
Abstract
In the modern automotive industry, the demand for road crack detection is increasing, but the current methods either over-pursuing the lightweight, which leads to the performance unchanged or even decreased or over-pursuing the performance index, and do not consider the limitation of computational resources, this paper proposes a model BL-YOLOV11, which achieves a balance between the performance and the improvement of the utilization of computational resources, and the model is better than the original model YOLOV11. In terms of performance, YOLOV11 improves Precision by 5%, Recall by 4%, and mAP@50 and mAP@50:90 by 4% and 2%, respectively, with only a 3% increase in computational resources, which is an effective improvement in balancing computational efficiency and performance.
Introduction
Roads serve not only as fundamental infrastructure for transportation but also as a key foundation supporting China’s economic growth, societal advancement, and national stability. They play a crucial role in driving both national and regional development. Alongside the progress of society and the economy, China has achieved significant milestones in road construction. Nonetheless, persistent issues caused by natural and human factors—such as cracking, rutting, surface deformation, and subsidence—have begun to emerge.
1
If not addressed promptly, these issues can lead to more severe traffic incidents. Statistical data presented in Figure 1 illustrates the frequency of traffic accidents in China in recent years (with minor icon adjustments), accident rates have consistently remained at a high level, largely due to deteriorating and aging road infrastructure.
2
Consequently, there is an urgent need for effective technological solutions to monitor road conditions in real time, enabling timely maintenance and thereby reducing the risk of accidents. Zhou et al.
3
have summarized several major technical methods currently employed for this purpose. Beyond the domain of road engineering, researchers in geotechnical engineering have also employed advanced numerical methods to address complex safety challenges. For instance, smooth particle hydrodynamics (SPH) has been applied to simulate the large sliding deformation of saturated slopes under earthquake action.
4
Although the application domain is different, both studies emphasize the importance of adopting innovative computational approaches to enhance safety assessment in critical infrastructure. Traffic accidents in 2016-2023.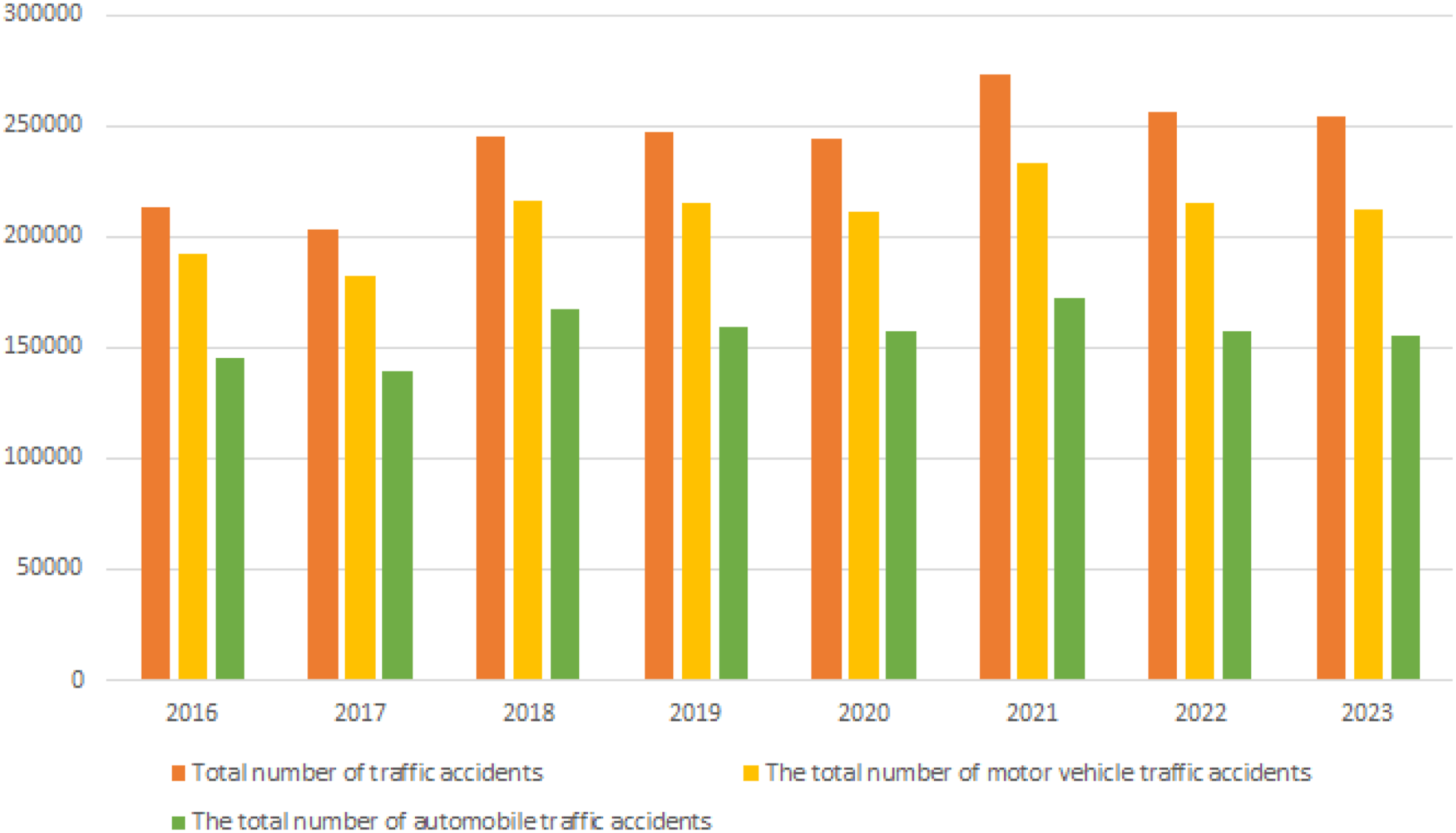
In the early stages, road condition assessment primarily relied on manual inspections. However, this approach was inefficient, requiring significant time and effort, and often influenced by the personal judgment of the inspector. 5 With the development of technology, computer vision has developed rapidly and been applied to various scenarios. Its research fields are extensive, such as 3D-HPE, 6 Object Detection, 7 and so on. Compared with manual inspection, the use of object detection methods in computer vision technology can save more resources. Traditional object detection methods include DPM, 8 Viola-Jones, 9 HOG + SVM, 10 sliding window-based methods, 11 and feature engineering-based methods 12 . However, traditional object detection methods have common limitations, 13 such as manual feature extraction, difficulty in adapting to complex scenes, low efficiency, and weak generalization ability.
