
Abstract
In the context of sustainable development, the effective construction of environmental corpus for business English interpretation is crucial for promoting the standardization of professional language services. Traditional corpus construction relies heavily on manual collection and annotation, which is characterized by low efficiency and high labor costs. To address these issues, this study proposes a computational framework integrating web crawler technology and deep learning-based annotation. For corpus collection, a targeted crawler algorithm is designed to automatically extract and preprocess sustainable development-related business English texts from multi-source platforms, achieving a data coverage rate of 92.3% for key environmental business domains. For annotation, an Attention-LSTM hybrid model is constructed to realize semi-automatic labeling of professional terms and contextual relationships. The model is trained on a manually annotated sample set, and experimental results show that its annotation accuracy reaches 89.7%, which is 18.5% higher than that of traditional rule-based methods, and the manual correction workload is reduced by 63.2%. This framework not only improves the efficiency of environmental corpus construction in business English interpretation but also provides a computational solution for domain-specific corpus engineering, laying a technical foundation for intelligent language service systems in sustainable development scenarios.
Keywords
Introduction
Business English interpretation is a bridge and link between different cultures in business activities. Cross-cultural business communication needs to be translated to accurately convey the connotation of another unfamiliar or unfamiliar language and culture in a familiar language and culture, so that both parties in business activities can deeply understand the intentions and reply of each other. Sustainable development is a hot topic in the society in recent years, and also a topic often mentioned in recent business activities. Many business activities are affected by the concept of sustainable development, or need to carry out business actions related to sustainable development, environmental protection, energy conservation and emission reduction. These changes make business English adapt to the environment of sustainable development and keep up with the trend of society and business activities.
Since the 1980s, with the advancement of computer technology, the development of computer-based corpora and the exploration of their application technologies have become focal areas of research among information processing and language experts in China. A corpus refers to a large-scale text database that has been scientifically sampled and systematically processed. It typically employs statistical methods and partitioned learning strategies to extract linguistic patterns embedded in authentic natural language, thereby facilitating deeper research into language understanding and natural language processing. Large-scale corpora such as the British National Corpus (BNC) have had a profound impact on lexicology, linguistic studies, and language technologies.1,2
In the context of sustainable development, constructing a domain-specific environmental corpus for business English holds considerable significance for both the advancement of business English as a discipline and its practical applications in society. The corpus construction process generally involves the acquisition of raw linguistic data, corpus preprocessing, and corpus classification, among other tasks.3,4 However, building a business English corpus has long been a labor-intensive endeavor due to the vastness and complexity of the required resources, as well as the meticulous nature of classification work. Therefore, exploring automatic and intelligent methods to assist in corpus construction is of critical importance.
In addition to the general challenges of corpus construction, the domain of sustainable development presents several unique difficulties. Firstly, the environmental discourse in business contexts involves an abundance of specialized terminology—such as “carbon offsetting,” “circular economy,” or “life cycle assessment”—which may not appear in general-purpose corpora. Secondly, this field is inherently interdisciplinary, intersecting business, legal, scientific, and policy-oriented language registers. This results in complex syntactic structures, diverse pragmatic markers, and hybrid expressions that require refined annotation strategies. Hence, an effective environmental business English corpus must be sensitive to these domain-specific linguistic phenomena to ensure accurate interpretation and training of NLP systems.
In recent years, the rise of artificial intelligence has led to the development of intelligence and automation in many fields. Crawler technology is a program or script that automatically grabs information from the World Wide Web according to certain rules. It is often used to collect and obtain resources. 5 There are also many machine learning based methods for corpus classification, such as the application of Bayesian network, 6 decision tree classification, 7 support vector machine, 8 and so on. Zhang et al., 9 used Bayesian networks to realize automatic recognition of false news. Sun et al. 10 proposed an efficient SVM based classifier for unbalanced corpora. However, although machine learning can achieve a certain degree of automation and intelligence, most of its features need expert recognition and manual coding. Deep learning is an end-to-end problem solving method. The trained neural network can automatically complete a variety of tasks, including classification and detection. RNN (Recurrent Neural Network), 11 LSTMs (Long Short Term Memory Networks) 12 and other models have been widely used in the field of natural language processing, enabling automatic speech recognition. Among them, RNN has the problem of long-term dependence, which LSTMs solved by introducing the concept of long-term memory. Although these deep learning methods can effectively achieve automatic speech recognition, their attention to all input features. This balanced focus way affects the improvement of speech recognition accuracy to a certain extent. How to apply automation technology and use automation and intelligent methods to help build a business English environmental corpus in a sustainable development environment is a problem we need to solve.
