, respectively. Subsequently, evaluation indicators were developed to adjust the training mode of athletes. Although these methods have been most commonly used in real life, their inefficiency and labor-intensive drawbacks still cannot be solved.
The second approach involves a more advanced and efficient artificial intelligence (AI) analysis method,15,16 which focuses on collecting and analyzing extensive sports data and physiological indicators while integrating individual differences for modeling and analysis. AI technology allows for the comprehensive quantification and evaluation of badminton players’ sports characteristics and physiological conditions. This provides objective data to support tactical research and, by incorporating motion data and other relevant parameters, facilitates the modeling and testing of various tactical strategies. The process allows for gradual optimization, ultimately enhancing tactical effectiveness and success rates.
For instance, Yan Kuan et al. 17 proposed a badminton tactical analysis and optimization method utilizing swarm intelligence algorithms.18,19 This approach incorporates multiple data analysis techniques and model-building methodologies, overcoming the limitations of traditional tactical design methods, and significantly improving players’ performance and chances of success in competitions. However, despite its precision and efficiency, this method has yet to be extensively tested in large-scale badminton tournaments, limiting its general applicability.
Methods
Data mining techniques
Data mining technology is a method of discovering patterns and trends hidden within a large amount of data by analyzing it. There are four main data mining techniques: association rule mining, 20 cluster analysis, 21 classification algorithms, and time series analysis. 22 Association rule mining is used to discover frequent relationships between data items, namely, “if… then…” association rules. This method can discover the frequency of a player choosing a certain tactic in a specific scenario and determine whether this tactic is related to winning. Cluster analysis is the process of dividing objects in a dataset into different groups, resulting in higher similarity between objects within the group and lower similarity between objects between groups. This method clusters players based on their competition data characteristics to identify different types of players or competition strategies. Classification algorithms are used to predict the categories of data objects. A classification model is established by learning training data of known categories, and then the model is applied to classify new data objects. Through classification algorithms, the performance of players can be evaluated and classified, predicting their success or failure rates in a specific tactic. Time series analysis is used to model and predict time series data, in order to reveal the trend and periodicity of data over time. By using time series analysis methods, the trends and preferences of players during the competition process can be understood, and the impact of these changes on the competition results can be determined.
Regardless of the type of data mining technology, it must go through the data mining process shown in Figure 1. For research on player tactics and strategies analysis in badminton competitions, this article tends to use association rule mining. The first reason is that the association rules are simple and intuitive. The second reason is that it is suitable for data with strong regularity, and the tactics and strategies in badminton competitions are very regular. The third reason is that it does not require pre-defined categories and is suitable for complex tactics and strategies analysis in badminton competitions. Cluster analysis requires dividing data objects into different groups, and the tactics and strategies of players in badminton competitions often vary continuously, so it is not applicable. Classification algorithms require pre-defined categories of players, and badminton competitions have high flexibility and diversity, so they are not applicable. Time series analysis is more suitable for modeling and predicting time series data, so it is not applicable. Process of data mining.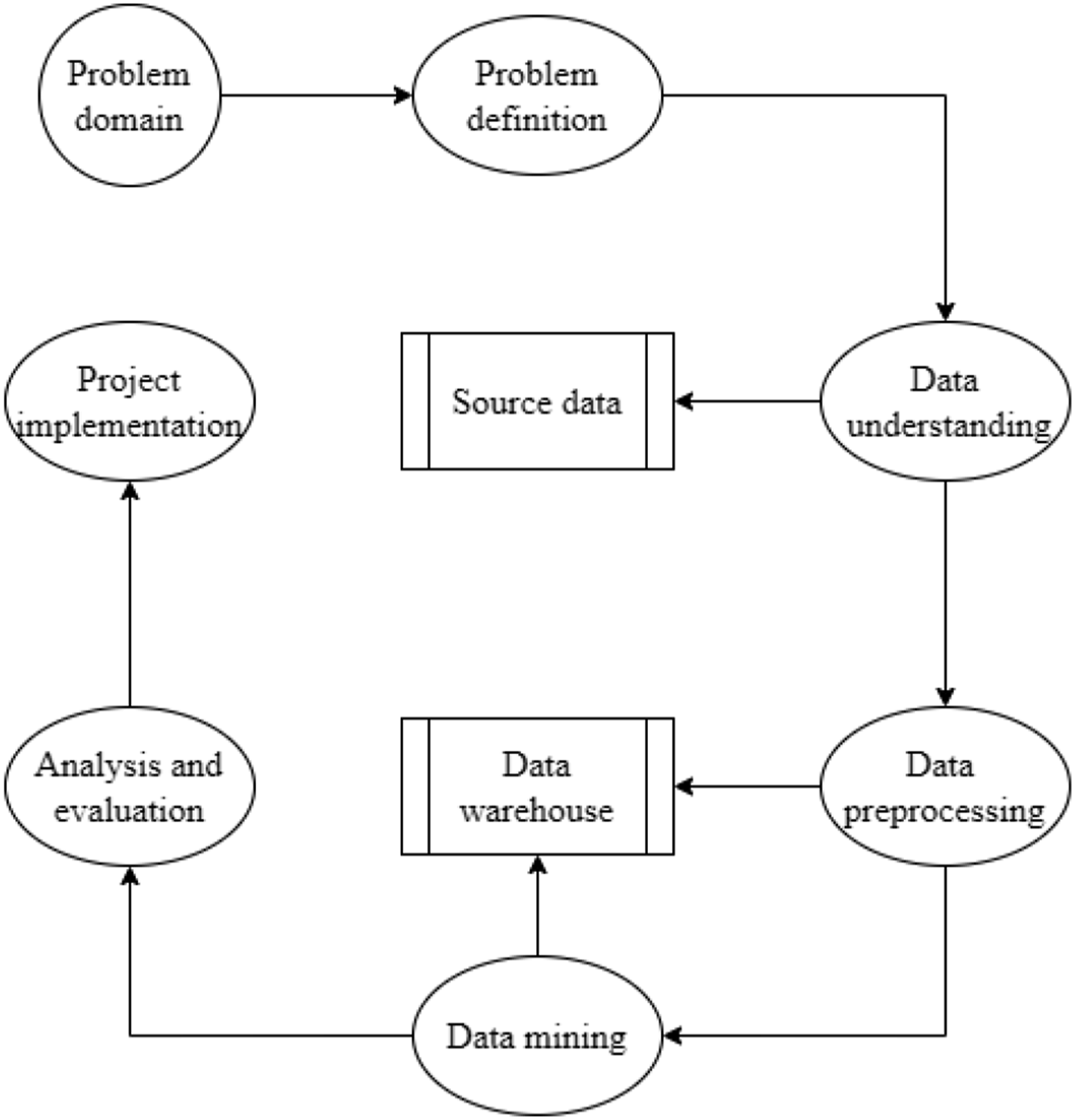
Association rules
Association rules have four concepts: item, itemset, support, and confidence.
Item
Items refer to individual elements and features, for example, “pre-serve smash,” “diagonal attack,” and “high-level player’s drop shot and lift” are all considered separate projects, each a discrete attribute.
Itemset
Itemsets refer to a collection of multiple items in a dataset, which in this article represents the various tactical combinations adopted by a player in a competition or a period of time. For example, if “pre-serve smash” is first used and “diagonal attack” is then used, the combination of these two events forms an itemset. In itemsets, the main focus is on frequent itemsets, which often contain the most useful information.
