
Abstract
Francis (2012a, 2012b, 2012c, 2012d, 2012e, in press) attacks individual papers through critiques that apply faulty logic to analyses ironically biased by cherry picking. However well intentioned, the critiques are probably counterproductive to their stipulated goal and certainly unfair to the targeted authors.
Keywords
In a growing number of critiques, Francis (2012a, 2012b, 2012c, 2012d, 2012e, in press) reports statistically significant evidence of publication bias tests in individual psychology papers and invites readers to completely ignore the results from those papers. These analyses are ironically biased because of cherry picking. The published critiques are but a small subset of those attempted: the subset with p < .1. More important, even if the analyses were correct, the conclusion to ignore evidence simply does not follow from the presence of publication bias; this fallacious inference confuses practical with statistical significance.
Cherry Picking
Replicate or show your drawer
Publication bias, the tendency to publish only statistically significant evidence, reduces the validity of reported p values. In the extreme, journals could be filled with the 5% of studies that are false positive, and authors’ file drawers could hold the remaining 95% (Rosenthal, 1979).
We can think of publication bias as a multiple comparisons problem. Suppose we run two studies but only one worked. The p value we ought to compute and report is the probability of one of the two studies working—not the default p value, which is the likelihood that one study works if only one study is run.
When studies are statistically independent (e.g., based on different sets of subjects), the likelihood that at least one of two works, under the null, is 1−.952 or 9.75%. For one of three it is 1−.953 or 14.3%. If we try enough studies we are all but guaranteed to get at least one to work. For example, with 44 attempts, 90% of the time (1−.9544 ) we will get at least one to work.
Although we should, we never do disclose—let alone correct for—the size of our file drawers. Instead, we address this problem with replications. Even if we got a study to work only after 44 attempts, there is still just a 5% chance of it working again under the null: replication p values are kosher. 1 When cherry picking, then, we should replicate or show our drawer.
Francis cherry picks but neither replicates nor shows his drawer
The question being asked in the critiques is “does Paper X suffer from publication bias?” Such a question does not lend itself to a replication because there is only one Paper X. We must, then, look into the file drawer and take into account how many papers other than X were tested.
This number, Francis acknowledges, is considerably greater than 0. Figure 1 plots the impact on false-positive rates as we increase the number of total attempts when, as is the case in the critiques, p < .1 is considered significant. While contemplating Figure 1, imagine how easy it is to arrive at false-positive evidence of publication bias when one is unconstrained by number of attempts (imagination aid: most journals have more than 10 papers per issue). 2
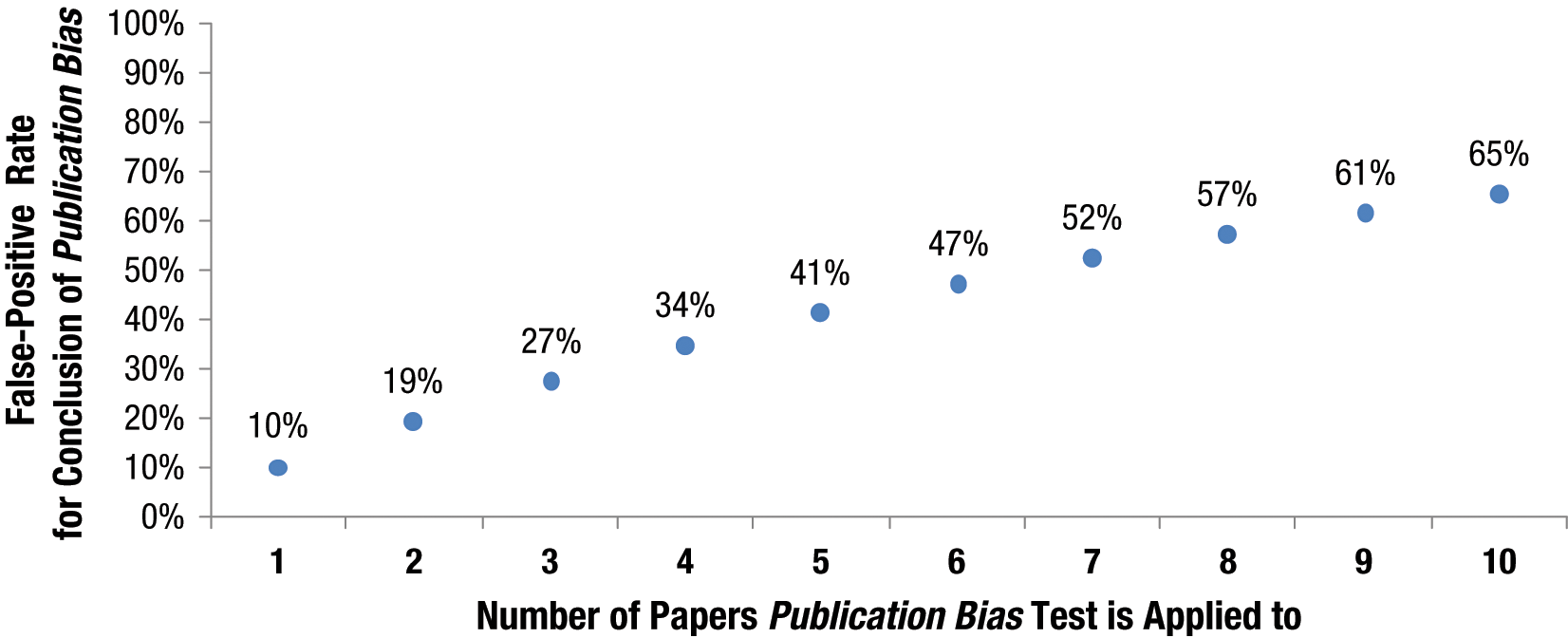
Likelihood of at least one analysis of publication bias obtaining p < .1 as more and more papers without publication bias are examined.
