
Abstract
T-distributed stochastic neighbor embedding (t-SNE) is an effective visualization method. However, it is non-parametric and cannot be applied to steaming data or online scenarios. Although kernel t-SNE provides an explicit projection from a high-dimensional data space to a low-dimensional feature space, some outliers are not well projected. In this paper, bi-kernel t-SNE is proposed for out-of-sample data visualization. Gaussian kernel matrices of the input and feature spaces are used to approximate the explicit projection. Then principal component analysis is applied to reduce the dimensionality of the feature kernel matrix. Thus, the difference between inliers and outliers is revealed. And any new sample can be well mapped. The performance of the proposed method for out-of-sample projection is tested on several benchmark datasets by comparing it with other state-of-the-art algorithms.
Introduction
The recent development in information technologies has led to an astonishing increase in the amount of data stored and consumed. 1 Visualization of high-dimensional data is one of the most important and fundamental tasks in big data handling, offering an intuitive interface to rapidly detect the structural elements of data, such as clusters or outliers.2,3
Dimensionality reduction (DR) techniques are widely used for high-dimensional data visualization, such as principal component analysis (PCA),4–6 locally linear embedding,7,8 isometric feature mapping9,10 and t-distributed stochastic neighbor embedding (t-SNE). 11 However, some of these methodologies are only used for supervised learning, and some are linear or non-parametric methods, with their own set of advantages and disadvantages in solving different problems. 12
T-SNE is one of the most effective nonlinear data visualization technologies. It can keep the low-dimensional features of similar high-dimensional pairs as close as possible so that the natural clusters of the original data are presented. 13 T-SNE has been successfully applied to visualize different types of data such as handwritten digital data, 14 genomic data, 15 engine vibration signals, 16 chemical process data, 17 and specimen thermograms. 18 However, t-SNE has limitations for out-of-sample extension because of its non-parametric characteristic. 19 Once the given samples are mapped, it is difficult to extend the mapping to new data points. In other words, t-SNE yields a new result every time a new data point is added, making it inapplicable for online data visualization. Even through several out-of-sample extensions of t-SNE have been proposed in the last few years, they still have drawbacks in outlier projection, computational time, or parametric selection.
To address the above problems, bi-kernel t-SNE is proposed for out-of-sample data visualization. The kernel functions of both the high-dimensional input data and the low-dimensional features are used to approximate the projections. PCA is then applied to reduce the dimensionality of the feature kernel matrix to two for visualization. With the bi-kernel mapping and PCA, outliers are depicted away from inliers in the two-dimensional (2D) scatter plots. The contribution of bi-kernel t-SNE is that it realizes an out-of-sample extension for t-SNE with few parameters and yields convincing inlier and outlier projections in linear time.
The rest of the paper is structured as follows. Section 2 briefly introduces some concepts about dimensionality reduction techniques. Section 3 reviews the original t-SNE and its several out-of-sample extensions. Section 4 details bi-kernel t-SNE, which is proposed based on kernel t-SNE and PCA. Evaluation measures for inlier and outlier mapping are introduced in Section 5. In Section 6, the effectiveness of bi-kernel t-SNE is illustrated with experimental results. Section 7 provides the discussion of the results. Section 7 concludes the paper.
Dimensionality reduction
In data visualization techniques, high-dimensional samples are mapped to a 2D space for visualization while preserving the data structure as much as possible.
20
Consider a dataset
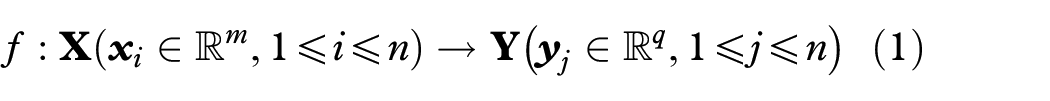
where q≪m, and typically q = 2.
Among the numerous DR techniques, many of them are non-parametric. Thus, out-of-sample data cannot be incorporated into the existing projection. Parametric projection techniques provide an explicit way to express the function f. When new samples come, they can be directly mapped with the learned function f.
In this study, we define that out-of-sample data has two categories: inlier and outlier. An inlier has the same label with the training samples or belongs to some structure in the original space. Outliers have different labels from all training samples. For inlier projection, the 2D embedding should belong to one of the training clusters. For outliers, the 2D projection should be separated from the training embedding. Ideally, the classes in outliers should be separated in the 2D map and far from the training regions in the meantime. However, many out-of-sample data projection methods only focus on inlier projection.
To evaluate a DR technique, both inlier and outlier projections should be discussed. There is no doubt that data visualization is a good way to show the existing clusters and outliers. However, we still need several indicators to gauge different properties of a DR technique in a quantitative way. Reviews of different quality metrics have been reported in many literatures.21–24 In this study, five quality metrics are used for inlier projection evaluation to see how well the projection can separate the clusters and how well the parametric projection can mimic the ground-truth projection. For outlier projection, we use the well-known F1 score and area under curve (AUC) to evaluate the performance. The evaluation measures for both inlier and outlier mappings used in this study are detailed in section 5.
T-SNE and its out-of-sample extensions
In this section, we first introduce t-SNE briefly and then discuss its several out-of-sample extensions.
As an unsupervised nonlinear DR technique, t-SNE calculates the similarity with conditional probabilities. It captures the local structure of the high-dimensional data very well, while also revealing the global structure. 13 It uses a symmetrized cost function with simple gradients and a student-t-distribution to compute the similarity in the low-dimensional space, solving the “difficult to optimize problem” and the “crowding problem” observed in SNE. The cost function, that is, KL divergence, is computed as
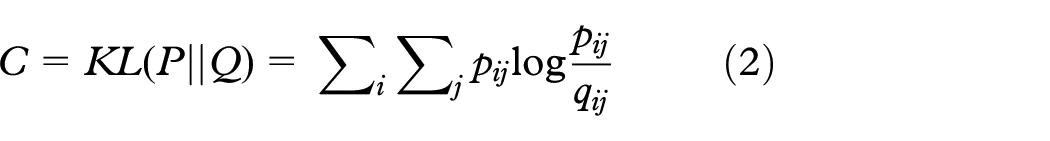
where P and Q are the joint probability distributions in the high-dimensional and low-dimensional spaces, respectively. Taking
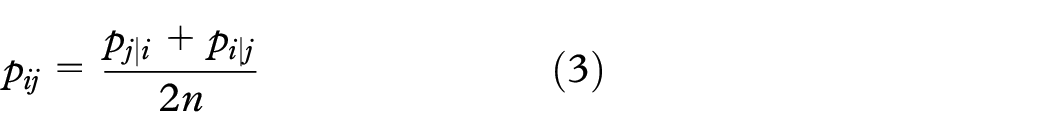
where n is the number of samples.

