
Abstract
With the rapid development of AI-driven personalized services, model training increasingly depends on highly sensitive user-side data, such as location, social behaviour, and biometric information. These data not only exhibit pronounced non-independent and identically distributed (non-IID) characteristics but also pose serious privacy risks when processed centrally. Achieving efficient personalized modelling while preserving data locality and privacy has thus become a critical challenge in the evolution of personalized AI. In recent years, personalized federated learning (PFL) has gained significant attention for its strong performance in addressing non-IID data challenges. However, existing approaches often fall short in effectively balancing collaborative efficiency with personalization. To overcome this limitation, we propose FedDAC, a dynamically adaptive, collaboration-enhanced personalized federated learning method. By quantitatively assessing the responsiveness of each parameter to non-IID data, FedDAC dynamically selects collaborative clients, ensuring effective cooperation while retaining personalized feature information. Extensive experiments on four benchmark datasets (EMNIST, CIFAR-10, CIFAR-100, and Tiny ImageNet) under two pathological non-IID settings show that FedDAC consistently outperforms strong baselines. It improves accuracy by 1.5–3.2% on average, reaching 5.9% on highly heterogeneous tasks. The source code is publicly available at https://github.com/Lixinqin9/FedDAC-MAIN.
Keywords
Introduction
Federated learning (FL) is an emerging paradigm of distributed machine learning that enables decentralized clients to collaboratively train models without exposing their private data (McMahan et al., 2017). This approach has been widely applied in various domains such as computer vision (Himeur et al., 2023), finance (Long et al., 2020; Pei et al., 2024), and healthcare (Rieke et al., 2020; Sadilek et al., 2021). Despite its potential, FL faces significant challenges due to heterogeneity in client data (Li et al., 2021), which adversely affects global model training (Gong et al., 2021). In particular, non-independent and identically distributed (non-IID) data (Zhang et al., 2021) lead to differences in local tasks across clients, making it difficult for the global model to perform well on all clients (Huang et al., 2021).
To address the issue of data heterogeneity, personalized federated learning (PFL) (Arivazhagan et al., 2019; Fallah et al., 2020; Li et al., 2021; Tang et al., 2021) has emerged as a promising solution. PFL allows each client to train a personalized model that better adapts to its local data distribution, mitigating the impact of non-IID data while still enabling knowledge sharing among clients (Pei et al., 2024). Existing PFL methods can be broadly categorized into two groups: one line of work focuses on extracting personalized features during local model updates to better fit each client’s data distribution, while the other achieves inter-client collaboration by sharing a subset of global model parameters (Collins et al., 2021; Dinh et al., 2020). Although these approaches have improved personalization, they still face challenges such as high communication overhead and privacy leakage risks (Chen et al., 2024; Hu et al., 2021; Li et al., 2021).
At the same time, over-reliance on personalization can slow global model convergence or hinder its adaptability across clients. Conversely, placing too much emphasis on collaboration may reduce the model’s ability to handle data heterogeneity, thereby compromising personalization. Many current PFL methods prioritize providing independent personalized models for each client while overlooking the importance of effective collaboration in global model training.
To address the imbalance between collaboration and personalization in existing PFL methods, this paper proposes a novel framework called FedDAC (federated learning with dynamic adaptive collaboration). This framework introduces a dynamic collaboration strategy based on a responsiveness evaluation mechanism, which assesses each client’s collaboration potential by analyzing key changes in parameter updates. A collaboration criterion is then derived from these changes to dynamically select a subset of clients for participation in global model sharing. This strategy allows for efficient control over which clients require personalized customization and optimization during aggregation.
To measure the collaboration standard among clients, a mask-based marking approach is employed, which not only reduces communication overhead but also helps mitigate privacy risks. Furthermore, an adjustable weighted aggregation strategy is integrated. By considering differences in data distributions and parameter responsiveness across clients, this strategy assigns similarity-based weights to optimize the aggregation process. This ensures that each client benefits from global collaboration while retaining the ability to build a personalized model tailored to its own data.
