
Abstract
Background
In minimally invasive surgery (MIS), maintaining consistent optical clarity is essential for surgical safety and efficiency. However, lens contamination events (LCEs) such as fogging and debris accumulation continue to disrupt visualization, requiring frequent camera removal and cleaning that prolongs operative time and is linked to surgical injuries.
Objective
Determine performance of an artificial intelligence (AI) model, LUCID, for the detection of laparoscopic lens contamination.
Methods
Surgical video footage was collected from the central Texas region and annotated to classify the lens state as “clean” or “dirty.” An AI model was trained on this dataset to detect lens contamination. 9 additional laparoscopic procedures were analyzed by the model and validated by human reviewers to determine true model performance.
Results
Across the 9 cases analyzed by LUCID and validated by reviewers, the model achieved an overall accuracy of 90.42%, with a precision of 94.45%, sensitivity of 91.19%, and specificity of 88.80%, demonstrating potential for the use of LUCID to assess optical clarity in MIS.
Conclusion
AI-enhanced visualization assessment presents a promising approach to enable objective detection of visual clarity in MIS. With compromised vision being a known problem with serious safety concerns, and future applications for AI-enhanced surgery requiring clear visualization for high performance, the importance of clear visualization is paramount more than ever before. Future work may look to standardize visual clarity across operative settings to mitigate variability in clinical outcomes.
Keywords
Introduction
Minimally invasive surgery (MIS) has revolutionized the field of surgery, providing patients with reduced recovery times, smaller incisions, and fewer complications compared to traditional open procedures. 1 Applying robot-assisted surgery (RAS) to minimally invasive procedures has further refined these advantages by offering enhanced precision, improved dexterity, and superior visualization. Although both MIS and RAS have advanced the surgical field, visual clarity during procedures remains a persistent challenge that significantly impacts surgical efficiency and patient outcomes.2-5
Lens contamination events (LCEs) such as fogging/condensation and debris accumulation (eg, blood, tissue residue, irrigation, etc.) can obscure the surgeon’s field of view, increasing operative time and surgical injuries/complications.4-6 LCEs necessitate frequent interruptions for lens cleaning, disrupting the workflow and increasing the cognitive load on the surgical team. 7 The assessment of visual clarity during MIS largely remains at the discretion of the individual clinician, leading to inherent variability and subjectivity across operating rooms (ORs). Research highlights the shortcomings of current visualization solutions in addressing these problems effectively, prompting the need for innovative strategies to enhance optical clarity during MIS.8,9 In MIS, surgeons operate with poor visualization nearly 40% of the time, a condition that drives almost one in five complications, forces repeated workflow disruptions, and adds over $2 billion in annual burden to the healthcare system, making it one of the most pervasive and costly hidden problems in modern surgery. 5
Visualization challenges in MIS stem from multiple factors, including body cavity humidity, patient anatomy, blood/irrigation splatter, and others - all of which may contribute to LCEs.10,11 The repeated need for manual lens cleaning interrupts the surgical flow and has been shown to comprise ∼7% of OR time, further increasing operative time and risk of complications.5,6,12 Moreover, the impact of visualization disturbances on surgeon performance and mental workload has been well-documented, reinforcing the critical role of uninterrupted optical clarity in ensuring optimal surgical outcomes. 7 Although various solutions such as anti-fog coatings, warm saline rinses, and specialized cleaning instruments have been explored, the current standard of care for maintaining optical clarity in surgery still requires scope removal from the body or continuing surgery under suboptimal visualization.3,5,8-10,13-15 Investigations reinforce the persistence of these issues and underscore the limitations of poor visualization in today’s MIS OR, despite substantial advancements in surgical imaging technologies. 5
Many studies have also explored the subjectivity of image interpretation in medicine and surgery, yet most studies focus on diagnostic applications. Publications consistently note that subjective assessment of medical visual data is linked to interpretive variability that may impact decision making, highlighting the need for objective, quantitative metrics to complement - but not replace - subjective clinical judgement.16-21 This may be one factor that helps explain the trend of objective quality metrics integrated in medicine and surgery, especially when combined with what was previously considered inactionable.22-30 Furthermore, AI models for visualization-based tasks are effectively trained on clear and pristine images, as such data quality helps ensure optimal AI accuracy and performance for the intended underlying functions. 22 For example, training an AI model to detect an anatomical landmark (eg, ureter) in surgery would likely not be able to detect said anatomy in an image that was foggy with condensation or partially covered in blood, as the visual obscuration could cause the model to miss key features needed during extraction to accurately detect the target structure confidently. As such, future surgical technologies leveraging AI or even general image analysis techniques will rely on clear visualization to function safely and effectively, thereby positing obscured visualization as a linchpin for the future of surgery. As MIS continues to gain widespread adoption in various surgical disciplines, addressing visualization challenges remains a priority for enhancing operative efficiency and patient safety. The inherent variability and subjectivity in assessing visual clarity during MIS, as highlighted by existing research, underscore the critical need for an objective and standardized approach. To address this challenge, we developed an AI-powered system designed to assess whether a laparoscopic camera is clean or obstructed in real time.
