
Abstract
The few perceptual–cognitive expertise and deception studies in the domain of law enforcement have yet to examine perceptual–cognitive expertise differences of police trainees and police officers. The current study uses methods from the perceptual–cognitive expertise and deception models. Participants watched temporally occluded videos of actors honestly drawing a weapon and deceptively drawing a non-weapon from a concealed location on their body. Participants determined if the actor was holding a weapon or a non-weapon. Using signal-detection metrics—sensitivity and response bias—we did not find evidence of perceptual–cognitive expertise; performance measures did not differ significantly between police trainees and experienced officers. However, consistent with the hypotheses, we did find that both police trainees and police officers became more sensitive in identifying the object as occlusion points progressed. Additionally, we found that across police trainees and police officers, their response bias became more liberal (i.e., more likely to identify the object as a weapon) as occlusion points progressed. This information has potential impacts for law enforcement practices and additional research.
Keywords
INTRODUCTION
On March 18, 2018, Stephon Clark was fatally shot by two Sacramento police officers, Mercadal and Robinet. Stephon Clark was reportedly using a tool bar to break into vehicles. Once Clark and the officers spotted each other, a pursuit ensued. A few minutes later, Mercadal and Robinet followed Clark around the corner of a house. Mercadal and Robinet lost sight of Clark, so they drew their pistols. Clark was seen by the Sheriff Department’s helicopter, moving towards the officers. As the officers glanced around the corner of the house, they opened fire— almost immediately. Afterward, Mercadal stated that, “He came up and then he kind of approached us with his hands out like this and then fell down” as his body-worn camera shows Clark holding both his hands out in a shooting position (Becerra, 2019, p. 4). The body-worn camera footage shows a cell phone that is partially visible near Clark’s hand as the officers draw near to him. No gun was found on or around Clark.
This type of error—in which an officer perceives that a suspect is holding a weapon when they are not in possession of a weapon—is not uncommon. Fachner and Carter (2015) classified this error as a threat-perception failure and found that such failures were a factor in 49% (i.e., 29 of 59) of officer-involved shootings in Philadelphia in which the suspect was unarmed. Threat-perception failures are a problem because if a citizen reaches into their pocket to retrieve a cell phone or their identification, an officer—who might also be under stress—could interpret this as a threatening movement towards a weapon and open fire. This type of error has also been referred to as a mistake-of-fact shooting (Aveni, 2003), a perceptual threat of an imminent assault (Shane & Swenson, 2018), and a misdiagnosis error (Taylor, 2019). Threat-perception failures can also occur when an officer perceives a suspicious movement from the suspect (i.e., tugging at the waistband, where a weapon may be concealed). The reason for this is because one indicator that a person may be carrying a weapon is them placing their hands in a semi-defensive position close to their waistband (Meehan et al., 2020).
Threat-perception failures can occur due to several contextual factors such as priming from a dispatch call (Mitchell & Flin, 2007; Taylor, 2020), previous experience/knowledge of a suspect, suspect race (James et al., 2016), or apparent deceptive and threatening behavior from a suspect (Aveni, 2003). Situational factors at the scene of an incident can further affect an officer’s perception and action. These factors include low lighting and poor visibility due to distance between the suspect and the officer (Aveni, 2003). An example of these factors at play is the shooting of Amadou Diallo by police in New York City in 1999 (Fritsch, 2000). Amadou Diallo, a Guinean immigrant, was standing near his apartment building in the early morning when he was stopped by four officers. The officers were primed with information regarding a serial rapist in the area and mistook Amadou as their suspect. Amadou reached for his wallet—ostensibly to produce an identification document (e.g., driver’s license)—which the officers perceived as a movement toward a weapon. Based on this perceived understanding of the situation, all four officers opened fire, killing Amadou. It is likely that the combination of contextual (i.e., priming) and situational (i.e., low light) factors played a role in this shooting.
Researchers across multiple domains are interested in threat-perception failures. For example, factors influencing police use of force that have been examined include suspect race (James et al., 2016), expertise (Boulton & Cole, 2016), and dispatch priming (Mitchell & Flin, 2007; Taylor, 2020). Recently, threat-perception failures have also been examined from the perspective of perceptual–cognitive expertise (Scott & Suss, 2019; Suss & Raushel, 2019). The advantage of exploring threat-perception failures through the lens of perceptual–cognitive expertise is the focus on the underpinning perceptual, cognitive, and decision-making abilities, rather than on situational factors. Additionally, this approach allows further exploration of factors that may create expertise in law enforcement (e.g., cue discrimination, attention allocation).
Perceptual–Cognitive Expertise
Perceptual–cognitive expertise is “the ability to identify and acquire environmental information for integration with existing knowledge such that appropriate responses can be selected and executed” (Mann et al., 2007, p. 457). Compared to less skilled performers, highly skilled performers know which cues (e.g., environmental information) are relevant, when and where those cues are likely to be available, and what those cues mean. In dynamic situations especially (e.g., sport, driving, aviation), skilled performers’ ability to anticipate near-future states contributes to their ability to make appropriate decisions (Suss & Ward, 2015). Fifty years of research into perceptual–cognitive expertise in sport has consistently found that skilled players anticipate their opponent’s actions more accurately than do less-skilled players (Williams & Jackson, 2018). For example, skilled tennis players are better at anticipating service direction than less-skilled players (Farrow et al., 2005). They do this by attending to global information (i.e., multiple features like the arm, racquet, trunk, and legs; Huys et al., 2009). Law enforcement incidents—such as the one in which Stephon Clark was killed by officers—are similar to other dynamic situations in which anticipation plays a role. Officers must anticipate a suspect’s actions (i.e., whether or not the suspect is drawing a weapon or a non-weapon) based on subtle, dynamic motion cues and respond appropriately under time constraint. Our main goal is to determine whether perceptual–cognitive expertise exists in these types of law enforcement incidents. Next, we will expand on the few perceptual–cognitive expertise studies in law enforcement.
Perceptual–Cognitive Expertise in Law Enforcement
Perceptual–cognitive expertise has been investigated in law enforcement shoot/do not shoot scenarios. Vickers and Lewinski (2012) compared novice and expert officers’ decision-making and gaze control in live-action roleplay scenarios. The expert pool was defined as officers who were members of an Emergency Response Team with extensive experience with violent encounters. Compared to the novice officers, expert officers made more correct use-of-force decisions and fixated on more relevant visual cues. Those relevant visual cues included the area where the suspect’s right hand would be—even when the suspect was facing away from them and their hands were not yet visible. Focusing on this area meant that the experts were directing their attention toward the areas where weapons are commonly stored or held. This allowed the experts more time to correctly identify the object the suspect was holding. Novices tended to shift their gaze from the suspect to their own weapon (i.e., the sights) on 50% of trials, resulting in their attention being diverted from the suspect. This is consistent with theory on expertise (Ericsson et al., 2006), stating that experts are superior at accessing and using abstract information for problem classification and thus discriminating signal from noise. In other words, acquiring expertise involves learning which information is integral to the task and which is irrelevant (Ericsson et al., 2006). In the Vickers and Lewinski (2012) example, the experts had previous experience with violent encounters, which facilitated their ability to distinguish signals (weapon) from noise (non-weapon). Similar to adversarial situations in sport, law enforcement officers sometimes face critical situations that are dynamic, time-constrained, and uncertain in nature. In these situations, successful performance depends on the ability to accurately anticipate an opponent’s move. Next, we will discuss the predominant method used by researchers to examine anticipation ability in these types of adversarial situations: the temporal-occlusion method.
