
Abstract
Language comprehension depends heavily upon prediction, but how predictions are generated remains poorly understood. Several recent theories propose that these predictions are in fact generated by the language production system. Here, we directly test this claim. Participants read sentence contexts that either were or were not highly predictive of a final word, and we measured how quickly participants recognised that final word (Experiment 1), named that final word (Experiment 2), or used that word to name a picture (Experiment 3). We manipulated engagement of the production system by asking participants to read the sentence contexts either aloud or silently. Across the experiments, participants responded more quickly following highly predictive contexts. Importantly, the effect of contextual predictability was greater when participants had read the sentence contexts aloud rather than silently, a finding that was significant in Experiment 3, marginally significant in Experiment 2, and again significant in combined analyses of Experiments 1–3. These results indicate that language production (as used in reading aloud) can be used to facilitate prediction. We consider whether prediction benefits from production only in particular contexts and discuss the theoretical implications of our evidence.
Introduction
When reading or listening, people can predict the next word that they will see or hear (e.g., Altmann & Kamide, 1999; Federmeier & Kutas, 1999; Van Berkum et al., 2005). But what mechanisms do they use to do so? Recently, a number of researchers have proposed that comprehenders predict by involving aspects of the system that is otherwise used to produce utterances (prediction-by-production: Dell & Chang, 2014; Federmeier, 2007; Pickering & Garrod, 2013; cf. Hickok, 2012). More specifically, comprehenders may covertly imitate the utterance that they are currently hearing and use this as the basis for determining what they themselves would say next if they were speaking.
However, the current evidence that production is used for prediction is largely indirect (see Pickering & Gambi, 2018). For instance, brain regions that are implicated in the production of tongue-articulated sounds are also active when comprehenders expect to hear such sounds (D’Ausilio et al., 2011), and tongue movements performed while listening to sentences appear to be affected by expectations about upcoming words (Drake & Corley, 2015). More recently, Rommers et al. (2020) had participants read sentence-final predictable or unpredictable words aloud or silently and found that the production effect (the finding that words read aloud are remembered better than words read silently) was smaller for the predictable words. This implies that participants used the production system to predict such words and therefore reading aloud added less benefit to memory. Moreover, participants found it difficult to remember whether a predictable word had been read aloud or silently, presumably because they engaged the production system in both cases.
All of these findings suggest a close link between production and prediction, but do not demonstrate that production is causally involved in prediction. There is also correlational evidence that people with better production skills are better at predicting language (Federmeier et al., 2010; Mani & Huettig, 2012), and some indirect evidence that prediction could be stronger in contexts where the production system is overall highly activated (Hintz et al., 2016; Hintz & Meyer, 2015), but again, these studies do not unambiguously demonstrate a causal role of production in how individuals predict.
A causal test of prediction-by-production would show that intervening on the production system changes how participants generate predictions, and one recent event-related potential (ERP) study provides this type of test. Martin et al. (2018) had Spanish-speaking participants read highly predictive sentence contexts followed by either expected or unexpected words that differed in grammatical gender (e.g., El rey llevaba en la cabeza una corona/un sombrero; “The king wore on his head a crown/a hat”). It is known that an article or adjective whose gender is consistent with an unexpected but not an expected upcoming noun leads to an enhanced N400 effect, suggesting that the comprehenders predict such information (Van Berkum et al., 2005; Wicha et al., 2004). Consistent with prediction-by-production accounts, Martin et al. found that the N400 response to articles whose grammatical gender was unexpected was reduced when participants simultaneously performed an articulatory suppression task that taxed the production system (i.e., repeatedly pronouncing a syllable), as compared to two control conditions (i.e., tongue tapping, listening to a recording of one’s voice pronouncing the syllable). Thus, limiting the availability of the production system during comprehension appeared to weaken the effects of prediction, implying that comprehenders use their production system to generate predictions.
In this article, we report a complementary test of prediction-by-production, asking whether increasing the engagement of the production system during comprehension can enhance the effects of prediction. In our experiments, participants read sentence contexts that either were (1a) or were not (1b) highly predictive of a final word, and we measured how quickly participants recognised that final word (Experiment 1), named that final word (Experiment 2), or used that word to name a picture (Experiment 3).
(1a) It was windy enough to fly a . . . kite.
(1b) They went to see the famous . . . show.
Crucially, we manipulated the engagement of the production system by asking participants to read the sentence contexts either aloud or silently. The primary purpose of the language production system is to convert a message into sound. According to most theories of spoken production, the speaker constructs the message to be conveyed, activates a network of relevant concepts, accesses lexical items and syntactic information, and then focuses the activation on a single form that provides the input to articulation (Levelt, 1989; see Goldrick et al., 2014). Reading aloud engages many of the stages involved in other acts of production, such as the construction of representations of sound (though perhaps not the message because it is provided by the written word itself: Levelt et al., 1999, argued that reading aloud may not require activation of the lexical concept). In particular, it engages many production mechanisms that are not involved in silent reading (where no sound is produced). Thus, reading aloud overall engages the production system to a greater extent than reading silently.
Our method has potential advantages over using articulatory suppression to reduce the availability of the production system during reading. We reasoned that a suppression design would be potentially hard to interpret, because articulatory suppression might interfere with verbal working memory, and thus disturb the ability of participants to comprehend the sentence contexts and generate predictions. By contrast, reading aloud, like spontaneous speech, demands the use of production processes such as formation of phonetic representations and articulation. Importantly, we do not claim that production processes are not used during silent reading. However, we maintain that their use is necessarily enhanced when reading aloud.
Returning to our experimental design, because the possibility of generating predictions is greater when comprehending highly predictive than less predictive contexts, any effect of prediction on language processing should be greater for (1a) than (1b). And as reading aloud engages production processes to a greater extent than reading silently, the effects of prediction should be further enhanced in the read-aloud mode.
Experiment 1 used a lexical decision task: after reading the sentence contexts, participants were instructed to indicate whether the sentence-final stimulus was a word (kite) or a nonword (kile). An interaction between predictability (low/high) and reading mode (silent/aloud) would implicate prediction-by-production under conditions when the task relies predominantly on comprehension. Experiment 2 used a go/no-go task in which participants were instructed to read aloud the sentence-final stimulus if it was a word, but not if it was a nonword. Here, an interaction would implicate prediction-by-production under conditions when the task involves comprehension (deciding if the stimulus is a word) and also some aspects of production (naming the word). Experiment 3 used a picture naming task in which participants were instructed to name a sentence-final picture stimulus whose name was highly predictable or not given the sentence context. An interaction would implicate prediction-by-production under conditions when the task strongly relies on production (i.e., relies on the whole process of production, from intention to articulation).
Experiment 1
Methods
Our data, materials, and commented analysis scripts are available at the Open Science Framework (OSF) website of this project: https://osf.io/xun2v/.
Participants
Twenty-four participants, who were Edinburgh University students and native speakers of British English, were paid £6. They had normal or corrected-to-normal vision and reported no language disorders. We set this sample size based on our intuitions about the effectiveness of the manipulation and our experimental design (which used a considerable number of items, 240 per participant).
Design
We used a 2 (Predictability: low vs high) × 2 (Reading Mode: silent vs aloud) × 2 (Stimulus Type: nonword vs word) within-subjects design. Reading Mode was blocked, and the order of reading silently/aloud was a between-subjects manipulation (Order: silent first vs aloud first). To increase reliance on top-down prediction, contexts and sentence-final stimuli were presented against a white-noise background (we reasoned that the engagement of prediction is particularly likely in the conditions of noise; see Pickering & Gambi, 2018). Moreover, sentence-final stimuli were displayed in a shade of grey that was individually selected to ensure participants’ word recognition was impaired but above chance (cf. Stanovich & West, 1979). Prior to the task, we carried out an individual pretest to determine the shade for the sentence-final stimuli.
Materials
To create the stimuli, 24 additional participants were asked to fill in the missing final word for 291 sentences truncated before the last word. From this set, we selected 120 high-predictability sentences (for which the most frequently chosen final word was selected, on average, by 89% [± 2] of participants; throughout the article, the values in square brackets indicate 95% confidence intervals) and 120 low-predictability sentences (for which the most frequently chosen final word was selected, on average, by 20% [± 1] of participants). High- and low-predictability sentences were matched for number of words,
An example of the stimuli used in Experiment 1.

Sentence contexts were displayed in a shade of grey identical for all participants (hex #393939). Sentence-final stimuli were presented in a shade of grey that was individually thresholded for each participant, using a pretest. The pretest involved five different shades, anchored on the neutral axis in the RGB space and differing in lightness level (#414141, #474747, #4D4D4D, #515151, #565656). Each of the 250 trials began with a central fixation cross displayed against a square of white noise (150 × 150 pixels, black and white; fixation cross shown for 500–1,000 ms, randomly varied). Then, a single word or a nonword was randomly displayed in one of the shades (300 ms). The participant pressed a key to signal whether they saw a word or a nonword (half of trials were words, half nonwords; these stimuli were not used in the main experiment). We identified the shade at which the participant was closest to 60% accuracy and used it for the sentence-final stimuli in the experiment.