With the rapid advancement of deep learning, it has become feasible to automatically extract features without manual intervention, delivering high-precision, strong generalization capabilities, and enhanced adaptability in complex scenarios. Detection approaches based on deep learning are generally categorized into two-stage and one-stage frameworks. For instance, Xu et al. 14 introduced a model built on Faster R-CNN, incorporating optimized strategies such as feature cascades, ASDN, Soft-NMS, and data augmentation to boost recognition effectiveness. Compared to conventional Faster R-CNN models, the mean Average Precision (mAP) increased by 16%, significantly outperforming the 38.6% achieved by HOG + SVM. Furthermore, Xu et al. 15 enhanced performance by refining the Mask R-CNN framework with a path-enhanced feature pyramid and an edge-aware detection branch. Although the two-stage structure yields better precision and robustness, it is resource-intensive, slower in processing, and less suitable for real-time road condition analysis due to its high computational demands.
One-stage object detection algorithms are known for their streamlined architecture, rapid inference, and low computational overhead, making them highly suitable for real-time road defect detection scenarios. Although their accuracy typically falls short of two-stage methods, advances in model design have significantly improved their performance. Lin et al. 16 introduced the RetinaNet framework along with the Focal Loss function, enabling high-precision single-stage detection that achieved a 2.3% performance gain over the Inception-ResNet-v2-TDM Faster R-CNN on the COCO dataset. Subsequently, Yan et al. 17 proposed a deformable SSD model by integrating deformable convolutions into the VGG16 backbone, resulting in a 3.1% mAP improvement on PASCAL VOC2007. However, models such as SSD and RetinaNet still exhibit limitations in detecting small-scale defects due to suboptimal feature pyramid structures. To address this, Xie et al. 18 developed FE-YOLO, enhancing multi-scale feature representation via an improved feature pyramid network and a k-means++ clustering algorithm, achieving detection accuracies of 83.9% and 98.9% on NEU-DET and DeepPCB, respectively. Building on YOLOv5, Zhong et al. 19 incorporated modules including C3ghost, EVC, and DyHead to refine feature extraction and boost performance, yielding increases in mAP, accuracy, and recall by 2.9%, 3.7%, and 7.2% on the RDD2022 dataset. Further improvements were realized by Wang et al., 5 who proposed the BL-YOLOv8 model with SimSPPF and LSK-attention mechanisms, enhancing mAP@0.5 by 3.3%, while reducing parameter volume and computational load by 29.92% and 11.45%, respectively. These advancements collectively demonstrate the growing potential of one-stage detectors in achieving a balance between real-time efficiency and detection accuracy for practical applications in road condition monitoring.
YOLO has significant advantages over single-stage detectors and has therefore attracted the attention of a wide range of researchers. In recent years, the YOLO series of algorithms has been continuously developed and improved, but there are still some shortcomings. One of these is the limitation of multi-scale feature fusion, 20 which is a common problem and causes the algorithm to have low recognition accuracy for small targets. In addition, the large number of parameters and computational complexity are also areas for improvement in the YOLO series of algorithms. When faced with complex real-time problems such as road detection, these deficiencies may prevent the algorithm from accurately identifying the target.
To address these issues, the study proposes a new BL-YOLOV11 algorithm. This algorithm improves on YOLOV11 by adding the MAF-YOLO module (which enhances multi-scale feature fusion and improves the accuracy of small target recognition) and improves the original C3k2 module using RepViTBlock (this improvement reduces the number of parameters in the model and avoids redundant calculations). Through these improvements, the study has further optimized the robustness and adaptability of the model.
Methodology
YOLOV11
YOLOv11 is a new-generation single-stage object detection model that mainly consists of three parts: the backbone, the neck, and the detection head. 21 In the backbone, images are processed by convolutional layers and the C3K2 module to extract features at multiple scales, which are then fused into a feature map.
The C3K2 module is an improvement over C2f and is formulated as follows:
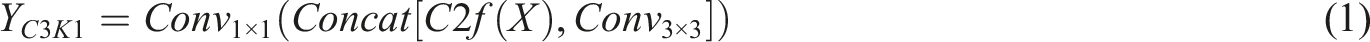
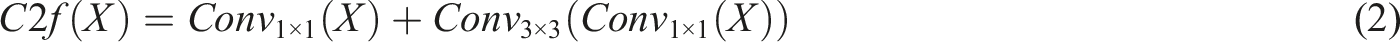
To further enhance feature representation, a C2PSA block is added after the SFFP feature pyramid. By integrating cross-stage partial connections with self-attention, multi-scale features are propagated more effectively to the neck. In the detection head, YOLOv11 adopts a decoupled design with three separate branches for classification, bounding box regression, and objectness prediction. Depthwise separable convolutions (DWConv) are introduced to reduce the number of parameters while maintaining accuracy. In addition, the anchor-free mechanism, proven effective in earlier YOLO versions, is retained.
These architectural improvements collectively enhance robustness and adaptability, enabling YOLOv11 to achieve stronger performance than its predecessors across diverse datasets.
RepViT_EMA
RepViT mainly uses the popular Vision Transformer (ViT) combined with the lightweight CNN architecture in recent years. 22 Vit is good at capturing global information and performing global modeling, but the model is computationally intensive and consumes a lot of memory, 23 and the latency is long. Lightweight CNN is good at capturing local information and constructing hierarchical representations, and has fewer parameters. Combining the two can not only perform global modeling but also better extract local features of the image, and the computational load is reduced, making it more suitable for use on lightweight devices. However, the two methods differ in the way they update gradients, which can cause oscillations and make it difficult to converge. In this study, the EMA (Exponential Moving Average) mechanism is introduced to smooth the update of experimental parameters, making the overall parameters more stable, and further reducing computational overhead while retaining channel information. 24
RepHMS
RepHMS (Re-parameterized Heterogeneous Multi-branch Structure) enhances feature extraction through multi-branch convolution, where different kernel sizes capture features at varying receptive fields. This design ensures that both small and large targets are represented adequately. In complex scenes, features extracted by different branches can complement each other, leading to more robust classification and localization.
