
Abstract
Evaluating the quality of generative design machine learning tools is a critical challenge. Existing methods range from human-based assessments to performance-based metrics and statistical comparisons. We focus on generative urban design and critically review the evaluation methods employed in recent literature. We experimentally test and comprehensively analyze these methods. We find that existing approaches favor disrupted designs over well-designed ones, have inherent limitations, and fail to capture the tool performance quality. To address this critical gap, we develop two strategies: (1) modifying the Fréchet Inception Distance (FID) score to align with specific design principles, and (2) leveraging visual language models to assess design outputs. Our experiments show that these approaches provide more robust and comprehensive evaluations. The findings underscore the need for practical and reliable evaluation frameworks for AI in design fields to advance the research in this field.
Introduction
Designing cities is one of the most intricate and consequential human endeavors. It involves orchestrating a web of dynamic, competing objectives, social, economic, environmental, and aesthetic, while navigating the perspectives of diverse stakeholders,1,2 As Rittel and Webber famously argued, such planning tasks are “wicked problems”: ill-defined, unsolvable in the traditional sense, and constantly evolving in response to changing constraints and values. 3
This inherent complexity has historically challenged Generative Urban Design (GUD), a field that uses algorithms to create, adapt, and optimize urban layout. Recent advances in Machine Learning (ML) are beginning to shift that boundary. By leveraging large-scale urban datasets, ML models can generate intricate and context-sensitive urban forms.4,5 ML offers a powerful new paradigm for designers, planners, and policymakers exploring alternative futures and design possibilities. 6
However, as this technological leap opens new possibilities, it also introduces a new challenge: How do we evaluate these generative models? Traditional evaluation methods rely heavily on expert judgment, which is time-consuming, subjective, and often struggles to capture the full complexity and nuance of urban design outcomes. Moreover, ML-based GUD systems can produce a huge number of novel designs, making expert-based validations largely inadequate. 7
Computation methods to measure specific key performance indicators can help experts evaluate the quality of multiple designs. However, ML-based GUD systems introduce novel failure modes that complicate evaluation. These include the generation of dysfunctional or incoherent urban forms, as well as mode collapse, where the generative model fails to capture the full diversity of the design space. In some cases, models may overfit by replicating elements from the training data. Additionally, the range of design solutions may be unacceptably narrow, limiting the usefulness of the tool. Furthermore, minor changes in hyperparameters can lead to disproportionately large shifts in model behavior, resulting in inconsistent or unpredictable outcomes. Conversely, models may produce near-identical designs in response to distinctly different inputs. Compounding these issues, hidden biases and errors often go undetected by conventional evaluation metrics, raising concerns about the reliability and robustness of these tools, highlighting the need for large-scale evaluation beyond traditional human assessment. 8 Without robust evaluation, GUD tools risk becoming black boxes: innovative yet unreliable.
Despite the growing interest in ML-based GUD, the evaluation of its outputs remains under-theorized and inconsistently practiced. The lack of a standardized framework not only hinders the comparison of tools and results but also limits trust and uptake among urban planners, designers, and policymakers.
This paper addresses this critical gap. It poses three key Research Questions (RQs):
To answer these questions, we employed a mixed-methods approach that integrates a critical literature review with experimental analysis. We first mapped and classified the evaluation strategies presented in the existing GUD literature. Then, we subjected selected methods to empirical testing, assessing their capacity to capture meaningful aspects of design quality.
This paper makes three key contributions: • A systematic mapping of evaluation methods used in GUD research to date. • A critical analysis of their limitations, especially in the context of novel, machine-generated urban forms. • Suggest two evaluation methods: (1) Domain-Guided FID: an adaptation of a well-known generative model metric, tailored for urban design semantics, and (2) Visual Language Model analysis: an approach that emulates expert assessment.
Together, these contributions aim to move the field from isolated experiments toward a shared foundation for assessing generative design tools that is both rigorous and responsive to the field’s complexities.
The rest of the paper is organized as follows and is visually summarized in the flowchart in Figure 1. The Background section offers an overview of ML applications in design, the various evaluation approaches currently in use, and their challenges. The Critical Literature Review section outlines the review methodology and categorizes the evaluation methods identified in the literature. These sections were published in a preliminary version of this article at eCAADE 2024, while the following sections extend the conference version. Schematic overview of the logical structure and flow of the paper; RQ1–RQ3 refer to the research questions.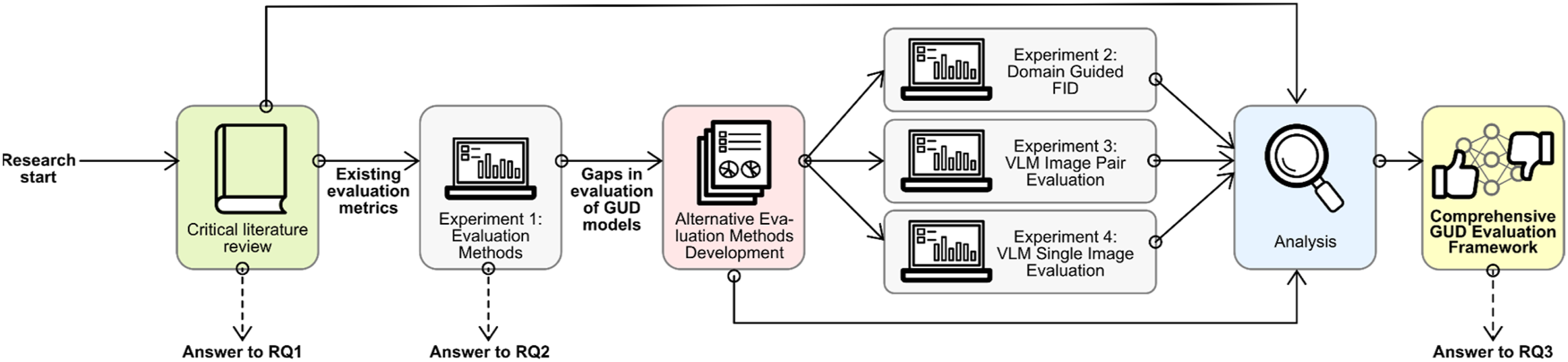
The Evaluation Methods Experiment section describes the primary evaluation method, presents the experimental results, and includes a deeper analysis to interpret the findings. Following that, the Alternative Evaluation Methods section proposes two complementary approaches: the first, Domain-Guided FID, introduces a domain-specific adaptation of the FID metric and presents its experimental validation; the second, Evaluation Using Virtual Language Models, explores a simulation-based assessment technique tested through two distinct experiments.
The Discussion section then interprets the overall findings, addressing implications and future research directions. Finally, the Conclusions section summarizes the contributions of the paper.
Background
The integration of AI into architecture and the built environment has long been pursued. 9 In the 1960s, computers were first used to automate design tasks and explore new possibilities, laying the groundwork for computational and systematic design methods that emphasized structured problem-solving and enabled algorithmic design generation and evaluation.10,11 The 1980s introduced expert systems that emulated human decision-making, while the 1990s brought parametric design and evolutionary algorithms, leading to the rise of “parametric urbanism”.12,13
Generative machine learning methods
Recent ML techniques and computational capacity have led to the application of deep generative methods in urban design. For instance, diffusion models are employed for design ideation, 14 and language models have been developed as chatbots to facilitate participatory design processes.15,16 However, most GUD literature focuses on image-based outputs due to the ability of images to capture spatial relations and produce engineering drawings, such as maps, plans, elevations, and 3D representations. Specifically, GUD literature focuses on two types of these models: Generative Adversarial Networks (GANs) 17 and Variational Autoencoders (VAEs). 18 GANs can revolutionize the field of urban design with applications ranging from façade merging 19 to assessing urban renewal potential, 20 showcasing their capability to mimic and innovate within the urban and architectural context. 21 VAEs have been pivotal, for instance, in facilitating the exploration of design spaces, including the generation of 3D objects resembling building wireframes 22 and the innovative design of architectural elements. 23
Evaluation of generative models
Researchers assess generative models using both qualitative approaches, based on human judgment, and quantitative methods, which provide standardized performance measures. However, evaluating these models remains challenging due to the subjective nature of generated outputs and the lack of ground truth labels; “ground truth” data typically consist of realized or selected design examples, which encode subjective designer decisions rather than objectively optimal solutions, offering no guarantee that these choices represent the best possible outcomes.24,25 Detecting issues like mode collapse, where a model fails to capture the full diversity of the design space, 26 or identifying repetitive and unoriginal designs further complicates assessment. Additionally, quantitative metrics may overlook critical aspects of design quality, such as aesthetic appeal and contextual relevance, while poor generation quality, including artifacts or distortions, poses further challenges. 27
Critical literature review
To answer our first research question, “What evaluation methods have been used in GUD research?”, we conducted a critical literature review of GUD.
