
Abstract
Face recognition is a remarkable human ability, which underlies a great deal of people’s social behavior. Individuals can recognize family members, friends, and acquaintances over a very large range of conditions, and yet the processes by which they do this remain poorly understood, despite decades of research. Although a detailed understanding remains elusive, face recognition is widely thought to rely on configural processing, specifically an analysis of spatial relations between facial features (so-called second-order configurations). In this article, we challenge this traditional view, raising four problems: (1) configural theories are underspecified; (2) large configural changes leave recognition unharmed; (3) recognition is harmed by nonconfigural changes; and (4) in separate analyses of face shape and face texture, identification tends to be dominated by texture. We review evidence from a variety of sources and suggest that failure to acknowledge the impact of familiarity on facial representations may have led to an overgeneralization of the configural account. We argue instead that second-order configural information is remarkably unimportant for familiar face recognition.
Face recognition is a fundamental human ability, which lies at the heart of our social world. We can recognize the people we know, family, friends, and colleagues, apparently without effort and across a huge range of conditions. This ability underlies our everyday interactions, and allows us to tailor our behavior continually. However, the ease with which we can recognize each other hides the difficulty of the task: How can we recognize a family member over changes in age, emotion, and view? How can we recognize the person in a photograph, in a home movie, or in the flesh? How can we recognize the person in poor lighting or an unexpected place? Although face recognition is not perfect over all these circumstances, it is nevertheless remarkably good, and errors are rare by comparison to successes.
Face perception has become a major focus for psychological research, and the topic attracts interest from a wide range of scientists: social, developmental, cognitive, and perceptual psychologists as well as neuropsychologists and neuroscientists. It is therefore perhaps surprising that we still know so little about the central question: How do we recognize the people we know? In this article, we suggest that one reason for slow progress in this field lies in the willingness to recruit a misleading idea. Configural processing is a key concept in face research. The central idea is that faces differ both in their constituent features (my mouth is different from your mouth) and also in their spatial layout (the distance between my mouth and nose is different from yours). Perception of the spatial layout underlies configural processing and is held to be critical for recognizing familiar faces. We argue below that the concept is problematic. After more than 30 years of use, it remains poorly specified, and vague definitions have perhaps contributed to its general appeal, rendering it hard to challenge. However, despite being difficult to pin down, we argue that there is now enough evidence to make the case that facial configurations are surprisingly unimportant in recognizing the faces of those people we know.
Before we begin our critique of configural processing, it is important to point out that the study of face perception is much broader than the problem of familiar face recognition. As well as signaling identity, faces provide the viewer with information about expressions, facial speech, gender, and focus of attention (via eye gaze). Faces can be judged as more or less attractive and as displaying particular personality traits. There has been considerable progress in understanding the perception of these signals. For example, the Oxford Handbook of Face Perception (Calder, Rhodes, Johnson, & Haxby, 2011) provides a comprehensive survey of the advances in a great many subfields of face perception. Following an influential early analysis of face perception by Bruce and Young (1986), many researchers are clear that different facial judgments can be based on different sources of information; for example, there is no logical reason why the information used to decide that a face is smiling is the same as the information used to decide that it is Bill Clinton. In fact, there are good reasons to propose that these sources of information are to some extent different: We can judge a smile in both familiar and unfamiliar faces, just as we can judge gaze direction and facial speech.
Because there are very many judgments that can be made on all faces, it is important to be clear that we are concerned here only with the recognition of familiar faces (i.e., how can I recognize a picture of Bill Clinton?). Because we plan to be critical of configural processing, it is important to spell out that we are critical of it only in this particular context. The concept has been recruited to explain a very wide range of phenomena, including all the various judgments listed above. In this article, we concentrate on the specific claim, commonly made in the literature, that familiar faces are recognized by using the spatial layout of their features. By “recognition” we mean the process of assigning an identity to any image of a known person, for example, “that’s Bill Clinton,” “that’s my wife,” or “that’s the person who works in the coffee bar.” This process is sometimes called “identification” and sometimes “individuation,” but for our purposes, all these terms are equivalent, and we will use “recognition” throughout.
Configural Processing: History and Definition
We do not provide a thorough review of the literature on configural processing here. There are already many good overviews (e.g., McKone & Yovel, 2009; Piepers & Robbins, 2012; Tanaka & Gordon, 2011). However, it will be helpful to recap the origins of configural processing and how the concept gained such wide currency. Early work on face processing tended to emphasize a distinction between featural and configural aspects of faces. Although neither of these terms was well defined, appeal was made to the everyday understanding of features (eyes, noses, mouths) and an intuitive notion of their configuration—that is, their spatial layout. Early observations ruled out the possibility that face recognition relies entirely on individual facial features. For example, familiar faces can be recognized from severely blurred images, in which it is difficult to see features clearly (Harmon, 1973). Even when viewers can see facial features clearly, early studies showed considerable sensitivity to subtle changes in their arrangement (Haig, 1984).
It is well established that faces are hard to recognize when presented upside down, a phenomenon known as the inversion effect (Yin, 1969). Attempts to understand this effect have been closely linked to configural processing. In addition to harming recognition, it turns out that inverting a face reduces viewers’ sensitivity to the spatial layout of features (Sergent, 1984). This finding led Diamond and Carey (1986) explicitly to hypothesize that “the large effect of inversion on face recognition results from the fact that faces are individuated in terms of relational distinguishing features” (p. 108).
To examine configural processing accounts of face recognition, we recruit the careful definitional distinctions made by Maurer, Le Grand, and Mondloch (2002) and adopted widely. These authors distinguish three types of configural processing: (a) detection of “first-order” relations, which define the basic arrangement of a face, that is, the fact that face detection relies on a layout of features such that two eyes appear above a nose, which lies above a mouth; (b) holistic processing, which coheres the features into a perceptual gestalt; and (c) sensitivity to second-order relations, that is, the specific spatial arrangement within the face or perceiving the distances between features. These three types of processing are tapped by different perceptual tasks, and Maurer et al. demonstrated that these processing types are behaviorally dissociable (though all are held to be affected by inversion).
