
Abstract
The recent wave of developments and research in the field of deep learning and artificial intelligence is causing the border between the intuitive and deterministic domains to be redrawn, especially in computer vision and natural language processing. As designers frequently invoke vision and language in the context of design, this article takes a step back to ask if deep learning’s capabilities might be applied to design workflows, especially in architecture. In addition to addressing this general question, the article discusses one of several prototypes, BIMToVec, developed to examine the use of deep learning in design. It employs techniques like those used in natural language processing to interpret building information models. The article also proposes a homogeneous data format, provisionally called a design pixel, which can store design information as spatial-semantic maps. This would make designers’ intuitive thoughts more accessible to deep learning algorithms while also allowing designers to communicate abstractly with design software.
Keywords
Introduction
Design is a complex cognitive process preceding creation, during which designers generate, analyze, query, and adjust a design proposition. Questions regarding the impacts, costs, and performance of the proposed artifact often arise. Some are subject to scientific inquiry and can be represented through mathematical models. Others rely more on cultural sensitivity, memory, and judgment. Some remain nebulous, with answers rooted in the habits and predilections of the designers. The design proposition itself is usually too complicated to be managed in human working memory, so designers rely on one or more external representations of the design proposal to capture and retain details. Beyond facilitating organization of the design, the external representation can be shared with other participants in the design process, becoming the central oracle for questions regarding the design.
Since the advent of computing technology, significant effort has gone into creating digital representations for design propositions on which computational processes can operate. Because many aspects of design propositions include a geometrical and mathematical component, the role of computer programs has typically been deterministic, driven by sets of instructions, allowing the designers to spend more time on the creative aspects of the design process.
Associative logic in creative processes
The creative part of design often follows an alternative to declarative/deterministic logic—associative logic—which is difficult to explain rationally. For a very basic version of this way of thinking, consider how a dog learns to follow the verbal command, “Sit.” No rational explanation connects the spoken word “sit” to the act of sitting. The spoken command is just a sound (different in different languages), and the dog associates that sound with the act of sitting. It does not seek an explanation. This association was probably reinforced by providing treats to the dog when it correctly obeyed the command. Computer programs can use a similar associative logic; the difference between this and deterministic logic is profound. If a computer program can learn by association, then the human programmer does not have to know the rational sequence of steps required to get the correct output from the given input. All that is needed are sample input–output pairs from which the computer can learn by association. Deep learning is a mathematical technique that emulates associative learning. Deep neural networks learn from a collection of input–output pairs (the “training data”), so it is not necessary to program in the exact logic of how to get from the input to the output. This escape from the details of the “how” of the task is what makes deep learning so attractive for tasks that are typically considered intuitive.
Associations do not necessarily require logic of the form “if this, then that”—that is, using direct comparison. Human designers make associations at various levels of abstraction when synthesizing new ideas. 1 In the order of increasing abstraction, they could use precedents, symbols, or metaphors. Associations made at a higher level of abstraction are more general, rich in nature, and can remain relevant in new situations. Associations play an important role in creativity and intuition. 1 For example, in animated movies and video games, characters designed to be “scary” often have features of carnivorous animals or of natural elements that are also “scary.” Their designers try to exploit the primal associations that we all are predisposed to make, to trigger those emotions in us. Qualities of objects like cute, creepy, scary, and so on are essentially associations. These also occur in language and literature. For example, “sunshine” and “warmth” have positive associations in the English language, but they do not have the same associations in, say, a language spoken in parts of South India with a very hot climate, where “stay cold” is a common greeting instead of “warm regards.” The reason for this mismatch of notions is because English-speaking cultures originated in colder parts of the world where sunshine is welcomed. This is an important characteristic of associative logic. There is no absolute correct or incorrect pairing of ideas, instead the “correct” response to a command, a query, or a thought is whatever one associates correctness with.
Deep neural networks mimic this behavior. There is no absolute correct or incorrect output; the neural network produces an output based on whatever associations it learned from the data it was trained on. If the training dataset is a good representation of the data to which the network will be applied later, then the network will produce “correct” answers. This is the fundamental characteristic that differentiates deep learning from genetic algorithms and other optimization techniques in the context of design. It is attractive precisely because it offers the potential of making headway on the more human and abstract aspects of design, where personal learning, preference, and culture prevail—the land of recognition, metaphor, and judgment. This also hints at the importance of relevant/quality training data for training neural networks, which is a crucial problem addressed in this research.