Support
Support measures the frequency of itemsets appearing in the entire dataset, such as the number of times a particular tactic appears in all plays divided by the total number of plays. In this article, it represents the prevalence of a certain tactic or strategy in a competition. If a tactical combination (itemset) appears frequently in multiple competitions, its support is correspondingly high. The calculation method is shown in Formula (1), where

Confidence
Confidence measures the reliability of association rules and represents the probability that the latter term occurs if the former term occurs. For example, in a match where a smash is used, the number of actual points scored is divided by the total number of smashes used. In this article, if a player adopts a certain tactic
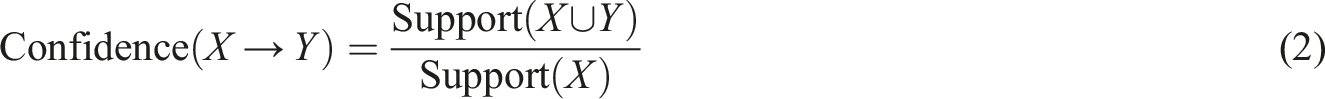
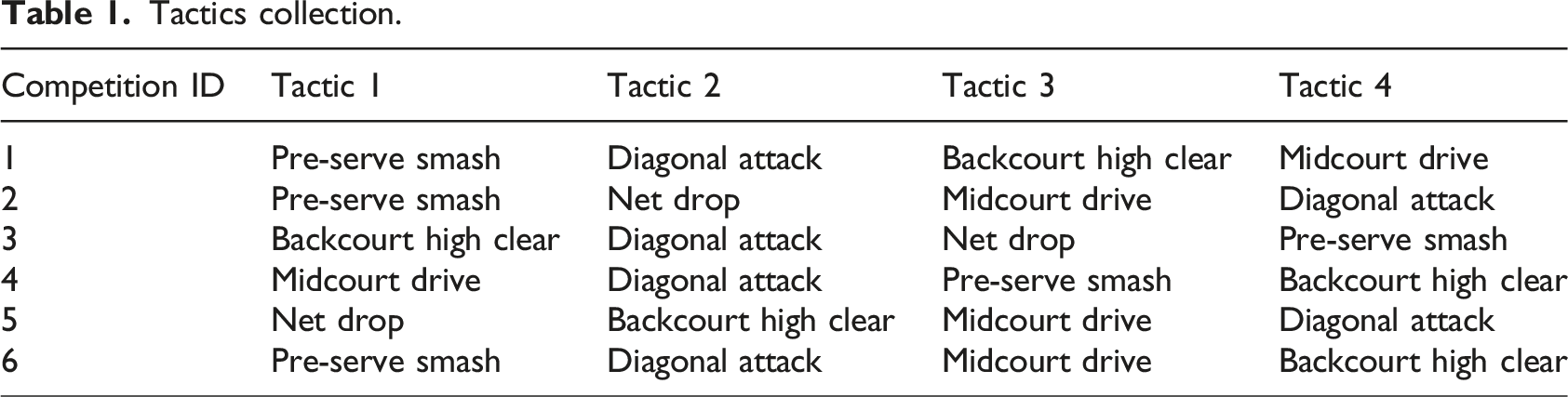
As shown in Figure 2, association rule mining first involves collecting data, mainly from video recordings and official statistics of competitions, and then converting the tactical behaviors of players in the data into discrete items. On this basis, a single item set is generated to calculate the support for each individual tactic, and candidate itemsets are generated to generate possible tactical combination itemsets. Their support is calculated. Support threshold is used to filter out tactic combinations that frequently appear in the dataset. A minimum support threshold based on specific needs is set. Itemsets with support above the threshold are retained, and itemsets with support below the threshold are removed. Finally, association rules are generated from the filtered frequent itemsets. For each frequent itemset, all association rules are generated and the confidence of each rule is calculated. Specific examples are shown in Table 1. Mining process diagram of association rules. Tactics collection.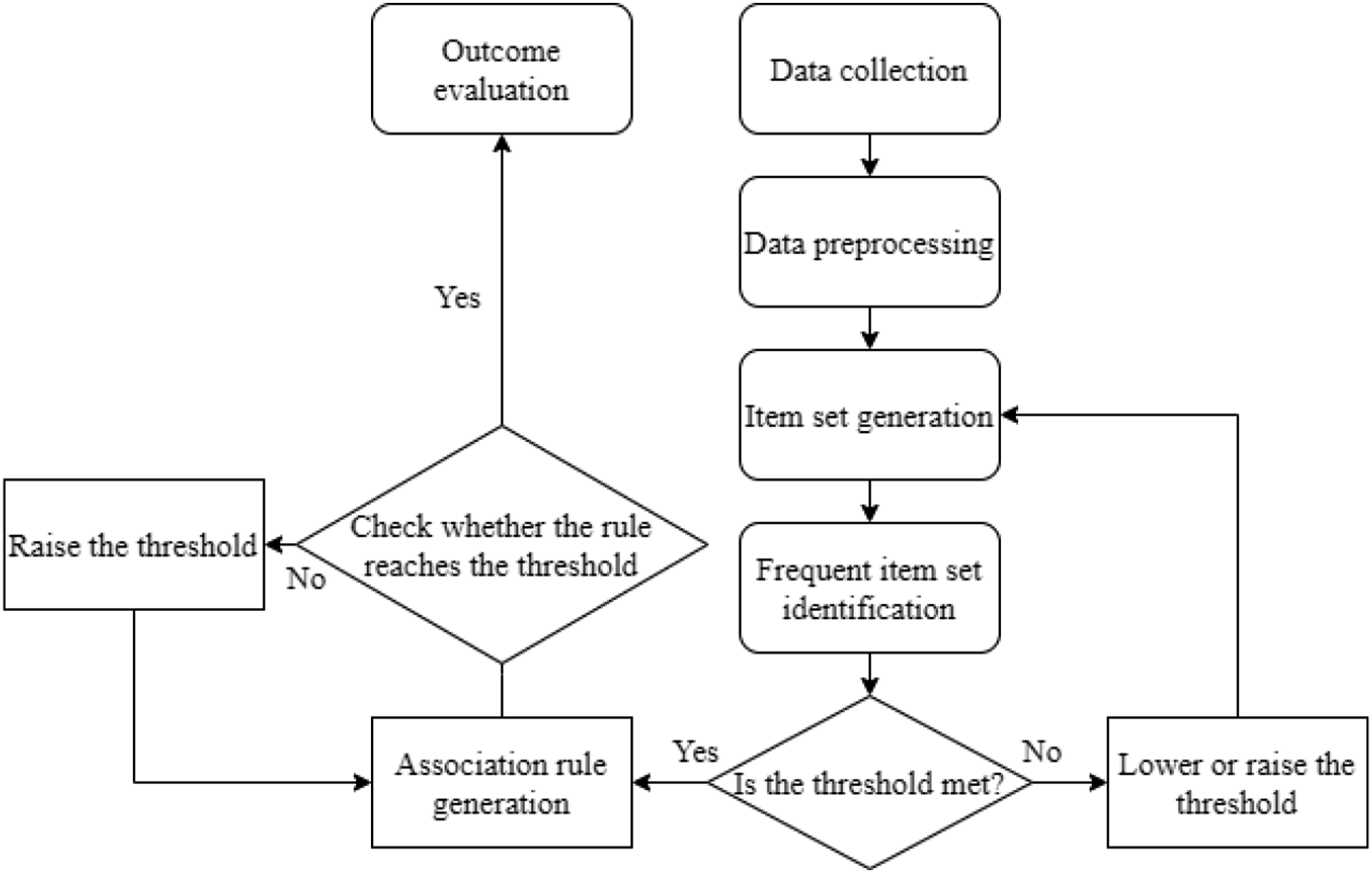
Examples of association rules.