The literature review process started with a dataset of 363 papers on AI and urban design obtained from Google Scholar, Semantic Scholar, and Cumincad until 2024. These articles were first manually filtered to include only those focused on generative AI, which resulted in 96 papers. Next, the dataset was further refined to include only studies that utilized generative AI applications to create novel urban designs. A total of 52 publications were identified, specifically addressing the generation of innovative urban designs.
Model evaluation methods found in the literature review. Some papers applied more than one method.

The reviewed studies are categorized into those that incorporate explicit model-evaluation procedures and those that do not. Within evaluation-based studies, four recurring evaluation strategies can be identified: human-based assessments; low-level computational pairwise comparisons; dataset-level statistical characterization of generated outputs; and Inception-derived scores. This classification is not intended to reflect mutually exclusive or standardized categories, but rather to clarify the differing assumptions underlying evaluation practices in GUD research. In particular, human pairwise judgments are conceptually distinct from low-level difference computations, and the term statistical is used here to denote the quantification of dataset-level characteristics, even though statistical analyses are also applied to human evaluations or Inception outputs. Likewise, KPI-based measures—though often statistical—typically assess isolated aspects of design outcomes rather than the GUD process itself.
Human-based evaluation methods
The first group used human-based evaluation, including expert surveys,28–30 extensive participant questionnaires, 31 and self-evaluation.32,33 Deshpande 30 enhanced the GPT-3 language model for generating neighborhood design concepts and assessed these using surveys distributed to experts. Ye et al. 29 evaluated the urban master plans created by their MasterPlanGAN through expert pairwise comparisons of generated and real plans involving architecture and urban planning professionals. Moreover, the evaluation process can extend to non-experts, aiming to gather a broader set of responses. Kelly et al. 31 developed the FrankenGAN, which can create 3D buildings, and conducted perceptual studies with 117 randomly selected participants via a crowdsourcing platform.
Figure 2 shows a common survey method using pairwise comparisons between generated and human-designed samples, with participants unaware of the design source. Participants quickly choose their preferred option, and statistical analysis is applied to responses from multiple participants. This approach is akin to the rapid scene categorization method used in the general GAN evaluation literature.
8
Illustration of qualitative human evaluation through pairwise comparisons.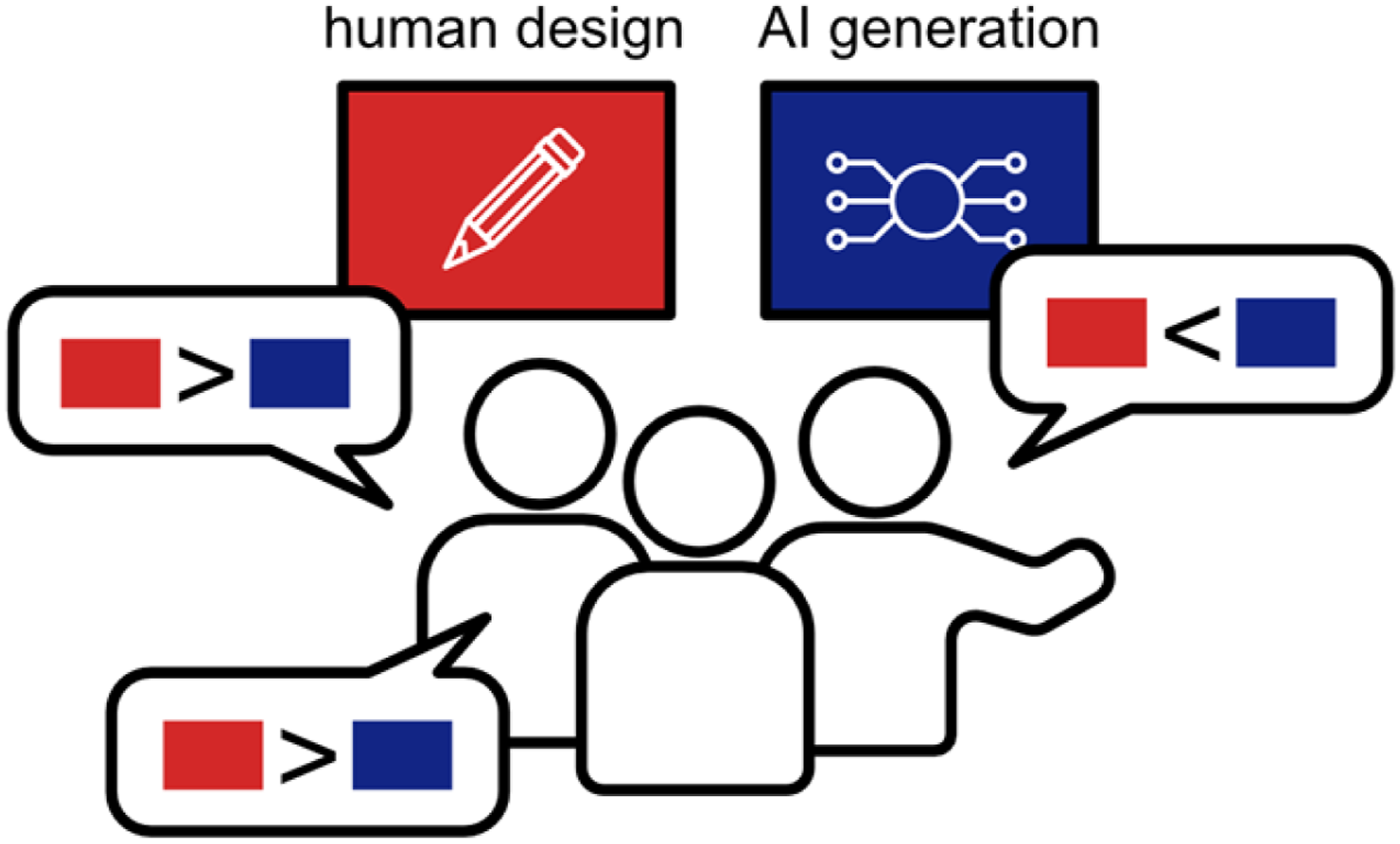
Low-level pairwise comparisons
The second group utilizes automatic pairwise comparison methodologies to measure the difference between AI-generated urban plans and those designed by humans. This is mainly reflected in pixel-level comparisons, as most generative models produce images. Common quantitative metrics include measures such as the Structural Similarity Index (SSIM), Peak Signal-to-Noise Ratio (PSNR), and the sharpness difference,5,34 which focus on image quality evaluation, providing numerical assessments that relate to human visual perception (see Figure 3). These metrics rely on comparisons of individual images with their reference versions to assess quality and similarity. Illustration of pairwise comparisons of basic design components, often pixels, using metrics like MSE and PSNR.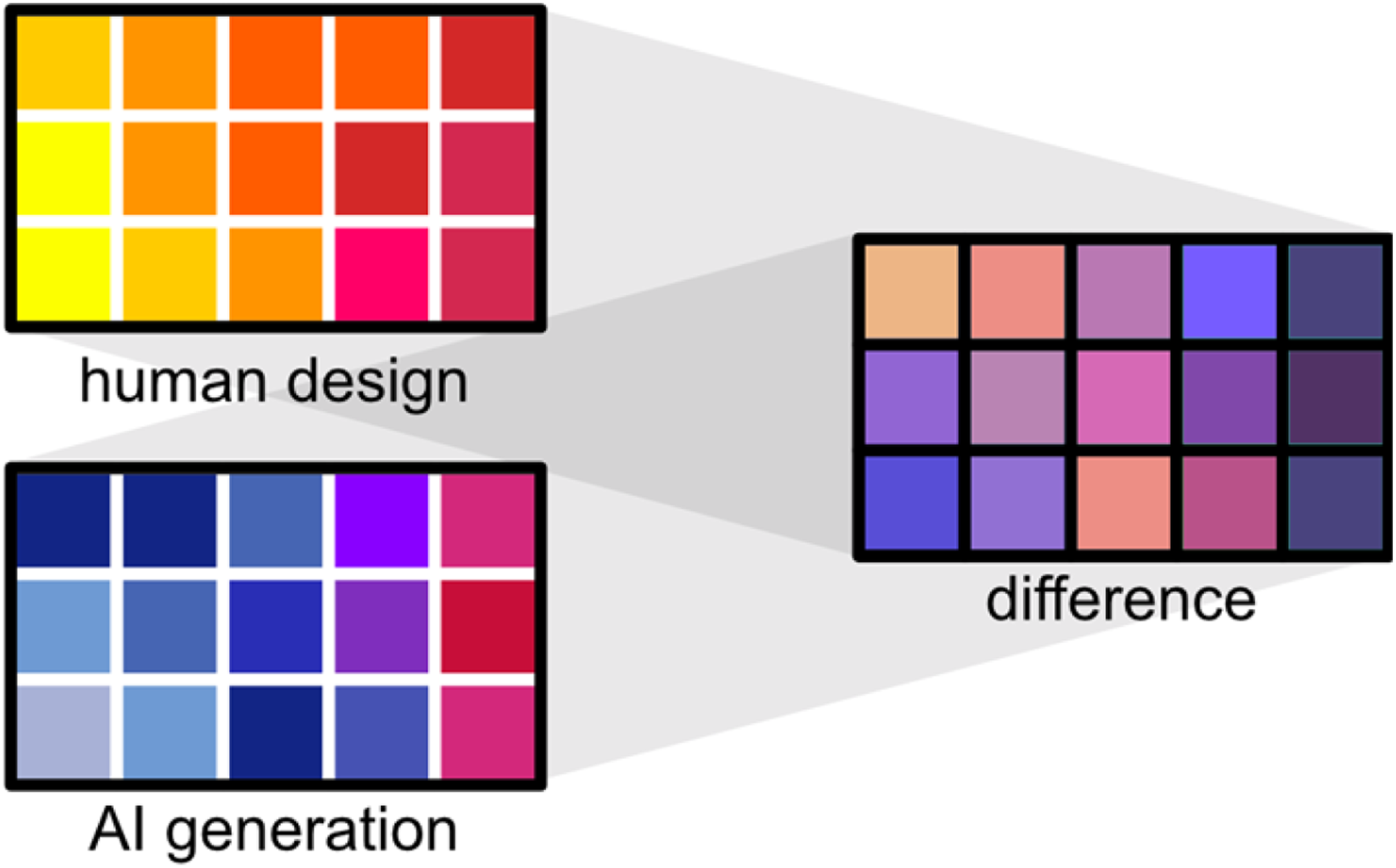
Quan et al. 35 used the Hausdorff distance. While this metric does not directly measure image quality, it evaluates the extent of difference between two sets of points, often representing boundaries or shapes in images. By comparing these sets to ground truth contours, the Hausdorff distance provides insights into object detection and segmentation accuracy.