The non-equivalent representations
A typical design workflow might start with abstract “concept” sketches that allow changes with relative ease followed by more detailed representations like massing and layout, drawings, models, and finally work toward a detailed representation, maybe a building information model (BIM), with all the information needed for executing the project. Although the chain of representations seems linear, the design process itself is hardly linear. As they explore options, the designers go back and forth along this chain.
Starting with an abstract representation (e.g. concept sketch) is helpful because such representations do not flood the designer with too many questions too soon—“what materials, dimensions, profiles, and so on?” An abstract representation also has a low cost of iteration, that is, changes are easier to make. As the designers make more decisions, they move on to more detailed, information-dense representations that answer more questions about the design. This process typically continues until the construction drawings are produced, but along the way, at any stage, a designer might decide to change a previous decision and may have to go back to a previous representation, make the change, and reflect that change in the more detailed representations. Because each representation in this chain has a different level of detail, there cannot exist a meaningfully deterministic mapping between two representations. For example, a simple three-dimensional (3D) boundary representation model cannot be automatically converted into a BIM model because a BIM model requires much more information than what a simple 3D model can provide. This applies for translation between any two data formats that have different levels of detail, like sketches to 3D models or plan drawings to BIM models. When humans interpret abstract representations to create detailed representations, they create more information from less information by using conventions that they learned through experience. The non-equivalence between various representations used in design processes necessitates human intervention to convert designs from one representation to another, which results in a high cost of iteration and experimentation. Understanding and synthesizing association opportunities offer designers a new way to leverage digital technology.
The mathematics of associations
Given the close relation between human capacity for association and creativity, 2 together with the fact that deep learning exposes mathematical techniques that emulate human-like association, a broad understanding of these mathematical techniques, their meaning, and scope is essential to assess the potential of these tools in design workflows.
To start with a basic condition: each possible image of resolution 100 × 100 pixels can be represented as a single point in a 10,000-dimensional hyperspace by interpreting the brightness of each pixel as a coordinate along one of the axes, where each axis represents one pixel. Images that are very similar to each other have many pixel values that correspond closely to each other in this hyperspace. As a neural network learns from such images it passes the input data (images) through its layers and changes the dimensionality of the data. So, passing 100 × 100-pixel images through a trained network can be a way of reducing the dimensionality of the data, making them easier to visualize.
Mathematical techniques like t-stochastic neighbor embedding (t-SNE) 3 can further improve the visualization of high-dimensional data by reducing the dimensionality to 2 or 3, by “unrolling” the data. A good analogy to understand how this unrolling works is map projections. If one were to take a transparent globe and project a shadow of all the land masses on a plane, it would result in a very confusing two-dimensional (2D) representation, which would not be very useful. In contrast, map projections work by unrolling and flattening the surface of the globe. This might not preserve the precise shapes of the continents, but it preserves their proximity and spatial relations, while reducing the high-dimensional data into a more convenient format. t-SNE works in a very similar way 4 when it is applied to the MNIST dataset, 5 which contains many 28 × 28-pixel, handwritten digits and is commonly used as a benchmark in deep learning for image recognition models. Each image in the MNIST dataset has 784 pixels, which means that it can be represented as a point in the 784-dimensional space. Figure 1 shows one such plot of the MNIST data, flattened to two dimensions using t-SNE.

MNIST data plotted using t-SNE.
The plot shows that the images corresponding to the same digit form a clear “shape” in the hyperspace. 4 When a neural network is trained on this dataset, it learns these shapes by adjusting its weights to approximate them, analogous to how the coefficients of a polynomial correlate to the shape of a plot. Once taught, the network can recognize any given image reliably by deciding which cluster it belongs to. The plot also shows that the green dots corresponding to digit “4” bleed over onto the brown cluster (digit 9), which is understandable because sometimes a handwritten 4 and 9 can be similar (Figure 2).

4s and 9s sampled from MNIST dataset.
The weights of a neural network that “learned” these shapes in hyperspace can be used to sample new points in the distribution corresponding to, say, digit “5” that does not exist in the training data. Essentially, the network writes a new digit “5.” This is what generative adversarial networks (GANs) do. 6 They learn the distributions in the training data and use the learned weights to generate new samples in the same distribution. This technique can be used to do more interesting things, like sampling the distributions to generate data with specific qualities. For example, in the MNIST data, we can sample a point in the hyperspace that is somewhere between two digits—corresponding to ambiguous looking digit. Or, we can generate, say, a digit “5” that maximizes its quintessential five-ness. In the hyperspace, this would correspond to a point in the “5” cloud, which is farthest from all other digit clouds.
