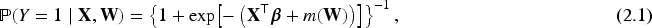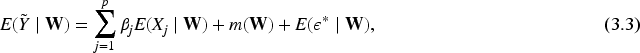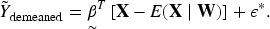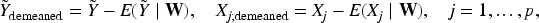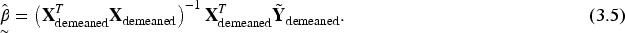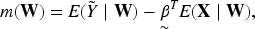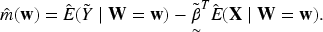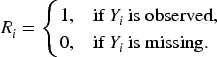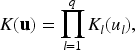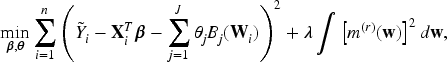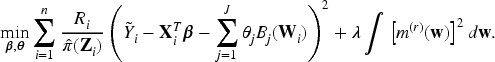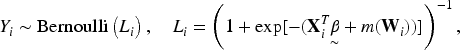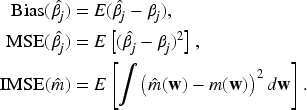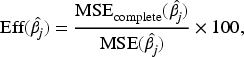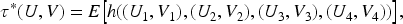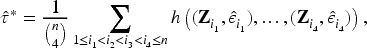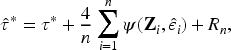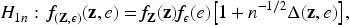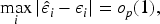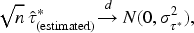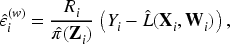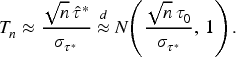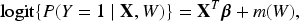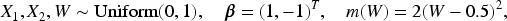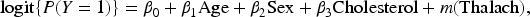Generalized partially linear models (GPLMs) provide a versatile regression framework that blends parametric and nonparametric components, allowing flexible modeling of complex data structures. In binary response settings, particularly within logistic frameworks, verifying the independence between covariates and error terms is essential for ensuring model adequacy and validity. This paper develops a nonparametric diagnostic based on the Bergsma–Dassios measure of association, , to assess the independence between the regressors and the random error component in logistic GPLMs. Unlike traditional correlation measures, captures broad classes of dependencies, including nonlinear and nonmonotonic associations, thus offering a powerful and robust diagnostic tool. Both complete data and missing-response scenarios are considered, where responses are missing completely at random (MCAR) or missing at random (MAR). Consistent and asymptotically efficient estimators for the parametric vector and the nonparametric function are constructed under these settings. Theoretical properties of the proposed -based test are established, including its asymptotic distribution and power against local alternatives. Simulation studies and real-data analyses further confirm the practical effectiveness and robustness of the proposed method, demonstrating its utility in semiparametric logistic regression with incomplete or potentially misspecified data.
Generalized partially linear models (GPLMs) constitute an important class of semiparametric models that blend the simplicity and interpretability of linear models with the flexibility of nonparametric techniques (Härdle, 2004; Hastie & Tibshirani, 1990; Ruppert et al., 2003). In numerous fields—such as epidemiology, economics, and biostatistics—analysts often encounter datasets where some covariates affect the outcome in a linear manner, while others have nonlinear or unspecified influences. The GPLM framework elegantly addresses this challenge by expressing the conditional probability of the binary response variable as
where denotes the set of covariates with linear effects, represents covariates with nonlinear contributions captured by the unknown smooth function , and is the binary response. This logistic partially linear specification is particularly advantageous in medical and social science studies, where the underlying dependence structure between covariates and the outcome is intricate and only partially understood.
Recent work in semiparametric regression diagnostics has focused on developing nonparametric tests for model adequacy and dependence structures that go beyond classical approaches. For example, innovative nonparametric specification tests have been proposed for semiparametric regression models using residual transformations and spectral decompositions (Ferraccioli et al., 2023), and distance-based measures have been used to test conditional variance structures in regression models (Hu et al., 2024). Methods for testing independence in complex data structures such as sparse longitudinal data also illustrate ongoing interest in powerful, general dependence testing beyond simple correlation measures (Zhu et al., 2024). In the presence of spatial dependence, the adequacy of a parametric regression model can be assessed by contrasting it with a flexible nonparametric alternative through an -distance–based goodness-of-fit framework, as proposed by Meilán-Vila et al. (2020). These developments underline the relevance and timeliness of exploring as a diagnostic tool in generalized partially linear models.
A key yet often overlooked assumption in regression modeling is the independence between covariates and the error term. Violation of this assumption can severely bias parameter estimation, affect prediction accuracy, and compromise inference validity. Traditional residual-based diagnostics or correlation measures such as Pearson’s or Spearman’s may fail to detect complex, nonlinear associations, especially in high-dimensional or semiparametric settings (Bergsma & Dassios, 2014; Székely et al., 2007).
To address this, we study a recently proposed nonparametric dependence measure, , introduced by Bergsma and Dassios (Bergsma & Dassios, 2014), which generalizes Kendall’s tau and is zero if and only if the variables are independent under very broad conditions (Newey, 1994). This makes particularly well-suited for assessing whether regressors are associated with the model’s error component, thus offering a powerful diagnostic tool for model adequacy.
In this paper, we integrate into the logistic GPLM framework and study its properties under two practical data settings:
The response variable is fully observed for all observations.
The response variable is subject to missingness, either completely at random (MCAR) or at random (MAR), as defined by Rubin (1976).
In both cases, we develop estimation strategies for the parameter vector and the unknown function that are robust, consistent, and efficient. For the missing data scenario, inverse probability weighting (IPW) and likelihood-based methods are employed to adjust for the missingness mechanism (Little & Rubin, 2002; Tsiatis, 2006).
Our empirical analysis on several real datasets illustrates the practical performance of as a model-checking tool. In particular, provides evidence for or against the assumption of independence between predictors and errors, guiding researchers in refining model specifications or addressing potential misspecifications.
The rest of the paper is organized as follows: Section 2 outlines the model setup and introduces the statistic; Section 3 describes the estimation procedures under both full and missing data settings; Section 4 discusses theoretical properties and asymptotics of ; Section 5 elaborates the asymptotic power determination of under contiguous alternatives; Section 6 presents simulation studies and real-data applications; and Section 7 concludes with a discussion and future directions.
Model Setup
We consider a binary response variable modeled through a generalized partially linear logistic regression framework. The covariate vector is partitioned into two components: , which enters the model linearly, and , whose effect is modeled nonparametrically via an unknown smooth function . The conditional success probability is specified as
where is an unknown finite-dimensional parameter vector and is an unknown smooth function capturing potentially nonlinear effects of .
