
Abstract
Variability in appearance across different images of the same unfamiliar face often causes participants to perceive different faces. Because perceptual information is not sufficient to link these encounters, top-down guidance may be critical in the initial stages of face learning. Here, we examine the interaction between top-down guidance and perceptual information when forming memory representations of unfamiliar faces. In two experiments, we manipulated the names associated with images of a target face that participants had to find in a search array. In Experiment 1, wrongly labelling two images of the same face with different names resulted in more errors relative to when the faces were labelled correctly. In Experiment 2, we compared this cost of mislabelling with the established “dual-target search cost,” where searching for two targets produces more search errors relative to one target. We found search costs when searching for two different faces, but not when searching for mislabelled images of the same face. Together, these results suggest that perceptual and semantic information interact when we form face memory representations. Mislabelling the identity of perceptually similar faces does not cause dual representations to be created, but rather it impedes the process of forming a single robust representation.
Matching the identity of unfamiliar faces is a challenging task because the appearance of a face can vary substantially from image to image. This within-face variability results from a range of physical and image-based factors—like expression, head angle, and lighting—that can dramatically alter how the same face appears in two different images. As a result, people often mistake two images of the same unfamiliar face as being two different people (Jenkins et al., 2011; Ritchie et al., 2015; White et al., 2014). Conversely, exposure to variability in appearance also appears to be important when becoming familiar with a face. For example, participants recognise unfamiliar faces more accurately after being trained with different images of the face compared with repeated exposure to the same image (Murphy et al., 2015) and are more accurate matching images of an identity after being exposed to greater variability in their facial appearance (Menon et al., 2015b; Ritchie & Burton, 2017). Therefore, variability in appearance can both help learning, by providing more informative exposure for perceptual learning, and hinder face learning, by impeding the initial grouping of facial images into a coherent identity representation (see also Devue, 2019).
Recent work in understanding the process of becoming familiar with a face has focussed on the question of how people derive robust memory representations from experience with natural face image variation (e.g., Ritchie & Burton, 2017). Experimental models of this process tend to use what have become known as “ambient” images of the face, which are images that contain natural day-to-day variations in facial appearance which represent the within-face variability seen in the real world (see Jenkins et al., 2011). Use of ambient images has been a significant advance over previous work using highly controlled studio-captured face images, allowing study of face recognition to better capture the challenge of face recognition in real-world tasks (Burton, 2013; Burton et al., 2011). Recent evidence suggests that using highly controlled images of faces in visual search led to profound underestimation of the difficulty of this task for real-world applications (e.g., Dunn et al., 2018).
A key challenge for understanding face learning is, therefore, to explain how people overcome the initial difficulty in linking ambient images of the same face together so that they might benefit from variability in appearance when learning the face. One proposal is that top-down processes play a critical role in guiding initial perceptual learning (Kramer et al., 2018), by cohering the perceptual input into a unitary representation. Menon and colleagues (2015a) provide initial support for this hypothesis, showing that providing accurate identity labels to images of unfamiliar faces improves the accuracy of subsequent recognition (see also Menon et al., 2018). Importantly, the benefit of identity attribution was found to depend on the memory demands of the task. While sequential matching tasks that require memorisation of the target face benefit from identity attributions, simultaneous matching tasks that do not require memorisation do not benefit. This implies that the benefit of identity attributions is tied to the formation of representations in memory (see Menon et al., 2015a).
In this article, we examine the relative contribution of bottom-up perceptual information and top-down identity labelling to the formation of representations of unfamiliar faces in a visual search task. Visual search tasks provide a useful paradigm for examining the formation of working memory representations. Because search targets must be stored and compared with a large number of possible candidate items, they place significant demands on working memory (see, for example, Duncan & Humphreys, 1989). In the few studies where visual search has been used to investigate face memory representations, improvements in search performance have been found to provide a very sensitive index of familiarity (Dunn et al., 2018; Tong & Nakayama, 1999).
