
Abstract
Establishing genres is the first step toward analyzing games and how the genre landscape evolves over the years. We use data-driven modeling that distils genres from textual descriptions of a large collection of games. We analyze the evolution of game genres from 1979 till 2010. Our results indicate that until 1990, there have been many genres competing for dominance, but thereafter sport-racing, strategy, and action have become the most prevalent genres. Moreover, we find that games vary to a great extent as to whether they belong mostly to one genre or to a combination of several genres. We also compare the results of our data-driven model with two product databases, Metacritic and Mobygames, and observe that the classifications of games to different genres are substantially different, even between product databases. We conclude with discussion on potential future applications and how they may further our understanding of video game genres.
Introduction
In game studies, there is a growing interest in defining genres and constructing a vocabulary for describing video games. However, most studies have either focused on ludological versus aesthetic features in defining video game genres (Aarseth, 1997; Apperley, 2006) or are limited to analyzing a single genre or a single game, consequently failing to generalize on the typical characteristics of genres in comparison to each other (Clearwater, 2011; Klevjer, 2005). Such a focus on individual games or individual genres has led to a situation where there are no established ways to assign genres to a large corpus of games. The solutions to many important research questions hinge on this omission: How does the genre landscape evolve? Which genres are most prevalent and which ones are disappearing? Which years or decades have been most productive in terms of genre innovation? The present article aims to introduce a novel method for automatic genre analysis that enables the treatment of thousands of games and hence offers a comprehensive view to the development of the genre landscape.
This article proposes a data-driven modeling approach for a large collection of games with the goal of creating a rich description of the changes in the genre landscape and determining each game’s genre profile. Data-driven modeling was chosen because it allows the genre structure to arise from the data “bottom-up,” rather than being imposed from above, and can analyze a vast quantity of data consistently which would not be easily possible manually. This radical departure from traditional genre analysis allows us to discern content topics (i.e., genres) automatically and provides an efficient and fast approach to analyze a large collection of games. Moreover, we allow the model to decide the number of topics present in the data each year which means that the genre classification is not stable; the emergence of new genres and the disappearance of old ones is possible over the years. Our results indicate that the bulk of genre innovation took place in the 1980s and since then, the genre landscape has been dominated by sport-racing, strategy, and action games. The results also reveal that games vary to a great extent as to how crisp their genre membership is: some games belong mostly to a single genre while others belong equally to several genres.
The proposed data-driven approach belongs to a machine learning model family, called topic models (Blei, Ng, & Jordan, 2003; Griffiths & Steyvers, 2004). Specifically, we use a recently developed topic modeling approach (Faisal, Gillberg, Leen, & Peltonen, 2013) in assigning genre to video games. We compare the results of the topic model to those achieved by retrieving genre data from public databases. The latter approach has been popular in sociological studies where there has been the need to assign genre to a large set of films (e.g., Hsu, Hannan, & Polos, 2011; Hsu, Kocak, & Hannan, 2009). These two methods offer different ways to assign genre to games. The topic model distils topics from a huge collection of games, where each game is described using a short synopsis written by avid gamers. 1 Here the term topic is used as a synonym for a genre. A topic in a topic model can be described as a theme that consists of a collection of words that tend to appear together and takes into account all words independent of whether they describe player actions, rules, goals, or aesthetics. Hence, these capture game characteristics included in the texts irrespective of whether they are interactive or representational. The second alternative relies on the classification made by the database users and administrators. Although these classifications are readily available, the different sources may classify titles differently which forces the researcher to find ways to moderate the inconsistencies.
As topic models are data-driven methods, the quality of their results is dependent on the input data, that is, the accuracy of the game synopses created by avid gamers. The synopses are produced in a wiki-based manner which means that the authors may have chosen to cover games that they feel strongly about and there may also have been a considerable time lag between game experience and writing the synopsis. However, the strength of the wiki-based system is that blatant inaccuracies are likely to be corrected by other users. In any case, the synopses may contain subjective experiences and opinions concerning the games. We see the synopses as gaming discourse that is based on the authors’ game experience, since, as genre theorists argue, genres are born from a variety of critical and popular discursive practices (cf. Altman, 1999; Clearwater, 2011). A major advantage of the topic model family is its ability to handle a vast amount of data consistently and efficiently, which may not be possible manually. The model family cannot make a distinction between interactive and representational characteristics. However, being neutral to the distinction may turn out to be a strength of the method because it forces researchers to see each genre as a dimension of its own that may be present in every game to an extent ranging from 0 to 100%. A game belonging to a particular genre to the extent of 100% would be a prototype of the genre in question. However, in reality, games tend to blend several genres to a varying extent. Therefore, the degrees of membership in each genre can be seen as dimensions in a game’s genre profile. For example, a game can belong to the action genre to the extent of 50%, to the strategy genre to the extent of 40%, and the remaining 10% can be divided among various other genres.