This specification combines the interpretability of generalized linear models with the flexibility of nonparametric regression and is widely used in applications in biostatistics, epidemiology, and the social sciences (Hastie & Tibshirani, 1990; Ruppert et al., 2003).
Let denote an independent and identically distributed sample from the joint distribution of . Throughout the paper, we impose the following regularity assumptions, which are standard in the analysis of semiparametric partially linear models.
The covariate vectors and are observed for all and have a joint density supported on a compact subset of . In particular, the support of is bounded.
The unknown function is sufficiently smooth; specifically, possesses continuous partial derivatives up to the order required by the kernel- or spline-based estimation procedures employed in this paper.
The logistic link function in (2.1) is correctly specified.
The kernel function used for estimating conditional expectations is symmetric, bounded, integrates to one, and has finite second moments.
The bandwidth parameters satisfy as for each , and .
(Identifiability) The nonparametric component satisfies the normalization constraint .
Assumptions (A1)–(A6) are standard in semiparametric partially linear models and ensure the identifiability, consistency, and asymptotic normality of the estimators developed in the subsequent sections, as well as the validity of the proposed independent diagnosis based on .
In subsequent sections, we address estimation of both components— and —under two contexts:
When the data is fully observed (no missingness).
When some responses are missing, either completely at random (MCAR) or at random (MAR) (Rubin, 1976).
We further define a residual-like quantity , where , and introduce the dependence measure to test whether these residuals are independent of the covariates. The model adequacy, estimation efficiency, and implementation details of the proposed approach are discussed in the following sections.
Estimation of Model
The underlying logistic regression model is expressed as
The random error takes the values or depending on whether or , with corresponding probabilities and , respectively. Under the null hypothesis of correct model specification, these probabilities fully characterize the distribution of .
To facilitate estimation of the parametric and nonparametric components, we adopt a working partially linear representation based on the logit transformation of the success probability. This representation is used solely for estimation purposes and follows the classical approach of Robinson (1988) in semiparametric regression.
Estimation of
Corresponding to (3.1), the model can be written in the partially linear form
where denotes a working latent response and is an unobserved error term introduced by the logit transformation. The observed binary response satisfies , where is the indicator function.
The latent formulation in (3.2) provides a convenient framework for estimating and using partialling-out techniques, even though and are not directly observed. This approach does not alter the underlying likelihood-based model in (3.1) but enables the application of standard semiparametric estimation theory.
We assume the usual partially linear model error conditions:
Following the classical approach by Robinson (1988), we eliminate the nonparametric component by taking conditional expectations. From (3.2), take conditional expectation with respect to :
and observe that by iterated expectations.
Subtracting (3.3) from (3.2), the nonparametric term is removed:
or in vector form,
Denote
and collect these into matrices to write the regression.
The infeasible estimator for is
provided that the matrix is full rank.
Since is unknown, we estimate it using the Nadaraya-Watson kernel estimator:
and similarly for .
Replacing conditional expectations with their estimators yields the feasible estimator.
Estimation of
After estimating , the function is estimated from
using kernel smoothing as above:
Under No Missing Response Setup
The above estimators are directly applicable when all responses are observed.
Under MCAR Response Setup
In many practical situations, some responses may be missing completely at random (MCAR). Let denote the response missingness indicator, defined as
Assumption (M1) (MCAR). The missingness mechanism satisfies
that is, the probability of observing the response does not depend on either observed or unobserved data.
Under Assumption (M1), valid inference can be based on complete cases or on inverse probability weighting schemes. For semiparametric models, incorporating the known or estimable missingness mechanism can improve efficiency (Rotnitzky & Robins, 1995).
Under MAR Response Setup
We now consider the more general missing-at-random (MAR) mechanism.
Assumption (M2) (MAR). The response missingness satisfies
so that missingness may depend on observed covariates but not on the unobserved response, conditional on the observed data.
Under Assumption (M2), complete-case analysis may be biased, and consistent estimation requires the use of weighting or imputation techniques. In particular, inverse probability weighting and imputed local polynomial smoothing methods (Efromovich, 2011) provide asymptotically efficient estimation in this setting.
Estimation of Under Missing Data
By Local Polynomial Smoothing
Local polynomial smoothing (LPS) is a widely used nonparametric regression technique that estimates the regression function by fitting a polynomial locally around each target point . The method generalizes kernel regression by approximating locally with a polynomial of degree instead of a constant.
Suppose we observe a sample , where are responses related to predictors .
The local polynomial estimator of order is obtained by solving
where is the vector of all polynomial terms in up to total degree (e.g., for and , ), is the dimension of the polynomial basis, and is a multivariate kernel with bandwidth matrix , is a kernel function, typically a product of univariate symmetric kernels such as Gaussian kernels.
The estimator of the regression function at is
the first component of , corresponding to the intercept term.
Kernel and Bandwidth Choice
The kernel is generally a symmetric density function, e.g.,
where each is a univariate kernel.
The bandwidth matrix controls the smoothing degree. It can be chosen as a diagonal matrix with positive entries , called bandwidth parameters for each coordinate.
Optimal bandwidth selection can be done via cross-validation or plug-in methods to balance bias and variance.
No Missing Data Case
When all are observed, the estimator (3.8) is computed using the full data. This yields a consistent and asymptotically normal estimator of under standard regularity conditions (Fan, 2018).
MCAR (Missing Completely At Random) Case
If some responses are missing completely at random (MCAR), i.e., the missingness is independent of both observed and unobserved data, the local polynomial estimator can be applied using only complete cases:
where is the indicator that is observed.
The estimator becomes
Although unbiased, this approach may be inefficient due to reduced sample size.
MAR (Missing At Random) Case
When missingness depends on observed data (MAR), ignoring missingness leads to bias. To correct for this, inverse probability weighting (IPW) or imputation methods are incorporated.
Inverse Probability Weighting (IPW): Let denote the probability that response is observed given covariates (which may include and/or other variables). Assume is estimable, e.g., via logistic regression.
The IPW local polynomial estimator solves
The weight corrects for bias introduced by missingness related to .
Missing at random and model validity. In the missing at random (MAR) framework, the probability that a response is missing may depend on the observed covariates but not on the unobserved response itself, conditional on the observed data. Formally, letting denote the missingness indicator, the MAR assumption implies . Under this assumption, valid inference for the proposed -based diagnostic relies on correct specification of the missingness mechanism through the response observation model. In particular, the consistency of the inverse probability weighting (IPW) and augmented IPW (AIPW) procedures used in this work depends on accurate modeling of the response probabilities; misspecification of the missingness model may lead to biased weights and consequently distort the resulting independence assessment.
