
Abstract
A traditional view of selective attention distinguishes between goal-directed and stimulus-driven mechanisms of attentional control. More recently, a large (and growing) body of research has identified a third class of control system—termed selection history—wherein attentional prioritisation is shaped by our prior experience with stimuli, independently of our goals and the physical salience of those stimuli. This article reviews work within this selection history literature demonstrating that prioritisation is rapidly and automatically modulated by learning about the rewards associated with stimuli, and argues for a framework that distinguishes between history-driven processes implementing attentional exploitation (the drive to leverage reliable information) and attentional exploration (the drive to resolve uncertainty, with the aim of validating potential new sources of information). Findings such as these highlight a fundamental and intricate interaction between learning and attention, wherein our prior experience shapes the way in which we extract information from our environment—with potential consequences for understanding the subsequent decisions that we make and choices that we take.

Introduction
It has been argued that we are living in an ‘attention economy’ (Davenport & Beck, 2001; Simon, 1971; J. Williams, 2018). In the digital age, the cost of producing and communicating information is lower than it has ever been, to the point that only a tiny fraction of the digital data that is generated receives any analysis at all (estimated at just 0.5% in 2015: Carpentier, 2023). Consequently, human attention—the cognitive process of filtering down the sources of information that enter our awareness—becomes the bottleneck for consumption. As such, attention has come to be seen as a scarce, and monetisable resource—because what we pay attention to shapes every decision that we make (Krajbich, 2019; Nelson-Field, 2024; Pearson et al., 2022).
At its heart, attention is about selection, or prioritisation: we are limited in the number of sensory stimuli that we can analyse at any one time, so we must prioritise some sources of information for further analysis (and potentially action), and de-prioritise others. In the context of vision—where most of the research on attention has been conducted—an influential framework sees visual attention as being implemented at the level of an attentional priority map, which provides a real-time representation of the priority of all of the stimuli currently present in the visual field, with selection occurring at the region of highest priority (Fecteau & Munoz, 2006). As originally conceptualised, priority in this map was held to reflect the combined influence of goal-directed and stimulus-driven inputs (Serences et al., 2005; Yantis, 2000). Here, goal-directed attentional control reflects salience that is based on the intentions of the observer: for example, if my goal is to find broccoli in the supermarket, I might assign a high salience to green items. By contrast, stimulus-driven attentional control reflects salience that derives from the physical distinctiveness of stimuli (in terms of their colour, motion, luminance, etc.) independently of the observer’s goals: for example, while looking for broccoli, my attention may be involuntarily captured by a brightly coloured advertisement for sponges, even though I have no current desire to buy sponges (e.g. Theeuwes, 1994; for a recent overview of the attention capture debate, see Luck et al., 2021).
More recently, however, this dichotomy has been challenged by findings suggesting that our attention is influenced by our prior experience in ways that fall outside the traditional distinction between goal-directed and stimulus-driven control (for reviews, see Awh et al., 2012; Le Pelley et al., 2016; Theeuwes, 2019). The underlying principle here is that our world is (in general) highly repetitive and therefore predictable, and our attention system can learn to make use of this predictability in order to learn settings for attentional control. For example, through substantial experience I have learned that a particular shade of purple (Pantone 2685C, to be precise) is associated with Cadbury’s chocolate bars, which I enjoy eating. As a result, my attention system might prioritise detection of this reward-associated colour in the future—to the point that, while shopping, a flash of purple in the confectionary aisle may capture my attention even though it is unrelated to my current goal (to buy broccoli), and is not particularly physically distinctive against the heterogeneously coloured background of the other items on the shelves.
Awh et al. (2012) introduced the term ‘selection history’ to refer to influences of prior experience on attentional priority that cannot be explained by either the voluntary selection goals of the observer or the physical characteristics of the selected items. The literature in this area has seen an explosion in recent years, with Google Scholar identifying over 6,000 articles referencing ‘selection history’ since Awh et al.’s paper. Researchers have now identified a range of ways in which experience influences attention, including (but not limited to) effects of prior selection as a target or rejection as a distractor (Kristjánsson & Campana, 2010), and statistical learning about likely target and/or distractor features (Sha et al., 2017; Stilwell et al., 2019) or locations (Geng & Behrmann, 2005; Wang & Theeuwes, 2018). Indeed, the concept of selection history is in danger of becoming something of a grab-bag for a range of phenomena that sit only loosely together and may not be mediated by a common, unitary mechanism. Indeed, it has been argued that selection history itself may be fractionated into a number of dissociable sub-processes (Anderson et al., 2021), raising the possibility that selection history should be viewed more as a general conceptual framework than as a specific mechanism. But I shall not pursue that debate further here; instead, in the remainder of this article I will focus on a particular (and particularly well-studied) facet of selection history, relating to how attention is influenced by learning about the predictive relationship between stimuli and rewards—and I will argue that research in this area can be usefully understood within a framework that distinguishes between attentional processes implementing exploitation versus exploration of reward information.
Reward Learning and Attentional Exploitation
Central to the idea of learning, and prediction more generally, are the closely (and inversely) related concepts of information and uncertainty. Stimuli are predictive to the extent that they provide information about—and hence reduce uncertainty about—what will happen next. In our stochastic and dynamic environment, there is clearly value in being able to anticipate the future, and in line with this idea, humans are voracious seekers of predictive information: weather forecasts, restaurant reviews, blood tests, stock market reports, and so on, all provide (perhaps imperfect) information that can be exploited to guide the decisions we make and actions we take.
A central tenet in the field of conditioning is that associative learning operates in the service of maximising reward through changing behaviour. 1 And this idea applies not only to overt behaviour, but also to attention (the ‘behaviour’ of prioritising stimuli for further analysis). That is, our attention system incorporates a mechanism that acts to prioritise stimuli that provide predictive information about upcoming rewards.
This impact of reward on attention has been shown in a wide range of procedures, using monetary rewards, food rewards, and social rewards, and investigating impacts on both spatial and non-spatial attention (for reviews, see Pearson et al., 2022; Rusz et al., 2020). Consider, for example, a study by Le Pelley et al. (2015; see also Pearson et al., 2016) in which, on each trial, participants were tasked with making a rapid eye movement (saccade) to a diamond-shaped target in an array of circles (see Figure 1a). Eye tracking provides an excellent index of attention since gaze and attention are typically tightly coupled: every saccadic eye movement is closely preceded by a shift of attention. Moreover, eye movements constitute an ‘online’ measure: we can infer shifts of attention directly, on a millisecond-by-millisecond basis, as opposed to making indirect inferences about attention on the basis of (say) differences in mean response time across sets of trials conducted under different conditions. Le Pelley et al.’s task was based on the additional singleton procedure (Theeuwes, 1992); one of the circles in the display was a colour-singleton distractor, coloured blue or red, while all other items (including the target) were grey. Critically, the colour of this distractor signalled the magnitude of reward that was available for making a saccade to the target, with blue and red assigned to the roles of high-value and low-value colours in a counterbalanced fashion across participants (Figure 1b). If the distractor was rendered in the high-value colour, there was a relatively large reward available for looking at the target (10 cents), whereas if the distractor was rendered in the low-value colour, there was a smaller reward available (1 cent).