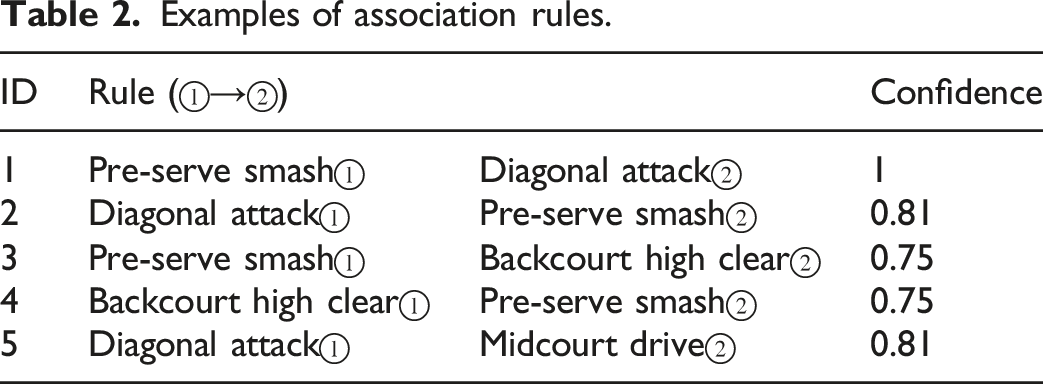
Rule 1 in Table 2 indicates that the confidence for “pre-serve smash” →“diagonal attack” is 1.00, meaning that in all cases where “pre-serve smash” is used, the player always closely adopts “diagonal attack.” Rule 2 states that the confidence for “diagonal attack”→“pre-serve smash” is 0.81, which means that in the case of using “diagonal attack,” the player has an 81% chance of using “pre-serve smash.” The other rules follow suit.
Apriori algorithm
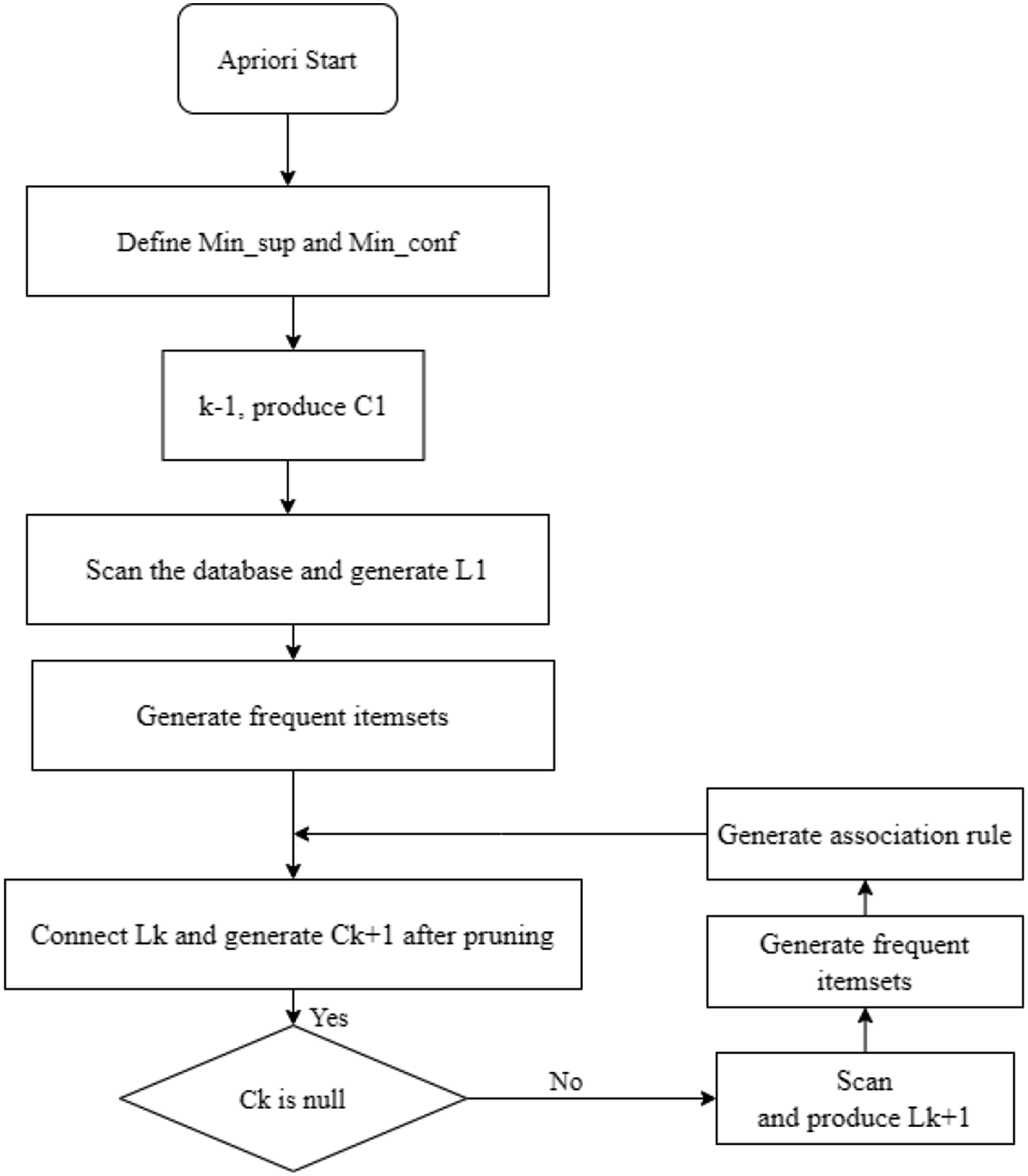
The Apriori23–25 algorithm is one of the classic algorithms used for mining association rules, and it is also the most commonly used algorithm in mining association rules. Its basic principle is monotonicity: if an itemset is frequent, all its subsets must also be frequent. This means that if an itemset is not frequent, then any superset containing that itemset cannot be frequent, which helps to reduce search space. Apriori algorithm is chosen because it is suitable for mining frequent patterns, strong interpretability and low computational complexity. Although techniques such as decision trees, random forests, support vector machines, and deep learning perform well in some applications, they are complex and computationally expensive. Figure 3 shows the flowchart of the algorithm. (1) In the initial stage, the algorithm scans the database and considers all single data items that have appeared as candidate 1-itemset, and marks the set of candidate 1-itemset as C1. (2) For each possible 1-itemset, the algorithm checks whether its transaction support exceeds the set minimum support threshold. When the support exceeds a certain threshold, the candidate 1-itemset is considered a frequent 1-itemset, and this set is marked as L1. (3) In scenarios with k>1, this algorithm performs the following operations multiple times. (4) A candidate (k + 1)-itemset is generated, that is, self-connection operations are performed on each k-itemset in the frequent itemset to obtain a set of candidate (k + 1)-itemset Ck + 1. (5) For each candidate (k + 1)-itemset in Ck + 1, the algorithm checks whether its transaction support exceeds the minimum support threshold set by the user. (6) The candidate (k + 1)-itemsets with support exceeding the set threshold are retained, forming a frequent (k + 1)-itemset, which is named Lk + 1. Flowchart of Apriori algorithm.
Defects of Apriori algorithm
Overall, the Apriori algorithm can effectively mine frequent itemsets and association rules in the dataset and uncover the inherent relationships and patterns between data, and its wide applicability can also be applied to the analysis of player tactics and strategies in badminton competitions in this article. However, it is still important to note its defects.
Combination growth of a large number of candidate itemsets
The Apriori algorithm generates a large number of candidate itemsets when mining frequent itemsets, including a large number of unrelated itemsets. This combination growth of candidate sets results in significant computational and storage costs for the algorithm. As the size of the dataset increases, the execution time and memory consumption of algorithms grow exponentially, resulting in low efficiency when processing large-scale datasets. Similarly, the badminton competition data in this article has a very large dataset, which results in a large number of candidate itemsets generated by the Apriori algorithm, making it difficult to obtain accurate tactical analysis results in a short period of time.