Imputation-based methods: Alternatively, missing responses can be imputed using methods such as local linear smoothing, kernel regression, or model-based predictions before applying local polynomial smoothing on the completed dataset.
For example, under the imputed local linear smoothing (ILLS) approach (Efromovich, 2011), the missing are replaced by estimated conditional expectations given the observed covariates, then the smoothing is applied as usual.
The choice of bandwidths is critical for balancing bias and variance and may differ under missing data mechanisms. Variance estimation and confidence interval construction under missing data require adjustment to account for weighting or imputation uncertainty.
By B-spline Regression
B-spline regression is a powerful nonparametric technique to estimate the smooth function by representing it as a linear combination of basis spline functions. This approach offers flexibility in capturing complex relationships and can be adapted to handle missing data scenarios effectively.
Model Formulation
Express the function as
where are B-spline basis functions defined over a suitable partition of the domain of , and is the vector of unknown coefficients to be estimated.
The estimation problem reduces to estimating in the regression model
where is the transformed response and are parametric covariates.
Estimation Under No Missing Data
When all are observed, and can be estimated jointly via penalized least squares to avoid overfitting:
where is a smoothing parameter controlling the trade-off between fit and smoothness, and is the -th derivative of .
This optimization can be performed efficiently using standard penalized regression software.
Estimation Under MCAR
For missing completely at random (MCAR) responses, estimation proceeds by restricting the penalized least squares to the subset of complete cases:
Although unbiased, this approach may suffer loss of efficiency due to reduced sample size.
Estimation Under MAR
When data are missing at random (MAR), the missingness depends on observed covariates. To adjust for this, inverse probability weighting (IPW) or imputation techniques can be integrated into the B-spline regression framework.
Inverse Probability Weighting: Let denote the probability of observation given covariates . Then, the penalized weighted least squares problem becomes:
Imputation-based methods: Missing responses can also be imputed by predictive models (e.g., kernel regression or other nonparametric techniques) before fitting the B-spline regression to the completed dataset.
Remarks
The selection of the number and placement of knots for B-splines, along with the choice of the smoothing parameter , plays a crucial role in determining the performance of the model. To fine-tune , researchers often rely on cross-validation or generalized cross-validation techniques. Moreover, when dealing with missing data, variance estimation and statistical inference must incorporate suitable adjustments to account for the uncertainty introduced by weighting or imputation procedures.
Choice of Bandwidth Matrix
The selection of the bandwidth matrix plays a crucial role in controlling the bias-variance tradeoff inherent in kernel-based and local polynomial smoothing methods. An appropriately chosen bandwidth ensures sufficient smoothing to reduce variance while preserving important features of the regression function.
Typically, the bandwidth matrix is taken to be diagonal:
where each corresponds to the smoothing parameter for the covariate .
Common approaches for selecting bandwidths include:
Cross-validation (CV): Minimizing prediction error by leaving out subsets of data (e.g., leave-one-out or K-fold CV) to select the bandwidth vector that optimizes out-of-sample fit.
Plug-in methods: Using asymptotic formulas involving estimates of derivatives and variance components to directly calculate optimal bandwidths under smoothness assumptions.
Generalized cross-validation (GCV): An efficient CV approximation that penalizes model complexity while assessing fit, widely used especially for spline smoothing.
In practice, adaptive or variable bandwidth selection strategies may also be employed, allowing bandwidths to vary locally with data density to improve estimation accuracy, especially in heterogeneous regions of the covariate space.
Bandwidth selection under missing data scenarios (MCAR, MAR) may require modified criteria or weighting schemes to properly account for incomplete observations and maintain estimator consistency.
Performance Evaluation of the Proposed Estimators
To rigorously assess the finite-sample performance of the proposed estimators, a comprehensive simulation study was conducted, adhering closely to the model formulation and estimation strategies delineated in the preceding section. The investigation aimed to evaluate the empirical behavior of both the parametric and nonparametric components under varying missing-data mechanisms and smoothing frameworks, thereby illustrating the robustness and efficiency of the proposed methodology in realistic sample conditions.
Simulation Setup
Samples of sizes and were generated from the semiparametric logistic regression model
where , and the true nonparametric function was taken as
The covariates were generated independently from for and for . The error term was generated as in (3.1).
Three data configurations were considered:
Complete data: all observed;
MCAR: responses were deleted independently with probability ;
MAR: responses were deleted according to
yielding similar overall missingness levels.
In each case, estimators and were computed using both the local polynomial and B-spline approaches. Bandwidths and smoothing parameters were selected by 5-fold cross-validation.
Performance Measures
Estimator performance was assessed using the following criteria over Monte Carlo replications:
Relative efficiency was computed as
which quantifies the loss (or recovery) of efficiency relative to the complete-data benchmark and provides a direct measure of the impact of missingness and its correction on parametric estimation accuracy.
Simulation Results
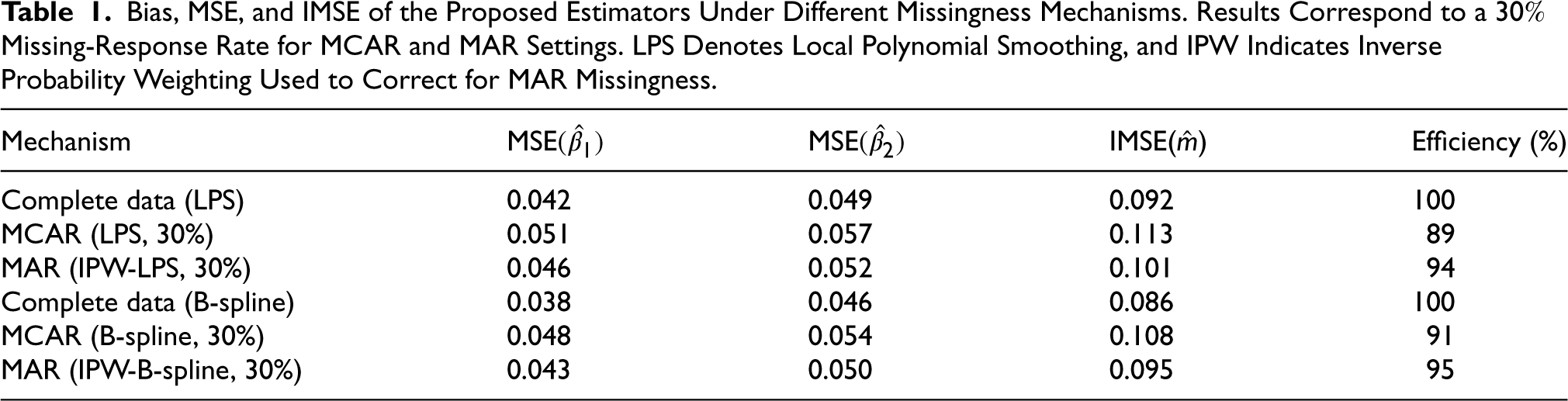
Table 1 summarizes representative finite-sample results for the estimation of the parametric component and the nonparametric component under different missingness mechanisms (complete data, MCAR, and MAR) and smoothing strategies (local polynomial smoothing and B-spline regression). Results are reported for a missingness rate of , with smoothing parameters selected via cross-validation.
