
Abstract
There are well-understood psychological limits on our capacity to process information. As information proliferation—the consumption and sharing of information—increases through social media and other communications technology, these limits create an attentional bottleneck, favoring information that is more likely to be searched for, attended to, comprehended, encoded, and later reproduced. In information-rich environments, this bottleneck influences the evolution of information via four forces of cognitive selection, selecting for information that is belief-consistent, negative, social, and predictive. Selection for belief-consistent information leads balanced information to support increasingly polarized views. Selection for negative information amplifies information about downside risks and crowds out potential benefits. Selection for social information drives herding, impairs objective assessments, and reduces exploration for solutions to hard problems. Selection for predictive patterns drives overfitting, the replication crisis, and risk seeking. This article summarizes the negative implications of these forces of cognitive selection and presents eight warnings that represent severe pitfalls for the naive “informavore,” accelerating extremism, hysteria, herding, and the proliferation of misinformation.
Anti-expert speech, fake news as a political weapon, the replication crisis, relentless health warnings associating cancer with everything we eat, and the richly documented pathologies of online inattention are all symptoms of a rising awareness that information is not benign (Bawden & Robinson, 2009; Carr, 2011; Eppler, 2015; Jacoby, Speller, & Kohn, 1974; Schoenfeld & Ioannidis, 2012; Schwartz, 2004). A common contributor to each of these problems and the focus of this article is information proliferation—the capacity to access and contribute to a growing quantity of information. According to the International Telecommunications Union (2017), more than 4 billion people are now mobile-broadband users, granting each near instantaneous power to access, create, and share information. This represents a 5-fold increase since 2010. Simultaneously, our technological capacities to store and share information have soared (Hilbert & Lopez, 2011; van den Bosch, Bogers, & de Kunder, 2016). 1 The result of this proliferation is that information is placed increasingly under the influence of an attention economy (e.g., Lanham, 2006) in which a growing number of people influence the evolution of information by what they pay attention to (e.g., Bakshy, Messing, & Adamic, 2015; Gentzkow & Shapiro, 2010).
Herbert Simon (1971) captured the central constraint on this attention economy when he noted that “information . . . consumes the attention of its recipients” (p. 40). We are limited in how much information we can attend to from outside sources (sometimes called the cocktail party problem; e.g., Conway & Cowan, 2001) and how much information we can process (e.g., in working memory; Miller, 1956). Thus, too much information threatens us with information overload and other pathologies of attention that have been well-documented elsewhere (Bawden & Robinson, 2009; Carr, 2011). This articles focuses on a less well-documented but perhaps more pernicious problem: how information-rich environments place information under the forces of cognitive selection, driving the evolution of information much like other forms of selection drive biological evolution.
The Evolution of the Information Ecosystem
The cognitive life cycle of information (see Fig. 1) provides a framework for understanding how cognitive selection shapes the evolution of information as it progresses from one mind to the next. In this life cycle, cognitive selection favors information that is more likely to be searched for, attended to, comprehended, encoded, and reproduced (e.g., Blackmore, 2000; Hills & Adelman, 2015; Kirby, Cornish, & Smith, 2008).

How information proliferation enhances the influence of cognitive selection. Information undergoes cognitive selection at each stage in its life cycle as it (a) passes from receiver to memory to producer and on to the next receiver. Information proliferation (b; denoted by the arrow and the letter “a”) increases the amount of information available to receivers and leads to competition for attention and future production. Cognitive selection implies that information loss (b; denoted by the letter “x”) is not random but instead driven by cognition’s biases for belief-consistent, negative, social, and predictive information, which influences the evolution of information in a feedforward process.
Information proliferation influences the evolution of information in two ways: by increasing competition for attention and reducing information’s generation time. Increasing competition for attention means that more signals compete for receivers, enhancing the role of cognitive selection. More competition is also functionally equivalent to greater amounts of background noise. Communication signals adapt to increasing noise in ways consistent with information’s life cycle by becoming easier for receivers to detect, recall, and reproduce (e.g., Arak & Enquist, 1995; Hills, Adelman, & Noguchi, 2017; Luther, 2009). This favors some kinds of information over others. For example, misinformation has an advantage in competitive environments because it is freed from the constraints of being truthful, allowing it to adapt to cognition’s biases for distinctive and emotionally appealing information (Hamann, 2001; Schomaker & Meeter, 2015). These are both factors associated with the empirical finding that lies proliferate faster than the truth (Vosoughi, Roy, & Aral, 2018).
