
Abstract
Pseudowords are letter strings that look like words but are not words. They are used in psycholinguistic research, particularly in tasks such as lexical decision. In this context, it is essential that the pseudowords respect the orthographic statistics of the target language. Pseudowords that violate them would be too easy to reject in a lexical decision and would not enforce word recognition on real words. We propose a new pseudoword generator, UniPseudo, using an algorithm based on Markov chains of orthographic n-grams. It generates pseudowords from a customizable database, which allows one to control the characteristics of the items. It can produce pseudowords in any language, in orthographic or phonological form. It is possible to generate pseudowords with specific characteristics, such as frequency of letters, bigrams, trigrams, or quadrigrams, number of syllables, frequency of biphones, and number of morphemes. Thus, from a list of words composed of verbs, nouns, adjectives, or adverbs, UniPseudo can create pseudowords resembling verbs, nouns, adjectives, or adverbs in any language using an alphabetic or syllabic system.
Pseudowords are stimuli created from letters that look like words but are not words. They differ from nonwords, which are also stimuli created from letters but do not look like words (CNLME is an example of a nonword in English). For a long time, pseudowords have been generated by changing one or more letters of an existing word (e.g., CLEAM created from CLEAN by Davis & Lupker, 2006). Pseudowords are intensively used in psycholinguistics research. They are essential in a task widely used in that field, namely the lexical decision task, where participants have to decide as quickly as possible whether the stimulus presented on the screen is a word. To cause participants to access their mental lexicon, it is essential that the pseudowords respect the phonotactic rules of the language; in other words that they are potential words.
In creating pseudowords for a lexical decision, it is difficult to avoid pseudowords that are too easy to reject. For example, with nonwords composed only of consonants (such as DZGLS), the participants will quickly realise that it is sufficient to detect the presence of a vowel to take the decision and will no longer need to identify the words. In this case, reaction times will no longer reflect the processes involved in normal reading. Of course, this example is extreme, but it shows how the construction of pseudowords or nonwords will influence the processing of words. To ensure that pseudowords are well-adapted to the words used in a lexical decision task, it is necessary that they conform to the orthographic rules. Orthographic rules are specific to each language and determine legitimate strings of letters. For example, in English, the letter sequence “qr” is not orthographically correct (it does not exist in any English word), whereas “qu” is perfectly valid (e.g., queen, quest, and quarter).
Another criterion that is relevant when creating pseudowords is the orthographic proximity of the pseudoword with real words. For the English Lexicon Project, Balota et al. (2007) created a lexical decision task with 40,481 words. They created 40,481 matched pseudowords by modifying one or two letters of the original words. This method of creating pseudowords raises the problem of the systematic orthographic proximity of the pseudoword and the original word. Indeed, for some pseudowords, participants can sometimes identify the original word (e.g., addomen from abdomen). The recognition of the original word can induce an unintended experimental priming bias that is not controlled by the experimenters.
Using the method of replacing one or two letters of the word, the identification of the original word is much easier for long words than for short words, as the percentage of letters common to the pseudoword and the original word is higher in longer words. Short pseudowords have more orthographic neighbours (number of words that can be derived by changing just one letter and preserving letter positions) than long pseudowords. Furthermore, the influence of the original word was notably shown by Yap et al. (2015) and Perea et al. (2005), who showed that reaction times to pseudowords are notably influenced by the frequency of the base word.
Being able to recognise the source word of a pseudoword may also affect studies that are specifically interested in the mechanisms used when reading pseudowords. As pseudowords, by definition, should generate limited lexical activity, they can be used to better understand sublexical effects. For example, they have been used to study the non-lexical pathway of the dual-route cascaded model (Coltheart et al., 2001), which states that words can be read through a lexical route or a grapheme–phoneme conversion route. In this framework, pseudowords allow one to study the properties of the grapheme–phoneme conversion pathway, because they are necessarily read by the non-lexical pathway (e.g., Proverbio et al., 2004). In this situation, it is crucial to generate pseudowords from which the original words are not identifiable. Moreover, before someone learns a word, it is a pseudoword for them. Thus, studying how adults learn pseudowords can reveal the processes involved in word acquisition.
