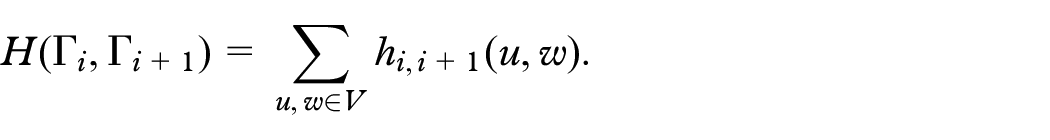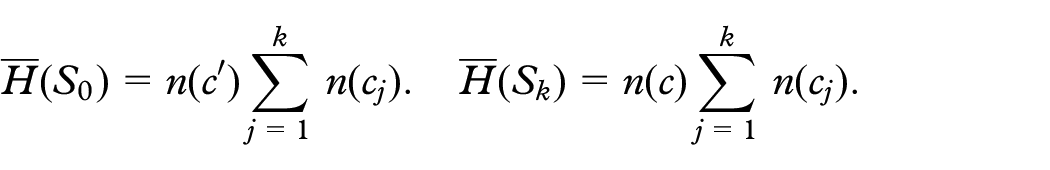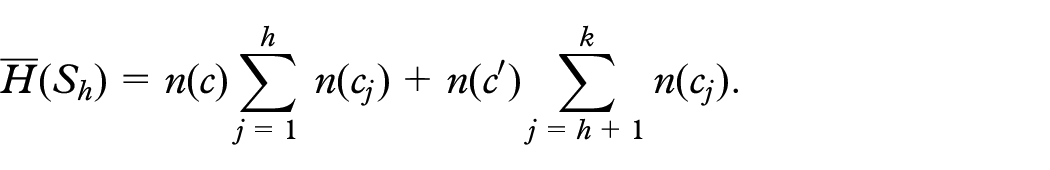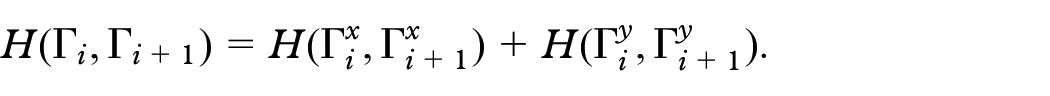One of the primary goals of many systems for the visual analysis of dynamically changing networks is to maintain the stability of the drawing throughout the sequence of graph changes. We investigate the scenario where the changes are determined by a stream of events, each being either an edge addition or an edge removal. The visualization must be updated immediately after each new event is received. Our main goal is to provide the user with an intuitive visualization that highlights the different connected components of the graph while preserving the user’s mental map after each event. The drawing stability is measured in terms of changes in the orthogonal relationships between vertices of two consecutive drawings. We describe two different visualization models, one for the 1-dimensional space and the other for the 2-dimensional space. In both models the connected components are drawn inside rectangular regions. To validate our approach, we report the results of an experimental analysis that compares the drawing stability of the online algorithm with that of an offline algorithm that knows in advance the whole sequence of events. We also present a case study of our online algorithm on a collaboration network.
Dynamic networks occur in many application domains, including sociology, finance, biology, cybersecurity, and telecommunications.1 For example, in a social network the edges can change depending on the evolution of the relationships between the different subjects. In a biological network that describes the interaction between genes and proteins, the edges can change depending on the temporal evolution of gene expression levels. In a computer network, the vertices represent different machines and communication links between the different vertices may become unavailable or may be resumed over time, depending on temporary hardware or software failures. All these application domains can strongly benefit from the use of visualization to support the analysis of how the phenomena modeled by the networks change over time.2
One of the primary goals of many systems for the visual analysis of dynamic networks is to maximize the drawing stability throughout the sequence of graph changes, which is correlated with the preservation of the user’s mental map.2,3 Many user experiments have been conducted to assess the importance of keeping a graph layout stable with respect to the execution of different analysis tasks. An early study by Purchase et al.4 focuses on hierarchical graph layouts and confirms this assumption only for some types of tasks. Archambault et al.5 experimentally study the benefit of preserving the mental map under two different ways of showing graph evolutions, namely animation and presentation of small multiples; they found that in both cases preserving the mental map seems to have little influence in terms of error rate and response time. Qualitative data collected by Archambault and Purchase6 suggest that, in terms of the users perception, preserving the mental map makes memorability tasks easier, although no statistic evidence is found on the user performances. Memorability tasks are important for information discovery and they are related to the capability of a user to remember elements and changes in the evolving network. Archambault and Purchase7 summarize the rich set of experimental works aimed to assess the impact of mental map preservation. Although they remark that none of these works has found conclusive evidence that supports the effectiveness of the mental map in the comprehension of a dynamic graph series, they also highlight possible limits of previous experiments and provide new insights for further investigations. Also, based on some experiments on static graphs, they conjecture that revisitation tasks on dynamic graphs could benefit from keeping the drawing stable. Revisitation tasks require to remember where objects in a particular space are located and how they can be reached a second time. A recent user study by Federico and Miksch8 investigates the role of an interaction technique for layout stability adjustment and gives some evidence that this type of interaction may increase accuracy in the execution of specific analysis tasks. Another recent study by Lezama et al.9 tries to further investigate the trade-off between drawing stability and drawing readability, based on a new mathematical model.
In this paper we restrict our attention to evolving networks where only the set of edges changes over time (while the set of vertices remains stable). Consider, for example, social networks in which the vertices represent a target set of email users and the edges represent their mail exchanges in a desired time window. Or graphs that model the traffic evolution on a LAN and that show only those links whose communication load trespasses a given threshold. More specifically, we study the scenario in which we are given a network with a fixed set of vertices and whose relationships may change over time. We assume that the changes in the network are determined by a stream of events, each being either an edge addition or an edge removal. The visualization must be updated immediately after each new event is received. Our main goal is to design an online algorithm to visually support a network analyst in identifying the different connected components of the graph while easily following the graph changes. In this respect, we believe that drastic changes in the graph layout should be avoided when small changes in the graph topology happen. In particular, any user would be totally disoriented if, after the addition or the removal of a single edge in the network, many vertices change their relative positions.
Contribution
We describe two different visualization models and related online algorithms, one for the 1-dimensional space and the other for the 2-dimensional space. The 1-dimensional visualization model adopts an arc diagram style,10 while the 2-dimensional model exploits a variant of orthogonal drawings,11,12 that is, drawings whose vertices are mapped to points of an integer grid and edges are drawn as chains of horizontal and vertical segments. In both models the connected components are regarded as clusters and are drawn inside rectangular regions. The drawing stability is measured in terms of changes in the orthogonal relationships of the vertices between two consecutive drawings, as suggested in a seminal paper by Misue et al.3 As a byproduct, our approach also satisfies a larger set of stability requirements that were proposed by Frishman and Tal13 about dynamic visualization of clustered graphs. In fact, our algorithmic strategy can also be adopted in the more general scenario in which the clusters do not necessarily represent connected components, and they can be merged or split.
To validate the proposed approach, we experimentally show that our online algorithm is competitive with an offline strategy that knows the whole sequence of events and that maximizes the drawing stability over all this sequence. We also present a case study of our online algorithm on a collaboration network.
Related work
The research in this work fits in the broad area of dynamic graph visualization. According to a recent survey of Beck et al.,2 the rich literature in this area can be classified into two main categories, timeline approaches and animation approaches, based on how changes in the graph are conveyed to the user.
Timeline approaches use a time-to-space mapping that creates static visualizations in which the time dimension is embedded into the graph layouts. Examples include juxtaposed or superimposed node-link diagrams, where the time dimension coincides with a geometric axis that is visually separated by the graph layouts.14–16 Another example are integrated diagrams in which the timeline is woven into the graph layout.17,18 A static visualization for dynamic trees, based on the popular treemap convention is proposed by Köpp and Weinkauf.19
Animation approaches adopt a time-to-time mapping that creates a sequence of distinct graph layouts, one for each time step, and shows to the user a layout per time. Examples of these approaches are presented both for online scenarios, where only past data can be used to compute the visualization in each time step,3,21,22 and for offline scenarios, where future temporal changes are also known, and the layout algorithm can take advantage of this knowledge to improve drawing stability throughout the animation.23–25 Our work belongs to the class of online animation approaches, since we promptly update the graph layout at each event of a temporal stream of changes. We also compare the drawing stability cost of our strategy with an offline strategy that knows the entire sequence of events in advance.
Our research is also strongly related to the problem of dynamic drawing of clustered graphs with only one level of clusters, where a cluster of vertices is drawn inside a rectangular region. Frishman and Tal13 address this problem and indicate a set of requirements in terms of vertex and cluster stability that the drawing algorithm should pursue. They describe a force-directed drawing algorithm with straight-line edges that takes as input a sequence of clustered graphs and that heuristically attempts to match the given requirements as much as possible. In our framework, clusters are not given as part of the input; they coincide with the connected components of the graph and therefore they are automatically induced by the changes in the set of edges. Also, we use neither straight-line edges nor a force-directed strategy; instead, we adopt drawing models and algorithms that make it possible to minimize (in an exact way) the drawing stability cost at each new event in linear time (refer to the next section). Alternative visualization approaches for dynamic drawing of clustered graphs have also been studied, where clusters are possibly organized into a hierarchy, graphs are not necessarily represented as node-link diagrams, and clusters are not necessarily represented as rectangular regions; we refer the reader to the following surveys or recent papers on the topic.2,26,27
Finally, our work is clearly related to the design of algorithmic techniques to draw graphs with multiple connected components. Several algorithms have been proposed in the literature to compute compact layouts of such graphs.28–31 These algorithms assume that the graph is static and aim to arrange the different components in such a way that the area of the drawing is minimized and two components do not overlap. Gansner et al.32 consider a dynamic scenario in which an initial drawing configuration for the different connected components of a graph is given, and each connected component may grow up and cause overlaps with other components. For this scenario, they propose a new drawing approach that removes overlaps between components and that keeps the relative positions of the different components stable. Their approach modifies and combines node-overlap removal techniques33 and polyomino-based packing techniques.29 Differently from our scenario, their approach is aimed to support a map metaphor visualization for clustered graphs with straight-line edges.
Models, metrics, and algorithms
In our dynamic scenario we start from an initial graph ; a subsequent stream of temporal events may change the set of edges of , while the set of vertices of remains unchanged. We formalize this scenario as follows. Consider a temporal sequence of graphs such that for each , is the graph at time and, for each , the set is obtained from by either adding a single edge or removing a single edge. Denote by the set of connected components of the graph . The addition of an edge to may cause the merging of two connected components into a single one, in which case . The deletion of a single edge to may cause the splitting of a connected component into two distinct components, in which case .
