
Abstract
The reliability and validity of the results can be jeopardized by techniques like deletion and imputation of the simple mean when there is a high percentage of missing data, which presents a significant challenge to decision and estimation theory. This challenge becomes more challengeable if population suffers with heterogeneity and the parameters of auxiliary variable are unknown because they are used to improvise the estimation by suggesting the improved estimators. In this paper, for a population with observed heterogeneity, we propose new exponential estimators to estimate the mean of the study variable using auxiliary variables when survey variables suffer from non-ignorable missing data at two sampling phases. To verify the efficacy of the suggested estimators, a number of pertinent and promising estimators have been modified in this context; the text offers the theoretical constraints of the comparative analysis along with the mathematical expressions of these estimators’ bias and mean square error
Introduction
Literature Review and Research Gap
In estimation theory, lack of response or missing data have potential to distort the results when missingness of the data is related with the variable of interest. In diverse disciplines of the data analysis, survey sampling plays crucial role and so the missingness of the data. The survey results based on the data that exhibits missingness may be sensitive of non-respondent, ignoring them may cause biased results. For instance, Allehoff et al. (1983) mentioned in his research on mental disorders, non-participation rate among 8-year-old children was 38.5% and was correlated with lower IQ values and scholastic values. Apart from cross-sectional and longitudinal data-collection methods, nowadays internet-based data collection method has got eye-catching popularity due to widespread availability of internet and the advantages it offers in terms of cost effectiveness, time effectiveness, real-time collection, and accessibility. Instead of having several advantages these methods may suffer from missing data when survey unit fails to respond the survey invitation, due to lack of willingness to participate, or due to the attrition of the survey unit whenever participants lose their interest during period of time.
In survey sampling, problem of missing data due to non-response gained recognition after Hansen and Hurwitz (1946) introduced an unbiased estimator for population mean based on sub-sampling the non-respondents. In order to estimate population mean
Nevertheless, since the second phase sample is selected for the study variable, there is a possibility of non-response for this variable because the mean of the auxiliary variable,
Despite the abundance of literature on non-response, little has been done to account for the presence of non-respondents during both phases of the survey sampling when the auxiliary mean is unknown. Therefore, there is wide scope of developing estimators for population parameters. So, in order to address the non-response that occurs in both sampling phases when the auxiliary mean is unknown, the main objective of this article is to estimate the population mean of the study variable using the exponential type estimator that is recommended for heterogeneous population.
Methodology and Notations
Our proposition is driven by the desire to optimize the utilization of currently available auxiliary information. Instead of using the estimated unknown population mean of the auxiliary variable based on all information available at the first phase sample and assuming missing information due to non-response on the second phase of sample for the auxiliary variable, we have taken into consideration the missing data issue in both the phase of sampling, which makes it more practical and applicable.