Frequent scanning of transaction databases
The Apriori algorithm requires multiple scans of the transaction database to discover frequent itemsets, and each scan requires a global scan of the database to calculate the support of itemsets. Especially for the large-scale dataset used in this article, frequent database scans can make the efficiency of the algorithm very low. Moreover, the data of badminton competitions requires real-time mining, real-time acquisition and analysis, and the frequent database scans of the Apriori algorithm cannot meet the real-time requirements.
Limited applicability of the algorithm
Due to the algorithm’s search method based on frequent itemsets, it has weak processing capabilities for high-dimensional and continuous attribute data. In the badminton competition mentioned in this article, the tactics of players involve multiple dimensions and continuous attributes. The Apriori algorithm cannot effectively mine these complex tactical patterns, resulting in incomplete and inaccurate tactical analysis results, and a comprehensive understanding of the player’s tactics and strategies.
Lack of user interaction in the algorithm
It should be noted that badminton competitions are an activity that requires communication. Coaches and athletes have rich domain knowledge and experience, and can provide reasonable suggestions for algorithms. However, the Apriori algorithm is unable to interact with users in real-time, and cannot be adjusted and optimized based on user needs and feedback, which leads to limitations in the algorithm’s interpretability and operability.
Constraint-based association rule-improved algorithm ACARMI
Based on the defects mentioned, the Apriori algorithm is studied, and a constraint-based association rule-improved algorithm ACARMI is applied. Since ACARMI is an algorithm that only adds some research of this article on the basis of other improved algorithms of the Apriori algorithm, the process of ACARMI is not further analyzed. The algorithm process is shown in Figure 4. The initialization phase determines the minimum support and minimum confidence and reads the transaction data from the database to convert it to Boolean-type data. When the database is scanned for the first time, all possible monomial sets are generated and the support for each monomial set is calculated. Then, the frequent monomial sets with support higher than or equal to the minimum support are filtered out. The second time the database is scanned, the support of each candidate item set is calculated, and the frequent item sets whose support is higher than or equal to the minimum support are filtered out. In the frequent item set filtering stage, the item sets that meet the constraint conditions are retained. Using an incremental mining approach, frequent item sets are updated with historical data, rather than globally scanning the entire database each time. In the generation stage of association rules, all possible association rules are generated from frequent item sets, the confidence of each association rule is calculated, and the association rules whose confidence is higher than or equal to the minimum confidence are filtered out. In order to ensure real-time performance, the implementation steps include real-time data collection, stream processing framework and the application of low latency computing technology. These measures ensure the real-time performance and high efficiency of the algorithm in practical applications. Flowchart of ACARMI algorithm.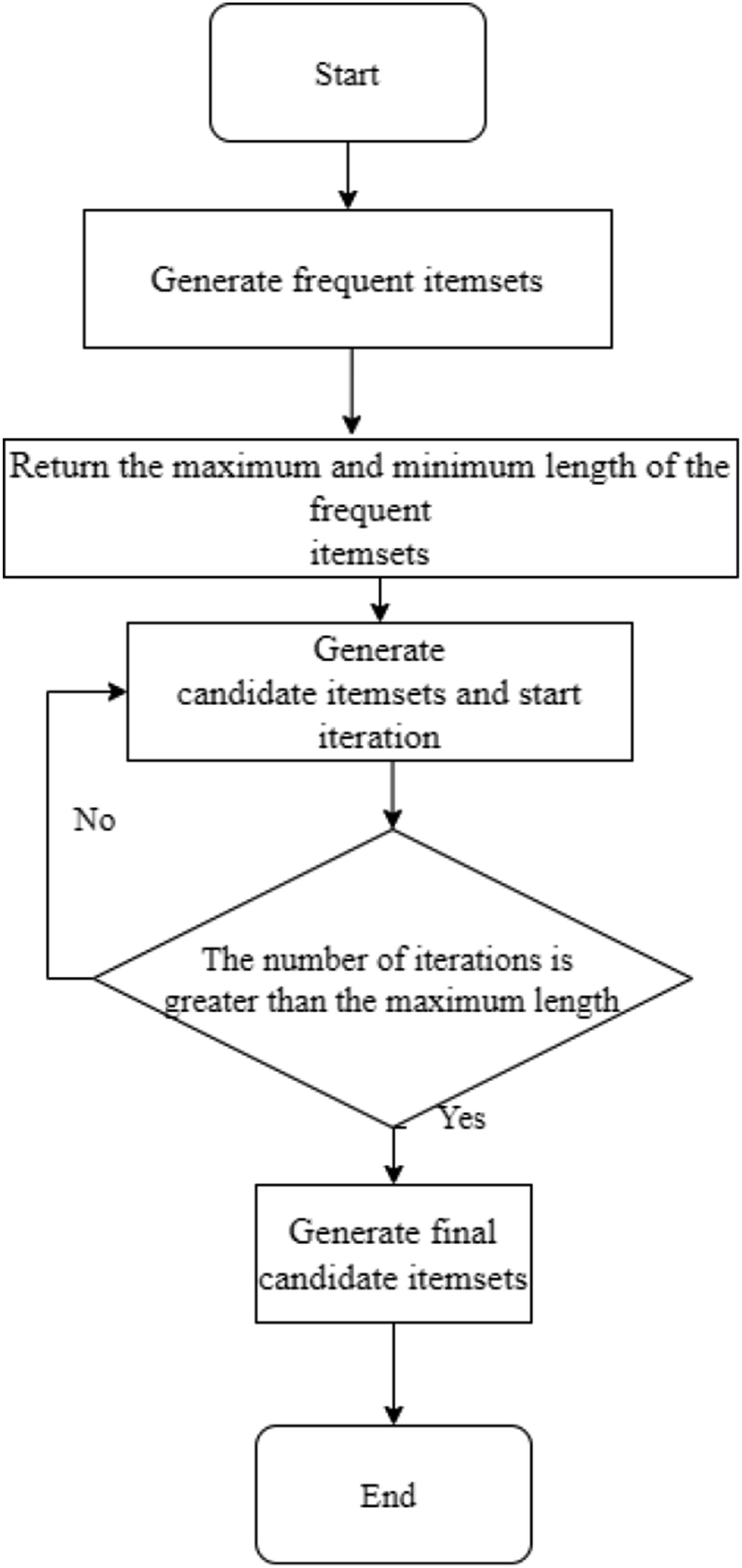
There are four main directions for improvement: the first is to reduce the generation and storage costs of candidate itemsets, by improving the candidate itemset generation strategy of the Apriori algorithm to avoid generating irrelevant candidate itemsets; the second is to apply incremental mining, which utilizes the update of historical data to dynamically update frequent itemsets, instead of scanning the entire database every time; the third is to use distributed computing platforms for data mining, dividing large-scale datasets into multiple subsets and assigning them to different computing nodes for parallel processing; the fourth is to apply some constraints, allowing users to provide constraints based on their own domain knowledge and experience and allowing users to adjust parameters in the mining process. A user feedback mechanism is applied to enable users to evaluate and provide feedback on mining results.
Design of badminton tactics and strategies system
Data collection module
Competition collection
Collection of badminton competitions.

Collection of basic information
Basic personal information such as the names, nationalities, genders, ages, heights, weights are collected. The date, location, level (local, national and international competitions) and stage of the competition (group stage, elimination game and final stage) are also recorded.
Scores are collected in terms of score data (score per game, total score, and loss per game). In the hitting data, the total number of strikes, successful strikes, mistakes, smashes, net plays, high clears, drives, and transitions. In terms of court area data, the number of strikes made by players in the forecourt, midcourt, and backcourt is recorded.
