
Abstract
There is substantial evidence that affectively charged words (e.g., party or gun) are processed differently from neutral words (e.g., pen), although there are also inconsistent findings in the field. Some lexical or semantic variables might explain such inconsistencies, due to the possible modulation of affective word processing by these variables. The aim of the present study was to examine the extent to which affective word processing is modulated by semantic ambiguity. We conducted a large lexical decision study including semantically ambiguous words (e.g., cataract) and semantically unambiguous words (e.g., terrorism), analysing the extent to which reaction times (RTs) were influenced by their affective properties. The findings revealed a valence effect in which positive valence made RTs faster, whereas negative valence slowed them. The valence effect diminished as the semantic ambiguity of words increased. This decrease did not affect all ambiguous words, but was observed mainly in ambiguous words with incongruent affective meanings. These results highlight the need to consider the affective properties of the distinct meanings of ambiguous words in research on affective word processing.
Introduction
Interest in the relationship between emotion and language has grown in cognitive science over recent years. Psycholinguistic research here has been conducted mostly from a dimensional perspective (see, for instance, Hinojosa et al., 2020, for a recent overview), according to which the human affective space can be described in terms of a few dimensions, the most significant being valence and arousal (Bradley & Lang, 1999; Posner et al., 2005). From this perspective, emotions vary in terms of both their hedonic value (ranging from pleasant-positive to unpleasant-negative, that is, the valence dimension) and the degree of experienced activation (ranging from activated-excited to deactivated-calmed, that is, the arousal dimension). One of the main issues of concern has been the question of whether affective content, as indexed by valence and arousal, influences word recognition (i.e., if affective words, such as party or death, which are positive and negative, respectively, are responded to differently from nonaffective, neutral words, such as table). The most common experimental approach has been through the use of the lexical decision task (LDT), in which participants are asked whether or not a series of letter strings constitute a legal word in a particular language; other tasks have also been used, although to a lesser extent (see, for instance, Ferré et al., 2018, or Hinojosa et al., 2010). Studies have yielded mixed findings: Although positive valence seems to facilitate word recognition (e.g., Kousta et al., 2009; Vinson et al., 2014), the effects of negative valence are unclear, with reports of an advantage (Kousta et al., 2009; Vinson et al., 2014), a disadvantage (e.g., Kuperman et al., 2014; Larsen et al., 2008), or even a null effect for negative words (Larsen et al., 2006; see Kauschke et al., 2019, for an overview).
Some authors suggest that such discrepant findings may be related to differences in arousal levels across studies, pointing to a possible interaction between valence and arousal (see Citron et al., 2013). Others argue that the cause may be the lack of an adequate control of lexical and semantic variables (e.g., Kousta et al., 2009; Larsen et al., 2006). The relevance of such variables has become apparent in several studies that have investigated their possible interaction with affective content during word recognition. For instance, the effects of affective content have been shown to be modulated by both lexical frequency (e.g., Kuchinke et al., 2007; Méndez-Bértolo et al., 2011) and concreteness (e.g., Ferré et al., 2018; Kanske & Kotz, 2007), in that the effects are greater for low frequency and abstract words, although results here are again inconsistent (see Palazova, 2014, for an overview).
It may be that other variables, not considered thus far, also have a modulatory role. The present study is the first to focus on semantic ambiguity in this context. Research on affective word processing has hitherto not taken into account that (1) words may have more than one meaning (i.e., semantically ambiguous words), or (2) the different meanings of a word may have incongruent valence values (e.g., cataract is a semantically ambiguous word, in that it can mean both “waterfall” and “eye disease,” a positive and a negative meaning, respectively). To the extent to which words of this kind have been included in past studies (probably without it being noticed), this might have contributed to the discrepancies noted above. For instance, a disadvantage for negative valence might not be found unless both meanings are negative. On the contrary, some of the words included in the neutral condition might actually be ambiguous words with incongruent meanings in terms of valence and would hence not be the most appropriate ones to be compared with affective words. To examine the degree to which these facts may have contributed to previous mixed findings in affective word processing and to explore whether such processing interacts with semantic ambiguity, a study is required that involves a large set of ambiguous and unambiguous words that are well characterised in terms of affective variables and other relevant variables. This is what we intend to do in this study.
Although this is the first time that the possible role of semantic ambiguity on affective word processing has been addressed explicitly, there are a few studies that, one way or another, have pointed out the need to explore the relationship between affectivity and semantic ambiguity. For instance, Briesemeister et al. (2012) focused on affective bivalent words, that is, words that contain ambivalent valences, as shown by high ratings on scales for both positivity and negativity (e.g., school). The authors found that those words were processed differently from both neutral and affective nonambivalent words (e.g., tolerance or attack, as examples of nonambivalent positive and negative words, respectively) in a LDT. To further explore this effect and the role of semantic ambiguity (i.e., affective ambivalent words are more likely to be semantically ambiguous than neutral words), the authors performed an additional experiment in which semantic ambiguity was matched across conditions (i.e., affective ambivalent, affective nonambivalent, and neutral words were matched with respect to number of meanings). The results revealed that differences between conditions diminished in comparison with their previous experiment, suggesting that semantic ambiguity might have a role in the ambivalence effect previously found. It should be noted, however, that the role of semantic ambiguity was not directly addressed in this study.