In order to solve the above problems, we propose a complete method to build a business English corpus in a sustainable development environment. The proposed method includes several key points. Firstly, the crawler technology is used to obtain the original corpus information and the obtained information will be manually screened next. In addition, in order to make the obtained expectation be processed by the deep learning algorithm, audio is converted into spectrogram as the main material for training and testing models. In order to help accurately label the corpus, the attention LSTM algorithm is proposed, which combines the attention mechanism to enable the LSTM algorithm to focus more on difficult samples and improve the accuracy of speech recognition. Finally, we designed a complete corpus construction scheme, and the proposed attention LSTM algorithm surpassed the original RNN and LSTM algorithm in accuracy.
Related work
Web crawler technology
Web crawler technology can capture network information more accurately and efficiently, and is widely used in information collection and acquisition. In recent years, many efficient crawler frameworks have emerged, the most commonly used of which is the Scrapy crawler framework. Scrapy is a framework designed to crawl network data and extract structural data. At the same time, it can help us quickly grab data with a small amount of code. Wang et al. 13 used the algorithm based on the Scrapy crawler framework to collect Taobao user behavior information, analyze user behavior characteristics, and then study the network characteristics of e-commerce. This shows that the sketch crawler framework has the ability to collect a large amount of information. Ramdani et al. 14 used the Scrapy framework to extract data from target websites and store the extracted data in comma separated files, so as to collect product information needed by college students and give feedback to users. This reflects the information collection ability of the crawler algorithm, but the author did not use this information to generate structured data. Sengupta et al. 15 used the Scrapy framework to help design the system architecture of the campus network search engine, which solved the problem that ordinary search engines could not timely collect campus network information and the time lag. Although the application of this crawler algorithm has collected information, it does not reflect the idea of big data. The above methods fail to filter and filter the collected information and construct the final structural features. For the construction of business English environmental corpus in a sustainable development environment, the Scrapy crawler framework can help us obtain a large number of original video files from the website, and just extract the audio from them, which can be used as the original resources. The practical crawler technology, which collects resources according to keywords, can greatly save the time for manual collection of corpus. The output of the crawler process forms the input foundation for our annotation pipeline. Once the web crawler extracts relevant video and audio data centered around sustainable development topics, the corpus is subjected to preprocessing to ensure transcription quality and topic relevance. This cleaned and segmented corpus serves as the input to the deep learning annotation module described in the following section. In this way, the crawler technology is not an isolated component but an integral part of the end-to-end corpus construction pipeline that ensures data availability, relevance, and scalability for subsequent model training.
LSTM recurrent neural network and attention mechanism
LSTM recurrent neural network is designed to solve the long-term dependence problem in RNN. Zhai et al. 16 used LSTM recurrent neural network to extract entities and their relationships, and captured the relationship between word sequences and dependency tree substructures. This application shows that LSTM has a good retention and capture effect for long dependencies in statements in natural language processing. Peddinti et al. 17 used LSTM model for acoustic modeling. Mei et al. 18 solved the pixel level classification problem of scene images by using LSTM recurrent neural network. This application makes use of the ability of LSTM to capture context information. This ability not only has good effect in natural language processing, but also has certain application value in the field of semantic segmentation. In general, LSTM model has good performance, but in the absence of attention mechanism, the limited computing power cannot be reasonably allocated, which is called the bottleneck of improving its prediction accuracy.
In recent years, transformer-based architectures such as Wav2Vec 2.0 19 and Whisper 20 have significantly advanced end-to-end speech recognition performance, particularly in low-resource and domain-specific tasks. These models leverage self-supervised learning and large-scale pretraining, which are promising directions for future corpus annotation frameworks. Additionally, corpus linguistics research has increasingly emphasized contextual metadata, multi-modal input, and user-generated content for domain corpus enrichment.
