
Abstract
We present an early prototype of a design system that uses Deep Learning methodology—Conditional Variational Autoencoders (CVAE)—to arrive at custom design spaces that can be interactively explored using semantic labels. Our work is closely tied to principles of parametric design. We use parametric models to create the dataset needed to train the neural network, thus tackling the problem of lacking 3D datasets needed for deep learning. We propose that the CVAE functions as a parametric tool in itself: The solution space is larger and more diverse than the combined solution spaces of all parametric models used for training. We showcase multiple methods on how this solution space can be navigated and explored, supporting explorations such as object morphing, object addition, and rudimentary 3D style transfer. As a test case, we implemented some examples of the geometric taxonomy of “Operative Design” by Di Mari and Yoo.
Keywords
Introduction
Machine Learning applications are currently entering the design world in a way that is both exciting and disturbing. There are reports of artists winning competitions with purely AI-generated artworks. 1 The latest generation of text-to-image software has created a veritable hype. There are countless popular science articles about it, many of them asking some variation of the question “are designers even needed anymore?” 2 Currently, graphic designers and artists are the ones whose turf these novel applications mostly tread on. There aren’t any equivalent 3D programs available yet. One of the main reasons for this is the lack of training data. While there is an abundance of data for pixel-based applications, 3D models suitable for training neural networks on interpreting and synthesizing 3D worlds are much harder to come by, especially for architectural design. As this situation is unlikely to change in the near future, the development for AI based 3D design tools probably needs to follow different paths and could take more time. For the moment at least, in architecture, designers are still needed. However, we believe that similarly elegant AI applications as in the image world will eventually also exist for the 3D realm. While we don’t expect that they will make architects redundant any time soon, they will certainly open up new ways to design.
Motivation
In this paper, we describe the development of an AI-based 3D design tool. We present an early prototype of a design system that uses Deep Learning methodology—Conditional Variational Autoencoders (CVAE). We believe our approach presents tentative solutions to two of the main obstacles that deep learning based 3D design tools currently face: the lack of training data and the lack of labels describing those data semantically. We demonstrate that by creating our own training datasets and by using a comprehensive taxonomy (we used the one from the booklet on Operative Design by Di Mari and Yoo 3 ) we arrive at custom design spaces that can be interactively and meaningfully explored.
As we explain in some detail in the following sections, our approach to solving the lack of training data is to use parametric models from which we generate thousands of 3D model variations. These models are then voxelized and reduced to the same 24 by 24 by 24 unit grid. The parametric models each have a semantic label, using the Operative Design 3 taxonomy. Note that the way we use the term “semantic label” in this paper is different from the way it is commonly used in deep learning projects to do with image segmentation, where each pixel is semantically labeled as being part of an object. In this paper, semantic labels describe a geometric property of the whole composition rather than individual voxels.
These labels (we used six in total in the tests described here) are encoded along with the voxel models and create a latent space that can also be navigated using and mixing expressions such as bend, taper, and twist. Needless to say, given the low resolution and the limited number of labels, the samples of our current results are a far cry from the astonishing results available in the AI text-to-image world. We are still only laying the groundwork. To do our prototype system justice, one needs to keep the bigger picture in mind. In this introduction, we therefore want to spend some time discussing this bigger picture. What can 3D generative deep learning tools, such as the one we are proposing, eventually do for architectural design?
On parametric design and design spaces
Parametric design is becoming increasingly popular and important in architectural practice. Arguably this is not only because parametric design tools have become more powerful and more accessible to the user but also because there is a growing need for their benefits. The main benefit is that parametric models define what is referred to as a “design space” or “solution space”: the sum of all possible design variations that result from changing its parameter values. A good design or solution space is one, which a user can then easily navigate to find fitting solutions.
A good parametric model will, for example, allow designers to quickly compare variations of a building’s proportions or to tweak a façade until the rhythm of the openings looks just right. Given the immense time-pressure architects tend to work under, this speed and flexibility is a strong advantage. But it is not the only way design spaces can be used. Parametric design also opens the door for optimization in design. A well-defined design space can not only be explored by human designers but also by algorithms that can compare and find the best solutions according to certain criteria. In other words: design spaces enable optimization.
While the idea of optimization in architecture traditionally enjoyed little popularity with architects as it appeared to go against their artistic aspirations, this is currently changing. With the imperative demands climate change imposes on the building sector, just guessing at resource- and energy-efficiency in design will no longer do. Algorithmic methods, not as a way to replace designers, but as a way to allow them to make more informed design decisions, are already used in many high-profile projects. As demand for environmentally conscious construction can be expected to continue to rise, optimization in design likewise will continue to become more important and more commonly used. 4
The problem with this premise, however, is that creating good parametric models is not trivial. In fact, it must be considered a design challenge in its own right. 5 In this paper, we argue that deep learning methods can be used as alternative ways to create design spaces—design spaces with unusual properties and novel ways to explore them.
Using deep learning to create design spaces
As mentioned earlier, our training sets are not real-world data, like in most deep learning developments, but generated from parametric models. In an earlier paper, we have shown that the design solution space of a parametric design model can under certain circumstances be successfully translated into the mathematical latent space of a neural network—not perfectly, but reasonably well. 6 Creating an imperfect copy of a parametric model with a neural network may seem pointless, but conceptually, this translation was an important step in developing our system. It provided the basis for the subsequent developments we report on in this paper, which go beyond this equivalency. We were able to combine training data from a variety of different parametric models in such a way that the resulting latent space contained not only the models used in training but also combinations of those models.
As we demonstrate in this paper, the deep learning method we used (CVAE) resulted in a design space of considerable complexity. Creating an equivalent design space with a parametric model, would be a difficult design challenge. On top of that, our AI-generated design space also contains semantic labels, opening up novel, and intuitive ways to navigate it.
Related literature
There is related literature regarding different aspects of our work: the use of neural networks in conceptual architectural design, the creation of 3D datasets for training neural networks, and the use of voxel data in deep learning applications. We provide some examples for each of these three aspects. Our approach is unique not so much in any of these aspects but rather in the way we combine them.
Use of neural networks in architectural design
As et al. 7 used Graph Neural Networks to explore an implementation of deep learning for conceptual design. Their aim was to evaluate existing design blocks, extract significant building blocks from them and merge them into new components. Through implementation of Generative Adversarial Networks (GANs) they were able to generate new designs. All their designs were represented through mathematical graphs. Newton 8 explored the implementation of GANs with regard to architectural design tasks. Most of the work was focused on 2D image generation, while also looking into the possibility of 3D voxel-based outputs. De Miguel et al. 9 implemented a Variational Autoencoder (VAE) for form finding of structural typologies. Although their implementation was successful the authors pointed out that they were unable to obtain a large diverse dataset, using instead variations of just two different 3D models. Koh 10 describes two 3D GAN based projects. The project 3D-GAN-Ar-chair-tecture implemented three trained 3D GAN Models. One was trained with 10,000 chair models, one with 4000 high-rise building models, and the third with a combination of both. The author was able to generate new variations of both chairs and buildings as well as interpolations between the two. The project 3D-GAN-Housing was trained on 5000 3D models from the Singapore Housing Development Board’s apartments, while encoding semantics and configurations of architectural programs directly into the dataset. After training a smooth interpolation between different buildings was possible. Asmaar and Sareen 11 developed a new workflow where through the implementation of GANs multiple 2D outputs were vertically stacked to create 3D voxel structures. Ren and Zheng 12 implemented a Neural Style Transfer for 3D voxelized shapes. This was achieved through the implementation of multiple 2D style transfers combining those outputs into a 3D structure afterwards. A well-known example is ArchiGAN by Chaillou. 13 Unlike some of the other examples, this GAN is completely image based, so its results are purely 2D. It can produce pixel based floorplans in different scales as well as different styles, depending on the training data: building footprints, program layout, and furniture layout.
Our approach differs from the ones cited here in that we use a different type of neural network: a Conditional Variational Autoencoder (CVAE). Furthermore, we solely work with 3D data derived from parametric models.
Creating custom datasets for AI based architectural design applications
The question of large enough datasets for neural network training is a key issue in deep learning. In particular 3D object datasets (especially models relevant to architectural design) are difficult to come by. A possible solution is the generation of one’s own datasets. Alymani et al. 14 presented a novel workflow to train a neural network to suggest appropriate building to ground relationships. The 3D architectural models were represented using topological graphs. They created the training datasets themselves. Newton 15 explored multi-objective qualitative optimization through the implementation of 3D-Convolutional neural networks. The necessary voxel based data for training was generated through the implementation of generative parametric design tools.
We also created our own datasets using parametric models. In fact, we used a set of very simple parametric massing models, inspired by the booklet on Operative Design by Di Mari and Yoo. 3
Generative neural networks for 3D voxel based design
Using 3D voxel data instead of pixel data is a common approach for 3D AI applications and we are by no means the first to use it. Andries et al. 16 implemented a Variational Autoencoder (VAE) to combine voxel geometries based on their affordances. Their work was focused on the creation of furniture and fixtures using 3D models taken from the ModelNet dataset. 1 Wu et al. 17 implemented a 3D GAN to generate novel voxel based objects, mostly furniture. Their approach explored a probabilistic latent space to generate these new outputs. Spick et al. 18 propose a 3D GAN which includes color information within the generated voxel outputs.
Our 3D voxel datasets were generated from simple parametric models and also include semantic descriptions.
Generative neural network architectures
According to Choeng
19
multiple neural network architectures can be useful as generative tools. Widely used ones are Variational Autoencoders (VAEs) and Generative Adversarial Networks (GANs). Xiao et al.