Taking
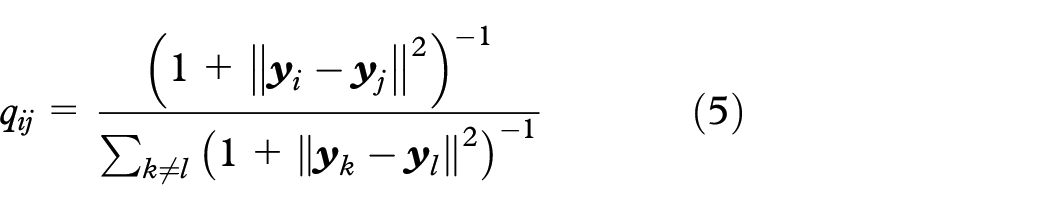
The objective of t-SNE is to find the optimal
The main limitation of t-SNE is that it is a non-parametric technique. 19 Once the given samples are mapped, it is difficult to extend the mapping to new data points. To overcome this drawback, some attempts have been made to extend t-SNE for out-of-sample projection.
Neural networks (NN) can learn many complex functions, including the t-SNE projection. Van Der Maaren
25
used restricted Boltzmann machines to learn an explicit projection between
Gisbrecht et al. 19 proposed kernel t-SNE, where low-dimensional features can be approximately mapped by a linear combination of normalized Gaussian kernels of high-dimensional data points. It retains the flexibility of the basic t-SNE and enables an explicit out-of-sample extension in linear computing time. Kernel t-SNE can be considered as one of the interpolation methods, where the weights are derived from kernel mapping instead of some distance. However, outliers are still not well projected with interpolation methods.
Boytsov et al.
27
proposed local interpolation with outlier control t-SNE (LION t-SNE) to incorporate both inliers and outliers. It is based on local interpolation in the vicinity of training data, outlier detection and a special outlier mapping algorithm. Outlier detection is applied firstly to determine if the new sample is an outlier. If it is not an outlier, inverse distance weighted interpolation is used to place the projection in the vicinity of some
Bi-kernel t-SNE
We discussed t-SNE and its several parametric variants in Section 3. Although these variants realize out-of-sample extension for t-SNE, they still have drawbacks in outlier projection, parameter selection, or computational time. To alleviate these problems, we present bi-kernel t-SNE in this section. It is proposed based on kernel t-SNE and PCA. Kernel t-SNE yields a simple out-of-sample extension with the kernel mapping. However, the mapping is performed directly on low-dimensional feature, which leads to a poor outlier projection. In bi-kernel t-SNE, the projection is approximated with the kernel functions of both the input data and the features. Then the dimensionality of the feature kernel matrix is reduced to two by PCA. With the bi-kernel mapping and PCA, outliers are mapped away from the existing region in the 2D scatter plots.
In this section, we firstly introduce kernel t-SNE and its drawbacks in outlier projection. Then we present the procedure of PCA. Finally, we propose bi-kernel t-SNE, together with a practical way for its parameter selection.
Kernel t-SNE
Kernel t-SNE was proposed to yield a simple out-of-sample extension for t-SNE with the kernel mapping. Denoting

where the elements in the matrix
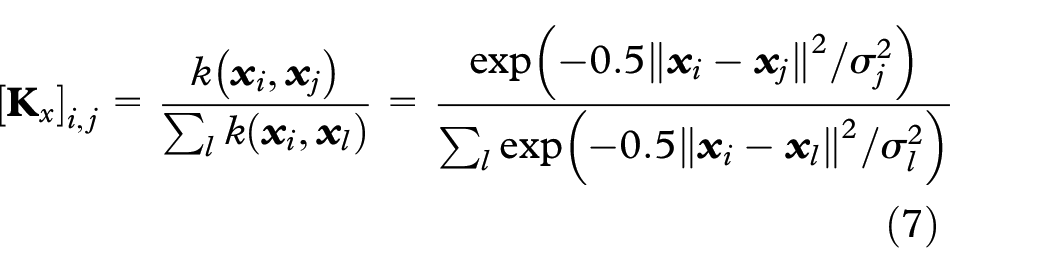
The parameter matrix

For the out-of-sample extension, the standard t-SNE is first used to map
Note that if the new sample is an outlier, the Gaussian kernel
PCA
PCA is one of the most widely-used DR method and has been used for outlier detection in many fields. The main idea of it is to project data to a new orthogonal coordinate system. The dimensionality of data is reduced by only choosing the first few principal components, while preserving as much data variation as possible.
Given a data matrix
(1) Normalize X with the means and variances.
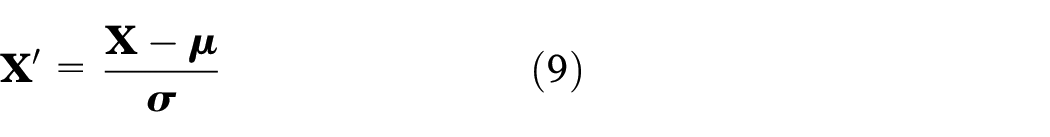
where
(2) The covariance matrix
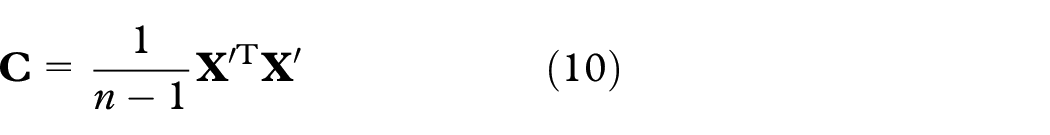
(3) By eigendecomposition,
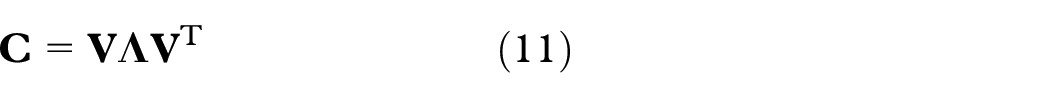
where
(4) The transformed matrix
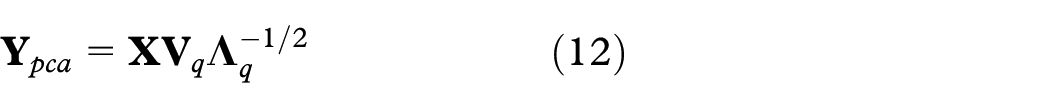
where
Bi-kernel t-SNE
In the testing procedure in kernel t-SNE, the difference between the outliers and inliers is submerged in

where kx and ky are the Gaussian kernels parameterized by the bandwidths σx and σy, respectively.