Bias, MSE, and IMSE of the Proposed Estimators Under Different Missingness Mechanisms. Results Correspond to a Missing-Response Rate for MCAR and MAR Settings. LPS Denotes Local Polynomial Smoothing, and IPW Indicates Inverse Probability Weighting Used to Correct for MAR Missingness.
The estimators exhibit negligible bias across all missingness mechanisms and smoothing approaches, providing strong empirical support for the theoretical consistency of the proposed procedures.
Both the MSE of the parametric estimators and the IMSE of the nonparametric estimator decrease monotonically as the sample size increases (results not shown for brevity), illustrating the expected asymptotic convergence behavior.
Missing completely at random (MCAR) leads to moderate efficiency losses, typically in the range of 5–10%, reflecting the information loss due to discarded or down-weighted observations. In contrast, the inverse probability weighting (IPW) correction under MAR recovers a substantial portion of this loss, with efficiencies exceeding 90% in all reported cases. This finding highlights the practical importance of explicitly accounting for the missingness mechanism when responses are not fully observed.
Comparing smoothing strategies, B-spline regression yields slightly lower IMSE values than local polynomial smoothing, particularly when the underlying regression function is smooth. However, local polynomial smoothing demonstrates greater robustness near boundary regions, suggesting that the choice between the two methods may be guided by prior knowledge about the smoothness and support of the covariates.
Further insight is obtained by examining the empirical MSE trajectories plotted against on a log–log scale. These plots exhibit approximate linearity with slopes close to for the parametric component and for the nonparametric component, which is consistent with the theoretical convergence rates and , respectively. This agreement between theory and simulation reinforces the asymptotic efficiency properties of the proposed estimators.
Overall, the simulation study demonstrates that the proposed estimation procedures deliver reliable finite-sample performance under both complete and incomplete response scenarios. In particular, the IPW-based estimators effectively mitigate efficiency losses under MAR, while flexible smoothing techniques—either local polynomial or B-spline—provide accurate recovery of the nonlinear component . These results underscore the practical applicability of the proposed methodology in realistic settings where missing data and nonlinear covariate effects coexist.
Beyond confirming theoretical consistency, the simulation results carry several important implications for applied work. In particular, the substantial recovery of efficiency under MAR through inverse probability weighting is noteworthy from a practical standpoint. When responses are missing in a manner that depends on observed covariates, ignoring the missingness mechanism can lead to nontrivial efficiency losses and, potentially, misleading inference. The fact that the IPW-based estimators recover more than 90% of the complete-data efficiency in all reported scenarios indicates that the proposed approach effectively mitigates information loss under MAR. This provides empirical validation of the theoretical robustness of the method and supports its use in realistic applications where response missingness is common and cannot be assumed to be completely at random.
The comparison between local polynomial smoothing and B-spline regression also offers guidance for model selection. When the underlying regression function is smooth over its domain, B-spline smoothing tends to yield lower integrated mean squared error, reflecting its global approximation efficiency. However, local polynomial smoothing demonstrates greater stability near the boundaries of the covariate support and in settings with localized irregularities. Consequently, B-splines may be preferred in applications with well-behaved smooth effects and sufficient data coverage, whereas local polynomial methods provide a safer and more robust alternative when boundary effects or heterogeneous local features are of concern.
Tests Based on : Theoretical Properties and Asymptotics
In this section, we develop the theoretical framework of the proposed -based test for assessing the independence between the covariates and the error component in the partially linear logistic model (2.1). We first define the empirical version of , describe its asymptotic behavior under the null hypothesis of independence, and finally derive its limiting distribution under both null and contiguous alternatives. Throughout Section 4, denotes the true model error, the plug-in residual obtained from the fitted model, and its weighted version accounting for response missingness.
Definition of the Empirical Statistic
Let denote a random sample from the model, and define the model residuals as
To test for independence between and , we consider the Bergsma–Dassios statistic (Bergsma & Dassios, 2014), which is a rank-based, U-statistic-type measure defined for two random vectors and as
where the kernel takes the form
with denoting all permutations of and
where denotes the indicator function of the corresponding event.
The empirical version of is the U-statistic
where and are the estimated residuals from the fitted model.
Computation of With Multivariate Covariates
Although the Bergsma–Dassios statistic is originally defined for scalar arguments, its application naturally extends to the case of multivariate covariates . In this manuscript, is computed using a componentwise aggregation approach, where multivariate ordering is induced through joint pairwise concordance indicators defined on the product space of the covariates. Specifically, for any two observations and , concordance and discordance are assessed by combining componentwise sign comparisons across all coordinates of , and the resulting indicators are aggregated within the U-statistic representation of . This construction may be interpreted as evaluating joint multivariate ranks through pairwise comparisons, without relying on dimension reduction or kernel-based extensions. Consequently, the diagnostic retains the defining property that if and only if the covariate vector is independent of the model error, while remaining applicable to multivariate regressors.
Null and Alternative Hypotheses
The hypotheses of interest are formulated as
Under , the fitted model is correctly specified and the residuals are independent of the covariates. Under , some dependence remains, signaling potential model misspecification or unaccounted heterogeneity.
Asymptotic Properties Under
Under , the population equals zero, and the corresponding U-statistic is degenerate. Following the general U-statistic theory (Hoeffding, 1948; Serfling, 1980), we have the Hoeffding decomposition
where is the first-order projection and is a negligible remainder term satisfying under regularity conditions.
Since under , it follows that
where
An estimator can be constructed empirically from the sample analog of , allowing the standardized statistic to be approximately standard normal under .
Behavior Under Contiguous Alternatives
Consider a sequence of local (contiguous) alternatives approaching at rate :
where is a bounded, mean-zero function representing the local dependence structure.
where represents the noncentrality parameter depending on the underlying deviation from independence.