Procedure
Each trial began with a central fixation cross, displayed against a square of white noise, surrounded by a white background (1,000–1,500 ms, randomly varied on trial-by-trial basis). Next, sentence contexts were shown word-by-word (300 ms ON, 200 ms OFF). On the screen before the final word, the background switched from white to yellow and then the sentence-final stimulus was displayed (300 ms). Participants were instructed to read the words on the white background aloud or silently and then to press a key to indicate whether they thought the sentence-final stimulus was a word or a nonword. They were told to never read aloud the sentence-final stimulus. Trials ended after the participant had responded to the stimulus (Figure 1) or after a response to the comprehension question (if a given trial was followed by a comprehension question). The experiment was divided into 2 blocks of 120 trials (read either aloud or silently), and each block was preceded by 8 practice trials where participants trained to perform the task in the presence of the experimenter. During the main task, if needed, the experimenter reminded the participants about the current reading condition. The experiment lasted about 30 min.
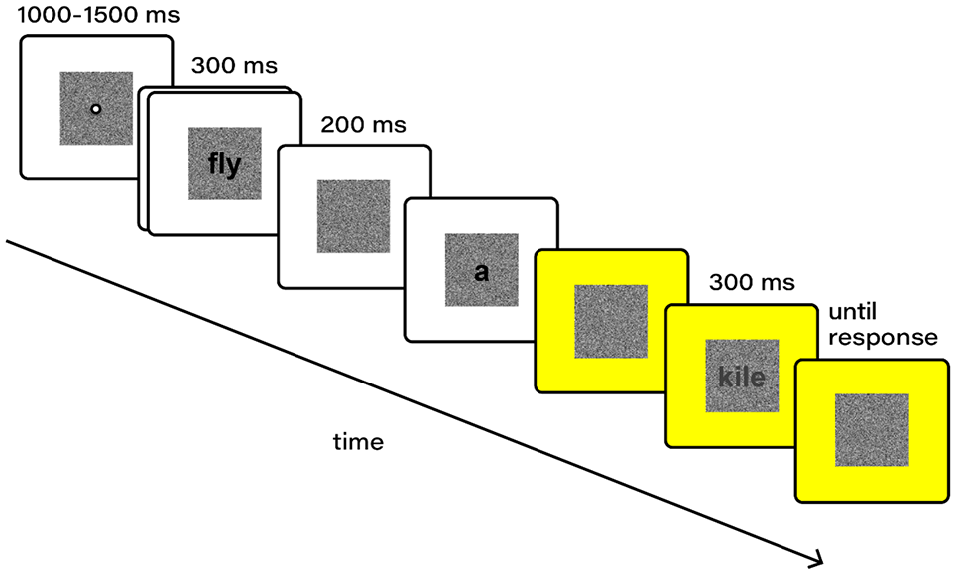
An example of a trial (nonword stimulus) in Experiments 1–2.
Results
To investigate whether engaging the production system increased the effect of predictability on lexical decisions, we first tested how likely participants were to judge the sentence-final stimulus as a word rather than a nonword. We ran a binomial generalised linear mixed model (GLMM) with Predictability (low vs high), Reading Mode (silent vs aloud), Stimulus Type (nonword vs word), and Order (silent first vs aloud first) as fixed effects, and specifying a maximal random structure. Effect-coded contrasts were applied to predictors in all models reported in this article (Predictability: low was set to −0.5, high to 0.5; Reading Mode: silent was set to −0.5, aloud to 0.5; Stimulus Type: nonword was set to −0.5, word to 0.5; Order: silent first was set to −0.5, aloud first to 0.5). See Supplementary Materials for further details about our models.
Not surprisingly, participants were more likely to respond “word” when reacting to sentence-final stimuli that were real words rather than nonwords and more likely to respond “word” following high- than low-predictability contexts (ps < .001; see means in Table 2 and regression results in Table 3). These effects of Stimulus Type and Predictability marginally interacted (p = .056), such that the effect of Predictability was slightly greater for word stimuli than nonword stimuli. However, there was no interaction between Predictability and Reading Mode (i.e., engaging production by reading aloud did not influence the effect of context predictability on the odds of making a “word” response, p > .250) and there was no three-way interaction among Predictability, Reading Mode, and Stimulus Type (i.e., engaging production did not influence the effect of predictability on the odds of correctly making a “word” response, p > .250). See Supplement for accuracy analyses confirming this pattern of results and for signal detection (d-prime) analyses of these data.
Percentages of “word” responses in Experiments 1 and 2.
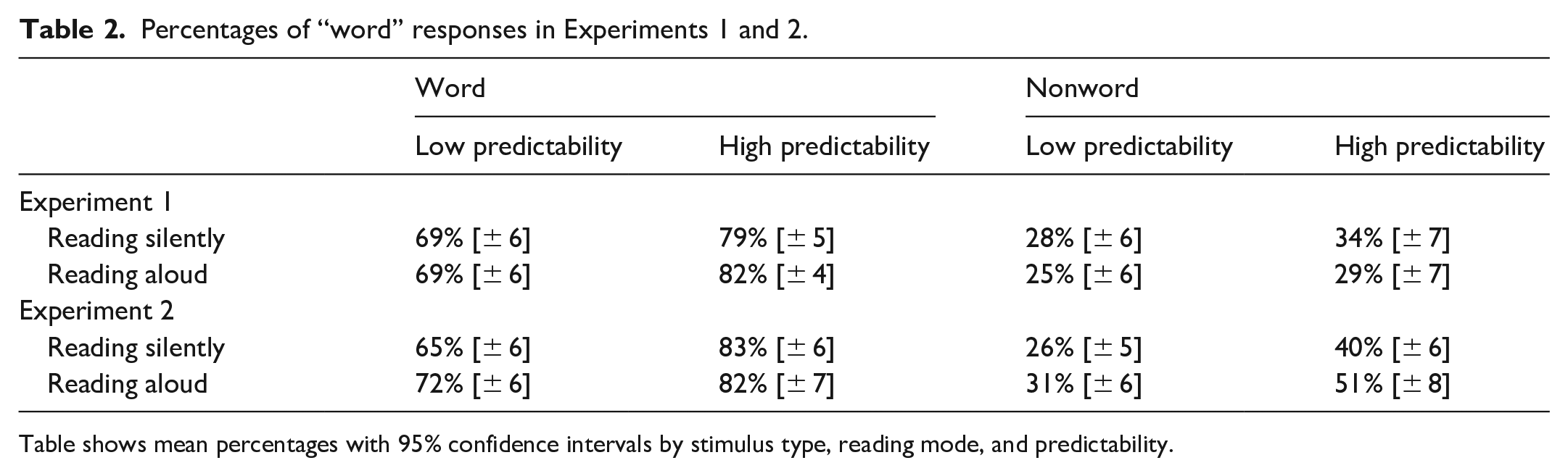
Table shows mean percentages with 95% confidence intervals by stimulus type, reading mode, and predictability.
GLMM analyses of “word” responses in Experiment 1.
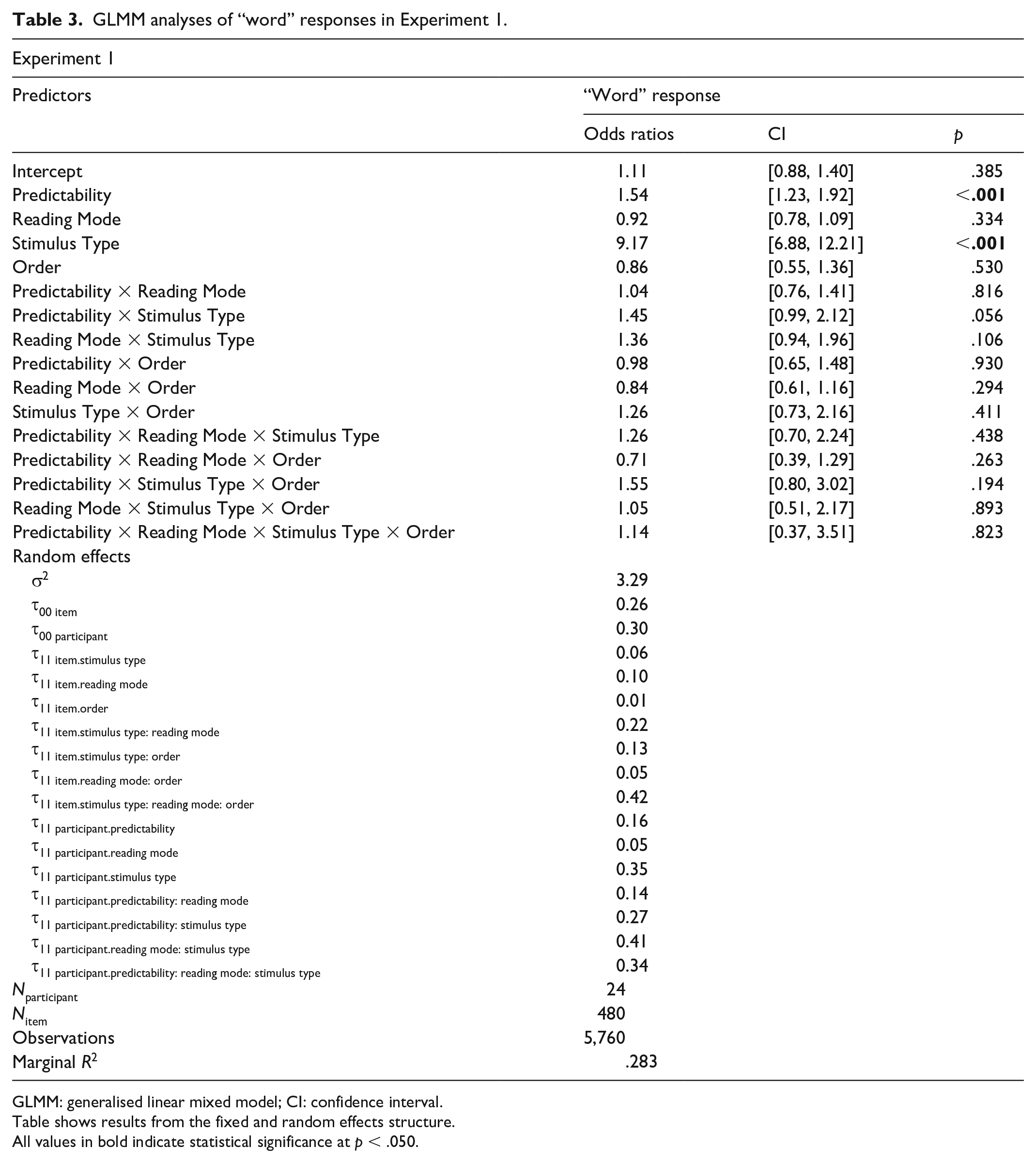
GLMM: generalised linear mixed model; CI: confidence interval.