Attention mechanism
Attention mechanism aims to allocate the limited computing resources reasonably, which can tilt more resources of neural network to the analysis of difficult samples. The earliest attention mechanism originated from the study of human vision, and was later widely used in various fields of computer. Li et al. 21 strengthened the machine translation algorithm by using the attention mechanism to increase the translation accuracy of English prefabricated parts. Bahdanau et al. 22 designed an end-to-end speech recognition method based on attention mechanism to achieve large vocabulary continuous speech recognition. This method is also combined with RNN. Sivakumar et al. 23 improved sentiment analysis methods using attention mechanisms, which applies a sentence embedding using universal sentence encoder along with an attention layer. Jia et al. 24 combined LSTM and attention mechanism to improve the accuracy of emotion analysis. Attention mechanism is used to enhance context relevance in different positions of sentences. For the construction of business English corpus in a sustainable development environment, some words or sentences that are not obvious in the original corpus 25 and difficult to be recognized by neural network can be more accurate through the attention mechanism module. The improvement of this accuracy is of great significance to the recognition and marking of auxiliary corpora.
Corpus construction
The overall process of building a business English environmental corpus in a sustainable development environment is shown in Figure 1. The overall corpus construction method consists of the following parts. First of all, since there is no relevant public data set, the original corpus needs to be obtained through crawling and manual processing. After obtaining the initial corpus, it is necessary to extract the features of the corpus to generate features that can be recognized and processed by deep learning. The next step is to select some corpus for manual annotation. The corpus to be labeled in this step accounts for one fifth of the whole corpus. The next step is to use the marked corpus to further train the depth learning model that has been pre trained. The final step is to use the trained model to label the remaining corpus and add it to the corpus. Overall flow chart of the construction method of business English environment corpus in sustainable development environment.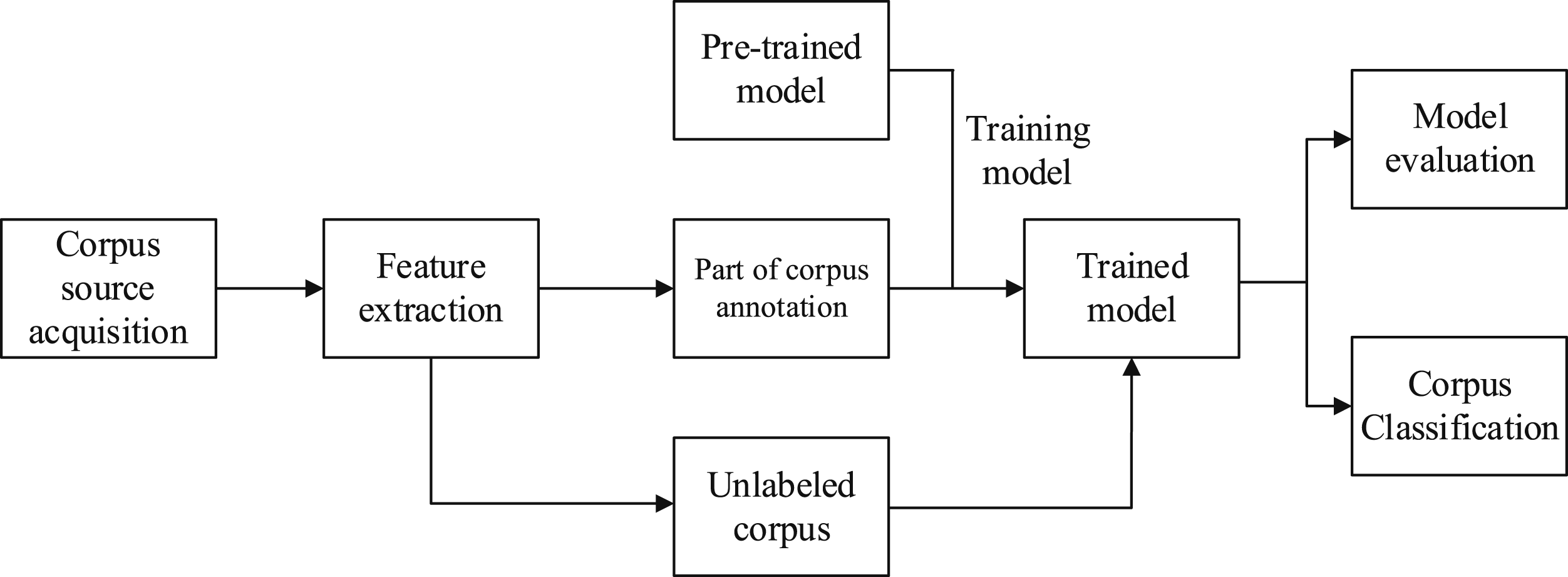
The biggest advantage of the corpus construction method we designed is the assistance of the LSTM combining with the attention mechanism and a new attention expression is proposed. With this help, the most tedious work of corpus tagging will save a lot of labor costs. Using this method, we only need a few annotations to train the model, and then use the trained model to label the rest of the corpus automatically. Only the labels automatically generated by the model need to be checked manually at the end, which is not the same magnitude as the workload of manual labeling. In the next two sections, we will introduce in detail the implementation of each step of the construction method of business English environmental corpus in a sustainable development environment.