20
as well as Vahdat and Kreis
21
identify three key requirements, which they deem important for a generative network to achieve: 1. The ability to produce readable, high quality output (e.g., a sharp output-image instead of a blurry one); 2. Diverse sampling: the ability to capture diversity in the training dataset and depict this in the generated outputs; 3. Fast and computationally inexpensive sampling: the speed of synthesizing novel output (necessary for real time applications).
Xiao et al. 20 discuss the Generative Learning Trilemma, which states that conventional generative models are capable of achieving only two out of these three requirements. GANs (used in much of the research work discussed in Section Related literature) produce high quality output at fast generation speed, but their sampling diversity performance is poor. VAEs on the other hand achieve good sampling diversity while synthesizing fast, however, their output quality is lower. Nevertheless we decided to use a VAE, or more specifically, a Conditional-VAE in our project. For the creation of conceptual design schemes we consider the ability to generate diverse outputs more important than the quality, which, given the low voxel resolution, will be relatively low anyway.
Autoencoders—Network architecture and principles
An autoencoder is a neural network which consists of three main parts: The encoder, the decoder, and the latent space or representation vector. 22 When the encoder compresses the input geometry, it decreases the number of digits needed for representing that input. This is achieved using so-called 3D-Convolutional layers whose function is to summarize and thus reduce certain parts of the input data into smaller chunks. Through the chaining of multiple 3D-Convolutional layers the encoder gradually reduces the original geometry representation, in our case 243 (13,824) digits, down to the size of the representation vector, which for this project were 256 digits. This compressed 256-long representation vector is also referred to as a “latent space” vector. The latent space can be understood as a high dimensional coordinate system, where each individual digit of the representation vector stands for a single axis inside this space. Choosing any point (multidimensional coordinate) inside this latent space and passing it through the decoder generates novel output. Thus, each latent space point represents one unique geometry.
Advantages of variational autoencoders
As Foster 22 explains, regular autoencoders are not well suited as generative tools since they perform poorly when synthesizing novel outputs. This is because there are gaps in the latent space between the points and the decoder does not have information about how to reconstruct output from those gaps. Variational Autoencoders (VAE) were developed to address these problems. 23 Using a multivariate normal distribution during encoding VAE can be trained so as to generate meaningful outputs from any place inside the latent space. This makes VAE much better suited as generative tools than regular autoencoders. However, navigating a 256-dimensional space is still very confusing. Rahman 24 points out that VAEs do not offer great control over the generation of new outputs. In other words, in order to be able to use the latent space like a design space comparable to that of a parametric model, we need more control over how to navigate it.
Advantages of conditional variational autoencoders
A Conditional Variational Autoencoder (CVAE)
25
aims to solve this navigation problem. The CVAE functions just like a VAE, however, it requires two inputs for the encoder: The geometry (just like a VAE) but also a semantic label describing that geometry. Consequently, the decoder also requires two inputs: The latent space point (just as the VAE) and a semantic label. Receiving those, the decoder generates an output representing the provided semantic label. To a human user, these labels provide much needed orientation for navigating the latent space. Figure 1 shows a diagram of a CVAE with all its essential parts. Diagram showing all important components of the voxel based CVAE.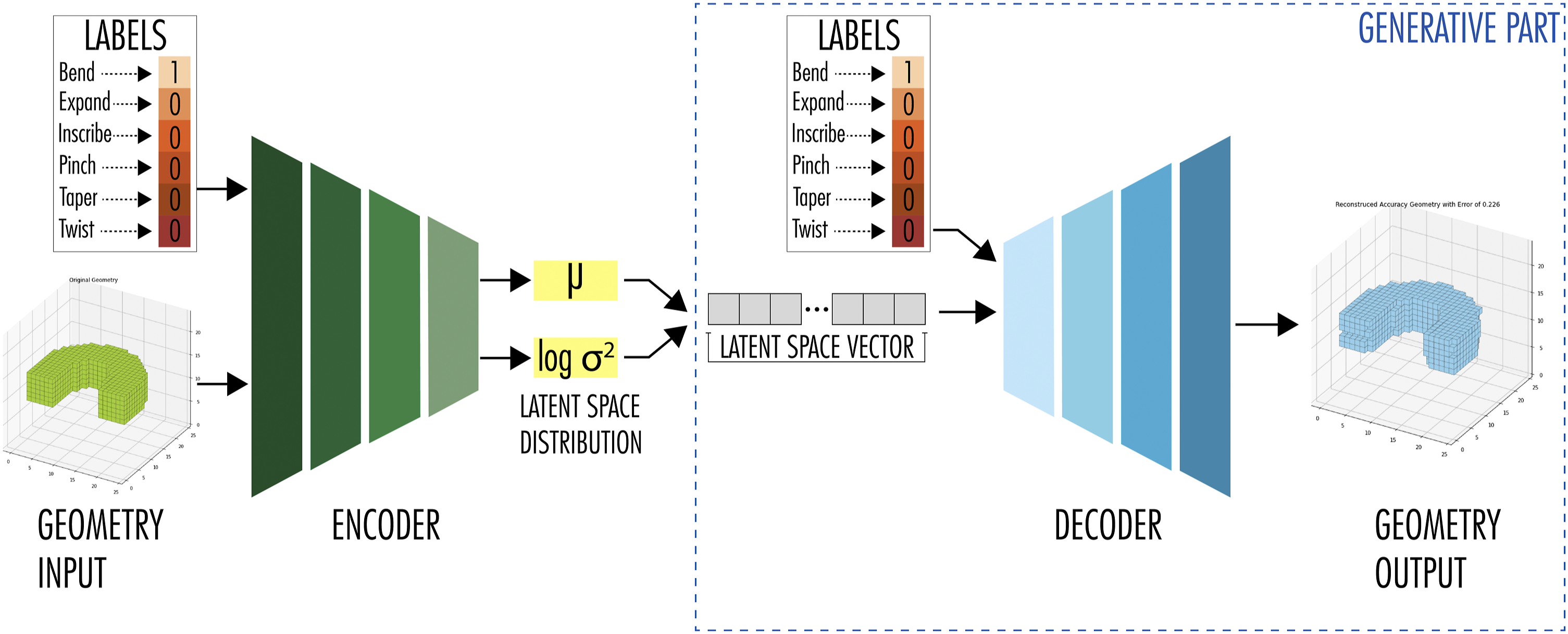
The workflow
In the following sections, we describe the different stages of our workflow. Stage one is the creation of the dataset, stage two is building and training the neural network with this dataset. Stage three is the latent space navigation: the successfully trained network is used to generate novel objects.
Training dataset creation
The size, quality, and diversity of the training dataset are key to producing a well working generative deep learning tool. We wanted to create a dataset that fulfilled the following requirements: 1. The 3D geometries should have different semantic labels. 2. Each individual semantic category can be produced by using a single low complexity parametric design script, that is, a narrow solution space. 3. The combination of individual objects with narrow solution space should lead to a wider, more diverse solution space. 4. The geometrical objects in the dataset should be grounded in the use for conceptual architectural design. 5. The geometries should be readable in voxelized representation.
The booklet Operative Design: A catalog of Special Verbs 3 by Di Mari and Yoo presents a taxonomy of simple geometrical operations that fulfills the above requirements. The authors explain: “These spatial operations are not ends unto themselves, but instead a set of illustrated beginnings to activate architectural inquiry, assembled to ignite the design process.” [3, p8]
In the logic laid out in the book, these operations can be used and combined in design exploration to create 3D shapes suitable for conceptual design. The authors demonstrate how certain combined operations have led to the real world realization of architectural projects. What makes Di Mari and Yoo’s work interesting for our experiment is not only the fact that their catalog of operations can easily be implemented in parametric design but that it is indeed a taxonomy, where every single operation has been semantically labeled by the authors. The combination of these operations is not only what is intriguing about their work, it is also precisely where our interest in our deep learning approach lies.
For this research six different operations were chosen from the catalog. Those were parametrically implemented using the Houdini FX 3D software.