A study that made a first step in that direction was the one conducted by Syssau and Laxén (2012), in which the authors orthogonally manipulated semantic ambiguity and valence in a LDT task. They found an interaction between both factors, in that participants responded faster to positive and negative words than to neutral ones only when they were unambiguous. According to the authors, a possible explanation for these findings is that the different meanings of some ambiguous words may have distinct affective polarities (i.e., one meaning may be positive and the other negative). Hence, the possible advantage for affective words would be overridden by the competition between those incongruent valences. As appealing as this explanation may be, Syssau and Laxén (2012) were not able to test it because they did not have valence ratings for each meaning. Indeed, they classified their experimental words (ambiguous and unambiguous) into positive, negative, and neutral categories by using affective ratings obtained following the common procedure in the field (that is, presenting each word in isolation, for example, cataract, and asking participants to rate its affective properties without considering whether it has a single or multiple meanings).
Taking into account all of the above, the aim of the present study was to examine the extent to which affective word processing is modulated by semantic ambiguity. The stimuli included were taken from the database of Huete-Pérez et al. (2020). The authors collected meaning-dependent affective (valence) ratings for ambiguous words (most of them were bisemic words, that is, they had two meanings). In particular, the ambiguous words were presented together with the definition of one of their meanings, and participants were asked to rate valence considering only that meaning. Hence, each ambiguous word had three different valence values in the database: a valence value for one of their meanings, a valence value for the other meaning, and a valence value obtained by asking participants to rate the word in isolation (i.e., without differentiating its meanings).
For the present study, we conducted a large lexical decision experiment with 504 words; half of these were unambiguous words, and the other half were ambiguous words. In light of the findings of Syssau and Laxén (2012), we expected to find a modulation of the valence effect by ambiguity, in that the effect should be larger for unambiguous words than for ambiguous ones. If this were found to be the case, an additional aim would be to examine whether the decrease in the valence effect observed with ambiguous words was due to the affective incongruence between their meanings. Specifically, we would expect the valence effect to be larger in ambiguous words whose meanings were affectively congruent in comparison to those with affectively incongruent meanings.
Method
Participants
Forty-seven undergraduate Psychology students from the Universitat Rovira i Virgili (URV, Tarragona, Spain) participated in the experiment. They were recruited using convenience-volunteer sampling. All gave their informed written consent and received academic credits for their participation. The data of one participant were removed from the analysis due to a technical problem in the display of the stimuli. Thus, there were 46 valid participants (40 women); these aged between 19 and 57 (M = 21.87, SD = 6.47) years.
Materials
The experimental stimuli were all the words (252 ambiguous words and 252 unambiguous words) included in the database of Huete-Pérez et al. (2020). Among them, there were 431 nouns (85.52%), 38 adjectives (7.54%), and 35 verbs (6.94%). 1 Ambiguous words mainly had two meanings (although a few had three), whereas unambiguous words had a single meaning, according to several measures included in Huete-Pérez et al. (2020). The following measures, obtained from that study, were used to characterise the ambiguous and unambiguous words: subjective number of meanings (NOM) of the word (on a 3-point scale: 0 = no meaning, 1 = one meaning, 2 = more than one meaning), subjective relatedness of meanings (ROM) of the word (ranging from 1 = unrelated meanings to 9 = same meaning), number of associates generated for each meaning in a free association task, dominance-subordination index (DSI; a ratio between the number of associates of the first/dominant meaning in relation to the number of associates of the second/subordinate meaning: for example, a value of 1 means that there is not a dominant meaning, a value of 2 means that the dominant meaning has twice as many associates as the subordinate meaning, etc.). In addition, the database of Huete-Pérez et al. also included a set of affective variables, some of which were considered in the present study, specifically the valence of the word presented in isolation (i.e., valence in isolation; ranging from 1 = completely sad/negative to 9 = completely happy/positive) and the valence of each meaning (ranging from 1 = completely sad/negative to 9 = completely happy/positive).
Apart from these ambiguity- and affectivity-related variables, many other sublexical, lexical, semantic, and affective variables were also considered: arousal, concreteness, familiarity, age of acquisition (AoA), logarithm of word frequency (log frequency), logarithm of lemma frequency (log lemma frequency), number of syllables, number of letters (word length), number of orthographic neighbours (N), number of orthographic neighbours of higher frequency (NHF), mean Levenshtein distance of the 20 closest words (old20), logarithm of mean bigram frequency (log bigram frequency), logarithm of trigram frequency (log trigram frequency), and logarithm of contextual diversity (log contextual diversity). The values of these variables were obtained from the following sources (with the help of the emoFinder online search engine, cf. Fraga et al., 2018): AoA ratings were taken from the databases of Alonso et al. (2015), Haro et al. (2017), and Hinojosa, Rincón-Pérez, et al. (2016); the ratings of arousal were taken from the databases of Ferré et al. (2012), Guasch et al. (2016), Haro et al. (2017), Hinojosa, Martínez-García, et al. (2016), and Stadthagen-González et al. (2017); the ratings of concreteness and familiarity were obtained from the databases of Duchon et al. (2013, EsPal), Ferré et al. (2012), Guasch et al. (2016), Haro et al. (2017), and Hinojosa, Martínez-García, et al. (2016); and the ratings of log bigram frequency, log contextual diversity, log lemma frequency, log trigram frequency, log frequency, old20, NHF, N, number of syllables, and word length were taken from EsPal (Duchon et al., 2013). Of note, the values of some of these variables were not available for some words in the aforementioned databases (specifically AoA, arousal, concreteness, and familiarity). In such cases, ratings were collected through questionnaires following the same instructions and procedures of the published normative studies.