Note that it is irrelevant whether we think of the study that worked as conceptually related to the failures before it or not. The math involved in compounding p values is the same when studies are about the same topic, and when they are not, and when the studies involve experiments or publication-bias tests. There is no way around it. Because the critiques were cherry picked without conducting replications, their p values are larger than reported.
The “my analyses are not supposed to generalize” defense
In personal communications, and in responses to authors whose work he has critiqued, Francis argues that it is fine for him to cherry pick. For example:
[critiqued authors] suggested that my investigations of publication bias engage in the very practice that I criticize. I would be susceptible to this criticism if I were making inferences about publication bias for the field in general.
3
We are concerned with a herring of a different color. We worry not whether the conclusion about Paper X applies also to Papers Y and Z. We worry that cherry picking increases the false-positive rate for Paper X (because it does).
Ignore the Advice to Ignore the Data
Let’s now consider the conclusion that if a paper has statistically significant evidence of publication bias its findings should be ignored.
Whatever its source, the presence of a publication bias means that the findings […] do not provide useful information about the claimed effect. (Francis, 2012a) Now that the data are known to be contaminated with publication bias, […]. Researchers […] are advised to ignore the findings […] and run new experiments. (Francis, 2012d, p. 177)
The conclusions are at odds with meta-analyses textbooks that propose correcting for publication bias, or assessing its potential impact, rather than eliminating data (see, e.g., Cooper, Hedges, & Valentine, 2009; Pigott, 2012; Rothstein, Sutton, & Borenstein, 2005). Francis has argued that because corrections are imperfect, we should not attempt them. The alternative of dropping all data, however, is merely another (even more imperfect) correction. Furthermore, because all journals exhibit some degree of publication bias, the logic behind this correction leads to the absurd conclusion that all published scientific knowledge should be ignored.
At its core, the “delete-all” correction confuses statistical with practical significance. Consider a literature with 100 studies, all with p < .05, but where the implied statistical power is “just” 97%. Three expected failed studies are missing. The test from the critiques would conclude there is statistically significant publication bias; its magnitude, however, is trivial. Ignoring the 100 studies is unwarranted by evidence and more generally counterproductive for the advancement of knowledge.
The test used by Francis merely examines if publication bias is present, not how consequential it is. We should hence draw conclusions only as to whether publication bias is present, not how consequential it is.
No Contradiction
Responding to an early draft of this article, Francis noted an apparent contradiction: I would appear to argue that publication bias invalidates his critiques but not the criticized papers. 4 Let’s decompose the critiques into a premise (critiqued Paper X suffers from publication bias) and a conclusion (Paper X contains no valid data). I have argued that the evidence for the premise is tainted by cherry picking and that the conclusion does not logically follow from the premise. Because only the critiques, not the criticized papers, suffer from such faulty logic, only the critiques, not the criticized papers, ought to be ignored. There is no contradiction.
By the Way, of Course There is Publication Bias
Virtually all published studies are significant (see, e.g., Fanelli, 2012; Sterling, 1959; Sterling, Rosenbaum, & Weinkam, 1995), and most studies are underpowered (see, e.g., Cohen, 1962). It follows that a considerable number of unpublished failed studies must exist. With this knowledge already in hand, testing for publication bias on paper after paper makes little sense: One is guaranteed to eventually reject a null we already know is false, but whose rejection tells us nothing about what we ultimately need to know—whether that specific finding is likely to be.
Jacob Cohen (1994) titled an article discussing shortcomings in our understanding of hypothesis testing “The Earth is Round (p < .05).” A similarly obvious statement followed by an italicized p is: “Some Failed Studies Are not Published (p < .1)”.
Footnotes
Declaration of Conflicting Interests
The author declared no conflicts of interest with respect to the authorship or the publication of this article.