Temporal-Occlusion Method
In sport, researchers have used the temporal-occlusion method to examine how well an athlete is able to anticipate the outcome of an opponent’s move in a rapid sequence of gameplay. Similarly, in law enforcement, officers must anticipate the outcome of a suspect’s movement in a sequence of movements. Using this method, it is possible to identify how early in a sequence of gameplay an expert is able to anticipate the intent of the opponent. The temporal-occlusion method has been defined as “the editing of dynamic visual images (typically filmed from a player’s perspective) in order to provide selective vision to different time periods or events within the actions of an opposing player” (Farrow et al., 2005, p. 330). In tennis, for example, researchers film player(s) serving from the perspective of the player receiving the serve. Multiple serves are filmed, both to the forehand and backhand side of the receiving player (i.e., camera). The video of each serve is then digitally edited to create a series of versions that are occluded (i.e., replaced by a black screen) at different points in the serving motion. Early occlusion points might be when the server has tossed the ball in the air, and then when the server starts to move their racket to meet the ball. Later occlusion points might include the point of racket–ball contact and the frame after which the ball leaves the racket. Participants (e.g., less skilled and skilled, based on ranking) view the occluded videos in random order and anticipate whether each serve will land to their forehand or backhand side. Typically, the dependent variables are accuracy (i.e., correct/incorrect) and response time. Using the temporal-occlusion method, researchers have found skill-based differences between experts and novices across a variety of sports including badminton, tennis, and baseball (e.g., Mann et al., 2007). More recently, sport researchers have turned to investigate deception as a technique that players use to increase their success in adversarial situations. We previously discussed how adversarial situations in sport and law enforcement are dynamic, time-constrained, and uncertain in nature. However, another feature of adversarial situations is their competitive nature. Specifically, each encounter has a single victor: the tennis player either successfully or unsuccessfully anticipates the direction of the opponents serve, and the police officer either correctly or incorrectly anticipates the object that a suspect is drawing. Deception is especially important in law enforcement, given the life and death nature of the situations that arise. For example, a suspect may try to deceive an officer by pretending to pull out identification while instead going for a weapon with the intent of harming the officer.
Deception
In sport, players sometimes perform a deceptive action immediately prior to switching to their actual, intended action. Examples of deceptive actions in sport include the pump fake in basketball and the side-step in rugby. When a player performs a deceptive action, their goal is to cause their opponent to anticipate—and respond to—the deceptive action, leaving the player able to carry out their actual, intended action with little or no opposition. To investigate how deceptive actions influence anticipation ability, researchers have used a variation of the temporal-occlusion method. For instance, Cañal-Bruland and Schmidt (2009) recorded videos of expert handball players performing penalty shots. In half the shots, the expert players were instructed to shoot directly at the goal, and in the other half they were instructed to fake a shot. In the “true shot” condition, the videos were temporally occluded one frame before the ball left the hand. In the “fake shot” condition, the videos were temporally occluded at a comparable point (i.e., similar shoulder, elbow, wrist, and ball position). Novice and expert handball players viewed the true-shot (i.e., non-deceptive) and fake-shot (i.e., deceptive) clips and anticipated if the ball was actually shot at the goal or was a fake shot. Compared to novice players, expert handball players were consistently quicker and more accurate in anticipating the deceptive and non-deceptive actions at each occlusion point. But novices and experts were both slower and less accurate in the deceptive condition versus the non-deceptive condition. A meta-analysis of the effects of deception on anticipation in sport found that deceptive actions resulted in a decrease in anticipation performance for novices and experts (Güldenpenning et al., 2017).
Deceptive actions can occur in law enforcement incidents. For example, an unarmed citizen wishing to commit suicide may perform a rapid “draw” motion with a non-weapon (e.g., cell phone) or even an empty hand (Swaine, 2015) in an attempt to get officers to shoot them. This is referred to as suicide by cop (Stincelli, 2004). This strategy can work because if officers wait until they can clearly identify the object the citizen is holding—and it turns out to be a firearm—they risk being shot. Under extreme stress and threat of injury or death, it is understandable that officers might read the available (deceptive) motion cues and respond to those, instead of waiting until they can clearly identify what the citizen is holding. Another example of a deceptive action can occur when a seasoned criminal (or simply a good actor) tries to convince an officer that they are retrieving a non-weapon (e.g., a wallet from their back pocket), but actually intend to draw a firearm and shoot the officer. Finally, a suspect in a highly stressful situation may reach for their cellphone or wallet (e.g., to show their ID), but an officer might mistakenly anticipate that the subject is drawing a firearm. Although there are steps officers can take to minimize the frequency of deceptive situations occurring (e.g., using de-escalation tactics), officers can nonetheless find themselves in the position of having to make a split-second decision based on subtle cues under threat of potential injury or death.
Current Study
In the current study, we operationalize deception by including—in addition to trials showing a person drawing a weapon—trials in which a person draws a non-weapon with the intent to convince an observer that they are, in fact, drawing a weapon. As in Scott and Suss (2019) and Suss and Raushel (2019), including deception as a within-subjects independent variable makes participants’ decisions about the type of object being drawn (i.e., weapon vs. non-weapon) amenable to signal-detection analysis (Green & Swets, 1966). The advantage of applying signal-detection theory in the context of law enforcement is that it provides independent measures of sensitivity and response bias. Sensitivity is a measure of a person’s ability to distinguish a signal from a non-signal (i.e., noise) and response bias is a measure of a person’s tendency to indicate that stimuli are signals.
For the purposes of the current study, sensitivity is the ability to accurately distinguish a “suspect” drawing a weapon (i.e., a signal) from a suspect drawing a non-weapon (i.e., noise). Response bias is a measure of one’s tendency to identify a stimulus as a weapon. A person who tends to identify the object being drawn as a weapon is said to have a liberal response bias and a person who tends to identify the object being drawn as a non-weapon is said to have a conservative response bias. Therefore, Scott and Suss (2019) and Suss and Raushel (2019) designed their studies with the combination of object type (weapon, non-weapon) and participant response (weapon, non-weapon) that results in four different performance classifications: (1) hit, in which a participant correctly identifies the object as a weapon; (2) miss, in which a weapon is misidentified as a non-weapon; (3) false alarm, in which a non-weapon is misidentified as a weapon; and (4) correct rejection, in which a non-weapon is correctly identified as a non-weapon. Measures of sensitivity and response bias were calculated from participants’ hit and false-alarm rates.