Visual search is also suited to our research question because a large body of previous work shows that visual working memory is hampered by representing multiple targets simultaneously (Ort et al., 2019; see also Olivers et al., 2011). This constraint in working memory can result in a “dual-target cost,” whereby search is less accurate with two targets compared with one. For example, dual-target costs have been shown when searching for a range of different targets, including simple shapes (Barrett & Zobay, 2014, 2020; Menneer et al., 2007), alphanumeric characters (Kaplan & Carvellas, 1965), colours (Menneer et al., 2009; Stroud et al., 2012), real-world targets (Hout & Goldinger, 2015; Menneer et al., 2007, 2009), and unfamiliar faces (Mestry et al., 2017).
Importantly, such dual-target costs for two unfamiliar faces (Mestry et al., 2017) stand in contrast to the gains in accuracy observed when multiple images of the same target face are shown to participants. In a recent study, we reported substantial gains in the accuracy of visual search when multiple images of an unfamiliar face target are shown before search (Dunn et al., 2018). Conversely, studies of both face memory (Bindemann et al., 2012; Megreya & Burton, 2006) and visual search (Dunn et al., 2019; Mestry et al., 2017) indicate that memory for unfamiliar faces is impaired when required to remember and recognise two targets compared with just one. We propose that the decisive factor in determining whether exposure to multiple images results in costs or benefits may be whether or not the images are assimilated into the same memory representation—that is, whether the images combine to form a unitary search template. However, it is not clear whether this assimilation can be determined solely by top-down identity labels, perceptual information, or by a combination of these sources of information.
We address this question here by manipulating the identity labels that are associated with target image pairs in a visual search task. Following Menon et al. (2015a, 2018), we presented pairs of ambient images of the same person that were either associated with the same name or with different names. Because perceptual information is identical in these conditions, differences in performance can be attributed to the effect of identity labels on the formation of working memory representations. To pre-empt our results, in Experiment 1, we show that identity labels affect search performance, confirming top-down modulation in the formation of search templates of unfamiliar faces. In Experiment 2, we then compare the effect of deceiving participants to believe that two images of the same person are of different people to the dual-target costs observed when the two targets are genuinely different people. The results of this experiment not only replicate the effect of identity labels observed in Experiment 1 but also show that this effect alone is not sufficient to account for dual-target costs.
Experiment 1
Based on earlier research (Menon et al., 2015a, 2018), we anticipated that the effects of identity attributions would be small. To provide the best chance of detecting these effects, we chose a search task that requires participants to exhaustively search for many instances of many targets rather than just one instance of one target. While previous work on the dual-target cost has given participants two targets but with only one appearing in the array (e.g., Mestry et al., 2017), another method to examine the dual-target cost is to have multiple targets appearing in the array per trial, which is referred to as multiple-target search task (or hybrid-foraging task; see Biggs, 2017; Wolfe et al., 2016). Using this paradigm provides two advantages when examining the dual-target cost. First, searching for multiple targets requires a more robust representation than single-target search, as the representation needs to allow matching to all of the target images. Second, as this paradigm requires multiple decisions to be made on every trial, it provides a richer source of data than single-target search without needing as many separate trials. For these reasons, multiple-target search tasks provide a more sensitive test of the robustness of the search template and are better suited to detect differences in the search template from identity attributions.
Method
Sample size estimation
We performed a statistical power analysis using G*Power 3.1 software (Erdfelder et al., 1996) based on accuracy data from Menon et al. (2015a). From this study, we estimated that the comparison between the 1ID condition and the 2ID condition resulted in an approximate Cohen’s d of 0.4, so a sample of 45 participants was needed to have an 80% chance of detecting a similar or larger effect size (α = .05, β = .8).
Participants
Forty-five undergraduate students (26 females, M age = 19.1, SD = 1.9) took part in the experiment in exchange for course credit. All participants reported normal or corrected-to-normal visual acuity and normal colour vision. Informed consent was obtained before the experiment began.
