
Abstract
This article addresses the question of appearance-based effects by looking at the U.S. House of Representatives election 2016. We broaden the focus beyond existing studies by offering a comprehensive and systematic analysis of the three traits attractiveness, competence, and likability while simultaneously taking into account confounding third variables and possible interactions. Corresponding to the comparative character of electoral competition in the districts, we developed a relative measure of the three traits which we apply in an online survey. This measure also takes into account the raters’ latency times, that is, their clicking speed, as a weighting factor for their ambiguity in the ratings. With these data we test whether appearance matters for the electoral outcome. We find that attractiveness positively affects the vote share, whereas perceived likability and competence play no role. The study also tests to what extent the found appearance effects are conditioned by incumbency status, age, and gender of the contestants. Furthermore, it gives hints which aspects of their appearance candidates could change to perform better at the ballot box.
Keywords
“What Is Beautiful Is Good”—At Least for Most of the Time and Most of the People
When Dion, Berscheid & Walster (1972) wrote these words more than 40 years ago, they were the first to show empirically that beautiful people are “assumed to possess more socially desirable personality traits” and “expected to lead better lives” (Dion et al., 1972, p. 285). Since then, a “beauty premium” (Praino, Stockemer, & Ratis, 2014, 1097) has been detected in sociological, economic, and psychological studies within virtually all fields of life. Attractive babies get more affectionate care by their mothers (Langlois, Ritter, Casey, & Sawin, 1995), good-looking pupils receive better grades (Dunkake, Kiechle, Klein, & Rosar, 2012) and are more likely to obtain a college degree (Gordon, Crosnoe, & Wang, 2013). Attractive persons have a better chance to get a callback when applying for a job (López Bóo, Rossi, & Urzúa, 2013), receive higher salaries (Hamermesh & Biddle, 1994), and do not have to deliver the same performance as their unattractive counterparts in sports (e.g., in soccer, see Hagenah, Rosar, & Klein, 2010). Still, although beauty often pays, it can also have negative effects. For example, Johnson, Podratz, Dipboye, and Gibbons (2010) show that attractiveness 1 is detrimental for women applying for masculine sex-typed jobs in which appearance is of minor importance (e.g., prison warden). This interaction effect between gender and attractiveness has been termed the “beauty is beastly” effect. It has been found to be particularly significant in high-level, managerial positions since in these jobs “male” characteristics are often regarded as important. Attractiveness of a woman is instead associated with femininity giving rise to preconceptions about her suitability for these kinds of jobs (Heilman & Saruwatari, 1979).
In politics, several studies confirm the effects of physical attractiveness on the likelihood of being elected. Already in the mid-1970s, Efrain & Patterson (1974) found a significant correlation between beauty ratings of candidates and their vote share in Canadian federal elections. Subsequent studies added several controls (e.g., incumbency status) and confirmed a general effect of beauty both in political systems as diverse as Australia, Finland, Brazil, Mexico, Switzerland, Germany, or the United States (Berggren, Jordahl, & Poutvaara, 2010; King & Leigh, 2009; Klein & Rosar, 2005; Lawson, Lenz, Baker, & Myers, 2010; Lutz, 2010; Rosenberg, Bohan, McCafferty, & Harris, 1986), and at different levels from subnational, to national, and supranational (e.g., Banducci, Karp, Thrasher, & Rallings, 2008; Rosar & Klein, 2014; Rosar, Klein, & Beckers, 2008). The explanation why people seem to base their vote at least partly on candidates’ appearance is rather straightforward: During campaigns, pictures of the candidates are readily available (e.g., from campaign posters or newspapers) and the electorate uses these pictures as “thin slices” (Ambady & Rosenthal, 1992) of information to infer personal traits of the contestants which they cannot readily learn about otherwise. When trying to infer these attributes, candidate appearances such as attractiveness are easy to assess. This creates a halo effect in which the easily available perception of appearance translates to other attributes and outshines other markers one might draw on. As a consequence, beauty regularly serves as a (subconscious) basis for inferring the trait of interest. In that sense, perceived attractiveness works as a heuristic which enables voters who do not know much (or anything) about the candidates—and thus could not make a well-founded choice—to gather enough information for deciding whom they want to vote for (see Barrett & Barrington, 2005; Bull & Hawkes, 1982; Sears, 1969). 2
The present article adds to this literature on appearance effects in three respects. First, we tackle an issue that is heavily disputed in the field of voting studies: the question which facial traits are actually most likely to help candidates in getting elected. Earlier works have often focused on single facial traits. More recently, different traits were tested against each other (Mattes et al., 2010; Olivola & Todorov, 2010), yet the results of these studies are not consistent. Some find that it is the mere attractiveness that matters (Berggren et al., 2010), whereas others emphasize that the competence associated with a given face is crucial (Todorov, Mandisodza, Goren, & Hall, 2005). To clarify this open question, we take both attractiveness and competence into account and introduce general likability as a third type of perception. Furthermore, we test these appearance factors against a broad array of variables that voting studies have already shown to influence election results, that have, however, only partially —if at all—been included in the more psychology-rooted studies mentioned above. Controlling for factors such as incumbency status, partisanship effects, or the disbursements spent by a candidate helps to single out the substantive effects of appearance and to ensure that the potential impact of a candidate’s appearance on her election result is not actually due to confounding variables.
