
Abstract
Civil engineers use numerical simulations of a building’s responses to seismic forces to understand the nature of building failures, the limitations of building codes, and how to determine the latter to prevent the former. Such simulations generate large ensembles of multivariate, multiattribute time series. Comprehensive understanding of this data requires techniques that support the multivariate nature of the time series and can compare behaviors that are both periodic and non-periodic across multiple time scales and multiple time series themselves. In this paper, we present a novel technique to extract such patterns from time series generated from simulations of seismic responses. The core of our approach is the use of topic modeling, where topics correspond to interpretable and discriminative features of the earthquakes. We transform the raw time series data into a time series of topics, and use this visual summary to compare temporal patterns in earthquakes, query earthquakes via the topics across arbitrary time scales, and enable details on demand by linking the topic visualization with the original earthquake data. We show, through a surrogate task and an expert study, that this technique allows analysts to more easily identify recurring patterns in such time series. By integrating this technique in a prototype system, we show how it enables novel forms of visual interaction.
Introduction
In what ways do building structures fail during an earthquake? This question has serious legal and economic implications: building codes such as the International Building Code 1 dictate safety standards, and these can have an impact on how much buildings cost. Building codes, in addition, do not necessarily reflect accurately the complicated ways in which buildings sway and break, and thus are constantly being revised since their introduction in the 1980s.2,3 In this paper, we present a novel technique for visually exploring data generated from simulations of building responses under seismic loads, and a prototype system built to support the visualization of such data.
Civil engineers often use small-scale, real-life experiments to understand the dynamics of buildings during such earthquakes. 4 This process can be slow and laborious, but the data analysis is comparatively straightforward. More recently, there has been a tendency to use simulated shake tables to explore a variety of scenarios and to study the forces and stresses exerted on buildings during such earthquakes. One of the central advantages of computational science is the drastic reduction in experimental costs: studies that once were prohibitively expensive and laborious to run are now performed entirely in silico. As a consequence, civil engineers now have an over-abundance of data, and the barrier to the creation of safer building and building codes is no longer in the creation of such studies, but rather in understanding the results of such simulations. In such a scenario, data analysis and interactive visualization play a critical role.
Specifically, the data generated by such computational simulations is a large ensemble of multivariate time series. These simulations take as input a specification of the structure of the building, and the ground acceleration of a recorded earthquake. Each run of the simulation records a number of physical variables (such as displacement, shear, moment, and acceleration) at a relatively high frequency (typically 400 samples per simulation second). Each of these variables is recorded for each of the building floors’ degrees of freedom for the duration of the earthquake.
Engineers wish to understand and compare the responses across a number of different earthquakes. The resulting ensemble of time series data has both periodic and non-periodic components. As we will show in Section 4, the frequency components change throughout the earthquake, which means that traditional frequency-domain analysis is not particularly well-suited. In response, in this work we collaborated with civil engineers that produce and study such data, in order to design a visualization that helps them in their analysis. Specifically, we contribute:
A novel technique (Figure 1) to extract periodic and non-periodic features from time-series ensembles that combines short-time Fourier Transforms with topic modeling (Section 4).
Acoordinated multiple-view prototype system that leverages the advantages of visually encoding topics and incorporates both local and global features (Section 5).
One quantitative study and an expert evaluation which show that this technique can provide a better infrastructure for visual analysis of this specific type of time-series data (Section 6).
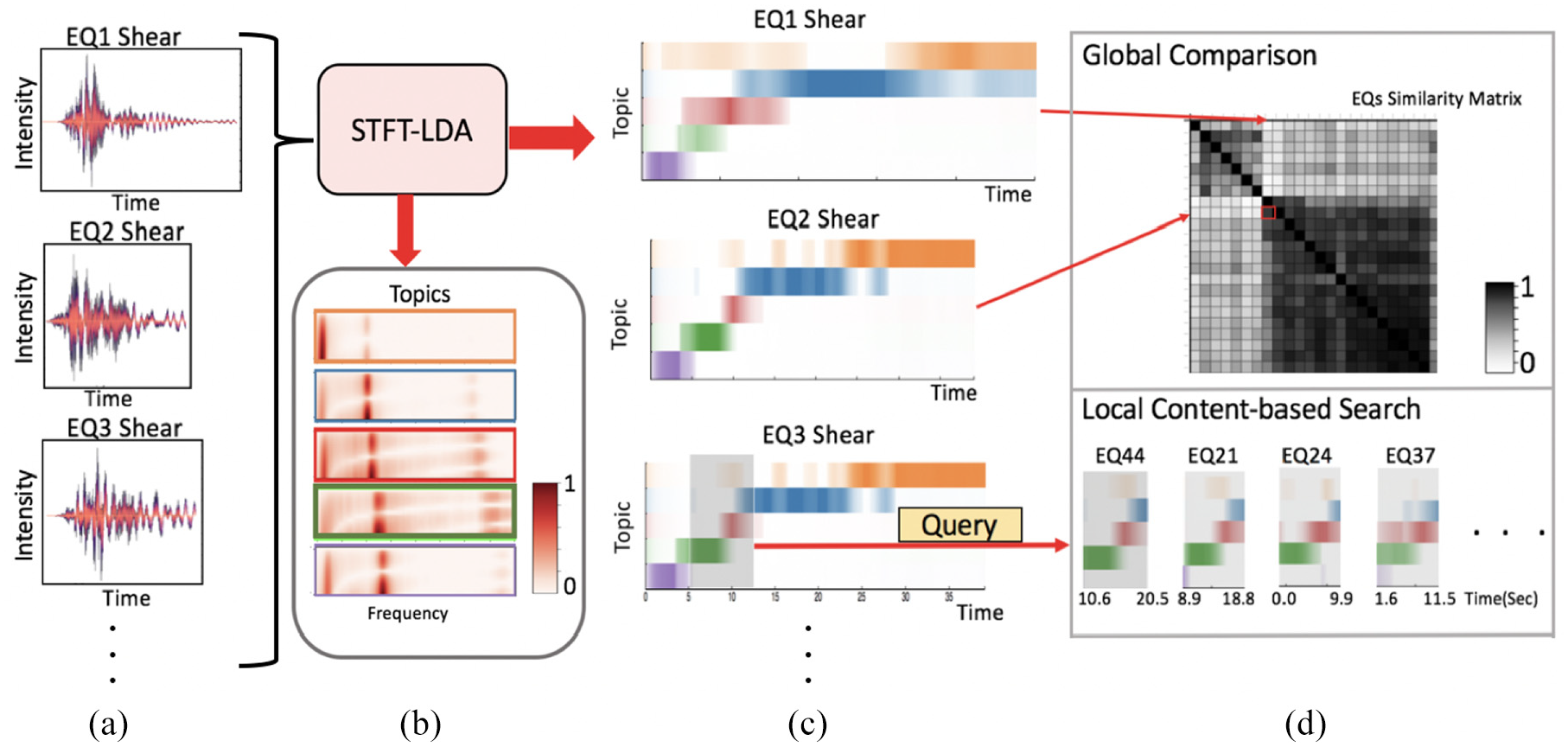
The technique we propose in this paper, STFT-LDA, captures variation patterns across multiple time and frequency scales, as well as different attributes in a multivariate time series (a). We show through one quantitative user studies and one expert evaluation (Section 6) that the visual summaries (c) provide better discrimination of the behavior of such multivariate time series. STFT-LDA uses topic modeling to capture variation patterns in the time series; in Section 6.2, we show that the topics themselves in (b) are meaningful and interpretable. Finally, the information generated by STFT-LDA itself enables powerful visual interaction modalities (d). Section 5.3 shows how the features enable a global overview that highlights overall similarities between the behaviors of all simulations, and Section 5.2 shows how our technique supports different forms of visual interaction such as content-based search for visual filtering, and global comparison of an ensemble of earthquakes.
Related work
Our visualization approach builds on concepts from time series analysis and visualization of topic models. We also describe recent research in the visualization of seismic data.
Visualizing time series data
Data having a temporal component appears frequently in a variety of settings, and thus there are numerous works on visualizing time series data. We highlight those works that study multivariate time series. We refer the reader to Aigner et al. 5 for a more complete overview of time series visualization.
Some of the earliest work on time series visualization focuses on questions of layout and best design choices for the display of time series data. Keim et al. 6 align pixel dense visualizations of time series to high recursive patterns. Weber et al. 7 use a spiral metaphor to draw time series data, interleaving multiple spirals when the data is multivariate. Carlis and Konstan 8 also use spirals, but stack multiple variables in 3D. Byron and Wattenberg 9 use streamgraphs to visualize multivariate time series data. More recent work has focused on how best to interact with time series. The TimeSearcher tool of Hochheiser and Shneiderman 10 provides an approach to interactively perform range queries of multiple time series data, which was later extended by Buono et al. 11 to provide example-based querying. The LiveRAC system of McLachlan et al. 12 couples multiple views and semantic zooming to present visualizations of system management data.