The remainder of this article is organized as follows. The next section reviews different approaches to define game genres. This is followed by a short description of the proposed methods and the data set used in this study. The subsequent section describes the results achieved via these methods. The final section presents discussion and concludes the article.
Related Work on Game Genres
Writings on video game genres tend to focus on two claims: (1) that game genres should take into account ludological and not just aesthetic or narrative characteristics of games and (2) that game genres should not be directly adopted from other media forms, such as film or literature. Apperley (2006) argues that conventional video game genres rely too heavily on the representational characteristics, that is, the visual aesthetics, of the games. He states that in order to create a vocabulary for discussing games, the nonrepresentational and interactive characteristics of games should be given center stage. In this way, similarities that are located deeper than representation could be discovered. Apperley states that this overreliance on aesthetics stems from adopting genre labels from prior media forms. 2 For ludologists, interactivity and simulation distinguish video games from other types of communication that rely on stories, characters, and themes (Clearwater, 2011). Therefore, video game genres should be based on rules, goals, and outcomes.
Many game researchers, however, take a more lenient stance and identify interactive elements and aesthetic elements as different dimensions of the genre landscape. For King and Krzywinska (2006), gameplay context consist of narrative and genre. The narrative dimension is not usually interactive, as the plot structure of the game cannot be changed by player action. The genre dimension, on the other hand, provides motivation for player actions and can influence gameplay options. Arsenault (2009) and Apperley (2006) both root for genre taxonomies that comprise interactive genres and thematic or iconographic genres and allow multiple-genre membership. In this way, games may be classified into one group based on gameplay and into another based on iconography or story. 3 Clearwater (2011), however, emphasizes that gameplay and iconography cannot be completely separated. He states that it may be useful to do so for analytical purposes but that such a separation is artificial.
At the moment, we do not know much about the benefits or drawbacks of one or multidimensional genre categorization because so far empirical research on video game genres has concentrated on single genres or even on single games. Klevjer (2005) points out that there is very little research that would generalize on the typical characteristics of game categories in comparison to each other. A look at recent textual and empirical research on video game genres confirms this assertion: The bulk of the studies concentrate on analyzing a single genre (e.g., Black, 2012; Carter, Gibbs, & Harrop, 2014; Chess, 2014; Gillespie & Crouse, 2012; Goetz, 2012; Hitchens, Patrickson, & Young, 2014; Lennon, 2010; MacCallum-Stewart, 2010; Paavilainen, Hamari, Stenros, & Kinnunen, 2013; Patterson, 2014; Thin, Hansen, & McEachen, 2011). Therefore, this body of work has not so far taken on the task of finding ways to assign genre to a large corpus of games but has concentrated on analyzing games typical to each genre more or less in isolation.
Additional challenges to the above-mentioned task come from different audiences using genre terminology differently and from genre innovation. Studios, retailers, critics, journalists, designers, and fans may use genre terminology in different ways, but they also interact with each other (Clearwater, 2011). Furthermore, Mäyrä (2008) points out that the genre system is in constant flux, as new influential games with certain combinations of features create pressure to establish a new genre. The audience expects the stability of genres to be tempered by innovation, either technical or stylistic (Apperley, 2006). Such innovation can come about in the form of multigenre games that use the conventions of several genres (Harper, 2011) or in the form of new genres that combine elements from existing genres and may attract new consumers to the game market (MacCallum-Stewart, 2010). Moreover, games vary as to how closely they align with a genre definition leading to core and peripheral games in relation to the genre (cf. Voorhees, 2009).
The origins of new game genres have not been extensively studied, but in film studies it has been found that new genre labels are originated by critics (Altman, 1999). Film studios have the incentive to emphasize the uniqueness of their product and to attract a wide audience. Assigning the product into a genre could make the audience see other films in that group as substitutes and it might also alienate a part of the audience. Critics, on the other hand, have the incentive of placing the film in relation to other similar films in order to provide information for the audience. Although genres may be in a way created by critics, innovations leading to the birth of a new genre come from the producers. Altman (1999) describes a cycle-genre system, whereby a studio creates a stream of a new kind of successful films (i.e., cycle) that are constructed by critics to form a new genre and this genre then spreads to the industry as a whole leading to copycat films by other studios. All such cycles, however, do not lead into the birth of a new genre. Although this model is based on the workings of the film industry, it appears to be suitable—to some degree at least—for analyzing the birth of game genres. A popular example of such a dynamic is the release of Doom and its sequels and the birth of the first-person shooter genre (cf. Arsenault, 2009).
