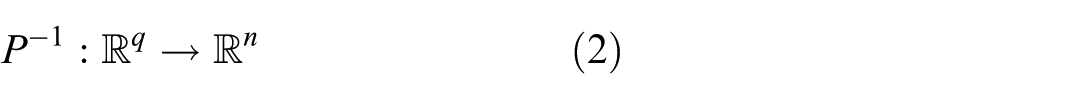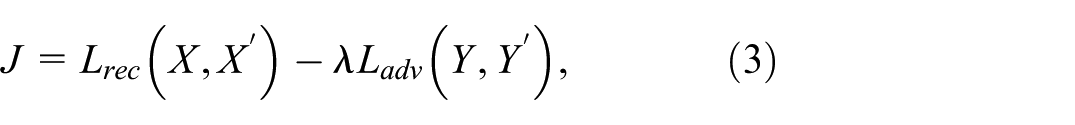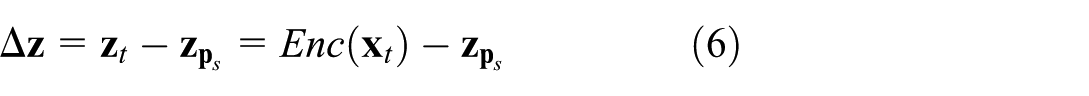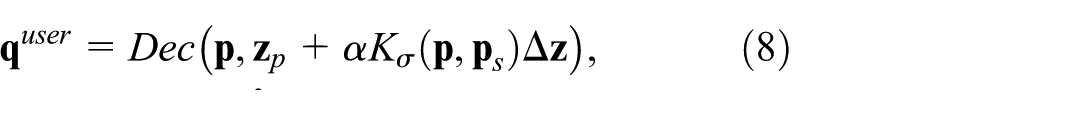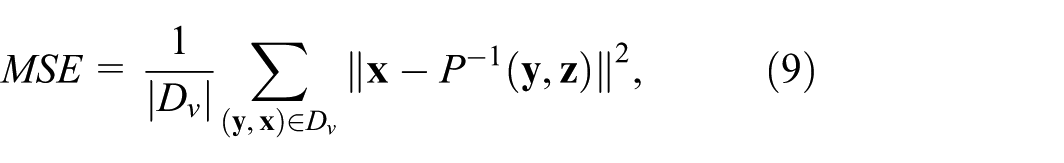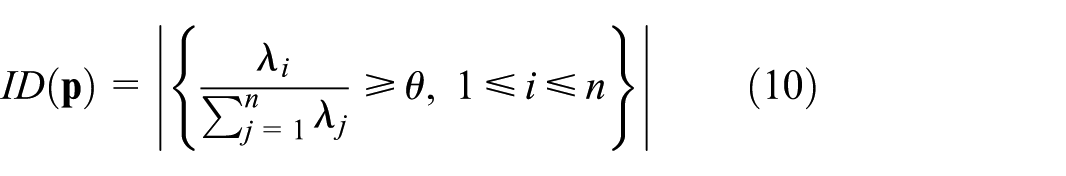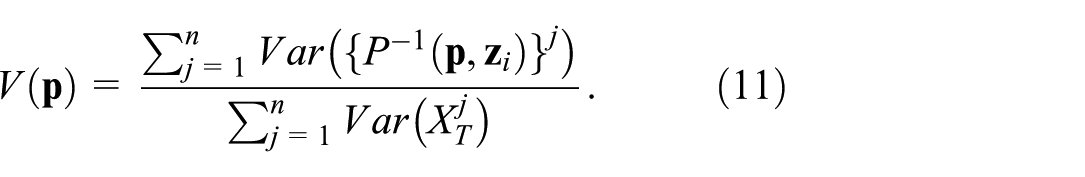Projections, also known as dimensionality reduction methods, aim to map high-dimensional data to 2D scatterplots for visual exploration. Inverse projection methods aim to map this 2D space to the data space to support tasks such as data augmentation, classifier analysis, and data imputation. Current methods suffer from a fundamental limitation – they can only generate a fixed surface-like structure in data space, which poorly covers the richness of this space. We address this by a new method that ‘sweeps’ the data space by a surface that is not fixed but under user control. Our method works generically for any technique and dataset, is controlled by two intuitive user-set parameters, and is simple to implement. We demonstrate it by an extensive application involving image manipulation for style transfer.
Multidimensional projections, also called dimensionality reduction (DR) methods, are established techniques for the visual exploration of high-dimensional data.1–3 Many DR methods have been proposed in the past decades, such as PCA, t-SNE, and UMAP, to mention just a few.
Inverse projections aim to revert the mapping produced by a given projection. They aim to generate highly plausible, yet hypothetical, data items from any location in the embedding space created by projecting a given dataset. This enables applications such as data augmentation,4,5 analyzing trained ML classification models by so-called decision maps.6–8 pseudolabeling for creating training sets,5 morphing and data imputation,9,10 and testing a classifier’s brittleness versus backdoor and data poisoning attacks.8,11
Both direct and inverse projections suffer from significant information loss.12 Direct projections cannot, in general, map data whose intrinsic dimensionality largely exceeds that of the 2D projection space while preserving data structure, that is, inter-point distances and neighborhoods.3,13 Yet, users expect that inverse projections allow them to examine large parts of a data space starting from its 2D projection space. However, a recent study has shown that all current inverse projection techniques only generate fixed, surface-like, structures in the data space, so the coverage of inverse projections is limited to a small part of the data.14
In this work, we enable inverse projections to represent surface-like structures whose location in data space is not fixed (as produced by existing inverse projection techniques) but rather controllable by the user. Intuitively put, the user controls two parameters that allow the surface to move between a fixed position – given by the direct projection – and positions that get close to data samples deemed of interest by the user. As one changes the control parameters, the said surface literally ‘sweeps’ the data space. Even though, for a given set of control parameter values, we still produce a surface, its sweeping effect covers points which a single, fixed surface, computed by existing inverse projection techniques, could not reach. Specifically, for a sample projecting to by a user-chosen technique , we find the information that is lost by and enable users to (interactively) control how to combine (information preserved by ) and (information lost by ) to compute our controllable inverse projection.
To realize this, we must answer three questions: (1) How to ensure is independent of (as we want to let compute and the user to control )? (2) How to compute for locations in the 2D space where no ground-truth sample projects? (3) How to control the structure created by the inverse projection, to enable users to explore large parts of the data space?
Our Loss-Controlled Inverse Projection (LCIP) answers these questions as follows: (1) We minimize mutual information to disentangle the and spaces. (2) We interpolate between values learned for known samples to fill in the ‘empty’ areas in a projection. (3) We allow users to interactively adapt to control the inverse projection’s shape.
To show our method’s abilities, we first study its disentanglement effect (section ‘Added value of disentanglement’) and next compare LCIP both visually and via quality metrics with 3 state-of-the-art inverse projections for 4 datasets and 2 direct projections (section ‘Comparison to other inverse projection methods’). Next, we show how LCIP’s interactive control creates higher-dimensional structures than surfaces, something existing methods cannot achieve (section ‘Controllability: Going beyond a fixed surface’). Finally, we show how our method can be used to support a style transfer application (section ‘User control of the inverse projection’). While our method can technically handle arbitrary high-dimensional data, we focus on image data which is easily interpretable – an important requirement for our technique where users aim to interactively control the structure created by the inverse projection (Figure 1).
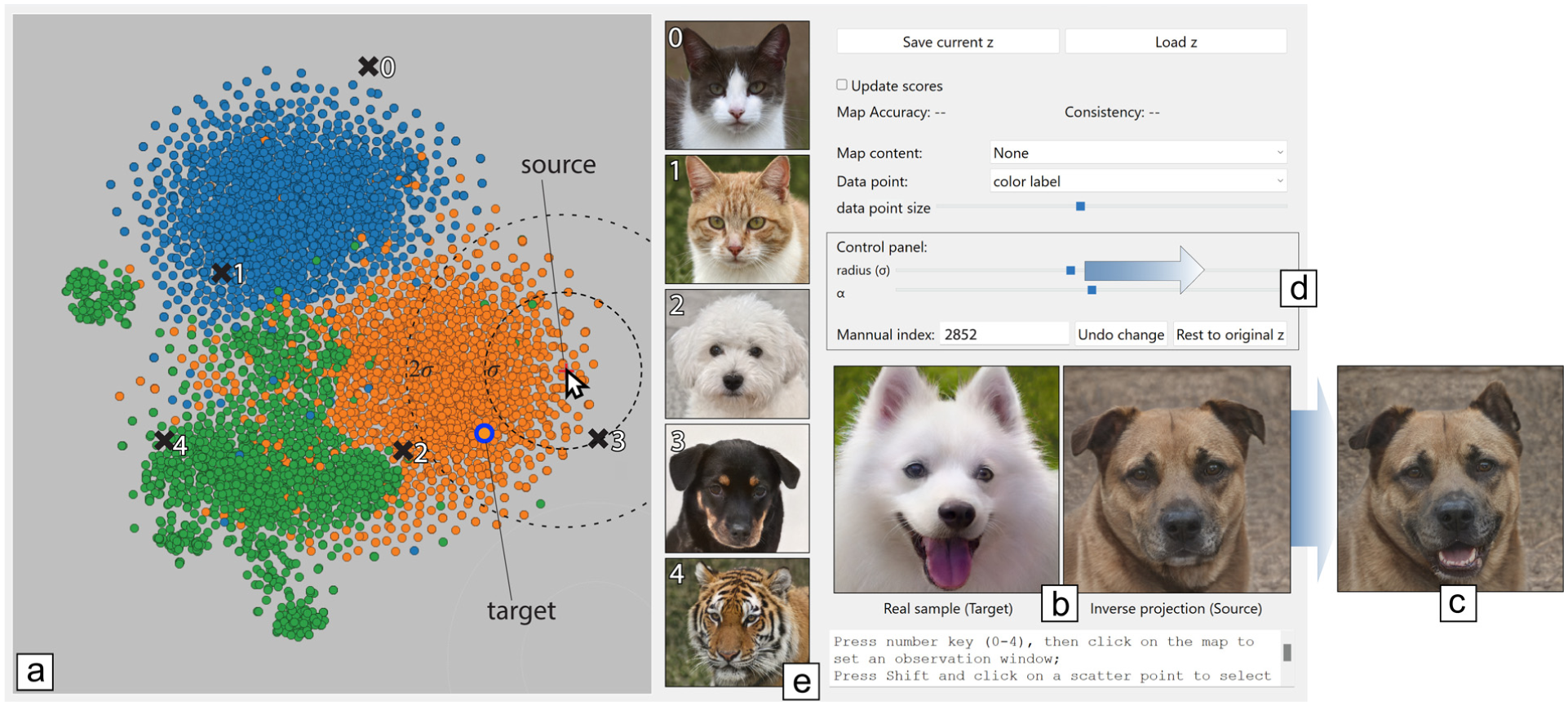
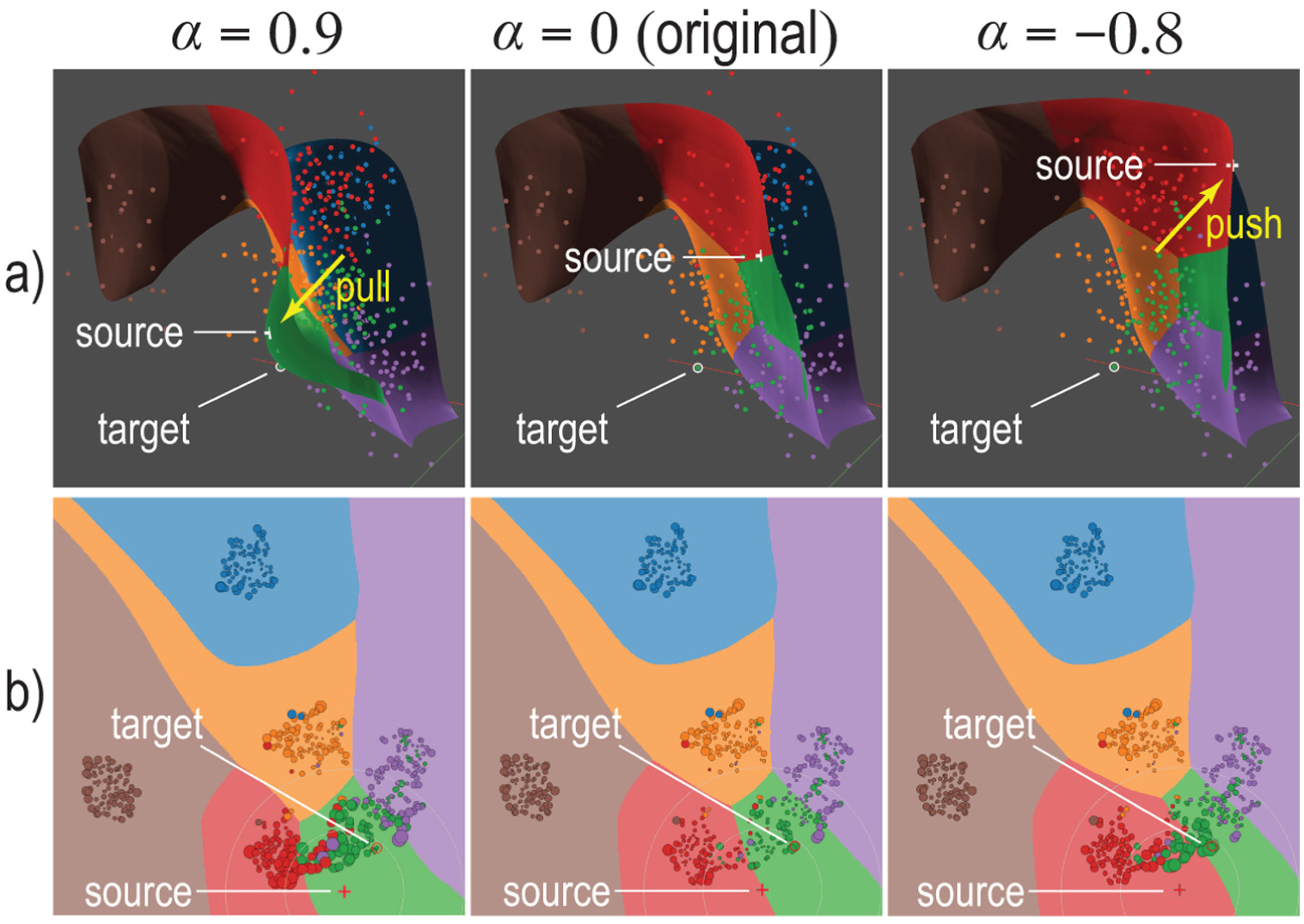
LCIP illustrated by a style transfer application. (1) Brush the projection (a) to find a frowning dog which we want to make smile (b, right). (2) Brush projection to find a target image with a smiling face (b, left). (3) Pulling a slider (d) changes the source towards the target, making the frowning dog smile without changing its identity, see result in (c). Adjusting the influence range affects how images close to the source get changed towards the target – see circles centered at mouse location in (a). We select a few extra points in the projection – marked 0–4 in (a) – to inspect how LCIP behaves there. Point 3 is close to the source, so it is strongly influenced by the source’s change; points 0, 1, and 4 are far away from the source, so they are not affected.
