
Abstract
Qualitative research methods have traditionally been criticised for lacking rigor, and impressionistic and biased results. Subsequently, as qualitative methods have been increasingly used in social work inquiry, efforts to address these criticisms have also increased. Applied thematic analysis provides structure and integrates reflexivity in qualitative research using textual data. In this article, we describe how applied thematic analysis was operationalised in a document analysis of the official records of parliamentary debates in the Australian State of Victoria relating to the introduction of Permanent Care Orders, an alternative to adoption for children residing out-of-home and unable to be safely reunified with their parents. We present this example to extend the knowledge base regarding applied thematic analysis and to demonstrate how step-by-step implementation of a purposeful methodology using trustworthy documentary data can effectively increase rigor and transparency, thereby reducing potential bias, in a qualitative analysis. First, we clarify key terms; then discuss the challenges of analysing textual data; consider the value of parliamentary debates as a textual data source; and provide a detailed description of the processes undertaken in the document analysis. Finally, we reflect on the application of applied thematic analysis in our study, highlighting its value in strengthening qualitative social work research using document analysis.
Keywords
Introduction
As qualitative methods have become increasingly utilised in social work inquiry, social work researchers have directed much effort to addressing criticisms of bias associated with an apparent lack of rigor in their research and the often impressionistic nature of their findings (Daly, 2009). Many researchers (e.g. Barusch et al., 2011; Danto, 2008; Guest et al., 2012) acknowledge that, in practice, bias may occur because of explicit or implicit value assumptions in the conduct of any method of research: Knowledge is not value free, and assumptions underlying any research effort, whether associated with a quantitative or a qualitative method, are laced with values. Some values are more implicit than explicit. (Allen-Meares, 1995: 5)
Among the various strategies recommended for strengthening rigor and minimising potential bias in qualitative social work research, ‘reflexivity’ is often considered crucial. Reflexivity refers to the researcher’s awareness of the influence they are having on what they are studying and, simultaneously, of how the research process is affecting them (Probst and Berenson, 2014). This description incorporates both concept (a state of mind) and practice (a set of actions). Reflexivity has also been described as the researcher’s ongoing reflection on their own engagement with their collection and analysis of data (Fischer, 2009). According to Johnson and Waterfield (2004), the aim of reflexivity is not to demonstrate neutrality and objectivity, but to make explicit the researcher’s contribution to all aspects of the interpretive research process. Reflexive practice thus requires researchers to both be aware of, and to explicitly discuss and document the meanings they associate with, social interactions in their constructions of knowledge throughout the various stages of their research (Gringeri et al., 2013). Reflexivity becomes the process through which researchers establish and communicate the grounds for the rigor and trustworthiness of their studies (Probst and Berenson, 2014).
Social work researchers often utilise qualitative and mixed methods studies to explore the complexities of human experience and to better understand the meanings people ascribe to their experiences. However, as highlighted by Bowen (2009), social research publications often lack sufficient detail about the procedures followed in the research and the ways in which issues of bias are overcome. In other words, social research publications often fail to adequately indicate the level of rigor and reflexivity in the research process. The creative potential of qualitative research nevertheless needs to be matched by systematic research process and rigorous reporting (Neale, 2016).
A range of methodological frameworks have been developed which systematise the research process and integrate reflexivity through the recording of an audit trail for the purposes of enhancing rigor and transparency (including traceability and replicability) in the application of qualitative, and especially interpretive, research methods. Examples of such frameworks include the hybrid approach to thematic analysis used by Fereday and Muir-Cochrane (2006), which incorporates both an inductive data-driven approach and a deductive approach using a template of codes developed a priori from the theoretical framework addressed by the research question; the range of analytic procedures outlined by Gilgun (2015), which build upon each other and clearly demonstrate the relationships between describing, analysing, interpreting and theorising in qualitative research; and applied thematic analysis (ATA), the inductive analysis framework for qualitative research developed by Guest et al. (2012). ATA can involve multiple epistemological, methodological and theoretical approaches, as well as multiple analytic techniques, from a range of disciplines. ATA was designed for use in the analysis of textual data as collected in traditional qualitative research methods, such as interviews and focus groups, but also for use in the analysis of text from existing data sources, such as those used in document analysis. Indeed, in addition to the structure and in-built reflexivity it provides, the flexibility of ATA was a key factor in its selection for the document analysis discussed in this article.
