
Abstract
The masked priming technique (which compares
Forster and Davis’s (1984) masked priming technique has become the gold-standard tool for researchers interested in the initial moments of letter and word processing. This technique allows researchers to manipulate the relationship between a forwardly masked and briefly presented prime (approximately 30–50 ms) and a target item, while minimising the non-automatic processes induced by visible primes (see Grainger, 2008, for a review). The type of prime–target relationship depends on the ingenuity of the researchers’ working hypothesis (e.g., to cite three instances: phonological priming:
Because of the short stimulus-onset asynchrony between prime and target, the magnitude of masked priming effects is small, in the range of 10–50 ms in behavioural studies. Thus, a problem faced by researchers using this technique is that it may not be sensitive enough to detect subtle manipulations or interactions (e.g.,
Another approach is to modify the technique to magnify the effects; this was a basic idea underlying the inception of the Lupker and Davis (2009) sandwich technique. The sandwich technique consists of a modification of the standard masked priming paradigm. The forward mask is followed by an initial masked prime identical to the target (the so-called pre-prime), followed by the prime of interest (see Figure 1 for an example). As in the standard technique, the target replaces the prime and is displayed until the participant responds. Note that both methods involve a prime that is pre-masked (by the pre-prime in the sandwich method and by the hash marks in the standard method) and post-masked (by the target in both methods), so strictly speaking, both procedures are forms of masked priming; hence, in the remainder of the article, we will refer to them as standard and sandwich techniques.
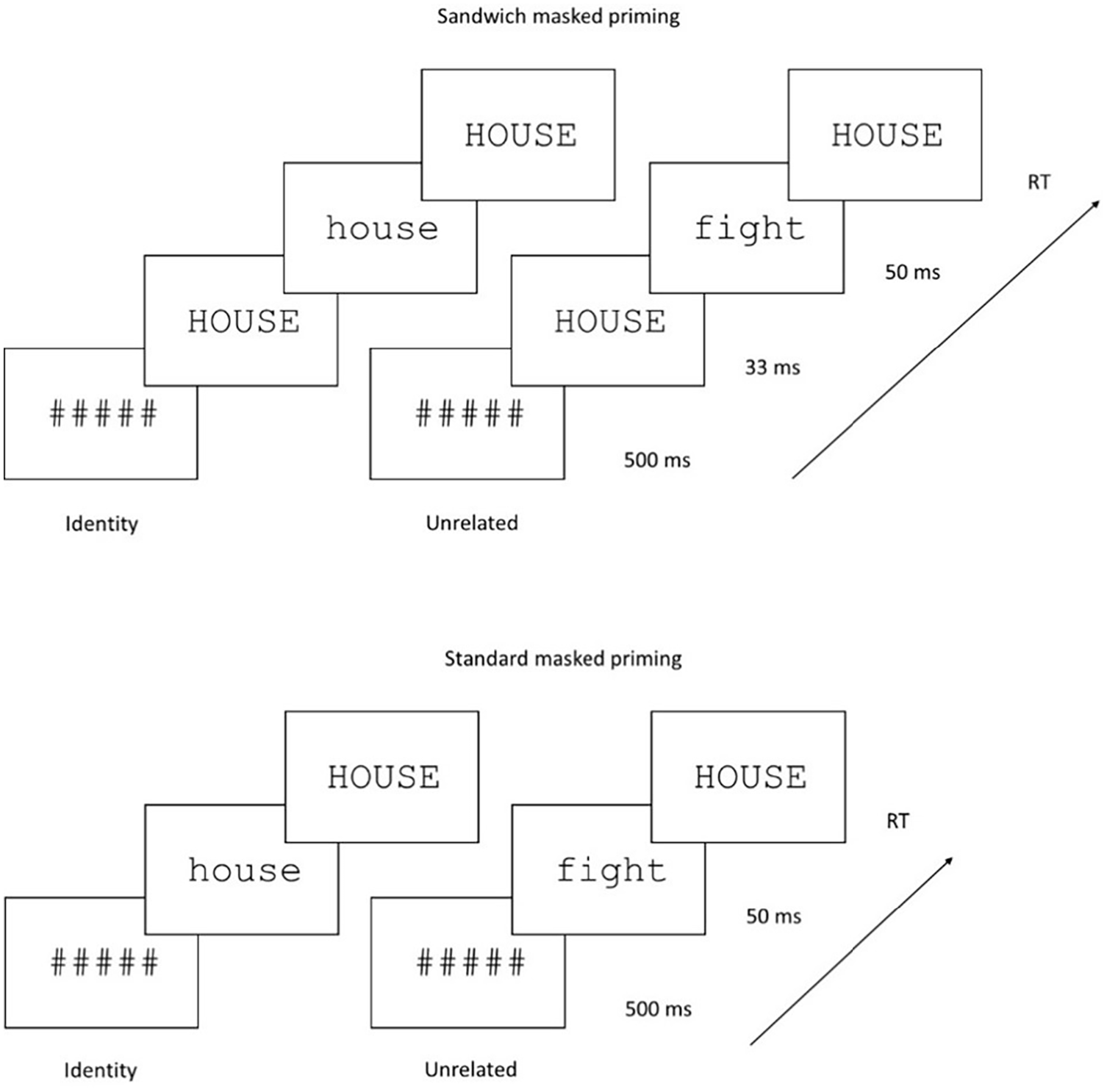
Sequence of events with the sandwich masked priming technique (top panel) and the standard masked priming technique (bottom panel).
