
Abstract
The aim of this study was to present a protocol for the validation of the Language ENvironment Analysis (LENA) System’s conversational turn count (CTC) for Vietnamese speakers. Ten families of children aged between 22 and 42 months, recruited near Ho Chi Minh City, participated in this project. Each child wore the LENA audio recorder for a full day. Two native speakers listened to 10-min extracts of the recordings from each family and labeled conversational turns according to the coding protocol. Their results were compared with the findings from the LENA software. A Spearman rank correlation test indicated a strong level of correlation between the LENA software and the human coders, rs(18) = .70, p < .001. The LENA System’s CTC provides a reasonably accurate estimate of conversational turns in Vietnamese recordings, showing that this protocol can yield significant results. Discrepancies between the coders and the software are discussed, and the strengths and weaknesses of the proposed protocol are highlighted.
The importance of providing copious amounts of quality language stimulation to very young children has been demonstrated repeatedly in the literature (Gilkerson & Richards, 2008; Hart & Risley, 1995). As a result, speech–language pathologists adhering to evidence-based practice frequently advise parents to increase the amount of talk they engage in with their children. In the past, monitoring these interactions was difficult. Many researchers relied on bulky and invasive home video recordings to observe parent–child talk; clinicians often depended on less reliable parent reports or observations during a session, which may not have simulated the home environment. In an effort to provide more accurate information, the LENA Research Foundation has designed a tool that allows speech–language pathologists to provide more individual feedback to families attempting to stimulate their child’s language development. The Language ENvironment Analysis (LENA) System includes a small audio recording device that can capture a child’s natural spoken language setting over an entire day. Software then automatically calculates how often adults spoke, children vocalized, and turn taking occurred, among other calculations (Gilkerson & Richards, 2009).
How the LENA System Works
A child wears a LENA digital language processor (DLP) in the pocket of a t-shirt, which keeps the microphone a set distance from his or her mouth. The DLP audio records for up to 16 hr. The recording is then uploaded to the LENA software, which automatically analyzes it using an algorithm-driven model. Based on areas of high acoustic energy, the software parses recordings into sound segments. Using features of human vocalizations such as decibels and pitch, it then sorts these sound segments into eight categories: key child, adult male, adult female, other child, TV/electronic sounds, noise, silence, and overlapping sounds. Overlapping sounds can consist of two speakers vocalizing at the same time or vocalizations in a high amount of background noise (Gilkerson, Coulter, & Richards, 2008). Segments falling into this category are disregarded in the remaining steps of analysis. To improve accuracy, the segments are then compared with training-models created by human coders in the LENA Research Foundation’s transcription corpus (Gilkerson et al., 2008). Segments are further classified as “clear” or “unclear” through a likelihood-ratio test comparing the sound segment with silence. Segments graded closer to silence are marked as “unclear” and are not counted in higher levels of automated analysis. All segments labeled clear “adult male” or “female” are processed by a speech recognition analyzer to estimate the adult word count (AWC). The analyzer is based on 46 English phones; therefore, AWC may not be accurate in all languages because the software employed to calculate it is language specific. Key child segments, representing the child wearing the device, are additionally categorized as either “vocalizations,” defined by qualities such as rhythm, pitch control, and duration reported to represent universal child speech development, “vegetative sounds,” such as sneezing, burping, or breathing, or “fixed signal sounds” indicative of emotional reactions like crying, screaming, or laughing (Gilkerson et al., 2008; Oller et al., 2010). Finally, a conversational turn count (CTC) is calculated by identifying all child vocalizations that occur within 5 s of a clear adult segment unless they are separated by an “other child” segment (Oller et al., 2010; see Xu et al., 2008, for more detail).
Existing Validation Studies
Thus far, only a handful of studies have been published validating the LENA System in languages other than English, including Spanish, French, Mandarin, and Korean (Canault, Le Normand, Foudil, Loundon, & Thai-Van, 2015; Gilkerson et al., 2015; LENA Research Foundation, 2008; Pae et al., 2016; Weisleder & Fernald, 2013; Xu, Yapanel, & Gray, 2009). Most of these studies investigated both AWC and child vocalization count (CVC). Only two additionally analyzed the accuracy of the CTC (Gilkerson et al., 2015; Pae et al., 2016). Sample size for these studies ranges from 10 (Weisleder & Fernald, 2013) to 70 in the LENA Research Foundation’s transcriptional corpus (Gilkerson et al., 2008).