Stimuli
Following recent work (Dunn et al., 2018), we sourced ambient images of faces that contain natural variation in appearance to better represent the within-face variability seen in the real world (see Jenkins et al., 2011). To do this, images of 20 Dutch celebrities who were unfamiliar to the Australian participants served as the targets and distractors in the visual search task (10 females, 10 males). For each celebrity, we collated 20 different images from Google Image Search in which the celebrity’s face was roughly front-on and clearly visible, but otherwise varied naturally in facial-, environmental-, and image-level characteristics. Each image was edited to remove the background, rescaled to be 190 by 285 pixels and converted to greyscale. Finally, the luminance profile of each image was normalised using the SHINE toolbox (Willenbockel et al., 2010). Removal of background and normalisation of luminance profile were both applied to prevent these factors providing non-facial cues for target recognition.
Procedure
Participants completed 40 trials of the multiple-target visual search task programmed in MATLAB using Psychtoolbox (Brainard, 1997). On each trial, participants were first shown images of a single search target in one of three conditions (see Figure 1a). On half of the trials, participants were shown one image of the target with a name below it (1IMG condition). On the other trials, participants were shown two images of the same target person. For half of these trials, participants were shown two different images of the same target, with each image having the same name below it (1ID), while for the remaining trials the two images of the same target were labelled with different names (2ID). In the 1ID condition, participants were instructed to find all the images of the target identity in the search array, and in the 2ID, they were instructed to find all the images of both identities (even though the images showed the same target). Participants viewed the targets for 3 s, with dual targets being presented on-screen simultaneously. The target identity changed from trial to trial, and each identity was a target on two separate trials: once in the 1IMG condition and again in either the 1ID or 2ID condition. The identities assigned to the 1ID and 2ID conditions were counterbalanced across participants.

(a) Example of the three experimental template conditions of target images in Experiment 1. Participants viewed either one image of a target face (1IMG), two images of the same target face with the same name underneath (1ID), or two images of the same target face with different names underneath (2ID). Participants were instructed to find all images of the target person (1IMG, 1ID) or “persons” (2ID) in a search array presented immediately after the target presentation. (b) Example of search array used in both experiments. Participants were instructed to find all images of the target(s) in the array.
After studying the targets, participants were shown the search array (see Figure 1b). They were instructed to find all images (either 4, 6, 8, or 10 unique targets) in the array of the target (1IMG, 1ID) or “targets” (2ID), by clicking each image with the mouse. They were able to terminate the trial via a keypress when they believed they had found all target images. The target images shown in the array were always different images to those shown on the target preview screen. In line with previous research where the target-to-distractor ratio was 1:5 (e.g., Wolfe et al., 2016), 40 distractor images were randomly selected to fill the array using the remaining Dutch celebrities that were the same gender as the target. This selection included a random number of different images for each distractor identity. None of the images shown as the targets or distractors in the array were repeated.
We also included a time delay penalty at the end of every trial to motivate participants to find as many of the targets as they could. The length of the penalty was determined by how many errors they made, increasing by 2 s for each missed target or false alarm made on the trial (i.e., 2 missed targets + 1 false alarm = 6 s of delay penalty). Participants were presented with a blank screen for the length of the penalty, delaying the beginning of the next trial. Similar time penalties have been used in other face recognition paradigms (e.g., Papesh & Goldinger, 2014), which aim to encourage more careful deliberation on each trial.
Upon completion of the experiment, participants’ familiarity with the Dutch celebrities and awareness of the 2ID manipulation were assessed via verbal debrief. Specifically, participants were asked whether they had recognised any of the faces used in the experiment and whether they had “noticed anything surprising or unusual during the experiment.” We planned to exclude any participant who gave a response which indicated that they did not believe our 2ID manipulation; however, no participant appeared to notice the deception.
Results
We compared the error rate for each template condition by calculating the average number of errors made on each trial, including both missed targets and incorrect selections. This measure was analysed in a one-way repeated-measures analysis of variance (ANOVA) with template (1IMG, 1ID, and 2ID) as the factor (see Figure 2). Follow-up comparisons were made with the appropriate Bonferroni adjustment (k = 3, p = .017).