Although Maurer et al.’s (2002) analysis has been influential, there is still some lack of clarity in the literature about what precisely is meant by configural processing. Some authors use the terms “holistic” and “configural” interchangeably, and some are unclear about what form of configural processing is being recruited in an explanation for a particular effect. Because we are, in this article, concerned only with a configural account of familiar face recognition, we will adopt Maurer’s terminology and make it clear that we are addressing only second-order configural processing here. This is an important specification as, fortunately, some authors have been clear in framing the hypothesis linking second-order configural processing to recognition. For example, Richler, Mack, Gauthier, and Palmeri (2009) wrote: “Because faces are made from common features (eyes, nose, mouth, etc.) arranged in the same general configuration, subtle differences in spatial relations between face features being encoded [are] particularly useful for successful recognition of a given face” (p. 2856). These “subtle differences in spatial relations between face features” are precisely those identified by Maurer et al. (2002) as second-order configural properties. Tanaka and Gordon (2011) were likewise clear in their definition: “We use the term ‘configural processing’ . . . to refer to encoding of metric distances between features (i.e. second-order relational properties)” (p. 178).
Popularity of Configural Processing Explanations
Why is face recognition so often explained in terms of configural processing? One contributing factor is that there is rather good evidence for the involvement of holistic processes—the precedence of the whole face over its parts. For example, individual features are best remembered when they are embedded in a complete face, rather than in isolation (Tanaka & Farah, 1993). Furthermore, when the top and bottom halves of two different faces are aligned, these tend to fuse perceptually into a novel identity (Young, Hellawell, & Hay, 1987), which in turn hampers the separate processing of individual halves relative to a nonaligned arrangement. This is known as the composite effect and strongly suggests that face recognition recruits the entire percept, rather than extracting local features independent of one another. The fact that viewers tend to see composite faces as a single person implies a role for one type of configural processing (holistic), but it does not necessarily imply a role for the involvement of second-order processing.
Another contributory factor may be that evidence is sometimes recruited from face perception tasks other than recognition. For example, there are very many studies examining the effects of configural changes on unfamiliar face image matching (i.e., judging whether two images are identical), and these normally demonstrate reduced sensitivity following inversion (e.g., Freire, Lee, & Symons, 2000; Le Grand, Mondloch, Maurer, & Brent, 2001; Rossion, 2008). Furthermore, there is debate about the exact nature of inversion effects, particularly as they affect configural processing (e.g., Goffaux & Dakin, 2010; Sekunova & Barton, 2008). However, all these studies examine a rather constrained task: Viewers are asked to report whether two images of unfamiliar faces are identical or not when they are upright or inverted. There seems to be no very compelling reason to assume that the processes involved in that task capture the processes involved in recognizing a friend in the street. Indeed, much evidence attests to dissociations between image recognition and face recognition and between familiar and unfamiliar face processing. We return to these distinctions below. Whether or not strict processing dissociations exist, familiar face recognition is undeniably a key part of our everyday perceptual experience. One of our central hypotheses is that explanations for different tasks (e.g., identical image matching or remembering unfamiliar face pictures) may have been overgeneralized to account for the phenomenon of everyday recognition, which is both more commonplace and more difficult to understand.
In addition to its intuitive appeal, a final reason for the popularity of configural accounts is probably the lack of a plausible alternative. If we consider a face to comprise its features (e.g., a particular nose and a particular pair of eyes) and their spatial layout (e.g., the distances between these features), then we might ask how each of these sources of information contribute to the recognition of that face. Experimentally, one can selectively alter features (e.g., by inserting a new nose) or change their layout (by graphically altering the feature location), and both of these are clearly very important for the percept (see research on constructing a forensic likeness, for example, Frowd et al., 2014). Very early studies taking this approach established that recognition cannot be carried by features alone (Bradshaw & Wallace, 1971; Matthews, 1978; Sergent, 1984). These studies showed that the time required for a viewer to judge two faces to be different is not predictable from a simple addition of the component differences. Thus, even in the 1970s and 1980s, there was little enthusiasm for approaches to face recognition that relied primarily on features. More recently, there have been some suggestions that one should consider the role of individual features more carefully (e.g., Cabeza & Kato, 2000; Rakover, 2002). However, even these modern reevaluations rely on an integration of featural and configural processing and present little challenge to the view that configural processes are key to understanding face recognition.
Given the history of face recognition research, one reason to retain a configuration-based hypothesis is the lack of any other useful theory. To avoid any narrative tension, we should point out that we are not going to propose a specific alternative here. Throughout this article, we will briefly mention some alternative approaches that warrant further exploration. However, the validity of our critique of the configural approach to recognition does not rely on the reader accepting any particular alternative.
Four Problems With the Configural Processing Approach
In what follows, we will consider four key problems with configural processing as a mechanism for familiar face recognition: (1) configural theories are underspecified; (2) large configural changes leave recognition unharmed; (3) recognition is harmed by nonconfigural changes; and (4) in separate analyses of face shape and face texture, identification tends to be dominated by texture. The second and third problems are two sides of the same issue, and each of the final three problems arise from well-established empirical evidence. However, we start with a more general problem, underspecificity, which has persisted over many years. In the final section of the article, we attempt to resolve these problems by suggesting fruitful approaches to future work.
Problem 1: Configural theories are underspecified
If faces are recognized by their metric distances between features, then one might expect researchers to operationalize this notion. Exactly which distances are important? In fact, this is never specified. Authors sometimes provide an example, without any commitment to the specific distances used; for example, “nose-to-mouth distance” and “interocular distance” have been suggested as candidates for key spatial relations (Leder & Bruce, 2000). However, these suggestions are intended only to make a general appeal to an intuitive notion of spatial layout. McKone and Yovel (2009) provided more detailed examples by suggesting landmark points within the face; however, these authors were concerned with explaining inversion rather than identification, and even these points are specifically flagged as being “theoretical ideas” rather than the actual distances that might be used in face perception.
