
Abstract
Against the backdrop of digital transformation in education, the integration of Mixed Reality (MR) and Artificial Intelligence (AI) has fostered a new “virtual-physical symbiotic” learning environment. However, current educational tools often fail to capture learners’ dynamic needs and the characteristics of 3D immersive scenarios, resulting in a disconnect between virtual character interactions and the teaching process. Existing approaches face various limitations: rule-based models struggle with the dynamics of three-dimensional spaces; collaborative filtering algorithms overlook spatial contextual features; and deep learning models lack joint modeling of emotion and context. These shortcomings highlight insufficient multi-source data integration and weak situational awareness. To address these challenges, this study proposes a virtual character recommendation method tailored to immersive learning environments. The model is composed of a transformation layer, a self-adversarial data generation layer, an embedding representation layer, and a virtual character prediction layer. It achieves dynamic matching between virtual characters and 3D interactive scenarios by incorporating multi-source data standardization, intelligent agent-based game simulation for scenario data generation, semantic vectorization of character features, and Long Short-Term Memory (LSTM)-attention mechanism fusion. This research marks the first application of MR spatial computation and self-adversarial learning in educational role recommendation, offering a technical framework to tackle adaptation challenges in immersive scene recommendations. The proposed approach contributes both theoretical innovations and practical guidance for the advancement of intelligent education.
Keywords
Introduction
In the process of digital transformation in education, MR technology,1–3 by constructing a three-dimensional interactive space integrating virtual and real elements, provides technical possibilities to overcome the time and space constraints of traditional classrooms. Meanwhile, the intelligent decision-making and learning capabilities of AI4,5 inject core momentum into the personalized development of educational tools. When the two are deeply integrated into educational scenarios, they not only give rise to a new type of “virtual-real symbiotic” teaching environment but also place higher demands on the interaction design of educational tools. Most existing tools6,7 still remain at the level of technical patching. In immersive learning scenarios, virtual characters, as key media connecting learners with virtual environments,8–10 suffer from recommendation mechanisms that fail to accurately capture learners’ dynamic needs and three-dimensional scene characteristics, resulting in a significant disconnection between character interaction and the teaching process, which limits the application depth of MR-based educational tools.
Exploring the development of educational tools that integrate MR and AI11,12 has core value in building effective paths for technology-empowered educational innovation. Virtual character recommendation methods oriented toward immersive scenarios can dynamically match suitable virtual characters based on learners’ cognitive states, 13 spatial interaction behaviors, 14 and emotional feedback, 15 upgrading learning scenarios from “static presentation” to “dynamic response,” and significantly enhancing the immersion and interactivity of MR environments. The deep coupling of AI’s self-learning mechanism with MR’s spatial computing capabilities breaks through the technical bottleneck of traditional educational tools in character interaction design, providing theoretical support for constructing a closed-loop educational system of “scene perception–character adaptation–intelligent feedback,” and has important innovative significance for promoting interdisciplinary research in the field of smart education.
Existing studies show significant limitations in the integration of virtual characters with MR educational scenarios. Literature16,17 proposed rule-based recommendation models that only complete character matching through predefined knowledge graphs, which cannot adapt to learners’ dynamically changing interaction needs in three-dimensional space, and the recommendation accuracy in complex experimental scenarios is less than 60%. The collaborative filtering algorithms adopted in literature, 18 although able to generate recommendations based on historical interaction data, ignore contextual features such as spatial coordinates and gesture trajectories in MR environments, resulting in a disconnection between recommended characters and scene interaction logic. Deep learning models in literature19,20 have improved recommendation efficiency, but lack joint modeling of virtual character emotional expression strategies and 3D scene characteristics, making it difficult for character interactions to resonate emotionally with learners. These studies show that existing methods have not fully integrated the immersive features of MR and the dynamic demands of educational scenarios, and there are obvious technical shortcomings in multi-source data fusion, contextual perception, and emotional interaction.
This study focuses on a virtual character recommendation method for immersive learning scenarios and constructs an innovative model composed of a transformation layer, a self-adversarial data generation layer, an embedding representation layer, and a virtual character prediction layer. The transformation layer performs feature extraction and standardization processing of multi-source data, converting learners’ spatial interaction data such as gesture trajectories and gaze focus points, as well as textual knowledge queries, into unified vector representations. The self-adversarial data generation layer uses an intelligent agent game mechanism to simulate learners’ dynamic behavioral patterns in 3D scenarios and generate serialized training data with multidimensional features including spatial coordinates and emotional feedback. The embedding representation layer uses word embedding techniques to convert attribute labels of virtual characters into high-dimensional semantic vectors, achieving unified representation of character features and learner states. The virtual character prediction layer integrates LSTM networks with attention mechanisms to capture temporal behavioral patterns of learners in MR scenarios and focus on key interactive elements, outputting a sequence of virtual characters adapted to the current scenario through probability ranking. The innovative value of this study lies in the fact that it is the first to introduce MR’s spatial computing capabilities and self-adversarial learning mechanisms into the field of educational character recommendation. Through multidimensional feature fusion and dynamic contextual modeling, it constructs a complete technical chain of “data–representation–prediction,” providing a systematic solution to the adaptability problem of traditional recommendation methods in immersive scenarios, and offering important theoretical breakthroughs and practical guidance for the intelligent and personalized development of MR educational tools.
Virtual character recommendation method for immersive learning scene construction
In the development of educational tools integrating MR and AI, the research on virtual character recommendation methods for immersive scenarios is a key approach to resolving the “disconnection in virtual-real interaction.” Current MR educational tools, although capable of constructing three-dimensional learning spaces, often present virtual characters in preset modes, failing to respond to learners’ dynamic needs in spatial interactions. When learners gaze at a cultural relic in an MR historical scene, static characters cannot recommend corresponding historical figures for explanation based on gaze tracking data; in chemical experiment operations, traditional characters are also unable to push experimental mentor characters in real-time according to gesture trajectory deviations. This “scene perception failure” leads virtual characters to become visual decorations, severely weakening the interactivity and authenticity of immersive learning. Therefore, it is urgent to conduct research on recommendation methods to endow characters with intelligence of “spatial perception–demand recognition–dynamic adaptation,” making virtual characters an interactive hub that activates the immersive sense of MR scenes.
