
Abstract
Industrial electrical automation fault detection is a guarantee for the stable operation of industrial systems. Focusing on issues of low detection accuracy and insufficient depth perception ability in the current research, this paper establishes a multimetric stereo vision measurement model of electrical equipment, and stereo-corrects the images of electrical equipment. Then a two-channel convolutional neural network (CNN) is designed to capture global and local characteristics of the electrical equipment image. Finally, the YOLOv8 approach was adopted as the baseline model to optimize the design of the feature fusion part of the network. The recognition head network was superseded by Dyhead dynamic recognition head. The loss function part is redesigned using Focaler-IoU to solve the fitting problem caused by sample imbalance. Experimental outcome indicates that the proposed technique boosts the mean Average Precision (mAP) by no less than 5.42%, which significantly improves the detection efficiency and reliability.
Introduction
Industrial electrical automation systems encompass a large number of electrical equipment, circuits, and complex control systems, and the integrity of their operation is a determinant factor in production stability and safety. 1 Currently, industrial electrical automation testing mainly relies on traditional testing methods. The inefficacy of these approaches is compounded by their human-dependence, creating unacceptable risks for testing timelines and data integrity. 2 As the industrial production scale and the increasing complexity of production processes expanding continuously, the integration level of electrical equipment is getting higher and higher, and the coupling between systems is also becoming stronger, making the manifestations of electrical faults more complex and diverse. Traditional testing methods are difficult to quickly and accurately locate the cause and position of the fault, which affects the timeliness of fault handling and may lead to production interruptions, equipment damage, or even safety accidents, causing significant economic losses to enterprises. 3 Therefore, in-depth research on efficient intelligent testing technologies for industrial electrical automation has important practical value for promoting the intelligent upgrading of industrial testing technology, enhancing the level of industrial automation, and improving quality control capabilities. 4
Early industrial electrical automation detection algorithms mainly used template matching detection technology. This technology calculates the similarity between the two using methods such as color histogram, 5 structural similarity (SSIM), 6 and cosine similarity algorithm, 7 and sets a reasonable threshold to distinguish defective samples from normal samples. Luo et al. 8 adopted a distance function as a descriptor and used geometric perimeter to calculate the shape distance between the template contour and the contour of the test image, finally achieving defect detection of electrical equipment. Ren et al. 9 used a geometric invariant moment matching method to achieve fault detection in industrial electrical systems, overcoming the shortcomings of poor shape matching recognition capability. Zhang and Zhu 10 adopted image segmentation and calculated the position information of white line contours in the template and the test image, achieving defect detection of electrical equipment.
Compared to template matching, machine learning methods have stronger robustness and better accuracy. They create complex function relationships between data features and labels, and achieve predictions for new sample features through the mapping between features and labels. Machine learning mainly includes two stages: characteristic vectorization and categorization. Characteristic extraction, which includes gradient histograms, 11 local binary patterns, 12 scale-invariant characteristic transform (SIFT), 13 and accelerated robust feature, 14 is an important step in machine learning. Commonly employed classification techniques span from SVM to K-nearest neighbors and decision trees. 15 Because machine learning highly depends on the feature extraction methods designed by engineers, this method does not require too much data. 16 achieved an accuracy of 99.8% for electrical fault patterns by combining gradient histograms with SVM. Ullah et al. 17 first extracted component features through SIFT, and finally implemented defect detection in industrial electrical automation by combining image pyramid matching with SVM.
Traditional machine learning algorithms are difficult to fully cover the features in these complex scenarios by designing one or several fixed feature extraction methods. Deep learning methods use data-driven approaches to adaptively extract inconspicuous features, and can learn complex relationships within large amounts of data and corresponding labels. Tang and Jian 18 used a binocular stereo vision algorithm to collect fault images of electrical equipment, and built a dual-branch network architecture by a CNN, and explored the role of feature fusion in improving detection accuracy. Zhang et al. 19 demonstrated that coupling Faster R-CNN with a one-class neural network effectively detects defects in industrial electrical systems. Thomas et al. 20 applied Transformer to feature fusion, extracting spectral features and spatial features from images in a dual-branch network, exchanging information between modalities to achieve attention to global feature information, but insufficient local feature extraction of images. Yoon and Yoon 21 developed a high-precision electrical equipment fault image collection system using a binocular camera, and obtained multi-scale features of images through Transformer, achieving feature fusion through cross-attention mechanisms to improve detection accuracy. Bellou et al. 22 introduced a cross-stage local module into the feature pyramid network derived from YOLOv8, introduced a path aggregation model into the feature fusion structure, and completed effective detection of electrical equipment images through improved regression loss.
