
Abstract
In recent years, neural heuristics leveraging deep reinforcement learning have exhibited considerable promise in addressing multi-objective combinatorial optimization problems (MOCOPs). Nonetheless, challenges persist in attaining both high learning efficiency and optimal solution quality. To address this issue, we propose a novel multi-objective optimization algorithm grounded in information geometry and machine learning principles, which integrates adaptive gradient descent with meta-reinforcement learning techniques to effectively tackle MOCOPs. In this paper, we present a meta-learning framework aimed at enhancing model performance in multi-objective combinatorial optimization through tensor remodeling, preconditioned gradient descent, and entropy regularization strategies. Experimental results demonstrate that the proposed method yields significant performance improvements across several classic multi-objective combinatorial optimization challenges, including the Multi-objective Traveling Salesman Problem (MOTSP), Multi-objective Vehicle Routing Problem (MOCVRP), and Multi-objective Knapsack Problem (MOKP).
Keywords
Introduction
When addressing practical applications, it is common to encounter problems involving multiple objectives that need to be optimized simultaneously, but the decision variables are subject to discrete choices, often in the form of combinatorial structures. These problems are referred to as Multi-Objective Combinatorial Optimization Problems (MOCOPs). Typically, this type of problem is defined as follows:
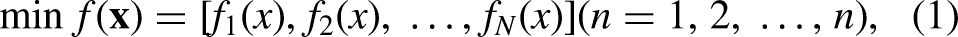
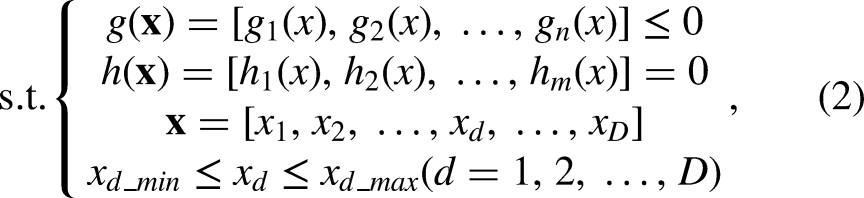
In the context of MOCOPs, the decision space is discrete, meaning that the decision variables
Thus, (1) represents a general formulation for a multi-objective combinatorial optimization problem, and (2) outlines constraints arising from discrete decision spaces, guiding the search for Pareto optimal solutions across competing objectives.
A fundamental distinction between MOPs and single-objective problems (SOPs) lies in their solution structures: MOPs exhibit a set of Pareto optimal solutions (the Pareto front), whereas SOPs typically yield a single global optimum or multiple equivalent optima. A solution
For minimization optimization problems,
MOCOPs are widely studied in the community of computational intelligence. Classic ideas for solving multi-objective combinatorial optimization problems include the Pareto optimization, weighted method,
We present a novel meta-reinforcement learning method, meta-reinforcement learning with gradient geometry adaptive tuning (GMRL), for preconditioned gradient descent, which facilitates geometric adaptive learning during meta-learning. We propose a more efficient fine-tuning method to effectively address all sub-problems. By incorporating dynamic learning rate adjustment and entropy regularization, the model has been enhanced in terms of convergence speed, training stability, and strategy exploration ability. Our experimental results on the few-shot learning benchmark task demonstrate that GMRL outperforms the state-of-the-art meta-reinforcement learning (MRL) family.
Furthermore, our experimental results on three classical MOCOPs confirm the effectiveness of our design.
Background
Multi-objective combinatorial optimization problems (MOCOPs) necessitate distinct methodological approaches due to their inherent computational complexity. The current research consensus delineates two foundational paradigms: exact methods and heuristic approaches. Exact Methods guarantee the identification of Pareto-optimal solutions through rigorous mathematical formulations, such as multi-objective branch-and-bound and dynamic programming. However, their exponential time complexity limits their applicability to large-scale problems. Heuristic Methods can be further categorized into four subclasses: single-solution metaheuristics , including simulated annealing (Bertsimas & Tsitsiklis, 1993) and tabu search Gendreau and Potvin (2005), which iteratively refine solutions toward optimality; population-based metaheuristics , such as NSGA-II (Deb et al., 2002) and MOEA/D (Zhang & Li, 2007), leveraging population diversity for global exploration; hybrid strategies, combining complementary algorithmic strengths to enhance search efficiency and solution quality; learning-based optimizers , such as neural combinatorial optimization (NCO) and reinforcement learning, which employ data-driven approaches to generate Pareto sets.
Over the last decade, advancements in neural network architectures have introduced innovative approaches to solving MOCOPs, giving rise to NCO algorithms. These methods leverage neural networks to automatically learn heuristics for solving combinatorial optimization problems, requiring minimal domain-specific expertise while often delivering high-quality solutions quickly. As a result, NCO has gained significant traction. Research in this domain is divided into two primary categories: end-to-end methods and improvement-based methods. End-to-end approaches aim to generate solutions independently, whereas improvement-based approaches integrate auxiliary algorithms to boost performance. This study concentrates on the end-to-end methodology.
Zhang et al. (2021) proposed the utilization of deep reinforcement learning algorithms to address multi-objective combinatorial optimization problems, introducing the MODRL. Lin et al. (2022) introduced the PMOCO method based on multi-objective reinforcement learning, which utilizes preference conditions to generate an approximate Pareto solution set and enhance the solution quality, speed, and model efficiency for solving multi-objective combinatorial optimization problems.
In 2017, the emergence of second-order meta-learning algorithm MAML and its derivatives provided a new approach for incorporating deep reinforcement learning into problem-solving. The integration of meta-learning into algorithms has been shown to improve their generalization ability. Zhang et al. (2023) presented Meta-DRL, a deep reinforcement learning algorithm based on the first-order meta-learning algorithm Reptile and an improved EMNH (Chen et al., 2023b).