To illustrate the problem, Figure 1 shows an attempt to characterize three well-known faces in terms of distance metrics drawn from the literature. The figure shows very clearly that these distances simply do not discriminate between three very different faces. The problem is that distances between features show as much within-person variability (differences between different photos of the same person) as between-person variability (differences between photos of different people)—meaning that these distances are not useful for discriminating between the individuals. Some of the within-person variability in Figure 1 is due to changes in facial expression, which affect the location of reference points (e.g., corners of the mouth). Figure 2 shows a complementary analysis based on standardized interocular distance, a measure that is invariant across expression. Once again, within-person variability is as large as between-person variability, presumably because of differences in viewing distance and properties of the camera lens (e.g., Harper & Latto, 2001). Of course, we understand that no proponent of configural processing would claim that these particular distances are necessary or sufficient for discriminating between people. But without some commitment to a measurement that could be used in this way, it is impossible to evaluate the claim that metric distances are important in face recognition. In fact, after so many years of use without specification, one wonders whether the concept could ever be operationalized.
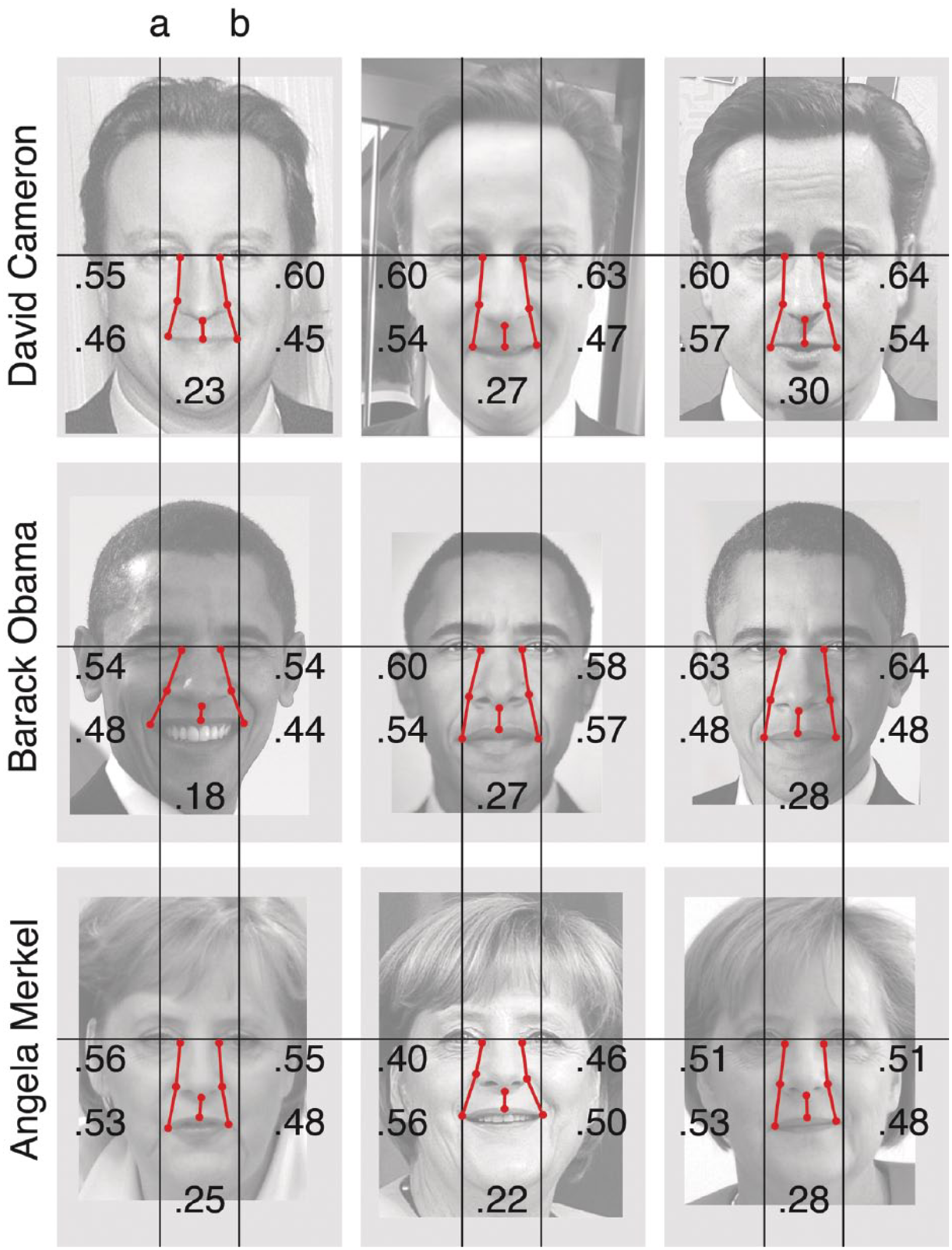
Metric distances between features for three well-known faces in three different photos each. Red lines show distance between the corner of the eye and the edge of the nose (left and right; Leder & Carbon, 2006), distance between the corner of the nose and the corner of the mouth (left and right; Leder & Bruce, 2000), and distance between the nose and the mouth (Leder & Carbon, 2006). Facial landmarks are not normally well defined, leaving ambiguity in their placement. Here we define the corner of the eye as the center of the canthus, the corner of the nose as the lateral extent of the nasal flange, and the corner of the mouth as the lateral extent of the vermillion zone. Nose-to-mouth distance is defined as the vertical length of the philtrum from the procheilon to the nasal septum. Photo size is standardized so that interocular distance (the distance between the center of the left pupil and the center of the right pupil, Point a to Point b) is the same for all images. Metric distances between features are expressed as proportions of standardized interocular distance. For all five measures, within-person ranges are large and overlapping, despite constrained pose. Thus, none of the metrics is individuating, even for these very dissimilar faces. All images used under Creative Commons or Open Government License. Attributions (top row left to right, middle row left to right, bottom row left to right): Ignis Fatuus [Public Domain]; Steve Bowbrick [CC-BY-2.0]; Byzantine_K [CC-BY-2.0]; United States Senate [Public Domain]; Martin Schoeller [CC-BY-2.0]; Pete Souza, The Obama-Biden Transition Project [CC-BY-3.0]; Marcello Casal Jr./ABr [CC-BY-3.0 Brazil]; UKOM (Nebojša Tejić/STA) [CC-BY-3.0 Unported]; Armin Linnartz [CC-BY-3.0 Germany].