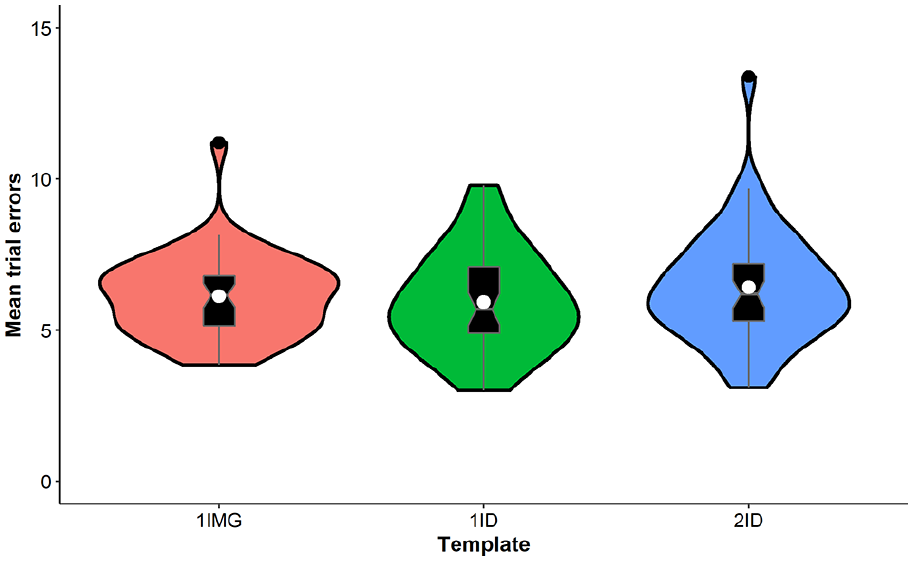
Violin plots showing the distribution of participants’ mean trial errors in Experiment 1. The white circle shows the mean for each condition.
There was a significant main effect of template, F(2, 88) = 3.82, p = .026,
We also calculated trial length for each participant, computing the time taken from when the search array was first presented to when the trial ended. We then analysed it, in the same way, using a one-way repeated-measures ANOVAs with template (1IMG, 1ID, and 2ID) as the factor. For brevity, analysis of search durations (trial length) is reported in Supplementary Materials but found no significant effects..
Discussion
Participants made more errors in the 2ID condition than 1ID condition, showing that identity labels associated with the target affected visual search performance. This provided initial support for the hypothesis that top-down influences from semantic labels modulate the formation of working memory representations of faces. However, we did not find clear evidence that mislabelling face images produced a dual-target cost, as the 2ID condition did not significantly differ from the 1IMG condition. Together, these findings suggest that while top-down influences can promote the formation of a more robust search template, they do not appear to be sufficient to induce dual-target costs when the labels suggest two different identities. However, the pattern of results was not conclusive, and because we did not include a dual-target condition that presented two genuinely different unfamiliar faces, we were not able to compare the effect of identity labels with dual-target costs directly. We addressed these concerns in a follow-up experiment.
Experiment 2
Experiment 2 replicated Experiment 1 and also included a genuine dual-target search condition so that we could directly compare the cost of searching for two genuinely different targets with the situation where participants are misled to believe they were searching for two targets.
Method
Sample size estimation
For this experiment, we estimated the effect size using the comparison between the 1ID and 2ID conditions in Experiment 1. A statistical power analysis using G*Power 3.1 software (Erdfelder et al., 1996) determined that this effect size (Cohen’s d = 0.385) was smaller than those found by Menon et al. (2015a). To protect against the risk of a Type II error in this more complex design, we targeted a larger sample of at least 90 participants giving us sufficient power to have a 95% chance of detecting an effect of this size (α = .05, β = .95).
Participants
Ninety-two undergraduate students (55 females, M age = 19.2, SD = 2.6) took part in the experiment in exchange for course credit. Again, all participants reported normal or corrected-to-normal visual acuity and normal colour vision, and informed consent was obtained before the experiment began.
Design
Participants completed two blocks of 40 trials. The first block was the “genuine” block where participants were either shown a search target of one image of a target face (1IMG), two images of the same target face (1ID), or two images of two different target faces (2ID-genuine). The second “deception” block was the same as the first, except that in the 2ID condition—when participants believed they were shown two images of different targets—they were shown two different images of the same person (2ID-deception). This design is illustrated in Figure 3.