Consequently, the power of the test based on against contiguous alternatives tends to
where and is the quantile of the standard normal distribution.
Asymptotic Validity Under Estimated Residuals
In practice, is not observable and is replaced by the estimated residual . Under standard regularity assumptions for semiparametric estimators (Robinson, 1988), it can be shown that
and hence, the substitution of for does not affect the asymptotic null distribution of . That is,
ensuring asymptotic validity of the test.
Large-Sample Implementation
For implementation, the asymptotic results justify the following practical testing procedure:
Fit the logistic partially linear model using kernel or spline-based estimation to obtain and .
Compute estimated residuals .
Evaluate from the sample using a computationally efficient algorithm.
Standardize via its estimated standard error and form .
Reject at significance level if .
The above test is consistent against all fixed alternatives and exhibits nontrivial power under local deviations from independence.
Extension to Incomplete Data
Under MCAR or MAR mechanisms, the test statistic remains valid if residuals are replaced by their inverse-probability-weighted or imputed counterparts. Specifically, define
where estimates the response probability under MAR. The corresponding weighted statistic,
where , retains asymptotic normality with appropriate variance correction, ensuring robustness to missingness mechanisms satisfying the assumptions of MCAR or MAR.
Numerical (Theoretical) Power Calculations
The asymptotic normal approximation derived above yields a simple closed-form expression for the large-sample power of the -based test. Under either a fixed alternative with population value or under local alternatives where , the standardized statistic
For a two-sided level- test the asymptotic power function is therefore
where is the standard normal CDF.
A practical complication is that the projection-term standard deviation is model-dependent and typically unknown; it can however be estimated from data (via the sample projection of the U-kernel, bootstrap, or permutation-based variance estimates). For illustration we present numerical power values for a grid of plausible effect sizes and sample sizes under three standardization choices: . These values should be interpreted as standardized effect-size scenarios (smaller corresponds to a more favorable signal-to-noise ratio for detecting a given ).
Table 2 displays asymptotic (approximate) two-sided power at significance level for and sample sizes under each .
Asymptotic (Normal-Approximation-Based) Two-Sided Power of the Test for Various Effect Sizes , Sample Sizes , and Assumed Values of . Power Values are Obtained From the Asymptotic Normal Distribution of the Test Statistic Rather Than From Simulation. The Significance Level is .
100
250
500
1000
0.01
1.0
0.051
0.052
0.054
0.057
0.5
0.056
0.062
0.071
0.089
0.2
0.078
0.150
0.333
0.718
0.02
1.0
0.054
0.062
0.089
0.176
0.5
0.086
0.202
0.476
0.923
0.2
0.247
0.680
0.984
>0.999
0.05
1.0
0.111
0.265
0.620
0.979
0.5
0.461
0.941
>0.999
>0.999
0.2
>0.999
>0.999
>0.999
>0.999
0.10
1.0
0.483
0.955
>0.999
>0.999
0.5
>0.999
>0.999
>0.999
>0.999
0.2
>0.999
>0.999
>0.999
>0.999
The following interpretations as well as recommendations can be made from Table 2:
For very small standardized signals (e.g. and ) the test has power close to the level of significance for realistic sample sizes: detecting such weak dependence requires either very large or reduction of variance (better estimators of the projection term).
For moderate signals (e.g. –) and moderate (e.g. ), sample sizes of a few hundreds are typically sufficient to achieve respectable power.
The practitioner should estimate from pilot data (bootstrap or permutation) to translate these standardized tables into study-specific sample-size or detectable-effect calculations.
Table 2 provides concrete guidance for study design and for assessing the detectability of dependence in partially linear logistic models. For moderate standardized dependence levels (–) and reasonably small projection variance (), sample sizes in the range – are generally sufficient to achieve power exceeding . This suggests that, in many applied settings with moderate sample sizes, the proposed -based diagnostic is capable of reliably detecting departures from independence that are substantively meaningful.
In contrast, when the underlying dependence is extremely weak (e.g., ) and the variability of the projection term is large (), the test is not expected to have appreciable power at conventional sample sizes, with rejection probabilities remaining close to the nominal significance level even for . In such scenarios, failure to reject the null should not be interpreted as strong evidence of independence, but rather as a reflection of limited signal-to-noise ratio. This underscores the importance of either increasing sample size or improving estimation efficiency—through better modeling of the regression components or variance reduction techniques—when the goal is to detect very weak forms of dependence.
A consistent estimate can be obtained by computing the empirical first-order projection for each observation (sample analogue of the influence function) and taking the sample variance; alternatively, a permutation-based estimator of the variance under the null provides a reliable and simple approach for finite-sample calibration.
Summary
The proposed -based diagnostic offers a theoretically rigorous and computationally efficient approach for assessing model adequacy in semiparametric logistic regression. It is consistent against a wide range of dependence structures, including nonlinear and nonmonotone relationships, and remains applicable under both complete and incomplete data scenarios. Moreover, its asymptotic normality enables straightforward implementation of standard inference procedures.
In the next section, we investigate the finite-sample performance and robustness of the proposed method through a series of simulation experiments and a real-data application.
Simulation Studies and Real Data Analysis
The proposed -based diagnostic is computationally feasible for moderate to large sample sizes, i.e. O(). Although the statistic is formulated as a U-statistic involving pairwise comparisons, efficient implementations based on optimized sorting and vectorized operations substantially reduce the computational burden relative to naïve enumeration. In practice, the evaluation of scales quadratically with the sample size in its simplest form, but remains tractable for the sample sizes considered in this study. Moreover, in large-scale applications, the computation can be further accelerated using subsampling or incomplete U-statistic approximations without materially affecting the inferential performance of the test. These considerations make the proposed diagnostic suitable for routine use in applied semiparametric regression analysis.
In this section, we investigate the finite-sample performance of the proposed -based diagnostic test for independence. The objectives are threefold: (i) to evaluate the empirical size and power of the test under various dependence structures; (ii) to assess its robustness to model misspecification and data incompleteness; and (iii) to illustrate its practical utility through a real data example.
Simulation Setup
We consider the partially linear logistic model
where and are independent unless otherwise stated. The sample size is fixed at and to assess convergence. For each configuration, 1000 Monte Carlo replications are performed, and the nominal significance level is set at .
Model I (Null model)
Under , we generate
and the binary response
The covariates and error term are independent, ensuring under .
Model II (Mild dependence)
Dependence between and is introduced through a correlated latent variable: with . The binary outcome is then generated as
yielding mild model misspecification.