According to the analysis of existing research on industrial electrical automation detection, the fault detection of industrial electrical automation systems has long relied on manual inspections, which are inefficient and unsafe. With the continuous development of image recognition technology, it is possible to determine whether there are faults in electrical equipment based on image information. However, the fault areas of power equipment generally have various practical problems, such as complex patterns and difficult feature extraction. To this end, this article puts forward an intelligent detection technology for industrial electrical automation in light of stereo vision and feature fusion. First, aiming at the problem that traditional visual imaging systems cannot accurately obtain the 3D information of the target, a multi-view stereo vision measurement model is established, and the projection transformation relationship between the target point in space and the picture points in the stereo picture pair is analyzed. The tensor-based planar calibration method is used to calibrate the equipment parameters, and the stereo correction of the image pair of the electrical equipment is performed in combination with the calibration parameters. Then, a CNN structure with parallel branches is designed based on ResNet-50. After each convolutional structure layer, it is divided into two branches. The right computational path continues employing the native feature extraction backbone, performing successive convolutions to aggregate global features, while the left branch serves as the local feature extraction branch. Finally, The YOLOv8 architecture serves as the foundation for optimizing feature fusion components, strengthening the algorithm’s multi-scale feature aggregation performance. The detection head undergoes architectural refinement through Dyhead integration, strengthening its capacity to process occluded characteristics. The loss function part is redesigned using Focaler-IoU, which solves the fitting problem caused by sample imbalance. Experimental outcome indicates that the Precision and Recall of the suggested technology are 93.64% and 91.52%, respectively, which can accurately detect faults in industrial electrical equipment.
Related theory
Binocular camera imaging principle
Unlike single-camera systems, binocular vision employs two monocular cameras to achieve stereoscopic perception. It acquires multi-perspective images of the target via dual cameras mounted on the same horizontal plane, and obtain information about the object in the 3D world by analyzing the disparity information between images, simulating the process of human eyes capturing external information.
23
Monocular stereo vision uses a single camera to infer depth information from a single image or a series of consecutive frames, combined with prior knowledge or deep learning models. It is suitable for cost-sensitive scenarios with low requirements for depth accuracy, where motion or prior information can be relied upon. Multi-camera stereo vision extends the principles of binocular vision by using multiple cameras to capture images from different angles. It leverages multi-view geometry to enhance the robustness and accuracy of depth estimation, making it suitable for scenarios requiring high precision, a wide depth range, or complex environments. Stereo vision simulates human vision by using two cameras to capture the same scene from different angles. It calculates the displacement difference between pixels using the principle of parallax and combines triangulation to restore depth information. This is suitable for scenarios requiring moderate accuracy, high real-time performance, and moderate depth ranges. The camera imaging model is divided into linear and nonlinear models, and the specific introduction is as follows. (1) Linear model. Camera imaging is the process of mapping a 3D object in reality into a 2D image through the camera’s projection. The imaging process is divided into a linear model without distortion and a nonlinear model with lens distortion. The principle of the linear model can be simplified to pinhole imaging. The distance between the object (2) Nonlinear model. Camera lens is usually composed of multiple groups of optical lenses. These lenses affect the propagation of light, resulting in image distortion and changes in position when a three-dimensional object in reality is projected through the lens into a two-dimensional image. This phenomenon is called distortion. The geometric aberrations of camera lenses are classified as either radial or tangential distortion. The second-order radial distortion coefficient typically produces barrel distortion, while higher-order terms may lead to pincushion distortion.
24
Pincushion distortion is concave inward, while barrel distortion is convex outward. The distortion arises due to non-ideal lens curvature violating the paraxial approximation. When light passes through the center of the lens, it causes a radial distortion distributed along the radius of the lens, making straight lines appear curved. Image deformation exhibits a positive correlation with radial distance from the optical center.
YOLOv8 target detection algorithm
Industrial electrical automation detection has high requirements for the precision and calculational burden of the model, so it is necessary to select an appropriate baseline object detection framework for the design of the object detection model. YOLOv8 network is a new generation of object detection algorithm, with advantages of high speed, light weight, and high accuracy. 25 YOLOv8 incorporates large-scale datasets such as Objects365 for pre-training during training, significantly enhancing the model’s generalization capabilities. It expands to instance segmentation and image classification tasks through a modular design. Compared to other YOLO models, YOLOv8 stands out with its core competitive advantages: a more efficient architecture, a more generalized detection mechanism, higher accuracy, and stronger task scalability. It particularly excels in small object detection, robustness in complex scenes, and ease of engineering deployment, making it the mainstream choice in both industry and academia. The YOLOv8 network framework inherits the tradition of the YOLO series, and is partitioned into four discrete components: input end, Backbone, Neck, and Head.
The design paradigm of YOLOv8’s backbone and neck modules follows YOLOv5’s proven framework. 26 The input pipeline of YOLOv8 integrates three core components: Mosaic data augmentation, adaptive anchor computation, and adaptive grayscale padding. The backbone network is based on the idea of segmenting and independently processing feature maps using CSP. This backbone network structure integrates convolution (Conv), cross-stage feature fusion (C2f), and simplified spatial pyramid pooling (SPPF) modules. This architecture simultaneously augments characteristic representation capacity while maintaining computational efficiency.
The Neck module of YOLOv8 is responsible for feature fusion operations, improving cross-hierarchical feature integration capability. The Head module uses a decoupled head to decouple the classification and detection processes and performs detection result calculation and output. In terms of loss functions, the network employs binary cross-entropy (BCE) for classification tasks, while adopting Distribution Focal Loss (DFL) and Complete Intersection over Union (CIoU) for bounding box regression. 27 YOLOv8 further improves the model’s detection capability while inheriting the lightweight and efficient tradition of the YOLO series and has found extensive applications across diverse domains with high real-time requirements.
