
Abstract
Pedestrian trajectory prediction plays a pivotal role in real-world applications such as autonomous driving, unmanned delivery, and intelligent surveillance. However, existing deep learning approaches still face critical challenges, including mode collapse and the generation of unrealistic trajectories in complex environments. To address these limitations, we propose Phase Fusion Network (PFNet), a novel trajectory prediction framework designed to enhance prediction accuracy in intricate digital media scenarios. PFNet introduces an innovative Graph Encoder (GE) that incorporates a probabilistic modeling strategy to better capture spatial features and pedestrian interactions. To mitigate mode collapse, a common limitation in GAN-based methods, PFNet employs a dual-discriminator mechanism that improves both the realism and diversity of predicted trajectories. Additionally, PFNet adopts a two-phase architecture, where the generation phase strengthens spatial representation and the prediction phase refines temporal consistency. Extensive experiments on standard benchmarks, including ETH, UCY, and the Stanford Drone datasets, demonstrate that PFNet consistently outperforms state-of-the-art methods in terms of both Average Displacement Error (ADE) and Final Displacement Error (FDE).
Introduction
With the rapid development of intelligent autonomous systems such as autonomous vehicles, unmanned aerial vehicles (UAVs), and delivery robots, the demand for advanced models capable of accurately perceiving, interpreting, and predicting human behavior has grown significantly. Among these challenges, pedestrian trajectory prediction is particularly critical, as it directly influences the safety, efficiency, and reliability of autonomous systems operating in dynamic and human-centered environments (Cai et al., 2021; Eiffert et al., 2020a; Li et al., 2020).
Early research in this field primarily employs simple motion models, which are only effective in scenarios with minimal pedestrian interaction. As research progresses, probabilistic models such as Hidden Markov Models and Gaussian Mixture Models are introduced to simulate more complex pedestrian behaviors (Lefèvre et al., 2011; Seeger, 2004). However, these methods rely heavily on hand-crafted features and primarily model local interactions, limiting their effectiveness in capturing the intricate dynamics of crowded or highly interactive environments (Liu et al., 2023).
Recent advances in deep learning, particularly the emergence of Generative Adversarial Networks (GANs), have significantly enhanced pedestrian trajectory prediction. GAN-based models have shown promise in modeling complex and dynamic trajectories, yielding substantial improvements in predictive performance (Kosaraju et al., 2019; Liu et al., 2023; Sadeghian et al., 2019). Despite these gains, traditional GANs suffer from notable limitations in this domain. They typically sample trajectories from fixed distributions—such as the Gaussian distribution—which constrains their ability to model the rich spatial-temporal dependencies inherent in real-world pedestrian behavior. As a result, these models often struggle to recognize behavioral patterns in complex environments and fail to capture nuanced pedestrian interactions. Moreover, conventional GANs that employ a single discriminator are prone to mode collapse, which limits the diversity and adaptability of the generated trajectories. This often leads to unrealistic or implausible predictions, including out-of-distribution (OOD) samples that compromise the model’s reliability (Dendorfer et al., 2021). To mitigate this, recent research has incorporated Graph Neural Networks (GNNs) to better model pedestrian interactions through graph structures. For instance, Shi et al. (2021) employed sparse graph convolution to capture interaction patterns, while Yu et al. (2020) integrated Graph Convolutional Networks (GCNs) into a Transformer architecture to extract both spatial and temporal dependencies. Other approaches, such as Social-BiGAT (Kosaraju et al., 2019) and Social-STGCNN (Mohamed et al., 2020), leverage GNNs to uncover the underlying topological structure of pedestrian dynamics. However, GNN-based models still face challenges in densely populated and highly dynamic scenes, as the extracted features may fail to comprehensively represent complex spatial relationships (Shi et al., 2021).
To effectively address these challenges, a novel framework, Phase Fusion Network (PFNet), is proposed to enhance the accuracy and robustness of pedestrian trajectory prediction, as shown in Figure 1. The framework consists of two core components: the Generation Phase and the Prediction Phase. In the Generation Phase, a GAN architecture is adopted, within which a Graph Encoder (GE) block is designed and a new probability distribution is introduced, allowing the generated data features to more accurately capture spatial characteristics of pedestrians and their interactions with other pedestrians. Moreover, to effectively mitigate the issue of mode collapse caused by a single discriminator, a dual-discriminator design is incorporated. By evaluating the generated data from multiple dimensions, the dual-discriminator mechanism further enhances the model’s ability to model complex environments and pedestrian interactions, which improves the quality and diversity of the generated trajectory features. While the Generation Phase enriches spatial feature data, achieving high-precision trajectory prediction requires effectively combining these features with temporal information. To this end, the Prediction Phase is introduced, which fuses the features generated in the Generation Phase and maps them to the channel dimension. Subsequently, further feature extraction is performed using architectures such as Convolutional Neural Networks(CNN), ensuring that the prediction of pedestrian trajectories is more accurate and reliable. The main contributions of the paper are as follows:
A novel GE block is designed and integrated into the GAN architecture to better capture spatial interaction features in pedestrian trajectory data. A specific probability distribution is proposed to effectively model the diversity of trajectory data and the topological characteristics of the graph structure, improving both the realism and variety of generated trajectory features. A dual-discriminator mechanism is introduced to address the common issue of mode collapse in GAN models. By evaluating the quality of generated trajectory features from multiple perspectives, this approach enhances overall model performance. A PFNet framework is proposed, consisting of a Generation Phase and a Prediction Phase, which collaboratively exploit spatial and temporal dependencies to achieve accurate and robust trajectory prediction.