We want to visually represent each graph by means of a node-link diagram in the plane such that the different connected components are clearly distinguishable. To this aim, we require that all the vertices of each connected component are inside a rectangular region and for any two components , and no edge of intersects . Within these constraints, we consider two specific drawing models, one that places the vertices in the 1-dimensional space (1D drawing model) and the other that places the vertices in the 2-dimensional space (2D drawing model). For each of these models, we design an online drawing algorithm that aims to maximize the drawing stability when it computes from . We measure the drawing stability in terms of changes in the orthogonal ordering between pair of vertices.3 As it will be clear in the next section, thanks to our drawing models, this stability criterion also guarantees the following stability criteria indicated by Frishman and Tal13 for dynamic drawing of clustered graphs, where our clusters coincide with the connected components of the graph: (1) The movement of clusters between successive drawings should be small; clusters that are not modified should remain in their previous (relative) position if possible; (2) the change in the size of clusters between successive drawings should be minimal, when the number of vertices in the cluster is similar; (3) movement of vertices inside a cluster should be minimized; (4) the size of each cluster should be proportional to the number of vertices it contains; (5) the drawing of each cluster should be compact; and (6) overlapping between vertices should be avoided and overlapping between cluster boundaries should be minimal.
Formally, for a vertex , denote by the position of in and by the position of in . For any two distinct vertices , the orthogonal ordering of and is preserved while passing from to if the following relations hold:
(a)
(b)
(c)
(d)
Hence, to measure the changes in the orthogonal ordering of a pair of vertices and in two consecutive drawings and , we define a cost function whose value is the number of relations (a)–(d) that are false, that is, that do not hold. The drawing stability cost for a pair of consecutive drawings and is defined as the sum of the aforementioned cost function over all pairs of vertices, that is:
Maximizing the drawing stability on two consecutive drawings and equals to minimizing the drawing stability cost .
The drawing stability cost of the whole sequence of drawings can be measured in different ways. In the implementation and experimental section, we will consider the total stability cost, defined as , and the maximum stability cost, defined as .
We remark that, in the context of orthogonal drawings, different measures of mental map preservation have been proposed by Bridgeman and Tamassia.34 Not all their measures apply to our scenario, because they are defined to quantify the difference between two drawings of the same graph rather than between consecutive drawings of a dynamic graph. However, minimizing our drawing stability metric for the 2D visualization model (which exploits a restriction of the orthogonal drawing convention) implies the optimization of some of the measures in Bridgeman and Tamassia,34 namely the orthogonal ordering measure and the Euclidean distance measure. In the following subsections we describe our 1D and 2D drawing models and the related online drawing algorithms. For a connected component , we denote by and the number of vertices and the number of edges of , respectively.
1D drawing model
Our drawing model that places the vertices in 1D is inspired by the popular arc diagram style, where the vertices of the graph lie on a common horizontal line, which we call spine, and the edges are drawn as semicircles above or below the spine. Although the name “arc diagram” stems from a work on the visualization of repetition patterns in string,10 this drawing style has a much older tradition and has been originally used to study crossing numbers of graphs.35,36 Arc diagrams are sometimes called line embeddings,37 and they are also referred to as two-page book embeddings if they have no edge crossings.38 Several papers also study edge crossings and crossing minimization in arc-diagrams.39−43 Applications of arc diagrams to the visualization of directed graphs have also been proposed.44 We finally remark that arc diagrams are conceptually related to circular drawings and chord diagrams, where the vertices are placed on a circle and the edges are lines that can be embedded inside or outside this circle.45–47 Chord diagrams have been recently proposed for the visual analysis of dynamic graphs in distributed software profiling.48 From a dynamic graph drawing perspective, minimizing the changes in the linear ordering of our 1D drawing model seems to be related to the problem of minimizing crossings in a storyline visualization.49,50 Indeed, a crossing between the lines representing two characters in a storyline visualization occurs when we invert the linear ordering of these lines along the vertical axis.
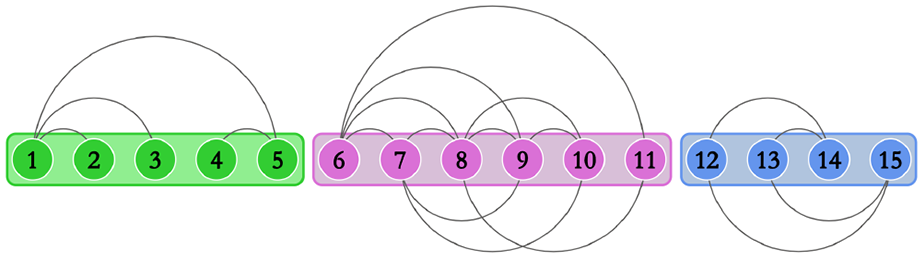
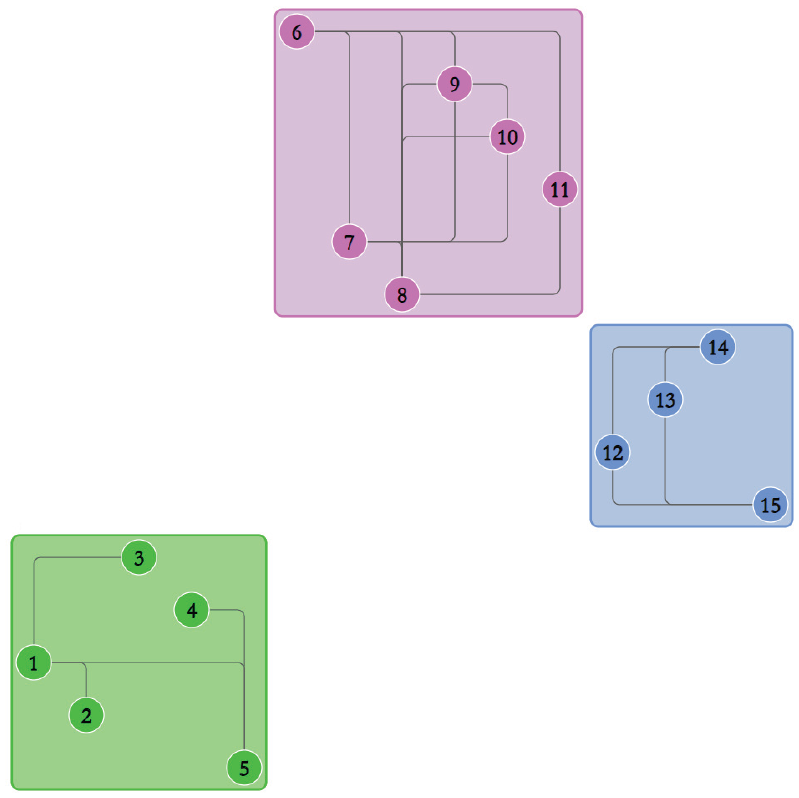
We compute the drawing of as an arc diagram where all vertices are equispaced and for each edge the diameter of its corresponding semicircle equals the Euclidean distance between and . Also, the fact that all the vertices of a connected component of are inside a rectangular region implies that these vertices are all consecutive in the linear ordering along the spine. We call such a drawing a connected-component-arc diagram or a cc-arc diagram for short. An example is shown in Figure 1.
A cc-arc-diagram of a graph with 15 vertices and 3 connected components; the rectangular regions of the different connected components have different colors.
Clearly, in a cc-arc diagram all vertices have the same -coordinate and no two vertices have the same -coordinate. Thus, changes in the orthogonal ordering of the vertices imply that relation (a) is violated, that is, the -ordering of some pairs of vertices is modified. The drawing stability cost equals the number of pairs of vertices that change their -ordering in and .
Our online drawing algorithm for dynamic cc-arc diagrams computes from , depending on the type of event at time .
Edge addition. When is obtained from by adding a new edge , two cases are possible:
and belong to the same component . In this case, and can be trivially drawn without any change in the orthogonal ordering of the vertices, that is, . Note that, for what concerns the drawing stability, can be arbitrarily drawn above or below the spine; in this case the edge addition is executed in time. Otherwise, one can choose the option that optimizes some desired quality metrics; for example, one can make the choice that minimizes the number of edge crossings, which takes time.