During training, RepHMS adopts a heavily parameterized multi-branch structure as described in equation (3):

For inference, the structure is simplified via re-parameterization, as shown in equation (4):

RepHMS therefore leverages a heterogeneous set of convolution kernels during training but avoids excessive fully connected layers, minimizing unnecessary parameter overhead. This approach provides both comprehensive feature extraction and efficient inference performance.
BL-YOLOV11
At present, although YOLOV11 has achieved good results in some datasets, whether it is feature extraction, computational efficiency or computational efficiency, it is leading the rest of the models, but we believe that there is still some room for optimization, and its performance in various aspects can be optimized. Therefore, the study proposes BL-YOLOV11. The specific model diagram is shown in the Figure 2. First, in the backbone layer, the C3K2 module is replaced with the ReHMS improvement to increase the model’s accuracy for small target detection, and also fully extract various features. However, on the one hand, considering that ReHMS may lead to complex structures during training, and on the other hand, in order to increase global modeling and thus better improve the model’s extraction of features from top to bottom, RepViT_EMA is introduced in the C3K2 part of the head layer for improvement, and a fusion module is used to allow the model to achieve an optimal balance of computational resources, inference speed, and model performance. BL-YOLOV11 model structure diagram.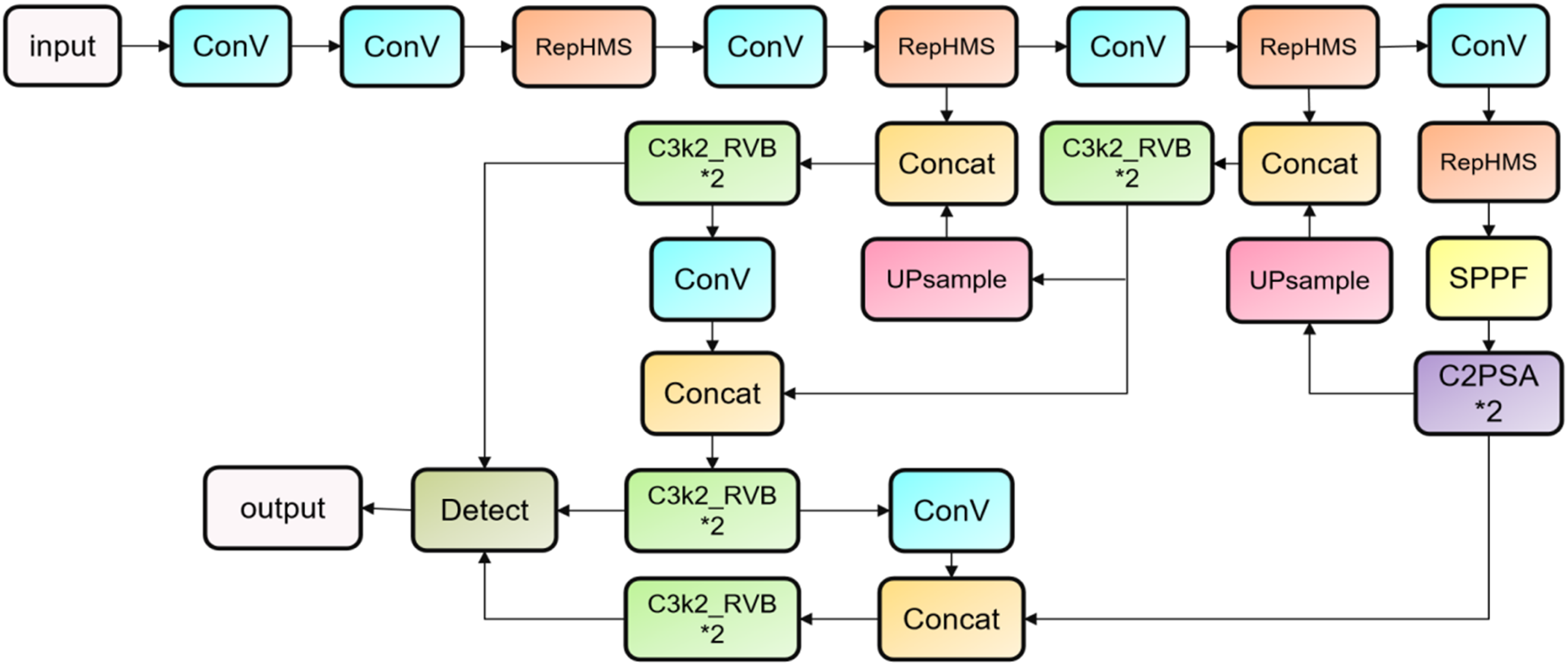
The backbone layers
In a model for object detection, the backbone is generally considered to be the foundation of the entire model. Its main function is to extract features, and its core goal is to extract features of different scales from the input image and fuse them with subsequent modules. The quality of the backbone directly affects the result. Therefore, the backbone layer of BL-YOLOV11 adopts hierarchical feature extraction, that is, extracting relevant features from each scale, and combining with the multi-scale feature fusion mechanism of RepHMS, to improve the accuracy of the model for small target detection tasks. The main modules are composed of RepHMS, SPPF (Spatial Pyramid Pooling – Fast), and C2PSA to optimize the expression ability of features of different sizes.
In the original YOLOV11 model, after the image has been feature-extracted by two convolutional layers, it is down sampled twice to extract primary texture information and then enters the C3K2 layer for feature extraction. However, considering that the C3K2 layer mainly relies on small-scale convolutions, it is poor at modeling long-distance dependencies and has a limited feature extraction path. Therefore, the study uses RepHMS to replace the original C3K2. On the one hand, it allows the model to extract different scales in different receptive fields, and also allows the model to use different sizes of convolution kernels at different scales, enhancing the model’s global modeling ability. The aggregation ability of features is further enhanced in SPPF so that it can better understand the connection between contextual information at different scales. Then, in order to further enhance the expressiveness of high-level features, the feature mAP enters C2PSA so that the channel dimensions can fully interact and high-level features can be better utilized, thereby better improving the robustness of the model in object detection.
Head layer
In object detection, the head layer is responsible for integrating features from multiple scales extracted by the backbone. BL-YOLOV11 adopts a multi-scale fusion strategy to enhance this process. Compared to the original model, the local feature extraction component C3K2 is optimized. To compensate for poor global modeling and reduce computational overhead, RVB_EMA is introduced, enabling better global feature learning. Additionally, multi-scale attention is applied to refine object detection. The extracted features pass through a feature pyramid structure, enabling the prediction of objects across various sizes. The head layer consists of up sample, C3K2_RVB_EMA, and Detect modules.