2
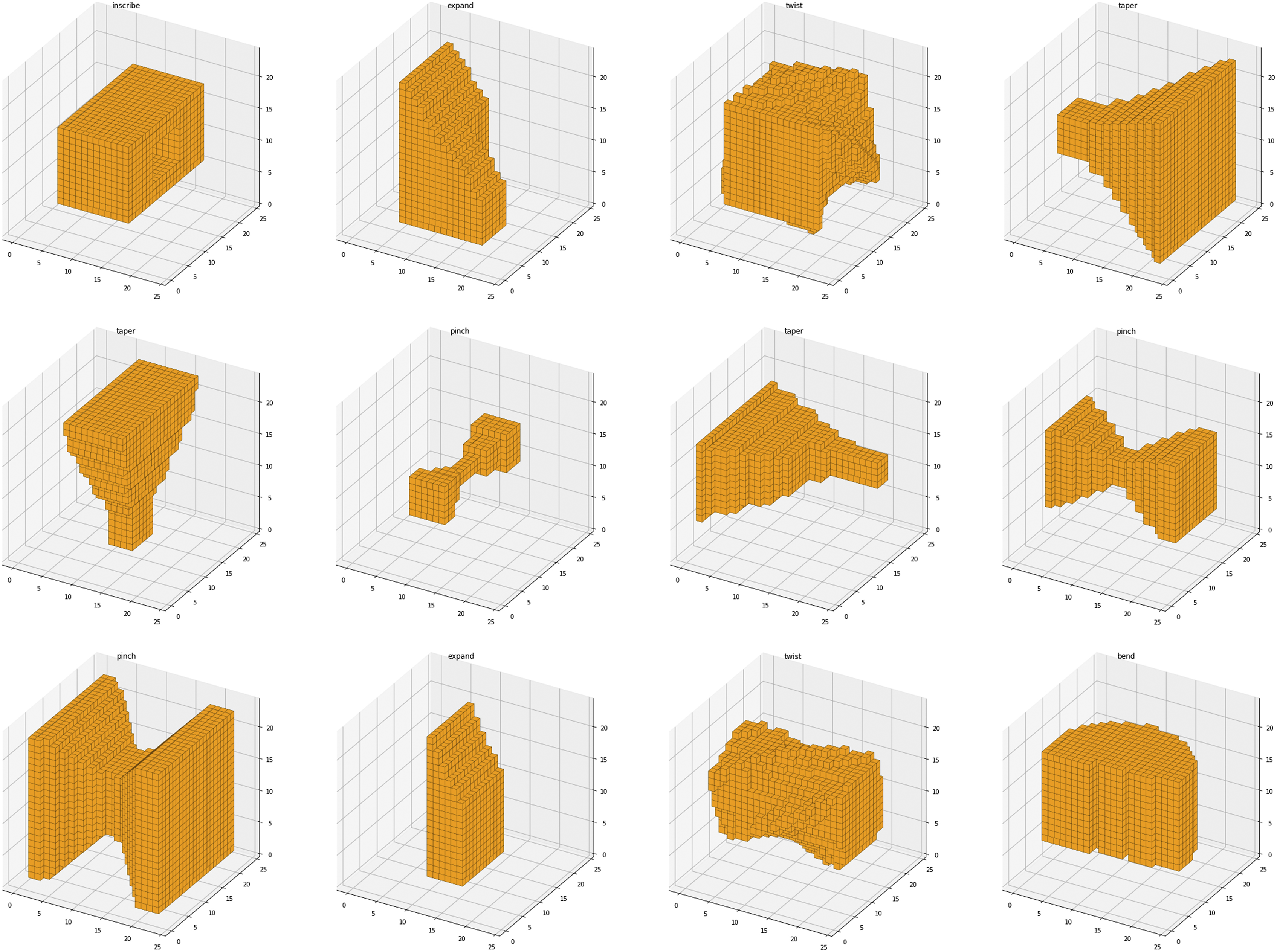
For each operation, a parametric script was created and its geometric output converted into voxel form. This data-generation workflow was automated. The following six geometrical operators were chosen for the project. 1. Bend: A bending deformation of the base volume with the bend axis at its middle section. 2. Expand: The rise or lowering of one edge of the base volume. 3. Inscribe: A Boolean difference of the base volume with an elongated cubic, producing a hole through the base volume. 4. Pinch: The reduction in thickness of the midsection of the base volume. 5. Taper: The reduction in thickness towards one end of the base volume. 6. Twist: A rotation of one end of the base volume producing curved sides.
For each operation, 10,000 random variations were created and exported totaling a dataset of 60,000 voxel shapes and their corresponding labels. Figure 2 shows samples of each of the six operations before voxelization was applied. Figure 3 shows multiple voxelized geometries from the dataset. Sample renderings of the six geometric operations created for the dataset. From left to right: Bend, Expand, Inscribe, Pinch, Taper, Twist. 10.000 different versions of each of these parametric models were used to train the CVAE. A subset of the dataset used to train the CVAE. All geometries are represented in voxelized form.
Training the neural network
The CVAE was created using the Python 3 programming language utilizing the Tensorflow 2 3 deep learning library. The basic network layer structure was adapted from the work of Brock et al. 26 implementing changes necessary to convert a VAE into a CVAE.
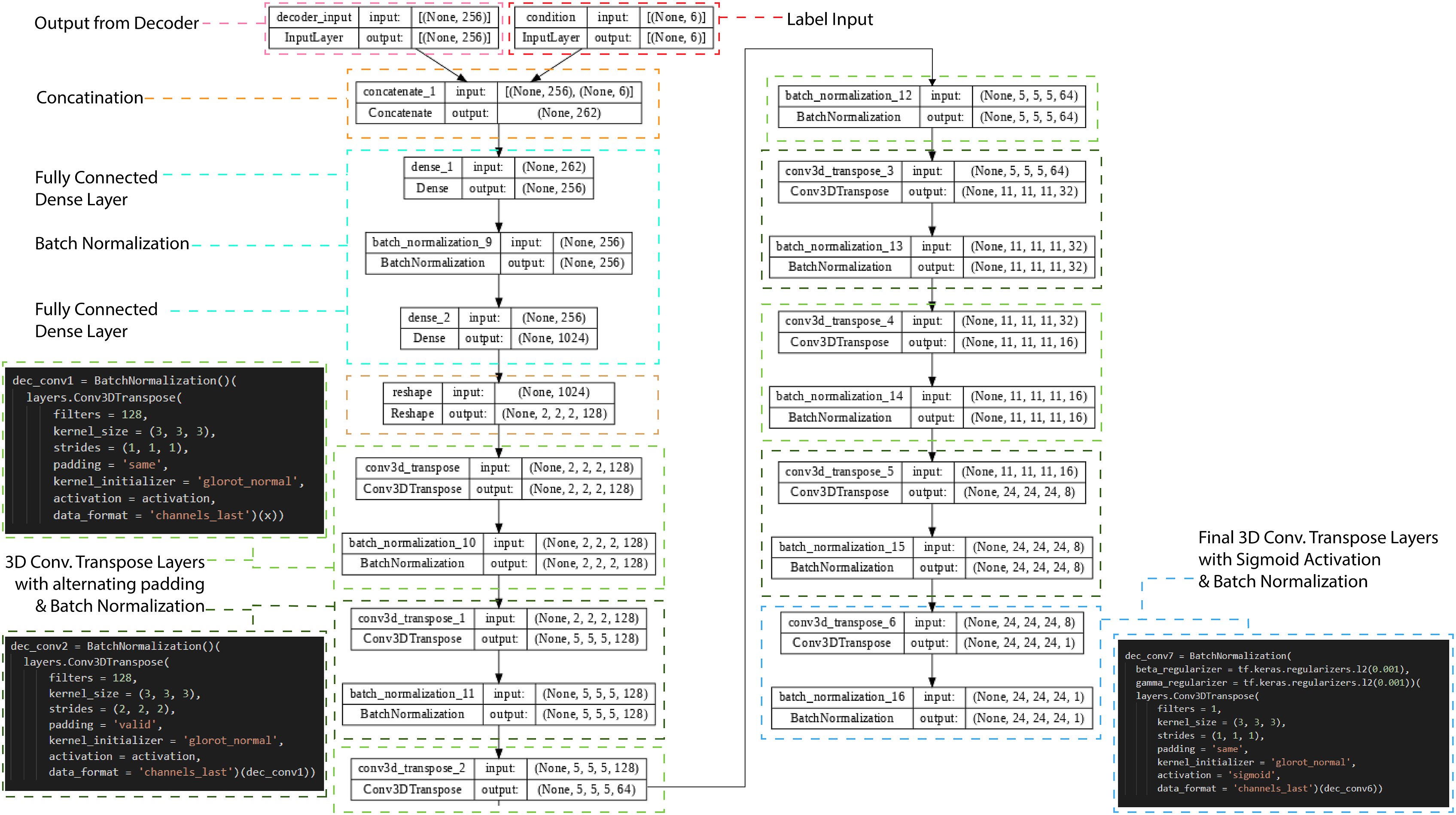
The encoder consisted of six 3D convolutional layers, transforming the input shape of 24 × 24 × 24 to the size of the latent space (1 × 256). The decoder’s input consisted of two layers: one of the latent space shape, and one of 1 × 6 for the labels input. Both layers were concatenated and upscaled with a series of seven 3D transposed convolution layers shaping to the final voxel output of 24 × 24 × 24. A detailed diagram of both the encoder and decoder with all their layers can be seen on Figures 4 and 5. A detailed diagram of the encoder, showing six convolutional layers, alternating with padding settings, followed up by concatenation layer and fully connected dense layer. Batch normalization layers were used throughout the network. A detailed diagram of the decoder, showing concatenation layer for input, followed by two fully connected dense layers, followed by seven Convolutional Transpose layers with alternating padding settings. Batch normalization layers were used throughout the network. 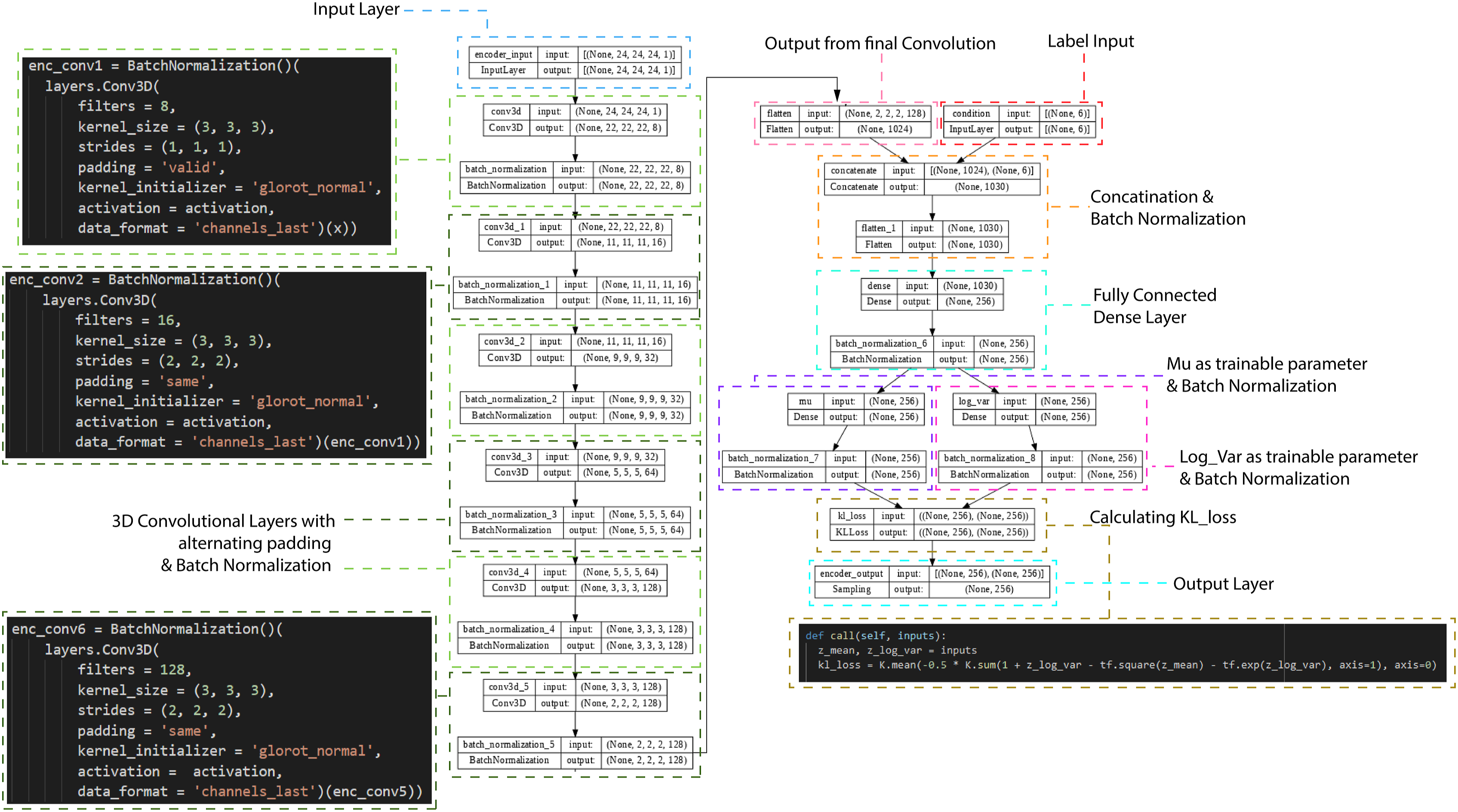
The chosen hyper parameters for training the final CVAE model.