Industrial electrical equipment image acquisition based on stereo vision technology
The multi-view stereo vision system based on visual imaging principles is mainly composed of multiple cameras arranged in the same direction and at the same distance. In the detection of industrial electrical automation equipment, it is necessary to collect 3D information of the surface of electrical equipment. This system is used to take photos of the electrical equipment to be inspected. 3D measurement based on multi-view stereo vision refers to the 3D stereoscopic imaging of the target from multiple angles by multiple cameras, and the stereo projection on the camera image plane forms a pair of stereo images. The multi-angle matching algorithm is used to obtain the pixel coordinates of corresponding picture points, and then spatial feature points are measured using the 3D measurement model, thereby correcting the image of industrial electrical equipment.
The rays corresponding to multiple cameras must intersect at the same spatial point, but due to the actual imaging problems of multiple cameras, especially point measurement errors and camera calibration errors, the 3D images cannot be completely concentrated at one point, but can only cross roughly at one point. Owing to the fact that the separation from the imaging system to the target is substantially larger than the focal length, based on the basic principle of central perspective, the position error extracted from the camera parameters or pixel points will cause a slight deviation in the imaging rays, leading to a large spatial point positioning error. To improve the precision of the imaging relationship, the initial value is usually computed first, and then the bundle adjustment method is used for optimization. In the constrained adjustment algorithm, it is assumed that the measurement noise of the pixel points has a Gaussian independent distribution characteristic and is isotropic with zero mean. Generally, by solving the camera parameters and spatial point coordinates, the corresponding image coordinates are obtained from the imaging model. The association among the coordinates of spatial points and those of picture pixel points is described as below.

For the spatial points of the detection model composed of multi-view stereo vision, the solution method usually uses the collinearity equation intersection method. Once the intrinsic and extrinsic parameters of multiple cameras have been ascertained, let the spatial point
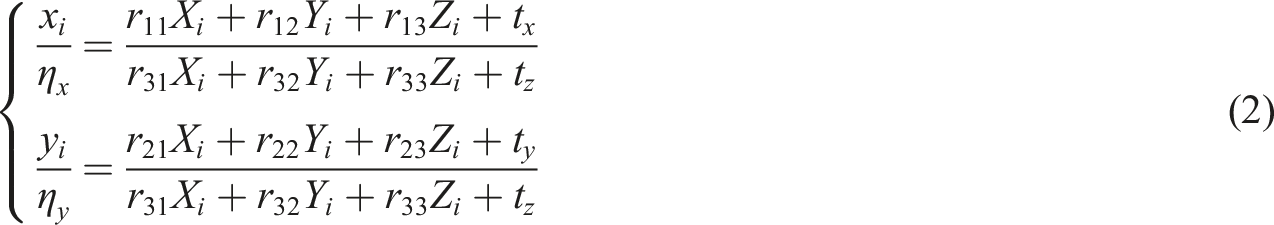
After organizing and converting equation (2), the linear equation system for point
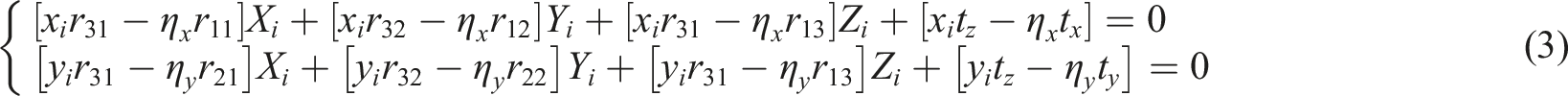
When there are multiple cameras, the number of equations in equation (3) will become twice the original. Through this formula, the acquisition results of industrial electrical equipment can be obtained.
Feature extraction of industrial electrical equipment based on multi-scale CNN
Based on the industrial electrical equipment images obtained in the previous section, this paper designs a multi-scale CNN to extract features. The commonly used convolutional neural networks for image classification are AlexNet, 28 VGG-16, 29 ResNet, 30 etc. Among them, ResNet-50 can achieve the highest detection accuracy with a low number of parameters, even exceeding the VGG-16 with the most parameters. Therefore, this paper uses ResNet-50 as the basic network structure for the algorithm research.
This paper designs a CNN structure with parallel branches based on ResNet-50. After each convolutional structure, it is divided into two branches. The right branch is the original feature extraction main network, continuing to perform convolution operations to extract features. The left branch is the scale feature extraction branch, flattening the features of this scale into a one-dimensional feature vector and saving it. After all scale feature extraction branches have extracted their respective scale features, they are concatenated into a combined feature for the next step of fusion.
