
Abstract
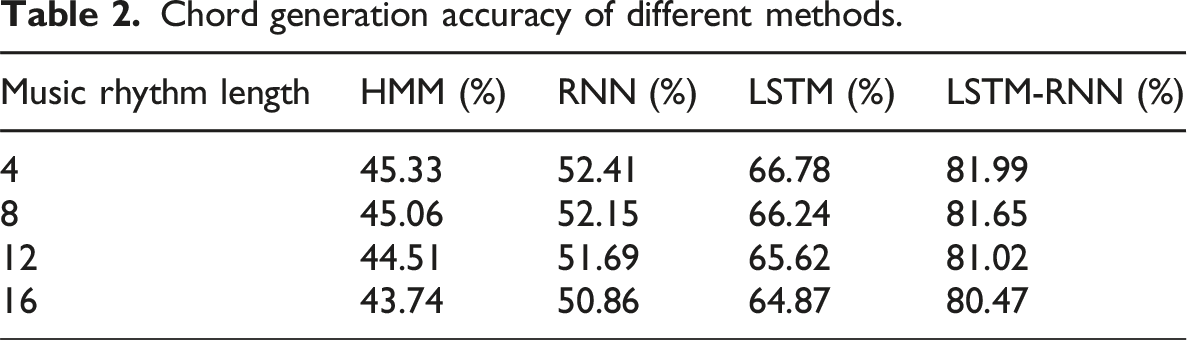
With the rapid development of computer information technology in China, algorithmic composition technology has received more attention in the field of musical composition. However, the accuracy of existing methods based on artificial intelligence algorithms for composition is relatively low, and the production effect cannot meet practical requirements when facing complex tracks. In view of this, this research designed the music element automatic generation method based on recurrent neural network. A music element automatic generation model based on resonant neural network is proposed. The improved algorithm is experimentally validated. The experiment showed that the system combined with the average field connection network, initial universal connection of resonant neural network, and detuned oscillator performed the best. The F-value reached 77.2%. The chord generation accuracy of the LSTM-RNN model was 81.99%, 81.65%, 81.02%, and 80.47%, respectively. The designed method can effectively achieve music production, meet high precision design requirements, and achieve good design results. This indicates that the music element generation method based on recurrent gradient frequency proposed in the study has good performance. It can accurately generate music elements, providing certain assistance and reference for the development of automatic generation technology of music elements in China. It is recommended to apply this method to more diverse scenarios in the future to complete music element generation.
Keywords
Introduction
Humanity has been conducting research on music for a long time. Music has become one of humanity’s greatest artistic pursuits. Many theories have been proposed in the study of music. Songwriters are also continuously summarizing their composition techniques.1,2 With the development of technology, applying computers for algorithmic composition has become an advanced technology for creating music works. In contemporary music, rule sets and algorithms are also considered as one of the ways to compose music. For example, western music Counterpoint is used to simulate the voice, which is one of manifestations of this algorithm. 3 Algorithmic composition is a precisely defined approach. This is also a way to represent finite length sequences. 4 When instructions describe calculations, the description starts with the initial input state. Clearly defined and limited transitions are executed in a certain order, resulting in output. In algorithmic composition, random algorithms are often applied. The input is usually a random parameter. After multiple transformations through specific transitions, a sequence of notes is ultimately formed. 5 However, existing music element generation methods have shortcomings in accuracy and applicability, which cannot meet practical application needs. Especially for complex tracks, existing methods cannot accurately capture their complex musical element symbols. Specifically, the generated music segments have significant shortcomings in terms of logic and global structural consistency. Secondly, existing methods often focus on generating a single element, such as rhythm or melody, without considering the synergy of multiple elements, which may result in a mismatch between the generated melody and harmony, or obvious errors in different elements such as harmony or rhythm. Therefore, the practicality of existing methods in generating music of different styles is weak. The research aims to construct an automatic music element generation method based on artificial intelligence algorithm to achieve more accurate and effective music element generation, meeting complex and diverse application needs. This research suggests that musical elements include melody, harmony, and rhythm. Music works are all composed of these three elements. Therefore, combining the advantages of recurrent neural network in data extraction, a music element automatic generation model based on recurrent Resonant Neural Network (RNN) is constructed. It is hope that this method can better generate music elements, providing more effective support for high-quality music creation.
The innovation of this study is as follows. Firstly, this study uses melody, harmony, and rhythm as the basic units for intelligent algorithm learning, providing a clarity learning objective for neural network models to achieve music generation, and effectively considering the integrity and coordination between music melodies, ensuring the quality of music generation. Secondly, this study innovatively combines recurrent neural networks and RNNs. The former can effectively capture the temporal structure of musical elements, while the latter can effectively enhance the modeling ability of the model in frequency-domain relationships such as pitch and harmony, thereby improving the rationality and fluency of music generation.
The contributions of this study are as follows. Firstly, this study utilizes a recurrent neural network model to represent music elements, achieving automatic continuation and combination of music elements. Secondly, this study combines RNNs and recurrent neural networks to construct an automatic music element generation model, namely, the GFNN-LSTM hybrid architecture. Thirdly, a detuning oscillator is introduced as a differentiable phase coupling module to achieve higher quality music element generation.