Finally, to have the same number of “yes” and “no” responses in the LDT, a total of 504 pseudowords were generated with Wuggy (Keuleers & Brysbaert, 2010). They were matched in length, subsyllabic structure, and transition frequencies to the experimental words.
Procedure
The experiment was conducted in groups of four participants in a quiet room. Participants carried out 12 practice trials before starting the experiment. Each trial began with a fixation cross (i.e., “+”) appearing in the middle of the screen for 500 ms. The stimulus then replaced the fixation point (Arial font, size 11, lowercase), and participants had to decide whether the string of letters was a Spanish word (pressing the “yes” button with the index finger of the dominant hand) or not (pressing the “no” button with the index finger of the nondominant hand). The trial finished when participants responded or the time limit of 2,000 ms had elapsed. Feedback was provided (“correct,” “incorrect,” or “no response”) for 750 ms. Trials were administered in a continuous running mode with an intertrial interval of 500 ms. There was a break every 126 stimuli (participants continued with the experiment by pushing a foot pedal). The DMDX software (Forster & Forster, 2003) was used to present the stimuli and to record participants’ responses.
Data analyses
This section describes the treatment and cleaning of the data, as well as the procedure followed to carry out the analyses. We obtained a data set of 23,184 reaction times (RTs) from the 46 participants who responded to the 504 words. The data set is available in the following OSF repository: https://osf.io/djgac From this data set, we removed RTs of incorrect responses, RTs below 300 ms, and RTs that exceeded 2.5 SD of each participant’s mean. In addition, we removed two unambiguous words because they showed a high percentage of incorrect responses across participants (>70%). We did not reject any participant because of the number of errors committed, as accuracy was very high (none of the participants committed more than 15% of incorrect responses). A total of 2,136 RTs (9.21% of the total) were rejected, and thus a data set of 21,048 RTs were included in the analyses.
RTs were analysed using linear mixed-effect models (e.g., Baayen, 2008; Baayen et al., 2008). To conduct the analyses, we used the lme4 package of R (Bates et al., 2019). We created different models, in which we introduced some or all of the following variables (as well as some of their interactions) as fixed effects: NOM, ROM, DSI, valence in isolation, valences’ difference, arousal, concreteness, familiarity, AoA, log frequency, word length (in letters), N, NHF, and log bigram frequency (see Table 1 for a summary of the descriptive statistics of the variables included in the analyses). It should be noted that not all the variables mentioned in the “Materials” section were included in the models because of their multicollinearity. If the correlation between predictors is greater than .70 (the conventional threshold for multicollinearity, see, for instance, Rodríguez-Ferreiro & Davies, 2018), decisions need to be made to mitigate the effect of multicollinearity because it can significantly affect linear mixed-effects models (Baayen et al., 2008). A possible solution is to keep only one of the predictors in each case (e.g., the one with the highest tolerance, which is an indicator of problematic multicollinearity when it is lower than 0.20; Menard, 1995). So we calculated correlations and variance inflation factors (VIFs; the inverse of tolerance, see Field, 2017) between the predictors and we left out from the analyses five of these: log lemma frequency (which had a high overlap with log frequency and log contextual diversity), log contextual diversity (with a high overlap with log frequency and log lemma frequency), log trigram frequency (with a high overlap with log bigram frequency), number of syllables (with a high overlap with word length and old20), and old20 (which had a high overlap with word length, N, and number of syllables). In addition, random intercepts for participants and words were included in each model, as well as by-participant random slopes, following a maximal random effects structure (Barr et al., 2013). However, in most cases, this maximal random effects structure did not converge or produced a singular fit (i.e., some random effects explained a near-zero variance), and we had to remove some random slopes from the model to achieve convergence (see the detailed specification of the models in the “Results” section). Random slopes were kept in the model only if they increased its fit significantly.
Descriptive statistics of the variables included in the analyses for the 252 ambiguous words and the 252 unambiguous words.
NOM: subjective number of meanings; ROM: subjective relatedness of meanings; DSI: dominance-subordination index; AoA: age of acquisition; N: number of orthographic neighbours; NHF: number of orthographic neighbours of higher frequency.
We first fitted linear mixed-effects models to the data (i.e., a model including only random effects). Then, outliers of 2.5 SD below or above the model residuals mean were removed from the data set (e.g., Baayen, 2008; Tremblay & Tucker, 2011). We rejected 562 observations through this procedure, and the subsequent models were refitted to the trimmed data. The significance of effects was determined using log-likelihood ratio tests (R function Anova). That is, we compared a model that included the effect of interest with one that did not include such an effect. We also included the results of the t test analyses of the coefficient estimates for each fixed effect. To this end, we used Satterthwaite’s approximations to the degrees of freedom of the denominator (p values were estimated by the lmerTest package, Kuznetsova et al., 2019).
