
Abstract
Early identification of children with type 1 diabetes at heightened risk for diabetic ketoacidosis (DKA) is necessary for preventive intervention. The present study aimed to examine whether an automated electronic medical record–based tool (the Risk Index for Diabetic Ketoacidosis [RI-DKA]) can reliably predict risk for future DKA using data obtained from only the first 6 months post diagnosis. Data were extracted for 3946 children who met the inclusion criteria. The RI-DKA showed an acceptable ability to discriminate between children who did and did not go on to experience a subsequent DKA event (area under the curve = 0.75), only slightly below the predictive ability in the RI-DKA validation sample. These findings indicate that the RI-DKA is a valuable tool for identifying at-risk children very early in the course of type 1 diabetes.
Keywords
Introduction
Identification of children with type 1 diabetes at heightened risk for diabetic ketoacidosis (DKA) is a necessary precondition for successful preventive intervention, and the earlier children can be identified, the better the chances are that clinicians can intervene prior to any episodes of DKA occurring. Early identification also increases the likelihood that recurrent episodes of DKA can be prevented in the highest risk children. In prior work, our group demonstrated the ability of an automated electronic medical record (EMR)–based risk index to reliably identify children at risk for DKA.1,2 The Risk Index for Diabetic Ketoacidosis (RI-DKA) extracts a patient’s most recent hemoglobin A1c (HbA1c) value, insurance status (public/uninsured vs. private), and prior history of DKA (present/absent) from the EMR and uses these data to generate a predictive risk score that is available to clinicians in real time.
In its typical operation, the RI-DKA extracts data from the previous 2 years to predict DKA occurrence in the next year. The present study aimed to examine whether the RI-DKA, using data obtained from only the first 6 months post diagnosis, can still reliably predict risk for subsequent DKA. If DKA risk can be determined early in the course of diabetes, potentially even before a DKA episode has occurred, targeted interventions in DKA prevention 3 would be greatly enhanced.
Methods
Data were extracted for children diagnosed with type 1 diabetes at Texas Children’s Hospital (Houston, Texas) over a 10-year period (October 4, 2010, to April 9, 2020). Children were included if they were ≤18 years of age, had at least one diabetes clinic encounter in the first 6 months after diagnosis, and had at least one subsequent clinic encounter per year for 6 years. A total of 3946 children met these inclusion criteria. Demographic and clinical data for the sample are shown in Supplementary Table S1.
Predictor variables were extracted automatically by the RI-DKA directly from the EMR. The index date (the date the score is generated) was set at 6 months post diabetes diagnosis. DKA was determined based on ICD-9-CM/ICD-10-CM diagnosis code, glucose ≥250 mg/dL (≥13 mmol/L), and pH level ≤7.30 and/or administration of intravenous insulin. The RI-DKA typically extracts DKA episodes from the prior 2 years, although for the present study, the window for prior events was shortened to the first 6 months following diabetes diagnosis. One hundred and sixty-one DKA events (excluding events at diagnosis) occurred in the 6-month observation window and were included as predictors. HbA1c values were obtained as part of routine clinical care, and the most recent HbA1c value (rather than an average) was used (it is designed this way so the index can update automatically whenever a new value is entered). Insurance was based on the patient’s insurance status on the index date. The algorithm then used these three variables (prior DKA, most recent HbA1c, and insurance) to predict DKA in the subsequent 12 months (the follow-up period).
Development and validation of the RI-DKA, and the derivation of risk scores and risk categories, have been described in detail elsewhere. 1 Of note, additional analysis since the original validation resulted in an expansion of risk categories from the original three (low, moderate, and high risk) to include a fourth (very high risk). This four-category model has better captured overall risk within our clinical population (data not shown) and is currently the model in use at our institution.