Social work researchers commonly collect textual data for analysis in qualitative and mixed methods studies, but also often use existing documents as a textual data source and report document analysis as part of their research methodologies. Analysis of existing documents is useful because it facilitates historical research which informs understanding of past influences on present policies, legislation, service systems and/or programmes. Existing government documents are a particularly good data source because of the official provenance of such records (Danto, 2008), as well as their generally high-quality contents.
In this article, we aim to extend the knowledge base relating to ATA by detailing how it was operationalised in a document analysis of the official government records of parliamentary debates in the Australian State of Victoria relating to the introduction of Permanent Care Orders, a guardianship-type alternative to adoption for children residing in out-of-home placements and deemed unable to be safely returned to their parents’ care. We present this in-depth example to demonstrate how step-by-step implementation of a purposeful methodology using a highly trustworthy documentary data source can effectively increase rigor and transparency and reduce potential bias in a qualitative analysis. First, we clarify key terms; then discuss the challenges of analysing textual data; consider the value of parliamentary debates as a source of textual data; and provide a detailed description of the processes undertaken in the document analysis. Finally, we reflect on the application of the ATA framework in our study, highlighting the ways in which it strengthens qualitative analysis in social work research.
Documents, document analysis, content analysis and thematic analysis
In practice, document analysis has often been used in combination with other research methods as a means of triangulation, to supplement and corroborate findings across different data sets with a view to reducing the impact of the potential biases in a study (Bowen, 2009; Connell et al., 2001; Danto, 2008). Document analysis has also been used as a stand-alone qualitative research method (Bowen, 2009). Document analysis refers to any systematic procedure for reviewing or evaluating documents; for ‘finding, selecting, appraising (making sense of), and synthesising data contained in documents – both printed and electronic’ (Bowen, 2009: 28). Document analysis involves an iterative process of superficial examination (skimming), thorough examination (reading), and interpretation.
Qualitative types of data can be broadly organised into text or images (Creswell and Plano Clark, 2011), with text by far the most common form of qualitative data analysed in social sciences research (Guest et al., 2012). Following from this, and notwithstanding that documents can originate from a very broad range of sources (Bryman, 2016), here we adopt the definition of ‘document’ used by Bowen (2009: 27): ‘Documents contain text (words) and images that have been recorded without a researcher’s intervention’.
While ‘document analysis’, ‘content analysis’ and ‘thematic analysis’ all deal with textual data, these methods are not interchangeable. Document analysis refers to the overarching method of analysing documents, which may include content analysis and/or thematic analysis. Content analysis refers to the process of organising and quantifying the contents of the data into pre-determined categories relevant to the central research question(s) in a systematic, replicable and objective manner. Content analysis may be exploratory (content-driven) or confirmatory (hypothesis-driven), depending on whether specific codes or analytic categories are determined by the researcher after of before some consideration of the data set. Content analysis techniques include applying word, or ‘keyword in context’, counts to large data sets using computer software designed for this purpose (e.g. NVivo, ATLAS.ti, MAXQDA, Dedoose, etc.).
Thematic analysis refers to identifying and interpreting, or ‘extracting’ (Connolly, 2003; Staller, 2015), patterns of meaning in the data. Thematic analysis moves beyond describing data to interpreting it, and thus requires relatively more involvement, including intellectual contribution, from the researcher (Staller, 2015). Clarke and Braun (2017) describe thematic analysis as a method to identify, analyse and interpret patterns of meaning, or ‘themes’, within qualitative data, which can be applied across a range of theoretical perspectives. They report that their approach to thematic analysis has become the most widely cited of the many different versions available since their original paper on this method was published in 2006. Bryman (2016), however, uses the term cautiously, arguing that thematic analysis is a somewhat ‘diffuse approach’ lacking sufficient agreed principles for defining the core themes in data (p. 697). Both content analysis and thematic analysis can be applied to the textual data of one document or multiple documents.