To enhance detection performance across scales, BL-YOLOV11 incorporates both FPN and PAN modules for hierarchical feature fusion. FPN up samples high-level features to strengthen the detection of small objects, while PAN down samples low-level features to better capture large objects. Their outputs are then concatenated across scales to form a unified representation. C3K2_RVB_EMA further enhances the fused features before they are forwarded to the Detect module for final object classification and localization, ultimately improving overall detection accuracy.
Experiment
Experimental environment configuration
Experimental Configuration.

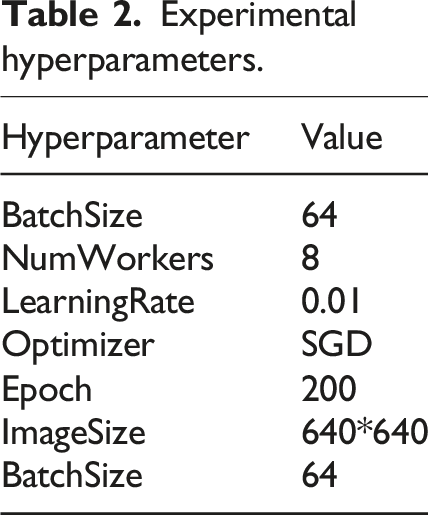
Experimental hyperparameters.
Dataset
In this study, the dataset used for training is a self-made dataset with a total of more than 4000 images, including more than 3700 images in the training set, more than 200 images in the test set, and 100 images in the validation set. There is only one category, “CRACK.” This simplifies the training of the model, allowing it to focus on one aspect of learning. On the other hand, considering that in reality, no matter what kind of crack it is, it is a potential threat that requires attention, and include various representations of cracks in the data, some of the more classic images, as shown in the Figure 3. Dataset samples.
Evaluation metrics
To comprehensively compare the performance of the proposed model with other approaches, several widely accepted evaluation metrics in object detection and deep learning were employed. These include GFLOPS, precision (as defined in equation (5), where true positives (TP) and false positives (FP) are considered), and recall (equation (6), involving TP and false negatives (FN)). In addition, the mean Average Precision at an IoU threshold of 0.5 (mAP@50) was calculated as detailed in equation (7), where Precision@50(i) denotes the class-wise precision, with n representing the total number of categories. Furthermore, the average precision across multiple IoU thresholds ranging from 0.5 to 0.95, referred to as mAP@50:90, was computed based on equation (8), which reflects the overall accuracy across varying levels of overlap.



Model training analysis
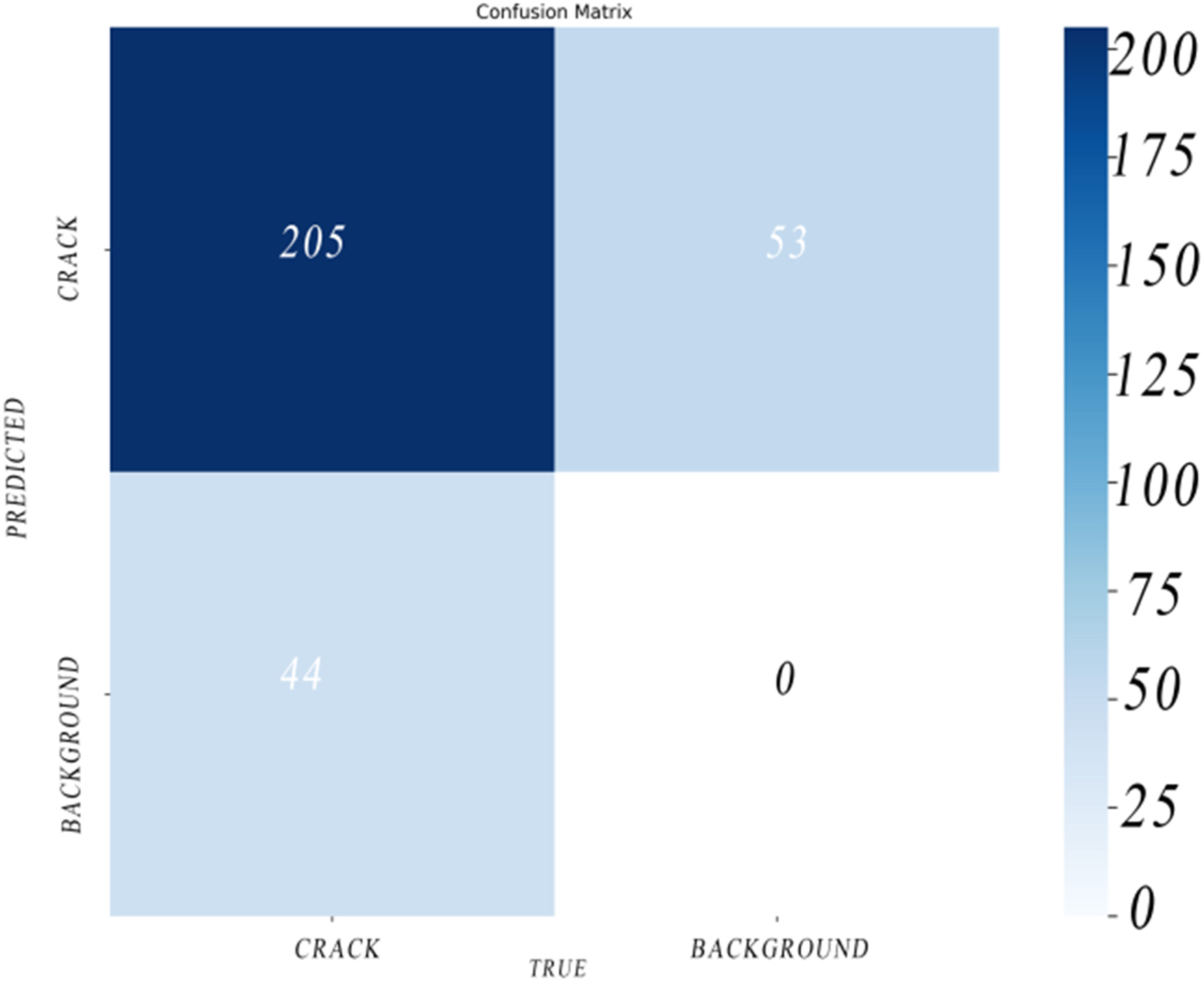
In order to evaluate the prediction and classification capabilities of BL-YOLOV11, the study observe and analyze the trends of loss function, precision, recall, and map during the model training process. In order to better reflect the accuracy and false detection of the model, the study also conducts a thorough analysis of the confusion matrix.