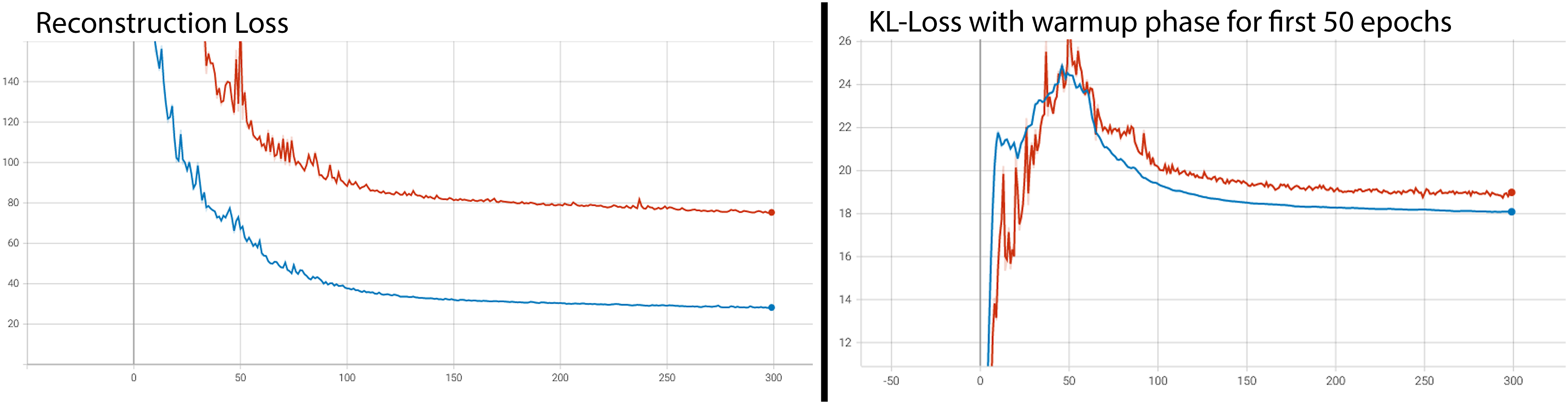
The training graphs for the reconstruction loss (left) and the KL-loss (right) showing both the curves for training data and validation data. Note: A Warm up phase was used for the KL-Loss in order to slowly ramp it up for the first 50 epochs during training.
Multiple training runs were performed with different settings using the Google Colab Pro 4 online computational service. Each trained model was saved for performance comparison. Comparing the inputs to the outputs voxel-elementwise was an objective quantitative method for evaluating reconstruction performance.
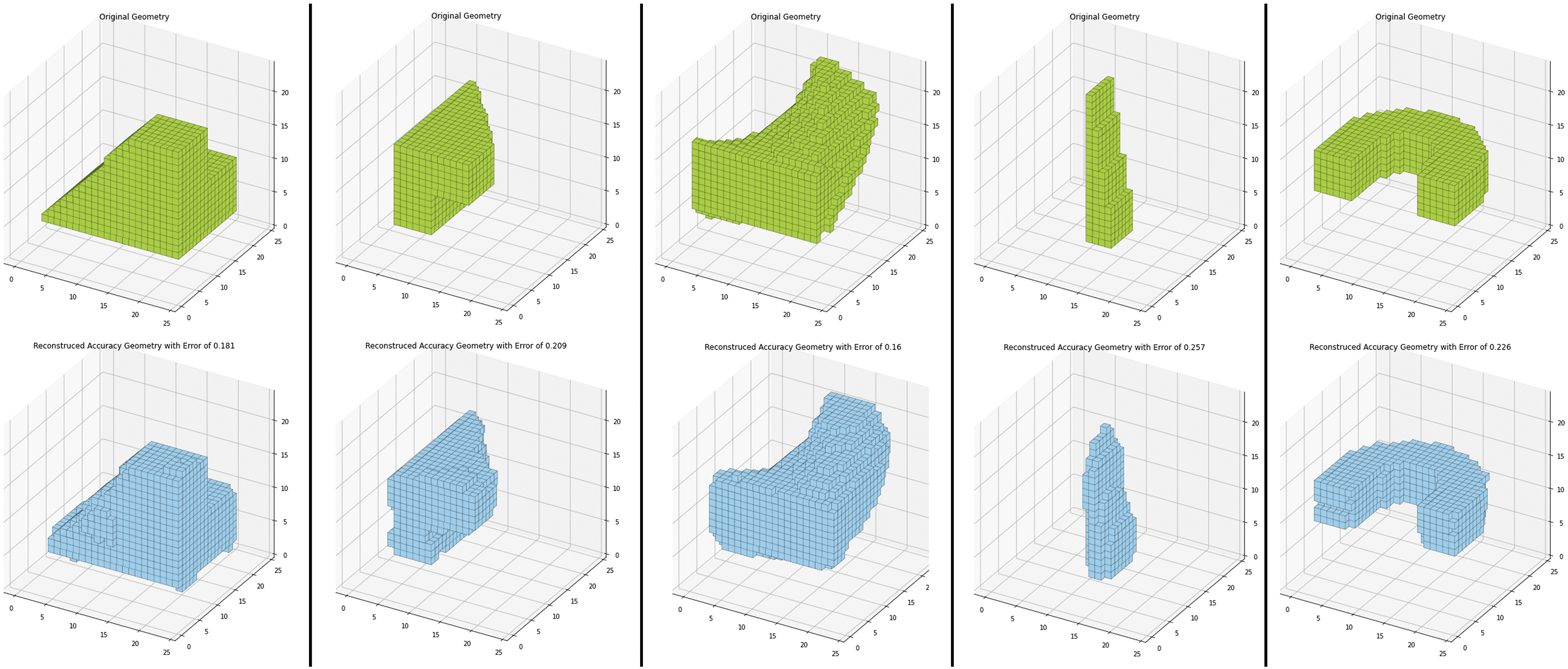
The generative performance of the model was evaluated in a more subjective manner by visually inspecting the generated outputs. However, two quantitative metrics could be established for that task: Firstly, inspecting the distribution of data points for each individual axis in the latent space. Secondly, projecting the 256 dimensional latent space into 2D using a method called Principal Component Analysis (PCA) and thus evaluating if the distribution of latent space points appeared to be continuous. The model we chose for further exploration had a reconstruction accuracy of around 75%. Figure 7 on the left side shows the distribution of the individual latent space axes for the first 50 axes. We expected those to be normally distributed, which was the case. Figure 7 on the right side shows 5000 latent space points projected from 256 dimensions into a 2D plane. We see a mostly continuous and even distribution of the points around the center (inside the black rectangle) with minor gaps. Figure 8 shows original geometries and their reconstructed counterparts. We note that certain geometrical operations are harder to reconstruct than others (like Twist), and that larger objects are also easier to reconstruct than smaller ones. Analytics of the latent space. On the left: The sampling distribution of the first 50 elements in the latent vector showing a normal distribution. On the right: Projection of 5000 latent space points from 256 dimensions into 2D using PCA. We can observe a mostly continuous and gap-free distribution around the center (inside the dark square). Evaluating reconstruction performance of the CVAE on five examples. On top the original geometry from the dataset. On the bottom the reconstructed geometry.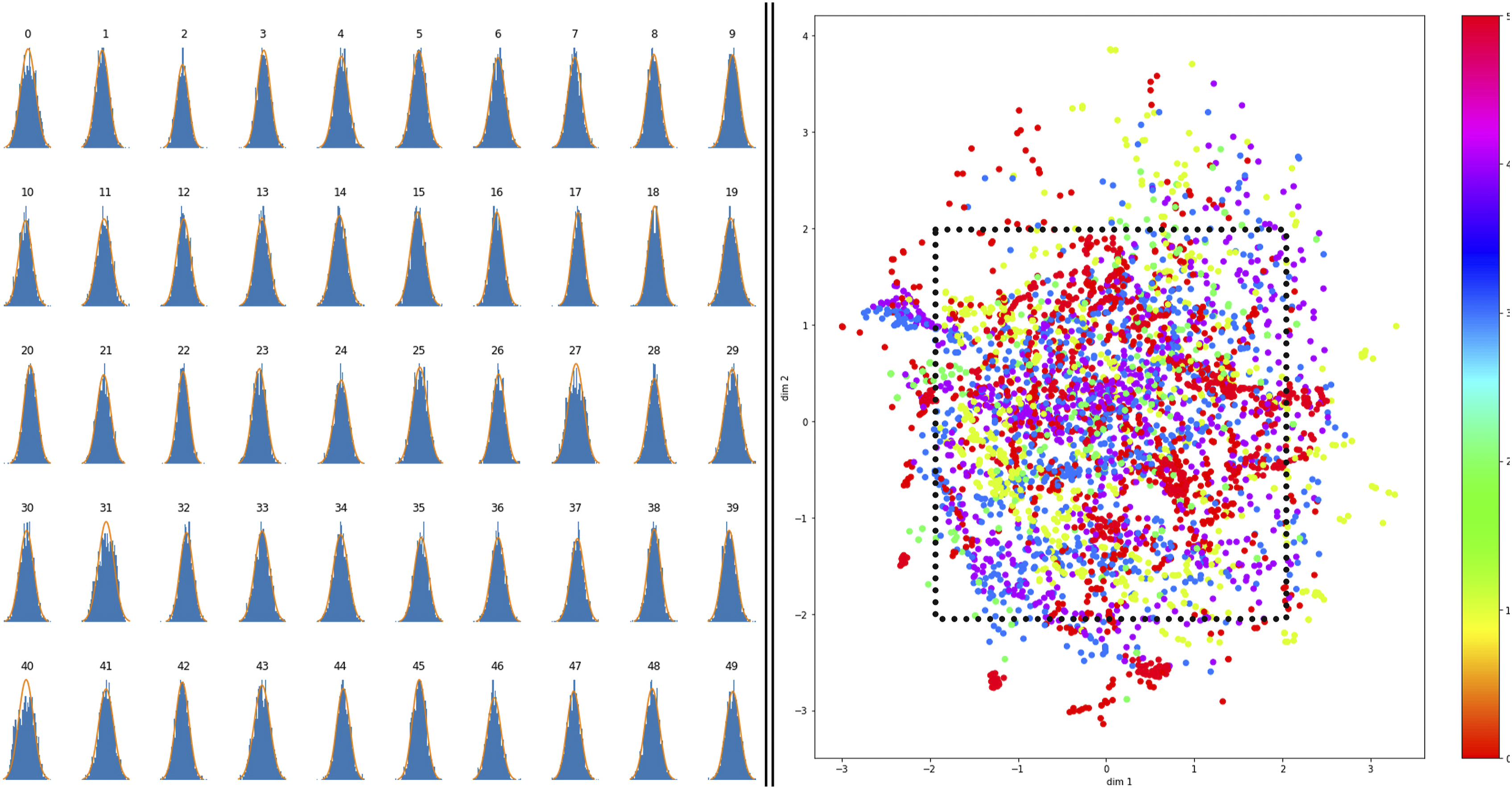
Latent space navigation
