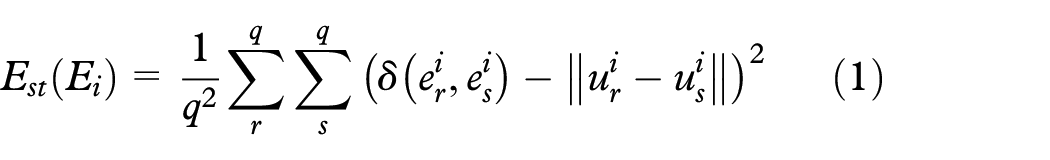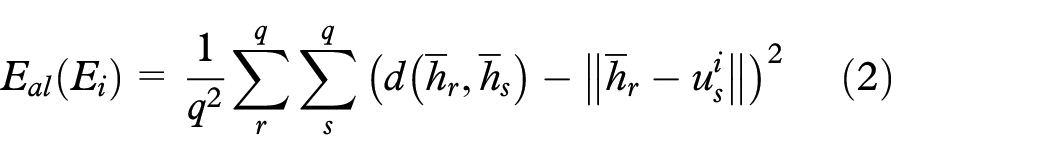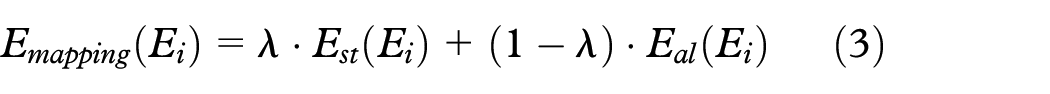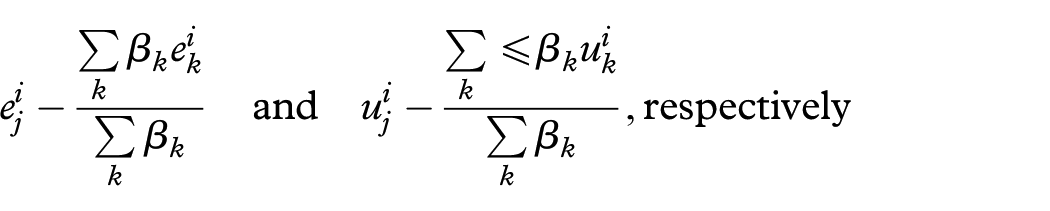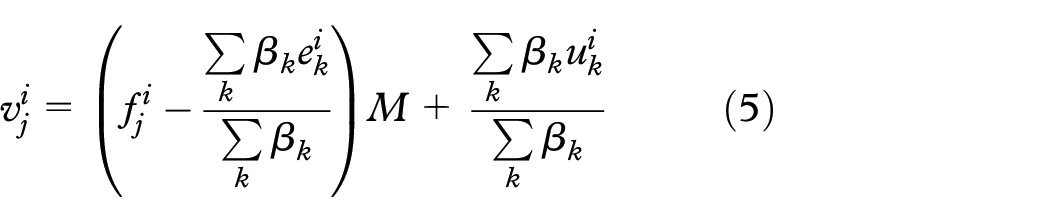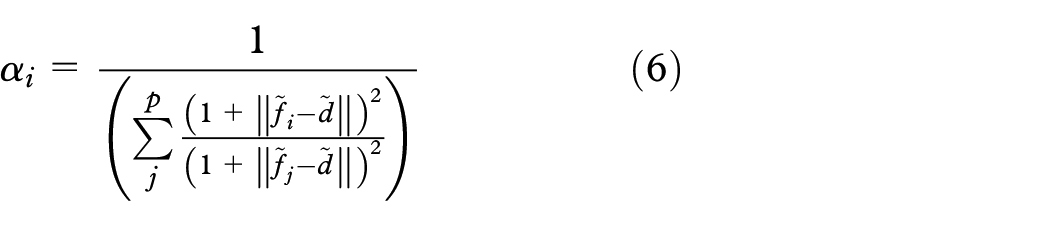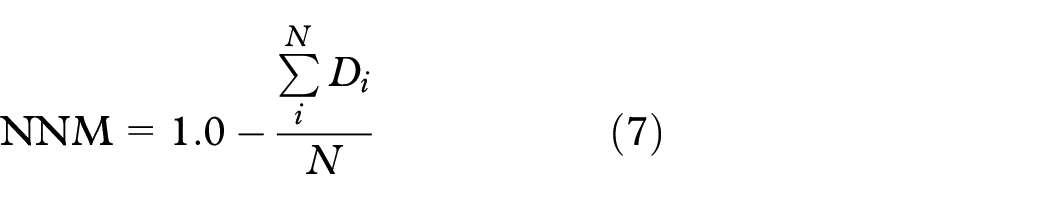The concept of involving users in the loop of analytic workflows refers to the ability to replace heuristics with user input in machine learning and data mining tasks. For supervised tasks, user engagement generally occurs via the manipulation of training data. But for unsupervised tasks, user involvement is limited to changes in the algorithm parametrization or the input data representation, also known as features. Typically, different types of features can be extracted from raw data, and the careful selection of the extraction strategy allows users to have more control over unsupervised tasks. Nevertheless, since there is no perfect feature extractor, the combination of multiple sets of features has been explored through a process called feature fusion. Feature fusion can be readily performed when the machine learning or data mining algorithms have a cost function, such as accuracy for classification tasks. However, when such a function does not exist, user support needs to be provided, otherwise the process is impractical. In this article, we present a novel feature fusion approach that employs data samples and visualization to allow users to not only effortlessly control the combination of different feature sets but also understand the attained results. The effectiveness of our approach is confirmed by a comprehensive set of qualitative and quantitative experiments, opening up different possibilities for user-guided analytical scenarios. The ability of our approach to provide real-time feedback for feature fusion is exploited in the context of unsupervised clustering techniques, where users can perform an exploratory process to discover the best combination of features that reflects their individual perceptions about similarity.
Machine learning and data mining techniques are, in general, split into supervised and unsupervised approaches or a combination of both. In supervised approaches, user knowledge can be input into the analytical process through sets of processed data instances. In unsupervised, knowledge can be added by changing algorithm parameters or the data representation, also known as features. For unsupervised methods, therefore, the challenge is not only to define the most appropriate set of parameters but also to find the data representation that best expresses user knowledge or expectation.
Depending on the application domain (e.g. text or image), there exist several approaches to constructing features, each providing complementary information about the original or raw data. Since there is no perfect feature, the idea of joining different representations is straightforward. This process is called data or feature fusion,1 and it can occur through combining the features’ vector representation or merging distances calculated from them. When the machine learning or data mining task involves a cost function, for instance, classification accuracy, it can be used to guide the combination. However, for tasks, like clustering2,3 or multidimensional projection,4,5 where such a function does not exist, support needs to be provided to allow users to build proper combinations. Otherwise, in practice, data fusion is impossible or useless given the abundance of possible combinations.
In this article, we present a novel feature fusion approach that allows users to control and understand the fusion of different feature sets. Starting with a small sample, users employ a simple widget to define the weights for the combination and observe in real-time the outcome through a scatterplot-based visualization. Once users find the weighted combination that best matches their point of view of similarity, the same weights can be used to combine the complete data set. In this way, we not only allow users to test different combinations easily but also enable the interpretation of the attained results.
In summary, the main contributions of this article are the following:
A novel feature fusion technique that allows users to explore and understand different combinations of features in real-time;
An approach to input user knowledge via controlling similarity relationships in unsupervised tasks with much more flexibility than parameter tweaking;
An interactive visualization-assisted tool for the clustering of image collections which allows for real-time tuning of the similarity among images to match user expectations.
Related work
The process of integrating information from multiple sources to produce a unified enhanced data model is called data fusion.1 The goal is to combine different data representations into a single model aimed at incorporating properties from various sources. Data fusion can occur in different ways, including combining features, that is, the vectorial data representation, or merging distances calculated from the various sources.
The concept of merging features is called feature fusion. Feature fusion aims to generate a unified vectorial data representation based on different sets of features (vectorial representations).6,7 The most straightforward approach is feature concatenation.8,9 In concatenation, given the sets of features , the unified representation is given by . Despite its simplicity, the literature reports several examples. In Wang et al.,10 Local Binary Pattern (LBP)11 and Histograms of Oriented Gradients (HOGs)12 features are concatenated to improve performance in pedestrian detection. In Manshor et al.,13 Scale Invariant Transform Features (SIFT)14 and boundary-based shape15 features are concatenated to improve object recognition. In Chu et al.,16 high, low, and medium layer features of a deep neural network are united to support object detection, and in Chun et al.,17 color and texture features are progressively concatenated to reduce model complexity in a content-based retrieval framework. Feature concatenation has also been used in the text domain. In Loni et al.,18 the authors extract seven types of lexical, syntactical, and semantic features and combine subsets of them to improve text classification.
Weights can be used in the concatenation process to control the influence of the different features. In this process, the unified representation is given by ,6 where are the weights. In Loni et al.,19 a weighted concatenation was used to improve text classification by combining lexical, syntactic, and semantic features. In Ma et al.,20 a neural network was used to learn the weights of a concatenation, combining different image features, such as color, shape, and texture, to improve classification accuracy. In You and Tang,21 the authors use a saliency detection model to fuse color and texture features through a weighting strategy. First color and texture features are transformed into saliency features, which are then combined linearly. Different from the previous weighted techniques, features are combined instead of concatenated, that is, the unified representation is given by . Such combination is possible since the saliency representations have the same dimensionality.