Illustration of the identity manipulations used in Experiment 2. Before searching on each trial, participants were shown images of the target with a name underneath. In the genuine block (top row), participants were either shown one image of the target (1IM), two images of the same target (1ID), or two images of different targets (2ID-genuine). In the deception block (bottom row), participants were shown the same three conditions, except in the 2ID condition the two images were of the same target but had different names underneath (2ID-deception).
This change in design from Experiment 1 had two benefits. First, having genuine and deception versions of the 2ID condition enabled us to directly test whether dual-target costs can be explained by top-down influences on the formation of separate working memory representations. Second, we hoped that asking participants to complete the “genuine” block first would minimise the possibility that participants did not believe the 2ID-deception condition in the subsequent block.
There are two critical comparisons in this experiment. First, a significant advantage for 1ID over 2ID-deception in the deception block would support the main finding of Experiment 1: that top-down identity attributions interact with perceptual information in the formation of search templates. Second, a significant advantage of 2ID-deception over 2ID-genuine conditions would signal that dual-target costs cannot be accounted for solely by top-down identity attributions.
Stimuli and procedure
The same 20 Dutch celebrities were used as for Experiment 1 with the addition of 20 UK celebrities to be used as additional targets (10 females and 10 males). These images were collected and edited in the same way and were normalised to match average luminance profiles using the SHINE toolbox (Willenbockel et al., 2010).
The same design as Experiment 1 was used but with the following changes. Participants completed 80 trials of the visual search task, with trials divided into two blocks (see Figure 3). In the first block (genuine block), participants were randomly presented with either one target identity (1IMG), two images of one target identity (1ID), or one image each of two different target identities (2ID-genuine). in the second block (deception block), participants were randomly shown the same three conditions. However, in the 2ID condition, the two different images were of the same person but labelled as two different people (2ID-deception, as in Experiment 1). Importantly, participants experienced these two blocks consecutively with no notable transition between blocks. Moreover, in the genuine block, 2ID targets were always the same gender, to mirror what participants would experience after in the deception block. The number of targets again varied from trial to trial, this time with either four, six, or eight targets in the array, and there were always equal numbers of each target in the 2ID-genuine condition.