Collection of tactics and strategies
Badminton tactical theory includes attacking, defending, and switching tactics. The choice of these tactics is influenced by the player’s technical level, physical condition, opponent’s characteristics, and the stage of the competition. The number of attacks, defenses, successful attacks, successful defenses, and tactical changes is recorded. In terms of serving strategy, the number of short serve times, long serve times, and serve score times is recorded. In terms of receiving and serving strategies, the number of moving forward to the net when receiving and serving, the drives when receiving and serving, and scoring when receiving and serving is recorded. In terms of strategy for attack and defense transition, the number of defense changing to attack and the number of attack changing to defense are recorded. In terms of psychological and tactical aspects, the number of maneuvering the opponent and the number of unforced errors are recorded. To design and implement the data collection module, video analysis technology, sensor technology, and manual recording methods are adopted.
Data preprocessing module
The algorithm used in this article is the ACARMI mining algorithm, which is association rule mining and requires data to be Boolean. In the process of data collection, there may be some errors and omissions in the data. Therefore, before conducting big data mining, this article needs to convert the data of these competitions into a unified format. Figure 5 shows the framework of a data conversion model, which involves discretizing continuous attributes, reducing dimensions, and processing null values. Architecture of data conversion model.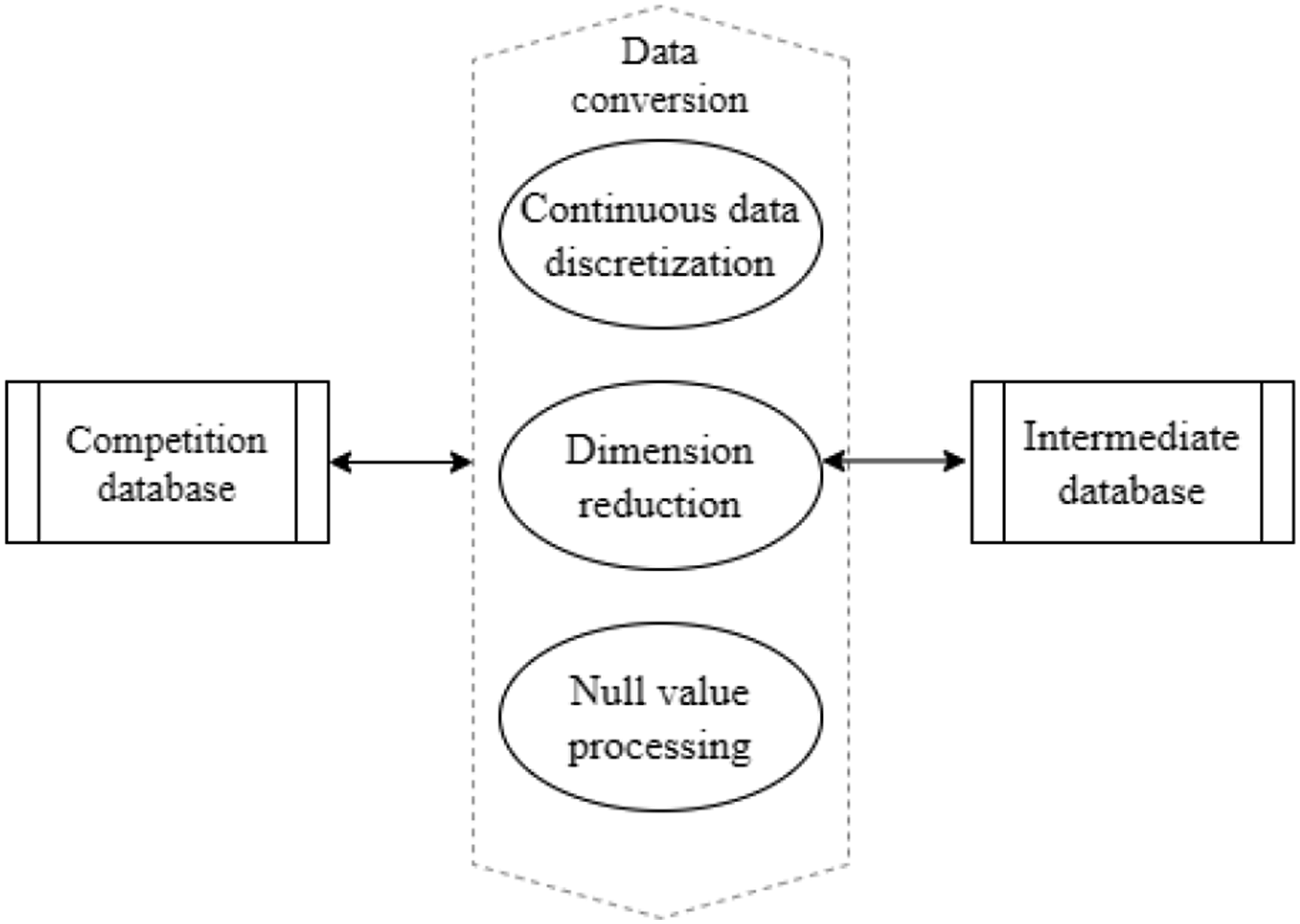
Discretization of continuous attributes
Continuous attribute discretization 26 is the process of converting continuous numerical data into discrete intervals or categories to simplify the data. This article adopts equal-width discretization and divides the data into three intervals (low speed, medium speed, and high speed). For example, the strike speed data of a player in a competition is (in km/h): 45, 52, 60, 48, 55, 62, 50, 59, 63, 47, and then the range for setting three intervals is low speed: <50 km/h, medium speed: 50–59 km/h, and high speed: ≥60 km/h. The converted data is low speed, medium speed, high speed, low speed, medium speed, high speed, medium speed, medium speed, high speed, and low speed.
Dimension reduction
Dimension reduction 27 simplifies the dataset by removing redundant or irrelevant features, reduces data dimensions, and improves the efficiency of data processing and analysis. This article adopts correlation analysis method. The dimensions include the competition time, the number of player’s strikes, the player’s first competition score, the player’s second competition score, the number of spectators, court temperature, and so on. After analysis, it is found that the number of spectators is not related to the tactics and strategies of the players, so this feature is removed. The player’s first competition score and the player’s second competition score similar features, so the two are combined to form the “player score.”
Null value processing
Null value processing 28 is a processing step for missing values in a dataset to ensure data integrity and consistency. This article adopts the methods of mean completer and deleting the records. For critical data, for example, player A’s number of strikes is “120, 150, 130, null, 140,” and the competition time (in minutes) is “30, 28, 32, 35, null.” If the average values of these two sets of data are 135 and 31.25 minutes, respectively, after mean completer, the data is “120, 150, 130, 135, 140” and “30, 28, 32, 35, 31.25.” For non-critical data, records containing missing values are directly deleted, but this method may lead to a reduction in data volume. The criticality of the data needs to be evaluated by professional personnel.
The final data may also contain abnormal data and noise data. In this article, statistical analysis is used to identify and process these data. For example, outliers are identified by Boxplot and standard deviation methods and processed by means of median replacement or removal. For noisy data, smoothing techniques such as moving average method or local weighted regression are used to reduce the impact of noise on data analysis. These steps ensure that the final data set is of high quality and reliable.
Design and implementation of ACARMI mining module
Frequent itemset statistics stage
An integer array is created to record the number of frequent itemsets, and the length of each array should be equal to the total number of different items in the database. When conducting the first database scan, it is necessary to traverse every record in the database and count the frequency of each item appearing in the entire database. Then, the statistical results are updated to the corresponding position in the integer array.
Selection stage of itemsets that meet constraint conditions
An array is redefined to record the selected set S that satisfies constraint C. A second scan of the database is performed, and each record in the database is traversed. Whether the items meet the set constraint condition is checked. When an item satisfies constraint C, it is added to the array.
Frequent itemsets generation stage
Higher-order frequent itemsets are generated based on the frequent itemsets obtained from the first step. For each frequent itemset, it is necessary to determine whether it is included in the items in set S. When the frequent itemset contains items in set S, it is added to the list of frequent itemsets, otherwise it is not considered.