Our work is most related to visual analytics systems that can help users identify patterns and structure within time series. Buono et al. 13 use similarity-based forecasting to search for patterns in historical time-series data and visualize predictions of future behavior. Guo et al. 14 use their EventThread system to cluster event sequences into categories using tensor analysis. Lin et al. 15 decompose time series using symbolic aggregate approximation to construct a hierarchical representation of patterns generated by a sliding window. Others have studied designing user-driven contexts based on novel interactions. In particular, Muthumanickam et al. 16 explore long time series by constructing a grammar of basic shapes based on user sketches. Correll and Gleicher 17 also study sketching for time series.
Finally, Jäckle et al. 18 explore multivariate time series data by constructing 1D MDS plots over sliding temporal windows. We similarly use a sliding window in the STFT, but our windowing scheme is designed to capture how frequency usage evolves over time. Miranda et al. 19 construct a “pulse” to identify cyclic patterns in time-series based on urban data. Instead of identifying cyclic patterns with topological tools, we focus on periodic structures that exist at various frequencies. The structures translate to important features and visualization primitives that convey intuition about the frequency domain.
Topic modeling and visualization
Topic modeling has been utilized frequently in the context of visualizing text data. In particular, our work utilizes latent Dirichlet allocation (LDA), pioneered by Blei et al. 20 as a probability generalization of latent semantic analysis. 21
In the field of text visualization, topic modeling is frequently used as a data processing step to provide more meaningful structure to unorganized documents. One feature of topic models is that they offer a means to project individual documents into a lower dimensional (typically 2D) spaces, providing views of the latent structure.22,23 Termite relies on an alternative display of topic models, using a tabular view that helps a user understand the distributions of terms both within and across topics. 24 Dou et al. 25 user the parallel coordinates metaphor to display LDA models in the ParallelTopics system. The UTOPIAN system of Choo et al. 26 uses force-directed layout to display topic models and Lee et al.’s 27 iVisClustering system couples graph layouts with other views to interactively steer the LDA model. Providing supervision to LDA has been studied by El-Assady et al. 28 who provide an iterative framework to adjust topics, informed by user studies by Lee et al. 29 Alexander and Gleicher 30 use buddy plots to visually compare multiple topic models and to derive comparison and understanding tasks.
More closely related to our own work are approaches that visualize connections between topic models and time. Luo et al. 31 couple event-based analysis for text collections to identify topics in a time series view in EventRiver. Wei et al.’s 32 TIARA visualizes the evolution of topics over time, by using a modified ThemeRiver 33 display. Cui et al. 34 also employ the metaphor of rivers, but focus on visualizing where specific events happen in the evolution of topics in TextFlow. The approach of Leadline is to associate topic themes with specific events, highlighting topic streams by their length and burst behavior. 35
While most works that couple topic modeling with time focus on visualizing document collections, LDA extends beyond just documents. Chu et al. 36 use LDA to discover topics from taxi trajectories. Hong et al. 37 use LDA to explore unsteady flow, mapping flow features correspond to words. Chen et al. 38 use LDA to categorize operation behaviors in the security management system. All these works share similarity to our own in that abstract, data-dependent concepts map to traditional components in topic modeling.
Frequency-domain analysis
The frequency-domain representation of time series data is a useful analysis tool for seismologists, as they are often interested in understanding periodic and non-periodic features. Fourier-based decomposition is widely used for filtering noise and helping to identify periodic phenomena,39–41 yet for time-localized behavior, Fourier methods are unsuitable. Short-Time Fourier Transform (STFT) preserve the frequency content dynamics over time, by shifting a spatially-compact window and calculating the Fourier transform in each small window. 42 Wavelet Analysis 43 is similar to STFT, but instead of using a fixed window, Wavelets enable multiresolution analysis via a set of windows whose functions resemble tiny waves that grow and decay in spatial support. Within seismology, Sinha et al. 44 employ the Continuous Wavelet Transform (CWT), Wang et al. 45 apply the Synchrosqueezing Transform to the seismic signal to achieve a higher precision than CWT. Wang 46 uses Matching Pursuit Decomposition to automatically determine the best spatial resolution.
While these methods provide useful analysis tools for understanding the time-frequency representation of a single, or few, time series, they are poorly suited for handling the large amounts of time series that the domain experts we work with typically face. Visually analyzing a large amount of spectrograms – be it produced from STFT or Wavelets – is cognitively demanding, and few methods exist that can help summarize such data. For instance, simply taking an average of spectrograms might obscure important details, while dimensionality reduction techniques fail to retain the time-frequency representations that are of interest to the domain experts.
Visualization of seismic data
We also discuss other efforts in visualization that focus on visualizing seismic and earthquake data. These techniques usually emphasize two- and three-dimensional views, typically coming from either simulation and/or observational data. Much of this research has focused on techniques, such as using images, 47 video, 48 or volume rendering49,50 to display earthquake data. Chopra et al. 51 deploy an immersive virtual environment to visualize earthquake simulations for domain scientists. Wolfe et al. 52 use ultrasound reflection to visualize seismic simulations as volume data. While these techniques are powerful, we note that they focus on significantly different data than what we present in this work, as we visualize a building response to a measured earthquake instead of the earthquake itself.
Even using different data, visualization systems for earthquake visualization are motivational to the analysis we employ, in particular in how they couple simulation with measured data. Yuan et al. 53 present a complete visual system for studying earthquake data from multimodal sources, including measured data. Patel et al. 54 interpret measured seismic data using the Seismic Analyzer to illustrate 2D seismic data. Hsieh et al. 55 also visualize time-varying field-measured data to produce time-varying volumetric renderings. Komatitsch et al. 56 provide comparisons of seismic waveforms produced between simulation and observational data. We again emphasize that while these works are inspirational in terms of studying seismic response, our work differs significantly in that we are focused on trends that help us compare numerical simulations of buildings under seismic loads.
Problem setup
We first describe the data that the civil engineers tend to produce via numerical simulation. In studying the behavior of buildings that experience earthquakes, civil engineers are concerned with analyzing simulations that produce sets of multivariate time series. A single simulation produces a time series that expresses each physical variable on each degrees of freedom of a floor for given an input, recorded earthquake signal. In this study, the simulations track 6 physical attributes of interest, for each floor: acceleration, shear, diaphragm force, moment, drift ratio, and interstory drift ratio. Each physical attribute is an important indicator of the building status. For example, shear measures the cumulative force parallel to each floor, while interstory drift ratio measures the positional difference between two floors at a given point in time. This gives a vector-valued time series for each attribute, and each simulation has 25,000 time steps in average in this study. Each attribute is normalized by dividing the raw value by a predetermined design limit. This has the benefit that any value of the time series above 1 or below negative 1 indicate that the building is operating out of its safe design specifications, and mitigates the issue of comparing variables of different units. For simplicity of discussion, in what follows we treat the combinations of floors and variables as a combined multivariate signal (and thus, we abuse language at times and simply refer to the quantity of interest as floor or variable).
Glossary of seismological terms
Earthquake simulation
A vibrational input that possesses the essential features of a real seismic event is applied to structures to study the effects of earthquakes on structures (Section 1).
Story shear
A term to measure the force parallel to each floor in a building (Section 3.2).
Mode
One of a set of independent vibration configurations a building can exhibit. Higher modes correspond to more complex configurations. Buildings can vibrate in multiple modes simultaneously (Section 3.2).
Ground acceleration
A time-varying attribute of the earthquake directly indicating the acceleration of the ground at a particular point in time (Section 5.3.2).
Impulse
A term describing a force applied onto the building by the earthquake over a very short period of time (Section 6.2).
Elastic and inelastic state
Under an elastic vibration, the building can resume to undeformed initial position when the external force is removed; however, inelastic vibration causes irreversible damage to the structure, and it may remain deformed even after the removal of the external force (Section 6.2).