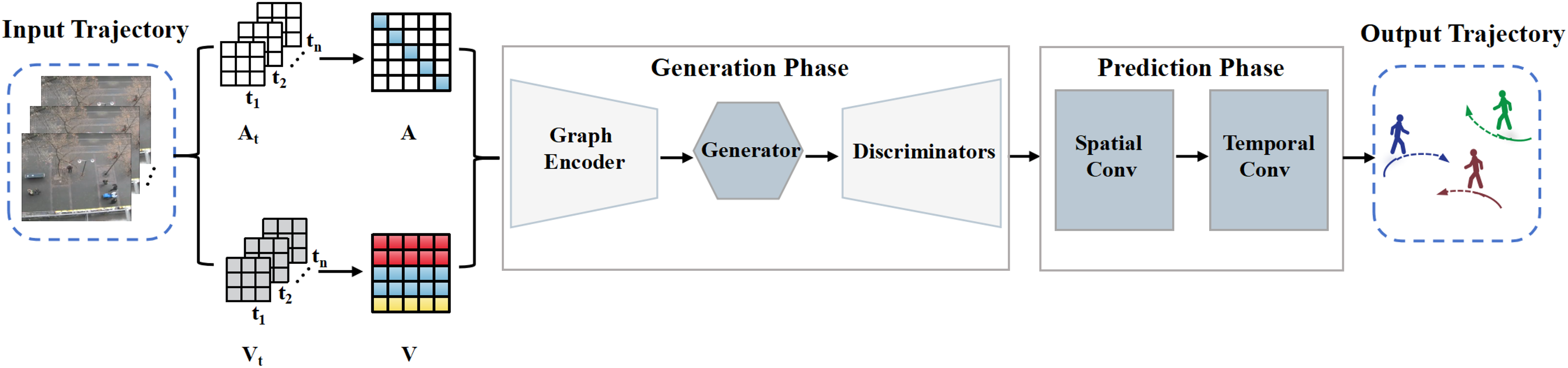
The framework of our proposed model PFNet.
Related Work
Graph Representation Learning
Graph Representation Learning provides a powerful framework for modeling graph-structured data. Among the various methods, Graph Convolutional Networks (GCNs) (Kipf & Welling, 2016a; Li et al., 2015) have emerged as a foundational approach, demonstrating strong performance across diverse domains, including physical system modeling (Battaglia et al., 2016; Li et al., 2018), healthcare (Liu et al., 2019), and recommendation systems (Fan et al., 2019). Building on their effectiveness, GE in this paper is designed following GCN principles. Despite their success, GCNs exhibit notable limitations. In deep architectures, repeated message passing across layers can lead to over-smoothing, where node representations become increasingly similar and lose discriminative power (Yang et al., 2022). Conversely, shallow GCNs often fail to capture sufficient structural information, resulting in limited expressive capacity.
To address these challenges, we propose an enhanced GCN-based architecture that decouples the standard GCN operations, mitigating the trade-off between network depth and representational power.
Generative Networks for Pedestrian Trajectory Prediction
Generative networks have gained increasing attention in trajectory prediction tasks due to their ability to produce multiple plausible outcomes and model the high uncertainty inherent in pedestrian motion. For example, Gu et al. (2022a) developed a diffusion model based on the Transformer architecture to capture temporal dependencies in trajectories. Kosaraju et al. (2019) proposed a GAN that integrates attention mechanisms with LSTM, enabling the generation of realistic trajectories that respect both social and physical constraints. Similarly, Sadeghian et al. (2019) introduced a GAN-based method that incorporates metric learning to structure the latent space, effectively capturing semantic context and trajectory geometry, which improves the quality of generated trajectories. Despite these advances, generative models continue to face challenges such as training instability and the generation of unrealistic trajectories.
To address these issues, we propose PFNet, which defines a more expressive probability distribution and introduces key components including a GE block and a dual-discriminator mechanism. In addition, the incorporation of a Prediction Phase allows for deeper fusion of spatial and temporal features, leading to significantly enhanced performance in trajectory prediction tasks.
Method
Trajectory prediction aims to forecast the future position coordinates of pedestrians. Given a sequence of observed positions over the time steps
This section presents a detailed description of the proposed PFNet framework. The Generation Phase is designed to produce feature representations enriched with graph-structured interaction information. These features are then passed to the Prediction Phase, which leverages both spatial and temporal cues to generate accurate predictions of future pedestrian trajectories.