Scott and Suss (2019) and Suss and Raushel (2019) focused on stimulus creation and validating the method in a law-enforcement context; as such, participants were undergraduate students with no law enforcement training. The current study aims to extend those two previous studies of deceptive movement in law enforcement situations by examining differences between police trainees and experienced police officers. Specifically, we are interested in whether experienced officers are better than trainees at distinguishing weapons from non-weapons, and whether they are able to do so earlier in the draw movement.
Hypotheses: Task performance
Based on Suss and Raushel (2019) and Scott and Suss (2019), anticipation performance will be determined using signal-detection measures of sensitivity and response bias. In sport, there are mixed findings regarding participants’ anticipation ability of deceptive movements as measured by researchers using response bias and the temporal-occlusion method. Several researchers have detected an overall negative-to-positive change in response bias as occlusion points progress (i.e., participants start off responding “noise” more often than “signal,” then progressively respond with “signal” as much as they respond with “noise”; Jackson et al., 2018; Takeyama et al., 2011). Conversely, Warren-West and Jackson (2020) found that the response bias trend becomes increasingly liberal (i.e., more “noise” responses than “signal” responses) as occlusion points progressed, but the trend becomes increasingly conservative at the later occlusion points (i.e., an almost equal amount of “noise” and “signal” responses). In the domain of law enforcement, Suss and Raushel (2019) and Scott and Suss (2019) found that participants exhibited a conservative response bias at early occlusion points and liberal response bias at later occlusion points. Therefore, we hypothesized that participants, regardless of experience, will exhibit a conservative bias at early occlusion points (H1). This bias will become increasingly liberal at later occlusion points, as additional information becomes available (H2). In other words, participants, regardless of experience, will identify the object as “non-weapon” more often than “weapon” at early occlusion points. Then, they will respond with “weapon” more often than “non-weapon” as the occlusion points progress.
Across the domains of sport and law enforcement, the findings are consistent regarding participants’ anticipation ability of deceptive movements as measured by researchers using the temporal-occlusion method: participants, regardless of experience, become more sensitive as occlusion points progress and more visual information becomes available. In other words, we expect that participants’ will become better at distinguishing between weapons and non-weapons at later occlusion points (H3; Jackson et al., 2018; Scott & Suss, 2019; Suss & Raushel, 2019; Takeyama et al., 2011; Warren-West & Jackson, 2020).
Hypotheses: Experience-level differences
There are mixed findings regarding how experience (e.g., low skilled vs. high skilled) affects response bias in sport research. For example, Takeyama et al. (2011) and Warren-West and Jackson (2020) found no overall significant group differences in response bias between low skilled and high skilled participants. However, Jackson et al. (2018) found that novice football players responded more liberally than expert football players. To the best of our knowledge, there has been no attempt to extend these findings to the domain of law enforcement. Based on these mixed findings, we hypothesized that overall, less-experienced officers will be more liberally biased (i.e., tend to identify the object as “weapon”) in their responses compared to experienced officers (H4).
The findings appear to be consistent regarding the low-skilled versus high-skilled participants’ anticipation ability differences of deceptive movements as measured by sensitivity—overall, low-skilled participants are less sensitive in their responses compared to highly skilled participants (Jackson et al., 2018; Takeyama et al., 2011; Warren-West & Jackson, 2020). To the best of our knowledge, there has been no attempt to extend these findings to the domain of law enforcement. Therefore, we hypothesized that experienced officers overall will be more sensitive in their responses compared to less-experienced officers. In other words, experienced officers are overall more likely to successfully identify the object compared to less-experienced officers (H5).
METHOD
Participants
Less experienced group
Twenty-four police trainees at a midwestern USA police academy were recruited via an announcement made by the academy’s the training staff. This group represented an entire cohort of trainees who were completing a 28-week training course at the academy. Trainees were informed that the purpose of the study was to assess how well law enforcement officers can detect innocuous and lethal objects that a suspect may be in possession of, while the suspect is making a threatening movement. The trainees’ mean age was 23.92 years (SD = 5.82). The majority of trainees (n = 13) self-identified as White; eight identified as Black or African American, two as Hispanic or Latino, and one as Asian/Pacific Islander. Six trainees had previously served in the Army and two in the National Guard. All trainees had completed the mandatory firearms training portion of the academy curriculum when they participated in the study. The trainees did not receive compensation for their participation.
Experienced group
Experienced police officers were recruited using two methods. First, a call for participants—including a link to the online study—was emailed to subscribers of Force Science News (https://www.forcescience.org/news/), a free bi-monthly e-newsletter on topics related to human performance in law enforcement. As such, subscribers are likely to be more knowledgeable about human-performance issues than nonsubscribers. Subscription is not limited to law enforcement officers. Second, a liaison from the Wichita Police Department (Kansas, USA) organized for a call for participants—including a link to the online study—to be emailed to sworn officers. A sworn officer is one who has taken an oath to support the constitution of the United States, their state, and the laws of their agency’s jurisdiction. Sworn officers include, but are not limited to, uniformed police officers, detectives, and officers serving in specialized units (i.e., SWAT). Selection of experienced police officers was not set by predefined criteria (i.e., years of experience) but rather by those who are sworn officers. Three hundred people clicked on the link in the two calls for experienced officers. Of those 300, 228 completed the informed consent (i.e., 76% of those who accessed the study) and 74 completed all 200 experimental trials (i.e., 24.6% of those who accessed the study and 37% of those who completed the informed consent). Of the 74 people who completed the experimental trials, 69 completed the final demographics survey and performance check (i.e., 23% of those who accessed the study and 93.2% of those who completed the experimental trials). The performance check was a yes/no question that asked participants whether they ran into problems (e.g., video lag, buffering issues) with the software. None of the 69 participants reported that they experienced video lag/buffering issues. The final sample comprises the 69 officers who completed the informed consent, experimental trials, and the demographics survey. The officers’ mean age was 45.70 years (SD = 10.52). The majority of officers (n = 59) self-identified as White; four identified as Asian/Pacific Islander, three as Hispanic or Latino, and one as Black or African American. Seven officers had previously served in the Army, six in the Marine Corps, and four in the Navy. The officers averaged 17.23 years (range: 3–48 years) of law enforcement experience. The officers did not receive compensation for their participation.