As first shown in a series of form-priming experiments conducted by Lupker and Davis (2009), the sandwich technique produces greater priming effects than the standard technique. This boost has since been replicated with various types of prime–target relationships (e.g., see Comesaña et al., 2016; Perea et al., 2014; Stinchcombe et al., 2012; Trifonova & Adelman, 2018, for behavioural evidence, and Ktori et al., 2012, for electrophysiological evidence). Indeed, because of the larger priming effects, the sandwich methodology has become the preferred option in many recent masked priming studies (e.g., Campos et al., 2021; Colombo et al., 2020; Gutierrez-Sigut et al., 2017; Ktori et al., 2014; Lupker et al., 2015, 2020a, 2020b; Meade et al., 2020; Taikh & Lupker, 2020; Ziegler et al., 2014).
Notwithstanding its utility in amplifying priming effects, the sandwich technique requires some further examination. The specific mechanisms at play and how they differ from the standard technique, have not been fully elucidated (see Lupker & Davis, 2009 vs. Trifonova & Adelman, 2018). Thus, it is not yet well understood whether the priming effects in the sandwich technique are simply magnified or, instead, the underlying processes are fundamentally altered. Exploring this question is the main goal of the present work. In the original Lupker and Davis (2009) experiments, task procedure (sandwich vs. standard) was manipulated between subjects, making it difficult to compare the nuances of the two techniques. Trifonova and Adelman (2018) have been the only researchers to date who employed a within-subject design for task procedure. However, their form-priming experiments focused on whether the characteristics of the pre-prime influenced word processing (e.g., how the pre-prime
To compare the two techniques, we manipulated the procedure (standard vs. sandwich) in a within-subject design where we compared the largest and most robust form of masked priming: identity priming (i.e., identity vs. unrelated primes). Our comparison aims to shed light on the processing differences between the two techniques. To do so, we also examine the distributional features of the RT data and the relative speed of correct and error responses in the two paradigms.
For identity primes, the activation from the pre-primes in the sandwich technique would naturally help word processing: the target word is presented as a pre-prime and as a prime (e.g., compare pre-prime:

Example of the initial processing cycles of an unrelated trial in the sandwich technique (top panel, pre-prime: house [10 cycles], prime: fight [20 cycles], and target [until response]) and in the standard masked priming technique (bottom panel, prime: fight [20 cycles] and target [until response]) in a leading competitive network model of visual word recognition (SCM; C. J. Davis, 2010). The thick horizontal line represent a response threshold, and the coloured lines represent the activation levels of the corresponding lexical units.
The above pattern was confirmed by simulations on the spatial coding model (C. J. Davis, 2010). We used the target words of C. J. Davis and Lupker’s (2016) Experiment 2—they were all five-letter words—paired with identity versus unrelated primes. 1 For the sandwich method, we simulated a scenario with a 33-ms pre-prime followed by a 50-ms prime, whereas for the standard technique, we simulated a scenario with a 50-ms prime. We found a greater identity priming effect in the sandwich technique than in the standard technique (69 vs. 47 processing cycles). This boost was exclusively due to the identity condition (an advantage of 24 processing cycles in the sandwich technique). For the unrelated condition, the sandwich technique produced slightly faster responses than the standard technique (an advantage of two processing cycles in the sandwich technique). Of note, in a form priming experiment, Trifonova and Adelman (2018, Experiment 2) found the opposite trend for unrelated pairs in the error rates (i.e., better performance in the standard technique); if this advantage for the standard technique becomes the dominant pattern of results, this would suggest that the way models simulate masked priming with the standard and sandwich techniques many need to be reevaluated.
To get a richer picture of the differences between the two techniques, we also aim to fully describe the distributional features of the RTs in the sandwich technique and standard methods; in the present work, we report delta plots (De Jong et al., 1994) and conditional accuracy functions (Bonnet & Dresp, 1993; Ollman, 1977). Critically, the study of RT distributions offers rich information to elucidate the time course of an effect (Balota et al., 2008; see also Heathcote et al., 1991; Ratcliff, 1979; Townsend & Ashby, 1983, for early research), because many theories of word processing make claims of the sequence and timing of mental operations, as can be seen in Figure 2. However, all previous studies with the sandwich technique only focused on the analysis of the mean RTs.