The training loss and performance index evaluation of BL-YOLOV11 are shown in the Figure 4. It can be seen from the figure that the model converges quickly during training, and most of the indexes slowly approach stability, which shows that the model has effectively learned the characteristics of road cracks and has good generalization ability. The confusion matrix is shown in Figure 5. From the matrix, the model has a good detection effect on most cracks, which shows that the model performs well in actual detection. However, there are still some false detections, indicating that there is still room for further optimization of the model, which provides a clear direction for further optimization. Through the above analysis, the performance indicators of BL-YOLOV11 are excellent, and it shows strong robustness in the task. BL-YOLOV11 training process. BL-YOLOV11 confusion matrix.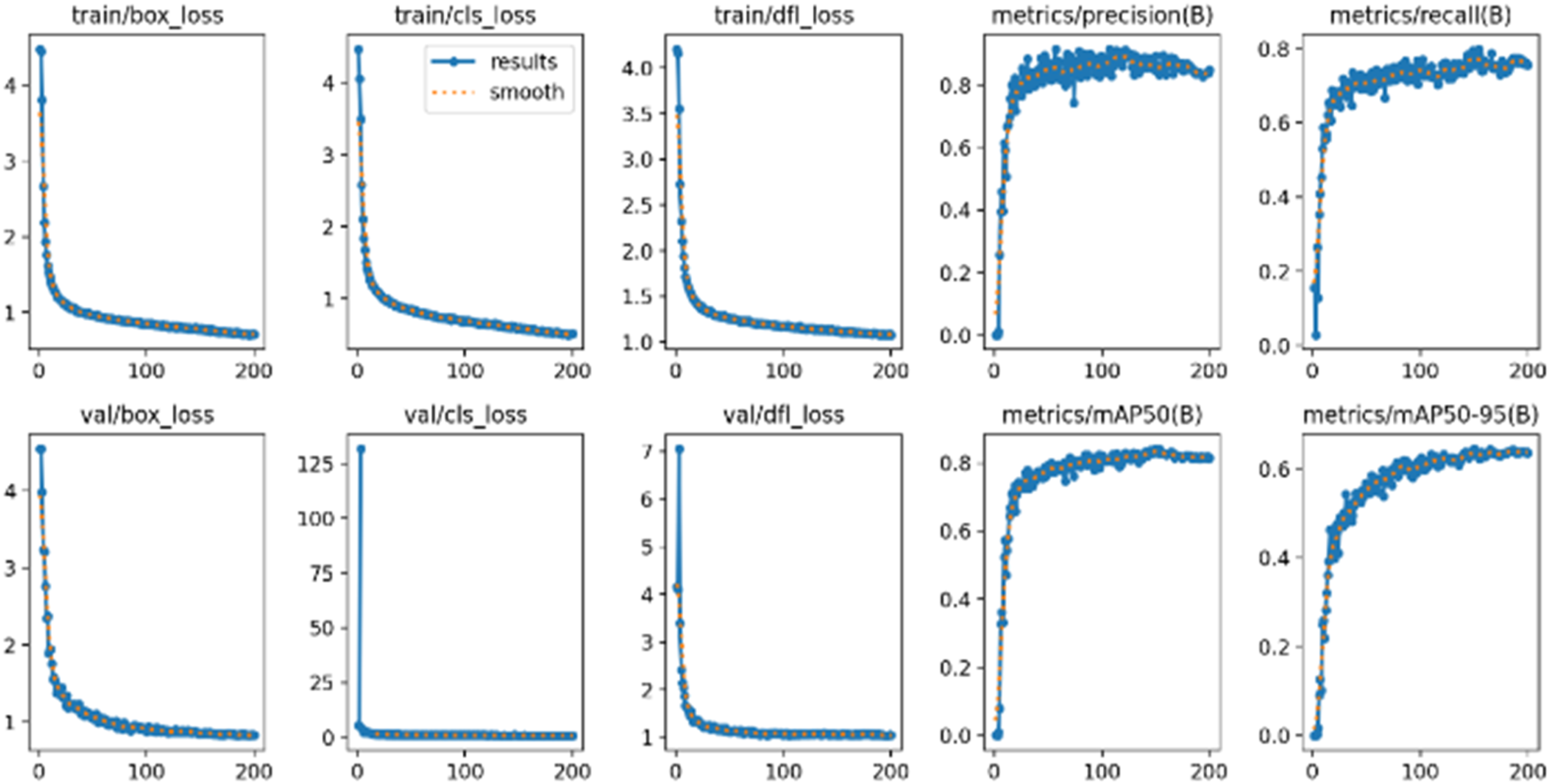
Performance comparison
Performance comparison of different models.