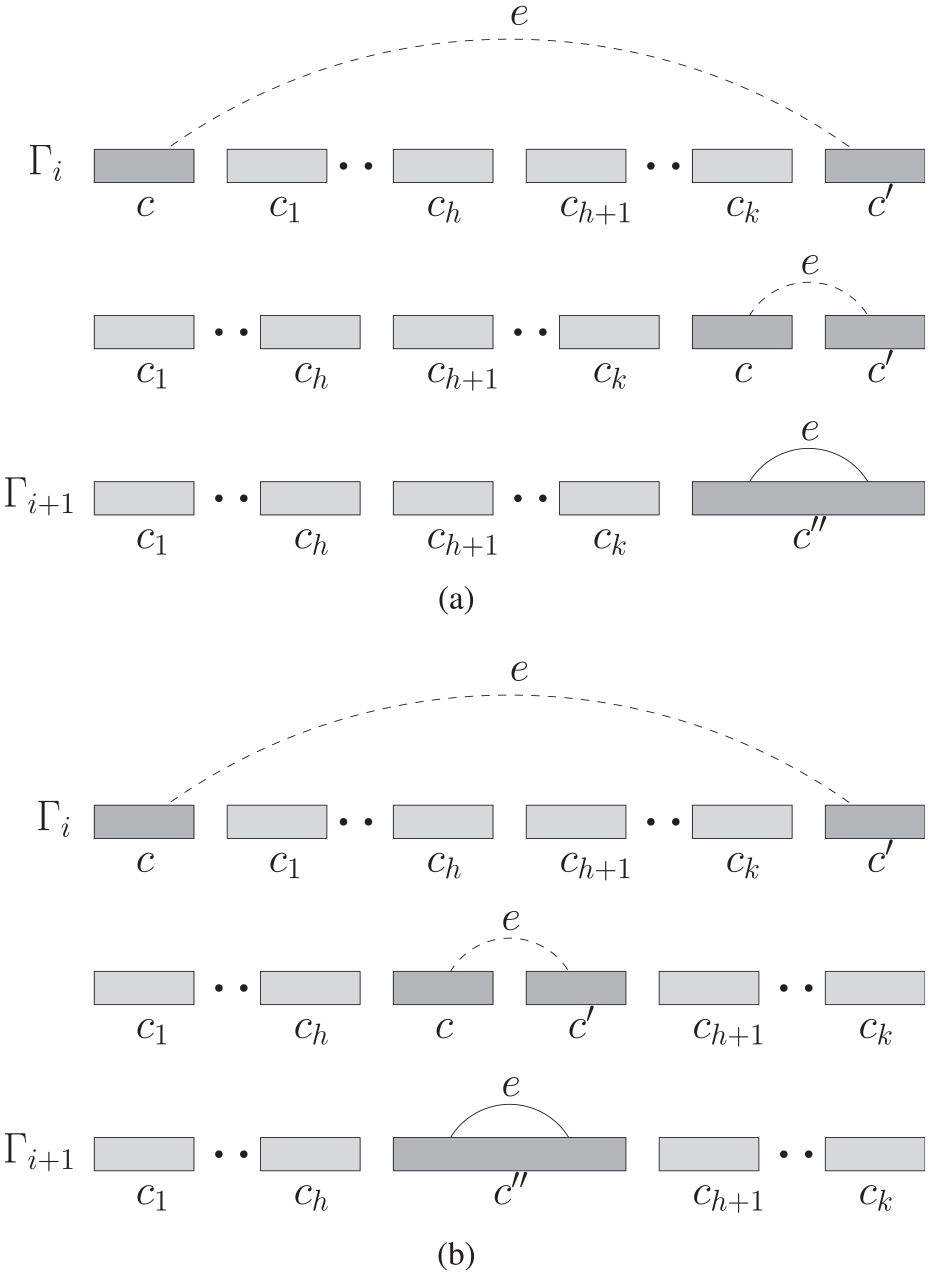
and belong to two distinct components and , respectively. In this case, the two components and are merged into a single component , which also includes edge . Let be the left-to-right sequence of connected components of between and (refer to Figure 2 for a schematic illustration). Merging and into requires to make and consecutive along the spine. This can be done in several ways. A possibility is to translate the vertices of toward , so that immediately follows in (see Figure 2(a)). A symmetric choice is to translate the vertices of toward , so that immediately precedes in . Another choice is to translate to the right and to the left, so that will be between two components and in , for some (see Figure 2(b)). Our algorithm places immediately after if , and immediately before otherwise. Lemma 1 shows that this choice minimizes the drawing stability cost . This translation takes time, needed to update the coordinates of the vertices between and plus the vertices of one among and . Then, edge is added as in the previous case.
Different ways of merging two components and into a single component : (a) is translated toward and (b) and are translated one toward the other.
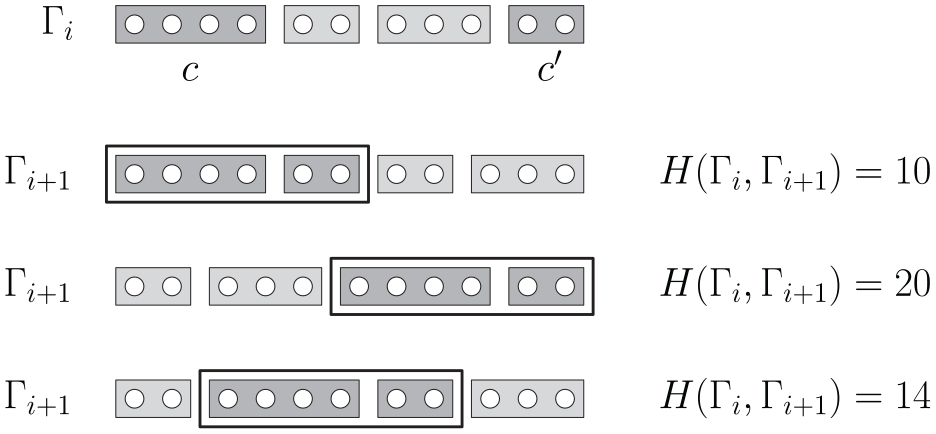
Lemma 1.Let be a subsequence of connected components along the spine of a cc-arc diagram and let be the connected component of obtained by merging and . The cost is minimized by replacing with the new subsequence if , and by the subsequence otherwise.
Proof. Denote by the subsequence of , by the subsequence , and by the subsequence , with . Denote by the drawing stability cost spent to obtain . The subsequence requires to translate to the left until it meets ; requires to translate to the right until it meets ; requires to translate to the right and to the left, until they meet in-between and . Thus we have the following costs for each subsequence, which correspond to the number of pairs of vertices that change their -ordering when passing from to :
Hence, if , we have and , thus is the cheapest solution. Otherwise, and , thus is the cheapest solution {q.e.d.}.
Figure 3 shows an example of merging two components and and three possible solutions to perform this operation. For each solution the corresponding cost is reported. The cheapest solution consists of moving toward .
Example of merging two components and in a cc-arc diagram (the edges of the diagram are not shown). Three different solutions and their drawing stability costs are shown. Translating toward is the cheapest solution.
Edge removal. When is obtained from by removing an edge , two cases are possible:
the connected component of remains connected after the removal of . In this case, and can be trivially deleted without any change in the orthogonal ordering of the vertices, that is, . This takes time.
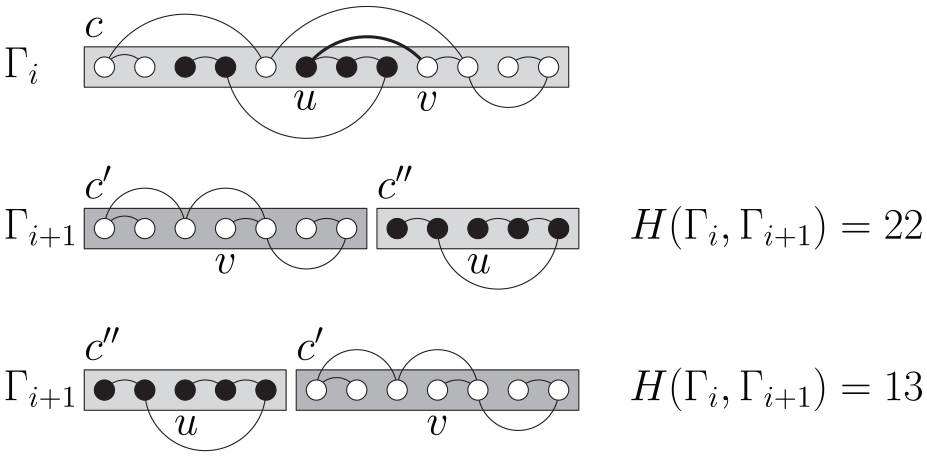
the connected component of is no longer connected after the removal of . In this case, denoted by the connected component of in , it will be disconnected into two connected components . Call white and black the vertices of and those of , respectively. Clearly, if is white then is black, and vice versa. In the drawing , black and white vertices may be in any order in the -ordering, while in all the white vertices (resp. black vertices) must be consecutive in the -ordering, so that they can be enclosed in the rectangular region (resp. ). To this aim, we have to translate all the black vertices before the white vertices or vice versa, without changing the relative -ordering of the vertices with the same color. For each vertex (i.e. for a white vertex), denote by the number of vertices of (i.e. black vertices) that are to the left of in . Symmetrically, for a vertex (i.e. for a black vertex), let be the number of white vertices to the left of in . Translating all the white vertices before the black vertices has the following drawing stability cost:
Translating all the black vertices before the white vertices has the following cost:
The drawing algorithm will chose the cheapest option between (1) and (2). Making this choice and updating the vertex ordering takes time. For example, Figure 4 depicts a connected component of a cc-arc-diagram ; in the next drawing , edge is removed and is split into two components and . The two ways of executing this change are shown, along with their corresponding drawing stability costs.
Example of splitting a component into two components and in a cc-arc diagram. In the example, the splitting is caused by the removal of an edge (the thick edge) from a cc-arc-diagram . The black vertices will be in the same component as in while the white vertices will be in the same component as . Translating all the black vertices before the white ones causes a smaller drawing stability cost.
2D drawing model
Our 2D drawing model adopts the popular orthogonal drawing convention, where vertices are mapped to points of an integer grid and edges are sequences of horizontal and vertical segments12,25,51–53 This kind of drawings has been widely studied for the representation of graphs with clusters of vertices drawn as rectangular regions.54–57 Our cluster regions correspond to the rectangular regions of the different connected components. Furthermore, in our drawing model we require that each row and each column of the grid contains exactly one vertex of the graph; this means that the drawing fits into a grid and there is neither two vertices with the same -coordinate nor two vertices with the same -coordinate. Drawings with this property have been recently studied by different authors to support dynamic graph visualizations, because they facilitate the insertion of a vertex or of an edge in the drawing while preserving the user’s mental map. They are called rook-drawings when the edges are straight lines58,59 and L-drawings when the edges have an orthogonal L-shape, that is, when each edge consists of exactly a vertical segment and a horizontal segment.11 Our 2D drawing model will be called cc-L-drawing, because it is an L-drawing with rectangular regions that enclose the different connected components. Note that, since no vertices share the same -coordinate or the same -coordinate, an L-shaped edge in the drawing can always be added without intersecting any vertex, except its end-vertices. Also, two edges may partially overlap, but this does not create ambiguities due to the fact that each edge has an L-shape. These properties remain true even if the clusters do not correspond to the connected components of the graph and there are edges that join vertices that belong to different cluster regions. Figure 5 depicts an example of a cc-L-drawing for the same graph shown in Figure 1.
A cc-L-drawing of the same graph with 15 vertices and 3 connected components shown in Figure 1.
On the negative side, we remark that rook-like drawings are consuming in terms of area requirement, because they do not allow the reuse of rows and columns. This makes our 2D model mainly suitable for the visualization of relatively small sets of target vertices and their relationships.
The vertex coordinates in a cc-L-drawing can be obtained by combining those of two cc-arc-diagrams, one along the -axis and the other along the -axis. The -ordering and -ordering of the vertices can be determined independently one of the other, provided that all the vertices of the same connected component are consecutive in each of the two orderings. More formally, if is a cc-L-drawing at time , denote by any cc-arc-diagram whose vertex ordering corresponds to the -ordering of the vertices of and by any cc-arc-diagram whose vertex ordering corresponds to the -ordering of the vertices of . Since the drawing stability cost only depends on the changes in the - and -ordering of the vertices (while it is not affected by the edge routing), it is immediate to see that:
Thanks to this observation, when an edge addition or an edge removal at time occurs, our online algorithm for cc-L-drawings can independently apply the same strategies described in the 1D drawing model on and on in order to compute . Figure 6 shows an example of edge addition that causes a merge operation; the projections of the vertices along the -axis and the -axis are also shown, which represent the linear orderings of the vertices in and , respectively. Figure 7 shows an example of edge removal that causes a split operation.