At the end of the experiment, participants completed a familiarity questionnaire which required them to respond whether they were familiar with the names of the UK celebrities when shown on screen one at a time. We again planned to exclude any participant who said they were familiar with the UK celebrities used in the task or gave a response which indicated that they did not believe the 2ID manipulation in the deception block, but no participant satisfied either criteria.
Results
Mean error rates for experimental conditions are shown in Figure 4. A 2 × 3 repeated-measures ANOVA with factors Block (genuine/deception block) and Template (1IMG, 1ID, and 2ID) showed a significant interaction between factors, F(2, 182) = 9.83, p < .001,
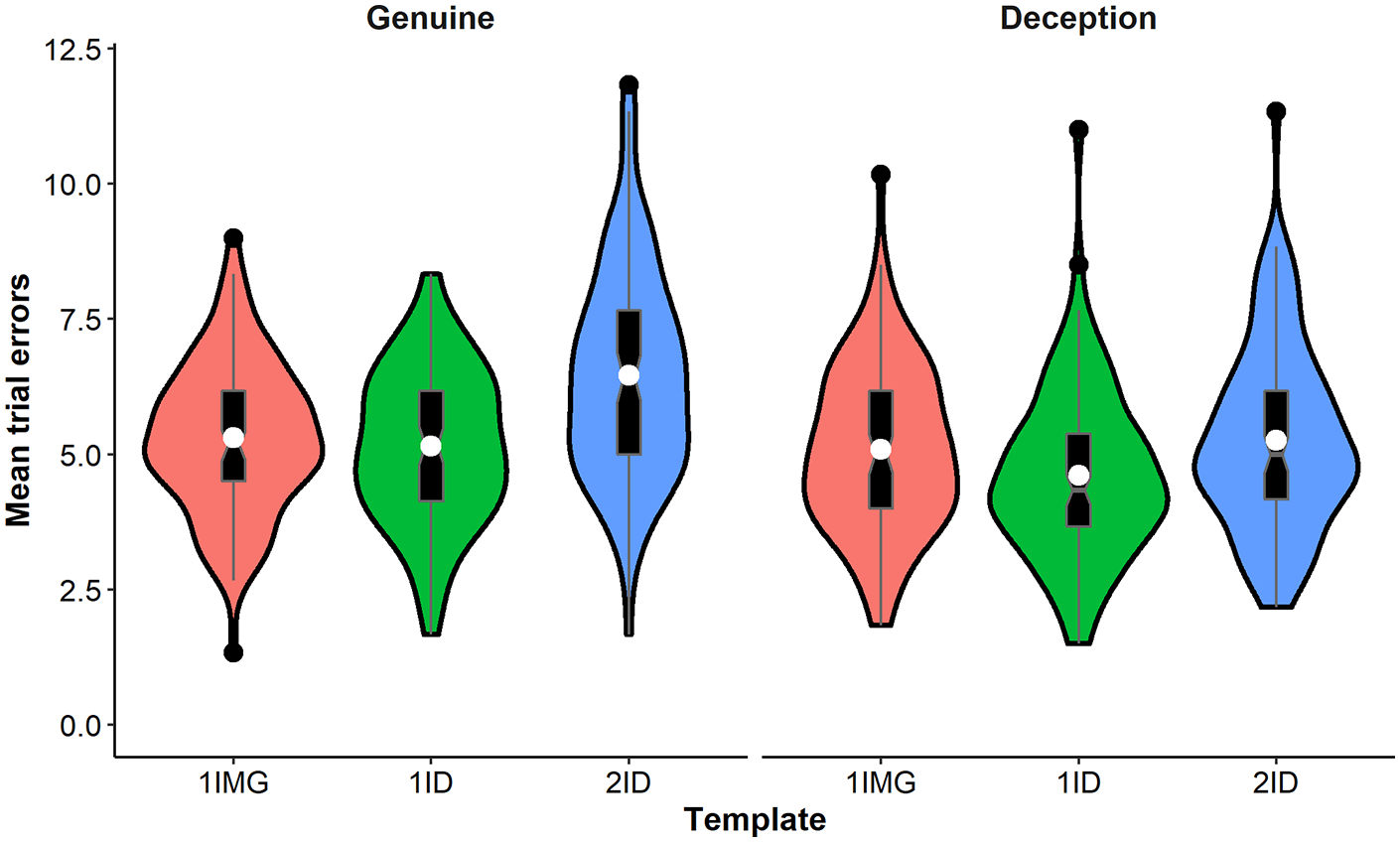
Violin plots showing the distribution of participants’ mean trial errors for each block in Experiment 2. The white circle shows the mean for each condition.
Importantly, results in the deception block replicated those of Experiment 1, with the planned comparison between 2ID and 1ID conditions showing higher error rates when images of the same face were mislabelled as different faces, t(90) = 3.40, p = .001, Cohen’s d = 0.394. This effect was also robust when accounting for possible practice effects between blocks (see analysis of covariance [ANCOVA] in Supplementary Materials).
To determine why the 2ID-genuine condition caused more errors than the 2ID-deception condition, we explored whether this may be in part due to differences in the perceptual similarity between the two targets. Our analysis indicates that on average two images of the same person are going to be perceptually more similar to each other than two images of different people (see Supplementary Materials for full details of this analysis). This suggests that these differences in error rates could be attributed to differences in the perceptual similarity between the two targets, with more dissimilar targets leading to poorer representation and greater error.
In line with previous research on the dual-target cost, the higher error rates found in multiple-target search can be attributed to differences in the quality of representation for the two targets. We found that across trials, there were significantly more errors occurring for one of the two targets rather than errors being equally distributed between the two targets (for full analysis, see Supplementary Materials). This supports the conclusion that increased error rates associated with multiple unfamiliar target search are in part a result of prohibited representations of “non-preferred” targets (see Mestry et al., 2017). Analysis of search durations (trial length) is reported in Supplementary Materials. Briefly, there were no differences in time spent for each condition in deception block, but there were differences in the genuine block, with the 2ID condition trials taking longer on average compared with the other conditions.