The network structure used for multi-scale extraction is called the feature extraction branch module (FEM). Its structure is composed of convolution modules and pooling modules. The convolution module consists of multiple
Industrial electrical automation intelligent detection based on improved YOLOv8
SD-FPN feature fusion module
In view of the challenges such as scale variation and occluding targets that are difficult to solve in industrial electrical automation detection, this paper proposes to improve the network based on the basic framework of YOLOv8 to meet the requirements of intelligent electronic automation detection in complex industrial environments. The structure of the intelligent detection model for industrial electrical automation based on the improved YOLOv8 is shown in Figure 1. To address the defects in the characteristic integration part, an SD-FPN characteristic integration part is designed to replace the Neck part of the initial network, significantly enhancing the ability to learn cross-scale and small target features; using a dynamic detection head Dyhead to enhance the feature representation capability of the network backbone, and integrating the latest dynamic convolution part to improve feature detection efficiency. The introduced Focal-PIoU loss replaces CIoU in the baseline, addressing class imbalance via dynamic gradient modulation. The structure of the intelligent detection model based on the improved YOLOv8.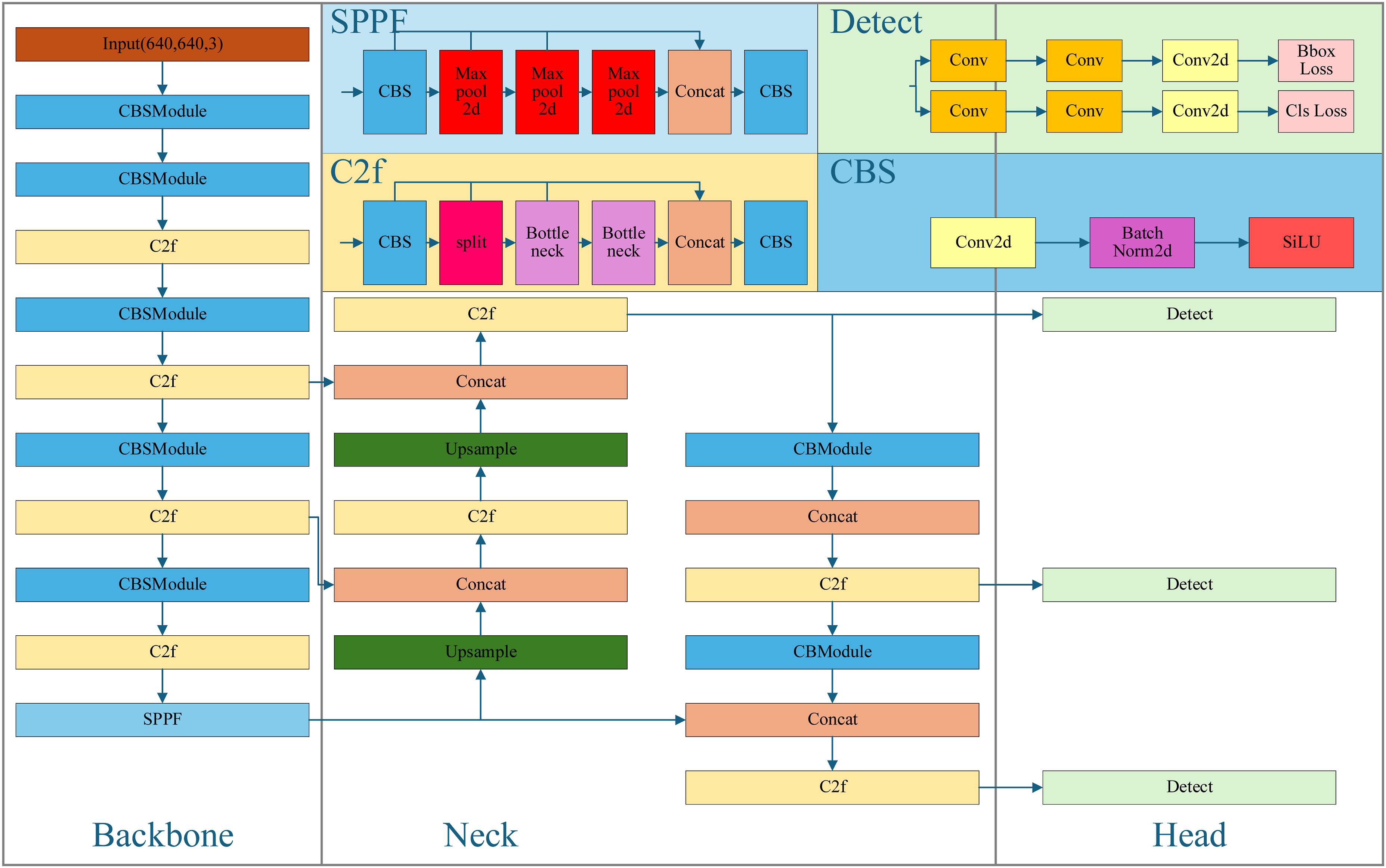
Intending to the issue that YOLOv8 has not fully solved the cross-scale feature fusion, this paper proposes a cross-layer dynamic fusion module SD-FPN to boost performance in detecting objects across varying scales, especially tiny instances, replacing the original network’s PAN-FPN structure. The design idea of the SD-FPN module is based on the cross-layer connection idea proposed by BiFPN, 31 and a dedicated small-object detection head is incorporated into the network architecture to improve distant low-resolution obstacle identification, the DySample lightweight dynamic upsampling module 32 is used for upsampling, improving the feature propagation efficiency of the module. For the feature information between different layers, the Semantics and Detail Infusion Module (SDI) multi-level feature fusion module is used for explicit fusion.
Due to the large down-sampling factor of YOLOv8, deeper characteristic pictures encounter difficulties in capturing the characteristic information of small objects, and the original BiFPN structure has limited improvement in feature extraction for small targets. This paper restructures the Neck part of YOLOv8 by referring to the idea of BiFPN, and augments the BiFPN with a dedicated small-target detection branch to compensate for the baseline network’s deficiency in micro-object characteristic extraction. By cross-layer connections, the feature information of each level is fully fused, augmenting hierarchical characteristic abstraction for improved micro-target detection across scales. The lightweight design of BiFPN also effectively reduces the computational pressure brought through the micro-scale characteristic extraction head, improving the overall efficiency of the feature fusion module. For the scenario of industrial electrical automation detection, which is information-intensive and has deployment requirements, this paper proposes using the DySample lightweight dynamic upsampling module as the upsampling tool in the Neck structure. The DySample module replaces dynamic kernel generation and dynamic convolution with point sampling technology. This method reduces the computational burden while simplifying the entire upsampling process. DySample maintains or exceeds the performance of traditional methods while achieving substantial reductions in both parameter count and computational latency. The main process of DySample is to generate sampling points through a sampling point generator and resample the input features through a grid sampling function. The specific process is detailed in Ref. 33.