Stimuli
Video stimuli were created by filming four actors, (1 female, 3 male) using a Canon Vixia HF R300 video cameras with a frame rate of 30 Hz. Each actor performed draw motions with two different objects: an inert, silver, Smith & Wesson Model 10 revolver with a 4 in. barrel and a blue LG GT360 cellphone. The actor tucked the inert revolver into their front waistband; they placed the cell phone in their front hip pocket. For each draw motion that was filmed, the actor stood facing away from the camera, with the object concealed from the camera’s view. An audio cue signaled them to turn to face the camera while drawing the object from concealment. Actors were instructed perform the draw-and-turn motion as quickly as possible, and to aim the revolver at the camera and pull the trigger. They were instructed to draw the cell phone in a similar manner to the revolver (i.e., to try and deceive someone into thinking they were holding a firearm, as a subject might do in a suicide-by-cop situation). Multiple trials were filmed for each actor/object combination.
After filming concluded, we scrutinized the videos for each actor/object combination and selected the most realistic one (e.g., the smoothest and fastest turn-and-draw motion). Each selected video was then digitally edited to create five temporally occluded stimuli: 1. Frame before the gun/cellphone is visible 2. Frame halfway between occlusion points 1 and 3 (rounded down) 3. Frame where object is fully visible yet pointed away from camera 4. Halfway between occlusion point 3 and 5 (rounded down) 5. Frame where object is fully extended toward the camera
This yielded 40 video stimuli (i.e., 4 actors × 2 objects × 5 occlusion points). Conceptually, this resulted in a 2 (object type: firearm vs. cell phone) × 4 (Actor) × 5 (occlusion point) × 5 (trial repeat) × 2 (experience: police trainee vs. experienced officer) quasi-experimental design. Object type, actor, occlusion point, and trial repeat were within-subject factors; experience was the only between-subject factor.
Stimuli Presentation
The online study was presented to all participants using Gorilla Experiment Builder (https://gorilla.sc/; Anwyl-Irvine et al., 2020). Participants were presented with on-screen instructions and were guided through 10 practice trials prior to starting the experimental trials. Each of the 40 video stimuli was presented five times, for a total of 200 experimental trials. The order of presentation of the 200 trials for each participant was randomized by the software. The videos used during the practice trials were drawn from the 40 test stimuli. At the start of each trial a black screen with a white, central fixation cross was displayed for 2 s, after which the video appeared and began playing automatically. All videos were 854 × 480 pixels. The video stimuli are publicly available at https://osf.io/cs68a/.
At the point of occlusion, the video was replaced by a black screen and participants indicated whether the object was a weapon or a non-weapon by pressing either the “A” or “L” keys on a standard keyboard. Within each experience group, participants were pseudo-randomly assigned to use “A” to indicate “Weapon” and “L” to indicate “Non-weapon” or vice versa. Each participant used their assigned keys for the duration of the experiment. As an aid to participants, the key assignments were visible at the top of the presentation window throughout the experiment. Participants did not receive any feedback about their performance during, or after, the experiment. Participants were asked to respond as quickly as possible after the video was occluded.
Procedure
The research was approved by the Institutional Review Board at Wichita State University (IRB: #4521). Participants were provided with a link to the online study on Gorilla. sc. All participants indicated their consent to participate via an online form that was presented when they accessed the study. Trainees completed the experiment on individual desktop computers in a computer lab at their police academy. All 24 trainees completed the experiment at the same time, in a single session. Law enforcement officers completed the study individually on their own desktop or laptop computer at a time and location of their choosing. After completing the practice trials, participants were instructed to take breaks as needed during the experimental trials. The time taken by trainees (M = 27.68 min, SD = 4.08 min) and officers (M = 28.11 min, SD = 4.07 min) to complete the 200 experimental trials did not differ significantly, t (90) = .23, p = .82. After completing the experimental trials, participants completed a demographics questionnaire and indicated whether they encountered technical difficulties during the online experiment. None of the participants reported encountering technical difficulties.
Data Analysis Plan
Random Effect Model Specifications and Comparisons

Note: Occlusion Point (OcclusionPoint.continuous; M = 2.5) was means-centered in Models 3 and 5, and was effect-coded in Model 2 (Occlusion Point 5 served as the {-1, -1, -1, -1} baseline).
Fixed Effect Probit Regression Model Specifications and Comparisons

Note: YOE (Years of Experience; M = 12.53) and OcclusionPoint (M = 2.5) were means-centered and Experience was effect-coded, with trainees serving as the {-1} baseline.
Results
Model Comparisons
Random effect comparisons
We compared random effects structures to assess the best fitting model. All of the random effect structures allowed the model intercept to vary by participant and actor from the clips; we conducted five key comparisons. We compared random effects structures that included the main effect of occlusion point as a categorical (Model 2) or continuous (Model 3) variable to control for individual differences in participants’ ability to obtain additional information at each occlusion point. We also compared a random effects structure that included the main effect of object (where 1 = gun and 0 = not gun) as a random effect to control for individual differences in sensitivity (Model 4). We also included a model that allowed both the main effects of object and occlusion point (as a continuous predictor) to vary (Model 5). Lower AIC and BIC values indicate less-complex models that are more likely to generalize out-of-sample. Therefore, Model 5 (AIC = 16,404.82; BIC = 16,467.30) was the best-fitting model.
Fixed effect comparisons
Five probit regression models were created and compared to determine the appropriate model structure for our hypothesis tests. Each of these models was built on the best-fitting random effect structure (see Table 2). These models allow us to examine how participants’ sensitivity and bias changed in response to experience level (1 = police officer, 0 = trainee), occlusion point, and years of experience. The model comparisons also allowed us to determine if (a) experience level or years of experience is a better predictor of differences in sensitivity (Models 2 and 3), and (b) if sensitivity is better explained through three-way interactions (Model 1) or independent two-way interactions (Models 4 and 5). Based on the model-fit values, Model 4 (AIC = 15,189.06; BIC = 15,289.85) was the best-fitting model. Model 4 includes the main effects of object, occlusion point, and experience level and the interactions between object and occlusion point and occlusion point and experience level.
Signal Detection Theory Results
According to Proctor & Van (2008), a sensitivity (d′) value of .0 is indicative of chance performance, while d′ of 2.33 represents near perfect sensitivity. A response bias (c) value of 0 indicates no bias, while c values above 0 indicates a conservative bias (i.e., more likely to respond “non-weapon”) and c values below 0 indicates a liberal bias (i.e., more likely to respond “weapon”; Stanislaw & Todorov, 1999). We analyzed the main effects of object, occlusion point, and experience level and the interactions between object and occlusion point and occlusion point and experience level. Our model intercept varied by individual differences in sensitivity by occlusion point and by the actor in the stimuli. Overall, our sample reported a slight liberal response bias (c = −.08). Additionally, our sample was able to discriminate the signal (object) over noise (no-object) at above chance levels (d’ = 1.61).
Parameter Estimates from a Fixed Effect Model and Probit Regression Model Predicting the Relationship Between Overall Participant Response Tendencies (Gun or Cell Phone) to the Fixed-Effects of Object (Gun or Cell Phone).