Background and related work
Projections and inverse projections
Projection: Let , , , be an -dimensional dataset. A projection
maps each to a , where . For visualization goals as in this work, we typically set . Projection techniques, such as PCA, t-SNE15 and UMAP,16 are covered by extensive surveys.3,13 We further denote any point in the projection space by .
Inverse projection: An inverse projection, also called backprojection or unprojection, is a function
that aims to reverse the effect of a given . We next denote by points in the data space obtained by applying the inverse to some 2D point , that is, For a dataset and its projection , is typically computed by minimizing errors of the form over . Crucially for applications, once is defined based on and , one can use it to infer data values for any , including so-called ‘gap areas’ between points in .
Unlike direct projections, only a few inverse projection methods exist. iLAMP9 builds local affine mappings that revert the LAMP direct projection.17 To address the lack of continuity and global mapping in iLAMP, a method using Radial Basis Functions (RBFs) was next proposed,18 UMAP16 builds both a direct and inverse projection based on preserving the data structure’s topology from to . DeepView8 enhanced UMAP with a classifier to produce a discriminative projection and used a modified UMAP for inverse projection. Self-Supervised Network Projection (SSNP)19 enhanced standard autoencoders20 with self-supervision using pseudolabels to create both direct and inverse projections. Blumberg et al.21 proposed a method to invert multidimensional scaling (MDS) that works well for .22,23 Finally, NNinv10,24 used supervised deep learning to invert any projection in a generic way, a method recently extended to autoencoders.25
Inverse projection applications: Inverse projections allow performing dynamic imputation to explore a high-dimensional data space using its projection10; Amorim et al.18 morphed between facial expressions using RBF inverse projections. Inverse projections enable creating so-called decision maps. Such maps provide insights into a trained classification model’s behavior7,8; allow pseudolabeling samples to create rich training sets5; and support explorations such as studying a model’s brittleness against data attacks.11 In all such applications, inverse projections are a key element of interactive visualization: In Amorim et al.18, users interactively sweep the projection space to create 3D models that morph between those present in a given set. In decision map applications, users interactively brush the decision map (created using inverse projections) to find which types of samples project for example, in areas close to decision boundaries or in other zones where misclassifications can occur. An extension of this scenario allows users to locate wrongly-classified zones in decision maps and interactively select samples falling in such areas to improve classification performance.5 In our work, we extend this interactivity by allowing users to actually determine the shape of the inverse projection.
Quality of inverse projections: Quality of inverse projections can be measured by the MSE , for points ; for so-called gap points, where inverse projections are actually useful, we do not have ground truth to test against. Previous work10,11,18,26 shows that smooth inverse projections are preferred as they ensure that small changes in 2D space (e.g. when the user drags a 2D point to unproject) yield small changes in data space. Gradient maps10 gauge this smoothness by computing the norm of the gradient of . Additional metrics capture the quality of decision maps11,26– these go however beyond evaluating inverse projections. We will use both MSE and gradient maps to evaluate our proposal.
Surface limitation of inverse projections: Recent work14 showed that all existing inverse projections map the 2D space to a fixed structure embedded in data space that is surface-like, that is, has intrinsic dimensionality close to two.27 While not unexpected, given that a aims to smoothly map to , this means that inverse projections only cover a very limited subspace of . How this subspace is constructed is completely non-transparent to, and not controllable by, users. The above imply serious limitations for inverse projection applications. Using inverse projections for data augmentation will lack diversity. One cannot be sure that a decision map truly depicts a classifier’s behavior when it shows only a small part of the data space – more exactly, the cuts of the true decision zones by the surface structure created by .14 How to explore the data space outside this surface structure and how to control this exploration, are two challenges not answered by existing methods. In our work, we enable users to interactively control how such surface structures sweep the data space via simple visual controls.
Information loss: Both direct and inverse projections incur information loss. For direct projections, if the data do not land on or close to a manifold, constructing a mapping that fully preserves data structure is hard.12 Inverse projection limitations are stronger – these always create a surface-like structure as discussed above. If we consider the project-unproject cycle, information loss always occurs.
Inverse projections are structurally similar to data reconstruction or data generation tasks that create high-dimensional data from low-dimensional representations. The (, ) cycle can be seen as an encoder-decoder structure, where the bottleneck is the 2D latent space. The dimensionality of this space is a critical factor for the quality of reconstruction and generation.28–30 Inspired by these observations, we aim to break the limitations imposed by our bottleneck – the visual space – by retrieving information lost during and using it to drive the construction of under user control. This will enable our to span structures with higher intrinsic dimensionality than two, and also control where these are placed in data space.
Disentangled representations and adversarial training
As stated in section ‘Introduction’, our first goal is to find the information lost during projection independent of the projection . Independence is often relaxed to minimizing mutual information or separating complementary factors.31 When achieved, this improves interpretability, reduces potential bias, and enhances generalization. For example, in handwriting recognition, separating text content (what an actual letter is) from its style (how the letter is written) helps model generalization. In speech processing, one aims to separate speech content from speaker’s identity .32
Minimizing mutual information between two latent representations, also called learning disentangled representations, can be done via adversarial training.32–36 Adversarial training, first used by generative adversarial networks (GANs) for image generation,37 creates high-dimensional realistic samples from low-dimensional latent codes. GANs jointly train a generator and a discriminator ; aims to create samples indistinguishable from real samples; tries to distinguish real from generated samples. Adversarial training has been extended to robust machine learning, domain adaptation, and disentangled representation learning. While diffusion models are now more popular for image generation, GANs are significantly more efficient.38 For example, DragGAN,38 an interactive image manipulation method, uses the StyleGAN2 architecture.39
Directly projecting high-dimensional datasets such as high-resolution images is challenging. In such cases, one typically models the data in the latent space of a pre-trained classifier such as InceptionV3 or VGG16.5,40 As we focus on inverse projection, we will retrieve images from the latent space of a generative model designed for this purpose, namely StyleGAN2. In detail: Let be the latent code that StyleGAN2 uses to generate images. Codes can be obtained by inverting StyleGAN2 pre-trained on the same dataset.39 For a given , the corresponding image is then given by . Adversarial training connects to our work in two ways: (1) We use it to enforce disentanglement between the information and the projection during the training of our inverse projection. (2) We use the space of an image dataset to ease the projection process.
Design of loss-controlled inverse projection
Inverse projection deep learning network architecture
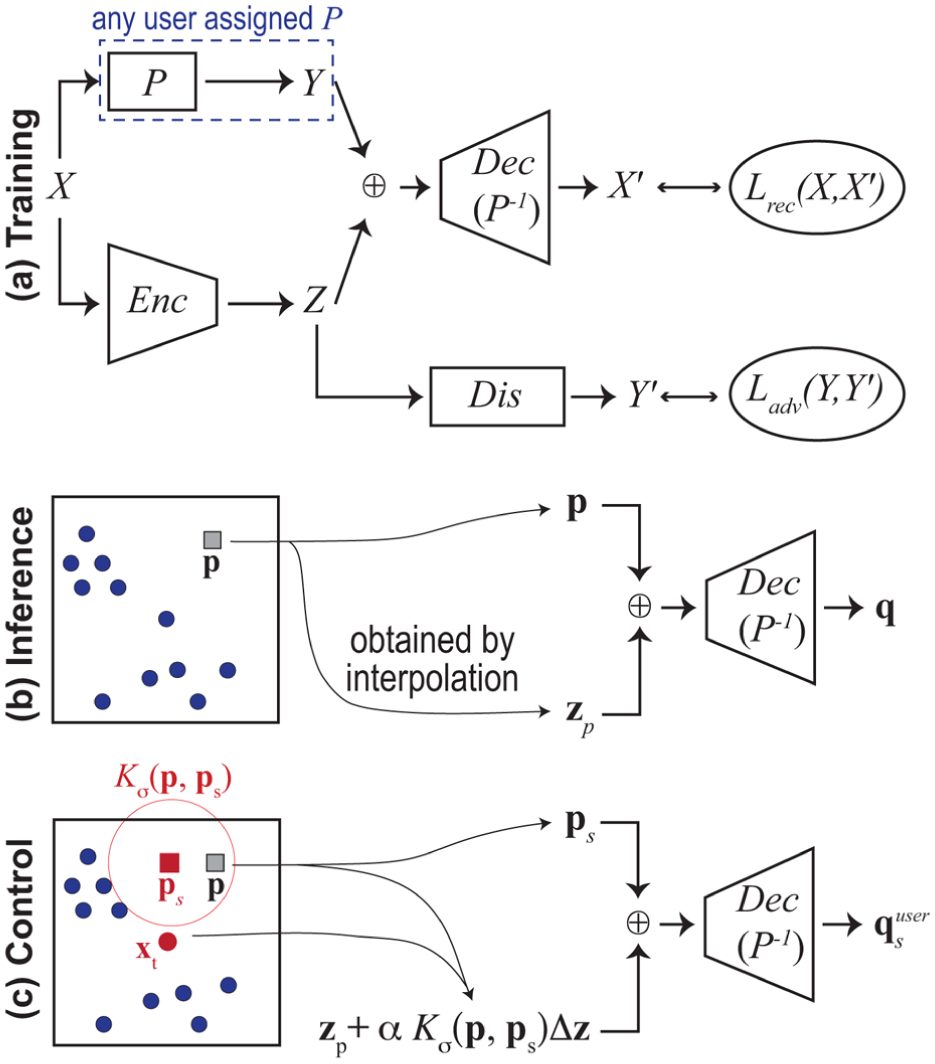
We implement our inverse projection using neural networks. Consider a dataset and its projection computed by any user-chosen projection technique . Our network has two key parts: an encoder that computes the information in lost by ; and a decoder which is also our inverse projection . reads the data and outputs a latent code . reads the concatenation and outputs the inversely projected data (Figure 2(a)). We also need to ensure that is not related to (see section ‘Disentangled representations and adversarial training’). We do this by a third discriminator network ; this network reads and outputs and is adversarially trained to minimize the error between and . and are jointly trained to (i) minimize the reconstruction error between and , and (ii) maximize the difference between and .
LCIP workflow. ⊕ denotes concatenation. (a) Training and . is a user-selected DR method that projects to . encodes into . uses to predict . () uses and to reconstruct . The adversarial network enforces disentanglement (section ‘Inverse projection deep learning network architecture’). (b) Inversely projecting a 2D point to data sample (section ‘Computing for the entire projection space’). (c) Users can refine the inverse projection by maneuvering the controls marked in red: a source point , a target point , a pull factor , and a kernel radius (section ‘Controlling the inverse projection’).
Let , , be the weight and bias parameters of , , and , respectively. Let be the reconstruction loss between and , and the reconstruction loss between and . When optimizing , we minimize , so learns to predict from . The cost function for optimizing and is given by
where is a hyperparameter that balances reconstruction versus adversarial loss, with the target of the optimization being
that is, we minimize and maximize while keeping fixed. Once trained, infers from and next inversely projects to .
Implementation: We use fully-connected networks for , , and . has 3 hidden layers (sizes 512, 256, and 128). has 4 hidden layers (sizes 128, 256, 512, and 1024). Each hidden layer of and is followed by a ReLU activation function. The final layer of is followed by a sigmoid activation function. has 2 hidden layers, each with a size of 128. Each hidden layer is followed by batch normalization and a ReLU activation function. The dimension of is set to 16 – a value we empirically found to be sufficient to capture the information loss of all studied techniques. We use these settings consistently for all tested datasets.
We use mean squared error (MSE) for both and (equation (3)). For (equation (3)), we ran a grid search over the range , and found that gives good results for all tested datasets. We train all networks using the Adam optimizer with a learning rate of . While training , we have noticed that the adversarial training requires more steps to stabilize, since it learns from a changing input. Hence, at each iteration, we update 5 times, then update and once. Our work is implemented using PyTorch41 with PySide6 (Qt) for the GUI, and is publicly available.42
Computing for the entire projection space
To apply our inverse projection (section ‘Inverse projection deep learning network architecture’) at a 2D projection point , we need the latent code computed from the sample that projects to . To apply our method to any 2D point , we need to estimate at that location. We do this by interpolating the values of the samples (see Figure 2(b)). We tested two methods: weighted k-NN ( neighbors) and smoothed RBF with a parameter-free thin plate spline kernel. RBF gives a smooth surface, while weighted k-NN is slightly faster. We discuss both interpolation methods in section ‘Comparison to other inverse projection methods’.