The challenges of analysing textual data
Analysing documents, like other qualitative research methods, has many positive aspects, but also some significant challenges. Qualitative data tend to be unstructured. However, to be systematic and rigorous in the conduct of their research, the researcher must start by imposing some order on the data (Neale, 2016). Many social workers are attracted to qualitative research methods, perhaps because they view them as a natural extension of the values and skills they employ as social work practitioners (Barusch et al., 2011). But they often find themselves with voluminous sets of data to analyse, and their confidence can rapidly disappear when confronted by such a large, as well as conceptually complex, task (Connolly, 2003).
The ATA framework was developed specifically to assist researchers to be purposeful and systematic in their planning and preparation for text-based qualitative analysis, no matter how large or small the research endeavour: …qualitative data analysis should be a thoughtful enterprise, not an ad hoc process.… many factors need to be considered beforehand to ensure that your analysis is both efficient and meaningful. (Guest et al., 2012: 31)
In relation to the document analysis presented here, the authors considered using content analysis as a stand-alone method but concluded it was too limited for our purpose, given the focus of content analysis is on describing the contents of a data set, not interpreting them. Even though we had identified a theoretical framework from the literature that seemed particularly applicable to our topic, we were not seeking to test a specific hypothesis. We wanted the data in our study to speak for itself and concluded that introducing the theoretical framework early in the document analysis could serve as a potential source of bias in interpreting the themes in the data set. Adopting a data-driven approach, we subsequently developed a research question aimed at identifying the key issues and ideas that informed the political debates associated with the introduction of Permanent Care Orders in Victoria. We also considered using thematic analysis as a stand-alone method in the document analysis but decided against this on the strength of the critique of thematic analysis regarding its relative lack of rigor in the literature. We were keen to focus specifically on rigor given the topical and controversial nature of the subject. Also, as the identification of themes was the primary aim of the document analysis, ATA offered a framework that would provide rigor in interpreting the contents of the documents while also offering flexibility to integrate analytic techniques involving basic quantification, as commonly used in content analysis and quantitative analysis, to help describe the strength of the thematic findings.
The value of parliamentary debates in qualitative research
Government documents in general constitute an invaluable source of textual data for qualitative research because of their official provenance (Danto, 2008), meaning they have high validity and trustworthiness. Specifically, the official records of parliamentary debates have other advantages for social work inquiry, too. Parliamentary debates reflect the nub of contemporaneous discourse in relation to policy making on a wide range of social issues of interest to social workers. Indeed, there are numerous examples of analysis of parliamentary debates in the context of research relating to child and family matters, both in the Australian context (e.g. Harrison et al., 2014) and internationally, for example: in the UK (Kirton, 2016), Canada (Kronick and Rousseau, 2015), Denmark (Wasshede, 2016), Finland (Nygård, 2009), Ireland (Smith, 2016) and Scotland (Tisdall, 2015), including PhD research (e.g. Smith, 1995). The official records of parliamentary debates are also valuable because of their high quality (Bryman, 2016). Pertinent to the study described in this article, Hansard, the official record of debates in the Victorian Parliament, undergoes a rigorous transcription and review process prior to being committed to the public record: Hansard is not a verbatim transcript of what is said in chambers. Rather it is an accurate report of speeches devoid of redundancies, obvious grammatical errors, slips of the tongue and factual errors. (Parliament of Victoria, 2017)
Method
ATA was selected as the methodology for this document analysis for several reasons. Firstly, as an inductive analysis framework, ATA suited the authors’ exploratory (or content/data-driven) approach to the research. Secondly, ATA’s accommodation of the use of single, multiple or no theoretical frameworks in one or more phases of the analysis suited the authors’ preference to analyse the data without reference to any theoretical framework of ideological perspectives in child welfare – at least, not in the early phases of the analysis. Thirdly, ATA’s exclusive focus on text suited the documentary source of data chosen for analysis – a high-validity, high-quality and easily accessed data source, which was viewed as further enhancing the study’s transparency and replicability. Fourthly, it was recognised that ATA could accommodate any number of relevant documents from Hansard deemed to be in scope because it can be applied to any sized data set. Finally, ATA’s synthesis of a range of epistemological and methodological approaches to research – including positivism, interpretivism, phenomenology, applied research and grounded theory (Guest et al., 2012) – meant it could accommodate multiple analytic techniques, both in the coding and subsequent stages of analysis; and the option to use additional analytic techniques later in the analysis to supplement those initially planned, as deemed appropriate to do so.