Some validation studies selected regions from full-day recordings that were fully transcribed (Canault et al., 2015; Weisleder & Fernald, 2013), whereas others were coded by humans to compare with LENA results (Gilkerson et al., 2008; Gilkerson et al., 2015). Regions are defined here as continuous sections of the full-day LENA recording extracted for analysis. The length of the region coded or transcribed varied across studies. No consensus has been reached regarding how regions can be selected to be most representative of both the activities engaged in over the full day and the distribution of speech sounds. The LENA Research Foundation’s transcription corpus (Gilkerson et al., 2008) and the French validation study (Canault et al., 2015) both selected regions high in child and adult speech. However, Gilkerson et al. (2008) selected their regions using an algorithm, whereas Canault and her team (2015) had volunteers select regions at random. Pae et al. (2016) selected regions from infants in their home environments and toddlers in a clinical setting. Weisleder and Fernald (2013) selected 20-min regions from the top-, middle-, and bottom-third of the AWC distribution in their sample, and Gilkerson et al. (2015) selected three 5-min regions with the highest CTC in the morning, afternoon, and evening. By spreading regions over the day, the authors hoped these would be more representative of the full day. Gilkerson’s team (2015) pointed out, however, that selecting regions with extremely high CTCs also increases the potential for more mislabeled segments, resulting in an unrepresentative sample. Other potential causes of mislabeling might include cultural differences in child-directed speech, unusual environmental conditions, unrepresentative sample selection, contextual factors such as time of day, and poor signal-to-noise ratio (Canault et al., 2015; Gilkerson et al., 2015).
There was also variation in the length of each region selected for analysis. Some of the studies sampled 1 hr per participant (Gilkerson et al., 2008), whereas others relied on 10-min samples (Pae et al., 2016). Regardless of the length of the region, how it was selected, or whether it was fully transcribed or simply coded, each of the validation studies found in the published literature to date has identified a significant correlation between the software and human coders for the measure under investigation. The correlation coefficient in these studies ranged from .92, p < .01 (comparing LENA AWC with human coding in English) in the LENA Research Foundation’s transcription corpus (Xu et al., 2009) and .64, p < .001 in Canault et al.’s (2015) study (comparing LENA AWC with human coding in French) with most results falling around .70 when comparing AWC and CVC with human coders in a variety of languages. The only published studies to report CTC correlations were Gilkerson et al. (2015) and Pae et al. (2016). Both reported that it was necessary to remove outliers to achieve a correlation between the LENA System and human coders, r = .72, p < .001 in Gilkerson et al. (2015) and r = .67, p = .001 in Pae et al. (2016). We, therefore, expected a correlation coefficient in this range for the pilot validation protocol.
Speech–language therapists often find themselves treating families from a variety of cultural and linguistic backgrounds that differ from their own. Finding assessments that can serve these families can be difficult. The LENA System may be a useful tool in evaluating and monitoring the language development of a child regardless of the family’s background. It may also provide clues about what aspects of language acquisition are related to culture and which are universal. This technology, however, is still being refined. To rely on LENA results, human coding and validation testing are required. Before the device can be used with diverse linguistic populations, we must be able to show that software built for English speakers can work in other languages.
Validating Vietnamese
This study used Vietnamese as an example language in this pilot protocol to validate CTC. It is the first study to use the LENA System in this language. Vietnamese is a monosyllabic, tonal, syllable-timed language (Romano, Mairano, & Calabro, 2011; Tang & Barlow, 2006). Although there are some reduplicated, compounded, and borrowed multisyllabic words, each Vietnamese word typically equates to a single syllable. Word order and function words compose all Vietnamese grammatical structures (Nguyen & Ingram, 2006; Nguyen, Laurent, Rossignol, & Vu, 2006). Vietnamese is also tonal. Vietnamese tones rely on contrasts in phonation such as creakiness and breathiness rather than on pitch height alone (Pham, 2003). Creakiness is produced when the vocal folds are tightly compressed during phonation causing lower than normal voicing, and breathiness is related to the amount of air that escapes from between the vibrating vocal folds. These language-specific prosodic features should not affect the LENA algorithm for identifying adult and child speakers in a conversational turn. Other tonal languages, such as Mandarin, have successfully been validated for LENA use (Gilkerson et al., 2015). In addition, stress in Vietnamese is typically secondary to the prosodic properties of phonological tone. Therefore, Vietnamese, like many tonal languages, is considered syllable-timed. Both Mandarin and French are also syllable-timed and both are valid for use with the LENA System (Abercrombie, 1967; Canault et al., 2015; Gilkerson et al., 2015; Romano et al., 2011). Accordingly, this rhythm would not be expected to affect our validation outcomes. Finally, Vietnamese phonology is not expected to affect validity outcomes as there is significant phoneme overlap between Vietnamese and English (Tang & Barlow, 2006). It was therefore expected that the LENA System would be a valid tool to quantify conversational turns in Vietnamese.
Validating CTC
This study sought to pilot a concise protocol for validating LENA measures that can be implemented with limited resources by clinicians or researchers hoping to make the technology accessible to a wider population. The authors chose to focus on a single LENA result to reduce the time commitment required for analysis. CTC was chosen as the primary outcome measure for this investigation. CTC identifies acoustic characteristics of adult versus child-spoken productions, which tend to be most closely related to the anatomical size of the vocal tract rather than a specific language (Lee, Potamianos, & Narayanan, 1999). As a result, CTC is likely to remain accurate regardless of the individual language.