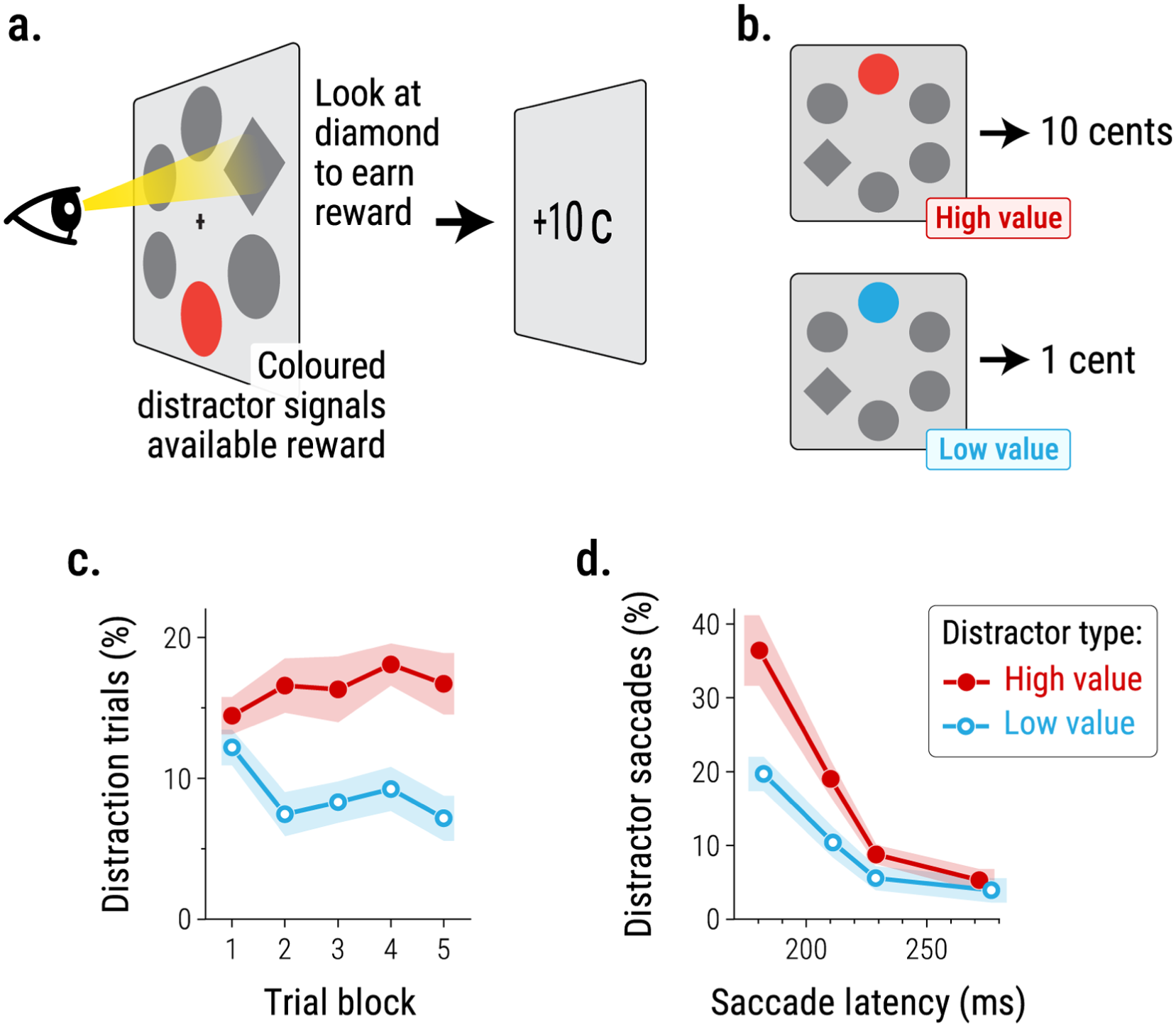
Le Pelley et al.’s (2015) value-modulated attentional capture task: (a) Participants’ task on each trial was to look at a diamond-shaped target. The colour of a colour-singleton circle in the display—termed the distractor—signalled the magnitude of available reward, (b) In this example, a red distractor in the search display signals a high-value reward (10c), and a blue distractor signals a low-value reward (1c): in the actual experiment, colour–reward relationships were counterbalanced across participants, (c) Over the course of the task, participants were more likely to look at the high-value distractor than the low-value distractor, even though this was counterproductive since looking at the distractor resulted in cancellation of the reward, (d) Proportion of first saccades directed towards the distractor as a function of saccade latency (i.e. time from onset of the search display to initiation of the saccade). The pattern of greater gaze capture by the high-value (vs. low-value) distractor was present even among participants’ lowest-latency (i.e. fastest) saccades. Data are redrawn from Le Pelley et al. (2015, Experiment 3).
Notably, participants were never required to attend to the reward-signalling distractor: their task was to look at the target to earn a reward. In fact, the task was arranged so that if participants ever did look at the coloured distractor prior to looking at the target, the reward that would have been delivered on that trial was cancelled. Consequently, the best strategy in this task was to ignore coloured items entirely and look directly at the target on every trial. Nevertheless, participants’ gaze was sometimes captured by the distractor, and the key finding is that their attention was more likely to be captured by the high-value distractor than the low-value distractor—even though this pattern was particularly counterproductive since it meant that participants missed out on more of the high-value rewards than low-value rewards (Figure 1c). The implication is that learning about the predictive relationship between distractors and rewards led to attentional prioritisation of the high-value distractor. This influence of reward value on attention cannot have been due to stimulus-driven control, since the physical salience of the high- and low-value distractors was equated across participants by counterbalancing. Moreover, it seems clear that the effect does not reflect goal-directed control of attention, since participants’ task was to look at the target, not the distractor, to earn points, and so attending to distractors was contrary to the task-goal. Even stronger evidence that this influence of reward value on attention is not a consequence of goal-directed attention comes from studies showing that the same influence is observed even if participants are explicitly instructed (at the start of the experiment) that looking at the distractors leads to cancellation of reward (Pearson et al., 2015; Watson et al., 2019, 2020), and hence are fully aware that attending to the distractors is directly contrary to their goal of earning points. As such, this value-modulated attentional capture (VMAC) effect constitutes an example of selection history automatically shaping attentional priority. Indeed, the fact that the VMAC effect persists (and if anything increases) over the course of hundreds or even thousands of trials (Le Pelley et al., 2015)—even though participants know that attending to distractors is counterproductive—is a testament to the power of automatic, experience-driven processes in shaping attention. Further consistent with the idea that VMAC reflects the operation of an early and automatic attentional process, this influence of reward on attentional capture has been shown to be present even among participants’ fastest saccades, within 180 ms of stimulus onset (Pearson et al., 2016): see Figure 1d.
A notable feature of the VMAC procedure described above is that the critical distractor stimuli constitute Pavlovian signals of reward. That is, these stimuli provide predictive information about the magnitude of the upcoming reward, but are not the stimuli that participants must respond to in order to earn that reward. Consequently, the observed pattern of VMAC must reflect prioritisation modulated purely by information value, rather than by instrumental significance for current decision-making (cf. Doyle et al., 2025). In this regard, VMAC has notable similarities to the phenomenon of sign-tracking observed in animal research, wherein animals are sometimes observed to approach and interact with a cue (the ‘sign’) that predicts a reward, rather than carrying out the response that obtains the reward itself (Colaizzi et al., 2020; Heck et al., 2025; Le Pelley et al., 2024). 2 Like VMAC, this sign-tracking behaviour is observed even under an omission schedule in which interacting with the sign results in omission of reward (Atnip, 1977; D. R. Williams & Williams, 1969).