These distributions exist in the hyperspace of all possible images of that resolution, and the idea of sampling distributions to create new images that have the desired qualities (like the quintessential “5” as discussed before) is a mathematical emulation of a creative process, albeit a very rudimentary one. 7 Even though the field of computer science arrived at this notion from a mathematical point of view, this is not far from how designers think about creative processes (Figure 3). They are connected at least at a metaphoric level. The notion of designs existing in “State Spaces”7,8 is analogous to the idea of hyperspace, and stretching the boundaries of these spaces with creativity is analogous to how networks sample distributions. At present, we are limited to rudimentary datasets and tasks because of computer power limitations. There are several other challenges that need to be addressed before trying to incorporate deep learning in creative workflows. Some of these are demonstrated later in this article.
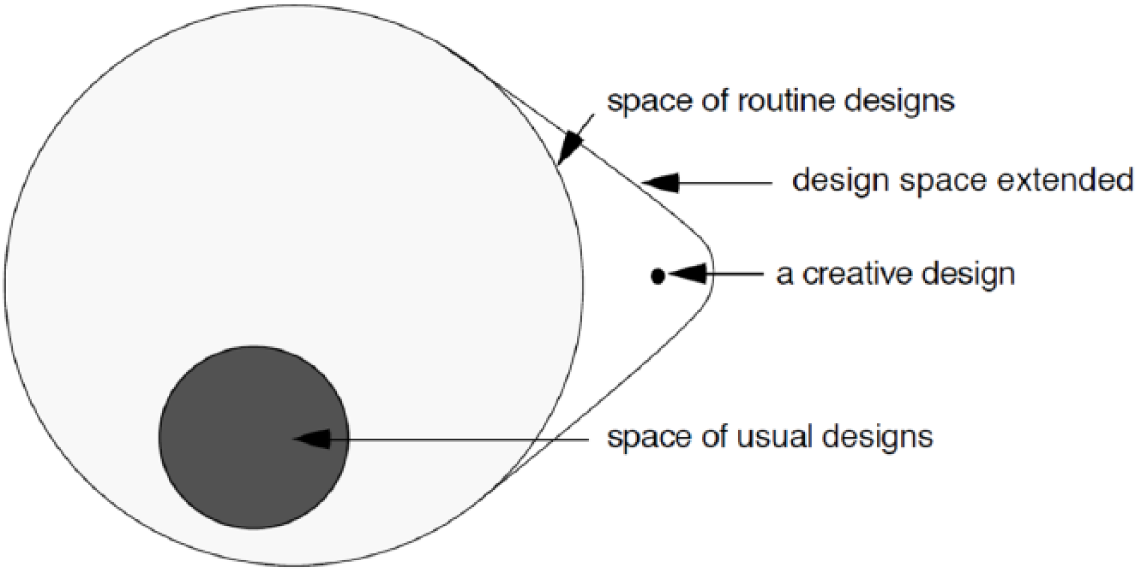
Designs existing in state spaces (Gero and Maher, 1991) 7 .
Building a vocabulary of design with BIMToVec
The core idea behind most deep learning techniques is that any real-world entity can be reduced to a feature vector—a list of numbers that describe that entity. And all such possible entities exist in the continuous “state space” of the features being measured. A continuous state space implies that there exists a linear interpolation between any two points (or images) in that space. With images this would allow something like a fade effect from one image to another. Every image within this interpolation would still be a valid image. But not all real-world data exist in such a convenient format.
Natural language processing (NLP) is one exception, since it involves streams of words and symbols, all from a superset known as the vocabulary. Each word in the vocabulary can further be treated as a list of characters, chosen from, for English, a collection of 26 letters. The deep learning algorithms used in NLP store and organize data in fundamentally different ways. Converting language into feature vectors is not as simple as it is with images. If we were to assign all the letters indices from 1 (for A) to 26 (for Z) and then treat words as arrays of these indices, which would not be dissimilar to how computers today interpret and display text. But that is not a valid quantification of the semantics of language. To start, the indices depend on the order of the letters in the alphabet, which is not based on quantitative reasoning, that is, “b” and “c” are not part of a linear interpolation between “a” and “d.” The largest estimate of the number of words in English is approximately 600,000. 9 If the average English word length is 5.1 characters, 10 the total number of possible words with 5.1 characters is 265.1 ≈ 16,457,507. This is much more than 600,000 because not every permutation of letters is a meaningful word. Vocabulary is very sparsely distributed within the set of all possible words. And more importantly, the discrete entities do not populate the feature space in a way that makes numerical sense. For example, the word “food” is semantically closer to the word “eat” than the word “fool,” despite having a closer resemblance in their spellings. So, even if we built a deep learning model that can understand this sparse distribution, it would be very difficult for that model to learn how words are related by meaning. These problems can be overcome using word embeddings, 11 which are well suited for data composed of discrete symbols (words) from a vocabulary. The training process begins with a randomly initialized set of n-dimensional vectors (n is typically a large number) and each word in the vocabulary is mapped to one of the vectors in the set. These vectors are trained on a corpus of text, identifying pairs of related words and then tweaking the corresponding vectors to move them closer to each other. This process is then repeated until the vectors in the n-dimensional space capture the semantic relations between the words to which they correspond. For example, in a trained word-embeddings set, the relation between the vectors corresponding to the words “King” and “Queen” would be the same as that between the vectors corresponding to the words “Man” and “Woman.” A well-trained embeddings set can capture several other forms of relations like verb conjugations and other more abstract concepts behind the words. This gives the deep learning model an understanding of the meaning of the text rather than the data (letters and letter arrays) used to represent it.