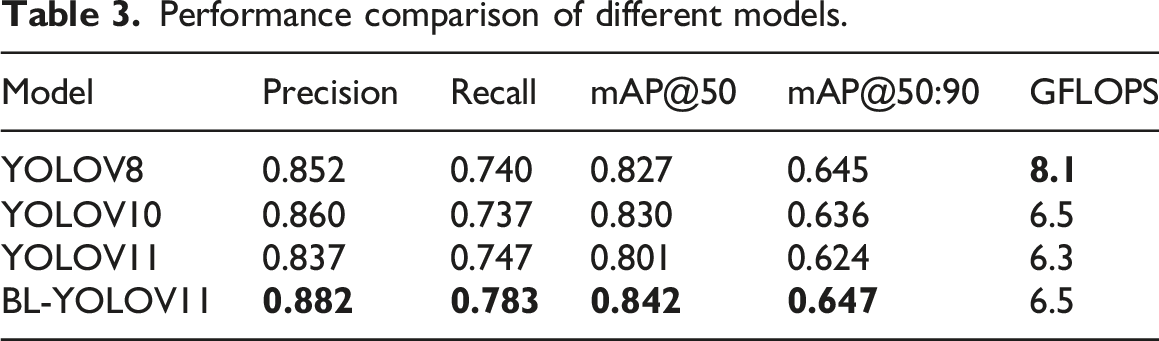
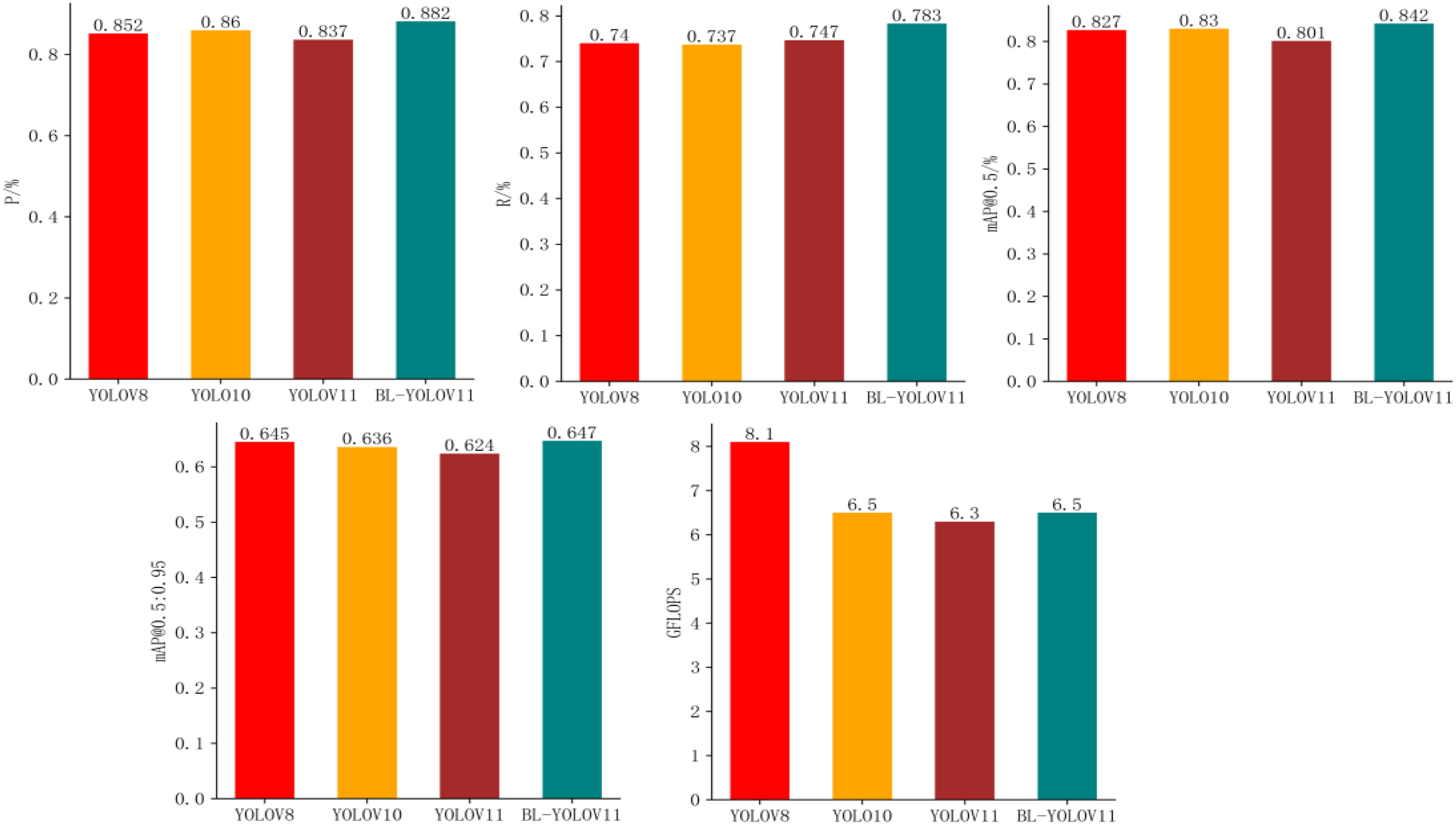
Comparison of the performance of different models.
First, in terms of Precision and Recall, our proposed model BL-YOLOV11 has a significant advantage over several other models, especially in terms of Precision, which is about 2-3 percentage points higher than YOLOV8 (0.852) and YOLOV10 (0.860). At the same time, Recall is also about 4-5 percentage points higher than other models, which means that it is more likely to detect objects missed by other models, and it has an advantage in reducing missed detections and the model also performed well in mAP@50 and mAP@50:90. In terms of mAP@50, BL-YOLOV11 also increased by 1-3 percentage points relative to the other models. Then there is mAP@50:90, where although YOLOV8 is similar to our model, with only a difference of 0.02%, indicating that the YOLOV8 model is indeed excellent in high-precision object detection, but YOLOV8’s GFLOPS is as high as 8.1, far exceeding the rest of the models. In contrast, our model has dropped by 32%, indicating that YOLOV8’s high-precision detection requires a certain sacrifice of computing resources. However, in reality, the computing resources for the road detection task are likely to be insufficient. Therefore, it is not difficult to conclude that BL-YOLOV11 can effectively reduce computing overhead without sacrificing accuracy and can balance the needs of computing resources and performance improvement. It can even bring its advantages into full play on devices with limited resources.
Visual analysis
In order to further verify the effectiveness of the improvements made to the original model by BL-YOLOV11, and to analyze its feature extraction and attention to the target region, this study uses the Grad-CAM heatmap method to visually compare and analyze the attention regions of the original model and BL-YOLOV11 for feature extraction.