Results
We performed two different analyses. The first of these included all the words, both ambiguous and unambiguous; the second was restricted to ambiguous words.
First analysis: Analysis with all the words—examining the interaction between ambiguity and valence in isolation
We created a model that included the interaction between NOM and valence in isolation to examine the interactive effect of these two variables in RTs:

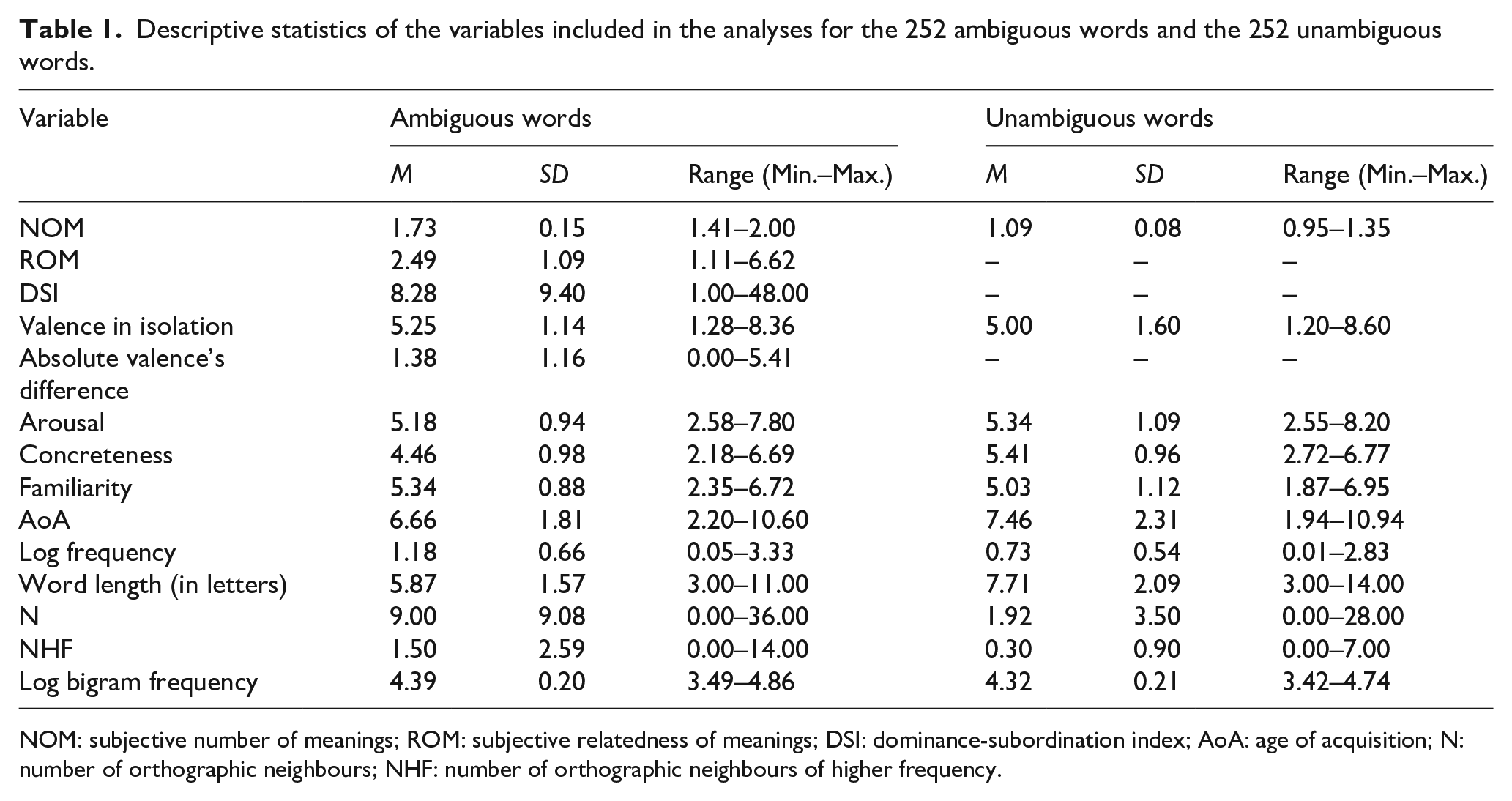
The analysis revealed a significant effect of NOM (see Table 2), where word recognition was faster as number of meanings increased, estimate = −87.50, SE = 23.71, t = −3.69, p < .001. Valence also showed a significant effect, estimate = −17.60, SE = 5.78, t = −3.05, p = .002, indicating that in comparison with neutral words, negative valence slowed down RTs, whereas positive valence made them faster. More importantly, the interaction between NOM and valence in isolation was significant, as the model including this interaction was significantly better than the model that did not include it, χ2(1) = 4.22, p = .040. This interaction showed that the effect of valence decreases as the number of meanings of the word increases, to the point that it completely disappears in the words with the highest NOM values, estimate = 8.72, SE = 4.29, t = 2.03, p = .042 (see Figure 1). Thus, unambiguous words (NOM close to 1) showed a clear valence effect (i.e., a slowdown for negative words and a facilitation for positive words), whereas highly ambiguous words (NOM close to 2) showed no effect of valence at all. Apart from the above findings, which were the main focus of interest in this study, it is worth mentioning that the other variables showed the commonly reported effects in the literature. Indeed, there was a facilitating effect of both lexical frequency and familiarity (both ps < .001), as well as of arousal (although in this case, the effect was marginal, p = .053), indicating that high frequency and familiar words, as well as highly arousing ones, are recognised faster than their low frequency, low familiar, and low arousing counterparts. On the contrary, number of letters, AoA, number of lexical neighbours, and bigram frequency had an inhibitory effect (all ps < .05). That is, higher values of the words in each of those variables were associated with slower RTs.