BIMToVec is a prototype developed as a part of this research that applies NLP-like techniques to interpret BIM models. Slightly modified versions of the algorithms used to train word embeddings in NLP were used to train it. A fundamental challenge to using these techniques is that, whereas text is a one-dimensional composition of discrete entities (words), a BIM model is a three-dimensional composition of discrete objects (including building elements like doors, walls, etc.). Another challenge is that, as yet, architects do not use model elements and element labels in precisely standardized ways. This makes the development of an adequate, uniformly applicable embeddings training set difficult. Nevertheless, a provisional embeddings dataset was developed and used to train BIMToVec to map each building object and building material in a BIM model to a 64-dimensional vector, in such a way that proximity in the vector space implies a semantic proximity in a design sense. For example, since doors almost always occur inside walls in designed buildings, one would expect the network to conclude that doors are closely related to walls.
Creating the dataset
The starting point for creating the dataset for BIMToVec was a collection of 142 IFC files downloaded from open online sources.12,13 These IFC files were sampled for groups of labels (object names and material names) that are closely related to each other semantically, with the intention of training the embeddings set against these labels. Three different sampling logics were used to decide when two labels are related to each other:
Spatial sampling. Objects that are in spatial proximity to each other are probably related to each other. For example, ceilings are probably related closely to slabs.
Material sampling. Object names and material names associated with that object are probably closely related. For example, glass is probably related to windows.
Containment tree sampling. In an IFC file (and in most other BIM data models), building elements are organized in a containment tree. The top of this tree has the site, which contains one or more buildings, one or more spaces, walls, and so on. Since this containment is deliberately designed to make sense of building models, the proximity of objects in this tree could be used as a measure of how closely they are related to each other.
Sampling names of objects and materials in BIM models pick up many naming conventions and compound names, so the labels were further decomposed into “atoms,” which are frequently occurring substrings. For example, “wood” might be a frequent substring appearing in “woodfloor” or “woodsiding.” The sampling was done using OpenBIM’s .NET IFC toolkit called xBim, 14 which loads the IFC contents into memory. This is then sampled using the three samplers described above, identifying all possible pairs of labels.
Training BIM embeddings
An embedding set was trained on the final dataset (1325 unique labels, 657 atoms, and 7.8 billion-related pairs). The embeddings were then trained by successively tweaking the vectors to maximize the dot product (proximity) of vectors corresponding to related labels (atoms). Figure 4 shows the final 64-dimensional embedding vectors, flattened to two dimensions using t-SNE and plotted with their corresponding labels.