Methods
The primary objective of this paper was to analyze how the proposed Vision Transformer model, LUCID (Lens Utility for Clarity Interpretation and Detection), performed regarding the classification of lens cleanliness as compared to human annotations.
Data Collection
Laparoscopic videos were collected from multiple clinical sites, representing a diverse range of surgical procedures, including common cases in gynecology and general surgery such as hysterectomies, laparoscopic cholecystectomies, appendectomies, oophorectomies, hernia repairs, splenectomy, and colon resections. A total of 77 de-identified cases comprising approximately 96 hours were annotated. During collection, all of the video properties were tracked for their varying frame rates and resolutions, although the majority of videos were collected at 1080p and 30fps. Each case name seen in this paper corresponds to a unique de-identified laparoscopic case that was analyzed.
Data Annotation
Trained annotators labeled video clips as “dirty” based on the presence of an LCE (blood, condensation, smearing, or other lens contaminants) on the scope lens as seen in the video frames (Figure 1). Video clips with a clear view of the field and no physical obstruction of the camera lens were labeled as “clean” (Figure 1). Any other frames viewed during the annotation process were labeled as unsure, noise, or out of body and excluded from training. Two independent annotators reviewed each frame to help ensure a robust and varied dataset in an attempt to ensure model generalizability against potential annotator subjectivity. Approximately 60% of the frames were confidently labeled either clean or dirty and used for model training and validation. Images demonstrating examples of “Clean” and “Dirty” frames based on the presence of Lens Contamination Events (LCE)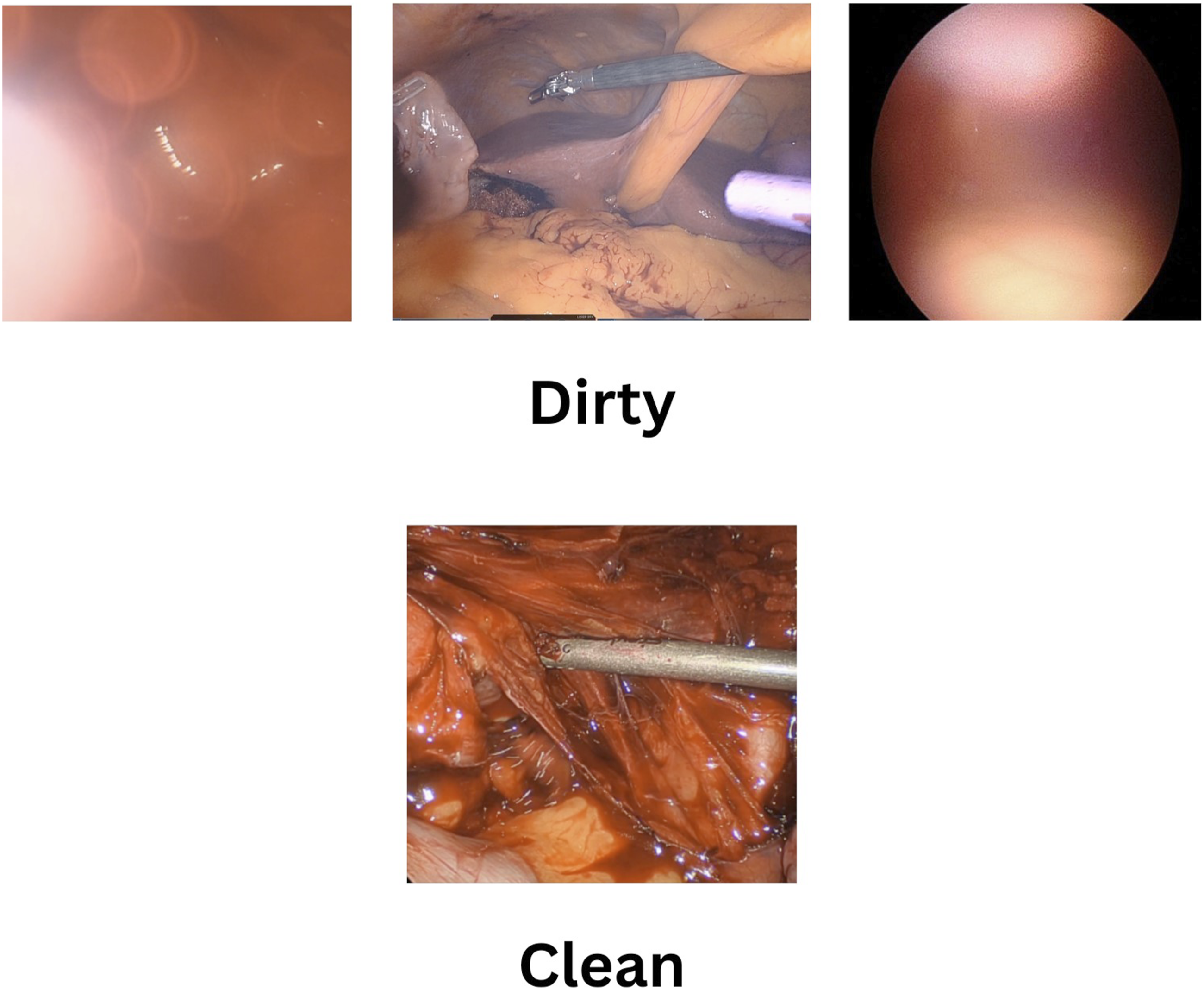
Dataset Generation