Corpus collection and processing
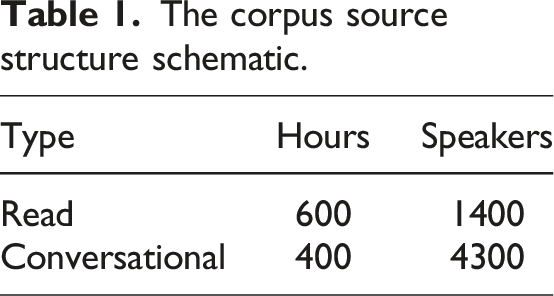
The construction of the environmental corpus of business English interpretation in the context of sustainable development is highly professional and complex. The text contains a large number of professional words, and the content is complex. In view of this fact, and in the absence of a relevant public corpus, the construction of the corpus requires the collection of a large number of original corpus resources. To solve the above problems, this paper uses the web crawler technology to crawl the video available on the network, and extract the audio. We selected some open speech websites and video websites to select videos based on sustainable development and English. After obtaining a large amount of audio data, we manually screen the collected audio and select coherent and clear audio files as the original materials. Finally, 1000 h of relevant audio were obtained through processing, including reading audio and conversation audio. Figure 2 shows the flow chart of language source acquisition. See Table 1 for the details of the original language sources. Original corpus acquisition process. The corpus source structure schematic.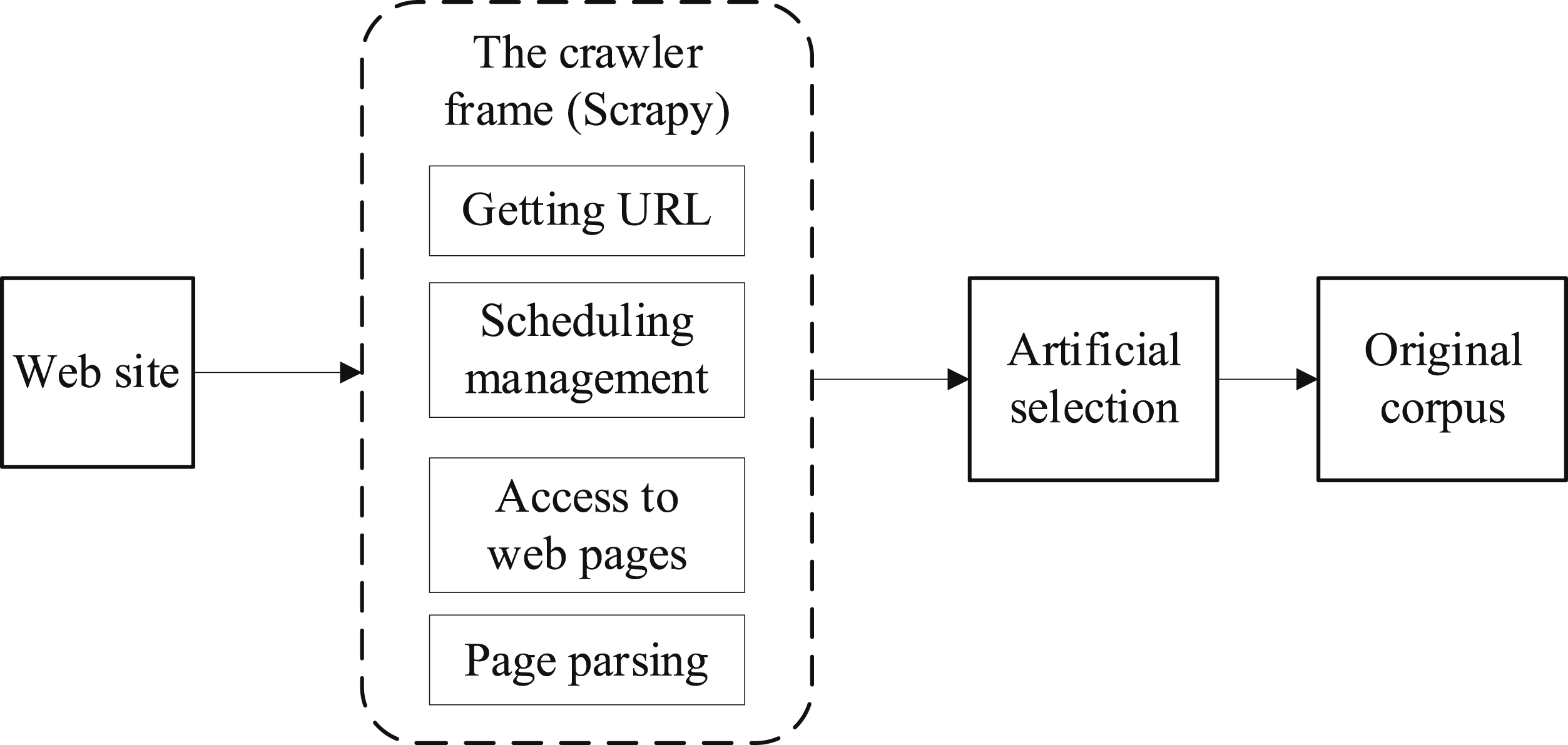