In practice, the feature concatenation is not recommended since it may result in high-dimensional feature vectors leading to the curse of dimensionality problem.6 One solution is to apply a dimensionality reduction after the concatenation,22 or to perform a distance fusion. In the distance fusion, instead of combining the vectorial representations, the distances calculated from the representations are combined. If represents the distance matrix calculated from , the resulting distance matrix is given by . In Degani et al.,23 a simple normalized combination of distances computed from different types of features is used to cover song identification. The distance fusion can also be performed using weights. In Huang et al.,24 weights are used to combine distances calculated from color and texture features to improve the results of a content-based image retrieval system. In Vadivel et al.,25 distances calculated from color and texture features are also combined to support content-based image retrieval applications. Finally, in Liu et al.26 and in Chu et al.,16 distances calculated from features extracted from different layers of a deep neural network are combined to improve retrieval tasks.
Different from data fusion, model fusion combines computational models instead of data. Such combination can be performed in two different ways: by combining different models (parametrizations) processing a single feature set (data set), or by combining different models processing different feature sets.27 The former is called ensemble learning and has been extensively used in classification tasks. The idea is to combine the predictions from different models using a voting strategy to improve model diversity and classification accuracy.28,29 Ensembles of classifiers typically outperform single classifiers30 and have been used in different domains, including remote sensing, computer security, financial risk assessment, fraud detection, recommender systems, medical computer-aided diagnosis, and others.27,31 Similarly, the later also employs a (weighted) voting strategy to combine different models, but in this case, the models use different sets of features as input. Examples of applications include fruit classification9 and sentiment analysis.32
Common to all these data and model fusion approaches is that combinations can only be performed when a loss function is available to guide the process, like in classification. If such a function does not exist, or there is a degree of subjectivity in the process, the combination without proper user support hampers its applicability in practice or real scenarios, and none of the mentioned approaches offer such support. In this article, we devise an approach to aid the process of feature combination to allow users to control the process to match individual expectations, enabling applications where user judgment is crucial.
Proposed methodology
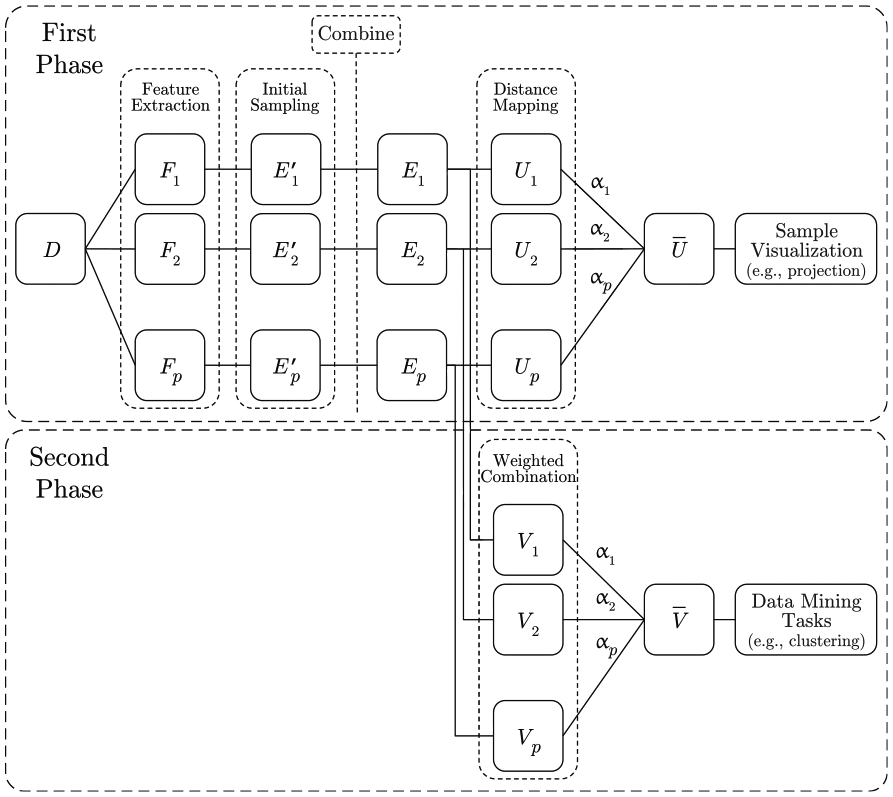
Our feature fusion approach employs a two-phase strategy to support users to define combinations that reflect a particular point-of-view regarding similarity. Considering an original or raw data set with elements (e.g. an image collection), and the different sets of feature vectors extracted from . In the first phase of our approach, initial sample sets are selected from each different set of feature vectors, and the indexes of these vectors are merged to compose a single list of indexes containing all elements captured by the different samplings. After that, new sample sets are built containing the different types of feature vectors. They represent the same elements given by this common list of indexes so that all sample sets have the same number of elements , that is, . Each sample is then mapped to a vectorial representation preserving as much as possible the distance relationships, and these representations are combined to generate a single representation , which is then visualized.
The user can then change the feature weights and observe the resulting combination in real-time. Once the sample visualization reflects the user expectations, that is, once proper feature weights are found, the second phase takes place, and these weights are used to combine the complete set of features . In this process, the mapped sample representations and the samples are used to construct models to transform each set of feature to a vectorial representation . Since these vectorial representations are embedded in the same space, they can be combined using the weights , obtaining the final vectorial representation that seeks to match the user expectations defined by the sample visualization. Figure 1 outlines our approach showing the involved steps. Next, we detail these steps, starting with the sampling and the distance preservation mapping.
Overview of our feature fusion process. Initially, a sample is extracted, combined, and visualized. Based on this, the user can test different weights to fuse the features and observe the outcome. Once a sample combination that reflects the user expectation is found, the same weights are used to combine the complete sets of features that can then be used on subsequent data mining tasks, such as clustering.
Sampling and mapping
The first step of our process is sampling. Since users employ the sample visualization to guide the feature fusion process, it is essential to have all possible data patterns from the different features represented. Therefore, we recover samples from each different set of features so as to represent the distribution of each set faithfully.
In this process, we extract samples from each set independently using a cluster-based strategy. We employ the k-means algorithm to create clusters, getting the medoid of each cluster as a sample, where is the number of instances in the raw data set . We set the number of clusters to since this is considered a useful heuristic for the upper-bound number of clusters in a data set.33 As explained, after extracting the sample sets , we merge their indexes to define a unified set of indexes, and create the sets having feature vectors with the indexes contained in the unified set of indexes. This is an essential and mandatory step since the sample visualization is constructed based on the combination of all features, and this combination is only possible to compute if the samples contain vectors representing the same data elements. Also, this increases the chance of representing the different patterns contained in the different sets of features. Notice that the combined sample features will have at most instances, enhancing the probability of having samples that represent the distribution and patterns of each set of features while not hampering the computational complexity of the overall process since .
After recovering the samples, we map them to a common -dimensional space, obtaining their vectorial representation so that we can combine them to obtain (for the sample visualization). In this process, each set of samples is mapped to preserving as much as possible the distance relationships. We do this by minimizing
where and are feature vectors in , is the distance between them, and and are the vectorial representations in the -dimensional space of and , respectively.
Besides preserving distance relationships, our mapping process aims to align the vectorial representations so that is placed as close as possible to without affecting the distance preservation of the individual mappings. This is necessary since the unified sample representation is calculated as a convex combination of these representations, that is, , with , and misalignments could result in meaningless unified representations. First, we calculate the average distance matrix by combining the distance matrices of all set of samples, where is the distance matrix calculated from . Then we map to the -dimensional space using equation (1) but replacing by obtaining . The idea is to use this average vectorial representation as a guide to align the vectorial representations minimizing
where is the distance between two instances of the average vectorial representation.
Joining equations (1) and (2) renders the function we optimize in our mapping process seeking to preserve, as much as possible, the distance relationships of the sample set of features in the vectorial representations while aligning them. This function is given by
where is used to control the importance of the distance preservation and the alignment to the produced vectorial representations. is a hyperparameter and can be changed to define a good trade-off between distance preservation and alignment.
To minimize equation (3), we use a stochastic gradient descent approach with a polynomial decay learning rate. We set the initial learning rate to , the decay power to , and the number of iterations , following common choices found in the literature.34 Algorithm 1 outlines our mapping process. Function randomly draws discrete values in the range , and function initializes the mapping coordinates, also randomly. We tested a deterministic initialization using Fastmap,35 but the gain in quality does not justify the computational overhead. Also, the first time the function is called, is not provided. In this case, is not computed and only is considered to calculate the mapping coordinates.
Notice that we normalize all features before this process, so that the Euclidean norm . Given the triangular inequality property , this guarantees a upper limit for the maximum pairwise distance between features. Therefore, the distances are in the same range despite the type of feature or its dimensionality, avoiding biasing the process toward the type of feature with the largest maximum distance. In addition, we define the dimensionality of the resulting mappings as the largest intrinsic dimensionality of , calculated using the maximum likelihood estimation.36 Such dimensionality can also be defined by the user if the target dimensionality is known, such as for visualization purposes.
Algorithm 1 Algorithm for mapping different feature sets to a common vectorial space.
▹ compute the average distance matrix map▹ into fordo MAP end for functionMAP INIT() ▹ initialize the mapping fordo ▹ learning rate RAND▹ draw random values fordo fordo end for end for end for return end function
Weighted feature combination
Given the sample vectorial representations , we build a set of functions using the process defined in Joia et al.37 to map each feature set into its vectorial representation preserving as much as possible the distance relationships while obeying the geometry defined in . In this process, each instance is mapped to the -dimensional space through an orthogonal local affine transformation , where is the dimensionality of .
The affine transformation associated with is defined so as to minimize
where , with the original feature representation of the kth sample in .