Discussion
This experiment was designed to test two hypotheses. First, it tested whether identity attributions affect the formation of face representations. Consistent with Experiment 1, we found that deceiving participants to believe two images of the same person were different people (2ID-deception) increased identification errors in visual search compared to when participants believed the two images were of one person (1ID). This shows that top-down identity attributions affect the formation of mental representations and subsequent visual search performance.
Second, we tested whether this effect of identity attribution was sufficient to account for dual-target visual search costs. We found that the large dual-target cost that occurred when participants searched for two different people (2ID-genuine) was larger than that observed when participants made different identity attributions to images of the same face (2ID-deception). As incorrect identity attributions did not account for all of the dual-target cost seen in the 2ID-genuine condition, it is clear that misleading labels on two different images of the same person are not sufficient to cause a dual-target cost. This suggests that the perceptual similarity between the two images of the same face (in the 2ID-deception condition) must allow a more accurate target search, thus reducing the dual-target cost relative to those seen in the 2ID-genuine condition.
General discussion
Across two experiments, we manipulated the identity labels given to image pairs of the same face to isolate the effects of top-down information on the formation of memory representations. First, in Experiments 1 and 2, we found that mislabelling images of the same target individual with different names caused poorer visual search performance relative to when the images were labelled with the same name, thus confirming top-down modulation from semantic information on the formation of memory representations. Second, in Experiment 2, we showed that this effect was not sufficient to account for the dual-target cost seen when participants are required to search for two different identities. The evidence for this was that fewer errors occurred when the two images of the same face were given different names than when the two images genuinely depicted different individuals and were given different names.
The first result demonstrates the important role that top-down mechanisms play during the early stages of face learning. Mechanisms involved in face learning have been of interest for many years, but initial studies used images taken in highly standardised conditions (Clutterbuck & Johnston, 2002, 2004; Tong & Nakayama, 1999), which do not reflect the full variation in a person’s appearance that is encountered in daily life (see Burton, 2013; Jenkins et al., 2011). In these studies, becoming familiar with a face produced clear performance benefits to face matching (see Clutterbuck & Johnston, 2002, 2004) and visual search (Tong & Nakayama, 1999), in the absence of top-down support from semantic identity labels. In more recent studies that used more variable images like those used here, initial guidance as to whether images do or do not show the same person—for example, from cues like the names or context in which they presented—appears to play an important part in face learning (Andrews et al., 2015; Dowsett et al., 2015; Menon et al., 2015a, 2018).
Here, we found that the top-down manipulation of identity attribution affected whether we observed evidence of face learning when images had naturalistic variability in appearance. This suggests that an entirely bottom-up account for initial stages of face learning is not sufficient when variation in appearance approximates real-world viewing conditions. Newly encountered or unfamiliar faces are at risk of being incorrectly categorised as belonging to different people, an effect that has been linked to the difficulty in distinguishing between within-face variability and between-face variability (Jenkins et al., 2011). Interestingly, recent evidence suggests that some individual’s faces can be more difficult to learn than others (Devue, 2019). Devue showed that faces which were highly variable in appearance were more poorly recognised than faces which had more consistent appearance when the faces had been encountered relatively infrequently, suggesting that high levels of variation in appearance inhibit initial face learning. In our studies, we found that providing cues to identity facilitated learning, possibly by helping observers correctly cohere instances of the same face rather than having to rely solely on perceptual information.
This is consistent with recent computational work by Kramer et al. (2018), who show that purely bottom-up statistical image descriptions do not provide an adequate model of human familiar face recognition. Instead, they found that when bottom-up statistical image descriptions were supported by top-down constraints, system performance more closely resembled human performance. Top-down links between semantic and perceptual information stores have been proposed in cognitive models of the face-processing system (see Bruce & Young, 1986; Burton et al., 1990), but the functional significance of this link is only starting to be explored. Our data suggest that initial stages of face learning—when forming working memory representations—involve an interplay between semantic and perceptual input to correctly cohere images of the same individual.