On the other hand, in recent years, the emergence and development of various large language models, such as ChatGPT, have injected new vitality into the development of neural combinatorial optimization algorithms. Recent studies have explored integrating large language models (LLMs) with evolutionary computation (EC) to automate heuristic generation (Chen et al., 2023a; Meyerson et al., 2023; Yang et al., 2024). A notable example is FunSearch (Romera-Paredes et al., 2024), which frames Automatic Heuristic Design (AHD) as a functional search problem. In this approach, heuristics are represented as programs, and an evolutionary framework employs an LLM to iteratively improve the quality of generated functions. While FunSearch has demonstrated success across various tasks, it is computationally intensive and requires significant resources to produce high-quality heuristics. To address these limitations, Liu et al. (2024b) introduced Evolution Heuristic (EoH), a new evolutionary paradigm that synergizes LLMs and EC to streamline automatic heuristic design. Beyond the aforementioned directions, researchers have explored integrating multi-task learning into combinatorial optimization. Ibarz et al. (2022) and Reed et al. (2022) developed a general agent capable of tackling various tasks, including COPs. Wang and Yu (2023) proposed a multi-task learning framework utilizing separate encoders and decoders for combinatorial optimization. However, their method struggles with complex Vehicle Routing Problems (VRPs) and requires adjustments to handle unseen problems. Liu et al. (2024a) introduced a novel approach for cross-problem generalization in VRPs by treating VRP variants as combinations of shared attributes. Their method enables solving multiple VRP variants simultaneously through an end-to-end multi-task learning framework.
Preliminary
Reptile
Reptile is a gradient-based meta-learning algorithm introduced in 2018 by Alex Nichol et al. Nichol et al. (2018) at OpenAI. The core idea behind Reptile is to enable a model (e.g., a neural network) to quickly adapt to new tasks by repeatedly sampling tasks, performing random initializations, and applying gradient updates to the model’s trainable parameters —typically the weights and biases of each layer in the network. These parameters control the transformations between layers (e.g., linear mappings in fully connected layers or convolutional filters in CNNs) and ultimately determine the model’s output for a given input. Unlike some other meta-learning algorithms, Reptile does not rely on second-order gradient information, making it computationally efficient. By training the model on multiple tasks using stochastic gradient descent (SGD) and incrementally updating the shared initial parameters (i.e., the starting point for task-specific fine-tuning) after each training session, Reptile allows the model to rapidly generalize across tasks.
The training process can be summarized as follows:
Reformulation of Tensors
This study employs the concept of expansion to reshape the gradient tensor of a convolution kernel into a matrix form. Tensor expansion, also referred to as matrixization or planarization, involves rearranging the elements of an n-dimensional tensor
The n-type expansion of the tensor X can be formally described as follows:
Each form corresponds to a different mode of expansion, allowing for flexibility in how the tensor is reshaped into a matrix. Its significance is as follows:
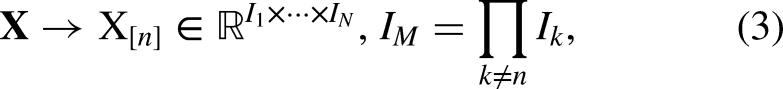
Riemannian Manifold
An
Preconditioned Gradient Descent (PGD)
PGD is a method designed to minimize the empirical risk, which represents the expected loss of a model on the training data. Specifically, the empirical risk is defined as the average loss of the model over the training dataset. For a model parameterized by
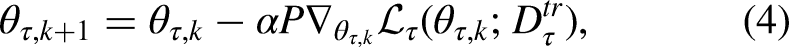
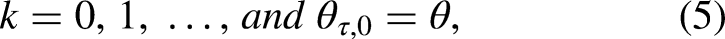
where
Methodology
Our meta-reinforcement learning algorithm with gradient geometry adaptive tuning (GMRL) includes a meta-learning process with gradient geometry adaptive tuning function (GAA), an effective fine-tuning process, and an inference process, as shown in Figure 1. GMRL is general, incorporating the first-order ladder-based Reptile algorithm (Liu et al., 2024b) as the core component for meta-learning, while employing the widely-used neural solver POCO (Kwon et al., 2020) as the foundational model. In the meta-learning process, the number of iterations for training model
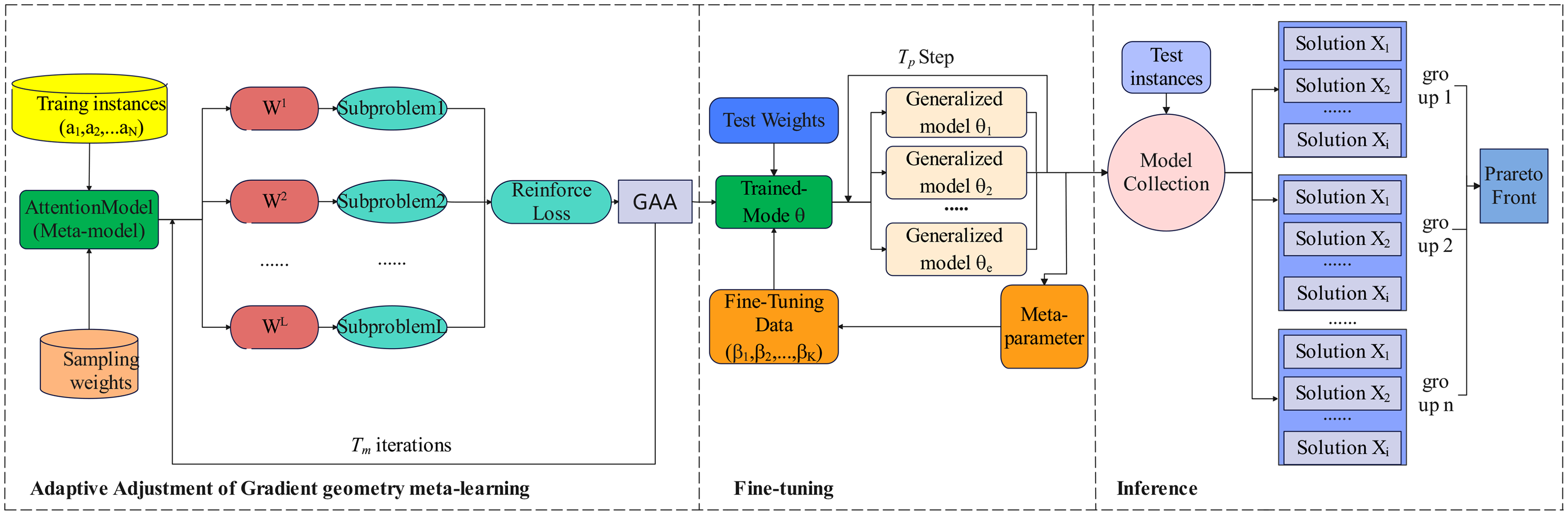
The overall framework of GMRL.