This chapter proposes a virtual character recommendation model for immersive learning scene construction, consisting of four key components. These four components are designed to systematically solve the character interaction problems in immersive MR scenes through tightly coupled technical design. Figure 1 presents the framework diagram of the virtual character recommendation model. The conversion layer serves as the data input entrance, whose core function is to break the heterogeneous barriers of multi-source data in the MR environment. When learners generate spatial interaction information such as gesture operations and gaze tracking data in a 3D scene, as well as knowledge queries in text form and scene annotations in image format, this layer extracts features and performs standardization to convert fragmented data into unified vector representations. This enables virtual characters to understand learners’ behavioral intentions in virtual-real fusion spaces based on consistent data foundations, laying a data basis for intelligent interaction in immersive scenes. The adversarial data generation layer and the embedding representation layer together build the semantic bridge for virtual-real interaction, while the virtual character prediction layer realizes the final closed loop of scene dynamic adaptation. The adversarial generation layer simulates learners’ possible spatial exploration paths, experimental operation deviations, and other dynamic behavior patterns in the MR scene through agent-based adversarial mechanisms, generating serialized data containing multidimensional features such as 3D coordinates, emotional feedback, and knowledge gaps. This effectively fills the gap of insufficient interaction data in immersive scenes using traditional methods and enables the recommendation model to cope with complex scene changes. The embedding representation layer converts virtual characters’ attribute tags into high-dimensional semantic vectors using word embedding techniques, allowing the character features to be compared with learners’ real-time state features in the same vector space. The virtual character prediction layer integrates LSTM and attention mechanisms to capture learners’ sequential behavioral patterns in MR scenes via LSTM, and focuses on key elements of current interactions using attention mechanisms. Finally, it outputs a virtual character sequence adapted to the current scene through probability ranking, realizing the closed loop of “scene perception–character matching–interaction feedback,” and making virtual characters a truly intelligent interaction hub that enhances the immersive sense of MR scenes. Framework diagram of virtual character recommendation model.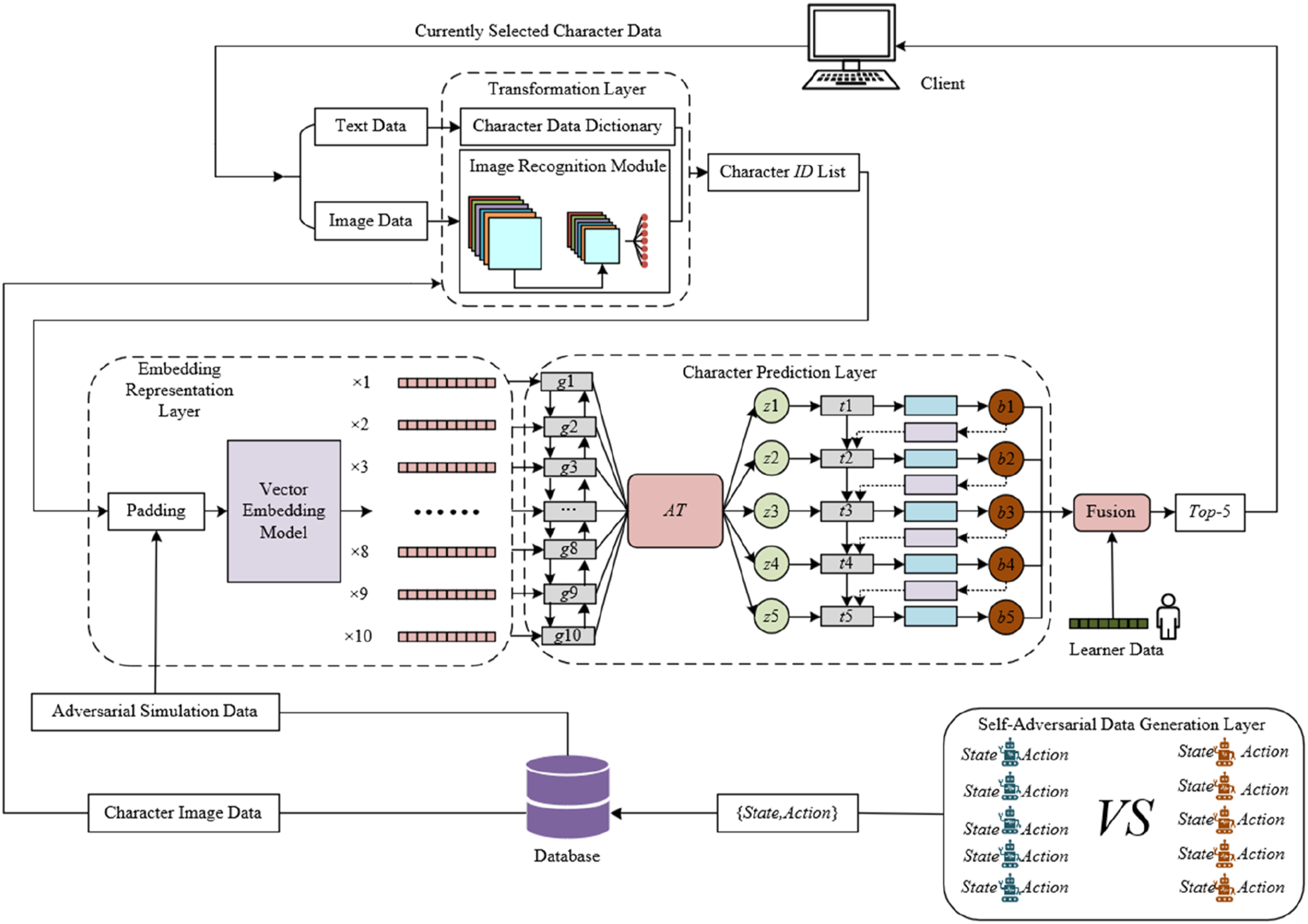
Adversarial data generation
Due to the lack of officially recorded sequences of virtual character selection by users in 3D space in real teaching scenarios, traditional data collection methods cannot obtain dynamic interaction data containing immersive features such as spatial coordinates and gesture trajectories. Therefore, this paper adopts AI agent-based self-adversarial methods to generate data, in order to address the scarcity of serialized interaction data in MR immersive scenes. Through adversarial games among 10 agents based on the HLRS model, it is possible to simulate the process of learners sequentially selecting characters in a MR environment. This method is also the technical key to breaking through the limitations of single-label recommendations and achieving multi-target dynamic adaptation. Traditional single-label data can only train models to predict a single character and cannot meet the demand for multi-character collaborative interaction in MR scenes. However, the data generated by agent adversarial training records the character combinations and recommendation lists in each round of confrontation, forming multi-label training samples. This data not only enables the model to learn the temporal dependency relationships between characters, but also captures the correlations of multidimensional features in MR scenes. As a result, the final recommended character sequence can both match learners’ cognitive needs and conform to the spatial interaction logic of the 3D scene, fundamentally solving the problem that traditional data cannot support multi-character dynamic recommendation in immersive scenes.