The trainable data amounted to about 57 hours or 207,000 seconds of clean or dirty surgical data. The trainable data resulted in a clean/dirty split of about 70/30, so overall, the dataset was heavily biased toward clean surgical frames. Of the 57 hours of trainable data, the model was trained on 70%, validated on 20%, and tested on 10%. Each of these train, validation, and test splits reflected the overall dataset’s general clean/dirty split of 70/30. Train, validation, and test splits were performed at the video level to prevent temporal leakage between sets.
AI Model Development
Several model architectures, such as basic CNNs (eg, InceptionV3), Vision Transformers (ViT), and video-based models including spatio-temporal architectures and 3D CNNs (eg, X3D), were researched and considered for this project. Basic CNNs proved to be less generalizable and more inconsistent, and 3D CNNs were deemed too heavy for this project. This project trained a Vision-Transformer model, which processes images by dividing them into fixed-size patches, embedding patches as tokens, and using self-attention mechanisms to learn relationships for image classification. 31 This model performs frame-level binary classification, and the architecture was chosen due to its high generalizability on sufficient data and moderate weight.
The model was initialized using PyTorch with weights from Vision-Transformer pretrained on ImageNet. Training was performed using the AdamW optimizer with an initial learning rate of 1e-7, batch size of 32, and weight decay of 1e-5. PyTorch’s ReduceLROnPlateau scheduler was applied over 25 epochs. The model was trained on 2 NVIDIA A100 GPUs. Training and evaluation were performed on a proprietary dataset not publicly available due to institutional and commercial protection constraints. While the dataset is not publicly released, most of the model architecture and training configurations have been provided to allow for reproducibility.