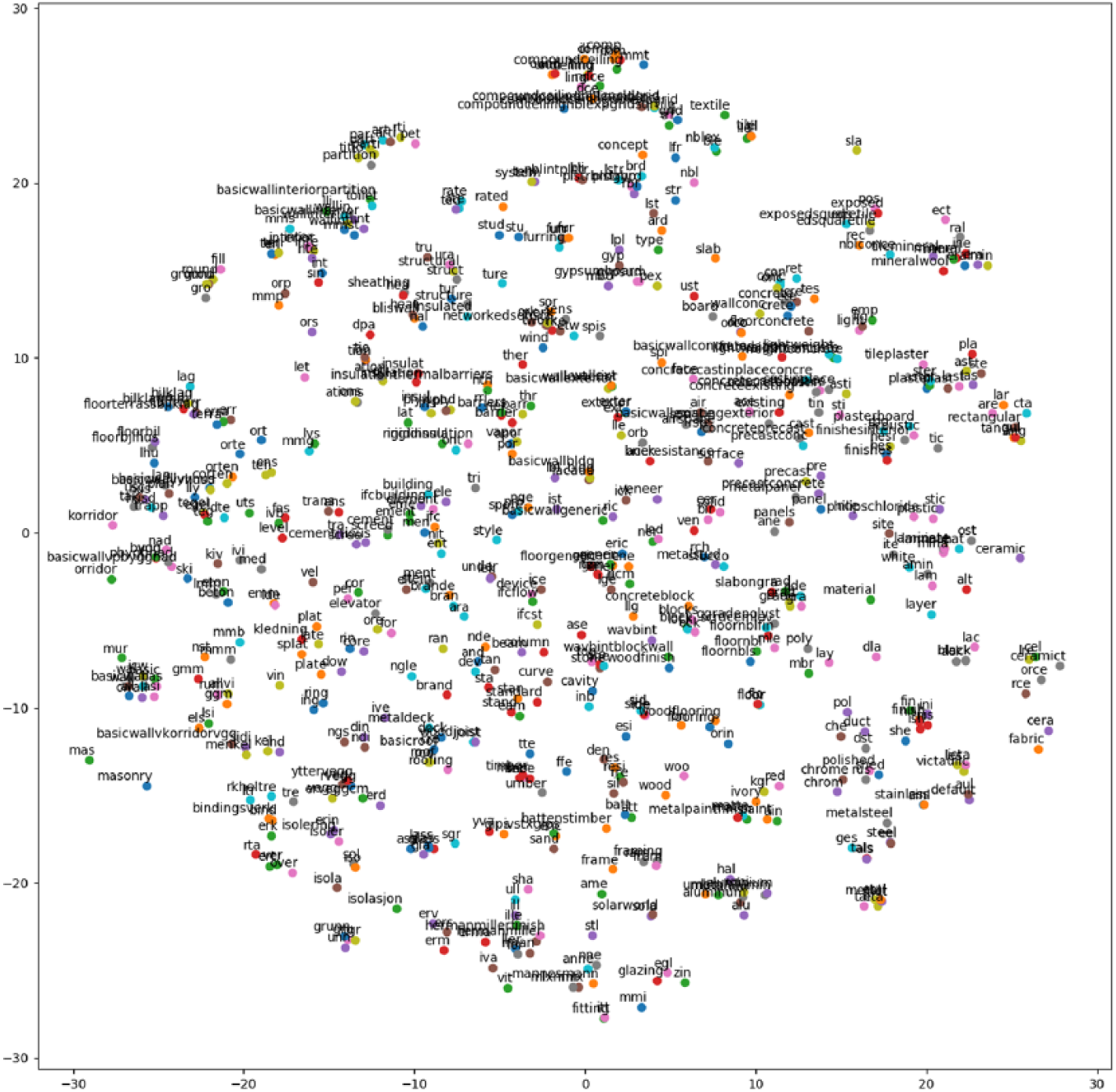
Trained embeddings (atom vocabulary), flattened to 2D using t-SNE.
Examination of the plot (Figure 4) reveals that the embeddings set captures some obvious semantic relations between building object labels. Various wall materials are clustered near the top center, and gypsum board, for example, is close to the wall cluster. All the metals, steel, chrome, and so on are clustered near the bottom right. The model clearly captured some of the semantics among these labels—encoding the perspectives of the designers who built the BIM models.
Although BIMToVec demonstrates that a deep learning can learn and interpret the semantics of BIM models, currently this can only be assessed generally through a basic visual inspection of the trained embeddings. It is not possible at this stage to do a more formal evaluation of how well these embeddings perform using the typical methods for evaluating/benchmarking embeddings. These methods are of two types: 15 (1) extrinsic methods, where the word embeddings are used in, say, a translation app and evaluated based on how well the app performs and (2) intrinsic methods, where the embeddings are queried for a predetermined list of pairs of related words (determined by humans) and calculating the proximity scores of a given embeddings set against this master list. It is too early for this research to be employed in a practical application, ruling out the extrinsic methods of evaluation. And, there is currently no widely accepted, rigorous standard for labeling BIM models or an agreed-upon semantics of building object labels, which rules out the intrinsic evaluation. In fact, there is not even a standardized vocabulary among building designers, which is evident in the dataset (e.g. a concrete masonry unit is sometimes called a “cmu,” a “concreteblock,” or a “block”). So, at this stage these embeddings cannot be evaluated reliably beyond visual inspections of t-SNE plots.
Discussion
An embeddings set that captures the semantics and concepts associated with the building elements and materials in a BIM model would allow designers to delegate more abstract tasks to the design application, which would not be possible with deterministic logic. For example, embeddings could be used to detect anomalies in models by comparing them to learned (trained) conventions. This could also be useful in performing meaningful clash detection, so that if the designer specifies that a clash between a bolt and a beam is a valid one, the application could then look up the embedding vector for the bolt, find vectors corresponding to other fasteners in the vicinity and extrapolate that rule to other clashes involving fasteners.