When the latent space and the decoder are detached from the neural network, the CVAE becomes a generative tool. The latent space of the CVAE is now the equivalent of a design space. It contains all the parametric models’ individual design spaces used for training the CVAE, but not only that. While the individual design spaces of each of the parametric models is quite narrow, the CVAE’s latent space is wide as it contains objects that share traits of the various training models. Navigating the latent space is a bit like witnessing morphing operations between the original parametric objects.
Similarly, the encoding of semantic labels into the final design space now allows those original labels to be mixed. Although the neural network was trained with binary labels—meaning every geometry had only one of the six label flags (Bend, Expand, Inscribe, Pinch, Taper, Twist) set to 100% and the other five to 0%—the decoder can be provided with different label configurations, and still synthesize geometry. For example, a label combination of 10% Bend, 20% Expand, 0% Inscribe, 0% Pinch, 80% Taper, and 20% Twist will also produce a result (note that the percentages do not have to add up to 100%). Since the neural network was not trained with objects of such label combinations, the CVAE’s design space is the mathematical interpolation based on the network’s feature extraction abilities. This interpolation is not linear and leads to novel geometric assemblies. Despite the low resolution of the voxel space, the combination of the geometric operations is usually well legible. This is very much in the spirit of Operative Design, 3 which suggests that these operations be combined.
Design space exploration
Navigating the latent-space as a design space is only possible with an appropriate user interface. The following three setups showcase different methods of how the generation and exploration of novel geometries can be controlled by the user.
Random latent space points with label switching
The setup shown in Figure 9 features a simple graphical user interface (GUI) with six sliders (each for one of the semantic labels), which give the user the ability to control the influence of each attribute (sliders ranging from 0–1, representing 0%–100%) for any point in the latent space. An image preview shows the output. The user then has the opportunity to modify the slider composition and create a new object, or create a new geometry with a different random latent space variable, keeping the previously specified label configuration. Pressing the Export Geometry button saves the produced output as an .stl file. Upon pressing the Analyze button, a 2D image projection is created showing the user where in the latent space every previously produced object is situated, as well as the average position of all objects from one single category, that is, the Functional Form (more information regarding Functional Form in Section Object addition through importance vector extraction). The GUI to control the generative CVAE with a preview of the created geometry. Six sliders let the user specify the desired label configuration. Buttons give the user the ability to create new geometry, generate a new random latent space point, export the generated geometry as an .stl file, and visually analyze the geometries inside the latent space.