Example of edge addition that causes a merge operation in a cc-L-drawing: (a) a cc-L-drawing and an edge (dashed) that must be added at time and (b) the drawing obtained by merging the green and the yellow component of (the resulting component is colored green); the drawing stability cost is minimized by translating the yellow component toward the green component in the -direction, while the -ordering of the vertices does not change. Hence, .
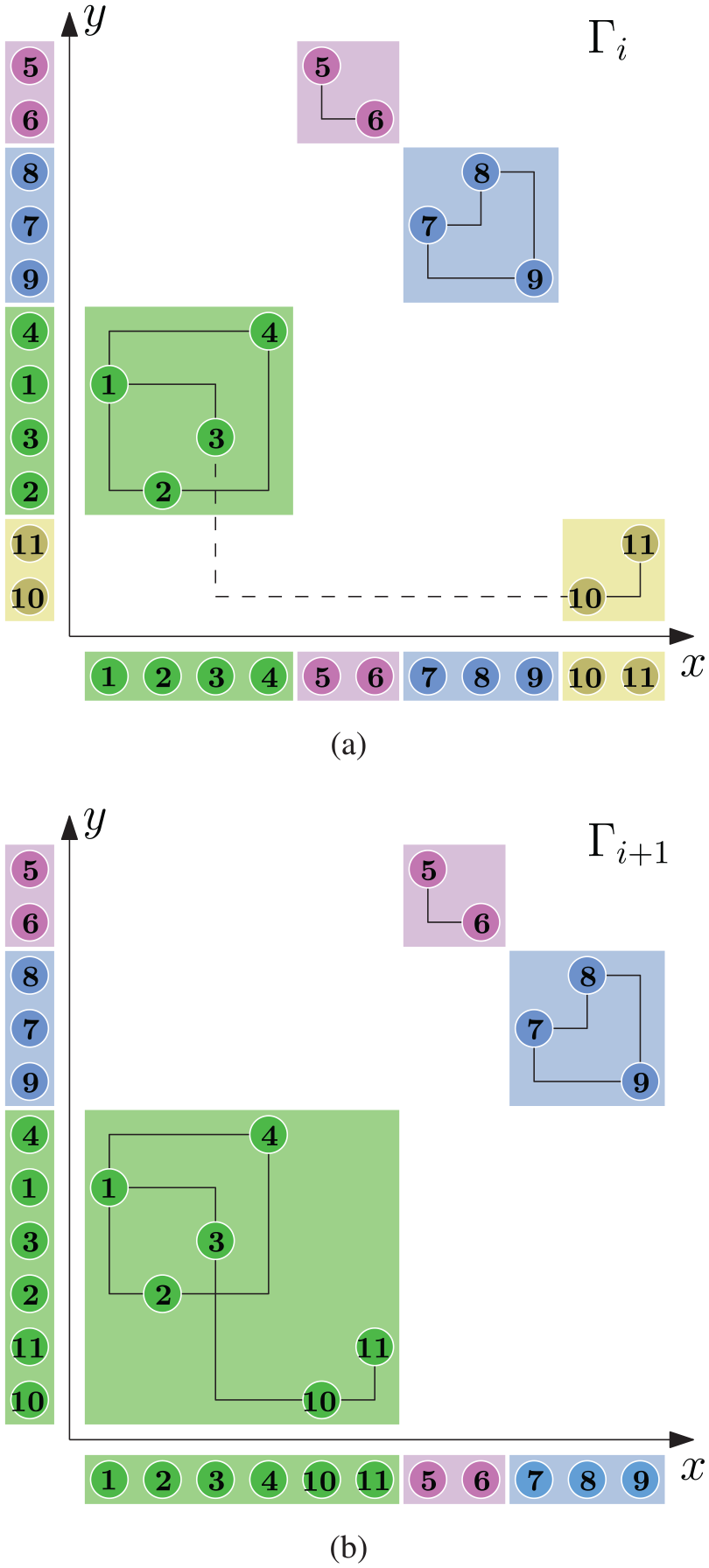
Example of edge removal that causes a split operation in a cc-L-drawing: (a) a cc-L-drawing with the edge (thicker) that must be removed at time ; after the edge removal, the vertices (in bold) will form a component and the vertices will form another component and (b) the drawing obtained by splitting the green component of into two components (colored green and yellow, respectively); the drawing stability cost is minimized by moving the bold vertices before the others in each of the two directions. This requires to change the -ordering of the pair of vertices and the -ordering of the pair of vertices . Hence, .
Implementation and experimental analysis
In this section we describe the results of an experimental study that compares our online algorithm with an offline algorithm that knows the whole sequence of operations in advance. Indeed, when deciding how to modify the drawing to obtain , an offline algorithm can take advantage of the knowledge of the operations that will be performed later to minimize the total (or the maximum) stability cost over the whole sequence, possibly making a suboptimal choice at step . For example, consider the 1D drawing model and suppose that consists of four components , , , and , in this order, whose sizes are , , , and , respectively. Assume that the operation to be performed is an edge addition that causes a merging of and . Translating toward costs , while translating toward costs . If the algorithm is not aware of the next operations, the best choice is to move to the right close to , as also stated in Lemma 1. Suppose now that the next operation causes the merging of and . We have two possibilities both costing . Thus the total cost for the two operations is . On the other hand, an offline algorithm would move toward to merge these two clusters, so that the next operation that merges and does not cause any stability cost, because and are already consecutive.
More in general, the following lemma proves that from a theoretical point of view the solution of our online algorithm can be arbitrarily worse than the solution of an offline algorithm.
Lemma 2.There exists a sequence of vertices and a sequence of merging operations for which the competitive ratio between the online algorithm and an offline algorithm is .
Proof. Consider, in the 1D model, a sequence of components () such that each has two vertices except that has one vertex. Suppose to have the following sequences of operations. The first operation merges with into a component . The second operation merges with forming a component ; the third operation merges with , and so on; the last operation merges with the large component created in the previous steps. The online strategy has a cost that is , because it moves toward in the first step and then at each successive step it moves the component in the first position to the second-last position. In contrast, the offline solution moves toward in the first step so that it does not need to make any other moves till the end; the total cost of the offline algorithm is therefore . Therefore, the competitive ratio between the online and the offline algorithms is {q.e.d.}.
Our implementation of the offline algorithm considers a tree of all possible candidate solutions, by considering an operation per time. At each step it creates a branch for every possible choice for the current operation. The tree of partial solutions is visited according to a DFS traversal and an upper bound on the value of the optimal solution is used to avoid exploring branches that lead to solutions whose value is worse than the current bound. The upper bound is initialized with the value of the solution computed by our online algorithm and it is (possibly) updated each time a complete solution is computed. Both the online and the offline algorithms have been implemented in Java and the experiments have been executed on a machine with an Intel Core i7-6700HQ processor at 2.60 GHz and 16 GB of RAM.
We conducted two experiments: In the first experiment (EXP-1) both edge additions and edge removals are performed; in the second experiment (EXP-2) only edge additions are considered. Note that the online and the offline algorithms behave the same over a sequence of edge removals only.
Test suite
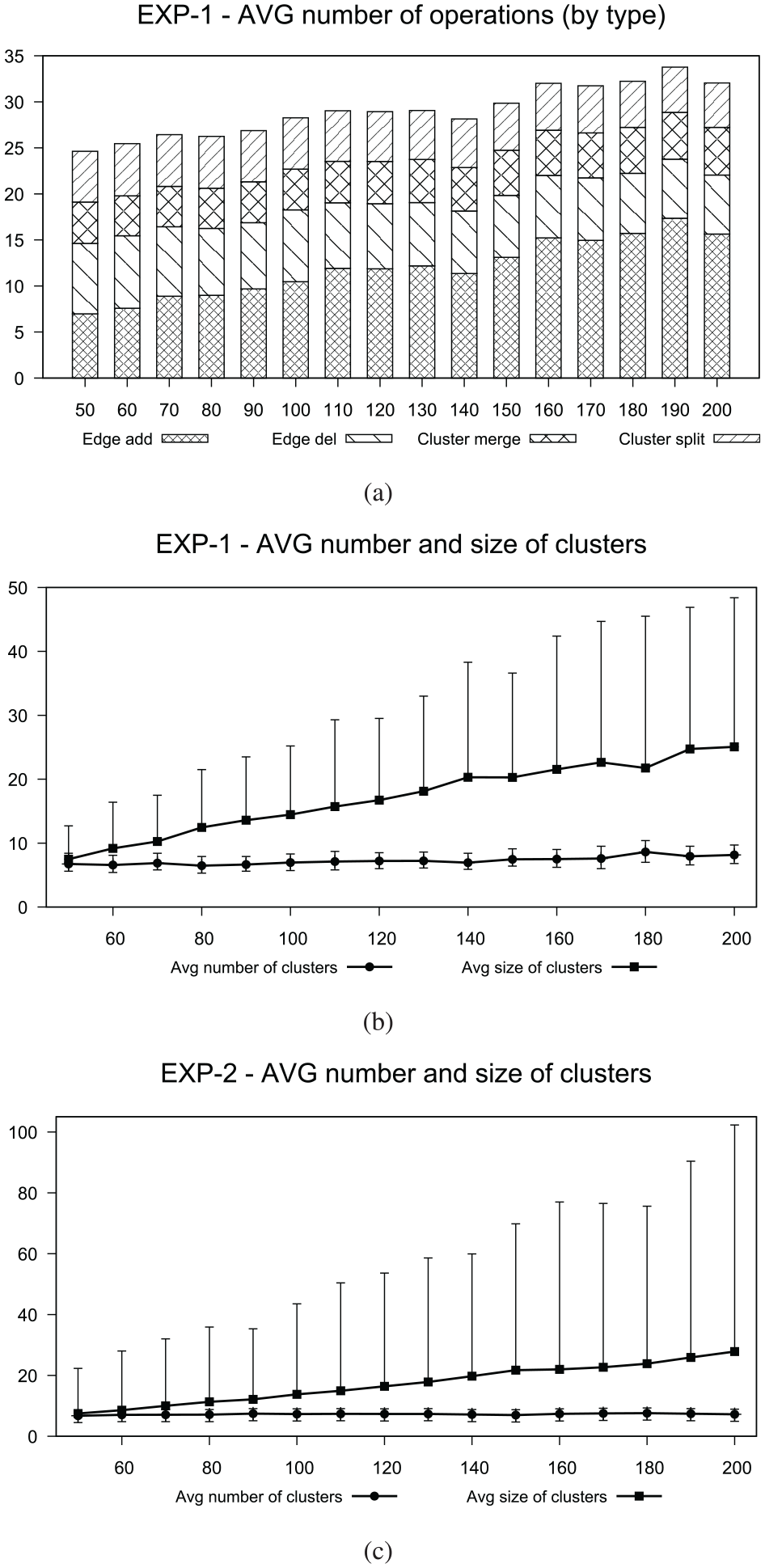
The test suite for EXP-1 is composed of instances, each consisting of an initial graph (with an initial drawing) and a sequence of events. An event is either an edge addition operation or an edge removal operation, which may imply an additional merging or splitting operation. For every , we generate instances each consisting of a graph with vertices and a sequence of events (edge addition/deletion) that guarantees exactly merging/splitting operations. On average, the number of operations is about . The chart in Figure 8(a) shows the average number of operations for each value of , subdivided by type of operations.