In addition, it is critical to consider the population's heterogeneity since it sheds light on the complexity, diversity, and variability among the various subgroups that make up the population. In order to address the population that shows observed heterogeneity among the population units in the current study, we have employed a stratified two-phase sampling scheme
Let us consider study variable
In accordance with Hansen and Hurwitz (1946), to compute the auxiliary mean, we choose a larger sample

Flow-chart for Two-phase Sampling Technique Under
As a result, in the first phase, the auxiliary mean estimates of
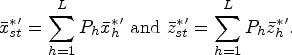
Here,
Similarly, following Hansen-Hurwitz (1946) technique at the second phase, mean estimates for study variable and auxiliary variables based on n units are given as:
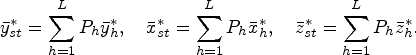
Here,
To determine the variance and covariance of the variables under consideration, let us consider the large sample approximations as –
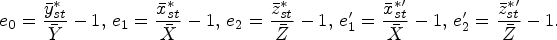
Such that,
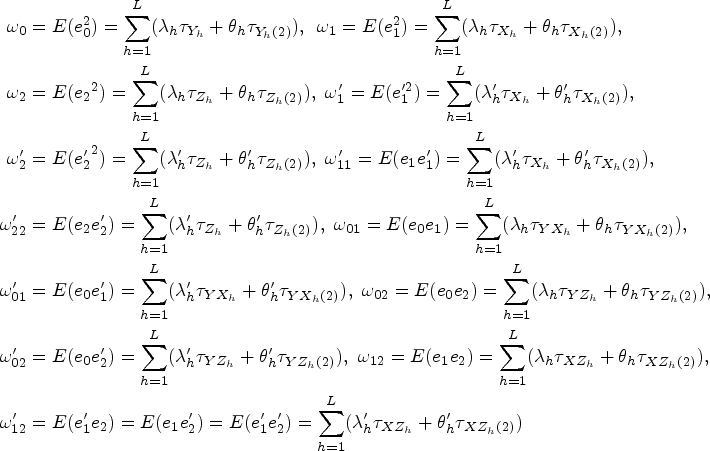
Here,
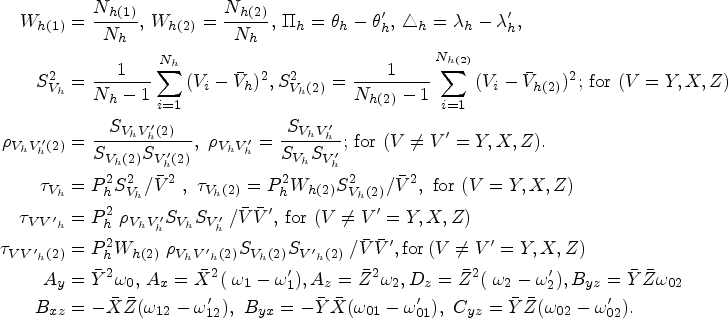
An approach to estimate the unknown mean of the study variable under a non-response population with inherent heterogeneity using improved estimators is presented in this section. Thus, in order to validate the performance of the suggested estimator, we have examined a few well-known existing estimators under