Equation (4) can be re-written in the matrix form , where denotes the Frobenius norm, is a diagonal matrix with entries , and and are matrices with the jth row given by the vectors
Based on that, is computed as , where and are obtained from the singular value decomposition of . Then, the vectorial representation of is given by
Equation (4) is subject to , which avoids scale and shearing effects, therefore, preserving the distance relationships of the input features. Also, notice that the sample vectorial representations dictate the geometry of the embeddings . Since they are aligned by the mapping process defined in the previous section, the linear combination can be performed to obtain the final embedding . That incorporates the patterns defined by each set of features, weighted according to the user’s point-of-view. For more information about this affine transformation and how the sample vectorial representation controls the final results, please refer to Joia et al.37
Feature combination widget
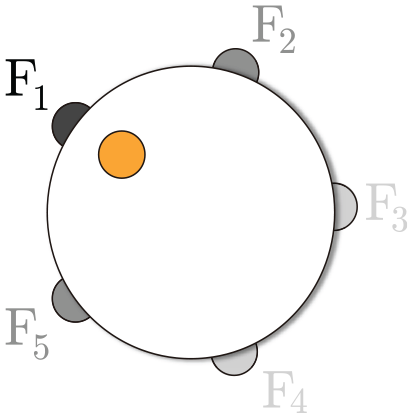
To support the feature sample combination, we create a widget inspired by the strategy presented in Pagliosa et al.38 The idea is to position anchors (circles) representing each different set of features on a circumference, computing the weights according to their distances to a “dial,” which can be freely manipulated by the user, contained in the circumference. If are the coordinates of the anchor representing the feature and the coordinates of the “dial,” the weight related to is calculated as
Initially, the anchors are equally spaced on the circumference following a random order. However, users can freely move them to produce the desired combinations. Also, to help the perception of the weights, we set the transparency level of the anchors and fonts according to . Figure 2 shows the combination widget. In this example, the “dial” in orange is closer to the anchor representing the feature , so the corresponding anchor is more opaque than the others.
Feature combination widget. Using the orange “dial,” users can control the contributions of the different types of features for the final feature combination.
In addition to this design, we have explored another option using multiple sliders, one per feature. Although sliders are commonly used in applications that involve setting multiple parameters, it proved to not be the best choice in our combination scenario. Given that changes in one slider affect the others (it is a convex combination), every user interaction requires adjusting several sliders at once. In our design, users need to manipulate only one dial (and optionally the anchors), providing a much faster exploratory process.
Results and evaluation
In this section, we evaluate our mapping and feature combination processes using different data sets in order to show that the sample manipulation effectively controls the complete feature fusion. Next, we describe the employed data sets, detail how we extract features, and present our quantitative and qualitative evaluation.
Data sets
We use five data sets in our tests, named STL-10,39 Animals,40 Zappos,41 CIFAR-10,42 and Photographers.43 These data sets come from a variety of different domains. The STL-10 consists of images split into classes of different objects. Similarly, CIFAR-10 contains images from commonly seen object categories (e.g. animals, vehicles, and so on) in lower resolution. The Animals data set is more specific and it is composed of images of animals in categories. Zappos is a data set for shoes with images from Zappos.com split into shoe categories. Finally, the Photographers consists of photos taken by well-known photographers. Table 1 summarizes the data sets, showing the number of instances and classes.
Data sets employed in the evaluations: size and number of classes.
Name
Size
Classes
STL-10
13,000
10
Animals
30,475
50
Zappos
50,025
4
CIFAR-10
60,000
10
Photographer
181,948
41
Features
We use four distinct methods to extract features, representing low-level and high-level image components. Low-level means that the dimensions of the feature vector have no inherent meaning, but represent a basic understanding of the image such as edges or color. High-level features have semantic meaning. For example, they denote the presence of an object or not in the image.
For the low-level features, we represent (1) color using LAB color histogram, (2) texture using Gabor filters44 with orientations and scales, and (3) shape using HoG technique12 with a window size of . For the high-level, we extract deep features from the pool5 layer using a pre-trained CNN CaffeNet.45 This network was trained on approximately images to classify images into 1000 object categories.
We believe that these features are discriminative for our data sets. For example, we can differentiate a leopard from a panda using a texture extractor. Texture can identify spots on a leopard, as well as differentiate them from other animals. Similarly, color features can be helpful to recognize pandas, where the more common colors are black and white. Also, HOG is helpful to differentiate the type of animals by their shape, for example, quadrupeds from birds. Finally, object recognition can complement the HOG descriptor. These examples can be generalized to other data sets as well.
Quantitative evaluation
To confirm the quality of our approach, we quantitatively evaluate our mapping and feature combination processes. For the mapping process evaluation, the five data sets of Table 1 are randomly sampled times, reducing them to of their original sizes. We sample the data since we cannot execute the mapping process on large data sets given its memory footprint of . Due to the random initialization (see Algorithm 1), we repeat the mapping process test times. Moreover, to ensure a common dimensional space, we calculate the intrinsic dimensionality of each set of features and choose the smallest value. This value is used to do the mapping. The minimum values of intrinsic dimensionality are , , , , and for STL-10, Animals, Zappos, CIFAR-10, and Photographer data sets, respectively.
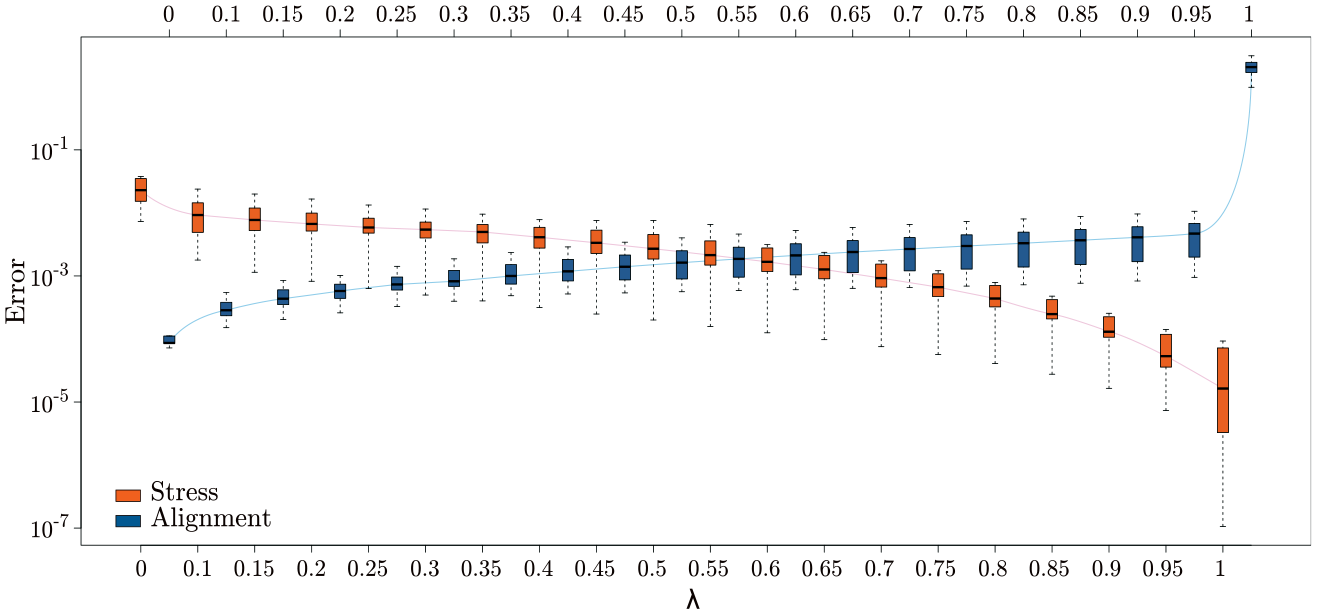
We use stress and alignment error to evaluate the mapping process (see equations (1) and (2), respectively). We summarize our results in Figure 3 varying the value of in the range . The stress boxplots (in orange) decrease as increases whereas the alignment boxplots (in blue) have the opposite behavior. This is the expected outcome since larger values of preserve the distance relationships, and smaller values align the data.
Comparing distance preservation versus alignment error with varying . The best trade-off is achieved in the range . The blue and orange lines connect the average values of the boxplots.
Setting preserves as much as possible the original distance relationships. This is reflected by the average stress , but it does not ensure any alignment . On the contrary, delivered almost a perfect alignment , but it does not enforce the distance preservation . In this article, we are interested in the best trade-off between distance preservation and alignment so that the alignment is obtained without penalizing the overall distance preservation. According to our experiments, we achieved this in the range , where both stress and alignment errors are nearly 0 for our experiments (see Figure 3).