Adaptive Adjustment of Gradient Geometry Meta-learning

GAA: Gradient Geometry Adaptive Adjustment
We consider an L-layer neural network 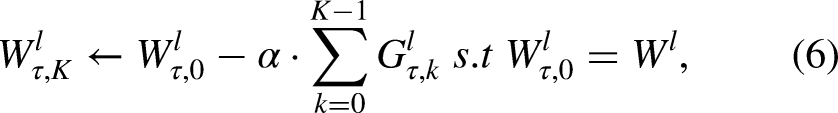
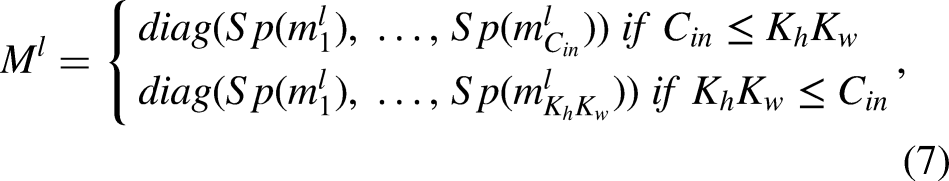
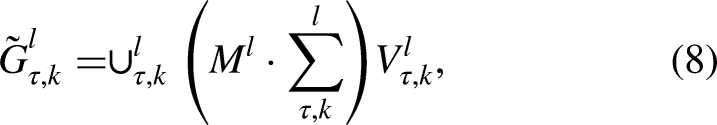
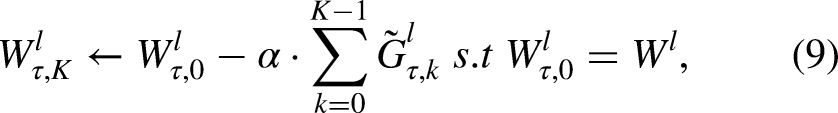

Let
Theorem 1 formally shows that GAA depends on the task-specific parameters
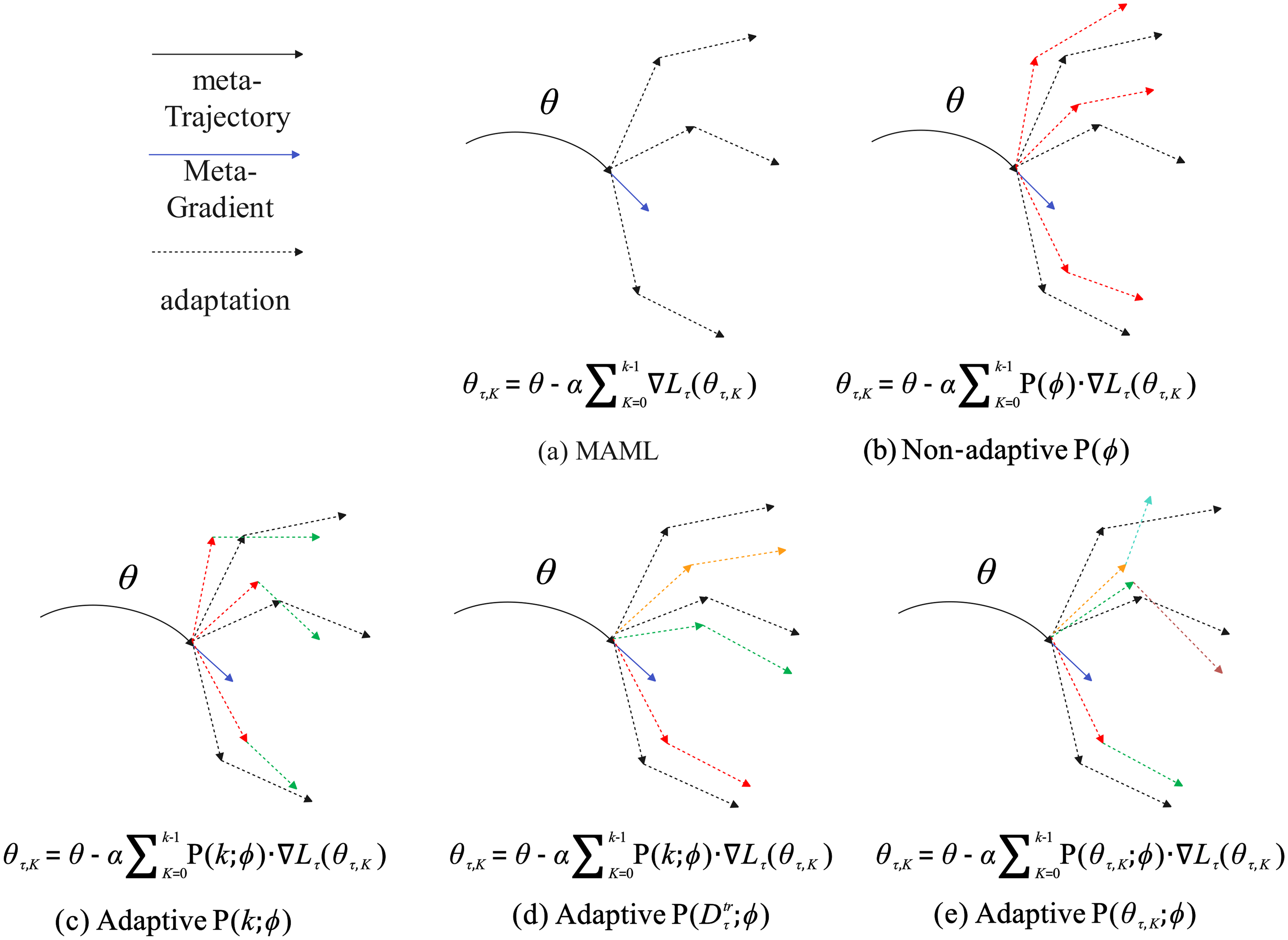
Diagram of MAML and PGD-MAML family.