These experiments also help describe the nature of the memory representations that underlie the multiple-image advantage. Typically, representations of unfamiliar faces are constrained by strict capacity limits in memory. These limitations impair performance when attempting to remember multiple different identities simultaneously (Bindemann et al., 2012; Mestry et al., 2017). Importantly, these limits are also observed when remembering multiple specific images of the same face, where there was a requirement to hold each of the specific images separately in memory (Dunn et al., 2019; Experiment 4), suggesting that the demands of maintaining multiple pictorial representations for faces are sufficient to incur a dual-target cost. Thus, because encoding multiple images of the same face did not result in a cost to search accuracy, this suggests that multiple images of a face are assimilated within a single representation rather than being held in memory as individual representations.
In Experiment 2, we also asked whether mislabelling images of the same unfamiliar face with different names produced dual-target costs that are found when people search for two unfamiliar face targets (Mestry et al., 2017). If the formation of face memory representations were entirely dictated by top-down information, then we would expect dual-target costs when holding two images of the same face that had been given separate names. While it is clear from recent computational (Blauch et al., 2021a; Kramer et al., 2018) and behavioural (Menon et al., 2015a, 2018; Schwartz & Yovel, 2016) studies that top-down information plays an important role in face learning, there is disagreement as to the relative contributions of bottom-up perceptual and top-down semantic representations to face learning and recognition processes. Some have emphasised conceptual information in distinguishing between familiar and unfamiliar face representations (Blauch et al., 2021a, 2021b; Rossion, 2018; Yovel & Abudarham, 2021), while others have emphasised the importance of interplay between perceptual and conceptual information (Kramer et al., 2018; Young & Burton, 2018).
While we found top-down modulation of face learning, we also found that this modulation is constrained by bottom-up perceptual information. If face learning was guided entirely by top-down information, then we would expect that applying different identity labels to the same face would produce separate representations in memory and produce a dual-target cost. However, while the increased errors caused by erroneous labelling of the images with different names imply some top-down modulation of the memory presentation, this manipulation did not cause the formation of dual-face representations that leads to a dual-target search cost. This suggests that top-down attributions cannot be the sole mechanism for face learning and instead imply that the assimilation of the memory representations is still possible without matching labels through perceptual processes.
This is consistent with previous evidence in the broader literature on visual search and working memory. Stroud and colleagues (2012) asked participants to search for target colours that varied in their similarity as defined within a region of colour space. They found that participants suffered a larger dual-target cost for two target colours less similar in shade—that is, further away in the colour space—than for two target colours more similar in shade (see also Stroud et al., 2012). Likewise, memory demands for representing multiple single-category targets are proportional to their similarity in representational space (see Jiang et al., 2016; Sims et al., 2012). We also find evidence that perceptual similarity affected the dual-target cost in the current studies. As the images of the genuinely different people are less similar to each other than different images of the same face, the higher error rate in the 2ID-genuine conditions can be taken as evidence that less similar targets incur a larger dual-target cost.
In summary, our results show that both perceptual similarity and top-down constraints from name information both contribute to the formation of face representations. We found that more robust representations of faces are formed when variable image pairs of a single face are co-presented with the same identity label compared with when associated with different labels. Paradoxically, labelling the images with different names did not induce a dual-target cost. Together, these results suggest that erroneously labelling the images with different names was not sufficient to lead to the creation of separate representations, but did inhibit the effective integration of the perceptual information available across the two images of the same person than was the case when both images have the same names (see also Burton et al., 2016; Menon et al., 2018). Future work is necessary to test this proposal further and to understand the interaction between perceptual similarity and top-down constraints in face representation more generally.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Ethics statement
This research was approved by the Human Research Ethics Committee at the University of New South Wales. The individuals pictured in this article have provided written informed consent for their image to be used.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported by an Australian Research Council Linkage Project grants to Richard Ian Kemp and David White (LP130100702, LP160101523) and by funding from the Australian Passport Office.