Feature extraction
Sonogram is the data recorded in different colors for the whole audio range. To build an environment prediction database of business English in a sustainable development environment, it is necessary to convert the collected and processed original corpus into spectrograms as the input features of the in-depth learning model. Sound signal is a one-dimensional signal, which can only see time domain information intuitively, but cannot see frequency domain information. Through Fourier transform (FT), it can be transformed to frequency domain but cannot see the time domain relationship. Therefore, the short-time Fourier transform is used to divide a long speech signal into frames, add windows, perform Fourier transform on each frame signal, and then stack the results of each frame signal along another dimension to obtain a sonogram that can be used as a two-dimensional signal. The Fourier transform formula can be expressed as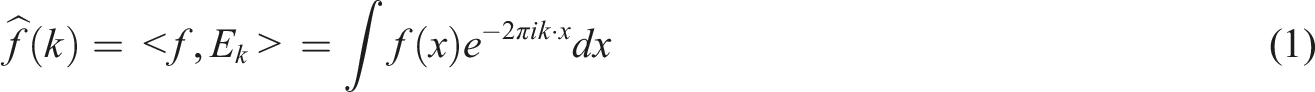
The complete audio feature extraction, that is, the process of converting audio files into spectrograms, is shown in Figure 3. Schematic diagram of audio file transferring spectrogram.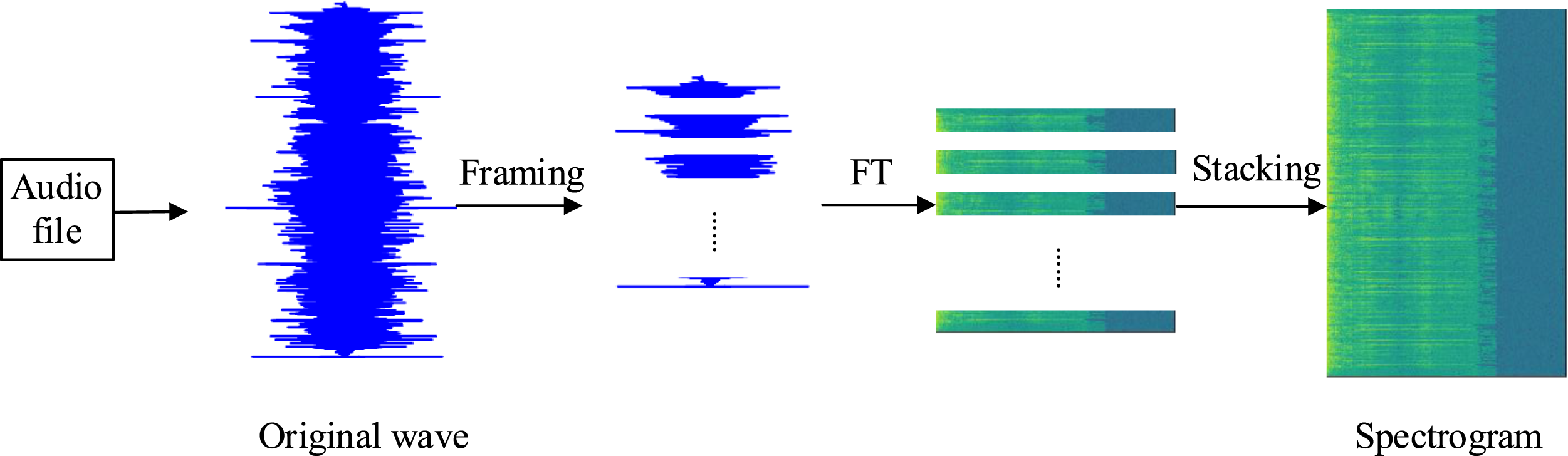
Attention LSTM corpus classification algorithm
In order to improve the accuracy of automatic tagging of business English environmental corpus under the sustainable development environment, we propose LSTM corpus classification algorithm with attention mechanism. The classification algorithm is based on LSTM algorithm, on which the attention mechanism module is added, so that the neural network has the ability to focus on input features. The structure diagram of Attention LSTM is shown in Figure 4. Attention LSTM structure diagram.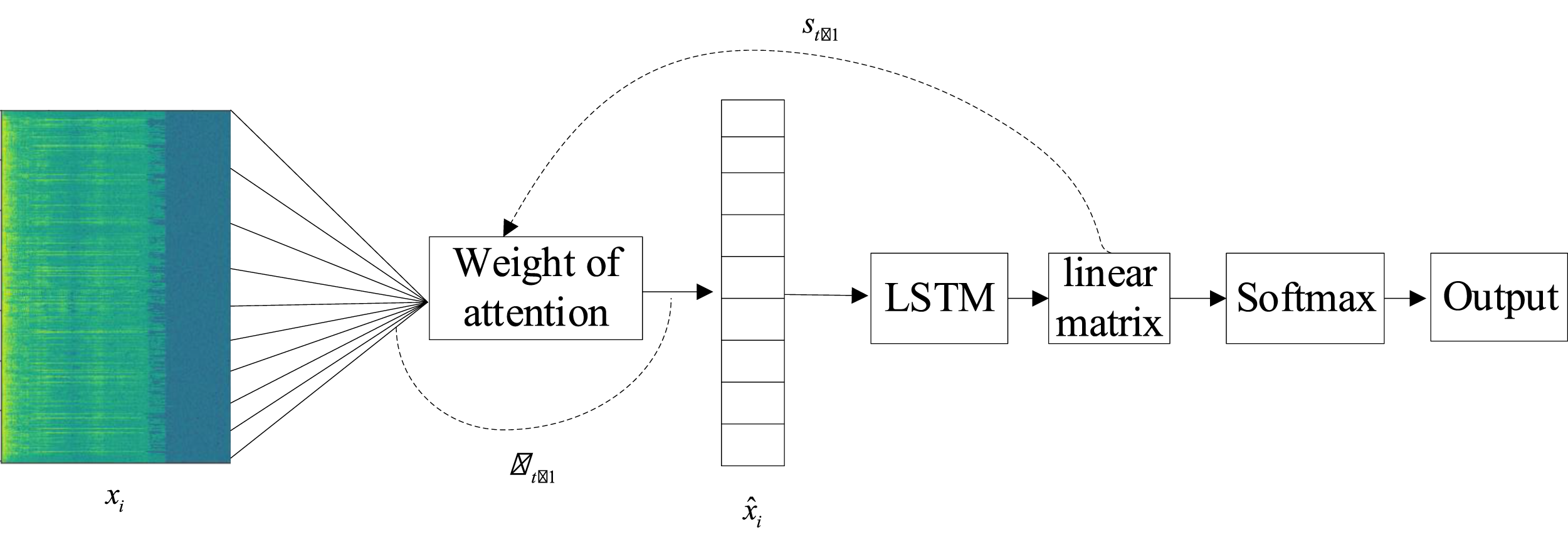
LSTM (Long Short Term Memory) is a neural network with the ability to remember long and short term information. The network introduces a gate mechanism to control the circulation and loss of features, which solves the long-term dependence of RNN. Because most of the original business English corpora we use are long sentences and complex structures, solving the problem of long-term dependency can greatly improve the accuracy of automatic tagging of the corpora.