Table shows results from the fixed and random effects structure.
All values in bold indicate statistical significance at p < .050.
Next, we analysed key-press reaction times (RT) on trials where participants correctly responded to sentence-final stimuli that were real words. We excluded outliers deviating more than 2.5 SD from each participant’s mean (2%) and ran a maximal-structure linear mixed effect (LME) model with Predictability, Reading Mode, and Order as predictors, and with by-subject and by-item random intercepts and slopes. We found that participants were faster to respond following high- than low-predictability contexts and were overall slower to respond after reading the contexts aloud (ps < .001; see means in Table 4 and regression results in Table 5). Although the interaction between Predictability and Reading Mode was not reliable, the descriptive pattern of results was consistent with our expectations: Predictability had a numerically greater effect when participants read the sentence contexts aloud rather than silently (p = .174). There were no other effects or interactions. See Supplement for further analyses confirming these findings (i.e., regression models conducted on normalised data and models robust to data contamination).
Participants’ RT in Experiments 1, 2, and 3.
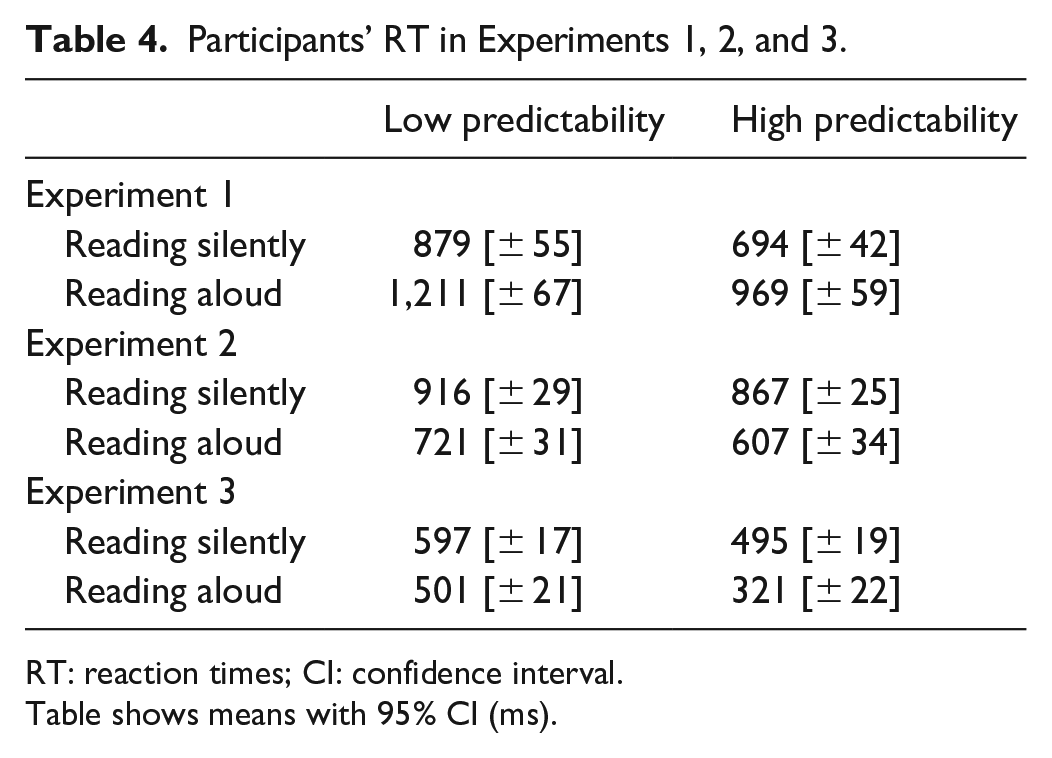
RT: reaction times; CI: confidence interval.
Table shows means with 95% CI (ms).
LME analyses of RT in Experiment 1.
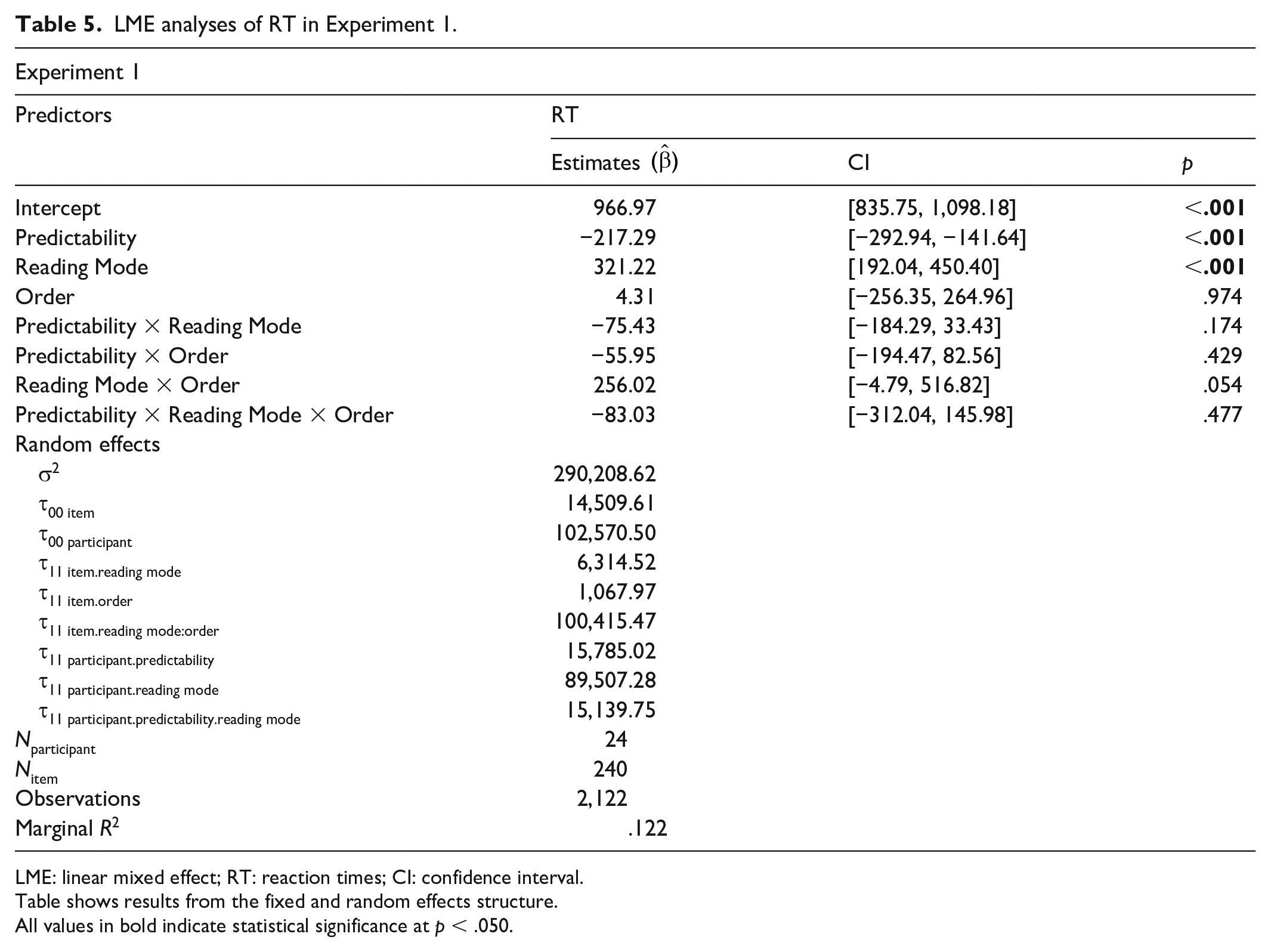
LME: linear mixed effect; RT: reaction times; CI: confidence interval.