Figure 1 summarises the operationalisation of ATA in the document analysis, the various phases of which are now each discussed below.
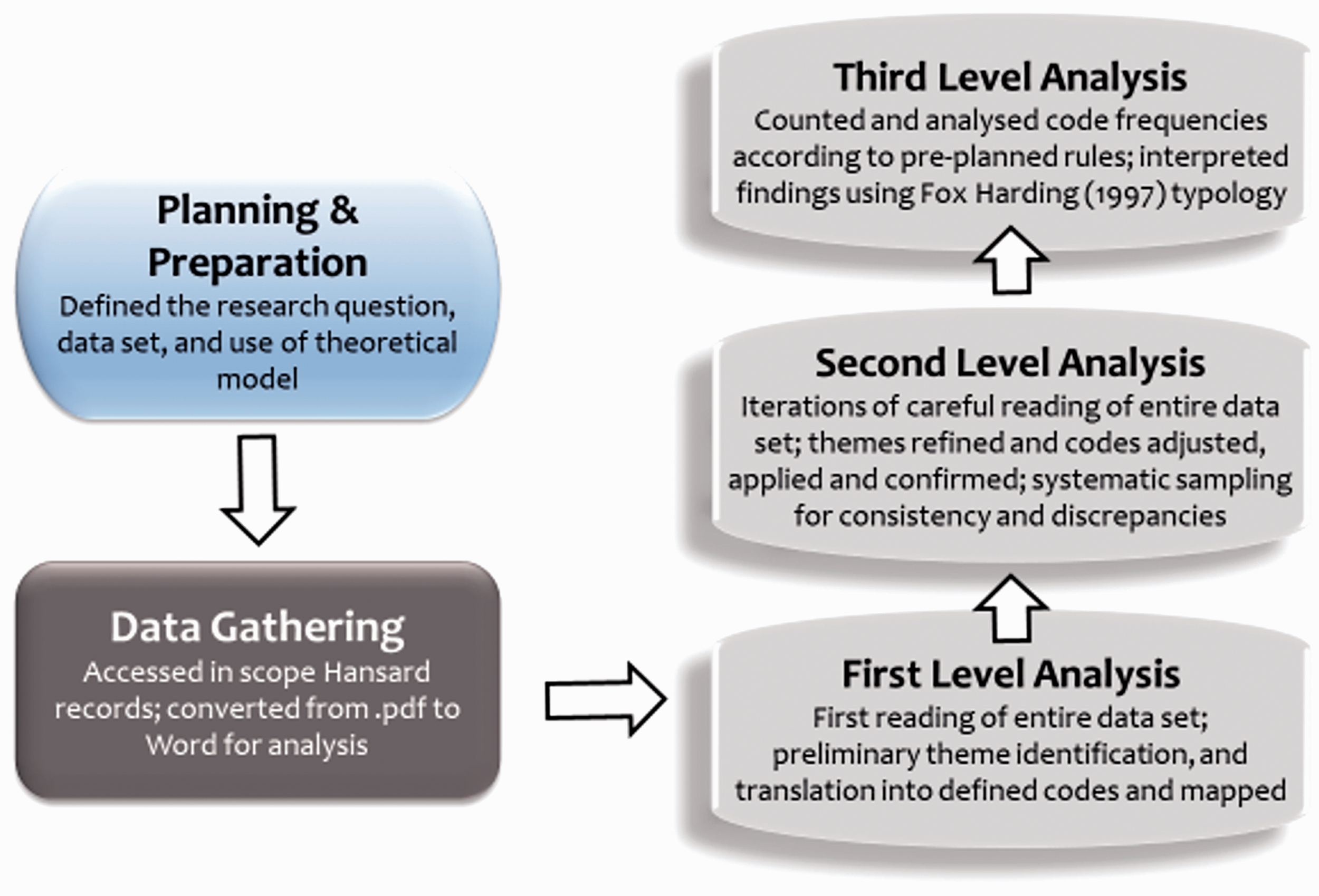
The operationalisation of ATA in a document analysis of Victorian Parliamentary debates (adapted from Mackieson et al., 2018).