The mean square errors 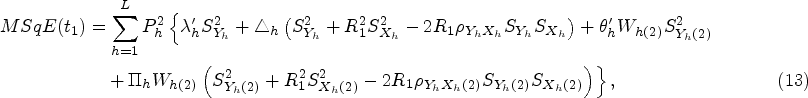
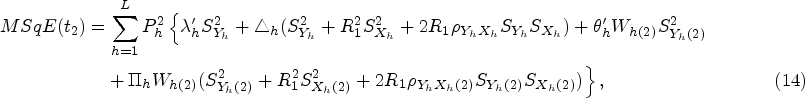


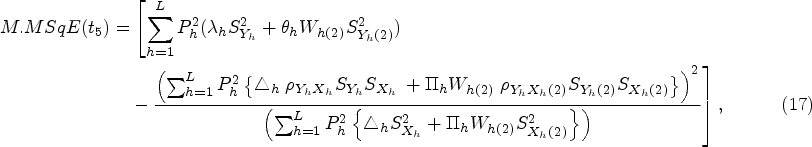

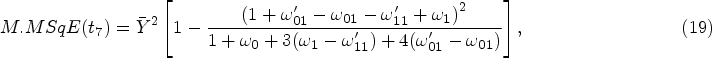
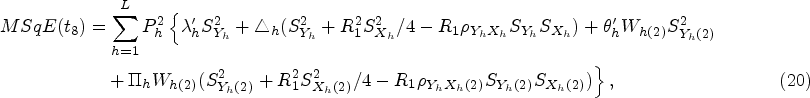
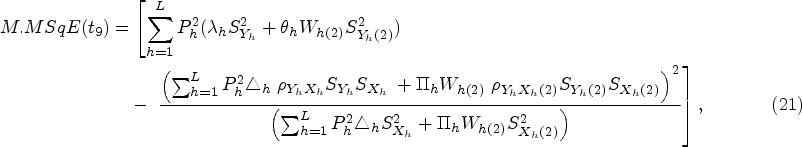
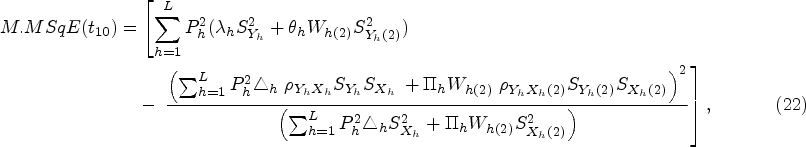
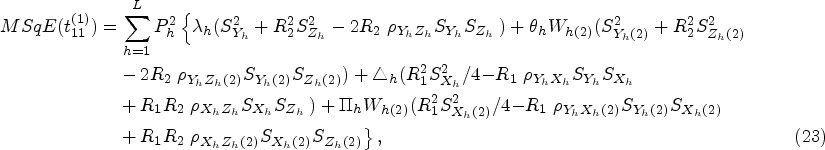
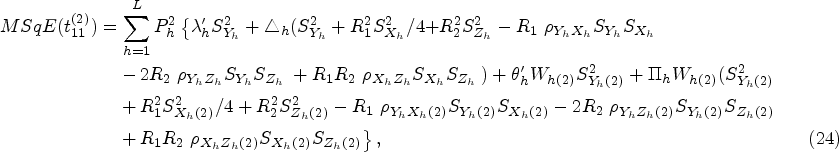
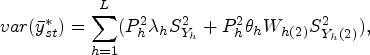
In recent years, many valuable estimators have been proposed to estimate the population mean using auxiliary variable when data under study suffer with missing response. The vital part of this framework is availability of auxiliary information with unknown mean and non-response at both the phases of sampling scheme. Inspired by Kumar and Zeeshan (2019) and Chaudhary et al. (2020), we suggest exponential estimators for population mean estimation for two different scenarios under STPS. We also state the theorems to further elucidate the traits of the proposed estimators based on approximation to the first degree
Situation-I
In this situation, we have considered that the population mean 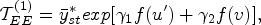
Bias and 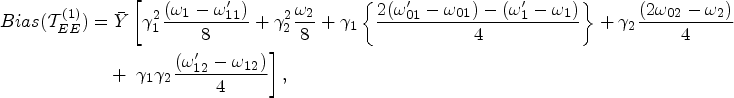
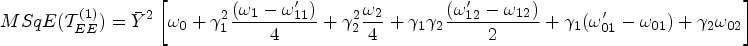
Under the approximations given in sub-section 1.2 the proposed estimator 
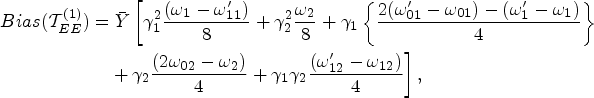
The expression for 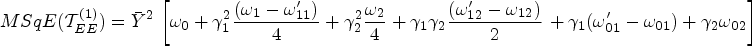
Minimum mean square error 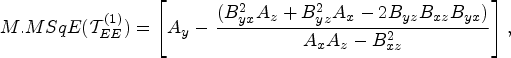