Related works
With the support of deep learning technology, music generation methods have been better developed. Combining various deep learning technologies to practice music generation has become a research hotspot. Malyi D conducted an in-depth analysis for existing music creation techniques and methods. The results showed that musical composition technology was fundamentally interrelated. The creators’ ideological intentions were explained from different perspectives. There is consistency between music language creation and historical and cultural evolution. 6 Zongyu Y et al. evaluated several music generation systems from six aspects, including style success, aesthetic pleasure, repetition or self-reference, melody, harmony, and rhythm. The results showed that the music generation method based on deep learning was significantly superior to other artificial synthesis methods. 7 Weiming L et al. utilized artificial intelligence (AI) for song creation. The model was validated by generating 5 different bass, drum, guitar, piano, and string tracks. The results indicated that many of the music clips generated by the proposed model were smooth. This model was more stable, realistic, which also had a faster fitting speed in music generation, indicating that the music generation method was effective. 8 Maryam M et al. proposed a multi-objective genetic algorithm (MO-GA) to generate polyphonic music segments. The proposed music generation system attempted to maximize the mentioned objective function to generate new music segments, including melodies and harmonies. The results indicated that the proposed method could generate pleasant fragments with the required style and length, as well as grammatical harmony. 9 Jin C et al. proposed a new generation network model based on transformer and guided by music theory to produce high-quality music works. While training and discriminating the network, the global and local loss objective functions were optimized to provide a reliable adjustment method for the reward network. The reward network and cross entropy loss were combined to guide the training of the generator and produce high-quality music works. Compared with other multi track music, the experimental results verified the effectiveness of the Generative model. 10
Recurrent neural networks are neural networks with fixed weights, external inputs, and internal states. It can be regarded as a parameter based on weights and external inputs, which can better describe the motion state. It has been widely used in various fields. Xing B et al. proposed a new robust non-singular terminal sliding mode (NTSM) control method based on recurrent neural network structure. Based on the adversarial generative network dynamics model and path following model, a robust NTSM steering controller was proposed. Then, recurrent neural network was applied to approximate the unknown dynamic part of the system online. Compared with existing methods, the proposed method had better performance. 11 Traditional neural network models have low accuracy, high complexity, and lack compatibility in predicting the bending degree of composite materials. Therefore, Zamyad H et al. proposed a mixture model with internal storage units to overcome existing weaknesses. The experimental data validation results indicated that the model had acceptable accuracy and flexibility. 12 Dsouza K B et al. proposed an automatic recurrent neural network encoder based on deep Long short-term memory (LSTM) to capture long-term dependence in Epigenome data. This method could capture potential representations of various gene phenomena, including gene expression, promoter enhancer interactions, replication time, frequent interaction regions, and evolutionary conservatism. The experimental results showed that this method was superior to existing methods. 13 Yang S B et al. developed a new method based on recurrent neural network to deal with stochastic model predictive control problems. The deterministic optimization problem generated was solved through a nonlinear optimization solver. The results demonstrated that the proposed method had high accuracy. 14 Lai W H et al. proposed a stacked recurrent neural network with gated recurrent units (GRUs) and jointly optimized soft time-frequency masks for extracting target instrument sounds from mixed instrument sounds. The stacked recurrent neural network model linked multiple simple recurrent neural network, making it an excellent model with temporal dynamic behavior and true depth. The results showed that this method could successfully extract Electric guitar and drum sound. 15
In conclusion, the music element generation method combined with modern advanced technology has been deeply studied, providing effective support for Musical composition and research. However, existing music generation technologies focus more on simulating and creating various musical sounds. There are still many shortcomings in the extraction and representation of specific musical elements and rhythm elements. Therefore, combined with the advantages of recurrent neural network in data mining, a factor generative model based on Recurrent neural network is constructed. It is expected that this method can better generate music elements, providing effective support for high-quality musical composition.
Automatic generation method of music elements based on resonant neural network
Representation method of music elements based on recurrent neural network
List of musical symbols with large amount of information and time structure can be captured through recurrent neural network. To automatically renew and combine existing elements and form an automatic element generative model, multi-level recurrent neural network is trained in the folk song Big data set. The model system will continuously refresh the parameters in the network during the training process to accurately predict subsequent notes. After completing the model training, the previous note in the model automatically generates the following notes to create a brand new sequence of note elements. The combination of duration and pitch is considered a note. The collection of note sequences forms the melody.
16
Therefore, note
The representation method of melody is shown in Figure 1. To reduce redundancy and control data size appropriately, time values and pitch are standardized. Firstly, a minor or C major is used to standardize the melody of a song. Based on common notes, the duration of other notes is further standardized.
17
Representation method of melody.
Construction of music elements generative model based on recurrent neural network
This study uses melody, harmony, and rhythm as the basic units of intelligent algorithm learning, which can provide clarity learning objectives for neural network models to achieve music generation. Therefore, after analyzing the basic elements of music, the study adopts a neural network model to construct a method for generating music elements. Neural networks belong to a type of nonlinear function, represented by Structural model of recurrent neural network.