Preliminary design study
Through regular meetings with civil engineers, we found that a key aspect of their analysis is understanding response and the fundamental vibration modes of the building, often determined by the mass of stiffness of the building. In particular, studying these time series helps them understand the fundamental vibration periods of the building, often determined by the height, support structure, and materials used to construct the building. As all objects have a natural vibrational period, understanding where deviations occur can often be indicative of damage. More specifically, the vibration behavior of a building can exist in different modes (Figure 2(c)) where either all floors are vibrating in alignment or out of alignment. For example, if all floors move in the same direction, back and forth, the building will vibrate like a pendulum swing. The civil engineers typically refer to a building in this state as a first mode. If the building undertakes shear stress from different directions at the same time, it will bend like an “S” shape, which is typically referred to as a second mode. If the building is swinging in the shape of an “M” or “W,” then this is typically called a third mode. In seismic analysis, these motions have received long-lasting focuses and civil engineers conduct many experiments in order to understand the internal connections between the mode behaviors of a building and earthquake.57–59
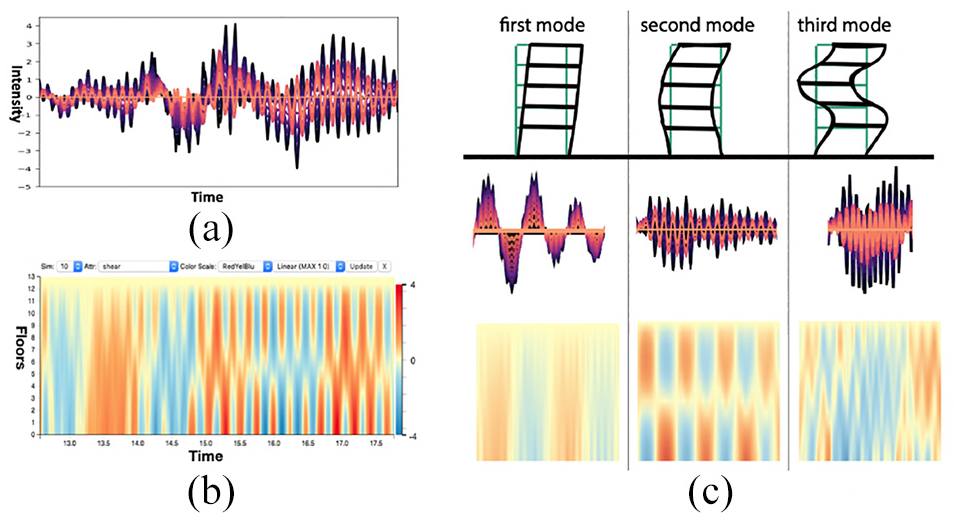
The preliminary system utilizes a 2D heatmap (b) to visualize a time series across different floors (a). The variation of the color indicates the change of one physical attribute, which also reflects the vibration condition of the building. A linear interpolation is applied to the values between floors to facilitate comparisons across floors and different timestamps. The color encoding simplifies the recognition of three basic vibration modes in (c), nevertheless, this method lacks the ability of summarizing the simulation behavior as well as making comparisons across different simulations. See Section 4 for the technique we propose to solve these problems.
Currently civil engineers use simple visualizations such as line plots (Figure 2(a)) to plot a building’s response to individual earthquake. However, it can be complex to directly analyze line plots as the data is measured across a range of floors and variables. Quickly spotting the mode of a building is challenging in this scenario, as differences between modes manifest as subtle visual differences. Moreover, in a real-world scenario, the building’s motion in an earthquake is often more complicated than simply three modes. Specifically, the movement is often disorderly and it also evolves slowly in response to damage, which leads to an evolution of material ductility that eventually alters the vibrational modes.
Thus, for our initial task, we built an infrastructure to enable civil engineers to visually explore multivariate time series and spot interesting patterns such as vibrational modes. Toward this end, we built a prototype interface using 50 earthquake simulations provided by the engineers. For each simulation, we utilize a 2D heatmap to visualize the response of each single physical variable plotted over time and building floor. As shown in Figure 2(b), users have access to different simulations and the corresponding physical attributes, and they can also choose different color scales and mapping methods to emphasize various patterns. We showed this visualization tool to the civil engineers and they agreed that this view is supportive in spotting periodic behaviors as well as understanding the deviations across both floor and time steps directly. In the meanwhile, choosing different color maps could help them simplify the signals and highlight interesting phenomena. In particular, civil engineers can roughly observe the main vibration mode of the building by reading the color patterns. Taking the shear attribute of an earthquake for example, in Figure 2(c), if the building is in the first mode, the colors of all the floors are either red or blue at the same time. On the other hand, if the building is in the second mode, the colors are always different for the upper and lower floors at the same time steps, which reflects that the directions of the shear attribute for corresponding floors are also opposite.
In moving to studying multiple earthquake simulations, however, the 2D heatmap has limitations. First, even though it reduces the complexity of the origin multivariate time series, the visualization is still too complicated for users to understand general patterns and make comparisons across different simulations. For example, civil engineers may spot some of the mode behaviors in a simulation, but the user may still need to recall and match these color patterns back and forth while inspecting another simulation. Secondly, this direct visualization of time series doesn’t help much in answering important questions like how the frequencies change throughout the earthquake or what is the highest intensity of the frequencies. Finally, this visualization is not scalable when more variables are introduced, specifically, considering two physical attributes at the same time. This is also a problem in previous methods when we are trying to visualize sets of frequency components across all earthquakes and their variables.
Task abstraction
In visually exploring multiple earthquake simulations, there are a set of tasks that civil engineers wish to achieve:
(T1) Summarizing Earthquake Behaviors. Civil engineers would like to understand the space of discriminative earthquake behaviors.
(T2) Exploring Collections of Earthquakes. It is challenging for civil engineers to even know where to begin their study. Having a general overview of earthquakes can help them decide what earthquake, or set of earthquakes, to study first.
(T3) Exploring Time-localized Earthquake Features. Given a single earthquake, the civil engineers would like to understand how an identified feature at a specific time interval relates to other earthquakes.
(T4) Identifying Deviations and Outliers in the Set. In addition to summarizing the aggregate behavior of earthquakes, the civil engineers also seek to understand which combinations of parameters/inputs produce results that deviate from the expected behavior.
Fundamental to satisfying these tasks is a notion of earthquake similarity, taken with respect to arbitrary time intervals. Similarity enables overviews of earthquake simulations, as measured across their entire duration, allowing the user to identify one or a small set of earthquakes to begin their analysis (T2). Given a single earthquake, similarity also enables the user to query earthquakes, either globally or locally in time, allowing the user to compare earthquakes at different time scales (T3). Finally, earthquakes that are dissimilar from the set can help to identify where large deviations have occurred that might necessitate further investigation (T4).
While there are many ways one can compute similarity between the time series data produced by earthquake simulations, in this work we seek a mechanism to produce an interpretable similarity measure. Key to this interpretation is producing visual representations of earthquakes that enable civil engineers to understand why, when, and where earthquakes are similar. Unfortunately, no technique in the literature supports such demands. The core of our approach is a method to transform multivariate time series into such a representation that improves how users visually comprehend trends and patterns across time series. In particular, we model multivariate time series through topic modeling. Concretely, each multivariate measurement in time is replaced by a distribution of topics that best explain the earthquake at that point in time.
Our topic model is designed in such a way that each topic, viewed as a time series, smoothly changes over time, and thus it is far easier to comprehend than the original earthquake simulation measurements. Furthermore, each topic is characterized as a distribution over frequencies for each variable, and thus topics are interpretable with respect to earthquake behaviors of interest to the civil engineers. This enables civil engineers to comprehend general earthquake behaviors by inspecting the individual topics (T1) as a mechanism for summarizing the group. These time-varying topic distributions underlie our visual analytics approach to exploring earthquake collections, as this representation drives how we compute similarity between earthquakes.
STFT-LDA: Topic modeling for multivariate time series
At the core of our visual analytics technique is a novel representation of multivariate time series, designed to capture domain-specific features in a manner that enables effective visual exploration. Time series data produced from earthquake simulations can be characterized as having periodic behavior that varies over time, where changes in periodicity often reflect different phases of the earthquake simulation. To capture time-varying periodic phenomenon, we use Short-Time Fourier Transform (STFT), 43 individually computed over all time series for each earthquake simulation. Although descriptive of earthquake behavior, the STFT alone does not make it easier for the user to perform visual exploration of collections of multivariate time series data. To this end, we perform topic modeling on the set of STFT, and use the learned topics for both visually encoding time series, as well as computing similarity over time series. We discuss the STFT and topic modeling in more detail below.
Short-time Fourier transform (STFT)
Besides inspecting the time series of seismic responses, civil engineers are concerned with their frequency domain representation, in order to distinguish periodic behaviors of earthquakes and how periodic behavior changes as the earthquake simulation progresses. The STFT is a suitable transformation for this purpose, as it captures the time-localized frequency content of a signal. The STFT is constructed by defining a temporal window of fixed size, which we denote by
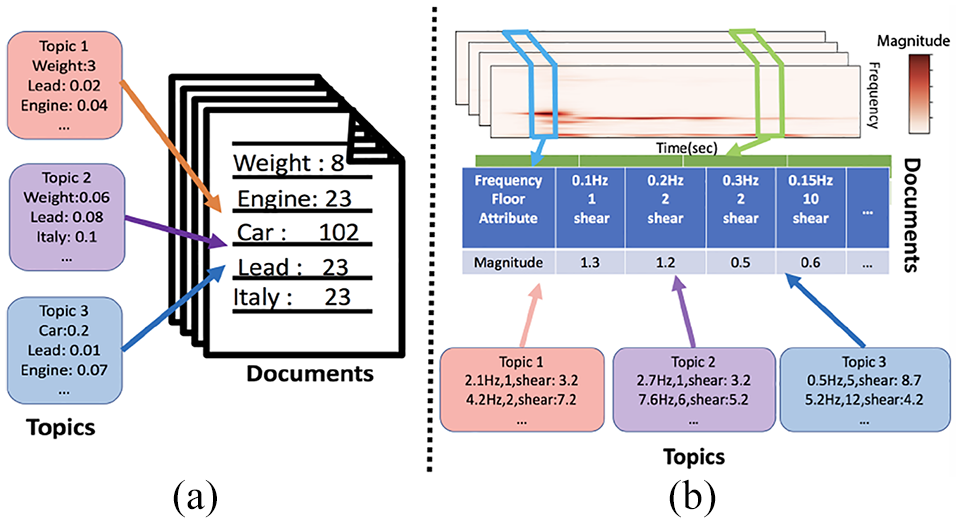
Traditionally, LDA (a) is used to summarize different distributions of word frequencies in documents into topics. In our paper, we use LDA to summarize distributions of frequency patterns obtained from STFT (b). Each “document” in our case is a collection of frequency distributions from each of the different attributes on the multivariate time series (specifically, one time series for the shear strength measured in each floor).