A number of studies have also examined the impact of pseudohomophony (nonwords spelling that can be pronounced like a word) to determine whether there are phonological effects in silent reading (see e.g., Besner & Davelaar, 1983; Taft, 1982). Another example of the use of the pseudowords utility is the study from Taft (2004) who manipulated the nature of the pseudowords in a lexical decision to examine whether inflected words are recognised via their stem.
Currently, the main tools used to create pseudowords for research are the ARC Nonword Database, WordGen, CGCA, and Wuggy. We describe them briefly before presenting our new tool for generating pseudowords.
Existing solutions for the generation of pseudowords
ARC nonword database
The ARC Nonword Database, developed by Rastle et al. (2002), contains 358,534 monosyllabic pseudowords, including 48,534 pseudohomophones. To generate these pseudowords, the authors used a grammar based on several phonotactic rules, allowing phonemes to be combined to create potential monomorphemic words. Once these phonological pseudowords were generated, the authors generate the associated orthographic forms using phoneme–grapheme correspondence rules. These pseudowords are grouped in a database that allows the user to select the items according to certain criteria (e.g., the number of neighbours or their bigram frequency [adjacent pairs of letters frequency]). However, the use of this database for research has two important limitations: it is only available in English and contains only monosyllabic pseudowords.
WordGen
WordGen (Duyck et al., 2004) is a software programme that uses the CELEX (Baayen et al., 1996) and Lexique (New et al., 2004) databases to generate pseudowords in Dutch, English, German, and French. These pseudowords can be generated according to their number of letters, the size of their neighbourhood, or the frequency of their bigrams. To generate a pseudoword, Wordgen concatenates a string of random letters and checks if this string of letters is a word. If it is not a word, it then checks the different properties requested and rejects the string of letters if one of these properties is violated. This means that if the parameters are strict, WordGen may take a long time to find potential candidates. It also means that it may be difficult for researchers not used to word with sublexical statistics to find the set of parameters that will allow good pseudowords according to the words in the experiment.
Wuggy
Wuggy (Keuleers & Brysbaert, 2010) is a software programme that, in its first incarnation, was able to generate pseudowords in Basque, Dutch, English, French, German, Serbian, and Spanish. The current version of Wuggy (0.3.2) can also generate pseudowords in Italian, Polish, Turkish, and Vietnamese. Wuggy uses a list of syllabified words. These words are decomposed into subsyllabic elements, and these subsyllabic elements are recombined to form pseudowords. To match the created pseudowords with the words given by the psycholinguistic researchers, Wuggy tries to filter the pseudowords with the same frequencies of subsyllabic elements and progressively widens these constraints in terms of frequencies to find a potential candidate. Wuggy is a powerful pseudoword generator, but it is not available for all alphabetic languages, and it produces pseudowords that do not necessarily respect the nature of the words (e.g., generate only present participle pseudowords in English).
None of these three solutions allows one to work from a corpus of words determined entirely by oneself. This ability, however, would allow one to control the properties of the input words and thus determine the properties of the generated pseudowords. For example, from a list of words composed of verbs, nouns, adjectives, or adverbs, one could create pseudowords resembling verbs, nouns, adjectives, or adverbs. This could be particularly interesting for languages in which the grammatical classes have specific orthographic properties. For instance, the present participles of French verbs have a specific ending “ant.” If UniPseudo is given only present participles as input, the generated pseudowords will all end with the specific ending. Whereas with Wuggy, this will not be the case because it will recombine sub-lexical elements taken from the whole set of French words and therefore pseudowords without this specific present participle ending will be generated.
Another advantage of generating pseudowords from a list of words provided by the researcher is that it allows one to work with any language, provided that it is alphabetic or syllabic. Current tools are based on orthographic and not phonological algorithms (except Wuggy for English, French, and Italian) and are therefore designed to generate pseudowords for reading or writing research. They cannot easily generate pseudowords for auditory research. A tool using a personalised word list could work directly on phonology whatever the desired language provided that the words in the personalised list would be transcribed in their phonological form (e.g., table → /teɪbəl/). More recently, two new generators have been proposed using a custom list of words to generate pseudowords, CGCA and UniPseudo, the latter of which is the subject of this article.