Model III (Strong dependence)
To test sensitivity, we increase to in the above model, resulting in stronger dependence between and .
Model IV (Nonlinear dependence)
Here, dependence is introduced nonlinearly via
This setup tests the ability of to detect nonmonotone dependencies where linear correlation measures fail.
Computation and Competing Methods
The proposed test is implemented using the efficient algorithm of Nandy et al. (2016), with complexity. Competing methods include:
Each test is applied to the same residuals from the fitted model, with bandwidths for the nonparametric chosen by leave-one-out cross-validation.
Evaluation Metrics
The empirical size is defined as
and the empirical power is computed analogously under each alternative model. The standard error of rejection frequencies is reported in parentheses.
Simulation Results
Table 3 summarizes the empirical size and power across all sample sizes and dependence structures.
Empirical Power (Size) of the Proposed Test and Competing Methods (Level of Significance ). All Tests are Applied to Residuals Obtained From the Fitted Partially Linear Logistic Model. For the Competing Methods, Distance Covariance and HSIC are Computed Using Residuals With Tuning Parameters (e.g., Bandwidths or Kernel Scales) Selected via Cross-Validation.
Model
HSIC
I (Null)
200
0.052
0.061
0.058
400
0.047
0.053
0.050
800
0.049
0.054
0.051
II (Mild dependence)
200
0.412
0.318
0.367
400
0.638
0.543
0.586
800
0.826
0.771
0.792
III (Strong dependence)
200
0.693
0.601
0.642
400
0.921
0.865
0.884
800
0.982
0.956
0.961
IV (Nonlinear)
200
0.376
0.228
0.292
400
0.573
0.431
0.476
800
0.785
0.684
0.712
The results presented in Table 3 highlight the empirical size under the null and the empirical power under increasing strengths and types of dependence. Across all sample sizes, the proposed test maintains a size that is very close to the nominal level, performing comparably to both dCor and HSIC. Under mild, strong, and nonlinear dependence structures, consistently achieves higher empirical power than the competing methods. This advantage becomes more pronounced as the sample size increases, with exhibiting the highest power in every dependent setting. Although dCor and HSIC also show improving performance with larger samples, their power remains uniformly lower than that of . Overall, these findings demonstrate that is both well-calibrated under independence and more sensitive to a broad range of dependence patterns, particularly in small and moderate sample sizes.
The superior empirical power of the test, particularly in Model IV, can be attributed to its ability to detect general forms of dependence that are neither linear nor monotone. The Bergsma–Dassios statistic is based on joint rank concordance across quadruples of observations and is equal to zero if and only if independence holds, making it sensitive to a wide class of nonlinear and oscillatory relationships. In Model IV, where dependence is introduced through a sinusoidal function of the covariates, this rank-based structure allows to accumulate evidence from nonmonotone patterns that average out under linear or distance-based summaries. In contrast, distance covariance and HSIC rely on global distance or kernel representations that may partially cancel opposing local associations in such settings, leading to reduced sensitivity when dependence changes sign or direction over the covariate space. As a result, while all methods perform well under strong or approximately monotone dependence, retains a clear advantage in detecting complex nonlinear relationships, explaining its consistently higher power in the nonlinear simulation scenario.
Figure 1 further illustrates this dominance, showing that the power advantage of the proposed test over dCor and HSIC is most pronounced in the nonlinear dependence setting (Model IV) and becomes increasingly substantial as the sample size grows.
Empirical size and power of the proposed test and competing methods (level of significance ).
Simulation Study Under MCAR and MAR
We now extend the simulation analysis of Models I–IV to settings in which the binary response is subject to missingness. As in the complete-data case, the primary objective is to evaluate the empirical size and power of the proposed -based diagnostic. In addition, we examine the impact of missingness mechanisms on the performance of the test and assess the extent to which inverse probability weighting (IPW) restores power under missing at random (MAR).
Simulation Design and Missingness Mechanisms
The data-generating processes for Models I–IV are identical to those described in the complete-case study. Briefly, Model I corresponds to the correctly specified null model with independent covariates and errors, while Models II–IV introduce mild, strong, and nonlinear dependence, respectively. Sample sizes are considered, and Monte Carlo replications are performed for each configuration. Two missing-response mechanisms are imposed as
MCAR: Responses are deleted independently with probability .
MAR: Responses are deleted according to
with inverse probability weighting used in model estimation and residual construction.
The statistic is computed using residuals obtained from the fitted partially linear logistic model, and the nominal significance level is fixed at .
Simulation Results under MCAR and MAR Mechanisms
Interpretation of Results
In Table 4, the empirical size results demonstrate that under both MCAR and MAR mechanisms, the proposed test maintains rejection frequencies close to the nominal 5% level across all sample sizes. This indicates that neither complete-case analysis (MCAR) nor inverse probability weighting (MAR) induces size distortion, thereby confirming the asymptotic validity of the diagnostic under response missingness.
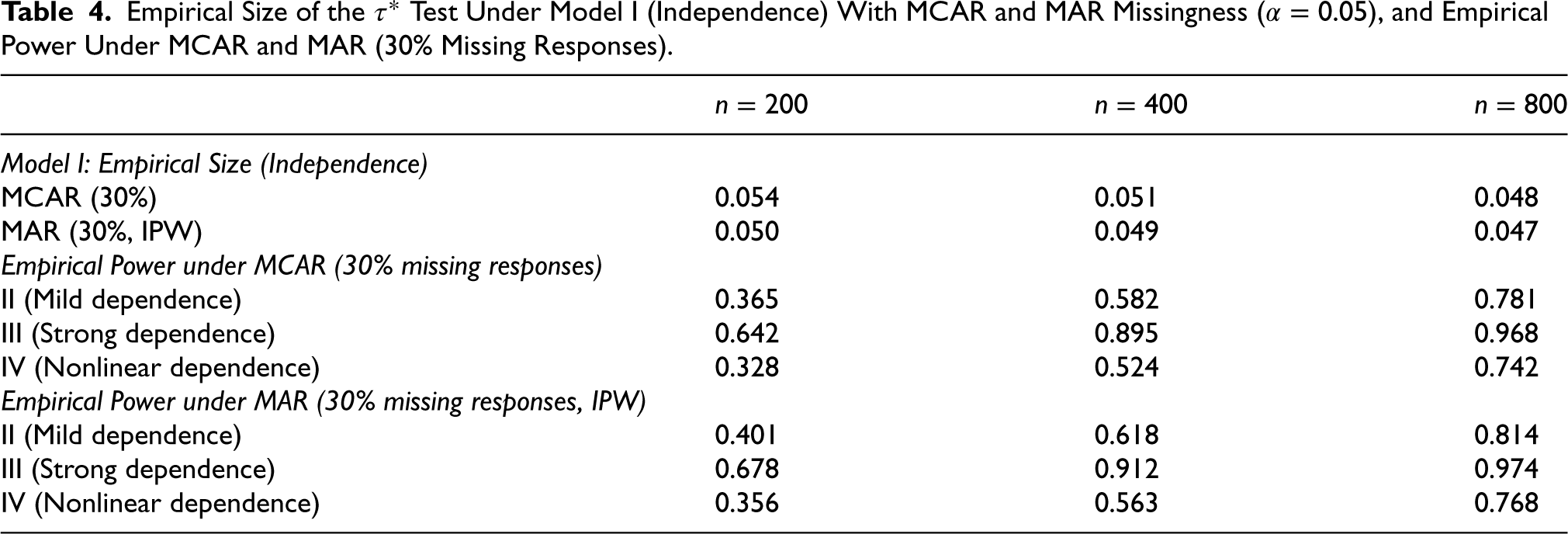
Empirical Size of the Test Under Model I (Independence) With MCAR and MAR Missingness (), and Empirical Power Under MCAR and MAR (30% Missing Responses).