(a) Average number of operations subdivided by type in EXP-1 (-axis), (b) average number and size (number of vertices) of connected components in EXP-1 (-axis), and (c) average number and size of connected components in EXP-2 (-axis). In (b) and (c), the error bars show maximum and minimum values; the minimum value for the cluster size is always 1, thus we do not show it. The -axis represents the number of vertices.
The instances are randomly generated as follows. We first generate an initial graph with vertices and edges, and we compute its connected components. To determine the initial layout of we randomly generate with uniform probability distribution the two linear orderings of the vertices along the -axis and along the -axis (for the 1D model the ordering along the -axis is ignored). In fact, since the online algorithm is not aware of the sequence of changes, there is no reason to prefer some specific vertex orderings. To generate the events, we repeatedly extract pairs of vertices. If the vertices of an extracted pair are adjacent in the graph we remove the edge (and thus we have an edge removal operation); if they are not adjacent we add the edge between them (and thus we have an edge addition operation). After the edge addition/removal is executed we update the set of connected components of the graph; if this set is changed, we add to the sequence of operations a component merge operation or a component split operation. With this generation procedure, we observed that extracting each pair of vertices with the same probability gives rise to an unbalanced situation where there is a giant component and several small components, and in this case the offline algorithm behaves very similarly to the online algorithm. This is because the giant component is never moved when a merge operation is performed. To make the set of experiments more meaningful, we modified the procedure so that it generates a sequence of events that guarantees a more balanced set of connected components. We select a pair of vertices with a probability that depends on the fact that the two vertices are adjacent or not; this probability is updated after each operation is generated. More precisely, let and be two vertices (notice that the two components and may coincide); we assign to the pair and a score equal to if and are adjacent and to if and are not adjacent. The scores are then normalized to be between and . Second, when the size (number of vertices) of a component is above a fixed threshold ( in our case), the probability is set to for every pair of non-adjacent vertices that involves a vertex of . The rationale behind these probability values is that they dynamically increase the probability of splitting big components and, at the same time, reduce the probability of merging two components into a big one. Figure 8(b) shows the average number of clusters and their average size throughout the whole sequence of graphs. The edges for the initial graph are generated with the same probability-based strategy, but only considering edge additions. Observe that, the probabilities used to generate the sequence of events avoid that the number of clusters becomes too small or too big; this is why this number remains approximately constant on average.
The test suite for EXP-2 is generated with the same strategy as above, but only considering edge additions. More precisely, we generate a sequence of events that guarantees merging operations. The average number of operations is about . We also removed the threshold on the size of clusters, because, having only edge additions, the size of clusters can only grow and the generation algorithm may get stuck. We remark that generating instances with a higher number of merging operations often causes quite long running times for the offline algorithm, which prevents us from completing the whole set of experiments in a reasonable time. Also, we observed that executing EXP-2 was much more expensive in terms of computational time than executing EXP-1. This is due to the fact that, having only merging operations, the clusters are bigger and the value of the optimal solution is higher. As a consequence, the upper bound on the value of the solution used to avoid the exploration of subtrees that cannot lead to the optimal solution is also higher and therefore less effective in reducing the exploration of the tree of candidate solutions. For this reason, we limited EXP-2 to 20 instances (instead of 70) for each fixed value of . Figure 8(c) shows the average number of clusters and the average size of the clusters for this second test suite.
Experimental comparison
In each experiment we compare the online algorithm for the 1D and 2D drawing models against the offline algorithm. For the 1D drawing model we study both the case when the offline algorithm minimizes the total stability cost and the case when it minimizes the maximum stability cost. For the 2D drawing model we only consider the minimization of the total stability cost, because for this model the execution of the offline algorithm to minimize the maximum cost turned out to be computationally too expensive. Namely, if we want to minimize the maximum stability cost in 2D, we cannot optimize independently the ordering of the vertices along the -direction and along the -direction. Thus, when considering a merge operation the number of possibilities to consider would be quadratic in the number of connected components rather than linear.
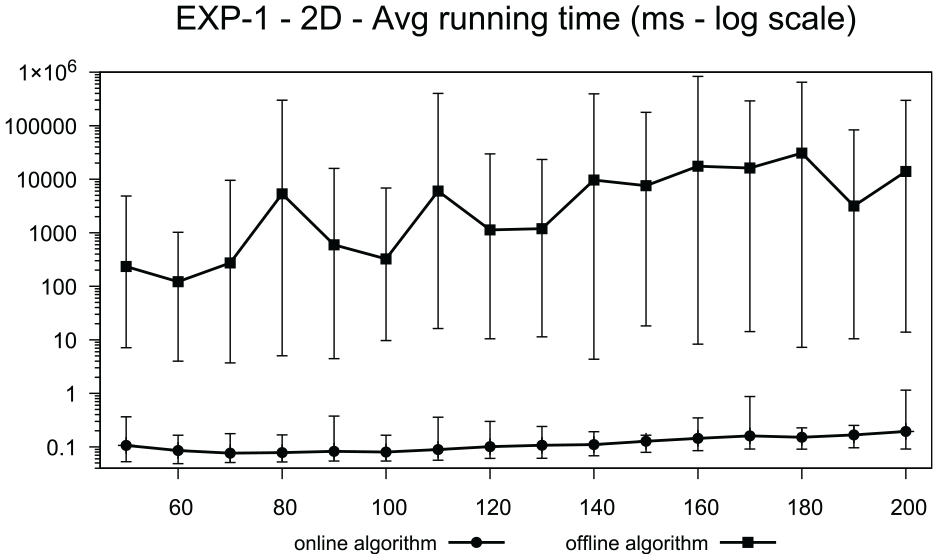
In terms of running time, for every instance the online algorithm is very fast and takes less than 1.15 ms. On the other hand, the offline algorithm is much more expensive and can even take several minutes. For example, the chart in Figure 9 shows the average running time of the two algorithms on EXP-1 and for the 2D drawing model. The results for EXP-2 and for the 1D drawing model are similar, thus we do not report the corresponding charts.
Average running time (with logarithmic scale) of the two algorithms on EXP-1 and for the 2D drawing model (-axis). The error bars show minimum and maximum values. The -axis represents the number of vertices.
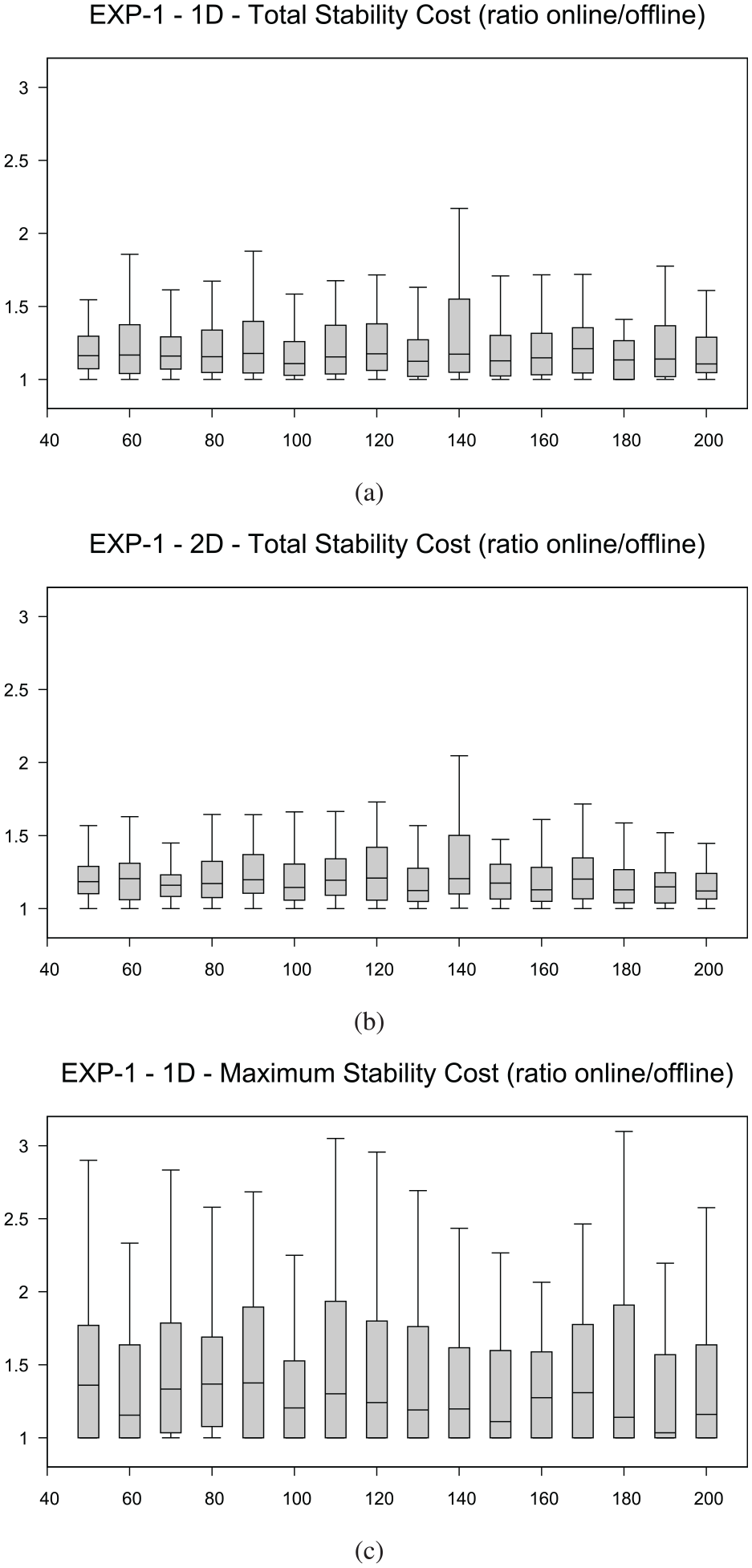
Concerning the stability cost, Figure 10 reports the data about EXP-1 for the two drawing models. In particular, for each value of , the charts show the distribution (summarized by means of box and whisker plots) of the ratio between the value of the solution of the online algorithm and the value of the optimal solution. The charts show a similar behavior: The total stability cost of the online algorithm approximates that of the offline algorithm by a factor of on average both in the 1D and in the 2D drawing model; the factor is on average for the maximum stability cost. The similarity of the experimental approximation factors in the 1D and 2D cases reflects the fact that our algorithmic strategy handles the 2D case by independently solving two 1D optimization problems, one for the -axis and one for the -axis.