Planning and preparation
The first phase in the operationalisation of ATA in the document analysis involved planning and preparation. This included the crucial task of defining the specific research question or questions that the document analysis was to address. As discussed earlier, this necessarily involved an iterative process of refining the research question to ensure a good fit with the characteristics and quantity of the source data, and selection of suitable analytic methods. This process was therefore undertaken in conjunction with a preliminary scan of Hansard to identify child welfare bills introduced to the Victorian Parliament that were associated with the introduction of Permanent Care Orders. Technically, the Hansard scan could have been performed via the Internet, thus entirely offsite. A decision was made, however, to conduct this scan onsite, enabling oversight by the Victorian Parliamentary Library’s Research and Inquiries Coordinator. In total, eight bills were identified as being in scope in relation to the finalised research question, which was: What were the key issues and ideas that informed the 1984–1989 political debates associated with the introduction of Permanent Care Orders in Victoria?
In this planning and preparation phase, numerous other decisions regarding how the document analysis would be conducted were made, including which theoretical model or models, if any, would be used; how it/they would be used; and at what stage or stages of the analysis. From the literature review, several theoretical frameworks were identified that could potentially have been used to inform the research and one, in particular, seemed especially pertinent. In line with our concern to minimise potential bias, however, we decided not to introduce theoretical concepts in the early phases of the research. Rather, we wanted the data to speak for itself, with the analysis of the data to inform the choice of theoretical framework.
Each decision made, and the rationale for it, was recorded in a single planning document, the ‘Research Plan & Codebook’ (Codebook). 1 The Codebook was a critical tool in the execution of this research, the content headings for which are provided in Figure 2. The Codebook captured the key elements and step-by-step process of the research. It clearly articulated the purpose and objective of the document analysis; the data (Hansard records) deemed to be in scope; the definitions of the terms used in the methodology (e.g. data, theme, code, coding); the rules to be used in applying the codes to the data set, including what/how much text was to be coded; the rules to be used for counting the frequencies of occurrence of the codes applied; how intra-coding reliability would be established; the data reduction techniques to be applied to the data set; the quantification and analysis techniques to be used for the results; and the expected outputs from the document analysis. Later in the research process, the code definitions and code map were also added to the Codebook.

The contents of the Codebook.
While it is often difficult to replicate qualitative research, the development of the Codebook enables an outside reader to both review the conduct of the research and to replicate it.
Data gathering
The second phase of the document analysis involved gathering the data deemed to be in scope and converting it to a usable format for coding purposes. As publicly available information, the Hansard records identified in the first phase of the research were accessed electronically via the Victorian Parliament’s website. The data set comprised 33 records from the upper and lower houses of the Victorian Parliament, totalling 412 pages in .pdf format. Copies of these records were then converted to Word format. Each Word document was systematically checked to ensure that the conversion had correctly translated all text and formatting and to make any necessary corrections before proceeding to the first-level analysis.
First-level analysis
The next phase of the research focused on thorough reading and preliminary interpretation of the contents of the entire data set. This involved a word-by-word analysis, identifying/extracting preliminary themes and transforming them into appropriate codes, as well as beginning development of a code map depicting how the codes linked to each other.
Each code definition included a code name (up to 12 characters); a code level, indicating the code’s relative position on the code map; a short definition of the code (up to 80 characters); a full definition of the code (up to 10 sentences); guidance regarding when to use the code; one or more direct quotes from the data exemplifying when to use the code; and guidance regarding when not to use the code. A sample code definition developed for a primary, or high level, theme is provided in Table 1. The relevant section for each code (or group of sub-codes) was assigned a different colour, highlighted accordingly in the Codebook.