We propose a novel dynamic collaboration strategy for PFL, which considers both the data distribution differences among clients and the responsiveness of parameters to non-IID data. This strategy dynamically adjusts client participation, enabling more active collaboration while avoiding the negative effects of non-IID data. We design a flexible and personalized adjustable weighting strategy under highly heterogeneous data settings. This strategy enables client-specific adaptation and demonstrates that dynamic weight adjustment can significantly enhance personalization performance. We conduct extensive experiments on four real-world datasets, demonstrating that FedDAC consistently outperforms existing methods under two heterogeneous FL settings.
Related Work
Personalized Federated Learning (Arivazhagan et al., 2019; Fallah et al., 2020; Li et al., 2021; Tang et al., 2021) has emerged as an effective solution to address the data heterogeneity challenges in Federated Learning. PFL aims to train a personalized model for each client to better fit the local data distribution (Zhang et al., 2020). The core idea of PFL is to encourage collaboration among clients while preserving privacy, thereby improving personalization performance for each individual client. Current approaches in PFL can be broadly categorized into two groups: data-based PFL and model-based PFL.
Data-based PFL focuses on reducing inter-client data heterogeneity to achieve personalization. These methods typically involve sharing a global dataset or exchanging private statistical information (Collins et al., 2021) across clients to minimize distributional differences. However, this comes with a significant risk of privacy leakage (Hu et al., 2021), especially in sensitive applications where such data sharing may violate privacy policies. Therefore, while data-based PFL methods can be effective, they are limited in their ability to ensure privacy. In contrast, model-based PFL (Marfoq et al., 2021; Yoon et al., 2021) addresses heterogeneity by customizing the models of individual clients without sharing raw data. This category can be further divided into single-model PFL and multi-model PFL (Tang et al., 2021).
Single-model PFL extends traditional FL algorithms to achieve personalized training. For example, FedProx (Li et al., 2020) introduces a proximal term in the client’s optimization objective to alleviate the impact of non-IID data. FedAvg FT and FedProx FT fine-tune global models generated by FedAvg (McMahan et al., 2017; Wang et al., 2019) and FedProx, respectively, to obtain personalized models for each client. These methods aim to tackle the challenges posed by non-IID data and enable clients to retain a customized model. However, single-model approaches are inherently limited in personalization capability, as a single global model often struggles to adapt to the diverse and heterogeneous nature of client data.
Multi-model PFL (Li et al., 2023), on the other hand, trains multiple models across clients to better meet personalization needs. For instance, FedPer (Arivazhagan et al., 2019) is specifically designed for non-IID settings and is particularly effective when client data distributions differ significantly. It assigns an independent personalized model to each client. ClusterFL (Ghosh et al., 2020; Li et al., 2021) groups clients into clusters based on loss values or gradients and trains a shared model within each cluster. This clustering strategy allows targeted optimization based on client similarity but may suffer when the clustering method is ineffective, particularly in highly heterogeneous settings. To improve this, FedEM (Marfoq et al., 2021) proposes a soft clustering approach that flexibly groups clients, enhancing personalization performance. However, FedEM requires each client to download multiple models, leading to increased communication costs and posing practical challenges.
While single-model PFL strikes a balance between global consistency and personalization, it often struggles to fully accommodate client heterogeneity. Multi-model PFL better fulfills personalization requirements, though it faces challenges such as communication overhead and the difficulty of effective clustering. In practice, balancing communication efficiency and personalization performance remains a major issue in multi-model PFL. Additional approaches include additive combinations of local and global models, such as FedVKD (Tao et al., 2022), APFL (Deng et al., 2020), and multi-task learning methods with model similarity regularization, such as pFedMe (Dinh et al., 2020). FedProto (Tan et al., 2022) decomposes the FL model into a shared feature extractor and a personalized component to realize PFL. Furthermore, FedALA (Zhang et al., 2023) proposes an adaptive local aggregation module that effectively combines global and local models to address client heterogeneity and improve performance in personalized FL. These approaches are particularly useful in non-IID scenarios where client data distributions differ greatly, but they may introduce privacy risks due to increased sensitivity in modelling.