EXP-1: (a) distribution of the ratio between the total stability cost of the two algorithms for the 1D drawing model (-axis), (b) distribution of the ratio between the total stability cost of the two algorithms for the 2D drawing model (-axis), and (c) distribution of the ratio between the maximum stability cost of the two algorithms for the 1D drawing model(-axis). The -axis represents the number of vertices.
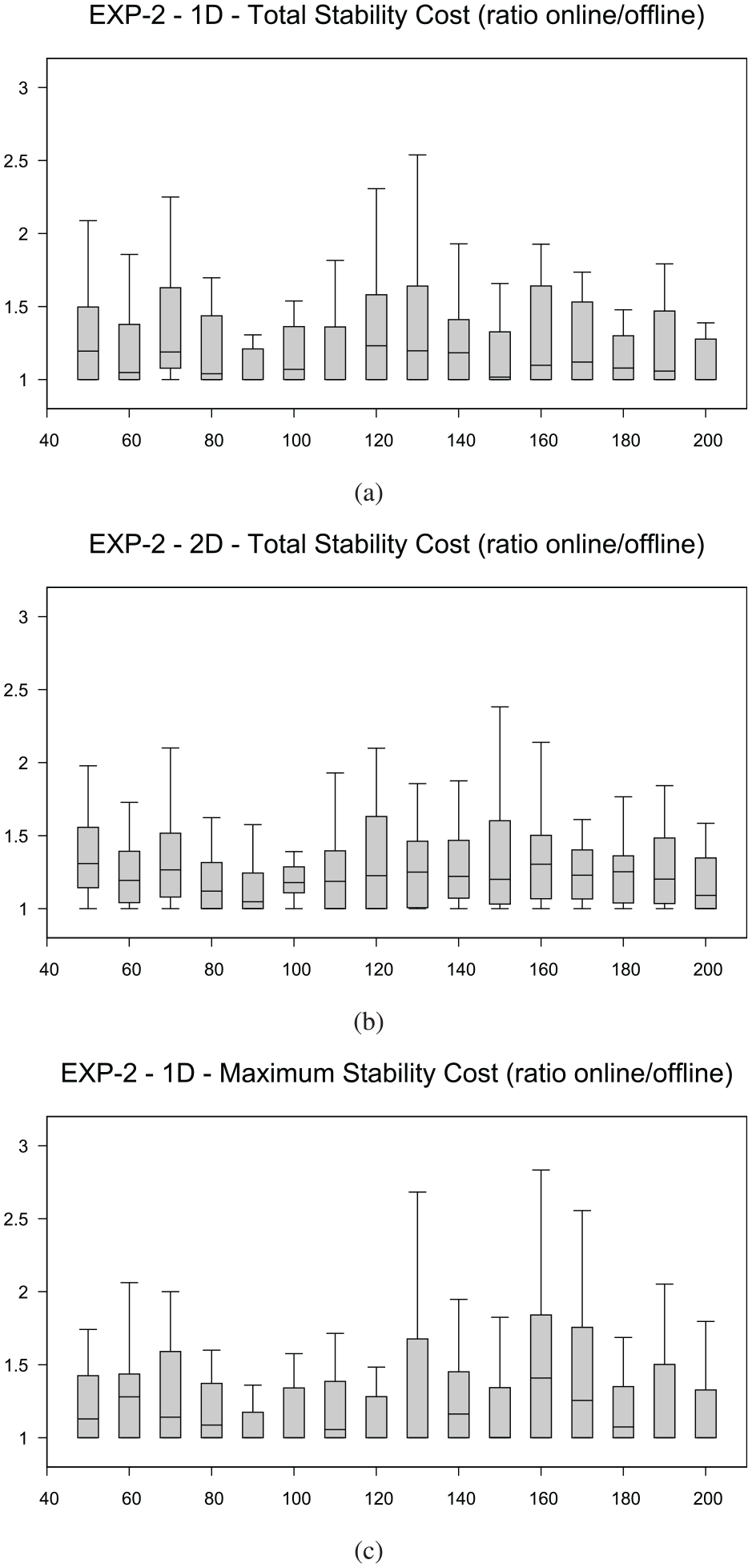
Figure 11 reports the distributions of the ratio of the stability costs for EXP-2. The charts show a behavior similar to that in Figure 10; in this case the average approximation factors are for the total stability cost both in 1D and in 2D, and for the maximum stability cost in 1D.
EXP-2: (a) distribution of the ratio between the total stability cost of the two algorithms for the 1D drawing model (-axis), (b) distribution of the ratio between the total stability cost of the two algorithms for the 2D drawing model (-axis), and (c) distribution of the ratio between the maximum stability cost of the two algorithms for the 1D drawing model(-axis). The -axis represents the number of vertices.
Table 1 reports the number of instances for which the online algorithm matches the cost of the offline algorithm, that is, those for which it reaches the optimum value. One can notice that the number of hits is larger for EXP-2 when there are only merge operations. This can be explained by observing that the solution space becomes larger if the sequence of operations includes both merging and splitting components. Namely, when there are only merge operations the number of clusters is smaller and their size is larger (see also Figure 8(c)).
Number of instances for which the online algorithm matches the optimum value.
EXP-1
EXP-2
1D total cost
184 (16%)
141 (44%)
2D total cost
52 (4%)
73 (23%)
1D max cost
341 (30%)
157 (49%)
Case study
As a proof-of-concept of our online visualization approach, we tested it on a dynamic collaboration network constructed from real data. Since we have free low-level access to the database of the Journal of Graph Algorithms and Applications (JGAA) (http://jgaa.info/), we opted for extracting information from it. In order to limit the scope of our case study, we decided to focus on a subset of papers in this database, namely those devoted to the specific topic “orthogonal drawing”. We chose this topic because it has a long tradition in graph visualization and involves JGAA publications that span a relatively long time window. We determined the relationships between the authors of these papers in terms of their collaborations, according to the following model. Denote by the set of extracted authors. For each pair of authors in sharing some JGAA paper , we created in the collaboration network a temporal edge having a starting date and an ending date . This temporal edge represents the life-time of the collaboration between and determined by . The ending date coincides with the publication date of , while the starting date is defined as , where is the number of pages of and is a positive constant that expresses a given number of weeks. According to this model, the life-time of the collaboration between and determined by is directly proportional to the number of pages (i.e. the size) of , which is a reasonable assumption. In particular, we fixed . If at any time from to another collaboration between and starts, due to a paper , the ending date of edge is updated to . The resulting network contains vertices and edges in the whole time window, determined by a total of papers.
To visually analyze the evolution of this network we implemented a graphical interface that adopts our 2D model for the series of drawings , representing the series of graphs . In this interface, the transition from to exploits a simple animation, depending on the type of event. When a new edge is inserted, the following sequence of actions is executed: the borders of vertices and are highlighted for a short time (e.g. 1 s); edge is physically drawn; if and did not belong to the same cluster (component), the border of their clusters are highlighted for a short time and then the two clusters are merged. Since our online algorithm places the new cluster in-between the previous two, this animation generally suffices to quickly recognize the merged cluster at the end of the process. When an edge is removed, the sequence of actions is as follows: edge is highlighted for a short time; edge is physically deleted from the drawing; if the removal of causes the split of the cluster of and into two clusters, all the vertices of one of these two clusters are highlighted for a short time and then the cluster is split.