The core principle of this method lies in constructing a serialized data generation mechanism with spatial contextual features by simulating the interaction and confrontation process of learners in MR scenes. 10 agents based on the HLRS model perform N rounds of adversarial games, using the selected character list of each round (characterList) as state input and outputting a recommendation list (recommendList) with recommendation scores, then randomly selecting one character (characterPick) from the top five in the recommendation list. This “state–action” closed-loop interaction essentially simulates the learners’ decision logic in the 3D scene. For example, in a chemical experiment scene, after Agent A selects the “experimental operation mentor” character, Agent B will use the HLRS model to recognize the spatial focus point of a test tube and then select the “safety supervision officer” character from the recommendation list. The resulting data pair of {characterList, recommendList} naturally incorporates immersive features such as spatial coordinates and operational contexts from the MR environment, solving the problem that real data does not record 3D interaction information. Moreover, by not considering personal interest data, this standardized agent-based confrontation ensures that the generated data focuses on the professional logic of the teaching scenario rather than individual preferences, thereby enhancing the general applicability of the data to immersive teaching scenes. The deeper principle also lies in the formation of a dynamic mapping mechanism of “character selection–scene feedback” through multi-agent confrontation. In each round of confrontation, the agent constructs training samples using the current character combination and recommendation list, so that the accumulated data list contains not only character sequences but also interaction chains with scene semantics. This data generation method breaks through the limitations of traditional single-label data, enabling the model to learn temporal dependencies of multi-character collaboration in MR scenes. As the agents continuously confront each other, the data list gradually forms a multidimensional dataset containing spatial features, character associations, and teaching logic, which not only supports the model in capturing learners’ behavioral patterns in 3D space but also adapts to the dynamically changing teaching goals in MR scenes.
Embedding vector representation
Before inputting the selected virtual character list into the model, data preprocessing is required, namely, performing ID padding and converting virtual character IDs into embedding vectors.
In MR educational scenarios, there is a natural temporal difference in learners’ character selection behavior. For example, historical dialogue scenarios may involve only 2–3 character selections, while team experiment scenarios may require 10 players to choose characters in sequence. This variability in data length causes the model to be unable to process it directly. The core principle of the ID padding mechanism lies in addressing the dimensional consistency problem of data input in MR immersive scenarios. Essentially, it achieves a unified computational foundation across interaction scales through standardized processing. By introducing a special padding token to uniformly pad sequences to a length of 10, it not only ensures that the bidirectional LSTM encoder can evenly process features at each time step but also implicitly encodes the spatial interaction logic of MR scenarios. Padding positions can be considered “virtual empty roles,” which correspond to “inactive interaction zones” in the 3D space. When the model processes the padded sequence, it can automatically ignore these virtual positions through the attention mechanism and focus on the spatial interaction events corresponding to real character selections. This provides a standardized data foundation for subsequent scene semantic analysis. The formula for padding the virtual character ID list is

Secondly, the principle of converting IDs to embedding vectors is based on the “role semantics - spatial interaction” mapping mechanism. Its technical logic is similar to how word vectors capture semantics in natural language processing, but it emphasizes encoding the multidimensional features of MR scenes. Through a specific word embedding model, each virtual character ID is mapped to a point in a d-dimensional vector space, where each dimension corresponds to a character’s attribute features. Take the character “Caesar” as an example: its embedding vector not only encodes the semantic label of “ancient Roman politician,” but also includes spatial attributes such as “trigger explanation within a 5-m radius in the Colosseum model.” When this vector is fused with the learner’s eye-tracking data in the encoder, the model can quickly identify the scene requirement to “recommend historically related roles to Caesar” via cosine similarity calculation. This mapping mechanism transforms discrete character IDs into continuous vectors containing scene semantics, solving the semantic gap between “character selection - spatial actions” in MR environments.
Role recommendation prediction
Traditional sequence recommendation relies on learners’ historical preferences, while this method focuses on the spatial features and instructional logic of the scene itself. When a learner performs test tube operations in an MR chemistry experiment scene, the recommendation model needs to recommend multiple roles such as “operation guidance,” “safety supervision,” and “principle explanation” based on the current spatial instrument status and operational steps. This multi-role collaborative recommendation mechanism is directly linked to the multidimensional instructional goals within the scene. Therefore, after stripping personal learner information, the task essentially transforms into “predicting a subset of role labels b that meet the current instructional needs based on the scene state sequence a,” which highly aligns with the multi-label classification feature of “one sample corresponds to multiple labels.”
The technical logic of this task definition is based on a direct mapping between “scene state - role labels.” Let the label space M be the set of all virtual roles, and sequence data a contain l scene interaction markers. The goal is to solve for the label subset b* that maximizes the conditional probability o (b|a). This modeling approach converts the spatial interaction sequence in MR scenes into multi-label classification input features. For instance, the hand gesture deviation sequence in an experiment operation will be transformed into feature vectors. The HLRSSeqNet network then calculates the affiliation probability of each role in M, and finally selects the top v roles with the highest probabilities as b*. Unlike traditional sequence recommendation, this task does not rely on learner profiling but uses self-adversarially generated scene data to train the model to capture direct mapping relationships such as “test tube tilt angle anomaly → recommend operation correction + safety warning role,” ensuring the recommendation results strictly align with the instructional logic within the scene. o (b|a) can be expressed by the following formula:

To cope with the temporal-spatial complexity of sequence data in immersive MR scenarios, this paper constructs a model containing an encoder, decoder, and attention module. In MOBA-type learning scenarios, learners’ virtual character selection behaviors have strict temporal logic, and the encoder can effectively capture such long-term dependencies through the LSTM structure. When the input contains the role selection sequence of 10 rounds of players, the encoder can extract implicit patterns such as “after selecting a safety supervisor role, the operation guidance role will inevitably follow.” This high-dimensional representation conversion mechanism encodes the scattered spatial interaction data in MR scenes into unified semantic vectors, providing the feature foundation with both sequential continuity and scene semantics for subsequent recommendations. The introduction of the attention module and decoder directly serves the “dynamic focus” demand of immersive scenarios. For example, in an MR chemistry experiment, if a learner’s gaze suddenly focuses on a test tube emitting white smoke, the attention mechanism assigns higher weight to the gesture deviation data at that time step, guiding the decoder to prioritize recommending the “hazard handling instructor” role. This technical chain of “encoder extracting global sequence features - attention focusing on local key interactions - decoder generating matching role combinations” enables the model to grasp the overall progress of the learning scene while responding to sudden spatial interaction events. Below, this paper will elaborate on the three modules mentioned above.