Second, we refine the tests of appearance effects by using relative measurements of a candidate’s appearance and by taking into account the raters’ ambiguity measured by the latency times in the rating. Relative measurement of appearance is the most appropriate way to test appearance effects, because the perception of candidates is affected by the available alternatives (Kenrick & Gutierres, 1980) and voting decisions are based on an assessment of and choice between two (or more) alternatives, as well. We therefore follow Todorov and colleagues and let raters compare actual contestants from one district (Ballew & Todorov, 2007; Todorov et al., 2005). Taking into account latency times is important, because it models the certainty of raters’ responses to candidate pictures. These moments of hesitation have hitherto not been included in previous research.
Third, our study thoroughly tests interaction effects between facial traits and further characteristics of candidates (e.g., age or incumbency status) and districts (e.g., toss-up district or unemployment rate). In fact, if appearance matters, it is likely that it does not affect all candidates in the same way and that properties of candidates or districts condition the relationship between appearance, evaluation, and ultimately vote choice. Although some of the existing studies have already indicated that such interactions may exist, a thorough test is still lacking.
In our empirical analyses, we find that attractiveness positively affects the vote share of candidates in the 2016 elections to the U.S. House of Representatives (HoR). Perceived likability and competence, in contrast, show no significant effects. These results are robust to controlling for many factors that have been proven to be relevant within voting studies (e.g., presidential votes, partisanship). Second, we find that attractiveness plays a stronger role for those candidates who have the incumbency advantage and in male-only or mixed-gender competitions. Only in female-only districts, likeability is of importance.
A Matter of Beauty, Competence, or Likability?
The finding that physical appearance affects electoral success is not unknown to the political science literature and has been demonstrated in different countries (Berggren et al., 2010; King & Leigh, 2009; Klein & Rosar, 2005; Lawson et al., 2010; Lutz, 2010; Rosenberg et al., 1986) and at different levels of governance (e.g., Banducci et al., 2008; Rosar & Klein, 2014; Rosar et al., 2008). As anything that emphasizes candidates relative to parties should also bring the associated processes to the fore, factors such as mediatization and personalization of politics (Esser & Strömbäck, 2014; Kriesi, 2012; McAllister, 2007) would also seem to increase chances that candidates’ appearances matter for vote choice (Mlodinow, 2012). Regularly, a decline in partisanship has been cited as underlying this increased importance of candidates (Kriesi, 2012). Yet, given that what is considered good-looking is rather uncontroversial, that physical appearance affects judgment at a subconscious level, and that even strong partisanship does not eclipse candidate effects on voting decisions, there appears a priori no reason to expect the recent resurge in partisanship among elites and the general public (Abramowitz & Webster, 2018; Bartels, 2018) to offset the effect of looks. Although beauty might interact with partisanship at an individual level, it most certainly also works on top of it. This is especially true when voters lack further information on the candidates—as has been shown in a recent study on the elections to the U.S. Congress Stockemer & Praino (2015). 3 In fact, psychological research has shown that people show a remarkable consistence in social judgments on faces depending on their facial traits (Todorov, Said, Engell, & Oosterhof, 2008; Zebrowitz & Montepare, 2008). This is why we can expect beauty to matter for Congressional election outcomes.
Although, by now, the general notion that physical appearance affects electoral success is acknowledged throughout several works within political science, different ideas about the underlying causal mechanisms remain. On one hand, most studies argue for a “what is beautiful is good”-halo effect. They regard attractiveness as a fundamental perception about a person which subsequently colors all kinds of ascribed attributes and therefore ultimately also affects voters’ decisions. On the other hand, and in contrast to this first approach, Todorov and colleagues (Olivola & Todorov, 2010; Todorov et al., 2005) show that it is not attractiveness, but the rapid, unreflective inferences of competence based on candidate pictures that affect election results of U.S. House and Senate races. According to them, although attractiveness may also matter to some degree—along with babyfacedness, familiarity, and age (see Olivola & Todorov, 2010)—the decisive factor is perceived competence. 4
In line with Todorov et al., Armstrong and colleagues show that ratings of candidates’ “facial competence” were better predictors for “the popular vote winners in the presidential primaries and general election [than . . . early] polling results” (Armstrong, Green, Jones, & Wright, 2010, p. 519). Parties could thus actively increase their electoral chances in the same way that companies merchandize their products by using an attractive packaging. In fact, this may already be done, particularly in competitive electoral districts as challengers sent to “toss-up” districts in U.S. House and Senate races have significantly higher facial competence scores than challengers in electorally safe districts (Atkinson, Enos, & Hill, 2009, p. 233).