VMAC and sign-tracking are consistent with the idea that the attention system acts rapidly and automatically to prioritise processing of signals of reward (indeed, other research suggests that the influence of reward may be even more deep-seated, modulating the initial perception of stimuli, i.e. whether and how they are perceptually encoded in the first instance: Cheng et al., 2021; Serences, 2008). This interpretation makes a connection with the concept of incentive salience in the behavioural neuroscience literature: the idea that signals of desirable outcomes become salient (and hence attention-grabbing) in their own right: ‘motivational magnets’ that come to elicit approach behaviour (Berridge & Robinson, 2003).
Intuitively, it makes sense that our attentional system should be geared towards prioritising information about the availability of reward. Rewards are (by definition) of value to us, and hence signals of reward are also likely to be of value since they can be used to guide ongoing decisions and behaviour in a way that makes obtaining reward more likely (though not in the unusual situation of the VMAC procedure, as discussed further in the next section). For example, if a forager has previously experienced that red berries are delicious, then it makes sense to prioritise detection of red items while searching for food in future, since red has become a signal for reward. Hence, we can characterise this influence of reward-signalling as a mechanism of ‘attentional exploitation’: our cognitive system acts to prioritise processing of items that provide reliable information about valued events, since the information provided by these stimuli can be used to guide (and optimise) ongoing behaviour.
It is clearly adaptive for our attention system to exploit prior (learned) knowledge when implementing attentional control settings. But why have a distinct, selection-history-based mechanism that implements this effect of reward learning on attentional priority automatically? Why not instead implement the influence of reward learning—and potentially other types of learning—via goal-directed attentional control (with the forager applying a top-down control setting that prioritises red items)? Anderson (2021) has argued that a key benefit afforded by involuntary attentional control is that it allows for offloading of attentional demands. Goal-directed search relies on creating and maintaining an attentional target template in active memory, making it cognitively effortful and slow (Theeuwes, 2018). By contrast, automating patterns of attentional control negates the need for this metabolically costly, volitional process; instead, repeated experience (e.g. of a stimulus predicting reward) causes settings to become wired in and implemented automatically and rapidly via a dedicated ‘hands free’ circuit, obviating the need for an active search template (Shiffrin & Schneider, 1977).
Offloading attentional demands to a dedicated selection-history mechanism for executing involuntary, experience-based attentional control comes at a potential cost, however. Through this approach, the attention system is essentially implementing a general policy that past experience is a useful guide for future behaviour. In the context of reward learning, this policy takes two forms: (1) The existence of the system implements the policy that it is (in general) beneficial to attend to reward-signalling stimuli; and (2) The influence of learning implements the policy wherein stimuli that signalled reward in the past will continue to do so in the future. I will consider each of these ideas in turn.
The Value of Attentional Exploitation
With regard to the first of these assumptions, in the regular environment, signals of reward are usually ‘tied to’ the reward itself, as in the case of our forager, where the signal (red colour) is closely integrated with the reward (the sweet taste of the berry). Under these conditions, responding to the signal will typically be beneficial for accessing the reward itself. As such, it does not seem unreasonable to assume that, over our evolutionary history, a policy of prioritising reward-signalling stimuli would be generally adaptive. In this sense, the VMAC procedure—wherein attending to reward-signalling distractors is directly counterproductive to obtaining reward—creates an artificial situation that is unlikely to arise often in the real world. In some sense, that is the point of the procedure: by putting an evolved system in an unusual situation we can learn something about the underlying nature of that system, much as visual illusions such as the Kanisza triangle or the hollow-face illusion (Gregory, 1970) are not stimuli that would arise naturally, but tell us about the nature of the processes underlying visual perception; a similar logic applies to the ‘cognitive illusions’ used by Tversky and Kahneman (1974) to probe the heuristics and biases underlying judgement and decision-making.
That said, the policy of prioritising reward-signalling stimuli can have drawbacks, particularly in the modern world where we are surrounded by signals of reward: logos of fast food restaurants, advertisements for luxury products, social media notifications on our phones, and so on. This reward-laden environment may increase the incidence of situations in which involuntary prioritisation of reward signals leads to distraction from ongoing tasks, rather than being helpful—increasingly so as advertisers’ reach into our daily lives becomes more all-pervading. For example, Ford recently patented a system allowing in-vehicle screens to display advertisements based on what the car’s cameras see passing outside (Kierstein, 2024), raising concerns about distracting attention from the road, particularly if drivers are tired or engaged in other tasks, which may limit their ability to use goal-directed control to overcome distraction by reward-associated stimuli.
The idea that reward-modulated attention can have negative consequences is particularly germane in the context of addiction. Many addictive drugs produce potent neural reward signals (Hyman, 2005), and so cues that are repeatedly paired with these drugs (packaging, locations, smells, etc.) may come to be automatically prioritised as reward signals, becoming ‘motivational magnets’ in their own right that elicit craving and consequently drug-seeking (Le Pelley et al., 2024; Tomie & Morrow, 2018; Tomie et al., 2008). Consistent with this idea, evidence suggests that people who are more prone to automatically prioritising reward-signalling stimuli (as measured in laboratory tasks using small monetary rewards) are also more prone to addictive and addiction-related behaviours (for a review, see Le Pelley et al., 2024). For example, in a recent preregistered study, Watson et al. (2024) found that the magnitude of the VMAC effect (that is, the tendency to prioritise signals of reward) was associated with severity of problematic alcohol use in a treatment-seeking clinical sample of alcohol users, and predicted the likelihood of participants having returned to use at a three-month follow-up. Further relevant evidence comes from animal studies of sign-tracking (which, as noted earlier, provides an analogue to VMAC as a measure of incentive salience). Some strains of rats show evidence of individual differences in their tendency towards sign-tracking, and rats exhibiting stronger sign-tracking tendency also show more evidence of ‘impulsive’ behaviour in tests of decision-making (Tomie et al., 1998), are more motivated to earn cocaine (Saunders & Robinson, 2010), are more sensitive to cocaine cues, and are more likely to relapse in response to drug-associated cues (Saunders & Robinson, 2010) compared to rats who do not show evidence of sign-tracking (for a review, see Robinson et al., 2018).
Thus attentional exploitation may be a double-edged sword: while there is clearly value to a process implementing automatic prioritisation of reward signals, this system may not be ideally evolved to suit our current reward-saturated environment.
Attentional Exploitation in a Dynamic Environment
The second policy implemented by a ‘hands free’ mechanism subserving automatic, learned prioritisation of reward signals is that stimuli that have signalled reward in the past will continue to do so in future. That is, previous experience that red berries consistently signal reward leads to a ‘prioritise red’ pattern being wired into a history-based salience process. Following on from the arguments made in the previous section, this pattern will likely be adaptive as long as red berries continue to signal reward. Of course, the world is not perfectly predictable. Red berries may usually be tasty, but perhaps sometimes a red berry is rotten, or comes from a different species that is bland. For any form of learning to be adaptive, the benefit of exploiting prior knowledge must be sufficient to outweigh the cost of potentially making occasional errors.