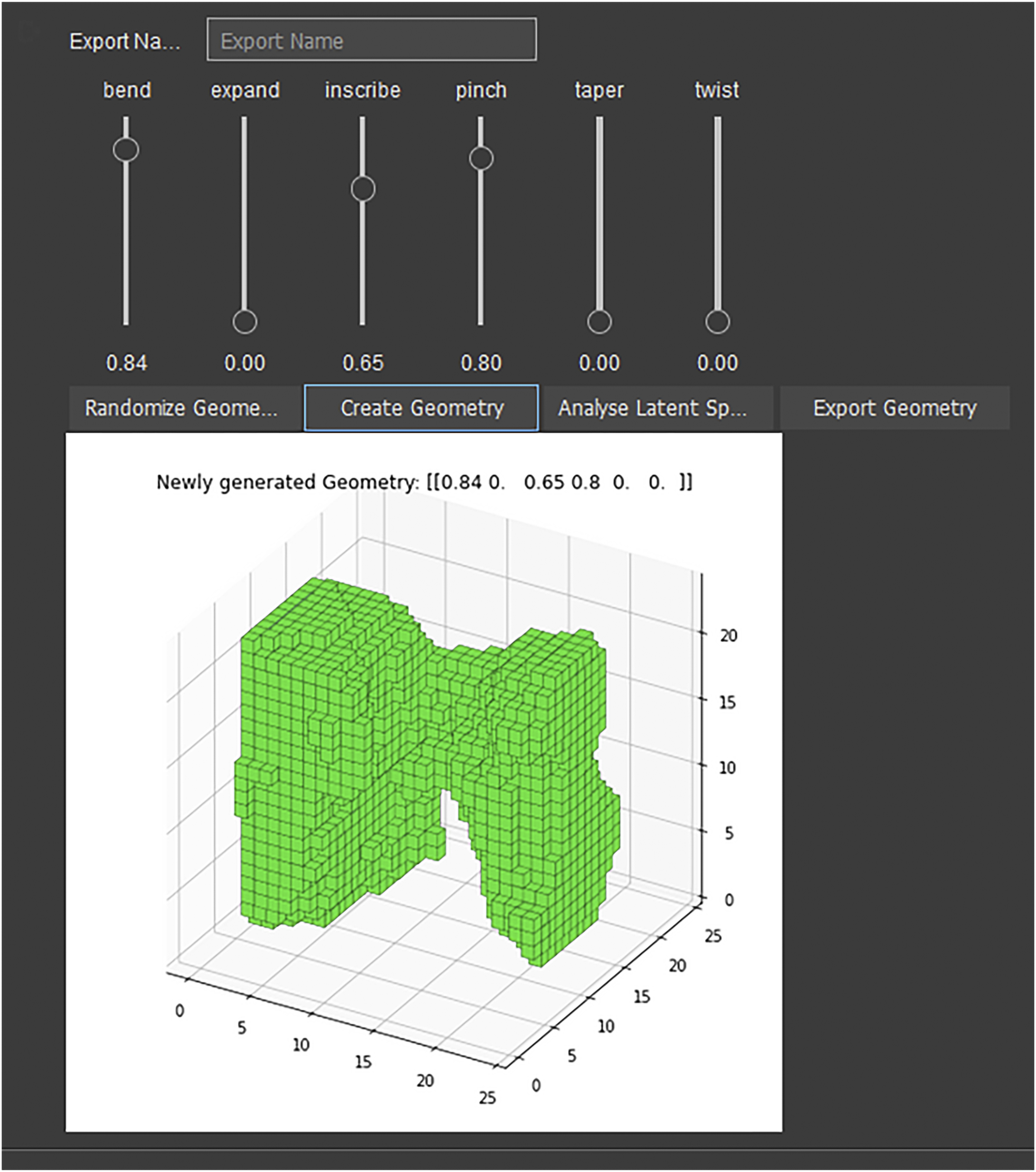
One advantage of this setup is that it allows for label switching: With the same latent space point coordinates, objects can be created with different labels set at 100%, This can be seen as a simple “style-transfer” from one object to the other. Figure 10 shows the results of this style-transfer for four different latent space points. The generative tool successfully learned the basic geometric properties of the base volume residing at that latent space coordinate. This includes the base volumes’ general shape, size, and orientation. Style-transfer performed on four different base volumes (One base volume per row). This is achieved by switching labels for the same latent space point. The different styles from left to right: Bend, Expand, Inscribe, Pinch, Taper, Twist. The base volume’s shape, size, and orientation are preserved.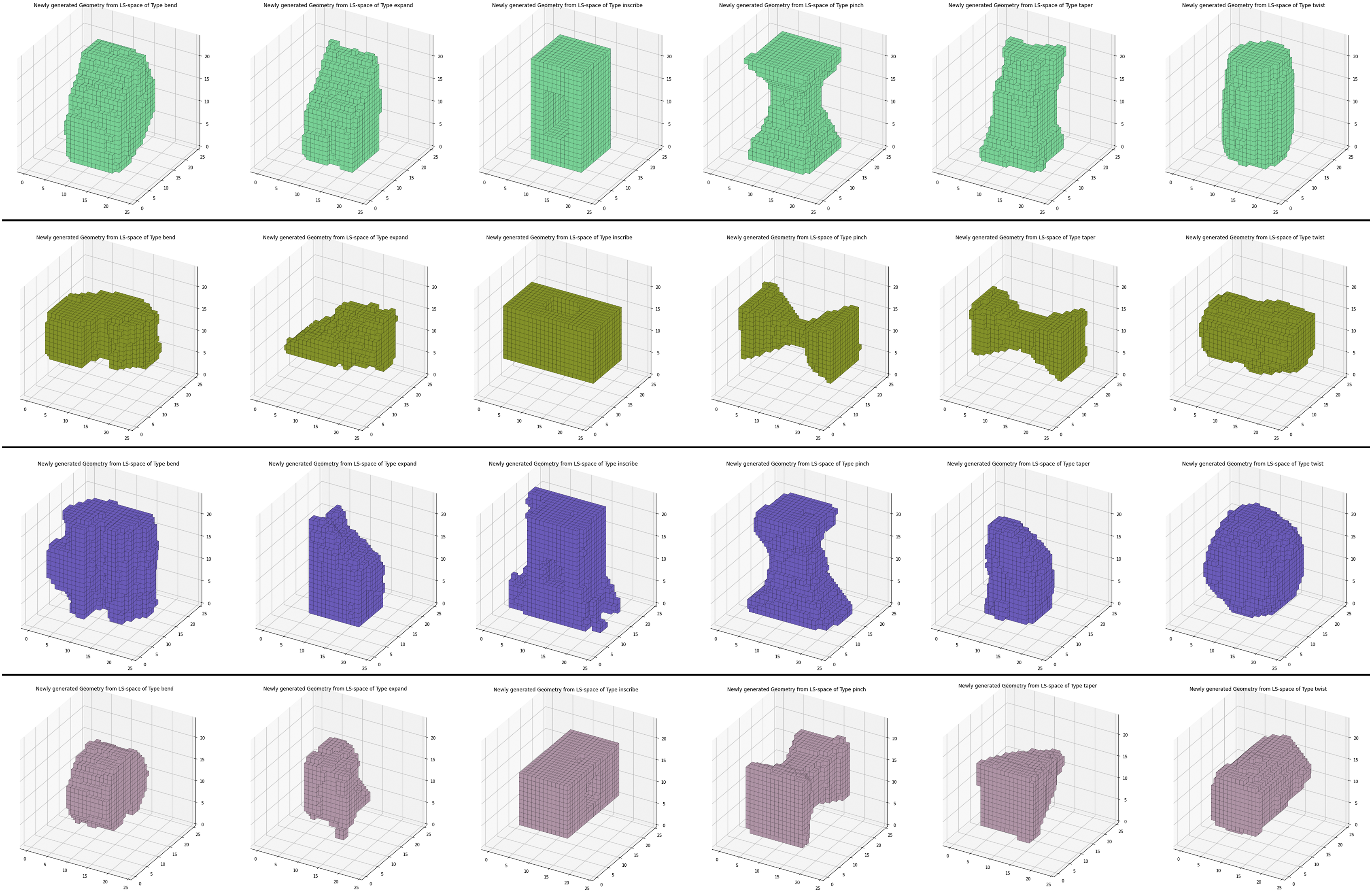
The same GUI can also create shapes based on multiple labels. Through this method, geometrical operations can be mixed. The results can be seen in Figure 11: Five different geometrical shapes were created with different amounts and degrees of label mixtures. For geometries created out of two labels, the individual operations can be easily read. Mixing more labels the operations get more intertwined, with their individual label readability decreasing. The ability to do label switching is possible because the neural network has a conditional decoder. This conditional generative structure enforces the disentanglement across the six operative terms via the conditional vector. Mixing geometries by providing semantic multi-labels to the decoder. This figure depicts five different mixing operations (left to right). On top the renderings of geometric outputs in voxelized form; Below the same output in smoothed representation. 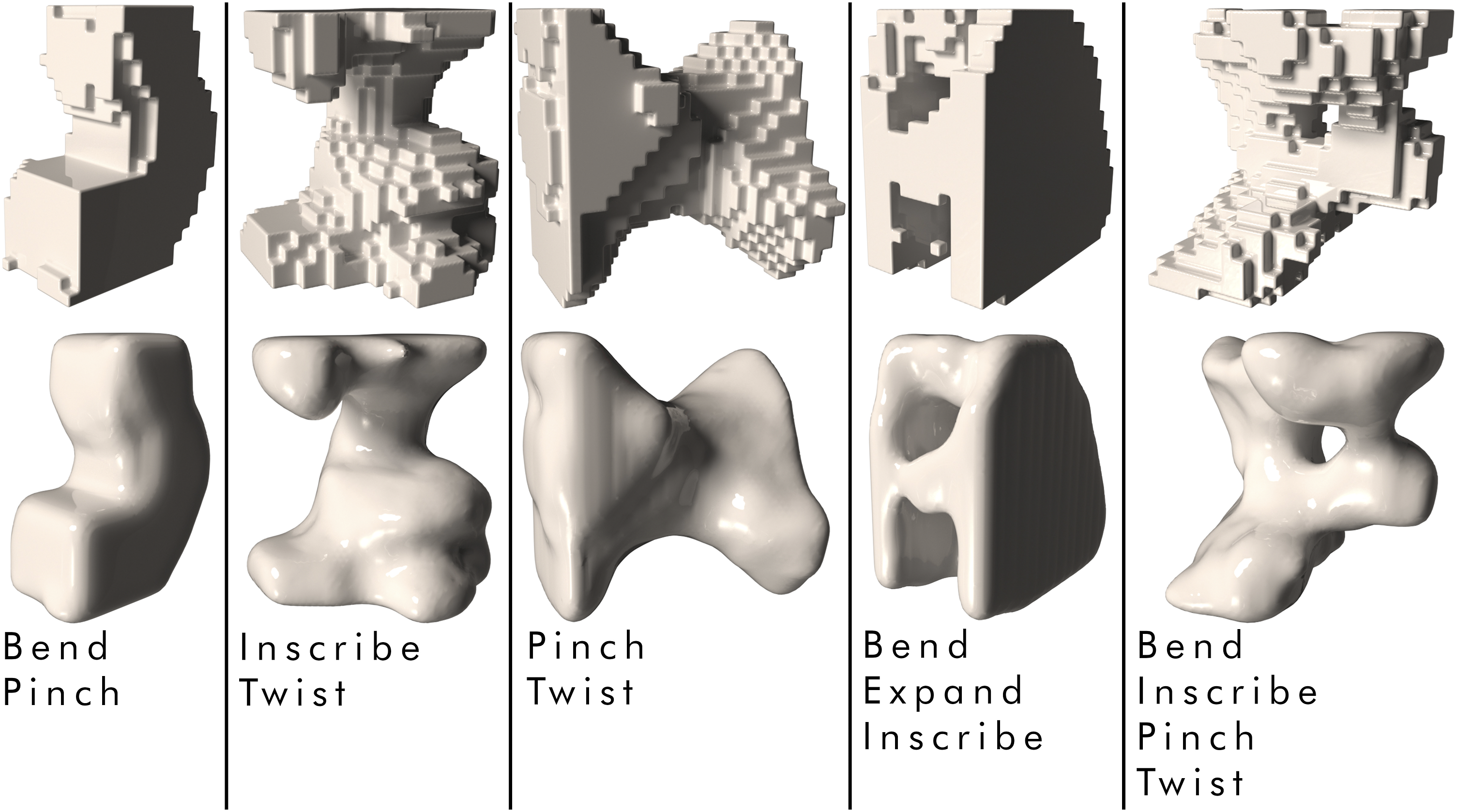
Morphing between two objects