When recurrent neural network fine tunes weights in reverse regression, if the weight value of one layer is very small, it will cause the weight value of the previous layer to disappear, resulting in gradient problems. Long Short-Term Memory Network (LSTM) is a variant of recurrent neural network, which preserves long-term dependency information in the input corpus compared to recurrent neural network. At the same time, LSTM can effectively avoid the vanishing gradient of recurrent neural network. The basic unit structure of LSTM mainly includes input gate, output gate, forgetting gate, and memory unit. All gate structures are composed of a feedforward neural network layer and an activation function. LSTM introduces the state concept in every layer of recurrent neural network. The state as network memory will change based on the input of each sample. To better simulate the distribution of time values and tones, two LSTM structures are used to represent two different rhythm networks. The hidden layer of time value and LSTM is composed of 128 Connection method and network structure.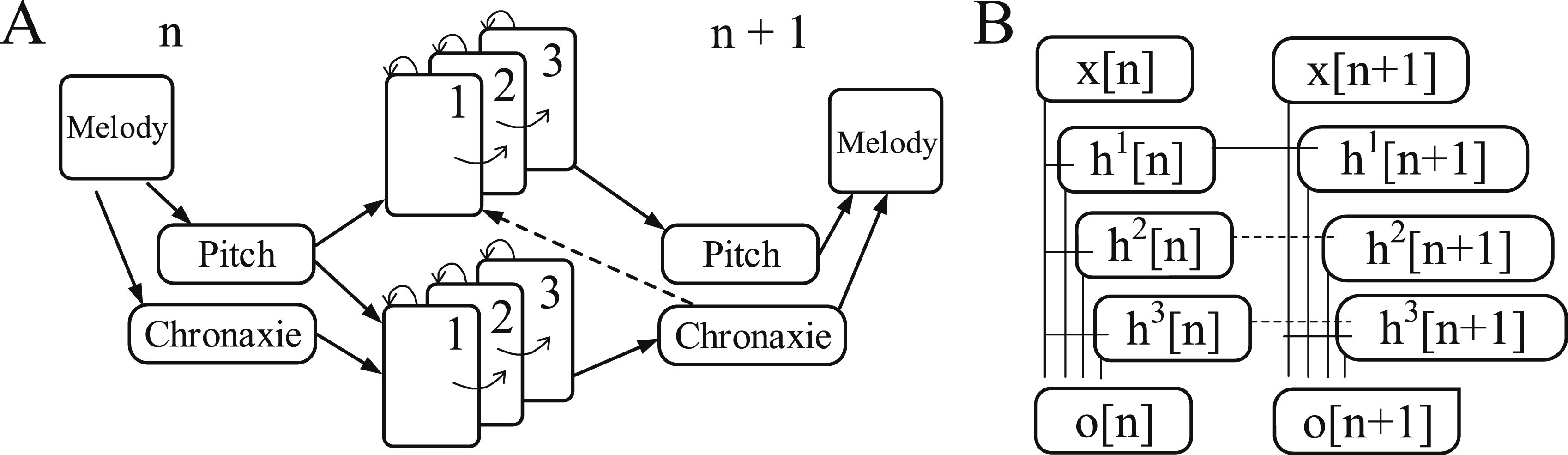
Figure 3(a) shows the note propagation method based on two LSTM structures. The time vector
The activation vector of layer
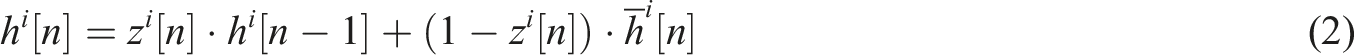
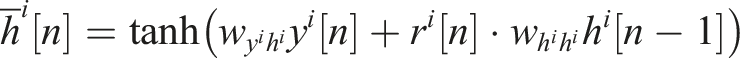
The updating gate
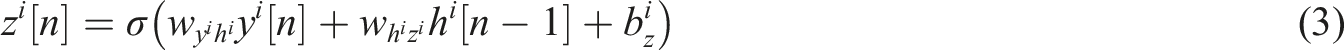
The calculation method for reset gate The process of combining LSTM and resonant neural network.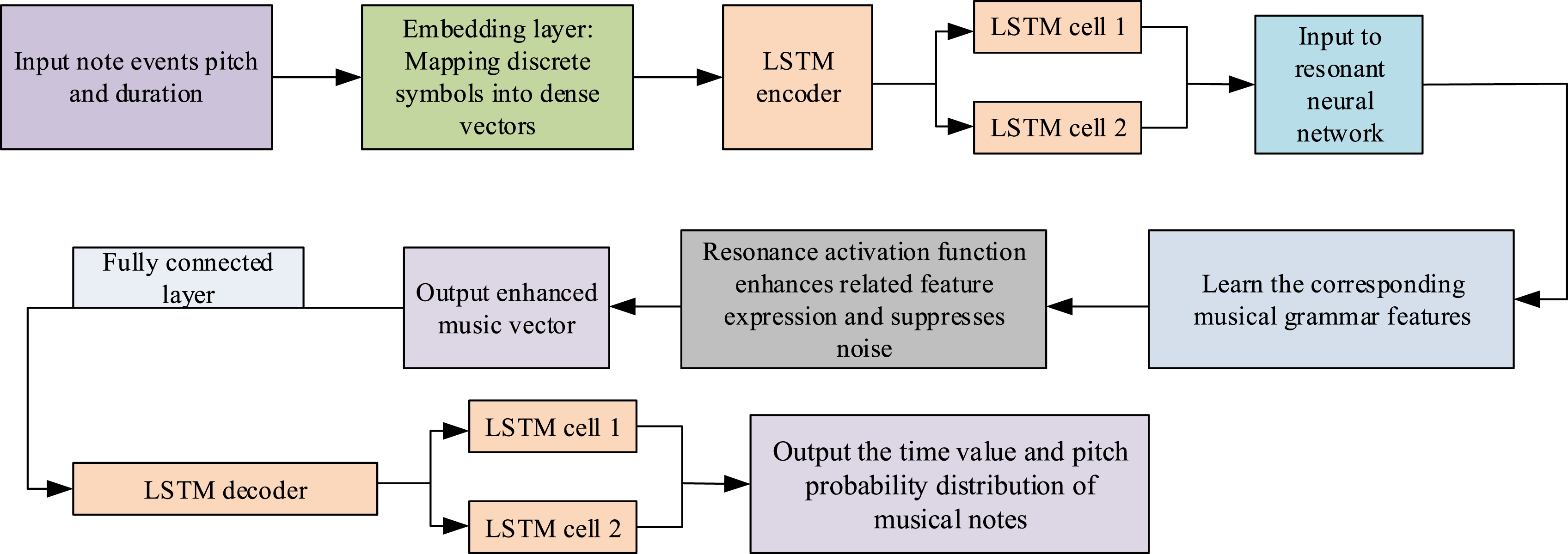
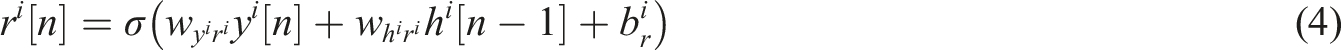

In Figure 4, music, represented as a series of discrete events (such as [Pitch, Duration]) being inputted. Then, these discrete symbols are mapped into continuous dense vectors through an embedding layer for processing. The LSTM encoder reads the entire input sequence. The final hidden state of the encoder is input into the RNN layer. This structure learns music patterns such as rhythm and melody. After encoding the information, the resonance mechanism is activated to enhance the characteristic signal while suppressing irrelevant information. Then output an enhanced context vector. Finally, by decoding the enhanced context vector output by the LSTM decoder as its initial state, the next note is generated note by note.