Recently, some methods have introduced customized aggregation weights for personalization, such as FedAMP (Huang et al., 2021), FedRep (Collins et al., 2021), FedDWA (Li et al., 2023), and FedBN (Li et al., 2021). These methods assign client-specific aggregation weights based on similarity, thereby promoting collaboration among similar clients. FedAMP uses an adaptive model propagation mechanism to dynamically adjust model updates for each client. However, because it requires all clients to participate in each training round, it lacks flexibility. Additionally, FedCAC evaluates the sensitivity of each parameter to non-IID data and dynamically selects clients with similar data distributions for collaboration, allowing more parameters to be shared and improving performance. However, although collaboration improves model performance, it may increase computational load and communication overhead in scenarios with significant data differences. FedAS (Chen et al., 2024), a framework for PFL, addresses inconsistencies within and between clients through federated parameter alignment and client synchronization. However, it faces the challenge of reduced communication efficiency due to over-reliance on personalization, while neglecting effective global collaboration.
While these methods are effective in certain scenarios, relying solely on customized aggregation weights to identify clients with similar data distributions remains challenging in practical applications, especially in cases of extreme data heterogeneity. Existing PFL methods often consider only partial factors affecting collaboration and lack a comprehensive collaboration guideline, making them difficult to adapt to complex non-IID environments. Although some methods mitigate non-IID effects by localizing sensitive model layers, they often underestimate the potential of collaboration, adopting overly conservative strategies that fail to fully leverage collaboration opportunities among similar clients.
To address these limitations, this paper introduces a novel collaboration guideline featuring a dynamic responsiveness evaluation mechanism. By analyzing critical changes in model parameter updates, the method assesses each client’s collaboration potential and selects appropriate participants for global collaboration. This effectively controls which clients require personalized customization, reducing communication overhead and mitigating privacy risks. Furthermore, an adjustable weighted aggregation strategy is introduced to refine client selection and aggregation based on data distribution differences and parameter responsiveness. By integrating personalized collaboration and adaptive weighting, the proposed method enables efficient information sharing while preserving data privacy, lowering communication costs, and enhancing personalization performance in heterogeneous federated learning scenarios.
Method
Overview of FedDAC
To address the challenge that traditional federated learning struggles to reconcile global model generalization with personalized needs under non-independent and identically distributed (non-IID) data settings, we propose the FedDAC framework in Figure 1.

An Overview of the System Architecture in FedDAC.
First, each client updates its local model
Important parameters are aggregated through localized collaboration, where only clients with similar data distributions are allowed to participate in updates. This helps preserve key personalized features and enables the distinction between important
Finally, an adaptive personalized model is initialized and returned to the local client.
Problem Description
Traditional federated learning methods typically train a single global model that is shared among all clients. However, in real-world applications, due to significant differences in data distributions across clients, a single global model often fails to meet the personalized needs of each individual client. To address the challenges of traditional federated learning, personalized federated learning (PFL) introduces a new optimization objective that aims to personalize the model for each client while maintaining coherence with the global model. Specifically, the objective of personalized federated learning can be formulated as:
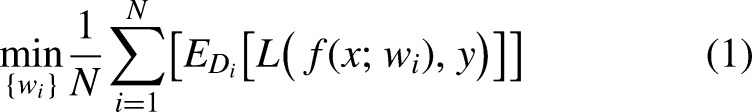
Dynamic Responsiveness Evaluation in FedDAC
In personalized federated learning scenarios, the contributions of model parameter updates vary significantly across clients due to task heterogeneity. To facilitate efficient personalization, FedDAC introduces a dynamic responsiveness evaluation mechanism that analyzes key parameter changes during local updates to control collaborative updates more effectively. This mechanism enables clients to customize their models while still participating in global knowledge sharing.
In designing the collaboration strategy, identifying parameters with high responsiveness to non-IID data helps optimize training and mitigate the negative effects of data heterogeneity on performance. However, responsiveness can vary across both training stages and parameters, making it essential to evaluate these dynamics comprehensively when selecting which clients and parameters to involve in collaboration.