Another possibility that BIMToVec embeddings suggest is the development of a new way of encoding design information using pixels of a bitmap to represent the embedding vectors of the objects behind each pixel, instead of the usual (R, G, B) color vectors. This would create a bitmap of concepts rather than colors (Figure 5). Such a bitmap would also be compatible with existing deep learning techniques that are designed to work with images. They would give the design application a deeper, semantic understanding of what the designer is looking at or working with. The next section of the article discusses this data format in more detail.
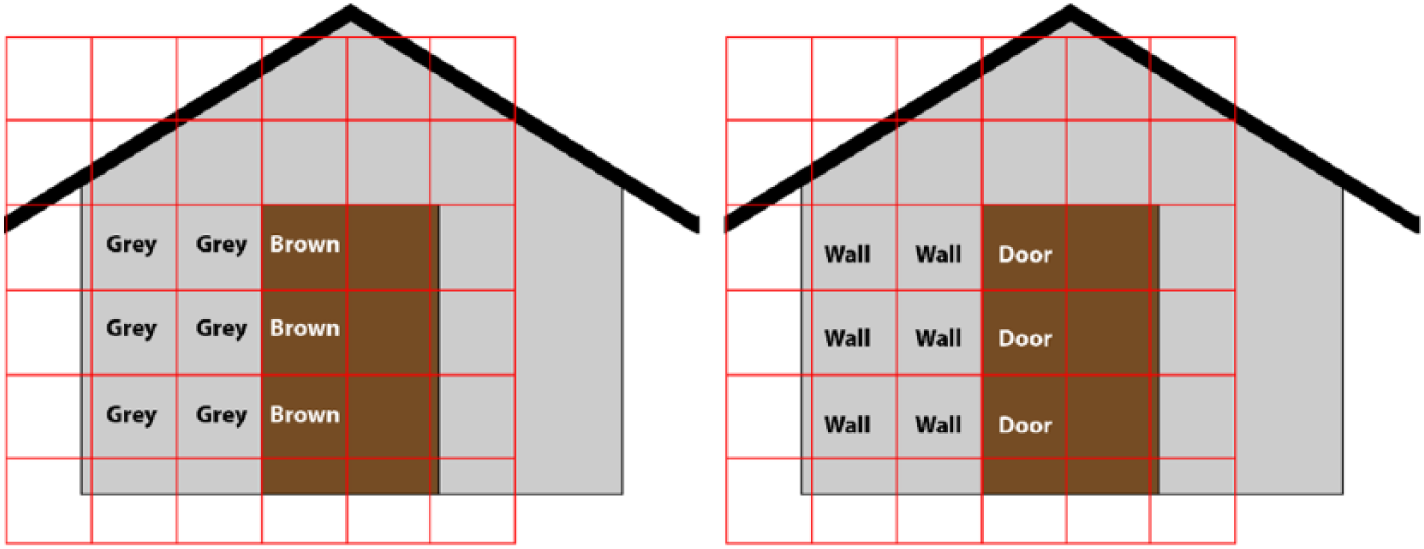
Left: bitmap of colors; right: bitmap of concepts.
Despite their potential, BIMToVec embeddings are not quite up to the quality needed for the program to contribute the design process. This is primarily because there is currently not enough curated data to develop an adequate training set. Word embeddings are typically trained for a vocabulary of about 50,000 words. By contrast, despite efforts to build a large dataset from publicly available BIM models, training for BIMToVec occurred with a final dataset of 1325 unique labels and 657 atoms. Furthermore, scarcity of data prevented any filtering the IFC files for designer bias. The available models all used different design conventions, different naming conventions, spellings, languages, and so on. So, the overall integrity of the embeddings used for the preliminary training of BIMToVec was low, with a lot of noise and meaningless strings.
Because of these challenges, the results of this research, though promising, are far from definitive. The BIMToVec prototype serves as a proof of concept for capturing design semantics, while exposing important issues that the building-design disciplines need to address and overcome before adopting deep learning into their workflows. The first challenge is to adopt a standardized vocabulary for BIM models, including universal libraries for materials and for object and assembly labels. These standards need to be agreed upon and rigorously implemented in BIM authoring applications. When put use among a large base of designers, this would produce a large enough body of standardized BIM models that could be used to train deep learning systems. Another challenge is to develop a standard means of evaluating BIM embeddings. Like in NLP, an accepted set of standardized, semantically related label pairs for building elements is required. These could then be used to benchmark alternative BIM embeddings. These obstacles are not dissimilar to those faced by the computer science and computer vision disciplines several decades ago. To overcome them, researchers in the early 2000s undertook several initiatives, like ImageNet, 16 whose only goals were to build large, reliable datasets. The building-design disciplines need to go through a similar phase of building datasets.