Data Preprocessing
Since the original pedestrian trajectory data is extracted from video frames and lacks explicit feature annotations (Lv et al., 2023), preprocessing is required before the data can be fed into the model. Given that the Generation Phase involves graph representation learning, the raw data must first be transformed into a graph-structured format.
A temporal graph
These interactions are quantified using the
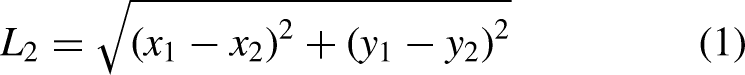
Based on Equation 1, each element
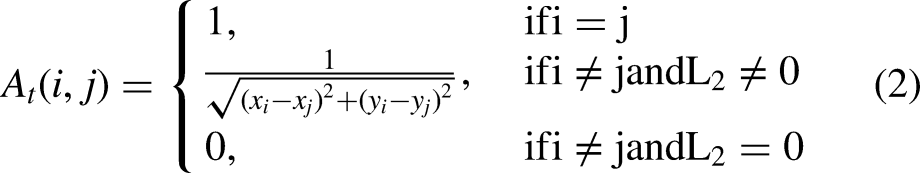
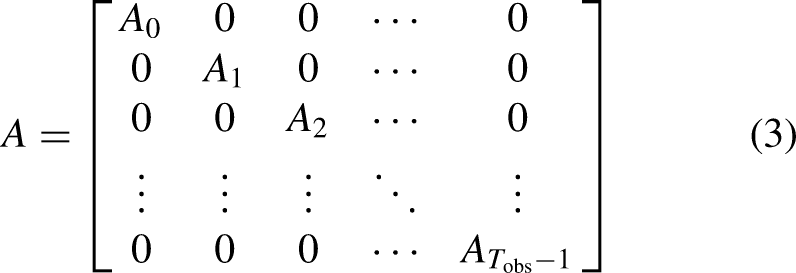
To effectively process multi-time-step data and capture pedestrian interactions from a broader temporal perspective, a block-diagonal adjacency matrix
To maintain consistency with the block-diagonal matrix
Generation Phase
To address the challenges outlined in Section “Related Work”, a GAN architecture is proposed that integrates a dual-discriminator mechanism with graph representation learning. The core components of this architecture include a GE, a Generator (

The framework of Generation Phase.
During this phase, the adjacency matrix
Overall, the architectural design not only preserves the topological structure of the graph but also improves the quality of the generated representations, thereby providing more reliable and informative features for the Prediction Phase.
Graph Encoder
To address the limitations caused by either excessive or insufficient GCN layers, a Feature Mapping and Propagation (FMP) architecture is introduced. This design builds upon the theoretical foundation of GCN by decoupling its message-passing operations into distinct components, resulting in a Message Passing Layer (MPL) and a Feed-Forward Layer (FFL). Specifically, multiple FFLs are applied prior to the MPL to enable deep and non-linear modeling of raw node features, thereby capturing complex relationships within the data. In parallel, the MPL aggregates these features to extract topological structure information. The formulation of the FMP architecture is presented below.
According to Kipf and Welling (2016b), the standard GCN operation can be expressed as:
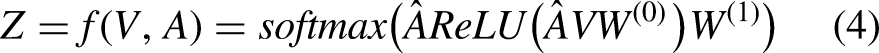
In GCN, message passing corresponds to the two multiplications involving

In this work, the FFL is implemented using a multilayer perceptron (MLP), defined as:
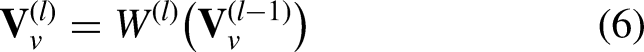
Greedy Energy Distance Sampling
Sampling directly from a normal distribution as the prior is often inappropriate, particularly when dealing with graph data that exhibit complex topological structures.
A commonly used alternative is Kernel Density Estimation (KDE), which models the distribution of node features in a non-parametric manner, as shown in Equation 7. KDE avoids strong assumptions about the distribution’s form and allows for flexible estimation of feature distributions. However, since KDE estimates the distribution solely based on
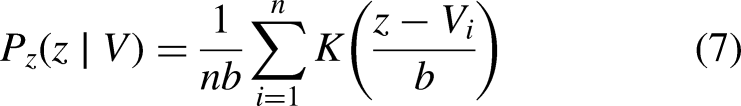
To address this issue, a new distribution
The Energy Distance (ED) between two distributions
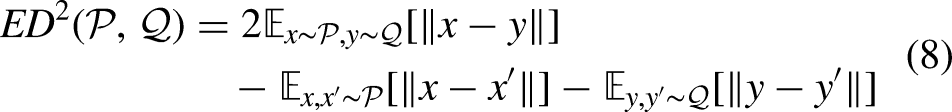
The GEDS procedure follows a greedy strategy and consists of the following steps:

The effectiveness of GEDS in generating a topology-aware sampling distribution is further analyzed in the subsequent section.