First, FedDAC evaluates the responsiveness of each parameter on the client side to identify those most sensitive to non-IID data. It then considers the influence of training stages on responsiveness to refine client and parameter selection. The responsiveness of a parameter refers to the degree of change in the loss function when the parameter is zeroed out. Given a model
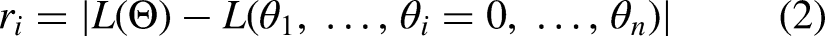
To reduce the computational cost of evaluating each parameter individually via forward passes, we approximate responsiveness using the first-order Taylor expansion. Specifically, for a parameter
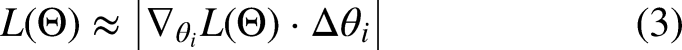

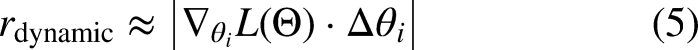
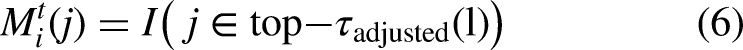

During aggregation, only parameters marked as important (i.e., where
To further elucidate this dynamic workflow, FedDAC implements a multi-step process that facilitates fine-grained and adaptive parameter collaboration in heterogeneous environments. During local training, each client computes updates for its parameters, denoted as
Parameter Collaboration Strategy Aggregation Design
In traditional federated learning methods, the heterogeneity of client data significantly impacts the collaboration effectiveness of the model. To effectively address this challenge, FedDAC introduces a flexible dynamic collaboration mechanism, conducting the second-stage aggregation filtering to better adapt to changes in the data distribution across different clients, thereby optimizing the collaboration process.
First, the previous section identifies a subset of parameters with high responsiveness to non-IID data. We then introduce a dynamic collaboration standard that divides model parameters into two categories: important parameters and less important parameters.
Based on the selected parameters, different aggregation methods are designed, assigning weightings to the less important parameters, which were identified in the first filtering step. This allows us to fully leverage cross-client collaborative information while also accounting for personalization needs. The clients then receive the aggregated results and combine them with their own masks to generate the new personalized model for the next round.
Important Parameter Aggregation Stage
To enable fine-grained collaboration, FedDAC introduces a similarity metric to quantify the similarity between client data distributions. By calculating the similarity between each pair of clients based on important parameters, it allows for more targeted and efficient collaboration.
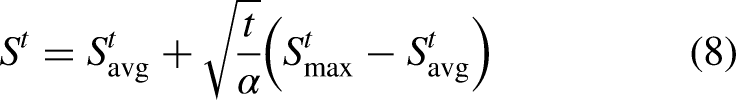
The collaboration set 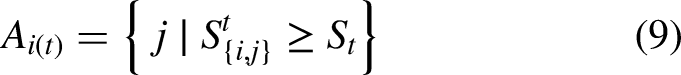
For important parameters, the aggregation method is more refined and complex. During aggregation, not only the influence of the global model must be considered, but also a weighting based on the similarity of client data distributions. By introducing the collaboration set 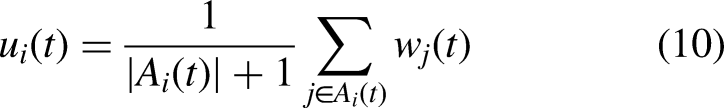
Less Important Parameter Aggregation Stage: Adjustable Weighting Strategy
For the aggregation of less important parameters, we propose a flexible and client-specific weighting scheme to enhance model personalization. This stage introduces an adjustable weighting rule, where each client
To measure the similarity between the local model of client 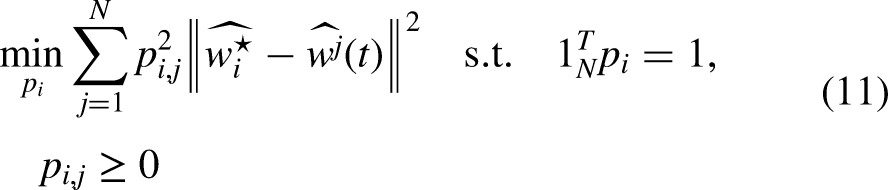
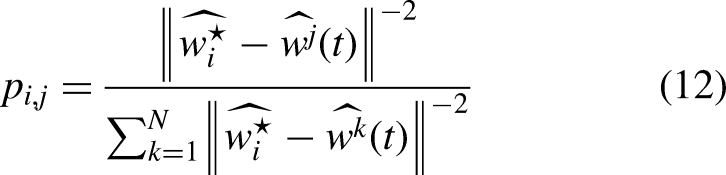
To further reduce computational costs and improve aggregation efficiency, only the top-

The personalized guidance model 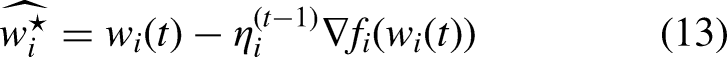
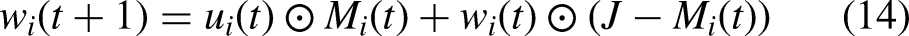
The complete training procedure of the FedDAC algorithm is detailed in Algorithm 2.