Encoder module
Figure 2 shows the structure of the encoder. The encoder module adopts the core principle of the bidirectional LSTM structure, aiming to solve the problem of spatiotemporal semantic dependencies in sequence data within MR immersive scenarios. Let {a1, a2, a3…., a10} be the input sequence of the encoder. Traditional unidirectional LSTM can only capture the forward information of the sequence, while the bidirectional LSTM enables the model to process the current time step’s virtual character embedding vector by integrating both the historical selection logic of x1-x4 and the future scenario clues of x6-x10 through parallel computation of forward and backward hidden layers. This bidirectional information fusion mechanism is particularly suitable for bidirectional association modeling of “operation steps-character needs” in MR environments. For example, in MR chemical experiments, the bidirectional LSTM can learn the temporal pattern of “adding reagent → selecting operation tutor” through the forward path, while capturing the foresight information of “heating phase → need for safety supervision” through the backward path. In the end, the ten-round character selection sequence is encoded into a high-dimensional semantic vector containing bidirectional temporal dependencies, allowing the encoder’s scene representation output to reflect both historical interaction trajectories and predict future scene needs, fundamentally addressing the problem of partial scene understanding caused by unidirectional processing in traditional models. Its technical principle is based on the synergistic effect of the gating mechanism and bidirectional information flow. For the input immersive learning scene matrix, let the size of the matrix vocabulary be denoted by |N|, the dimension of the embedding vector be denoted by f, and the cell state at time s be denoted by Z
s
. The forget gate d
s
, input gate u
s
, and output gate p
s
of the bidirectional LSTM dynamically regulate the information flow in the cell state and can be calculated respectively by the following formulas: Encoder structure.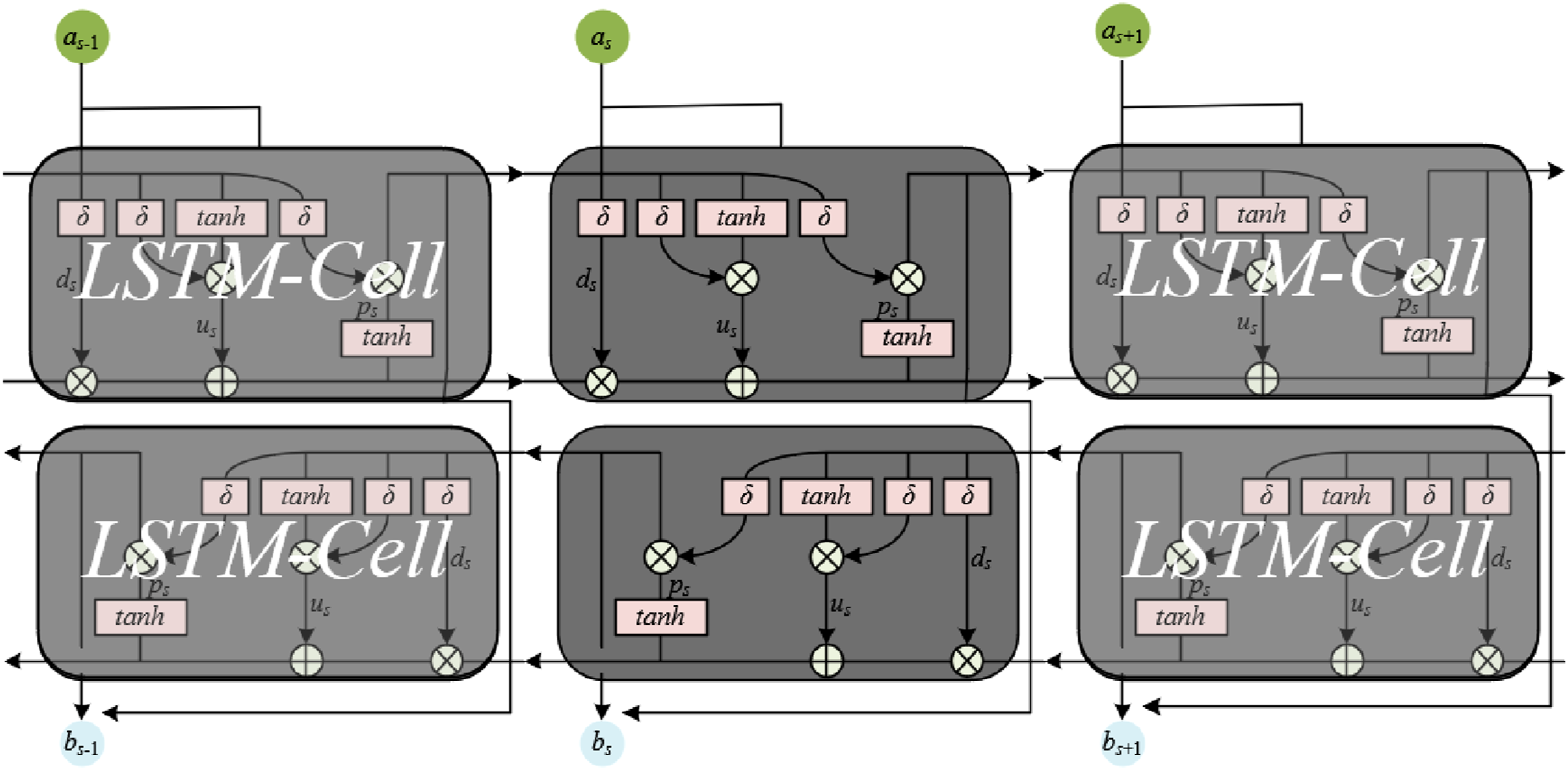






Assuming the output of the hidden layer of the forward LSTM unit is denoted by g→
u
, and the output of the hidden layer of the backward LSTM unit is denoted by g←
u
, then the hidden state of the input character vector a
u
at time u can be obtained by the following formula:



Attention module
In MR environments, the input sequence includes multidimensional data such as learners’ gesture trajectories, gaze focus, and instrument states. The attention mechanism calculates the importance scores of embedding vectors at each time step, enabling the model to automatically focus on the most critical scene features for the current recommendation task. For instance, when the learner fixates on the Caesar statue during a MR history scene, the attention module assigns a high weight to the gaze coordinate data at that time step, guiding the decoder to prioritize the “ancient Roman historian” character rather than other irrelevant background interactive information. This dynamic weighting mechanism transforms instantaneous focus in three-dimensional space into a computable attention distribution, ensuring that the recommendation model can respond in real-time to unexpected interactive events in the MR scene, thereby solving the technical bottleneck of traditional models in distinguishing the importance of scene information. Figure 3 shows the network structure of the attention module. Taking the input at time s of the decoder as an example, suppose the corresponding weight matrix is represented by n, Q, and I, the hidden layer state of the decoder at time s-1 is represented by ts-1, and the weight of the u-th hidden layer at time s is represented by β
su
. The application process of the attention mechanism can be represented by the following formulas: Attention module network structure.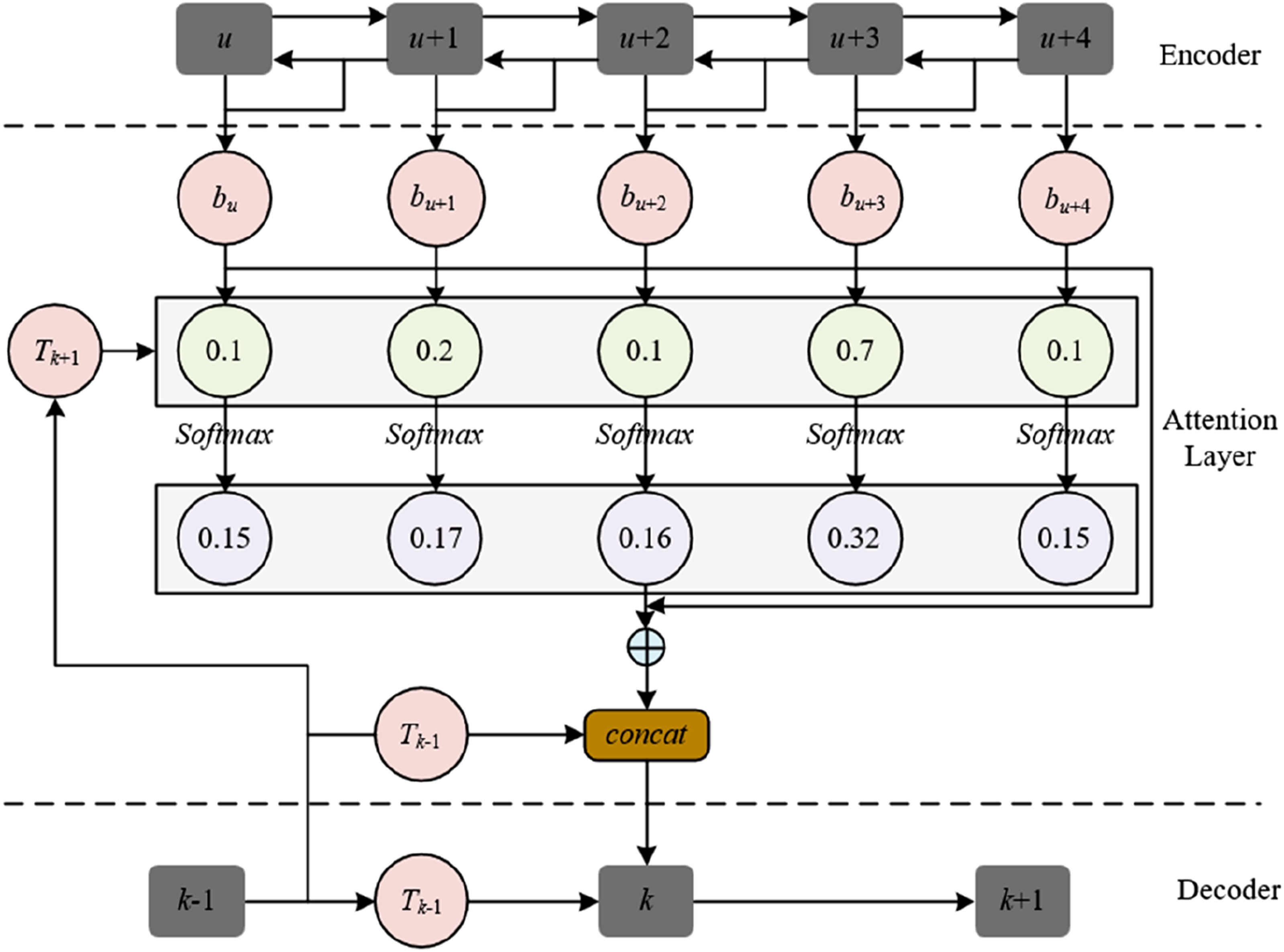