Theoretical Analysis of GEDS
Principal Component Analysis (PCA) is applied to reduce the dimensionality of the selected feature matrix
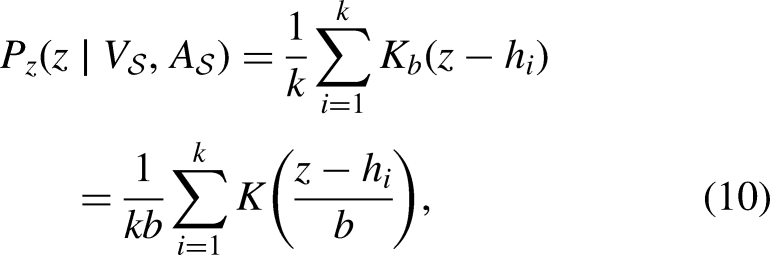
As illustrated in Equation 11, GEDS progressively refines the sampling distribution, transitioning from a structure-agnostic prior to a fully structure-aware distribution:
This progression ensures that the learned prior more accurately captures the underlying structure of the graph data, thereby improving the alignment between the latent space and the true data manifold.
Adversarial Loss
The core of generative networks lies in the adversarial loss, which is primarily designed to enable adversarial training between the generator and the discriminator. Its goal is to minimize the discrepancy between the real distribution
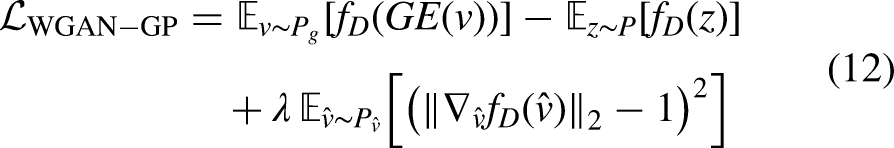
The loss functions for GE, discriminators
The latent representation of Following the WGAN-GP formulation, the loss for GE is defined as:
Similarly, the real feature data The corresponding generator loss is:
As described in Section 3.2, to ensure the quality of the data generated by First, the latent representation of the adjacency matrix, denoted as Then, the differences between
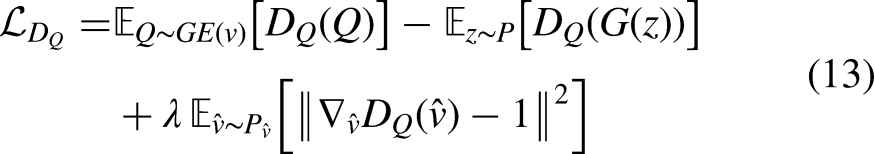

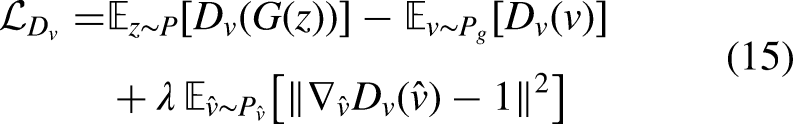
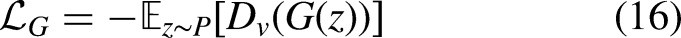
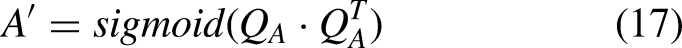
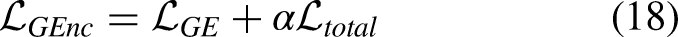
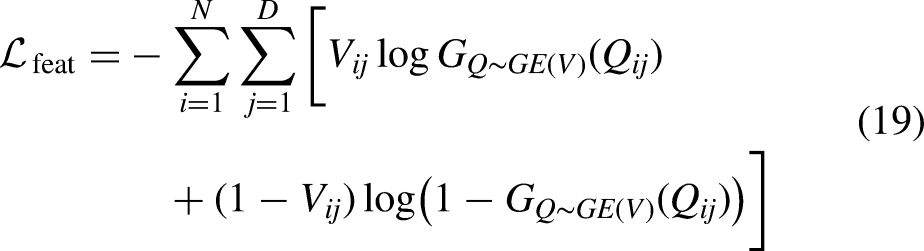
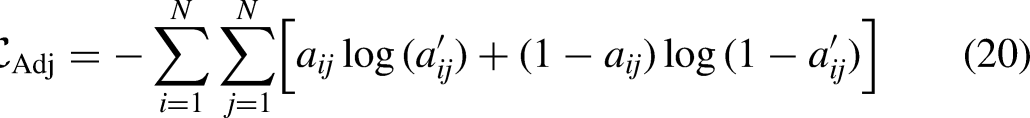
Prediction Phase
Through adversarial learning in the Generation Phase, feature representations enriched with graph structural information,

The framework of Prediction Phase.