Gan et al. 36 employed R square and root mean square error to evaluate their UDGAN model, which combines GAN and a Genetic Algorithm (GA) to reproduce a specific designer’s style while optimizing the results according to morphological parameters. Furthermore, Owaki and Machida 37 used GAN with Long Short Term Memory (LSTM) components to generate road networks and evaluated the results with accuracy and edge-overlap measurements.
Jiang et al. evaluated their building layout generation method with different numerical metrics, Mean Absolute Error (MAE), and Mean Square Error (MSE) for comparison between real and synthesized instances on the pixel level. 5 The authors also applied SSIM and PSNR for image quality and Kullback–Leibler Divergence (KLD) between ground-truth and generated samples with regard to several design attributes, such as building counts and area, for attribution compliance verification. SSIM and PSNR measurements were also used by Allen-Dumas et al. 34 to evaluate the GAN results of neighborhood images, where the input consisted of land cover images and the requested neighborhood type.
Zuo et al. 38 applied machine-learning programs to generate urban fabric images, whose quality and similarity to real data samples were evaluated by the Hausdorff distance. They have also employed multidimensional scaling, a method aligned with the third, low-level statistical evaluation approach, which is explained in the following section.
Similarly, Han et al. 39 integrated pairwise comparisons with statistical analysis to evaluate the performance of their autoencoding tree neural network. This network, trained on 3D city datasets encoded as binary trees, was designed to generate new city layouts. Evaluation was conducted using accuracy metrics such as coverage and minimum matching distance, alongside a novel metric introduced by the authors, termed the overlapping area ratio. In addition, they measured the Jensen-Shannon divergence, a statistical metric that falls into the next group.
Low-level statistical evaluation
The third group includes measures that take a statistical approach and compare actual versus generated data distributions, as illustrated in Figure 4. These include the Maximum Mean Discrepancy (MMD), Jensen-Shannon Divergence (JSD), Hellinger Distance (HD), Wasserstein Distance (WD), and covariance (COV). Illustration of a statistical evaluation method, which shows the comparison of probability distributions of the design components using metrics like JSD and MMD, which quantify the discrepancy or divergence between the distributions, or COV, which measures the statistical relationships between variables.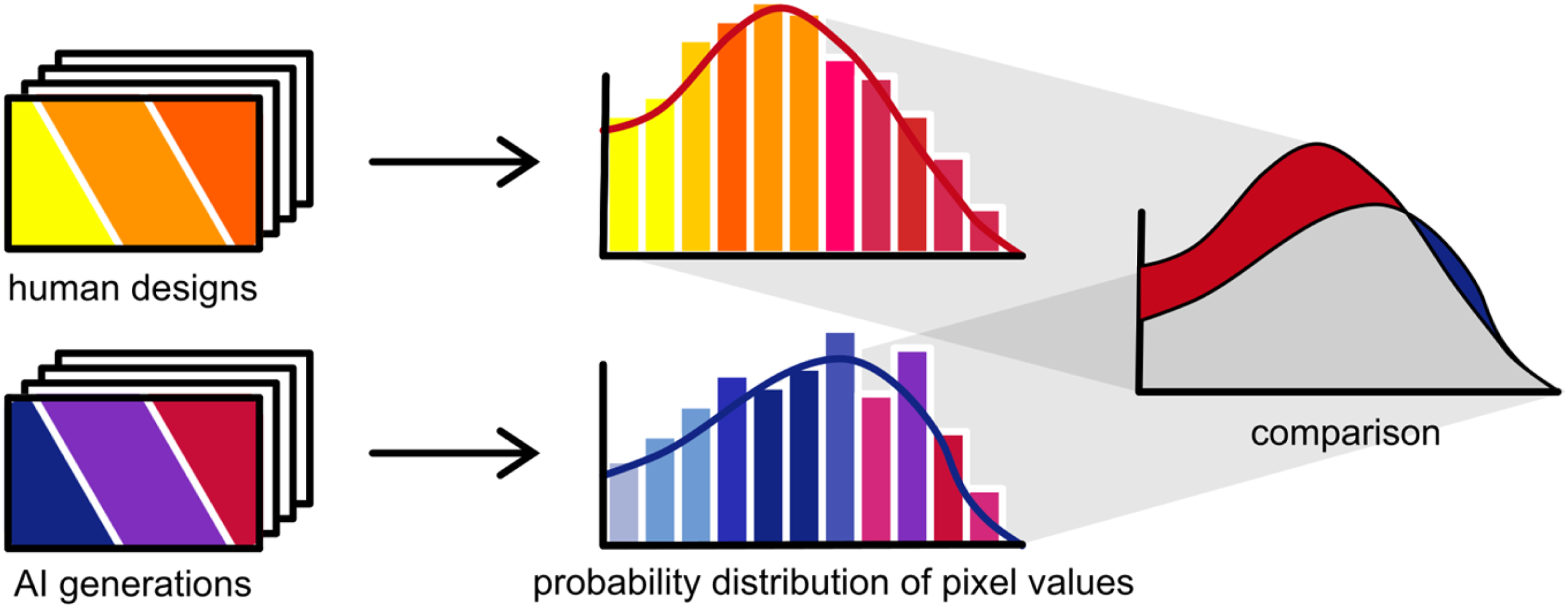
Wang et al.40,41 developed a GAN model based on a graph autoencoder and graph convolutional network for the generation of land-use configurations and evaluated the results by the distances between the distribution of generated and well-planned configuration vectors using KLD, JSD, HD, and WD. The latter two distance metrics were also employed for the land-use configurations in He et al. 20 JSD, MMD, and COV were used by Du et al. 42 to assess their 3D building generation method, which was based on improved FrankenGAN. 31 Zuo et al. 38 used multidimensional scaling (MDS), which visualizes the similarities or dissimilarities among data points in a lower-dimensional space, for the evaluation of their generated urban fabric dataset. Lastly et al. 43 used GAN to qualitatively reproduce the complex spatial organization observed in global urban patterns and showed that the generated images were able to quantitatively recover certain key high-level urban characteristics by assessing them with spatial summary statistics on urban form.