A custom dataset generator implemented in PyTorch was used with the DataLoader API during training. Each frame was resized to 224x224, and pixel values were normalized to the range [0,1]. During training, random augmentations including horizontal flip and random rotation of 15° were applied. No augmentations were applied to validation or test sets. To handle the dataset’s bias towards clean frames, random downsampling of clean frames was applied during training. Validation and test sets were left unmodified.
Detailed information about the underlying AI model (LUCID) architecture and training parameters is proprietary. However, the system’s core functionality - using the model to derive and present lens cleanliness information - is described in U.S. Patent Application/Grant [US20250288185A1], which provides additional technical detail regarding the computer-assisted method. 32
Model Evaluation
The model was deployed on a laptop and validated using the holdout test set to assess generalization on unseen surgical videos within the original dataset. As such, there was no physical implementation of the model on a self-sustaining hardware, nor was the technology used in a clinical setting. Model performance was also evaluated through accuracy, precision, sensitivity, and specificity. The holdout test set represented 10% of the trainable data and consisted of 9 full cases that were never seen during the training process. The AI model’s classifications were then compared against the human-annotated ground truth data to determine model accuracy, precision, sensitivity, and specificity in detecting dirty vs clean frames. In the context of the proposed AI model assessment, accuracy denotes the overall correctness of its classifications in distinguishing between clean and dirty laparoscopic lenses. Precision essentially indicates the reliability of the model’s predictions; effectively, higher precision translates to the model being correct more often when classifying