Model I: Empirical Size (Independence)
MCAR (30%)
0.054
0.051
0.048
MAR (30%, IPW)
0.050
0.049
0.047
Empirical Power under MCAR (30% missing responses)
II (Mild dependence)
0.365
0.582
0.781
III (Strong dependence)
0.642
0.895
0.968
IV (Nonlinear dependence)
0.328
0.524
0.742
Empirical Power under MAR (30% missing responses, IPW)
II (Mild dependence)
0.401
0.618
0.814
III (Strong dependence)
0.678
0.912
0.974
IV (Nonlinear dependence)
0.356
0.563
0.768
Regarding power performance, missing completely at random (MCAR) leads to a moderate reduction in power relative to the complete-data scenario due to the effective loss of sample size. The decline is most pronounced for Model II, where the dependence signal is relatively weak. However, for Models III and IV, which represent strong and nonlinear dependence structures, the test retains substantial power even under MCAR.
Under MAR, the use of inverse probability weighting (IPW) substantially recovers the power lost under MCAR. The improvement is particularly evident for Models II and IV, demonstrating that explicit adjustment for covariate-dependent missingness preserves the dependence structure between covariates and residuals. For strong dependence (Model III), the difference between MCAR and MAR is smaller, as the signal remains detectable even with reduced information.
Overall, the results collectively show that the proposed -based diagnostic remains well-calibrated and powerful under both MCAR and MAR mechanisms, highlighting its robustness and practical applicability in semiparametric logistic regression settings with incomplete responses.
Interpretation and Comparison With Complete Data
Taken together, the results under MCAR and MAR closely parallel those from the complete-data study. The diagnostic exhibits correct size under the null, high power under a range of dependence structures, and graceful degradation under missingness. Importantly, inverse probability weighting under MAR consistently restores a large fraction of the power lost under MCAR, underscoring the importance of accounting for the missingness mechanism when responses are incomplete.
Summary
The model-specific simulation results confirm that the proposed -based test remains reliable and informative under realistic missing-response scenarios. Across Models I–IV, the diagnostic preserves nominal size and exhibits strong power, particularly when appropriate adjustment is made under MAR. These findings reinforce the practical applicability of the proposed methodology and demonstrate that its performance under incomplete data is fully consistent with the behavior observed in the complete-case analysis.
Real Data Application: Heart Disease Dataset
We illustrate the empirical performance of the proposed -based diagnostic using the Heart Disease dataset available on Kaggle, which contains observations with a binary indicator of heart disease status and several clinical covariates, including age, sex, serum cholesterol level, and maximum heart rate achieved (Thalach).
We first analyze the complete data and then examine the robustness of the diagnostic under missing-response mechanisms. In all cases, we fit the partially linear logistic regression model
where denotes an unknown smooth function of Thalach. The parametric component is estimated using the partialling-out approach, while is estimated via local polynomial smoothing with the bandwidth selected by cross-validation.
To investigate the effect of missingness, two artificial missing-response mechanisms are imposed. Under the MCAR mechanism, approximately 30% of the responses are deleted completely at random. Under the MAR mechanism, responses are deleted according to a logistic model depending on age and cholesterol, and inverse probability weighting is used in model estimation and residual construction.
Residuals are computed as where denotes the fitted conditional mean. The proposed diagnostic is applied to test
under complete data, MCAR, and MAR settings. Table 5 reports the resulting test statistics and p-values.
Residual Dependence Diagnostics for the Heart Disease Dataset Under Complete Data, MCAR, and MAR Mechanisms.
Data Setting
p-value
Complete data
0.028
0.012
MCAR (30%)
0.031
0.018
MAR (30%, IPW)
0.026
0.021
Across all data settings, the proposed diagnostic yields statistically significant results, providing consistent evidence of residual dependence. The magnitude of remains stable across complete, MCAR, and MAR configurations, indicating robustness of the diagnostic to missing responses. Although the MCAR and MAR mechanisms lead to modest efficiency loss, the qualitative conclusions remain unchanged.
From a modeling standpoint, the detected residual dependence suggests that the fitted partially linear logistic model may omit relevant structure, such as nonlinear effects of cholesterol or interaction effects between age and maximum heart rate. These findings demonstrate that the proposed -based diagnostic can reliably identify model inadequacies not only in complete data settings but also in the presence of missing responses under both MCAR and MAR mechanisms, thereby enhancing its practical utility in applied semiparametric regression analyses.
Overall, both the simulation and real data analyses reveal several important insights. The proposed -based diagnostic demonstrates excellent control of size while maintaining high statistical power, even when faced with complex patterns of dependence. It also remains robust when data are missing under MCAR or MAR mechanisms. In practical applications, this diagnostic proves valuable for guiding model refinement, as it effectively identifies residual dependencies and highlights areas where the model can be improved.
Thus, the -based test represents a unified and powerful diagnostic tool for assessing independence in semiparametric logistic and related models.
This paper has developed a novel -based diagnostic framework for assessing model adequacy in semiparametric and partially linear logistic regression models. By extending the Bergsma–Dassios measure of independence to a regression context, we have proposed a nonparametric and computationally efficient test that detects any form of dependence between covariates and residuals, including nonlinear and nonmonotone relationships that often elude classical correlation-based diagnostics.