Despite the constant change in the genre landscape, many static game genre classifications exist in books, reports, research articles, and online databases (see Table 1). There appears to be a consensus on the existence of action, shooting, role-playing game, strategy, simulation, sports, racing and fighting genres. However, the variation among these classifications is considerable and the terms are not well established. It is important to notice that in addition to genre labels, there is considerable variation in the number of genres these sources identify. 4 Another difference between the classifications concerns multiple-genre membership. Gamerankings.com and mobygames.org allow multiple-genre membership, that is, more than one main genre can be assigned to a game. Metacritic.com allows only a single genre to be assigned to a game.
Comparison of Genre Classifications.
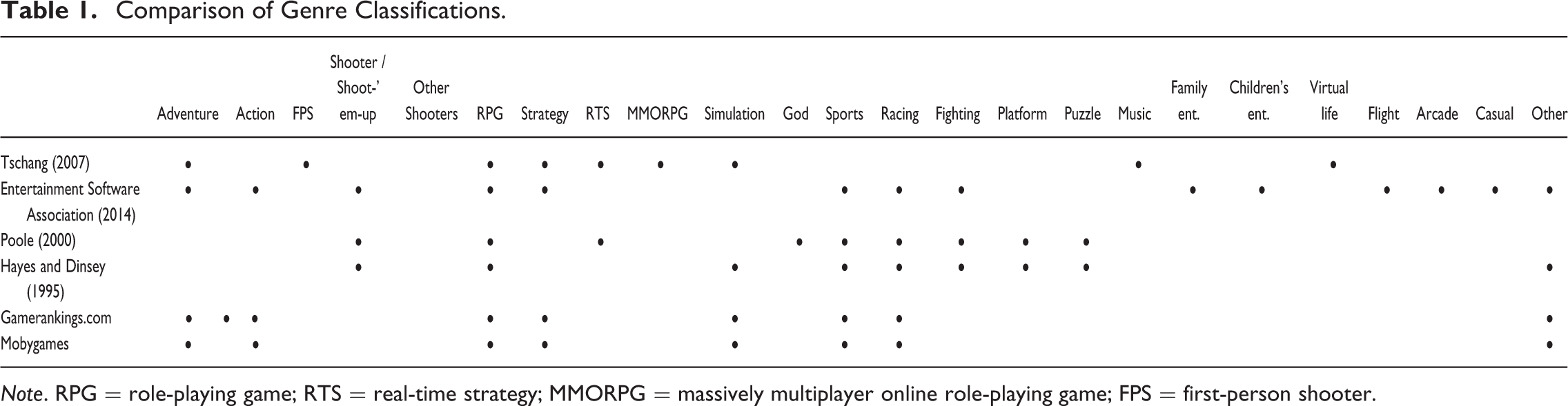
Note. RPG = role-playing game; RTS = real-time strategy; MMORPG = massively multiplayer online role-playing game; FPS = first-person shooter.
Based on this review, we note that the genre literature lacks a method that applies the multidimensional genre system formulated by King and Krzywinska (2006), Arsenault (2009), Apperley (2006), and Clearwater (2011) to a large corpus of games in a consistent manner. This means that we are unable to systematically analyze changes in the genre landscape in terms of genre innovation and changes in the dominance of different genres. In order to understand the long-term evolution of the video game domain, it is critical that we can organize games into groups based on both representational and interactive elements. The organization should be data-driven, based on relative characteristics of the games, and not be imposed based on manual classifications. In order to find a classification system corresponding to these specifications, we compare two methods, data-driven modeling and product databases, in assigning genre to a large corpus of video games.
Data and Method
Game Data Sets
We use two data sets to illustrate our methods. Mobygames.com is a wiki-based database of video games published since 1979 (a total of 33,397 games) and has been previously used in academic research (see e.g., Balland, De Vaan, & Boschma, 2013; Mollick, 2012). In this database, genre is assigned through the consensus of the contributors. Metacritic.com relies on genre classifications provided by game publishers, and hence these two sources offer conflicting data on genre classification concerning many games.
Our sample includes games published on major consoles during 1979–2010. We define major consoles to include Atari 2600, Channel F, ColecoVision, GameCube, Genesis, Intellivision, Jaguar, Neo-Geo, Neo-Geo CD, NES, Nintendo 64, Odyssey, Odyssey 2, PlayStation, PlayStation 2, PlayStation 3, Sega 32x, Sega CD, Sega Dreamcast, Sega Master System, Sega Saturn, SNES, TurboGrafx-16, TurboGrafx-CD, Wii, Xbox, and Xbox 360. This results in data sets of 10,309 games from Mobygames classified into 8 genres and 4,991 games from Metacritic classified into 36 genres (Metacritic database starts from 1996 and hence the sample is smaller).