a lens state. Sensitivity measures how good the model is at identifying all actual clean lens states, where higher sensitivity scoring means the model is effective at correctly identifying frames with clear visualization. Conversely, specificity assesses how effectively LUCID correctly identifies instances of contamination (dirty frames), collectively providing a comprehensive evaluation of its performance in assessing lens clarity. Higher specificity means the model excels at correctly identifying when visualization is poor.
Results
The holdout data were used to analyze AI model performance. LUCID achieved an overall accuracy of 90.42%, with a precision of 94.45%, sensitivity of 91.19%, and specificity of 88.80%. Across all surgeries, the model produced 5.96% false negatives and 3.63% false positives of all surgical video frames. The model correctly identified 61.68% of all frames as clean frames (eg, true positives), and 28.74% of frames were correctly classified as dirty (eg, true negatives). The confusion matrix (Figure 2) provides a detailed breakdown of these outcomes, where sensitivity is captured in the True Positive cell (True Clean-Predicted Clean, top left cell) and specificity is captured in the True Negative cell (True Dirty-Predicted Dirty, bottom right cell). Confusion matrix (row-averaged normalized data) comparing predicted and actual classification for dirty and clean classification after deployment of the AI model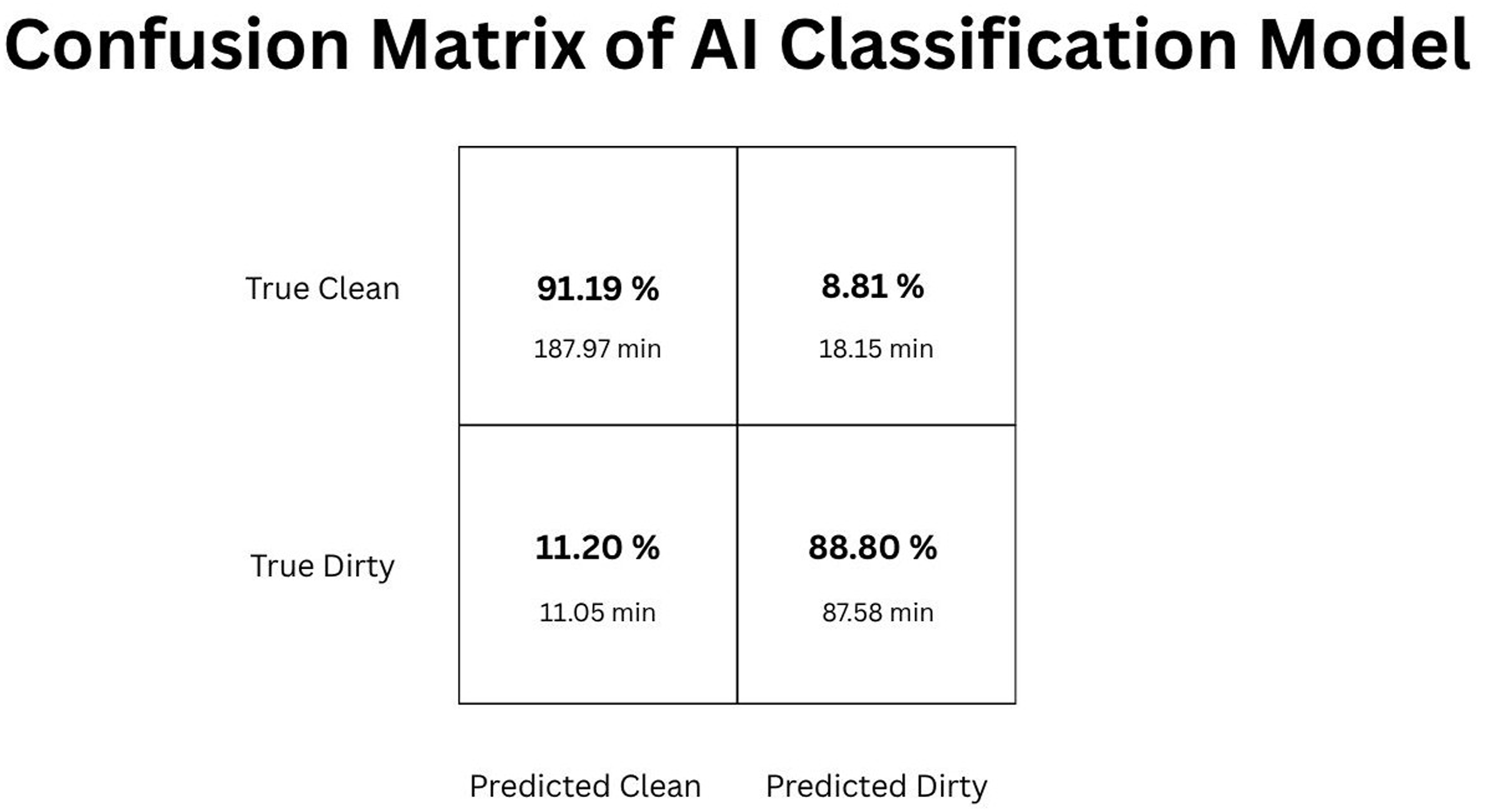
Analysis of case-level performance (Figure 3) showed variability across procedures in the test dataset. Case length averaged 33.86 ∓ 23.36 minutes. The case-averaged total accuracy of the model was 90.77% ∓ 5.25%. Most cases exhibited some degree of suboptimal visualization, with the proportion of predicted dirty frames in each case ranging widely from 1.33% to 98.95%, averaging predicted dirty case percentage from 44.35% ∓ 43.15% (with actual total prevalence of ground truth labels for poor visualization sitting at 32.37%). Case data with video length, lens clarity with model classification and ground truth labels, and model accuracy per case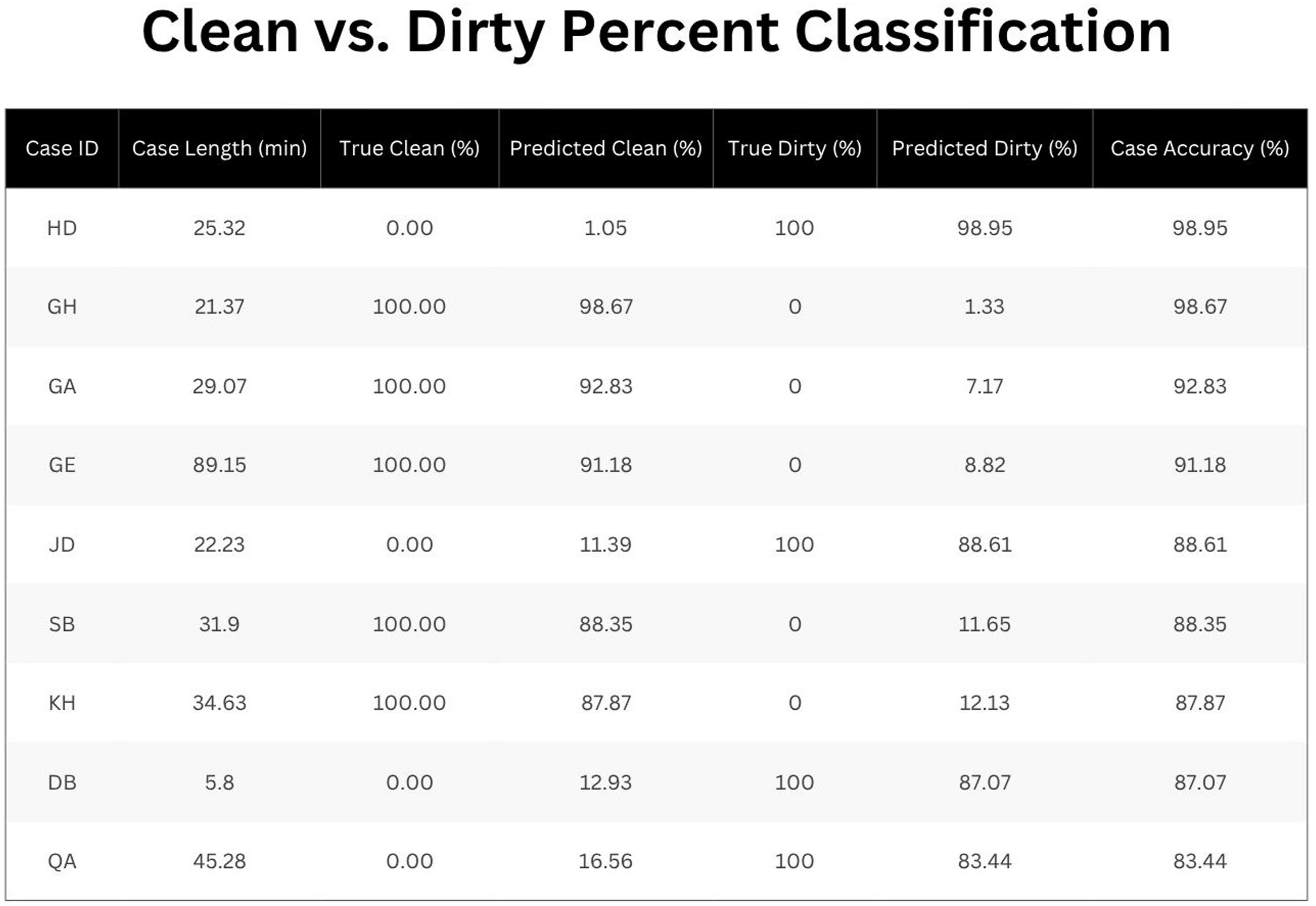