In the standard technique, masked identity priming has repeatedly shown a shift between the RT distributions of the identity and unrelated conditions (i.e., identity priming), with the magnitude of identity priming being close to that of the prime duration (e.g., Gomez et al., 2013; Gomez & Perea, 2020; Perea et al., 2018, for a similar finding). This pattern supports Forster’s (1998) claim that the identity prime produces a “head start” advantage when processing the target word: The identity pair
In sum, to provide the first full description of the sandwich technique, we designed a lexical decision experiment that examined the similarities and differences in masked identity priming with the standard and sandwich techniques. The findings of this study are also relevant to inform us of whether the sandwich technique taps similar encoding processes (i.e., a head-start advantage) as the standard priming technique or whether the two tasks are more different than originally thought. Keep in mind that, in the sandwich technique, the pre-prime presentation adds complexity to the information processing; that is, the system must handle with three strings in brief succession (see Forster, 2009; Trifonova & Adelman, 2018). To rephrase our research question, an apt analogy might be that the two methods can be thought of as measuring devices for cognitive processes and the present study aims to understand whether these devices are qualitatively different as they detect different signals, or quantitatively different, as they may magnify the same signal to different levels.
Method
Participants
A total of 36 undergraduate students from the University of Valencia volunteered to participate in the experiment—this ensured 2,160 observations per condition, in line with Brysbaert and Stevens’s (2008) suggestion for masked priming experiments. All participants were native speakers of Spanish with normal/corrected vision and no history of reading disorders. This study was approved by the Experimental Research Ethics Committee of the University of Valencia, and all participants signed an informed consent form.
Materials
We selected 240 word targets of 5 letters, which were extracted from Fernández-López et al.’s (2019) Experiment 1. The average Zipf frequency was 4.15 (range 3.74–4.61) and the mean OLD20 was 1.41 (range: 1.00–2.65) in the EsPal Spanish database (Duchon et al., 2013). Each target word (e.g.,
Procedure
Testing took place in groups of 4–6 participants in a quiet laboratory room. Computers equipped with DMDX software (Forster & Forster, 2003) displayed the stimuli and registered the timing/accuracy of the responses. Each trial started with a pattern mask (#####) displayed for 500 ms in the centre of a computer screen. In those trials with the sandwich technique, the uppercase target stimulus was presented for 33 ms as a pre-prime, followed by a 50-ms lowercase prime stimulus which, in turn, was replaced by the uppercase target stimulus—this was presented until response or 2 s had elapsed. In the trials with the standard technique, the pattern mask was followed by the 50-ms prime, and then replaced by the target (see Figure 1). All stimuli were presented in 14-pt Courier New black font on a white background. Participants were instructed to decide whether the uppercase stimulus was a word or not by pressing a green button (“word”) or a red button (“nonword”) with their index fingers. Both speed and accuracy were stressed in the instructions. Instructions did not mention the existence of any briefly presented primes. A total of 16 practice trials preceded the 480 experimental trials. Each participant received a random sequence of trials. The session lasted 18–22 min.
Results
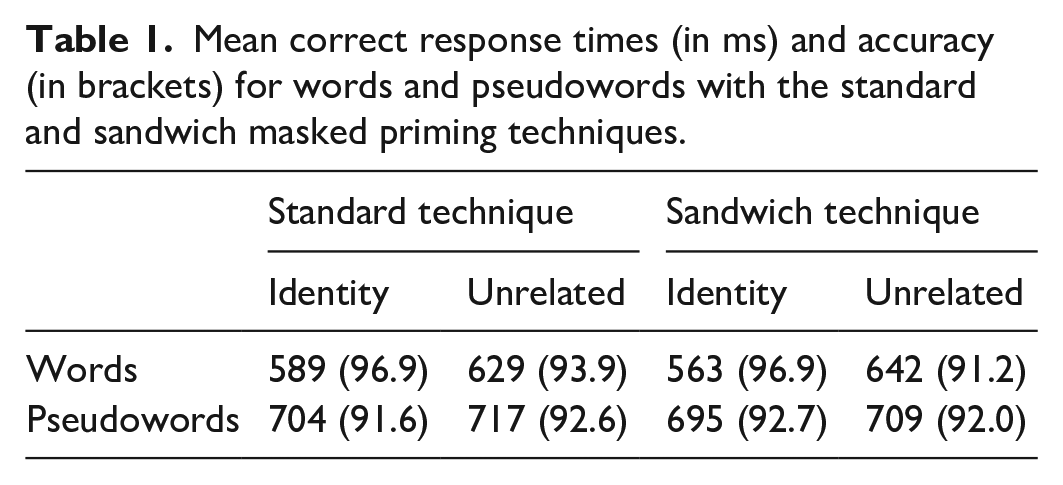
Error responses and anticipations (RTs faster than 250 ms: 2 correct responses and 4 incorrect responses) were omitted from the latency analyses. Timeouts after 2.5 s were categorised as errors (there were 32 timed out responses and 1,091 error responses out of 17,280 trials). Table 1 displays the mean RTs for correct responses and the accuracy in each condition. We first present the inferential analyses using Bayesian linear mixed-effects models, and then we present the exploratory data analyses.