Information proliferation also reduces information’s generation time—the time it takes for information to move from one mind to another. This is analogous to biological evolution’s generation time. A general rule of evolution is that faster generation times accelerate adaptation (e.g., Thomas, Welch, Lanfear, & Bromham, 2010). The more rapidly that people can access, select, and reproduce preferred information, the more readily will that information reflect the cognitive biases of its users.
Although cognitive selection can produce beneficial outcomes by selecting for valuable information, the focus here is on selective forces that drive unwanted outcomes of information proliferation, such as extremism, hysteria, herding, and misinformation. In the remainder of this article I will look at biases that when combined with information proliferation produce each of these outcomes. In particular, I will focus on cognitive selection for information that is (a) belief-consistent, (b) negative, (c) social, and (d) predictive.
Selection for Belief-Consistent Information
Belief-consistent selection encompasses a range of psychological phenomena associated with tendencies to seek out, encode in memory, and reproduce information consistent with prior beliefs. The processes underlying belief-consistent selection are often difficult to distinguish in practice but roughly correspond to confirmation bias, biased assimilation, and motivated reasoning, respectively. A paradigmatic example is that giving people balanced information on ideological issues frequently leaves them more polarized on such wide-ranging topics as capital punishment, legal cases, vaccines, climate change, the effects of video games, and politics (Corner, Whitmarsh, & Xenias, 2012; Greitemeyer, 2014; Lord, Ross, & Lepper, 1979; Munro & Ditto, 1997; Munro et al., 2002; Nan & Daily, 2015; Westen, Blagov, Harenski, Kilts, & Hamann, 2006).
Although Asch (1955) is often considered a standard example of selection for social information, what this research also showed is that when a person held an unpopular belief, the presence of one other person who shared that belief was sufficient to reinforce the first person’s level of public commitment to this minority opinion so that it was nearly as high as in the absence of any opposition. Similarly, when like-minded people share views—even when they all have the same information—these views tend to be held with more confidence (Schkade, Sunstein, & Hastie, 2010; Sunstein, 2002). This happens even when performance is unchanged (Tsai, Klayman, & Hastie, 2008).
Information proliferation effectively adds fuel to this fire. Belief-consistent selection becomes more prevalent as information increases (Fischer, Schulz-Hardt, & Frey, 2008; Kardes, Cronley, Kellaris, & Posavac, 2004). Information proliferation therefore leads people to personalize information and avoid belief-inconsistent information. Algorithms do this for us in the form of recommender systems and search engines guided by browser history. On social media, tendencies for in-group selection lead to filter bubbles and echo chambers that further reduce individual exposure to information diversity even as they increase diversity across social media as a whole (Barberá, Jost, Nagler, Tucker, & Bonneau, 2015; Nikolov, Oliveira, Flammini, & Menczer, 2015).
The tendency to select like-minded individuals in decision making is often associated with groupthink, with groups defensively insulating themselves from external views. Groupthink has been blamed for numerous political and economic fiascos (Bénabou, 2012). Information proliferation now extends the capacity for groupthink globally, organizing and polarizing groups from political ideologues to international terrorists (Aly, Macdonald, Jarvis, & Chen, 2016).
Why does belief-consistent selection exist? There are a number of likely contributors: Selecting belief-consistent information provides a rewarding feeling of sensemaking while reducing identity-threatening information (Chater & Loewenstein, 2016; Festinger, 1962); an unwavering argument—that sweeps inconsistencies under the rug—better influences others (Mercier & Sperber, 2011; Trivers, 2011); and people view information and the attitudes associated with it as cultural codes that allow communities of like-minded individuals to identify their in-group and cooperate on that basis (e.g., Marshall, 2015). These contributors are all further reinforced by people’s tendency to understand and recall information in relation to narrative structures for causality that they already understand (e.g., Bartlett, 1932), which represents a cognitive blind spot for information that is inconsistent with prior beliefs.
Selection for Negative Information
Heightened sensitivity to negative information is part of our evolutionary heritage. This sensitivity leads us to weight disadvantages over advantages in information seeking and decision making (Tversky & Kahneman, 1991) and drives the well-known news trope: “If it bleeds, it leads.” When applied to information proliferation, a negativity bias induces us to identify and recommunicate information about risk at the expense of more balanced information.