Having now the latent code for any , we can inversely project to the data space (Figure 2(b)) as
Controlling the inverse projection
To allow users to effectively control the shape of the inverse projection in data space, two questions arise: (1) How to do this easily, that is, by changing a small number of intuitive parameters in a direct, visual way; and (2) How to make our cover zones in data space where plausible samples exist, so that is useful for real-world applications.
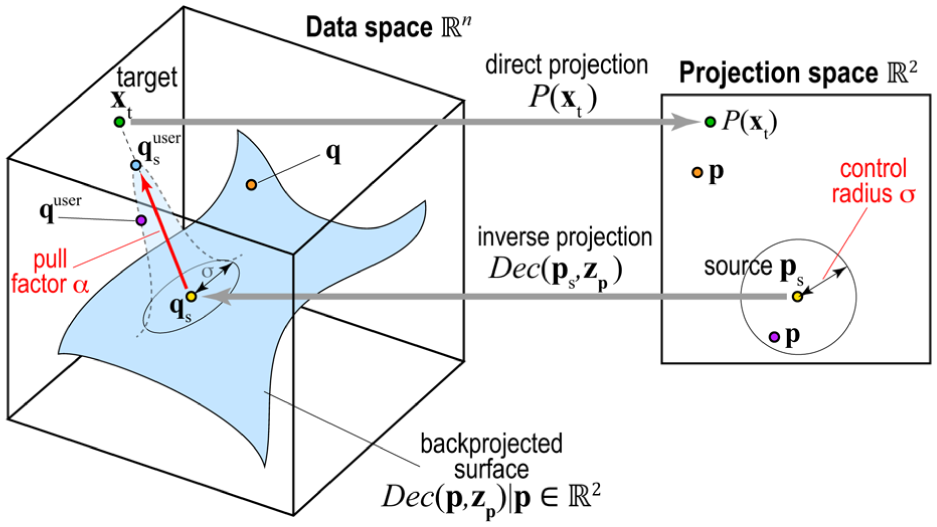
We solve both problems by the pipeline shown in Figure 2(c), which we explain next (see also Figure 3). Let , called a target sample, be a data point that we want to make our inverse projection go close to. Users can discover such points by brushing the projection with a tooltip to see the values (Figure 3, green point). The user next selects a 2D source point and manipulates it to control (Figure 3, yellow point). We then ‘pull’ the inverse projection of towards by adjusting (initially computed by interpolation as described in section ‘Computing z for the entire projection space’) – see the red arrow in Figure 3. To achieve this pull, we first compute the difference
Intuitively, tells how much the latent codes of the source and target differ, that is, what we need to change in the source’s inverse projection to make it become the target. With , we compute the user-controlled inverse projection of as
where is a factor giving the pull magnitude (Figure 3, light blue point). Yet, this adjustment only changes at the single location . 2D points close to will not be affected by this pull, as their inverse projections still follow equation (5). The inverse projection will exhibit a discontinuity or lack of smoothness around , which is undesired (section ‘Projections and inverse projections’). We could get smoothness by applying to all such 2D points. However, this changes the inverse projection globally– the source will equally influence all inversely-projected points, no matter how far these are from . We jointly achieve smoothness and local control by weighing the adjustment based on distances in the projection space to the source . That is, after adjusting the inverse projection at (equation (7)), we replace equation (5) by
where is a Gaussian centered at and controls the source’s influence. Larger values make control more global and yield smoother inverse projections; smaller values work oppositely. When is close to the source (Figure 3 purple point), its inverse projection gets pulled towards the target – see light-blue bump on the surface in Figure 3. When is far from (Figure 3 orange point), its inverse projection stays on the surface given by equation (5). Figure 1 shows this control mechanism in action for a simple style transfer application. Here, the dataset contains images of various animal faces. The user selects the source by picking a location in the projection – not necessarily an actual projected sample. The image for this point is computed by the inverse projection – see the sad-looking dog in Figure 1(b), right. Next, the user selects a target sample – see the happy-looking dog in Figure 1(b), left. Pulling a slider changes and morphs the source towards the target. The user can see how far/strong the effect of changing the source propagates over the projection by selecting other images (Figure 1(e)) and assessing their changes during source manipulation.
Controlling the inverse projection. User parameters are marked in red.
Evaluation
We evaluate our inverse projection method on several datasets and projection techniques. We first study the effect of disentanglement both qualitatively and quantitatively and show that our latent codes are indeed independent of the projected information (section ‘Added value of disentanglement’). Then, we show that our inverse projection (without interactive control) reaches similar quality to existing inverse projection methods (section ‘Comparison to other inverse projection methods’). Finally, we show that our interactive control breaks the surface-like limitation discussed in section ‘Controllability: Going beyond a fixed surface’.
For we use t-SNE and UMAP, known for their high quality13 and used in other inverse-projection studies.8,10,24,26 Given their high quality, measured for example, by trustworthiness, continuity, and other projection quality metrics on a range of datasets and hyperparameter settings (see Espadoto et al.13 for details), this means that the vector will capture, globally speaking, the information present in the high-dimensional data which the projection was unable to capture due to the intrinsic dimensionality of exceeding two and not ‘spurious’ errors caused by the projection algorithm itself.
We use the following datasets:
MNIST: 70K samples of handwritten digits (0–9), each a grayscale image flattened to a 784-size vector.43
Fashion-MNIST: 70K samples of 10 fashion categories (e.g. T-shirts, trousers, dresses), each a grayscale image flattened to a 784-size vector.44
HAR: 10K samples of smartphone accelerometer and gyroscope data capturing six human activities (walk, walk upstairs, walk downstairs, sit, stand, lay).45
of AFHQv2: AFHQv2 has 15K color images of animal faces in 3 classes: dogs, cats, wild animals.46 Its is a latent space used by StyleGAN2 models39 to generate images (section ‘Disentangled representations and adversarial training’). For ease of exposition, we next show the generated images instead of the raw codes .
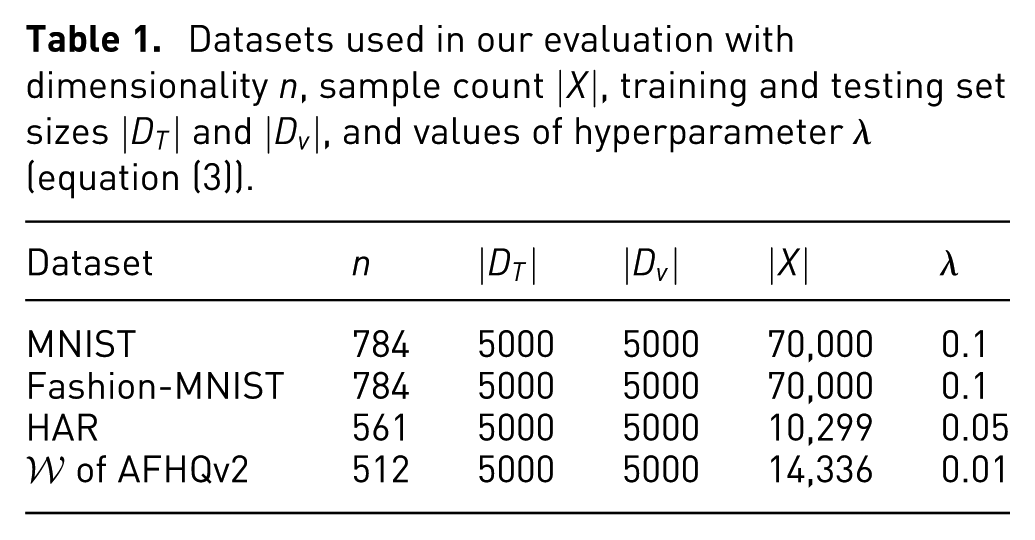
For a dataset and its projection , , we form the pairedset , and split it into training and test subsets. Table 1 summarizes the above, including the dataset-specific choice of the hyperparameter (equation (3)).
Datasets used in our evaluation with dimensionality , sample count , training and testing set sizes and , and values of hyperparameter (equation (3)).
Dataset
MNIST
784
5000
5000
70,000
0.1
Fashion-MNIST
784
5000
5000
70,000
0.1
HAR
561
5000
5000
10,299
0.05
of AFHQv2
512
5000
5000
14,336
0.01
Added value of disentanglement
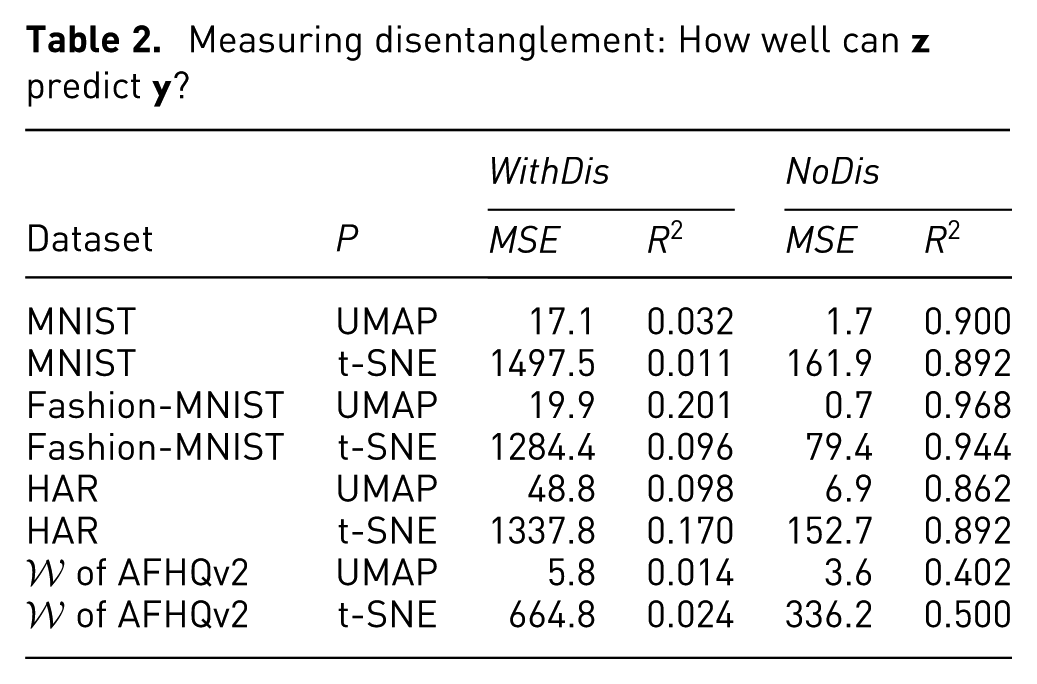
To show the added value of the disentanglement, we compare our results using the loss in equation (3); (called next WithDis) with the same network trained without (called next NoDis).
Quantitative evaluation: We measure disentanglement by how well predicts . Poor predictions mean better disentanglement, that is, more independent and .31,35,47 We measure this by training a post hoc regression model to predict from . This model is a neural network with one hidden layer (100 units) followed by ReLU activation, trained for 200 epochs using the Adam optimizer. We measure and on a hold-out test set. We expect that WithDis should yield low and high – that is, and are independent and/or different. Conversely, we expect that NoDis should yield high and low – that is, and are correlated and/or similar. Table 2 shows that and for WithDis and NoDis indeed match the expectations, thus confirming our claimed disentanglement.
Measuring disentanglement: How well can predict ?
Dataset
WithDis
NoDis
MNIST
UMAP
17.1
0.032
1.7
0.900
MNIST
t-SNE
1497.5
0.011
161.9
0.892
Fashion-MNIST
UMAP
19.9
0.201
0.7
0.968
Fashion-MNIST
t-SNE
1284.4
0.096
79.4
0.944
HAR
UMAP
48.8
0.098
6.9
0.862
HAR
t-SNE
1337.8
0.170
152.7
0.892
of AFHQv2
UMAP
5.8
0.014
3.6
0.402
of AFHQv2
t-SNE
664.8
0.024
336.2
0.500
Qualitative evaluation: We visually evaluate disentanglement by selecting two samples and of MNIST dataset and their t-SNE projections and . These are two images of digits 0 and 7 – see Figure 4(a). Let and be the codes of these two images. These are shown in a UMAP projection of the values for the dataset in Figure 4(b). We linearly interpolate between and , and and , respectively, with 10 steps. This yields interpolated values which we inversely project to the data space using both WithDis (Figure 4(c)) and NoDis (Figure 4(d)). We see from the t-SNE projection that the label information is well-preserved in the projection space (Figure 4(a)) – that is, digits of the same type, for example, zeroes or sevens, are well grouped. In contrast, the UMAP projection of strongly mixes labels (Figure 4(b)). This is desired, as should capture a digit’s writing style and not its class. We next see that, as we change using WithDis, the digit’s style changes – see columns in Figure 4(c); while, as we change , the digit itself changes – see rows in Figure 4(c). Hence, WithDis disentangles and well. In contrast, for NoDis, the inverse projection changes only when changes – see columns in Figure 4(d); when changes, the digit stays the same – see rows in Figure 4(d). Hence, NoDis keeps the latent codes and entangled.
Showing disentanglement on the MNIST dataset. (a) 2D t-SNE projection . (b) UMAP projection of using . (c) Inverse projections of the linear interpolation between two data points in the and spaces, using (c) and (d).
Comparison to other inverse projection methods
We now compare our inverse projection LCIP to iLAMP,9 RBF,18 and NNinv.24 We show that LCIP yields similar if not higher quality even without using its control mechanism (which we discuss separately in section ‘Controllability: Going beyond a fixed surface’).