High-level statistical evaluation
The fourth group of evaluation methods employs advanced metrics that compare distributions of higher-order conceptual structures rather than pixel-level details, as Figure 5 illustrates. This approach is realized primarily in the Fréchet Inception Distance (FID) score,
44
which examines urban characteristics or similarities within the feature space. Features are high-level representations of images that capture important characteristics like shapes, textures, and patterns, rather than raw pixel values. These features are obtained using a pre-trained Inception model, a neural network trained on a large dataset like ImageNet to recognize objects and patterns in images. When an image is passed through the Inception model, it generates a feature vector by processing the image through its layers. These feature vectors are mathematical summaries of the image content, representing its high-level semantic information. The FID score uses these features to compare the real and generated image distributions, assessing how similar they are. A lower FID score means the generated images are more similar to the real ones, indicating higher quality and better realism. This metric considers both the mean and variance of the features, capturing differences in content and style. Illustration of a machine learning evaluation method, which shows how feature vectors are extracted from pixel-based datasets using the Inception v3 model; their distributions are then compared using the FID score.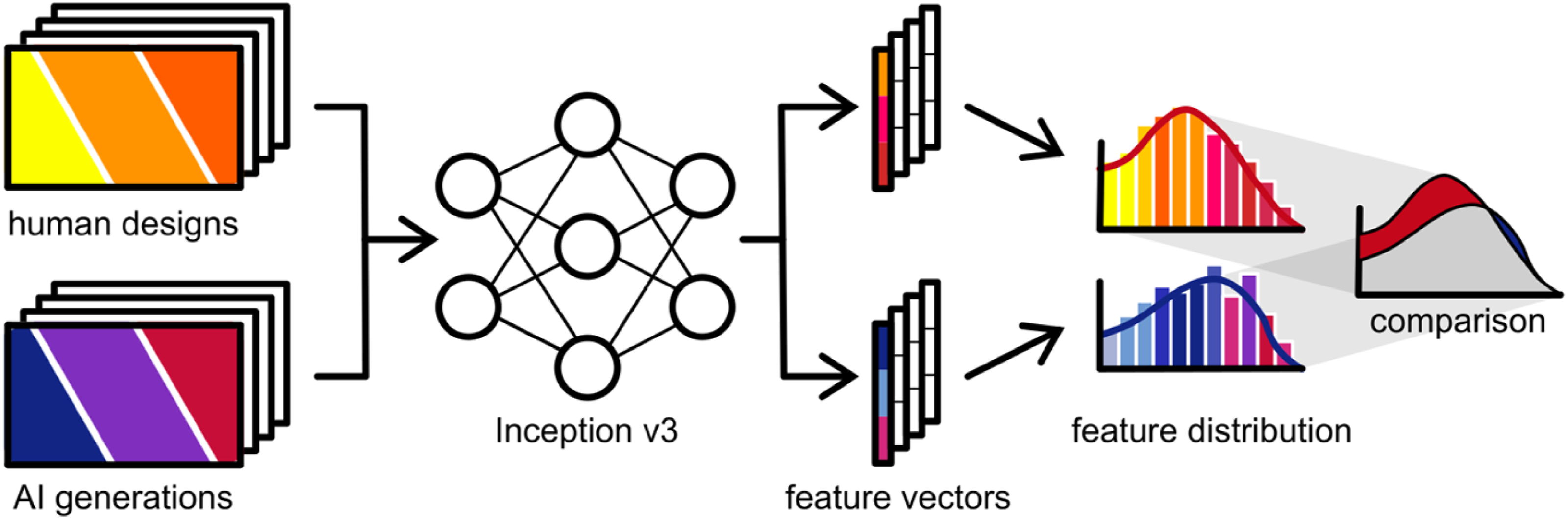
Ali and Lee 19 developed the styleGAN-based iFACADE model to generate facade images and evaluated the results both by the FID score and by comparing different features such as the number of floors, windows per floor, and clarity of the image. FID score is also the primary evaluation metric in other studies that generate urban layouts.35,45,46 Ye et al. 29 presented the FID score alongside human evaluation measurement, as described earlier in this section.
Wu and Biljecki 47 incorporated the FID score alongside the mean intersection over union (mIoU) between the inputs and generated images in their evaluation of a GAN model, which was trained to translate street network input into synthetic building footprint data. Sun et al. 48 also used the mIoU to evaluate the performance of their O-GAN configuration, which generates remote-sensing images of underrepresented class instances.
The Inception Score (IS) 49 is another metric that relies on high-level features extracted by the Inception v3 model. While it is widely used in the general image generation literature, it appears to be less common in GUD literature.
Key performance indicators evaluation
The fifth group evaluates the model outputs using key performance indicators, such as energy efficiency, profitability, building sizes, and walking distances. However, these performance indicators do not necessarily reflect the quality of the generative process itself, particularly in terms of originality, variability, or comprehensiveness of the results. Consequently, relying solely on performance indicators fails to provide a comprehensive and rigorous assessment of the model’s generative capabilities.
In their study, Han et al. 50 integrated Deep Reinforcement Learning (DRL) and Computer Vision (CV) techniques into urban planning using Ladybug tools, with a DRL agent generating layouts and multiple performance metrics, including a CV algorithm, evaluating factors like sunlight exposure, solar heat, and aesthetics. Nagy, Villaggi, and Benjamin 51 also used parametric design to generate many design options according to predefined constraints and then used a GA to optimize profitability and solar-panel locations. Their assessment was based on the optimization goals, i.e., the profitability of the project and the potential for energy generation. Cheng, Leung, and Van Ameijde 52 combined GA with accessibility and walkability analysis and evaluated their results with walkability, amenity accessibility, open space creation, visual experience, and height-to-width ratio. Fattahi Tabasi et al. 53 generated urban layouts and optimized the results using Ladybug tools according to two objective functions: increasing solar radiation received and increasing the wall distances. The results were assessed accordingly by the distances between buildings and the solar radiation received. Koenig et al. 54 developed a graph-based data structure for representing urban design problems in evolutionary multi-criteria optimization and showed the results of their algorithm versus random search as two-dimensional views on the four-dimensional Pareto-front. Lima et al. 55 investigated Grasshopper computational optimization techniques, some of which incorporate ML tools, at the urban design scale and compared their results regarding the optimization goals of transit accessibility: physical proximity index and infrastructure cost.
Finally, one paper employed semantic evaluation to assess the performance of the generative model in terms of its alignment with the expected action. In the study, diffusion models allowed users to annotate specific elements in urban scenes and replace them with other objects using text prompts. 56 The evaluation utilized the CLIP (Contrastive Language-Image Pretraining) methodology to determine the model’s accuracy in executing user intentions.
No comprehensive evaluation
The last group comprises papers that lack a comprehensive evaluation method for the generated outputs or those that are content with presenting only a limited number of examples alongside discussions on the showcased results. For example, Dong 57 and Dong and Lin 33 trained a cycle-GAN with OSM tile images, where the input is Nolli Maps of the natural and environmental elements, and the output includes the associated urban fabric. Noyman and Larson 58 trained DCGAN to create natural street view images for given semantically segmented input to create urban manipulations through the CityScope platform. Kuang et al. 59 utilized diffusion models through the ControlNet platform to learn the architectural styles of arcade buildings in urban historical quarters and enable architects to generate arcade facades using text. Zhang et al. 60 employed cycleGAN for street renovation, where the model learns to map buildings’ contours into fully designed and styled buildings. Yao et al. 61 combined a pix2pix GAN and a GA to fill in polygons within the city with low/high-density buildings, and Boim, Dortheimer, and Sprecher 21 employed a GAN to reproduce complex morphological patterns of non-planned settlements. De Miguel Rodr´ıguez et al. 22 represented 3D buildings through connectivity vectors and employed VAEs to generate novel objects from a continuous latent space. While VAEs inherently offer diversity, the analysis of results lacks a quantitative evaluation of the functionality and quality of the newly generated buildings.
Evaluation methods experiment
To answer the second research question, “To what extent are the identified GUD evaluation methods suitable for evaluating urban design outcomes?”, we conducted an experiment to test the existing automatic GUD metrics and identify their limitations.
Method
We adopted a set of automatic metrics capturing different aspects of urban design quality, selected according to categories identified in our literature review. A concise description and visual overview of these metrics are provided in Subsections 3.2–3.4 and Figures 3–5.