Mean correct response times (in ms) and accuracy (in brackets) for words and pseudowords with the standard and sandwich masked priming techniques.
Bayesian linear mixed-effects analyses
The RT and accuracy data were modelled with Bayesian linear mixed-effects models in R (R Core Team, 2020) using the brms package (Bürkner, 2020). This package, which uses the programming language Stan as its core, allows us to fit the maximal random effect structure models allowed by the experimental design (see Barr et al., 2013). The fixed effects were relation (identity vs. unrelated; coded as −0.5 and 0.5) and procedure (sandwich vs. standard; coded as −0.5 and 0.5). As usual in masked priming experiments, we conducted separate analyses for word and nonword trials.
The fitted model was as follows:
We used the ex-Gaussian family function to model the RT data and the Bernoulli family function (1 = correct, 0 = incorrect) to model the accuracy data. For the fits of each model we employed four chains, each with 5,000 iterations (1,000 warmup + 4,000 sampling). All R̂ values were 1.00, thus meaning that the four chains converged successfully. In the output, the Bayesian linear mixed-effects models indicate the estimate of each fixed effect, its standard error, and its 95% credible interval. For inference purposes, those intervals that did not include zero were interpreted as significant. In the case of a significant interaction, we computed the simple effect tests with the emmeans package (Lenth et al., 2020)—this package provides the 95% highest (posterior) density (HPD) interval for each effect. Note that this method yields what is called Bayesian shrinkage, which means that posterior estimates might be shifted from the empirical effects due to the prior and the data from other conditions.
Word targets
Response times were faster for identity pairs than for unrelated pairs (b = 72.35, SE = 3.78, 95% credible interval [CrI] [64.58, 79.56]) and responses were faster in the sandwich than in the standard technique (b = 25.65, SE = 2.70, 95% CrI [20.74, 31.29]). As expected, there was clear evidence of an interaction between the two factors (b = −32.76, SE = 4.09, 95% CrI [−40.80, −24.78]). This interaction reflected that, for identity pairs, responses were substantially faster in the sandwich than in the standard technique (95% HPD [−31.29, −20.7]); in contrast, for unrelated pairs, responses were faster in the standard than in the sandwich technique (95% HPD [0.75, 13.6]).
The analyses on the accuracy data showed that participants were more accurate for identity pairs than for unrelated pairs (b = −1.16, SE = 0.19, 95%CrI [−1.52, −0.79]). While the 95% credible intervals of the other parameters included zero, accuracy was lower in the sandwich than in the standard technique (b = 0.18, SE = 0.23, 95%CrI [−0.28, 0.65]) and the size of the identity priming effect was greater in the sandwich than in the standard technique (interaction: b = 0.40, SE = 0.26, 95%CrI [−0.11, 0.90]).
Nonword targets
Responses to nonwords were faster in the trials with the sandwich technique than in the trials with the standard technique (b = 17.54, SE = 3.67, 95% CrI [10.37, 24.72]). We also found a small advantage of identity over unrelated pairs (b = 9.83, SE = 5.07, 95% CrI [0.22, 19.93]). There were no clear signs of an interaction between the two factors (b = −4.21, SE = 5.11, 95% CrI [−14.30, 5.7]).
The analyses on the accuracy data did not show any effects (relation: b = −0.14, SE = 0.16, 95% CrI [−0.45, 0.18]; procedure: b = −0.14, SE = 0.16, 95% CrI [−0.45, 0.17]; relation*procedure: b = 0.21, SE = 0.21, 95% CrI [−0.20, 0.61]).
To summarise, the results with the Bayesian linear mixed-effects models on word trials showed that, for identity primes, the presentation of the target word in the sandwich technique yielded faster responses than the standard technique (
Exploratory data analyses
To further examine the nature of the priming effects underlying the sandwich and standard techniques, we compared the empirical RT distributions for both techniques. We focused on delta plots and conditional accuracy functions, as they describe how the latency distributions differ. Note that these methods do not have established inferential properties, so in our discussion we focus only on large effects.