Inverse projection error: We first measure the Mean Squared Error (MSE) of the inverse projection on the test set
where is ignored for iLAMP, RBF, and NNinv. For LCIP, we compute at by smoothed RBF and weighted k-NN interpolation of (section ‘Computing for the entire projection space’). We call these two variants LCIP (rbf) and LCIP (knn), respectively. We also compute and denote it by LCIP*. While this is not the intended way to get (as we cannot do this for any 2D point, see section ‘Computing for the entire projection space’), this measures the quality of our method if we could compute exactly. Figure 5 shows that iLAMP, RBF, NNinv, and LCIP have similar MSE on . Yet, LCIP* has a lower MSE on MNIST and Fashion-MNIST. Hence, our method can produce inverse projections with lower error when is properly provided. The quality gap between LCIP* and LCIP (rbf) or LCIP (knn) can be filled by interaction (see next section ‘User control of the inverse projection’).
MSE of the studied inverse projections.
Visual quality in gap areas: MSE testing can only be done for points in , where we have ground truth samples for . Yet, one wants to use inverse projections precisely in the gaps between 2D projected points (section ‘Projections and inverse projections’). One way to assess quality there is to study how inversely projected samples from gap areas look like. Ideally, we want to get plausible samples which follow the overall nature of the data in a given dataset.
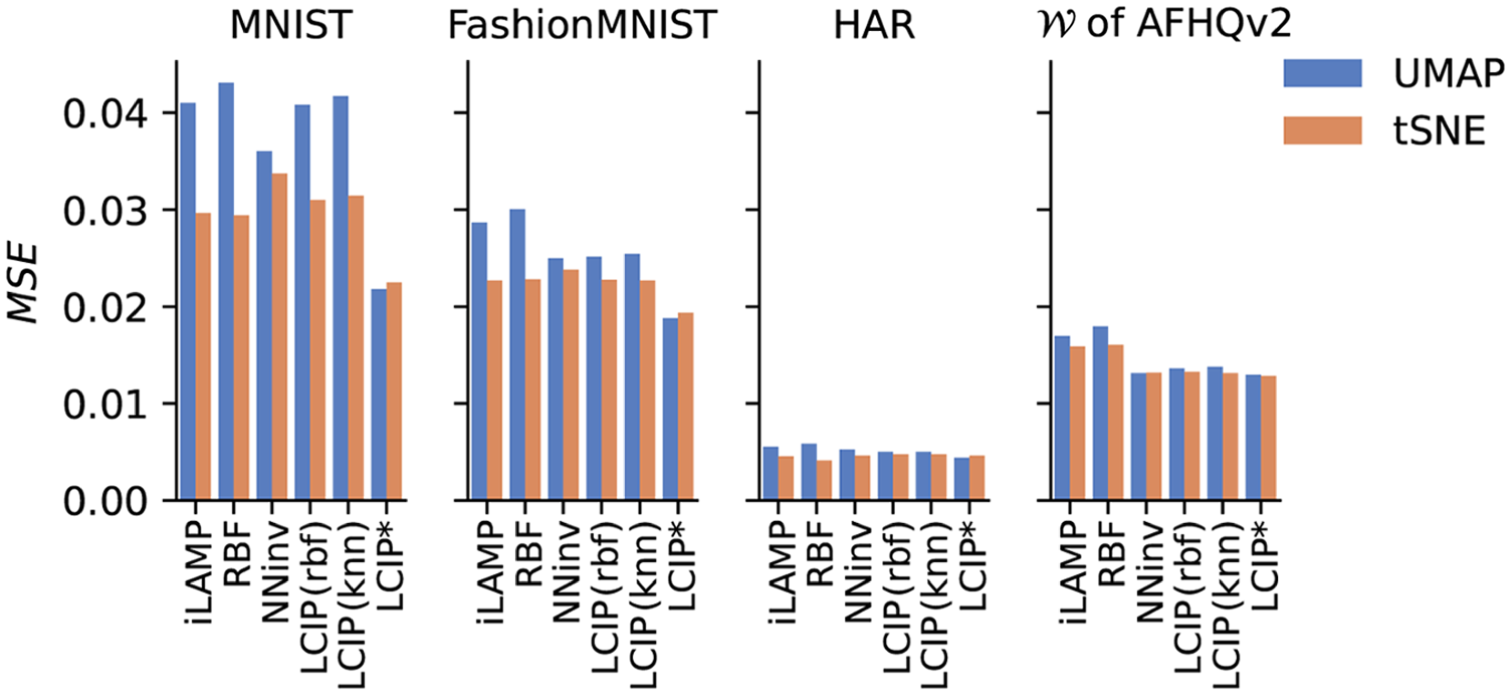
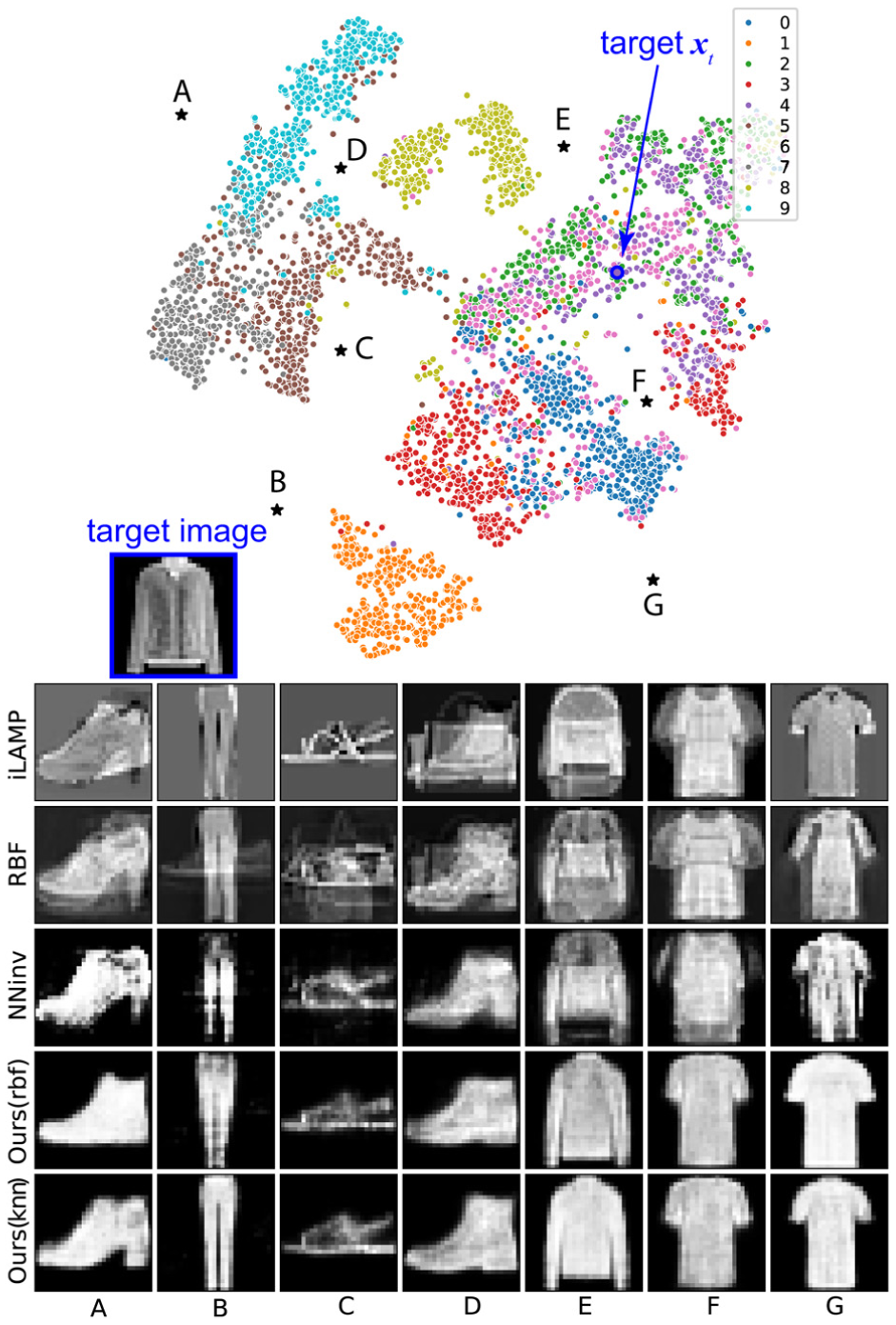
Figure 6 shows the four studied methods on MNIST. Images (b) show that LCIP produces more plausible digits than the other methods even at locations far away from data samples (e.g. A, C, M). We also see that iLAMP and RBF are more sensitive to outliers. For example, consider the green point (near K, class 2) located in between the pink (class 4) and purple (class 6) clusters, while the main green cluster is down at the bottom of the projection. The inverse projection of ‘K’ (close to the green point) is a ‘2’ in iLAMP and RBF, while it is a ‘6’ in NNinv and LCIP, so iLAMP and RBF feel the effect of this single outlier strongly whereas NNinv and LCIP do not. Separately, iLAMP creates gray backgrounds (e.g. A, B, C, F, M) which are not only far away from the actual data distribution but also not what one would expect for MNIST. Images (c) show the inverse projections from points along a line between images U (digit 9) and V (digit 8) in the projection. iLAMP, RBF, and NNinv generate spurious shapes that do not resemble any digit during this interpolation process – this is very likely due to the few outlier points from different classes present along this line. In contrast, LCIP morphs the 9 to an 8 following, we argue, a more natural set of intermediate images. As such, if one desires an inverse projection which is less sensitive to outlier points, LCIP is preferable.
Visual comparison of inverse projection, MNIST dataset. (a) 13 points A-M are selected in the projection space at various distances from projected samples. (b) The inverse projections at these locations using the tested inverse projection techniques. (c) Results obtained by inversely projecting points along a line between the locations U and V in the projection.
A further way to test inverse projection quality in gap areas would check whether for points in such gaps – that is, whether images created by LCIP would be placed by at the 2D locations from where they were inferred. However, this requires a parametric projection function . We do not want to impose such constraints on our pipeline but rather allow users to pick any technique – in particular, t-SNE; as such, we do not perform the above-mentioned test.
On Fashion-MNIST, iLAMP and RBF mix several images in the reconstruction (Figure 7). For example, at point A, iLAMP and RBF mix high heels and boots; at point B, RBF mixes shoes and pants; at point F, iLAMP and RBF mix a wider and a narrower T-shirt. NNinv doesn’t have this problem, but it produces jagged (e.g. at points A, B, C, G) or ambiguous shapes (e.g. at points E, F). LCIP keeps the reconstructed shape clear and recognizable in all cases.
Visual comparison of the inverse projection, Fashion-MNIST dataset.
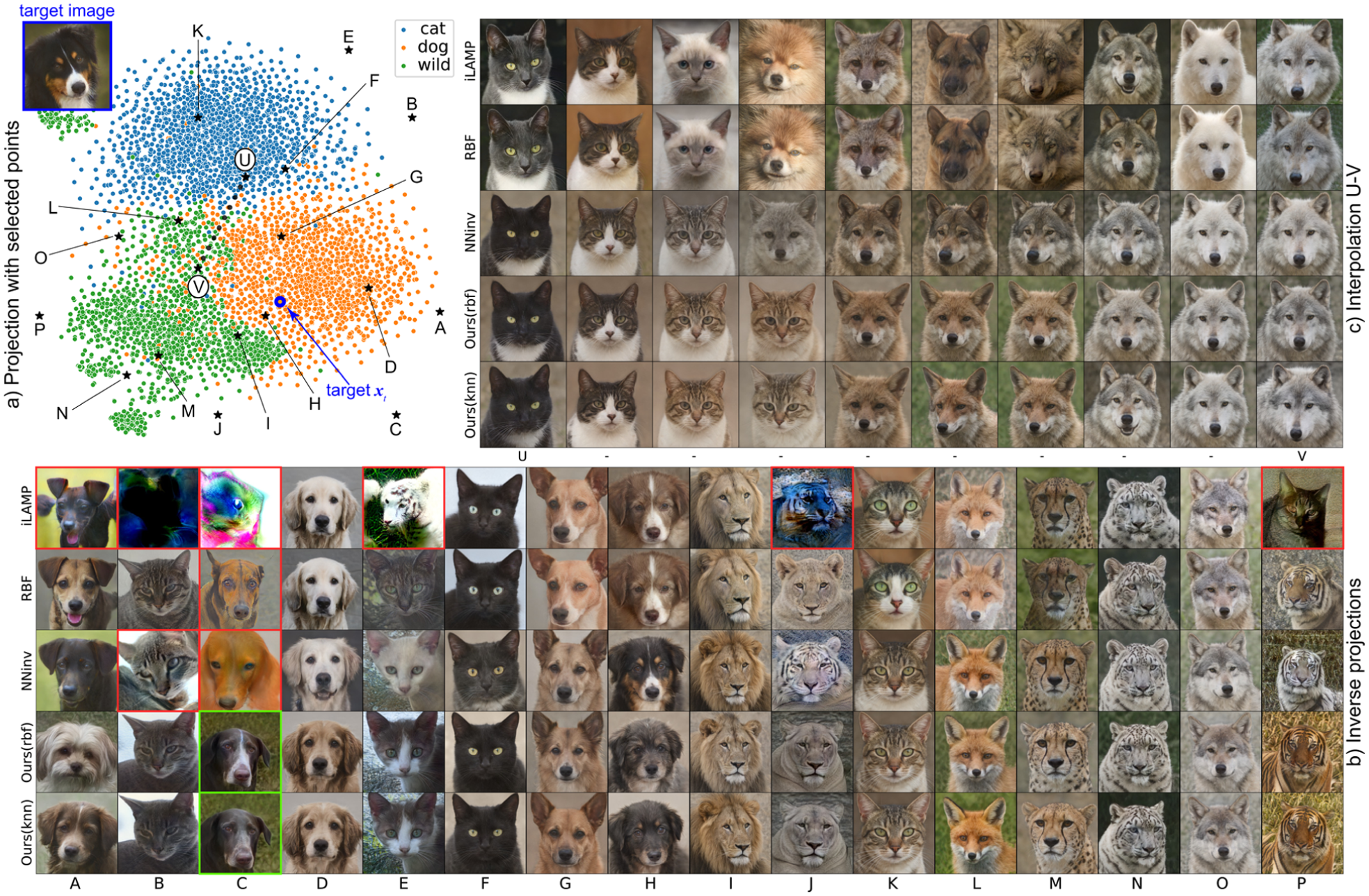
On AFHQv2, all tested methods work well when the inversely-projected 2D points are close to training samples. Once a 2D point is further away, iLAMP becomes problematic (see A, B, C, E, J, P). In extreme cases, all methods but ours have issues. For example, at point C (Figure 8), iLAMP produces a mass of colors with indiscernible shapes; RBF produces color distortions and a dog with only one ear; NNinv produces a dog but in a strange appearance, also with color distortions. In contrast, LCIP produces realistic images in all cases.