Topic modeling STFTs using latent Dirichlet allocation (LDA)
Although the STFT is descriptive of the phenomena present in the earthquake time series, it is not an ideal visual encoding for exploration. It is necessary for the user to visualize the STFTs across all variables, but such views scale poorly in the number of variables. To build a visual representation that compactly represents a set of STFTs, we turn to topic modeling. Topic modeling has traditionally been used to obtain a better understanding of textual data. More specifically, as illustrated in Figure 3(a), given a set of documents where each document is comprised of a set of words and corresponding word counts, topics are learned from the data such that each topic is a mixture over words, and documents are mixtures over topics. The topics are meant to capture latent themes in the document corpora, with each document typically represented with a few predominant topics, or themes, rather than its original set of words.
In our scenario, we treat a multivariate time series earthquake as a time series of documents. More specifically, our vocabulary of words corresponds to a binned set of frequencies. In particular, we treat frequencies corresponding to different variables in the earthquake as being distinct, thus our vocabulary
Illustrative example
We use the topics for visualization with two different views, see Figure 4 for an illustration of a synthetic example modeled with three topics. First, we visualize a given multivariate signal by visually encoding each document in its time series through its topic distribution, as shown in Figure 4(c). This view shows colored stripes to visualize each topic and its evolution across time. Each row is associated with a given topic, and we opacity-map each document’s normalized topic weight. Within any given column, the topic weights will sum to 1.0.
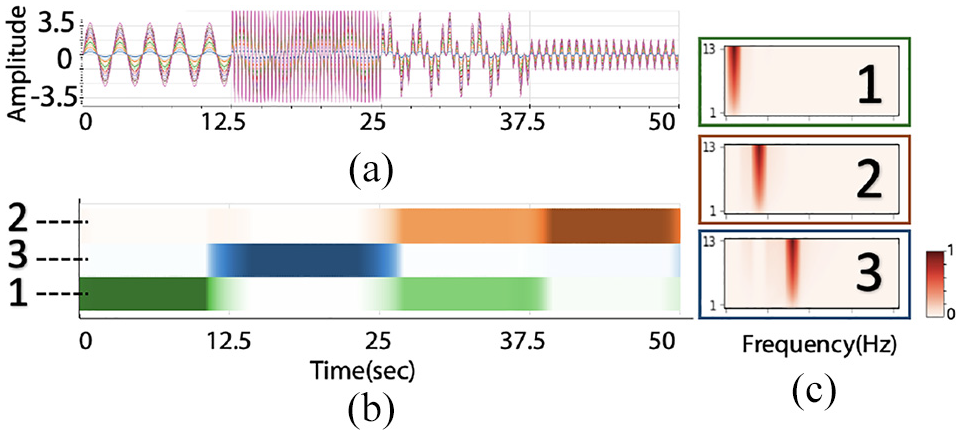
A synthetic, multivariate time series generated to illustrate the behavior of STFT-LDA. The time series (a) goes through four different phases, characterized by different amplitudes and frequencies. In this case, we use STFT-LDA to generate three topics (b) which characterize the overall variability in the time series, and the summary view (c) shows how the patterns change over time and how they relate to one another.
Second, we compactly visualize a topic as a 2D scalar field, where the
We illustrate how these views help describe the original signal (Figure 4(a)). Our synthetic example models a single earthquake that consists of 13 time series where each time series has four phases, while the time series lasts for 50 s. Within each phase, these 13 time series have same frequency but different amplitudes. The first phase is a sinusoid with frequency 0.4 Hz, in the second phase the sinusoid increases to a frequency of 3.2 Hz, in the third phase the sinusoid changes to a combination of frequencies 0.4 and 1.6 Hz, while in the last phase the sinusoid’s frequency shifts to 1.6 Hz. The sample rate is
For STFT computation we select a window size of 5 s, and slide the window every 0.125 s. Due to the simplicity of our signal, we want the STFT to be more precise in the location of the frequency/amplitude transitions. For topic modeling, we set the number of topics to three to match the number of frequencies in the data. We expect the model to capture the frequencies and separate them into different topics, and the topic transitions should occur approximately when the frequency changes in the signal.
Figure 4 summarizes the results. As shown in Figure 4(b), each topic clearly picks out the distinct frequencies in the original data. Figure 4(c) shows the time-series document-topic view, where the distinct color changes between topics accurately capture the transitions between frequencies present in the original time domain. It also accurately splits to two topics when there is a mixture of frequencies in the third phase. The transition between topics along the time series is clearly indicated by the color changes and the time approximately match the frequency changes in the time domain. This exemplifies the typical use-case of the topic-oriented view STFT-LDA: the user obtains an overview of trends more easily than trying to detect patterns in the original time series.
Figure 4(b) offers an alternative view of the data by emphasizing the topics themselves. The bounding boxes match the colors used in (c). Obviously, each topic identifies one distinct frequency in the signal data. Since the frequency distribution of each topic is like an impulse function where almost everywhere else is zero, we expect the topic modeling to pick out the individual frequencies. The opacity of the colors at that frequency encodes the different amplitudes of each time series.
System description
We implemented and experimented with STFT-LDA in a prototype system (Figure 5). We used an initial collection of 50 simulations of responses to earthquakes. Each building had 13 floors, and we investigated the variable of shear on each floor, resulting in a 13-dimensional signal whose lengths varied from 30 to 200 s. Each simulation is the result of a custom simulation developed by two of our coauthors in Matlab where parameters such that the structural method and input earthquake signal were varied. We use python libraries like scikit-learn(https://scikit-learn.org/), NumPy(https://numpy.org/), and SciPy(https://www.scipy.org/) to process the simulation data with different filters like STFT and LDA. We use R for its corrplot package 60 for hierarchical clustering (to reorder the rows and columns of the matrix view) as well as for the analysis of the user study results. All the calculated data are stored in the backend system as binary files in the file system. The application web server is implemented with Flask. 61 For the frontend design, we mainly rely on JavaScript library D3 62 and draw on both SVG and HTML5 Canvas for better performance. In this section, we discuss each view and interactions we implemented as well as the insights of this simulation dataset we discover by using this prototype system.
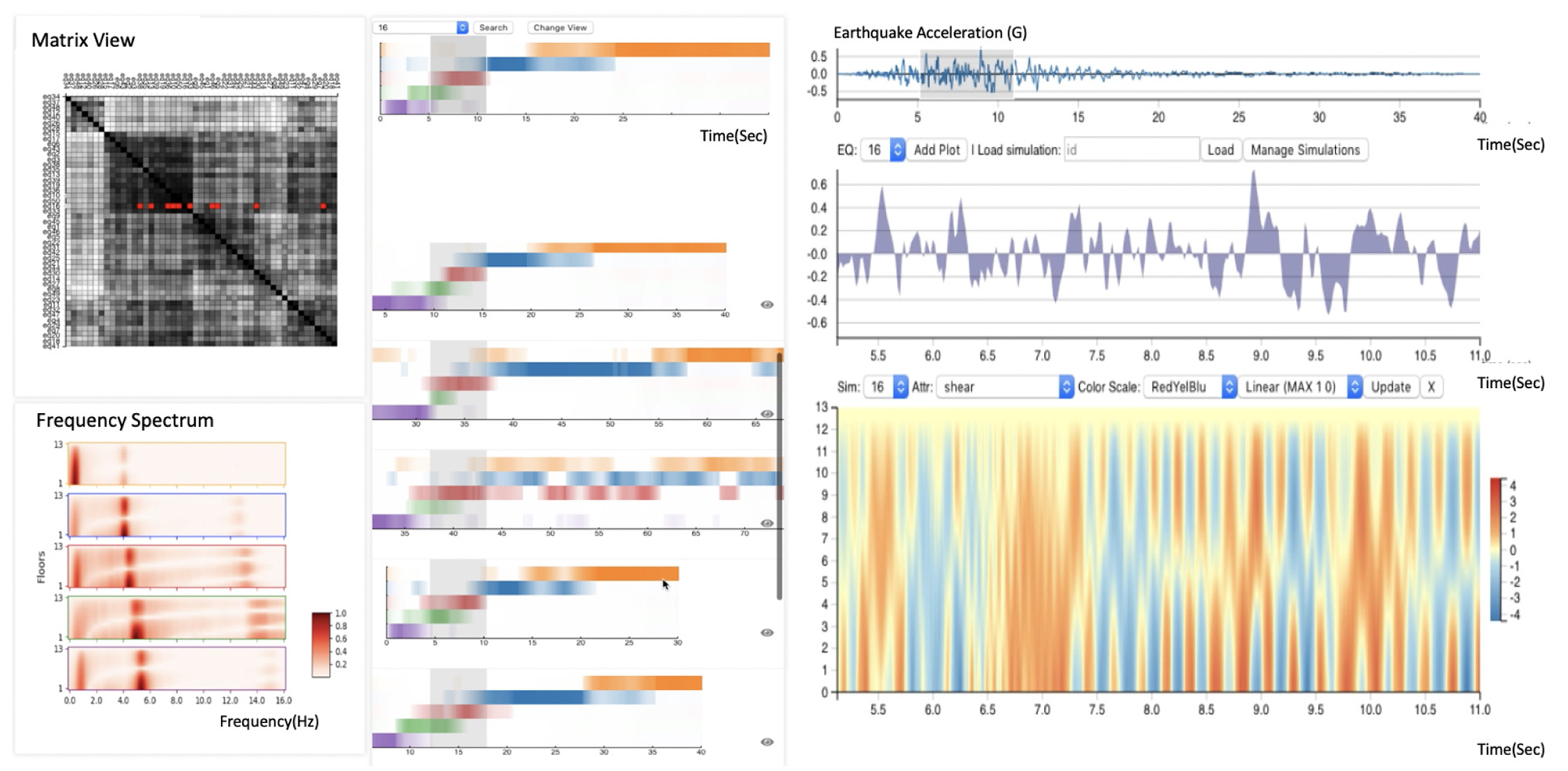
The prototype system consists of four views. The matrix diagram (top left) is used for navigation and summarizes the overall behaviors across all the earthquakes. To understand the frequency distribution of each topic, the analysts can refer to the frequency spectrums (bottom left) for details. The opacity of the color indicates the relative magnitude of a frequency for a specific floor. The core of the system is the topic representation of each earthquake simulation (middle). It includes a content-based search module to help quickly identify similar partial time series across different simulations. The last part (right) is a details view that supports further exploration of simulation time series and helps civil engineers interpret the responses of buildings from another aspect.