The elusive design pixel
Deep learning models prefer homogeneous data formats, which is one of the reasons why some of the most popular applications of deep learning are image related. This is possible due to that amazingly convenient primitive called the “pixel,” whose instances when repeated in large numbers can represent complex graphic information without needing additional definitions. However, human designers prefer data formats that are richer than color/value pixels with discrete labels and primitives that do a better job of capturing design intentions. An example of this dichotomy in the context of 3D modeling is homogeneous formats like meshes or voxels versus the formats like extrusions and sweeps, which human designers prefer for their ability to capture modeling intentions. We believe a new way to store design information is needed, one that would be compatible with deep learning models and the workflows of human designers at the same time—a “pixel” for design purposes—the elusive design pixel. The range of representations that a design goes through in a typical workflow makes this a very challenging proposition. Such a data format also has the potential to solve the problem of non-equivalence of various representations used in design workflows, as mentioned in section ” The non-equivalent representations.”
Imagining a design pixel with emulated homogeneity
The starting point for creating a homogeneous data format for building-design purposes would be to train a high-quality, reliable set of embeddings for building model vocabulary used in the Architecture-Engineering-Construction (AEC) disciplines. As discussed in section “Discussion,” this requires a high-quality curated, standardized set of BIM models for training. If a high-quality embeddings set is trained, it would capture the complex semantic relations among the building elements, materials, assemblies, and so on. Now, consider a deep learning model like Compose3D, 17 which can interpret a sketch (image) of a perspective view, recognize the objects in the sketch, their positions and orientations (for the purposes of rapid prototyping). Assume that the input sketch depicts an interior of a room with some furniture. Instead of saving the sketch as an image, the Compose3D network could look up the embedding vectors for the objects recognized in the sketch, and since it knows their position and orientation, it could represent and store the idea behind the sketch as a spatial composition of embeddings. These data would be very potent since it captures not the sketch, but the ideas behind it. It would have the embeddings for the furniture objects represented in the sketch, say, seating, for example, and using these embeddings, along with the spatial information it could infer whether the seating is for a living room or a classroom. GraphMapper, 17 a deep learning model that can interpret plans, could be modified to convert plans into spatial distributions of embeddings vectors. Google’s “Auto Draw” is another such deep learning model 18 that can recognize what the user is trying to draw and replace it with a cleaner version of the object fetched from a library of existing drawings.
It should be possible to train a family of deep neural networks, each capable of interpreting a design representation (sketches or plans or bubble diagrams, etc.) and then convert it into a spatial distribution of embeddings vectors, which would serve as a central homogeneous repository for the design information, irrespective of what representation the designer is working with at that moment. It would store the design as a spatial composition of ideas and not geometry.
Constructing ideas, not models
A design application that can take advantage of such a family of deep learning models would allow the user to seamlessly switch between various representations during the design process. Consider the furniture layout example from earlier: The user can sketch out a furniture layout, which a deep learning model interprets and converts to a spatial distribution of embedding vectors. When the user is ready to switch to a 3D model and continue the design process, the design application can then fetch the 3D models for the recognized objects from a library and recreate the scene in 3D using the spatial information. The application would use another deep learning model to do this, taking advantage of learned conventions to make decisions where necessary. This would allow the user to seamlessly switch from a sketch to a 3D model as necessary. By extrapolation, a family of deep learning models that could achieve lossless bidirectional conversion between our central data format (spatial distribution of embeddings) and various design representations would allow seamless transfer of ideas across representations (Figure 6).