If the parameter space possesses an inherent geometric structure, the conventional gradient
Efficient Fine-tuning
Once the metamodel is trained, it can be fine-tuned with many gradient updates to derive a custom submodel for a given weight vector. In the fine-tuning stage, we introduce a dynamic learning rate adjustment mechanism, which can make the model adapt to different learning rates in different training stages, so as to improve the training efficiency and stability. Second, we introduce entropy regularization, which enhances explorability and enables better generalization. Its detailed update is shown in Equation 10.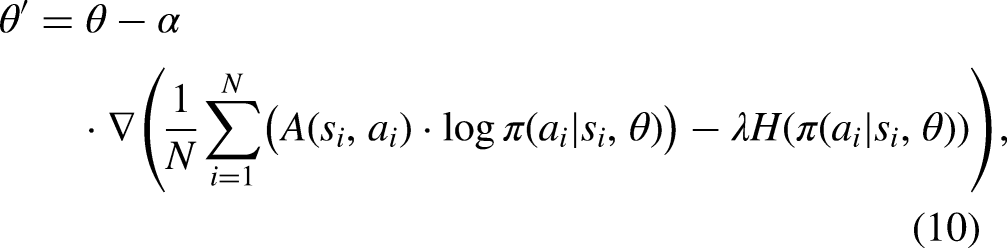
where
Experiments
We conducted computational experiments to assess performance on the MOTSP, the MOCVRP, and the MOKP. Following the approach outlined in Chen et al. (2023b), Lin et al. (2022), we evaluated instances of varying sizes: n = 20, 50, 100 for MOTSP/MOCVRP and n = 50, 100, 150 for MOKP. The experiments were executed on a system equipped with a 13th Gen Intel Core i9-13900KF processor and an RTX 4090 GPU.
Problem Setting
Our experiments focus on MOTSP (Lust & Teghem, 2010a), MOCVRP (Lacomme et al., 2006), and MOKP (Bazgan et al., 2009), applying a unified model setup across all tasks with variations in input sizes and masking methods specific to each problem. The core policy model is based on an attention-based encoder (Kool et al., 2018).
To generate the training and evaluation datasets, we create random problem instances with controlled characteristics to ensure diversity and assess model performance under varying difficulty levels. For MOTSP, instances are generated with uniformly distributed node coordinates on a
For MOCVRP, customer locations are randomly generated in a unit square and scaled to
For MOKP, item weights and two profit values per item are generated such that the pairwise correlation between objectives can be set to desired levels (conflicting or harmonious). Knapsack capacity tightness is controlled by setting it to
For training, we generate 10,000 random problem instances per epoch and run the model for 3000 iterations, progressively reducing the training dataset size. The optimization process employs the ADAM algorithm with an initial learning rate of
Hyperparameters
To ensure fairness in comparison, the parameter settings are consistent with EMNH (Chen et al., 2023b). The meta-learning rate, denoted as lambda, is gradually reduced from the initial value
Metrics
Metrics. The performance of GMRL is assessed based on solution quality, primarily using hypervolume (HV) and Gap (Lin et al., 2022). HV evaluates the hypervolume of solutions, while Gap measures the relative difference in hypervolume compared to our approach. Additionally, Time represents the duration required to solve 200 randomly generated test instances.
Baselines
We introduce three strong baselines that utilize WS (weighted sum) scalarization to ensure a fair comparison. These include the cutting-edge meta-learning-based neural heuristics, MDRL (Zhang et al., 2023) and EMNH (Chen et al., 2023b), as well as the advanced multi-task learning-based neural heuristic, MTNCO (Liu et al., 2024a). These three frameworks rely on problem-specific heuristics to generate and explore feasible solutions across various tasks. Each neural heuristic adopts POCO as the foundational model for solving single-objective subproblems, with identical training data sizes and 3000 iterations applied across the three multi-objective combinatorial optimization problems.
Experimental Results
The performance evaluation of MOTSP, MOCVRP, and MOKP across various scales is detailed in Tables 1 to 3. These tables present key metrics, including average HV, gap, and the total runtime required to solve 200 randomly generated test instances. To determine the significance of observed differences, a Wilcoxon rank-sum test was applied with a 1% significance threshold, ensuring a rigorous statistical analysis of the comparative outcomes. In addition, in order to compare the generalization ability of the proposed algorithm, we designed three experiments. First, MOCVRP-50 was trained by EMNH and GMRL respectively, and the model was fine-tuned by EMNH’s fine tuning method to solve MOCVRP-20 and MOCVRP-100. The results are shown in Table 4. Secondly, MOCVRP-50 was trained by EMNH, and the model was fine tuned by EMNH and GMRL respectively to solve MOCVRP-20 and MOCVRP-100. The results are shown in Table 5. Finally, to compare the ability of algorithms to solve practical problems, GMRL tested on three datasets, KroAB100, KroAB150, and KroAB200 (Lust & Teghem, 2010b). The comparison results with other algorithms are shown in Table 6. Best-performing results and those without significant differences are highlighted in bold, while suboptimal or non-significant results are marked with underlines. Methods annotated with ”-Aug” denote inference outcomes enhanced with additional instances, as described in Lin et al. (2022).The Gap between HV and GAP of all methods and GMRL-Aug is given in the report. During the experiment, the training data size of all algorithms will gradually decrease by a factor of 10. The results obtained will be displayed in batches.
Results of 200 Random Instances of MOCOPs at Original Scale.