While all LENA measures provide compelling information regarding child language development, CTC is particularly intriguing. Many researchers believe parent–child interactions are key to children’s language learning processes (Kuhl, Tsao, & Liu, 2003; Warren & Brady, 2007). Children exposed to more child-directed speech in their first years of life have been found to demonstrate higher overall language and vocabulary levels as well as higher IQs (Hart & Risley, 1995; Hoff, 2006; Hoff & Naigles, 2002; Hurtado, Marchman, & Fernald, 2008; Huttenlocher, Vasilyeva, Cymerman, & Levine, 2002). Turn taking between children and their parents is therefore a noteworthy feature of conversation that appears to have a large impact on child development (Zimmerman et al., 2009). Of all of the LENA measures, CTC most closely represents these parent–child interactions, making it a logical candidate for validation as it is both intellectually useful and language independent.
Validating all of the LENA functions for one language can be a time-consuming and expensive process. However, given the known universal features of language and the nature of the LENA System algorithms, an abridged process may allow for accurate validation. This pilot study posed two questions: (a) Based on previous research, can validation for the LENA System be demonstrated by employing a concise protocol with a small sample, reducing the need for extensive validation studies? and (b) Is the LENA CTC valid for use with Vietnamese speakers?
Method
Participants
Ten families volunteered to participate in this pilot project. All of the families lived in the Binh Duong Province, Vietnam, outside of Ho Chi Minh City, and were monolingual speakers of the southern dialect of Vietnamese. Five of the children had hearing loss, wore hearing technology, and used listening and spoken language as their primary means of communication. The remaining children had typical hearing as defined by passing a distortion product otoacoustic emission (DPOAE) test. All the children passed the Nipissing District Developmental Screening (McLay, 1998), indicating that they had no disabilities other than hearing loss. The children’s age ranged from 22 to 42 months (M = 30.5, SD = 6.9), and their mothers represented a range of educational backgrounds (see Table 1 for demographic information).
Demographics.
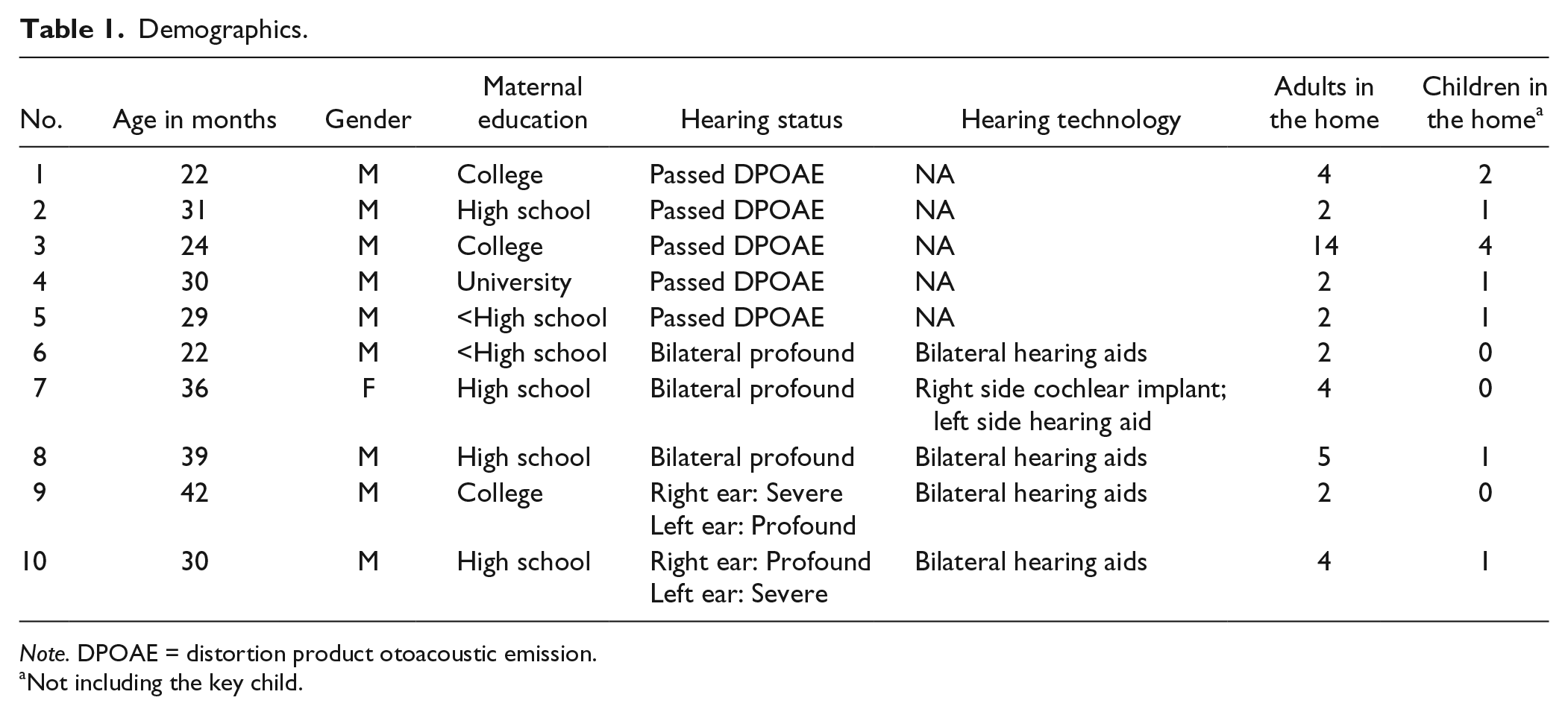
Note. DPOAE = distortion product otoacoustic emission.