CGCA
The CGCA algorithm (König et al., 2020) is the most recent tool. It can take a wordlist or a corpus as input. It extracts all unique tokens from the input to create the origin wordlist. From the origin wordlist, it extracts all possible character-grams (bigrams, trigrams, 4-grams, 5-grams, etc.) and assigns them to three possible positions: the beginning, middle, or end of words. Finally, it iteratively generates and validates each chain of character-grams. It outputs a list of pseudowords specific to the words used to generate them. CGCA is available as a script on GitHub and needs to be run it in a terminal (which non-programmers are not necessarily familiar with).
UniPseudo
UniPseudo has the following features:
It is accessible through a web interface (http://unipseudo.lexique.org/).
The pseudowords it generates are constructed from words given by the user. This property allows the user (1) to generate pseudowords in any language based on an alphabetic or syllabic system, (2) to generate pseudowords with diacritical marks, and (3) to generate pseudowords that respect the orthographic statistics of the input word list. Concerning (2) diacritical letters are considered as different letters and thus UniPseudo will generate pseudowords which probability of appearance of diacritical letters will be similar to the frequency of diacritical letters present in the user’s input. Concerning (3), it allows one to generate pseudowords that look like inflected verbs (e.g., from Table 1: beaped), nouns (e.g., from Table 1: encher), or adjectives. It can also generate pseudowords that look like low-frequency words and contain potentially less-frequent sublexical parts, or high-frequency words and contain potentially more frequent sublexical parts. Furthermore, it can be used to generate words resembling early- or late-acquired words. Take the example of verb generation in English. If one enters only 5-letter English verbs in the infinitive form, one obtains as output 5-letter pseudowords that could be verbs in English. An important point is that the proportion of irregular pseudoverbs in the list should be comparable to that of irregular verbs in the working corpus. Once it has a sufficient list of words of a certain length with certain properties (we recommend at least 100 words, but, in general, the more the better), UniPseudo generates pseudowords that share the properties of these words. Thus, it is possible to generate pseudowords with one or a combination of characteristics (frequency of letters, bigrams, trigrams or quadrigrams, number of syllables, frequency of biphones [adjacent pairs of phonemes], number of morphemes, etc.).
In addition to generating orthographic pseudowords, the algorithm can also generate phonological pseudowords. Thus, for an auditory lexical decision, it is possible to generate pseudowords with certain phonological characteristics. If phonemes are coded by single Unicode letters, the algorithm will also be able to generate phonological pseudowords. The algorithm operates on single segments sequentially using simple transitional probabilities. For example, to generate pseudowords of two syllables starting with an occlusive and ending with a nasal vowel, the user only needs to provide a corpus of input words based on phonological representations rather than orthographic representations of words.
It also allows words from 64 languages to be easily imported and thus pseudowords to be generated in these 64 languages.
It can also generate pseudowords in non-Latin alphabets.
Its source code is available at https://github.com/chrplr/openlexicon/tree/master/apps/unipseudo.
Algorithm used by UniPseudo
UniPseudo uses an algorithm based on Markov chains. It requires a set of words of a given length (e.g., all 6-letter nouns). From this set, it extracts all trigrams (or bigrams if the user decides so) at a given position (e.g., for a word of 6 letters [123456], there are four trigrams: 123, 234, 345, and 456). Then, to create a pseudoword, it starts by randomly selecting a trigram among those starting in initial position (respecting the frequencies in the original corpus). Then it selects randomly a second trigram that start with the two letters finishing the first one, among trigram starting in second position. This process is repeated until the last trigram is reached (the fourth one for a word of six letters). Thus, trigrams are selected by the frequency of the input given by the user: a trigram which is frequently in the input will have more probabilities to be selected during the constitution of the pseudowords. This algorithm allows pseudowords to be generated that are similar to the original words. Examples of pseudowords based on six-letter lemmas that are either nouns or verbs are given in Table 1 in French and English.
Examples of six-letter pseudonouns and pseudoverbs generated with UniPseudo.

This algorithm has the advantage that strong constraints can be placed on the word-selection algorithm.
UniPseudo is using an algorithm based on Markov chains similarly to CGCA, although its creation was not accompanied by a specific publication. Indeed, it was already available online in a less modern and less option-rich format on the Lexique website in 2012, 1 and it has also already been used to create the pseudowords for the MEGALEX mega-study (Ferrand et al., 2018). In contrast to CGCA, UniPseudo takes the position of bigrams and trigrams in the word more finely into consideration as far as this is a specific position. CGCA only takes into account the beginning, middle, and end positions of the word.