In the original feature fusion operations of YOLOv8, the network uses the concat feature concatenation operation to concatenate feature map tensors along a specified dimension to achieve information fusion between feature maps of different layers. Although this method is effective in simple scenarios, it has insufficient information fusion capabilities in complex scenarios. During the feature fusion process, the input feature resolutions of different layers are different, and their contributions to the feature fusion part are unequal. This work substitutes the conventional concatenation operation in characteristic fusion with the proposed SDI module, significantly improving the joint representation of high-level semantics and low-level details. The SDI module was first proposed in U-net V2, which finely adjusts characteristics at various levels through spatial and channel attention mechanisms, and explicitly achieves hierarchical characteristic integration through element-wise Hadamard multiplication of semantic and detail characteristic pictures. This design enhances the interaction between features while further optimizing the efficiency of feature fusion.
The feature fusion of the SDI module is specifically implemented through the following steps. Among the hierarchical characteristic pictures generated through the encoder, spatial and channel attention schemes are deployed on the characteristics at every level

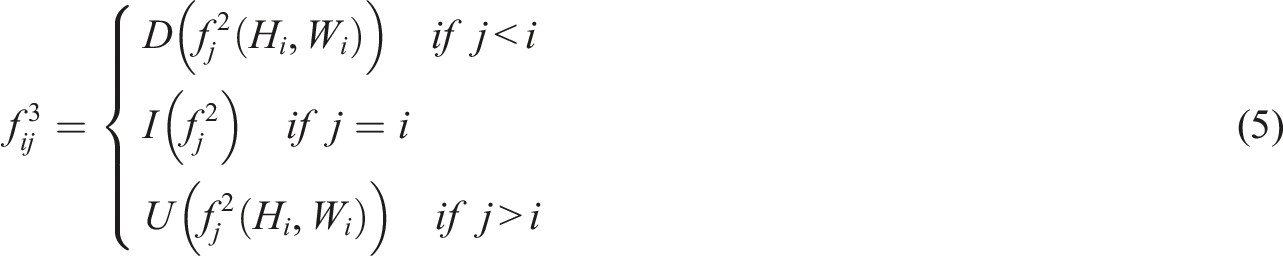


Detection head Dyhead based on dynamic convolution and attention mechanism
The detection head of the industrial electrical equipment detection model based on YOLOv8 does not fully utilize the feature information at various scales, and has limited capability in processing complex spatial information, potentially resulting in false negatives or false positives for occluded object detection. The output of the YOLOv8 backbone is characterized by a rank-3 tensor of shape (L, S, C), where L and S represent spatial extents, and C denotes feature channels, it is possible to optimize the recognition capability of the recognition head for occluded objects by combining attention mechanisms with the three feature tensor dimensions. The dynamic detection head Dyhead 34 integrates attention mechanisms across all feature tensor dimensions of the detection head through unified scale-aware attention, spatial-aware attention, and task-aware attention.
Dyhead unifies the object recognition head by fusing various self-attention mechanisms, substantially improves the representational capacity of the detection head while maintaining computational efficiency. Dyhead first constructs a feature pyramid from the features obtained from the SD-FPN part, and align hierarchical characteristic representations through scale harmonization, Constructing a three-dimensional feature tensor F, where L, S, and C stand for the dimensions of scale, space, and channel, individually. Dyhead integrates the detection head via sequential attention mechanisms encompassing scale perception, spatial localization, and task-specific adaptation.

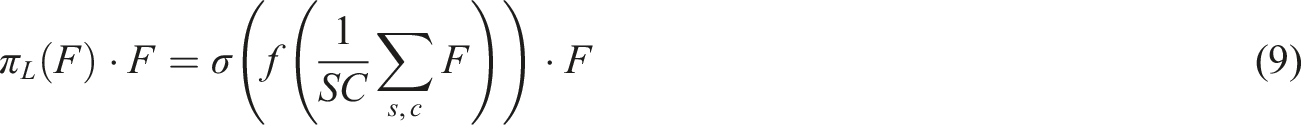
The space-aware attention is used for information discrimination among spatial locations and feature layers. For the goal of further optimizing the characteristic extraction ability for occluded objects, this article uses the deformable convolution DCNv4
35
in the space-aware attention mechanism to induce sparsity in attention mechanisms, and then aggregates features from various levels at identical spatial coordinates, represented by the attention function
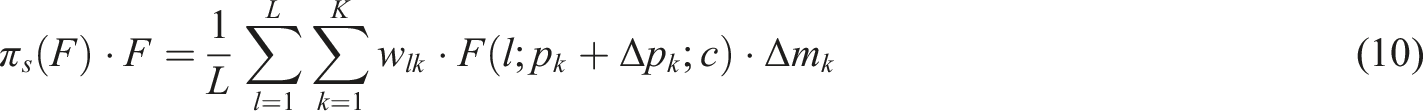
The task-conditioned attention module selectively activates feature channels in a task-dependent manner.