On minimizing the equation (31) with respect to
Here it may be verified that the
In this situation, considering that the population mean of both the auxiliary variables i.e., 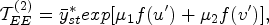
and
Bias and 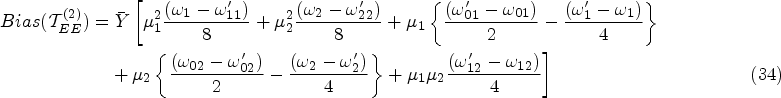
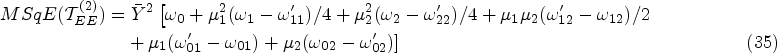
Similarly, as the previous theorem makes clear, the proposed estimator 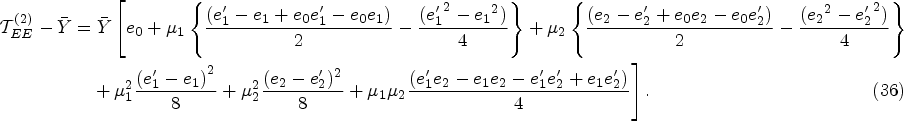
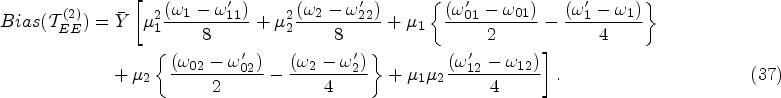
Furthermore, squaring and taking the expectation of equation (36) gives the 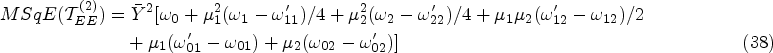
The minimum mean square error 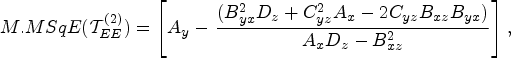
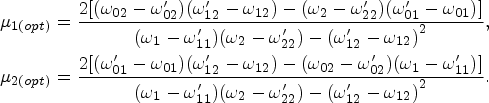
The optimum value of the optimizing constants is obtained by minimizing equation (38) in relation to
The equation (39) will be subject to the same conditions as in remark 1, i.e.,
To provide a clear understanding of the practical limitations for the applicability of the proposed estimators, theoretical constraints have been established by comparing the efficiency of the suggested estimators in terms of mean square errors against all previously known competing estimators.


Numerical Analysis of Performance of Proposed Estimators