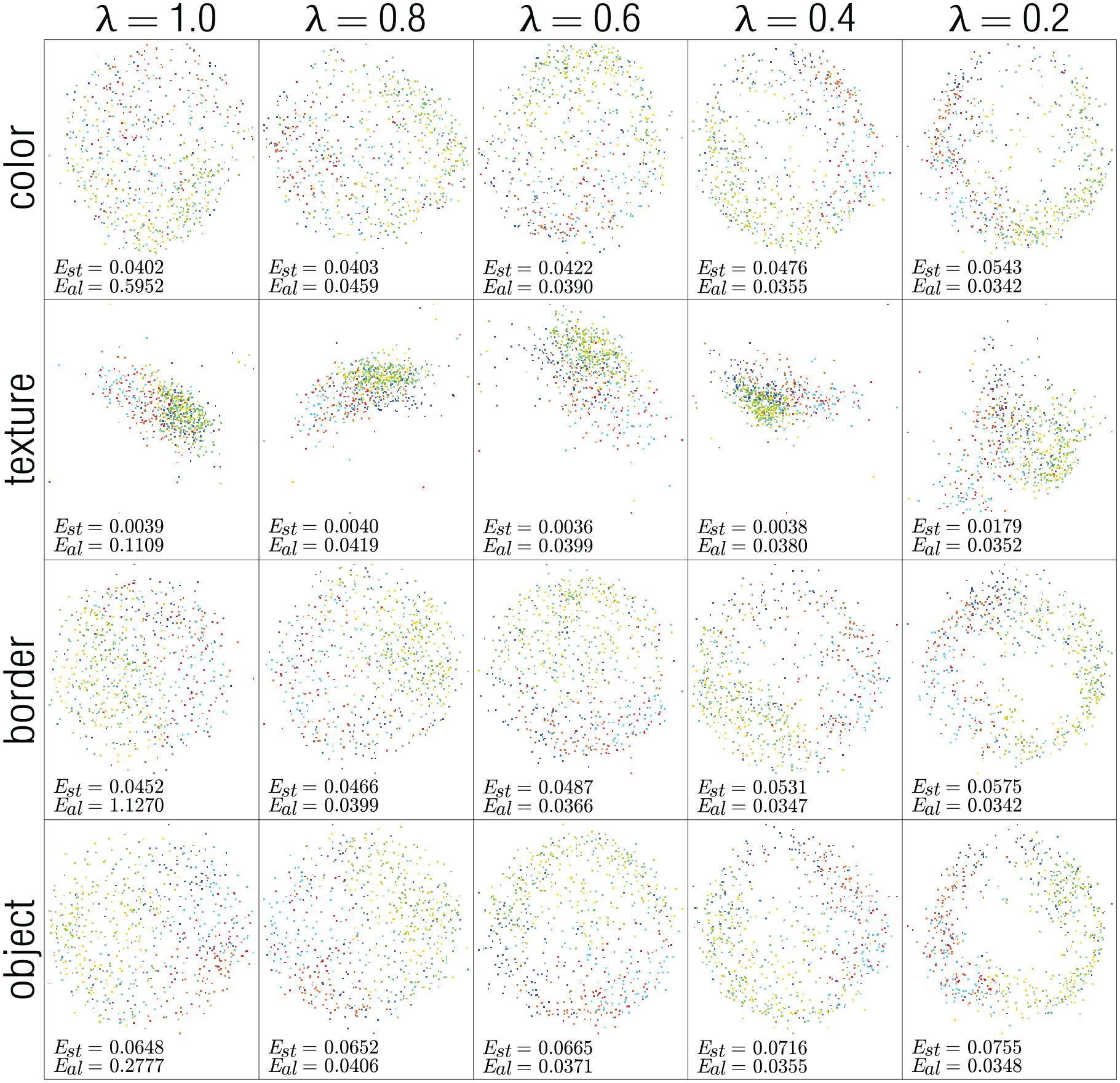
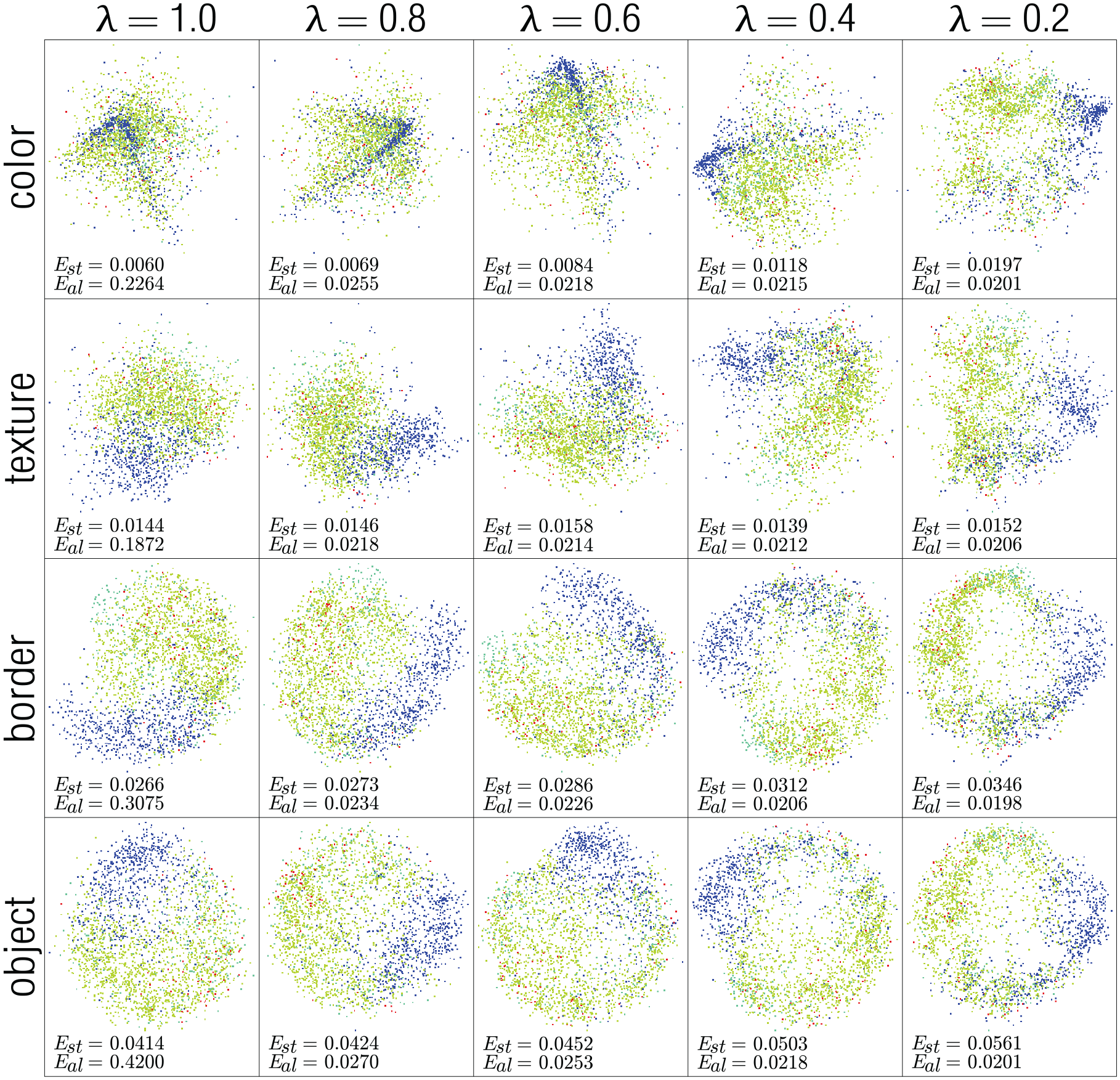
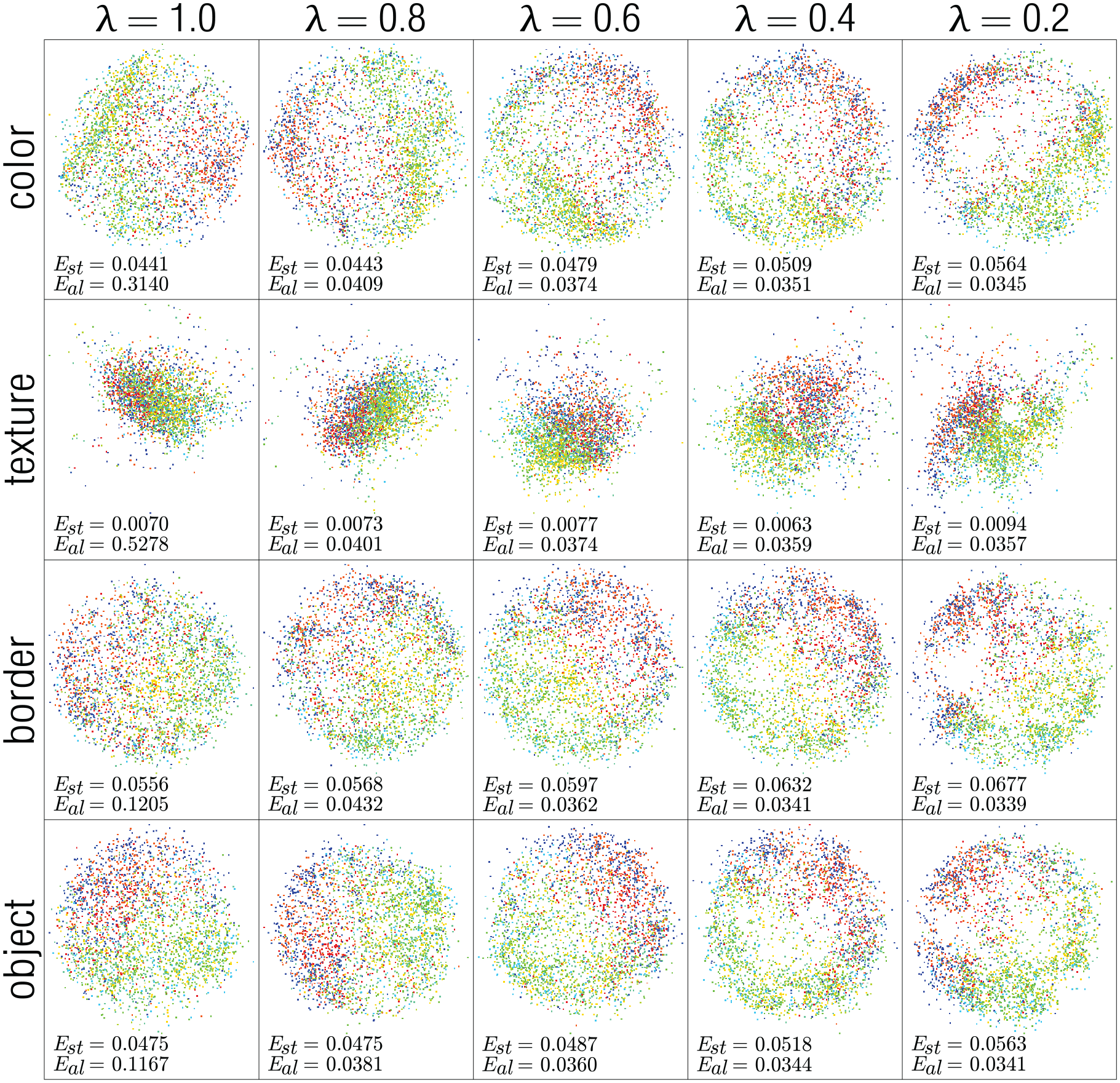
For visual inspection, we map the samples setting the target dimensionality to two. We show the results for the STL-10, Zappos, and CIFAR-10 data sets in Figures 4–6, respectively. In these figures, the points are colored according to image class. The stress and alignment error values are shown at the bottom-left corner of each projection. To show the influence of values in the mapping process, we vary in the range . Notice that in the first column of all figures, the visual representations of each feature (color, texture, border, and object) are misaligned among themselves. That is, points belonging to the same class are placed in different regions on the different projections. For instance, in the first column of Figure 4, the points colored in green are positioned at the bottom in the projection of the color features, on the right in the projection of texture features, and on the left in the projections of the border and object features. The second column depicts results with . The projections start to align, and points belonging to the same class are placed in similar regions across the different projections. We observe a small increase in the stress error, but the alignment error decreases considerably compared with the first column (see the measure at the bottom-left corner). The same behavior is observed in the remaining columns. As expected, as lambda decreases, the alignment improves (alignment error decreases), and the distance preservation decreases (stress error increases). However, the stress changes are minimal, showing that our approach is capable of aligning different feature spaces while preserving the distance relationships in them.