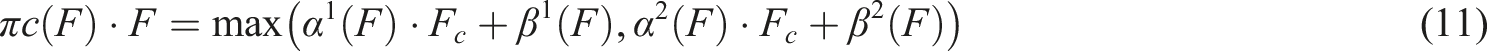
Focaler-PIoU loss function
The original YOLOv8 adopts the CIoU algorithm as the basis for the metric. Although the CIoU algorithm can reflect the model’s prediction accuracy in most scenarios, this metric still has shortcomings such as gradient disappearance and sensitivity defects. This article introduces the Powerful-IoU 36 loss function to substitute the original CIoU loss function. Powerful-IoU (PIoU) achieves faster convergence and higher accuracy than CIoU by combining a size-adaptive penalty factor for the target and a gradient adjustment function in light of the anchor box quality, and further enhances the attention to medium-quality anchor boxes by introducing a non-monotonic attention.
The PIoU loss function comprises a size-adaptive penalty factor and a gradient-modifying function based on the anchor box’s quality. To start with, a penalty factor P that is adjusted according to the target size is brought in.
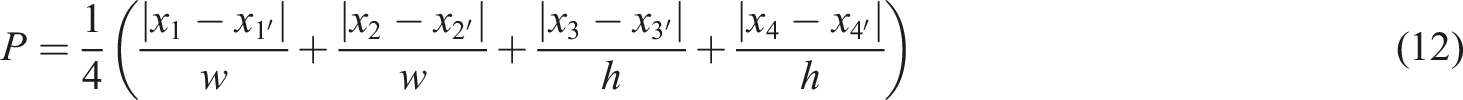

This function provides a small gradient when the anchor box quality is poor, and the maximum gradient when the quality is moderate, to promote the anchor box to regress quickly and accurately to the target box. The final expression of PIoU is as follows.

To enhance the loss function’s adaptive regression capability across samples with varying complexity levels, PIoU is nested with Focaler-IoU to form Focaler-PIoU. Focaler-IoU reformulates the IoU loss through a piecewise linear transformation of the intersection-over-union metric, so as to intend to samples of various difficulties during the bounding box regression, as shown in equation (15).
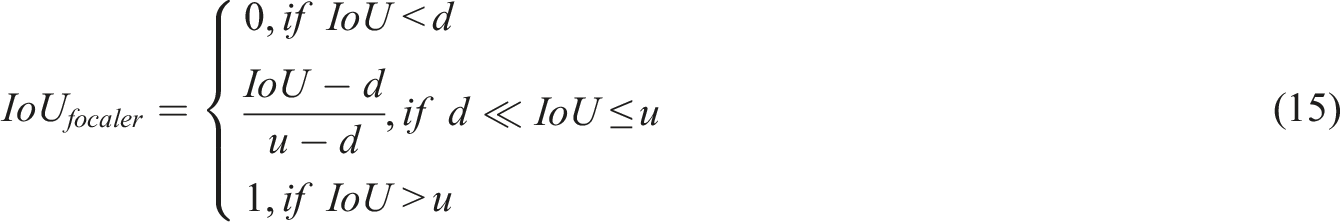
Experimental design and analysis of results
Analysis of industrial electrical automation detection results
This paper uses the industrial electrical cabinet fault dataset collected in Ref. 37, which includes periodic vibration signals collected under constant speed 800r/min no-load conditions, with a sampling frequency of 15 kHz, as well as 8637 electrical cabinet fault image data. In the experiment, the study selected Ubuntu 18.04 as the operating system, Intel Core i7-8700K as the processor, 16 GB of memory, and NVIDIA GeForce GTX 1080 Ti as the graphics card. The deep learning framework used was TensorFlow 2.0. In the experiment, the Epoch was set to 500, the Batch size was 12, the studying rate was 0.001, the optimizer was SGD, and the training mode was parallel training.