Of more importance in the current context is the issue of what happens if the predictive relationships in the environment change in a systematic way. Perhaps the season changes, or our forager moves to a new area where red berries are no longer desirable. It has been argued that hands-free attentional control—as implemented by history-based mechanisms—will be relatively inflexible and sluggish in the face of a changing environment: control settings that have been established and wired-in on the basis of prior experience will run on, unless and until the agent engages goal-directed processes to update and modify these control settings (Anderson, 2021). And empirical data suggest that people are often somewhat resistant to expending the cognitive effort required to recalibrate attentional control settings to maximise task performance, persisting with prior patterns of prioritisation even when doing so leads to suboptimal performance (Irons & Leber, 2016).
In the context of reward, it has been shown that people can deploy top-down processes to update learned attentional control settings rapidly in response to a change in the world, if they are given clear motivation to do so. For example, in a study by Stankevich and Geng (2015), participants initially performed a task in which (say) green items signalled high-reward feedback, and red items signalled no-reward feedback, which led to attentional prioritisation of the high-reward colour (as indexed via response times). Participants were then instructed that rewards would no longer be available before carrying on with the task in the absence of any reward feedback. This instruction led to an immediate decrease in the magnitude of the attentional bias to the (former) high-reward colour, suggesting that the top-down knowledge of the change in reward structure was sufficient to prompt participants to update their attentional control settings. That said, the reward-related attentional bias was not entirely eliminated; even despite the explicit instruction, and experience of the task under the new reward structure, a (smaller) bias towards the former high-reward colour persisted throughout the latter phase of the task.
Further evidence of persistence of reward-related attentional bias is seen in studies where, rather than changing the relationship between cues and rewards, the value of the rewards themselves is changed (De Tommaso & Turatto, 2021; De Tommaso et al., 2017; Le et al., 2024; Watson et al., 2022; but see also Pool et al., 2014). For example, Watson et al. (2022) used a version of the VMAC search task described earlier (cf. Figure 1) in which different distractor colours signalled that a rapid saccade to the target would earn either water or potato chips. Participants were initially trained on this task when they were thirsty, but not hungry, such that water rewards would be more valuable than chips rewards. Under these conditions, gaze data showed that participants came to automatically prioritise the water-signalling distractor (even though—as in previous versions of the task—this was a counterproductive pattern since looking at this distractor led to cancellation of the reward). Then, once participants had acquired this bias, Watson et al. decreased the value of the water reward for half of the participants by having them drink until they were no longer thirsty, before all participants carried on with the task. Critically, this change in reward value had no impact on the size of the previously-established attentional bias towards the water-signalling distractor (relative to the chips-signalling distractor), as compared to participants for whom water had not been devalued (i.e. participants who were thirsty throughout the task).
The implication of these findings is that reward-related attentional prioritisation can become ‘habit-like’, resulting in attentional control settings that are (at least in part) resistant to updating in the face of subsequent changes in knowledge and/or experience (Le et al., 2024). That is, patterns of learned prioritisation can persist in influencing behaviour even in the face of a change in the environment that renders those stimuli no longer desired. It remains to be established what aspects of environmental change and task features (e.g. relating to participants’ explicit knowledge, or their incidental experience of reward feedback) promote or hinder flexible updating of reward-related attentional biases. This question is an important target for future research—particularly in light of the role of reward-related attention in addictive behaviours that was noted earlier. Consider a person who, after years of heavy drinking, wants to quit—that is, their explicitly stated desire for alcohol has decreased. However, if a ‘habit-like’ attentional bias—which is resistant to a change in reward value—continues to automatically prioritise attention to alcohol-related stimuli (e.g. pub signs, liquor stores) then these stimuli may continue to exert an influence on behaviour, interfering with the goal of abstinence (Le Pelley et al., 2024). Consistent with this idea, Albertella et al. (2021) tested a large (non-clinical) sample of participants who had signed up for a one-month voluntary alcohol abstinence challenge (as part of a ‘dry January’ campaign), and found that VMAC magnitude assessed at baseline predicted the likelihood of successfully completing the challenge: participants who were more susceptible to having their attention captured by reward signals were more likely to fail the abstinence goal (assessed via self-report).
More generally, it has been argued that learned patterns of attentional prioritisation can shape motivated behaviour within a ‘biased competition’ framework, by influencing which stimuli are chosen to act as targets of subsequent action (for more detail, see Le Pelley et al., 2024). According to this account, so-called slips of action (e.g. drinking alcohol while one is intending to abstain) result from prioritisation of task-inappropriate cues as a consequence of repeated and rewarded prior selection of those cues: in effect, ‘habitual control of goal selection’ (Cushman & Morris, 2015).
Attentional Exploration
Up to this point, we have considered a selection-history-based mechanism of attentional control that is based on predicted reward magnitude, wherein stimuli that signal the availability of large reward become more likely to capture attention than signals of smaller reward. I have characterised this as an ‘exploitative’ process, since it invokes a mechanism that acts to prioritise those stimuli that are likely to be of most use to us as targets for ongoing behaviour: our forager benefits from prioritising red items since this helps him to quickly detect tasty berries, which he can then eat. Hence, this value-modulated system involves exploiting current knowledge in order to optimise current behaviour (cf. Sutton & Barto, 2018). This idea of an exploitative attentional mechanism is broadly in line with findings of animal studies suggesting that attention operates to maximise current information (and minimise current uncertainty), wherein stimuli that provide immediate, diagnostic information about subsequent events receive attentional priority over those that do not (Gottlieb et al., 2020).
However, a growing body of recent research suggests this may not be the whole story, indicating that selection-history mechanisms may not always act in the service of exploiting reliable information (Cho & Cho, 2021; Chow, Garner, Pearson, Heber, & Le Pelley, 2025; Ju & Cho, 2023; Le Pelley, Pearson, et al., 2019; Pearson et al., 2024). For example, Chow, Garner, Pearson, Heber, and Le Pelley (2025; see also Le Pelley, Pearson, et al., 2019) had participants perform a search task similar to that shown in Figure 1, but rather than varying the reward magnitude associated with each distractor colour, we instead varied the reward uncertainty associated with each distractor. One distractor colour provided ‘diagnostic’ reward information: whenever this colour appeared in the search display, a rapid saccade to the target earned 20 points (with points later converted into money). 3 If the search display contained a distractor in the other, ‘uncertain’ colour, a rapid saccade to the target earned 0 points on a random 50% of trials, and 40 points on the other 50% of trials (Figure 2a). Thus, both distractor colours were associated with the same expected (mean) reward value, but differed in their predictiveness—that is, the amount of information they provided about the specific reward available on each trial. Under these conditions, attentional exploitation would be reflected by greater prioritisation of—and hence greater capture by—the diagnostic distractor (which provided immediate, accurate information about available reward) than the uncertain distractor (which did not). Contrary to this hypothesis, Chow, Garner, Pearson, Heber, and Le Pelley (2025; see also Le Pelley, Pearson, et al., 2019) found that participants’ gaze was more likely to be captured by the uncertain distractor than the diagnostic distractor (see Figure 2b, ‘uninstructed’ group). This uncertainty-modulated attentional capture (UMAC) effect was pronounced even among participants’ fastest eye movements (Figure 2c), consistent with an early and automatic influence of uncertainty on attentional prioritisation.