Topic view
To analyze the data, we computed the STFT on each earthquake using SciPy’s STFT filter using a window size of 5 s with a sampling frequency of 0.125 s. The output of the STFT is then processed through Scikit-learn’s LDA filter with the batch learning method, setting the number of topics to five. The visualization for these five topics are shown in Figure 6(l). The bounding boxes match the color stripes used in Figure 6(r). Each topic is visualized as a 2D heatmap, where the
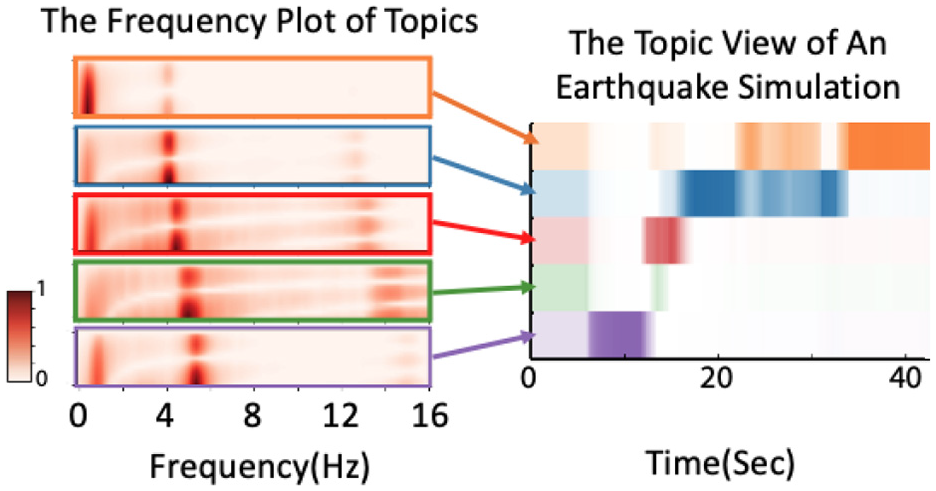
Our topic representation also helps connect to the concept of vibrational modes. Buildings vibrate mainly in the fundamental natural frequency (first mode) or as damage happens the floors may vibrate out of alignment (second, third modes). The topic representation helps to see if the floors are vibrating at the same frequencies, which can be verified if the signals are aligned by looking at the signal views.
Design choices
In the frequency spectrum, we use a red sequential colormap to indicate the normalized magnitude of the frequency for each floor. We choose five qualitative colors to represents the five topics and we utilize the opacity to represents the percentage of topics at every time interval.
Content-based search
We also implemented an interface for content-based search against temporal regions of earthquakes, see Figure 7 for an illustration. This content-based search directly relies on using the topic representations (i.e. STFT-LDA data). The user can brush on a continuous area of one earthquake simulation and quickly search for the most similar parts of equal length among all the other earthquake simulations, where we use Euclidean distance as the similarity measurement. We then use a cross-correlation process to calculate the sliding distance where an accumulation array stores fast Fourier transform to speed up the process (for full details, refer to Appendix). We pick the two most similar parts from each simulation data, order all of them by the distance and return the top simulations. All the search results are translated such that the similar parts are aligned (Figure 7(a) and (c)). The search results will also be highlighted in the matrix diagram view. We can hover on the icon to show details of the results including the earthquake number, rank, distance between the result part and the search part and the time range of the result part.
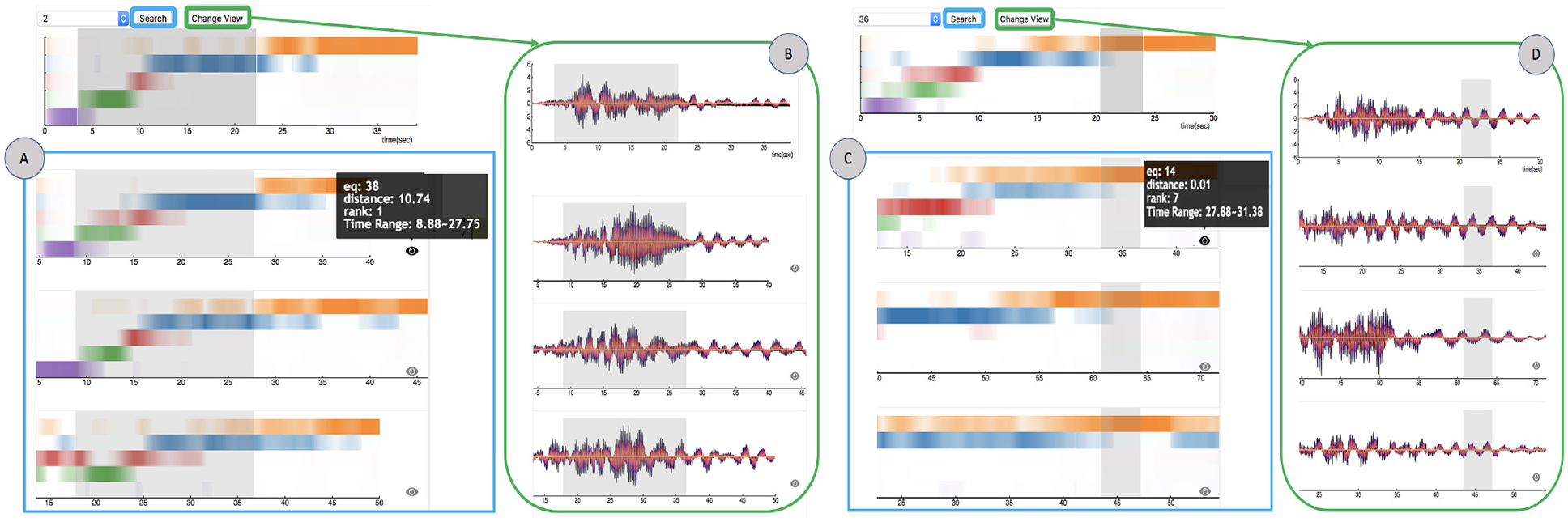
The content-based search illustrates how topic modeling helps to identify regions that are locally similar and dissimilar. (a, c) show two different brushed regions in the top simulation and three of the most similar results aligned. For (a), a user can quickly see all three are similar hits and then validate this comparison in (b). For (c), the topmost hit ends up having a different behavior prior to the selection, which can be confirmed in (d).
This feature also allows the user to compare against the signal view as a validation. Figure 7(b) and (d) shows how these two views align. Shared brushing highlights the same time regions in both views so that users can cross compare. In particular, this view helps to show both regions where earthquakes are locally similar as well as regions where earthquakes are dissimilar.
Figure 7(a) shows an example where the user has selected multiple topics and searched for a particular sequence. The search hits that are returned show three cases that are quite similar. Figure 7(c) shows a different example, where the user has selected only a single topic to find other earthquakes that express this topic. As a result, the most similar earthquakes in the selected region of time appear to have a significantly different behavior in the time steps prior to the selection. The topmost hit (second row) appears to have a more continuous transition between topics, while the next two closest hits (third, fourth row) appear to transition in different ways. The third row shows a more regular transition from the blue to the orange topic, while the fourth row shows that the blue and orange topics appear to be mixed.