The probability distribution of note pitch

Formula (6) indicates that the network output
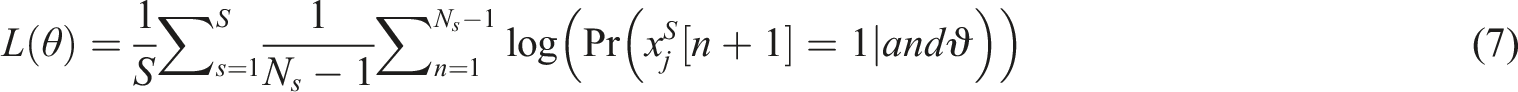
Construction of music elements automatic generative model based on resonant neural network
The rhythm perception based on the neural inspiration model is known as the RNN. In RNN, the oscillator network is distributed across a spectrum. The internal connections between oscillators can be trained through Hebbian-type learning. RNN is the connection matrix connected to a typical oscillator. When the network signal is stimulated, if the frequency distribution is within the rhythm range, the pulse can form an integer proportion with resonance. Thus, these resonances can be explained as perceptions for hierarchical metric structures.
20
RNN is implemented in MATLAB, which includes 192 oscillators and exhibits a logarithmic distribution between the natural frequencies of 0.5Hz–8 Hz. RNN consists of two LSTM networks, the first with 192 linear inputs corresponding to each oscillator in RNN and occupying the real part of each oscillator’s output. The second network has only one linear input and contains frequency information of the input signal. When generating music elements, the measurement structure of music elements should be given special attention. Any given musical rhythm can be classified as strong or weak. When a given level rhythm is considered strong, it will also appear in the next highest level, which is the hierarchical structure of the music rhythm. In theory, the hierarchical structure of the music rhythm may include various phrases and rest notes. A simple music rhythm metric analysis is shown in Figure 5. Measurement analysis of music elements.
Music rhythm analysis shows that the occurrence time of music structure is similar to the basic pattern of brain mechanics. There is a resonance between the nervous system and the rhythm pattern of music, as shown in formula (8).
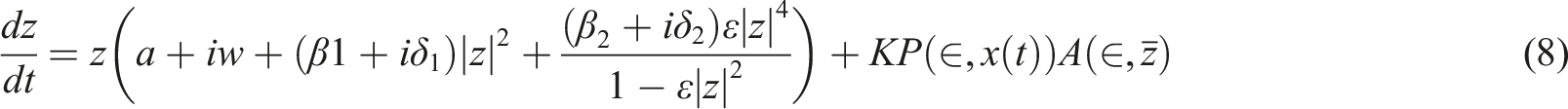
A RNN model will be trained to predict audio data and form expressive rhythmic events. The function activation mainly relies on the input and output of audio in the model. The schematic diagram of the RNN model is shown in Figure 6. Resonant neural network.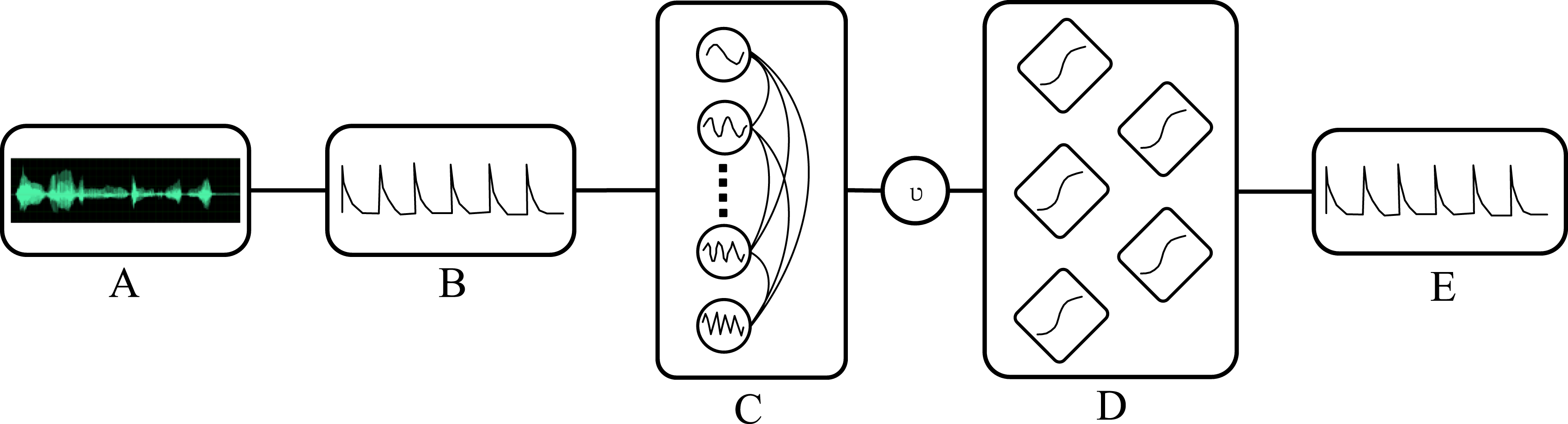
In Figure 6, (A) represents the input audio data, B represents converting the audio signal into a rhythm form that can be distinguished from it, C represents multiple oscillators, D represents RNN representing the audio data, and E represents the output audio event activation function. The main dataset used in the study is dataset