The preferential sharing of risk information leads to social risk amplification (Kasperson et al., 1988). In a study by Moussaïd, Brighton, and Gaissmaier (2015), information was communicated through a chain of individuals, similar to the children’s game “telephone.” The first individual in the chain was introduced to the information through a set of balanced articles discussing triclosan, an antibacterial agent. As this information was proliferated from one individual to the next, it rapidly lost key facts about triclosan’s usefulness while preserving and adding additional but unsupported information about downside risks related to health consequences and prevalence. As a real-world example, when the first Ebola case was diagnosed in the United States, Twitter posts mentioning Ebola jumped from 100 per min to 6,000 per min and rapidly produced inaccurate claims that Ebola could be transmitted through food, water, and air (Luckerson, 2014).
The Ebola example reflects another potential bias in risk communication: Social risk amplification is especially prominent for dread risks—unpredictable, catastrophic, and indiscriminant risks to life and limb such as plane crashes, nuclear disasters, epidemics, and terrorism (Slovic, 1987). Jagiello and Hills (2018) found that social risk amplification was substantially larger for dread risk (e.g., nuclear power) than for nondread risk (e.g., food additives). Moreover, Jagiello and Hills (2018) also found that socially amplified risk was resilient to the reintroduction of the initial balanced information. This supports one of the central threats of information proliferation: Information proliferated through individuals is better adapted for cognition than information designed to provide a more balanced perspective (see also Ng, Yang, & Vishwanath, 2017).
Social risk amplification helps to explain the recent rise in what Kahneman (2011) calls the precautionary principle, a propensity to base decisions about new technology on their potential downside risks without considering their potential benefits. Information proliferation rapidly makes risk the reason for taking one action over another. At the extreme, this incites hysteria and motivates Ulrich Beck’s (1992) claim that we are currently living in a risk society.
Selection for Social Information
People’s appetite for social information has led some to suggest that smartphones induce hypernatural social monitoring (Veissière & Stendel, 2018) and others to observe that information on social media crowds out other kinds of information in memory (Mickes et al., 2013). Where people do not have strong ideological convictions otherwise, social information can lead to herding and undermine collective wisdom (Asch, 1955; Lorenz, Rauhut, Schweitzer, & Helbing, 2011; Raafat, Chater, & Frith, 2009).
Salganik, Dodds, and Watts (2006) studied people’s music choices by allowing people to listen to fragments of songs and then download a song of their choice. Some participants could also see what other people had chosen. Groups of independent decision makers were more like other independent groups, sharing their diversity of views, than were groups exposed to social influence, which rapidly diverged from one another. There was also more inequality among winning songs when individuals had social information than when individuals chose in isolation. In other words, social information both added noise and amplified it. The same socially fueled “preferential attachment” is blamed on long-tailed distributions of citation counts among scientific papers (Clauset, Larremore, & Sinatra, 2017) and observed in online auctions in which bidders follow bidders instead of other quality indicators (Huang & Chen, 2006; Simonsohn & Ariely, 2008).
When problems are easy, social information can be good: Social connectivity increases the rate at which groups converge on optimal solutions. But for hard problems, high levels of social connectivity prevent groups from finding optimal solutions because they lead groups to exploit suboptimal solutions too quickly (Barkoczi & Galesic, 2016; Fang, Lee, & Schilling, 2010; Lazer & Friedman, 2007; Mason, Jones, & Goldstone, 2008).
Imitating others provides humans with what Bandura (1965) called no-trial learning. Such no-trial learning is especially effective in uncertain environments in which the informational contingencies are complex, mistakes are costly, other people have good information, and individuals need to coordinate to produce effective outcomes (Goldstone & Gureckis, 2009; Kameda & Nakanishi, 2003). But when an individual can use information from another individual to make a decision, neuroimaging evidence indicates that this turns off the executive processing associated with a more critical evaluation of the choice (Engelmann, Capra, Noussair, & Berns, 2009). The proliferation of social information therefore threatens our better judgment.
Selection for Predictive Information
A bias for pattern identification can be completely devoid of other biases and still run aground in a sea of data. The problem arises because information proliferation promotes spurious correlations. Consider that the probability of a false positive (type I error) approaches 1.0 as the number of comparisons increases. 2 When a single researcher performs multiple tests, he or she can correct for this by lowering α values (Bonferroni corrections). The problem of multiple researchers performing multiple tests can be alleviated by publishing negative results, avoiding “the file drawer problem.” But when multiple researchers test multiple hypotheses, there is presently no cure: Even if all hypotheses were preregistered and every individual researcher reported all tests, the absolute number of type I errors would grow with the number of researchers (Ioannidis, 2005).