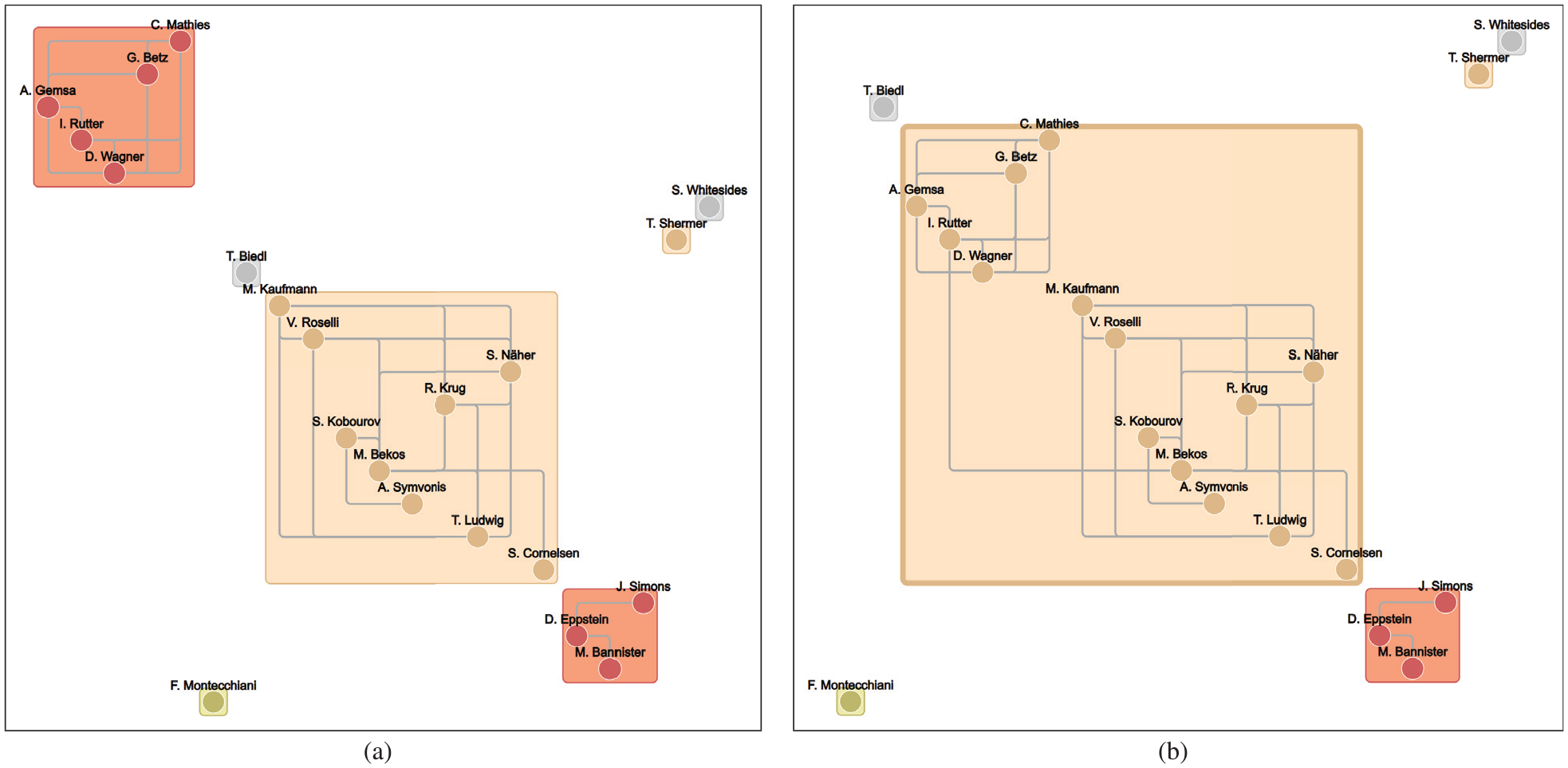
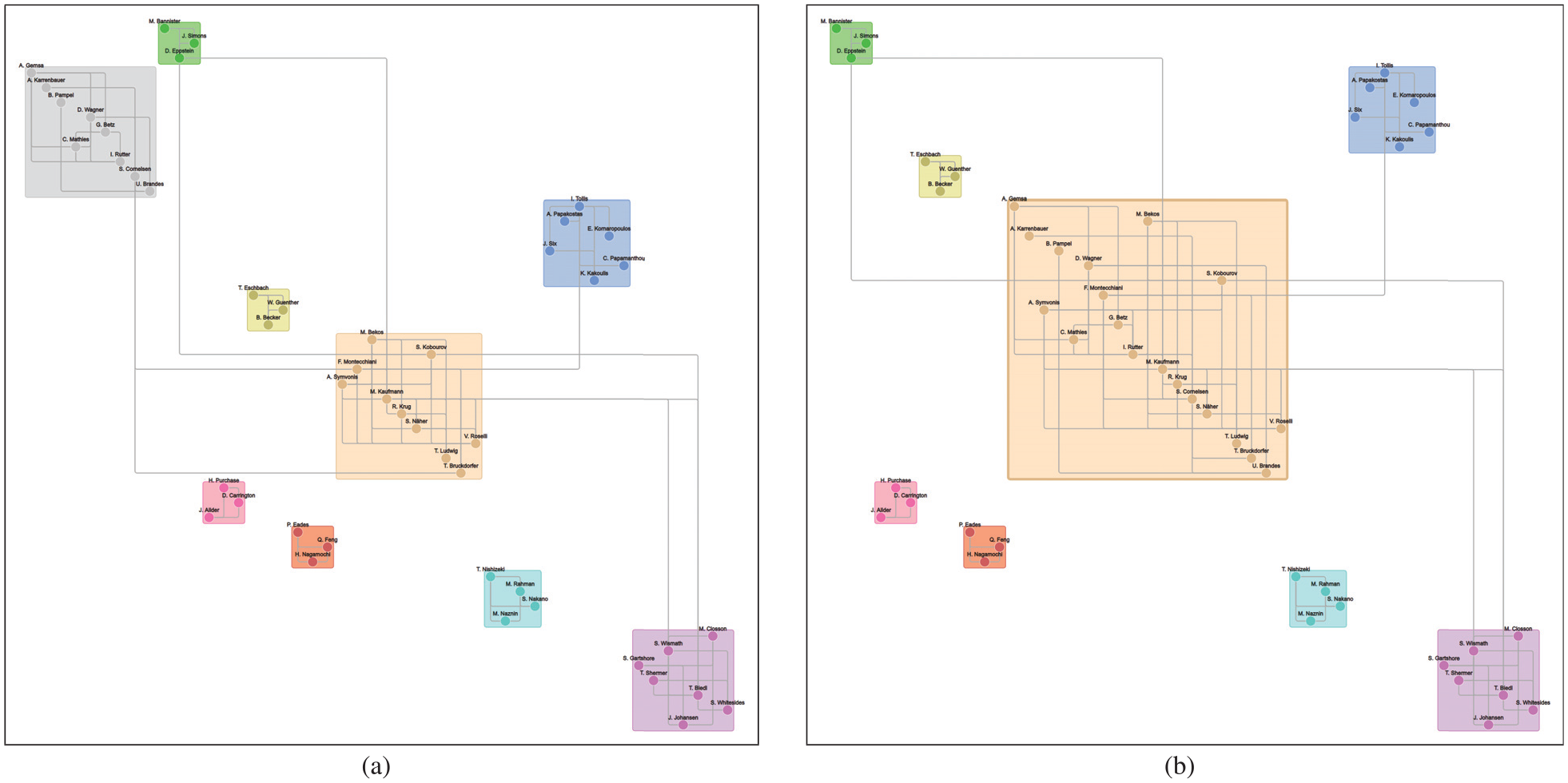
The analysis of the dynamic network started from a situation in which there was no relationship between authors. During an initial phase of the evolution we progressively observed the formation of several small connected components, consisting of up to four vertices. We noted that each component clearly represented a well distinct group of authors working in a specific geographic area; for example, we could observe the three components {Eades, Feng, Nagamochi}, {Biedl, Shermer, Whitesides, Wismath}, and {Kakoulis, Papakostas, Six, Tollis}. Merging and splitting operations of small components were observed for a considerable portion of the time window (approximatively until of the evolution). Then, we progressively observed to the formation of few bigger components; in particular, at a time corresponding to about of the time window we could identify two main distinct connected components, one consisting of vertices and the other consisting of vertices. These components reflected two different communities, with the majority of researchers from Germany. After a while, these two components were merged together, due to new collaborations between subsets of their elements, for example, a collaboration between Rutter (who belonged to the community with vertices) and Bekos (who belonged to the community with vertices). We verified that this new collaboration was on a paper about boundary labeling, a topic strictly related to orthogonal drawings. In the remaining part of the time window this new big component grew up to about vertices. In the tail of the evolution we observed several splitting operations, which witnessed the end of the collaborations in the considered time window. Figure 12 reports a portion of the visualization generated by our interface in two different time instants, namely immediately before and immediately after the merging of the two aforementioned components with and vertices, respectively. A video showing an animation of this network is available at https://www.youtube.com/watch?v=fAx-4b69Vbw.
Two consecutive time instants of a portion of the JGAA evolving network. Passing from (a) to (b) two components have been merged due to the insertion of an edge between Bekos and Rutter.
We finally remark that our algorithmic approach can be applied to the visualization of dynamic networks where clusters do not necessarily coincide with the connected components of the graph, but are determined by some automatic clustering algorithm that uses only cluster split and cluster merge operations. For example, Figure 13 shows the visualization (by means of our interface) of a co-authorship network (with a subset of authors in the previous example, but with different types of relationships) in two different time instants, where clusters represent denser portions of the network. The two time instants still refer to the situation before and after a merging operation.
Two consecutive time instants of a dynamic co-authorship network, where clusters do not coincide with the connected components.
Concluding remarks
We presented two models for dynamic visualization of graphs, focusing on highlighting the different connected components of the graph. For these models, we described online algorithms that aim to maximize the drawing stability over a sequence of events. We reported the results of an experimental study that showed good performance of the online algorithm when compared to an offline algorithm that knows the whole sequence of events in advance. Also, as a proof-of-concept of our approach, we described a case study on a real network performed by means of a graphical interface that animates the sequence of graph changes through our online algorithms. We conclude with some theoretical and application remarks.
Theoretical remarks
Lemma 2 shows that in theory the online solution can be arbitrarily worse than the offline solution. An intermediate strategy can be studied where the updates on the drawing are executed only after a certain number of steps; this number can be regarded as a parameter of a visual analytics system for dynamically evolving networks. Such intermediate strategies should have a positive impact on the running times and it may avoid the worst case effect of Lemma 2.
As a second remark, our offline strategy has a time complexity that is exponential in the number of merging/splitting operations. We find it interesting to study the complexity of the offline problem, namely is it possible to design a polynomial-time offline algorithm or is this optimization task NP-hard? In the second case, is there any (offline) approximation algorithm?
We finally mention the possibility of studying variants of our drawing stability cost function, where not only the number of pairs of vertices that change their relative ordering is considered but also the specific vertices involved over all these pairs. For example, suppose that are four vertices that occur in this linear ordering. According to our cost function, the new ordering would cost 3 while the ordering would cost 2. However, the first ordering may be judged more stable than the second one, because each costly pair involves . Similar considerations can be found in the literature about how to evaluate the visual complexity of a graph layout. For example, counting the number of block crossings (pairs of intersecting bundles of edges) has been proposed as an alternative to counting the number of edge crossings.60,61
Application remarks
Our theoretical model has some clear limits in terms of its applicability. It is specifically conceived to analyze the evolution of some types of dynamic relationships over a target set of vertices. Extensions to a broader set of scenarios can be considered. For example, one can assume that also a single vertex may appear or disappear at every time instant. In our algorithmic approach, the addition of a vertex easily corresponds to the addition of a trivial connected component, which can be added in any position of the current layout. On the contrary, the removal of a vertex causes the removal of all its incident edges, and therefore the potential fragmentation of a connected component into several ones. In this respect, an interesting problem is how to efficiently choose the removal order of the edges incident to that leads to the minimum cost. Another interesting extension is to consider more complex types of events such as the insertion/removal of multiple edges at a time. This would allow the analysis of dynamic phenomena at a coarser scale. Although such a complex event can be easily adapted to our model by breaking it down into a sequence of elementary events, a more global approach might lead to a more effective solution.