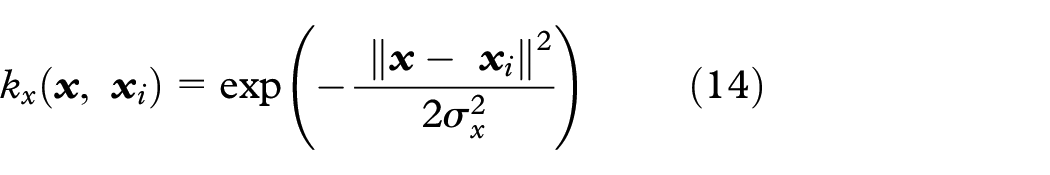
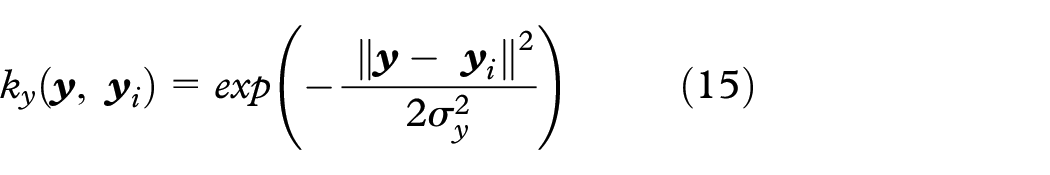
For each training and testing data,
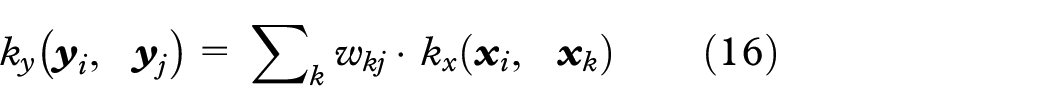
Assuming that

We apply the least-squares method to solve the equation and obtain

Then PCA is applied to reduce the dimensionality of
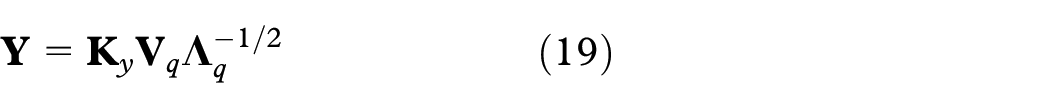
where
In bi-kernel t-SNE, the original t-SNE first maps
Table 1 summarizes the training and testing procedures of bi-kernel t-SNE. The matrices
Training and testing procedures of bi-kernel t-SNE.

Parameter selection
Bi-kernel t-SNE has two parameters, that is, σx and σy, which are the bandwidths of the Gaussian kernel functions. The bandwidth determines the smoothness and divergence of the kernel function. Proper choice of the bandwidth will have a profound effect on the performance of the out-of-sample extension. According to the definition (equations (14) and (15)), the value of the Gaussian kernel decreases with increasing Euclidean distance and ranges between 0 and 1.
We present a practical way to determine the values of σx and σy in bi-kernel t-SNE. The main idea is that all elements in
For training data, the Gaussian kernel is equal to 1 when the two samples are the same, which is the upper bound of the range. The lower bound ξ can be derived as the kernel value of the farthest training data pair, which is

where
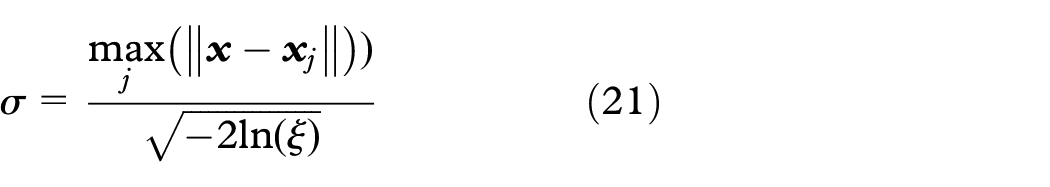
To get a robust kernel function, the farthest data pair is replaced by the median of the farthest l data pairs.
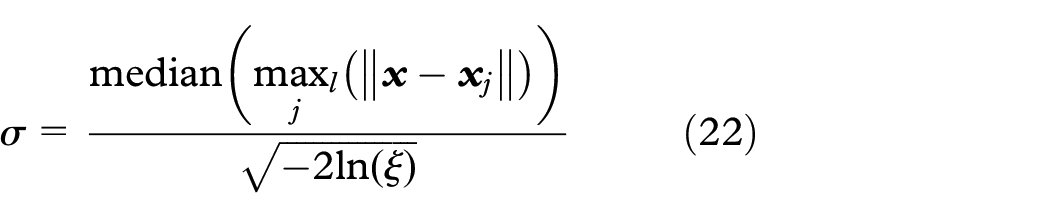
where
Evaluation measures
To evaluate the inlier and outlier projection ability of the proposed method, two sets of quality metrics are introduced for comparison with the state-of-the-art approaches. Trustworthiness, continuity, neighborhood hit, Shepard diagram correlation, and quality neighborhood are used to quantify the performance of bi-kernel t-SNE in inlier projection. F1 score and AUC are used for outlier projection quality evaluation. The definition of them are listed in Table 2.
Projection quality metrics.

Quality metrics for inlier projection
All the quality metrics range in [0, 1] with 1 being the best. In this article, K is set to 10.
Quality metrics for outlier projection
The outliers should be detectable if they are mapped separated from the inliers. Here, the mean squared k-nearest neighbor distance D is used for outlier detection. 31

F1 score and AUC range in [0, 1], with 1 being the best.
Experiments
In this section (1) we discuss the parameter selection in bi-kernel t-SNE; (2) we test the ability of bi-kernel t-SNE in extending the t-SNE projection to inliers; (3) we test the performance of bi-kernel t-SNE in projecting outliers; (4) we measure the computational time needed for bi-kernel t-SNE with respect to varying number of samples. Both inliers and outliers are out-of-sample data. The inliers have the same labels as the training data. The outliers have different labels with the training data.
We use three out-of-sample extensions of t-SNE, that is, kernel t-SNE, 19 LION t-SNE, 28 and DL t-SNE, 21 and four parametric DR algorithms, that is, UMAP, 35 AE, PCA, and KPCA, as benchmark methods for comparison. The experiments were executed on a computer with Pytorch 1.3.1, Python 3.7.4, Windows 7, CPU: Intel Core i7-4710 2.5GHz, and RAM: 8GB. The quality metrics and computational time are averaged over 10 runs.