Three groups were set up, with the group containing the approach suggested in this article as the experimental group. By plotting the vibration waveforms of the fault detection results of the three groups, the vibration waveforms under different sample data volumes were intuitively displayed, as shown in Figure 2. The vibration amplitudes of the vibration waveforms of the two control groups were generally larger, which increased the complexity and uncertainty of fault detection to some extent. Further, during the detection process, the data of the two control groups showed various abnormal detection results and some cases where the abnormalities could not be clearly detected. These phenomena directly led to a decline in the overall detection effect, indicating that traditional detection methods have limited ability to capture and identify subtle faults without specific processing or optimization. However, when the experimental group reached 600 sample points, the vibration waveform amplitude suddenly dropped abnormally to below −2 mm, which clearly indicated a fault at this point. This significant change demonstrates the effectiveness of the approach suggested in this article and its superiority in accurately identifying faults in complex vibration data. Vibration waveforms for electrical equipment fault detection under different data quantities.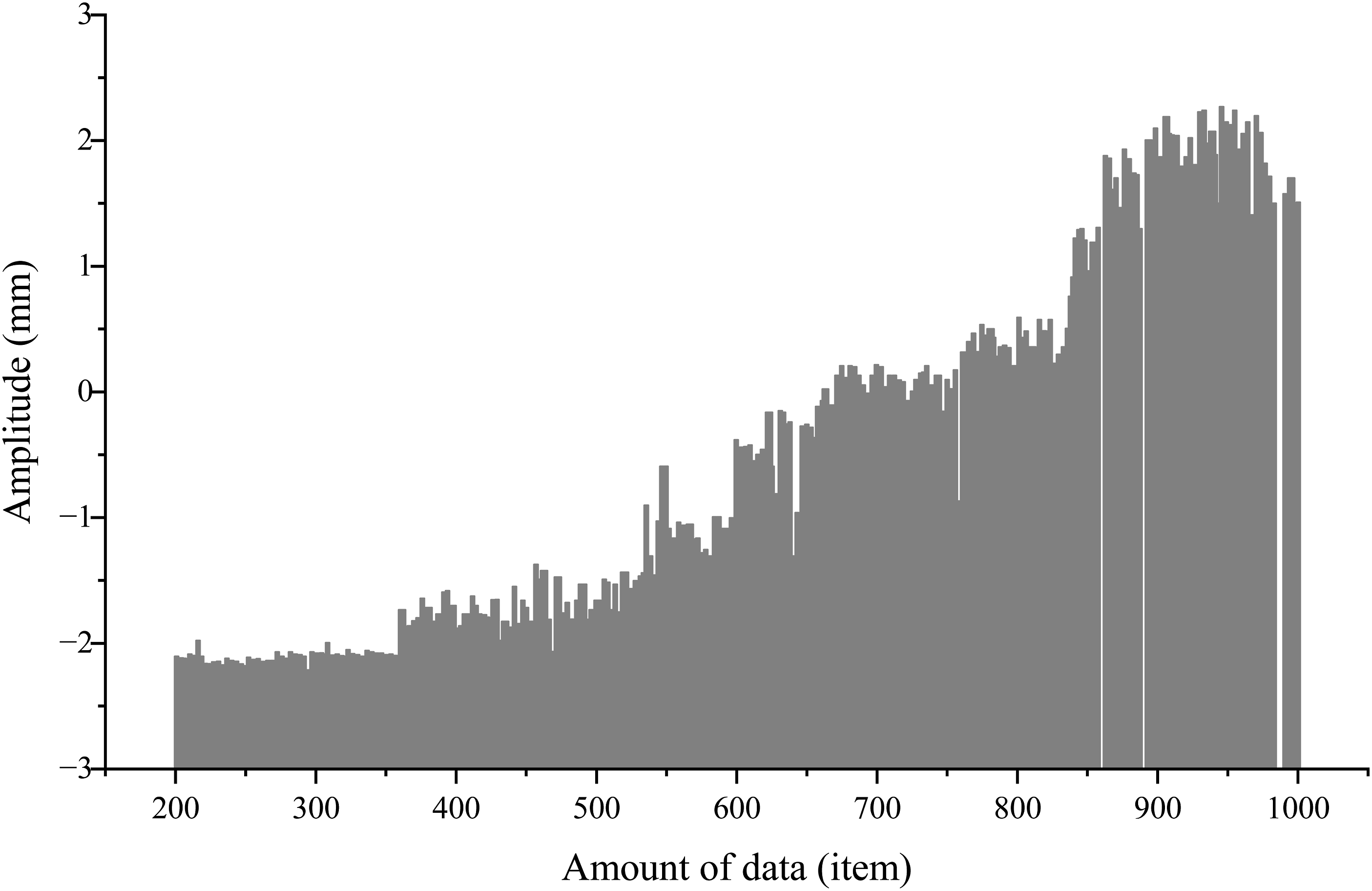
In the analysis of detection effects in industrial electrical automation, the Loss curve represents the difference between the actual target value and the forecasting target value. All parameters in the proposed method OURS were further optimized and improved, allowing the loss function value to continuously decrease, thus obtaining a network model with more accurate performance. As shown in Figure 3(a), this model performed well in terms of learning rate due to the optimized loss function. IOU is another vital evaluation indicator for measuring the detection effect of the model. The closer the difference between the forecasting box and the annotated box, the higher the overlap between the annotated box and the predicted box. As shown in Figure 3(b), as the number of batches increased, the rectangular box could perfectly overlap with the target device. Loss curve and IOU curve.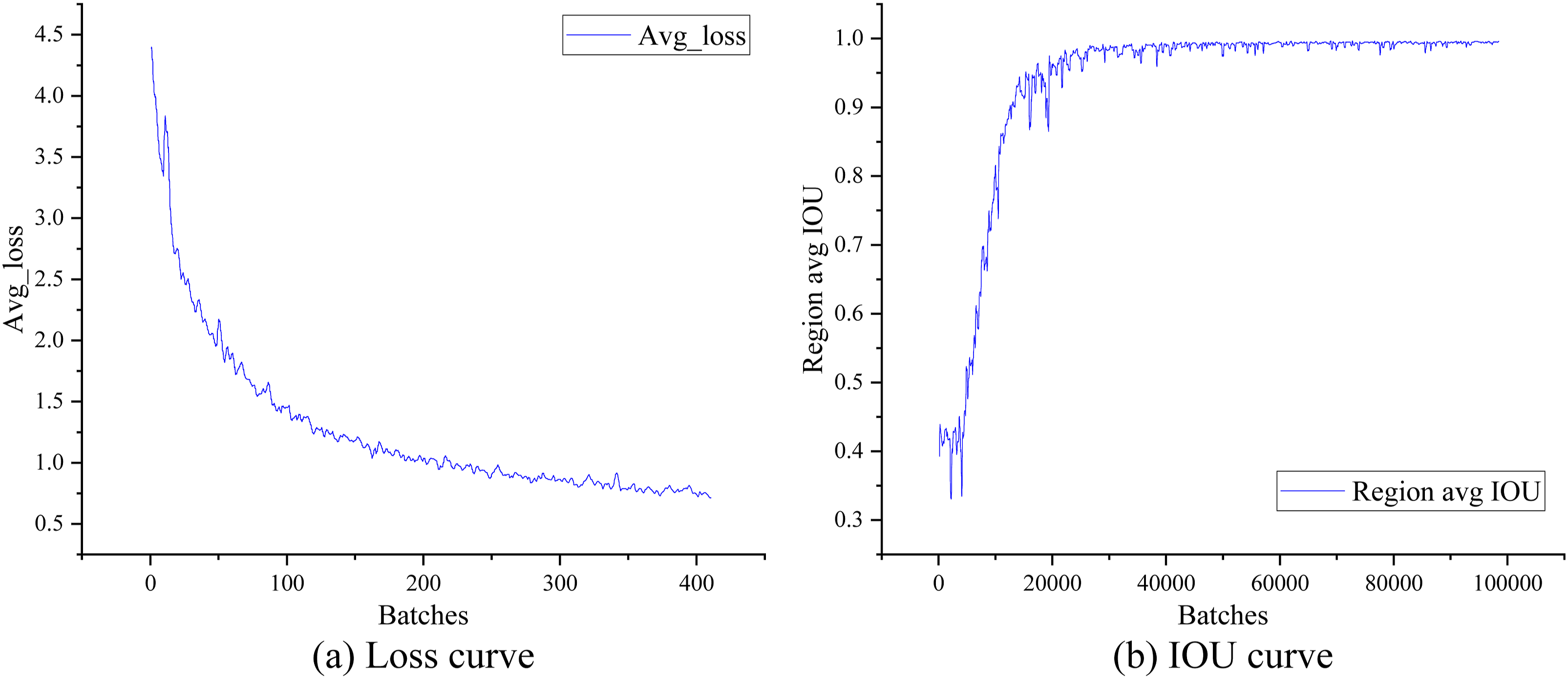
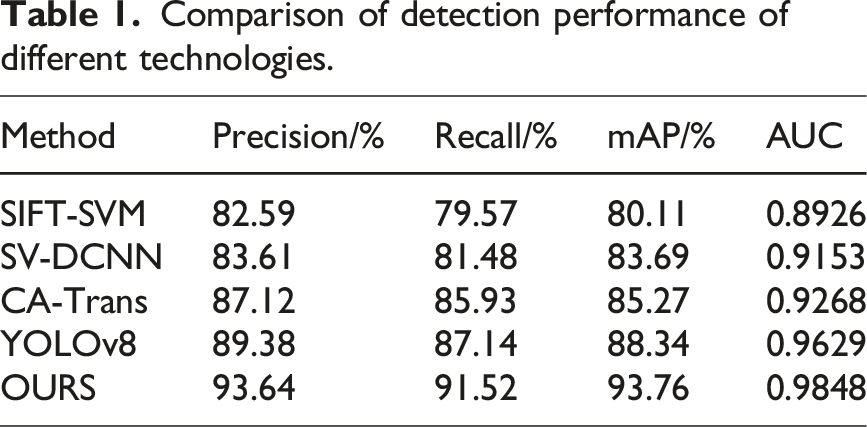
Quantitative analysis of detection performance
Comparison of detection performance of different technologies.
Conclusion
