
Abstract
Autonomous underwater vehicles (AUVs) are seeing increasingly widespread adoption in marine exploration, search and rescue, and military applications. As a core enabling technology, underwater path planning faces significant challenges, in this article an intelligent path planning algorithm named A*-MPPO-DWA is proposed to enhance the efficiency and accuracy of path planning for AUV in complex dynamic environments. The proposed hierarchical framework operates as follows: firstly, the A* algorithm performs global path search and preliminary planning to ensure a feasible route from the start to the goal point. Secondly, the MPPO (multiphase path optimization) strategy refines the path through multiphase decision making. Different from conventional path smoothing and single-stage optimization methods, MPPO integrates dynamic obstacle detection and ocean current compensation into a three-stage progressive optimization pipeline, which realizes global topology preservation, redundant node elimination, and adaptive smooth correction simultaneously, rather than simple geometric smoothing. It can effectively handle complex dynamic environment. Finally, the DWA (Dynamic Window Approach) algorithm is employed for local path smoothing and real-time obstacle avoidance by integrating adaptive velocity control, enabling the AUV to avoid collisions and excessive steering during mission execution. Experimental results demonstrate that the proposed algorithm achieves superior stability and accuracy. Against baseline approaches using A* or DWA, the A*-MPPO-DWA algorithm shows significant advantages in key metrics, including path length, number of path turns, obstacle avoidance success rate, and computational time.
Keywords
Introduction
In recent years, autonomous underwater vehicles (AUVs) have been extensively deployed in fields such as ocean resource exploration, marine environmental monitoring, and underwater search and rescue operations, thanks to their ability to operate independently in harsh and inaccessible underwater environments. 1 Path planning, as the core technology for AUV autonomous navigation, directly determines the efficiency, safety, and mission success rate of AUVs. However, in dynamic underwater environments—characterized by randomly moving obstacles (e.g. floating debris and marine organisms) and changing ocean currents—traditional path planning methods often struggle to balance global path optimality and real-time local adaptation, posing a significant challenge for AUV autonomous navigation. 2
Effective path planning for AUVs requires not only generating a globally optimal or near-optimal route but also possessing the capability for real-time obstacle avoidance and flexible adaptation to complex and dynamic surroundings. Consequently, achieving a balance between global path planning and local obstacle avoidance has become a critical issue in the research of AUV path planning algorithms.
Path planning methods for AUVs are generally categorized into global and local approaches. Global path planning algorithms, such as A*, Dijkstra, and RRT* (Rapidly exploring Random Tree), focus on generating an optimal route from the start point to the goal point in a known environment. Among these, the A* algorithm is widely used due to its clear heuristic logic and high efficiency in finding optimal paths. 3 However, in dynamic environments, the path updating efficiency of the A* algorithm is low, and it cannot effectively cope with rapidly moving obstacles, as its planning relies on pre-known environmental information. In contrast, local obstacle avoidance algorithms, represented by the Dynamic Window Approach (DWA), achieve real-time obstacle avoidance by adjusting the AUV's velocity and motion states based on real-time sensor data. Nevertheless, DWA often fails to find a globally optimal path due to its local decision-making nature and can easily become trapped in local minima (e.g. surrounding by convex obstacles), leading to mission failure.4,5
To overcome the limitations of these individual algorithms, researchers have explored fusion strategies. For example, some studies have combined the A* algorithm with DWA to use the global path of A* as a guidance for DWA's local planning. However, such simple fusion lacks effective handling of dynamic environmental changes, and the path between the global and local layers often has poor continuity, leading to excessive steering of AUVs. In addition, existing fusion algorithms rarely consider the impact of ocean current disturbances on path quality, which is a key factor affecting AUV navigation in actual underwater environments. 6
To address the above issues, this article proposes an intelligent path planning method based on an A*-MPPO-DWA hierarchical framework, specifically optimized for AUVs in complex dynamic underwater environments. The core design idea is to introduce a multiphase path optimization (MPPO) module between the global planning (A*) and local planning (DWA) layers to achieve smooth transition and dynamic adaptation. Firstly, the A* algorithm performs global path search and preliminary planning to ensure a feasible and globally near-optimal route from the start to the goal point. Secondly, the MPPO module, enhanced with a dynamic obstacle detection mechanism and ocean current compensation model, refines the global path through multiphase decision making, improving the path's adaptability to dynamic obstacles and reducing the impact of ocean currents. Finally, an adaptive velocity control strategy is introduced into the DWA algorithm, which leverages real-time environmental information (e.g. obstacle distance and current speed) to optimize the evaluation function of DWA, thereby improving the effectiveness of local path smoothing and real-time obstacle avoidance. Experimental results demonstrate that the proposed fusion algorithm effectively enhances path planning performance in complex dynamic scenarios, reducing fluctuations in path length, improving obstacle avoidance effectiveness and success rate, shortening execution time, and ensuring global path near-optimality.
To address the aforementioned challenges and balance the needs for real-time performance and accuracy, an intelligent path planning method based on the A*-MPPO-DWA hierarchical framework is proposed for AUVs in complex dynamic underwater environments. The main contributions of this study are as follows:
