
Abstract
Presidential vote shares in legislative districts are widely available for congressional districts and are often used by scholars in their research. Here, I describe the general methodology to construct statewide vote shares within districts and apply these methods to a new database of presidential vote shares within 36 states’ legislative districts.
Keywords
Measures of districts’ political tendencies are central to understanding elected officials’ representation of constituents. Scholars use surveys to measure state ideologies (e.g., Carsey and Harden 2010; Erikson, Wright, and McIver 1993), but sample sizes of even the largest surveys are insufficient to create similar measures for congressional districts, much less state legislative districts. Scholars thus commonly use presidential vote share within a district to provide measures of districts’ political tendencies (e.g., Gelman and King 1994; Jacobson 2013). The presidency is the only nationally elected office, which enables interstate comparisons of districts. Publications such as the Almanac of American Politics and CQ Researcher report these statistics for congressional districts, but there are no similar comprehensive resources for state legislative districts. 1 As a consequence, state politics scholars typically measure districts’ partisan tendencies vote shares to the legislative offices (e.g., Hogan 2004; Stratmann and Aparicio-Castillo 2006), imputed values from county level data (Shor and McCarty 2011; Klarner and Reynolds 2013), demographic characteristics of the districts believed to be associated with partisanship (Koetzle 1998), or use predictive models employing a basket of these determinants (Levendusky, Pope, and Jackman 2008). However, election outcomes are sometimes the topic of scholarly investigation, so using lagged vote shares to predict current vote shares introduce biases that can be difficult to control for. Lagged vote shares can be particularly problematic measures following a redistricting. Furthermore, county and district boundaries often do not correspond (Klarner and Reynolds 2013), and demographic characteristics may not serve as a perfect proxy for partisanship.
Interested persons, most notably redistricting consultants, historically calculate presidential votes within congressional districts using data-intensive methods that are prohibitively costly and time-consuming for state politics scholars to duplicate. However, with accessible data increasingly available online, these barriers have been lowered significantly. In this note for the Practical Researcher, I describe how vote shares for statewide offices may be constructed for legislative districts, provide 2000 presidential vote within pre- and post-2000 redistricting state legislative districts and point interested readers to additional resources that enable similar calculations for other offices and elections.
Calculating Votes within Districts
Only a few state election officials provide statewide or local jurisdiction-wide election results within legislative districts, and where they do, they typically report only presidential vote by congressional district. Scholars can duplicate states’ calculations using precinct-level election data and expand them to other states. 2 In most states and localities, legislative district boundaries mostly coincide with precinct boundaries. To calculate votes for any elected office within a legislative district, a scholar may follow three deceptively simple steps:
Obtain a list of precincts within a legislative district.
Obtain the election results reported by precinct for the office of interest.
Total the election results for the office of interest by legislative district.
The first challenge is obtaining the precinct-level data. Most state election officials provide statewide precinct-level election data online, although there are a few state election officials who provide only paper copies for a fee—especially for historical data—or will refer the scholar to local election officials. Navigating the various state websites can be challenging, and like the websites, precinct data are not in a common format. 3
Three details of how precinct-level election data are organized may prevent accurate construction of votes for the office of interest within legislative districts. First, in some jurisdictions, precincts may be split by two or more legislative districts in the same election as another office for which one may wish to tally vote shares within the legislative districts. Thus, a precinct’s election results may include a statewide office and two or more state legislative offices for the portions of the district located within the precinct. A strategy to address concurrent election split precincts is to note the fraction of each legislative office’s total vote reported within the precinct and apportion the votes for the office of interest accordingly. It may be further preferable to apportion votes by the candidates’ parties, but this is impossible when a candidate runs unopposed by a major party candidate, as often occurs with state legislative elections (Niemi et al. 2006). 4
Second, votes for statewide contests are sometimes reported in special jurisdiction-wide precincts. These “nonpolling place” votes may include mail votes, in-person early votes, provisional votes, and various other classifications. Failing to account for nonpolling place votes can lead to biases when they differ significantly from polling place votes. For example, in seven states that differentiate between in-person Election Day votes and in-person early votes in the 2012 general election, President Obama’s vote share averaged 4.2 percentage points higher among the in-person early votes. 5 A strategy to account for nonpolling place votes is to apportion these votes into precincts proportional to the polling place votes within precincts. 6 More sophisticated methods tabulate individuals’ voting mode in a given election available from voter registration files, where this information is available. The number of nonpolling place votes can then be tallied for all registered voters in each precinct and used to apportion nonpolling place votes to precincts.
Third, precinct boundaries change, posing a problem when calculating vote shares within districts for offices occurring in different elections. Precinct boundaries change for many reasons. In an expected low-turnout election, election officials may consolidate precincts together to reduce the number of polling locations and the associated costs of administering the election. When a precinct becomes overpopulated, election officials may split the precinct into new precincts. Election officials may draw entirely new precinct boundaries, sometimes, but not exclusively, as a result of a redistricting or annexation, resulting in both splits and consolidations, in a process called “reprecincting.” Inevitably it seems, precincts’ names or identifying numbers do not match perfectly across elections. Some election officials make available electronic maps or cartography of their precinct boundaries that can help resolve discrepancies. As a last resort, local election officials are usually responsive to questions about precinct changes. Once changes have been resolved, votes for an office of interest can be allocated by summing votes in consolidated precincts or disaggregating votes across split precincts. However, it is often the case that a few orphan precincts will exist that have no obvious correspondence to the base geography used to calculate votes in districts. In these cases, votes are dropped when precincts cannot be assigned to a district.