Association rule extraction stage
Finally, based on the frequent itemset list, the association rules of the ACARMI algorithm are extracted to generate candidate association rules. For each candidate association rule, its confidence is calculated. This article defines a minimum support of 5%, a specified minimum confidence threshold of 12%, and then filters out association rules that meet the requirements. The association rules that meet the requirements are stored and output as mining results. In the experiment of this article, the setting of the minimum support range is based on the analysis of the data set distribution to ensure that meaningful frequent item sets can be mined, while not generating too many low-frequency item sets to avoid excessive computing overhead.
Implementation effect of system
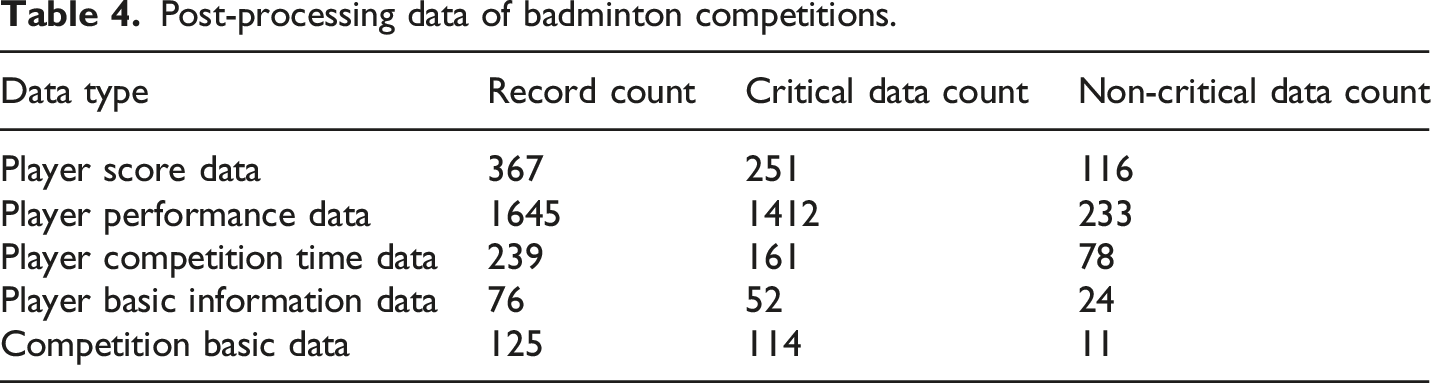
Based on the data collected from six top badminton competitions in the previous sections, these match data come from detailed video recordings and official statistical data, covering player performance, tactical choices, field movements, and technical applications, ensuring transparency and reproducibility of the research. This article preprocesses the data and obtains 2452 pieces of data, including 1990 pieces of critical data and 462 pieces of non-critical data. The data is divided into five categories: player score data, player performance data, player competition time data, player basic information data, and competition basic data.
Post-processing data of badminton competitions.
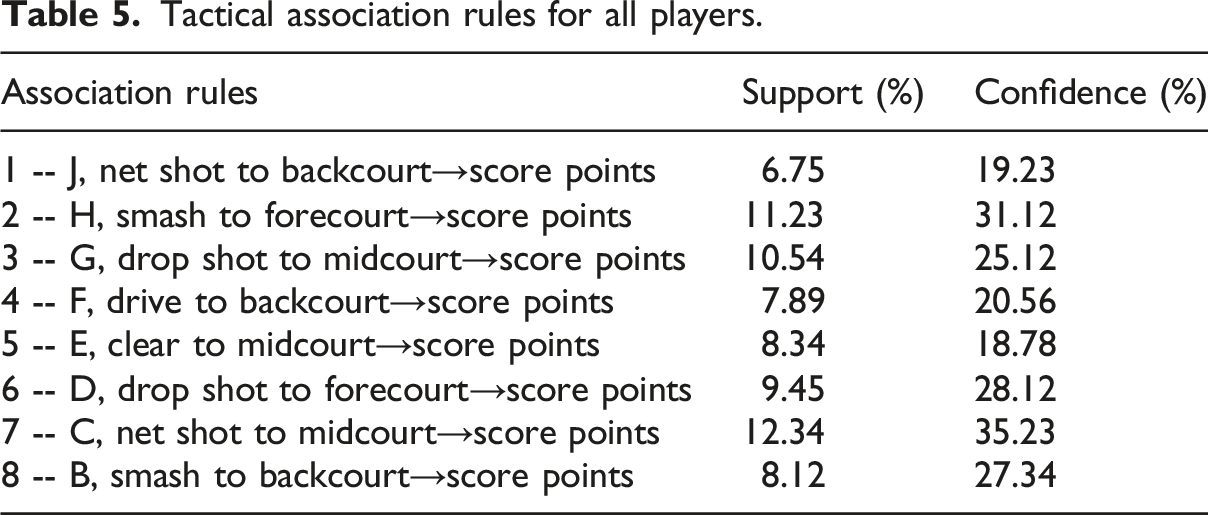
Tactical association rules for all players.
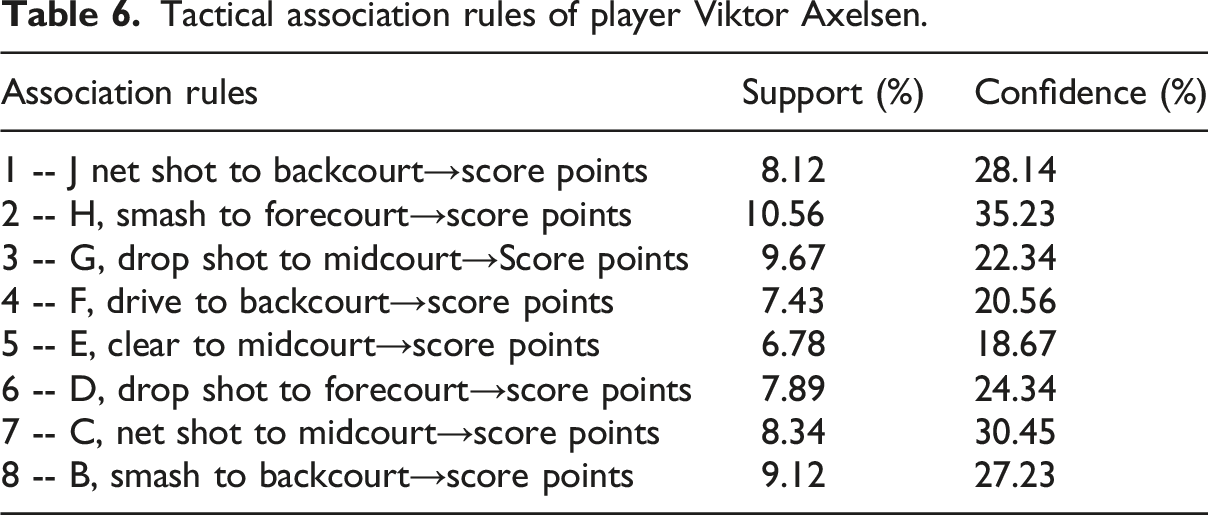
Tactical association rules of player Viktor Axelsen.
Comparison of algorithms
This section uses an Intel Core i7-10700K processor, 32 GB DDR4 memory, 1 TB NVMe SSD storage, and Windows 10 Pro 64-bit operating system. Data mining uses the Python programming language, and the main toolkits include Pandas, NumPy, Scikit-learn, and APyori. The experimental code is written and run in Jupyter Notebook, and Matplotlib and Seaborn are used for data visualization and results presentation.