Intending to the issues of low detection accuracy and insufficient characteristic extraction in existing industrial electrical automation detection technologies, this article suggests an intelligent detection technology for industrial electrical automation in light of stereo vision and feature fusion. First, aiming at the problem that traditional visual imaging systems cannot accurately obtain three-dimensional information of the target, a multi-view stereo vision measurement model is established, and the projection transformation relationship between the target point in space and the picture points in the stereo picture pair is analyzed; the tensor-based planar calibration method is used to calibrate the equipment parameters, and the stereo correction of the image pairs of electrical equipment is performed in combination with the calibrated parameters. Then, a CNN structure with parallel branches is designed based on ResNet-50. After each convolutional structure, it is divided into two branches. The right branch continues the convolution operation of the original feature extraction backbone network to extract global features, while the left branch serves as a local feature extraction branch. Finally, the improved YOLOv8 algorithm is used for fault detection of industrial electrical equipment. Several improvements are made to the YOLOv8 algorithm, which has disadvantages in fault detection of electrical equipment. The characteristic integration part of the network is redesigned to enhance the model’s ability to fuse characteristics of targets of various scales. The Dyhead dynamic detection head is introduced to improve the efficiency of the network in extracting occluded features. The loss function was redesigned using Focaler-IoU, effectively solving the problem of sample imbalance. Experimental outcome indicates that the mAP of the proposed technology is 93.76%, which is improved by 5.42%-13.65% compared to the comparative technology, and can achieve relatively accurate fault detection of industrial electrical automation, meeting the demand for high-precision detection in complex industrial electrical automation environments.
The industrial electrical automation fault detection algorithm proposed in this paper significantly improves the detection accuracy on the test dataset compared to the original model, but the lightweight work of the model is insufficient, which may affect the deployment on mobile devices. In the future, model lightweight methods such as pruning and distillation can be considered to reduce the model parameters with minimal precision loss.