Three experimental datasets were generated to evaluate these metrics, as illustrated in Figure 6. The first, ground-truth (GT) dataset, was composed of map tile images generated from OpenStreetMap (OSM) using QGIS software with the QuickOSM plugin,
62
rendering only urban features like roads, parks, and buildings. It consisted of approximately 500 instances. Two manipulated datasets were generated based on the GT dataset: a disrupted set and a rotated one. Sample tiles used in the experiment.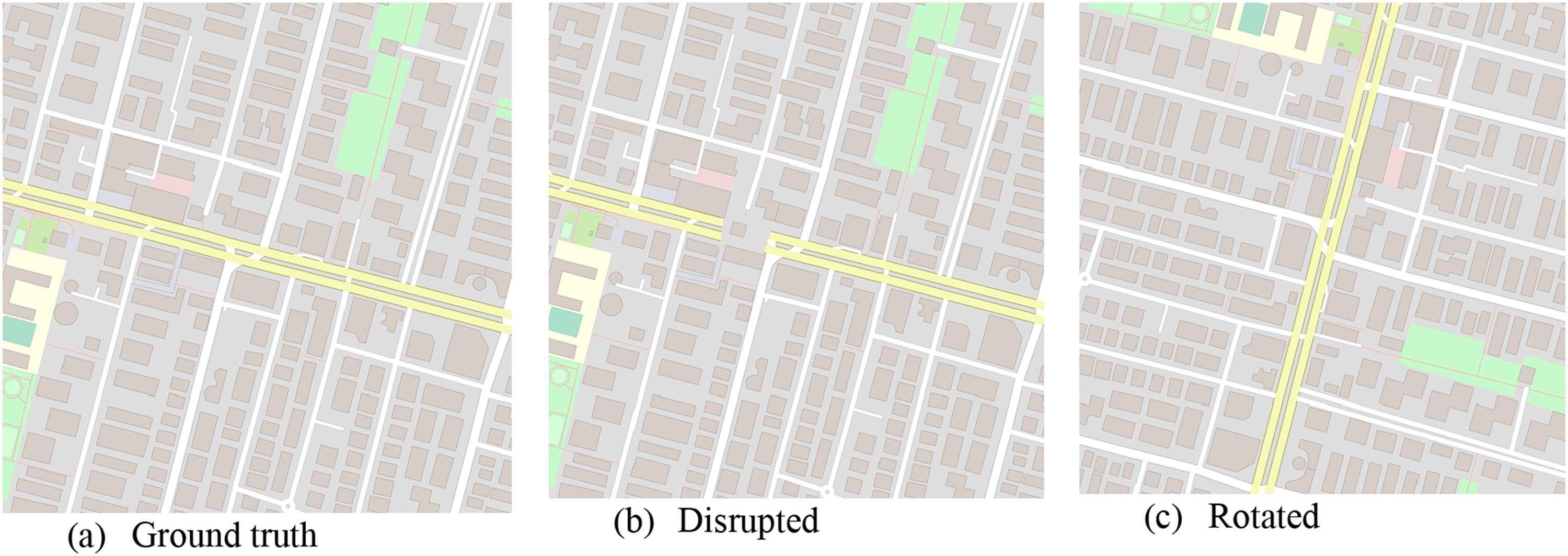
The first manipulation aimed to deliberately compromise the functionality of the urban design by removing road sections, creating dead ends, and jittering building positions, resulting in disorganized neighborhoods that violated key regulations. Each GT tile was modified in one of five regions (top-left, top-right, bottom-left, bottom-right, and center), producing five disrupted versions per tile with 3 to 20 alterations. The second type of manipulation involved randomly rotating or mirroring the GT tiles. This manipulation altered the visual appearance of the tiles while preserving their aesthetic and functional integrity. The rotated set was also created with five versions of each GT tile: rotations of 90, 180, and 270 degrees, along with left-right and up-down mirroring.
This experimental setup of controlled manipulations was chosen to ensure methodological precision. The aim was to test whether commonly used image-based evaluation metrics can detect violations of architectural logic rather than general degradations in visual quality.
Using outputs from existing GUD models would have introduced multiple overlapping artifacts (e.g., blurriness, noise, or incomplete forms), making it difficult to isolate which specific aspect of a metric’s response was being tested. In contrast, the use of clean, artificially manipulated datasets enables a controlled examination of metrics’ sensitivity to structural inconsistencies while holding all other visual parameters constant. Accordingly, rotated images function as a control condition that maintains architectural relationships and logic, while the disrupted dataset deliberately introduces localized structural inconsistencies as the experimental condition.
Results
Distance between the Ground Truth and the rotated and disrupted datasets using different GUD metrics. For each metric, the better score is highlighted in bold. A concise description of these metrics is provided in Subsections 3.2–3.4
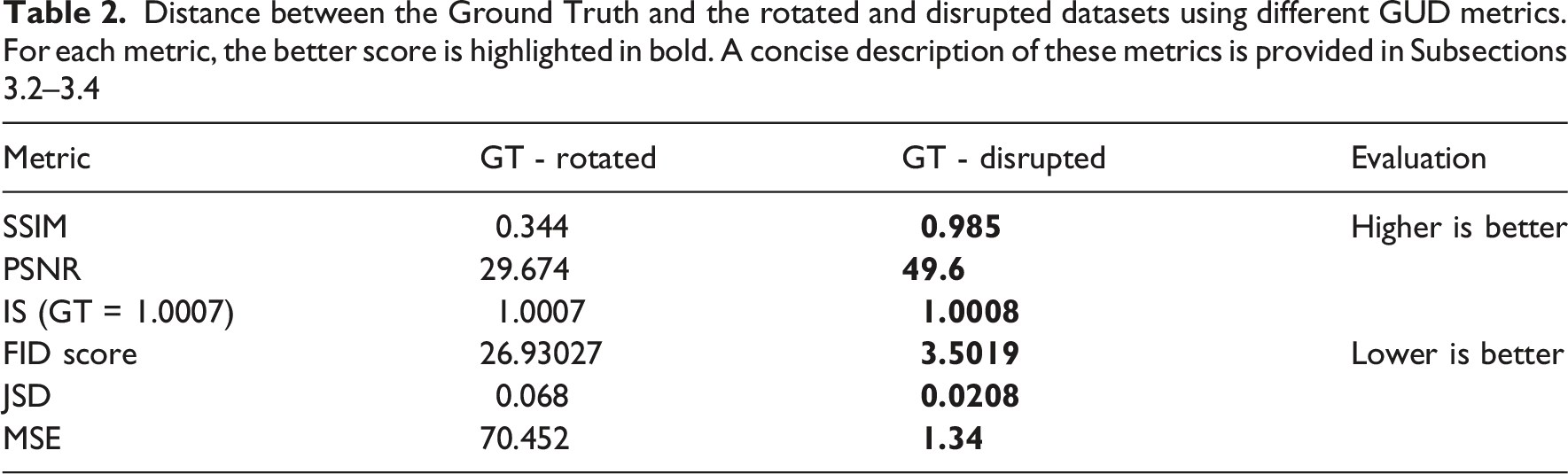
We hypothesized that GUD metrics would favor functionally disrupted tiles over rotated ones due to their reliance on raw pixel values. Rotations cause widespread pixel changes, while functional disruptions are more localized. Consequently, metrics may assess the rotated dataset as more distant from the GT, regardless of functional impact. Table 2 presents the outcomes of the experiment. As expected, the results confirmed that the disrupted dataset consistently received better scores across all metrics.
It is easy to see why metrics that rely solely on pixel differences fail to account for the functional significance of small changes in the disrupted dataset. Metrics that focus on the distance between pixel distributions (e.g., JSD) are similarly prone to inaccurate evaluations, as the disruptions involved localized replacements of specific urban objects with other elements of the standard urban fabric. In this case, the disrupted dataset holds a slight advantage over the rotated dataset due to its near-complete similarity to the GT dataset in all the untouched areas.
However, the inability of the FID score to identify the superior dataset warrants clarification. Although FID is intended to assess image content and semantics, and should theoretically be unaffected by orientation, it shows a marked bias toward the disrupted dataset—stronger than that of simpler metrics.
The Inception Score (IS) offers a complementary view. Like FID, it uses the Inception model for feature extraction but evaluates datasets independently. All datasets yield nearly identical IS values of around 1—typically signaling poor quality—despite the images being visually clear. This suggests the model interprets them as blurred due to difficulty processing their content.
A consistent pattern emerges: as image abstraction increases, classification accuracy declines. Trained on natural images, the Inception model misinterprets unfamiliar urban forms—correctly recognizing a dome (Figure 7(a)) but misclassifying an aerial city view (Figure 7(b)). As abstraction grows, the model’s confidence paradoxically increases while its predictions diverge from the true content (Figures 7(c) and (d)), indicating a deeper form of misclassification.
63
Inception V3 predictions in response to different types of urban image inputs. The top-5 predicted categories are presented with their corresponding confidence levels. Image (a) is CC0 licensed. Image (b) is a photo by Jens Oliver on Unsplash. Image (c) is from Wikimedia Commons and licensed under the Creative Commons Attribution-Share Alike 4.0 International license by user IM3847. Image (d) was taken from our GT dataset.
Alternative Evaluation Methods
Recognizing the limitations of existing methods, we propose two optional solutions to address the need for scalable and reproducible evaluation metrics in GUD. One approach refines existing automatic metrics to better suit urban design outputs. The other explores automating expert assessment by leveraging Visual Language Models (VLMs) as proxies for human evaluators.