Studies testing both—perceived attractiveness and competence—are scarce and the few existing analyses have come to inconsistent results. Although Berggren et al. (2010) conclude that at least for Finnish nonincumbent candidates “beauty is more strongly correlated with success than . . . perceived competence” (p. 8), Olivola & Todorov (2010) arrive at a contrary conclusion. Two studies for the elections to the German Parliament found both traits—attractiveness and competence—to boost the chances of direct candidates to get elected (Jäckle & Metz 2016, 2017), although attractiveness seems to be the more powerful one. One reason for the diverging results may be that existing studies use both absolute and relative ratings and consider both consensus and majoritarian democracies with differing electoral systems. Our work tries to help clarify the situation by taking up a direct relative measurement but employing it in a majoritarian setting. With the United States having been at the forefront of mediatized politics and candidate-centered electoral campaigns for decades (Arbour, 2014; McAllister, 2016), it could be assumed that attractiveness as a role-unrelated factor is at least of the same or even of greater importance than the more role-related factor competence.
From these theoretical considerations and the review of the literature, we expect that attractiveness and perceived competence affect election results. We therefore derive the following hypotheses:
In addition, we test for likability as a third, role-unrelated predictor which so far has received little attention. Likability has mostly been examined for the United States after Wattenberg (1990) wrote about “the rise of candidate-centered politics” (see Bishin, Stevens, & Wilson, 2006). A shortcoming of most studies is, however, that they only focus on well-known politicians. Yet, if people already follow their gut feelings when assessing well-known politicians like U.S. presidential candidates (where information is easily available), likability should play an even greater role when voters are less familiar with the candidates. Moreover, appearance studies usually consider likability as a further control variable without considering possible interactions with other variables. Thus, it comes as no surprise that these studies find only little, if any, evidence of an independent likability-effect (e.g., Berggren et al., 2010). However, Rule et al. (2010) have shown that a perceived factor “power” (but not “warmth”) was predictive for the electoral success of U.S. Senators, whereas for the Japanese members of the Diet, the effects were reversed. “Warmth,” which can be seen as indicating general likability, may thus matter in certain cultural contexts but not in others—and should thus not be dismissed prematurely as a relevant predictor. According to findings for Germany, likability does not matter in most situations, but it may yield a decisive edge when two female candidates compete (Jäckle & Metz, 2017). 5 Taking these findings together we can assume perceived likability to be at best a second-order appearance trait and thus formulate the following hypothesis:
In terms of the strengths of the three appearance effects, the state of the art and the theoretical discussion above suggest the following hypothesis:
Although existing studies have provided strong indications that appearance matters for electoral outcomes, such effects may vary between contexts. As an example, Praino et al. (2014) have found that the relative importance of attractiveness and competence depends on the configuration of the opponents’ gender: competence seems to be more important for inter-gender races, whereas in intra-gender races it is attractiveness, because [b]etween two men or two women, it is fairly easy to determine with a glance who is more attractive than the other; when comparing a man with a woman, however such assessment becomes much trickier, even at times impossible [and . . . ] voters end up choosing the second easiest path, that is, they determine who appears to be more competent. (Praino et al., 2014, p. 1111)
Other studies suggest that the effects of appearance, particularly of attractiveness are conditioned by further context variables:
a. Male candidates seem to benefit more from beauty than females, probably because physical attractiveness may also carry negative connotations particularly for women (the “dumb blonde syndrome”; King & Leigh 2009, p. 591).
b. Attractiveness has a stronger effect for challengers than for incumbents, probably because voters know more about incumbents already and therefore need to resort less to thin slices of information on their physical characteristics to arrive at a decision (King & Leigh, 2009).
c. With attractiveness being correlated strongly with youth, it can be argued that particularly in races where a young candidate competes against an old candidate, attractiveness should play a greater role (see, for example, McLellan & McKelvie, 1993).
These considerations lead to the following conditional hypotheses:
Research Design
This section introduces our research design. First, we describe how we measure perceived attractiveness, competence, and likability with an online survey. The second subsection can be seen as a prestudy for the main analysis and aims at inspecting the robustness of the ratings. It explores which features in the pictures shape the perception of the three traits and thus highlights what makes for a good-looking candidate. We then describe how we measure the independent variables attractiveness, competence, and likability on the district level and how we apply a weighting procedure for ambiguity in the ratings that is based on respondents’ latency times. Subsection “Statistical Model, Dependent Variable, and Controls” describes our statistical model and the operationalization of the dependent variable and the controls.
Measuring Perceived Attractiveness, Competence, and Likability
Setting up the experiment
In the first step, for each congressional district, we collected photographs of the two candidates who won most votes in that district at the 2016 elections. 6 We have sought to collect pictures that resembled those used in election campaigns as much as possible, because it is these pictures that voters will most probably have in mind and assured that the pictures were as similar as possible in terms of presentation. 7
As the images’ backgrounds may also affect appearance ratings (especially when containing objects such as flags that may have a different relevance for German raters and U.S. voting population), we used two different picture sets. In Set 1, the pictures all had the original background, in Set 2, the background was replaced for all pictures by a uniform slate-gray background (see Figure 1). We control for the role of picture set in our analysis below.

Two examples for regular and slate-gray background.