This mechanism enables the attention module to capture the implicit association between “spatial actions-character needs” in MR scenes. For example, when a learner quickly moves gestures in three-dimensional space, the attention module recognizes the corresponding “emergency operation” scenario of the action, dynamically adjusts the weight distribution to recommend virtual characters with emergency guidance ability, and realizes a closed loop of “scene focus change → attention weight adaptation → accurate character recommendation,” fundamentally improving the real-time interaction and immersion of virtual characters in MR environments.
Decoder module
In MR environments, the interaction of learning scenes has strict temporal characteristics. The unidirectional LSTM can, through iterative updates of the hidden layer states, gradually generate virtual characters adapted to the current scene stage based on the bidirectional temporal features provided by the encoder. Its technical principle is based on the collaborative effect of temporal state transitions and scene constraints. The decoder prevents recommending already selected characters repeatedly through a masking vector mechanism, which directly serves the authenticity requirement of interaction in MR scenes. Specifically, the hidden layer state t
s
at time s integrates the global scene representation from the encoder and the local key features from the attention module. When generating the character probability distribution at the current time step, the masking vector sets the probability of already selected characters to zero, forcing the model to choose the option most semantically matched to the current scene from the remaining candidate characters. Specifically, suppose the hidden state of the decoder unit at time s-1 is denoted by ts-1, the context vector at time s is denoted by z
s
, and the global character embedding vector of the decoder unit’s predicted label at time s-1 is denoted by h (bs-1). The weight parameters are represented by Q
p
, Q
f
, and N
f
, the nonlinear activation function is denoted by d, and the masking vector at the current time step s is denoted by L
s
. Then t
s
can be computed using the following formulas:



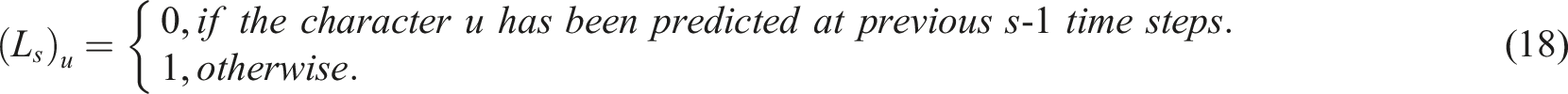


Learner data fusion
In the MR environment, although the teaching logic of the scene itself is the basis of recommendation, learners’ interest preferences toward virtual characters directly affect the sense of immersive interaction. When the recommended characters output by the model are highly matched with the learners’ interests, the degree of learner participation in interaction with characters in the MR scene will be significantly improved. Therefore, multiplying the global probability distribution b
s
output by the decoder with the learner’s interest vector is essentially a semantic fine-tuning of the recommendation result through interest weights: for example, a learner interested in “Ancient Roman Military” will have an interest vector that enhances the recommendation probabilities of characters such as “Caesar” and “Pompey,” while suppressing the weights of irrelevant characters, making the recommendation results not only consistent with the teaching logic of historical scenes but also matched with the learner’s personalized preferences. This enables the construction of a “one scene per person” immersive interactive experience within a professional teaching framework. The character probability distribution across all time steps b
sst
can be defined as follows:


The technical principle of this fusion mechanism is based on the linear transformation between probability space and interest space. For the virtual character probability distribution generated by the decoder through softmax, each element in the learner interest vector corresponds to the interest strength of the virtual character. By element-wise multiplication, the fused probability distribution is obtained, realizing the transformation from “scene recommendation probability → personalized recommendation probability.”