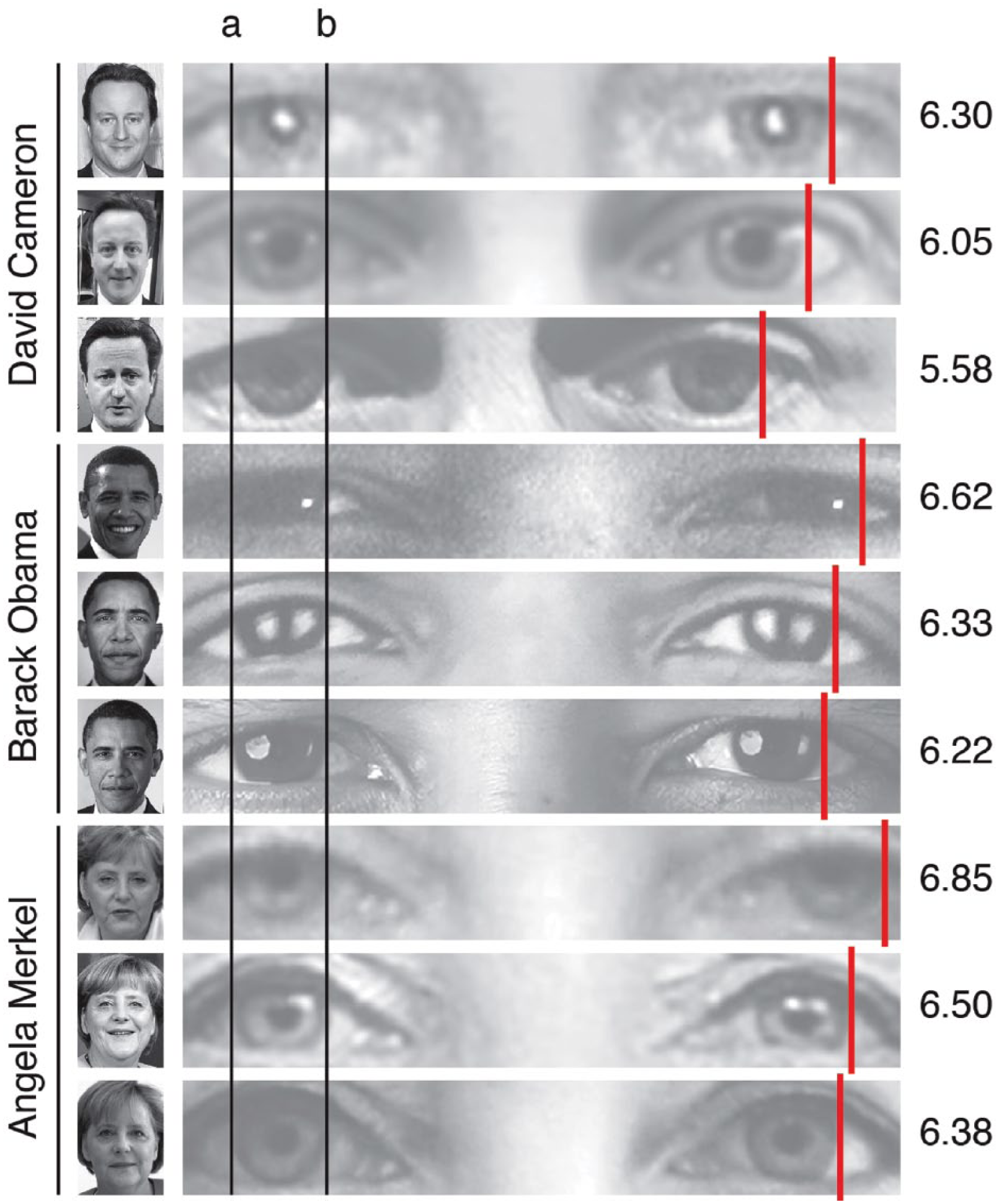
Metric distances between the eyes for three well-known faces in three different photos each. Photo size is standardized so that iris diameter (Point a to Point b) is the same for all images. Distance between the lateral edge of the left iris (a) and the lateral edge of the right iris (red line) is expressed as a multiple of standardized iris diameter. Within-person ranges for this metric are large and overlapping, so that the metric is not individuating. Attributions as per Figure 1.
In the early days of automatic face recognition research, approaches based on the metric distances between features were tried many times (Kanade, 1973; Kelly, 1970). However, these consistently failed to produce workable solutions. No group has ever found a set of facial measures that uniquely identify one person, being similar across instances of that person and different from everyone else. Modern-day automatic systems rely much more heavily on reflectance-based information (see Zhao, Chellappa, Phillips, & Rosenfeld, 2003), and we return to this approach below. Similarly, an approach to recognition based on measurements between features (anthropometry) has been shown to be unworkable in forensic identification (Kleinberg, Vanezis, & Burton, 2007). Neither of those fields (computing or forensics) has any commitment to particular theories of human face perception. They have moved away from metric distances between features for the entirely practical reason that it does not work. It is, of course, possible that new research will be published one day that specifies a set of measurements that are stable enough to be useful in uniquely identifying someone. However, progress to date has not been promising, and many researchers in face recognition apparently ignore this fact, recruiting configural processing as a theoretical tool without any operationalization to use and no attempt to develop one.
Problem 2: Large configural changes leave recognition unharmed
If recognition relies on “subtle differences in spatial relations between face features” (Richler et al., 2009, p. 2856), then it follows that disrupting these spatial relations should harm recognition. However, this is not borne out by the evidence. Instead, recognition of familiar faces appears to be remarkably robust under a range of deformations.