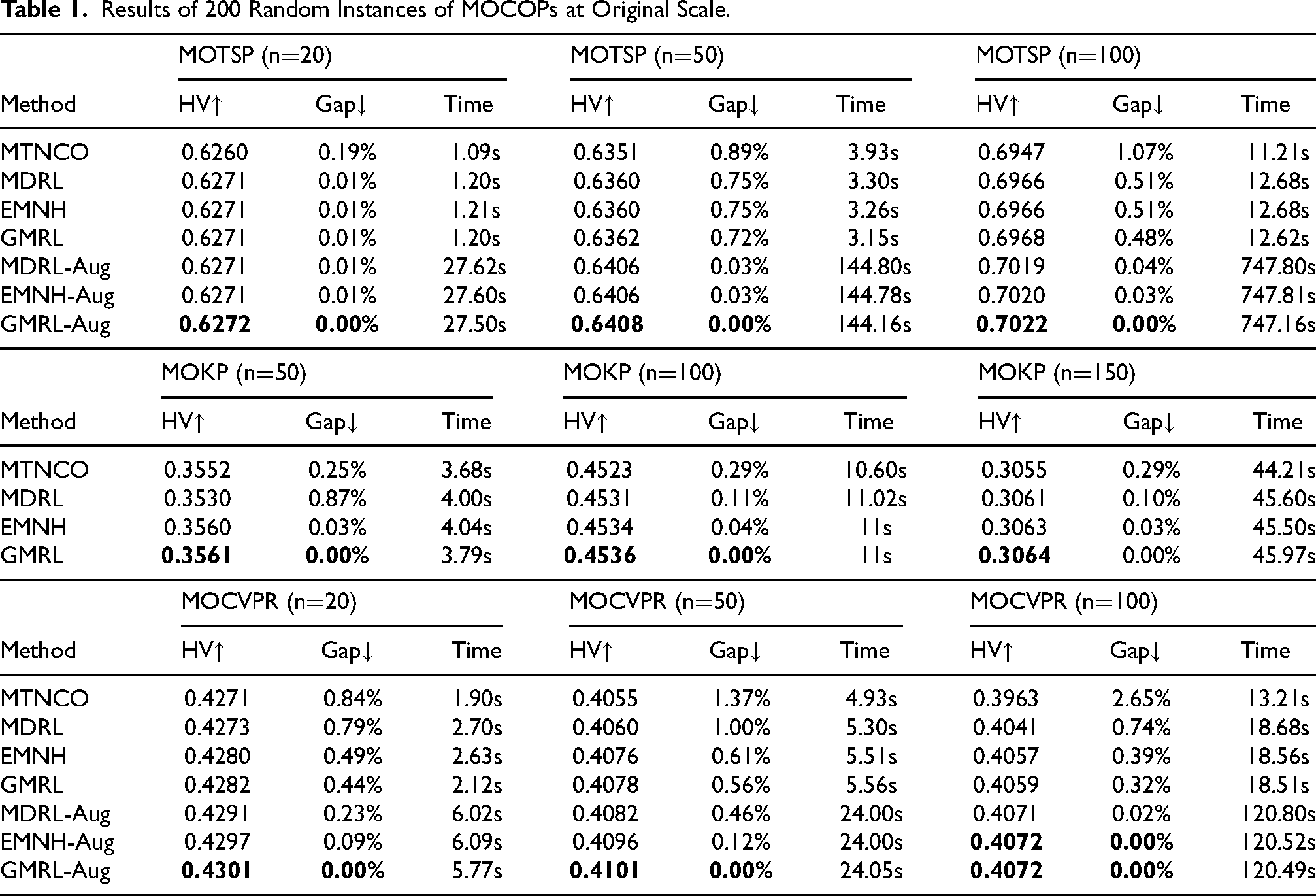
Results of 200 Random Instances of Small Scale MOCOPs.
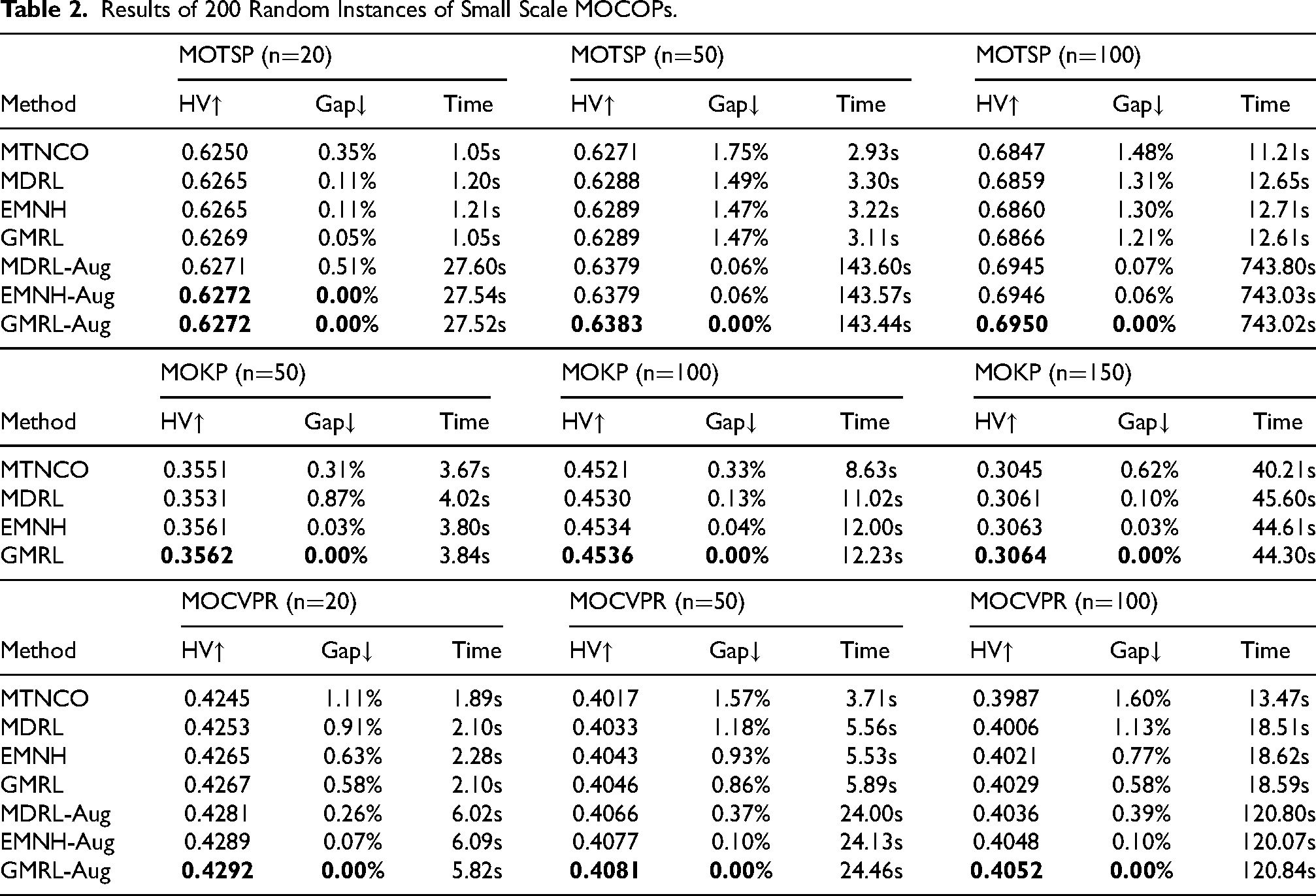
Results of 200 Random Instances of Extremely Small scale MOCOPs.