Delta plots
Delta plots are frequently used to display how a latency effect (e.g., identity priming, or task) evolves across time (see De Jong et al., 1994; Ridderinkhof et al., 2004). These plots are constructed as follows:
We obtain the RTs at the desired quantiles (here we use .1, .2, .3, .4, .5, . . . .9) for every participant for each of the conditions to be compared, only for correct responses.
We average the RTs obtained in Step 1 across participants (these averaged quantiles are also called vincentiles in the RT literature; see Ratcliff, 1979).
For each of the quantiles in the vincentiles (a) we find the average between the two conditions, and (b) then compute the differences (i.e., the delta) preserving the sign.
The last step is to plot the points (as many points as there are quantiles), with the averages (Step 3a) on the x-axis, and the delta (Step 3b) on the y-axis.
As is evident from Step 3b, delta plots are based on residual quantiles (i.e., RTs at quantiles in condition A minus condition B), and hence can provide us with some indication of the temporal dynamics of an effect when interpreted within the lens of process models. For example, a flat line at around y = 50 ms would mean that there is a 50-ms shift in the RT distributions—this could be interpreted as faster encoding times in evidence accumulation models (see Gomez et al., 2013, for an example of such interpretation in the standard masked priming technique). Alternatively, an ascending function would indicate that the effect grows for slower responses, and it could be interpreted as a difference in the rate of evidence accumulation.
As just indicated, in delta plots, one needs to contrast two conditions; in our analysis of the two priming methods, it makes sense to perform two separate comparisons that are presented in two different delta plots: (a) the effect of prime type in the standard and sandwich techniques (across condition comparison: unrelated vs. identity; Figure 3), and (b) the effect of procedure for identity and unrelated pairs (within-condition comparison: standard vs. sandwich; Figure 4).

Delta plot comparing unrelated primes to identity primes. The points represent the difference RTunrelated—RTidentity at the .1, .2, .3, .4, .5, .6, .7, .8, and .9 quantiles.
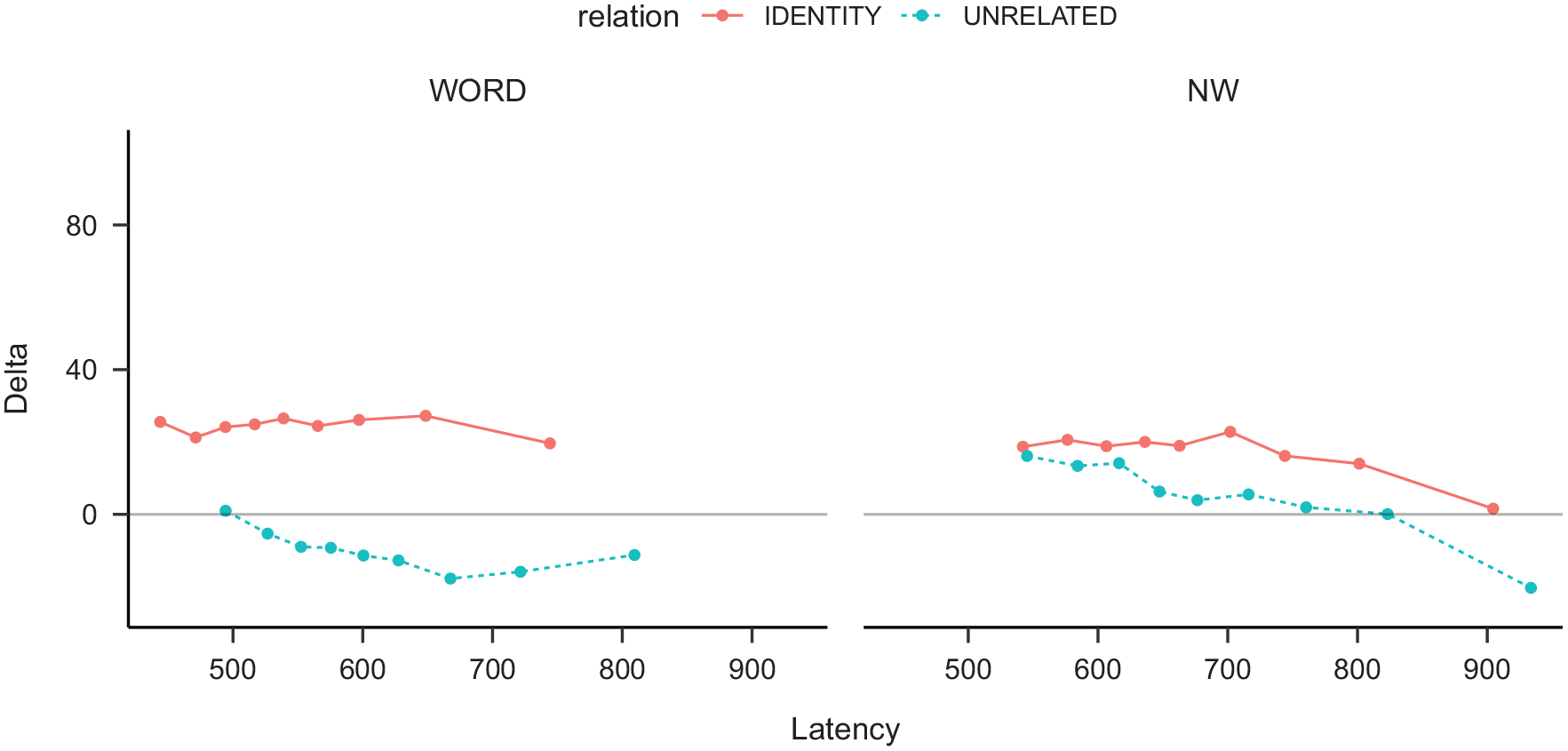
Delta plot comparing the standard and sandwich techniques. The points represent the residual of RTstandard—RTsandwich at the .1, .2, .3, .4, .5, .6, .7, .8, and .9 quantiles.