If positive findings enjoy a selection bias for publication, then the proportion of false positives in print will increase with the number of unique hypotheses tested. Moreover, more information (i.e., covariates) combined with a bias for positive results invites researchers down a “garden of forking paths” during analysis, where a plethora of alternative analyses make positive findings easy to generate and deceptively intuitive given post hoc theorizing (Munafò et al., 2017; Simmons, Nelson, & Simonsohn, 2011).
Similar biases play out in economic decision making. People who experience monetary payoffs from a set of alternatives tend to choose increasingly risky alternatives (seeking rare but illusory gains) as the set size of possible alternatives increases (Ert & Erev, 2007; Noguchi & Hills, 2016). This happens because high-variance alternatives, in comparison with low variance alternatives, are more likely to produce extreme outcomes. The probability that one of them will do so increases with the absolute number of high-variance alternatives considered (Fig. 2). As a consequence, the likelihood of spurious “super” performers (as well as “super” failures) grows with the number of contenders purely as a function of statistical noise (see Denrell, 2005; Denrell & Liu, 2012; Shermer, 2014).

The probability of choosing a risky alternative as a function of the number of alternatives considered. A decision maker chooses between m alternatives, half of which are safe and pay off S with a probability of 1.0; the other half are risky and pay off R (> S) with a probability p and otherwise 0. As the number of alternatives from which to choose increases, a decision maker who chooses the outcome with the highest sample payoff after one sample from each alternative will be increasingly likely to choose a risky option. This follows 1 − (1 − p)m/2 and a similar logic to type I errors.
Data-driven machine learning is not a solution. Without input from theory, “blind” machine learning can do far worse as a result of the curse of dimensionality—too many predictors and not enough data to tease them apart (Huys, Maia, & Frank, 2016). In “Trouble at the Lab” (2013), The Economist quotes Massachusetts Institute of Technology’s Sandy Pentland as reporting that three quarters of machine-learning results are nonsensical because of “overfitting.” An iconic overfitting example is Google Flu Trends, which rapidly went from online oracle to victim of big data hubris when it began overpredicting influenza-like illness by a factor of 2 relative to the Centers for Disease Control and Prevention (Lazer, Kennedy, King, & Vespignani, 2014). Similar cases have been made against data-driven approaches to election prediction (Gayo-Avello, 2012) and criminology (Chan & Bennett Moses, 2016). Given the nested black-box nature of many proprietary machine-learning algorithms, overfitting is often extremely difficult to detect in real-world settings, which also happen to be the places where they can do the most harm (e.g., O’Neil, 2017).