The model also demonstrated strong discriminative performance, achieving an area under the receiver operating characteristic curve (AUC) of 0.962 on the held-out test set, indicating a high ability to distinguish between clean and contaminated frames across classification thresholds (Figure 4). In this context, clean frames were defined as the positive class, such that true positive predictions correspond to correctly identifying frames with clear visualization. Receiver Operating Characteristic (ROC) Curve demonstrating an Area Under Curve (AUC) of 0.962 on the holdout data set
Discussion
This study demonstrates the feasibility of using LUCID to objectively assess laparoscopic visualization quality in real time. This objective assessment is particularly crucial because, as highlighted in the introduction, the evaluation of visual clarity in MIS largely remains at the discretion of individual clinicians, leading to inherent variability and subjectivity across operating rooms. LUCID offers a standardized, quantitative approach that can mitigate these inconsistencies, providing a more reliable foundation for surgical decision-making. The model achieved an overall accuracy of 90.42%, correctly identifying clean and dirty frames aligned with the ground truth, with sensitivity, precision, and specificity demonstrating relatively balanced performance across classification metrics. Performance is further affirmed with strong alignment between the overall model accuracy and the average accuracy across individual cases (90.77%). While these results reflect only preliminary development, they represent a meaningful advance toward objectively assessing visualization quality during surgery, which may prove valuable for impacting clinical and economic outcomes.