Resulting 2D mapping process for the STL-10 data set. As decreases, the features get more aligned (see last column). Bottom-left numbers correspond to stress and alignment error.
Resulting 2D mapping process for the Zappos data set. As decreases, the features get more aligned (see last column). Bottom-left numbers correspond to stress and alignment error.
Resulting 2D mapping process for the CIFAR data set. As decreases, the features get more aligned (see last column). Bottom-left numbers correspond to stress and alignment error.
For the feature combination, we assess the degree that the distance relationships of the sample are preserved in the feature fusion of the whole data set, intending to demonstrate the effectiveness of the user sample manipulation on the produced data set. In this evaluation, we first randomly generate different weight combinations summing up to and apply them to the sample data. Then, we reuse these weights for the whole data fusion and measure if the distance relationships induced by the weights on the sample are preserved in the whole data set. We use the Nearest Neighbor Measure (NNM)46 to evaluate the degree of preservation.
The NNM quantifies the distance preservation using the similarity of each instance in the whole data with its nearest neighbor in the sampled data. The NNM is given by equation (7), where is the smallest distance among the instance in the complete data set and the instances in the sample, and denotes the number of instances. In the original article, the authors normalized each dimension of the data to the range . However, this results in the loss of the magnitude of the dimensions, hampering our feature weighting process. Therefore, we change the normalization per dimension by a unit vector normalization per instance to avoid such an effect. The output of NNM is within the interval with larger values indicating better results
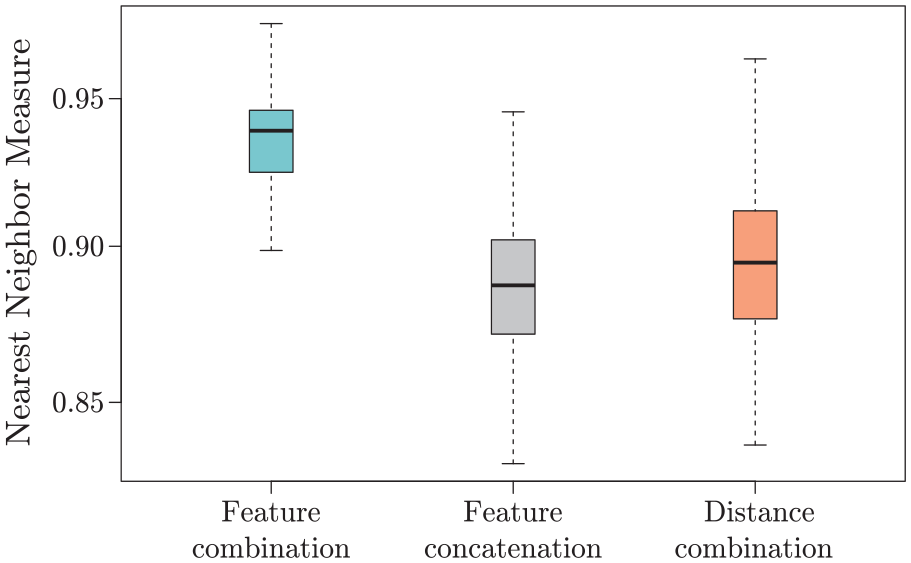
We compare the NNM values of our feature fusion with two baselines: feature concatenation and distance fusion (see section “Related Work”). Boxplots in Figure 7 show that our approach outperforms the other two baselines by at least . The mean value of our method is , and the baselines achieved are and , respectively. Hence, our method preserves more accurately the data patterns presented in the sample and its distribution in the whole data set fusion.
The NNM evaluation. We compare our approach of user-guided feature fusion (light green box), with two baselines: feature concatenation, and feature distance combination. Our feature fusion strategy surpasses current state-of-the-art strategies, indicating that the similarity patterns observed in the sample data combination are preserved in the complete data set fusion.
Qualitative evaluation
Besides the quantitative evaluation, we also present an example based on projections for qualitative evaluation. The reasoning is to project the complete combined data set , showing that the patterns observed in the sample projection are preserved on the complete projection. In this example, we use our approach to explore large photo collections considering different user perspectives about similarity among images. We use the photographers data set. In addition to the features described in subsection “Features”, we create a new set of features to describe each photographer. We use Wikipedia articles about each photographer and construct a bag-of-words vector to represent them. Photos of the same photographer share the same feature vector, and the similarity among photos is defined as the similarity between texts describing the photographers.
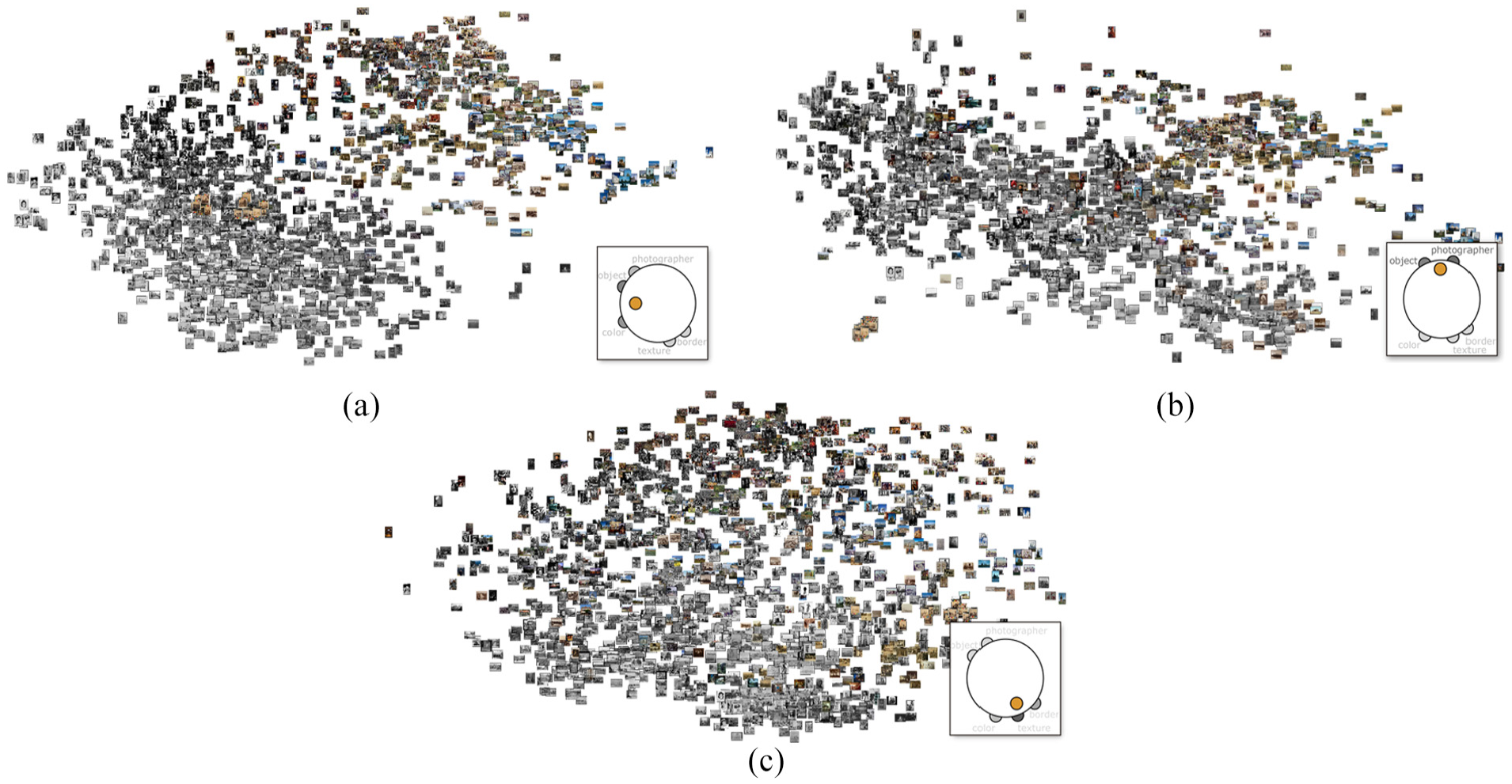
As explained before, based on a sample and using our approach, users can combine different features by employing the combination widget (see Figure 2) until the sample visualization reflects a particular understanding regarding the similarity among photos. Figure 8 shows three different combinations. The first (Figure 8(a)) provides more importance to color and the objects contained in the photos, with little importance given to information about photographers. The second (Figure 8(b)) is defined using the idea of photographic style from43 fusing objects and Wikipedia features. Finally, the third (Figure 8(c)) shows the result of combining texture, borders and a small amount of color.