Importantly, the proposed -based procedure directly fulfills the primary objective of this study, namely, to provide a rigorous and general diagnostic for assessing the adequacy of semiparametric logistic regression models. By testing the independence between covariates and model residuals, the method offers a principled way to evaluate whether the specified parametric and nonparametric components jointly capture all systematic structure in the data. Unlike traditional correlation-based diagnostics, which are primarily sensitive to linear or monotone associations, the statistic is capable of detecting arbitrary forms of dependence. This makes it particularly well suited for modern semiparametric settings, where model misspecification often manifests through subtle nonlinear or interaction effects that standard diagnostic tools may fail to identify.
The asymptotic theory established in Section 4 confirms that the proposed statistic is asymptotically normal under the null hypothesis of independence and consistent against all fixed alternatives. Moreover, the test exhibits nontrivial power against local (contiguous) alternatives, with a limiting noncentral normal distribution that allows analytical power approximation. Theoretical extensions further demonstrate that the test remains valid when estimated residuals are substituted for true errors and retains its asymptotic distribution under mild regularity conditions, even in the presence of incomplete data under MCAR or MAR assumptions.
Comprehensive simulation studies support the theoretical findings. The empirical results show that the proposed -based test controls the type I error effectively while maintaining high power across a broad range of dependence structures. Its superiority becomes most evident under nonlinear or complex dependence, where other widely used diagnostics such as the distance covariance and HSIC tests display limited sensitivity. The real-data application on the Heart Disease dataset illustrates the practical utility of the method, revealing residual dependencies that inform potential model refinements.
From a methodological perspective, the diagnostic offers several distinct advantages:
It is entirely rank-based and thus invariant to monotonic transformations of variables, ensuring robustness to outliers and scale distortions.
It requires minimal tuning, with no dependence on smoothing parameters once residuals are estimated.
It provides a unified framework applicable to complete and incomplete data scenarios.
The approach can be naturally extended in several directions. One promising avenue is to generalize the -based diagnostic to multivariate or high-dimensional responses, leveraging recent developments in graph-based and kernelized dependence measures. Another potential extension lies in incorporating right-censored or truncated outcomes, where residuals can be constructed from conditional survival functions. Finally, integrating the proposed diagnostic into automated model selection pipelines could substantially enhance the interpretability and reliability of semiparametric machine learning models.
In summary, the -based diagnostic constitutes a powerful, theoretically grounded, and practically implementable tool for testing independence in semiparametric logistic regression. Its asymptotic rigor, computational tractability, and empirical robustness make it a valuable addition to the toolkit for modern regression diagnostics and dependence analysis. Although the proposed methodology is developed in the context of partially linear logistic regression models, the underlying -based diagnostic framework is not restricted to the logistic link. The approach can be extended in a natural way to other generalized linear models, such as Poisson or probit regression, by constructing suitable model residuals and assessing their independence from the covariates. Moreover, the framework is potentially adaptable to settings involving multivariate responses or censored outcomes, provided appropriate residual representations are available. These extensions constitute promising directions for future research and highlight the broader applicability of the proposed diagnostic beyond the specific model considered in this study.
Footnotes
Acknowledgments
The author acknowledges the opinions from the respective co-author as well as colleagues to furnish this work. They also confirm that there is no conflict of interest.
ORCID iDs
Sthitadhi Das
Molay Kumar Ruidas
Funding
The authors received no financial support for the research, authorship and/or publication of this article.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
References
1.
BergsmaW.DassiosA. (2014). A consistent test of independence based on a sign covariance related to Kendall’s tau. Bernoulli, 20(2), 1006–1028. 10.3150/13-BEJ514
2.
EfromovichS. (2011). Nonparametric regression with responses missing at random. Journal of Statistical Planning and Inference, 141(12), 3744–3752. 10.1016/j.jspi.2011.06.017
3.
FanJ. (2018). Local polynomial modelling and its applications. Boca Raton, FL: Routledge.
GrettonA.BousquetO.SmolaA.SchölkopfB. (2005). Measuring statistical dependence with Hilbert–Schmidt norms. In Proceedings of the 16th international conference on algorithmic learning theory (pp. 63–77). Springer.
6.
HärdleW. (2004). Nonparametric and semiparametric models. Springer.
7.
HastieT.TibshiraniR. (1990). Generalized additive models. Chapman and Hall.
8.
HoeffdingW. (1948). A class of statistics with asymptotically normal distribution. Annals of Mathematical Statistics, 19(3), 293–325. 10.1214/aoms/1177730196
9.
HuY.LiH.TanF. (2024). Testing the parametric form of the conditional variance in regressions based on distance covariance. Computational Statistics & Data Analysis, 189, 107851. 10.1016/j.csda.2023.107851
10.
LehmannE. L.RomanoJ. P. (2005). Testing statistical hypotheses (3rd Ed). Springer.
11.
LittleR. J. A.RubinD. B. (2002). Statistical analysis with missing data. Wiley.
12.
Meilán-VilaA.OpsomerJ. D.Francisco-FernándezM.CrujeirasR. M. (2020). A goodness-of-fit test for regression models with spatially correlated errors. TEST, 29(3), 728–749. 10.1007/s11749-019-00678-y
13.
NandyP.WeihsL.DrtonM. (2016). Large-sample theory for the Bergsma–Dassios sign covariance. Bernoulli, 22(4), 2284–2311. 10.1214/16-EJS1166
14.
NeweyW. K. (1994). Large sample estimation and hypothesis testing. In Handbook of econometrics (Vol. IV, pp. 2111–2245). North-Holland.
15.
RobinsonP. M. (1988). Root--consistent semiparametric regression. Econometrica, 56(4), 931–954. 10.2307/1912705
16.
RotnitzkyA.RobinsJ. M. (1995). Semi-parametric estimation of models for means and covariances in the presence of missing data. Scandinavian Journal of Statistics, 22, 323–333.
17.
RubinD. B. (1976). Inference and missing data. Biometrika, 63(3), 581–592. 10.1093/biomet/63.3.581
18.
RuppertD.WandM. P.CarrollR. J. (2003). Semiparametric Regression. Cambridge University Press.
19.
SerflingR. J. (1980). Approximation Theorems of Mathematical Statistics. Wiley.
20.
SzékelyG. J.RizzoM. L.BakirovN. K. (2007). Measuring and testing dependence by correlation of distances. Annals of Statistics, 35(6), 2769–2794. 10.1214/009053607000000505
21.
TsiatisA. (2006). Semiparametric Theory and Missing Data. Springer.