Topic Models
Topic models are unsupervised machine learning models suitable to extract hidden topics discussed in a collection of documents. Each document is represented by the text it contains. We use the documents describing the games (here referred to as “game synopses”) from Mobygames that are written by volunteer contributors. The game synopses were cleaned through established text-mining methods (detailed description in Appendix).
The topic models are able to distil topics from the text of the documents by learning the descriptive statistics concerning their content. In the classical topic models, these statistics refer to (a) the probability of different words for each topic and (b) probability of different topics for each document. These statistics can help a researcher to understand the hidden topic structure of the documents. This means that the model can compress the content of a large corpus to show topics and their prevalence. 5 This compression is performed by an algorithm that learns as it handles the data. The algorithm adjusts itself, as it continues to explore the content of the documents and ends up with a topic structure that best fits the given data set (for introduction to machine learning see Alpaydin, 2014; Bishop, 2006).
The classical topic model, also referred to as Latent Dirichlet Allocation (LDA; Blei et al., 2003; Griffiths & Steyvers, 2004) is the simplest topic model. The intuition behind the classical LDA is that documents contain a mixture of multiple topics. Classical LDA requires the researcher to specify the total number of active topics in the entire document collection before the actual analysis. We use our recently developed nonparametric extension of the model (LDA; Faisal et al., 2013), where the total number of topics is learned automatically from the data, avoiding the requirement for the user to specify the total number of topics (or genres) before the analysis. This implies that the number of genres also arises from the data rather than having a researcher to decide it. We provide a brief description of the LDA model in the Appendix. Here we illustrate how the LDA model uncovers hidden topic (or genre) structure by considering its results on an example game synopsis for the game Eternal Sonata 2008, a typical role-playing video game. Figure 1 shows the synopsis of the game where we have highlighted different words that the LDA model assigns to the top three topics. These are words about the topic action (highlighted in blue) such as fight, combat and action, words about strategy (highlighted in red) such as move, time, and battlefield, and words about sport-racing (highlighted in green) such as character, world, and real time. Knowing that this game blends the three topics; “strategy,” “action,” and “sport-racing,” help us situate it in the collection of other game synopses. Given a collection of documents, the LDA models each document as a probability distribution over identified topics. In the example synopsis, the distribution over topics places the highest probabilities on strategy, action, and sport-racing (Figure 1; right). Note, the three topics are not user defined, but rather each topic has a distribution over all words in the vocabulary which is identified by the LDA model (we discuss this distribution and Table 2 that shows corresponding top words for each topic in the Results section).

Illustrative example of topics extracted from a sample game. Synopsis of the game Eternal Sonata 2008 (developed by tri-Crescendo and published by Namco Bandai Games) tagged according to topic assignment. The Latent Dirichlet Allocation (LDA) model first chooses a distribution over topics (the histogram on the right, showing probabilities for the top three topics in the synopsis), then for each word chooses a topic assignment (the colored words in the game synopsis). The topics and topic assignments in the figure are the result of the multitask LDA model fit from the actual data.
The 15 Most Frequent Words for Each Topic.