Continuing with the third challenge, split precincts are particularly prevalent following redistricting. To achieve exacting population equality, redistricting authorities usually draw districts out of the lowest level of census geography possible: what is known as a census block. Census blocks roughly correspond to city blocks in urban areas, but because they follow political boundaries and visible features, their boundaries can follow streams and road medians. A typical precinct is thus composed of many census blocks. During redistricting, consultants take the extra step of disaggregating precinct-level election results into census blocks so that they may evaluate alternative redistricting plans, which because they are drawn from census blocks typically split precincts. 7
Merging election and census data involves developing a list of the smaller census blocks contained within the larger precincts. Starting three years preceding the decennial census, the Census Bureau launches “Phase Two” of their redistricting data collection. 8 During Phase Two, state officials transmit political boundaries to the Census Bureau so that they may be included in the Census Bureau’s geography. Precincts and their variants are incorporated into the census geography as Voting Tabulation Districts (VTDs). For example, circa 2007 precincts are delineated in the 2010 census geography. VTDs are explicitly contained with the census geography hierarchy, they do not split census blocks, and thus are a valuable data resource to correspond precincts with census blocks. However, caution is warranted. States transmit VTDs to the Census Bureau, but the boundaries and names may not be those used in a contemporaneous general election, or any election for that matter, and the names may not be consistent with those listed in election results. 9 Some states by law freeze changes to their precincts once they are transmitted to the Census Bureau, but many continue to split, consolidate, and otherwise reprecinct as they see fit. A few states pre-2000 census—such as Arkansas, Kentucky, Montana, Ohio, Oregon, and Rhode Island—did not comprehensively participate in the 1997 Phase Two by transmitting any or all of their precinct boundaries to the Census Bureau. In these states, precinct boundaries typically must be obtained from local election officials, a task beyond the capacity of this project. An exemplary transparent state, Ohio, compiled and publicly released these data. 10
Sometimes, defining post-redistricting districts in census geography is challenging. Redistricting software uses a common data format to describe districts in census geography called the block equivalency file, which lists districts associated with unique identifiers for each census block. Block equivalency files are the easiest to manipulate, and all commercial redistricting software produce them, but some states release only images of their districts, making it very difficult for researchers to backward engineer block equivalency files. 11 Furthermore, new districts may not be precisely defined in census geography such that new districts split census blocks. Often this occurs for zero population blocks, such as marshes or lakes, and is inconsequential to the exercise of computing votes within districts. Where such census blocks have nonzero populations, I apportion election results among districts. I use a naive approach to simply divide votes evenly among districts. Votes may also be apportioned according to districts’ areas within split blocks, but caution should be exercised since population is rarely uniformly distributed across geography. The most sophisticated method is to pinpoint geo-code individual voter registration addresses and assign votes to districts splitting blocks in proportion to the number of registered voters. However, this data-intensive approach is not practical with the limited resources of this project.
Available Data
Until recently, only state governments had the resources to collect precinct boundaries, collect election data, and merge these data together for redistricting (Altman, Mac Donald, and McDonald 2005). There are four notable scholarly data collection efforts for precinct-level election data. The Record of American Democracy is an archive for precinct level for selected states, from 1984 to 1990 (King et al. 1997). The Federal Elections Project is an archive for 2000 precinct-level election data (Lublin and Voss 2001). The Harvard Election Data Archive archived circa 2010 precinct-level election data and merges these data to the 2010 VTDs (Ansolabehere and Rodden 2011). The fourth data dissemination effort of note is the Public Mapping Project, which processed some data from the Harvard Election Data Archive and some data made publicly available by states during their post-2010 redistricting efforts, to disaggregate 13 states’ election databases to the census block level, thereby directly enabling the calculation of some statewide office election returns into legislative districts (McDonald and Altman 2012).
Following the 2000 redistricting, I collected reports and redistricting databases produced by the states. Among other information in these reports is sometimes the 2000 presidential vote in the pre- and/or post-redistricting districts. Where these reports were unavailable, redistricting databases of merged election and census data provided a means of calculating this information where census block-level descriptions of the old and new legislative districts were available. Where these redistricting databases were unavailable, I used the Federal Elections Project archive to merge these precinct-level data with census data or data obtained directly from state election officials, using the procedures described above. A project funded by the now-defunct JEHT Foundation enabled additional election data collection and processing of these data into states legislative districts.
I attempted to compute 2000 presidential vote shares for all legislative districts but fell short in data collection efforts in 14 states. Data collection typically did not occur in these states because precinct boundaries were not described in census geography, and these states did not publicly release their own database, even if they may have constructed these data for internal use. Recreating these states’ efforts would have required contacting local election officials for their precinct boundaries, digitizing these boundaries, and associating these data with election results and districts.