Sample code definition for a primary, or high-level, theme.

As work on interpreting the themes and developing corresponding codes progressed, the decisions already made and recorded in the Codebook were frequently reviewed to assess congruity, following which they were either confirmed or amended. This process also informed the refinement of the schedule for the sequencing of subsequent steps in the research.
Second-level analysis
The second level of analysis entailed multiple iterations of the coding development, coding, systematic sampling, checking (including close analysis of any discrepancies) and code refinement cycle that was planned in the previous phase to codify relevant sub-themes. A sample code definition developed for a sub-theme is provided in Table 2.
Sample code definition for a sub-theme.

In all, 29 codes were established: 27 thematic codes and 2 non-thematic codes (‘Not-Relevant’ and ‘Maybe’), which were used as data reduction techniques to filter out text segments interpreted as not contributing to the thematic content of a debate (for example, an administrative detail specific to the parliamentary process, an interjection or a personal criticism of another parliamentarian).
Application of the codes involved highlighting the corresponding text segment in the colour assigned to that code in the Codebook, and inserting the code name in bold upper-case text at the end of the respective colour-highlighted text segment. This provided two visual cues, thus enabling ready verification of the code assigned to the text segment (i.e. when checking whether the code’s colour and name were congruent) and efficient application of Word’s search functionality (i.e. searching by code name) for later use. The amount of text to which codes were applied was not uniform – a coded text segment variously included a whole sentence, part of a sentence, a paragraph, a page or multiple pages, as applicable.
Each of the three final iterations of the coding cycle involved, firstly, applying the most relevant code to every sentence of the text in a ‘clean’ (i.e. not previously coded) copy of the full data set. No less than two days after completion of such a full coding pass, a systematically selected sample from the entire data set (different each time) was independently re-coded on clean copies of the selected pages. Any discrepancies in the coding between the full pass and the systematically sampled pass were then closely examined, as were any data segments coded ‘MAYBE’. The final process of each coding cycle (except for the final one) involved refining the codes, code definitions and/or coding rules, as necessary.
The researchers referred constantly to the Codebook throughout this phase, and made amendments to that document right up until commencement of the final iteration of the coding cycle – aside from adding the start and completion dates for each process undertaken to maintain the audit trail.
Third-level analysis
The research phase involving the third level of analysis comprised two parts: the first involved applying the pre-planned counting rules to the occurrences of codes applied to the data set and interpreting the results; and the second involved analysis of those results that would lead to the identification of an appropriate theoretical framework.
In this case, the occurrence of an assigned code was counted only once in a parliamentarian’s contribution(s) to the debate on a bill, whether it occurred once or multiple times. This use of relative, rather than absolute, code frequencies was intended to avoid over-representation of themes and sub-themes that were repeated in the numerous contributions made by some parliamentarians, particularly the house spokesperson for each political party, compared with other parliamentarians who contributed only once to a given bill debate or, indeed, to only one bill debate. The strength of each theme was measured by simply summing and converting to percentage the number of parliamentarians whose contributions to the debates included the corresponding code, as applied in the final coding cycle. The results were presented in several bar charts depicting the respective themes, sub-themes and arguments interpreted (i.e. identified and coded) from the parliamentarians’ contributions. The textual data were then combed (i.e. Word-searched and re-read) for a comprehensive range of quotes indicative of each theme, sub-theme or argument. The quotes were collated in an Excel file, to enable ready extraction of relevant evidence when preparing the outputs of the document analysis.
The highest level themes identified from the data were: the rhetoric of rights; the ‘hierarchy of family’ debate; child protection is everybody’s business; and the politics of influence. Several models were considered, but the four-fold classification of ideological perspectives in Western child welfare developed by Fox Harding (1997) was deemed to provide the most useful way of exploring these themes. Fox Harding’s typology comprises the following four perspectives: laissez faire, which advocates a minimalist view of the state’s role in child welfare, with intervention only in extreme cases; state paternalism and child protection, which advocates extensive, including coercive, state intervention; defence of the birth family and parents’ rights, which advocates an extensive state role, preferably via supportive interventions enabling children to remain in/or be returned to their parents’ care; and children’s rights and child liberation, which accords the child/young person a key role in defining their own welfare. The findings were analysed and synthesised by the researchers in the context of Fox Harding’s typology, and are reported elsewhere (Mackieson et al., 2018).