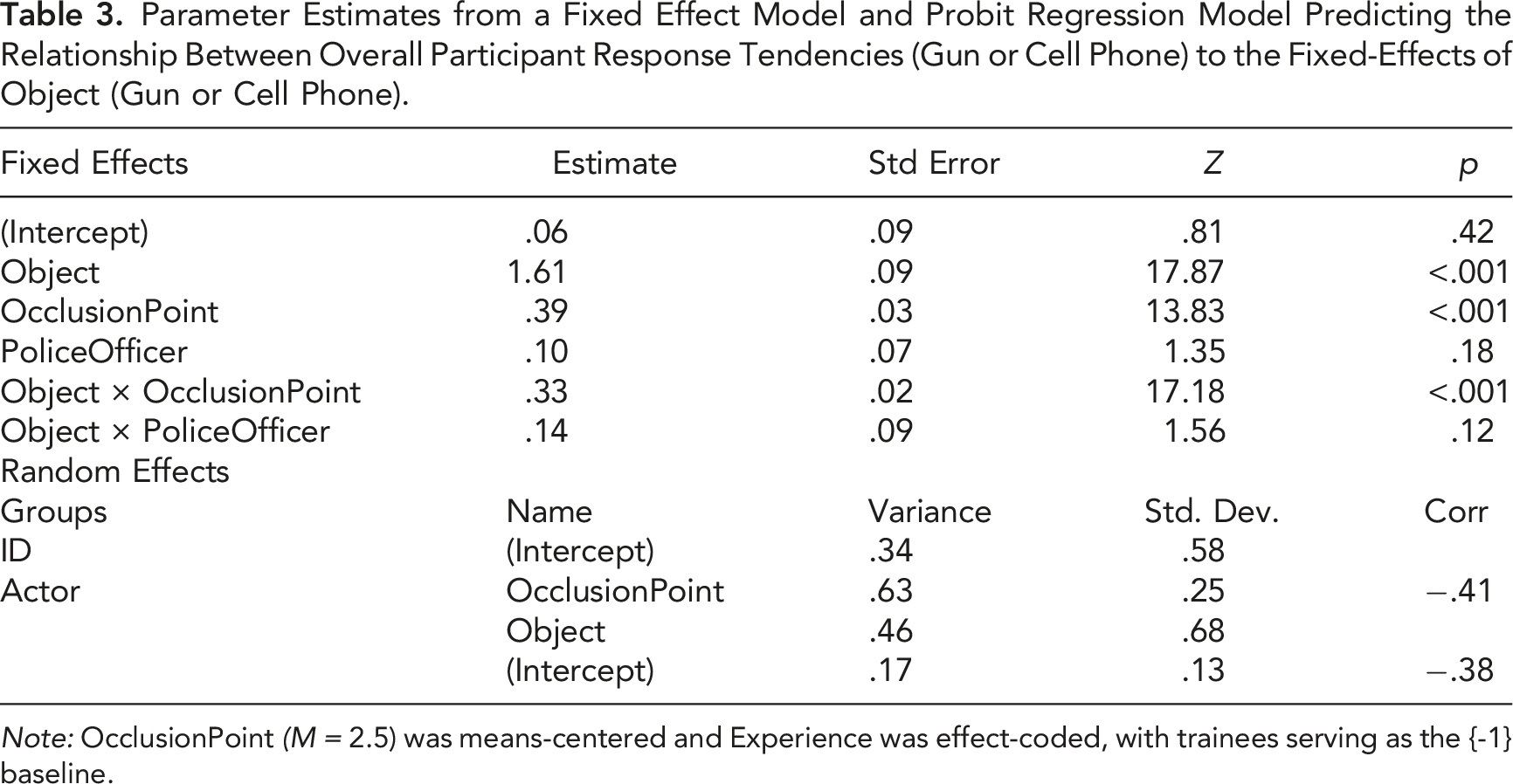
Note: OcclusionPoint (M = 2.5) was means-centered and Experience was effect-coded, with trainees serving as the {-1} baseline.

The relationship between response bias and occlusion point. Error ribbons represent ± 1 SE.
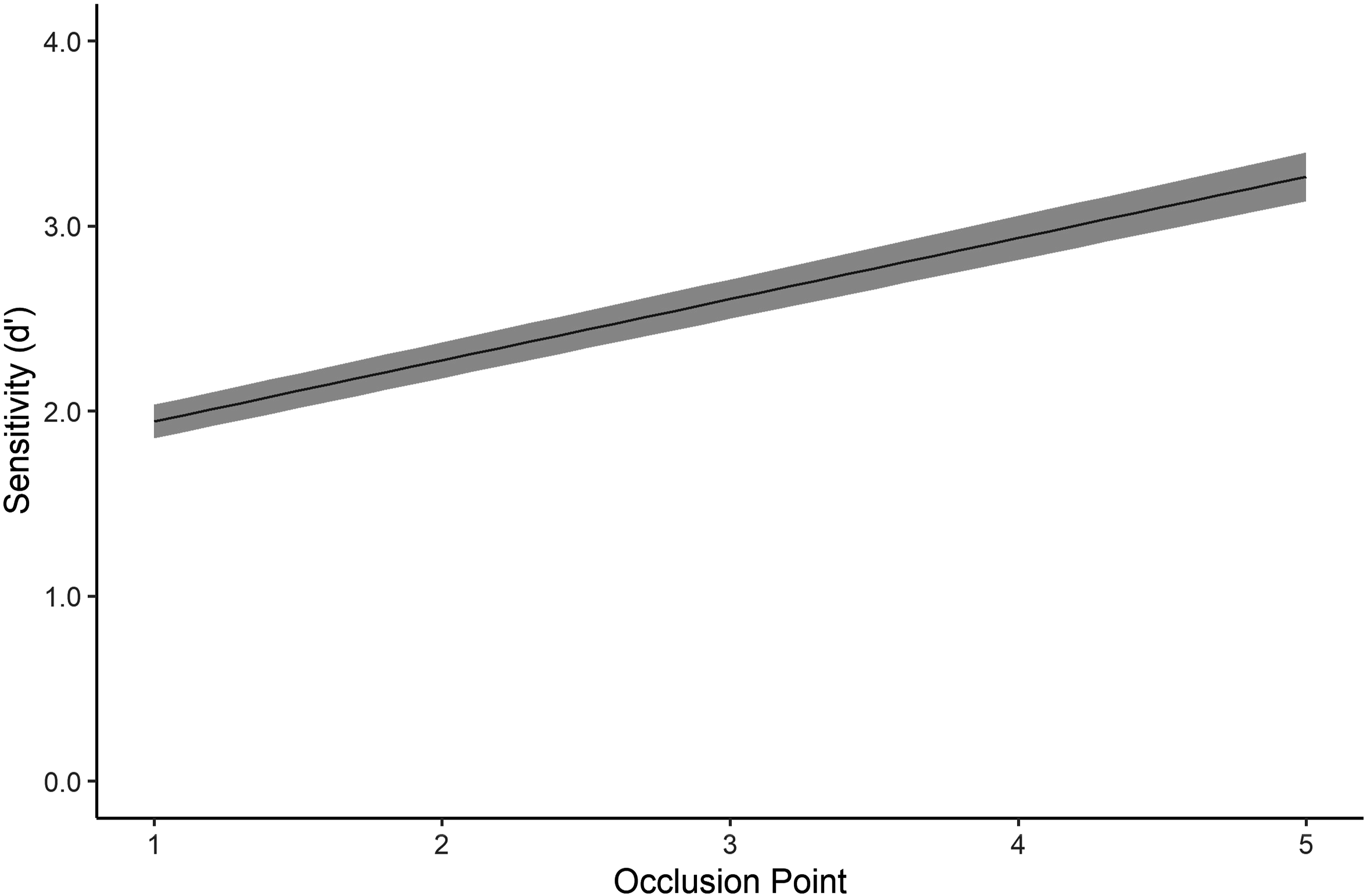
The relationship between sensitivity and occlusion point. Error ribbons represent ± 1 SE.