Domain-Guided FID evaluation using task-specific latent representations
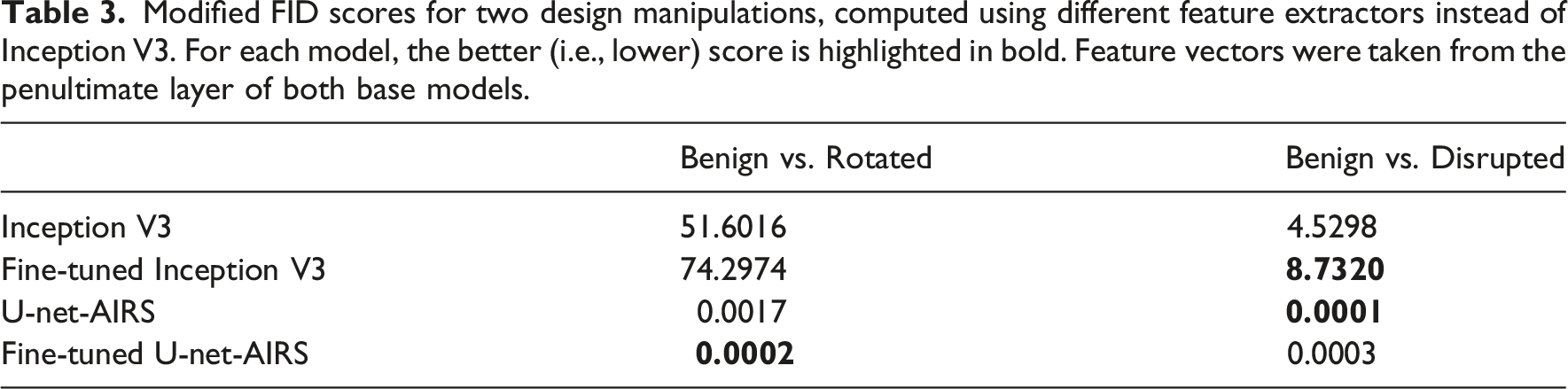
The first solution involves modifying the FID score method and incorporating urban and architectural design considerations into a designated deep learning module. To explore how different task-specific representations influence FID calculations, we conducted experiments with four distinct models, each chosen to isolate specific factors in spatial understanding and domain alignment.
Some of these models were fine-tuned on subsets of the dataset described in the first experimental section. The retraining involved adding a binary classification head to each base model, using RMSprop as the optimizer. For the FID computations, the feature vector was extracted from the final batch normalization layer of the base model.
The first model is the standard Inception V3 model pre-trained on ImageNet, used as the baseline feature extractor in the original FID calculation. This model was included to serve as a reference point for evaluating the performance of alternative feature extractors. Note that these scores differ from those in Table 2 due to being calculated on a slightly different subset of the dataset to ensure a fair comparison across models.
The second model is the same Inception V3 model, now fine-tuned on our dataset, where the task emphasized inspecting design validity. This configuration allowed us to examine the benefits of incorporating explicit functional criteria into the representation learning process.
The third model, U-net-AISM, 64 is a U-Net–based image segmentation model pre-trained on road segmentation from aerial imagery. It was chosen to test whether spatial representations learned from functionally significant features, like road networks, can capture urban logic. The fourth model is the same U-net-AISM architecture, fine-tuned on our dataset to perform the same task as the Inception V3 model.
Modified FID scores for two design manipulations, computed using different feature extractors instead of Inception V3. For each model, the better (i.e., lower) score is highlighted in bold. Feature vectors were taken from the penultimate layer of both base models.
Evaluation using visual language models
The second evaluation direction explores the use of advanced VLMs, which can jointly process textual and visual inputs. By prompting models appropriately, we can create an ensemble of “expert” personalities, enabling scalable and reproducible evaluations. The model’s ability to understand natural language prompts allows for flexible and nuanced evaluation criteria, enabling the framework to capture diverse perspectives and preferences in evaluating urban designs. Furthermore, leveraging language models for evaluation aligns with recent advancements in multimodal AI, promoting interdisciplinary approaches to GUD evaluation.
Experiment 1: Pairwise comparison of designs
To evaluate VLMs’ ability to distinguish between well-structured and flawed designs, each model was presented with two side-by-side images: one depicting a valid (“benign”) urban design and the other a structurally disrupted version. Models were prompted to select which plan had better connectivity, indicating their choice numerically and providing a brief explanation.
Six different VLMs were tested. As shown in Figure 8, the results indicate mixed performance. Gemini 1.5 achieved the most promising outcome, correctly preferring the valid design in approximately 70% of the comparisons and selecting the disrupted version in only 0.7% of cases. Other models, such as Claude and Gemini 2, often failed to differentiate between the options, frequently responding with “0” (equal). GPT-4o occasionally failed to complete the task as instructed, misinterpreting the input or producing malformed responses. Model decisions on image comparison tasks.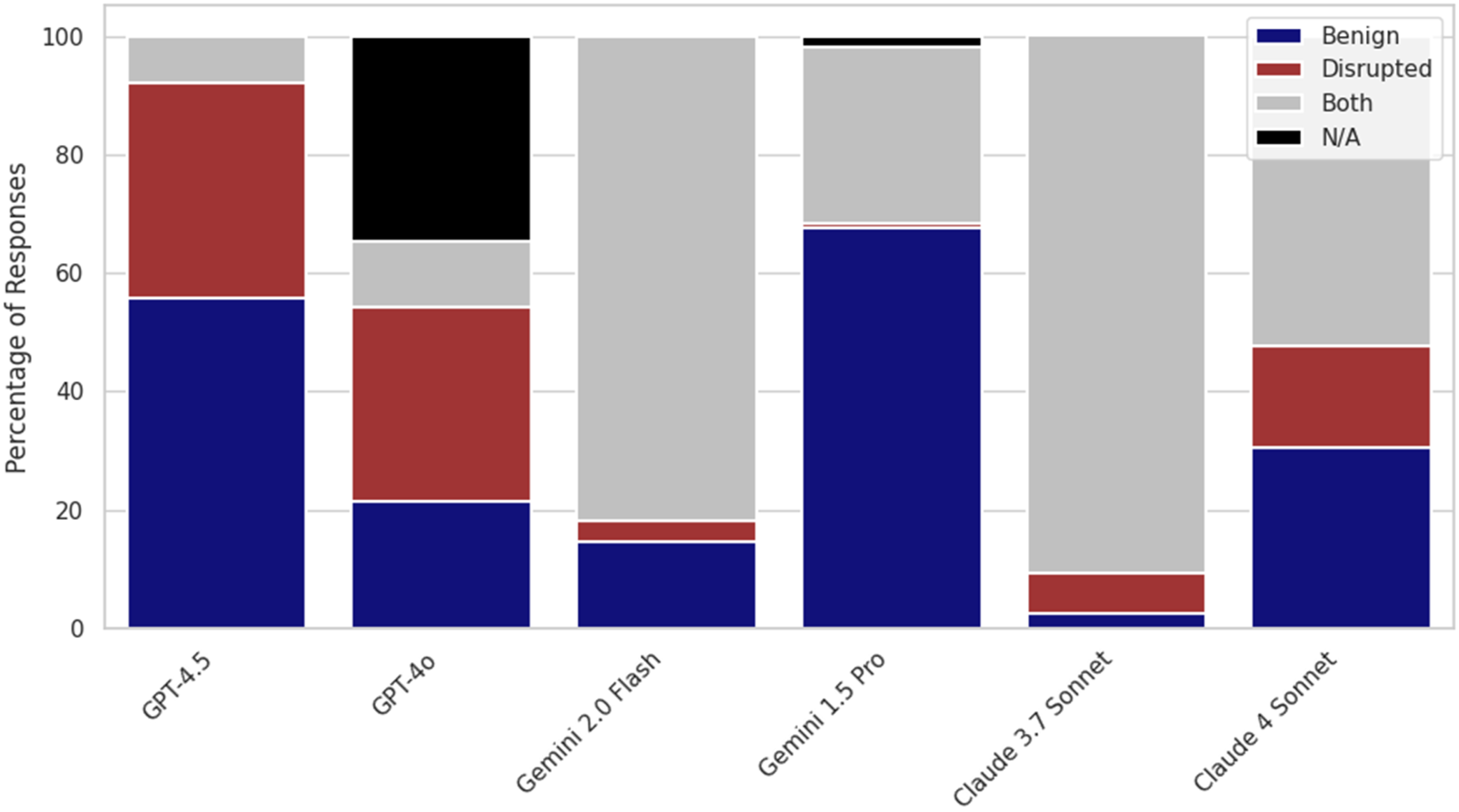
Experiment 2: Scoring single plans
To evaluate whether VLMs could reliably score individual urban plans, each model was presented with a single image from either the benign or disrupted dataset. Models were prompted to assign a numerical quality score from 1 (very poor) to 10 (excellent) and provide a brief justification, taking into account multiple aspects of urban design, including road connectivity, building placement, overall functionality, and walkability/accessibility.