To verify the advantages of the ACARMI algorithm, this article applies an improved algorithm based on the Apriori algorithm: FP-Growth (frequency pattern growth)29,30 algorithm and DHP (direct hashing and pruning)31,32 algorithm for comparison. FP-Growth algorithm can improve the mining efficiency by constructing frequent pattern trees, which is suitable for large-scale data sets, but has a large memory consumption. DHP algorithm reduces the candidate item set by hashing technology and pruning strategy, which improves the execution efficiency of the algorithm, but hashing conflict may affect the processing effect of high-dimensional data. The running times of the ACARMI algorithm, FP-Growth algorithm, and DHP algorithm are compared under different support levels and different number of constraints, respectively. The minimum support is set to 1.2%–12% (10), with constraints of 1, 2, 3, 4, and 5, respectively. The mining rule still runs as “tactic→score.”
As shown in Figures 6 and 7, under the same minimum support, the running time of the FP-Growth algorithm is significantly higher than that of the ACARMI algorithm in this article. Its initial running time is around 1490 ms, while the algorithm in this article runs around 355 ms in this experiment, and the final running times are around 410 ms and 75 ms, respectively. Under the same number of constraints, the initial running time of FP-Growth is around 610 ms, while the initial running time of the algorithm in this article is only around 150 ms. The final running times are around 175 ms and 45 ms, respectively. Overall, the efficiency of the algorithm proposed in this article is higher than that of the FP-Growth algorithm under the same conditions. Comparison of running time under different minimum support (FP-Growth). Comparison of running time under different number of constraints (FP-Growth).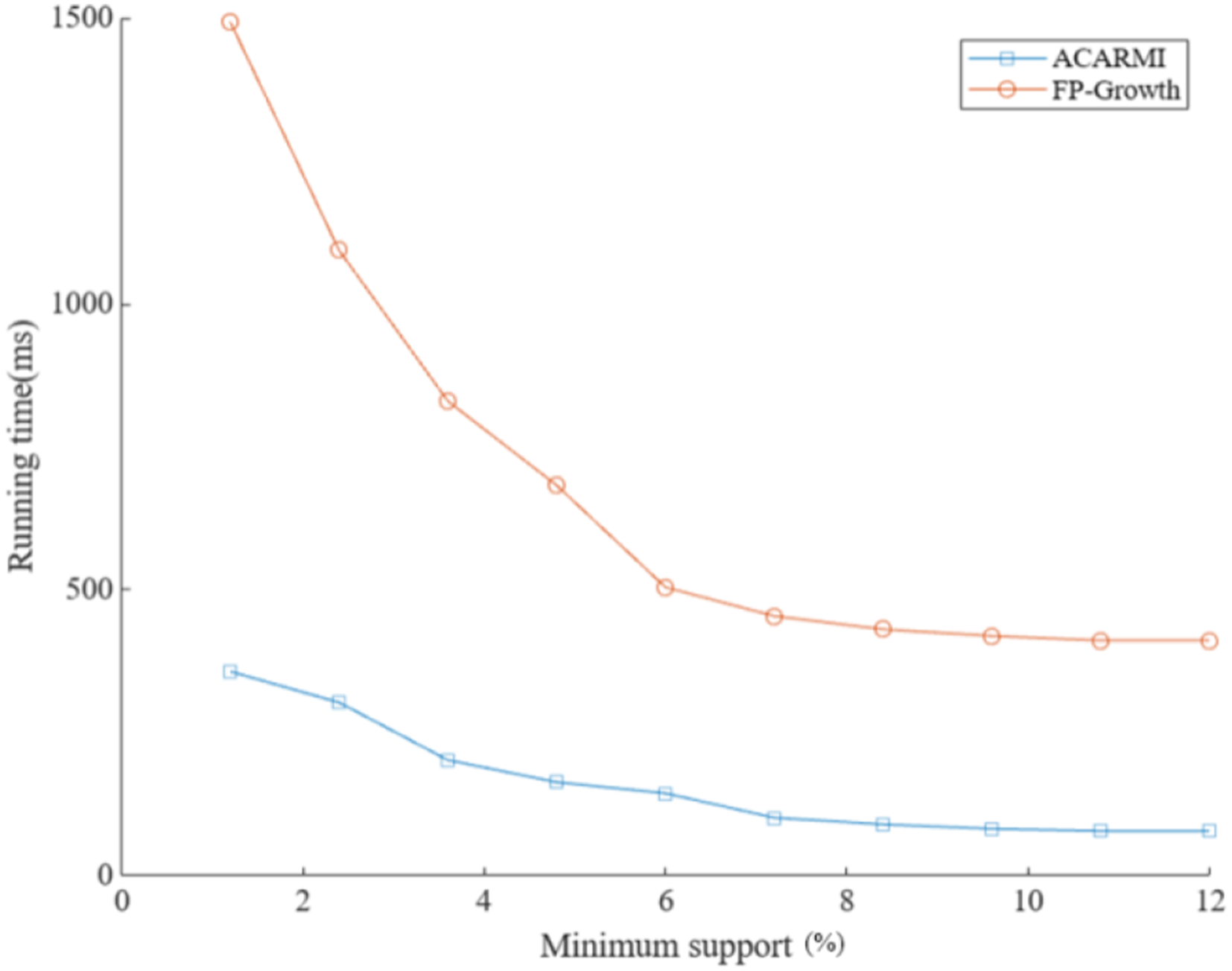

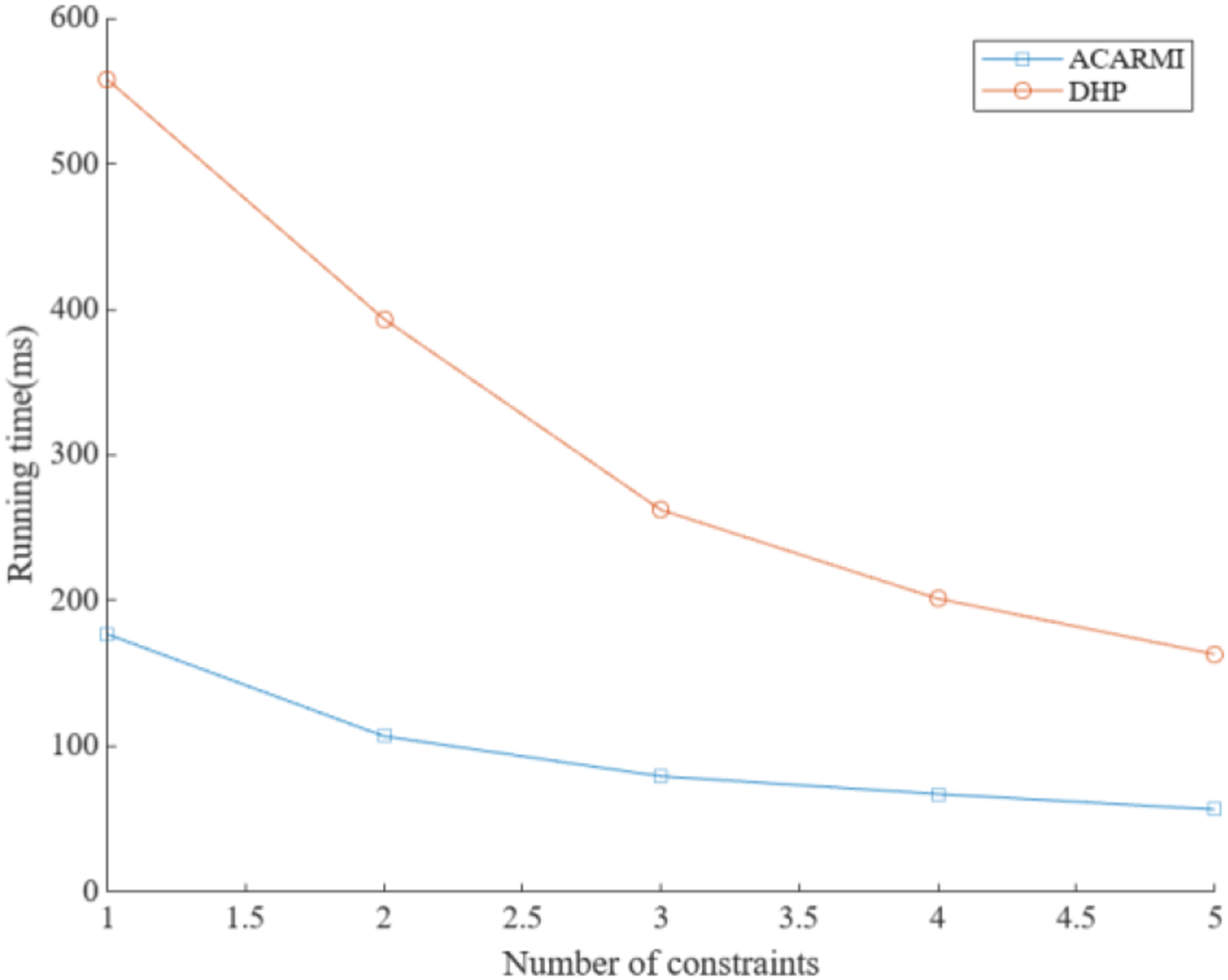
As shown in Figures 8 and 9, the algorithm proposed in this article can process transaction data more efficiently and maintain lower running time under different support conditions. In contrast, the DHP algorithm has high running time under different minimum support levels. Its initial running time exceeds 660 ms, and the final running time is about 195 ms. However, the initial running time of the algorithm in this article is only about 165 ms, and the final running time of the algorithm in this article is about 35 ms. Under different constraint conditions, the initial running time of the algorithm in this article is about 175 ms, and the final running time is about 55 ms. The initial running time of the DHP algorithm is about 560 ms, and the final running time is about 160 ms. Overall, the running efficiency of the algorithm in this article is higher than that of the DHP algorithm. Comparison of running time under different minimum support (DHP). Comparison of running time under different number of constraints (DHP).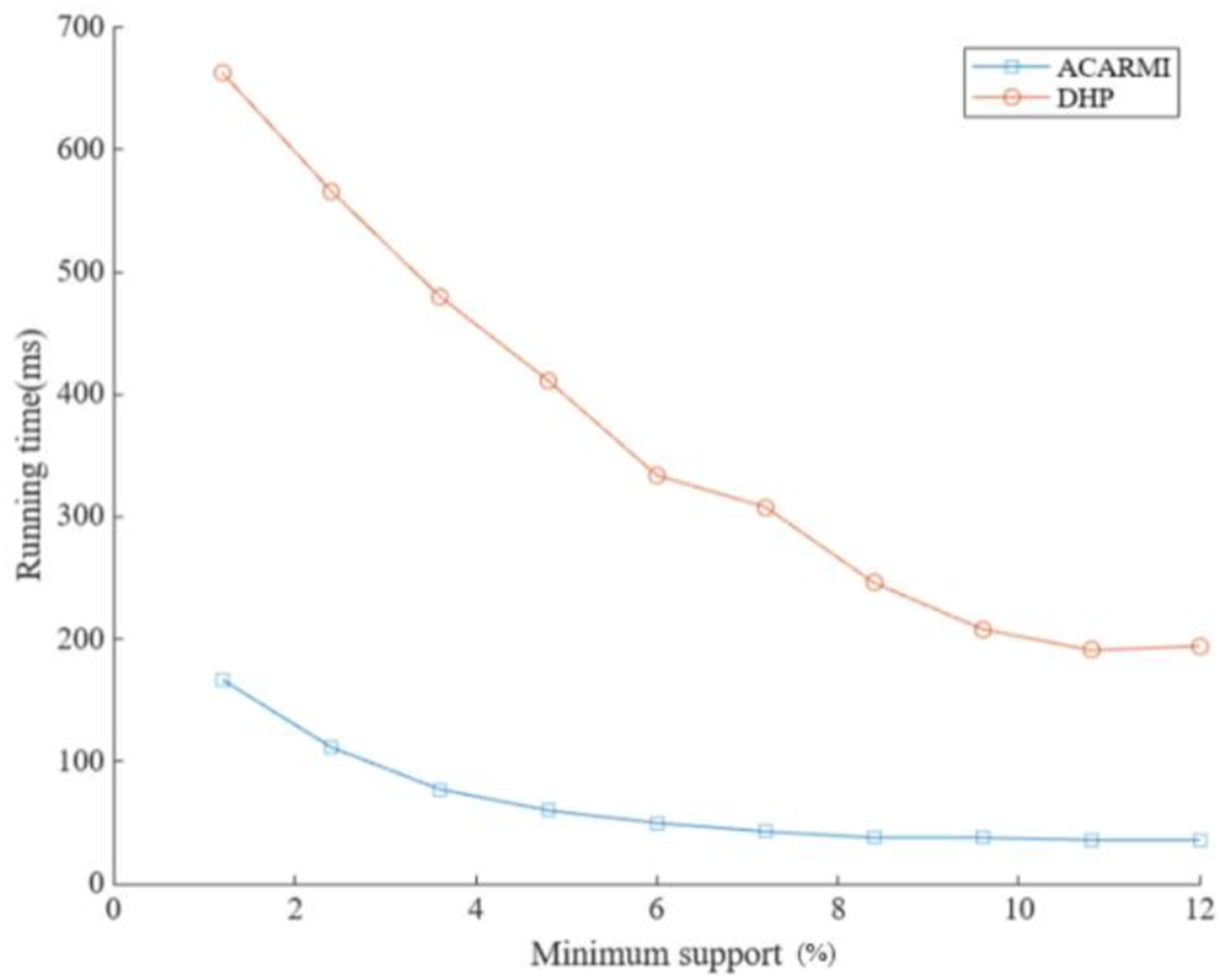