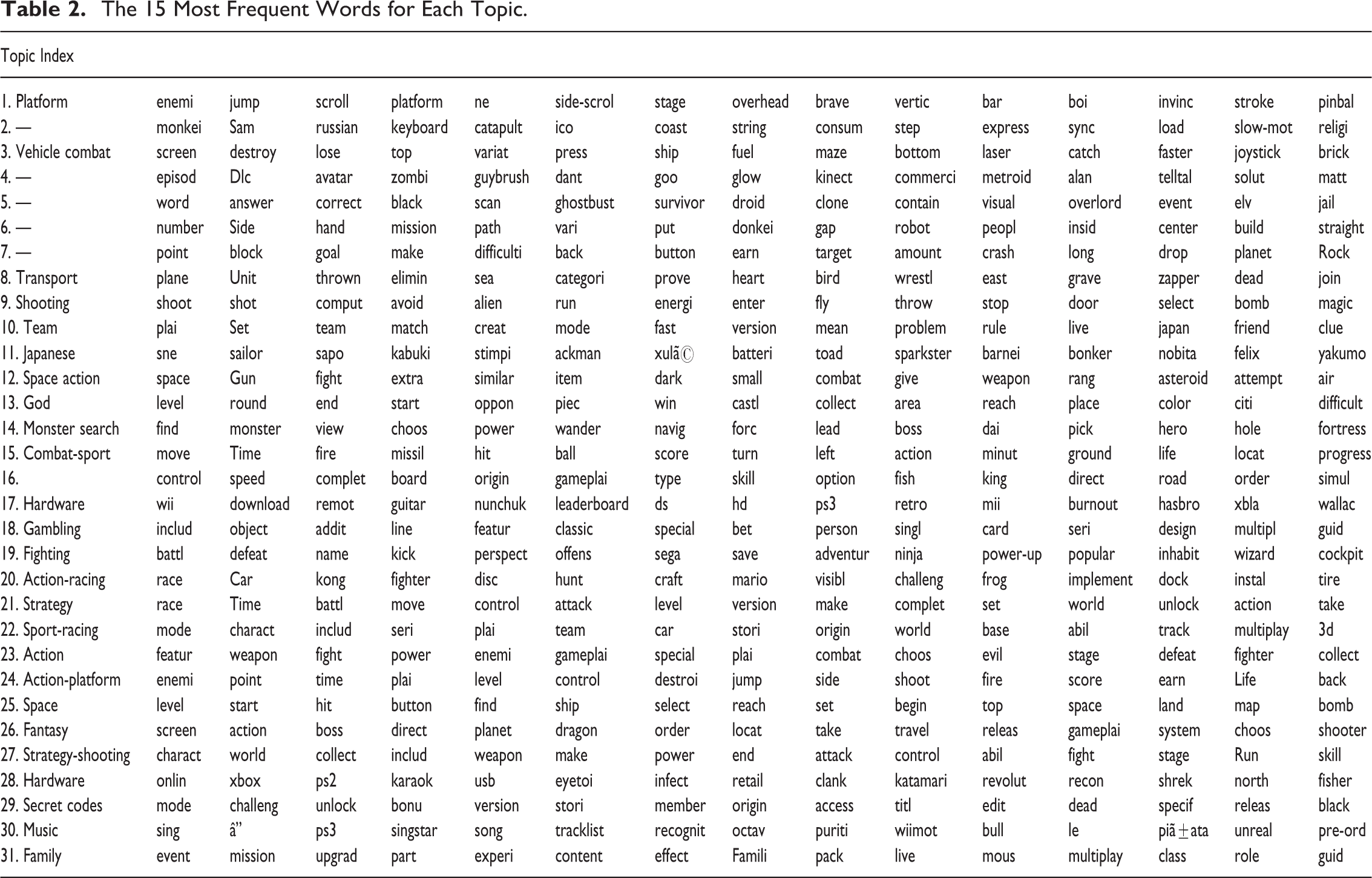
LDA models can help game researchers in creating a useful genre system because (1) the genres arise from the characteristics of the game population, (2) all characteristics present in the textual data are taken into account and not limited based on ludological or aesthetic preferences, (3) the number of genres is not limited and hence new genres may be born and old ones may disappear over time, and (4) each game can belong to several genres to a differing extent.
Comparison With Genre Assigned in Databases
To compare the results attained via the LDA model, we calculated the frequency of each genre per year in Mobygames and Metacritic product databases. The results are presented as the percentage of games launched in a year that are assigned to a particular genre.
Results
The LDA model finds 31 topics or genres in the overall collection of synopses in games from 1979 to 2010. Table 2 lists the top 15 most probable words in each topic. We use these top most probable words and assign a genre label to each topic (first column of the table). Next, Figure 2 shows the evolution of most likely topics across different years as provided by the LDA method. Up to 1990, there are many topics competing for dominance, and there are frequent changes in which topic is the most prevalent. Thereafter, three topics become dominant. The most prevalent is topic number 22 which has mode, team, car, and track among its most probable words and we label the topic as sport-racing. The second most prevalent topic, number 21, includes words such as battle, attack, level, unlock, and world which lead us to label it strategy. The third topic, number 23, includes weapon, fight, enemi, 6 combat, and defeat, and we label it action. In Table 2, the majority of the 31 topics have been labeled with such descriptors.