A novel hierarchical fusion framework with innovative MPPO module for dynamic path planning: this article proposes an A*-MPPO-DWA three-layer hierarchical framework, which introduces the MPPO module to bridge the gap between global planning and local planning. Different from existing path smoothing algorithms (e.g. B-spline, Bezier, polynomial fitting) that only focus on geometric smoothness, and different from traditional multistage optimization methods with single decision objective, MPPO is designed with a three-stage progressive decision-making mechanism: redundant node elimination, global polyline compression and local safety refinement. It integrates dynamic obstacle detection and ocean current compensation model, and optimizes path safety, smoothness and adaptability while preserving global optimality. This solves the problems that traditional smoothing methods are difficult to adapt to dynamic disturbances and multistage optimization lacks environmental perception. The MPPO module is designed with a multiphase decision-making mechanism, which integrates real-time dynamic obstacle detection and ocean current compensation models. It can adjust the path in phases according to the changes of environmental factors (e.g. obstacle movement trajectory, ocean current direction and speed), effectively reducing the path deviation caused by dynamic disturbances and improving the path's robustness. Compared with the traditional A*-DWA fusion method, this framework solves the problem of poor path continuity between layers and improves the adaptability to dynamic environments, achieving a better balance between global optimality and local real-time performance. The optimized path from MPPO provides clear theoretical guidance for DWA: it outputs compact key waypoints as local subtargets, offers smooth heading reference, and sets safe navigation constraints. This helps DWA avoid local optima and focus on real-time obstacle avoidance. 2. Adaptive DWA algorithm optimized for underwater scenarios: An adaptive velocity control strategy is introduced into the traditional DWA algorithm. The strategy dynamically adjusts the weight coefficients of the DWA evaluation function (e.g. distance to obstacle, velocity consistency, and path deviation) based on real-time environmental information, solving the problem that DWA is prone to local minima and improving the success rate of real-time obstacle avoidance.
The subsequent chapters of this article are arranged as follows: chapter 2 elaborates on the design of the A*-MPPO-DWA path planning algorithm. It focuses on the intelligent global path planning based on A*-MPPO, including the introduction of ocean current weights in the A* algorithm and the multiphase path optimization strategy of MPPO; chapter 3 presents the dynamic window method path planning model integrating ocean current disturbances, covering the AUV state model, ocean current vector field construction, local target switching mechanism, and multiobjective evaluation function. Chapter 4 presents that the a* algorithm, MPPO strategy and DWA algorithm are integrated according to the underwater dynamic environment. Chapter 5 presents the simulation experiment results and related analysis. It designs comparative experiments in complex dynamic environments, evaluates the performance of the proposed algorithm from the perspectives of global path planning quality, executed trajectory efficiency, and motion control smoothness, and compares it with classical algorithms such as A*, Dijkstra, and RRT variants. Chapter 6 summarizes the full text, clarifies the effectiveness and advantages of the A*-MPPO-DWA algorithm, and puts forward future research directions, such as integrating more complex environmental models and expanding the collaborative path planning functions of multiple AUVs.
In brief, this study proposes the A*-MPPO-DWA framework. Experiments show that the proposed algorithm significantly reduces path length, turning times, and travel time, and improves stability and obstacle avoidance performance. The framework effectively balances global optimality and local real-time performance for AUV navigation in complex dynamic underwater environments.
Intelligent global path planning for underwater dynamic environment based on A*-MPPO
In underwater missions, especially in complex dynamic environments, AUVs need to carry out efficient and reliable path planning to avoid obstacles, cope with dynamically changing environmental conditions, and minimize energy consumption and time consumption. Traditional path planning methods, such as the A* algorithm and the DWA algorithm, perform well in static or simple environments, but their performance is often limited when dealing with ocean currents, dynamic obstacles, and complex underwater environments. 7
This chapter will focus on introducing the AUV underwater dynamic environment path planning method based on A*-MPPO. Firstly, we will analyze the challenges in the underwater dynamic environment, especially the impact of ocean current disturbances on path planning. Next, we propose an intelligent path planning framework that integrates the A* algorithm and the multistage path optimization algorithm (MPPO), aiming to enhance the path planning efficiency and safety of AUVs in dynamic waters. We further analyzed the advantages of this method in the face of dynamic obstacles and environmental disturbances, and verified its effectiveness through simulation and experiments.
Traditional A* algorithm
The A* algorithm is a heuristic search algorithm widely used in path planning, which integrates the advantages of Dijkstra algorithm (guaranteeing global optimality) and greedy best-first search algorithm (high search efficiency). Its core idea is to evaluate each candidate node in the search space through a comprehensive cost function, and always select the node with the minimum comprehensive cost for expansion, thereby efficiently finding the optimal path from the start point to the target point.
8
The A* algorithm is a heuristic search algorithm widely used in path planning. Its main idea is to determine the path selection by calculating the f value of each node:

Among them: f(n) is the comprehensive cost of node, representing the estimated total cost from the start point to the target point through node. The g(n) is the actual cost from the start point to node, which is usually the Euclidean distance or Manhattan distance from the start point to node along the generated path. This part is accurately calculated based on the already explored path, ensuring the reliability of the cost. The h(n) is the heuristic estimated cost from node to the target point, which is used to guide the search direction and improve the search efficiency. Common heuristic methods include Euclidean distance, Manhattan distance, and Chebyshev distance. For underwater AUV path planning, Euclidean distance is usually adopted due to the continuity of the underwater navigation space, and its calculation formula is shown in Formula. 9
Common methods for calculating the cost of movement include Euclidean distance and Chebyshev distance. The distance from and to Manhattan can be expressed respectively as:

In the formula: x1, y1 and x2, y2 are the coordinates of the current node and the target node, respectively; h1 (n), h2 (n), and h3 (n) are the estimated algebraic values between two points calculated using Euclidean distance, Chebyshev distance, and Manhattan distance, respectively. 10
The core idea of the A* algorithm is to calculate the cost of each node and always select the node with the smallest cost for expansion, thereby ultimately finding the optimal path.
Utilize the MPPO strategy to optimize multistage decision making of the path
The traditional A* algorithm achieves efficient search under the premise of ensuring optimality through the evaluation function, but it still has the following deficiencies in complex obstacle environments: (1) the weights of the heuristic function are fixed, making it difficult to dynamically adjust the search behavior according to the complexity of the environment; (2) the search path is prone to getting close to the edge of obstacles, and the safety margin is insufficient; and (3) search results often contain a large number of redundant nodes and frequent turns, making them difficult to be directly applied to subsequent motion planning. 11
In response to the above problems, based on the standard A* framework, this article systematically improves the algorithm from three aspects: node expansion strategy, evaluation function design, and path structure optimization, and proposes an improved A* global path planning method based on multistage path optimization algorithm. It adopts the MPPO algorithm as a multiple improvement strategy for the path, aiming to optimize the path through multiple iterations, thereby achieving efficient global and local path planning in a dynamic environment. Under the premise of ensuring path safety, smooth, and simplify the original path of A*. This path significantly reduces unnecessary turns and is more in line with the motion characteristics of the AUV. It provides a high-quality global reference path for the subsequent Local Dynamic Programming (DWA) algorithm, effectively enhancing the safety, smoothness, and engineering usability of the path.
Improvement of node expansion strategy
During the node expansion stage, traditional A* typically adopts an eight- or four-neighborhood search method. Although neighborhood search has stronger connectivity, it is prone to the problem of slanting through the vertices of obstacles, thereby posing a collision risk in actual movement. 11 For this reason, this article makes a constrained improvement to the node expansion strategy.
During the node expansion process, the algorithm still generates candidate child nodes around the current node as the center, but through the dual detection mechanism of the CLOSED set, it strictly restricts the oblique expansion behavior of child nodes when approaching obstacles. When a candidate child node has an adjacent relationship with an obstacle in the horizontal or vertical direction, the corresponding diagonal expansion node will be actively eliminated, thereby effectively avoiding the “corner crossing” phenomenon. This constraint mechanism ensures the integrity of the search while enhancing the geometric feasibility and safety of the path in a discrete raster environment.12,13
Improvement of the evaluation function based on the risk potential field
This article introduces an improved evaluation function based on obstacle risk perception in the node expansion stage, and its form is defined as:

Among them, g(n) represents the cumulative path cost from the starting node to the current node; h(n) the Euclidean distance from the current node to the target node;
In the specific implementation, the risk potential field
This design decouples the search logic from the cost model, enabling the algorithm to have good scalability while maintaining the overall framework unchanged. It can further integrate ocean current disturbances, energy consumption models or risk preference weights.
Improvement of multiple zigzag path optimization strategies
In the known obstacle space, the A* algorithm is evaluated to ensure the efficiency of path search and meet the requirements of global planning in the initial stage by optimizing the path quality evaluation function. However, the number of path turning points obtained by this algorithm is too large, the path smoothness is poor, and the initially planned path is overly complex. In complex environments, the traditional A* algorithm is difficult to ensure the safety of AUV during their movement. Therefore, this article adopts a redundant node optimization method. This method can eliminate all redundant turning points and obtain a smoother and safer path. 14
To address this issue, this article proposes a MPPO framework. Without altering the global topological optimality, the path is progressively refined through multiple optimization policies. The proposed MPPO framework consists of three sequential strategies: path backtracking reconstruction, global polyline compression, and local safety-oriented refinement, forming a coarse-to-fine optimization pipeline.
Decision-making stage 1: Eliminate redundant points. The optimization method of redundant nodes is shown in Figure 1. NS is the starting point and NT the target point. The path planned by the traditional A* algorithm is (NS,N1,N2,N3,N4,N5,N6,N7,NT), and its path exists at multiple nodes. To address the above issues, this article optimizes the redundant nodes of the A* algorithm. The basic idea of the optimization is: on the path planned by the traditional A* algorithm, if the distance between nonadjacent nodes is less than the distance between planned nodes, the straight line formed by the paths of nonadjacent nodes does not collide with obstacles, and the vertical distance between this straight line and the obstacle is greater than or equal to the safe radius distance, then the intermediate nodes are redundant nodes and can be deleted, only the initial nodes, intermediate inflection points and target nodes are saved. Retain the path as (NS,N3,N8,N5,NT), repeat the above loop, and finally form a new optimized path as (NS,N3,NT). If a straight line collides with an obstacle, the detection of the nonadjacent node will be skipped, and the detection of the next round of nonadjacent nodes will continue. Decision-making stage 2: Path smoothness optimization. The optimized path after arc processing is shown in Figure 2, and the newly optimized path is (S,N3,T). Its path length, turning points and safety performance have all been improved, but there is still a problem of poor smoothness. This is because the large steering of AUV during its movement causes it to drift, which is not conducive to the actual control of AUV. In the A* algorithm, the path passes through many nodes, especially when there are many obstacles, the path often contains a large number of sharp turns. To reduce these sharp turns, we first carry out secondary zigzagging optimization. The core idea of quadratic polyline optimization is to reduce the number of intermediate nodes by connecting every other node on the path.
The specific steps of path smoothness optimization are as follows: it is known that the coordinates of starting point s, turning point N3, and target point t are (M1, N1), (m2, N2), and (M3, N3), respectively. When AUV turns, considering safety factors, it will not collide with obstacles. Here, the radius AO and BO of arc AB are set as R, which can be obtained from the geometric model:


Redundant node optimization.

Path smoothness optimization.
Among them:

Among them: β is the included angle between line segment SN3 and line segment N3T;

Similarly, the AS distance is:

When lAD ≥ R, lBE ≥ R, and β>90°, the path smoothness optimization is performed, otherwise the path smoothness optimization is skipped. Simultaneous equations (10) to (12) give:

where (

where (

Innovation of MPPO compared with existing algorithms
Existing path smoothing algorithms mainly include geometric smoothing methods (such as B-spline curve, Bezier curve, and arc interpolation) and traditional multistage optimization methods. These methods have the following limitations15,16:
Conventional path smoothing algorithms only focus on reducing path curvature and turning angle from geometric perspective, without considering dynamic obstacles and ocean current disturbances, and cannot adjust the smoothing strategy in real-time according to environmental changes. Traditional multistage optimization algorithms mostly adopt single objective or fixed weight decision making, lack of obstacle risk potential field and current compensation mechanism, and it is difficult to balance path safety, smoothness, and global optimality. Most existing methods cannot realize the smooth transition between global path and local planning, resulting in poor path continuity and easy to cause AUV shaking.
In view of the aforementioned existing limitations, the innovations of MPPO proposed in this article are as follows:
Progressive three-stage optimization mechanism: It realizes redundant node elimination, path smoothing, and safety refinement in turn, which is different from the one-step smoothing of traditional algorithms. Integration of environmental perception: MPPO introduces obstacle risk potential field and ocean current compensation model into the optimization process, rather than pure geometric optimization. Bridge overall and local planning: It provides a smooth and robust global reference path for DWA, solving the problem of poor connection between global and local layers in traditional A*-DWA fusion. Guarantee safety and smoothness at the same time: While optimizing path smoothness, it strictly constrains the safe distance from obstacles, which is more suitable for dynamic underwater environments.
This section presents the first core innovation of this article, that is, the MPPO strategy, which provides a solid foundation for the subsequent global–local guidance.
Dynamic window method path planning model (DWA) integrating ocean current disturbances
The DWA is a sampling-based local trajectory planning method in the velocity space. This algorithm comprehensively considers the kinematic constraints of the AUV and the environmental information it is in, and constructs a feasible velocity set that satisfies the velocity and acceleration limitations, namely the “dynamic window.”15,16 In this velocity space, samples are taken for different velocity combinations, and corresponding motion trajectories are generated within the short-term prediction range. Subsequently, the candidate trajectories are comprehensively evaluated through a predefined multi-objective evaluation function, and the optimal trajectory is selected as the current control instruction. By constantly repeating the above process, the AUV can adjust its motion strategy in real time in a dynamic environment, thereby achieving safe, efficient, and well-adapted target point navigation. 17
Kinematics modeling and parameter configuration of AUV
In order to achieve path optimization and obstacle avoidance control based on the DWA, this article introduces a two-dimensional differential drive model in the path tracking process to describe the motion state of AUV. The state of the AUV is represented by a five-dimensional vector, which contains information on its position, orientation, linear velocity, and angular velocity. In the initial stage of the simulation, the initial heading angle is set to −Π/3 radians to specify the starting direction.
The kinematic model parameters are represented by the vector kinematic and include the following contents:

Among them,
AUV state model and motion prediction
The AUVs state vector is defined as:

Here,
Its kinematic equation based on the differential model is: The speed constraint of the AUV itself is: The velocity space sampling consists of a dynamic window composed of the current velocity, acceleration, and maximum velocity: To ensure that the AUV can effectively avoid obstacles during movement, that is, its speed drops to 0 when it is about to collide with an obstacle, the safe braking distance of the AUV is constrained. The formula is as follows:
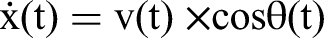

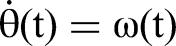

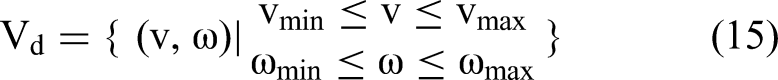

In conclusion, the AUV speed space must comply with these three constraints, and the range of speed magnitudes can be expressed as:

Current situation and limitations of classic DWA
The classic DWA is a local obstacle avoidance algorithm with velocity space sampling as the core. It generates candidate trajectories within a finite time prediction window based on the kinematic constraints of the AUVs and selects the optimal speed control pair (v, Lack of modeling for external disturbances (such as ocean currents and wind fields); The path correction ability is limited when facing dynamic obstacles
18
; It is difficult to handle the tasks of continuous target point navigation and local target selection
19
; Completing tasks alone is prone to getting stuck in local optima.
20
This article proposes a DWA integrating ocean current disturbances (abbreviated as DWA-OCEAN), which is a local obstacle avoidance algorithm based on the rolling evaluation of predicted trajectories. This method introduces a flow field interference modeling module on the basis of the traditional DWA to simulate the actual navigation behavior of underwater AUVs in complex fluid environments.
Construction of ocean current vector field
Firstly, for the construction of the ocean current vector field, a perturbation estimation function for ocean current based on two-dimensional interpolation was designed. This function takes the current state of the AUV as input and outputs the ocean current velocity vector at the current position, which is used for motion state correction.

Among them, u(x,y) and v(x,y) are the ocean current velocity components in the x and y directions, respectively, which are obtained through linear interpolation.
The influence of disturbances on the AUV's state is introduced through the following correction terms:

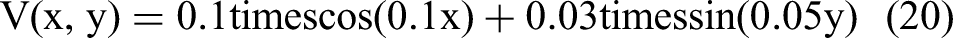
Among them, U(x,y) and V(x,y) represent the ocean current velocity components in the x and y directions, respectively, forming a stationary flow field in which the field strength varies with the spatial distribution. The ocean current vector field is obtained by on-board current sensors and predeployed environmental models. The real-time measured current data is directly mapped to the MPPO process to adjust path safety, smoothness, and direction, so as to realize dynamic current compensation.
Local target switching mechanism
In Dynamic Window Method (DWA) path planning, if the planner always takes the global target point at the far end as the tracking object, the following problems may cause navigation failure. The reasons are as follows:
There is an obstruction between the current pose and the target point.
21
Ocean current disturbances or local path oscillations lead to a decrease in “accessibility”; Frequent direction changes by the navigator in the corner area can easily cause trajectory shaking or stagnation, getting stuck in local optimum.
22
Therefore, this article introduces a rolling local target switching mechanism. At each moment, the subtarget selection function is determined whether to enable it based on the distance between the current state and the global target. This function dynamically selects the subtarget with the best local reachability by combining factors such as distance, obstacle density, and orientation consistency, significantly improving path smoothness and local navigation robustness.
First, make a conditional judgment: At any time t, define the current position:

Set the threshold ɛ to determine whether to switch the local target:

Otherwise, the goal remains the end:

To consider ocean current disturbance in local target selection, a current alignment term is integrated into the cost function. This term penalizes targets that require sailing against the current and prefers directions consistent with the ocean current, thus reducing energy consumption and improving navigation stability.
Traverse the path node and construct the target cost function:

The final local target selection is:

Evaluation function
After the linear velocity and angular velocity of AUV are combined with its kinematic model, its velocity sampling can simulate countless paths in the velocity space. The evaluation function is required to evaluate each path and select the path with the highest score as the AUV travel path. The traditional evaluation function is as follows:

Among them,
This section presents the second core innovation of this article: the adaptive DWA algorithm with ocean current compensation and local target switching, which improves the real-time obstacle avoidance performance.
Fusion algorithm
In the global map constructed by the AUV, when environmental information and obstacle distribution have been fully acquired, the improved A* algorithm can effectively complete global path planning.
23
However, unexpected situations may still occur in the actual complex marine environment, such as dynamic interference from other AUVs or the sudden appearance of unknown obstacles. Without an effective real-time obstacle avoidance mechanism, the AUV is highly susceptible to collision risks. To achieve safe and efficient navigation of the AUV in complex dynamic environments, this article integrates the improved A* global path planning algorithm with the DWA local planning algorithm, which possesses real-time obstacle avoidance capabilities.24,25 The improved A* algorithm provides the DWA with a reference for the globally optimal path, while the DWA, based on this, achieves rapid response to dynamic obstacles, thus balancing global optimality and local safety. Then the MPPO module performs multiphase optimization to obtain a smooth, safe, and near-optimal reference path with compact key points. Theoretically, the MPPO output supports the DWA local planner through three core guidance mechanisms:
Local subtarget guidance: MPPO decomposes the global path into a series of adjacent subtargets. DWA tracks these nearby subtargets step by step instead of the remote final goal, which effectively suppresses local minima and path oscillation. Trajectory smoothness guidance: The curvature, turning angle, and continuity optimized by MPPO provide DWA with stable motion constraints, reducing frequent direction changes. Safety corridor guidance: The obstacle risk potential field and safety distance constraints in MPPO form a safe motion range, so DWA can perform real-time obstacle avoidance within a reliable safety range.
Furthermore, to enhance the operational safety and trajectory executability of AUV in complex environments, this article makes targeted improvements to the evaluation function of the DWA algorithm, thereby enhancing its comprehensive tradeoff capabilities in terms of target guidance, obstacle avoidance, and motion smoothness.


Among them:
To enhance the adaptability and efficiency of trajectory generation, this article sets the weighted parameter vector evaluation = [0.05, 0.2, 0.3, 3.0] for the dynamic window evaluation function, corresponding in sequence to the heading angle deviation factor, obstacle distance factor, speed factor, and prediction time window (unit: seconds).
On the global path of the improved a* algorithm, the dynamic window method based on the improved safety distance evaluation subfunction is used for local path planning, and finally the dynamic obstacle avoidance of AUV is realized. The specific steps are as follows:
Step 1: Build the environment grid map, and set the starting point and target point of AUV.
Step 2: Use the improved a* algorithm for global path planning, generate collision free optimal path, and extract key nodes as global guidance information.
Step 3: Unknown static obstacles and unknown dynamic obstacles are introduced into the global map to simulate the complex dynamic environment.
Step 4: Use laser radar, current sensors, and other equipment to sense the surrounding environment in real time, update local environmental information (including dynamic obstacles and ocean current data), and judge whether there are unknown obstacles in the dynamic window.
Step 5: If no obstacle is detected, the AUV travels along the global optimal path; if an obstacle is detected, the collision prediction is made and the obstacle avoidance strategy is started.
Step 6: Use the dynamic window method with improved safety distance evaluation function to carry out local path planning, and return to the global path to continue moving after obstacle avoidance.
Step 7: Judge whether the AUV has reached the target point. If it has reached the target point, the algorithm ends. Otherwise, return to step 4 to continue execution.
The real-time environmental information sensed in step 4 (including dynamic obstacles and ocean current data) is immediately fed into the MPPO module. The MPPO updates the global reference path and adjusts the key nodes online. Key nodes are defined as the critical waypoints extracted by MPPO after multiphase optimization, which serve as local subtargets for DWA. These key nodes are updated dynamically according to real-time environmental changes to ensure that DWA always tracks feasible and safe local targets. The process of AUV path planning algorithm based on a*-mppo-dwa algorithm is shown in Figure 3.