Not including the key child.
Each child was asked to wear a DLP for at least 12 hr on a day when he or she was at home, as opposed to child care, and in good health. While recording, parents were asked to keep a written log of the activities the child participated in during the day and whom they were with.
Training Protocol for Human Coders
Two Vietnamese-speaking volunteers underwent training to prepare them for the task of coding prior to hearing the Vietnamese recordings. Both volunteers had some level of postsecondary education and had some knowledge of communication developmental delays and disorders. One coder was located in Toronto, Canada, and had fluent English skills. The other lived in Ho Chi Minh City, Vietnam, and had a conversational level of English. The training protocol was completed in English so that coders could become accustomed to the LENA System’s coding methods with data that have already been shown to be valid.
For training purposes, three 5-min regions with high levels of conversational turns were selected from English recordings that were part of a LENA System pilot project conducted in the Childhood Hearing Loss Lab at the University of Toronto. Each coder was provided with a written set of instructions to follow (detailed below). During training, coders could ask questions, refer to each other’s work, and view the software’s results. Training took between 3 and 5 hr. After coding the three regions, both volunteers reported feeling confident in their skills and Vietnamese coding commenced.
Coding Protocol
In consultation with the LENA Research Foundation, the authors chose to select two contiguous 5-min regions from each participant, in a manner similar to Gilkerson et al. (2015). It was anticipated that a slightly shorter length would prove faster to analyze while still providing enough data to show significant results. The LENA Research Foundation provided an SPSS script that ranked each region by number of conversational turns and then randomly selected two continuous regions from the middle 20% for each participant. This process prevented human bias in selection and potentially avoided issues related to the high rates of mislabeling by the LENA software in regions with a significant amount of conversational turns. Gilkerson et al. (2015) suggest that their data sample, selected from segments with high CTCs, may have inadvertently increased the chances of locating a labeling error. By sampling from the middle 20%, this pilot attempted to minimize the possibility of encountering false positives.
Coding was conducted using Transcriber software (Boudahmane, Manta, Anoine, Galliano, & Barras, 2008). LENA recordings can be easily exported as .trs files into Transcriber, an open source program, which allows for the annotation of speech signals (see Figure 1 for an example of how the LENA software segments and labels appear within Transcriber).
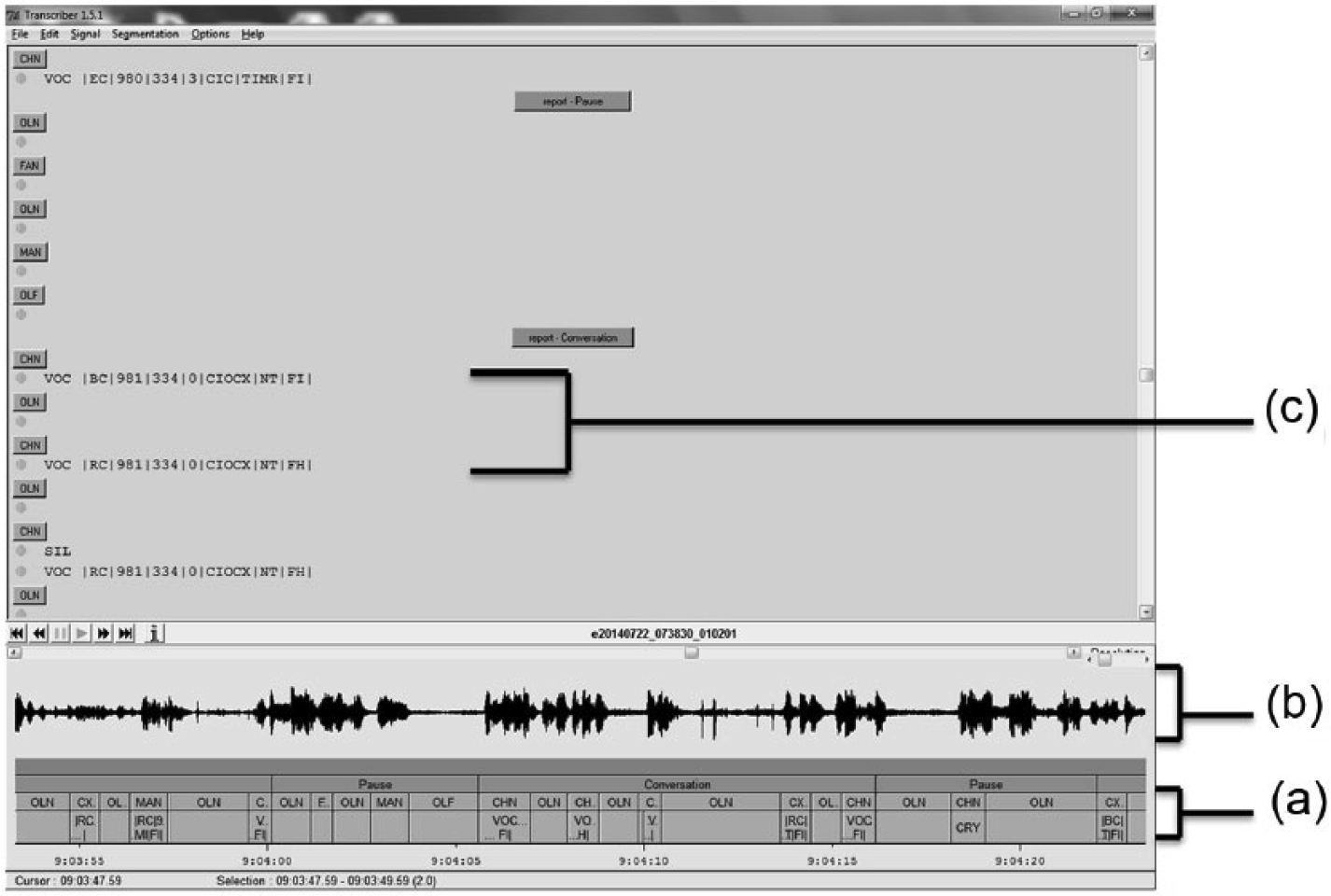
LENA software coding displayed in Transcriber software.
A three-stage protocol was implemented with guidance from the LENA Research Foundation based on their previous validation experiences (Kim Coulter, LENA Research Foundation, personal communication, August 18, 2013). The two coders each independently calculated a CTC by following the series of steps listed below:
Each 5-min region identified by the algorithm was segmented by change in sound type (speaker, electronic sound, noise, etc.). The coders first segmented the region by placing boundaries in Transcriber at the beginning and end of each distinct sound type. No limitations were placed on segment length at this stage (see Figure 2 for an example).
Each segment was labeled. While the LENA System uses eight distinct labels (male adult, overlapping noise, other child, etc.), this pilot protocol used only three: key child (vocalizations produced by the child wearing the DLP), adult (collapsed across both male and female), and other. “Other” included crying, vegetative sounds, distant and overlapping sounds, TV and electronic sounds, other children, noise, and silence. Each segment, created by the boundaries set in Step 1, was labeled with a letter: “c” representing the key child, “a” representing adult speech, and “x” representing other sounds (see Figure 2 for an example).
Finally, the coders counted conversational turns. All instances where segments coded as “a,” that were longer than 0.9 s, and occurred within 5 s of a segment coded as “c,” that was more than 0.5 s long, were counted as a turn. Any segment occurring between speakers was required to be 5 s or less and could only be labeled “x” to be considered a turn. Therefore, “x” segments did not prohibit turns. Utterance lengths were originally set according to LENA specifications, 1 s for adults and 0.6 s for children (Oller et al., 2010; Krista Ingle, LENA Research Foundation, personal communication, September 25, 2013). However, during protocol development, it appeared that shortening the times by 1 ms yielded more accurate results. The initiating utterance, whether produced by the adult or the child, was labeled with a “0,” and the response was labeled with a “1” (see Figure 2 for an example). After this step was complete, the coder counted the number of 1s to calculate the number of turns within the region.

Human coders’ results as displayed in Transcriber software.
The coders did not produce a transcription of the recording. Instead, they coded the elements used by the software to calculate CTC. Validation studies conducted by members of the LENA Research Foundation have used this method in the past (Gilkerson et al., 2008; Gilkerson et al., 2015). Similar to the LENA software, this protocol labeled occurrences of overlapping speech or noise as “other.” Any speaker segments that may have qualified as part of a possible turn were disqualified for having occurred in a noisy auditory environment. This is a limitation of the software as well as the pilot protocol.
Both coders were volunteers and worked on the protocol part-time when it was convenient for them. Coding of the entire data set took roughly 2 months. Interrater reliability was 20%. Seventy-one percent of disagreements between coders were related to a speaker (“adult” or “key child”) versus “other” label (Step 2 in the protocol). Twenty-one percent of disagreements were over segment length, which affected whether an adult utterance or a child vocalization could be counted within a turn (Step 1 in the protocol). Remaining mismatches were related primarily to coder error on Step 3: failing to count a turn that had successfully been coded. The first author, therefore, identified 108 locations where the coders disagreed with each other on the identification of a turn (per 5-min region: M = 5.4, SD = 2.9). She then facilitated a videoconference in which the coders came to an agreement on those segments. The meeting lasted approximately 3.5 hr.