To facilitate spatial feature extraction, a transformation is first applied to
During the extraction of features from

To model temporal dynamics and generate accurate future trajectories for each pedestrian, Temporal Convolution (TC) is applied to
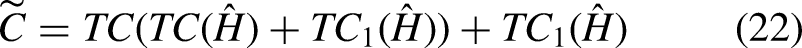
Loss Function
This formulation follows the assumptions established in Lv et al. (2023) and Eiffert et al. (2020b), where the predicted trajectory coordinates for each pedestrian, obtained from the Prediction Phase, are modeled as following a bivariate Gaussian distribution. Specifically, for the
Let
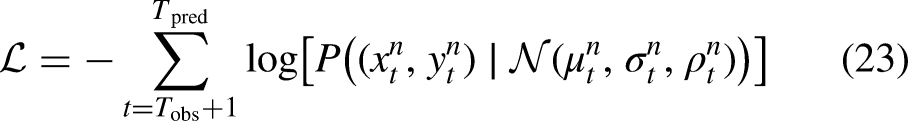
Quantitative Evaluation
Experimental Setup
Evaluation experiments are conducted on publicly available benchmark datasets, including ETH (Pellegrini et al., 2010), UCY (Lerner et al., 2007), and the Stanford Drone Dataset (SDD) (Robicquet et al., 2016). The ETH and UCY datasets cover five distinct scenes: ETH, HOTEL, UNIV, ZARA1, and ZARA2, providing position trajectories for 1,536 pedestrians over multiple time steps. The SDD dataset consists of high-resolution aerial videos recorded above the Stanford campus, with densely annotated trajectories of pedestrians, cyclists, and vehicles navigating complex urban environments.
Following previous methods, the first 3.2 seconds (
The Average Displacement Error (ADE) and Final Displacement Error (FDE) are used as evaluation metrics to quantitatively assess the performance of PFNet and other state-of-the-art (SOTA) models. The metrics are defined as follows:
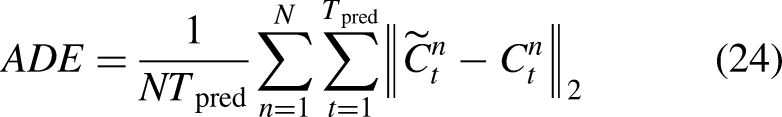
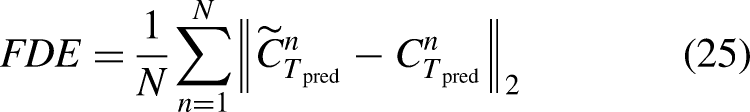
In the PFNet model, the hyperparameter
Comparison with SOTA Methods
The following SOTA methods are selected as baselines for comparison:
Social-GAN (Liu et al., 2023): A pedestrian trajectory prediction method based on a recurrent sequence-to-sequence architecture that employs a novel pooling mechanism and a recurrent discriminator.
SR-LSTM (Zhang et al., 2019): A data-driven LSTM-based model that incorporates message passing and socially-aware information selection to predict pedestrian trajectories based on the intentions of nearby agents.
STAR (Yu et al., 2020): A spatiotemporal graph-transformer framework that integrates graph convolution and temporal attention mechanisms for trajectory prediction.
PECNet (Mangalam et al., 2020): A human trajectory prediction model that uses a non-local social pooling layer and a truncation strategy to enhance multimodal prediction.
Trajectron++ (Salzmann et al., 2020): A modular, graph-structured recurrent model for multi-agent trajectory forecasting, combining agent dynamics with contextual environmental information.
AgentFormer (Yuan et al., 2021): A Transformer-based multi-agent trajectory prediction model that jointly captures temporal and social dependencies through an agent-aware attention mechanism.
SGCN (Shi et al., 2021): A sparse graph convolutional network designed for pedestrian trajectory prediction that models directed interactions and motion trends using sparse spatiotemporal graphs.
MID (Gu et al., 2022b): A model that encodes motion uncertainty through a parameterized Markov chain and balances trajectory diversity and determinism via a Transformer-based diffusion process.
TUTR (Shi et al., 2023): A Transformer-based model that unifies trajectory components, social interactions, and multimodal prediction within a single framework.
BOsampler (Chen et al., 2023): A Bayesian optimization-based sampling method that models trajectory prediction as a Gaussian process and adaptively explores diverse plausible paths.
LED (Mao et al., 2023): A diffusion-based trajectory prediction framework featuring a learnable jump initializer to accelerate inference while producing accurate and diverse multimodal predictions in real time.
UTD-PTP (Tang et al., 2024): A transformer-based diffusion model designed for complex campus scenarios, leveraging digital twin environments to improve prediction accuracy and generalization.
LADM (Lv et al., 2024): A VAE-based diffusion model that incorporates pedestrian group relationships via a pedestrian–group interaction module (PGIM), enhancing multimodal trajectory prediction through a diffusion-based refinement process.