Having collected all pictures, we set up an online survey in the second step that served to show 30 pairs of candidates to raters, each pair representing one congressional district. These raters were asked to indicate which of the two persons they deemed more attractive, competent, and likable—thus, the word rating does not mean a rating on a point-scale in our research, but a choice between the two candidates. Aggregating these binary decisions to the level of the electoral district (see below for this step) transforms these raw data then to an average that can be interpreted as a relative rating measuring between 0% and 100%. Letting respondents choose between pairs of candidates in such a relative way has several important advantages over absolute ratings: As Kenrick and Gutierres (1980) have shown, subjects rated a person as comparatively less attractive after having seen pictures of beautiful people—thus, when it comes to appearance, alternatives do matter and thus should be accounted for. As such, we expect our approach to reproduce the situation in an electoral district more faithfully: First, real-life voters are probably unaware of the looks of most candidates outside their own district. Thus, presenting raters with alternatives that may affect their selection of more beautiful, competent-, and likable-looking persons but that real-life voters probably never see merely amounts to adding noise. In contrast, constraining measurement to alternatives effectively available to voters should minimize differences between actual voters and our raters. Second, virtually all models of electoral choice assume that an option is not picked because of its absolute merit but rather because it is the best (or closest) available alternative. Any effects of perceived personal traits should thus be based on the relative advantages or disadvantages a candidate has compared with his or her opponent within a district. And third, to the extent that rating appearances is a matter of cognitive effort, a relative evaluation is more parsimonious as it avoids an absolute standard of reference. Our measurement takes these points into account and follows the suggestions by Ballew and Todorov (2007) as well as by King and Leigh (2009) and Stockemer and Praino (2015) who also have stressed the importance of measuring perceived traits in a relative way. 8
In the third step, we had to recruit a sample of raters. This is not trivial, because when raters recognize the candidates their ratings might no longer rely on appearance alone but also depend on the candidate’s person or party. Different strategies have been adopted as solutions, such as using only the shapes of the candidates’ faces (Little, Apicella, & Marlowe, 2007), manipulating the photos (Armstrong et al., 2010), or assuring that raters do not know the politicians shown in the photos, for example, by recruiting raters from abroad. 9
We follow the latter approach and have opted to sample raters from Germany to evaluate pictures of U.S. politicians as these are not generally familiar to German citizens. 10 As a number of psychological studies has confirmed that facial appearance ratings are largely consistent through different cultures (e.g., Langlois et al., 2000; Little et al., 2007), we can assume that there are no major differences between the ratings of Germans and U.S. Americans (except the fact that the Germans should recognize less candidates and thus base their decisions more exclusively on the candidates’ appearance). Moreover, to assure unbiased ratings, we also asked the raters at the end of the main survey whether they had recognized a person and whether they knew his or her name. Districts in which a rater recognized a candidate were then excluded from the analysis for that rater. 11
Due to this sampling decision, raters were furthermore unaware that they selected among politicians. They were given no information on the persons they rated. 12 Candidate pairs presented were chosen randomly from the entirety of all 401 included congressional districts—33 districts had to be omitted because there was either no competing candidate (e.g., Terry Sewell was the only candidate for Alabama’s seventh district) or for one of the candidates there was no picture available (e.g., Democratic candidate for Georgia’s sixth congressional district Rodney Stooksbury who received 38.3%, could not be found and was even called the “ghost candidate” in local news; Martinez, 2016). 13
All in all, to avoid any biases potentially stemming from the rating procedure, we randomized across participants (a) which set of pictures was brought before a rater, (b) which of the 401 districts were presented and in what order, (c) which candidate appeared on the left/right half of the screen, and (d) the ordering of buttons for rating across raters. A screenshot of the rating tool can be seen in Figure 2.

Screenshot of the online rating tool.
The rating process was conducted as follows: Before the survey, participants were explicitly instructed to base their selection solely on their very first impression and their gut feeling. According to Ballew and Todorov, “rapid and unreflective face judgments” do a better job at predicting the electoral outcome than if the participants are asked to make a deliberated decision and “think carefully about their choice.” Furthermore, Bar, Neta, & Linz (2006) showed “that consistent first impressions can be formed very quickly” (only 39 ms were needed in their study to form a first impression, p. 269). We therefore gave respondents the sufficient but brief time period of 10 s 14 to choose who of the two candidates looks more beautiful, who looks more competent, and who looks more likable. We indicated the remaining time by means of a clearly visible countdown. This exposure time is clearly not as short as in other studies and therefore it is not completely possible to regard all judgments as “rapid and unreflected” in the view of Ballew & Todorov (2007) but it is still short enough to prevent raters from intensely deliberating about the contestants (p. 17948). Furthermore, this setup allows to test in a straightforward fashion how a single respondent rates the candidates regarding all three traits at once. When time ran out or the participant clicked the third item, there was a 2-s countdown on a blank screen before the next pair of pictures was presented. Each rater had to perform 30 such ratings of candidate pairs. Although other studies had participants rate up to several hundred pairs (see, for example, Atkinson et al., 2009), we chose this relatively small number to help raters remain focused on the task. Furthermore, with only 30 rated pairs of candidates, raters should be less likely to develop systematic response patterns which could bias the results.