Experimental results and analysis
The ablation experimental results shown in Figure 4 indicate that the proposed model outperforms the versions with core modules removed in all key performance metrics. Specifically, in terms of Micro-F1, the proposed model achieves 0.69, which is higher than 0.674 when the global embedding module is removed and 0.684 when the attention module is removed, indicating better overall prediction ability of the virtual character sequence. In terms of Recall, the proposed model reaches 0.635, which is significantly higher than 0.22 after the attention module is removed. In terms of Precision, the proposed model scores 0.777, slightly higher than the comparison groups, reflecting the high accuracy of the recommendation results. For Hamming-Loss, the proposed model achieves the lowest at 0.0253, indicating stronger control over incorrect predictions in multi-label character recommendation. These data show that the synergy between the global embedding module and the attention module is the key factor in improving model performance. The experimental data fully validate the effectiveness of the proposed virtual character recommendation method for immersive learning scenarios. The significant performance degradation after removing the global embedding or attention module in the ablation experiments further proves that these modules are irreplaceable in fusing spatial interaction semantics and focusing on key scene elements. Ablation experiment results of the proposed model.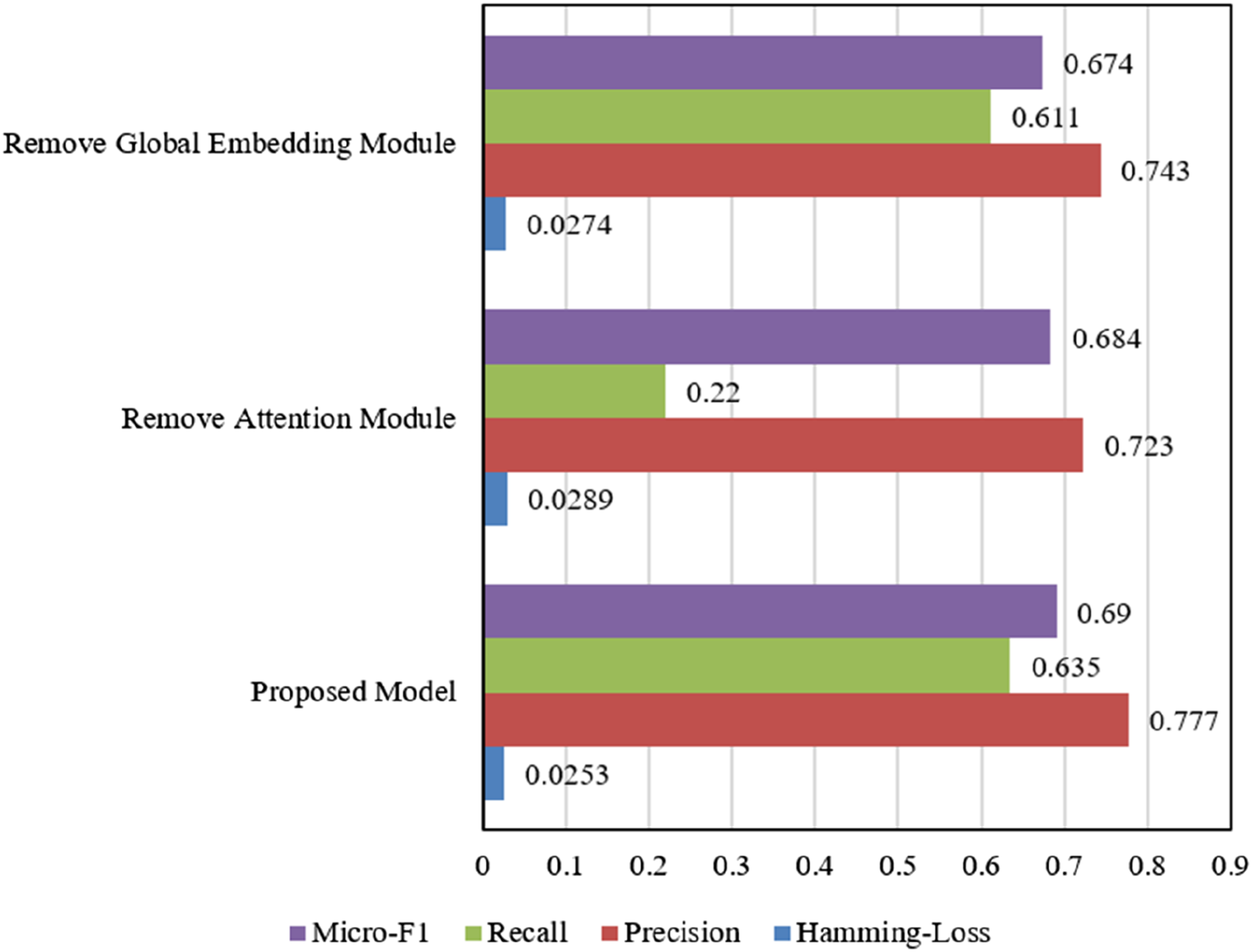