User-defined similarity configurations. Based on a small sample, users can interactively combine different features seeking for the combination that best approaches a particular point of view. This combination is then propagated to the entire data set for a complete projection. The widget at the bottom-right helps to control such combination and indicates the importance of each feature. (a) The combination provides more importance to color and the objects contained in the photos. (b) It gives more importance to the objects and the information about the photographers and (c) It provides more importance to texture, border, and color features.
Once a feature combination has been defined that reflects the users’ point of view, a projection representing the complete photo collection is constructed. Figure 9 shows the produced layout using the weights established in Figure 8(a). In this figure, since the color is an important feature, we observe a clear separation between black-and-white and colorful images. Also, given the weight assigned to the feature representing objects, it is possible to notice a separation among photos of people, landscapes, and houses in certain regions of the figure. We zoom in on two small portions of the projection (at the top and at the right side) to show this effect. On the colored images (right), we observe images with sky and forest. On the gray images (top), we observe houses, sky, and forest.
Photographers data set projection using the weight combination of Figure 8 (a). Since a larger weight is assigned to the color feature, a clear global separation between black-and-white and colorful photos can be observed. This configuration also considers the presence of objects and photographer information.
Figure 10 depicts the final projection using the weights defined in Figure 8(b). In this figure, we zoom in on a region at the bottom-left, and here, we mainly find portrait images. Remember that in this weight combination, our goal was to represent the photographic style. The selected photos are from two well-known photographers, Van Vechten and Curtis, who mostly work with portraits, presenting similar styles.43 These examples qualitatively attest that the similarity patterns observed on the sample projection are preserved in the complete projection, corroborating the quantitative results measured using the NNM index.
Photographers data set projection using the weight combination of Figure 8 (b). A larger weight is assigned to the object and photographers features. Photos with similar visual features are grouped. The zoom-in region (bottom-left) shows photos of well-known photographers that share similar styles (portrait photos).
Application: user-guided clustering
One of the most appealing application scenarios for our approach is to assist non-supervised data mining strategies, such as clustering techniques. Clustering techniques seek to split sets of data instances into groups so that instances belonging to the same group are more similar to each other than to those in other groups. Typically, clustering is a subjective task that depends on the way the similarity is computed, which could vary from user to user, and the ability to explicitly control and understand similarity is the benefit our approach offers.
Following, we present an example of using our approach to control clustering results of a sample from the photographers data set containing 7800 instances. In this example, we define different weights for features and observe how this influences the composed groups. In Figure 11, we analyze the transition between color and Wikipedia features. Color starts with weight and decreases to weight as Wikipedia weight increases from to . We generate new fused features in each intermediate state. In each combination state, we compute clusters using the mean shift algorithm.47 We opt to use this algorithm because we do not need to provide the number of clusters as input, so the produced results directly reflect the provided similarity (or combination of features).
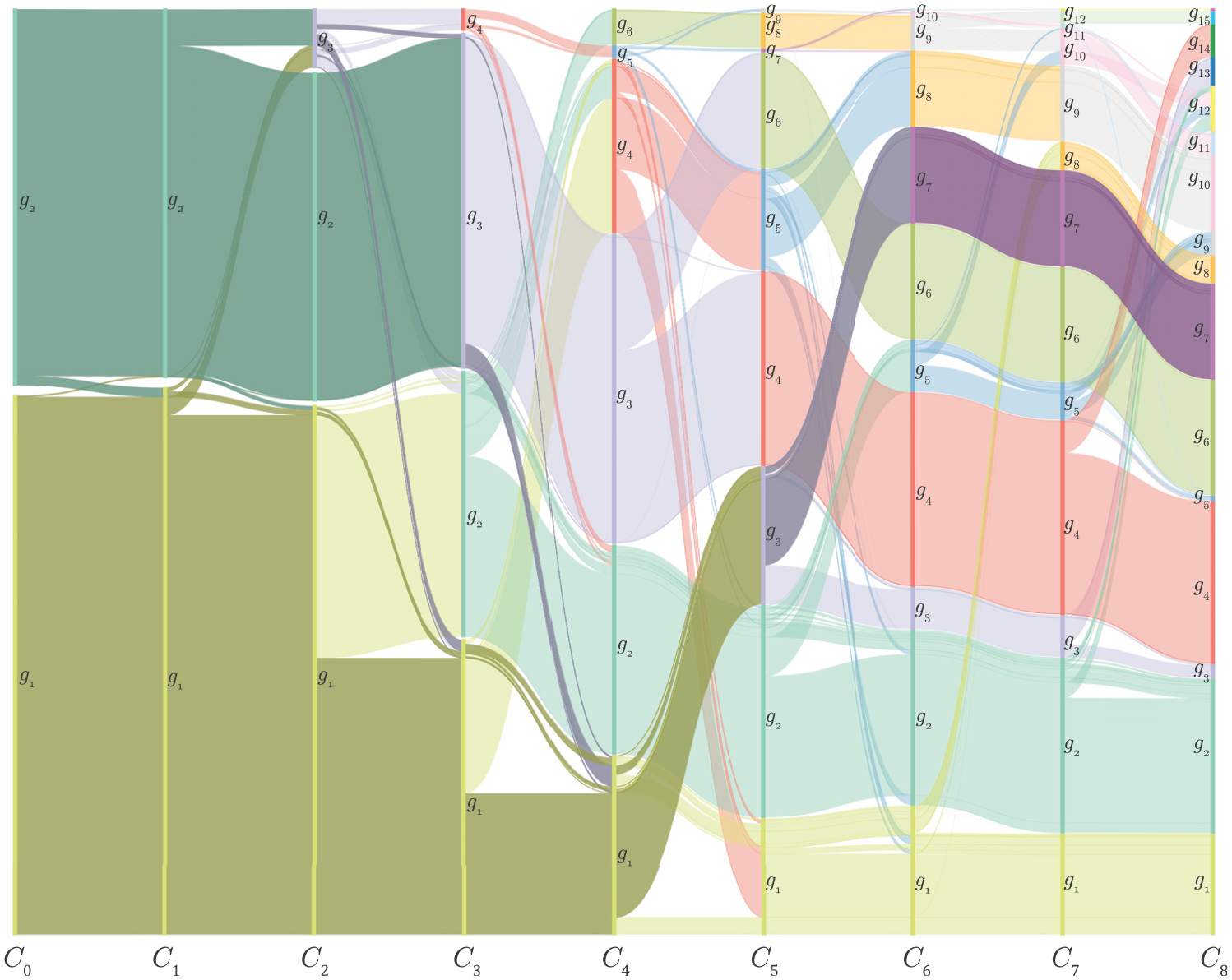
Using parallel sets to visualize cluster formation. The parallel sets visualization shows nine clusterings results computed using the means shift algorithm. Axes and represent the clustering results for color and Wikipedia features, respectively. Intermediate clusterings denote combinations of these features.
We display the different clustering configurations (for each combination) using the parallel sets.48 In the parallel sets, the vertical axes represent different clusterings , where indicates a different weight combination of features. All axes contain a set of groups where different colors represent different groups. Curves between axis and are colored using the colors of the groups in . This coloring scheme improves the perception of membership changes between different clusterings results. To reduce cluttering, we implement a simple filtering strategy to remove non-relevant curves. For each group in , we evaluate how many instances from this group are redistributed in the groups in . If the quantity is less than a percentage threshold, the curves representing these instances are removed. This threshold is a user parameter and can be adjusted accordingly.
Figure 11 shows parallel sets with axes representing clusterings results with a filtering threshold equal to 0.1. axis represents the results for the color feature only (no Wikipedia feature is considered). It has two groups, one presenting colorful photos and the other black-and-white photos. shows fused features with weight to color and weight to Wikipedia. Most of the two groups presented in remain in , but some instances change their membership.
From , more groups are composed, and the colorful and black-and-white photo division is lost. Finally, represents the clustering for the Wikipedia feature only (no color feature). Note that from clusterings to , the groups are more stable, that is, most of the items in a particular group tend to be assigned to the same group as increases. In order to analyze the semantic meaning of the groups, we select the purple group from , and we check its correspondent instances backward. Photos of that group were taken by Brumfield, Gottscho, and Horydczak, which are three iconic American photographers. We map the data from to the visual space using the force-scheme technique.49Figure 12(d) shows the result where each photo border is colored with its group color. As can be observed, photos are similar in content and appearance, as the work of their photographers is focused on architectural photography. We also observe that there is a mixture of colorful and black-and-white photos in this group. However, clustering shows a clear separation between these two types of photos (Figure 12(a)). Looking at the sequence of curves from clustering to , it is possible to analyze the group and see when photos of this group are merged backward. We highlighted the path in the parallel set with darker colors for easy navigation. From to , the groups are stable. Instances of these groups are also projected and depicted in Figure 12(d) and (c). In , is formed with instances from and groups. Corresponding instances from are mapped in Figure 12(b). Note that in , colorful and black-and-white photos are mixed.
Projections produced by the force-scheme technique for the purple group of instances in . The color of the border indicates the group the photo belongs to. The purple group instances are selected from , , and and mapped in (a), (b), and (c), respectively. The projection of the purple group in is shown in (d). In (a), two groups are visible. In (b), these groups are less separate. Both in (c) and (d), there is only one group according to the clustering technique. However, in (d) there is a small group inside this group that distinguishes three photographers with similar styles.