Visual comparison of inverse projections, AFHQv2 dataset. (a) Dataset projection with 16 selected locations both close and far away from data samples (A–P). (b) Inverse projections at A–P created by all tested methods. (c) Inverse projections of points on a line between locations U and V in the projection.
Smoothness comparison: We next evaluate smoothness using gradient maps.10 These are images which depict the gradient norm at every pixel of the projection space. Figure 9 shows these maps for the tested inverse projections on MNIST with the UMAP projection; additional datasets and projections, shown in the supplementary material, follow the same pattern. Bright colors (high gradients) show points where the inverse projection ‘jumps’ in data space when its input moves between neighbor pixels. Such jumps are undesirable (see section ‘Projections and inverse projections’). We see that LCIP achieves the smallest gradient norms (see color legends) for all datasets and direct projections.
Gradient maps for the tested inverse projections for UMAP on MNIST.
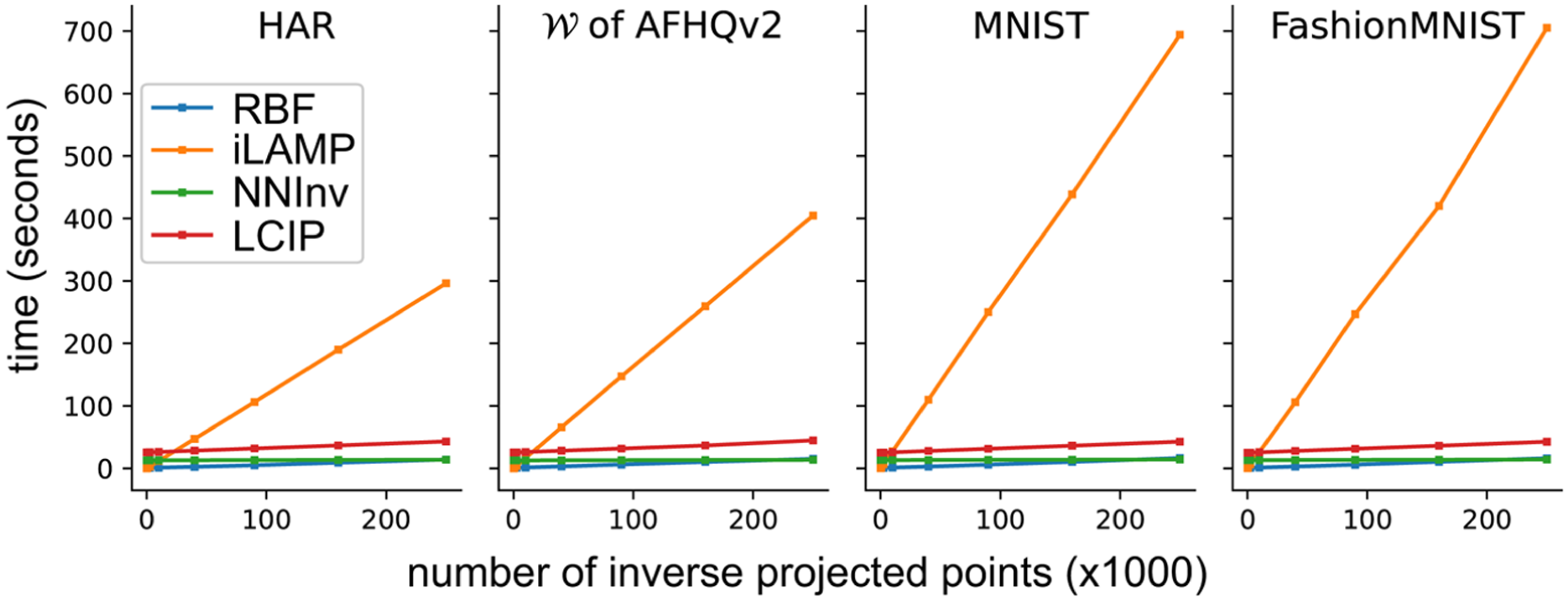
Computational speed:Figure 10 shows timings for the four studied inverse projection methods on a PC with an Intel Core i5-12400 CPU and NVIDIA GeForce RTX 3090 GPU. The y-axis shows the (constant) training time plus inference time (linear in the projected points count). All methods show similar speed except iLAMP which is visibly slower. Although LCIP requires slightly more training time due to its adversarial training, its slope is nearly identical to NNinv and RBF, showing the same high scalability. Separately, our evaluations show that the results of LCIP (rbf) and LCIP (knn) are very similar. Since LCIP (rbf) is theoretically smoother, we will use it in our following experiments.
Inverse projection speed. Training time is the y-intercept on the charts. Line slopes show how inference time depends on the number of inversely projected samples.
Controllability: Going beyond a fixed surface
We have shown so far that LCIP can construct a ‘fixed’ inverse projection from a given dataset and its projection with results which are comparable – and often better – than other existing inverse projection techniques in terms of generating plausible results in gap areas, inverse projection MSE, inverse projection smoothness, and speed. Yet, the key feature of our method is its ability to dynamically control the inverse projection, which we describe next.
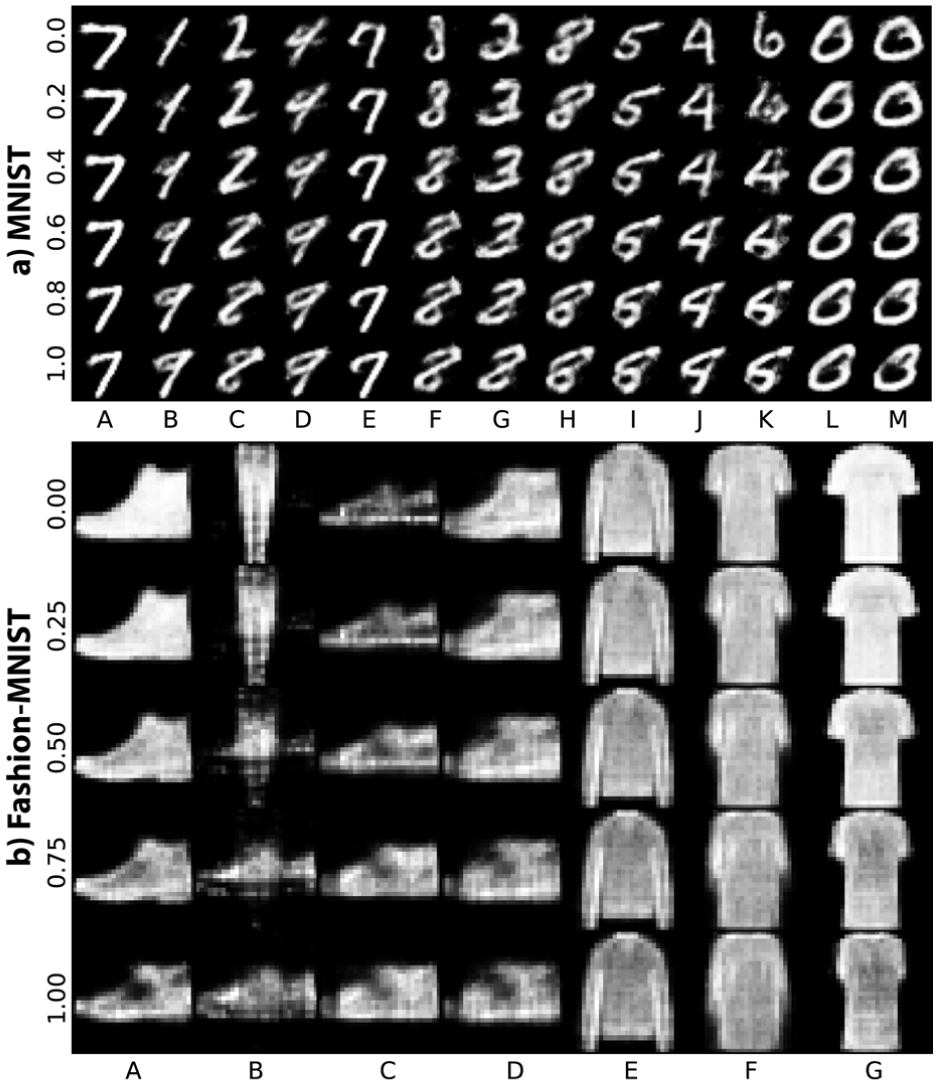
Control effects:Figures 11 and 12 show how the inverse projection changes when values are adjusted towards selected targets in MNIST, Fashion-MNIST and AFHQv2. Targets are marked by (blue) in Figures 6–8 with their images shown as insets. In Figures 11 and 12, topmost rows show the selected source images ; rows below show how the inverse projection ‘sweeps’ the data space between source and target as the user increases . For example, when selecting an italic-like ‘0’ digit in MNIST as target and increase , the inverse projections gradually become more italic, no matter which source image is selected (Figure 11). We see similar changes in Fashion-MNIST, see the subtle changes in shoe and shirt styles (Figure 11 bottom). For AFHQv2, the target is a dog tilting its head (inset image in Figure 8). As we increase , all selected source animals in the inverse projection rotate their heads with similar angles (Figure 12).
Controlling the inverse projection for MNIST (a) and Fashion-MNIST (b). Targets are the blue-outlined inset images in Figure 6 for (a) and Figure 7 for (b). Rows in the two images show the effect of increasing user control .
Controlling the inverse projection for AFHQv2. The target is the blue-outlined image in Figure 8.
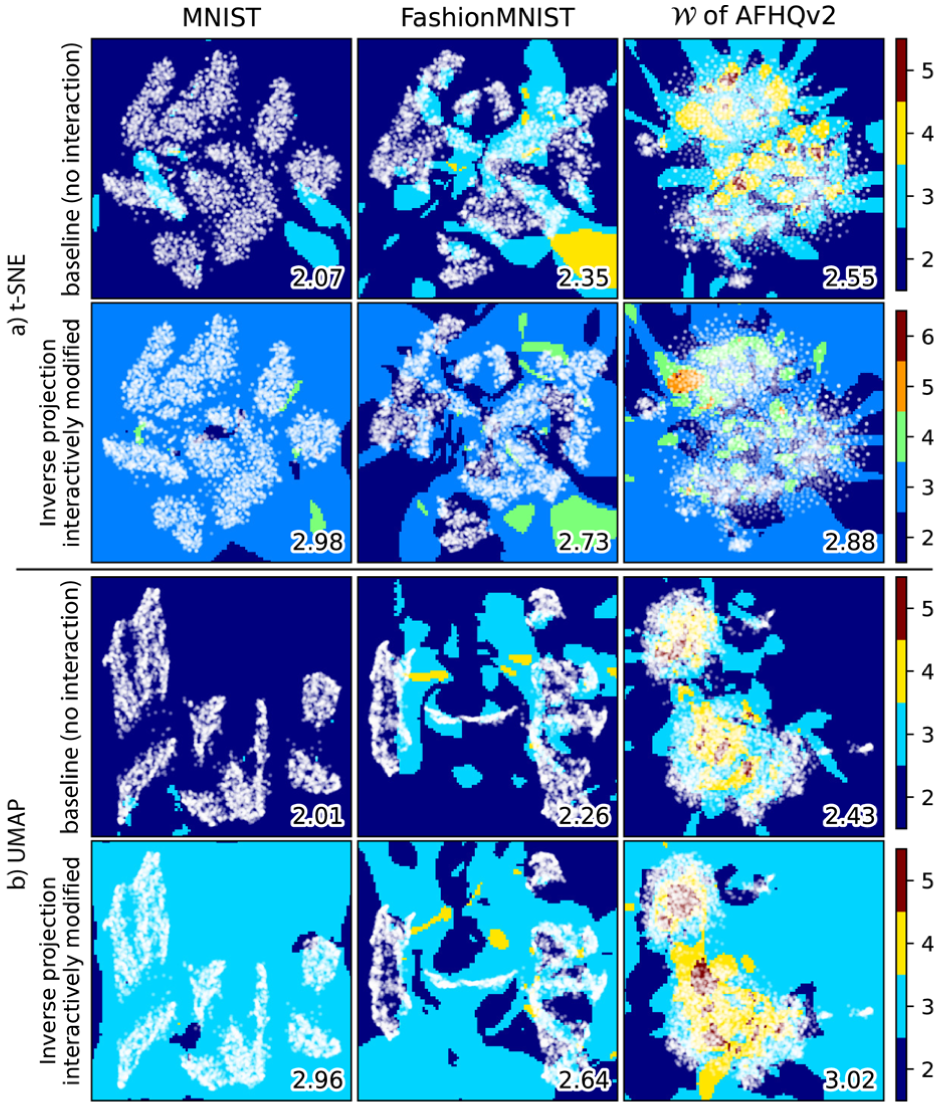
Increased reach: While LCIP generates inverse projections that go beyond a fixed surface, a key question is how much beyond such a surface it can reach. To quantify this, we evaluate the Intrinsic Dimensionality (ID) of the inverse projection (run without interaction) using the Minimal Variance method.48 In detail, we sample a set of pixels in the 2D projection space and map these through LCIP (without interaction) to get . For each query pixel , we consider its inverse and define the neighborhood , where sets a fixed-radius neighborhood in data space. We assess how close is to an embedded surface by computing the eigenvalues , , of the covariance matrix of , sorted in descending order, and then evaluate
with . counts how many principal directions each explain at least a fraction of the total variance of . If is close to , it means that the inverse projection locally creates a surface around the backprojection of pixel and its neighbors. We call this ID value the baseline.