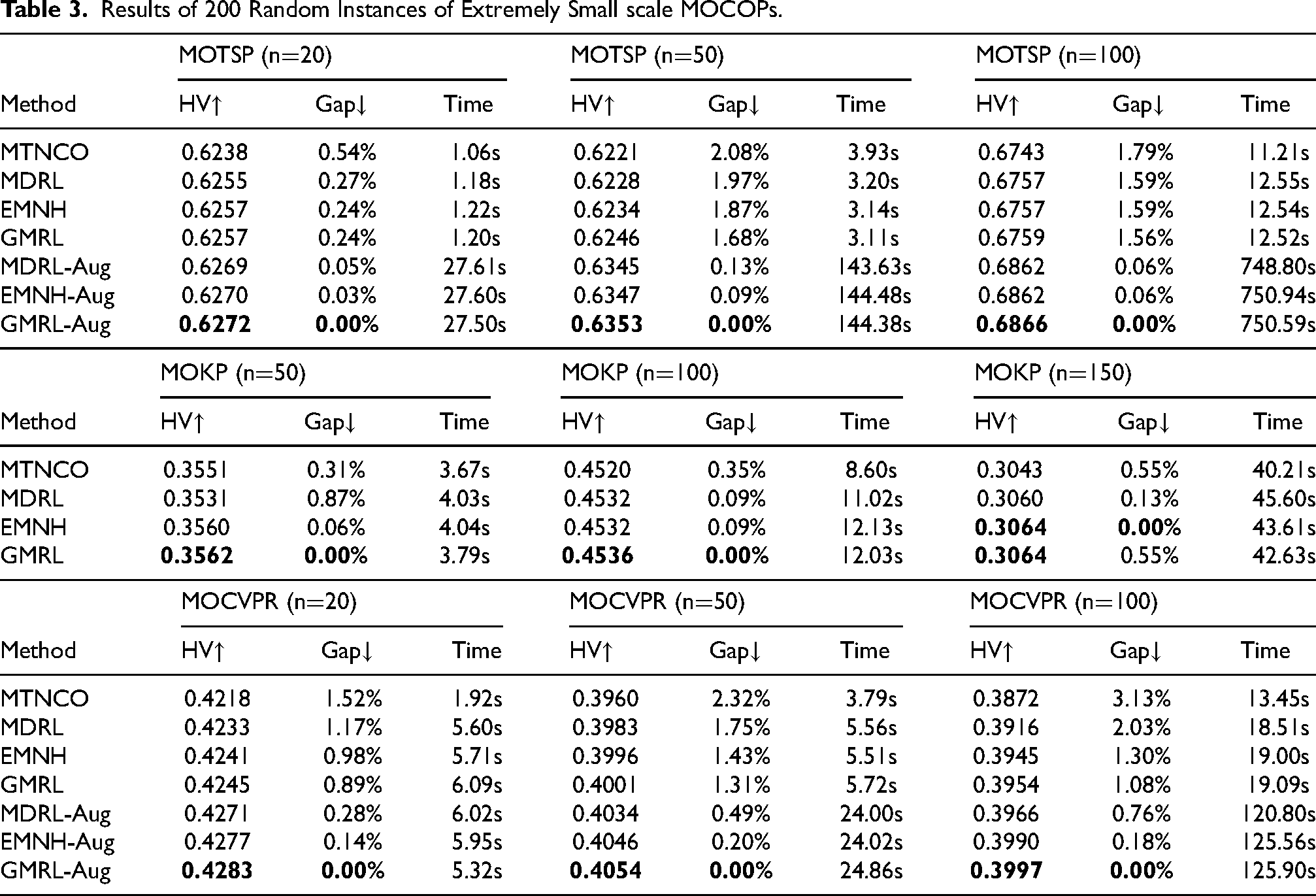
Comparison Results of Generalization Ability of Two Algorithm Models.
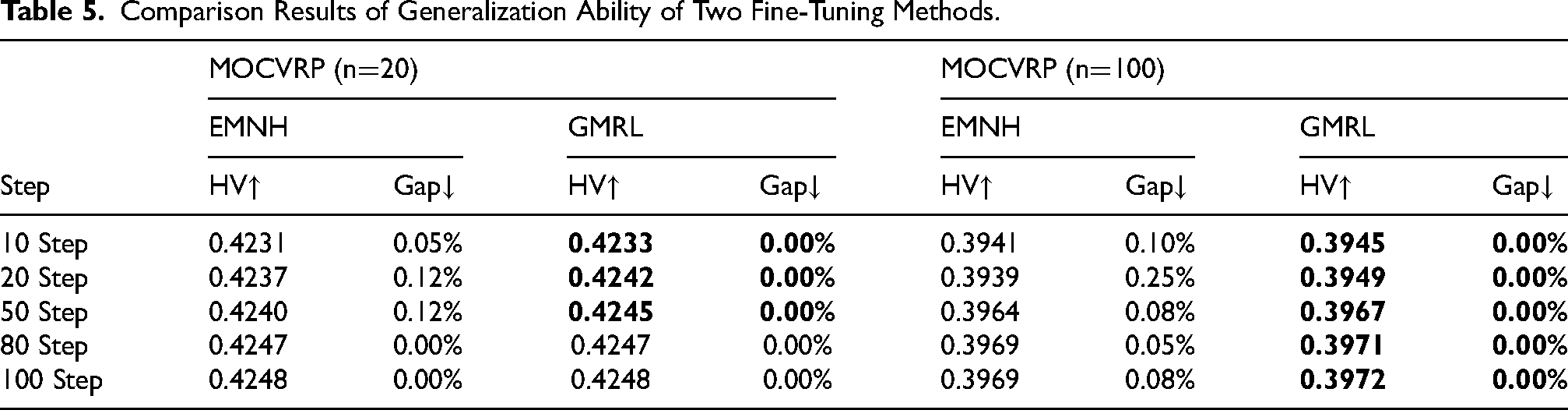
Comparison Results of Generalization Ability of Two Fine-Tuning Methods.