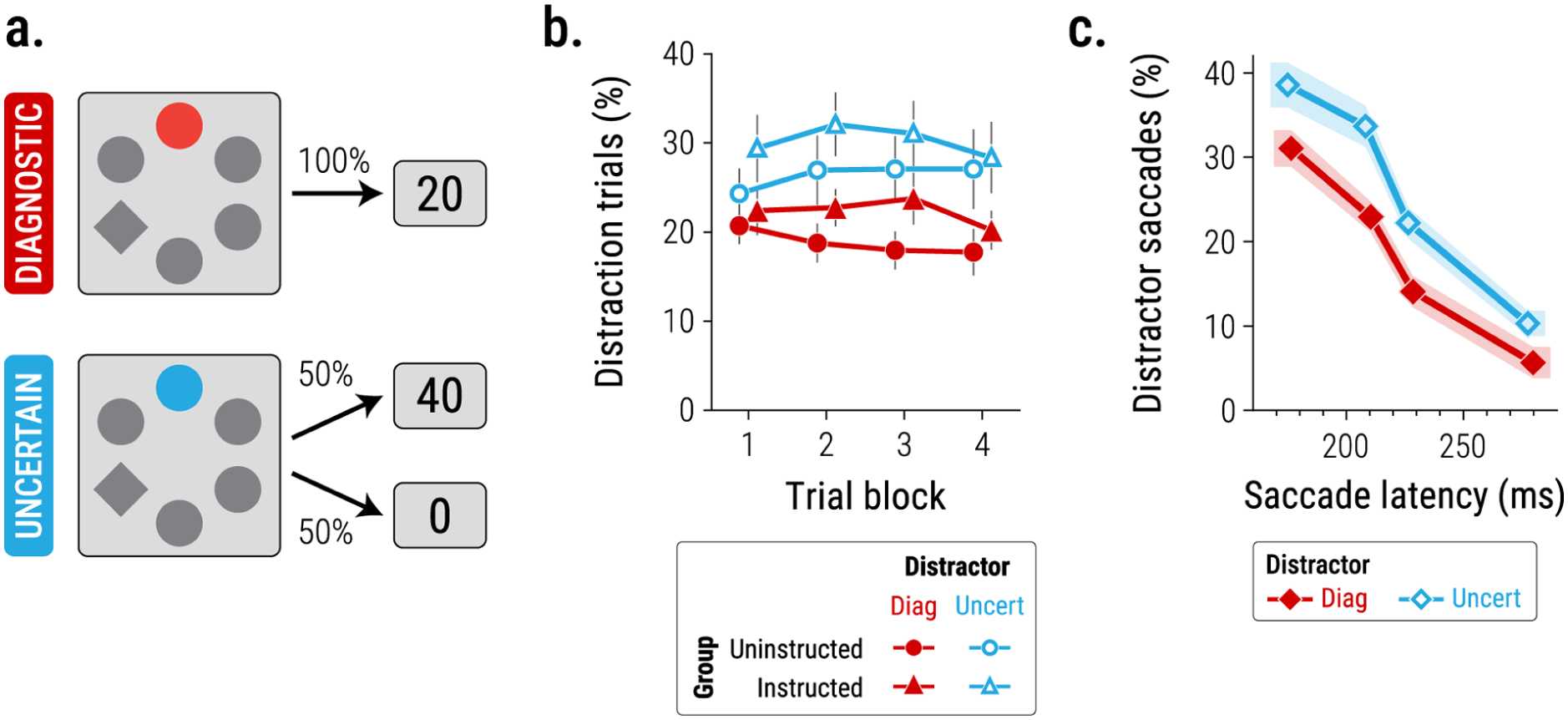
Study of uncertainty-modulated attentional capture (UMAC) by Chow, Garner, Pearson, Heber, & Le Pelley (2025): (a) A ‘diagnostic’ (diag) distractor signalled availability of 20 points on every trial; an ‘uncertain’ (uncert) distractor signalled 40 points on half of trials, and 0 points on the other half of trials (at random), (b) Across the course of the search task, the uncertain distractor was more likely than the diagnostic distractor to capture participants’ attention (higher proportion of distraction trials, that is, trials on which participants looked at the distractor prior to looking at the target during the search task). This pattern was observed in a group of participants who learned the colour–reward relationships only via trial-by-trial experience of reward feedback (group Uninstructed), and in participants who were explicitly told the colour–reward relationships at the outset, in addition to subsequently experiencing feedback (group Instructed), (c) Across both groups, the pattern of greater prioritisation of the uncertain (vs. diagnostic) distractor was present among participants’ fastest saccades. Redrawn from Chow, Garner, Pearson, Heber, & Le Pelley (2025).
Uncertainty is not an all-or-none factor: it varies along multiple dimensions. One such dimension, entropy, reflects the number and probability of different outcome events that may occur, which influences how surprising each observed outcome is (Shannon, 1948). Other things being equal, entropy increases as a function of the number of distinct event outcomes. For example, rolling a six-sided die has greater entropy (2.58 bits) than flipping a coin (1 bit). Another dimension of uncertainty, variance, reflects the spread of the distribution of outcomes and indicates how far each possible value is from the expected value. Studies of UMAC suggest that both of these properties play a role in promoting attentional prioritisation of stimuli associated with uncertain outcomes. Ju and Cho (2023) used a design in which the critical distractors were matched in both expected value and outcome variance, but differed in outcome entropy—and found evidence of greater attention to high-entropy items than low-entropy items. By contrast, Pearson et al. (2024) used a design in which distractors were matched in expected value and entropy, but differed in variance—and found evidence of greater attention to high-variance items than low-variance items. The implication is that UMAC is driven by the experience of outcome uncertainty as a broad concept, rather than being tied to one specific element of uncertainty.
Of course, one could argue that—even though the two distractors were matched in their objective expected value in the studies noted above—participants nevertheless (for some reason) perceived the more uncertain distractor as having higher subjective value than the more diagnostic distractor, so that the observed difference in prioritisation could be reconciled with a mechanism based on reward magnitude. However, this interpretation was ruled out in a further experiment by Pearson et al. (2024), which put influences of reward magnitude and reward uncertainty in opposition. Here, a low-value/high-variance distractor was paired with 0 points on 50% of trials, and 100 points on the other 50% of trials; by contrast, a high-value/low-variance distractor was paired with 70 points on 50% of trials, and 100 points on the other 50% of trials (Figure 3a). Consequently: (1) the high-value/low-variance distractor was associated with higher reward magnitude (expected value); and (2) the low-value/high-variance distractor was associated with greater reward uncertainty: both distractors had equal outcome entropy (since each could be followed by two distinct outcomes), but the variance of possible reward outcomes was larger for the low-value/high-variance distractor. Notably, Pearson et al. found that the low-value/high-variance distractor was more likely to capture participants’ attention (Figure 3b), even though participants could accurately report—when asked after the search task—that it had lower expected value (Figure 3c). These findings are consistent with the idea that the impact of uncertainty on prioritisation reflects a separate process from that driven by reward magnitude (as implicated in earlier studies of VMAC); indeed, in Pearson et al.’s study, uncertainty had a larger influence on attention than did magnitude.