The model’s specificity is of particular clinical interest, as it correctly identified nearly nine of every ten contamination events. LUCID demonstrates early promise as a potential safeguard against compromised visualization. Lens contamination poses an economic burden of $2.2 B in the US, as well as direct risks regarding delays in recognition or addressing obscured views, which contribute to errors and surgical injuries, as literature shows poor visualization is directly linked to ∼1 in 5 patient injuries in MIS.4-6,33,34 Specificity, with moderately strong performance, reflects a current conservative classification tendency in which clean frames were sometimes misclassified as poor visualization, which may be preferable from a clinical perspective since classifying a clean lens as dirty seems less of a concern than classifying a compromised view as clear. This tradeoff may be acceptable in early system development, but minimizing false negatives will be essential for potential clinical relevance/application. Future work should incorporate further technical development to mitigate the clinical impact of brief OR misclassifications.
In Figure 3, the percentage of each case under suboptimal visualization is shown. While the test set included a small sample size with a large standard deviation, the case-averaged time under suboptimal visualization (32.37%) aligns well with the expanding literature showcasing ∼40% of MIS operating time being spent under suboptimal visual conditions. 5
Limitations of the study include the variability in surgical cavity illumination, video quality, procedure type, patient anatomy, and camera angle, all of which introduce potential noise into both model performance and manual annotations. The sample size of the unseen test set is also relatively small. Additionally, this study did not include a formal, systematic comparison between model architectures. Future studies comparing Vision Transformer models with standard convolutional neural networks (CNNs) and 3D CNNs would provide valuable insight into performance trade-offs in surgical visualization tasks. A primary limitation of this study is the reliance on a relatively homogenous and, in part, monocentric video dataset collected from the central Texas region used for both model training and testing. This ultimately suggests that model generalizability remains unrealized across more diverse clinical settings. The variability in case-level performance further underscores the need for significantly larger and more heterogeneous datasets to enhance model robustness across diverse procedures, lighting conditions, imaging systems, and other relevant variables - all items to be considered in future work. Furthermore, most AI model training sessions, including those in this study, rely on manual labeling by human reviewers, which can introduce variability. Using multiple reviewers and consensus frameworks could improve labeling consistency in future studies. Future iterations should consider extensive data expansion to cover the breadth of variables for a more generalizable model, such as including a greater breadth of surgical cases across several surgical specialties, as well as add data analysis features to increase value to clinicians and risk-, safety-, and quality-focused administrators and executives. This data may then be leveraged for improved clinical and economic outcomes.
Conclusion
Although subjectivity in medical image interpretation has been widely studied (primarily in diagnostic radiology and pathology), little work has examined the intraoperative environment where visualization is dynamic, and suboptimal visualization is a daily issue.
We present an AI model, LUCID, designed to evaluate laparoscopic lens clarity. LUCID, in its early stages of development, shows current feasibility and long-term promise to identify lens debris on laparoscope lenses, where debris causing suboptimal visualization is a longstanding source of intraoperative inefficiency, economic burden, and is linked directly to safety concerns around patient injury. LUCID demonstrated moderate but clinically relevant performance in detecting lens contamination. The model’s consistent identification of clean segments supports its feasibility for potential future application(s).
LUCID holds multiple potential real-world applications. In a clinical workflow, the system would operate alongside the laparoscopic video feed, continuously analyzing image quality and providing real-time feedback (eg, alerts or visual indicators) to prompt the surgical team when lens clarity degrades. An automatic triggering of an intervention, such as an automated lens cleaning solution, would be clearly applicable, supporting documented clinician preferences. 35 Most intriguingly, another application can be for LUCID to serve as an essential ‘enabling layer’ for the next generation of AI-enhanced surgical technologies, such as real-time anatomical landmark recognition and instrument tracking. By consistently monitoring visual quality inputs, LUCID safeguards against performance reliability and repeatability of these downstream AI tools, which will be paramount for patient safety and surgical efficiency for the surgical AI tools in the ORs of today and in the future.