Summary of effects of the valence in Isolation × NOM model (analysis including all the words).

NOM: subjective number of meanings; AoA: age of acquisition; N: number of orthographic neighbours; NHF: number of orthographic neighbours of higher frequency.
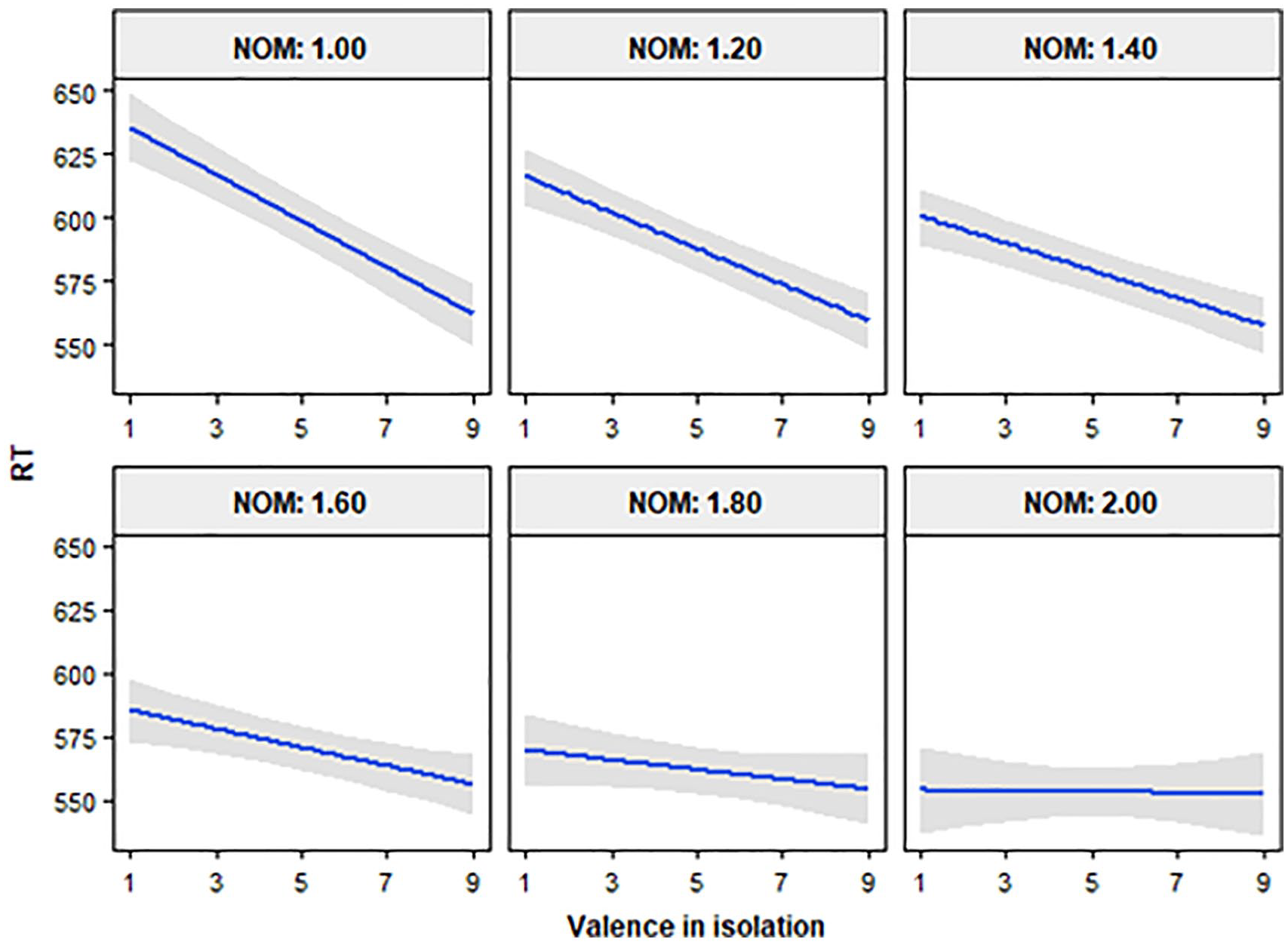
Interaction between ambiguity and valence in isolation.
The above results reveal that the valence effect decreases as ambiguity increases. To know whether this pattern of findings is due to the affective incongruence between the two meanings of some of the ambiguous words included in the data set, we carried out a second analysis restricted to ambiguous words.