Grad-CAM is a kind of activation mapping method based on gradient weights,
25
which can visually display the degree of attention paid by the model to the target position. The left part of Figure 7 shows the original image of the dataset, the middle part of Figure 7 shows the heat map generated by YOLOV11, and the right part of Figure 7 shows the heat map generated by BL-YOLOV11. Comparison of the thermal images of the YOLOV11 and BL-YOLOV11 models.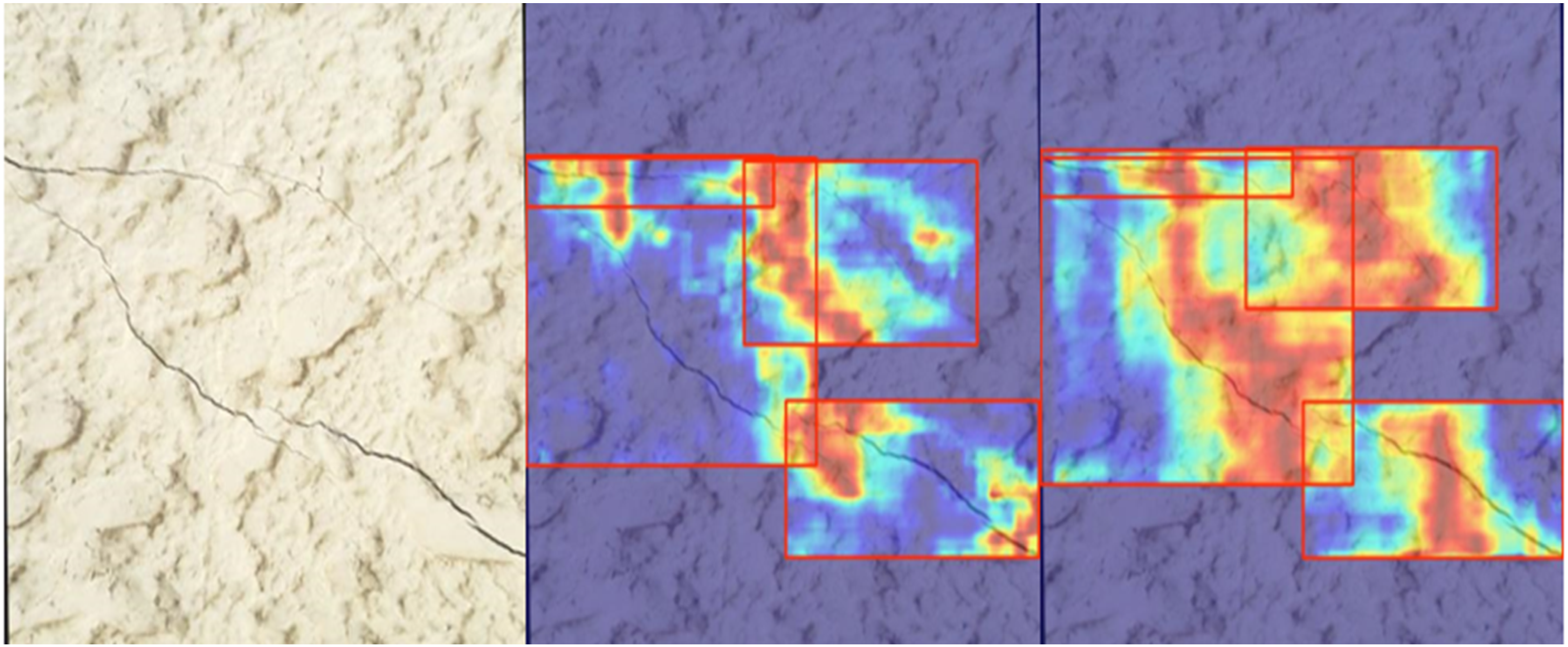
In the heat map, the darker the color, the higher the model’s attention to the region. By observing the above three figures, it can be found that BL-YOLOV11 can accurately focus on the region of cracks in the image, and the focusing effect has been significantly improved compared to the original model, which reflects that the fusion of RepHMS and RepViT_EMA has significantly improved the model and greatly enhanced the model’s focusing effect on features.
Ablation experiment
Ablation study results.
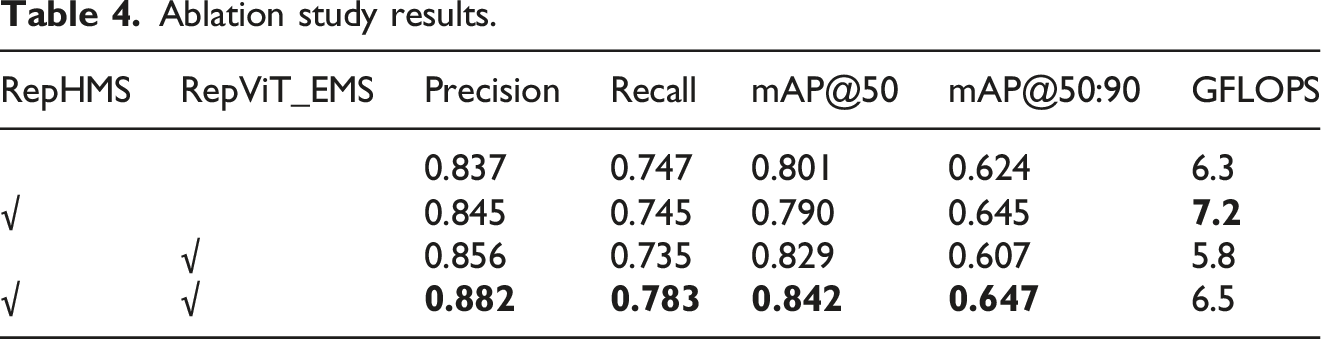
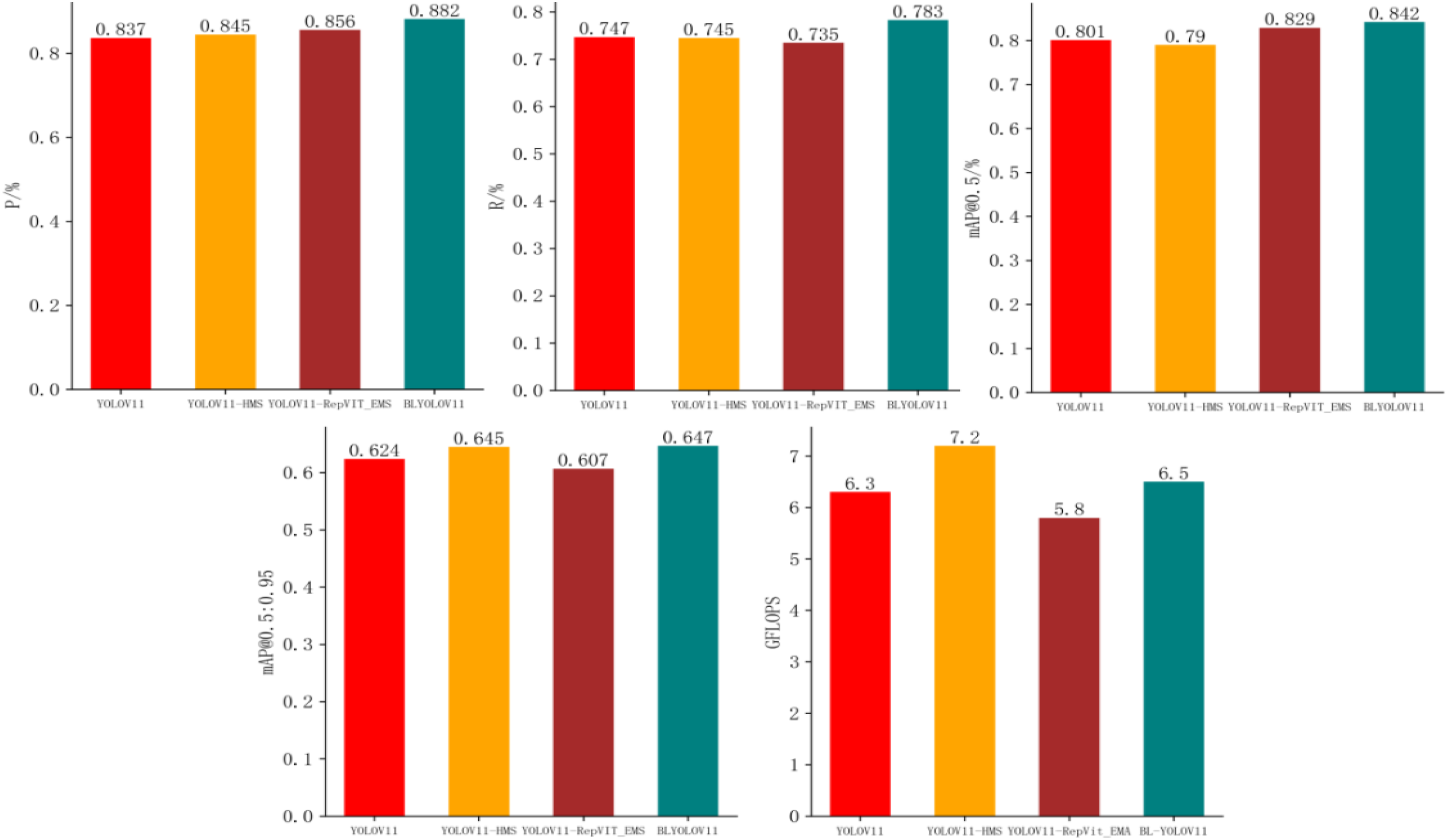
Comparison of ablation experiment.
According to the above table and bar charts, when baseline introduce HMS, it is easy to see that the Recall and mAP@50 metrics have decreased, but the decrease is not significant, only 0.2% and 1%, which is within the range of normal fluctuations. Later, it was found that this mAP@50:90 has been improved by about two percentage points, so it has certain advantages in high-precision detection. However, GFLOPS has increased by 14%. It can be seen that these two percentage points of improvement have been obtained at the expense of computing resources. Next, after introducing RepViT_EMS, the study found that although the Recall and mAP@50:90 of this set of experiments decreased slightly, its Precision and mAP@50 both increased by two percentage points. What is more noteworthy is that its GFLOPS has dropped significantly, which obviously shows that it has reduced unnecessary calculations. Compared with the original model, it has decreased by 7%. After the module is introduced, the computing resources not only do not increase, but instead decrease, and the performance is also improved, and the accuracy is improved.
In conclusion, the introduction of both modules in the current model BL-YOLOV11 has led to significant performance improvements across multiple evaluation metrics compared to the original YOLOV11. Specifically, Precision increased by approximately 5 percentage points, Recall by 4 percentage points, mAP@50 by 4 percentage points, and mAP@50:90 by 2 percentage points. Notably, these enhancements were achieved with only a 3% increase in FLOPs relative to the baseline model. The experimental results suggest that the RepViT_EMS module