Results
All recordings were collected in June and July of 2014. The recordings ranged from 12 hr to 14 hr 22 min (M = 13 hr 9 min, SD = 57 min). There was no significant difference in full-day LENA-calculated CTCs between the children with and without hearing loss (U = 15, p = .69). This is consistent with previous research comparing the LENA results of children with and without hearing loss in the United States (Caskey & Vohr, 2013; VanDam, Ambrose, & Moeller, 2012). Results from both groups were therefore pooled for analysis.
LENA results for the number of conversational turns per region ranged from zero to five (M = 2.5, SD = 1.54), whereas the human coders’ results ranged from zero to six turns (M = 1.75, SD = 1.71). CTC results from the human coders and the automated LENA data were compared using a Spearman rank correlation test. The findings showed a strong correlation between the LENA System and the human coders, rs(18) = .70, p < .001 (see Figure 3). There was no significant difference between the LENA System’s turn count and that of the human coders (U = 143, p = .12). However, unlike the LENA Research Foundation’s own validation study (Xu et al., 2009), the software’s counts were, on average, 0.75 turns higher than the coders’. There was no need to remove outliers in the data set, as was done in the Mandarin and Korean studies (Gilkerson et al., 2015; Pae et al., 2016).
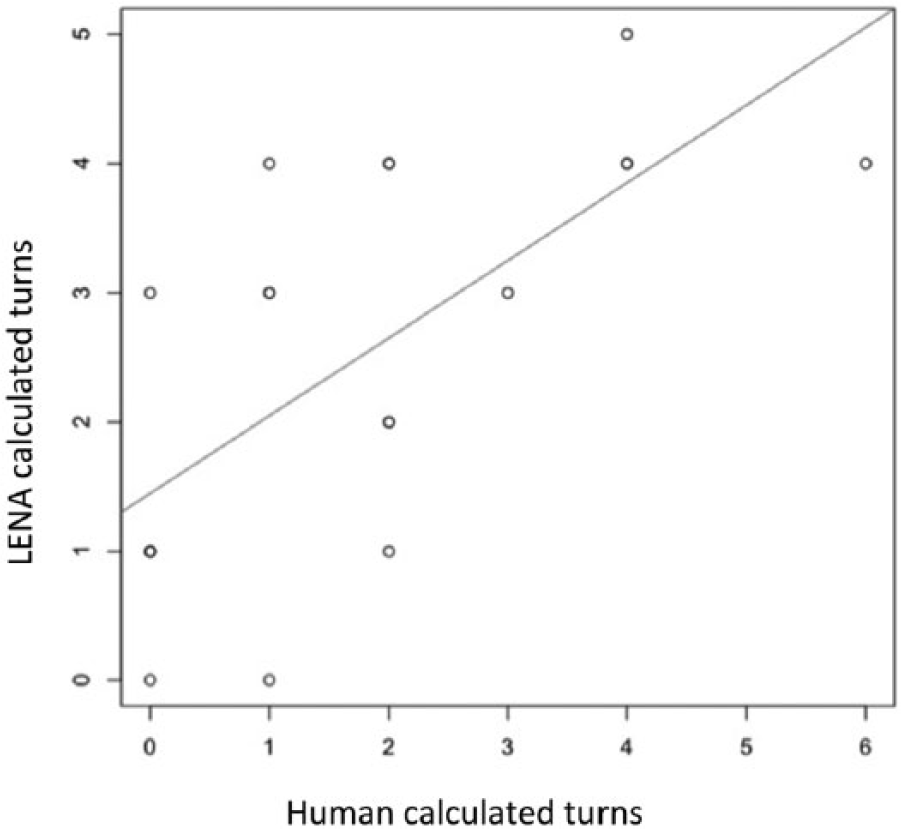
Correlation between LENA System’s CTC and human coders’ CTC.
Within the audio samples, LENA software reported that 8% of the regions were child speech, 5% were adult speech, 16% were electronic sounds, 3% were silence, and 18% were unclear and distant vocalizations, other children, and general noise like bumps. Fifty percent were labeled as overlapping speech. Due to the nature of the pilot protocol, similar information related to human coding is unavailable. However, of the turns identified by the coders, 33% of the disagreements with the LENA System were labeled as overlapping noise and 8% were labeled crying, other children, or TV, by the software. Three percent occurred when the LENA System labeled an adult as a child. The remaining segments showed agreement between the coders and the machine.