A different method for creating new geometries is the linear interpolation, that is, morphing, between two geometries. For any two geometries from the dataset the coordinates in the latent space can be recorded. Then multiple equally spaced apart latent space coordinates are calculated between the two. The number of new coordinates can be specified by the user. In case the two objects have different semantic labels, those labels are also recorded and gradually interpolated with the same number of steps. The pairs of interpolated coordinates and labels are then fed through the decoder to produce a morphing sequence from one object to another. Besides producing new geometries, this method is also useful to evaluate how evenly the latent space is distributed (KL-Loss performance). Figure 12 shows the morphing between two geometries of different labels depicted in 12 steps. We can observe a smooth transition between each step. Around the midpoint interpolation we achieve an even mixture of both objects. Morphing from one geometry to another in twelve distinct morphing steps (with geometries of different labels). At the very left top is the starting geometry, at the very left bottom the ending geometry. Figure depicts morphing steps successively from top left to right and then bottom right to left. On the very right top and bottom are the geometric mixtures around the morphing midpoint.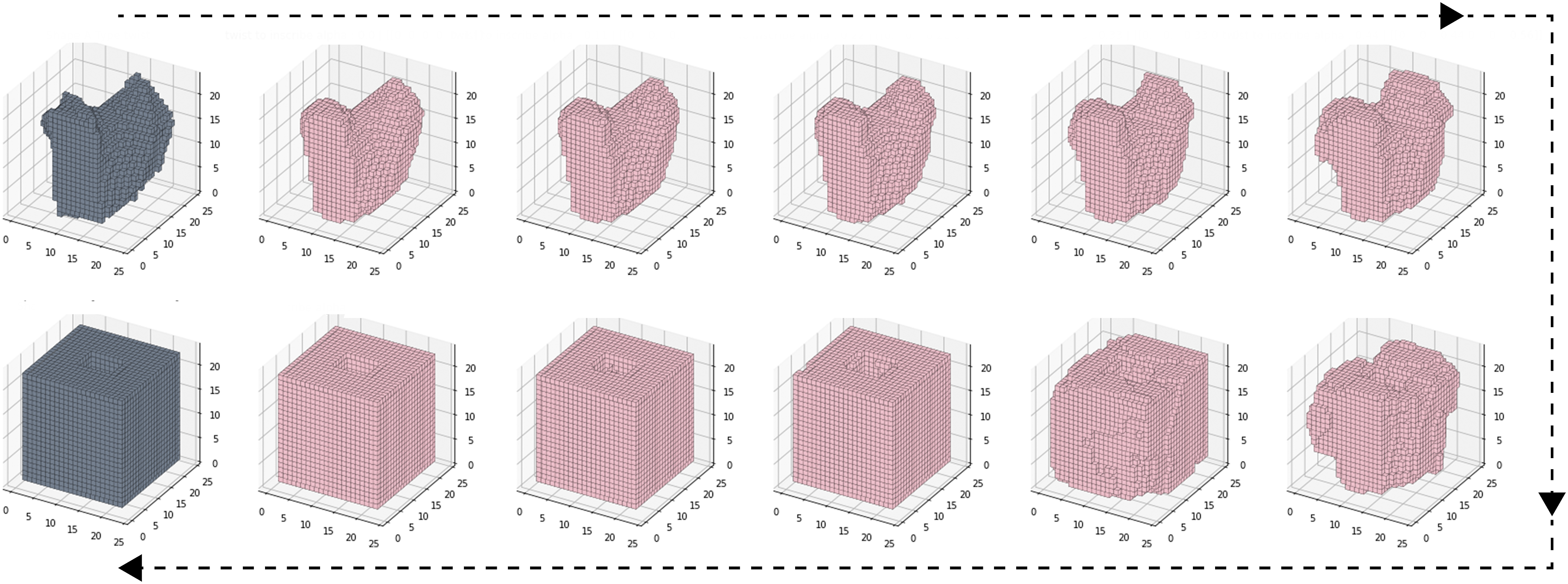
Object addition through importance vector extraction
Andries et al.
16
developed a method for adding voxel geometries, based on the concept of functional form. They used a VAE-generated latent space and inferred label categories directly from the dataset. The functional form is calculated by finding the mean coordinate for each object category with the same label. We modified their approach for use with a CVAE. We found that this method increases the level of control over the design space compared to using just the label categories as shown in Section Random latent space points with label switching. Figure 13 shows the functional forms of the six operations. We can see how the functional forms capture the geometric essence of each individual operation. The six functional forms; On top left to right: Bend, Expand, Inscribe; On bottom left to right: Pinch, Taper, Twist.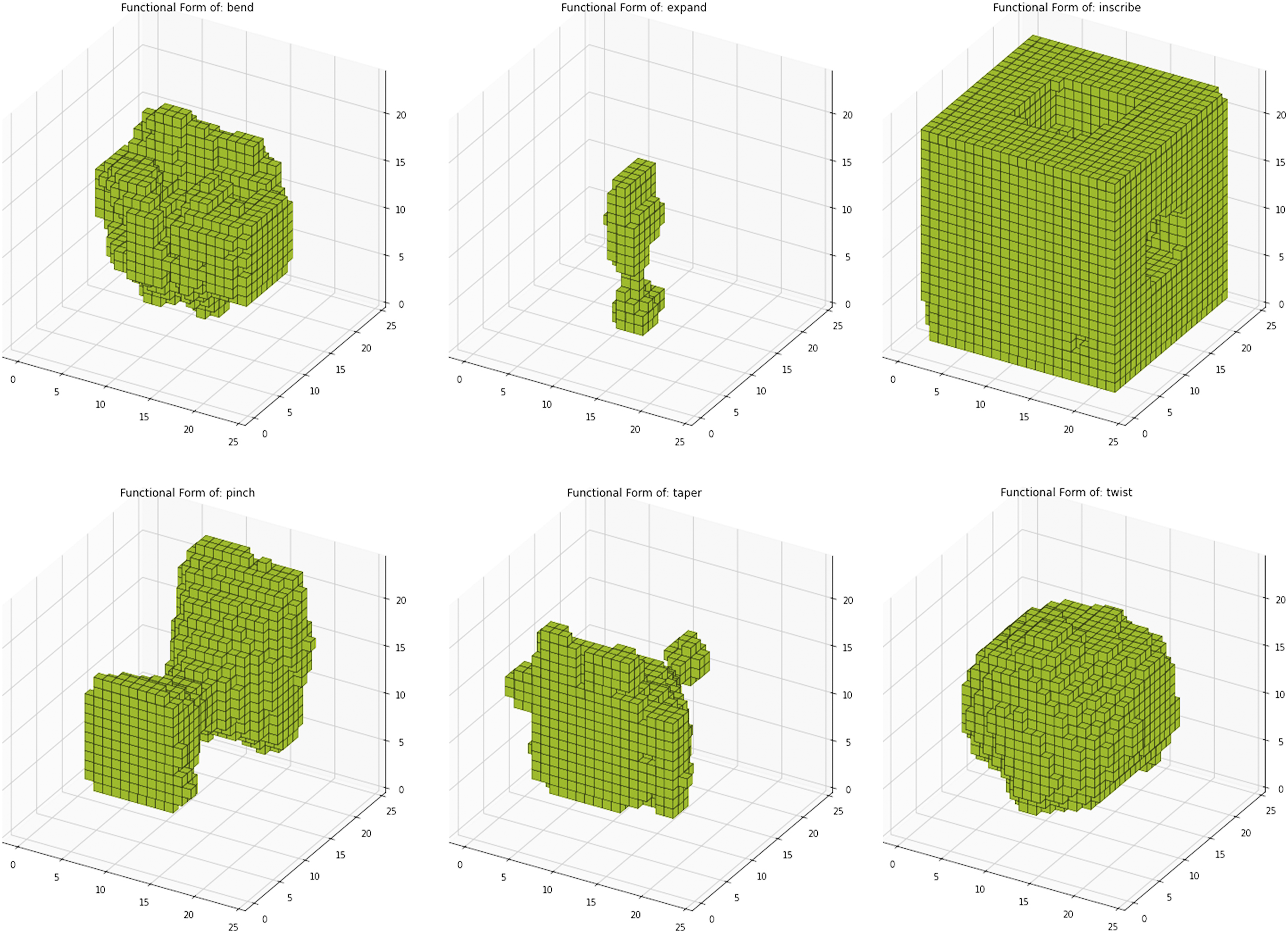
Using a so-called importance vector, the functional form method allows geometries to be combined arithmetically, preserving the main features of both geometries in the combined output. When combining two geometries, a base-object has to be declared as well as a top-object. The latent space point for the combined object is then calculated using the importance vector. For this experiment, a GUI was created that allows the user to control this geometry arithmetic, using sliders and buttons similar to the GUI shown in Figure 6. We performed a variety of additions of two geometries, the results can be seen in Figure 14. Adding two geometries using the importance vector method. Figure shows four different additions, one in each row.