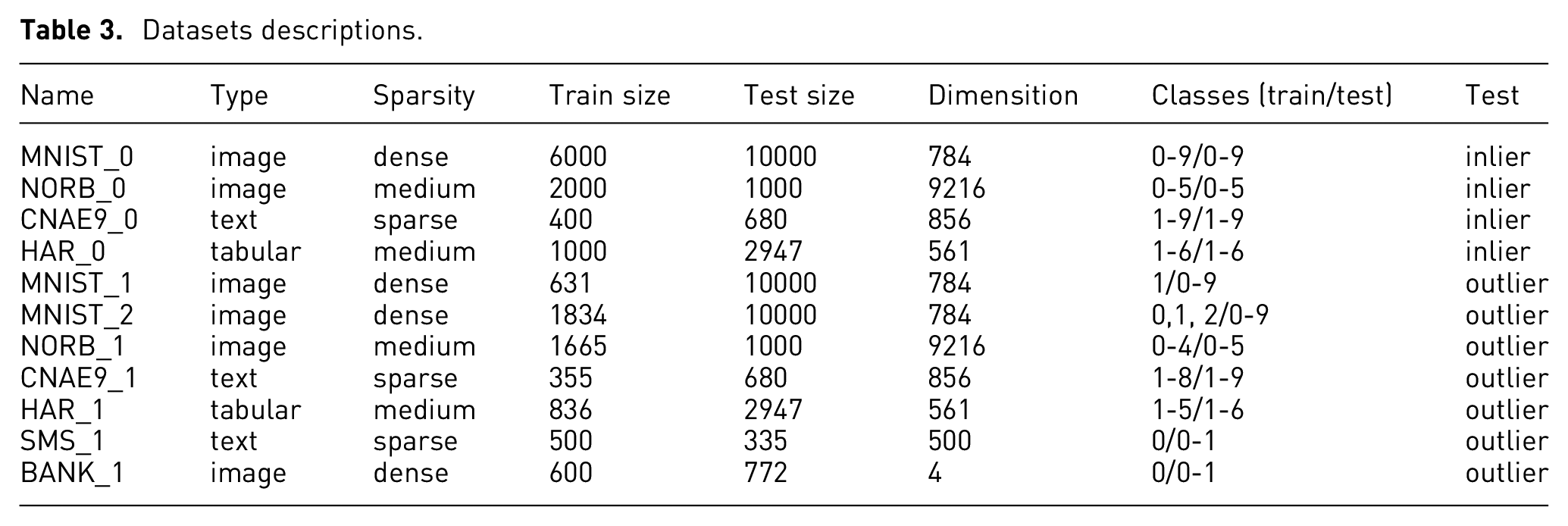
Based on data type, sparsity and dimensionality, we chose the following six datasets to conduct eleven experiments for inlier and outlier projection tests. The eleven subdatasets used in the experiments are descripted in Table 3. Among them, four subdatasets are used for inlier projection test and seven are used for outlier projection test.
The MNIST 36 dataset contains 60,000 handwritten digits images from 0 to 9. Each image has 28×28 pixels.
The NORB 37 dataset contains 48,600 different toys images under six different lighting conditions. The number of pixels of an image here is 96×96.
The CNAE9 38 dataset contains free text descriptions of Brazilian companies categorized into nine categories.
The Smartphone Dataset for Human Activity Recognition (HAR) dataset 39 is collected from 30 participants with six activities.
The SMS Spam Collection (SMS) 40 is a public set of SMS labeled messages collected for mobile phone spam research. There are 723 samples under class 0 and 112 samples under class 1.
The banknote authentication (BANK) data 41 were extracted from images taken from genuine and forged banknote-like specimens. There are 762 observations under class 0 and 610 observations under class 1.
Datasets descriptions.
Parameter setting
We use NORB_1 and HAR_1 datasets to discuss the parameter setting in bi-kernel t-SNE. Different values (0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, and 0.9) were chosen for ξx and ξy to calculate the quality metrics. As all these metrics range over [0, 1], and we consider them equally important, the average of the seven quality metrics is used to evaluate the performance of different parameters. The results are shown in Figure 1. Darker color means better projection quality. For different datasets, the projection performances are slightly different. For NORB_1 dataset, the projection quality is better when ξx and ξy are greater. For HAR_1 dataset, it is better when ξx is smaller and ξy is greater. In general, better performance is obtained when 0.6≤ξ≤0.8. We set ξx and ξy to 0.7 in this study.
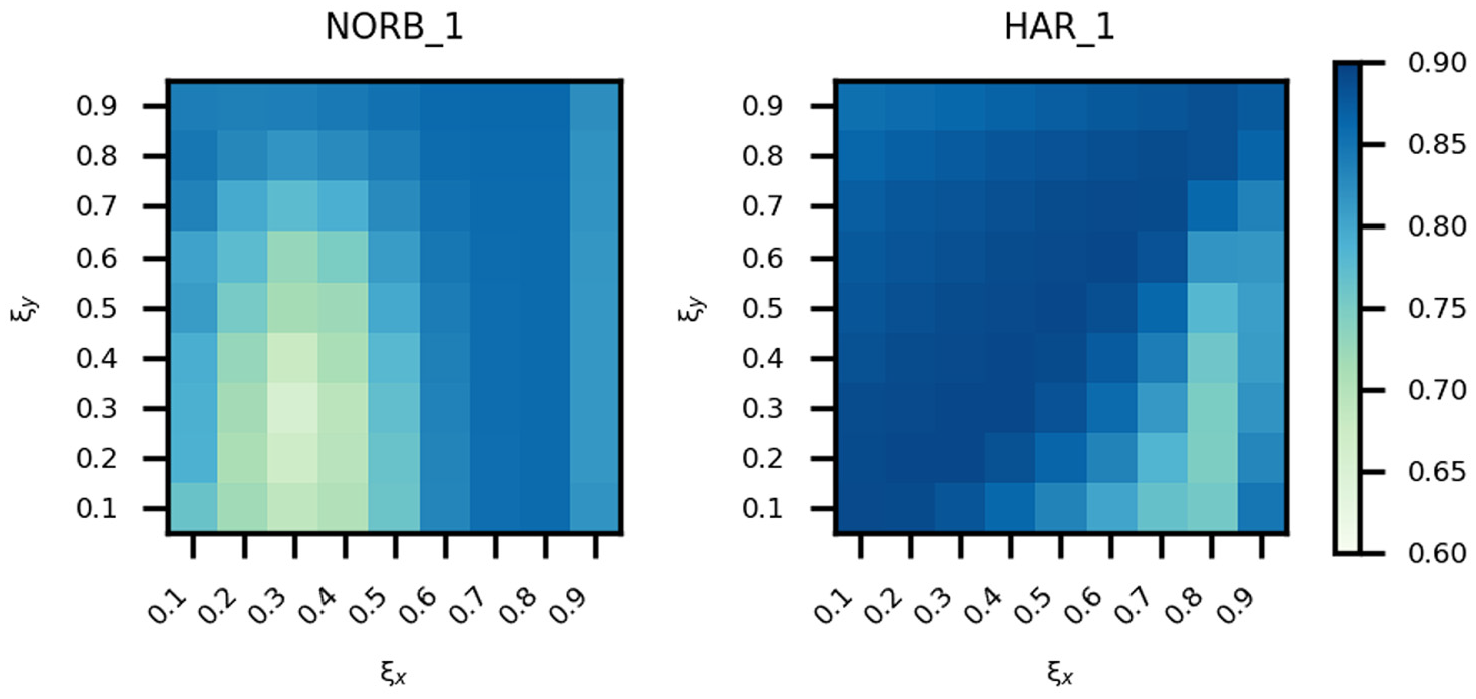
Projection performance of different parameters on NORB_1 and HAR_1 datasets.