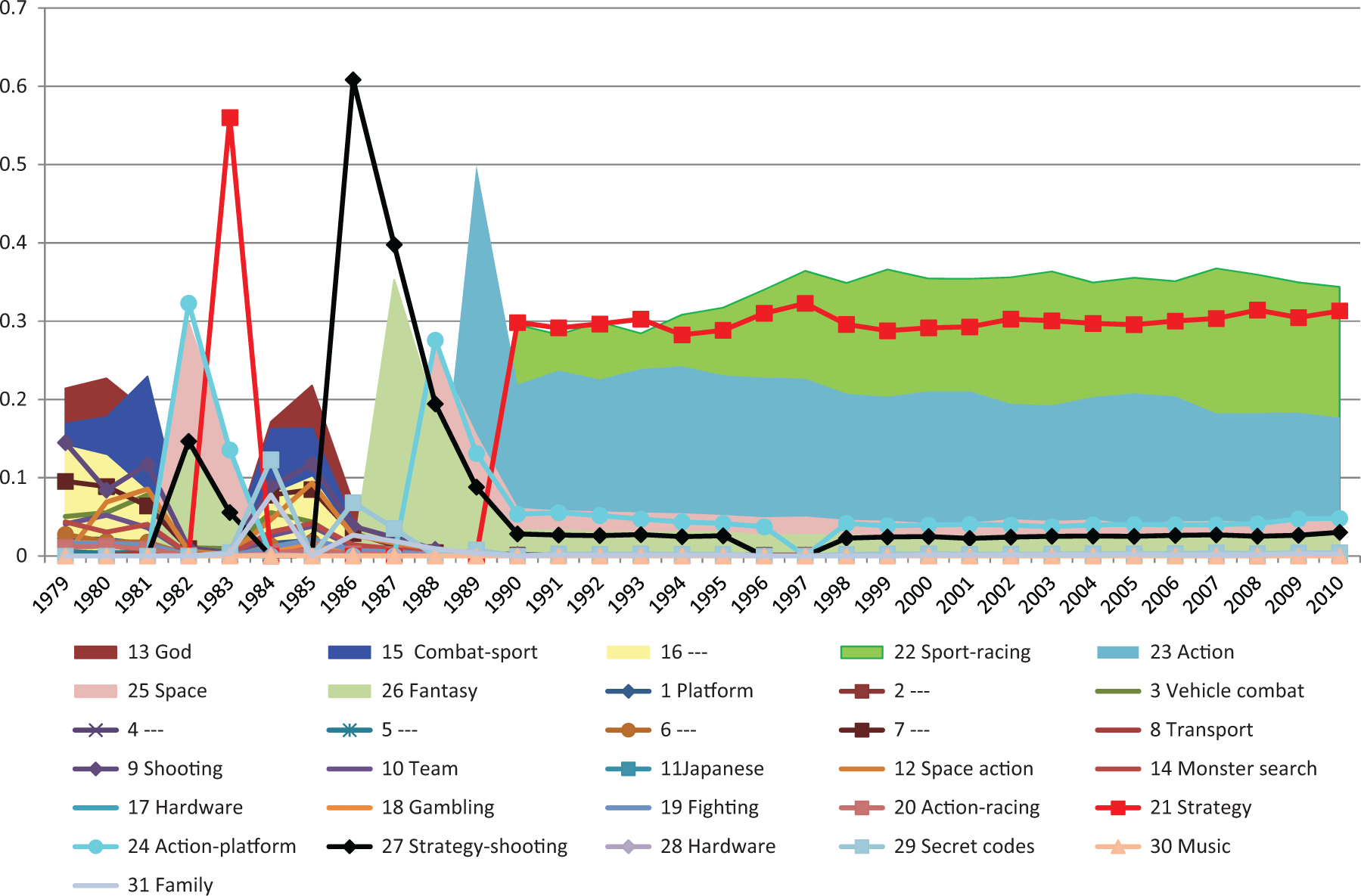
Game topics and their probabilities (shown on y-axis) over time (shown on x-axis) in the sample based on the Latent Dirichlet Allocation (LDA) model.
There are also other topics that have been prevalent at some point but have lost their standing. Topic 27 (labeled strategy-shooting) is about collecting, weapons, power, attacking, and ability. Topic 26 (labeled fantasy) is about planets, dragons, and travel. Topic 24 (labeled action-platform) deals with jumping, shooting, firing, and scoring, and topic 25 (labeled space) with ships, maps, and space. In addition to topics describing game content, there are two topics describing hardware. These cannot be interpreted as genres, but they capture the hardware components included in the games synopses.
Figures 3 and 4 drawn on the basis of Mobygames and Metacritic data reveal a different picture of fluctuations in game content. In the Mobygames classification, the majority of games is assigned to the action genre, while sports is the second most prevalent category. In the Metacritic classification, no genre attains such prevalence, and the dominance shifts between racing, action-adventure, and action genres but for the most part not more than 20% of the games are assigned to any one genre.

Games per genre in Mobygames (% of games per year).

Games per genre in Metacritic (% of games per year).