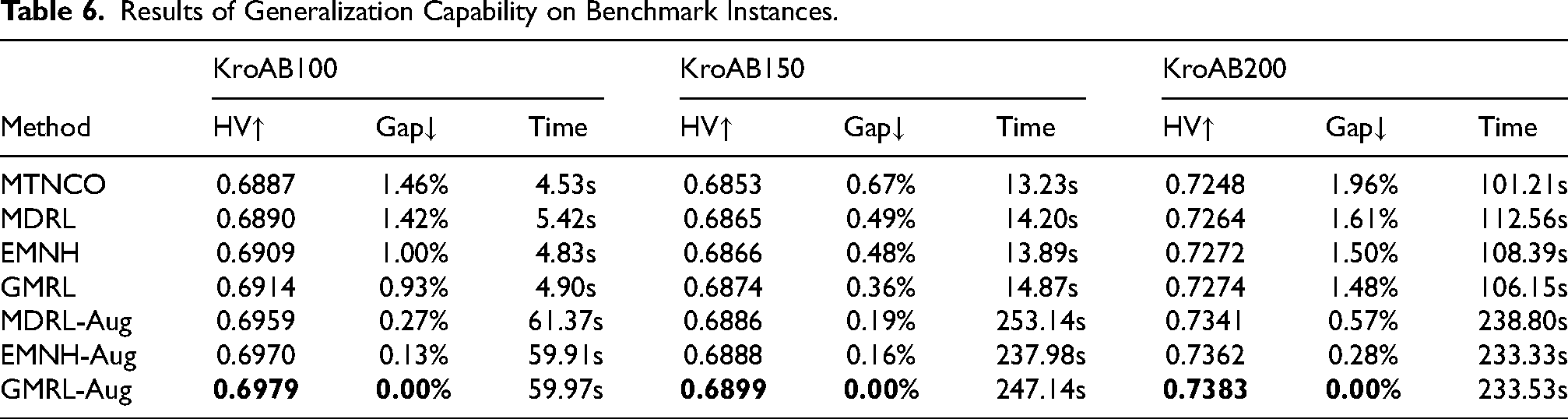
Results of Generalization Capability on Benchmark Instances.
Analysis of Results
According to the results in Tables 1 to 3, GMRL-Aug outperforms the currently more advanced neural heuristics on all three problems. When data augmentation is performed, GMRL-Aug further improves the solution and outperforms other baselines on MOTSP with n
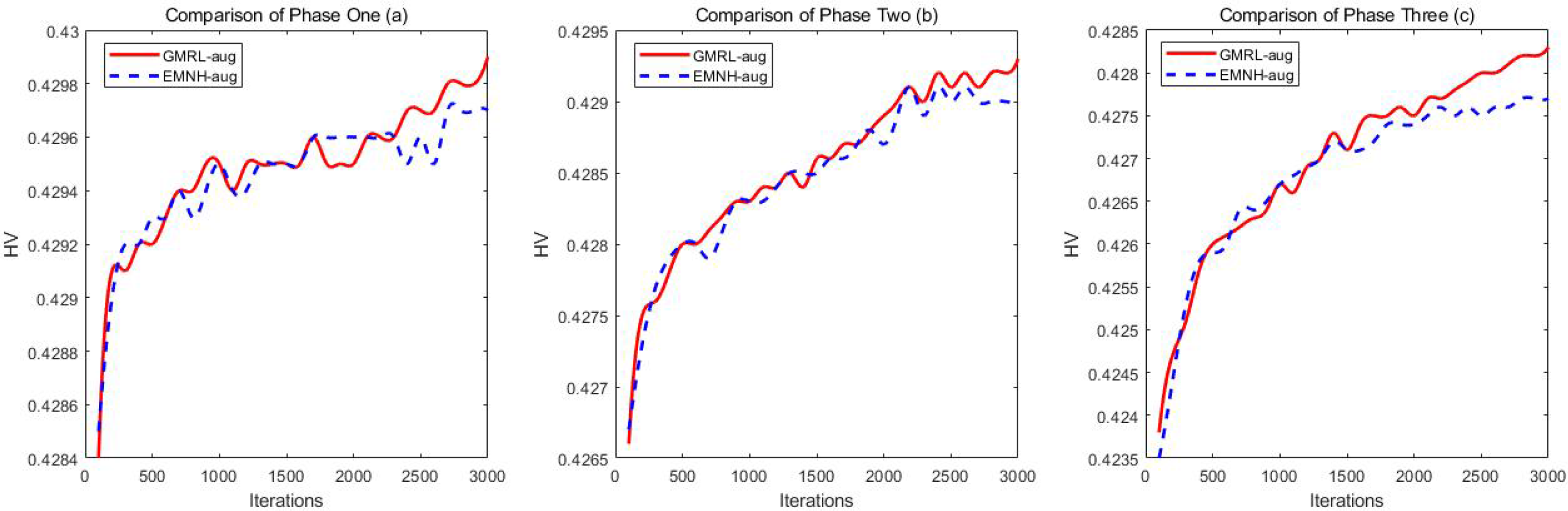
Comparison of MOCVPR-20 in Three Phases.