The relationship between response bias and experience level. Error bars represent ± 1 SE.

The relationship between sensitivity and experience level. Error bars represent ± 1 SE.
Post Hoc Power Analysis
We conducted two post hoc power analyses with the simr package (Green & Macleod, 2016) to compute the power required to find an effect size for the ability to detect how changes in occlusion point affect d’ and c. The analyses ran 500 simulations on our dataset and used an alpha equal to .05. The results revealed that we could achieve a power of .80 with approximately three participants (see Figure 6), and that a power of 1.0 would be achieved with 10 participants (see Figure 5). As our trainee (n = 24) and experienced (n = 69) samples were both greater than 10, we conclude that we had near perfect power.
Exploratory Analysis on Completion Time
As reported in the Method section, time to complete the experimental trials did not differ significantly by law enforcement experience (i.e., trainees vs. officers). But it was possible that participants who performed better (i.e., were more sensitive) did so because they took longer to complete the experimental trials. To test for this, we first calculated each participant’s overall sensitivity (d′) using the 200 experimental trials and then checked whether participants’ d′ scores were normally distributed, using a Shapiro–Wilks test, W (90 = .98, p = .26). As the data were normally distributed, we proceeded with two exploratory analyses. First, we conducted a simple linear regression to determine if time to complete the trials predicted sensitivity. Time to complete the experimental trials was not a statistically significant predictor of sensitivity, F (1, 89) = .42, p = .52 and accounted for less than 1% of the explained variability in sensitivity. Second, we compared the amount of time it took the least sensitive performers to complete the experimental trials to the time it took the most sensitive performers. To do this we first ordered participants’ sensitivity scores from lowest to highest, and then divided the distribution into quarters (Gelman & Park, 2009). We then compared the lower (n = 23) and upper (n = 23) quarters—representing the least sensitive and most sensitive performers, respectively—using an independent-samples t test. Time to complete the experimental trials did not differ significantly between the least sensitive (M = 27.90 mins, SD = 5.06) and most sensitive (M = 29.14 mins, SD = 3.93) performers, t (44) = .93, p = .36, Cohen’s d = .27.
DISCUSSION
The purpose of this study was to examine experience-based differences in perceptual–cognitive expertise between police officers and trainees in an object-identification task. We used the temporal-occlusion method—an approach commonly used to examine perceptual–cognitive expertise in sport and other dynamic domains—to examine anticipation ability. We analyzed the data using a modern approach to handling signal-detection data.
Based on previous perceptual–cognitive expertise studies, we expected that participants—regardless of experience—would exhibit a conservative response bias at early occlusion points (H1). Then, we expected that their response bias would become increasingly liberal at later occlusion points, as additional information becomes available (H2). Hypothesis 1 was not supported, while hypothesis 2 was supported: response bias was slightly liberal at early occlusion points and this bias became increasingly liberal as the occlusion points progressed. This runs partially contrary to our previous studies examining perceptual–cognitive expertise in law enforcement (Scott & Suss, 2019; Suss & Raushel, 2019), in which participants were conservatively biased at early occlusion points, but became liberal in the responses at later occlusion points. This relationship indicated that even when the object was fully visible, police trainees and police officers were more likely to identify the object as a weapon rather than a non-weapon. This is interesting because participants did not continue to stay unbiased in their responses. Instead, participants responded in a manner to maximize the number of hits (i.e., correctly identifying the object as a weapon) at the expense of increasing the number of false alarms (i.e., incorrectly identifying the object as a weapon), similar to the findings of Suss and Raushel (2019) and Scott and Suss (2019). By maximizing the number of hits at the expense of increasing false alarms, police officers could inadvertently shoot unarmed suspects to decrease the risk of missing detection of a lethal weapon. The risk of missing a weapon is consequential, as it could result in serious physical harm to the officer. This is reflected in Fachner and Carter’s (2015) finding that 49% of officer-involved shootings involved threat-perception failures. Adopting a liberal response bias could be framed as a rational response to manage risk in these situations. But the more liberal the response bias, the higher the likelihood of a false alarm. Therefore, it behooves police agencies to emphasize—during training and operational duties—the need for officers to avoid situations in which they might feel that they have no other option than to respond using lethal force. Even when these situations cannot be avoided, it is still imperative for officers to manage incidents (e.g., using communication, distance, cover, and time) such that they are not compelled to make a split-second object identification judgment, which—from the current findings—might bias them to response using lethal force (e.g., see Curtis, 2021). Following mistake-of-fact shootings, officers who misperceive a threat might be able to justify their actions (e.g., shooting) as being reasonable—from a legal perspective. However, the public’s perception of what is reasonable might be at odds with legal definitions of reasonableness; the public generally expects police officers’ performance to be unbiased or even conservatively biased (i.e., displaying a tendency to not use lethal force), even under stressful conditions (Loughlin & Flora, 2017).
We note that the tendency toward a liberal response bias in law enforcement is not limited to object identification; a similar bias has been observed in law-enforcement research examining deception detection in law enforcement interview situations. For example, Meissner and Kassin (2002) showed experienced police investigators video clips of interviews conducted with actors. Half of the clips showed actors who had committed a mock crime (e.g., shoplifting), while the other half showed “innocent” actors who were only in the vicinity of a mock crime. Those who committed the mock crimes were instructed to lie and maintain their innocence during the interview; those who were truly innocent were instructed to tell the truth about their whereabouts. The police investigators judged each suspect’s guilt or innocence. The investigators adopted a liberal response bias, in that they tended to judge suspects as “deceitful” rather than as “truthful.” By adopting a liberal response bias, the investigators committed more false alarms (i.e., instances in which they judged an innocent person as being deceitful) than they would have if they were unbiased, or had adopted a conservative response bias.