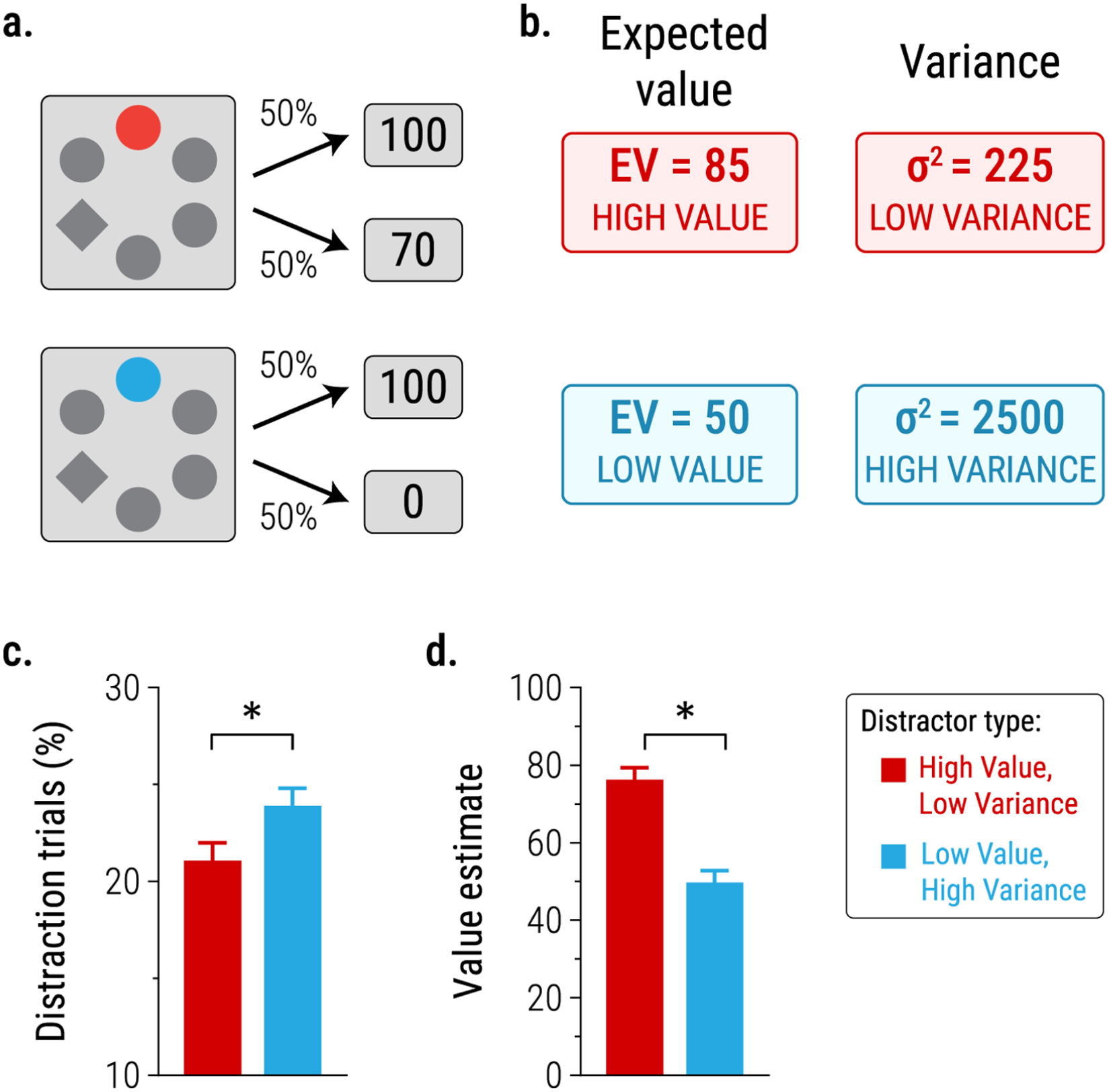
The study of attentional priority by Pearson et al. (2024, Experiment 3) pitted influences of reward magnitude (expected value, EV) and reward variance (σ 2 ) in opposition: (a) A high-value, low variance distractor signalled availability of 100 points on 50% of trials, and 70 points on the remaining 50%. A low-value, high-variance distractor signalled 100 points on 50% of trials, and 0 points on the remaining 50%, (b) The low-value, high-variance distractor was more likely to capture participants’ attention (higher proportion of distraction trials, i.e. trials on which participants looked at the distractor prior to looking at the target during the search task), (c) When asked to estimate the mean (expected) reward value associated with each distractor, participants correctly reported a higher value for the high-value, low-variance distractor. * indicates p < .05. Redrawn from Pearson et al. (2024).
In sum, recent studies point to the existence of a selection-history process that acts to automatically prioritise stimuli on the basis of their predictive uncertainty, distinct from the value-based mechanism highlighted by earlier research. Whereas the value-based mechanism can be seen as a process of attentional exploitation of current reward information, the uncertainty-based mechanism can instead be seen as reflecting a different ‘mode’ of information-seeking: one that prioritises exploring current sources of uncertainty with the aim of uncovering new information (Chow, Garner, Pearson, Heber, & Le Pelley, 2025; Chow, Garner, Pearson, Theeuwes, & Le Pelley, 2025; Ju & Cho, 2023; Pearson et al., 2024). This view implicitly assumes that our cognitive system seeks to build an accurate mental model of the predictive relationships in the world; that is, to reduce prediction error to zero (cf. Dayan et al., 2000; Pearce & Hall, 1980). In the UMAC task used by Le Pelley, Pearson, et al. (2019), prediction error created by the variable reward paired with the uncertain distractor may drive attention to automatically prioritise this item, with the idea that exploring its features will support new learning that allows for more accurate predictions to be made in future (though the stochastic nature of the rewards in this task means this goal will never be attained, since outcomes are ultimately unpredictable). By contrast, once it is established that the diagnostic distractor signals 50 points, prediction error falls to zero and there is no further drive to explore this stimulus in order to learn more about it. Thus, attentional exploration acts in the service of learning, highlighting items whose consequences are (currently) imperfectly understood in an attempt to improve this understanding so that we might be better-placed to exploit the information provided by a more accurate mental model in the future.
Notably, the attentional exploration underlying UMAC seems to operate relatively automatically. Chow, Garner, Pearson, Heber, and Le Pelley (2025) demonstrated that explicitly informing participants of the true predictive status of each distractor at the outset of the task—which should negate any top-down drive to strategically prioritise distractors in order to discover more about them—had no impact on the UMAC effect that was observed, relative to a group of participants who were not informed of the distractor–reward relationships (and could learn only via trial-by-trial experience): see Figure 2b. Based on these findings, we suggested that UMAC may reflect the operation of an automatic learning-based mechanism—a selection history mechanism—that implements attentional exploration driven by experience of reward uncertainty, in turn via experience of prediction error—much as suggested by Pearce and Hall (1980) in their algorithmic model of associative learning (see also Dayan et al., 2000).