Experiments
Baseline Coverage and Result Interpretation
We conducted extensive experiments on four widely used image classification benchmark datasets: EMNIST (Cohen et al., 2017), CIFAR-10 (Wu et al., 2023), CIFAR-100 (Krizhevsky et al., 2010), and Tiny ImageNet (Krizhevsky & Hinton, 2009). To comprehensively evaluate the robustness of FedDAC in heterogeneous data scenarios, we adopted two different non-independent and identically distributed (non-IID) settings.
To highlight the effectiveness of client collaboration, we assign a small amount of data to each client. Each client has 500 training samples and 100 test samples, with the test data partitioned in the same non-IID manner as the training data to reflect real-world application scenarios.
To validate the adaptability of FedDAC to different model architectures, we employed different neural networks on the EMNIST, CIFAR-10, CIFAR-100, and Tiny ImageNet datasets. For EMNIST and CIFAR-10, we used a lightweight CNN model (McMahan et al., 2017) widely adopted in federated learning. It includes two convolutional layers with ReLU activation and max pooling, followed by two fully connected layers. The input channels are 1 for EMNIST and 3 for CIFAR-10, with the feature dimensions set to 1024 and 1600. For CIFAR-100 and Tiny ImageNet, we used the ResNet-10 and ResNet-18 models (Le & Yang, 2015), respectively, with pre-trained backbone networks that enhance feature extraction capabilities.
In the FedDAC training configuration, we set appropriate parameters for different datasets as shown in Table 1. Specifically, the local training epochs for each client were set to 10 for EMNIST and CIFAR-10, and 5 for Tiny ImageNet and CIFAR-100. The batch size was fixed at 100 to ensure training stability and computational efficiency. The optimizer used was SGD with momentum, and the initial learning rate was set to 0.01. For the global federated training, 40 clients were selected in each round. CIFAR-10 and Tiny ImageNet were trained for 300 rounds each to guarantee sufficient optimization and convergence across datasets.
FedDAC Experiment Configuration Table.

To comprehensively evaluate the effectiveness of FedDAC, we conducted extensive comparisons against eight representative PFL baselines, including FedAvg McMahan et al. (2017), FedProx Li et al. (2020), FedAMP Huang et al. (2021), FedPer Arivazhagan et al. (2019), FedRep Collins et al. (2021), pFedMe Dinh et al. (2020), and FedBN Li et al. (2021). These baselines were carefully selected to reflect a broad spectrum of personalization strategies within federated learning: from classical global aggregation (FedAvg), regularization-based methods addressing non-IID challenges (FedProx), and adaptive collaboration schemes (FedAMP), to partial model personalization (FedPer, FedRep), local optimization with proximal constraints (pFedMe), and normalization-aware approaches (FedBN). While some very recent methods were not included, our selection focuses on well-established and widely adopted algorithms to ensure meaningful, reproducible, and fair comparisons that accurately reflect the current landscape of personalized FL research.