DTGAN (Xie et al., 2024): A GAN-based model for graph sequence data that automatically captures implicit social interactions using random-weighted graphs, achieving improved trajectory prediction without relying on predefined interaction rules.
Comparison with SOTA Methods
Experiments on the ETH and UCY datasets are conducted to evaluate the performance of PFNet, with results summarized in Table 1. As shown, the proposed model achieves the best average ADE and FDE across all five benchmark subsets, consistently outperforming existing SOTA methods. Notably, compared to the early Social-GAN model, PFNet reduces ADE by 43% and FDE by 89%.
Comparison of SOTA on the ETH/UCY dataset (ADE/FDE).

This significant improvement can be attributed to the incorporation of the GE block into the GAN framework, which enhances the model’s ability to capture spatial interactions among pedestrians. Moreover, the dual-discriminator mechanism strengthens the representational power of the generated data, improving both quality and diversity.
When compared to probabilistic models such as BoSampler and LED, PFNet exhibits stronger modeling capability and superior prediction accuracy. This advantage stems from the introduction of the GEDS method, which avoids the limitations of fixed prior distributions commonly used in traditional methods. In contrast, BoSampler and LED rely on relatively simple sampling strategies that do not fully account for graph structure and topological dependencies. As a result, they may struggle to model complex spatial relationships, leading to suboptimal prediction outcomes in crowded or dynamic scenes.
In comparison to SGCN and STAR—both of which also leverage spatial-temporal modeling—PFNet demonstrates a 17% and 15% reduction in ADE, and a 31% and 36% reduction in FDE, respectively. While SGCN and STAR incorporate innovations in graph structure learning and attention mechanisms, their reliance on GNNs alone limits their capacity to model complex generative distributions. In contrast, PFNet enhances the model’s ability to capture intrinsic data distributions through the integration of the GE block and iterative adversarial training. Furthermore, the incorporation of a dedicated Prediction Phase allows the graph-structured representations learned during generation to be effectively utilized for trajectory prediction, leading to more accurate and robust forecasts.
We further compare PFNet with two diffusion-based models, LADM and UTD-PTP. LADM achieves competitive ADE/FDE scores (0.19/0.34 on average), especially on structured scenes like UNIV and ZARA1, but is slightly outperformed by PFNet in more dynamic environments such as ETH. UTD-PTP also shows solid performance (0.21/0.37), particularly on HOTEL, yet its lack of explicit graph structural modeling limits its effectiveness in scenarios with complex pedestrian interactions. In contrast, PFNet achieves the best results across all five datasets and delivers more consistent predictions, benefiting from its structure-aware design and adversarial training framework.
Finally, we include DTGAN in the comparison, a GAN-based model that learns implicit social interactions via graph representations with random weights. However, its lack of explicit structure-aware priors and temporal fusion leads to underperformance, particularly on highly interactive scenes like UNIV and ZARA1. PFNet surpasses DTGAN by 57% in ADE and 62% in FDE.
These quantitative results validate the superior accuracy and generalization capability of PFNet, which can be attributed to its holistic architecture that integrates graph encoding, structure-aware prior modeling, dual adversarial training, and temporal decoding.
We further evaluate PFNet on the challenging Stanford Drone Dataset (SDD), which features diverse pedestrian behaviors and complex scene layouts. As reported in Table 2, PFNet achieves competitive performance compared to recent SOTA models. Specifically, it attains an ADE of 8.41 and an FDE of 12.13, outperforming the diffusion-based LED model and significantly improving upon Trajectron++. While MID achieves a slightly lower ADE, PFNet offers a better balance between short-term and long-term prediction accuracy, as reflected in its superior FDE. These results demonstrate the effectiveness of PFNet in generating accurate and stable trajectory predictions under complex real-world conditions, further confirming its robustness and generalization capability beyond the ETH/UCY benchmark.
Comparison of SOTA on the SDD Dataset (ADE/FDE).

To provide a more intuitive understanding of the prediction results, trajectory visualizations on the ETH and UCY datasets are presented in Figure 4. As shown, the trajectories predicted by PFNet align more closely with the ground-truth paths compared to those generated by the SOTA LED model.

Visualization of pedestrian trajectory prediction results on the ETH/UCY dataset. Observed trajectories are shown as solid blue lines, ground truth trajectories as solid orange lines, PFNet predictions as dashed red lines, and LED predictions as solid green lines across five scenarios. PFNet predictions demonstrate superior alignment with the ground truth, indicating improved prediction performance. For enhanced clarity, we recommend viewing the figure in color and at an enlarged scale.
Ablation Studies
To further analyze the contribution of each component in the proposed PFNet, ablation studies were conducted on the five benchmark datasets. In these experiments, specific modules of PFNet were either removed or replaced with alternative implementations. The detailed ablation settings are as follows:
The results of the ablation studies are presented in Table 3. As shown, PFNet-w/o-GEDS exhibits a notable performance drop across all datasets due to the substitution of ED-based sampling with a Gaussian distribution. This performance degradation arises because the GEDS method captures the distributional characteristics of trajectory data more effectively, providing a more accurate probability distribution during the Generation Phase. This allows the generator
Comparison of Ablation Studies on PFNet (ADE/FDE).