This section aims to conduct two types of analyses for efficiency comparison: a simulation analysis using simulated data (symmetric and asymmetric) accounting for population type, and an empirical analysis using two different real-world data sets. During the present numerical analysis, we have taken the same sub-sampling factor k in both the sampling phases which may also vary depending on the choice and demand of the surveyor.
Efficiency Analysis on Simulated Data
We have used following statistical tools available in R software- mvrnorm (), unonr (), sample (), sampling (), moments ().

For both situations I and II, we have generated hypothetical symmetric and asymmetric data sets with parameters mentioned below with respect to variable

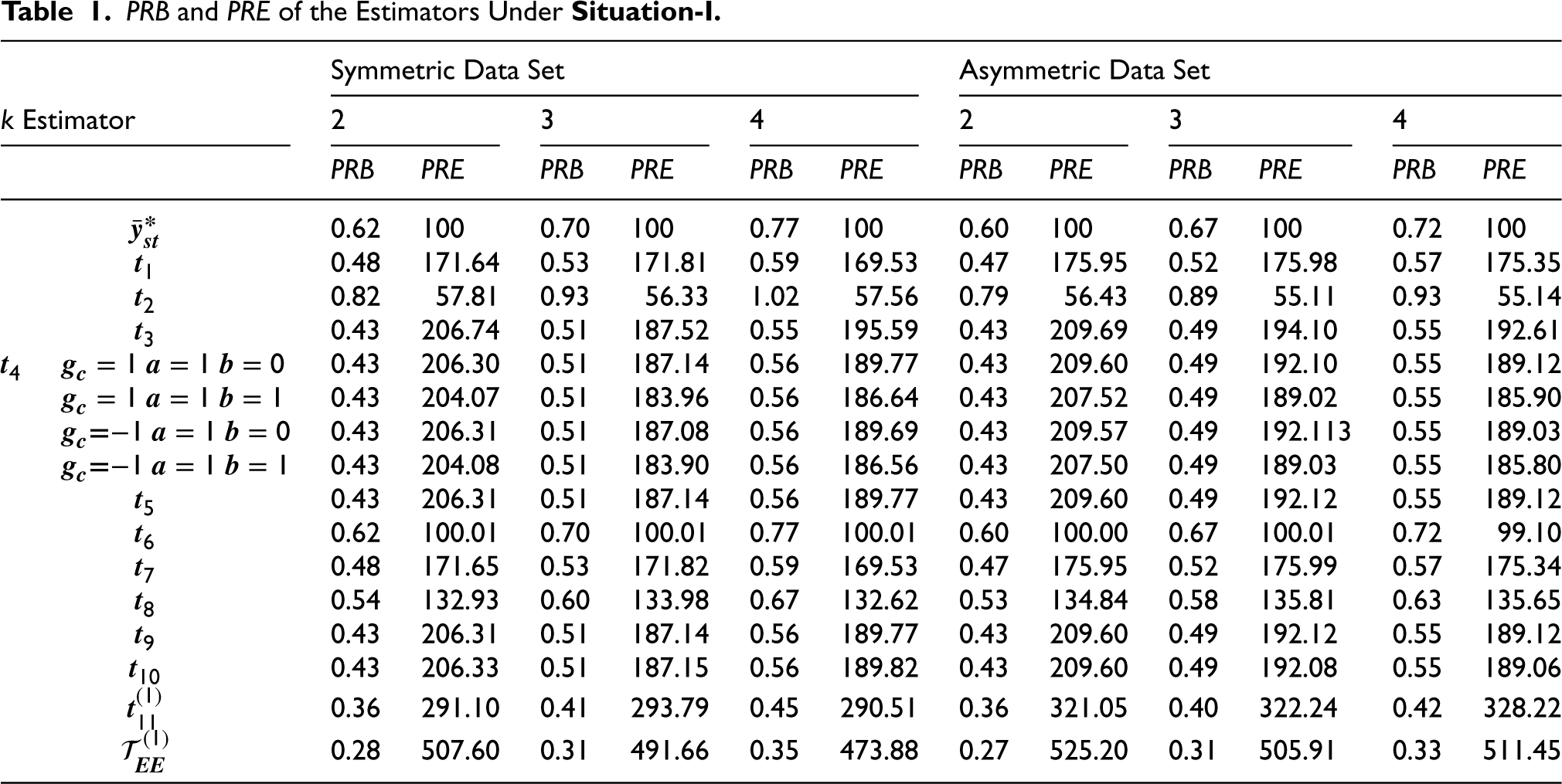
The percentage relative efficiency
and
of the Estimators Under Situation-I.

For the empirical investigation of numerical analysis, we used the Hypertension Arterial Mexico Data Set, which is accessible at https://www.kaggle.com/datasets/frederickfelix/hipertensin-arterial-mxico. The data set includes raw information (such as Cholesterol level, gender, different glucose results etc.) taken from the national health and nutrition survey (ENSANUT) https://ensanut.insp.mx/encuestas/ensanutcontinua2022/descargas.php.
In the present investigation, two distinct sets of variables are taken into consideration:

Based on the particular circumstances surrounding their non-response, we classified 20% of the units as non-respondent groups using gender as the primary stratification criterion, the parameters for Combinations 1 and 2 are shown in Table 3.
Parameters of Real Data Sets.