The setup allows multiple additions to be performed on top of each other, and to experiment with various label slider combinations. The results are geometries such as the ones shown in Figure 15. Five generated objects (left to right) created by chaining multiple additions one after another. On top rendering of voxelized representation. At the bottom the smoothed representation.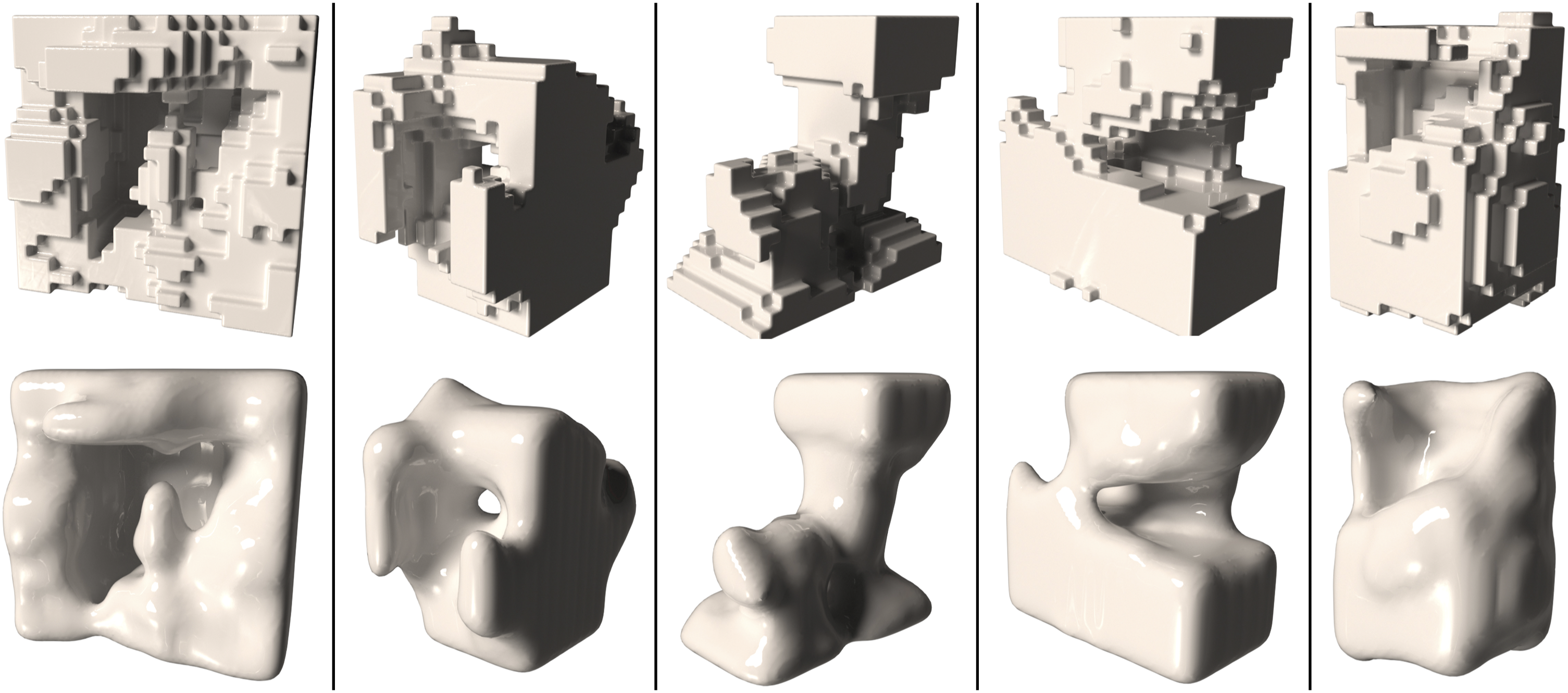
Evaluation of the results
We see the presented system as an early prototype of a deep learning based generative tool for architectural design. While we are currently only operating on low-res voxel models and are still some ways away from any practical application, we believe that our experiments already demonstrate that this approach has potential and could be developed into a useful design tool.
Latent space as design space
Our approach is based on the idea that the latent space of a neural network can be seen as the equivalent of a design space in parametric modeling. While setting up a parametric model of some complexity is in itself a considerable design challenge, the training of our neural network is in fact rather straightforward provided there is a sufficient dataset. The complexity of its latent space results from the combination of very simple parametric models.
By generating our own training datasets, we achieve two objectives: Firstly, we solve the problem of a lack of 3D architectural data applicable for deep learning training. Secondly, we demonstrate in Sections Random latent space points with label switching through Object addition through importance vector extraction that there are interesting ways available for users to navigate the resulting latent space as a design space. Operations such as style-transfer, morphing, or semantic mixing are usually difficult to achieve in parametric models. For our deep learning based generative tool, they are straightforward built-in features. So, not only is the design space richer, more complex, and more varied than that of the individual parametric models that were used for training, there are also ways to explore it that are intuitive as well as surprising.
Regarding the creation of the training data: We do not suggest that a sufficient dataset can be built from a single parametric design script. This would defeat the purpose of the whole deep learning based generative network. However, we demonstrate that our approach allows for many different parametric models to be combined to generate a design space that can be navigated in novel and meaningful ways. In this way, multiple parametric design scripts, potentially from multiple designers, are combined to form a valid dataset. We propose that such custom datasets be created to tackle specific design challenges and that architects using this approach would not only navigate the latent space but also curate the dataset it is based on.
Design spaces and the optimization paradox
For algorithmic applications such as optimization, the latent space is indeed equivalent to a design space. As briefly mentioned in the introduction, optimization is becoming increasingly important in design. Design spaces are a necessary prerequisite for any optimization. As long as options are infinite, no optimization is possible. Of course the flip side of this is that any design space will, by its very nature, rule out many more potential schemes than it contains. So, the paradoxical fact is that design spaces at the same time enable as well as severely limit the impact and potential benefit of optimization methods. Our system of course does not change this fact. But it makes it easier to create design spaces that contain a larger variety of different schemes as well as any mixed type between them than typical parametric design approaches would.
“Operative design” as test case
We applied some of the taxonomy described by Di Mari and Yoo 3 in what they call “Operative Design” as a test case for our CVAE. Their basic operations not only directed the simple parametric models we used in our training, they also provided the semantic labels we used to control object generation. That the CVAE allows us to combine and mix their operations and play with them just as they demonstrate in their booklet, validates the idea that our system could become the basis of a conceptual design tool. At the same time, we want to point out that our system could also be trained with very different kinds of parametric models and labels and then also be used for very different design space explorations at other stages of the architectural design process.
Designing via the mixing console
Emmerer 27 envisions digital tools for architects in analogy to an audio-mixing console where designers can interactively control different semantic design features and enhance or reduce their influence as a way of testing out design alternatives. We find this vision rather compelling. While sliders as a way to control parametric models are now common, Emmerer’s vision goes much further in that he doesn’t see his mixing console as controlling individual geometric parameters, but rather spatial qualities. As he puts it: “A machine-based counterpart needs to be posited vis-à-vis the mysterious ‘associative bond’ that allows us to recognize the qualities of a building design.” [27, p. 65]. Emmerer proposes what he calls “Architecture Routines” to create this associative bond. The semantic labels we use to control the generation of geometries are very different from Emmerer’s routines, yet, arguably they similarly do not control any individual dimension, but rather act globally on the whole model.
Limitations and future outlook
Voxels, being a coarser version of the original 3D objects, reduce geometrical information. Increasing architectural detail will definitely be a goal in future research. We want to explore meshes 28 and point-clouds 29 as well as voxel based volumes, 30 to replace the binary voxel representation used in this paper. Although VAEs and CVAEs have been shown to have good generative quality, outputs lack quality, as a blurring effect occurs due to the generative learning trilemma. 20 Xiao et al. 20 propose a Denoising Diffusion GAN to overcome those issues. Zeng et al. 31 argue for the use of Denoising Diffusion Models (DDMs) for 3D object generation, proposing LION (Latent Point Diffusion Model). In the future, we also plan to explore these options.
Conclusion
In this paper, we present an early prototype of a generative design tool that uses deep learning methodology—Conditional Variational Autoencoders (CVAE)—to create and explore novel design spaces.
To overcome the problem of a lack of training data for 3D objects based in architectural design, we created our own data using an automated parametric design workflow. We explain how our approach is conceptually related to parametric design and we demonstrate how, based on a collection of very simple parametric models, it opens up the possibility to create large and varied design spaces that transcend the limitations of the individual parametric models used for training. We show that even in its current early prototype stage, the system supports design explorations such as object morphing, object addition and rudimentary 3D style transfer through the use of semantic labels. With regard to style and style transfer Del Campo et al. 32 note that “features learned by a neural network… can allow us as designers to rethink the low level visual components that comprise a given ‘style’ and how neural representations of style can be used as a method of architectural interrogation” [32, p 183].
The current state of the project produces geometry that is too coarse or undefined to be used in practice. It is a proof of concept that shows how deep learning can create design spaces that transcend the limitations of the individual parametric models used in training.
There are still many obstacles that need to be overcome until generative 3D design tools will achieve similarly stunning results as the current generation of image synthesis software. Yet, given the current pace of progress, it is probably just a matter of time until deep learning tools for 3D design become part of the daily workflow of architects. In the meantime, we believe that research such as ours can help to reflect on and explore these future possibilities.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.