Two Mechanisms of Reward-Driven Attention
To summarise, the framework proposed here points to two distinct mechanisms that operate—relatively automatically—to shape attentional prioritisation based on our previous experience of reward. 4 A value-based, exploitation mechanism acts to prioritise stimuli that have previously been associated with larger rewards, in the service of optimising current behaviour: since reward-associated items are typically valuable targets of motivated behaviour (e.g. approaching or choosing them will usually be beneficial), it makes sense to have an attentional system that is geared towards rapid, ‘hands-free’ processing of such reward-related items. In addition, an uncertainty-based, exploration mechanism acts to prioritise stimuli that have previously been associated with a greater degree of uncertainty in experienced reward, in the service of optimising future knowledge by directing cognitive resources towards learning more about the true significance of these items.
This idea of an exploit/explore framework for attention has theoretical antecedents in the literature on conditioning and associative learning (for reviews, see Le Pelley, 2004; Le Pelley et al., 2016). For example, Mackintosh (1975) proposed a model of conditioning wherein attention was modulated by the extent to which stimuli signalled outcome events, such as rewards—effectively implementing a process of attentional exploitation. Likewise, Pearce and Hall (1980) put forward a model in which attention was based on experience of prediction error, implementing a form of attentional exploration. It could be argued (and not unreasonably) that much of the more recent work on selection history—such as that reviewed here—has involved researchers from the attention literature ‘rediscovering’ principles from the field of conditioning. In doing so, however, this research has brought a more refined conceptualisation of what attention actually is. Early work in the conditioning literature treated attention as a unitary construct, and so failed to address the level at which effects were operating. By contrast, more recent tasks and measures derived from the visual attention literature allow for a much richer and more precise view of the way in which learning shapes attention—we can distinguish between effects reflecting top-down versus selection-history-driven control, for example, and can examine dynamic changes in patterns of prioritisation with millisecond resolution in ways that were not previously possible.
While important foundational steps have been taken in this research area, this is an active field and a number of critical research questions remain open. I will end by highlighting some potential directions for future work.
The Nature of the Outcome
All of the studies discussed here used rewards as outcomes. Indeed, this has been the case for much of the existing work on selection history, though the specific nature of the reward has varied, including money, symbolic points, game-like feedback (sound effects, the chance to unlock digital ‘medals’ etc.), food and drink, or social rewards (for reviews, see Pearson et al., 2022; Rusz et al., 2020). But rewards are not the only motivationally significant stimuli: aversive events (punishments, threats and losses) will also motivate behaviour. Less research has examined the impact of learning about aversive stimuli on attentional capture, though what research there is suggests that an exploitation-type process operates to prioritise signals of aversive events in much the same way as signals of reward (Grégoire et al., 2022; Mikhael et al., 2021; Nissens et al., 2017; Wentura et al., 2014)—the implication being that attentional exploitation is based on the motivational significance of the outcome, rather than its valence (appetitive or aversive; positive or negative). It makes sense that our attentional system should be geared towards prioritising signals of both reward and threat, given that both are likely to be important for ongoing behaviour. However, to my knowledge, no research has examined attentional exploration in the context of aversive outcomes (e.g. by pairing stimuli with different levels of monetary loss, or a mixture of rewards and losses), and this remains a task for the future.
That said, designing experiments to examine the impact of aversive events presents methodological challenges. For example, while it is straightforward to motivate participants to respond to earn a reward, it is harder to motivate responding that will result in a loss. One approach has been to use negative reinforcement, wherein responding prevents an aversive event that would otherwise have occurred (Le Pelley, Watson, et al., 2019; Nissens et al., 2017; Wentura et al., 2014), but interpretation of findings from studies using this approach is complicated by the possibility that successful avoidance of an otherwise-expected aversive event is viewed by participants as a positive outcome, that is, a form of reward (Anderson & Britton, 2020; Mikhael et al., 2021). Moreover, studies that have attempted to compare the degree to which prioritisation is influenced by reward versus loss (Becker et al., 2020; Yan et al., 2022) are complicated by difficulty in matching the frequency with which rewards versus losses occur, and of equating the psychological salience of reward versus loss values (Pearson et al., 2022).
The Nature of the Task
In this article, I have focused primarily on studies in which the critical stimuli are Pavlovian signals of reward. An alternative approach is to use a more instrumental procedure, in which the critical stimuli are themselves the targets that participants must attend (and respond) to in order to earn reward. Studies using this approach have demonstrated evidence of both attentional exploitation (Anderson & Halpern, 2017) and attentional exploration (Cho & Cho, 2021). That said, interpretation is complicated here since, even in these latter studies, the reward-related stimuli also have a Pavlovian relationship with reward: the stimulus signals the magnitude of reward that is available (Pavlovian), and attending to this stimulus leads to reward delivery (instrumental). This makes it difficult to separate out the influence of each component. It remains for future research to investigate the similarities and differences in selection history processes mediated by Pavlovian versus instrumental conditioning more selectively.
Integrating Attentional Exploitation and Attentional Exploration
The framework proposed here distinguishes between two ‘modes’ of automatic attentional prioritisation: attentional exploitation (prioritising stimuli on the basis of current knowledge about the outcome that they signal), and attentional exploration (prioritising stimuli on the basis of current uncertainty, driven by potential future knowledge that they might provide). A critical next step will be to determine how these mechanisms interact, and potentially compete, to determine overall priority: how does our attentional system strike a balance between exploring—to build a more accurate mental model of the world—and exploiting—to make use of existing knowledge? This will involve establishing the features of tasks and individuals that lead to seeking reliable information versus prioritising sources of uncertainty: that is, how ‘task architecture’ can be manipulated to alter the explore/exploit balance point. For example, exploration requires holding beliefs in mind and updating them based on incoming sensory evidence; this is more cognitively demanding than exploitation, which merely involves acting on existing beliefs. This raises the (testable) possibility that the balance of attentional modes is mediated by availability of cognitive resources, which could be manipulated by imposing a working memory load or secondary task (cf. Watson et al., 2019).
Selection History Versus Top-Down Control
Here, I have reviewed evidence consistent with a history-driven influence of uncertainty on attentional capture, labelled as attentional exploration. These findings stand in contrast to a parallel body of existing work demonstrating information-seeking behaviour, illustrating conditions under which observers preferentially attend to stimuli that provide immediate, diagnostic information about subsequent events over those that do not (Foley et al., 2017; Horan et al., 2019; for a review, see Gottlieb et al., 2020). A notable point of difference between work on UMAC—consistent with attentional exploration—and research highlighting information-seeking for cues that resolve current uncertainty lies in the task objectives. In studies of UMAC, attending to the reward-signalling distractors is counterproductive to the goals of the task—and this is the basis of the claim that UMAC reflects an automatic, history-driven impact of uncertainty on attention. By contrast, in studies demonstrating information-seeking behaviour, observers were typically required to make a saccade to the cue in order for the task to proceed (Blanchard et al., 2015; Bromberg-Martin & Hikosaka, 2009), and in many cases, attending to the critical cue was directly beneficial because doing so provided instrumental information that could be used to improve the accuracy of subsequent responding (Foley et al., 2017; Horan et al., 2019). This raises the possibility that these previous findings reflect top-down (volitional), rather than selection-history-based (automatic) influences on attentional selection (though see Doyle et al., 2025). In other words, when we are given the choice to intentionally gather information about an upcoming event, we may prefer to sample from a source that provides more reliable information and so resolves our uncertainty about what will come next. However, selection history may create a competing drive toward attentional exploration that acts to prioritise—and potentially drive capture by—signals of more variable outcomes. Future research could test this speculation.