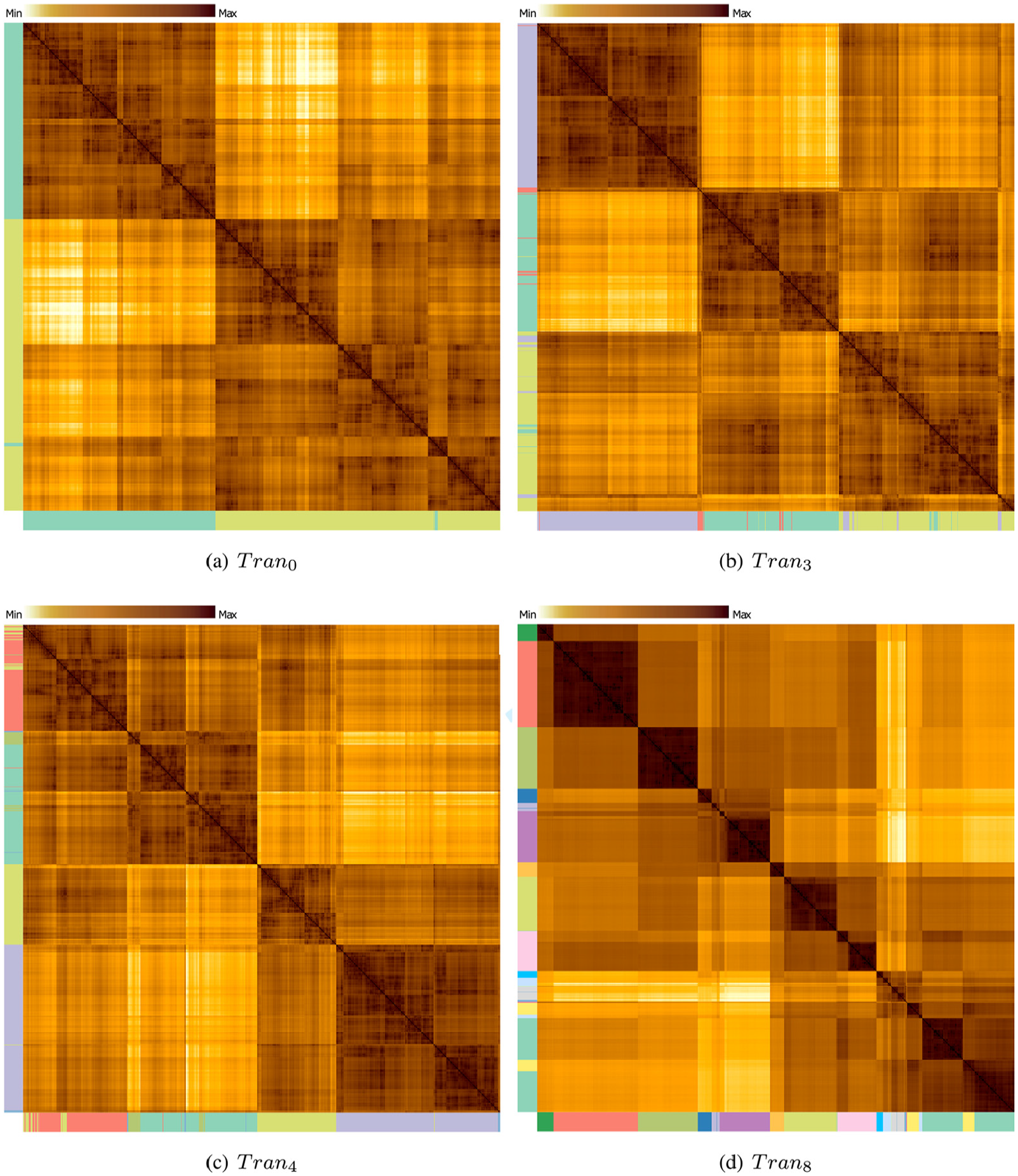
Parallel sets are useful tools to show the difference between clustering results. However, they do not show the similarity relationships between instances. In order to explore clusters and the relationships between instances, we also visualize the pairwise dissimilarity matrix produced from a given feature combination as a heatmap. In our representation, similar items are rendered in brown colors, whereas dissimilar ones are rendered in pale orange colors. The order (rows and columns) of our representation is obtained using the position of the leaves in a dendrogram generated by average linkage hierarchical clustering.50–52
Figure 13 shows dissimilarity matrices using the same weight combinations that generate , , , and on parallel sets. In Figure 13(a), we can spot two groups (two dominant brown areas on the main diagonal). The colored margins indicate the groups of the instances given by the clustering algorithm. In Figure 13(b), the two major groups remain, but sub-groups can be noticed inside the larger ones. Figure 13(c) also shows two significant brown areas on the diagonal. However, these groups have the same size. In the previous matrices, one group is bigger than the other because the color feature has more weight and the data set has more black-and-white than colorful photos. In Figure 13(c), the Wikipedia feature begins to have more contribution in the combination process forming clusters that group photos according to style and color. Finally, in Figure 13(d), there are several groups on the main diagonal and two major groups that intersect. A possible explanation is that some photographers tend to shoot similar object categories, but they are from different schools of thought.43
Similarity matrix for four different weight combinations. (a) represents color feature only, showing two groups (brown areas on the main diagonal). (b) and (c) represent different weights for color, and Wikipedia features, both displaying two major brown areas but with different sizes. (d) represents the Wikipedia feature only, and it has several small groups on the diagonal and two major intersected groups. These visualizations show how the different weight combinations influence the similarity calculation between instances, matching with the group formation presented by the parallel sets.
Discussion and limitations
The quantitative and qualitative results presented in section “Results and Evaluation” show that the patterns observed on the sample feature fusion are accurately represented in the final feature fusion , suggesting that similarity relationships can be successfully controlled through the manipulation of small portions of large data sets. However, as in any sampling process, we are susceptive to misrepresentations of patterns that could reduce the quality of the final result. We tried to address this using a clustering technique to sample the data from different features and merging these samples. Nevertheless, it is not possible to guarantee that misrepresentation will not occur. This is the price of supporting a real-time approach, and real-time is a critical element in an exploratory process that is based on user judgments to define the “correct” answer—the right combination of features that reflect a personal point of view about similarity. In this scenario, the ability to allow users to perform and check different feature combinations instantaneously is of vital importance. Moreover, allowing users to interact with small samples reduces the cognitive overload imposed on them, especially when handling large data sets.
A critical aspect of our approach is that the resulting feature fusion is an -dimensional data set, so not intended for visualization purposes (although it can be visualized as any multidimensional data set). Thereby, the user involvement in our process is through the feature combination widget and the analysis of the weight combination via the sample visualization (first phase of our approach). Although we have presented visual representations for the clustering results, they are meant only to show how effectively the feature combination can be used to control the clustering results. Our intention was not to provide a new visualization for clustering methods. Moreover, the interaction is not with the clustering parameters but through the manipulation of the input space, so our approach could be employed with other subjective unsupervised techniques that rely on user expectations.
Finally, our approach provides support to unsupervised tasks where the result is subject to individual perception, like on the definition of similarity among images, instead of proposing a mechanism to improve a quality measure, like accuracy for classification. For enhancing quality measures, especially for supervised classification, user interaction usually is not necessary, and deep learning approaches tend to produce unbeatable results, particularly when processing image collections. However, for subjective unsupervised methods, where user expectations and interpretability are essential components to control the final results and to understand them (based on the feature meaning), is of utmost importance, and this is the core contribution of our approach.
Conclusion
In this article, we proposed a novel approach for feature fusion that successfully allows users to control the fusion process. It is a two-step strategy where, starting from a small sample of the input data, users can quickly test different feature combinations and check in real-time the resulting similarity relationships. Once a combination that matches the user expectation is defined, it is propagated to the whole data set through an affine transformation. Our experiments show that the complete data set combination preserves the similarities from the sample configuration, making our approach a very flexible mechanism to assist the feature fusion process.
We have applied the proposed feature fusion approach to allow users to control and understand the results of clustering techniques. Clustering is one of the most attractive application scenarios for our approach given the subjectiveness involved in unsupervised tasks. Currently, visualization assisted clustering techniques only allow users to control the results by changing technique parameters.53–56 Enabling users to guide the input feature configuration renders a much more flexible control, since users can explicitly steer the semantics of the input data and the similarity relationships (e.g. images are similar due to the color vs images are similar due to the presence of objects). Therefore, the proposed methodology controls the cluster formation while still allowing for a natural interpretation of the composed groups.
Footnotes
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research has been funded by CAPES-Brazil and the Emerging Leaders in the Americas Program (ELAP) with the support of the Government of Canada.
ORCID iDs
Gladys M Hilasaca
Fernando V Paulovich
References
1.
BostromHAndlerSFBrohedeM, et al. On the definition of information fusion as a field of research. Technical report, University of Skövde, Skövde, 2007.
2.
XuRWunschDII. Survey of clustering algorithms. Trans Neur Netw2005; 16(3): 645–678.
3.
TanPNSteinbachMKumarV. Introduction to data mining. 1st ed.Boston, MA: Addison-Wesley Longman, 2005.
4.
NonatoLGAupetitM. Multidimensional projection for visual analytics: linking techniques with distortions, tasks, and layout enrichment. IEEE Trans Vis Comput Graph2018; 25: 2650–2673.
5.
SachaDZhangLSedlmairM, et al. Visual interaction with dimensionality reduction: a structured literature analysis. IEEE Trans Vis Comput Graph2017; 23(1): 241–250.
6.
MangaiUGSamantaSDasS, et al. A survey of decision fusion and feature fusion strategies for pattern classification. IETE Tech Rev2010; 27(4): 293–307.
7.
SudhaDRamakrishnaM. Comparative study of features fusion techniques. In: Proceedings of the 2017 international conference on recent advances in electronics and communication technology (ICRAECT), Bangalore, India, 16–17 March 2017, pp. 235–239. New York: IEEE.