Table shows results from the fixed and random effects structure.
All values in bold indicate statistical significance at p < .050.
Finally, we analysed responses to the context comprehension questions and found that participants were similarly engaged with the task whether they were reading aloud or silently and whether they were reading high- or low-predictability contexts. They responded correctly to the questions on 90% of trials, and the odds of providing a correct answer did not differ across conditions (ps > .250; full results in Supplement).
Experiment 2
Experiment 1 did not find statistical evidence that engaging the production system enhanced the use of prediction in a lexical decision task, as indicated by the lack of a significant interaction between Predictability and Reading Mode. However, the descriptive pattern of participants’ response times in Experiment 1 was suggestive of the possibility that production does affect prediction (i.e., predictability had a larger numerical effect on response times when reading aloud vs silently). At this stage, we speculated that an effect of production on prediction might be easier to identify when the experimental task itself relies on the production system (see Huettig, 2015). Thus, in Experiment 2, we investigated whether engaging the production system causes larger effects of predictability in a task that required a spoken response.
As before, we asked participants to read high- and low-predictability sentences either aloud or silently, but now they also had to read aloud the final word if they decided it was a word, and not otherwise. In this experiment, participants’ decisions whether to name the sentence-final stimulus reflect their ability to comprehend, as in Experiment 1, but the time to articulate that name reflects processes of spoken language production. If prediction-by-production helps subsequent production processes, then participants should take less time to articulate the name after reading high- than low-predictability contexts, and this boost should increase when they read the contexts aloud.
Methods
Participants
We recruited 32 further participants from the same population and on the same terms as in Experiment 1. We increased the sample size based on the possibility that Experiment 1 was underpowered (see Supplement for an estimation of the sample size needed to detect prediction-by-production effects).
Materials, procedure, and design
The experiment was identical to Experiment 1, except that participants were instructed to read the sentence-final stimulus out loud if it was a word and not do so otherwise. Responses were recorded for 3,000 ms from the onset of the sentence-final stimulus, using a microphone positioned in front of the participant.
Results
Two trained coders analysed the recordings from the experiment. For each trial, they identified whether participants named the sentence-final stimulus and calculated naming time (i.e., time from stimulus onset until participants started articulating the name). The inter-rater reliability between coders for this measure was in the excellent range (two-way random, consistency intraclass correlation coefficient [ICC] = .99; calculated on 6% data; Cicchetti, 1994).
To test whether prediction-by-production affected the decisions to read the sentence-final stimuli, we analysed the odds of naming each sentence-final stimulus across conditions, using a binomial GLMM with Predictability, Reading Mode, Stimulus Type, and Order as fixed effects, and including a maximal random structure. The means are presented in Table 2 and the results from the model in Table 6.
GLMM analyses of “word” responses in Experiment 2.
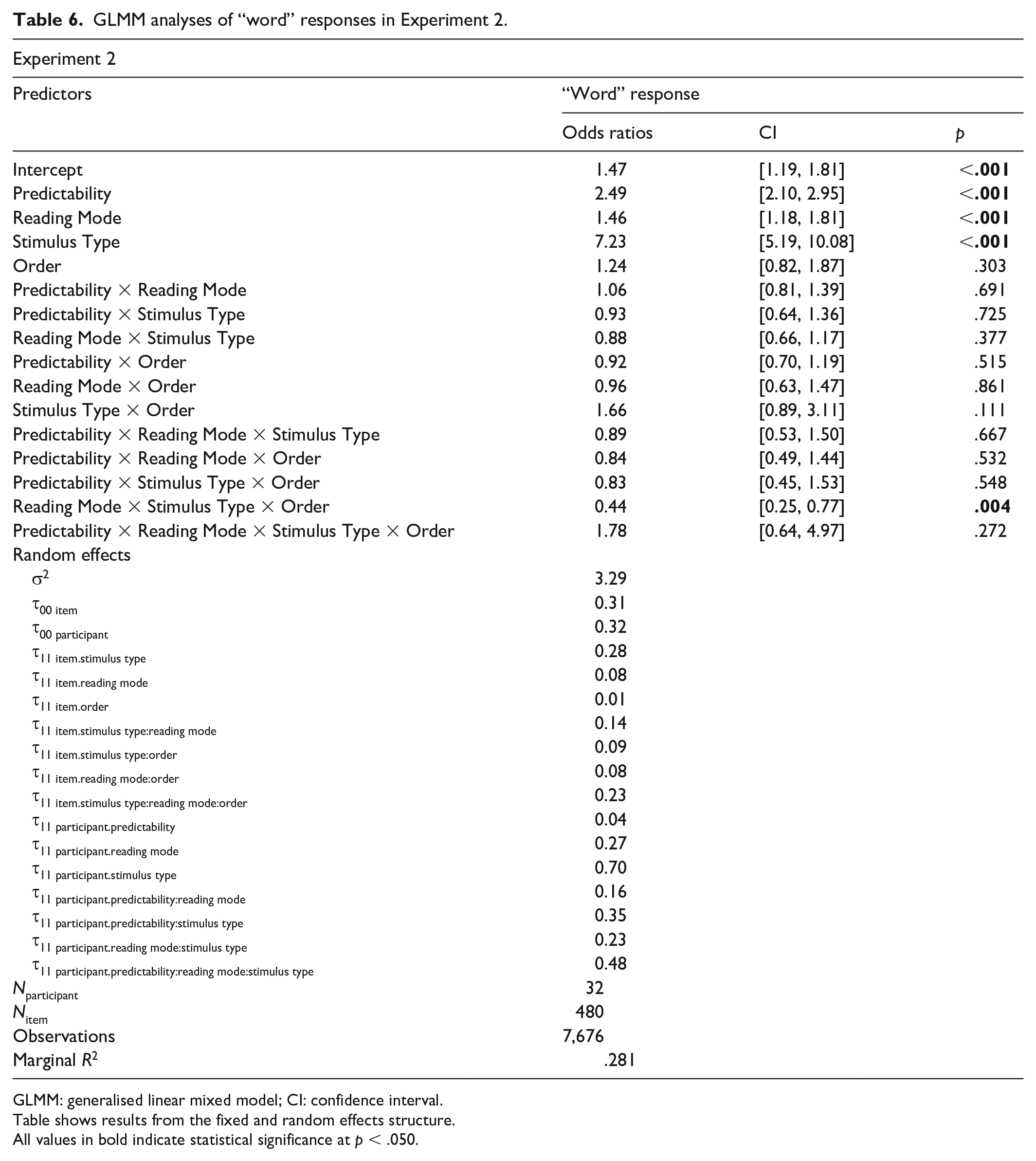
GLMM: generalised linear mixed model; CI: confidence interval.
Table shows results from the fixed and random effects structure.
All values in bold indicate statistical significance at p < .050.
We found that participants were more likely to name the sentence-final stimulus after a high-predictability context (an effect of Predictability, p < .001) and were more likely to name the stimulus if it was a word (an effect of Stimulus Type, p < .001). However, these effects showed no tendency towards an interaction (p > .250), and there were no further interactions involving both Predictability and Reading Mode, suggesting that the effects of predictability were similar whether participants were reading aloud or silently (ps > .250).
We also found that participants were more likely to name the sentence-final stimulus after they had read the context sentence aloud than silently (an effect of Reading Mode, p < .001), perhaps because it was more difficult for them to inhibit their spoken response in this case. Furthermore, the effect of Reading Mode interacted with Order and Stimulus Type (p = .004), reflecting the fact that participants who read aloud in the second block made more “word” responses (i.e., meaning they read the final stimuli out loud) after reading aloud than silently both for word and nonword stimuli (word stimuli:
Next, we analysed participants’ naming times for the sentence-final stimuli. When the final stimulus was a word, participants named it on 77% [± 2] of trials. From these trials, we excluded by-participant outliers as per Experiment 1 (<1%) and then trials where in reading aloud participants were still reading the context after the onset of the sentence-final stimulus (a further 18%). Because of this, three participants lost more than half observations in read-aloud mode and were excluded from analysis (leaving n = 29). We ran a maximal-structure LME model with naming time as the dependent variable, Predictability, Reading Mode, and Order as fixed effects, and with by-subjects, by-items random intercepts and slopes. The means are presented in Table 4 and the regression results in Table 7.
LME analyses of RT in Experiment 2.