Permormance analysis of music elements automatic generative model based on resonant neural network
The corresponding experiments are designed to analyze the performance of the automatic Generative model of music elements based on the cyclic RNN. To automatically generate music datasets that meet the requirements of the model, a program is written to compile and parse the music symbol list of the abc notation. At the same time, the form of symbols is transformed until the model requirements are met. The dataset used in the study is Free Music Archive (FMA), which is an open and easily accessible dataset for experimental analysis. It provides full-length and high-quality audio, pre calculated functionality, as well as audio tracks and user level metadata, tags, and free-form text (such as biographies). It includes 106,574 tracks and 14,854 albums from 16,341 artists, with a note length range of 136 ± 83, which includes information about duration and tone conversion. The study uses the Min-Max Scaling method to compress data to [0,1]. Pitch and duration are two distinct characteristics, and they are studied separately for processing. Pitch is an ordinal variable, which is processed by One-Hot encoding: treating each pitch as an independent category, resulting in a high-dimensional sparse vector. Then, the Min-Max Scaling is used for processing. Firstly, clarify the range of pitch, pitch_min = 21 (MIDI note 21, A0, piano bass), pitch_max = 108 (MIDI note 108, C8, piano treble). Then, process it by using pitch_normalized = (original_pitch - pitch_min)/(pitch_max - pitch_min). Duration is a continuous positive variable. Its distribution is usually long tailed (with many short notes and a few very long notes). The study uses proportional time encoding. For example, a quarter note is denoted as 1, and an eighth note is denoted as 0.5. After standardization preprocessing, the dataset usually has a value of 1. This increases the probability of other transitions to carry out unified time value conversion. The specific content is shown in Figure 7. From Figure 7, Statistics of tone harmony and time conversion information.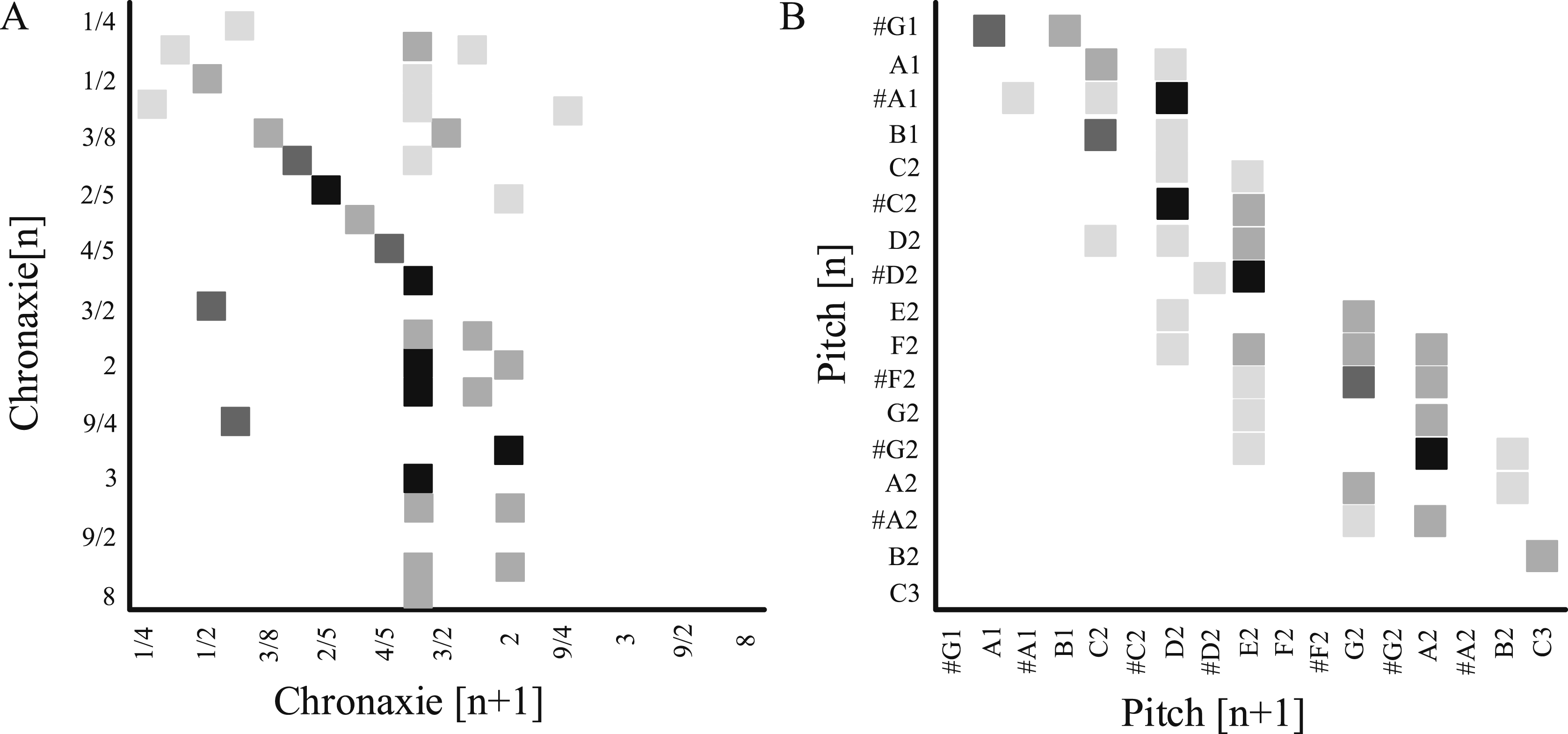
Through the next note value, the subsequent note distribution model is constructed to determine the effective distribution law of the decomposition time value and pitch. This ensures the correct calculation of the conditional probability value. Finally, an example is automatically generated for the corresponding melody, as shown in Figure 8. The Example of automatic melody generation.