From the visualization point of view, we observe that the algorithms for the 1D drawing model can be naturally applied to circular drawings and to chord diagrams. Also, as already observed in the previous sections, our drawing models and strategies can be used for the visualization of dynamic clustered graphs where clusters do not necessarily coincide with connected components. In this case, the possible presence of edges that join two clusters may suggest to optimize additional criteria other than the vertex/cluster stability. For example, one can try to minimize edge stress52 so that clusters connected by many edges are closer in the visualization than weakly connected clusters. Finally, we observed that the area requirement of L-drawings is high and does not allow the visualization of large graphs. It is interesting to investigate more compact types of layouts that keep subdrawings within the bounding box of their vertices, while keeping the drawing stable at each edge insertion/removal.
Footnotes
Acknowledgements
This work started at the Shonan Meeting: “Reimagining the Mental Map and Drawing Stability”, 10th-13th, 2018. We acknowledge the organizers of the workshop and the anonymous reviewers of this manuscript for their valuable comments and suggestions.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was partially supported by the project MIUR, Grant 20174LF3T8 “AHeAD: efficient Algorithms for HArnessing networked Data.
ORCID iD
Walter Didimo
References
1.
NewmanMBarabasiA-LWattsDJ.The structure and dynamics of networks: Princeton studies in complexity. Princeton, NJ, USA: Princeton University Press, 2006.
2.
BeckFBurchMDiehlSWeiskopfD.A taxonomy and survey of dynamic graph visualization. Comput Graph Forum2017; 36(1): 133–159.
3.
MisueKEadesPLaiWSugiyamaK.Layout adjustment and the mental map. J Vis Lang Comput1995; 6(2): 183–210.
4.
PurchaseHCHogganEEGörgC. How important is the “mental map”? - an empirical investigation of a dynamic graph layout algorithm. In: Graph drawing, volume 4372 of lecture notes in computer science. New York: Springer, 1996, pp.184–195.
5.
ArchambaultDWPurchaseHCPinaudB.Animation, small multiples, and the effect of mental map preservation in dynamic graphs. IEEE Trans Vis Comput Graph2011; 17(4): 539–552.
6.
ArchambaultDWPurchaseHC. The mental map and memorability in dynamic graphs. In: PacificVis’12, pp.89–96. IEEE Computer Society, 2012.
7.
ArchambaultDWPurchaseHC.The “Map” in the mental map: experimental results in dynamic graph drawing. Int J Hum Comput Stud2013; 71(11): 1044–1055.
8.
FedericoPMikschS. Evaluation of two interaction techniques for visualization of dynamic graphs. In: Graph drawing, volume 9801 of lecture notes in computer science. New York: Springer, 2016, pp.557–571.
9.
LezamaARChountaIAGöhnertTHoppeHU.Visual stability in dynamic graph drawings. i-com2015; 14(3): 220–230.
AngeliniPDa LozzoGDi BartolomeoM, et al. Algorithms and bounds for L-drawings of directed graphs. Int J Found Comput Sci2018; 29(4):461–480.
12.
DuncanCAGoodrichMT.Planar orthogonal and polyline drawing algorithms. In: Handbook of graph drawing and visualization. New York: Chapman and Hall/CRC, 2013, pp.223–246.
BrandesUCormanSR.Visual unrolling of network evolution and the analysis of dynamic discourse?Inform Vis2003; 2(1): 40–50.
15.
BurchMVehlowCBeckFDiehlSWeiskopfD.Parallel edge splatting for scalable dynamic graph visualization. IEEE Trans Vis Comput Graph2011; 17(12): 2344–2353.
16.
GreilichMBurchMDiehlS.Visualizing the evolution of compound digraphs with timearctrees. Comput Graph Forum2009; 28(3): 975–982.
17.
ShiLWangCWenZQuHLinCLiaoQ.1.5d Egocentric dynamic network visualization. IEEE Trans Vis Comput Graph2015; 21(5): 624–637.
18.
van den ElzenSHoltenDBlaasJvan WijkJJ. Dynamic network visualization withextended massive sequence views. IEEE Trans Vis Comput Graph2014; 20(8): 1087–1099.
19.
KöppWWeinkaufT.Temporal treemaps: static visualization of evolving trees. IEEE Trans Vis Comput Graph2018; 25(1): 534–543.
20.
FrishmanYTalA.Online dynamic graph drawing. IEEE Trans Vis Comput Graph2008; 14(4): 727–740.
21.
GorochowskiTEdi BernardoMGriersonCS.Using aging to visually uncover evolutionary processes on networks. IEEE Trans Vis Comput Graph2012; 18(8): 1343–1352.
22.
DiehlSGörgCKerrenA. Preserving the mental map using foresighted layout. In: VisSym, pp.175–184. Eurographics Association, 2001.
23.
FengKWangCShenHLeeT.Coherent time-varying graph drawing with multifocus+context interaction. IEEE Trans Vis Comput Graph2012; 18(8): 1330–1342.
24.
GörgCBirkePPohlMDiehlS. Dynamic graph drawing of sequences of orthogonal and hierarchical graphs. In: Graph drawing, volume 3383 of lecture notes in computer science. New York: Springer, 2004, pp.228–238.
25.
EiglspergerMGutwengerCKaufmannM, et al. Automatic layout of UML class diagrams in orthogonal style. Inf Vis2004; 3(3): 189–208.
26.
VehlowCBeckFWeiskopfD.Visualizing dynamic hierarchies in graph sequences. IEEE Trans Vis Comput Graph2016; 22(10): 2343–2357.
27.
VehlowCBeckFWeiskopfD.Visualizing group structures in graphs: a survey. Comput Graph Forum2017; 36(6): 201–225.
28.
DogrusözU.Two-dimensional packing algorithms for layout of disconnected graphs. Inf Sci2002; 143(1–4): 147–158.
29.
FreivaldsKDogrusözUKikustsP. Disconnected graph layout and the polyomino packing approach. In: Graph drawing, volume 2265 of lecture notes in computer science. New York: Springer, 2001, pp.378–391.
von LandesbergerTGörnerMSchreckT. Visual analysis of graphs with multiple connected components. In IEEE VAST, pp.155–162. IEEE Computer Society, 2009.
32.
GansnerERHuYNorthSC.Interactive visualization of streaming text data with dynamic maps. J Graph Algorithms Appl2013; 17(4): 515–540.
33.
GansnerERHuY.Efficient node overlap removal using a proximity stress model. In: Graph drawing, volume 5417 of lecture notes in computer science. New York: Springer, 2008, pp.206–217.
NicholsonTAJ. Permutation procedure for minimising the number of crossings in a network. Proc Inst Electr Eng1968; 115: 2126.
36.
SaatyT.The minimum number of intersections in complete graphs. Proc Natl Acad Sci USA1964; 52(3): 688–690.
37.
MasudaSNakajimaKKashiwabaraTFujisawaT.Crossing minimization in linear embeddings of graphs. IEEE Trans Comput1990; 39(1): 124–127.
38.
BernhartFRKainenPC.The book thickness of a graph. J Combin Theory Ser B1979; 27(3): 320–331.
39.
BinucciCDi GiacomoEHossainMILiottaG.1-page and 2-page drawings with bounded number of crossings per edge. Eur J Combin2018; 68: 24–37.
40.
CimikowskiR.Algorithms for the fixed linear crossing number problem. Discrete Appl Math2002; 122(1–3): 93–115.
41.
CimikowskiRShopeP.A neural-network algorithm for a graph layout problem. IEEE Trans Neural Netw1996; 7(2): 341–345.
42.
HeHSkoraOVrt’oI.Crossing minimisation heuristics for 2-page drawings. Electron Notes Discrete Math2005; 22: 527–534.
43.
KlawitterJMchedlidzeTNöllenburgM. Experimental evaluation of book drawing algorithms. In: Graph drawing, volume 10692 of lecture notes in computer science. Springer, 2017, pp.224–238.
44.
PretoriusAJvan WijkJJ.Bridging the semantic gap: visualizing transition graphs with user-defined diagrams. IEEE Comput Graph Appl2007; 27(5): 58–66.
45.
GansnerERKorenY.Improved circular layouts. In: Graph drawing, volume 4372 of lecture notes in computer science. New York: Springer, 2006, pp.386–398.
46.
KrzywinskiMScheinJBirolN, et al. Circos: an information aesthetic for comparative genomics. Genome Res2009; 19(9): 1639–1645.
47.
SixJMTollisIG.Circular drawing algorithms. In: Handbook of graph drawing and visualization. New York: Chapman and Hall/CRC, 2013, pp.285–315.
48.
ArleoADidimoWLiottaGMontecchianiF.Profiling distributed graph processing systems through visual analytics. Future Generation Comp Syst2018; 87:43–57.
49.
GronemannMJüngerMLiersFMambelliF.Crossing minimization in storyline visualization. In: Graph drawing, volume 9801 of lecture notes in computer science. Springer, 2016, pp.367–381.
50.
KostitsynaINöllenburgMPolishchukVSchulzAStrashD. On minimizing crossings in storyline visualizations. In: Graph drawing, volume 9411 of lecture notes in computer science. Springer, 2015, pp.192–198.
51.
Di BattistaGEadesPTamassiaRTollisIG. Graph drawing: algorithms for the visualization of graphs. Upper Saddle River: Prentice-Hall, 1999.
52.
KaufmannMWagnerD (eds). Drawing graphs, methods and models (The book grow out of a Dagstuhl Seminar, April 1999), volume 2025 of lecture notes in computer science. New York: Springer, 2001.
53.
KiefferSDwyerTMarriottKWybrowM.HOLA: human-like orthogonal network layout. IEEE Trans Vis Comput Graph2016; 22(1): 349–358.
54.
BatageljVBrandenburgFDidimoWLiottaGPalladinoPPatrignaniM.Visual analysis of large graphs using (X, Y)-clustering and hybrid visualizations. IEEE Trans Vis Comput Graph2011; 17(11): 1587–1598.
55.
Di BattistaGDidimoWMarcandalliA. Planarization of clustered graphs. In: Graph drawing, volume 2265 of lecture notes in computer science. New York: Springer, 2001, pp.60–74.
56.
Di GiacomoEDidimoWLiottaGPalladinoP. Visual analysis of one-to-many matched graphs. J Graph Algorithms Appl2010; 14(1): 97–119.
57.
EadesPFengQNagamochiH.Drawing clustered graphs on an orthogonal grid. J Graph Algorithms Appl1999; 3(4): 3–29.
58.
AuberDBonichonNDorbecPPennarunC.Rook-drawings of plane graphs. J Graph Algorithms Appl2017; 21(1): 103–120.