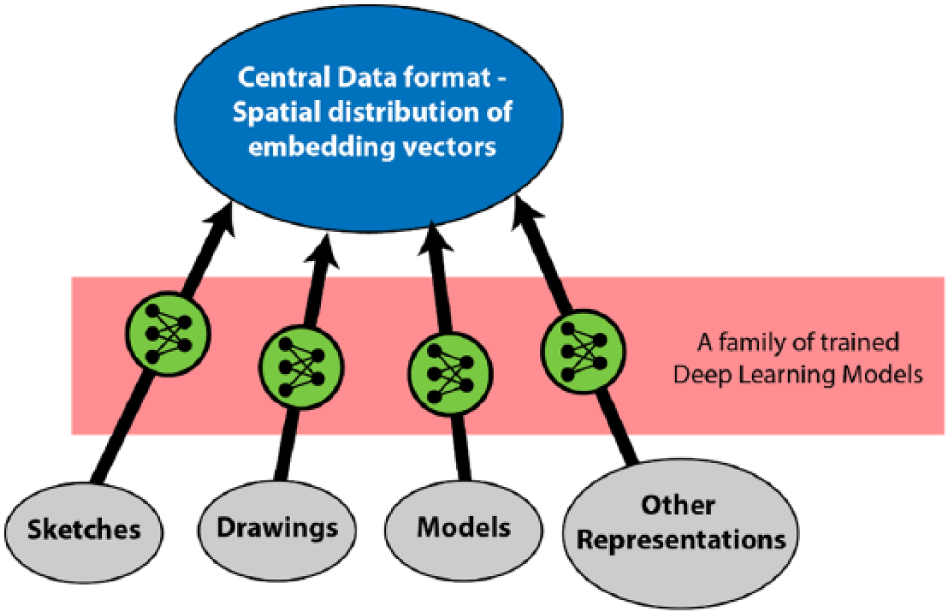
Schematic: elusive design pixel.
The proposal that lossless bidirectional transfer would be possible is a bold claim but understanding similar strategies that are employed in NLP might shed some light on the feasibility of that speculation. In NLP, there is a concept of a “thought vector,” which is created by converting sentences into lists of embeddings 19 using a trained embeddings set like Word2Vec 20 and this list is then passed to a recurrent neural network (RNN), 21 which outputs a final vector representing its state at the end of the sentence. The internal representation of a sentence in the RNN is called the thought vector, which supposedly represents the meaning of the sentence in vector space. These thought vectors have been proven to be very effective in translation apps that use deep learning. A sentence is converted into a list of embedding vectors. These pass through an encoder RNN that outputs the thought vector. The vector then passes through the decoder network, which outputs a series of embedding vectors. Corresponding words to these vectors are then found in an embeddings set of a different language, finishing the translation process. Some of the best translation applications today use versions of this technique. 22 In this process, the thought vector essentially represents the idea behind the input sentence, which brings us back to the comparable design pixel data format. In both cases, the idea behind a concrete representation—a drawing in the case of the elusive design pixel and a written sentence in the case of NLP—is being converted into a vector that represents the idea behind the concrete representation. A designer using this technique could move from representation to representation during the workflow, while the data are stored in a central embeddings-based data format. Working this way would be analogous to editing text in one language, then later editing the same text in a different language, while the ideas in the text are stored independently as thought vectors. Unfortunately, even the best translation models today cannot do high enough quality translation to make a multi-language editing workflow feasible. Although the thought-vector models of today work well for one-way translation of text, the integrity of bidirectional translation is quite poor, often losing some of the text’s meaning. So, editing a design across multiple representations might be a possibility in the future, but it is too soon to make any concrete speculations about how that might work.
Challenges
There are some fundamental, almost philosophical questions that representation of designs as idea maps and text as thought vectors bring up. Can an idea exist in isolation from concrete representations that are used to express the idea? The answer to this question is not clear at this point, but, given how different representations all can point to the same idea during a design workflow, it might be possible for design ideas to exist in isolation from concrete representations as higher dimensional vectors. These questions can be especially difficult to think about, given how counterintuitive high-dimensional vector space operations are.
The judgment, habits, and practices of designers vary greatly both at an individual level and across cultures. Individual designers with varied aesthetic styles are unlikely to create large enough datasets in their work to reliably train a deep learning model to emulate their own creative process. Even if that obstacle were overcome, and if a model could be trained on a designer’s work, such a model would only be useful in a small number of contexts. However, this does not preclude the use of deep learning models for more generic kinds of creative work, such as class detection or furniture arrangement.
It is difficult to make concrete speculations about the effects of deep learning far into the future. Deep learning will likely have to go through a long process of evolution and adaptation before it becomes useful for designers. The burden of creating standardized datasets will likely force deep learning applications into narrow niches in the design field where the vocabulary is small and design parameters are tightly constrained, as in the design of shoes or boat hulls. It will also likely gain momentum in the field of graphic design mainly because graphic data already has a homogeneous data format—pixels. The eventual effects of deep learning in building design are unlikely to manifest themselves in precisely the ways indicated here, but there is plenty of evidence to suggest that deep learning could introduce a set of mathematical techniques that, if applied in creative processes, would have a significant effect on how designers work. These changes may seem threatening to some designers who might fear that automation will replace the creative process, but they are more likely to manifest themselves as model checkers, best practice advisors, and virtual design assistants, rather than as competitors.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.