Effect of prime type (Figure 3)
For word trials, when calculating priming effects as RT for unrelated primes minus RT for identity primes, we found a relatively flat line for the identity priming effect in the standard technique (all points lie between 38 and 51 ms), thus replicating earlier research. In contrast, in the sandwich technique, the identity priming effect was not only greater than in the standard technique (as attested by the higher values in the y-axis), but it progressively increased from the .1 quantile (63 ms) to the .7 quantile (95 ms)—it decreased slightly in the .9 quantile, though. For the nonword trials, we found a small identity priming effect that slowly grew across quantiles, with a steeper slope in the sandwich technique.
Effect of technique (Figure 4)
For word trials, when calculating the effect of technique as standard minus sandwich, we found an approximate flat line for the identity primes (around 25 ± 5 ms for all quantiles). This pattern indicates that responses were overall faster in the sandwich than in the standard technique. In contrast, we found a line that lies on the negative numbers for the unrelated primes (i.e., responses were slower in the sandwich than in the standard technique)—note that this difference effect grew as quantiles increased from .1 quantile (−.5 ms) to .8 quantile (−.16 ms; i.e., a negative slope). We found functions with negative slopes for the nonword targets, but with points above zero for the most part. This pattern reflected that responses were faster in the sandwich technique, but this advantage decreases (or even reversed, in the unrelated condition) for the slower responses.
Note that delta plots highlight the dynamics of effects across different points of the latency distributions. However, they do not convey information about accuracy as they are only built with correct responses; hence, we resort to conditional accuracy functions to explore accuracy issues as explained below.
Conditional accuracy functions
Conditional accuracy functions (Bonnet & Dresp, 1993; Ollman, 1977) allow us to visualise how accuracy evolves as latencies increase. These plots were generated as follows:
For each type of item and each participant, we divide all responses into 5 equal-sized bins based on their latency; to do so, we included both correct and error responses.
We averaged the RTs and accuracies for each bin across all participants, and then calculate (a) the average RT for each of the bins and (b) the accuracy within each bin.
The last step is to plot the points (as many points as there are quantiles), with the averages (Step 3a) on the x-axis, and the conditional accuracies (Step 3b) on the y-axis.
As is evident from Step 3b, conditional accuracy functions can indicate whether the accuracy in the responses for a given condition varies across the latency of the responses to such condition. For example, a flat line at around y = .90 would mean that the accuracy for that condition (90%) is equal for fast and for slow responses. In addition, an ascending function would indicate that the fast responses tend to be less accurate, and a descending function would indicate that slow responses tend to be less accurate.
The panels in Figure 5 show the conditional accuracy for all the conditions in our experiment. Two patterns are worth highlighting: for words, the fastest 20% of responses in the unrelated condition in the sandwich method tend to be less accurate than slower responses, which is reversed for the identity condition. For nonwords, the conditional accuracy functions are remarkably similar in the two techniques: fastest responses tend to be less accurate for the identity primes than for the unrelated primes, but this pattern reverses for the slower responses. This is consistent with the idea that familiarity influences lexical decision (e.g., Masson & Bodner; cf compound-cues), particularly for fast responses, which could be sensitive to the orthographic match of the prime and target. A match could bias for “word” responses, and fast responses might be most affected by this bias.