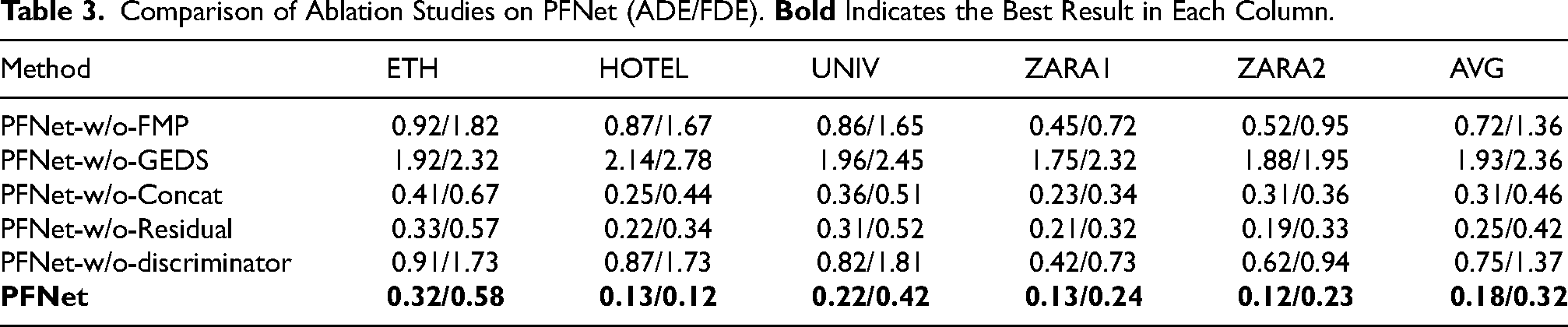
The performance decline observed in PFNet-w/o-FMP is primarily attributed to the replacement of the FMP architecture with a conventional two-layer GCN. The original FMP module, by employing multiple Feed-Forward Layers (FFLs) and integrating several Message Passing Layers (MPLs), facilitates deeper, non-linear feature extraction while preserving structural flexibility. Its decoupled design enhances the model’s capacity to capture intricate relationships and topological dependencies within the data. In contrast, traditional GCN architectures lack this flexibility and expressiveness, leading to weaker feature learning and ultimately poorer performance in both ADE and FDE. These findings underscore the effectiveness of stacking multiple FFLs and MPLs in the FMP architecture for capturing meaningful spatio-temporal representations.
While PFNet-w/o-Concat performs better than the previous two variants, it still falls short of the full model. Replacing the concatenation operation with element-wise addition reduces the expressiveness of feature fusion in the Prediction Phase, limiting the model’s ability to retain and integrate both original and generated features, thus negatively affecting prediction accuracy.
PFNet-w/o-Residual shows only a slight decline in performance, indicating that residual connections contribute positively to model stability. Their inclusion helps preserve feature information and alleviate gradient vanishing during training, thereby supporting improved convergence and prediction performance in the full PFNet model.
Using a single discriminator (PFNet-w/o-discriminator) results in a 76% ADE and 77% FDE increase on average, compared to the full model. This significant degradation highlights the importance of the dual-discriminator design in enhancing both the accuracy and stability of trajectory generation.
In summary, the ablation study demonstrates that each component plays a critical role in the overall performance of PFNet. The careful architectural design and integration of these modules collectively enhance the model’s ability to accurately and robustly predict pedestrian trajectories in complex scenarios.
Model Efficiency Analysis
To assess the practicality of PFNet in real-world scenarios, we conduct a comprehensive evaluation of model efficiency, including parameter size, training time, and inference latency, as summarized in Table 4.
Comparison of Model Efficiency in Terms of Parameters, Training, and Inference Time.