With further refinement, including expanded training datasets, improved labeling, and integration of temporal context, a future version of LUCID could serve as the foundation for a closed-loop visual optimization platform. By reducing reliance on subjective human assessment, this approach could help standardize how visual clarity in MIS is recognized and leveraged across different ORs with varying levels of clinical experience within each OR team. While not a replacement for clinical decision making, such objectivity may enable more consistent understanding of visualization quality between institutions and surgical teams, and further hold potential for positively impacting economic and clinical outcomes in MIS. Unlike traditional methods that rely on subjective human interpretation or require manual intervention, LUCID provides continuous, real-time, automated assessment of lens clarity. This capability addresses a long-standing challenge in MIS by offering a consistent, data-driven measure of visualization quality, which is essential for both improving surgical performance and enabling the next generation of AI-enhanced surgical technologies.
This aligns with broader efforts across digital surgery and robotic platforms to incorporate intelligent assistance and maintain optimal operative conditions. LUCID establishes a foundation for a digital framework that can reliably detect poor visualization during surgery, ensuring that intraoperative video streams used by AI applications remain consistently interpretable in real time. With the advent of surgical AI, it is expected that future tools will leverage this technology to enhance operative performance with functions such as anatomical landmark recognition, instrument tracking, and workflow analysis. Because these models depend on clear video data to operate safely and effectively, the ability to flag obscured visualization as it occurs in surgery will be essential for safety and efficacy. In this way, LUCID functions not only as a tool for measuring intraoperative clarity but also as an enabling layer that supports the broader ecosystem of AI in surgery. For instance, consider an AI model designed for anatomical landmark recognition or instrument tracking. Such a model relies heavily on clear visual input to function accurately and safely. If the surgical field becomes obscured by lens contamination, the performance of these downstream AI applications could be severely compromised. LUCID, by continuously monitoring and flagging suboptimal visualization, could serve as a foundational ‘enabling layer,’ ensuring that other AI tools receive consistently high-quality video data, thereby enhancing their reliability and ultimately contributing to safer and more effective AI-assisted surgeries.
As visualization quality becomes an increasingly recognized determinant of surgical performance and safety, systems that can monitor and maintain lens clarity autonomously represent a logical step forward to improve clinical and economic outcomes, especially with expectations surrounding the integration of a myriad of visual-based AI tools in the ORs of the future. This study provides preliminary evidence supporting the development of future smart surgical assistance tools that preserve uninterrupted, high-quality visualization throughout minimally invasive procedures.
Footnotes
Acknowledgements
The research was conducted utilizing resources and data generated during the ongoing development of the ClearScope device, without direct financial sponsorship influencing the design, conduct, or reporting of this study.
Ethical Considerations
All laparoscopic videos analyzed in this study were restricted to intraoperative views of the surgery and contained no patient identifiers. The data did not constitute identifiable human subject information and were not considered PHI under HIPAA. As a result, the research was determined to be exempt from IRB review under institutional policy.
Consent to Participate
Informed consent for information published in this article was not obtained because all patient information was de-identified, and patient consent was not required. Patient data will not be shared with third parties.
Author Contributions
Sayani: Literature Review, Data Collection, Data Interpretation, Investigation, Writing, Zhu: Literature Review, Data Collection, Data Analysis, Data Visualization, Writing. Quadri: Literature Review, Data Collection, Data Analysis, Data Interpretation, Data Visualization, Writing. Yokananth: Literature Review, Data Collection, Data Interpretation, Investigation, Writing. Du: Literature Review, Data Collection, Writing. Schmidt: AI Model Development, Data Analysis, Writing. Srinivasan: AI Model Development, Data Analysis, Writing. Idelson: Supervision, Conceptualization, Writing - Review & Editing. Uecker: Supervision, Conceptualization, Writing - Review & Editing.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared the following potential conflicts of interest with respect to the research, authorship, and/or publication of this article: Dr Uecker and Dr Idelson are co-founders of ClearCam Inc and hold equity in the company. They are also compensated for their roles. Ms. Schmidt is an employee of ClearCam Inc and receives wages. Ms. Srinivasan was previously an employee of ClearCam Inc and received wages. All other authors declare no competing financial interests related to this work. The authors affirm that the study was conducted with scientific independence and that the data analysis and interpretation were performed objectively.