One of the most powerful demonstrations shows that stretching images in the x- or y-axis direction (so they are too wide or too tall) has no effect on recognition whatever. Participants show no reduction in speed or accuracy to make a familiarity judgment when the image is stretched up to twice its normal vertical height (Hole, George, Eaves, & Rasek, 2002). This finding is truly remarkable. Such a transformation deforms almost all metric distances between features. All angles, ratios of distances, and measures (except those in one dimension) are entirely lost. A stretch of up to twice the normal height of an image introduces changes to all metric distance between features that must far exceed the differences in these measures between people.
It could be argued that a simple linear stretch is not really so profound a distortion of a facial image. Some nonlinear deformations do make face recognition harder (e.g., shearing, in which a rectangular photo is slanted to the left or right; Hole et al., 2002). Perhaps the visual system is able to undo the effects of linear stretch before the face recognition system is recruited. However, this is a circular argument. One does not know, when looking at an image, what its true aspect ratio should be. In order to rescale a photo of Elvis correctly, one would need first to recognize it as Elvis—and to recruit his characteristic metric distances in order to discount the transformation in these distances. So the robustness of recognition across even this rather simple transformation is a considerable challenge to configural accounts of recognition. This robustness can be found in more fundamental measures of recognition. An early event-related potential (ERP) component sensitive to the repetition of individual familiar faces, the N250r, was found to be equivalent whether a target face was preceded by a veridical or a stretched prime face (Bindemann, Burton, Leuthold, & Schweinberger, 2008). Somehow, the neural processes involved in priming a representation of a familiar face are able to discount this severe alteration to the spatial layout of features.
In fact, face recognition is well established to be robust over much more complex transformations than linear stretch. Figure 3 (after Harper & Latto, 2001) shows the effect of simply changing the distance from the camera to the subject. Such a change in perspective is typically not even noticed by a familiar viewer but is apparent only when one sees multiple photos of the same person together. However, it is clear that the spatial layout between features is changed in rather complex, nonlinear ways. Once again, the size of these transformations produces changes that presumably exceed the differences between people—a severe problem for a configural account of recognition.
Top row: Images of the same person taken at difference distances (from approximately 0.5 m to 3 m). From Burton (2013). Bottom row: middle and right-most images from the top row overlain to standardize right eye and nose between images, respectively. Poor registration shows the extent of the differences between these images, even in apparently stable measures. For example, simply altering the viewing distance leads to large changes in the distances between the eyes, between nose and mouth, and all measures depicted in Figure 1.
In some recent work, Sandford and Burton (2014) tested a very simple hypothesis derived from a configural processing account of recognition. Images of faces were shown to viewers in the wrong aspect ratio (either “too wide” or “too tall”). These appeared in a computer window, and the participant’s task was simply to resize them, using a mouse to drag the corner of the window “until they look right.” From a configural theory of recognition, the authors hypothesized that this task would be much easier for familiar than for unfamiliar faces. If people really differentiate those they know by the “subtle differences in spatial relations between face features” (Richler et al., 2009, p. 2856), then one should be able to adjust these images more accurately for a known face than for an unfamiliar one, whose spatial arrangement is unknown. In fact, across a series of experiments, the authors found no evidence for this prediction. In general, viewers were very poor at the task and were satisfied with resizing the images rather inaccurately. In some experiments, participants made greater errors for familiar than unfamiliar faces, while in others there was no difference. Furthermore, the task was shown to be sensitive to familiarity in other stimuli: When viewers were asked to resize company trademarks, they were able to do this more accurately for familiar than unfamiliar items. Thus, far from relying on accurate, detailed knowledge of the metric distances between features, viewers accept as veridical a very large range in these distances. In summary, it seems that viewers are very tolerant of distortions to familiar faces; different types of change, some of them rather large, seem not to harm recognition at all.
Problem 3: Recognition is harmed by nonconfigural changes
In contrast to the results discussed in the previous section, there are a number of situations in which recognition is severely impaired by changes that leave facial configuration unaltered. We consider the effects of photographic negation, line drawings, and the odd effects of caricature.
It has been known for many years that it is very hard to recognize a face in photographic negative (Galper, 1970). However, if faces are recognized through the metric distances between their features, it is not easy to explain why this should be so. Exactly the same information is present in photographic positives and negatives, and viewers have no difficulty pointing out the eyes, noses, and mouths. Negation does reduce viewers’ ability to distinguish between two face images with different spatial distances between features, that is, second-order configural properties (Kemp, McManus, & Pigott, 1990). However, it is not clear why this should be. Furthermore, the effect is additive to an effect of inversion, suggesting the two effects have different loci (Kemp et al., 1990). Altogether, it is hard to see why a system that can extract differences within a plane would be challenged by a transformation that leaves these distances unchanged. In fact, later explanations of the photographic negation effect dispense with configural accounts altogether (Bruce & Langton, 1994; Johnston, Hill, & Carman, 1992; Kemp, Pike, White, & Musselman, 1996). Instead, these accounts place the weight of the effect in the perception of pigmentation and shape, based on the perceptual assumption that light shining from above illuminates surfaces in predictable ways. These explanations fit with an account of recognition that is not tied closely to configuration but rather relies on what we will call “texture” in the following section.
A second transform of interest is the effect of presenting faces as line drawings. For example, drawings traced from facial photographs are recognized rather poorly (Davies, Ellis, & Shepherd, 1978; Rhodes, Brennan, & Carey, 1987). In itself, this is a rather interesting problem: Line drawings preserve spatial layout, so perhaps a configural account of recognition should predict good recognition. In fact, simple introduction of “mass,” that is, black shading introduced by luminance-thresholding an image, significantly improves performance (Bruce, Hanna, Dench, Healey, & Burton, 1992). This thresholding provides no additional information about the spatial layout of features, suggesting that the marked improvement in recognition is being driven by nonconfigural processing. The boost to performance seems likely to be based on information about the surface reflectance of the face, rendered at its simplest in this manipulation.