Results
A total of 440 DKA events occurred in the prediction (outcomes) window, for an incidence of 11.1%. Out of 3946 children, 6 were missing HbA1c data and were excluded from further analysis. Of those with complete data, the majority (3352; 84.9%) fell in the low-risk group, 503 (12.7%) fell in the moderate-risk group, 76 (1.9%) fell in the high-risk group, and 9 (0.2%) fell in the very-high-risk group. Incidence of subsequent DKA events in each risk group was 3.0%, 7.2%, 10.5%, and 33.3%, respectively. As can be seen in Table 1, all three factors in the RI-DKA were significantly associated with subsequent DKA. The RI-DKA showed acceptable ability to discriminate between children who did and did not go on to experience a subsequent DKA (area under the curve [AUC] = 0.75; Fig. 1), only slightly below the predictive ability in the validation sample (AUC = 0.78).

DKA, diabetic ketoacidosis; HbA1c, hemoglobin A1c.
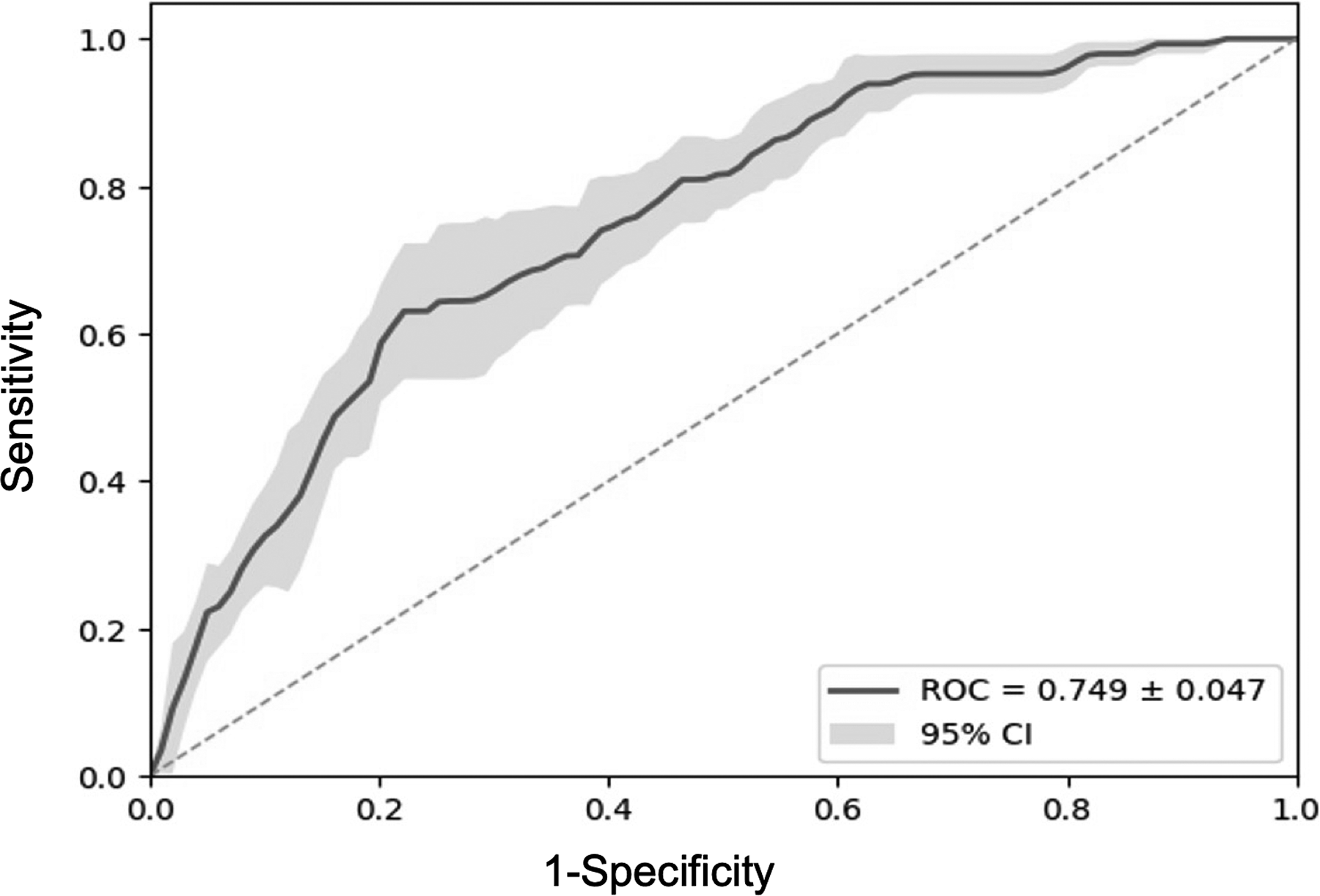
Receiver operating characteristic (ROC) curve for the multivariate logistic model. CI, confidence interval.