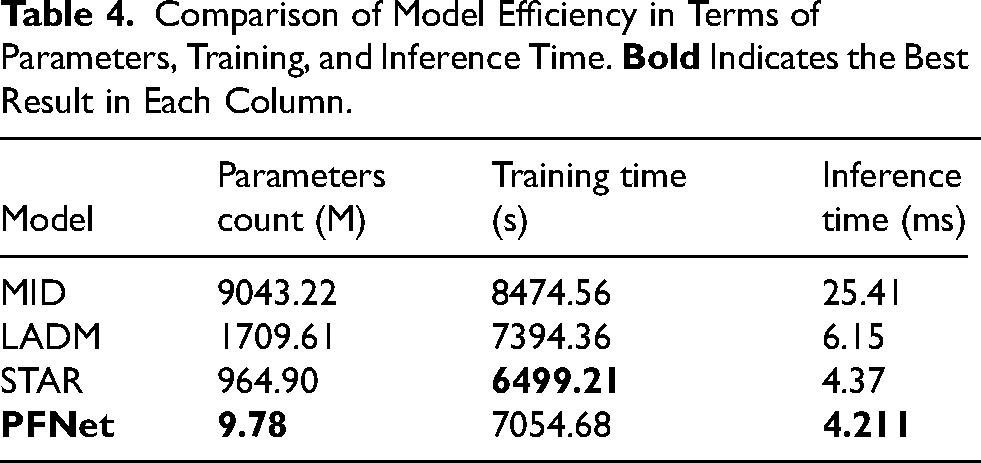
PFNet demonstrates significant advantages in terms of computational efficiency. Despite incorporating a dual-phase architecture and adversarial training mechanism, PFNet requires only 9.78 million parameters—substantially fewer than MID (9043.22M), LADM (1709.61M), and STAR (964.90M). In addition, PFNet achieves a competitive training time of 7054.68 seconds, indicating stable and efficient optimization during training. Most notably, it achieves the lowest inference time of 4.211 milliseconds, enabling responsive prediction in time-sensitive applications such as autonomous driving and intelligent surveillance.
These results collectively highlight PFNet’s efficient design and strong deployment potential, demonstrating that it can deliver high prediction accuracy with manageable computational overhead.
Robustness Analysis
To assess the stability and reliability of PFNet, the standard deviations of ADE and FDE across the five subsets of the ETH/UCY benchmark are reported in Table 5, based on five independent runs. The results show that PFNet consistently achieves low standard deviations, indicating robust and stable performance across diverse scenarios. For instance, in the ETH and UNIV scenes, which involve complex pedestrian interactions, PFNet maintains standard deviations of only 0.068 (ADE) and 0.012 (FDE), respectively. Similarly, in structured environments such as HOTEL and ZARA1, the fluctuations remain minimal, with standard deviations as low as 0.013. These observations demonstrate that PFNet not only delivers accurate trajectory predictions but also exhibits high consistency across different environments, validating its generalization capability and robustness under real-world conditions.
Standard Deviation of PFNet on the ETH/UCY Dataset (ADE/FDE) with Paired-test Statistics (
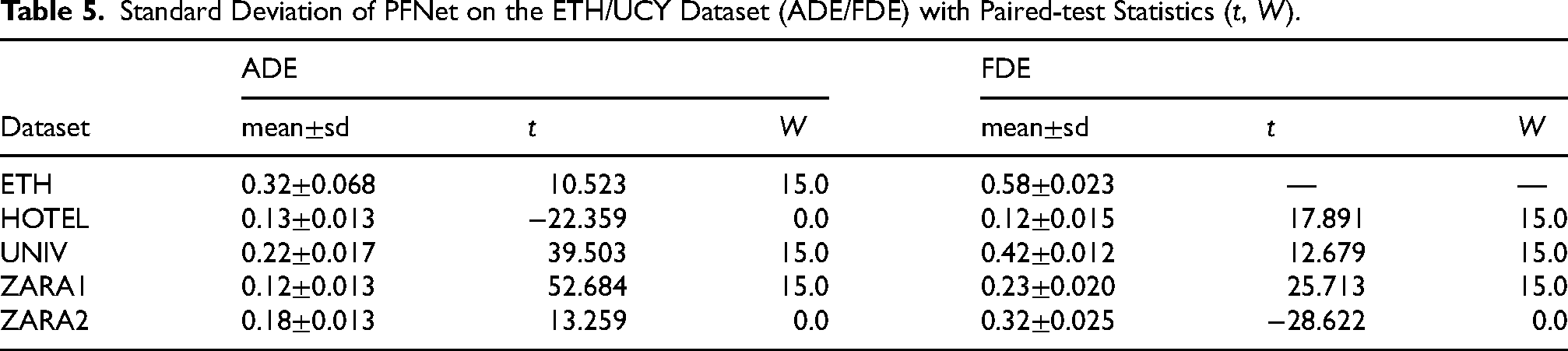
In addition, the table reports paired-test statistics against the best baseline model (LED): the paired t-statistic (
Conclusion
In this paper, PFNet is proposed for trajectory prediction. By employing a GEDS and a dual-discriminator mechanism, challenges in traditional GAN-based trajectory prediction models, including OOD issues and mode collapse, are effectively addressed. Furthermore, the integration of the
Since PFNet adopts a GAN-based framework, future work will primarily focus on improving training stability and convergence speed. Additionally, when handling large-scale graph data, the introduction of advanced graph pooling techniques is considered a feasible and effective approach to further enhance the expressive power and computational efficiency of the model.
Footnotes
Acknowledgments
The authors declare that there are no acknowledgments for this work.
Ethical Approval and Informed Consent
This study does not involve human participants or animals; therefore, ethical approval and informed consent are not applicable.
Funding
The author(s) received no financial support for the research, authorship and/or publication of this article.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
The data supporting the findings of this study are available from the corresponding author upon reasonable request.