Conclusions
The problems described here are not easily remedied. They are in part the negative outcomes of cognitive heuristics that have paid for themselves in our evolutionary past. The adaptive value of these heuristics represents the light side of information, including features such as in-group identification and risk avoidance (see Table 1). The dark side is that cognitive selection’s reliance on these heuristics in an information-rich environment distorts what information is available and reduces our capacity to use that information objectively.
The Effect of Cognitive Selection on Information Proliferation
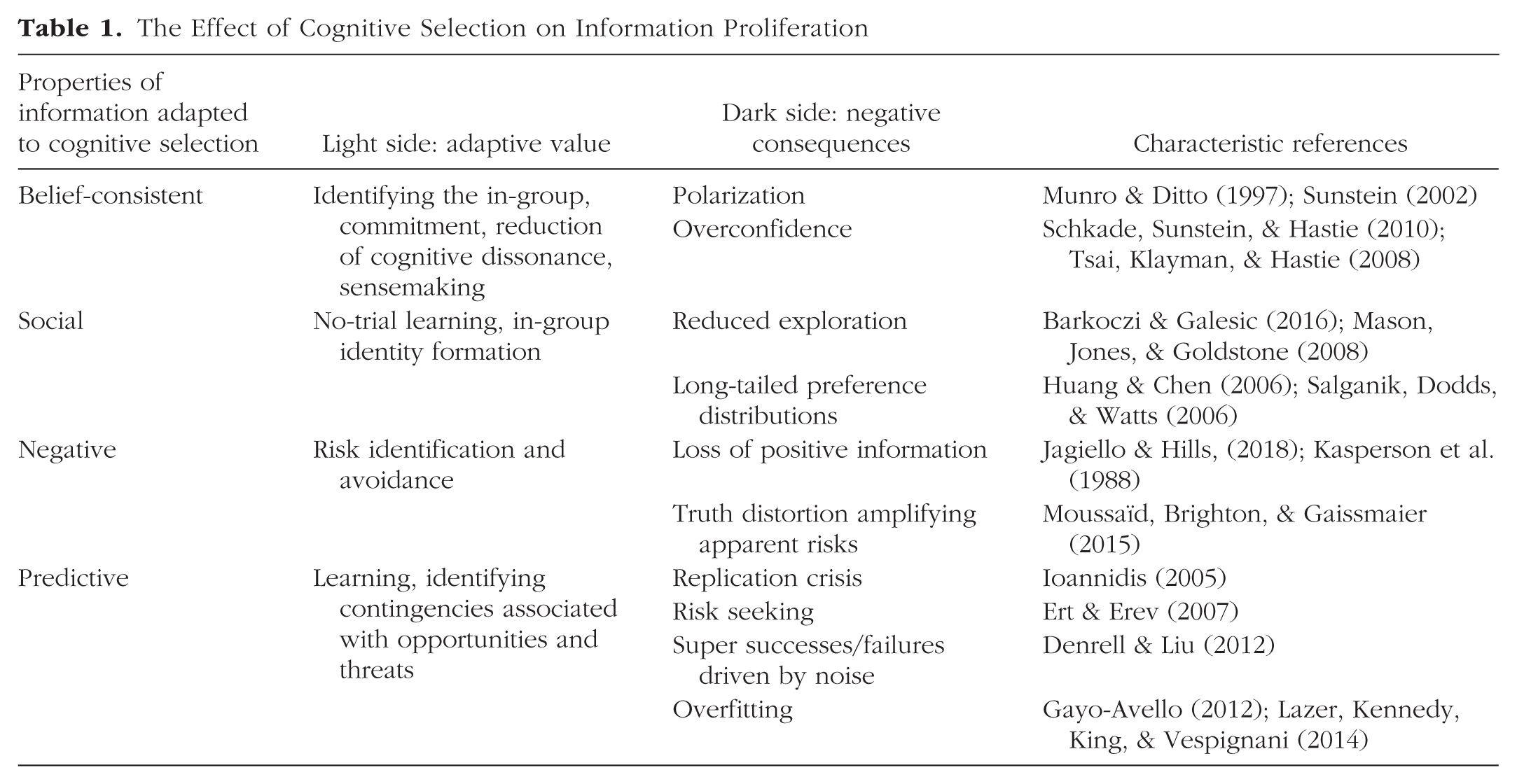
These problems can be summarized by the following eight warnings for contemporary information environments: (a) Information becomes more appealing to humans as it moves through human minds; (b) balanced information about ideological issues reinforces divergent beliefs; (c) when people share similar divergent beliefs with one another, they often become more confident in their beliefs, even when they learn that the people with whom they have shared their beliefs know nothing more than they do; (d) information about costs proliferates more readily than information about benefits, which can prevent cost-benefit analysis and reduce decision making to risk avoidance; (e) social information crowds out individual quality indicators and impairs objective assessments; (f) social information reduces exploration for hard problems; (g) more information can lead to overfitting and the detection of spurious correlations driven by rare events; and (h) as we become aware of more alternatives, the most appealing alternatives become increasingly risky.
These warnings reflect advantages for misinformation in information-rich environments. Like science, information is to some degree self-correcting. In a just attention economy, maladaptive information should eventually lead to costs borne by those who use it. But the rate of correction necessary to resolve misinformation increases with the rate of its proliferation. Developing methods to keep up with this tide of misinformation is a growing interdisciplinary concern, cutting across science and politics alike (e.g., Lazer et al., 2018; Lewandowsky, Ecker, & Cook, 2017; see also Simon, 1976). Understanding how cognitive selection interacts with information proliferation is a key step in this process.
Footnotes
Acknowledgements
I thank Li Ying, Cynthia Siew, So Young Woo, Yonghua Cen, Annasya Masitah, Eva Jimenez Mesa, and Tomas Engelthaler for numerous helpful discussions and comments.
Action Editor
Marjorie Rhodes served as action editor and June Gruber served as interim editor-in-chief for this article.
Declaration of Conflicting Interests
The author(s) declared that there were no conflicts of interest with respect to the authorship or the publication of this article.
Funding
This work was supported by Royal Society Wolfson Research Merit Award WM160074 and a fellowship from the Alan Turing Institute.