Reflections on the operationalisation of the ATA framework
The operationalisation of ATA in this document analysis of parliamentary debates increased rigor and reduced potential bias in several ways. It provided a clear and comprehensive structure for planning and conducting the research encouraging the practice of reflexivity throughout the study. It also incorporated a clear audit trail, which provides a level of transparency that enables replicability of the work. ATA expects the researcher to record the research process in detail, which means that it is available to other researchers who might wish to replicate the study or check the study’s findings in more detail.
Document analysis is a repetitive process, the iterative nature of which has been somewhat simplified in the linear representation of this study in Figure 1. However, from a practical perspective, the ATA framework was useful because it provided a thorough, yet flexible, structure that enabled segmentation of the data set, and facilitated conceptualisation of the analytic phases and scheduling of the associated research processes in a realistic manner that enabled close adherence in practice.
Following the ATA framework, planning and preparation underpinned the smooth execution of this document analysis. ATA prompted decision-making but did not prescribe the outcomes of those decisions. The emphasis on documenting the decisions and the reasons for having made them facilitated development of a clear and congruous plan from the beginning. A valuable framework for qualitative research in and of itself, ATA also enabled an early career researcher to learn the discipline of a highly structured research design that interrogates bias at each step of the research process.
Every research method has limitations, as well as strengths, and ATA is no exception. Perhaps the most obvious area on which to question ATA, particularly as a method for interpretive research, is its effectiveness in ensuring trustworthy analysis of the qualitative data. In other words, how well did ATA ensure an accurate interpretation of the subjects’ voices in the parliamentary debates? ATA deals with this challenge by systematising the research process and enabling the use of a range of analytic devices – including basic quantitative techniques – to structure and quantify the data, and so supplement the traditional narrative techniques (e.g. presenting relevant quotes). At its simplest, this means that the greater the consistency between the findings from the interpretive and quantitative analyses, the greater the trustworthiness of the findings – therefore, the more grounded are the findings in the source data.
Still, without going to the trouble of replicating the study, the questions remain: how can the reader readily validate the trustworthiness of the findings? How can the quality of the intellectual processes involved in the generation of the findings be validated? The answers are at least partially available in the research plan and Codebook developed and maintained throughout the study. The nature of the research decisions recorded (for example, the more text that is coded, the more comprehensive and reliable the results are likely to be, and in this study all the text was coded), and the richness of the definitions and descriptions of the codes developed to encapsulate the themes identified (including the example quotations from the source documents), provide prima facie evidence of the degree of accuracy of the themes and concepts translated from the data. While perhaps not as explicit as also using, for example, iterative categorisation (IC) – a systematic technique specifically designed for managing the analysis of textual data (Neale, 2016), the codebook is both a vital tool in conducting a study using ATA, and an easily accessed piece of evidence for verifying the trustworthiness of the study.
Conclusion
There is no escaping that document analysis can be a laborious qualitative research method – especially where a data set may comprise hundreds, or even thousands, of pages. However, parliamentary debates are publicly available usable data that can be drawn upon efficiently in studies without going through lengthy ethical processes. Furthermore, data sources such as Hansard are particularly useful as they are of high relevance in terms of the social policy issues that social work researchers are interested in investigating. The added bonus is that their provenance ensures both high validity and high quality. ATA is therefore a valuable methodology for social work researchers of all levels of experience wishing to undertake document analyses. ATA contributes to the conduct of strong qualitative research by providing a comprehensive, yet flexible, structure which incorporates reflexivity, thereby reducing potential bias; increasing rigor, transparency and replicability; and strengthening the processes through which researchers gain theoretical insights. Overall, ATA provides a solid baseline for understanding and communicating how textual data can be analysed effectively, a baseline enhanced by use of the official records of parliamentary debates as the data source.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This study was supported by an Australian Government Research Training Program Scholarship.