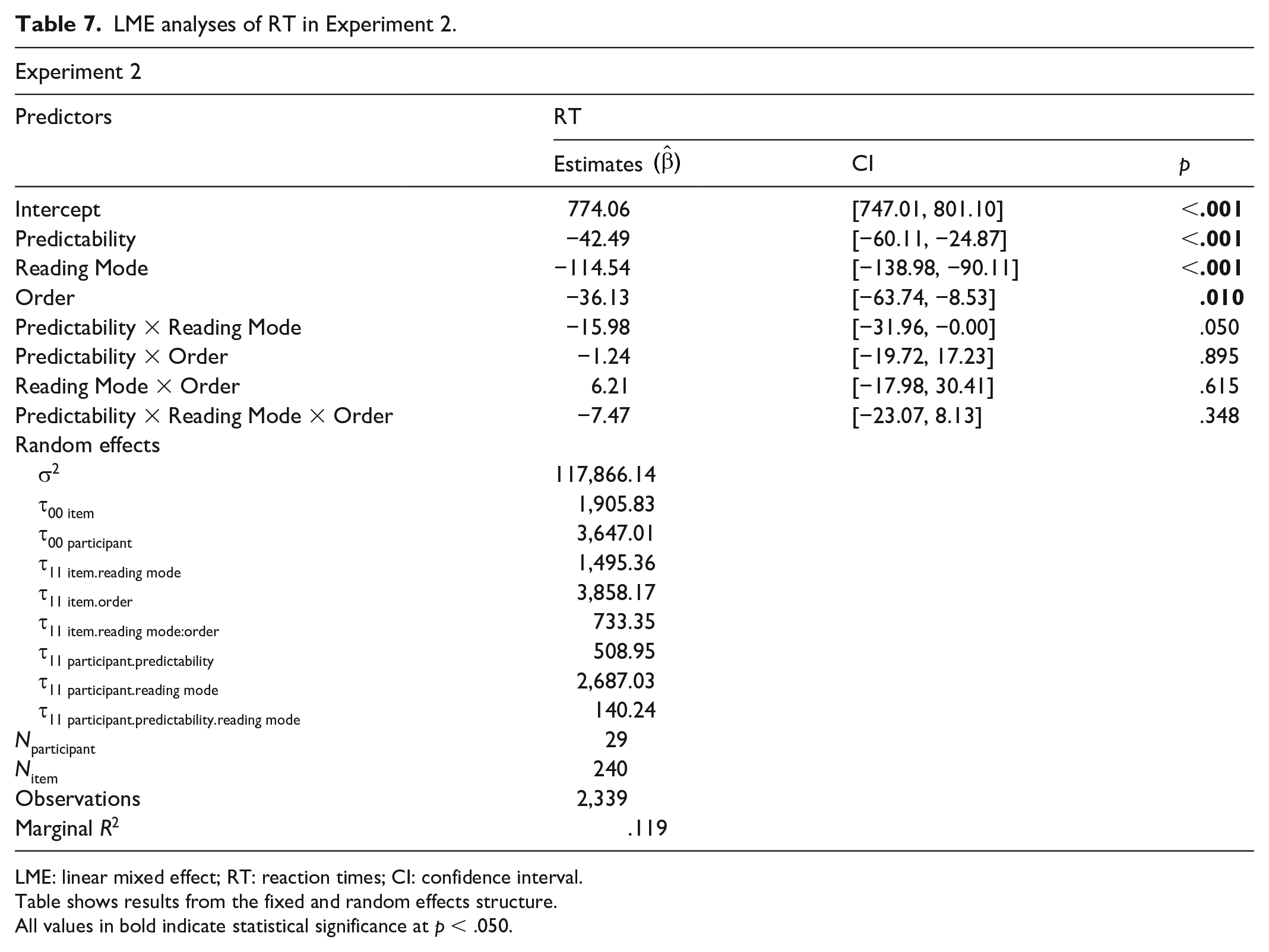
LME: linear mixed effect; RT: reaction times; CI: confidence interval.
Table shows results from the fixed and random effects structure.
All values in bold indicate statistical significance at p < .050.
Unsurprisingly, we found that naming times were affected by Predictability and Reading Mode: Participants were faster to name the final word after a high-predictability context and were also faster after they had read the context aloud (both ps < .001). Crucially, and just as in Experiment 1, we observed that the numerical difference between high- and low-predictability contexts was greater in reading aloud. The interaction between Predictability and Reading Mode was marginal in our main LME model (p = .050), but significant in further analyses accounting for the non-normal distribution of our response time data (i.e., robust models and analyses on normalised data; see Supplement). In addition, we found an effect of Order (p = .010): participants who read aloud in the first block were faster to name the final word than those who read aloud in the second block (
When answering the comprehension questions, participants were more likely to produce a correct response following highly predictable contexts (
Experiment 3
Experiment 2 revealed a numerical pattern consistent with the claim that the production system plays a role in generating predictions: the effect of contextual predictability appeared to be enhanced when the production system had been engaged during context processing. However, the critical interaction was marginal in our main analyses (though significant in the supplementary analyses).
We conjectured that prediction-by-production effects might be clearest when the task engages all processes of spoken production. An important demonstration of production being implicated in prediction comes from the ultrasound imaging study of Drake and Corley (2015), where context predictability affected the tongue movements performed while naming pictures. Thus, in Experiment 3, we replaced word naming with picture naming.
Methods
Participants
We recruited 32 further participants from the same population and on the same terms as in the previous experiments. We set sample size based on Experiment 2.
Design
We used a 2 (Predictability: low vs high) × 2 (Reading Mode: silent vs aloud) within-subjects design. Participants read high- and low-predictability sentence contexts, half of the time aloud, and half of the time silently (the order of reading silently/aloud was counter-balanced between participants; Order: silent first vs aloud first). The sentence contexts were followed by a picture stimulus which participants named aloud into a microphone.
Materials
We developed new stimuli appropriate for picture-naming. There were 60 high-predictability and 60 low-predictability sentence contexts, length-matched:
An example of the stimuli used in Experiment 3.

Each participant saw two lists each comprising 30 high- and 30 low-predictability sentences. Lists were matched for context length, picture name agreement, name frequency, and name length in syllables (all p > .107). Trial order was randomised within each list for each participant. The order of lists was counterbalanced between participants. Twelve trials were followed with a yes/no context comprehension question. Pictures and norms for picture name agreement were taken from the Bank of Standardized Stimuli (BOSS v.2; Brodeur et al., 2014). Norms for picture name frequency and length were taken from SUBTLEX-UK (van Heuven et al., 2014).
Procedure
Trials began with a fixation cross, followed by a sentence context presented as in Experiments 1–2. Each context was followed by a picture and participants were instructed to name it with a single word, as fast as possible. Responses were recorded for 3,000 ms from picture onset by a microphone positioned in front of the participant. Trials ended after the timeout of the recording (Figure 2) or the question response (if a given trial was followed by a comprehension question).
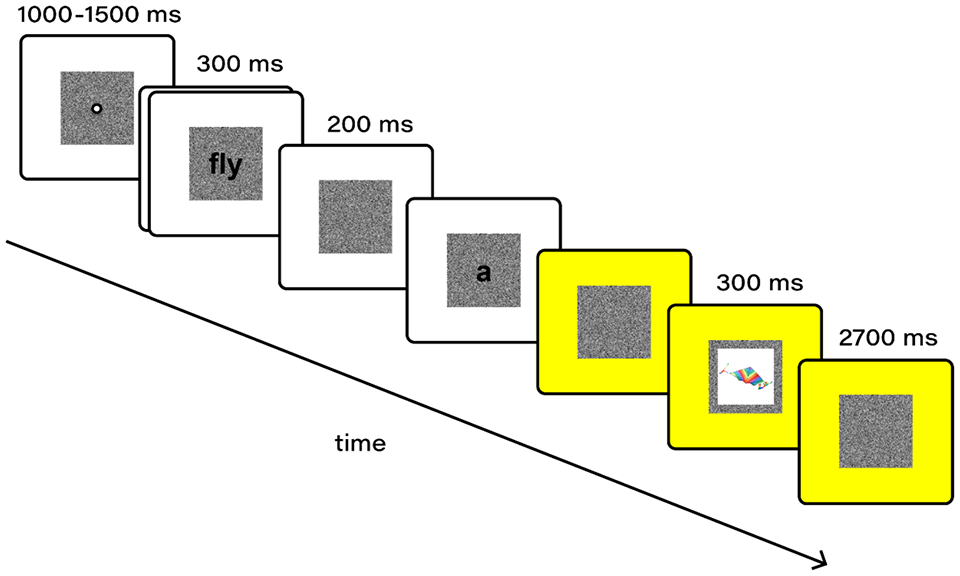
An example of a trial in Experiment 3.
Results
Three trained coders calculated participants’ RT (i.e., time from picture onset until naming onset). The inter-rater reliability was again excellent (two-way random, consistency ICC = .99; calculated on 6% data). Prior to the analyses we removed by-participant outliers as per Experiments 1–2 (3%), and trials on which participants were still reading the sentence context aloud after the onset of the picture (16%). As a result of this, one participant lost more than half observations in read-aloud mode. We excluded their data from further analyses (leaving n = 31).
To test whether reading the context aloud enhanced the facilitative effect of prediction on picture naming, we ran a maximal-structure LME model with Predictability, Reading Mode, and Order as fixed effects, and by-subjects, by-items random intercepts and slopes. As in Experiment 2, participants named the pictures faster after a high-predictability context and also faster after reading the sentence context aloud (both ps < .001; see Tables 4 and 9). But most importantly, we now observed a reliable interaction between Predictability and Reading Mode: the effect of Predictability on naming times was greater when participants had read the sentence contexts aloud than silently (p < .001). Once again, these findings were confirmed by further analyses (i.e., robust models and analyses on normalised data; see Supplement).