Conclusion
This article utilizes data mining techniques to focus on the tactics and strategies of players in badminton competitions. The first step is to introduce the techniques required in this article and makes certain improvements. Then, relevant data of badminton competitions is collected, and the data is standardized through the data preprocessing module. The ACARMI algorithm is used for association rule mining, and the association rules of players’ tactics and scores in badminton competitions are extracted from the data. A comparative analysis is conducted between the ACARMI algorithm and other improved algorithms, and the results show that the ACARMI algorithm has significant advantages in running efficiency. This article is of great significance for coaches and players to develop effective tactics and strategies in badminton competitions, which can help improve the win rate and tactical execution efficiency. The results of this article also have important value in practical application. Through data-driven tactical analysis, coaches can develop more scientific and effective training plans, and players can constantly adjust and optimize their tactics according to data feedback, so as to achieve better results in the competition. However, there are also some shortcomings in this article, such as limitations in the data sample. The data is all obtained from players in world-class competitions, without considering ordinary and amateur players. ACARMI algorithm performs well in association rule mining, but there is still room for improvement, and the efficiency and accuracy of the algorithm need to be further optimized. The ACARMI algorithm improves the efficiency by reducing the candidate item set and applying incremental mining, but its computational complexity still has room for optimization under high-dimensional data sets. The data sample is only from six top-level badminton matches, and the sample size is small, which may affect the universality of the results. In future research, using more competition projects, applying the knowledge of more experts, and attempting to combine other data mining techniques, such as deep learning, can be considered to further enhance the depth and breadth of research. In addition, machine learning and deep learning are also widely used in tactical analysis to capture complex tactical patterns and hidden features. In future research, machine learning and deep learning can be combined to further improve the depth and accuracy of tactical analysis. The method in this article can also be applied to other sports such as basketball, football, tennis, etc., to explore the tactical rules and optimization strategies of different sports.
Footnotes
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.