We expected that participants, regardless of experience, would become more sensitive as occlusion points progressed and more visual information became available (H3). The results support this hypothesis: sensitivity increased as occlusion points progressed. This indicated that trainees and police officers were better able to discriminate a gun from a cell phone when more visual information was available. This is in line with our previous studies examining perceptual–cognitive expertise in law enforcement (Scott & Suss, 2019; Suss & Raushel, 2019) and the general trend in sport research (Farrow et al., 2005; Mann et al., 2007). This is not a surprising finding: Officers should clearly be better able to distinguish between weapons and non-weapons as more visual information becomes available. This highlights the tradeoff between waiting for more information and exposing oneself to greater risk. Anecdotally, we have spoken with officers (i.e., not participants in this study) who had deliberated over this tradeoff and decided—a priori of any contextualized situation—to maximize sensitivity by waiting for a suspect to complete their draw motion so they could clearly ascertain whether the suspect actually posed a threat. The officers who described this strategy were clearly aware that they were exposing themselves to greater risk. In effect, they calculated that the cost of a false alarm was so high that the added risk was worth accepting to avoid shooting an unarmed subject (i.e., a false alarm). When hits and false alarms have different expected values, the optimal response bias will no longer be a neutral one (i.e., neither liberal nor conservative; Wickens et al., 2013). The officers who said they would wait for the suspect to complete the draw motion also espoused a conservative response bias (i.e., they assumed that not every person they encountered posed a lethal threat). However, they appeared to factor in more than just expected utility (i.e., expected financial gains or losses) in adopting a conservative response bias. Rather, their determination of the optimal response bias was based on subjective expected utility: the personal cost in guilt, and possibly post-traumatic stress, that they expected to suffer if they made the wrong decision. Officers who decide to maximize sensitivity and who adopt a conservative response bias must also weigh the potential cost of ridicule and criticism at the hands of their fellow law-enforcement officers. For example, a Canadian officer who decided not to shoot a man who drew and “aimed” a cellphone was criticized by other law-enforcement officers (Kipling, 2018). One possible criticism is that an officer who adopts such a strategy exposes other officers on the scene to unnecessary risk. Officers who feel that their fellow officer exposed them to unnecessary risk are likely to lose trust in, and respect for, that officer.
We also expected that overall, trainees would be more liberally biased (i.e., tend to identify the object as a weapon) in their responses compared to experienced officers (H4). The results did not support this hypothesis: trainees did not show a significantly different response bias in their responses compared to police officers. Finally, we expected that, overall, experienced officers overall would be more sensitive in their responses compared to trainees (H5). The results did not support this hypothesis: police officers were not significantly more sensitive than trainees. Typically, experienced athletes tend to outperform novice athletes in regard to accuracy (Mann et al., 2007) and experienced police officers outperform novices in correct use-of-force decisions (Vickers & Lewinski, 2012). However, if there was an expert advantage, this may have been eliminated due to the deceptive actions from the stimuli. A meta-analysis of deception in sport found that in 33% (8 of 24) of studies, skilled players’ anticipation ability decreased when deception was present (Güldenpenning et al., 2017). The current study uncovered important information about how people are able to anticipate the actions of others. For example, research in sport has demonstrated that both novices’ and experts’ anticipation ability increases as more visual information becomes available (Farrow et al., 2005). In other words, across the domains of sport and law enforcement, regardless of experience, anticipation ability increases as the amount of visual information increases.
One reason that we did not find experience-based differences in performance could be that patrol officers do not develop skill in object identification as a matter of course. In other words, their training may not include sufficient practice identifying objects in dynamic situations, and/or they may not experience many—or any—such incidents in the course of their operational duties. Another consideration is the high level of stress—and associated risk of injury or death—that officers are likely to be under when detecting and assessing threats. Under such circumstances, officers may choose to adopt a liberal response bias to maximize their own safety. Athletes, on the other hand, typically practice perceiving and responding to dynamic actions of the type of they encounter in competition. Some athletes even deliberately practice anticipating opponents’ movements (e.g., Fadde & Zaichkowsky, 2018). Extensive practice, with feedback, is the main way in which athletes develop anticipation skill. Athletes also have the opportunity to test and refine their skill on a regular basis during actual competition. It is possible that through perceptual experiences encountered during practice and competition, athletes’ ability to identify and integrate relevant information becomes more efficient, leading to increased visual expertise (Güldenpenning et al., 2017).
Additionally, a lack of motor expertise may have contributed to the lack of anticipation skill. Common coding theory (Prinz, 1997) suggests that planned motor actions and visual–perceptual information are represented similarly in the brain as a common code. Thus, perception and action share a common representation. Accordingly, the pickup of visual–perceptual information by an observer maps onto their motor representation and facilitates a motor response. Thus, when an observer picks up visual cues from an opponent, this perceptual–motor representation facilitates the anticipation of the subsequent action (Brenton & Müller, 2018). In other words, experience performing a motor task (e.g., tennis serve) should enhance anticipation ability for the same task (i.e., predicting whether an opponent’s serve will be to the receiving player’s forehand or backhand side). In the current study, the experienced officers likely did not have a perceptual–motor representation that facilitated their ability to anticipate the suspect’s actions. Felons who carry firearms typically carry those firearms in a concealed manner, and do not use holsters (Meehan et al., 2020; Pinizzotto et al., 2006). As far as we know, police officers do not create a motor representation of drawing a concealed weapon tucked into their front waistband by practicing that motion in training. Instead, they are typically trained to draw their unconcealed weapon from an external hip holster—a generally similar, but different motor task. Furthermore, they likely are not trained to deceptively draw innocuous objects (e.g., a cell phone) from their pockets. Therefore, police officers have likely not been afforded the opportunity to develop the appropriate visual–perceptual and motor representations necessary for anticipating a suspect’s actions. This is also generally consistent with theories of expertise that emphasize the importance of learning which information is integral to the task and which is irrelevant (Ericsson et al., 2006).
Limitations
Researchers have previously measured the accuracy and response time of participants to identify expertise differences. Therefore, it is possible expertise differences could be identified through means such as accuracy and response time. Another consideration related to response time is that in operational environments, police officers may have to very quickly make critical decisions about how to respond in ambiguous situations. In keeping with this, we instructed participants to respond as quickly as possible to each experimental trial. However, future research in this area could further emphasize speed by imposing a brief response window (e.g., 500 ms) after the occlusion point; responses recorded after the response window would be invalid.
The video stimuli were recorded at a standard frame rate (i.e., 30 Hz). The motion blur that occurred might therefore not accurately represent perception during real-world encounters. Future studies should consider filming at 60 frames per second or above and present the stimuli on 60 Hz or above monitors. There is historical concern that the inherent conditions of laboratory experiments may confound the empirical findings of perceived novice/expert differences from the perceptual–cognitive expertise paradigm (Abernethy et al., 1993) to the effect that the empirical effects are not comparable to field-based expertise performance. Field-based studies have historically elicited the greatest expert performance; however, the main issue is whether the type of task accurately captures novice/expert differences (Mann et al., 2007). Moreover, the main concern should be on whether participants are responding to the variable of interest and not a confounding variable in the environment, something that laboratory experiments are superior at, and field-based approaches lack (Mann et al., 2007).