Other views
Matrix diagram view
STFT-LDA splits each earthquake simulation into a set of segments with a fixed window size, and each segment is simply represented as a vector of weights. For any two segments coming from two earthquakes, we compare them directly using the Euclidean distance between these two vectors. Then, we calculate the similarity between any two earthquake simulations by mapping the set of segments to a Gaussian distribution in Hilbert space, and use Bhattacharyya’s similarity to compare the earthquakes. 63
We use matrix diagrams to visualize the behavior across earthquakes as a global comparison mechanism. These are implemented using D3’s existing matrix diagram infrastructure. Each cell in the across-earthquake matrix represents the similarity between two entire simulations using Bhattacharyya’s measure. In our tool, users can select a cell in the matrix in order to show the details of two earthquake simulations. In the matrix, we reorder the sequences of the simulations using hierarchical clustering with complete linkage using the R package corrplot. This matrix view helps to demonstrate how STFT-LDA produces meaningful global comparisons. For example, in Figure 5 (top left) we can observe four major clusterings. We can click the corresponding cell to do pairwise comparisons. And the the results in the content-based search will also be reflected in the matrix.
Design choices
The matrix diagram is designed as grey-scaled for two reasons: 1. the sequential color scheme can be used to encode the similarity value; 2. the color channel can be used for other interactions like highlighting the content-based search results or clicking mark.
Details view
While the topic presentation provides a highly-compressed summary of simulations’ overall behaviors, the analysts still prefer a direct visualization of the responses for each floor. This will be a good complement for analyzing the stress condition of different floors. To support further exploration of simulation time series and help civil engineers interpret the responses of buildings from another aspect, the system also includes multiple modules visualizing these time series directly. The views include a line chart visualizing the earthquake acceleration for navigation (Figure 8(b)), an area chart showing the impulses of brushed earthquake time regions (Figure 8(c)), and a 2D heatmap for visualizing the building responses quantified by different physical attributes across all the floors (Figure 8(d)).
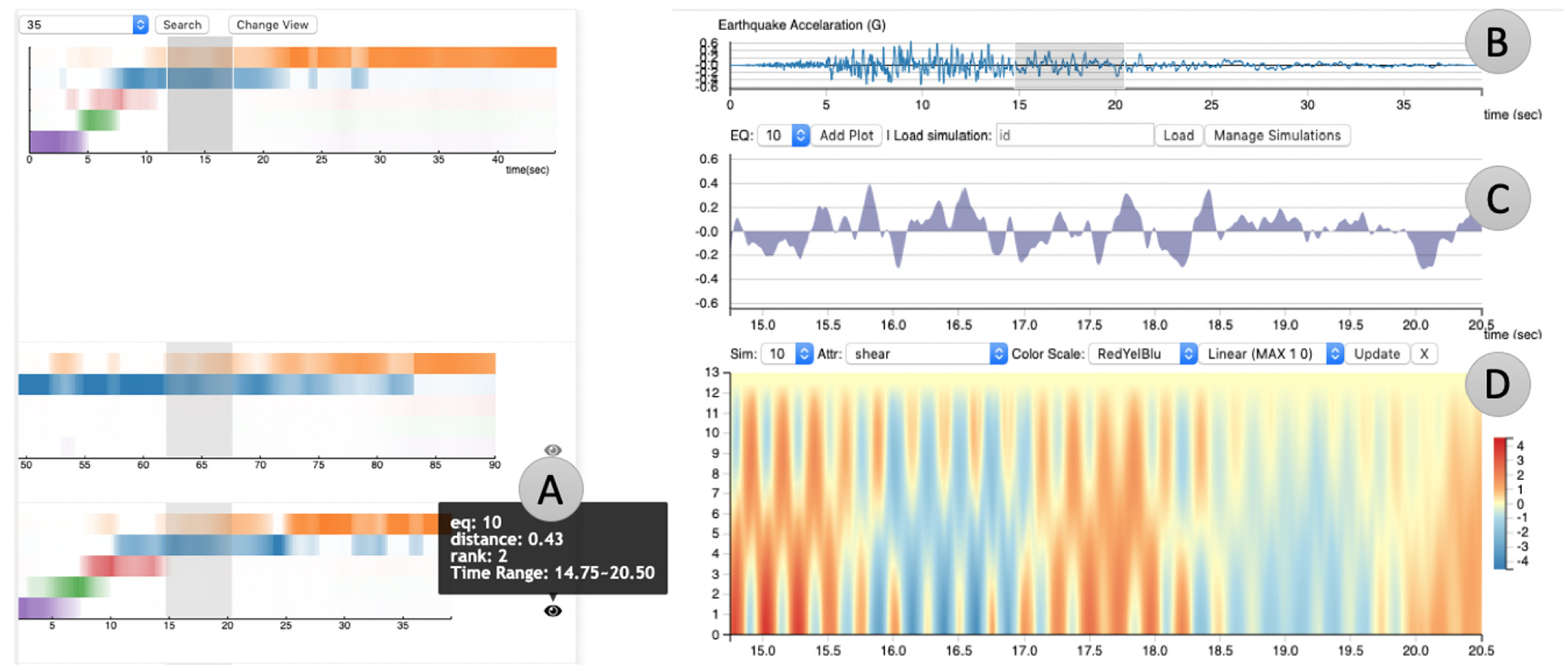
Analysts can select a portion of the ground acceleration (b) and drill down into a specific earthquake simulation (d), to visualize the response of a single physical variable plotted over time (x coordinate) and building floor (y coordinate). (c) is an area plot visualizing the selected portion of the ground acceleration. By utilizing STFT-LDA, analysts can quickly navigate and zoom in to the similar partial simulations. In (a) an analyst can quickly switch from EQ35 to EQ10 and zoom into time range of 14.75–20.50 s automatically by clicking on the eye icon.
Earthquake acceleration is an attribute of the earthquake that directly indicates the intensity the of simulation, and we plot it as a line chart for overview and a gray area plot for details. What’s more, we present a 2D heatmap view over time (
We built interactions between the search module and the details view to help explore the multivariate data and spot interesting patterns. For example, as shown in Figure 8, when a user brushes on a portion of the topic view and searches for similar partial simulations, these views will automatically zoom into the same time region being searched. What’s more, by clicking on the eye icon in the searching results, user can also quickly switch to highlighted time regions in other earthquake simulations.These interactions enable quick access to the specific time range in earthquakes of the user’s interest. They also keep the synchronization of the time range between the time domain and frequency domain and allow the user to analyze similar time intervals discovered by topic views in the time domain as well.
Design choices
We choose diverging color scales for emphasizing the differences and both continuous and discrete colormaps are provided in the view as the former facilitates preserving values and the latter can help filter unimportant values by setting up different thresholds. To help users easily identify patterns over time and floors, we choose to show one attribute each time instead of using small multiples.
Evaluation
In the previous sections, we argued that STFT-LDA is practical to implement and provides a number of attractive features in the context of a larger visual analysis system. However, one central question remains: does STFT-LDA actually produce visual representations that more readily distinguish different features of the multiple time series? To evaluate the effectiveness of the technique and resulting time-series visualization, we designed and conducted a surrogate task with two conditions which we now describe.
Surrogate task
Broadly speaking, we sought to study whether participants in the study would be able to distinguish differences in the features that generated the time-series data. The true, ecologically-grounded task of the analyst involves studying, at a potentially fine level, differences in the behavior of these time series. Such real-world tasks lack a clear notion of ground truth, making quantitative experiments particularly challenging. In order to arrive at one such design, we created a simpler, surrogate task, for which we do have ground truth.
In the study of building responses to earthquakes, engineers create numerical simulations of a number of different building structures, and test these structures against the same recordings of earthquakes. In addition, these simulations have an additional free parameter, the “load” of the earthquake, a multiplicative factor of the ground acceleration that is used to simulate more (or less) severe versions of the same event.
The surrogate task we designed is a visualization matching forced-choice task, where the participants are shown three stimuli, laid out on a computer screen as shown in Figure 9. Each of the stimuli shows the same span of time during one fixed earthquake; the difference in the time series comes from a combination of earthquake load and building structure. Crucially, one of the images on the bottom is generated with the same type of building structure as the one on the top. Participants are asked to select the image on the bottom of the screen that looks “the most similar” to the one on the top. We consider the answer correct if it matches the building structure.