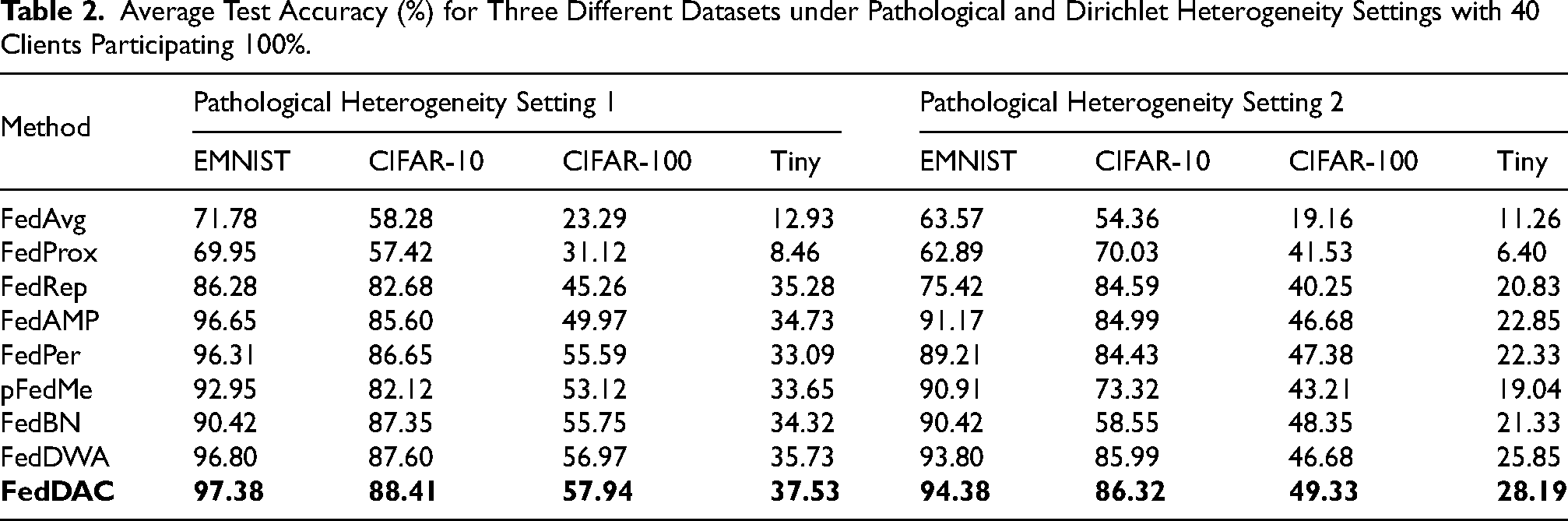
The experimental results, summarized in Table 2, demonstrate that FedDAC consistently outperforms all compared methods across various datasets and non-IID scenarios. Under both pathological and Dirichlet heterogeneity settings, FedDAC achieves the best performance across all four datasets–EMNIST, CIFAR-10, CIFAR-100, and Tiny ImageNet–surpassing mainstream methods such as FedAvg, FedProx, FedRep, and FedAMP. Notably, on the more challenging and heterogeneous datasets CIFAR-100 and Tiny ImageNet, FedDAC reaches accuracies of 57.94% and 37.53%, respectively, showing a significant improvement over the second-best methods. This performance advantage stems from FedDAC’s integration of dynamic anonymous credentials and a contribution-aware aggregation mechanism within the federated learning process. By protecting client identity and data privacy while dynamically adjusting aggregation weights based on each client’s actual contribution to the global model, FedDAC effectively mitigates the negative impact of data heterogeneity. Furthermore, its design balances personalized local learning with shared global knowledge, allowing the model to better adapt to scenarios with substantial statistical differences across clients. Overall, the robustness and adaptability demonstrated by FedDAC validate its practical value and potential in heterogeneous federated learning tasks.
Average Test Accuracy (%) for Three Different Datasets under Pathological and Dirichlet Heterogeneity Settings with 40 Clients Participating 100%.
The Impact of Collaboration Strategy on the Experiment
The Impact of Dynamic Responsiveness Strategy
To investigate the impact of the dynamic responsiveness strategy on the experiment, we conducted experiments using three different methods: “Dynamic collaboration”, “Static collaboration” and “No collaboration” to select client sets for training. During the training process, the collaboration standard was first used to locate all important parameters, excluding the influence of key parameter collaboration. The results are shown in Figure 2.

Comparison of Collaboration Strategies. From Left to Right: CIFAR-10, CIFAR-100, and Tiny ImageNet.
As we can see, the accuracy of the “Static collaboration” strategy exhibited oscillations in the early stages, which suggests that it randomly selected some important parameters, failing to ensure model stability. Furthermore, as training progressed, its accuracy did not reach a satisfactory level, indicating that the impact of non-IID data was not effectively handled.