LME analyses of RT in Experiment 3.
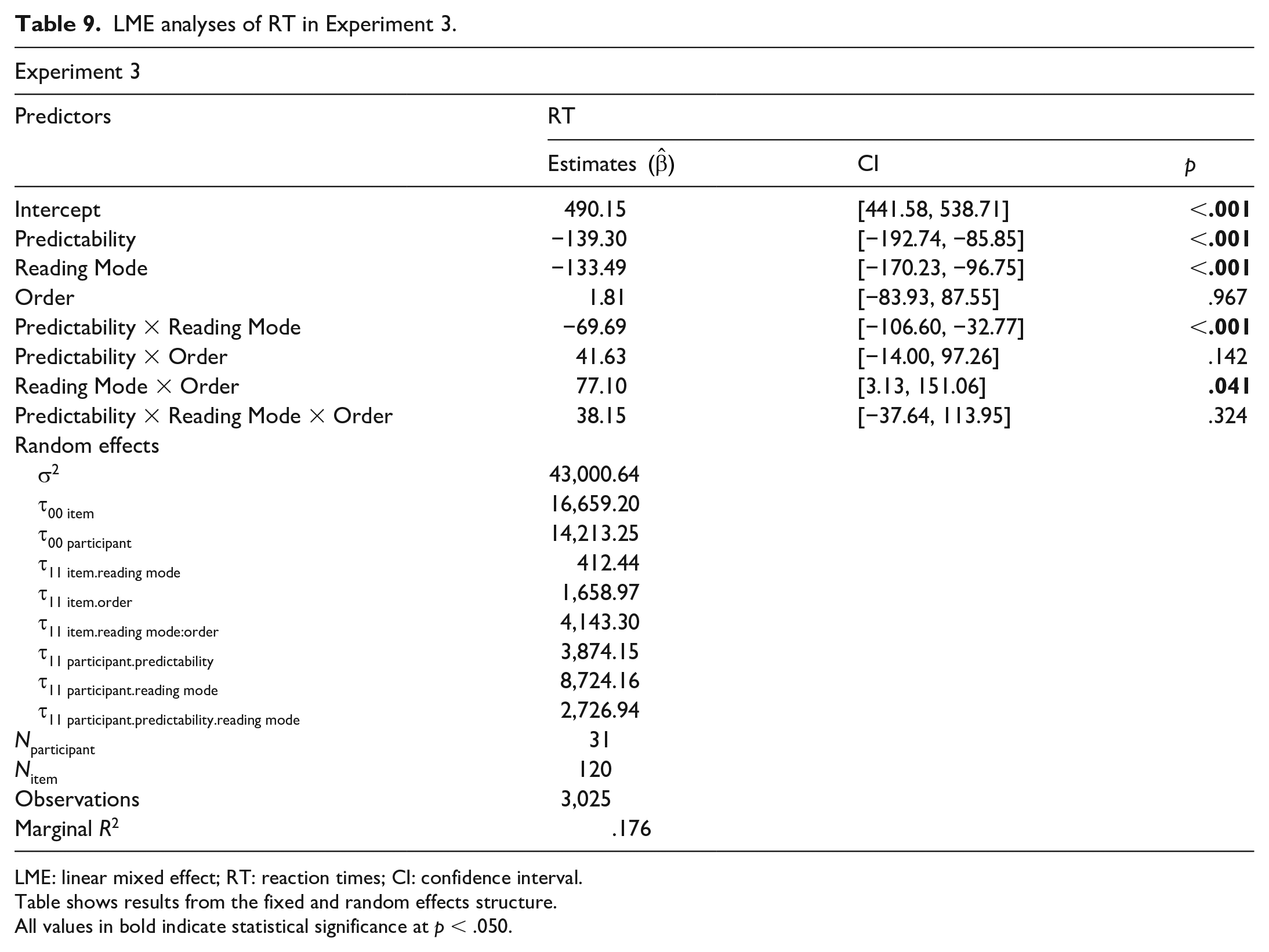
LME: linear mixed effect; RT: reaction times; CI: confidence interval.
Table shows results from the fixed and random effects structure.
All values in bold indicate statistical significance at p < .050.
There was also an additional interaction between Reading Mode and Order (p = .041), such that the effect of reading aloud tended to be greater in participants who read aloud in the second block (
Finally, we found no evidence that the key interaction between Predictability and Reading Mode could be explained by general context comprehension: although participants were more likely to correctly answer comprehension questions after high- than low-predictability contexts (
Mini meta-analysis
Three experiments tested whether engaging the production system would enhance the effects of linguistic prediction on three different tasks—lexical decision, word naming, and picture naming. In analysing the response times of Experiment 3, which used a picture naming task, we observed a robust interaction between Predictability and Reading Mode, indicating that Predictability had a greater effect on response times when participants read the sentence contexts aloud rather than silently. However, in Experiment 1 (lexical decision), the relevant interaction was not statistically significant, and in Experiment 2 (word naming), it was marginally significant.
An important question is whether this pattern of findings reflects a theoretically meaningful difference among those studies. In particular, whereas the task used in Experiment 1 relied on production processes to a very small extent (i.e., manual lexical decision), Experiment 2 relied on production more strongly (i.e., spoken go/no-go), and Experiment 3 involved a measure that very strongly engaged production processes (i.e., picture naming involves production from intention to articulation), which raises the possibility that production affects the use of prediction only in tasks that themselves strongly rely on the production system. Alternatively, however, the difference in statistical significance between the experiments could potentially reflect lack of power in Experiments 1–2, which used a smaller number of participants than Experiment 3, or perhaps result from chance variation in the observed statistical effect. Consistent with this, the numerical pattern of response times in Experiments 1–2 did follow the direction expected if an interaction had been present.
To choose between these alternatives, we conducted a so-called mini meta-analysis of our three experiments (Cumming, 2014; Cumming et al., 2012; Goh et al., 2016). For each experiment, we calculated Cohen’s d for the size of the Predictability and Reading Mode interaction (Table 10) and fit random-effects meta-analytic models using the package metafor v.2.0-0 (Viechtbauer, 2010). To test if the overall effect size across the three experiments was greater than zero, we fit a model that only contained an intercept term; that intercept term was statistically significant, B = −.51 (.26), CI = [−1.02, −0.04], z = −1.97, p = .048, suggesting that the summary effect size of the interaction across experiments was −0.51. To test whether task type (how strongly it relied on production) moderated the interaction effect size, we conducted a second regression in which that distinction was included as a moderator (i.e., we compared the effect size among the three experiments). However, the effect of task type was not statistically significant, B = −.23 (.32), CI = [−0.86, 0.39], z = −0.73, p > .250. These data provide no support for the claim that prediction-by-production is limited to contexts that strongly rely on the production system. But crucially, our results indicate that the critical effect of production on prediction is robust when considering the totality of our data.
Cohen’s d and 95% CI for the size of the predictability and reading mode interaction in Experiments 1–3, including information about the experimental task, sample size (after exclusions), and average number of items per participant per design cell (after exclusions).
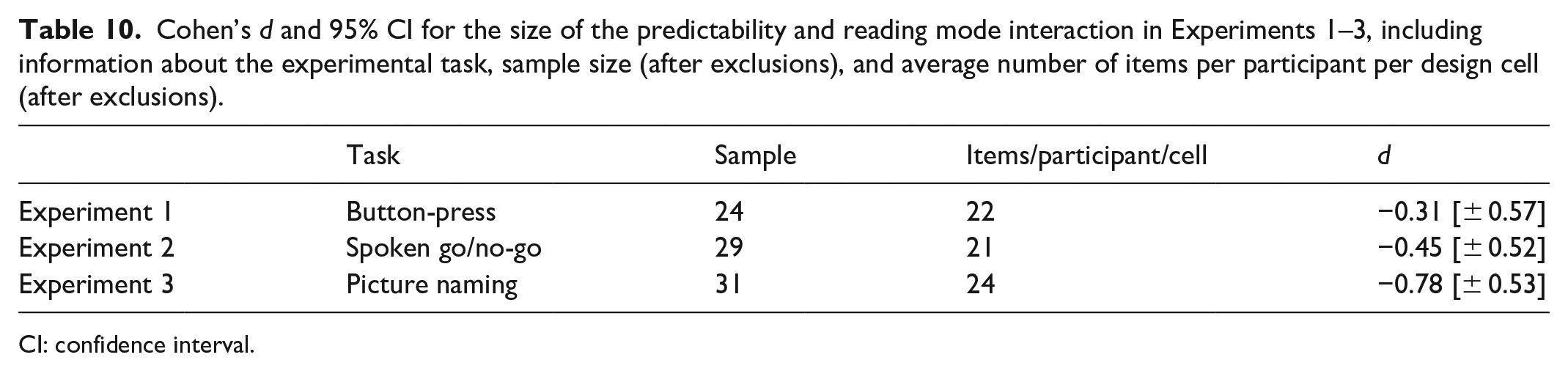
CI: confidence interval.