Discussion
The RI-DKA showed an acceptable ability to identify children at risk for subsequent episodes of DKA based on insurance status and only the first 6 months of DKA and HbA1c data. Predictive performance was only slightly lower within this foreshortened time frame. In contrast to the RI-DKA validation cohort, 1 in which prior DKA had the greatest predictive power, insurance had greater predictive power in this sample. This makes sense, as the time window for experiencing DKA was shorter in the present sample compared to the validation cohort (6 months vs. 2 years). Nonetheless, the fact that DKA events within this brief period retain significant predictive power is consistent with the clinical observation that early-occurring DKA often presages a more challenging disease course. During the immediate post-diagnosis period, after insulin therapy is initiated, HbA1c tends to fall substantially and remains at its lowest levels over the first year. 4 DKA events that occur during this more protected period may therefore be markers of significant challenges with diabetes management. Early-occurring DKA is also associated with reduced residual β-cell function, 5 making DKA recurrence more likely.
The present findings indicate that the RI-DKA is a valuable tool for identifying at-risk children very early in the course of type 1 diabetes. Findings from prediction tools with an AUC <0.80 should be interpreted with caution, as such models are more susceptible to false-positive and false-negative classifications. Nonetheless, when used as a rapid, automated screening approach, the RI-DKA can efficiently identify children who may benefit from closer surveillance of their diabetes management and targeted support for DKA prevention.
Ethical Considerations
This study was approved by the Baylor College of Medicine and Texas A&M University Institutional Review Boards.
Consent to Participate
The requirement for informed consent to participate was waived by the Baylor College of Medicine and Texas A&M University Institutional Review Boards.
Data Availability
Data are available upon request from the authors.
Authors’ Contributions
D.D.S., M.E., D.J.D., D.B., and S.K.L. contributed to the conception and design of this study. D.D.S., M.E., A.R.S., D.J.D., D.B., R.S., and S.K.L. contributed to acquisition of data or analysis and interpretation of data. D.D.S. wrote the article with extensive input from M.E., D.J.D., and S.K.L. The primary statistical analyses were done by M.E. with assistance from A.R.S. All authors reviewed/edited the article and approved the final article for publication. D.D.S. is the guarantor of this work and, as such, has full access to all the data and takes responsibility for the integrity of the data and the accuracy of the data analysis.
Footnotes
Acknowledgments
The authors would like to dedicate this article to the memory of their colleague and friend, Madhav Erraguntla, who sadly passed away while this article was under review. Dr. Erraguntla made substantial contributions to the conception, design, and data analysis of this study. He was an integral member of the study team whose considerable intellectual contribution to their work in predictive health care analytics has been invaluable. He will be deeply missed. The authors would also like to thank Mark Rittenhouse, Data Architect at Texas Children’s Hospital, for his contributions in building the enterprise data warehouse, and Kelly Timmons, RN, BSN, Senior Systems Analyst at Texas Children’s Hospital, for her contribution in building the RI-DKA into the Texas Children’s Hospital EMR.
Author Disclosure Statement
D.J.D. has served as an independent consultant to Dexcom, Insulet, and Sanofi, separate from this work. The other authors declare no potential conflicts of interest with respect to the research, authorship, and/or publication of this article. M.E. was deceased at the time of acceptance of the article, and the Journal was unable to confirm details of any conflicts of interest related to this article.
Funding Information
This work was supported by The
Supplemental Material
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.