In all, I constructed 2000 presidential vote shares for the upper and lower state legislative districts in 32 states in the pre- and post-2000 redistricting. In four states, data were available for either pre- or post-redistricting districts, as described in the codebook accompanying the data archive (McDonald 2014). I also report some data beyond the first post-redistricting election. In Arizona, Massachusetts, North Carolina, and New Hampshire, I collected new district boundaries for additional state legislative redistricting, either by choice or court action. In all, I calculated presidential vote shares for 10,362 legislative districts. 12 Carl Klarner graciously assisted to develop state legislative district identifiers consistent with the State Legislative Elections Returns (Klarner et al. 2013) so that scholars may incorporate these data into their research.
Despite the challenges described above affecting the data reliability, the data possess construct validity. Figure 1 plots the 2000 two-party presidential vote on the x-axis against the 2000 two-party state legislative vote—in upper and lower chambers—on the y-axis. The contested elections show the expected correlation. Keep in mind this plot does not take into account any other electoral factors such as incumbency or the presence of minor party candidates. Indeed, there are hints of incumbency effects in Figure 1, as a discerning eye can observe a kink in the scatterplot around 50% two-party presidential vote that reasonably corresponds incumbents of different partisan stripes being elected from districts that are competitive or favor their political party. The high correlation of these data thus suggests that the two-party presidential vote in state legislative districts may be an important control variable for analyses of state legislative election processes such as understanding incumbency and campaign finance effects.
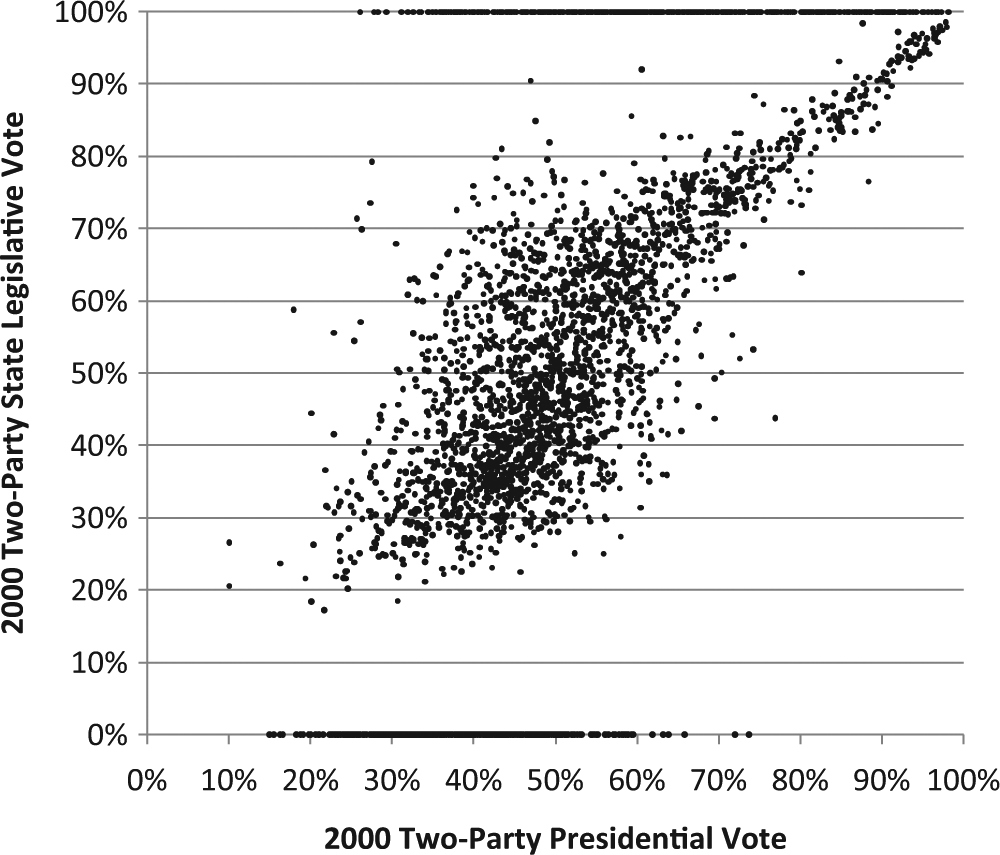
Scatterplot of 2000 two-party presidential vote and 2000 two-party state legislative vote.
I welcome further contributions to these data from the state politics community and will strive to update them as warranted. Recent data collections and the prevalence of online resources (Ansolabehere and Rodden 2011; Altman and McDonald 2012) make possible the extension of these data to the post-2010 redistricting and beyond. I hope scholars will welcome these data for their research agendas. These data are further in the public interest. By not fully participating in Phase 2, or by failing to provide correct data to the Census Bureau, states effectively make redistricting processes more opaque to public scrutiny (Altman and McDonald 2010). Compiling these data can thus also educate the media and public about redistricting and legislative politics.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The JEHT Foundation provided partial support for the project.