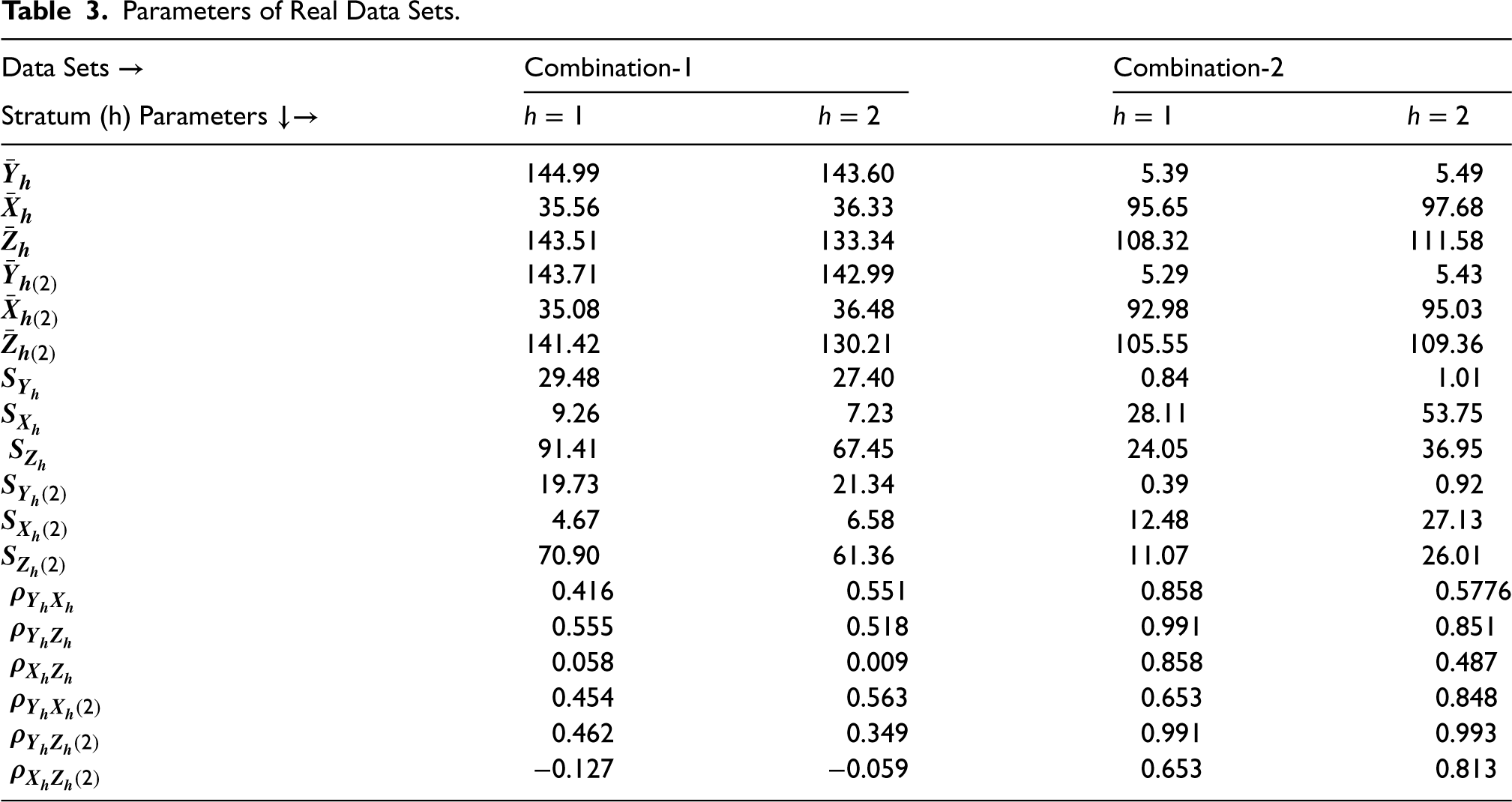
Parameters of Real Data Sets.
To further clarify the methodology of the sampling procedure, a schematic description is provided in Figure 2.

Sampling design in empirical data set.