How to use UniPseudo
UniPseudo is available as a web application at the following address: http://unipseudo.lexique.org/. Figure 1 shows the interface.

Screen capture of UniPseudo’s interface.
To use UniPseudo, the user follows these steps:
Select the desired length of the pseudowords.
Decide whether the algorithm will use trigrams or bigrams. In general, it is advisable to use trigrams. For short words (3, 4, or 5 letters); however, it is preferable to use bigrams, because trigrams yield results that are too similar to existing words.
Select a language among 64 possibilities. Selecting a language also allows the use of the Word Import Tool (see below). If these features are not required, the user should choose the first option, “Other.”
Copy the list of words on which the algorithm will base the pseudowords, with a line break separation between each word. To generate word lists, one can use specialised databases for a given language (e.g., Lexique for French and the English Lexicon Database for English). As mentioned earlier, it is recommended to include at least 100 words, but, in general, the more the better. For instance, in Figure 1, we copied all 877 words from Lexique 3.83 that met the following criteria: six letters, two syllables, lemma (not an inflected form), noun, and a subtitle lemma frequency 2 strictly greater than one occurrence per million (so as not to include too rare orthographic forms).
Choose the number of pseudowords that UniPseudo should generate.
Use the “Show Constraints” button to set additional constraints to the output if you want to. The user can set constraints such as the maximum number of accented characters possible in a pseudoword, the maximum number of successive consonants or the maximum number of identical letters possible in a pseudoword.
Press the “Go” button.
You get the requested pseudowords in the UniPseudo window. A manual selection phase of the items is then necessary. If you want, for example, 50 pseudowords, we advise you to generate at least 150 pseudowords to be able to select the 50 best candidates proposed by UniPseudo. If the user performing the manual selection selects on average one pseudoword out of three as he or she goes through the list, he should minimise possible systematic bias. Indeed, the pseudowords of the list are presented in a completely random order.
If you want to know the construction steps of each pseudoword, the details are presented step by step in the “Pseudowords details” tab.
When the process is complete, the generated pseudowords appear in the right part of the window. The user can click on “Download Pseudowords” to download an Excel file containing the generated pseudowords.
Once the pseudowords have been generated, the chosen trigram, its position, and the origin word can be displayed by clicking on the “Pseudowords with details” tab (see the online Supplementary Material 1). For example, the pseudoword tensus is composed of the trigram ten in first position (from the word tennis), the trigram ens in second position (from the word pensée), the trigram nsu in third position (from the word consul), and the trigram sus in last position (from the word dessus).
Word Import Tool
There is another way to generate pseudowords with UniPseudo without having to first build a custom list of base words. For the 64 languages for which there is a database in WorldLex (Gimenes & New, 2016; see Supplementary Material 2 for the list of the 64 languages), it is possible to automatically import a word list of the desired length into UniPseudo (see Figure 2). Only words with a frequency strictly greater than 0.5 are imported so as not to include too rare orthographic forms.