Finally, we consider the effect of spatial caricature—in which the location of points within a face are exaggerated with respect to a prototype, usually the average of many faces. The caricature technique produces images in which the distinctive aspects of a face are enhanced, that is, distinctive feature shapes and distinctive distances between these features are made even more distinctive. Under some circumstances, caricatures of known people are better recognized than the originals (for an overview, see Rhodes, 1996). This effect is sometimes taken as evidence for configural processing—though at first sight, it is hard to imagine how this could work. The caricature transformation, by its nature, affects some parts of the face more than others, introducing a very complex transformation; for example, if someone has a large nose but an average mouth, then the caricature changes the nose considerably but leaves the mouth unaltered. Such alterations would seem to change the metric distance between features quiet considerably and in rather complex fashion. For the effect to be consistent with configural processing, it would seem that one would need to define configuration in much more complex ways than metric distances between the features.
In fact, it is interesting to note that spatial caricaturing appears to work best when the image is degraded in some way. The technique was originally developed for line drawings (Brennan, 1985), and research has shown that caricatured drawings of familiar faces were recognized faster than drawings that preserved the original spatial layout of features (Rhodes et al., 1987). At that time, photorealistic caricaturing was not available, but the interpretation of poorer recognition performance found for caricatured line drawings (when compared with veridical photographs) may exemplify the strong focus on spatial information for face recognition by researchers at that time: “these results may simply mean that photographs contain so much more spatial information than hand-drawn caricatures that they are more recognizable despite being less distinctive” (Rhodes et al., 1987, p. 475; emphasis added). In fact, a similar recognition speed advantage for spatial caricatures over undistorted images turned out to be hard to replicate in the case of photorealistic images that contain texture information, unless one makes the recognition task particularly difficult (Benson & Perrett, 1991; Calder, Young, Benson, & Perrett, 1996; Kaufmann & Schweinberger, 2008; Rhodes, Byatt, Tremewan, & Kennedy, 1997). Overall, then, evidence from caricaturing provides little support for a strong role of spatial information in the recognition of (undegraded) images of faces.
Problem 4: In separate analyses of face shape and face texture, identification tends to be dominated by texture
In the introduction, we noted that computational approaches to face recognition typically do not attempt to solve the problem by analyzing the spatial relations between features. In fact, many computational approaches separate face “shape” and “texture,” and a variety of methods have been used to achieve this (Beymer, 1995; Burton, Miller, Bruce, Hancock, & Henderson, 2001; Vetter & Troje, 1995). Figure 4 shows one way in which this operation can be performed. In this example, shape is defined as a set of anatomical points in an image, and these are marked up (usually by hand) for all images in the set. A common shape is then defined: often the average shape of all set members. Using standard face morphing techniques, each face is then deformed to the same common shape. (Technically, this is achieved by warping the color or gray levels contained in each triangle of the source image, so that it fits the shape of the corresponding triangle of the target shape. For details, see Beale & Keil, 1995.) The resulting images are often called “shape-free” faces, because their shape is common—that is, one cannot use simple shape to discriminate between the faces in Figure 4b. This procedure allows separate analysis of shapes (grid points prior to morphing) and “shape-free faces,” in which shape and feature placement align for all faces in the analysis. The information remaining in these “shape-free” images is difficult to name, because it includes texture, color, reflectance, and information based on the capture device. We use the term “texture” here as a shorthand for all these, while acknowledging that other authors use different terms.

a: Decomposition of a face image into shape and texture components. From Burton, Jenkins, Hancock, & White (2005). b: Two further celebrities whose shape has been morphed to the same common shape template (from Burton et al., 2005). Images depict Susan Sarandon and Sylvester Stallone.
Separation of face shape and texture is usually performed as a computational convenience, because it allows faces to be normalized prior to some statistical treatment, such as principal components analysis (Burton, Wilson, Cowan, & Bruce, 1999; Calder, Burton, Miller, Young, & Akamatsu, 2001). However, a few computational studies have explicitly compared the diagnostic information carried in the shape and texture components separately, and in these cases information in the texture components has been found to dominate recognition of identity (Calder et al., 2001; Hancock, Burton, & Bruce, 1996; Taschereau-Dumouchel et al., 2010).
There are also some studies in which the separate contributions of shape and texture have been tested in the recognition of familiar people, many of these exploiting standard ERP effects in face perception. Results suggest that shape is important in learning a face but, once learned, plays rather little role in recognition. For example, spatial caricaturing (with texture unchanged) has a clear ERP effect for unfamiliar faces (more negative occipitotemporal P200 and N250 responses) but no effect on familiar faces (Kaufmann & Schweinberger, 2008). Recognition performance has also been shown to be better for naturally distinctive faces than for spatially caricatured faces (Schulz, Kaufmann, Walther, & Schweinberger, 2012), suggesting that nonspatial distinctive information (i.e., texture) plays a significant role in recognition. In line with this idea, Itz, Schweinberger, Schulz, and Kaufmann (2014) directly contrasted the effects of spatial caricaturing with texture caricaturing (i.e., exaggerating luminance and coloration, while leaving shape unchanged). Faces were learned in one of three versions (veridical, spatially caricatured, or texture caricatured) and later recognized among analogous versions of nonlearned unfamiliar faces. Recognition performance for learned faces was best for the texture-caricatured version (when compared with both the spatially caricatured and veridical versions).