Second analysis: Analysis restricted to ambiguous words—examining the interaction between valence in isolation and the difference in valences of the meanings of ambiguous words
We focused on the 252 words that were ambiguous, according to the NOM values in the database of Huete-Pérez et al. (2020). For the analysis, we computed a new variable, which we called “difference in valences” (hereafter DIV), which was the absolute difference between the valence ratings of the two meanings of an ambiguous word. Of note, this variable is an index of the congruence/incongruence in valence between the two meanings of an ambiguous word. For instance, if the two meanings are positive (i.e., in the 6–9 range of the valence scale), there would be a small difference in valence (i.e., this would be an ambiguous word with congruent affective meanings). In contrast, if one of the meanings is positive and the other is negative (i.e., in the 1–4 range of the valence scale), there would be a large difference in valence (i.e., this would be an ambiguous word with incongruent affective meanings).
The analysis was performed on a total of 8,851 RTs. The interaction between valence in isolation and valences’ difference was included in the model:

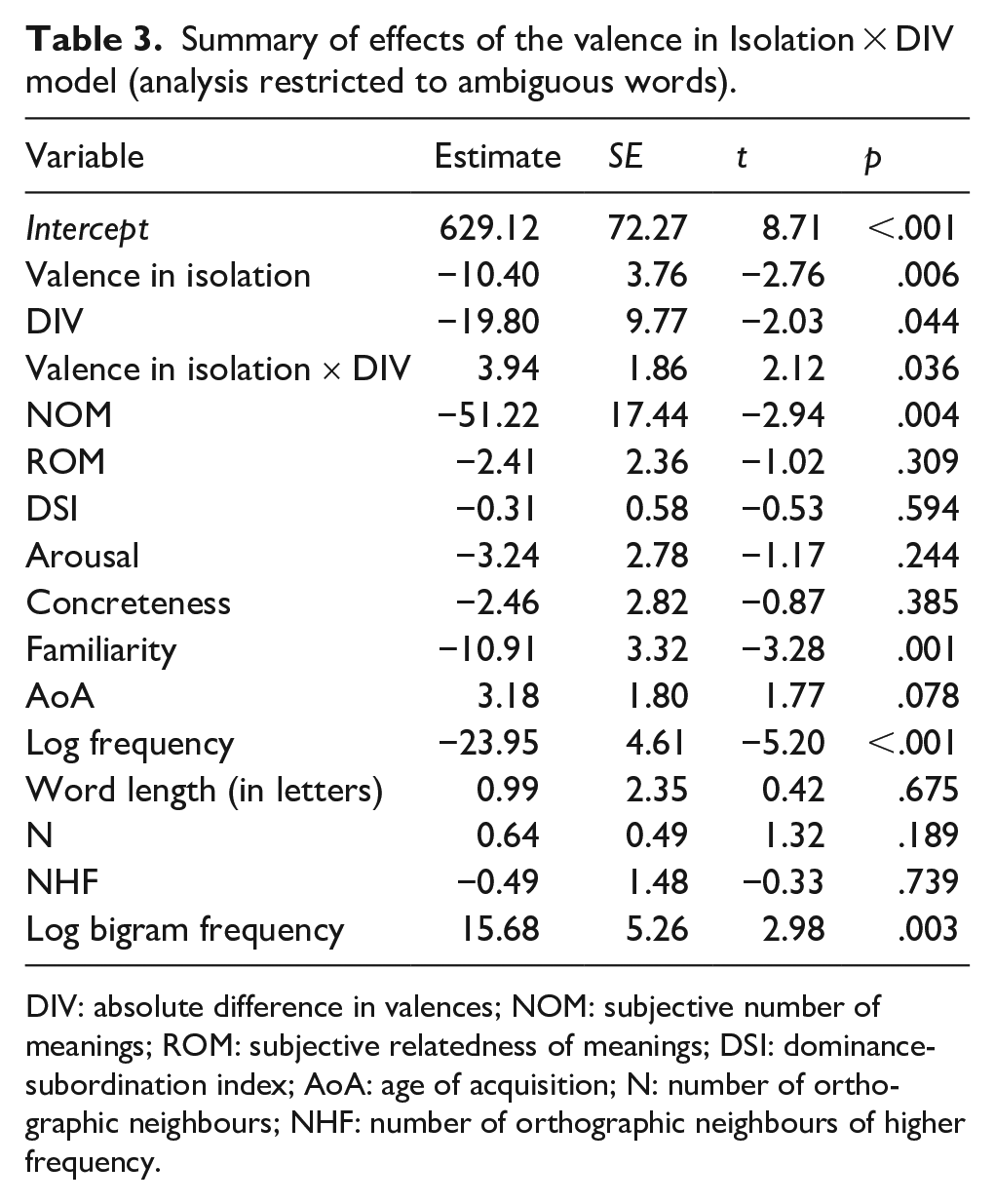
Similar to the previous model, the results showed a significant effect of valence (see Table 3), estimate = −10.40, SE = 3.76, t = −2.76, p = .006. In addition, there was a significant effect of DIV, estimate = −19.80, SE = 9.77, t = −2.03, p = .044. More importantly, the interaction between valence in isolation and DIV reached statistical significance, given that the model that included such interaction was better than the model that did not include it, χ2(1) = 4.77, p = .028. This interaction indicates that the valence effect decreases as the difference between the valence of the meanings of an ambiguous word increases (see Figure 2), estimate = 3.94, SE = 1.86, t = 2.12, p = .036. Therefore, ambiguous words whose meanings have similar valence values (i.e., affectively congruent words) showed a clear valence effect, whereas ambiguous words whose meanings have very different valence values (i.e., affectively incongruent words) showed no valence effect. Finally, in the same line as in the first analysis, we also found here a facilitating effect of NOM, lexical frequency and familiarity (all ps < .005), and an inhibitory effect of bigram frequency (p = .003) and AoA (although marginally significant, p = .078). No other significant effects were observed.