Next, we adjust LCIP by globally adding values via equation (8), for 50 uniformly sampled values of (yielding ), and use equation (10) to measure the ID of all these inversely-projected pixels taken together.
Figure 13 shows that the baseline has at roughly all pixels of the sampled projection space (with small higher-ID areas close to the sample points). Figures in the bottom-right corners of the images show the average over all projection space pixels. We see that, when using LCIP without user control, LCIP creates roughly a surface embedded in , much like other inverse projection techniques.14 When using control, we get an ID roughly equal to 3, that is, ‘shifts’ our inverse-projection surface to span a 3D space in . Some ID values of 2 are likely due to the value of those areas being insensitive to the selected target, that is, and are close in the first place. Note that we only use a single target point here. If we used target samples which span a -dimensional space in , we would obtain an inverse projection of . Figure 15, (discussed later in this section) shows the same effect: changing pulls the inversely projected surface into areas far outside the original fixed surface, confirming the increased reach measured above.
Intrinsic dimensionality of LCIP without and with interaction for different datasets and direct projections.
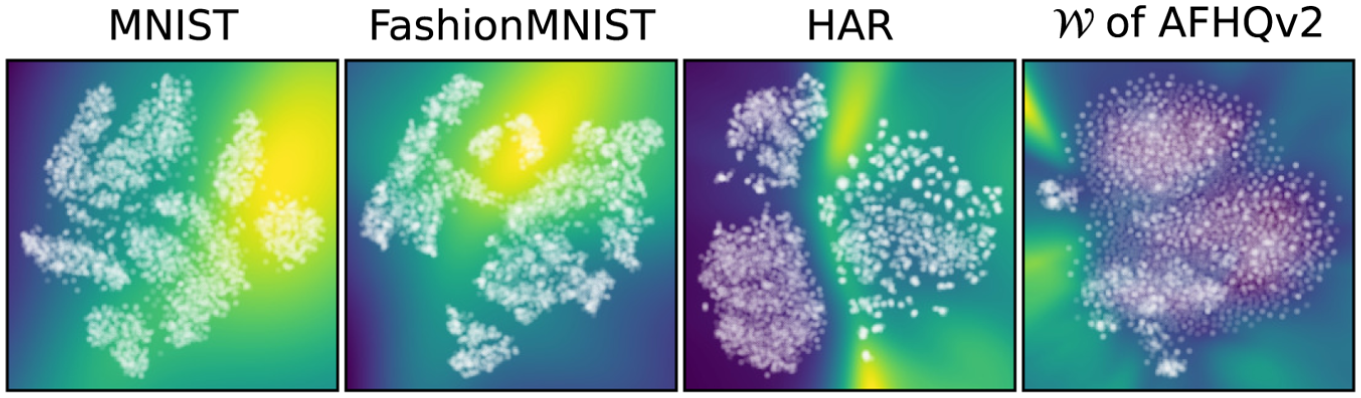
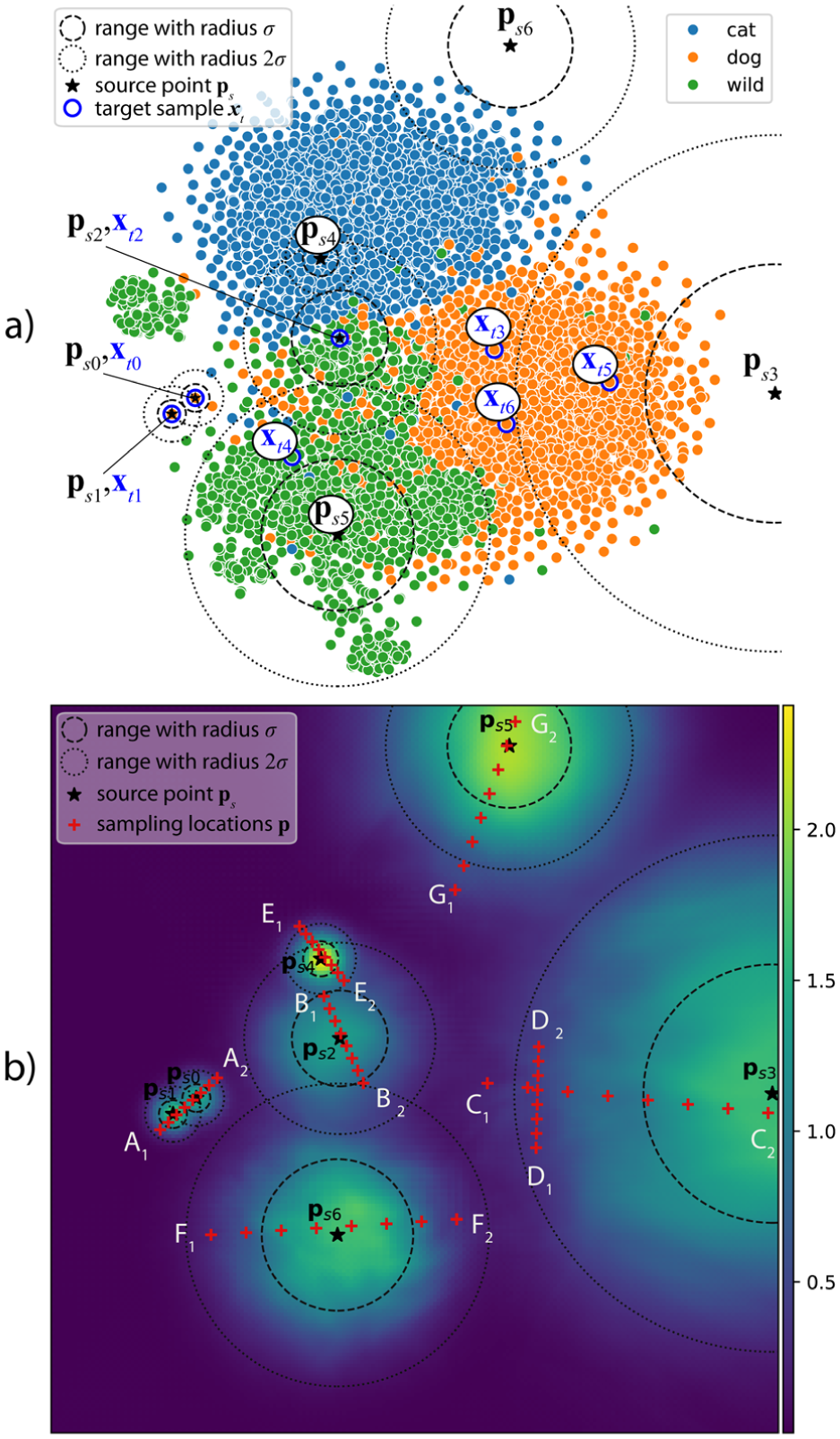
Flexible control: We further study the impact of using more control targets . For this, we consider a training set with 5000 points. For each , we compute its latent code , consider it as a target for our control mechanism, and consider each pixel of the projection space as source point. For each such , we measure the variance
over the set , across all data dimensions . Higher values of indicate that the inverse projection of is more sensitive to control, and vice versa. The denominator in equation (11) accounts for the spread of the training set in data space. If this spread is low, we should not expect that our inverse projection reaches far in the data space, and vice versa.
Figure 14 shows the results. On of AFHQv2 and HAR, variance is lower near data samples and higher in gap areas, telling that inverse projections are more ‘nailed’ when there is ground-truth data around, and more flexible when there is no ground truth nearby. On MNIST and Fashion-MNIST, the pattern seems not to be related to the distance to data samples. We believe that this is an effect of t-SNE’s known tendency to compress (or stretch) point neighborhoods from data space to projection space.49 That is, areas showing a low normalized variance in Figure 14 may actually map points which are close in data space, where our inverse projection does not have the freedom to move much; conversely, areas of high variance may map points far away in data space, where our inverse projection has more freedom to move. These maps provide users with insights on where interaction is likely to be most effective: Interacting with source points in high-variance areas will produce inverse projections which ‘sweep’ the data space more freely, which is the core goal of interaction; interacting with source points in low-variance areas is likely not going to discover new areas in data space.
Normalized variance of inverse projections produced by 5000 different values, t-SNE direct projection. See equation (11) and related text.
Exploring decision maps: As mentioned in section ‘Background and related work’, inverse projections are a key element to compute decision maps which are used to depict the behavior of trained classification models of the type .7,8,11 A decision map colors all pixels of the projection space by . As explained, existing inverse projections only depict the model’s behavior on a single, fixed surface embedded in . How the model behaves outside of this surface is left unexplored.
LCIP allows users to interactively change this surface to explore specific data-space regions close to samples of interest and in directions of interest. Figure 15 shows this using a synthetic 3-dimensional dataset with 6 classes and a lightweight fully connected classifier (mirroring the setup presented in Wang and Telea14). Since , we can directly visualize the inversely projected surface created by LCIP. The middle column of Figure 15 shows the fixed surface and corresponding decision map for , that is, similar to other inverse projection methods. We would now like to explore the behavior of the classifier outside this surface – more specifically, close to the sample marked source and in the direction towards the sample marked target. We first use to pull the surface from source towards target. The left column of Figure 15 shows how the surface locally deforms accordingly; this effectively demonstrates the effect outlined earlier in Figure 3. At the same time, the decision map changes to show us how the model behaves in previously unseen areas in data space that the deformed surface goes through now. Next, we set to push the surface from source away from the target, as shown in the right column of Figure 15. This explores the model on the other side of the original fixed surface. Interactively changing allows us to see the model’s behavior on a dense set of surfaces which sweep the data space around the source and in the positive/negative direction of the target. Choosing different sources and targets enriches our understanding of the visualized classifier in specific areas of interest.
(a) Inversely projected surface and (b) corresponding decision maps produced by LCIP for a synthetic 3D six-class blob dataset and classified by a 3-layer fully connected deep-learning network (hidden layers of size 512/256/128). Users can vary to ‘sweep’ the 3D space with the inversely projected surface and corresponding decision maps.
User control of the inverse projection
We now show how the control of LCIP works in practice using the tool shown in Figure 1(a). Based on how far the selected source is from the selected target in projection space, we have in practice two types of control: target is (1) close to, respectively (2) far away from, the source. In (1), we expect to gradually but fully change towards the target; In (2), we only expect a partial change, for example, style-wise. We show next that LCIP yields indeed these two different effects.
Local control: Target is close to source
We next show how our control helps with two challenges that frequently occur in inverse projection usage when the target projects close to the source . Consider first the limit case where . The difference between the target and the controlled inverse projection is fully controlled by . When , the inverse projection of becomes , that is, the inverse projection fully changes towards the target .
Now consider the case where projects close to, but not exactly at, the source . In the following, note that the choice of the target is application dependent, that is, depends on towards which data sample of special interest one wants to locally ‘pull’ the projection.
Inverse projection correction: While good inverse projections should have a low MSE (equation (9)), they do not yield at all projected samples . For instance, in Figure 16(a), and are two points at the margin of clusters. As such, their inverse projections and should not be strongly influenced by other points; ideally, and should equal the samples and that project there. Yet, this is not the case: The inverse projection images and are not similar to the sample images , (Figure 17). We can control our inverse projection to make it closer to the data. As we add to with higher values, the inverse projection gradually changes towards the target – see Figure 17 top two rows. The distances are also reduced, reaching minima for (Figure 17).
Close and far-away control of the inverse projection, AFHQv2 dataset. (a) 2D locations where we performed interaction. See also Figures 17 and 18. (b) Assessing smoothness of controlled inverse projection at various sampling locations (+). Color encodes the distance at each pixel. Figure 19 shows the inverse projections at these sampling locations.
Local control – adjusting the inverse projection when . Locations of and are shown in Figure 16(a). Numbers in upper right corners show . Numbers in lower left corners show the control parameter .
Overlap separation: Overlapping points in a projection are common. More precisely, projection techniques can place samples which are (very) far apart in data space very close in the projection space – in the limit, such points can even overlap given the finite size used to draw points in a visualization. This can be quantified by various projection quality metrics for example, trustworthiness.50,51 For example, in Figure 16(a), the area around point – which corresponds to a cat (denoted ) – shows overlapping samples of cats (blue) and wild animals (green). This overlap is due to the projection – the samples are actually separable in data space. Existing inverse projection methods will map to a cat, a wild animal, or a mix of them in a fixed and uncontrollable way. Our method allows controlling the inverse projection of to be more like a cat or a wild animal: We see that is initially a fox (Figure 17, bottom row, left). Setting the cat image as the target and as source, we see how the inverse projection gradually transforms from a fox into a cat as we increase (Figure 17, bottom row, columns ).
Far-away control: Target is far from source
In this scenario, the controlled will not go completely toward , since . Rather, only what is controlled by will change. It is important to note that it is hard to tell, in general, what exactly controls as this depends on what is lost in the projection , which in turns depends on the actual projection technique used and on the dimensionality of the input data. Our specific claim is thus: Given that there is such a loss, we (1) capture this loss and (2) allow users to ‘put it back’ in the computation of the inverse projection – unlike existing inverse projection techniques which behave as if this loss would not exist.