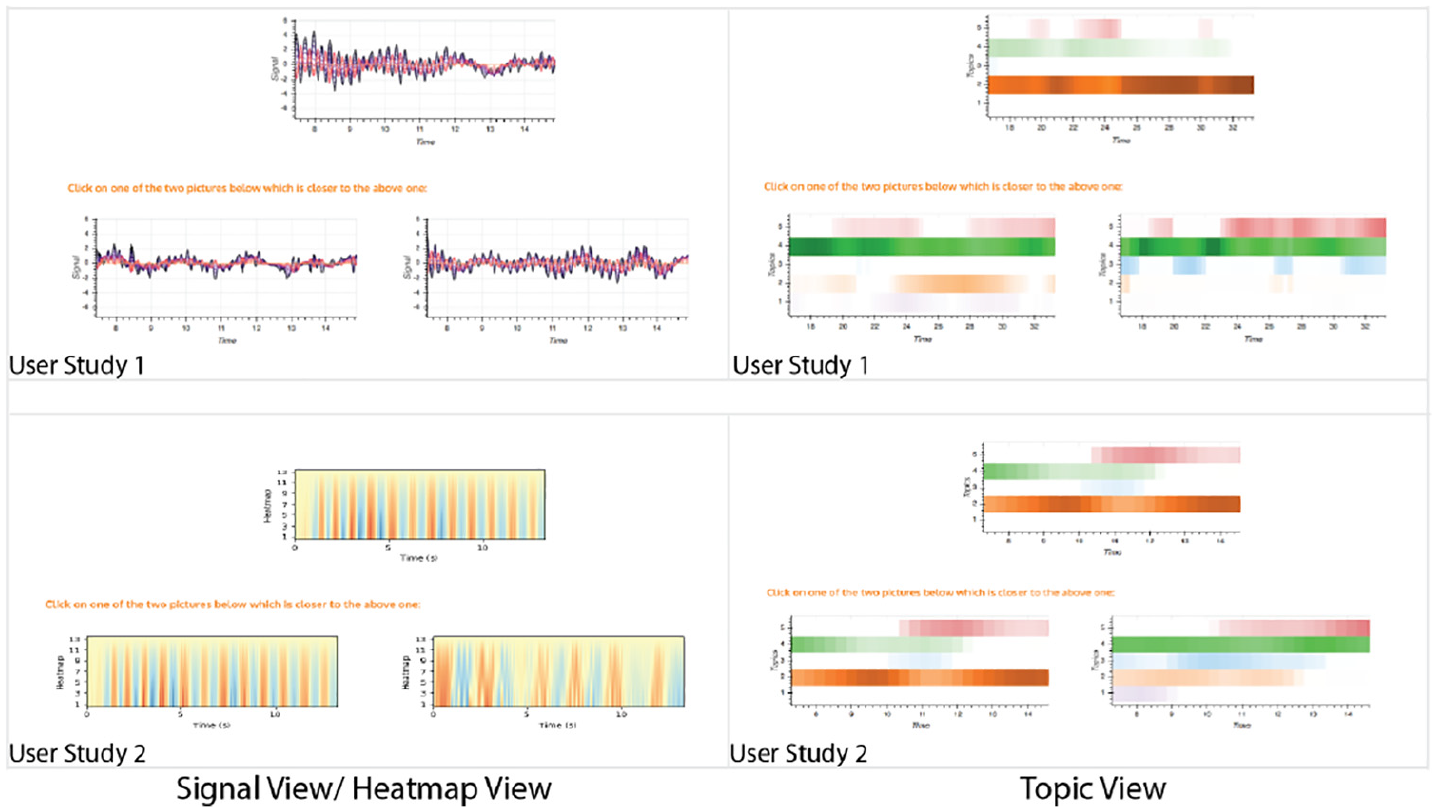
Some samples from the stimuli presented to participants in the surrogate task presented in Section 6.1. The particular stimuli presented are chosen to highlight the range of variation between easy and hard examples in the surrogate task. The full set of stimuli and source code to reproduce the analysis is submitted as Supplemental Material.
Since “most similar” is a markedly subjective notion, and since participants of the study are not trained in analyzing earthquake simulation data, we provided a short training session where participants are given instant feedback as to whether or not they answered correctly. Although this is not an exactly realistic scenario, we believe the training session provides information for the kind of pattern that the analysts should be expected to find in real-world analyses.
Hypothesis and design
Our hypotheses are:
STFT-LDA will provide higher accuracy in correctly identifying similar patterns, compared to a time-series signal view;
STFT-LDA will provide higher accuracy in correctly identifying similar patterns, compared to a time-series heatmap view.
We have done two independent trails for these two conditions. For the first trial, the “visualization” independent factor is whether the stimulus is a “topic view” (from the results of STFT-LDA) or a “signal view” (from a traditional multiple time-series view). We use a within-subject design for the “visualization” factor, and use randomization to counterbalance the order in which the factors are presented to each participant. All participants are shown the same stimuli for the training session, although the order in which the training session stimuli are presented is also randomized across participants. The dependent factor in our study is simply whether or not the participants picked the correct value, as defined above. Each participant is given a number of such baseline judgment tasks. For the second trail, we keep all the other settings same as the first one except that the “signal view” is replaced with a “heatmap view.”
Pilot study
We performed an informal, untimed pilot for our study with two participants, each answering an unlimited number of judgment tasks (until they informally decided to stop). The exploratory information gathered from this study suggested we should expect to see around a 10% absolute improvement in performance from the signal-based/heatmap-based visualization to the topic-basic visualization, and we also learned that those participants did not take more than 10 s to answer any of the baseline judgment tasks. This gave us sufficient information to design an experiment with sufficient length to give enough power to test the hypothesis. Ultimately, we arrived at a design where each user answers 30 basic tasks and 4 “trivial” tasks designed to exclude participants who could not understand these instructions. The trivial tasks showed an identical copy of the target image as one of the alternatives. We designed the analysis such that if any participant answers any of the trivial tasks incorrectly, we would discard the entirety of their input. In addition, the actual responses for the trivial tasks are discarded.
Participants
We recruited a total of 19 participants in the first trial, and 22 participants for the second one. The time interval between two trails is around 13 months which minimizes the possibilities of mutual effect between two trials. The participants were recruited by local volunteering in classes and research meetings, and comprise a mix of graduate students and researchers in computer science and data visualization. Because we were not interested in post-hoc analysis of demographic information, we did not formally collect such information as gender or age of participants. For all the participants, no data was discarded due to incorrect answers for the trivial tasks.
Analysis
Our study design enables a relatively simple statistical analysis, in which we can use Fisher’s exact test for count data.
64
The exact count tables for this study can be seen in Figure 10. Fisher’s exact test allows us to reject the null hypotheses in two trials at
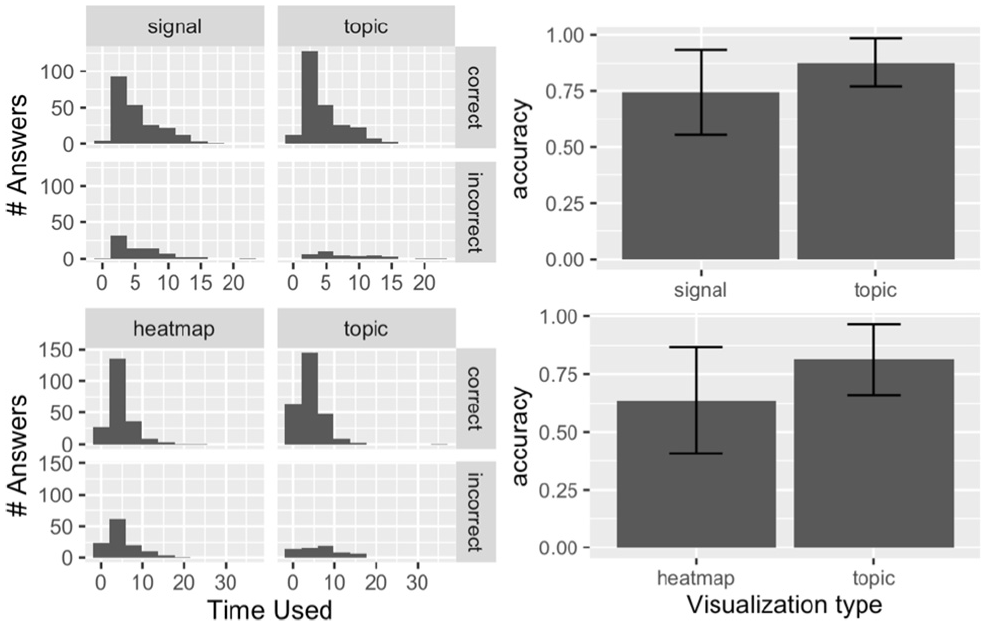
Summary of analysis of surrogate task. On the left, we show a histogram of the times participant took to answer the tasks, broken down by whether they answered correctly or not, and visualization type. On the right, we show sample accuracy for the “topic” and “signal/heatmap” factors, together with the (estimated via binomial approximation) standard deviations. We find that the null accuracy hypothesis can be rejected with
Study materials and data
We have made the study materials, data, and analysis available as part of the Supplemental Material in the form of CSV files, R Markdown scripts to reproduce the analysis, and the actual generated analysis document.