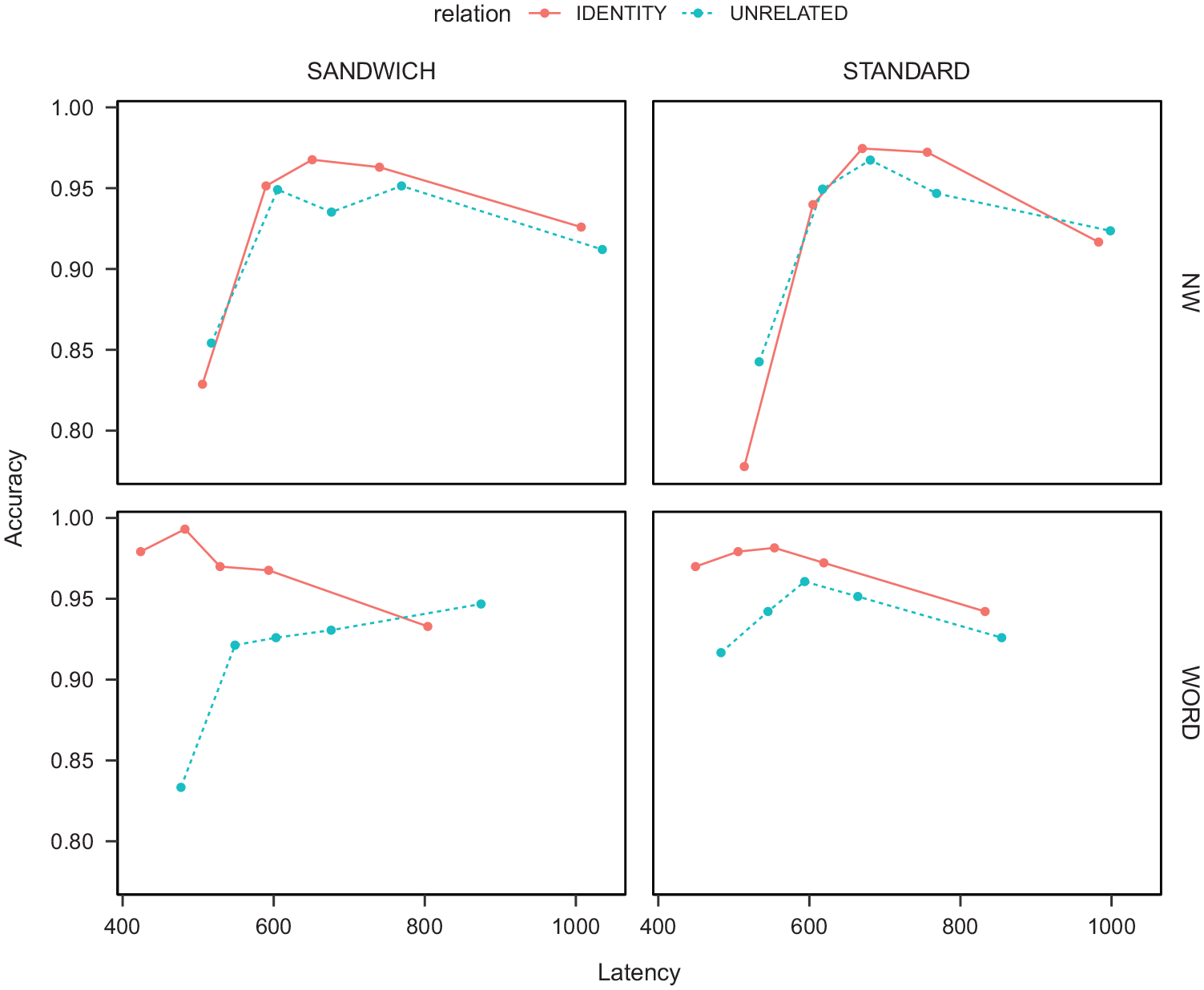
Conditional accuracy functions, the points represent the accuracy and average RT of the responses within equal-sized bins (20% of responses per bin).
Discussion
An increasing number of masked priming researchers now opt for the sandwich technique due to its promise of greater effect sizes than the standard technique. However, the mechanisms underlying this boost are still not well understood. To fully characterise the sandwich technique, we conducted a lexical decision experiment comparing the sandwich and standard techniques in a within-subject design. We focused on masked identity priming effects for three reasons: (a) theoretical models offer straightforward predictions (Forster, 1998); (b) it has already been modelled with the standard masked priming technique (Gomez et al., 2013); and (c) the magnitude of the effects is much larger than with other types of prime–target relationships (i.e., we may capture more easily potential interactions). To elucidate whether the differences between the standard and sandwich methods were merely quantitative or also qualitative, we examined the locus of the boost in the sandwich technique and the time course of the effects for both techniques via delta plots and conditional accuracy functions.