AUV path planning algorithm based on A*-MPPO-DWA algorithm. AUV: autonomous underwater vehicle; DWA: Dynamic Window Approach; MPPO: multiphase path optimization.
The above fusion framework integrates the MPPO optimization and adaptive DWA modules, which fully reflects the overall innovation of the three-layer A*-MPPO-DWA structure proposed in this article.
Simulation experiment results
This article is dedicated to a comprehensive performance evaluation of the proposed A*-MPPO-DWA hybrid algorithm through a series of meticulously designed simulation experiments. Conducted in complex environments featuring both static and dynamic obstacles, the experiments provide a comparative analysis against several classical and state-of-the-art benchmarks, including Classic DWA, Dijkstra, and RRT variants. The evaluation rigorously assesses performance from two critical perspectives: global path planning quality and local motion control smoothness. The following sections present a detailed exposition of the experimental results, followed by an in-depth discussion that validates the efficacy and superiority of the proposed methodology.
The following is the path planned by each algorithm without current interference and dynamic obstacles (Figures 4–8).

The classic A* algorithm.

D* algorithm.

The fixed sampling RRT algorithm. RRT: Rapidly exploring Random Tree.

The optimized RRT algorithm. RRT: Rapidly exploring Random Tree.

The A*-MPPO-DWA algorithm. DWA: Dynamic Window Approach; MPPO: multiphase path optimization.
The efficacy of the global path planner is paramount for overall navigation performance. We quantitatively compared the A*-MPPO-DWA algorithm against benchmarks using key metrics: number of turning points, number of nonsmooth turning points, total path length, task completion success rate, and obstacle avoidance safety, characterized by the minimum distance to obstacles. The comparative results are systematically presented in Table 1.
The path planned by each algorithm without current interference and dynamic obstacles.

DWA: Dynamic Window Approach; MPPO: multiphase path optimization; RRT: Rapidly exploring Random Tree.
Simulation experiment conclusion:Path optimality and smoothness: The proposed A*-MPPO algorithm demonstrates a statistically significant superiority in path quality. It achieves the shortest path length (22.65 m), outperforming the next best, Dijkstra, by approximately 11.2%. More notably, A*-MPPO generates a path with only two turning points, both of which are smooth (zero nonsmooth points). This starkly contrasts with the jerky, piecewise-linear paths produced by geometric planners like Dijkstra (7 nonsmooth points) and the erratic, inefficient paths from sampling-based RRT variants. The generated path's inherent smoothness drastically reduces the kinematic constraints on the local tracker, facilitating stable and efficient motion execution.
Guaranteed safety and robustness: A critical differentiator is the adherence to a safe navigation distance. While algorithms like Dijkstra and Classic DWA find geometrically feasible paths, they violate the safety margin by maintaining a zero minimum distance from obstacles, rendering them impractical for real-world applications with perceptual uncertainties. The A*-MPPO algorithm not only complies with the safety threshold but maintains a substantial margin of 0.85 m, the highest among all evaluated algorithms. This is attributed to the integration of a safety-centric reward function within the MPPO framework. Furthermore, the failure of the Standalone DWA algorithm to reach the goal underscores the inherent myopia of reactive local planners in complex environments, a limitation effectively circumvented by our hierarchical approach.
The simulation experiment also compares the path with ocean current disturbance and dynamic obstacle disturbance planned by each algorithm in the dynamic environment. The following are the experimental results (Figures 9–13).

The classic A* algorithm.

D* algorithm.

The fixed sampling RRT algorithm. RRT: Rapidly exploring Random Tree.

The optimized RRT algorithm. RRT: Rapidly exploring Random Tree.