contributes to parameter reduction and computational efficiency while simultaneously enhancing Precision and mAP@50. In contrast, the HMS module demonstrates a substantial impact on high-precision detection metrics. These two components exhibit complementary effects: RepViT_EMS emphasizes efficiency and baseline accuracy, whereas HMS reinforces fine-grained detection. Together, they enhance overall detection performance while maintaining computational efficiency, thereby making BL-YOLOV11 more robust and adaptable to a wide range of downstream tasks.
Conclusion
This study presents an enhanced BL-YOLOv11 model aimed at improving the performance of unmanned road inspection systems. By replacing the original C3K2 module in the YOLOv11 backbone with the RepHMS module, the model gains superior multi-scale feature extraction capabilities, which significantly enhance its effectiveness in detecting small-scale objects. Furthermore, the integration of the C3K2 module from the head layer into the RepViT_EMA module improves the model’s ability to capture global contextual information while reducing redundant computation.
Experimental results demonstrate that BL-YOLOv11 achieves notable improvements over existing models such as YOLOv8, YOLOv10, and YOLOv11 across a range of road crack detection tasks. Specifically, the proposed model yields substantial gains in precision, recall, mAP@50, and mAP@50:90. Compared to the baseline, precision and recall increase by 5 and 4 percentage points, respectively, while mAP@50 and mAP@50:90 improve by 4 and 2 percentage points. Importantly, these improvements are achieved with only a 3% increase in computational complexity, demonstrating a favorable balance between accuracy and efficiency. In addition, Grad-CAM visualizations confirm that the model exhibits enhanced attention to critical defect regions, thereby improving feature localization and interpretability.
In future work, we aim to investigate strategies that achieve a more optimal balance between lightweight model design and detection accuracy. Particular attention will be directed toward the integration of lightweight attention mechanisms (e.g., ECA, MobileViT, or dynamic convolution) to further enhance feature representation under limited computational budgets. In addition, we plan to explore deployment strategies on edge devices such as Jetson Nano and mobile platforms, thereby promoting the practical application of BL-YOLOv11 in real-world road inspection tasks.
Footnotes
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by University Natural Science Foundation of Anhui Province (Grant No.2023AH051550) and Anhui Quality Engineering Project (Grant No. 2023jyxm0787, 2024aijy397).
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.