Summary of effects of the valence in Isolation × DIV model (analysis restricted to ambiguous words).
DIV: absolute difference in valences; NOM: subjective number of meanings; ROM: subjective relatedness of meanings; DSI: dominance-subordination index; AoA: age of acquisition; N: number of orthographic neighbours; NHF: number of orthographic neighbours of higher frequency.
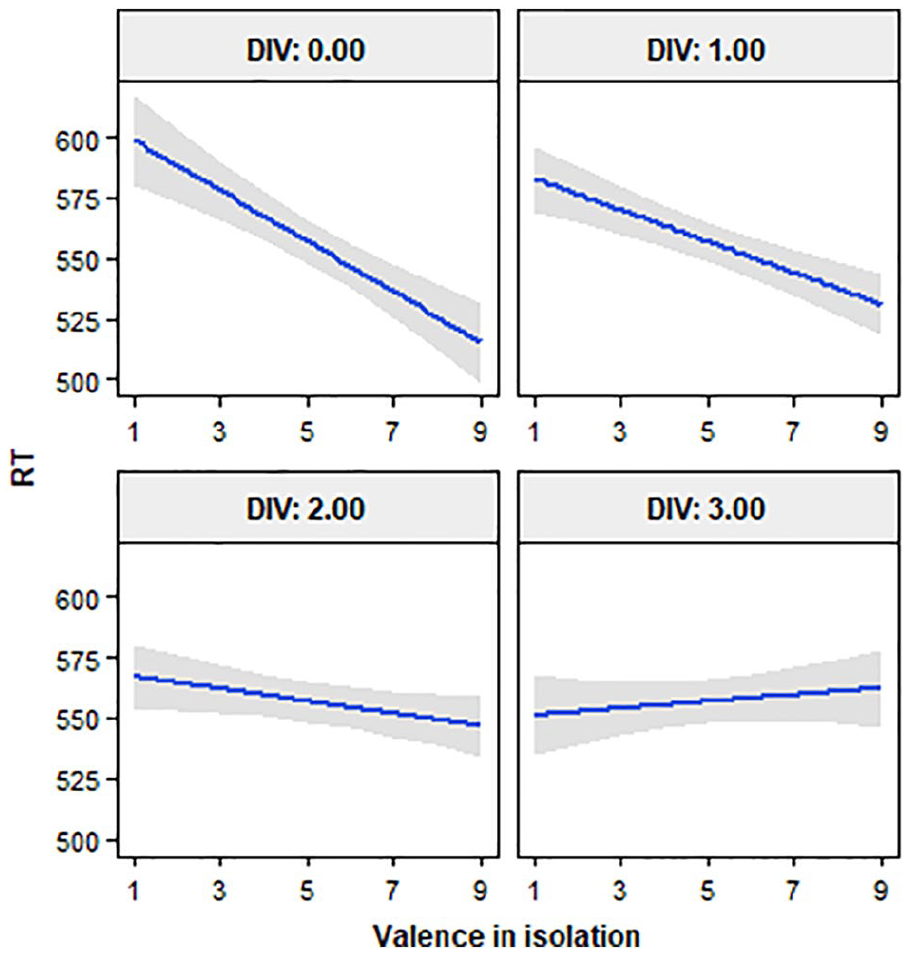
Interaction between valence in isolation and DIV of the meanings of ambiguous words.
Discussion
The present study examined whether affective word processing is modulated by semantic ambiguity. The results of a large-scale lexical decision study provided evidence of such modulation. In particular, a valence effect was observed in which positive valence made RTs faster, whereas negative valence slowed them. Importantly, the valence effect decreased as the semantic ambiguity of words increased. Such a reduction is not due to semantic ambiguity per se, but rather to the affective incongruence between the meanings of some ambiguous words.
This is the first large-scale study in which the interaction between affectivity and semantic ambiguity has been explored. Our results are in line with those reported in Syssau and Laxén (2012), where a valence effect restricted to unambiguous words was found. The authors speculated that this finding might be due to the distinct affective polarity of the meanings of some ambiguous words. Syssau and Laxén could not test this possibility because they did not have the valence value for each meaning. The present findings, showing an interaction between valence in isolation and DIV (i.e., the absolute difference in valence between the distinct meanings of ambiguous words), have revealed that this seems to be the case. Indeed, the results of our second analysis, which was restricted to ambiguous words, show that there is a clear valence effect in affectively congruent ambiguous words. In contrast, the valence effect diminishes as the affective incongruency between the distinct meanings of ambiguous words increases.