The “No collaboration” strategy, which does not involve collaboration, led to slow convergence and poor final accuracy, as the impact of each client’s local task during collaboration was significant.
The “Dynamic collaboration” strategy outperformed all other strategies in terms of convergence speed and accuracy across all datasets, indicating that our strategy can efficiently and accurately select parameters relevant to non-IID data.
The Impact of the Adjustable Weighting Strategy
In this paper, for the “less important parameter stage” we designed a collaboration-based aggregation strategy based on similarity. For the less important parameter stage, we introduce a more flexible and personalized weighting scheme, further utilizing the selected clients. We conducted training experiments based on the optimal parameters from the first stage.
The “No weighted strategy” adopts a simple strategy for aggregating important parameters, showing rapid initial improvement but poor performance in the later stages, failing to achieve a good result. In contrast, with the “Weighted strategy” we apply the adjustable weighting strategy to further aggregate the less important parameters, resulting in more stable model convergence, and the final accuracy is better than the “No weighted strategy”. The experiments show in Figure 3 that our strategy can better perform model aggregation and achieve good results in non-IID data scenarios.

Comparison of Weighting Strategies. From Left to Right: CIFAR-10, CIFAR-100, and Tiny ImageNet.
The Impact of Parameters on Experimental Results
The Impact of
In the FedDAC mechanism,
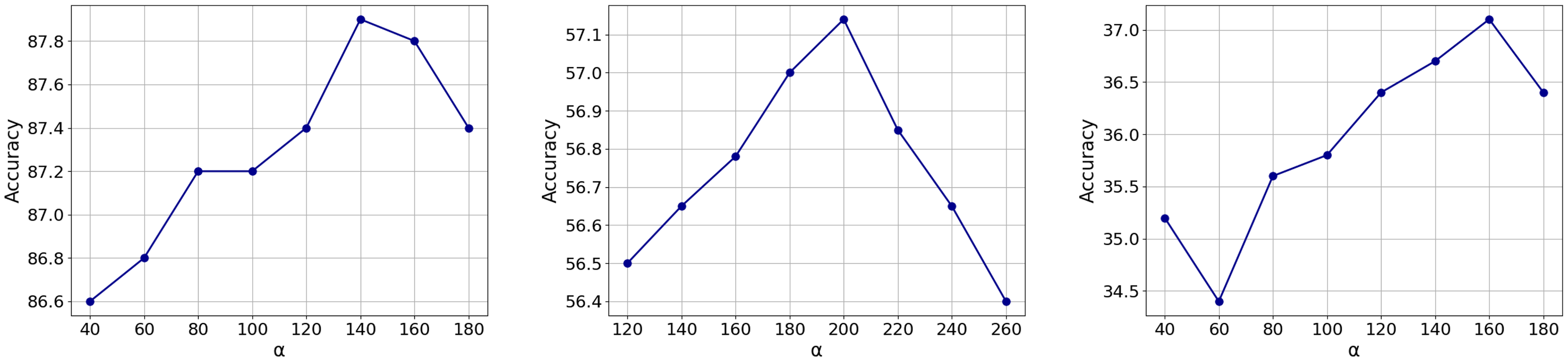
Model Accuracy (%) with Different Parameters of α Under the Pathological Heterogeneity Setting Scenario. From Left to Right: CIFAR-10, CIFAR-100, and Tiny ImageNet.