The results, shown in Figure 9, reveal that VLMs generally assigned similar scores to both benign and disrupted designs. Only two models, GPT-4.5 and Claude 3.7, exhibited a statistically significant difference between the score distributions of the two datasets. Contrary to expectations, the score distributions largely overlapped, suggesting that current VLMs are not yet reliable in providing consistent and discriminative assessments of urban design quality. These findings highlight the need for further refinement of such models before they can be fully trusted for expert-level evaluation tasks in this domain. Design quality scores for benign versus disrupted urban plans; Bars represent mean values ± standard deviation. Statistical significance between conditions is indicated by asterisks below the model names (p < .05 = *, p < .01 = **, p < .001 = ***).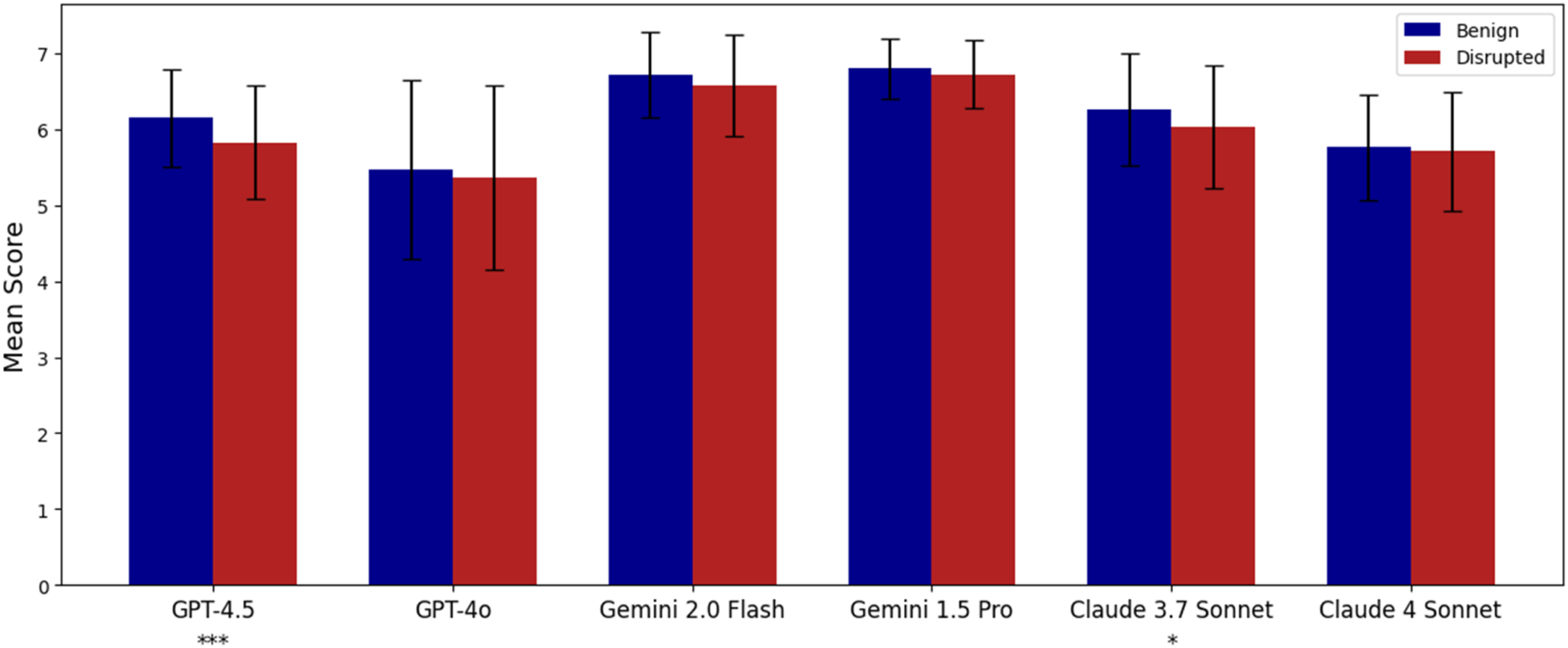
The most direct path to enhance the performance of VLMs is to employ more advanced models. Another effective strategy involves refining the prompt design to elicit more accurate and structured responses. Figure 10 illustrates the feasibility of both directions. In this experiment, we modified the prompts and adjusted the score computation procedure. Instead of requesting a general quality score based on the model’s holistic assessment, the new prompts instructed the models to identify and count specific violations of architectural and urban design logic in each input plan. The final scores were then derived by applying predefined violation weights. Design violation scores for benign versus disrupted urban plans; Statistical notation as in Figure 9.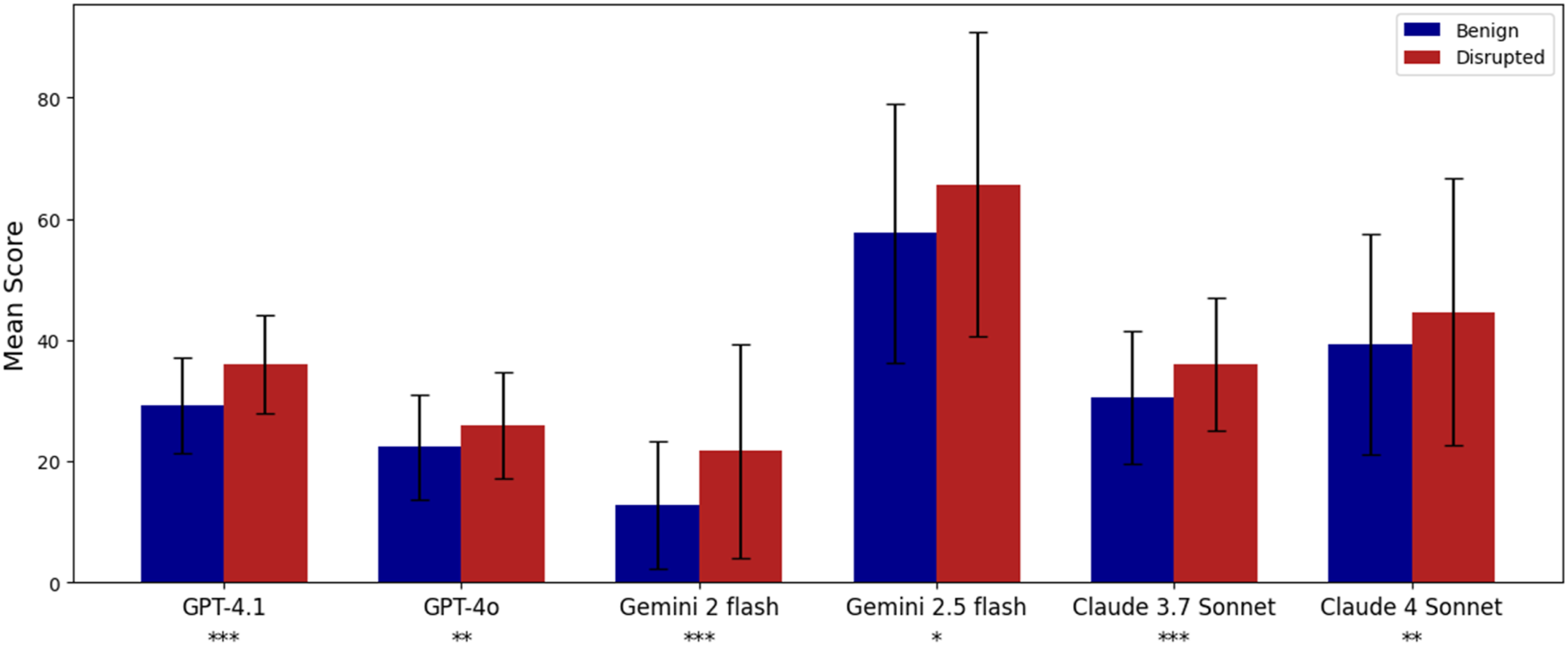
This structured approach reduced subjective bias and enhanced the models’ ability to differentiate between benign and disrupted datasets. Models that had previously failed to distinguish between the two conditions, as well as more advanced versions of these models, achieved statistically significant separation under the revised setup.
Discussion
Integrating ML into urban design offers a transformative opportunity to rethink how we conceptualize, generate, and evaluate urban spaces. However, realizing the promise of ML in urban design depends on addressing a critical bottleneck: evaluation. Without reliable methods to assess the quality and coherence of generated layouts, even advanced models risk producing visually appealing but conceptually weak designs.
Our analysis and experiments underscore the inadequacy of current evaluation metrics for GUD, as they prioritize visual similarity over functional and contextual integrity. To illustrate these shortcomings, we conducted a controlled experiment using a deliberately simplified dataset, providing a consistent baseline for assessing metric behavior. The uniform visual semantics and spatial structure of OSM data enabled clear distinctions between “logical” and “disrupted” designs, while simple geometric manipulations—rather than complex generative artifacts—allowed us to isolate the metric’s ability to discriminate structurally coherent from incoherent layouts. These results establish a conceptual baseline; however, the generalizability of these findings is limited by the simplified experimental setup and the dataset size. This can be addressed in future studies.
E valuating urban design: Beyond performance
Defining what constitutes ”good” design in the urban context is itself a multifaceted challenge. In the case of ML-generated designs, this means going beyond simple visual resemblance or basic performance indicators.
KPIs provide one avenue for quantifying urban design quality. These include metrics related to walkability, connectivity, access to green space, density, resilience to environmental stressors, and socioeconomic inclusivity.
However, performance metrics alone are not sufficient, since not all design goals are easily quantified. Moreover, the iterative and often ambiguous nature of design processes means that novel, outlier, or speculative designs may be more valuable than statistically average ones, even if they initially score lower on KPIs. Evaluation, in this sense, must also account for variability, diversity, and innovation, not merely optimization.