We illustrate the above with a few examples. In our studies, we found that, for the MNIST–t-SNE combination, the digit is controlled by , while controls the digit’s style; for the AFHQv2–t-SNE combination, the type of animal faces is controlled by , while the animal poses are controlled by . Controlling shapes the inverse-projected surface as desired, enabling user-controlled data generation, as illustrated next.
Consider a source far from any target, that is, in a gap area in the projection. All existing inverse projection techniques produce surface-like structures in such areas (section ‘Projections and inverse projections’). Our control breaks this limitation: Take point which is in a gap area (Figure 16(a)). Its inverse projection is a sad-looking puppy (, Figure 18 top-left). We now pick as target a happy dog (, Figures 16(a) and 18 top-right). As we increase , the sad puppy gradually smiles and finally laughs with open mouth (Figure 18, , top row). Note that the puppy’s appearance, for example, hair color and ear shapes, do not change to the target – only its ‘style’ changed. This control also works with source and target from different classes. The inverse projection of is a cat looking ahead (Figure 18, left column, second-top image). We choose as target a tiger looking up ( in Figure 18, right column, top image). By increasing , the cat gradually looks up without becoming a tiger (Figure 18, , row).
Far-away control – adjusting the inverse projection when . Locations of and are shown in Figure 16(a).
Lowering has the opposite effect. Take a front-facing cheetah as source (Figure 18, left column, 3rd image from top); and a left-facing dog as target (Figure 18, right column, 3rd image from top). Increasing , the cheetah turns its head left (Figure 18, , row 3). Lowering , the cheetah’s head turns right (Figure 18, , row 4). At , the cheetah starts becoming a tiger, since cheetahs and tigers overlap in the projection. This decrease triggers overlap separation (section ‘Local control: Target is close to source’). Finally, we choose a source in a gap area whose is a black-and-white front-facing cat (Figure 18, left column, bottom image). We set as target a left-facing dog (, Figure 18, right column, bottom image). Increasing , the cat’s head turns left (Figure 18, , row 5). Lowering , the cat’s head tilts right and fur changes color to brown (Figure 18, , row 6).
By adjusting , users can control subtle style features, such as the expression or direction a subject is facing, without altering a sample’s core identity. This ability extends across different classes and also far from any projected data sample. In other words, LCIP supports tasks such as user-controlled data generation where keeping the original data’s integrity, while introducing desired variations, is desired.
Smoothness of controlled inverse projections
Section Visual comparison of inverse projections, AFHQv2 dataset. (a) Dataset projection with 16 selected locations both close and far away from data samples (A–P). (b) Inverse projections at A–P created by all tested methods. (c) Inverse projections of points on a line between locations U and V in the projection. showed that LCIP without user control is smooth. User control should not affect this as ’s input smoothly varies with , and (equation (8)) and itself is smooth (being the neural network outlined in section ‘Design of loss-controlled inverse projection’). Yet, let us test this in practice. We choose 7 source points and sample seven lines … in projection space with 8 samples each (Figure 16(b), samples: +; source points: ★). We next set different and values for the source points and compute their inverse projections. Figure 19 shows the inverse projections without and with control. Images in each row – thus, over a set of per-line sampling points – smoothly change in both cases. To further confirm this, Figure 16b color-codes the difference between the inverse projection without and with control at each pixel. The result is a smooth signal, with large values close to the source points and small values further away, exactly as aimed by local control (equation (8)). Supplemental materialFigure 2 supports this by showing gradient maps before and after user control. The smoothness of LCIP with user control is further confirmed by a user study (see section ‘User study: Evaluating LCIP in practice’, Task 3). Yet, Figure 19 shows that some image sequences change more rapidly than others – see for example, the sequence , third row from top. This is explained by the fact that equal steps in projection space (Figure 16(b)) may map to small, or larger, steps in data space due to the nonlinearity of the used t-SNE projection.
Smoothness with/without control: Inverse projections at 8 locations (columns) around 7 source points (rows). Images are ‘+’ marks in Figure 16(b).
User study: Evaluating LCIP in practice
We conducted a user study with 15 participants (P1–P15). We used four tasks to measure the Uniqueness (T1) and Fidelity (T2) of the generated data; and Smoothness (T3) and Controllability (T4) of LCIP. We used AFHQv2 (Figures 1 and 16), a complex but still interpretable dataset. T1–T2 follow Amorim et al.’s18 evaluation of inverse projections. T1–T3 used images printed on paper ( cm) to ease task execution. For T4, participants used our tool; we collected user feedback on controllability and usability via post-task interviews. For full details, see supplementary material.
T1 Uniqueness: Participants were shown 10 images randomly picked from AFHQv2 (set A) and 10 images (set B) created by LCIP (fixed) applied to the original image’s location in the projection, see Figure 20 top. For each B image, participants were asked to choose the most similar image in A or reject all if none looked similar. Several B images can be assigned to one A image. T1 also helped participants to get to know the dataset as they were always informed if images were original or generated. We measured the uniqueness of generated images by aggregating participants’ choices – fewer associations indicating higher uniqueness.
User evaluation. Top: 10 image pairs used for Task 1: Uniqueness. Bottom: 10 original images (O1–O10) and 10 generated images (G1–G10) used for Task 2: Fidelity.
Results: Images G6 and G7 were always assigned to the originals O6 and O7. G10 was assigned 11/15 times to the original O10 alongside G4 and G8. For O8, most users selected O8 itself as the most similar image. Most users reported they could easily find a similar image for most images; a few could not find one at all. Statistical analysis confirms this: Participants completed 150 matching trials with correct assignments, yielding an observed accuracy . A one-sample -test against chance level () gives (), so we reject and support . The 95% confidence interval is fully above 0.1, so participants performed 0.347 (34.7%) above chance.
Interpretation: LCIP (fixed), that is, without user control, could generate images that are assignable to a ground-truth image. However, this highly depends on the local variance of the data. This can be seen by users selecting 3–4 different images in some cases, while in others, they unanimously selected the same single image. While participants said that it was not easy to find a similar image, they assigned correct counterparts above chance; this supports the claim that LCIP can generate visually distinct images.
T2 fidelity: Participants were shown 20 images (Figure 20 bottom) and asked to tell whether each was original or generated. Ten images were randomly selected from AFHQv2; the other 10 were created by LCIP (fixed), sampled based on point density in the projection to ensure a representative set. By assessing one’s ability to distinguish between original and generated images, this task gauges the fidelity of LCIP.
Results: Most participants incorrectly classified most images: image G8 (13/15 original), image O3 (13/15 generated), and image G1 (12/15 original). Results for G3, G4 and G6 were close to a tie – 8/15 users marked these as original. Images O6 and G5 were correctly classified as original, respectively generated, by 10/15 users. Overall participants achieved only 39.67% accuracy, much below the 50% chance level. The 95% confidence interval lies fully below 0.5. This leads us to reject the alternative hypothesis and tells that participants were unable to reliably distinguish between original and generated images.
Interpretation: Users mentioned looking for artifacts in the images to tell whether they were generated or not. Some participants agreed when asked whether ‘normal’ imperfections in an image made them think it was generated, while the generated image generally looked clean and polished. Overall, results show that LCIP creates data which is hard to distinguish from true data.
T3 Smoothness (natural interpolation order): Participants were given a start and end image created using LCIP and 6 in-between interpolated images – see rows marked with rows in Figure 19(b–d, f, and G), yielding five trials for this task. Users were asked to arrange the interpolated images in the perceived correct order between the start and end images using paper printouts set on a table. The match between the participants’ order and the actual interpolation order was used to measure the smoothness and understandability of LCIP.
Results: Participants could recover the interpolation order at high rates: 11 (trial 1); 13 (trial 2); all (trial 3); all but one (trial 4); and 11 (trial 5). Participants reported that they found it easy to order the images. In cases with larger changes in the animal’s appearance, for example, fur color, participants mentioned using features like facial expressions or viewing directions to infer the order. For each trial , we compared the number of correctly ordered intermediate images with the chance baseline (six intermediate images give a success probability). One-sample -tests strongly rejected in favor of ; even the weakest trial yielded (). Hence participants achieved significantly higher scores than chance.
Interpretation: Most users recovered LCIP’s interpolation order, telling that our method creates smooth transitions. Since users were particularly successful in trial 3, our results show that LCIP can create meaningful and smooth transitions between species (here, cat and fox).
T4 Controllability: Participants were introduced to the LCIP image-manipulation tool (Figure 1) by a free exploration phase. Next, they were asked to pick a dog image and modify it to make it smile using source image 2852 (a white laughing Samoyed) as reference; and next to do the same with a cat image.
Results: All users could transfer the smile in image 2852 to other dogs. Using the slider was found intuitive and easy – less so for the slider. Users did not overall succeed in transferring the smile from the dog to a cat image, yet found that other cat features, for example, fur or viewing direction, got more similar to the dog image. Directly manipulating images to transfer styles like ‘sticking out the tongue’ was found useful by all participants (P1–P15). Transferring desired styles between different animal species consistently was found difficult (P1, P4, P7, P15). Participants first struggled to understand what the and parameters actually mean; this improved with practice for over half of them (P2, P3, P7, P9, P11–P15). Critiques included insufficient labeling of parameters; improvements suggested adding more visual explanations of how parameters affect the high-dimensional data (P3, P7, P13, P14). The simple handling of sliders, showing changes visually, and ability to compare projections with original images were found helpful and functional (all participants except P1, P4 and P8). Some participants wished more precise controls to adjust image features such as fur color, eye shape, or body posture (P9, P12–P15). Overall, the ability to manipulate projections and visually track change effects were found exciting and useful (P10–P14).
Interpretation: Most T4 participants had positive impressions of LCIP’s ability to support style transfer and consistently managed to get the desired results for the dog image (less so for the cat image). Expectedly, learning to effectively use LCIP’s parameters to get the desired results took some effort. We should note that this task is quite challenging; its success depends not only on LCIP’s abilities but also on the used data – for example, if only a few smiling cat examples exist compared to dog ones, it is much harder for any interpolator to transfer a smile style from a dog to a cat.
Discussion
We next discuss several aspects of our method.
Controllability: To our knowledge, LCIP is the first user-controlled inverse projection that breaks the limitation that inverse projections land on a surface embedded in D (section ‘Controllability: Going beyond a fixed surface’). LCIP allows this inversely-projected surface to be put anywhere and smoothly adjusted (section ‘Smoothness of controlled inverse projections’ and Task 3 in section ‘User study: Evaluating LCIP in practice’). Related to this point, we also note the differences between LCIP and other data augmentation or interpolation techniques such as SMOTE52: While all inverse projections do data augmentation by construction, classical data augmentation works purely in data space, driven by structural or statistical properties of the dataset to be enriched. In contrast, inverse projections (like ours but not only) enrich a dataset in a controlled way – the added points must map to 2D locations in the embedded (projection) space. This allows one to actually explore the (enriched) data space by exploring the 2D projection space.
Genericity: We demonstrated LCIP with image style-transfer as this is an illustrative application for inverse projections. Yet, LCIP is not limited to image data, as shown by the controllable decision maps example in section ‘Controllability: Going beyond a fixed surface’; nor should it be seen as competing with dedicated image-style-transfer methods. Our method can control inverse projections created by any user-selected projection of any high-dimensional dataset . On the other hand, the practical application of LCIP – or, for that matter, any other inverse projection – to explore a high-dimensional data space works easiest when the data are directly displayable, for example, for images or 3D shapes.18 If data were abstract feature vectors obtained by for example, an autoencoder, or samples of a time series, LCIP (or other inverse projections) would technically work equally well but user control of the inverse projection would be less intuitive. This is not a problem of inverse projections but of how to intuitively display high-dimensional data samples in a 2D projection space. How to do this effectively for non-visual data e.g. audio data or general-purpose feature data is an open problem for future research.
Quality: Our evaluations show that LCIP has higher quality in gap areas than existing inverse projection techniques (section ‘Comparison to other inverse projection methods’). Also, LCIP creates smoother-varying data samples (when its 2D input changes smoothly). The user study (section ‘User study: Evaluating LCIP in practice’) further confirmed the uniqueness, fidelity, and smoothness of LCIP. Smoothness is of key added value in user-driven applications; non-smooth inverse projections would cause difficulty and confusion for users who aim to control how 2D points are backprojected to the data space.
Scalability: LCIP’s speed is linear in the number of inversely projected points and, in practice, similar to state-of-the-art inverse projection methods, for example, NNinv (section ‘Gradient maps for the tested inverse projections for UMAP on MNIST’).
Projection: We tested LCIP using two projection methods, t-SNE and UMAP, as these methods consistently score high projection quality metrics for datasets of varying (intrinsic) dimensionality and of different provenances,13 making them prevalent methods in visualization and visual analytics. This means that the 2D scatterplots that t-SNE and UMAP create allow an easier exploration by users than those from a lower-quality . In turn, this makes the information lost during projection to be lower than when using a low-quality , which makes LCIP’s interactive control easier. Yet, for specific datasets, other techniques than t-SNE or UMAP could yield higher quality and thus be preferable as basis for LCIP. LCIP can handle any in a fully black-box manner, so using other techniques can be directly done when desired.
Ease of use: To inversely project a source point, LCIP needs minimally only selecting that point in the 2D projection space. To modify the inverse projection, one needs also to select one target point (from the projected ones) and a ‘pull’ factor telling how much the source will change towards the target. Such operations are simple to perform in a GUI by clicking (to select points) and pulling a slider (to change ). Users can also change how smooth the inverse projection is around a source point by changing – again, just by pulling a slider.