Except for σx and σy, there are other parameters in bi-kernel t-SNE and other methods. The perplexity in all t-SNE-related methods is set to 40. The bandwidths in kernel t-SNE and KPCA are determined by the lower bound of the training kernel, which is the same as the way selecting σx and σy in bi-kernel t-SNE. DL t-SNE has three fully connected hidden layers, with 256, 512, and 256 units, respectively, followed by ReLU activation functions. It uses a two-element output layer and the sigmoid activation function to encode the 2D projection. 21 The learning rate is set to 0.0001. The training epoch is 10. AE has one hidden layer with 16 neurons in the encode unit. 22 The sigmoid function is used after each hidden layer. The number of neurons in the output layer is 2. The learning rate is set to 0.0001. The training epoch varies from 2 to 10 according to different sizes of the datasets.
Inlier projection test
Different classes in the training dataset are projected to separated regions in the 2D map by t-SNE. As an out-of-sample extension of t-SNE, bi-kernel t-SNE should be able to mimic the ground-truth projection and extend to inliers.
Figure 2 shows the ground-truth projections of bi-kernel t-SNE performing on four datasets, comparing to kernel t-SNE, LION t-SNE, DL t-SNE, UMAP, AE, PCA, and KPCA. In Figure 2, the training projection results of t-SNE-based methods are similar, which are better than other data visualization techniques. In particular, MNIST_0 and CNAE9_0 datasets can only be well projected by t-SNE-based methods and UMAP. Different clusters in NORB_0 and HAR_0 datasets are easily separated by all technologies, except that UMAP maps some samples that have the same label to separated regions.
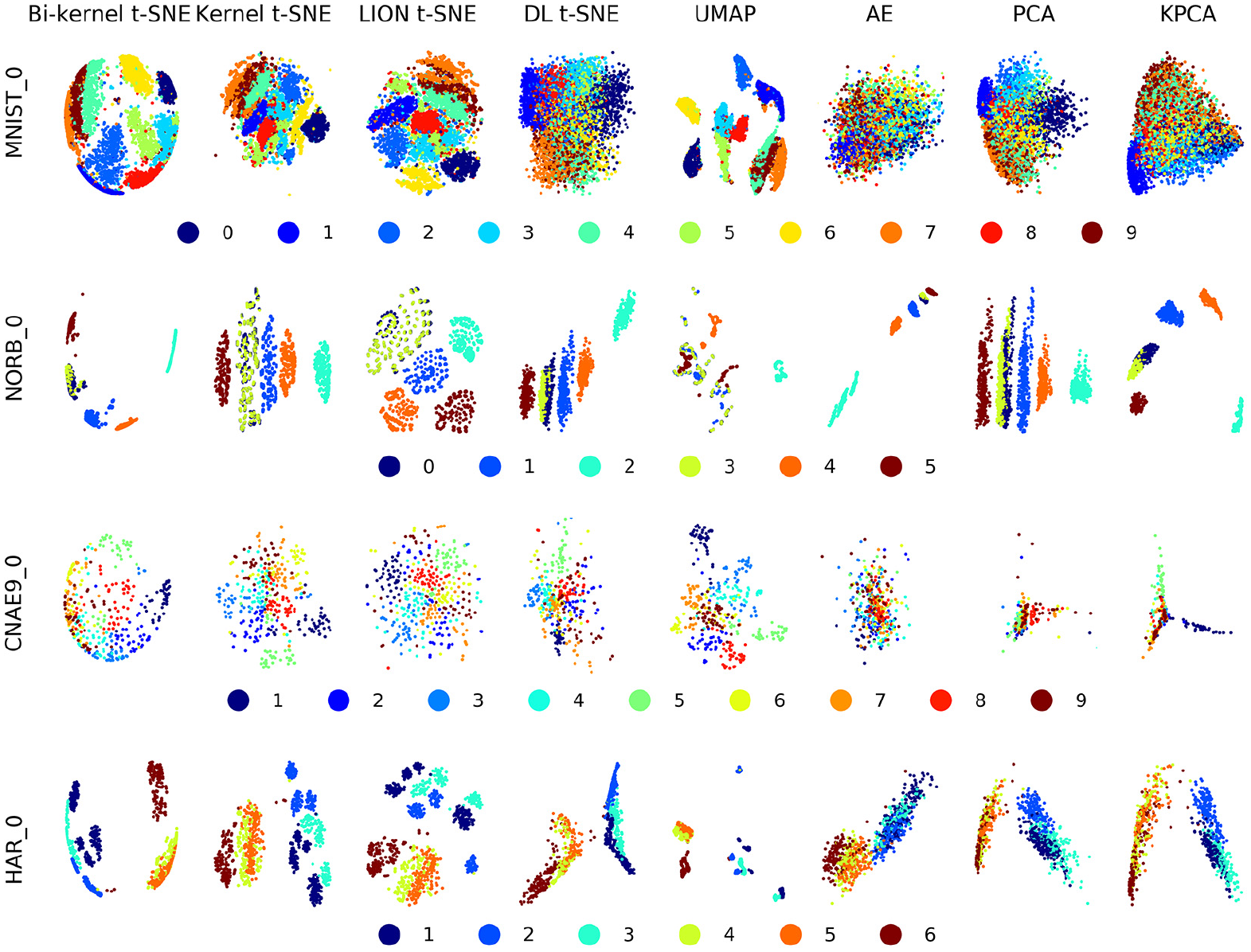
Training projection results of eight techniques on four datasets.
Figure 3 shows the inlier projections. Each color stays in the same area as it stays in Figure 2, which means that all methods can extend the projection to inliers. However, the testing projections can only be similar to or marginally worse than the training projections. The clusters in the testing projections mix more than in the training projections. In other words, if the ground-truth projection is worse than others, it is hardly possible that the testing projection will be better. To compare our proposed method with other state-of-the-art data visualization techniques, the quality metrics are calculated and shown in Figure 4. The quality metrics are slightly different for various algorithms on these four datasets. In general, t-SNE-related methods and UMAP obtain greater quality metrics on most datasets, compared with other state-of-the-art techniques. Bi-kernel t-SNE yields similar results to other t-SNE-based methods and UMAP, which indicates a well inlier projection ability.