Output results evaluation for resonant neural network model.

An output result of the recurrent RNN model is shown in Figure 9. Multiple peaks appear in the target output value. Multiple peaks appear in the target output because the input sample contains distinct features. The input music sample data itself has some rhythm variation patterns. Therefore, the model attempts to generate a peak for each feature during operation. Therefore, multiple peaks appeared. The actual output is the test results obtained from the designed research model, while the target output is the exact rhythm change pattern of the sample. The actual output result should be as close as possible to the target output value. Overall, there is a certain difference between the actual output value and the target output value. The actual output value is slightly smaller than the target output value. When the running time is 15.2 s, the difference between the actual output and the target output is 0.15. When the running time is 16.4 s, the difference between the two is 0.2. When the running time is 16.7 s, the maximum difference between the two is 0.3. When the running time is 18.5 s, the difference between the two is 0.02. Overall, the maximum difference between the actual output value and the target output value is 0.3. However, the peak variation between the actual output value and the target output value is basically coincident. This indicates that the LSTM-RNN music element generation network model constructed in the study has good performance. This neural network system can effectively capture the rhythm structure, generating new music rhythms. One output result of the resonant neural network model.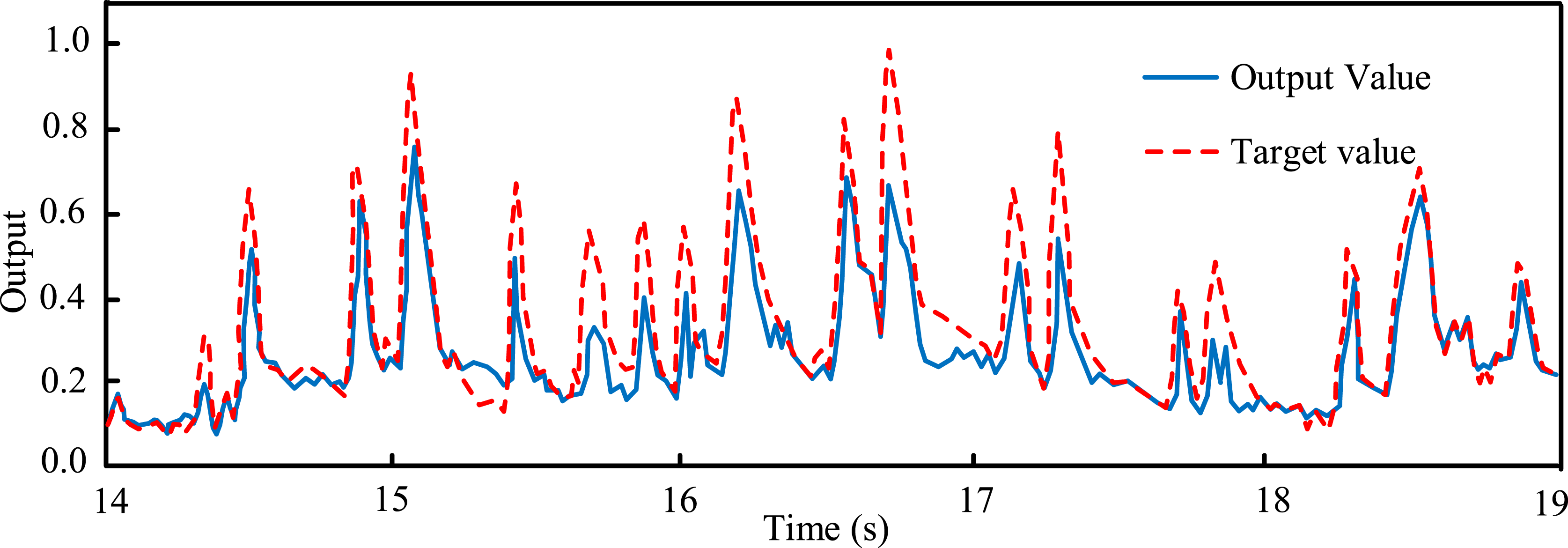
Chord generation accuracy of different methods.