Generalization: Three levels of generalization exist for both direct and inverse projections : (1) Transductive: can handle a given dataset but needs re-training from scratch when data changes (e.g. t-SNE). (2) Out-of-sample: can handle without retraining any dataset drawn from the same distribution as its training data (e.g. UMAP, NNP, and all the inverse projection methods mentioned in this article, including LCIP). (3) Cross-domain inductive: can handle without retraining data drawn from different domains. No direct or inverse projection method we are aware of attains type 3 flexibility. In particular, for inverse projections, this would mean building a single model which can output data of different dimensionalities without retraining or changing model architecture. This is a significant challenge which we leave for future work.
Limitations: LCIP disentangles the information captured by a projection from what cannot capture, and next manipulates this information to control the inverse projection. We argued that this makes good sense technically. Yet, from a practical viewpoint, as T4 in section ‘User study: Evaluating LCIP in practice’ also shows, it is by far not clear for a user what a given would capture (and thus not under user control) and what is, thus, controllable. Our experiments showed that, for selected datasets, the projection captures the core similarity of items, while the lost information – under user control – mainly affects a generic attribute we called ‘style’. Yet, what exactly style is; how it differs from what a given projection captures; and how much style is controllable in practice, are questions that we cannot formally answer for all datasets and all projection methods. Separately, LCIP is limited to the convex hull of samples in . As shown in Task 4 in section ‘User study: Evaluating LCIP in practice’, transferring the ‘sticking out tongue’ style from a dog to a cat image is generally not successful, likely due to this combination falling outside of the said hull. Exploring how to make go beyond this convex-hull space is a valid option to investigate. Finally, while our examples of style transfer on images are, we hope, convincing evidence for LCIP’s abilities, more use-cases are needed to strengthen our claims of added value of controllable inverse projections.
Conclusion
We have presented an inverse projection method that allows users to break the barrier of creating two-dimensional, fixed, surfaces embedded in the data space – a property exhibited by all inverse projection methods we are aware of. To do this, we split the information present in the high-dimensional data into (1) information captured by a projection technique and (2) a latent code, namely, information that such a technique cannot capture. Next, we allow users to interactively control this latent code and thereby generate a dynamic inverse projection which can effectively ‘sweep’ the data space between the samples used by the direct projection it aims to invert.
Several experiments show that our method meets a number of key requirements for inverse projections: Our method is – in absence of user control – at least as accurate, and as computationally scalable, as state-of-the-art inverse projection techniques. When user control is added, our method enables users to specify where the inverse projection should adapt to so-called target data points, and where the underlying direct projection should purely drive it. This control is simple to perform as it involves changing two linear parameters – an action radius and an action amount. The data points generated by our method change smoothly as the control parameters change – which is desirable from a practical perspective. Also, we showed that our method can cover a larger area of the data space – measured in terms of intrinsic dimensionality – than other inverse projection methods. Last but not least, we showed that our inverse projection method creates data samples (images in our studies) that look more natural than those created by existing inverse projection methods.
LCIP could be used next to assist user-controlled 3D shape morphing18– its control would directly allow users to select specific target shapes to use during the morphing. Separately, LCIP can help data augmentation by e.g. subsampling a dataset to be augmented to get the sources; hand-picking specific samples (having e.g. different styles) as targets; and creating the desired number of augmented samples by our interpolation. Smart sampling strategies like SADIRE53 can be used both to highlight samples in the projection scatterplot which are interesting for users to explore or manipulate first via LCIP; and also, potentially, to fine-tune LCIP’s training by adding extra weights to such samples. We also plan to make LCIP’s control more intuitive by displaying the kind of information that is captured by our latent codes, thereby showing users what they would control when manipulating LCIP’s parameters. Finally, we plan to refine LCIP’s local control of decision maps (section ‘Controllability: Going beyond a fixed surface’) to allow analysts to explore trained models around regions of interest in simpler, but more effective, ways.
Supplemental Material
sj-pdf-1-ivi-10.1177_14738716261455130 – Supplemental material for LCIP: Loss-controlled inverse projection of high-dimensional image data
Supplemental material, sj-pdf-1-ivi-10.1177_14738716261455130 for LCIP: Loss-controlled inverse projection of high-dimensional image data by Yu Wang, Frederik L. Dennig, Michael Behrisch and Alexandru Telea in Information Visualization
Footnotes
ORCID iD
Yu Wang
Author contributions
Yu Wang: Conceptualization, Methodology, Software, Investigation, Formal analysis, Visualization, Data curation, Writing – original draft. Frederik L. Dennig: User study design and execution, User study analysis, Writing – review and editing. Michael Behrisch: Writing – review and editing. Alexandru Telea: Conceptualization, Supervision, Writing – review and editing.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Supplemental material
Supplemental material for this article is available online.
References
1.
LespinatsSAupetitM. CheckViz: sanity check and topological clues for linear and nonlinear mappings. Comput Graph Forum2011; 30(1): 113–125.
2.
SorzanoCOSVargasJMontanoAP. A survey of dimensionality reduction techniques. arXiv, arXiv:1403.2877, 2014.
3.
NonatoLAupetitM. Multidimensional projection for visual analytics: linking techniques with distortions, tasks, and layout enrichment. IEEE TVCG2018; 25: 2650–2673.
4.
RodriguesFCM. Visual analytics for machine learning. PhD Thesis, University of Groningen, 2020.
5.
BenatoBCGrosuCFalcãoAX, et al. Human-in-the-loop: using classifier decision boundary maps to improve pseudo labels. Comput Graph2024; 124: 104062.
6.
RodriguesFCMEspadotoMHirataR, et al. Constructing and visualizing high-quality classifier decision boundary maps. Information2019; 10(9): 280.
7.
OliveiraAEspadotoMRHirataJr, et al. SDBM: supervised decision boundary maps for machine learning classifiers. In: Proceedings of the international conference on information visualization theory and applications, Algarve, Portugal, 5–7 March, 2011, pp. 77–87.
8.
SchulzAHinderFHammerB. DeepView: visualizing classification boundaries of deep neural networks as scatter plots using discriminative dimensionality reduction. In: Proceedings of the thirty-fourth international joint conference on Artificial Intelligence, Montreal, QC, Canada, 16–22 August 2025, pp. 2305–2311.
9.
AmorimEBrazilEVDanielsJ, et al. iLAMP: exploring high-dimensional spacing through backward multidimensional projection. In: Proceedings of the IEEE symposium (or conference) on visual analytics science and technology, Vienna, Austria, 3 November 2025, pp. 53–62.
10.
EspadotoMApplebyGSuhA, et al. UnProjection: leveraging inverse-projections for visual analytics of high-dimensional data. IEEE TVCG2021; 29(2): 1559–1572.
ZhengJShenHYangJ, et al. Autoencoders with intrinsic dimension constraints for learning low dimensional image representations. arXiv. arXiv:2304.07686, 2023.
13.
EspadotoMMartinsRKerrenA, et al. Toward a quantitative survey of dimension reduction techniques. IEEE TVCG2019; 27(3): 2153–2173.
14.
WangYTeleaA. Fundamental limitations of inverse projections and decision maps. In: Proceedings of the 19th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISIGRAPP 2024), Vol. 1, Rome, Italy, 27–29 February 2024, pp. 571–582. SCITEPRESS.
15.
Van der MaatenLHintonG. Visualizing data using t-SNE. J Mach Learn Res2008; 9(11): 2579–2605.
16.
McInnesLHealyJMelvilleJ. UMAP: uniform manifold approximation and projection for dimension reduction. arXiv. arXiv:1802.03426, 2018.
17.
JoiaPCoimbraDCuminatoJA, et al. Local affine multidimensional projection. IEEE TVCG2011; 17(12): 2563–2571.
18.
AmorimEVital BrazilEMena-ChalcoJ, et al. Facing the high-dimensions: inverse projection with radial basis functions. Comput Graph2015; 48: 35–47.
19.
EspadotoMHirataNTeleaA. Self-supervised dimensionality reduction with neural networks and pseudo-labeling. In: Proceedings of the international conference on information visualization theory and applications, Algarve, Portugal, 5–7 March, 2011. SciTePress, pp. 27–37.
20.
HintonGESalakhutdinovRR. Reducing the dimensionality of data with neural networks. Science2006; 313(5786): 504–507.
21.
BlumbergDWangYTeleaA, et al. Inverting multidimensional scaling projections using data point multilateration. In: Proceedings of the 15th International EuroVis Workshop on Visual Analytics (EuroVA), Odense, Denmark, 27 May 2024. The Eurographics Association.
22.
TorgersonWS. Multidimensional scaling: I. Theory and method. Psychometrika1952; 17: 401–419.
23.
KruskalJB. Multidimensional scaling by optimizing goodness of fit to a nonmetric hypothesis. Psychometrika1964; 29(1): 1–27.
24.
EspadotoMRodriguesFHirataNST, et al. Deep learning inverse multidimensional projections. In: Proceedings of the 10th International EuroVis Workshop on Visual Analytics (EuroVA), Porto, Portugal, 3 June 2019, pp. 13–17. The Eurographics Association.
25.
DennigFLGeyerNBlumbergD, et al. Evaluating autoencoders for parametric and invertible multidimensional projections. In: Proceedings of the 16th International EuroVis Workshop on Visual Analytics (EuroVA), Luxembourg, 2 June 2025. The Eurographics Association.
26.
WangYMachadoATeleaA. Quantitative and qualitative comparison of decision map techniques for explaining classification models. Algorithms2023; 16(9): 438.
27.
AnsuiniALaioAMackeJ, et al. Intrinsic dimension of data representations in deep neural networks. In: Advances in Neural Information Processing Systems 32 (NeurIPS 2019), Vancouver, BC, Canada, 8–14 December 2019, pp. 6109–6119. Curran Associates, Inc.
28.
WangYYaoHZhaoS. Auto-encoder based dimensionality reduction. Neurocomputing2016; 184: 232–242.
29.
MarinIGotovacSRussoM, et al. The effect of latent space dimension on the quality of synthesized human face images. J Comm Softw Sys2021; 17(2): 124–133.
30.
PadalaMDasDGujarS. Effect of input noise dimension in GANs. In: Neural information processing. Lecture notes in computer science. Springer, pp. 558–569.
31.
MoyerDGaoSBrekelmansR, et al. Invariant representations without adversarial training. In: Advances in Neural Information Processing Systems 31 (NeurIPS 2018), Montréal, Canada, 3–8 December 2018, pp. 9084–9093. Curran Associates, Inc.
32.
HadadNWolfLShaharM. A two-step disentanglement method. In: Proc., IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018, pp. 772–780. IEEE.
33.
MathieuMFZhaoJJZhaoJ, et al. Disentangling factors of variation in deep representation using adversarial training. In: Advances in Neural Information Processing Systems 29 (NIPS 2016), Barcelona, Spain, 5–10 December 2016, pp. 5041–5049. Curran Associates, Inc.
34.
XieQDaiZDuY, et al. Controllable invariance through adversarial feature learning. In: NIPS’17: proceedings of the 31st international conference on neural information processing systems, Long Beach, CA, USA, 4–9 December 2017.
35.
JaiswalAWuYAbdAlmageedW, et al. Unified adversarial invariance. arXiv, arXiv:1905.03629, 2019.
36.
ZhengZSunL. Disentangling latent space for VAE by label relevant/irrelevant dimensions. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019, pp. 12192–12201. IEEE.
37.
GoodfellowIJPouget-AbadieJMirzaM, et al. Generative adversarial networks. arXiv, arXiv:1406.2661, 2014.
38.
PanXTewariALeimkühlerT, et al. Drag Your GAN: interactive point-based manipulation on the generative image manifold. arXiv, arXiv:2305.10973, 2023.
39.
KarrasTLaineSAittalaM, et al. Analyzing and improving the image quality of StyleGAN. arXiv, arXiv:1912.04958, 2020.
40.
EspadotoMHirataNSTTeleaA. Deep learning multidimensional projections. Inf Vis2020; 19(3): 247–269.
41.
PaszkeAGrossSMassaF, et al. PyTorch: an imperative style, high-performance deep learning library. arXiv, arXiv:1912.01703, 2019.
XiaoHRasulKVollgrafR. Fashion-MNIST: a novel image dataset for benchmarking machine learning algorithms. arXiv, arXiv:1708.07747, 2017.
45.
AnguitaDGhioAOnetoL, et al. Human activity recognition on smartphones using a multiclass hardware-friendly support vector machine. In: Proceedings of the third international workshop on ambient assisted living, Vitoria-Gasteiz, Spain, 3–5 December 2012, pp. 216–223.
46.
ChoiYUhYYooJ, et al. StarGAN v2: diverse image synthesis for multiple domains. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019, pp. 8185–8194. IEEE.
47.
JaiswalAWuRYAbd-AlmageedW, et al. Unsupervised adversarial invariance. In Advances in Neural Information Processing Systems 31 (NeurIPS 2018), Montréal, Canada, 3–8 December 2018, pp. 5097–5107. Curran Associates, Inc.
48.
TianZZhaiX, Van Driel D et al. Using multiple attribute-based explanations of multidimensional projections to explore high-dimensional data. Comput Graph2021; 98: 93–104.
49.
ChatzimparmpasAMartinsRMKerrenA. t-viSNE: interactive assessment and interpretation of t-SNE projections. IEEE TVCG2020; 26(8): 2696–2714.
50.
VennaJKaskiS. Visualizing gene interaction graphs with local multidimensional scaling. In: Proceedings of ESANN’06, 14th European Symposium on Artificial Neural Networks, Bruges, Belgium, 26–28 April 2006, pp. 557–562. d-side group.
51.
VennaJPeltonenJNyboK, et al. Information retrieval perspective to nonlinear dimensionality reduction for data visualization. J Mach Learn Res2010; 11: 451–490.
Marcilio-JrWEElerDM. SADIRE: a context-preserving sampling technique for dimensionality reduction visualizations. J Visual2020; 23: 999–1013.
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.