The experiments considered so far in this section look at separation of “shape” and “texture” (or “reflectance”) in photographic stimuli. But 2-D photographs are generated from the projection of 3-D objects, and some researchers have examined the information carried in the 3-D shape itself (i.e., the pure spatial layout) without any surface texture. For example, graphically rendered 3-D busts of familiar people are rather poorly recognized by viewers and much less well recognized than photos of faces taken in corresponding poses (Bruce et al., 1991). More sophisticated technology allows simultaneous capture of 3-D shape and surface reflectance, and it is possible to view each independently (O’Toole, 2011; O’Toole, Price, Vetter, Bartlett, & Blanz, 1999). Figure 5 shows independent representations of these two face components (Hill, Bruce, & Akamatsu, 1995). Research with these types of images consistently shows that texture components dominate recognition of identity. For example, in Figure 5, the shape of a particular person is rendered highly accurately, whereas the texture is mapped to a rectangle. Despite this, people are still better at recognizing the person in the texture than in the shape. Similarly, when shape and texture are mismatched so that one person’s texture is “wrapped around” another’s shape, viewers’ identity judgments seem to rely almost entirely on texture, with very little effect of 3-D shape (see Bruce & Young, 2012). Once again, such demonstrations suggest that the spatial layout of the 3-D features does not provide a strong cue to recognizing a familiar person.

Facial surface data captured by a 3-D scanner. Information is gathered from a camera that rotates around the head. This delivers x-y-z coordinates, which can be rendered as a surface (left), and color information, which can either be mapped onto that surface or displayed as a color map (right). Figure from Bruce and Young (2012).
Resolution
We have now provided rather varied evidence suggesting that familiar face recognition is unlikely to be achieved by configural processing, at least as it is currently understood. We have raised four problems with the account, the final three of which depend on empirical data. In this final section, we consider the appeal of configural processing and attempt to offer a more positive direction for future research.
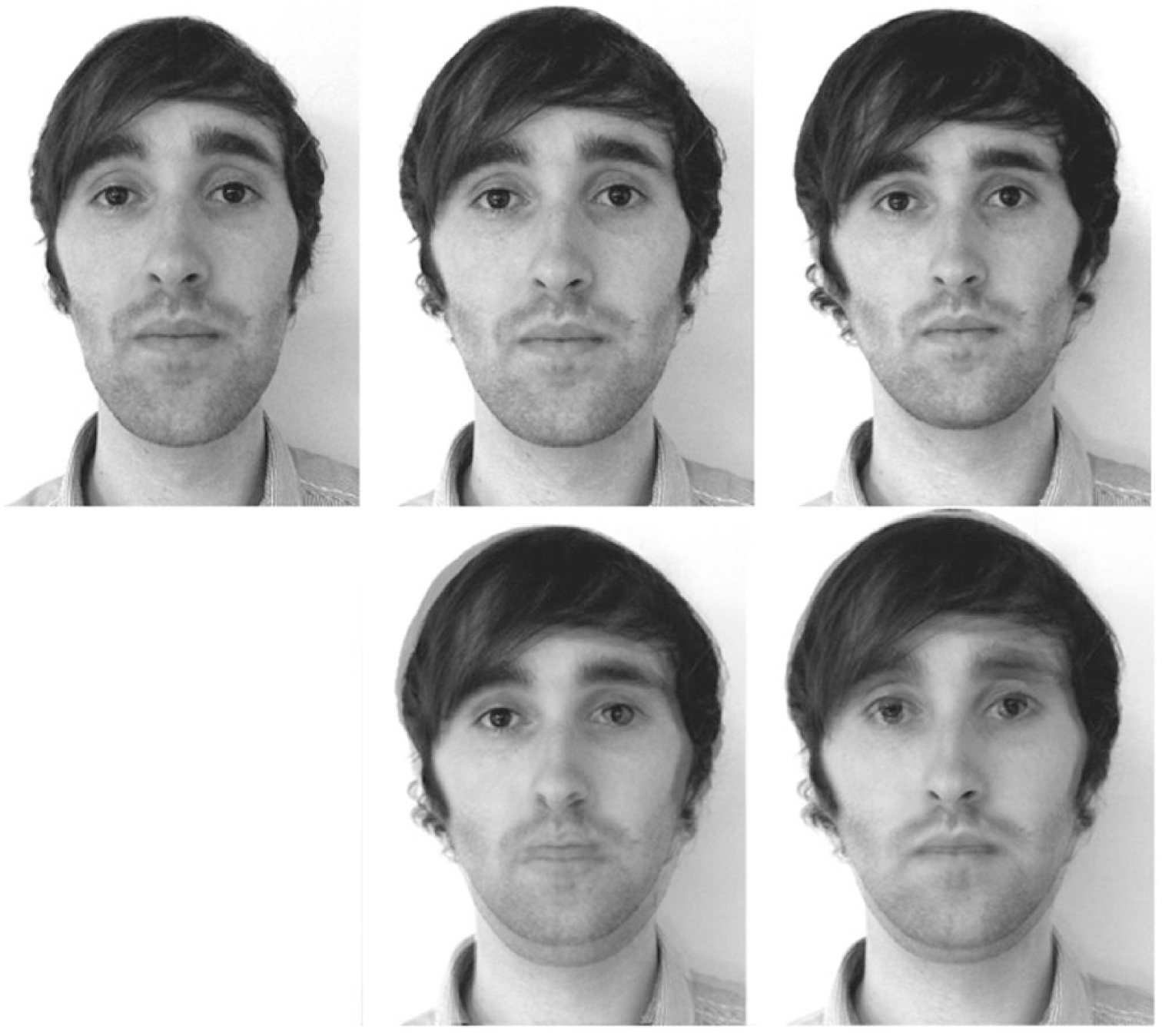
Configuration is a concept that maps most easily onto a specific instance of a face (a particular photo, say) rather than a generic representation. Given a photo of a face, it is relatively straightforward to imagine measuring key distances within it. Let us take, for example, the distance between the corner of the nose and the corner of the mouth—simply because it is one of the distances mentioned by Leder and Bruce (2000). This distance will clearly change, through changes in expression and speech and, over longer time periods, changes in health and age. Thus, it seems like a very bad candidate for differentiating between people: It is so elastic within a person that this variability would surely exceed that between people. However, at the core of configural theories of face recognition is the assumption that, for key distances between features, within-person variability (what is different about two images of the same person) is negligible when compared with between-person variability (what is different about two images of different people). This assumption seems unwarranted. For example, Jenkins, White, Van Montfort, and Burton (2011) demonstrated much larger within- than between-person variability on a number of face dimensions and on the perception of these (see also Burton, 2013; Burton, Jenkins, & Schweinberger, 2011; Jenkins & Burton, 2011). In fact, we hold that it is a failure to acknowledge within-person facial variability that has misled us into believing that the problem of face recognition is essentially the problem of distinguishing between two face images.