In order to take a look at the micro-level differences in genre assignment between the LDA model and the Mobygames genre labels, we have chosen five well-known games for further analysis. These are Red Alert (1996), Harvest Moon (1997), Pro Evolution Soccer 3 (2004), Drake’s Fortune (2007), and X-Men Legends (2004). For each of these games, Figure 5 presents the distribution over the corresponding top five topics in LDA (fantasy, space, action-platform, action, sport-racing, and strategy) and the assigned genre in Mobygames. Of these five games, X-Men Legends and Red Alert receive the highest probability for the action genre, Pro-Evolution Soccer 3 and Drake’s Fortune have the highest probability for sport-racing, while Harvest Moon gets the highest probability for strategy.

Latent Dirichlet Allocation (LDA) distribution over top topics and corresponding Mobygames genres. All LDA topics that are at least 8% probable for any of the five games are considered as top topics and plotted in the figure, while the Mobygames genres are listed beside the game name in parentheses.
It is noteworthy that there is considerable variance in the probability distributions. Although Pro Evolution Soccer 3 and Drake’s Fortune both have sport-racing as their most dominant topic, for Pro Evolution Soccer 3 this dominance is much stronger. While both games have action as the second most dominant topic, Drake’s Fortune has that to a greater extent than Pro Evolution Soccer 3. Therefore, the classification created by the LDA model sees Pro Evolution Soccer 3 as more of a sports-racing game than Drake’s Fortune, and Drake’s Fortune as more of an action game than Pro Evolution Soccer 3. This indicates that the LDA model does not simply determine multiple-genre membership, but it can assign games to different genres with varying degrees of dominance.
It is also noteworthy that there are differences between the games as to how equally it is seen to belong to several genres. Pro Evolution Soccer 3 is dominated by the sports-racing genre, whereas X-Men Legends has very similar probabilities for action, strategy, sport-racing, and space topics. This indicates that the LDA model sees some games as more closely following a single genre (crisper membership) and others as a combination of multiple genres (genre straddling).
We can also notice that there is some overlap between the LDA-based genre assignment and the Mobygames genres. A notable difference is that the classifications in the online databases have 8 (Mobygames) and 37 (Metacritic) genres, whereas the topic model generates 31 genres arising from the data. Our results indicate that it matters greatly which method is used to assign genre to video games. This means that further research is required introducing alternative methods and comparing them. One important advantage of the topic model is that it provides much richer information on the genre affiliations of each game. It enables us to distinguish between core and peripheral genres in games with multiple-genre membership and to create a genre profile for each game. We are unaware of other methods able to do this in an efficient manner.
Discussion and Conclusions
Our exercise with two alternative methods of assigning genre reveals that the chosen method has a substantial impact on which genre is assigned to each game, how games are distributed among genres, and how the distribution evolves over time. We believe that the most important benefit of the LDA method is that the genre structure arises from the data. Hence, it does not impose an existing classification but allows the data set to determine the genre landscape and its evolution.
Many commentators state that there is not much innovation taking place in video games (e.g., Tschang, 2007). Our results from the LDA exercise indicate that the years of extensive genre innovation are behind us, and the genre structure has remained relatively stable since the early 1990s. The bulk of the genre innovation appears to have taken place during the 1980s when many genres have been prevalent for a short period of time and then been replaced by others. The period of active genre innovation in the 1980s may have been due to rapid technological development in consoles and aggressive competition between them. It may also have been due to the significant growth in the user population whose tastes have been unknown by game developers and publishers leading to extensive experimentation. As technological and market uncertainties have been resolved, genre innovation has declined. Further research could help shed light on the relationship of genre innovation and changes in the technological and user environment. By limiting the data-driven analysis to specific consoles (or a set of similar consoles), it could be possible to use the statistics created by the LDA model to analyze whether there are differences between the game populations related to different consoles as to their innovativeness and diversity. In this way, it might be possible to tie the successes and failures in the console market into the successes and failures of different genres. Another possibility would be to compare the innovative dynamics of the early video game industry to that of the early film industry. Ample data on early films exist, and it would probably be possible to find a database of film synopses. Such a comparative analysis could help us to elaborate on the differences between games and movies in how they are consumed, how they are dependent on technology, and how such differences affect innovation.
Our analysis is limited to inter-genre innovation and does not capture possible within-genre innovation. Genres are dynamic (Myers, 2003), and future analyses on game content should take this into account. Dynamic LDA models (Blei & Lafferty, 2006; Ren, Dunson, & Carin, 2008) allow the analysis of changes in topic (genre) content. This is made possible by allowing topics to dynamically evolve over time. Effectively, topics for documents that appear later in time are smoothly evolved from topics that appear in earlier documents. Extensions of multitask LDA models toward dynamic topic modeling offers opportunities for examining changes in the social construction of genres over time and may reveal interesting innovation trends in game content. That type of analysis would be the logical next step in our research.