On average, each congressional district was presented to 51.75 (SD = 7.19) raters. For attractiveness, the mean number of ratings for each pair of candidates is 45.08 (SD = 6.73; minimum = 26; maximum = 74), for competence it is 47.07 (SD = 6.56; minimum = 30; maximum = 71), and for likability it is 47.93 (SD = 6.78; minimum = 30; maximum = 75), respectively. All ratings are thus based on a sufficiently large sample according to the truth of consensus method (Patzer, 1985) which holds that already a much smaller number of raters produce an accurate measurement of attractiveness. Finally, we also measured—with an accuracy of 10 ms—how long a participant needed to click the respective button. We use these latency times as a measure of ambiguity as will be detailed in section “Operationalization of the Independent Variables: Ambiguity in the Ratings.”
After the 30 ratings, participants had to fill out a small survey. 15 In total, 694 raters completed the rating, whereas 100 raters stopped somewhere in the middle of the 30 picture pairs (and did not fill out the survey). For the following analysis, we will only resort to those with complete data available. Although our sample is not representative for the U.S. American electorate, it is more diverse than standard student samples with the increased heterogeneity working in our favor to offset potential effects stemming from raters’ individual attributes (see Figure A1 in the online appendix for a descriptive overview of the raters). 16
Apparent Properties of the Faces Influencing the Perception of the Three Traits
As a first step preceding the main analysis, we test which properties of the candidates’ pictures lead to evaluations as the more attractive, competent, or likable of the two presented candidates. In case the following analysis discovers effects of these appearance traits on the electoral results, it might be of interest how candidates could actively boost their appearance ratings. Furthermore, we show to what extent properties of the raters influence the results and thus our nonrepresentative sample of raters potentially biases the results. 17 We estimate nine different logistic models: each trait (attractiveness, competence, and likability), in each of the three district types (male vs. male, female vs. female, and female vs. male races). The results clearly show that several properties in a picture can shape our perception of a person, for example, the age of the candidate has a negative effect on attractiveness, whereas it has a positive effect on competence. Sometimes the effects are conditioned by gender of the opponents, for example, wearing a blazer or a suit only increases competence in female-only districts. Overall, the findings are very similar for male and female raters as well as for the two types of pictures: regular background versus slate-gray background (see Online Appendices A2 and A3). Furthermore, appearance ratings are largely stable across groups of young versus old raters and raters who perceive themselves as more leftist or more rightist (see Online Appendices A4 and A5). Some smaller differences (e.g., Black candidates are rated as more likable and attractive by leftist raters, whereas there is no significant effect of skin color on the ratings of rightist raters), are not large enough to warrant separate treatment of the groups. The most striking finding is indeed that most individual features of the candidates (hairstyle, tie, etc.) have almost no effect on the ratings, and if they have an effect (such as wearing glasses or the quality of the photo), these effects are similar over all groups of raters.
Operationalization of the Independent Variables: Ambiguity in the Ratings
To test the three facial traits we aggregate the ratings to the district level. So far, we have treated all ratings as similar. Each click had the same weight. Yet, it may sometimes be difficult to decide who is more attractive, likable, or competent—that is, ratings may range from clear-cut to hard-to-decide and ambiguous. This makes the raw ratings difficult to interpret, in particular if a large portion of the raters had trouble deciding. For computer-assisted telephone interviewing (CATI) research, Bassili argues that “opinions that are expressed quickly are usually more strongly associated with established evaluations” or “are usually more free of conflict than opinions that are expressed slowly” (Bassili, 2000, p. 4). This idea can be adapted to our context: Assuming that raters in doubt require more time to decide, we can use latency times until click as a proxy for ambiguity in the decision which candidate is more attractive (competent, or likable). Furthermore, the most pronounced form of ambiguity can be assumed if a rater does not click a button at all. In that case he or she could not decide between the candidates, similar to a 50/50-chance to click one of them. According to this finding, it makes sense to weight the ratings with respect to latency times to account for ambiguity.
Of course, raters are different regarding their overall clicking speed. For this reason, we center the latency times on the rater specific minimal and maximal latency times for each trait. The fastest click of each rater is assigned a weighting factor of 1.0, whereas the slowest click gets a weight of .2 (this reflects the assumption that clicking one of the candidates even after a relatively long latency time does not reflect complete ambiguity on behalf of the rater). The resulting weighted proportion of clicks for the winning candidate is then used as the independent variable in the analysis. 18
To test the extent to which the three traits are interrelated in the raters’ perception we correlated the weighted scores for the winning candidates of all electoral districts. The results show only a medium–strong relation (r = .54) between attractiveness and likability, whereas the other two correlations between (a) competence and attractiveness and (b) competence and likability are no higher than r = .25. The three traits can therefore be seen as relatively independent from each other.
Statistical Model, Dependent Variable, and Controls
To analyze the effects of perceived attractiveness, competence, and likability on the performance of U.S. House candidates at the 2016 election, we estimate ordinary least squares (OLS) regressions. Note that as our research strategy involves a relative assessment of the three traits (=weighted proportion of clicks for the winning candidate compared with the runner-up), this relational element also has to be reflected in the dependent variable. We therefore construct the dependent variable as the difference between the vote share of the winning candidate and the vote share of the runner-up. Taking a look at this variable shows that it is slightly skewed to the right and that on average, the winning candidate had a lead of 32.1 percentage points, whereas the maximum observed difference between the winner and the runner-up was close to 100 percentage points.