The modality by which participants identify the object may also have an effect on perception and action. Witt et al. (2020) compared participants’ shoot/do not shoot responses to static stimuli under two conditions: in one condition the participants held a gun-shaped object and in the other condition the participants held a neutral object (i.e., a spatula). Compared to when they held a neutral object, participants took longer to correctly respond to do not-shoot stimuli and made more incorrect responses when they held the gun-shaped object. Therefore, future studies should consider using a modified weapon—rather than a keyboard—to indicate responses.
Future Research
One potential area for future research is the role that cognitive load has on an object-identification task with the stimuli used in this study (see Mugford et al. 2013). Singh et al. (2020) found that participants trained in a first-person-shooter task demonstrated more racial bias under high cognitive-load conditions. Varying the level of cognitive load may produce differing bias performance on this object-identification task. Under low-load conditions, participants tended to be unbiased in their responses. Police sometimes encounter stressful situations such as shoot/do not shoot scenarios. Thus, simulating high-load conditions may better represent operational conditions, resulting in improved transfer of anticipation skill.
Sport researchers have measured several indices of attention allocation (number of fixations, fixation duration, and quiet eye duration) to examine differences in visual attention between novices and experts (Vickers, 1996). In sport, experts typically exhibit few fixations of longer duration, while novices require more fixations of shorter duration to obtain the necessary amount of visual information to correctly anticipate the outcome of an event. Additionally, sport researchers have demonstrated that prolonged quiet eye period, or the period of time when event related visual information is processed and motor plans are formed to successfully complete an action, demonstrates expert and novice differences in the anticipation of event outcomes (Vickers, 1996). Researchers could measure these attention-allocation indices with an eye-tracking device. Such an approach could be used to determine the information (i.e., cues) that the best performing police officers attend to when successfully anticipating the outcome of a use-of-force scenario. The results could be used to design and test a training program for police.
Sport researchers have also used point-light displays to examine performance metrics and expertise differences (e.g., Wright et al., 2011). Researchers create point-light displays by attaching reflective markers on a person’s major joints (i.e., shoulder, elbows, knees, hips). Sport researchers have found that expert participants had an advantage over their novice counterparts in anticipating the outcome of an event (Loffing & Cañal-Bruland, 2017). Point-light displays could also alleviate the motion-blur issue. The use of point-light displays would also remove other confounding or contextual information, such as clothing, gender, facial expression, and skin color.
Following on from research that has examined perception–action coupling in sport (e.g., Brenton, Müller, & Harbaugh, 2019), researchers could test whether officers’ anticipation ability is improved by practicing drawing unholstered weapons from concealed locations on their body—mimicking the way a potential felon might behave. Such a training intervention study should also include the opportunity for officers to practice drawing non-weapons from concealed locations on their body—in the manner of someone intending to commit suicide by cop, as well as in the manner of a compliant citizen who is retrieving a non-weapon (e.g., identification). In this future study, police officers would be randomly assigned to three groups: visual–perceptual training, visuomotor training, or a control group. All three groups would participate in a video-based temporally occluded pre-test and post-test consisting of the video stimuli from this study to examine improvements in anticipation ability. All groups would also complete a transfer test with different suspects from the training trials. In the training phase, the visual–perceptual training group would observe temporally occluded videos of a suspect drawing an object (e.g., gun or cell phone) and anticipate the object type (weapon or non-weapon)—just as participants did in the current study. Such training could use the same temporally occluded video stimuli used during the current study. The visuomotor group would participate in the same visual–perceptual training, but after each trial participants would receive feedback through an unoccluded trial and then physically perform the draw from the trial with the object from the trial. Based on the findings of Brenton, Müller, and Dempsey (2019), we anticipate that the visual–perceptual and visuomotor groups would both improve equally in anticipation ability. However, we anticipate that the visuomotor group—with the combined visual–perceptual and motor training—would anticipate unfamiliar suspects’ actions better in the transfer test. Such evidence, if obtained, would support the incorporation of motor practice that mimics potential suspects’ actions into police training.
Conclusion
By including law enforcement experience as a factor, this study advances prior work examining anticipation in an object-identification task (Scott & Suss, 2019; Suss & Raushel, 2019). In dynamic situations with the potential for deception on the part of the subject, the ability for a police officer to anticipate a suspect’s action is crucial. Failures in anticipation and threat-perception can have devastating consequences to those involved in mistake-of-fact shootings—citizens and officers alike. Investigating these types of situations from the perspective of perceptual–cognitive expertise is fitting due to the dynamic nature of confrontations in which the outcome depends on being able to identify relevant kinematic information. Even though we did not identify significant differences between police trainees and experienced police officers, the use of dynamic, temporally occluded video stimuli to examine perceptual skill is a principled approach to identifying skilled anticipation, if it indeed exists. Such an approach is essential for assessing whether perceptual–cognitive skill in law-enforcement object-identification tasks can be developed and improved through training.
It appears that officers, on the whole, are not attuned to the cues of weapon presentation. Therefore, as it is likely that officers do not develop anticipation skill through training or operational experience, consideration should be given to developing training specifically designed to develop this skill. Research on perception–action coupling suggests that one way to do this may be to combine visual practice—using temporally occluded video stimuli—with motor practice of the very motions that officers need to distinguish between. Given the high stakes of some police–citizen interactions and the potential for subjects to attempt to deceive officers about their true intent, developing perceptual–cognitive expertise could mean the difference between life and death—both for citizens and officers.
Footnotes
Acknowledgments
We would like to thank Major George Sims from the Kansas City Kansas Police Department, Sergeant Kenneth Kimble from the Wichita Police Department, and Force Science News for assisting in participant recruitment.
Dakota Scott is a graduate student studying Human Factors at Wichita State University. His research interests include decision making of law enforcement in dynamic, ambiguous, and uncertain situations. He earned his B.S. in Psychology at Emporia State University (2018) and his M.A. in Psychology at Wichita State University (2021).
Lisa Vangsness, PhD, is an Assistant Professor of Human Factors Psychology at Wichita State University. Her research investigates the relationship between peoples’ Judgments of Difficulty (JODs) and their task engagement. She currently studies this relationship within the contexts of academics, rehabilitation, and automation. Dr Vangsness’ employs creative methodologies (e.g., video games, LMSs) and analysis strategies (e.g., latent profiles, multi-level modeling) to answer these research questions. Lisa also serves as a statistical consultant for various laboratories.
Joel Suss, PhD, is an assistant professor at Wichita State University. He earned his PhD in Applied Cognitive Science and Human Factors at Michigan Technological University (2013). His research interests focus on perceptual–cognitive expertise and human performance in police, security, and military domains. He applies a range of cognitive task analysis techniques to understand and improve human performance in volatile, uncertain, complex, and ambiguous environments.