From the data in Figure 5, it can be seen that when bidirectional LSTM is used as the encoder base unit, the model achieves comprehensive superiority in core performance metrics. Specifically, the bidirectional LSTM reaches a Micro-F1 of 0.681, Recall of 0.622, Precision of 0.783, and Hamming-Loss of only 0.0232, all outperforming GRU (Micro-F1 0.665, Precision 0.724), TextCNN (Micro-F1 0.659, Precision 0.711), and NTM (Micro-F1 0.566, Precision 0.574). This shows that in processing sequential interaction data in MR scenes, bidirectional LSTM can capture both forward and backward information through its bidirectional hidden layer structure, more efficiently encoding the spatiotemporal semantic dependencies of the scene. Among the comparison units, GRU suffers from insufficient capability in unidirectional sequential modeling, TextCNN is limited by local feature extraction, and NTM has weak generalization ability in complex scenes, all leading to performance degradation, further highlighting the rationality of using bidirectional LSTM as the encoder base unit. The experimental data strongly validate the effectiveness of the proposed method. The synergy between bidirectional LSTM and other modules in the model builds a complete immersive scene character recommendation framework. This design allows the model to handle the multidimensionality of spatial interaction in MR educational scenes and enhance the understanding of scene logic through bidirectional temporal encoding. The data show that the advantages of the bidirectional LSTM-driven model in Micro-F1, Precision, and Hamming-Loss directly reflect its precise modeling ability of “character sequence–spatiotemporal interaction–teaching logic” in immersive scenes. Impact of different encoder base units on the performance of the proposed model.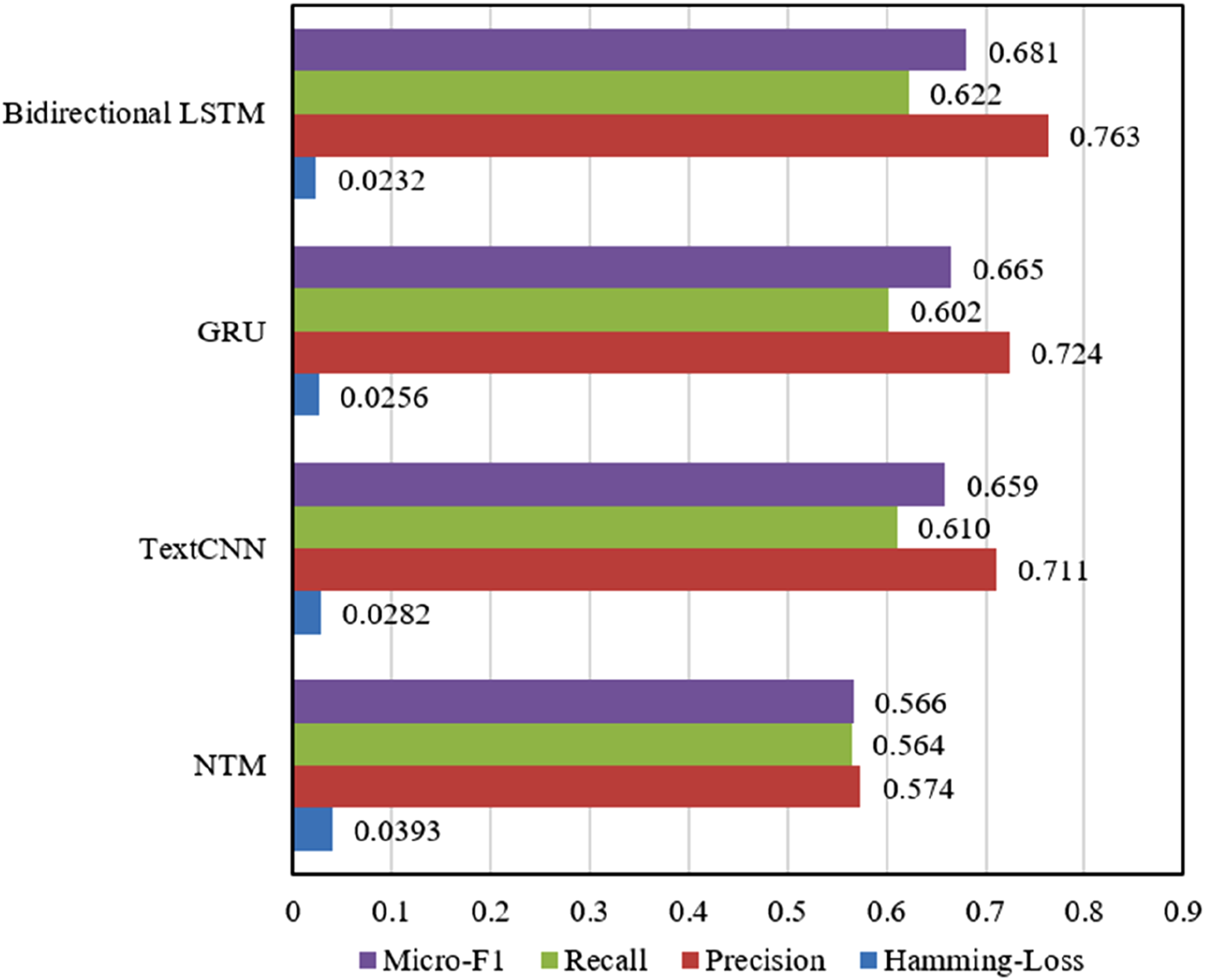
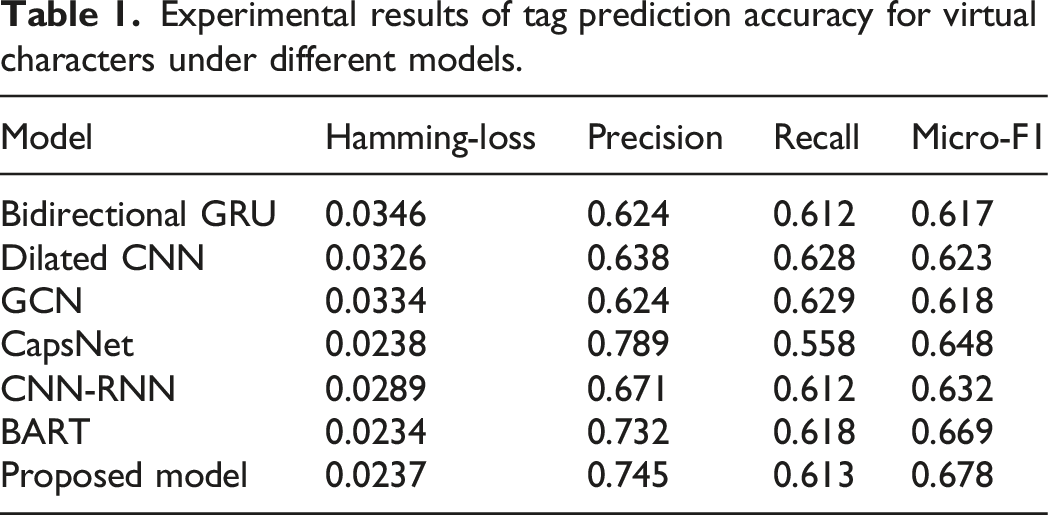
Experimental results of tag prediction accuracy for virtual characters under different models.