We propose that a full account of face recognition will rely on two fundamental principles: First, the processes involved in perception of familiar and unfamiliar faces are, to some extent, different; and second, in order to understand familiar face recognition, it is necessary to understand how faces vary not only between person but also within person. The two proposals emerge from work showing that unfamiliar face perception relies to a large extent on pictorial representations (Hancock, Bruce, & Burton, 2000; Megreya & Burton, 2006, 2007). Our perception of an unfamiliar face seems to be tied quite strongly to a particular image of that face. So, when trying to remember someone or match two images of that person, performance is severely impaired if the two images are not identical (i.e., photos were taken at different times or under different conditions). In contrast, familiar face recognition relies on more robust representations. Recognition generalizes across a very large range of images, including poor-quality images in novel contexts (Burton et al., 1999). This ability to generalize suggests that representations of familiar faces are more abstract than those for unfamiliar faces; they survive surface changes and seem to rely on properties that can be extracted from a wide range of individual photos.
This distinction between familiar and unfamiliar faces may hold the key to understanding the role of configural processing in face recognition. If one focuses entirely on the problem of telling faces apart, then it is relatively straightforward to imagine how configural processing is an attractive candidate. However, it is only when one sees multiple images of people, all perfectly recognizable, that it becomes clear that configural differences within different images of a person’s face can far exceed configural differences between people (see Fig. 6). We proposed above that second-order configuration is a property of an image, not of a face (Figs. 1 and 2). Images are unchanging, and it is easy to see how one can make measurements on a particular photo; what is harder to see is how such measurements generalize across different photos of the same face. Because image-level analysis is prevalent in perception of unfamiliar faces, it may be that configural processing is engaged when the viewer does not know the face, even though it is not critical when the viewer does know the face.

Ambient photos of British Prime Minister David Cameron. All images used under Creative Commons or Open Government License. Attributions (top row, left to right; bottom row, left to right): Department for Culture, Media and Sport [CC-BY-2.0]; Zasitu (Own work) [CC-BY-SA-4.0]; English Foreign and Commonwealth Office [Open Government License v1.0]; Richard J. Cole [CC-BY-SA-3.0]; Umakanth Jaffna (Own work) [CC-BY-SA-4.0]; English Foreign and Commonwealth Office [Open Government License v1.0]; Willwal.Willwal at en.wikipedia [GFDL]; Russell Watkins/Department for International Development [CC-BY-SA-2.0]; English Foreign and Commonwealth Office [Open Government License v1.0]; Department for Culture, Media and Sport [CC-BY-2.0]; English Foreign and Commonwealth Office [Open Government License v1.0]; Xtrememachineuk at en.wikipedia [Public Domain].
We do not intend to develop this theoretical position further here. Our critique of configural processing does not depend on providing an alternative account of face recognition. But neither is it a counsel of despair. We have shown how it is possible to examine different components of the face, without relying on metric distances between features. Indeed, our consideration of texture, in the previous section, is one such approach. It is important that we note that a rejection of the underspecified configural account does not imply that a holistic approach to face recognition should be abandoned. We simply emphasize that there are many theoretical possibilities, such as those based on image statistics (e.g., Hancock et al., 1996; Turk & Pentland, 1991), in which faces are built of component parts, but these parts all contain information that crosses the whole face. One of the most compelling pieces of evidence for whole face processing is the composite face effect (Young et al., 1987; and see Rossion, 2013, for a recent methodological review), and the arguments presented here are all consistent with a holistic processing account of recognition.
We have been careful to specify that the arguments above refer only to familiar face recognition and to point out that tasks relying on picture-level analysis are more plausible candidates for a configural approach. However, it is certainly possible that there are other phenomena in face perception that are vulnerable to similar criticisms. For example, although we have been generally supportive of holistic processing accounts throughout this article, it is true that these, too, tend to be poorly specified. We propose that future theoretical proposals need to be much more tightly specified, in at least two regards: First, any account relying on metric distances should provide an analysis of which specific distances are intended. Without candidates for an operationalization of a theoretical concept, any such account remains uncompelling. Second, it is probably time to abandon circularity in these accounts. To take one example, it is not clear that the configural processing account of inversion is actually an account of the phenomenon. A statement that configural processes are not recruited when viewing inverted faces is rather unsatisfying if one cannot say more. What exactly is not recruited, and why?
One well-studied inversion phenomenon is the Thatcher Illusion (Thompson, 1980; see the original article and Bruce & Young, 2012, for examples), in which inverting the eyes and mouth of a photo renders it grotesque—a perception that disappears when the entire face is then inverted. In a recent review, Peter Thompson, inventor of the illusion, commented: “I have often been asked why the effect occurs, and have often recited the mantra of configural coding not being available when faces are turned upside down, but my heart isn’t really in the explanation” (Thompson, Anstis, Rhodes, & Valentine, 2009, p. 932). Thirty years after the effect was first reported, this reflects a spectacular lack of progress. At the very least, we hope this article will spur those who disagree with us to provide a more detailed specification of configural processing. But our true hope is to have persuaded readers that, for familiar face recognition, the configural account is wrong.
Footnotes
Declaration of Conflicting Interests
The authors declared that they had no conflicts of interest with respect to their authorship or the publication of this article.
Funding
The researchers received funding from the European Research Council under the European Union’s Seventh Framework Programme (FP/2007-2013)/ERC Grant Agreement n.323262, from the Economic and Social Research Council, UK [ES/J022950/1], and from Deutsche Forschungsgemeinschaft (DFG; grants Schw 511/10-1, KA2997/2-1 and ZA 745/1-1) in the context of the DFG Research Unit Person Perception (FOR1097).