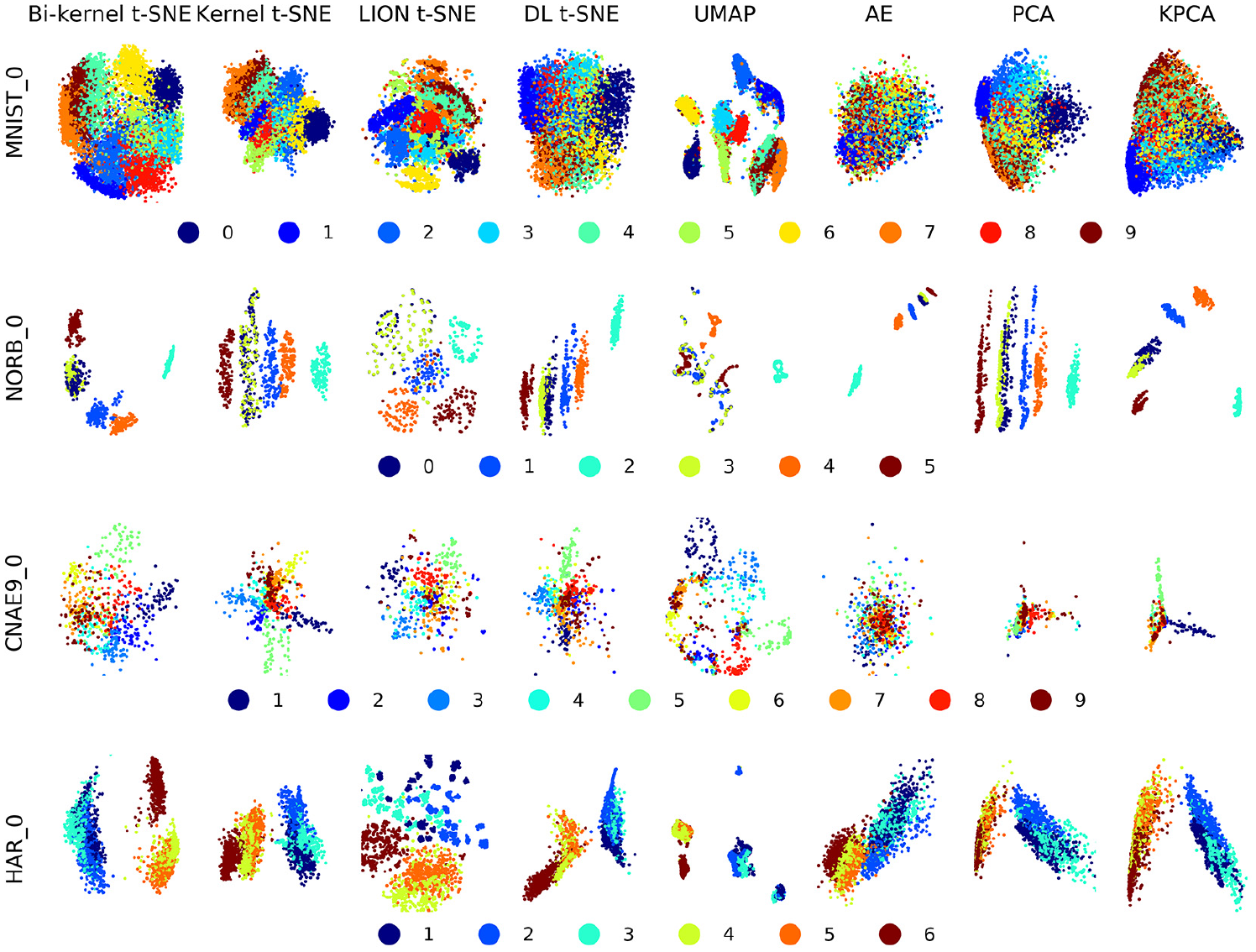
Testing inlier projection results of eight techniques on four datasets.
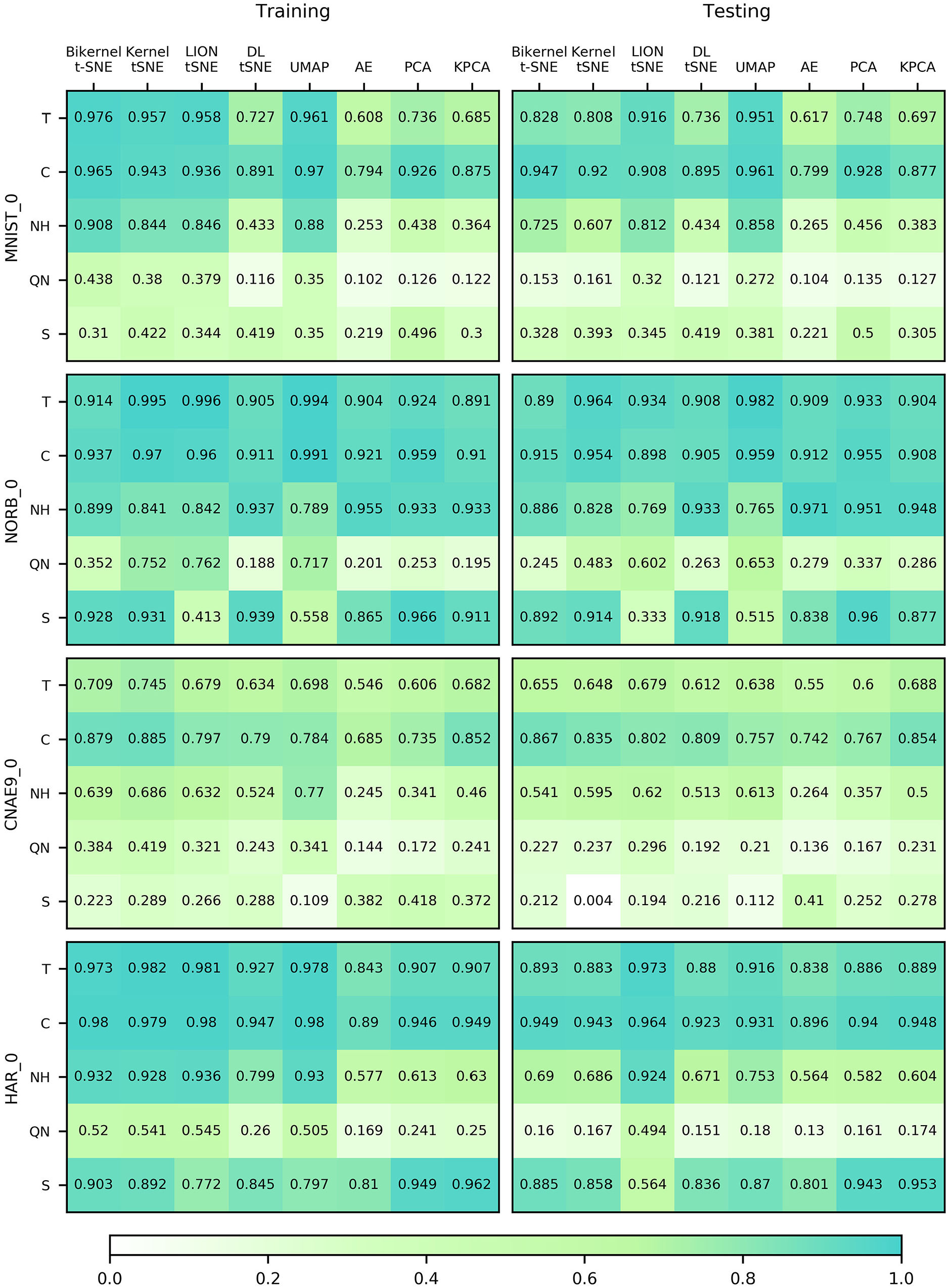
Inlier projection quality metrics comparison.
Outlier projection test
To evaluate the performance of bi-kernel t-SNE in outlier projection, seven experiments were conducted. In each experiment, the number of testing classes is more than that of training classes. Figure 5 shows the testing visualization results on seven datasets and Figure 6 shows the quality metrics, that is, F1 score and AUC.