We also used a mini meta-analysis to conduct a control analysis on the possibility that participants engaged more deeply with the experimental materials when reading them aloud. Recall that participants in our experiments answered comprehension questions. In Experiments 1 and 3, accuracy on those questions was equivalent across the two reading modes but, in Experiment 2, accuracy was slightly higher in the reading aloud condition—a 3% difference that was marginally significant. We conducted a random effects meta-analysis across Cohen’s d effect sizes calculated for each experiment (difference in proportion of correct answers between conditions). Across experiments, we found that the estimated effect size was small and not significantly different from zero, B = .23 (.25), CI = [−0.25, 0.72], z = 0.95, p > .250. We thus conclude that enhanced context comprehension in the reading aloud condition is unlikely to explain the critical interaction between reading mode and predictability found in our studies.
“Omnibus” LME analysis
To further verify the findings from our mini meta-analysis, we combined the data from all three experiments (i.e., we merged the final datasets involved in the LME analyses reported above) and ran a LME model with Predictability (low vs high), Reading Mode (silent vs aloud), and Task (Experiment 1 vs Experiment 2 vs Experiment 3) as predictors, and by-participant and by-item random intercepts and slopes (effect-coded contrasts were applied to Predictability and Reading Mode in the same manner as in the LME analyses reported above; the reference level of Task was set to Experiment 1).
The results are presented in Table 11. There were main effects of Predictability (p < .001) and Reading Mode (p < .001), indicating that response times were longer for low- than high-predictability contexts and for reading aloud than silently. More importantly, the critical interaction between Predictability and Reading Mode was significant (p = .022), but the three-way interaction between Predictability, Reading Mode, and Task was not (ps > .281). These findings are consistent with the meta-analysis: they imply that prediction is facilitated by engaging production, but they provide no evidence for the possibility that such facilitation is stronger in tasks that more strongly rely on the production system.
An “omnibus” LME analysis of RT data from Experiments 1–3.
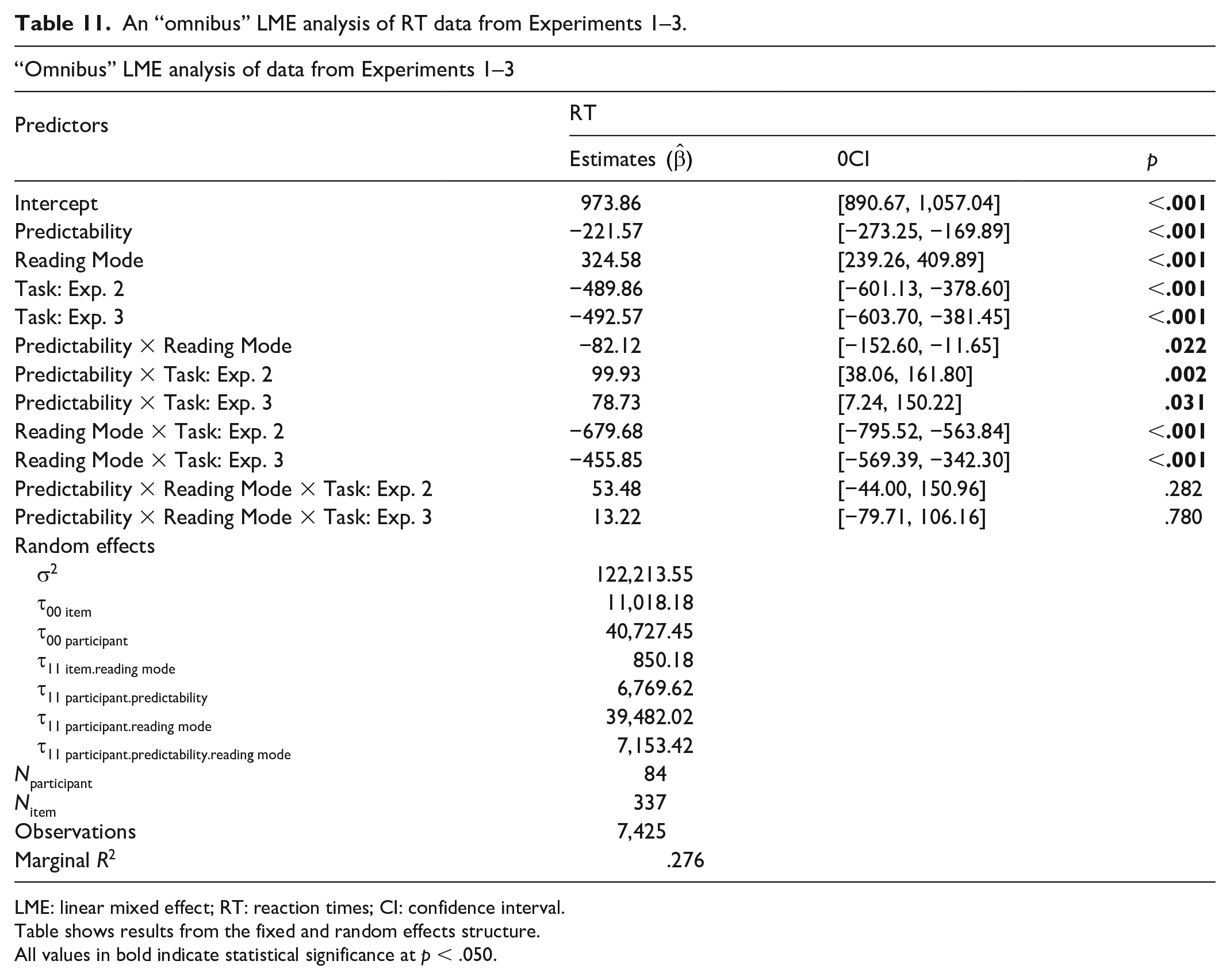
LME: linear mixed effect; RT: reaction times; CI: confidence interval.
Table shows results from the fixed and random effects structure.
All values in bold indicate statistical significance at p < .050.
In addition, the analysis revealed some effects of Task: there was a significant two-way interaction between Task and Reading Mode (ps < .001), such that in Experiment 1 reading aloud was associated with longer response times and in Experiments 2–3 with shorter response times compared to reading silently (see Table 4). This difference might have been caused by the fact that in the reading aloud condition of Experiment 1 participants had to switch between the task of reading out the sentence contexts and producing a manual response to the sentence-final stimuli. In Experiments 2–3, the response was spoken and so there was no task-switching. Moreover, the analysis also found a significant and unexpected interaction between Task and Predictability (ps < .032), indicating that the facilitative effect of prediction was greater in Experiment 1 than in Experiments 2–3 (Table 4); it could be that naming—as an overlearned task—is less affected by contextual support than a less-practised lexical decision task.
General discussion
We investigated how activating the production system by reading aloud potentially enhances the effects of linguistic prediction on language processing. Across three experiments, we found that the effect of contextual predictability on response time was greater when participants had read the sentence contexts aloud rather than silently: this effect was clearest in a picture naming task that itself strongly relied on production processes (Experiment 3), was statistically marginal in a go/no-go task that engaged production to a lesser degree (Experiment 2), and was not significant in a manual lexical decision task (Experiment 1). Although the evidence from Experiments 1 and 2 is not strong when considered in isolation, two analyses involving combined data from all our studies—one a mini meta-analysis and one an omnibus mixed model analysis—suggested that the overall evidence was consistent with a significant effect of reading aloud on prediction.
The importance of these studies is that they clarify the causal relationship between engagement of the production system and use of predictive processing in language. By contrasting reading silently versus reading aloud, we compared the effects of prediction in situations where the production system was fully available but engaged in comprehension to a greater or lesser extent. We found that effects of linguistic prediction were enhanced when the engagement of the production system was greater and that this degree of enhancement was sufficient to significantly affect behavioural responses (at least in the picture naming task of Experiment 3). This finding accords with prior work that suggested a link between prediction and language production (e.g., Drake & Corley, 2015; Federmeier et al., 2010; Mani & Huettig, 2012; Rommers et al., 2020) and with the ERP study by Martin et al. (2018) that showed linguistic predictions can be reduced by suppressing the production system. Critically, our study goes beyond that work by demonstrating that the production system can facilitate linguistic predictions and that this facilitation can affect behavioural, rather than just neural, responses. Our behavioural evidence is particularly important because there is controversy about the reliability of some supposed neural signatures of prediction (Nieuwland et al., 2019). By contrast, there is no controversy about the finding that prediction facilitates behavioural responses such as the ones studied here, and so our data can be more directly interpreted.
We now interpret our findings in relation to Pickering and Garrod’s (2013) account of how the language production system is involved in prediction. Pickering and Garrod argued that comprehenders use a particular form of prediction-by-production that they call prediction-by-simulation. When people produce utterances, they learn the relationship between their intention (or production command) and the linguistic (and non-linguistic) properties of their intended utterance, such as the sounds of the words that they utter. Over time, they learn to predict aspects of their experience of producing an utterance, as soon as they have the intention to produce that utterance, using so-called forward models (cf. Hickok, 2012). For example, they might develop the intention to say kite and then rapidly predict that they will experience themselves saying /kaIt/ (or perhaps just the initial /k/). When they hear someone else speaking, they covertly imitate that person and (making allowances for differences between that person and themselves) use their forward models to predict their upcoming experience of what the speaker will say next. So if they covertly imitate someone saying It was windy enough to fly a . . ., they then predict the experience of hearing /kaIt/ (or /k/).