The results from the LDA model also enable further examination of successful and failed game genres. The timing of their introductions in relation to the dynamics of the genre structure would shed light on what kind of an environment is conducive to genre innovation. Are new genres more likely to take on when also other new genres are introduced? Are initial sales important in predicting genre popularity 7 over the longer period? Can a concentrated genre structure (i.e., a small number of popular genres) inhibit genre innovation? In music, it has been found that new genres may fail to gain popularity because there is an insufficient contrast with existing genres (Hannan, Pólos, & Carroll, 2007). This could also be tested in games with the help of the LDA results. Overall, connecting data on genre innovation with sales data would be an important step in understanding where the sweet spot between too much familiarity and too much innovation lies. It would also be interesting to see whether certain genres are able to persist despite low sales.
In LDA, the meanings of a topic can be interpreted based on the top most probable words of the genre. We believe that any suitable manual or automatic interpretation of a topic/genre based on the cumulative semantic meanings of top words would be suitable. In our study, we have resorted to a manual interpretation of each genre based on its top 15 most probable words indicated by the topic model. Future work can benefit from ongoing efforts in the machine learning community to automatize the interpretation of the top words (see Lau, Newman, & Baldwin, 2014; Newman, Lau, Grieser, & Baldwin, 2010).
Genre studies emphasize that genres are retrospect: They can only be observed once a sufficient number of products have been produced and the discourse around them has developed (Altman, 1999; Arsenault, 2009). The genre structure generated with the LDA model is also retrospect and therefore is of only limited usefulness in making predictions. Moreover, the LDA model cannot make clear distinctions between interactive and representational genres but blends these dimensions based on how they are blended in the texts describing the games. Hence, it follows Clearwater’s (2011) view which holds that gameplay and iconography cannot be completely separated.
As the LDA model relies on the textual descriptions created by avid gamers, the game descriptions become critical for creating an accurate genre structure. This may be seen as a weakness of the method, but it also has the advantage of bringing in the social aspect of genres. Genres are dependent on how the audience talks about them and how they use genre vocabulary when discussing individual products (Altman, 1999; Clearwater, 2011). Therefore, using game synopses as the data source includes user experience and how that experience is vocalized. However, there may be game characteristics that are very difficult or impossible to put into words whereas certain visual cues may be much easier to express verbally. Detailed case studies on games with similar LDA-based genre profiles could help us to discover such elements and shed further light on the nature of game experience in general. Moreover, such micro-level analysis could help us to see whether genre-specific jargons emerge. Inspiration for further steps could be sought from political and media studies where there are rich traditions of quantitative content analysis of various topical texts, such as presidential addresses (see Krippendorff, 2012). Similarly, complementing our analysis with context information (either at sentence level or writer’s ideology, e.g., by borrowing developments from computational discourse analysis, see Lin, Xing, & Hauptmann, 2008) could improve the findings.
Our analysis indicates that the results of genre assignment and genre evolution vary depending on which method is used to assign genre to games. Genre assignment is a crucial step when empirical research is conducted in studying changes in game content. Rather than offering a definite solution to this problem, we encourage the researcher community to introduce and test alternative methods. In this study, we have evaluated the topic model that is neutral to whether game characteristics are representational or interactive. Future studies that can focus the analysis on one or the other characteristic would enable us to distinguish between how the game content landscape changes in aesthetic and ludological terms.
If we look at individual games (Figure 5), genre assignment based on LDA or product databases both lead to sensible results and in that sense both methods are viable alternatives for getting a genre label when analyzing individual games. On the other hand, if we are interested in the evolution of or trends in the genre landscape over many years across thousands of games, then different methods lead to different results. The proposed LDA method appears more attractive in this scenario as it assigns multiple genres to each game with different probabilities that sum to 100%. This probabilistic assignment when used to cumulatively build a trend of genres across several years and thousands of games provides a more efficient and powerful tool. This being said we encourage researchers to devise alternative schemes for the challenging problem of studying genre trends and evolution across many years.
Footnotes
Appendix
Authors’ Note
Both authors contributed equally.
Acknowledgment
The authors would like to thank the Aalto Science-IT project for computational resources.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Ali Faisal has received funding from the Finnish Foundation for Technology Promotion. Mirva Peltoniemi has received funding from Academy of Finland (grant number 137808).