For word trials, we found the expected boost in the sandwich technique (a 79-ms priming effect with the sandwich technique vs. a 40 ms priming effect with the standard method; i.e., a 39-ms boost), thus replicating earlier research (see Lupker & Davis, 2009, for the first demonstration). Critically, the use of a within-subject design allowed us to discover that while the major component of the 39-ms boost in the magnitude of priming effects in the sandwich technique was due to the faster responses to identity pairs (26 ms: 563 vs. 589 ms in the sandwich and standard techniques, respectively), there was also a component due to the slower responses to unrelated pairs (13 ms: 642 vs. 629 ms, in the sandwich and standard techniques, respectively)—note that Trifonova and Adelman (2018) also found an effect in this direction for unrelated pairs in the accuracy data. As indicated in the Introduction, C. J. Davis’s (2010) spatial coding model would have predicted not only substantially faster responding in the identity condition in the sandwich than in the standard technique, but also slightly faster responding in the unrelated condition. Thus, the effect of the unrelated priming conditions predicted by the spatial coding model does not match the observed data. We found that the responses were slower in the sandwich technique than in the standard technique after an unrelated prime. The discrepancy in the unrelated trials suggests that the pre-prime in the sandwich technique may influence target processing in a way that cannot be captured in the present implementations of masked priming in interactive activation models like the spatial coding model.
In addition, the exploratory data analyses (both delta plots and conditional accuracy functions) offer valuable information on the underlying processing differences between the standard and sandwich techniques. For word targets, the delta plot on the standard technique showed, as expected, that masked identity priming reflects essentially a shift in the RT distributions (see Figure 3; see also Gomez et al., 2013; Gomez & Perea, 2020). This pattern is entirely consistent with the commonly shared assumption that masked identity primes have a “head start” advantage during an early encoding stage (i.e., a “savings” effect; Forster, 1998; see also Gomez et al., 2013). In contrast, the delta plot with the sandwich technique showed a different picture: the magnitude of masked identity priming grows stronger in the higher quantiles (see Figure 3). At first glance, one might interpret this last pattern as being due to some involvement of decision processes for identity primes in the sandwich technique. However, this interpretation misses the critical information provided by within-condition comparisons (see Jacobs et al., 1995). The advantage of the identity primes in the sandwich technique is approximately constant along quantiles (see left panel of Figure 4), thus reinforcing the idea that the identity primes are processed similarly in the two techniques (i.e., an encoding effect; Forster, 1998). Instead, the largest differences across tasks occur in the unrelated priming condition, where there is a costlier processing in the sandwich technique as latency increases. Of note, the delta plot in the left panel of Figure 4 also allows us to visualise that the difference between the sandwich and the standard method manifests itself in both identity and unrelated primes: the sandwich technique yields faster responses for the identity primes and slower responses for the unrelated primes.
The conditional accuracy functions shown in Figure 5 provide further clues on the differences between the two techniques. The fast responses in the sandwich method for the unrelated condition are much less precise than the fast responses for any other condition in the experiment. This pattern suggests that the pre-prime interacts with the prime in ways that affect the early moments of processing of the target. One possible explanation for the divergent pattern in the unrelated primes across technique is the following. Because of the briefness of the pre-prime, its processing may overlap with the prime, creating a jumbled orthographic code that would impair the first moments of target processing—note that this interpretation has some resemblance with the legibility effect described by C. Davis and Forster (1994). For instance, for
In sum, the present experiment has both theoretical and practical implications. On the theoretical side, the shift in the RT distributions for identity pairs in the sandwich and standard technique strongly suggests that the extra time from the pre-prime does not alter the underlying processes beyond encoding. Notably, the story is different from unrelated primes: the pre-prime in the sandwich technique hinders the processing of unrelated prime-target pairs. Further research with a better temporal resolution (i.e., ERPs) is necessary to uncover these differences—note that the Ktori et al. (2012) ERP sandwich experiment did not include a block with the standard technique. On the applied side, one basic question is shall we continue using the sandwich technique? The answer from the present experiment is “yes.” Even in the largest manipulation in priming experiments (i.e., identity primes), we found a similar pattern in the two techniques for identity pairs—except for the expected processing advantage in the sandwich technique due to the pre-prime. At the same time, researchers should be cautious in interpreting some of the across-condition priming effects in subtle manipulations in the sandwich technique, as these effects may derive not from facilitation in the related condition but rather from some inhibition in the unrelated condition and might consider using both the identity and unrelated conditions as controls when exploring more subtle manipulation (e.g., does corn prime ACORN?). Perhaps an analogy from the physical sciences is apt. We explored whether the sandwich technique is a more powerful microscope than the standard masked priming technique. Our results indicate that a better way to think about it is as a different catalyst that triggers related but slightly processes.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The research reported in this article has been partially supported by Grants PRE2018-083922 (M.F.-L.) and PSI2017-86210-P (M.P.) funded by MCIN/AEI/ 10.13039/501100011033, and the Grant GV/2020/074 (A.M.) from the Valencian Government.
Ethical approval
The procedures involving human participants in this study were approved by the Experimental Research Ethics Committee of the Universitat de València and they were in accordance with the Declaration of Helsinki. All participants provided written informed consent before starting the experimental session.