Our evidence that context predictability impacts sentence processing is compatible with several prediction accounts (e.g., Huettig, 2015; Kuperberg & Jaeger, 2016; Kutas & Federmeier, 2011; Pickering & Gambi, 2018). But our finding that reading aloud enhances prediction provides support for Pickering and Garrod’s (2013) account. Reading aloud increases the engagement of the production system—and, as the production system is used in prediction, reading aloud increases prediction. In this sense, our data are also compatible with other prediction-by-production models, notably the early computational model of Chang et al. (2006) which proposed that prediction in comprehension is carried out by the production system, and Dell and Chang’s (2014) framework which provides computational evidence for equating prediction and production.
One interesting aspect of our data is that reading aloud led to stronger predictions (i.e., shorter naming times), but not necessarily more accurate ones (i.e., the proportion of correct “word” responses did not improve in reading aloud). This finding is again consistent with Pickering and Garrod (2013) who proposed that comprehenders use their production system to simulate how the perceived utterance will unfold. It is thus possible that engaging the production particularly strongly makes the prediction mechanism more “selfish”, leading to predictions that more closely reflect what would the comprehender say, rather than what is the likely continuation from the speaker.
In addition, this pattern of results resonates with the claim that linguistic prediction involves production up to the stage of phonological planning (Pickering & Gambi, 2018; Pickering & Garrod, 2013; for a discussion, Huettig, 2015). The phonological stage of language production is typically associated with a small number of planned utterances (Levelt et al., 1999; Peterson & Savoy, 1998). For example, whereas several representations may retain a high activation status at the lexico-semantic stage (It was windy enough to fly a . . . PLANE, BALLOON, KITE), at the phonological stage a single representation is likely to remain active (/kaIt/). As overt production necessarily involves phonological planning to a greater extent than silent comprehension, our reading aloud manipulation might have increased the role of phonology in the forward model, in turn constraining the number of generated predictions. Moreover, fewer predictions to choose from should mean smoother response selection, particularly when participants produce a spoken response (i.e., shorter naming times in Experiment 3).
It is important to note that there has been some controversy about phonological prediction, with the findings of Delong et al. (2005) not being replicated by Nieuwland et al. (2018). However, there is clear evidence of phonological prediction in another study using ERPs (Ito et al., 2020) and in the “visual world” eye-tracking paradigm (Ito, Pickering, & Corley, 2018; Kukona, 2020). It thus appears most likely that comprehenders do engage in phonological prediction, but prediction of phonology is more limited than semantic or other types of prediction, presumably because it implicates later stages of the production process (see Pickering & Gambi, 2018). In our study, reading aloud engages phonological processing and therefore is particularly good at enhancing phonological predictions. However, it may be that reading aloud also enhances other aspects of prediction (such as semantics)—we cannot distinguish between these alternatives based on our results.
This brings us to one of the main questions related to linguistic prediction: under what circumstances can comprehenders use the production system to predict? Although this issue remains under debate, some preliminary conclusions may be drawn at this stage. In particular, it appears that comprehenders might not always rely on prediction-by-production. There is some indication that this type of prediction may be resource-intensive (Hintz et al., 2017; Ito et al., 2016) and so its use could be limited when cognitive resources are scarce (cf. Huettig & Janse, 2016; Ito, Corley, & Pickering, 2018). More importantly, there is evidence that prediction can be achieved without the contribution of forward models (i.e., comprehenders might predict based on the activation of event schemes; Amsel et al., 2015; Kukona et al., 2011; Metusalem et al., 2012). Indeed, it seems that prediction may sometimes occur without engaging the late production processes (phonology, articulation), and there may be routes to prediction that do not involve production at all (Huettig, 2015; Pickering & Gambi, 2018). On such occasions, comprehenders might instead rely on prediction-by-association (i.e., they might predict based on the spreading activation between representations; Collins & Loftus, 1975).
However, there are times when the use of prediction-by-production seems likely. For example, prediction-by-production could be particularly engaged when the spoken or written signal is distorted by environmental noise. Nuttall et al. (2016) observed that motor evoked potentials in the cortical lip area elicited by transcranial magnetic stimulation (TMS) were larger when comprehenders listened to distorted rather than normal speech, particularly when they listened to lip-articulated sounds. Furthermore, Adank et al. (2010) showed that comprehension of accented speech in noise can be improved by training the production system—participants whose training involved imitating the speaker’s accent were better at subsequently understanding this accent than control participants who did not imitate. Although these studies do not directly show that such improvements in comprehension are due to prediction-by-production, they are compatible with the idea that this mechanism may be used to support language processing in the conditions of increased difficulty.
The use of prediction-by-production could also be encouraged in contexts that involve an overall heightened activation of the production system. Specifically, it has been argued that comprehenders might be inclined to use this mechanism in dialogue (Pickering & Garrod, 2021; Scott et al., 2009). Due to its collaborative nature, dialogue requires the interlocutors to carefully coordinate each other’s utterances (Clark, 1996; Clark & Wilkes-Gibbs, 1986). The ability to predict how the current speaker will continue would prove very useful. In addition, dialogue requires a near-constant activation of the production system—even while listening, the comprehenders provide feedback to the speaker, for instance by expressing understanding or signalling the desire to take the speaking turn.
Indeed, there is some evidence that prediction-by-production could be more prominent in contexts that strongly rely on production. In Hintz and Meyer (2015), participants listened to basic mathematical equations and made fixations to numbers corresponding to the results of these equations. Fixation latencies were shorter on trials where participants heard an incomplete equation (one plus five is) and spoke the expected result (six), compared to trials where they heard a complete equation and did not speak (one plus five is six), consistent with the notion that prediction is facilitated in the conditions of an increased involvement of production. However, as this study did not manipulate predictability (i.e., due to the simplicity of the equations, the results were always highly predictable), it may be that the faster fixations were instead caused by participants being more engaged with the task in the speaking condition (this interpretation is supported by the finding that other, non-predictive fixations were also faster in this condition). Clearer evidence comes from Hintz et al. (2016) where sentence completions were read more quickly after predictable than unpredictable contexts. Importantly, such an advantage occurred only in a task where participants also named pictures that appeared as part of the completions, implying that behavioural effects of prediction might occur especially in contexts where the production system is overall highly activated.
At the first glance, it may seem that our data conform with this hypothesis. The effect of prediction-by-production appears to be particularly well pronounced in the task that more strongly relied on the production system (i.e., picture naming), compared to the tasks that engaged production to a lesser extent (i.e., go/no-go and manual lexical decision). However, the statistical analysis of our data does not support these intuitions—we found no evidence for an effect of experimental task on prediction-by-production (as attested both by the mini meta-analysis and the LME analysis on combined data). Our study therefore provides little insight into any relationship between the overall activation of the production system and the use of prediction-by-production.
One interpretational issue for our study is whether activating the production system enhanced prediction in an indirect fashion by facilitating the comprehension of the context. For example, one could speculate that reading aloud might have been more engaging for our participants and thus encouraged them to process the contexts more deeply (see Hintz & Meyer, 2015). However, to our knowledge, no existing theory makes this claim. In fact, a converse argument is that allocating resources to overt production might hinder deep processing of the text, particularly in fast reading (recall the quick presentation rate in our paradigm). Importantly, our control analysis showed that comprehension of context sentences was equivalent across the different conditions of reading aloud versus silently (note that Martin et al. 2018 reported a similar result). Thus, it seems unlikely that context comprehension or, more generally, the allocation of mental resources, differed greatly between reading aloud and silently. That said, our measure of comprehension has limitations—the comprehension questions appeared after the participant had read the context sentence and responded to the sentence-final stimuli; this is a common procedure used to avoid distracting participants from the main task (e.g., Hintz et al., 2016; Martin et al., 2018). The consequence of this procedure is that our measure taps into off-line, rather than online comprehension. For this reason, our analysis of the comprehension questions cannot rule out the possibility that reading aloud enhanced online processing to some degree.
In sum, our study provides some evidence that the production system plays a role in making linguistic predictions and that such prediction-by-production can be observed directly at the behavioural level. These findings contribute to the growing body of research suggesting that production may be causally implicated in prediction and set the stage for a more precise delineation of the relationship between production, comprehension, and prediction.
Supplemental Material
sj-docx-1-qjp-10.1177_17470218211028438 – Supplemental material for The role of language production in making predictions during comprehension
Supplemental material, sj-docx-1-qjp-10.1177_17470218211028438 for The role of language production in making predictions during comprehension by Jarosław R Lelonkiewicz, Hugh Rabagliati and Martin J Pickering in Quarterly Journal of Experimental Psychology
Footnotes
Author contributions
All authors contributed to the development of the study concept and design. Testing, data collection, and analysis were performed by J.R.L. The manuscript was drafted by J.R.L. and M.J.P. and H.R. provided critical revisions. All authors approved the final version of the manuscript for submission. We would like to thank Ivana Bačanek for help with developing Figures 1 and ![]() .
.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported by a School Research Support Grant from the School of Philosophy, Psychology and Language Sciences, University of Edinburgh to J.R.L. and by a grant from the ESRC (ES/L01064X/1) to H.R.
Data accessibility statement
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.