The data were examined post hoc to identify sound type, if any, between the initiator and the respondent in the counted conversational turns. The coders found no segments between the initiator and the respondent in 63% of the turns. The remaining turns included intermediary segments that were less than 5 s long and labeled with an “x” in compliance with the protocol. Twenty-three percent of all the turns were separated by noise, 12% were separated by overlap, and 3% were separated by TV. None of the speakers were separated by an “other child” segment.
Half of the analyzed regions were selected from between 7 a.m. and noon, and half represented times between noon and 8:30 p.m. According to the daily logs, the selected regions represented activities all families commonly engaged in. Three samples represented play with either an adult family member or another child, three represented eating a meal or snack, and two reported visits with extended family members. The final two samples were shopping and studying, respectively. Shopping, like playing, eating, and visiting, appeared on almost every log. Daily trips to the market to buy fresh food are a regular part of life in Vietnam. Study time was seen frequently on the daily logs of children with hearing loss and likely represented times at which parents were focused on teaching their children language skills. Other activities that were regularly reported included napping, which did not create a lot of conversational turns for obvious reasons, bathing, which may not have demonstrated high CTCs because the DLP was removed from the child to protect the technology from water damage, and television viewing, which is known to reduce CTCs (Christakis et al., 2009). The algorithm was therefore able to select regions that represented the types of activities in which families in Vietnam typically participated.
Discussion
The correlation between the LENA software and human coders based on 100 min of audio provides justification for the use of the LENA-generated CTC with Vietnamese speakers. This section addresses issues that arose in the pilot project that may require further investigation, such as coder training and representative sampling. The impact of cultural differences on parent–child interactions and daily living, which may affect LENA analysis, are also discussed.
None of the currently published LENA validation studies detail how their coders or transcriptionists were prepared. By sharing our training protocol here, we hope to make the process more transparent and encourage more discussion around training practices for coding LENA data. Future research implementing training protocols for coders should consider more intensive practice to ensure higher levels of initial agreement. Reviewing the entire data set rather than just possible turns might also be beneficial. Training within the test language may improve results as well.
Although the sample size used in this study was small, the correlation was highly significant (r = .7, p < .001), indicating that a larger sample may not be necessary. Moreover, the LENA System software was designed to statistically analyze 10- to 16-hr recordings, substantially longer than a 5-min region. A larger region, like the ones that would be obtained through typical LENA use, would likely show even higher levels of correlation between human coders and the LENA-generated CTC in any language (Canault et al., 2015; Xu et al., 2008). Although some researchers argue that a correlation coefficient of .70 may seem relatively low and could potentially be increased by continued data collection, it is well within the range of correlation results obtained in studies of other languages (Canault et al., 2015; Gilkerson et al., 2015; LENA Research Foundation, 2008; Pae et al., 2016).
This study yielded positive results for clinicians and researchers who are interested in validating the LENA System in other languages. However, a number of issues arose in this pilot project that may require further investigation. Replicating this protocol with a different set of participants may be of interest in future research. While there was no significant difference between the CTCs of children with and without hearing loss, validating the LENA System with a more homogeneous sample could be explored. Parents of children with hearing loss may have been instructed, during speech–language therapy sessions, to engage with their child in a certain manner that could affect turn taking. The LENA System has been validated for English speakers aged between 2 and 36 months (Xu et al., 2009). Future validation for Vietnamese should expand its age range to at least match this age range. Sampling regions from more time points throughout the day may also create an even more representative sample of parent–child talk in Vietnam.
Surprisingly, perhaps, the largest discrepancies between the coders and the LENA software may not be directly related to the phonetic or phonologic makeup of the language in question. Culture, as Gilkerson et al. (2015) pointed out, may play a role in LENA results. For example, they explain that, in Mandarin, adult female/key child confusions are common and are likely related to a rise in pitch associated with the use of “motherese.” Due to the simplified coding system used in the current study, there was no way to confirm whether or not a similar coding error pattern occurred in Vietnamese, as the coders did not distinguish between male and female adult speakers. It does appear, however, that a small number of the disagreements between the coders and the LENA System were examples of adults being labeled as children. Vietnamese and Chinese people have been in contact for thousands of years, which has impacted their language use (Alves, 2001; Womack, 2006). Therefore, we could speculate that the likelihood of similar cultural practices around motherese could be expected and the impact of these customs on LENA CTCs could potentially be similar for both groups.
Although the simplified labeling protocol can be useful, the resulting lack of detail does make it more difficult to describe possible causes for disagreement between the human coders and the LENA results. Although not essential for calculating CTC, asking coders to label the gender of the adult speaker in future validation studies using this protocol may represent a small adjustment that could add significantly to the understanding of the larger LENA analysis. This change would allow investigators to examine issues like the one brought to light by Gilkerson et al. (2015) regarding motherese. In addition, LENA software does not count a turn if a segment labeled “other child” separates the speakers. Although this pattern did not occur in the present data set, future studies implementing a similar protocol should include “other child” in their labeling scheme to avoid mismatches; aligning the coding methodology more closely with the software program.