The Impact of
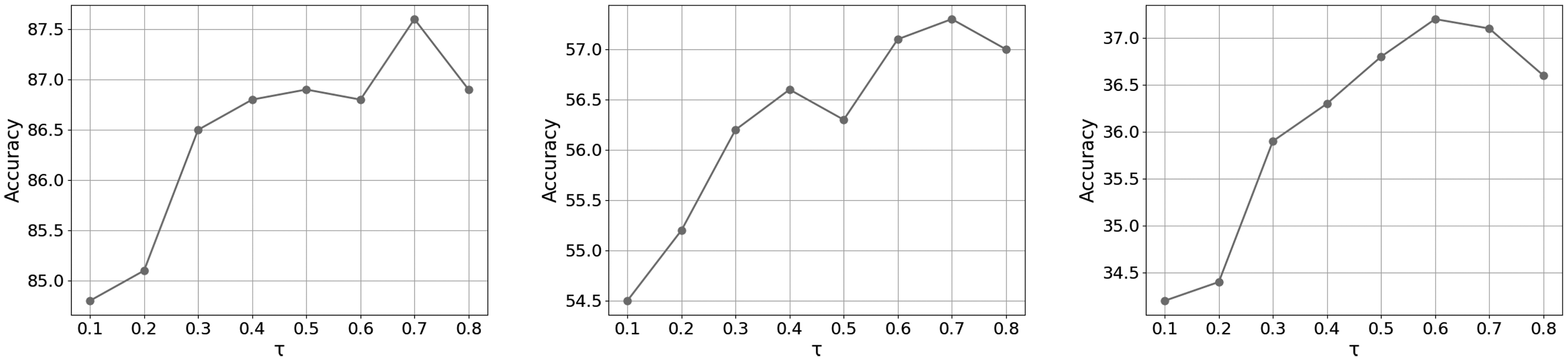
Model Accuracy (%) with Different Values of τ Under the Pathological Heterogeneity Setting Scenario. From Left to Right: CIFAR-10, CIFAR-100, and Tiny ImageNet.
The Impact of
The value of

Model Accuracy (%) with Different Values of k Under the Dirichlet Non-IID (α = 0.5) Scenario. From Left to Right: CIFAR-10, CIFAR-100, and Tiny ImageNet.
Discussion
Summary of Findings and Contributions
This paper introduces FedDAC, a novel personalized federated learning framework that dynamically balances collaboration and personalization by evaluating client responsiveness and data heterogeneity. Unlike existing approaches that either overly emphasize collaboration or personalization, FedDAC adaptively selects clients for global model aggregation based on parameter update patterns. It further incorporates a mask-based marking mechanism to reduce communication overhead and mitigate privacy risks, along with an adjustable weighted aggregation strategy to optimize the contribution of each client according to their data distribution and responsiveness. This combination enhances both the generalization ability of the global model and the personalization quality on each client, addressing critical challenges in non-IID federated learning scenarios.
Extensive experiments on four widely-used benchmark datasets–EMNIST, CIFAR-10, CIFAR-100, and Tiny ImageNet–demonstrate that FedDAC consistently outperforms strong baselines, achieving an average accuracy improvement between 1.5% and 3.2%. On more heterogeneous datasets like Tiny ImageNet, the performance gain reaches up to 5.9%. These results confirm the effectiveness and robustness of the proposed dynamic adaptive collaboration strategy in diverse non-IID environments, highlighting FedDAC’s potential for practical deployment in real-world personalized federated learning applications.
Limitations and Future Work
Despite its strong performance, FedDAC still has several areas for improvement. Firstly, the current client selection mechanism heavily relies on historical performance, which may lead to frequent selection of specific clients, potentially limiting generalization to underrepresented data. Secondly, the framework assumes relatively uniform computational capabilities across clients, which may not hold in real-world scenarios, where device heterogeneity can impact training fairness and efficiency.
To address these issues, future work will explore more balanced and representative client scheduling strategies to improve fairness and robustness. We also plan to integrate privacy-preserving techniques such as differential privacy and secure multi-party computation to strengthen data protection. Furthermore, investigating FedDAC’s compatibility with heterogeneous model architectures will be essential for broader edge deployment scenarios.
Conclusions
This paper addresses the challenges of non-independent and identically distributed (non-IID) data in personalized federated learning (PFL) by proposing a dynamic adaptive collaboration framework, FedDAC. Additionally, we introduce a comprehensive PFL collaboration guideline that simultaneously considers data distribution differences between clients and the responsiveness of each parameter. Based on this guideline, the method uses quantitative metrics to evaluate the responsiveness of each parameter and dynamically selects clients with similar data distributions for collaboration on important parameters. Our experimental results demonstrate that under the guidance of the proposed guideline, our FedDAC method effectively enables each client to gain more support from other clients, leading to superior performance in a wide range of complex non-IID scenarios.
Footnotes
Funding
The author(s) received no financial support for the research, authorship and/or publication of this article.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.