Unlike general-purpose attention modules, our framework incorporates a term-aware attention weighting scheme, which adjusts the focus of the LSTM decoder based on the estimated domain relevance of incoming tokens. Specifically, attention weights are modulated by a term-likelihood factor derived from a domain-specific keyword embedding layer, allowing the model to more effectively prioritize rare and context-sensitive terminology (e.g., “carbon neutral,” “emission trading”). Furthermore, our mechanism integrates signal quality indicators (e.g., signal-to-noise ratio estimates) into the attention score computation, enhancing robustness for low-fidelity audio samples. This task-specific dual adaptation—semantic sensitivity and signal-aware gating—differentiates our model from standard attention-LSTM architectures.
This paper proposes an attention mechanism for context extended input features. The purpose of this module is to give different attention to frame features from different times. This attention mechanism weights the frame 



Experiment and analysis
Due to the relatively small amount of data related to sustainable development that we have collected, we have used the LSTM model with frozen weights as our skeleton model. After adding the attention structure, we only use a relatively small number of labeled samples to train, and then use the trained model as the final model to participate in the evaluation. All experiments were completed in the following environments: Intel (R) Xeon (R) Bronze 3204 CPU @ 1.90 GHz, 32 GB RAM, GPU Tesla V100, CentOS Linux release 7.6.1810.
Analysis on the accuracy of corpus construction methods

The WER of proposed corpus construction.

This experimental result shows that this deep learning speech annotation assistance method has sufficient accuracy, can assist the annotation of a large number of speech samples, and greatly saves labor costs.
The Attention-LSTM model comprises two layers with 256 hidden units each. We apply a dropout rate of 0.3 to the output of each LSTM layer. The model is trained using the Adam optimizer with an initial learning rate of 1e-3, decayed by 0.9 every 10 epochs. Batch size was set to 32, and training continued for 50 epochs. The attention mechanism uses a dot-product scheme with trainable context vectors. All experiments were implemented in PyTorch 1.12 and executed on an NVIDIA Tesla V100 GPU.
Comparison of attention LSTM method and other existing methods
Comparison of the proposed method with existing methods.
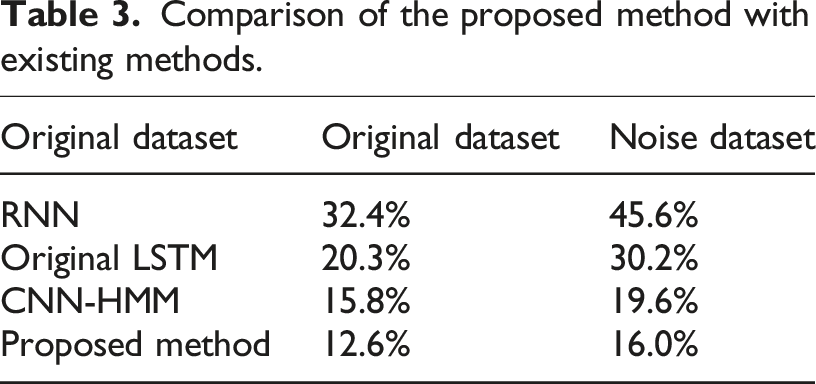
The experimental results show that our attention mechanism module makes the model reduce the WER of 7.7% and 13.8% on two different datasets compared with the original LSTM model. The reason why the error rate in the noisy data set is reduced more is that the attention mechanism has a certain effect on the resource tilt of difficult samples, making the original noisy audio part obtain more computing resources, thus improving the effect of speech recognition under noise. In addition, compared with the CNN-HMM speech recognition method, the error rate of attention LSTM has also decreased significantly, by 3.2% and 3.6%, respectively, in the two data sets. The combination of LSTM and attention mechanism has greatly improved the model, and fully meets the requirements of automatic corpus tagging, which can facilitate the construction of corpus.