Previous literature has noted that a noisy environment can negatively affect correlation between LENA outcomes and human coders (Canault et al., 2015; Xu et al., 2009). Including recordings made in noise in validation is important, however, as the LENA System is designed to capture a child’s natural environment, which is often noisy. Validating LENA results in noise allows for better generalization of results in the natural environment. Future studies may test Vietnamese in a quiet environment to fine-tune the automated software.
Most of the disagreements between the coder-identified turns and the software’s results involved the LENA System labeling a speaker as overlapping noise. Past research has reported similar deviations in agreement when there are a large number of overlapping segments (Canault et al., 2015; Xu et al., 2009). According to the LENA results, 50% of the segments in this sample were labeled as overlapping noise, whereas only 18% were labeled as such in the Mandarin sample (Gilkerson et al., 2015). While overlapping noise does not always impede the identification of a turn, as mentioned earlier, if an adult and the child are participating in verbal exchanges in a noisy environment, the LENA System will likely label those segments as overlapping noise (and the present protocol would label them as “other”). In this case, the potential turns would not be included in the CTC. This is a limitation of both the LENA System and the protocol, which may be especially salient in Vietnamese homes. As is common in Asia, many Vietnamese households include extended family members. The homes sampled for this study were comprised of two to 14 adults (M = 4.1, SD = 3.7) and up to four other children in addition to the key child (M = 1.1, SD = 1.2). We suggest larger families lead to more occasions for overlapping speech, which both the LENA software and the human coders struggled to label. In addition, the activities the Vietnamese families participated in throughout the day, such as going to the outdoor market, may create more instances for overlapping noise than the American families in the Natural Language Corpus (Gilkerson & Richards, 2009).
In addition to its inhabitants, the physical characteristics of the home itself may also play a role in the amount of overlapping sound recorded by the LENA System. Southern Vietnam is hot and humid, and therefore, homes tend to have open windows and large entranceways open to the street. The houses have concrete walls, tile floors, and hard wooden furniture to keep the home cool. This creates loud reverberating environments. In addition, houses often have tin roofs that generate a great deal of noise during the rainy season, when these recordings were produced. We suggest, in combination, these living arrangements may have had an impact on the accuracy of both the LENA System and the pilot protocol by creating a noisy auditory environment that was difficult to parse. Future studies conducted in other non-Western communities may need to account for the physical home environment when interpreting LENA results.
By disregarding potential turns, CTC results may be underrepresenting the amount of communicative interactions the child is engaged in. Although not significant, the LENA software did overestimate turns compared with the human coders. This might reflect how difficult the coders found distinguishing speakers from background noise. However, slightly overvaluing turns may also be a strength of the software, which allows it to compensate for turns lost to overlapping noise. Given the small sample size in this pilot, further data collection should be completed with Vietnamese families to confirm that this amount of overlapping noise is not unique to this data set and that a significant number of turns have not been lost.
Alternatively, LENA results that disregard speech segments in noise may be reflective of the amount of language a child is capable of processing. Children with and without hearing loss often struggle to learn language from stimulation presented in noise (Klatte, Bergstrom, & Lachmann, 2013; Manlove, Frank, Vernon-Feagens, 2001; Maxwell & Evans, 2000). Therefore, LENA results may, in fact, be more representative of what a child is able to understand rather than what has simply been presented. Viewed from this perspective, discounting turns in overlapping segments may be a strength of the LENA System rather than a limitation. Further testing is needed to confirm this hypothesis.
These considerations emphasize the importance of understanding the culture, lifestyle, and environment of those using the LENA System to correctly interpret the results. When culture is accounted for, however, this proposed simplified validation protocol could be useful to researchers and clinicians who may have minimal resources to validate basic elements of the LENA System, such as CTC, both quickly and efficiently. This pilot demonstrates that a small sample size can produce a statistically significant result.
Conclusion
The LENA System is an exciting new tool that can provide detailed information about a family’s language environment. Despite using a small sample size, the results obtained through the pilot protocol presented here show support for the use of the LENA CTC in Vietnamese. This procedure could be adapted by other researchers who are looking for a less labor-intensive method to investigate CTC in other languages. However, more intensive coder training, a slightly more detailed coding protocol, and a larger and more representative sample could add to future research. By validating the LENA device for a variety of languages used by diverse cultural groups, we may eventually be able to generate a fuller understanding of the universals as well as the individual cultural practices involved in child language development, which may also help to provide service to families seeking speech and language intervention.
Footnotes
Acknowledgements
The authors would like to thank the LENA Foundation; the Global Foundation for Children With Hearing Loss; Ng Thanh Thu Thuy and the Thuan An Centre for Disabled Children; interpreters Ton Tho Dang Khoa, Le Thi Nhon Hoa, Nguyen Bich Huyen, and Do Thi Hien; and coders Hien Thai and Nguyen Nguyen. They also thank Nicole Bazzocchi for her assistance.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.