In all average field networks, the evaluation metrics are relatively higher than those of other networks, but they have a large standard deviation. This reflects that the range of round results obtained through cross validation methods fluctuates greatly. The convergence of the mean field network requires more steps. The music speed can also be seen as the mutual holding process of local oscillator groups, which is more conducive to the implementation of beat tracking. A strong resonance phenomenon appears in the local area, and the frequencies between oscillators are similar. Local regions can also change with changes in stimulus frequency, moving resonance regions along the frequency gradient direction. The Sound track loudness chart (t = 1).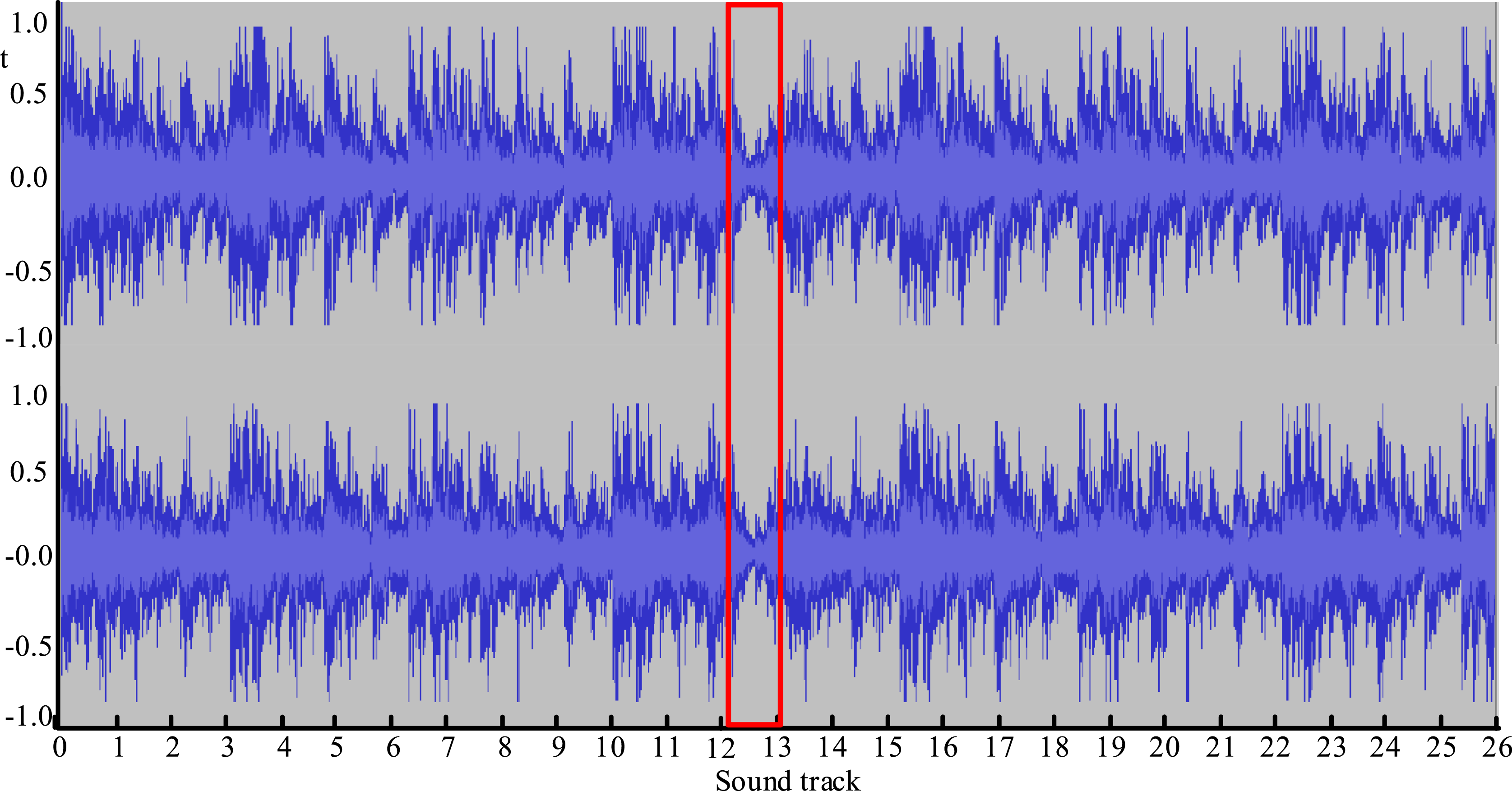
When t = 2, the amplified response value is analyzed, as shown in Figure 11. The red box represents the audio connection point. From Figure 11, when the time is t = 2s, the variation area is longer and the musical elements appear less compact. In terms of the auditory, the music clearly has a certain sense of confusion. The analysis of track loudness indicates that some soundtrack loudness maps have significant long segment weakening. The effect of element generation is poor. Sound track loudness chart (t = 2).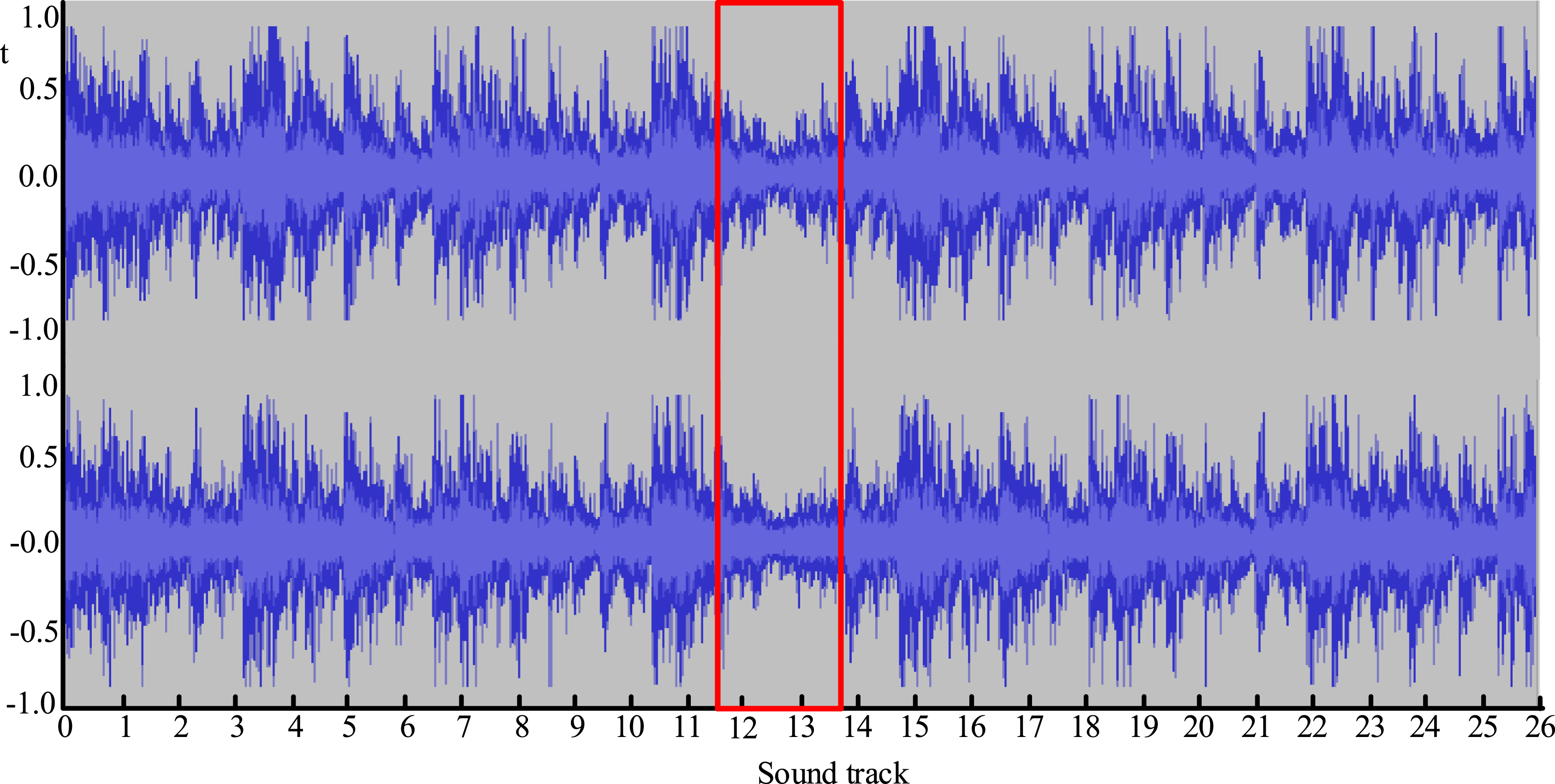
From the above results, it can be seen that the music element generation method designed in the study has better results, including automatic melody generation and accuracy in chord generation. At the same time, it also has a smoother effect in the connection of sound track loudness, and the generation effect of music elements is better. Compared with the GAN used in Reference 8, the method designed in the study achieves a smoother sound track effect, as the RNN network used in the research