The Impact of Reward-Based Attentional Prioritisation on Decision-Making
The idea of an explore/exploit distinction is clearly not new: it has been a particular focus in the context of reinforcement learning and decision-making, examining how we use the information we have gathered to guide our choices (Mehlhorn et al., 2015; Sutton & Barto, 2018). But this neglects a key question: where did that information come from in the first place? Consider a supermarket shopper, facing shelves full of thousands of items. It would be impossible to evaluate the pros and cons of every item before making each selection; instead, attention acts to select a subset of items for further consideration, and filters out others (Krajbich, 2019). And the research reviewed here suggests that the process of information-gathering is itself shaped by our previous experience of reward: the implication is that, by implementing patterns of reward-based prioritisation, our attention system may be automatically ‘nudging’ us towards making certain choices rather than others (Pearson et al., 2022): Figure 4.
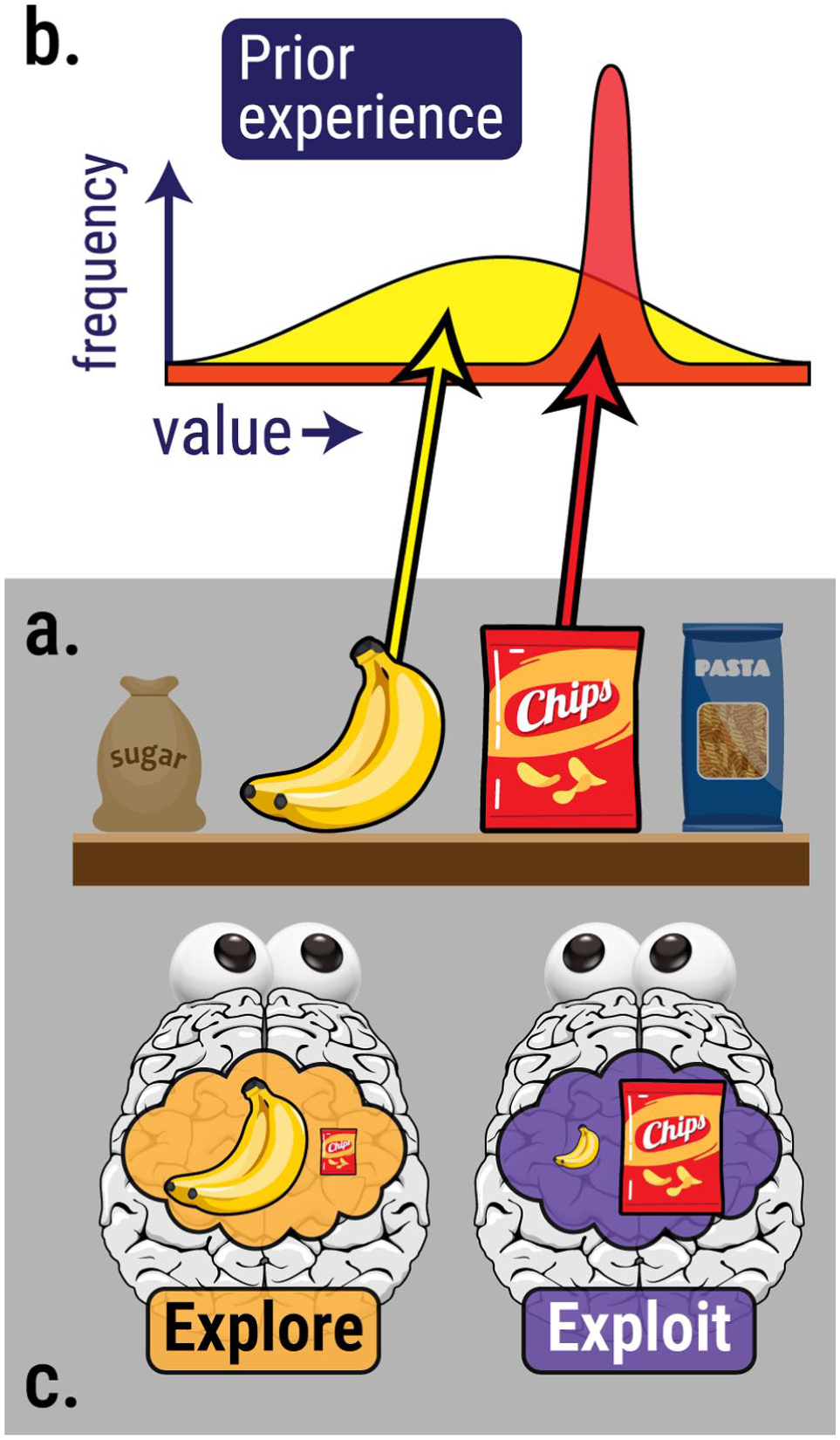
History-driven attention and choice: (a) A shopper wants to buy a snack, (b) The chip packet is a reliable signal of reward: in the past, chips have always been quite tasty. Bananas have greater variance: some are delicious, but others are unripe or rotten, (c) If attention acts to prioritise sources of diagnostic information (exploitation), the shopper will be biased towards buying chips; if attention prioritises sources of uncertainty (exploration), the shopper will be more likely to buy bananas.
This raises the question of how learned patterns of reward-based prioritisation act to shape ongoing decision-making behaviour. This is a critical issue, since it is our choices that ultimately determine our interaction with the world. Earlier I noted findings suggesting a relationship between reward-modulated attention and real-world addictive behaviours (Le Pelley et al., 2024), which provides prima facie evidence that these attentional processes can indeed bear on people’s overt decisions—an idea that is central to the popular concept of the ‘attention economy’ (Davenport & Beck, 2001). Recent studies have begun to examine the impact of reward-modulated attention on decision-making at a mechanistic level, within the framework of evidence-accumulation models such as the attentional drift diffusion model (Gluth et al., 2018, 2020) and this represents an exciting avenue for future investigation.
Conclusion
The idea that what we learn influences what we pay attention to has a venerable history: James (1890/1983) described ‘derived attention’ as a form of attention that ‘owes its interest to association with some other immediately interesting thing’ (p. 393). When making this point, however, James may not have appreciated how fundamental, and how intricate, the interaction between learning and attention is. Here, I have focused on just one facet of this interaction, wherein learning shapes prioritisation of reward signals, and I have argued that evidence is consistent with the operation of distinct mechanisms implementing attentional exploitation and exploration at an automatic level. But this is just one element of a complex and multifaceted relationship between learning and attention: for example, other research has shown that prioritisation is also influenced by prior learning about stimulus locations, or features, and the previous responses that we have made (Anderson et al., 2021). A critical next step will be to establish how these different influences are integrated into the attentional priority map to determine overall prioritisation (do they reflect different processes, or different facets of a unitary system?—see Anderson, 2024), and how they influence ongoing behaviour. More generally, this body of research demonstrates the extent to which plasticity permeates through our cognitive system: at seemingly every level of the information-processing pathway, we are a product of our own experience.
Footnotes
Acknowledgements
I would like to thank Ben Newell for valuable feedback on a draft of this article.
Funding
The author disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by Australian Research Council grants DP200101314, DP240102605 and DP260101915, and an AUSMURI grant from the Australian Department of Defence.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.