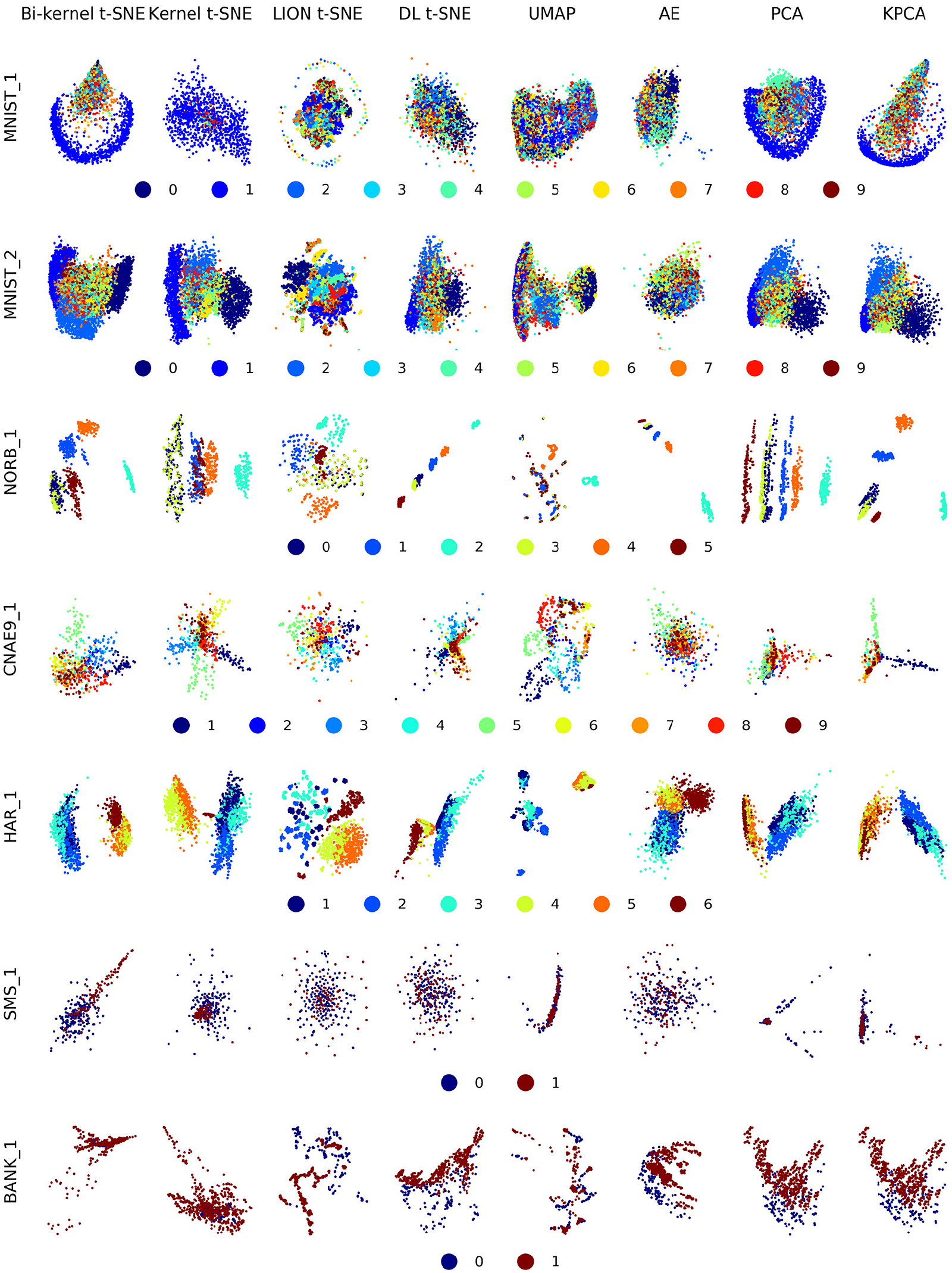
Outlier projection results of eight techniques on seven datasets.
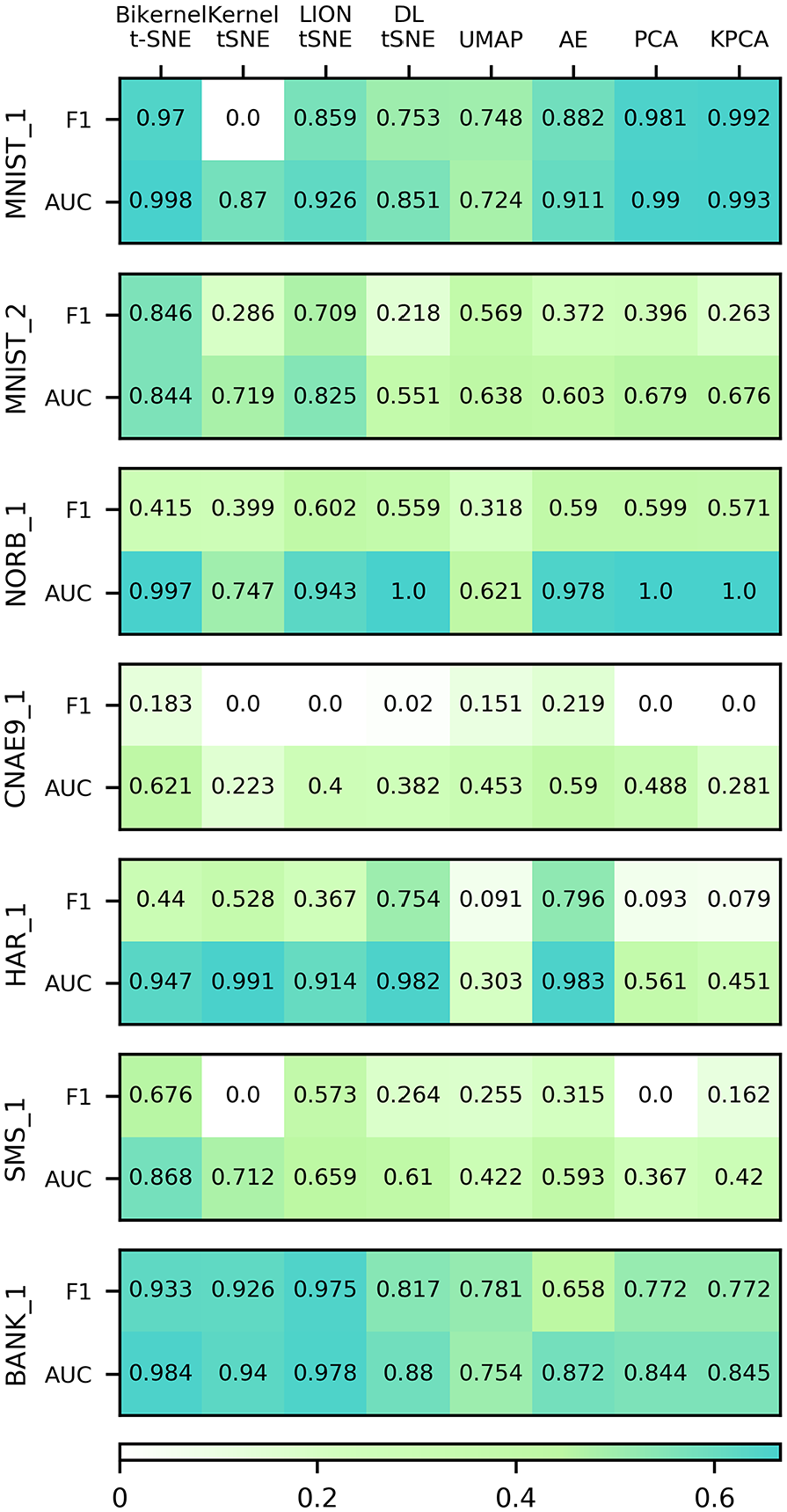
Outlier projection quality metrics comparison.