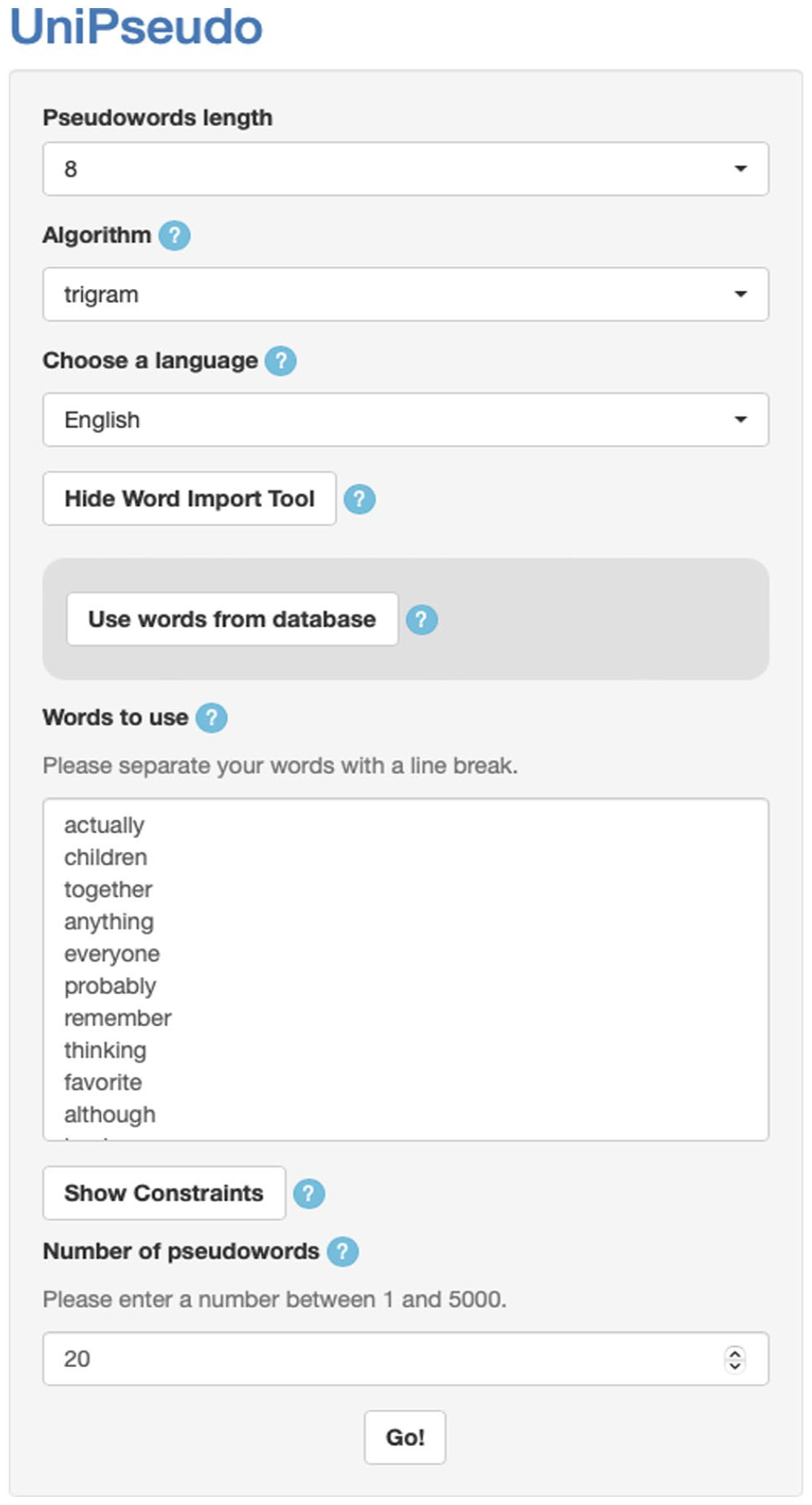
Screen capture of the Word Import Tool.
To use the Word Import Tool, the user follows these steps:
Choose the length of the pseudowords.
Choose whether the algorithm will use trigrams or bigrams.
Choose a language among 64 possibilities.
Click on “Show Word Import Tool.”
Click on “Use words from database” to import words of the selected language and chosen length.
Choose the number of pseudowords desired.
Choose if you want to use custom constraints.
Click on “Go!”
Comparison of UniPseudo with existing tools
First, we compared the quality of the pseudowords proposed by UniPseudo to those proposed by Wuggy and CGCA. For this, we used the LD1NN algorithm (Keuleers & Brysbaert, 2010). This algorithm assesses how easy (or not) it is for a participant to determine whether the presented stimulus is a pseudoword. For each stimulus in a lexical decision, LD1NN calculates the Levenshtein distance (the minimum number of operations, i.e., deletions, insertions, or substitutions required to turn one word into the other) between the current stimulus and the previous ones. This allows it to identify the stimuli closest to the current stimulus. Finally, it calculates the probability of giving a word response based on the relative frequency of words and pseudowords in this close neighbourhood.