The A*-MPPO-DWA algorithm. DWA: Dynamic Window Approach; MPPO: multiphase path optimization.
Simulation experiment conclusion: the results confirm that the theoretical advantages of the A*-MPPO-DWA global path translate directly into superior practical performance. The algorithm's trajectory is characterized by the fewest number of waypoints (7), a direct consequence of its smooth global plan. This leads to the shortest executed path length (24.47 m) and, most importantly, the fastest travel time (175.34 s). The reduction in travel time is significant, approximately 2.6% faster than the optimized RRT and over 29% faster than the RRT with fixed sampling. This efficiency stems from the reduced need for the local planner to make frequent and drastic velocity corrections, allowing the AUVs to maintain a higher average speed. This conclusively demonstrates that the A*-MPPO-DWA framework enhances not just path quality but also overall task efficiency (Table 2).
The path planned by each algorithm with current interference and dynamic obstacles.

DWA: Dynamic Window Approach; MPPO: multiphase path optimization; RRT: Rapidly exploring Random Tree.
In addition, the smoothness of the velocity profile is a key indicator of motion stability, energy efficiency, and mechanical wear. We analyze the variance and standard deviation of control outputs (orientation, linear velocity, and angular velocity) to quantitatively compare the smoothness of different DWA-based local planners in both static and dynamic environments (Figure 14; Table 3).

Comparison of local obstacle avoidance parameters in static environments.
Comparison of local obstacle avoidance parameters in static environments.

DWA: Dynamic Window Approach; MPPO: multiphase path optimization.
In a static environmental, the proposed DWA-OCEAN exhibits a markedly superior smoothness profile. Its orientation variance is reduced by 13.8% compared to the Classic DWA, indicating more stable heading control and less oscillatory behavior. More substantial improvements are seen in velocity control: linear velocity variance is reduced by 12.4% and angular velocity variance is slashed by 37.9%.These reductions in variance and standard deviation are statistically significant (p < 0.05, nonparametric test) and confirm that the optimized objective function in DWA-OCEAN effectively suppresses high-frequency control oscillations (Figure 15; Table 4).

Comparison of local obstacle avoidance parameters in dynamic environments.
Comparison of local obstacle avoidance parameters in dynamic environments.

DWA: Dynamic Window Approach; MPPO: multiphase path optimization.
In a dynamic environment, the proposed DWA-OCEAN exhibits a markedly superior smoothness profile. Its orientation variance is reduced by 11.3% compared with the classic DWA, which means the heading control is more stable and the anti-interference ability is stronger under dynamic disturbances. The linear velocity variance is decreased by 27.1% and the angular velocity variance is reduced by 21.4%. These reductions in variance and standard deviation are statistically significant (p < 0.05, nonparametric test), which fully proves that the improved algorithm can still maintain stable motion state and effectively suppress speed jitter in complex dynamic environments with obstacles and ocean current disturbances.
Conclusion
This article proposes a new AUV path planning method through the improvement and integration of the A* and DWA algorithms, providing an effective solution to the autonomous navigation problem in dynamic environments. This method not only optimizes the application of traditional path planning algorithms in dynamic environments, but also improves the real-time performance and adaptability of path planning. In terms of global path planning, by introducing the dynamic cost function adjustment mechanism and the MPPO module with innovative three-stage progressive optimization, which is different from existing path smoothing and multistage optimization algorithms, the improved A algorithm can better adapt to environmental changes and enhance the efficiency and accuracy of path updates. Meanwhile, the DWA algorithm enhances the effect of local obstacle avoidance by integrating adaptive speed control with environmental information, avoiding situations where the path is not smooth or is locally optimal. In addition, the MPPO module acts as a theoretical bridge that converts the global optimal path into actionable local guidance for DWA, including subtargets, heading references, and safety constraints, which ensures the stability and robustness of the entire framework.
Especially when facing dynamic obstacles and ocean current disturbances, the fusion algorithm can adjust the path in real time, ensuring that the AUV can navigate safely and stably in complex environments, and the response speed and adaptability of path planning have been effectively improved. The experimental results also show that the fusion algorithm can significantly reduce the path calculation time, with both adaptability and efficiency reaching a relatively high level, providing a reliable solution for AUV path planning in practical applications. In the future, by integrating more complex environmental models and AUVs collaborative tasks, the method proposed in this article is expected to provide more efficient path planning technical support for fields such as underwater detection, marine engineering, and emergency search and rescue.
Footnotes
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This project is supported by the National Natural Science Foundation of China (52431012) and the Creative Activity Plan for Science and Technology Commission of Shanghai (23550730300).
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data availability statement
Data sharing not applicable to this article as no datasets were generated or analyzed during the current study