In addition to the variables that measure perceived appearance, we control for a number of features that characterize the electoral district and can all be seen as proxies for districts with demographic and/or economic specifics that could influence voting results in a way that the candidates either have a tighter race or one of them wins by a large majority: incumbency status and years of incumbency, gender of the candidates, 19 percentage of male, Black and Hispanic citizens, percentage of citizens without health insurance, and those with a high level of education. Furthermore, we control for the proportion of senior-to-youth citizens, the economic situation (measured via unemployment rate, the rental vacancy rate, and the median household income), and whether the district was expected to be contested before the 2016 election (classified as “not safe” or even “toss-up” by at least one of the four major predictions 20 just before the elections on November 8). In addition, we include the age difference of the candidates in the district, a dummy indicating whether the winning candidate was a Republican and the absolute difference between the percentages for Donald Trump and Hillary Clinton at the presidential elections 21 to be able to rule out that major partisanship effects bias the results. And finally, we control for the share of total disbursement of the winner compared with the sum of disbursements by both winner and runner-up. Although probably correlated to the incumbency status, this control variable leads to a harder test of the hypothesis because one could argue that if campaigns have more funds these resources could lead to more professional campaigns and a more competent and attractive appearance of the candidates (see Atkinson et al., 2009). In that case any effect of attractiveness would be spurious. All variables used in the regressions measure at the level of the electoral district. Table A7 in the online appendix gives an overview of all variables, their operationalization, and sources. Following our second research question, we also test interactions between the three perceived appearance variables and the configuration of the electoral race in terms of gender, incumbency, and age.
Results
In a first step, we estimate main effects models (see Table 1). The models differ by the picture set used for the appearance ratings (regular background in Models 1 and 2 vs. uniform, slate-gray background in Models 3 and 4). Models 2 and 4 replicate Models 1 and 3, respectively, using a stepwise backward procedure.
Main Effects Models.
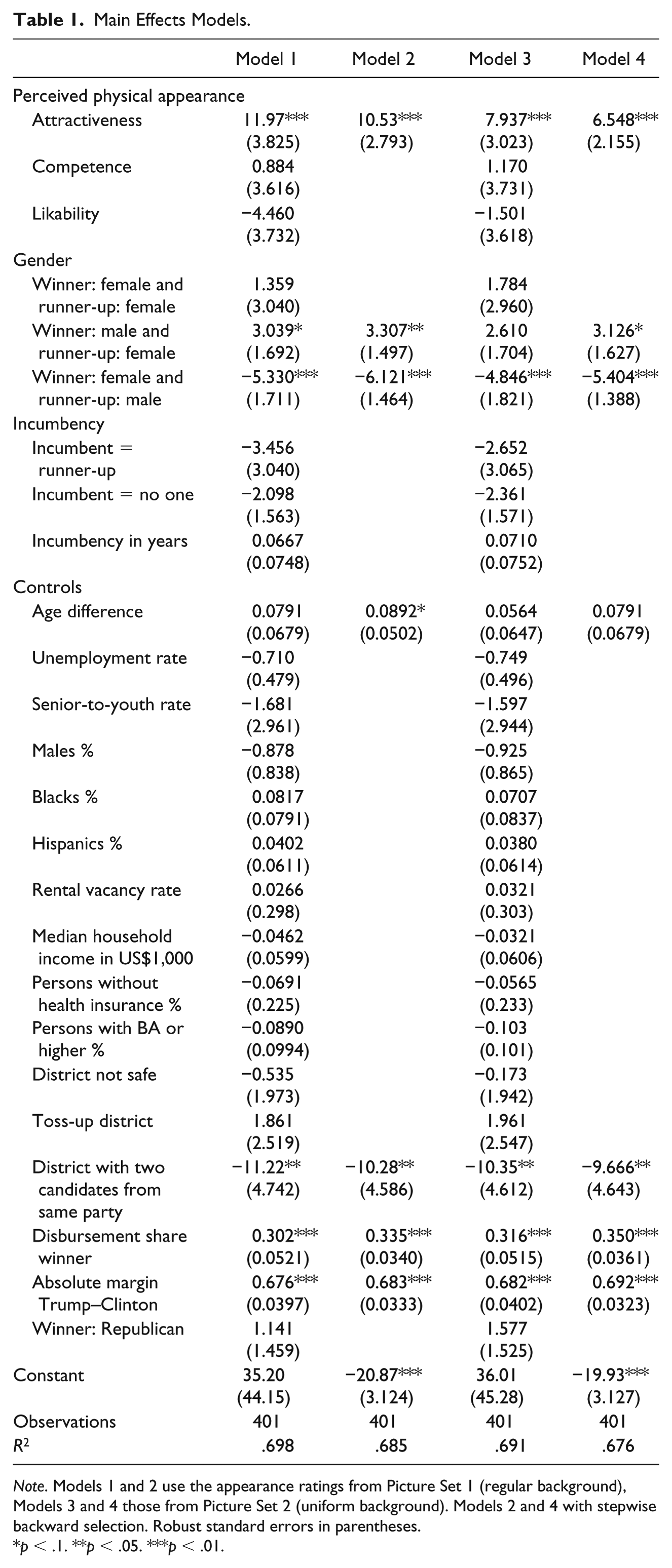
Note. Models 1 and 2 use the appearance ratings from Picture Set 1 (regular background), Models 3 and 4 those from Picture Set 2 (uniform background). Models 2 and 4 with stepwise backward selection. Robust standard errors in parentheses.
p < .1. **p < .05. ***p < .01.