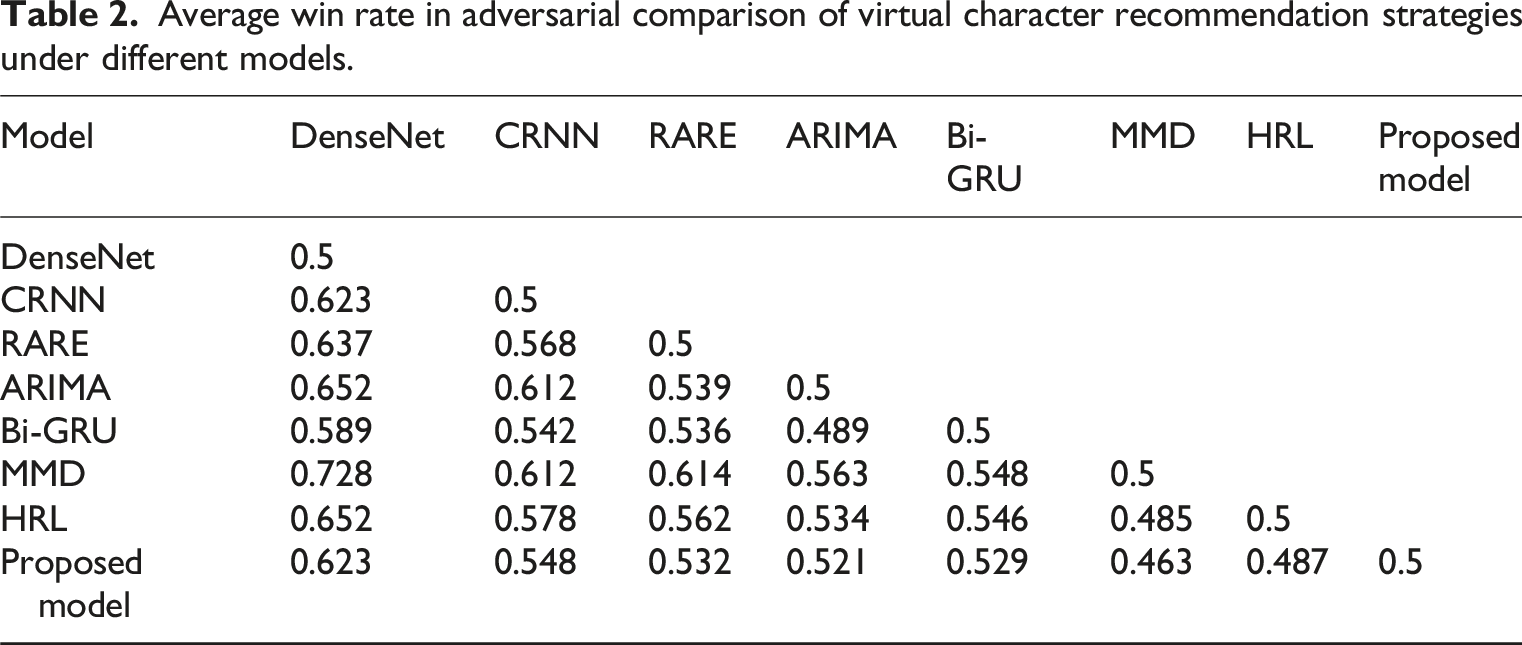
Average win rate in adversarial comparison of virtual character recommendation strategies under different models.
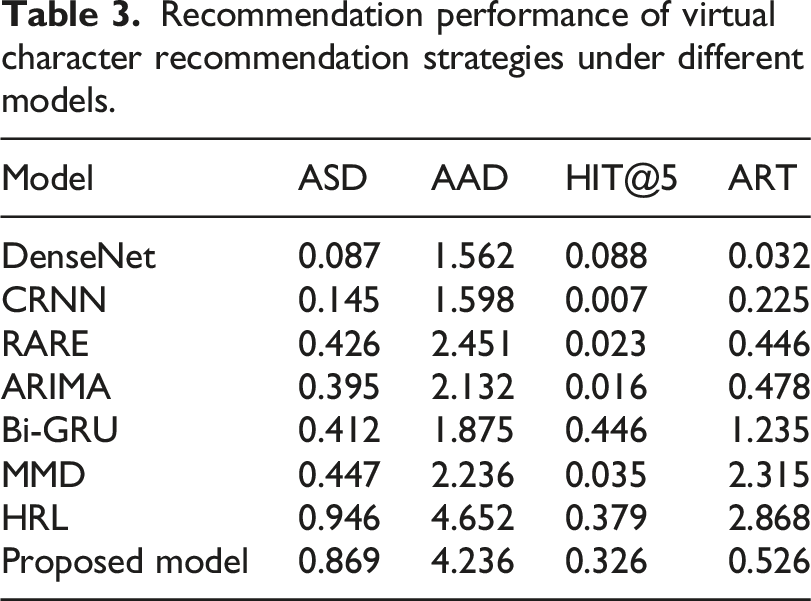
Recommendation performance of virtual character recommendation strategies under different models.
Conclusion
This study focuses on a virtual character recommendation method for immersive learning scenarios and constructs an innovative model composed of a transformation layer, self-adversarial data generation layer, embedding representation layer, and virtual character prediction layer. The transformation layer integrates multi-source data, converting learners’ spatial interaction data such as gesture trajectories and gaze focus, along with textual knowledge, into unified vectors to provide foundational scene inputs for the model. The self-adversarial generation layer simulates dynamic behaviors in three-dimensional scenes through agent-based game modeling, enhancing the realism of training data and improving the model’s adaptability to complex interactions. The embedding representation layer uses word embedding techniques to semantically map virtual character attributes and learner states into a unified space, strengthening the semantic association between characters and scenes. The prediction layer combines LSTM and attention mechanisms to accurately capture temporal patterns and key interaction elements in MR scenes and outputs character sequences adapted to the scene. Experimental data fully validate the effectiveness of the model: in the virtual character label prediction accuracy experiment, the model outperforms comparison models in Micro-F1 (0.678), Precision (0.745), and other metrics, demonstrating a strong ability in deep semantic modeling of scenes. In the recommendation strategy adversarial and performance experiments, the model performs prominently in ASD, HIT@5, ART, and other metrics, proving its capability to effectively improve the scene adaptability, precision, and real-time responsiveness of recommendations, thus providing technical support for the construction of MR immersive learning environments.
However, this study has certain limitations. On the data level, the collection of large-scale dynamic scene data is costly, and the model’s computational complexity lacks sufficient real-time optimization on edge devices, which limits its application in real-time interactive scenarios. Regarding scene coverage, the ability to handle highly interactive multimodal data and cross-scene transfer needs to be improved; in particular, the global optimization capability of recommendation strategies in large-scale multi-character collaborative scenarios requires enhancement. Future research directions include: (1) optimizing the model architecture with lightweight design to reduce computational costs and adapt to edge devices, and adopting federated learning and self-supervised learning to improve data utilization efficiency and generalization ability; (2) expanding scenarios and interactions by exploring multimodal fusion strategies and reinforcement learning mechanisms to achieve dynamic interaction between recommendations and learning feedback, thereby constructing a closed-loop system. In summary, through technical innovation and experimental validation, this study provides an effective solution for character recommendation in MR educational scenarios. Future work should continuously optimize along the dimensions of data, scenes, and interpretability, further deepening the integration of “AI + MR” in the education field, and contributing new ideas and paradigms for educational tool development and instructional model innovation.
Footnotes
Funding
The author received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.