ML-generated design requires a new evaluation paradigm
While earlier studies have questioned the validity of pixel-based similarity measures such as FID and IS,7,8 our literature review reveals that these concerns have not been fully recognized or addressed within the GUD community. Yet, given the unique spatial, functional, and semantic dimensions of urban design, the limitations of such metrics are particularly pronounced. By extending these broader critiques into the context of GUD, this study highlights the need for evaluation methods that account for urban-specific characteristics. Moreover, we propose and test new directions for adapting and refining evaluation frameworks—approaches not previously explored in this field. Although the results are preliminary, they offer promising indications for future, more targeted investigations.
Our experiments show that domain-specific models provide more meaningful evaluations than generic computer-vision metrics. Replacing the Inception V3 backbone in FID with networks trained on urban segmentation or morphological validity improved functional consistency. While preliminary, these results provide a strong indication that more appropriate choices of architecture, training objectives, and datasets can yield improved outcomes in future studies.
Similarly, early tests with VLMs highlight their potential as flexible, prompt-driven evaluators that can incorporate qualitative design dimensions. Although current VLMs remain mostly immature and struggle to interpret urban structures reliably, continued progress in this area promises scalable and context-aware evaluation tools.
T oward a comprehensive evaluation framework for GUD
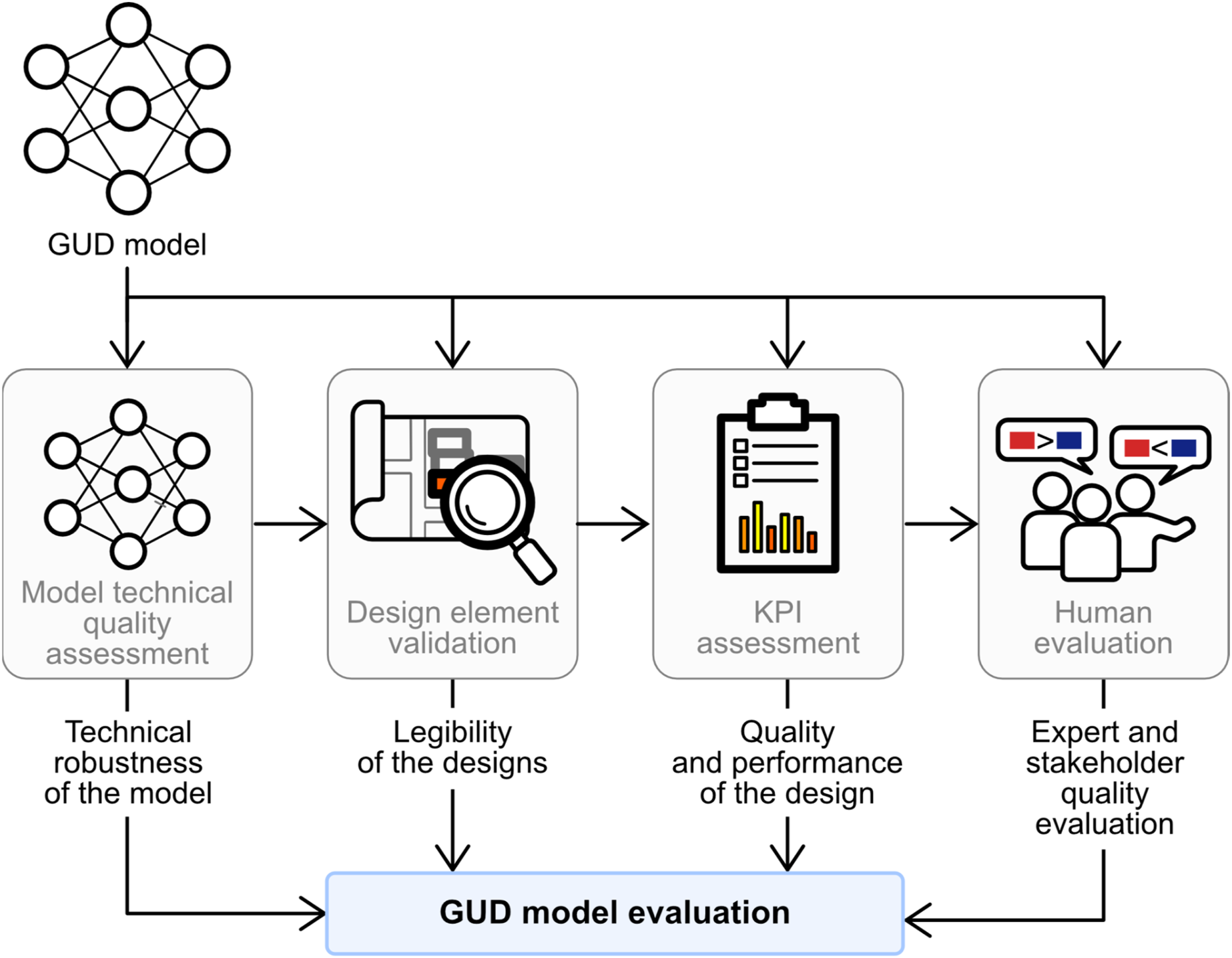
To address current challenges, we propose a modular, multi-criteria evaluation framework for GUD that accommodates the complexity and layered nature of urban design and the capabilities of generative models (see the schematic in Figure 11). This framework spans four levels of analysis: model, elements, performance, and human evaluation. (1) Model technical quality assessment. At the foundational level, models must be evaluated for their technical robustness. We propose adapting metrics like FID by substituting the standard Inception V3 classifier with models trained on domain-relevant tasks. For example, a U-Net architecture pre-trained on road segmentation—and fine-tuned via transfer learning—showed superior performance in reflecting the functional integrity of generated designs. This domain-adapted FID can serve as a model-centric evaluation tool that reflects urban plausibility rather than visual fidelity. (2) Design element validation. Using trained computer vision models, generated outputs can be assessed for the presence and correctness of specific urban elements, such as roads, pathways, zoning patterns, or public spaces. For instance, segmentation models or classifiers can verify whether essential infrastructure elements are present and organized in ways that respect urban principles like connectivity and hierarchy. This level ensures that designs are not just generative but legible and actionable from a planning perspective. (3) KPI assessment. Using urban simulations, generated designs can be evaluated against various real-world KPI such as economic, sustainability, mobility, climatic, and social impact. Importantly, such evaluations can be statistical, allowing researchers to identify whether one model systematically outperforms another across important metrics and scenarios. (4) Human evaluation. Despite the power of computational metrics, human expertise remains indispensable in real-life urban design. Planners, architects, and community stakeholders must provide feedback incorporating values, perceptions, and goals that data cannot yet capture. While such evaluations are time-intensive and not scalable, they are essential for ground-truthing models and calibrating automated evaluations to align with real-world expectations. In future iterations, VLMs may offer scalable approximations of this layer by interpreting and comparing generated outputs through natural language prompts. Schematic overview of the proposed four-tier evaluation framework for GUD.
Establishing foundational standards is crucial to ensure the utility of the proposed framework. First, a standardized representation format for urban data is needed to facilitate consistent interpretation and processing by generative models and evaluation tools, such as CityGML or GeoJSON.
Second, an accepted catalog of KPI evaluation methods must be defined. This catalog would specify how to assess core urban outcomes such as economic viability, mobility, diversity, and environmental and social impact, drawing from industry benchmarks and academic literature. Establishing these standards will enhance the reproducibility and transparency of experiments and support meaningful cross-comparison between models and studies, accelerating progress and consensus within the GUD research community.
Conclusions
This study addresses a key gap in GUD: the evaluation of ML–based design outputs. Through a critical review and controlled experiments, we show that commonly used evaluation metrics often respond more strongly to visual disruptions than to meaningful violations of urban or architectural logic, limiting their suitability for assessing machine-generated urban forms.
The paper provides a structured mapping of evaluation methods currently used in GUD research, and critically analyzes their limitations. It also introduces two complementary evaluation approaches: Domain-Guided FID, which adapts a standard generative metric to urban design semantics, and VLM-based analysis, which approximates expert-level assessment at scale. Finally, it proposes a 4-tier evaluation framework for GUD that considers model quality, validity of urban elements, KPIs, and human preferences.
Future research should prioritize validating these methods across diverse urban contexts to ensure their robustness. A critical next step involves refining Domain-Guided FID by exploring representations derived from urban-specific pretraining, alternative model architectures, training datasets, and training protocols. Simultaneously, the VLM-based evaluation must be stress-tested against evolving VLMs to assess their sensitivity to urban nuances and their stability across prompt formulations. Moving forward, the most promising path lies in hybrid evaluation schemes that fuse domain-specific metrics with VLM assessments to minimize individual biases. By integrating expert-led calibration rather than manual oversight, future frameworks can use human insight to refine the underlying logic of automated systems, ensuring that GUD tools remain both computationally efficient and professionally accountable.
Footnotes
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Israel Ministery of science and Technology and the Israel National Digital Agency; 6445.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.