8.
AnneKRKuchibhotlaSVankayalapatiHD. Acoustic modeling for emotion recognition. Berlin: Springer, 2015.
9.
KuangHChanLLLiuC, et al. Fruit classification based on weighted score-level feature fusion. J Electronic Imaging2016; 25(1): 013009.
10.
WangXHanTXYanS.An HOG-LBP human detector with partial occlusion handling. In: Proceedings of the 2009 IEEE 12th international conference on computer vision, Kyoto, Japan, 29 September–2 October 2009, pp. 32–39. New York: IEEE.
11.
AhonenTHadidAPietikinenM.Face recognition with local binary patterns. In: Proceedings of the 9th European conference on computer vision (Euro’15), Prague, 11–14 May 2004, pp. 469–481. Berlin: Springer.
12.
DalalNTriggsB. Histograms of oriented gradients for human detection. In: Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, 20–25 June 2005, pp. 886–893. New York: IEEE.
13.
ManshorNRahimanARMandavaR, et al. Feature fusion in improving object class recognition. J Comput Sci2012; 8: 1321–1328.
14.
LoweDG. Object recognition from local scale-invariant features. In: Proceedings of the 7th IEEE international conference on computer vision, Kerkyra, Greece, 20–27 September 1999, pp. 1150–1157. New York: IEEE.
15.
GonzalezRCWoodsREEddinsSL. Digital image processing using MATLAB. Upper Saddle River, NJ: Prentice Hall, 2003.
16.
ChuJGuoZLengL. Object detection based on multi-layer convolution feature fusion and online hard example mining. IEEE Access2018; 6: 19959–19967.
17.
ChunYDKimNCJangIH. Content-based image retrieval using multiresolution color and texture features. IEEE T Multimedia2008; 10(6): 1073–1084.
18.
LoniBKhoshnevisSHWiggersP. Latent semantic analysis for question classification with neural networks. In: Proceedings of the 2011 IEEE workshop on automatic speech recognition & understanding, Waikoloa, HI, 11–15 December 2011, pp. 437–442. New York: IEEE.
19.
LoniBVan TulderGWiggersP, et al. Question classification by weighted combination of lexical, syntactic and semantic features. In: Proceedings of the 14th international conference on text, speech and dialogue (TSD’ 11), Pilsen, 1–5 September 2011, pp. 243–250. Berlin; Heidelberg: Springer.
20.
MaGYangXZhangB, et al. Multi-feature fusion deep networks. Neurocomput2016; 218(C): 164–171.
21.
YouTTangY. Visual saliency detection based on adaptive fusion of color and texture features. In: Proceedings of the 2017 3rd IEEE international conference on computer and communications (ICCC), Chengdu, China, 13–16 December 2017, pp. 2034–2039. New York: IEEE.
22.
YuWZhuQ. Quick retrieval method of massive face images based on global feature and local feature fusion. In: Proceedings of the 2017 10th international congress on image and signal processing, biomedical engineering and informatics (CISP-BMEI), Shanghai, China, 14–16 October 2017, pp. 1–6. New York: IEEE.
23.
DeganiADalaiMLeonardiR, et al. A heuristic for distance fusion in cover song identification. In: Proceedings of the 2013 14th international workshop on image analysis for multimedia interactive services (WIAMIS), Paris, 3–5 July 2013, pp. 1–4. New York: IEEE.
24.
HuangZCChanPPKNgWWY, et al. Content-based image retrieval using color moment and Gabor texture feature. In: Proceedings of the 2010 international conference on machine learning and cybernetics, vol. 2, Qingdao, China, 11–14 July 2010, pp. 719–724. New York: IEEE.
25.
VadivelAMajumdarAKSuralS. Characteristics of weighted feature vector in content-based image retrieval applications. In: Proceedings of the international conference on intelligent sensing and information processing, Chennai, India, 4–7 January 2004, pp. 127–132. New York: IEEE.
26.
LiuPGuoJMWuCY, et al. Fusion of deep learning and compressed domain features for content-based image retrieval. IEEE T Image Process2017; 26(12): 5706–5717.
27.
KimKLinHChoiJY, et al. A design framework for hierarchical ensemble of multiple feature extractors and multiple classifiers. Pattern Recogn2016; 52(C): 1–16.
28.
Mendes-MoreiraJaSoaresCJorgeAM, et al. Ensemble approaches for regression: a survey. ACM Comput Surv2012; 45(1): 10:1–10:40.
29.
DietterichTG.Ensemble methods in machine learning. In: Proceedings of the first international workshop on multiple classifier systems (MCS ’00), Cagliari, 21–23 June 2000, pp. 1–15. London: Springer.
30.
SchneiderBJackleDStoffelF, et al. Visual integration of data and model space in ensemble learnings. In: Proceedings of the IEEE visualization in data science (VDS), Phoenix, AZ, 1October2017, pp. 75–87. New York: IEEE.
31.
WoniakMGrañaMCorchadoE. A survey of multiple classifier systems as hybrid systems. Inf Fusion2014; 16: 3–17.
32.
XiaRZongCLiS. Ensemble of feature sets and classification algorithms for sentiment classification. Inf Sci2011; 181: 1138–1152.
33.
PalNRBezdekJC. On cluster validity for the fuzzy c-means model. IEEE T Fuzzy Syst1995; 3(3): 370–379.
34.
WilsonDRMartinezTR.The need for small learning rates on large problems. In: Proceedings of the international joint conference on neural networks (IJCNN’01) (Cat. No.01CH37222), vol. 1, Washington, DC, 15–19 July 2001, pp. 115–119. New York: IEEE.
35.
FaloutsosCLinKI. FastMap: a fast algorithm for indexing, data-mining and visualization of traditional and multimedia datasets. SIGMOD Rec1995; 24(2): 163–174.
36.
LevinaEBickelPJ.Maximum likelihood estimation of intrinsic dimension. In: Proceedings of the 17th international conference on neural information processing systems (NIPS’04), Vancouver, BC, Canada, 1 December 2004, pp. 777–784. Cambridge, MA: MIT Press.
37.
JoiaPCoimbraDCuminatoJA, et al. Local affine multidimensional projection. IEEE Trans Vis Comput Graph2011; 17(12): 2563–2571.
38.
PagliosaPPaulovichFVMinghimR, et al. Projection inspector: assessment and synthesis of multidimensional projections. Neurocomputing2015; 150(Part B): 599–610.
39.
CoatesANgAYLeeH. An analysis of single-layer networks in unsupervised feature learning. In: Proceedings of the fourteenth international conference on artificial intelligence and statistics (AISTATS 2011), Fort Lauderdale, FL, 11–13 April 2011, pp. 215–223, http://proceedings.mlr.press/v15/coates11a/coates11a.pdf
40.
LampertCNickischHHarmelingS.Learning to detect unseen object classes by between-class attribute transfer. In: Proceedings of the 2009 IEEE conference on computer vision and pattern recognition, Miami, FL, 28 November 2012, pp. 951–958. Tübingen: Max Planck Institute for Biological Cybernetics.
41.
YuAGraumanK.Fine-grained visual comparisons with local learning. In: Proceedings of the 2014 IEEE conference on computer vision and pattern recognition (CVPR ’14), Washington, DC, 23–28 June 2014, pp. 192–199. Washington, DC: IEEE Computer Society.
42.
KrizhevskyA. Learning multiple layers of features from tiny images. Technical report, University of Toronto, Toronto, ON, Canada, 2009.
ChenLLuGZhangD. Effects of different Gabor filters parameters on image retrieval by texture. In: Proceedings of the 10th international multimedia modelling conference (MMM ’04), Brisbane, QLD, Australia, 5–7 January 2004, p. 273, Washington, DC: IEEE Computer Society.
45.
JiaYShelhamerEDonahueJ, et al. Caffe: convolutional architecture for fast feature embedding. In: Proceedings of the 22nd ACM international conference on multimedia (MM ’14), Orlando, FL, 3–7 November 2014, pp. 675–678. New York: ACM.
46.
CuiQWardMRundensteinerE, et al. Measuring data abstraction quality in multiresolution visualizations. IEEE Trans Vis Comput Graph2006; 12(5): 709–716.
47.
ComaniciuDMeerP. Mean shift: a robust approach toward feature space analysis. IEEE T Pattern Anal2002; 24(5): 603–619.
48.
KosaraRBendixFHauserH. Parallel sets: interactive exploration and visual analysis of categorical data. IEEE Trans Vis Comput Graph2006; 12: 558–568.
49.
TejadaEMinghimRNonatoLG. On improved projection techniques to support visual exploration of multidimensional data sets. Inform Visual2003; 2(4): 218–231.
50.
SokalRRMichenerCD. A statistical method for evaluating systematic relationships. U Kans Sci Bull1958; 28: 1409–1438.
SanderJQinXLuZ, et al. Automatic extraction of clusters from hierarchical clustering representations. In: Proceedings of the 7th Pacific-Asia conference on knowledge discovery and data mining (PAKDD ’03), Seoul, South Korea, 30 April–2 May 2003, pp. 75–87. Berlin; Heidelberg: Springer.
53.
KwonBCEysenbachBVermaJ, et al. Clustervision: visual supervision of unsupervised clustering. IEEE Trans Vis Comput Graph2018; 24(1): 142–151.
54.
KernMLexAGehlenborgN, et al. Interactive visual exploration and refinement of cluster assignments. BMC Bioinform2017; 18(1): 406.
55.
BruneauPPinheiroPBroeksemaB, et al. Cluster sculptor, an interactive visual clustering system. Neurocomputing2015; 150: 627–644.
56.
JentnerWSachaDStoffelF, et al. Making machine intelligence less scary for criminal analysts: reflections on designing a visual comparative case analysis tool. Vis Comput J2018; 34: 1225–1241.