To test the relevance of the pseudowords generated by UniPseudo, we selected from Lexique 3.83 all the French words of eight letters having a lemma frequency higher than 1 and containing neither space, dash, nor apostrophe. From these words, we generated 2,400 pseudowords with CGCA and UniPseudo using trigrams. Then we randomly selected 2,400 words and used Wuggy 0.2.2b2 to generate only one pseudoword per selected word using the default options (“match length of subsyllabic segments,” “match letter length,” “match transition frequencies,” and “match subsyllabic segments 2 out of 3”). The word and pseudoword lists used are available on Open Science Framework. 3 Once the three lists were generated (same 2,400 words and 2,400 different pseudowords for the three tools), we randomised their order and then applied the LD1NN algorithm to the resulting word and pseudoword list. The results are presented in Figure 3.
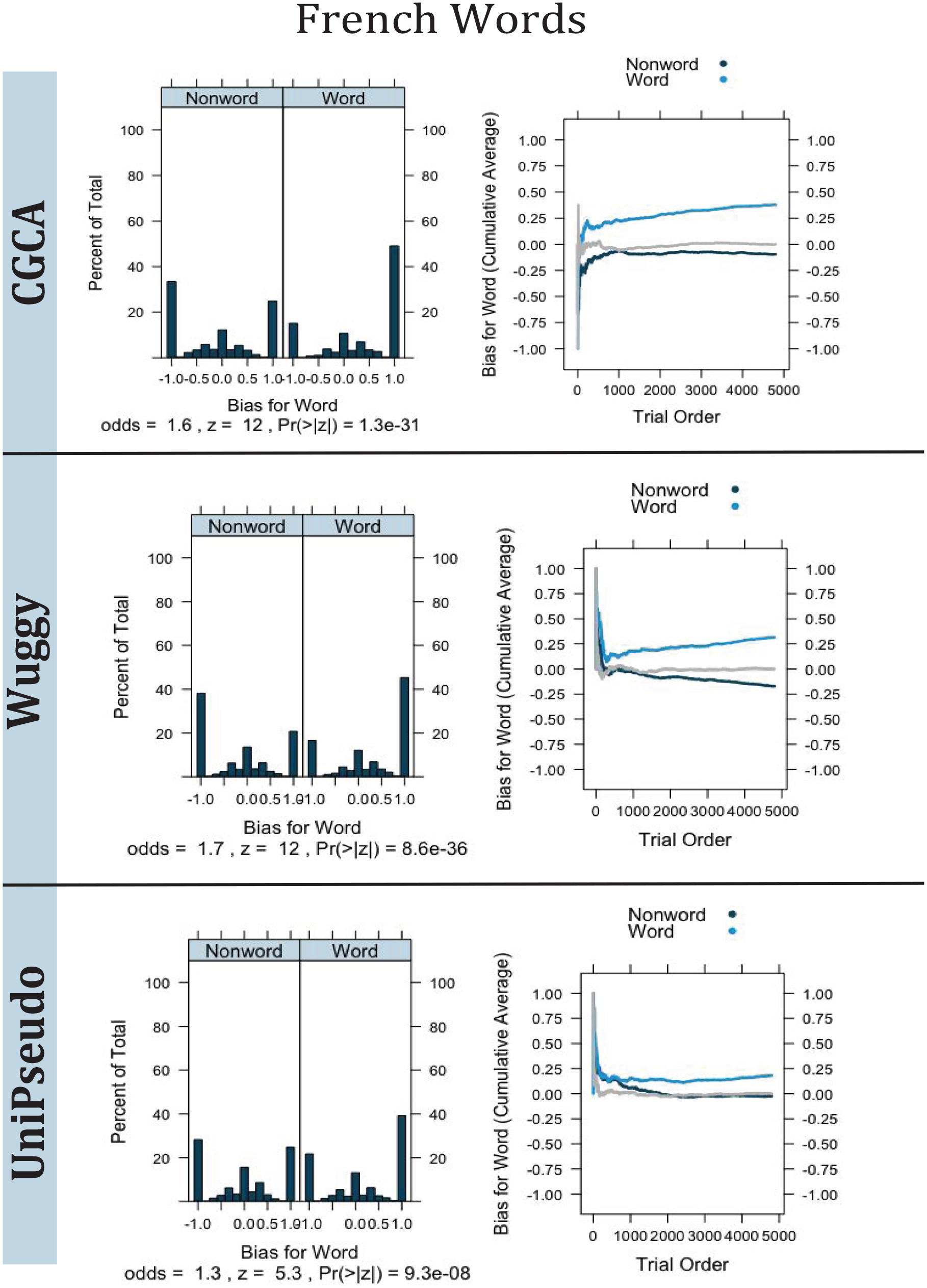
Results of LD1NN algorithm presented with a group of 2,400 French 8-letter words and 2,400 8-letter nonwords created using CGCA, Wuggy, and UniPseudo algorithms. Left panel: distribution of word bias for both words and nonwords. Right panel: cumulative average of word bias for words and nonwords; the grey line indicates the numerical bias for words based on the percentage of words vs. nonwords processed up to that point.