It might be argued that the valence congruence effect is a semantic relatedness effect in disguise. Concretely, congruent affective meanings might be more semantically related than incongruent affective meanings. Research on semantic ambiguity has revealed that the processing of ambiguous words is facilitated by the semantic relatedness of their meanings (Klepousniotou & Baum, 2007; Rodd et al., 2002). Hence, the modulation of RTs by valence congruence might be the result of a confound with semantic relatedness. There are, however, several findings that rule out this possibility. The first one is derived from the second analysis conducted here, where the ROM variable (i.e., a measure of the relatedness between the distinct meanings of ambiguous words) was introduced. ROM failed to show any effect on RTs, whereas both the effect of DIV and the interaction between DIV and valence were significant (see Table 3). Importantly, we introduced the interaction between ROM and DIV in an additional analysis and found that it was nonsignificant either (estimate = 2.47, SE = 2.15, t = 1.15, p = .252). Finally, we also computed the correlation between ROM and DIV of the ambiguous words used in this study and found that it was far from being significant (r = −.07, p = .28). These results suggest that affectively congruent ambiguous words are not necessarily more semantically related than affectively incongruent unambiguous words and that the valence congruence effect found here is not due to semantic relatedness.
The present findings have clear implications for our understanding of the role of affective content on word recognition. They may be explained within two different frameworks. The first one is related with work on semantic ambiguity. Many studies in the field have demonstrated that the different meanings of ambiguous words are activated when those words are presented in isolation (e.g., Haro & Ferré, 2018). For instance, when participants read the word cataract, both the positive and the negative meaning of that word would be activated. The incongruence between the affective sign of the two meanings may produce a competition between them. As a matter of fact, the role of competition in the explanation of some of the semantic ambiguity effects observed in the literature has been emphasised in different models (see Eddington & Tokowicz, 2015, and Rodd, 2018, for recent overviews). The consequence of such competition would be a slowdown in lexical decision times, when compared with a word whose two meanings have the same affective sign.
The second possible explanation comes from research on affective stimuli processing and the motivational function of emotion, which leads to different action tendencies associated with distinct emotions. Indeed, positive emotions are generally correlated with approach tendencies, whereas negative emotions are linked to withdrawal/avoidance tendencies (e.g., Roseman, 2008). Although such action tendencies have been scarcely investigated when the emotional stimuli are words, a few studies suggest that they may have also a role in word processing (e.g., Citron et al., 2016; Huete-Pérez et al., 2019). The congruency/incongruency between the action tendencies associated with the distinct meanings of ambiguous words might account for the present findings. For instance, in ambiguous words with two positive meanings, congruency between the action tendencies associated with each meaning would facilitate word recognition. However, in ambiguous words with both a positive and a negative (or neutral) meaning, the distinct action tendencies associated with each meaning would produce a conflict that might cancel out the advantage in RTs commonly found for positive words. This explanation fits well with the one provided to explain the distinctive processing of affectively ambivalent (not necessarily semantically ambiguous) words in comparison with affectively monovalent words (Briesemeister et al., 2012).
Apart from the possible theoretical explanation of the present findings, they also have clear methodological implications for word recognition research. Psycholinguistic researchers interested on the role of affective word content commonly select their experimental stimuli from normative databases. In such databases, each word has a valence value (i.e., the “valence in isolation” measure used here), and this value has been obtained by asking a large group of participants to rate the word (e.g., Eilola & Havelka, 2010; Ferré et al., 2012; Guasch et al., 2016; Moors et al., 2013; Redondo et al., 2007; Stadthagen-González et al., 2017; Võ et al., 2006; Warriner et al., 2013). None of these studies has taken into account the possibility that some words may have more than one meaning. However, considering the present results, valence in isolation seems to be a better measure of the emotionality of unambiguous words than that of ambiguous words. In the first case, the valence rating represents a single meaning. In the second case, the valence rating would be the result of the activation of the different meanings of ambiguous words. For this reason, such rating would not be representative of the specific affective value of each meaning, especially when ambiguous words have incongruent affective meanings (see Huete-Pérez et al., 2020).
Considering the above, the available normative affective data on ambiguous words may not be adequate to select experimental stimuli, mainly for studies where only one of the meanings is intended. The inadequacy of such affective ratings has been evidenced by some of the analyses performed by Huete-Pérez et al. (2020), who found that, among their data set, there was a high percentage of ambiguous words (54.37%) whose meanings had an incongruent valence (e.g., one of the meanings was positive, and the other was negative or neutral). Interestingly, many of those words had valence ratings on the neutral range of the scale when presented in isolation (i.e., they would be classified as neutral words according to their values in the published affective databases). Hence, they may have been included as members of the neutral condition in some studies, despite not being neutral at all. This in itself may have contributed, in some cases, to the mixed findings in the field.
In sum, the interaction between valence and ambiguity reveals that the affective effects in word processing are modulated by semantic ambiguity, suggesting that the affective incongruence between the distinct meanings of some ambiguous words can override the valence effect. This should be taken into account by researchers when they select their experimental materials and highlights the need to consider the valence of each meaning separately in research on ambiguous affective word processing.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This study was supported by Ministerio de Ciencia, Innovación y Universidades (Grant Nos. PID2019-107206GB-I00 and RED2018-102615-T); by Universitat Rovira i Virgili (Grant No. 2018PFR-URV-B2-32); and by the Xunta de Galicia (Grant No. ED431B 2019/2020).