Expert study
We conducted an expert study to evaluate the usefulness of our prototype system, where the expert is one of the our coauthors who has worked in structural and earthquake engineering for years. It was deployed on a cloud server and executed in a web browser (Chrome). Before the formal study, we piloted the user study with two Ph.D students, who have never seen the visualization. The information we gathered helped us design each session and estimate time for each question. Then we scheduled the meeting with the expert via Skype and we recorded his computer screen with audio during the conversation. The entire user study consists of three parts and took around 90 min in total. The first part is a training session. In this session, we quickly introduced STFT-LDA, demonstrated the usage of our prototype system, and gave the expert enough time to experience the different visualization modules and ask any questions required to fully understand the visualization approach and its implementation. In the second part, the expert user needs to answer eight questions using the system (Table 1). To match the four general tasks we summarize in Section 3.3, we designed two questions for each task, ranging from summarizing earthquake behaviors to making comparisons between earthquakes. At last, we collected the expert’s comments on both STFT-LDA approach and the prototype system for evaluations and further improvements.
Questions asked in the expert study.

Overall the visualization approach received very positive feedback from the expert. With the visualization, most of the tasks can be solved much easier than directly utilizing previous visualizations like line plots and our approach significantly reduces the effort in exploring the simulations and benefit the analysis procedure. The user also revealed many interesting findings that were not noticed about the data before. The results are strongest for Task 1 and Task 3, whereas for Task 2 and Task 4, the expert found the visualizations were a modest help.
The expert agreed that Task 1 is well supported by the visualization approach. He gave detailed descriptions of the frequency variations for different floors while inspecting the spectrum of each topic, and he immediately associated that with possible vibration modes of the building (Figure 6). He also showed strong interests in the search module and visualization of the time series (Figure 8) and tended to use them together to identify the similar impacts from different earthquakes and explain these time ranges. For answering Questions 1 and 2, the expert analyzed what happened to the building when one particular topic dominates. For example, based on the topic spectrum, he speculated that the “orange topic” is a strong indication of building under the first mode. By brushing on the time range where the “orange” topic is dominant, similar time intervals could be easily found for in other earthquakes. After inspecting these time intervals in the time series visualization (Figure 8(d)), the expert noticed that all the floors are changing in the same direction while the bottom floor has the strongest vibration intensity. This confirmed his original guess and he also reported that the earthquake impulses under the “orange topic” are often very weak and tend to happen at the end of earthquakes.
The expert also reported that the visualization is helpful in comparing different earthquakes in Question 5. He reported that the topic representation simplifies the complicated multi-dimensional time series while preserving discriminative features. He stated that he can make quick comparisons by simply identifying which topic dominates in the earthquake. For further explanations, the expert referred to the topic spectrum and vibration modes for details. This result is also consistent with the conclusion in the quantitative user study (Section 6.1).
Question 6 is about interpreting the topic transition (“purple-green-red-blue”) in Figure 7. The expert stated that the visualization approach was very helpful in this task. By utilizing the prototype system, the expert found out that this kind of topic transition indicates the structure damage. He further explained that when the earthquake first hit the building, the impulse was often small, thus the building was vibrating in a high-frequency, low-intensity second mode (“purple topic”); then the magnitude and frequency of the impulse both rose to a very high level(“green topic) and persisted for a small amount of time (“red topic”). Once this large impulse hit the structure, it changed the frequencies of the building due to two reasons: first, the larger impulse caused more serious vibrations; second and most important, this impulse had changed the vibration of the building from elastic to inelastic and caused irreversible damage to the structure. Due to this material damage, the building’s vibration changed to a different high-frequency second mode (“blue topics”), which coordinates with the structure changes. The expert stated that finding and analyzing these material damages is one of the main concerns for structural engineering and it is supported by the visualization approach.
The lower ratings for Tasks 2 and 4 are somewhat surprising. The expert stated that although the correlation matrix and the scatter plot provided a summary view for navigation and exploration, it was still difficult for him to find obvious clusters or identify outliers in the dataset due to two main reasons: visually, the expert user didn’t feel confident distinguishing clusters in the matrix view or associating “unique” earthquake with the lightest row or column in the matrix; methodologically, instead of showing a single score to indicate the similarity between two earthquakes, he would like to use the ratios of each topic in an earthquake as a measurement for clustering.
For the modules in the prototype system and interactions between them, the expert stated that most of the them were very useful. In particular, he was very excited about the search module. Previously, in order to understand how an identified feature in one earthquake relates to other earthquakes, the civil engineer needed to manually go through each earthquake. The expert reported that the search module makes this process much easier and the response speed is very fast. The expert also appreciated the automatic zoom-in interaction in the details view for brushing in the topic view. However, the expert user also gave suggestions for improvements. For example, suggested a view to demonstrate the percentages of each topic within one earthquake. He also expected to see the topic representations of other single attribute or multiple attributes. He also suggested ordering the topics by the absolute energy of each topic. In summary, the expert agreed that STFT-LDA and the prototype system are very helpful for summarizing responses, especially for identifying similar behaviors across different earthquakes. The expert stated that this method helped solve the problem that the civil engineers can only inspect the data from one perspective, either the frequency distribution, magnitudes, or time series for each floor. With our visualization system, the expert could now explore the time series, time window, frequency heatmap, and different behaviors at the same time. On the other hand, there were some limitations regarding the identification of clusters and outliers, and for future work we plan to address these issues.
Discussion, limitations, and conclusion
The data generated by the earthquake simulations contains, in addition to the shear variable attribute we use in the paper, a number of other attributes such as displacement and moment. Even though in principle STFT-LDA can handle the summarization of multiple attributes in a natural way, we focus on one attribute for two reasons. First, it is not clear whether or not a system built to encompass the complete variety of data in the simulation should summarize over these different attributes, or instead provide topic-based views of each of those attributes separately. Second, a quantitative evaluation of the relative merits of these two design decisions is not straightforward. These are both attractive avenues for future work.
STFT-LDA is a practical way of analyzing multivariate time series that combine periodic and non-periodic components. STFT-LDA is capable of capturing the periodic behavior without obfuscating time information. Specifically, it can handle high-dimension data and simplify the complex time series to compositions of different topics. Compared to traditional dimension reduction methods like PCA, the topic components are interpretable and they have specific behaviors. Moreover, it has both flexibility and scalability. For example, as we discussed above analysts can in principle generate topics over two attributes over all floors if they care about the influence of two attributes together. Similarly, STFT-LDA can be used to generate summarizations of all simulation attributes over one particular floor. While a full study of these design decisions is beyond the scope of this paper, extending STFT-LDA to such scenarios is a natural topic for future work.
A particularly promising contribution of the work is exploring time series data through windowed frequency analysis. While we used the STFT in this work, which we think is particularly amenable to LDA for topic modeling, other approaches such as wavelets or matching pursuit might also be fruitful ways to explore this or similar data.
Our approach has two key user parameters: the window size and the number of topics. In our work, we used domain knowledge to set the window size to 5 s, which was based on domain information of the lowest frequencies of interest that we observed in our simulations. Using a shorter window would exclude such behaviors, while using a larger window would only increase computation time with no added benefit. Our work suffers from the same limitation as previous topic modeling works, in that setting the number of topics often requires iteration. We set the number of topics to five after experimentation. In our runs, typically, we saw no more expressiveness with using a large number of topics, as new topics typically only captured the transition regions between topics.
Finally, the expert that we have in Section 6.2 is also one of our coauthors of this paper. We are aware that having coauthors in the evaluation is potentially problematic, but in this case we lack practical alternatives since they are almost the only people qualified to understand this. Each simulation is designed and run by him and his advisor, as well as the structural method and the input earthquake signal. Thus, they know this unique data better than any other civil engineers. On the other hand, this research is also in the coauthor’s thesis. 65 They have been investigating relationships between the buildings and the earthquakes for a long time. In summary, to verify if our approach and system can actually help users understand these simulations, they are the most proper domain experts.
In conclusion, we have shown that STFT-LDA is an attractive approach for analyzing periodic and non-periodic features of multivariate time series. Because it accurately captures both local and global features of the time series in a simple descriptor, the visual summaries we can display from the result are more effective at distinguishing seismically relevant characteristics of the simulations. We integrate the full STFT-LDA pipeline into a prototype interactive visualization system. Our surrogate tasks and expert study shows our approach can help civil engineers quickly summarize earthquake behaviors and identify deviations and outliers.
Supplemental Material
sj-gz-1-ivi-10.1177_14738716211038618 – Supplemental material for STFT-LDA: An algorithm to facilitate the visual analysis of building seismic responses
Supplemental material, sj-gz-1-ivi-10.1177_14738716211038618 for STFT-LDA: An algorithm to facilitate the visual analysis of building seismic responses by Zhenge Zhao, Danilo Motta, Matthew Berger, Joshua A Levine, Ismail B Kuzucu, Robert B Fleischman, Afonso Paiva and Carlos Scheidegger in Information Visualization
Footnotes
Appendix
Author Note
Any opinions, findings, and conclusions or recommendations expressed in this project are those of author(s) and do not necessarily reflect the views of the National Science Foundation
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This material is based upon work supported or partially supported by the National Science Foundation under Grant Number 1815238, project titled “III: Small: An end-to-end pipeline for interactive visual analysis of big data”.
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.