On the left panel of Figure 3, each vertical bar should be read as the percentage of nonword stimuli (left subpanel) and word stimuli (right subpanel) that had a particular bias for a word response (positive) or for a nonword response (negative). As shown on the left panel of Figure 3, the probability of a nonword being considered a nonword (the leftmost bar on the left subpanel) is less strong for UniPseudo than for CGCA or Wuggy. A pseudoword is a good stimulus if it looks like a word. Indeed the answer to decipher whether a stimulus is a word should require lexical access and not only the detection of surface features of the pseudoword construction.
In the right panel, one can see that LD1NN increasingly detects words more effectively in the lists generated by CGCA. When the pseudowords are made by Wuggy, the algorithm also tends to detect words and pseudowords increasingly effectively, but the bias remains lower than that of CGCA, especially for pseudowords. For UniPseudo, one can observe a reduced bias for both words and pseudowords, and this bias does not tend to increase with each trial.
We performed another analysis similar to the one described above but with lemmas (uninflected forms) only. We selected all 8-letter words that were lemmas without spaces, hyphens, or apostrophes and had a subtitle lemma frequency of at least 1 occurrence per million words. We used these words to create 1,800 pseudowords with CGCA and UniPseudo. Then we randomly selected 1,800 words from which we created 1,800 pseudowords with Wuggy by asking it to generate only one candidate with the default options. Once the 1,800 words and 1,800 pseudowords were generated, we randomised their order and then applied the LD1NN algorithm to the list of words and pseudowords obtained. Again, the results on the right-hand side of Supplementary Material 3 show that LD1NN is better at guessing that the pseudowords are pseudowords when they are created by CGCA and Wuggy than when they are generated by UniPseudo. Moreover, as the trials progress, LD1NN is better at discriminating between words and pseudowords when the pseudowords come from Wuggy and CGCA than when they come from UniPseudo. The logistic regression indicates that LD1NN distinguishes words from pseudowords when the pseudowords are made with CGCA (z = 6.7, p < .001) or Wuggy (z = 9.4, p < .001), whereas it does not distinguish words from non-words when the pseudowords are made with UniPseudo (z = 0.1, p = .92).
Finally, we ran simulations in English to check that these results were not due to some peculiarities of French. We selected English words from WorldLex 4 with a surface frequency of at least 1 occurrence per million words. The results are presented in Supplementary Material 4 (all words) and 5 (English lemmas). The results are similar to the results observed in French. LD1NN has more difficulty discriminating between words and pseudowords when the pseudowords are made by UniPseudo than when they are made by Wuggy or CGCA, although the performances of UniPseudo and Wuggy are more similar than in previous simulations. In general, LD1NN has more difficulty discriminating words from pseudowords with the English lexical decisions than with the French ones, suggesting that it is easier to generate good pseudowords in English than in French. Compared with Wuggy and CGCA, UniPseudo produces particularly interesting results because it combines n-grams whose position in the original word list is preserved. This allows it to favour pseudowords with a valid structure in all languages without the need for additional checks.
Supplementary analyses (Supplementary Material 6–9) were conducted on the pseudowords generated by CGCA, Wuggy, and UniPseudo to investigate the quality of the different pseudowords lists. For the word and pseudoword lists that were generated for the previous four analyses (LD1NN), we calculated frequency indices for the words and for the pseudowords. For French words and lemmas, we used Lexique-Infra (Gimenes et al., 2020) to compute the frequency of letter types and tokens, bigram types and tokens and trigram types and tokens. For English words and lemmas, we used N-Watch (Davis, 2005) to compute the frequency of bigram types and tokens and the frequency of trigram types and tokens. The type frequency corresponds to the number of occurrences of a given string (letter, bigram or trigram) in a corpus, while token frequency weighted the number of occurrences by the frequency of the words. The properties of the words and pseudowords were then compared using Welch’s t-test because the homogeneity of variances were not respected (Brow-Forsythe test: p < .05). A significant test indicated statistically different properties between the word list and the pseudoword list. Overall, the analyses (Supplementary Material 6, 7) show similar results to those obtained with LD1NN confirming the quality of the pseudowords generated by UniPseudo.