method contains multiple oscillators, which can better reduce the impact of noise and improve the music element generation effect. Xu X et al. used convolutional neural networks to analyze music elements, but this method requires solving too much parameter data in application, which limits its application. 21 By comparison, the music element generation method based on RNN designed in the research has simpler operations and parameter requirements. Overall, the designed method has significant advantages.
Performance comparison on different datasets.
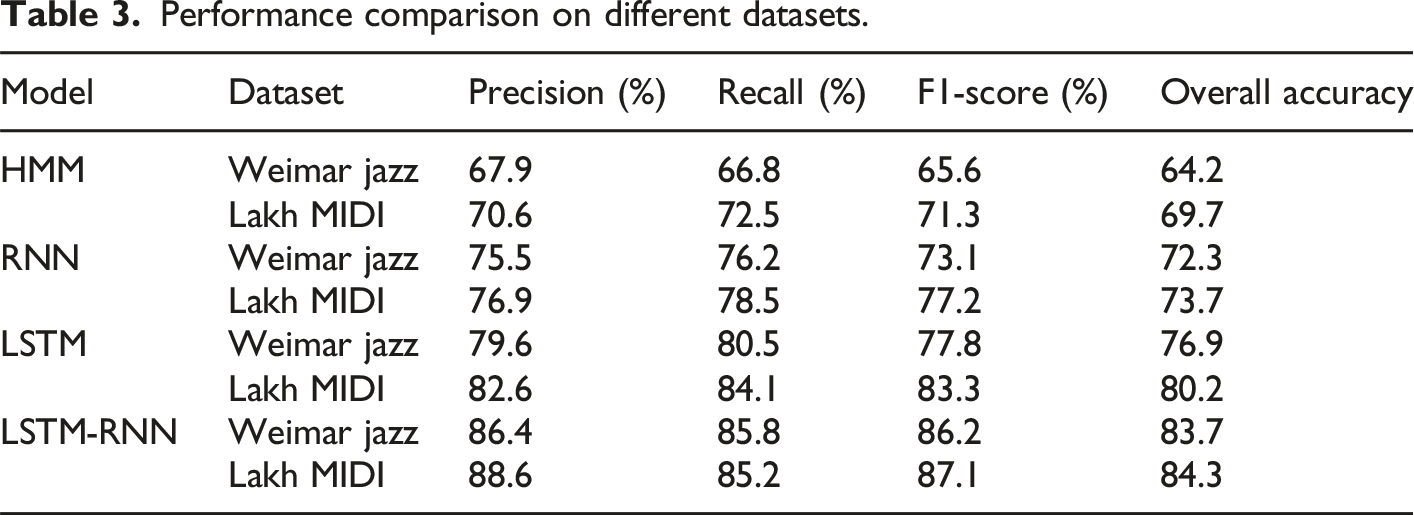
All models performed slightly better on the Lakh MIDI dataset than on the Weimar Jazz dataset. This may be because the harmony and rhythm of popular music are simpler and more regular than jazz music, and the challenges in the generation process are smaller. The Precision, Recall, F1 score, and Overall accuracy of LSTM-RNN on the Weimar Jazz dataset are 86.4%, 85.8%, 86.2%, and 83.7%, respectively. The Precision, Recall, F1-score, and overall accuracy of LSTM-RNN on the Lakh MIDI dataset were 88.6%, 85.2%, 87.1%, and 84.3%, respectively. The research method performs better than other comparative methods on two different datasets, indicating that the method has stronger generalization ability and robustness. From this perspective, the research method has great potential in practical applications and has good adaptability.
Conclusion
In the field of musical composition, the research designs the music element automatic generation method based on the recurrent RNN to realize the automatic generation of music elements. From the experimental results, after standardizing and preprocessing the sample data, the time value of the dataset is usually 1. This increases the probability of converting other states into unified time values, of which