Generally speaking, the explained variance is good and results are consistent across the models. 22 Regarding perceived attractiveness, competence, and likability, there is a clear finding: Only being seen as attractive helps the candidate while competence and likability do not have a significant effect. As the dependent variable is the difference in the first votes between winner and runner-up, the coefficients have to be interpreted as follows: A change in perceived attractiveness from 0 to 1 (i.e., from no one rating the winner as more attractive to 100% rating the winner as the more attractive candidate) increases the distance in the first votes between the winner and the runner-up by 11.97 percentage points (Model 1). Hence, the main effect models clearly show that physical appearance in terms of perceived attractiveness affects vote shares for House candidates even when controlling for other relevant factors such as absolute differences in presidential vote shares, incumbency, disbursements, or the economic situation in a district. Attractiveness is even the third most important predictor in our model according to the standardized coefficients (see Table A9 in the online appendix). This is a substantial effect.
Regarding the control variables, age and incumbency status 23 show no significance, whereas the gender matters: male candidates win by a larger majority and women, respectively, win by a significantly smaller majority compared with men. Among the controls, the absolute difference between the share of presidential votes for Trump and Clinton explains most of the variance. With every percentage point of the margin between the two presidential candidates, the winning HoR candidate expands his or her lead by 0.67 percentage points. The percentage of total disbursements by the winner compared with the runner-up is the second most influential variable. Each percentage point of the total disbursements the winner spends more than the runner-up increases his or her lead by 0.30 percentage points. Most of the other controls are not significant. Thus, sociodemographic and economic factors play no big role. Only in the special case that two candidates from the same party compete in a district there is a significant effect. In these districts the races are tighter so that the elected candidate wins by a smaller margin. Interestingly, even the preelection prediction of a district to be “not safe” or even “toss-up” adds no additional explanatory power to the models.
Of the first three hypotheses regarding the main effects, only the expected positive effect of attractiveness can be corroborated empirically. For the elections to the HoR the role-unrelated factor attractiveness obviously presents the heuristic which is used most often. In contrast, perceived competence and likeability are not significantly correlated with the electoral results if we consider the main effects independent from the context (for interactions, see below). Consequently, the fourth hypothesis which stated that attractiveness has the strongest effect of the three appearance traits is also confirmed.
With respect to the background of the pictures, we furthermore find that the appearance effects are stronger if the three traits have been rated on the basis of those pictures with the regular background. With Models 1 and 3 being completely identical in terms of cases and variables—except for the appearance traits—comparing the effects between these two models shows to what extent the appearance of a candidate not only depends on her face, hairstyle, and outfit, but also on the background of the picture. Although the effects for the controls do not change much between Models 1 and 3, the effect for attractiveness indeed shrinks by more than 4 points.
All interaction models used to address Hypotheses H5a to H5d are based on Model 1 from Table 1. The interactions were tested in separate models. Figure 3 presents the results of all interaction models as marginal effect plots (with point estimates and 95% confidence intervals). It illustrates the marginal effects of the three appearance traits (columns) on voting results conditioned by our main independent variables: incumbency, gender, and age. With respect to the first interaction hypothesis the first graph in the first line of the figure shows that, although attractiveness indeed matters for voting results in male-only districts as H5a proposed, it is also significantly positive in both types of mixed districts. Only for female-only districts does attractiveness not matter. In contrast, although likability is generally not a relevant predictor of the voting result (see Table 1), the third graph in the first line illustrates that this is different in female-only districts: Here, as theorized in H5b, the more likable candidate gains more votes. H5c expected the attractiveness effect to be stronger for challengers. Yet, the results show that the opposite is true (see the first graph in the second line). If the 2016 winner had already been a member of the House before, attractiveness increases the size of the difference in vote shares. This means that attractiveness seems to be more important for incumbents than for challengers. This effect is partly due to the larger number of incumbents who win their district. Nevertheless, it is not just that the conditional effects for “no one” and “runner-up” fall short of significance; they are also much weaker than the one for “winner.” Thus, the attractiveness effect for incumbents indeed exists. 24

Marginal effects of the interactions between the three appearance traits and incumbency, gender, and age (+95% confidence interval).
The final interaction hypothesis posited that the attractiveness effect is stronger the bigger the age difference between the opponents is (H5d). In the first graph in the last line of Figure 3, we therefore present how age conditions the relationship between attractiveness and vote shares. Although by trend the marginal effects plot reveals that the effect of attractiveness increases the older the winner is in contrast to the runner-up, the confidence intervals largely overlap for the whole scale of age differences. Therefore, against the expectation formulated in H5d, age does not seem to condition the effect of attractiveness very strongly.