The
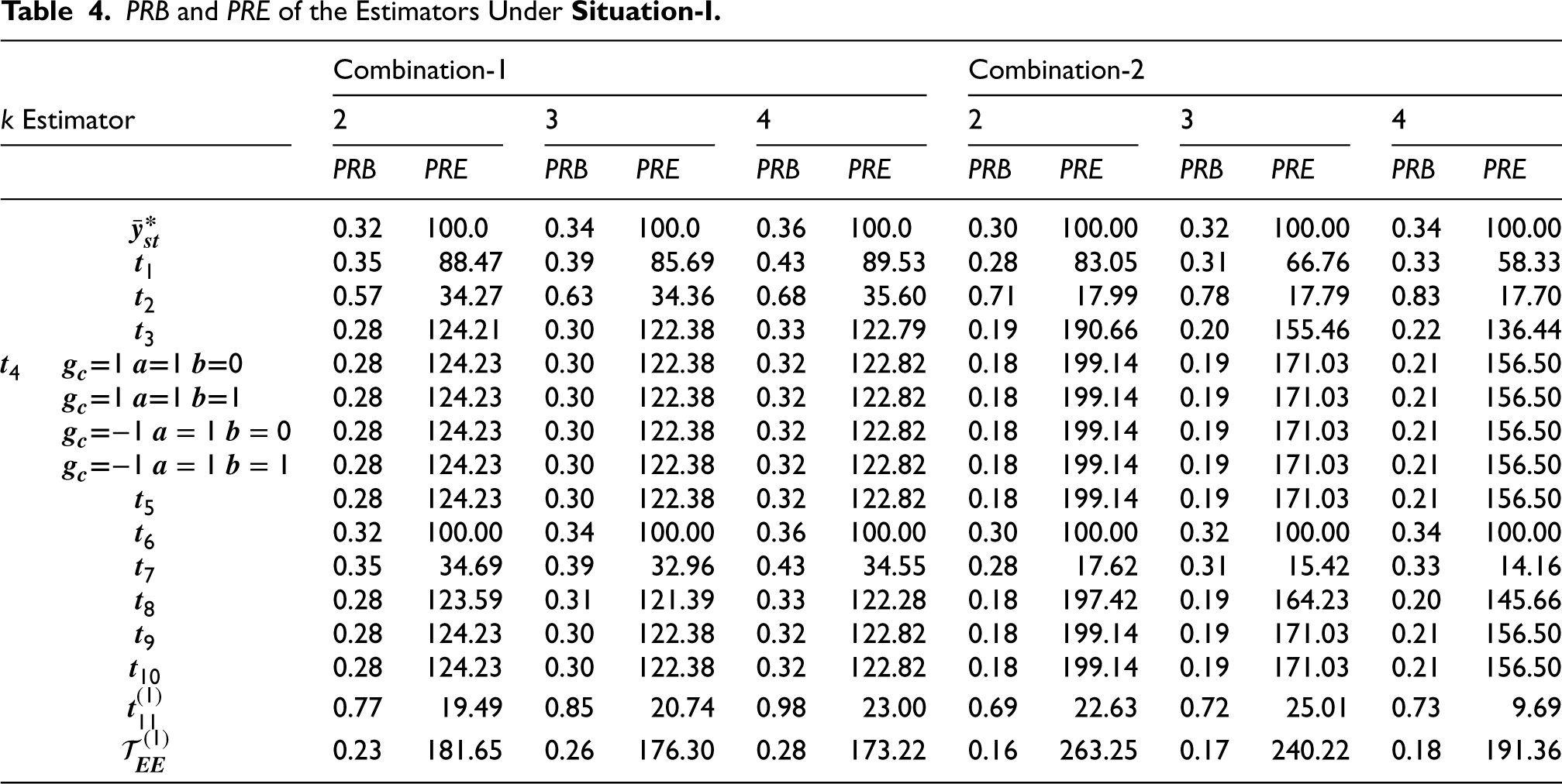
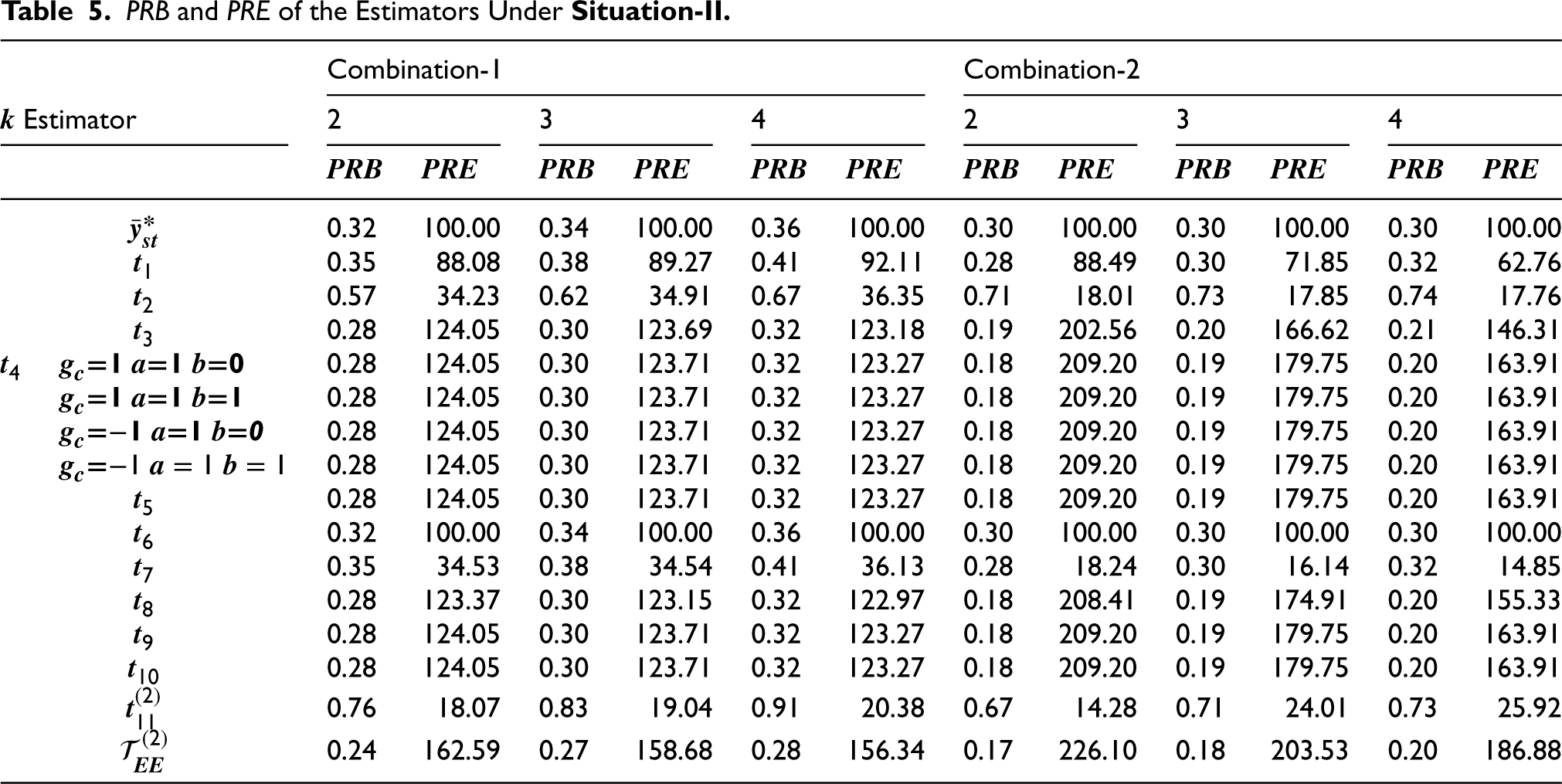
Furthermore, it can be observed from a computational analysis of the proposed estimators’ performance on a hypothetical multivariate data set for various combinations of
This research contributes to the ongoing efforts to improve the efficiency of estimation procedures when it comes to use the unknown population mean of an auxiliary variable in mean estimation with observed heterogeneity and missing information. The objectives are convinced in mean estimation with observed heterogeneity by putting forth novel exponential estimators based on the dual use of auxiliary information for two different real situations that handle non-ignorable missing data at two concurrent sampling phases. Furthermore, under
Based on simulation and empirical studies, Tables 1, 2, 4 and 5 show that our proposed estimators are more efficient than various existing and modified estimators (given in section 2) at all levels of sub-sampling factor
Footnotes
Acknowledgments
The authors express their gratitude to the Editor-in-Chief and Co-Editor-in-Chief for reviewing the manuscript, and to the distinguished referees for their insightful comments that significantly enhanced the current version of the research paper.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.