In line with König et al. (2020), two different researchers manually coded the number of polymorphic, near polymorphic and one-character dissimilarity for the first 100 8-letter pseudowords generated by CGCA, Wuggy or UniPseudo in our previous French words analysis. König et al. (2020) defined polymorphic pseudowords as pseudowords that consist of a real root plus one of more affixes, near polymorphic pseudowords as pseudowords whose root does not exist in the language but include at least one affix, and one-character dissimilarity pseudowords as pseudowords that are one character away from at least one real word within the language. 5 To be able to compare the index, “one-character dissimilarity” was also computed for the first 100 words used in our previous French words analysis. The results are presented in Table 2.
Results from the comparison suitability evaluation (per 100 pseudowords).
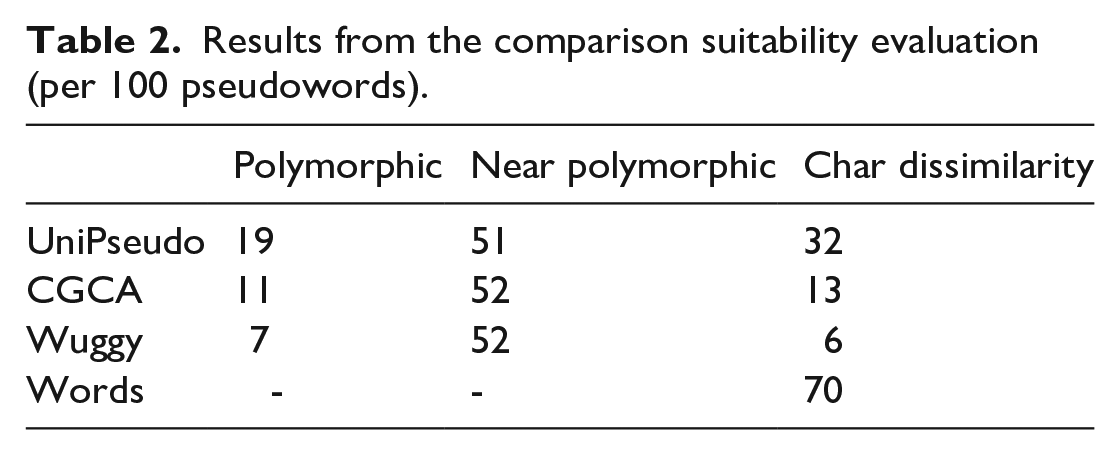
The polymorphic pseudowords generated by UniPseudo have higher counts (19%) than any of the other pseudowords generators (11% for CGCA and 7% for Wuggy) suggesting that UniPseudo pseudowords are more word-like. For the near polymorphic pseudowords counts do not differ across the different generators. Finally, the number of pseudowords being one character away from a real word is higher for UniPseudo (32%) than for CGCA (13%) and Wuggy (6%). Wuggy results in a lower number than CGCA. Interestingly, words tend to have more neighbours (70%) than all generators.
Conclusion
UniPseudo is an algorithm for generating pseudowords from a customizable database that allows the user to closely control the characteristics of the input items. It produces pseudowords in any language based on orthographic or phonological forms or on any other string representation of the input word base. Compared with the existing tools, UniPseudo generated pseudowords that were closer (according to the LD1NN algorithm) to the source words. This powerful new pseudoword generation tool is freely available and should be a valuable tool to facilitate the work of psycholinguists.
Supplemental Material
sj-docx-1-qjp-10.1177_17470218231164373 – Supplemental material for UniPseudo: A universal pseudoword generator
Supplemental material, sj-docx-1-qjp-10.1177_17470218231164373 for UniPseudo: A universal pseudoword generator by Boris New, Jessica Bourgin, Julien Barra and Christophe Pallier in Quarterly Journal of Experimental Psychology
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Data accessibility statement
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.