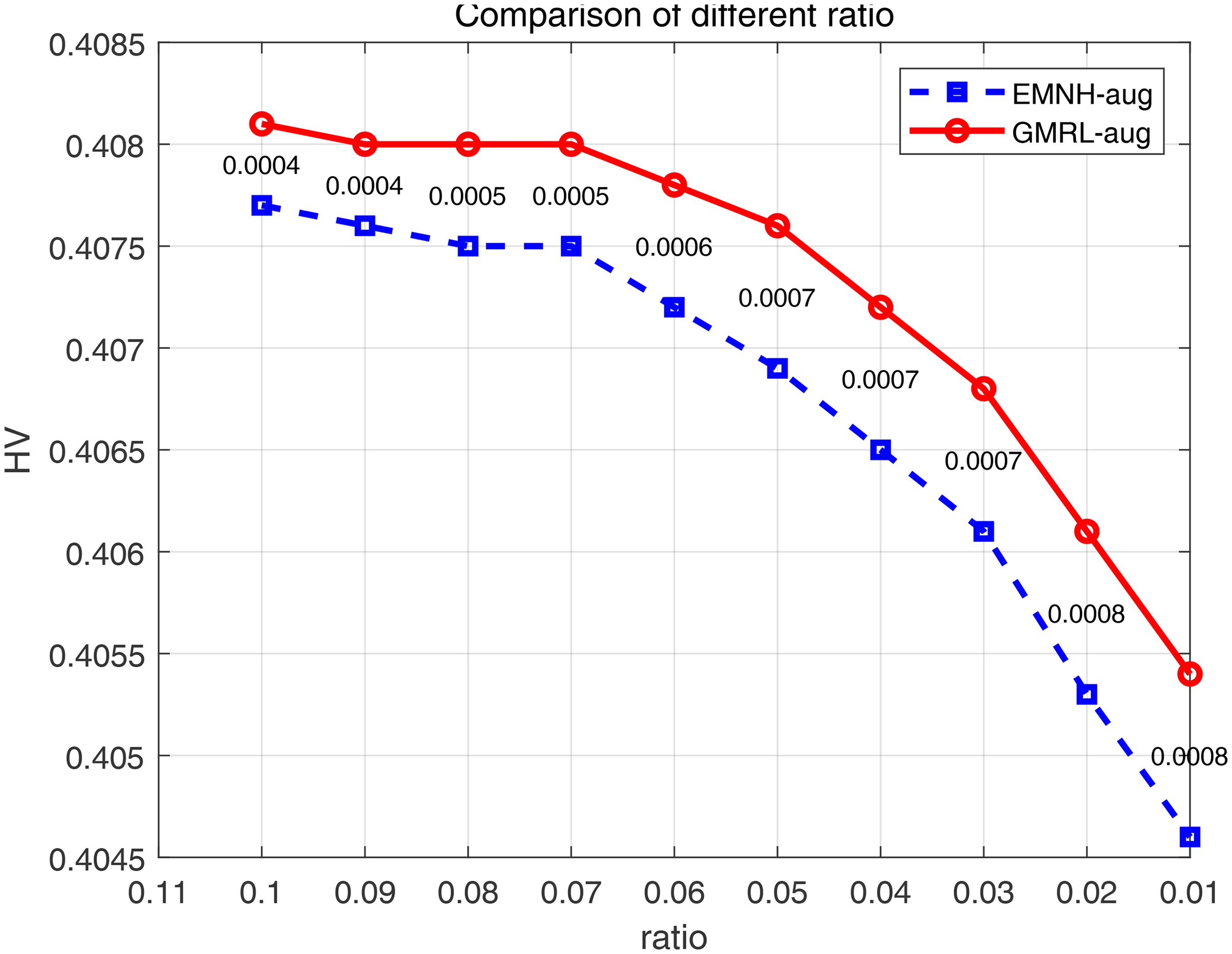
Comparison of MOCVPR-50 at different scales.
In terms of generalization capability, as shown in Table 4, models trained by GMRL demonstrate superior performance and faster convergence speed in cross-problem-size generalization. The results in Table 5 further indicate that GMRL’s fine-tuning methodology also achieves higher performance and faster convergence speed in cross-problem-size generalization. Analysis of both tables reveals that the Global Adaptation Algorithm (GAA) plays a more crucial role than Efficient Fine-tuning (EF) in achieving these results. Furthermore, when the number of fine-tuning steps is 20, GMRL exhibits its largest performance lead over alternatives. When fine-tuning data is relatively sufficient (e.g., at 80 and 100 steps), the difference in HV values between the two algorithms becomes small, and both achieve favorable results. According to the results in Table 6, GMRL-Aug outperforms the comparative algorithm across all three benchmark datasets. GMRL-Aug improves performance through multiple inference runs and ensemble strategies, which inevitably increases computational time. Notably, its performance lead widens progressively as the problem scale increases. This demonstrates that GMRL possesses enhanced capability for tackling complex real-world problems. Therefore, the improvements brought by GMRL are more meaningful under the following conditions:
GMRL-Aug enhances performance by running multiple inferences and aggregating results, though this inevitably increases computation time. This trade-off makes it especially suitable for: (1) applications where solution quality outweighs computational costs (e.g., high-value logistics optimization), (2) offline planning (with flexible time constraints), (3) establishing performance upper bounds for the method.
Conclusion
In this paper, we propose the Gradient-adaptive Meta-Reinforcement Learning (GMRL) algorithm, which improves data efficiency and training stability through tensor reparameterization and preconditioned gradient optimization. Extensive experiments on multi-objective combinatorial optimization problems (including MOTSP, MOCVRP, MOKP) and standard benchmarks demonstrate that GMRL achieves competitive solution quality–particularly in data-scarce scenarios and cross-scale generalization tasks, where it shows superior convergence speed. The enhanced GMRL-Aug variant further advances performance boundaries, albeit with higher computational demands–a worthwhile trade-off for precision-sensitive offline applications . Although GMRL, as a neural heuristic, does not theoretically guarantee exact Pareto optimality, its exceptional data efficiency and robustness represent a significant advancement. Future directions include: (1) extending GMRL to constrained MOCOPs with complex feasibility conditions, (2) developing efficient augmentation strategies to reduce computational costs , and (3) investigating synergy with large language models for initial solution generation and heuristic refinement .
Footnotes
Acknowledgments
This research is supported by the National Natural Science Foundation of China (Grant No. 62576239), the University Natural Science Research Project of Anhui Province (Grant No.2023AH040056), the Natural Science Research Project of Anhui Province (Graduate Research Project, Grant No. YJS20210463), the 2023 New Era Education Quality Engineering Project of Anhui Province (Graduate Research Project, Grant No. 2023xscx086), the funding plan for Scientific research activities of academic and technical leaders and reserve candidates in Anhui Province (Grant No.2021H264), the top talent project of disciplines (majors) in Colleges and universities in Anhui Province (Grant No. gxbjZD2022021), the University Synergy Innovation Program of Anhui Province, China (GXXT-2022-033) and supported by the Graduate Innovation Fund of Huaibei Normal University (Grant No. CX2023043).
Authors contribution statement
Mingshi Wang: Conceptualization of this study, Methodology, Software, Writing. Fangzhen Ge: Supervision, Writing - Review & Editing, Funding acquisition. Debao Chen: Visualization, Investigation. Longfeng Shen: Supervision. Huaiyu Liu: Data curation.
Funding
The author(s) received no financial support for the research, authorship and/or publication of this article.
Declaration of Conflicting Interests
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Data availability
Data will be made available on request.