Summary and Discussion
We began this article asking whether perceived attractiveness, competence, or likability can predict electoral success of House candidates, and whether appearance effects are conditioned by incumbency status, gender, and age of the candidates. To answer these questions, we took great care to obtain valid appearance ratings—regarding attractiveness, competence, and likability—for the candidates from all of the 401 Congressional districts, where at least two candidates competed and pictures of both the winner and the runner-up were available. First, we have gathered relational ratings based on the direct comparison between candidates of a district to accommodate real-world conditions (voters will compare available candidates instead of judging them in the way a jury in a beauty contest would). 25 Second, we chose raters who were unfamiliar with U.S. politics and thus did not generally know the candidates from the pictures they rated. Third, we used latency times as an indicator of ambiguity that was used to weight the ratings. In addition, our preanalysis of attractiveness showed that raters were very consistent in their evaluations of attractiveness, which makes us confident that our results are not driven by the sample of raters.
Using the difference between the first vote shares of the winner and the second-placed candidate as dependent variable, we find that only attractiveness positively affects the vote share. Perceived likability and competence, in contrast, show no significant effects. These results are robust to controlling for factors that have been proven to be relevant within voting studies such as presidential votes, partisanship, incumbency, total money spent for the campaign, age, and gender of the candidates, the economic situation within the electoral district and the ethnic profile of the district. Including these controls is important as it helps to eliminate potential misspecifications of the models and thereby to single out the substantial effects of appearance. Yet, most existing studies in the field, having their roots in psychological research, neglect these politically important variables.
Relating our findings back to this literature, our results do not support the idea of Todorov and colleagues (2005) that competence wins. Rather our results back the work of Berggren and colleagues (2010) that attractiveness is the relevant factor. Our study thus lends additional support to the idea of a beauty premium: Even when controlling for many relevant covariates, attractiveness still exerts an influence on House candidate’s electoral performance. Given that we also know that attractiveness is partly influenced by physical characteristics, such as beards or glasses, this is an important finding for candidates and their election campaigns in the United States.
A second major contribution of this study is the systematic test, whether gender, incumbency, and age condition the appearance effects. Contrary to the results of King & Leigh (2009), we find that attractiveness plays a stronger role for those candidates who have the incumbency advantage. This comes as a surprise, because voters can rely on other information when making up their mind about incumbents (they probably know more about them), while they should be more likely to rely on other shortcuts, such as attractiveness, for evaluating challengers (see King & Leigh, 2009). With regard to gender, we find that while attractiveness plays a big role in male-only districts, it also helps in mixed-gender districts. Only in female-only districts does attractiveness not matter. Instead, in these districts we find another appearance trait to be important. Being perceived as likable based on one’s looks helps a female candidate when competing against another woman. At this point, we can only speculate why likability seems to work as an evaluative dimension for women, but not for men. 26 One option might be that the attractiveness heuristic at least in politics works differently for men and women. While voters seem to have no problem basing their decision in male-only or mixed districts on the role-unrelated factor beauty, this is not the case for female candidates. In these cases, voters seem to rely on cues that people believe to be at least a bit more role-related, such as perceived likability—stressing that empathy and compassion might be the factors voters would like to see in a female politician; and the appropriate heuristic is therefore perceived likability.
Perceived competence on the contrary never shows up as a relevant factor in any of the models. These results at least partly contradict the findings by Praino and colleagues (2014) who found that competence is more important if women compete against men in a district, whereas attractiveness is decisive in races between only male or only female candidates
We conclude that for elections to the U.S. HoR beauty always “pays” and is never “beastly.” In contrast, perceived competence and likability show no major effects on the vote share. Particularly for incumbents and older politicians, their physical appearance is a factor they can hardly neglect particularly in the tough fight for contested districts. A candidate’s result compared with the opponent can be boosted by up to 12 percentage points just by looking (much) more attractive. Yet, while attractiveness matters, it is not everything—other factors, particularly the partisanship variable measuring the margin between the two presidential candidates and the disbursements of the candidates, which is markedly related to incumbency, also strongly influence the degree of electoral success. Nevertheless, for candidates themselves, it certainly matters that their appearance may help or hinder being perceived as attractive and that this perception has an impact on their chances of success at the ballot box. Candidates aware of the mechanism could actively try to shape their appearance and thus boost not only their attractiveness rating but also their chances at the elections. Our data show that, for example, a simple change from wearing glasses to contact lenses could already make a difference.
Supplemental Material
Online_Appendix_Revise_29.07.2019 – Supplemental material for A Catwalk to Congress? Appearance-Based Effects in the Elections to the U.S. House of Representatives 2016
Supplemental material, Online_Appendix_Revise_29.07.2019 for A Catwalk to Congress? Appearance-Based Effects in the Elections to the U.S. House of Representatives 2016 by Sebastian Jäckle, Thomas Metz, Georg Wenzelburger and Pascal D. König in American Politics Research
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Supplemental Material
Supplemental material for this article is available online.
Notes
Author Biographies
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.