Firstly, we would like to discuss how bi-kernel t-SNE overcomes the aforementioned drawback of kernel t-SNE in outlier projection. Taking MNIST_1 dataset as an example, class 1 is used for model training and all the other nine classes are outliers. Outliers are usually far from the training set. The Gaussian kernel
Secondly, we compare bi-kernel t-SNE with other out-of-sample extensions of t-SNE and several state-of-the-art data projection methods. For MNIST_1 dataset, class 1 is used for model training and all the other nine classes are outliers. It can be seen that most methods can separate class 1 with other classes (row 1 in Figure 5). For MNIST_2 dataset, classes 0, 1, and 2 are used for training and the other seven classes are outliers. Only bi-kernel t-SNE and LION t-SNE can separate the outliers with the inliers (row 2 in Figure 5). F1 score and AUC of them are relatively greater than other methods (Figure 6). However, all methods cannot separate different classes in outliers. For the rest five datasets, samples from the last class are outliers. The outliers in NORB_1, HAR_1, and BANK_1 datasets are quite different from the inliers so that they can be correctly projected to separated regions by many methods (rows 3, 5, and 7 in Figure 5). However, for NORB_1 dataset, AUC of kernel t-SNE and UMAP is significantly lower than it of other methods (Figure 6). UMAP, PCA, and KPCA do not work well on HAR_1 dataset. For CNAE_9 and SMS_1 datasets, all data visualization techniques have considerable difficulty in separating the outliers with the inliers (rows 4 and 6 in Figure 5). Only our proposed method obtain greater F1 score and AUC on SMS_1 dataset (Figure 6).
Summarizing above, bi-kernel t-SNE and LION t-SNE are much better than others in separating outliers from inliers. Bi-kernel t-SNE yields better outlier projections than LION t-SNE on most datasets, especially on SMS_1 dataset.
Computational time comparison
Computational time measures the complexity of the algorithm, which is crucial to its applicability in large data projection. In this section, we compare the computational times of bi-kernel t-SNE, kernel t-SNE, LION t-SNE, and DL t-SNE. The running times of them are dominated by the original t-SNE and the respective out-of-sample mapping techniques.
The experiments were carried out on MNIST dataset. We used 500, 1000, 2000, 3000, 4000, 5000 and 6000 samples for training. Then we used the model trained by 2000 samples as the ground truth for testing. The number of testing samples also ranges from 500 to 6000. Figure 7 shows the results. The training procedure of LION t-SNE takes the least time since it is the same as the original t-SNE. Bi-kernel t-SNE is only a little slower than the other parametric extensions of t-SNE. In practice, one can train only once and extend the projection to bigger dataset. Hence, testing time is more important for a parametric projection technique. The testing procedures of bi-kernel t-SNE and kernel t-SNE take similar time, which is about one order of magnitude slower than DL t-SNE and two orders of magnitude faster than LION t-SNE. This is an important result, since LION t-SNE is the only out-of-sample extension of t-SNE that works well on outliers as we aware of. Only a little more training time and orders of magnitude less testing time, together with the projection quality, show that our proposed method is a competing alternative.

Computational time comparison between bi-kernel t-SNE, kernel t-SNE, LION t-SNE, and DL t-SNE on MNIST dataset.
Discussion
Bi-kernel t-SNE enables out-of-sample extension for t-SNE, realizing convincing out-of-sample visualization results in linear time. With the bi-kernel mapping and PCA, our proposed method overcomes the drawback of kernel t-SNE in outlier projection. Specifically, bi-kernel t-SNE can extend the original t-SNE projection to inliers, achieving a similar inlier projection quality to kernel t-SNE, LION t-SNE, and DL t-SNE. For outlier projection, the performance of bi-kernel t-SNE is a little better than LION t-SNE and significantly better than other benchmark methods.
Only two parameters exist in bi-kernel t-SNE, except for the perplexity. They are the bandwidths of the Gaussian kernel functions and can be simply determined by specifying lower bounds for the training kernels. This is much easier than the parameter selection in pt-SNE. Moreover, there is no need to worry about overfitting in model training.
The computational time cost by the testing procedure of bi-kernel t-SNE is almost the same as kernel t-SNE and orders of magnitude less than LION t-SNE. Among the several out-of-sample extensions of t-SNE, LION t-SNE is the only one that works well on outliers as we aware of. Considering this, bi-kernel t-SNE is more applicable to visualize large data on a relatively low-performance equipment.
Bi-kernel t-SNE still has limitations in outlier visualization, which is also the well-known problem in machine learning. For example, when the outlier contains more than two classes, it is very possible that their 2D projections overlap with each other. A parametric data visualization method can only learn the data structure in the training data. For unseen data structures in outliers, however, most parametric DR algorithms have difficulty in revealing them. How to extend the original t-SNE projection to unrelated data and generate a well-separated outlier visualization is still a difficulty.
Conclusion
In this paper, a bi-kernel t-SNE is presented for out-of-sample data visualization, realizing convincing visualization results in linear time and overcoming the limitations of kernel t-SNE for outlier projection. The explicit mapping between the high-dimensional space and the low-dimensional space is approximated using the Gaussian kernel matrices of both input data and features. PCA is then introduced to reduce the dimensionality of the mapped kernel matrix and reveal the difference between the outliers and inliers. Two groups of comparative experiments conducted on the inlier and outlier projections demonstrate the ability of bi-kernel t-SNE.
This proposal opens the way for t-SNE toward outlier detection since the outliers and the inliers are well separated by bi-kernel t-SNE. Potential future work will expand on outlier online detection in other fields. Besides that, how to extend the ground-truth projection to unrelated data and generate a well-separated outlier visualization will be also considered in our future work.
Footnotes
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work has been supported by National Natural Science Foundation of China (61803005, 61640312, and 61763037), Natural Science Foundation of Beijing Municipality (4192011 and 4172007), Key R & D project of Shandong Province (2018CXGC0608), China Scholarship Council, and the Beijing Municipal Commission of Education.