Evaluation metrics for semantic fidelity and term annotation.
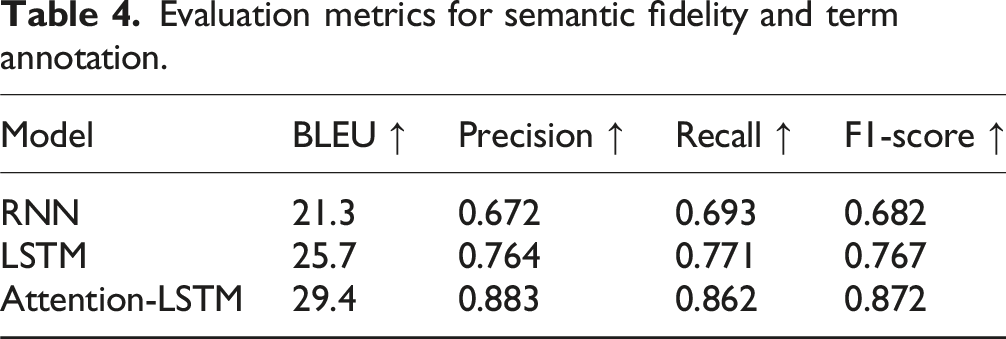
As shown in Table 4, our proposed Attention-LSTM framework outperformed both baseline models across all four evaluation metrics. The BLEU score reached 29.4, indicating stronger preservation of semantic content and phrasal consistency in the automatically transcribed outputs. This is particularly significant in an interpretation context, where preserving meaning is as critical as recognizing words.
In terms of terminology annotation, the proposed model achieved an F1-score of 0.872, compared to 0.767 for base LSTM and 0.682 for RNN. The improvement stems from the attention mechanism’s ability to prioritize domain-relevant terms, which often carry nuanced and low-frequency patterns. Notably, precision was slightly higher than recall, suggesting that the model is more conservative—likely favoring correctness over over-identification.
Result display
In order to prove the effectiveness of our proposed corpus assisted tagging method, we selected some labeled samples to display, which are from the part related to sustainable development in the TED classic speeches. The original audio is represented by an acoustic chart. We give the original English letters and the results of the auxiliary annotation method behind the acoustic chart to compare the effectiveness of the display method. The results are shown in Figure 5. Display the results of automatic annotation methods.
The results demonstrate that the automatic annotation assistant method proposed in this study exhibits high accuracy in recognizing sentence grammar within interpretation tasks related to sustainable development. Furthermore, the method effectively identifies domain-specific terminology commonly used in business English, such as “sustainable,” “energy efficient,” and “Celsius.” These findings confirm the method’s effectiveness and practical applicability in the construction of a business English interpretation corpus.
Conclusion
In the context of sustainable development, the construction of business English environmental corpus is of great significance for the industrial progress and social application of business English. In view of the difficulties of corpus collection and tagging in the construction of corpus, we give a complete method of corpus construction. This includes the use of crawler technology to extract audio and video files with keywords such as sustainable development, environmental protection, low-carbon life, etc. from the Internet, and process the feature forms that can be processed by deep learning. Attention LSTM is proposed to assist the tagging of corpus. Compared with some existing methods, our method has fewer errors in corpus auxiliary marking, which means it has a greater auxiliary role in corpus construction. The experiment proves that our method can save a lot of human resources in the process of corpus construction, and has certain contributions to the corpus construction and business English industry.
While our current framework primarily utilizes audio data and its spectrogram representations for corpus annotation, we recognize that interpretation is inherently a multimodal activity. Video-based corpora, enriched with facial expressions, gestures, and synchronized transcripts, offer crucial non-verbal cues that can enhance semantic disambiguation and pragmatic understanding. In future iterations of our framework, we plan to integrate visual features (e.g., lip movement, speaker posture) and aligned textual transcripts to construct a richer multimodal corpus. This extension aligns with recent trends in interpretation studies and is expected to improve both annotation accuracy and interpretive fidelity.
Footnotes
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
Datasets can be provided upon request.